【MySQL】6.MySQL主从复制和读写分离
主从复制
主从复制与读写分离
通常数据库的读/写都在同一个数据库服务器中进行;
但这样在安全性、高可用性和高并发等各个方面无法满足生产环境的实际需求;
因此,通过主从复制的方式同步数据,再通过读写分离提升数据库的并发负载能力
类似于sync,但sync是对磁盘文件做备份,而mysql主从复制是对数据库中的数据、语句做备份
mysql支持的复制类型
1.statement:基于语句的复制;
在服务器上执行sql语句,在从服务器上执行同样的语句;
mysql默认采用基于语句的复制,执行效率高
2.row:基于行的复制;
把改变的内容复制过去,而不是把命令从服务器上执行一遍
3.mixed:混合类型的复制;
默认采用基于语句的复制,一旦发现基于语句无法精确复制时,就采用基于行复制
主从复制的工作过程
1.mysql节点将数据的改变,记录到二进制日志(bin log)中;
当master上的数据发生改变时,就会将其写入二进制日志中
2.slave节点会在一定时间间隔内对master的二进制日志文件进行探测,看是数据否发生改变;
如果有变,就会开始一个I/O线程去请求msater的二进制日志
3.同时master 节点会为每一个I/O线程启动一个dump线程;
用于向其发送二进制事件,并保存到slave节点本地的中继日志文件(relay log)中;
slave节点将启动sql线程从中继日志中读取二进制日志,并解析成sql语句在本地逐一执行;
保证slave节点与master节点数据一致;
最后I/O线程和sql线程会进入睡眠状态,等待下一次被唤醒
ps:
中继日志通常位于 os 缓存中,所以中继日志的开销很小;
复制过程有一个很重要的限制,复制在slave上是串行化的;也就是说,msater上的并行更新操作不能在slave上操作
mysql主从复制延迟
1.master服务器高并发,形成大量事务;slave来不及复制执行
2.网络延迟
3.主从设备硬件差异(cpu主频、内存io、硬盘io)导致
4.本来就不是同步复制而是异步复制
从库优化mysql参数;增大innodb_buffer_pool_size,让更多操作在Mysql内存中完成,减少磁盘操作
从库使用高性能主机;包括cpu强悍、内存加大。避免使用虚拟云主机,使用物理主机,这样提升了i/o方面性。
从库使用SSD磁盘;
网络优化,避免跨机房实现同步(尽量在同一个路由器下做)
核心
核心为:两个日志,三个线程;工作原理和流程
实验
环境准备
master服务器:192.168.67.12 mysql5.7
slave服务器:192.168.67.13 mysql5.7
slave服务器:192.168.67.14 mysql5.7
amoeba服务器:192.168.67.11 jdk1.6,amoeba
客户端服务器:192.168.67.11systemctl stop firewalld
systemctl disable firewalld
setenforce 0mysql主从服务器时间同步
主服务器安装ntp
#查看是否安装ntp
[root@master ~]# rpm-q ntp#安装ntp
[root@master ~]# yum -y install ntp[root@master ~]# vim /etc/ntp.conf
--末尾添加--
#设置本地为时钟源,注意修改网段127.127.主库网段.0
server 127.127.67.0
#设置时间层级,标准为8(限制在15内)
fudge 127.127.67.0 stratum 8

开启服务
#开启服务
[root@master ~]# service ntpd start
Redirecting to /bin/systemctl start ntpd.service
同步为北京时间
[root@master ~]# date -R
Thu, 28 Mar 2024 00:12:07 -0700[root@master ~]# timedatectl set-timezone Asia/Shanghai
[root@master ~]# date -R
Thu, 28 Mar 2024 15:13:59 +0800
从服务器安装ntpdate
[root@slave1 ~]# yum -y install ntpdate
[root@slave2 ~]# yum -y install ntpdate
slave开启ntpd,进行时间同步
[root@slave1 ~]# /usr/sbin/ntpdate 192.168.67.12
28 Mar 00:21:30 ntpdate[5317]: adjust time server 192.168.67.12 offset 0.005099 sec
[root@slave1 ~]# date
Thu Mar 28 00:21:45 PDT 2024
[root@slave2 ~]# /usr/sbin/ntpdate 192.168.67.12
28 Mar 00:21:30 ntpdate[5317]: adjust time server 192.168.67.12 offset 0.005099 sec
[root@slave2 ~]# date
Thu Mar 28 00:21:45 PDT 2024#命令执行成功但是时间没有完成同步的话,就直接也同步成北京时间吧
[root@slave1 ~]# timedatectl set-timezone Asia/Shanghai
[root@slave2 ~]# timedatectl set-timezone Asia/Shanghai报错
[root@slave1 ~]# /usr/sbin/ntpdate 192.168.67.12
28 Mar 00:03:19 ntpdate[4967]: the NTP socket is in use, exiting
#表示ntp服务被占用#关闭防火墙和安全等级
systemctl stop firewalld.service
setenforce 0设置定时任务,每30分钟与master进行一次时间同步

![]()
主服务器的mysql配置
[root@master ~]# vim /etc/my.cnfserver-id = 1
#添加主服务器,开启二进制日志
log-bin=master-bin
binlog_format = MIXED
#允许slave从master复制数据并写入到自己的二进制日志
log-slave-updates=true
重启mysql
[root@master ~]# systemctl restart mysqld
登录mysql,给从服务器授权
[root@master ~]# mysql -uroot -p123456#replication slave固定格式,表示所有从服务器拥有权限
mysql> grant replication slave on *.* to 'myslave'@'192.168.67.%' identified by '123456';
Query OK, 0 rows affected, 1 warning (0.00 sec)#刷新权限
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
查看主服务器的状态
mysql> show master status;
#显示如下,表示配置正确
+-------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+-------------------+
| master-bin.000001 | 603 | | | |
+-------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
#File 列显示日志名,Position 列显示偏移量
从服务器的mysql配置
[root@slave1 ~]# vim /etc/my.cnf#修改,注意id与Master的不同,两个Slave的id也要不同
server-id = 11
#添加,开启中继日志,从主服务器上同步日志文件记录到本地
relay-log=relay-log-bin
#添加,定义中继日志文件的位置和名称,一般和relay-log在同一目录
relay-log-index=slave-relay-bin.index
#选配项;
#当 slave 从库宕机后,假如 relay-log 损坏了,导致一部分中继日志没有处理,则自动放弃所有未执行的 relay-log,并且重新从 master 上获取日志,这样就保证了relay-log 的完整性。默认情况下该功能是关闭的,将 relay_log_recovery 的值设置为 1 时, 可在 slave 从库上开启该功能,建议开启。
relay_log_recovery = 1[root@slave2 ~]# vim /etc/my.cnf
server-id = 12
relay-log=relay-log-bin
relay-log-index=slave-relay-bin.index
relay_log_recovery = 1重启mysql
[root@slave1 ~]# systemctl restart mysqld
[root@slave2 ~]# systemctl restart mysqld配置同步
#进入从库的mysql
mysql -uroot -p123mysql> change master to master_host='192.168.67.12',master_user='myslave',master_password='123456',master_log_file='master-bin.000001',master_log_pos=603;
Query OK, 0 rows affected, 2 warnings (0.02 sec)
启动同步
#启动同步;如有报错执行 reset slave;
start slave;
查看从服务器的状态
#查看 Slave 状态
show slave status\G;
//确保 IO 和 SQL 线程都是 Yes,代表同步正常。
*************************** 1. row ***************************Slave_IO_State: Waiting for master to send eventMaster_Host: 192.168.67.12Master_User: myslaveMaster_Port: 3306Connect_Retry: 60Master_Log_File: master-bin.000001Read_Master_Log_Pos: 1052Relay_Log_File: relay-log-bin.000002Relay_Log_Pos: 770Relay_Master_Log_File: master-bin.000001#负责与主机的io通信Slave_IO_Running: Yes#负责自己的slave mysql进程Slave_SQL_Running: YesReplicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0Last_Error: Skip_Counter: 0Exec_Master_Log_Pos: 1052Relay_Log_Space: 975Until_Condition: NoneUntil_Log_File: Until_Log_Pos: 0Master_SSL_Allowed: NoMaster_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: NoLast_IO_Errno: 0Last_IO_Error: Last_SQL_Errno: 0Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 1Master_UUID: f266c8ca-e5ad-11ee-a96d-000c29ab119cMaster_Info_File: /usr/local/mysql/data/master.infoSQL_Delay: 0SQL_Remaining_Delay: NULLSlave_SQL_Running_State: Slave has read all relay log; waiting for more updatesMaster_Retry_Count: 86400Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version:
1 row in set (0.00 sec)ERROR:
No query specified
一般情况下,Slave_IO_Running:No 的可能性:
1.网络不通
2.my.cnf配置有问题
3.密码、file文件名、pos偏移量配置的不对
4.防火墙没有关闭
验证主从复制
主服务器上进行执行建库、建表;
查看主服务器和从服务器上数据库的情况
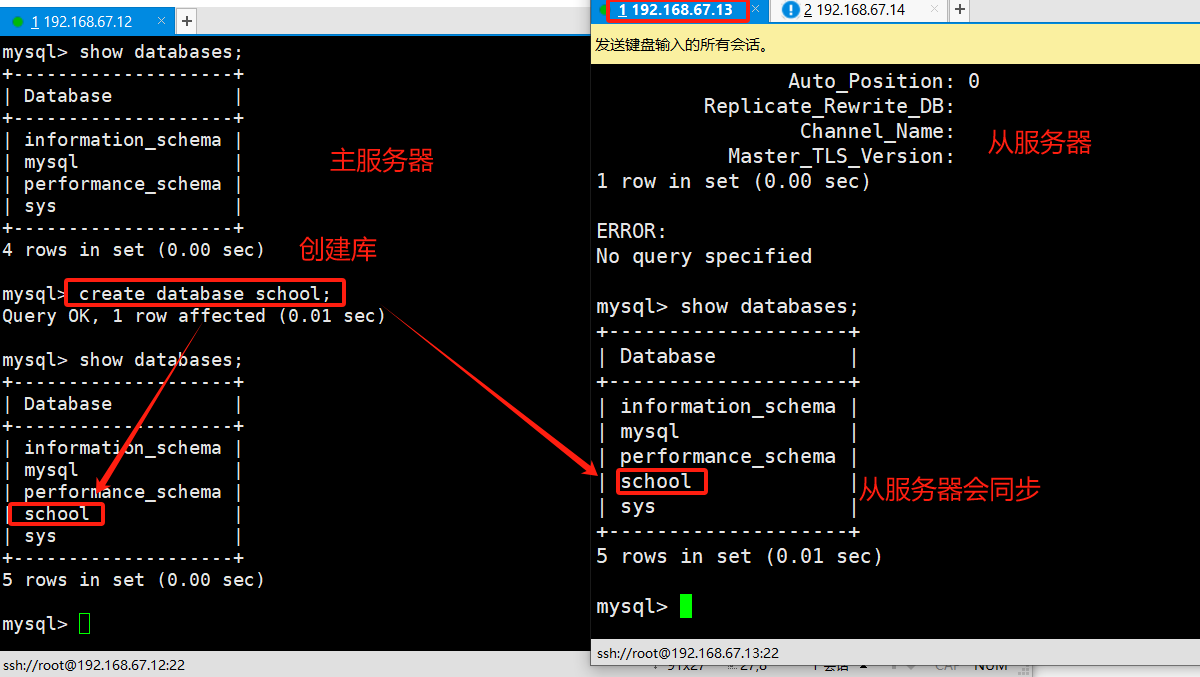
如数据中途加入主从复制的库 需要导出主服务器库 的库文件并且导入到从服务器中
读写分离
读写分离作用:解决高并发
为什么做读写分离:锁行锁表,影响使用;
1.什么是读写分离?
一般来说是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
2.为什么做读写分离?
数据库“写”操作是比较耗时的;但“读”是很快的(相比写快得多)
例如:有1000条数据,写可能要3分钟,读可能只要5秒钟
所以读写分离可以解决,由于数据库的写入使查询效率变慢的问题
3.什么情况下要做读写分离
程序使用数据库多,但更新少,查询多的情况下考虑使用;
利用数据库主从同步,通过读写分离来分担数据库压力,提高性能
mysql读写分离的原理
读写分离:只在主服务器上写,只在从服务器上读;
常见的mysql读写分离类型
1.基于程序代码内部实现
在代码中根据select、insert 进行路由分类;是目前生产环境应用最广泛的方法
优点:性能好,不需要额外的硬件设备
缺点:需要开发人员来实现,运维做不了;
而且并不是所有应用都适合在程序代码中实现读写分离,
大型复杂的java应用,如果在程序代码中实现读写分离,对代码改动就比较大;不合适
2.基于中间代理层实现
代理一般位于客户端和服务器之间,代理服务器接到客户端的请求通过判断后转发到后端数据库;
主要有以下的代表性程序:
mysql-proxy:是MySQL的开源项目,通过其自带的lua脚本进行sql判断
由于使用MySQL Proxy 需要写大量的Lua脚本,这些Lua并不是现成的,而是需要自己去写。这对于并不熟悉MySQL Proxy 内置变量和MySQL Protocol 的人来说是非常困难的。
altas:是由奇虎360的Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目;
它是在mysql-proxy 0.8.2版本的基础上,对其进行了优化,增加了一些新的功能特性;
360内部使用Atlas运行的mysql业务,每天承载的读写请求数达几十亿条;
支持事物以及存储过程。
amoeba:由陈思儒开发,作者曾就职于阿里巴巴;
该程序由Java语言进行开发,阿里巴巴将其用于生产环境;
但是它不支持事务和存储过程。
Amoeba是一个非常容易使用、可移植性非常强的软件。因此它在生产环境中被广泛应用于数据库的代理层。
读写分离实验
amoeba服务器配置
环境
master服务器:192.168.67.12 mysql5.7
slave服务器:192.168.67.13 mysql5.7
slave服务器:192.168.67.14 mysql5.7
amoeba服务器:192.168.67.11 jdk1.6,amoeba
客户端服务器:192.168.67.11systemctl stop firewalld
systemctl disable firewalld
setenforce 0主、从安装jdk1.6
#上传amoeba和jdk1.6的包
[root@amoeba opt]# rz -E
rz waiting to receive.
[root@amoeba opt]# rz -E
rz waiting to receive.
[root@amoeba opt]# ls
amoeba-mysql-binary-2.2.0.tar.gz jdk-6u14-linux-x64.bin rh
[root@amoeba opt]# [root@amoeba opt]# cp jdk-6u14-linux-x64.bin /usr/local/
[root@amoeba opt]# cd /usr/local/
[root@amoeba local]# ls
bin games jdk-6u14-linux-x64.bin lib64 sbin src
etc include lib libexec share
#给执行权限
[root@amoeba local]# chmod +x jdk-6u14-linux-x64.bin
#执行
[root@amoeba local]# ./jdk-6u14-linux-x64.bin
执行后,一直按空格,直到more消失、看到yes;输入yes,按回车
//按enter回车出现下面的窗口直接点否即可

[root@amoeba local]# ls
bin games jdk1.6.0_14 lib libexec share
etc include jdk-6u14-linux-x64.bin lib64 sbin src
[root@amoeba local]# mv jdk1.6.0_14/ /usr/local/jdk1.6
[root@amoeba local]# ls
bin games jdk1.6 lib libexec share
etc include jdk-6u14-linux-x64.bin lib64 sbin src
修改环境变量,并刷新
#配置环境变量
[root@amoeba local]# vim /etc/profile
#--G--o--在页尾添加
export JAVA_HOME=/usr/local/jdk1.6
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin/:$PATH:$HOME/bin
export AMOEBA_HOME=/usr/local/amoeba
export PATH=$PATH:$AMOEBA_HOME/bin#刷新环境变量文件
[root@amoeba local]# source /etc/profile
[root@amoeba local]# java -version
java version "1.6.0_14"
Java(TM) SE Runtime Environment (build 1.6.0_14-b08)
Java HotSpot(TM) 64-Bit Server VM (build 14.0-b16, mixed mode)
安装amoeba软件192.168.67.11
#解压amoeba包
[root@amoeba local]# cd /opt/
[root@amoeba opt]# ls
amoeba-mysql-binary-2.2.0.tar.gz jdk-6u14-linux-x64.bin rh
[root@amoeba opt]# mkdir /usr/local/amoeba
[root@amoeba opt]# tar zxvf amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/#赋权
[root@amoeba opt]# chmod -R 755 /usr/local/amoeba/
#执行amoeba,显示amoeba start|stop 说明安装成功
[root@amoeba opt]# /usr/local/amoeba/bin/amoeba
amoeba start|stop
[root@amoeba opt]#配置 Amoeba读写分离,两个 Slave 读负载均衡
#进入数据库
[root@slave1 ~]# mysql -uroot -p123#先在Master、Slave1、Slave2 的mysql上开放权限给 Amoeba 访问
#给master和两台slave配置一个test用户并赋权
mysql> grant all on *.* to test@'192.168.67.%' identified by '123456';
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> grant all on *.* to test@'192.168.67.%' identified by '123456';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> grant all on *.* to test@'192.168.67.%' identified by '123456';
Query OK, 0 rows affected, 1 warning (0.00 sec)#查看test用户的权限
mysql> show grants for test@'192.168.67.%';
+------------------------------------------------------+
| Grants for test@192.168.67.% |
+------------------------------------------------------+
| GRANT ALL PRIVILEGES ON *.* TO 'test'@'192.168.67.%' |
+------------------------------------------------------+
1 row in set (0.00 sec)
回到amoeba服务器配置amoeba服务
[root@amoeba opt]# cd /usr/local/amoeba/conf/
[root@amoeba conf]# ls
access_list.conf dbserver.dtd functionMap.xml rule.dtd
amoeba.dtd dbServers.xml log4j.dtd ruleFunctionMap.xml
amoeba.xml function.dtd log4j.xml rule.xml
#先备份再修改,安全
[root@amoeba conf]# cp amoeba.xml amoeba.xml.bak
#修改amoeba配置文件
[root@amoeba conf]# vim amoeba.xml--30行--user设为amoeba
<property name="user">amoeba</property>
--32行--密码设为123456
<property name="password">123456</property>
--115行--默认池为master
<property name="defaultPool">master</property>
--117-去掉注释-读为master,写为slaves
<property name="writePool">master</property>
<property name="readPool">slaves</property>[root@amoeba conf]# ls
access_list.conf amoeba.xml.bak function.dtd log4j.xml rule.xml
amoeba.dtd dbserver.dtd functionMap.xml rule.dtd
amoeba.xml dbServers.xml log4j.dtd ruleFunctionMap.xml
#先备份一下
[root@amoeba conf]# cp dbServers.xml dbServers.xml,bak
#然后修改配置文件
[root@amoeba conf]# vim dbServers.xml--23行--注释掉 作用:默认进入test库 以防mysql中没有test库时,会报错
<!-- <property name="schema">test</property> -->
--26--修改
<property name="user">test</property>
--28-30--去掉注释
<property name="password">123456</property>
--45--修改,设置主服务器的名Master
<dbServer name="master" parent="abstractServer">
--48--修改,设置主服务器的地址
<property name="ipAddress">192.168.67.12</property>
--52--修改,设置从服务器的名slave1
<dbServer name="slave1" parent="abstractServer">
--55--修改,设置从服务器1的地址
<property name="ipAddress">192.168.67.13</property>
--58--复制上面6行粘贴,设置从服务器2的名slave2和地址
<dbServer name="slave2" parent="abstractServer">
<property name="ipAddress">192.168.67.14</property>
--65行--修改
<dbServer name="slaves" virtual="true">
--68行--根据67行可得1表示轮询,不用改
<property name="loadbalance">1</property>
--71行--修改
<property name="poolNames">slave1,slave2</property>启动amoeba
#启动amoeba,&前要加空格表示后台执行
[root@amoeba conf]# /usr/local/amoeba/bin/amoeba start &
[1] 10941
[root@amoeba conf]# log4j:WARN log4j config load completed from file:/usr/local/amoeba/conf/log4j.xml
2024-03-28 03:52:58,806 INFO context.MysqlRuntimeContext - Amoeba for Mysql current versoin=5.1.45-mysql-amoeba-proxy-2.2.0
log4j:WARN ip access config load completed from file:/usr/local/amoeba/conf/access_list.conf
2024-03-28 03:52:58,962 INFO net.ServerableConnectionManager - Amoeba for Mysql listening on 0.0.0.0/0.0.0.0:8066.
2024-03-28 03:52:58,979 INFO net.ServerableConnectionManager - Amoeba Monitor Server listening on /127.0.0.1:60369.
#按ctrl+c 返回
^C[root@amoeba conf]# lsof -i:8066
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 10941 root 55u IPv6 74178 0t0 TCP *:8066 (LISTEN)
#查看8066端口是否开启,amoeba默认端口为TCP 8066
[root@amoeba conf]# netstat -anpt | grep java
tcp6 0 0 127.0.0.1:51646 :::* LISTEN 13892/java
tcp6 0 0 :::8066 :::* LISTEN 13892/java
tcp6 0 0 192.168.67.11:35286 192.168.67.14:3306 ESTABLISHED 13195/java
tcp6 0 0 192.168.67.11:52086 192.168.67.12:3306 ESTABLISHED 13195/java
tcp6 0 0 192.168.67.11:46220 192.168.67.13:3306 ESTABLISHED 13195/java
...省略客户端配置
#安装mariadb 并开启服务
[root@amoeba ~]# yum -y install mariadb-server mariadb[root@amoeba ~]# systemctl start mariadb.service#连接amoeba服务器
[root@amoeba ~]# mysql -uamoeba -p123456 -h 192.168.67.11 -P8066
//通过amoeba服务器代理访问mysql ,在通过客户端连接mysql后写入的数据只有主服务会记录,然后同步给从服务器
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 1369543768
Server version: 5.1.45-mysql-amoeba-proxy-2.2.0 Source distributionCopyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.MySQL [(none)]>
测试
#在主服务器上创建库school和表class
mysql> create database school;
mysql> use school;
mysql> create table class (id int(2) zerofill,name char(10),score decimal(5,2));
#可以看到从服务器会同步写入#在两台从服务器上
#关闭同步
mysql> stop slave;
Query OK, 0 rows affected (0.00 sec)#分别从master、slave1和slave2上添加一条数据,然后通过客户端查看
//在master上
mysql> insert into class values(1,'master',100);
Query OK, 1 row affected (0.00 sec)
//在slave1上
mysql> insert into class values(2,'slave1',90);
Query OK, 1 row affected (0.01 sec)
//在slave2上
mysql> insert into class values(3,'slave2',90);
Query OK, 1 row affected (0.00 sec)
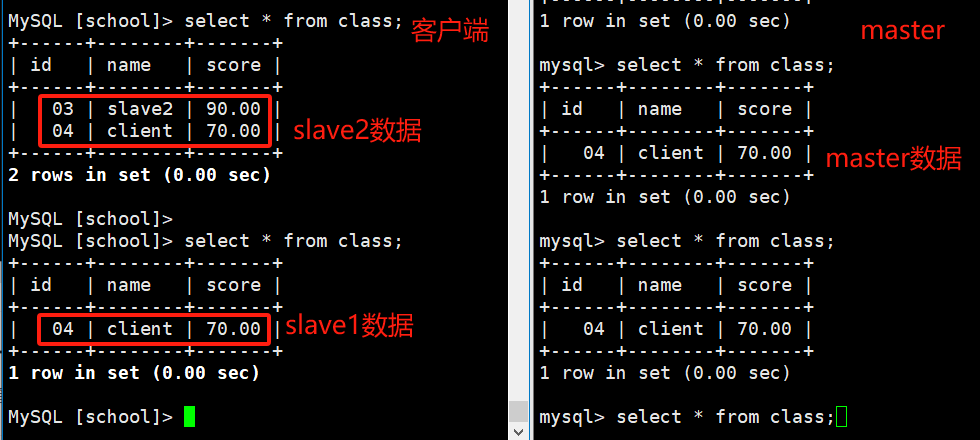
从客户端查询class表数据
MySQL [school]> select * from class;
//客户端会分别向slave1和slave2读取数据,每次只会读取其中之一(轮询显示);
//显示的只有在两个从服务器上添加的数据,没有在主服务器上添加的数据
可以看到客户机只能看到从数据库的信息,而且每次只能看到其中一个库的数据
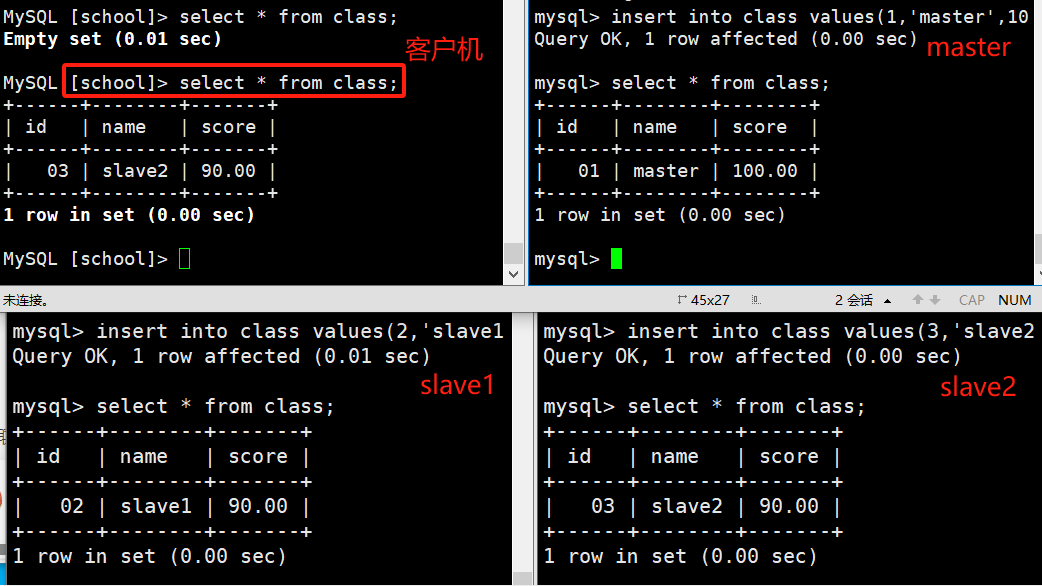

从客户机端,向表中添加数据
#从客户机向class表写入数据
MySQL [school]> insert into class values(4,'client',70);
//只有主服务器上有此数据

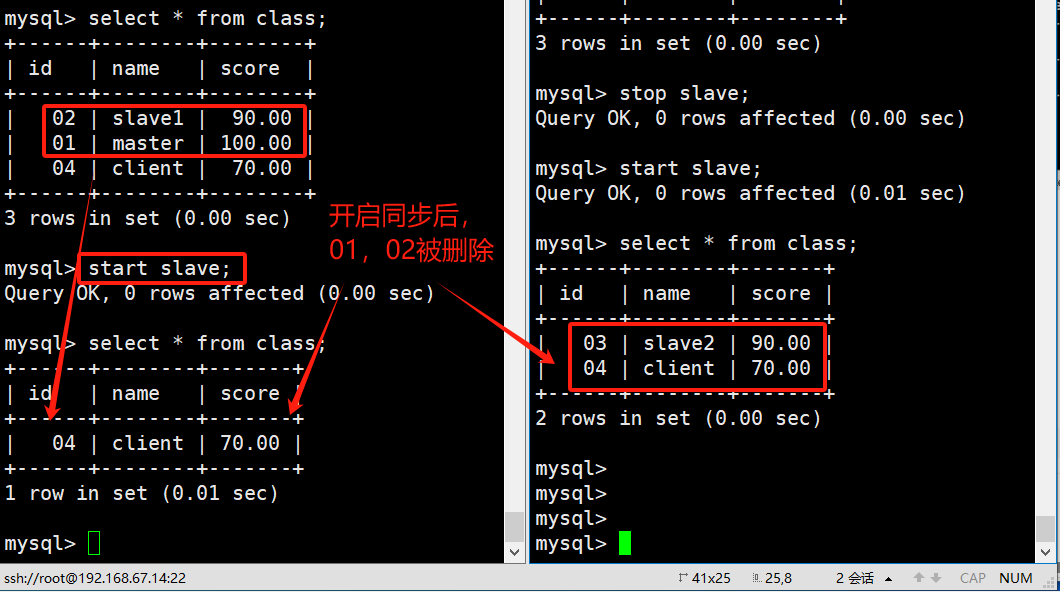
开启两个从库的同步
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
//在两个从服务器上执行 start slave; 即可实现同步在主服务器上添加的数据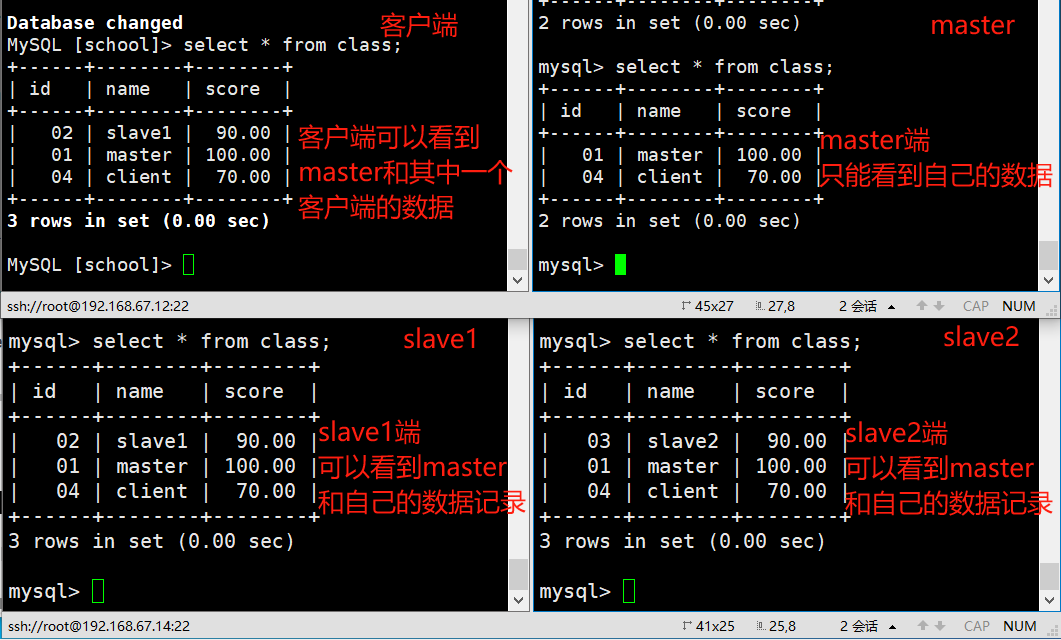
关闭从服务器的同步,master端删除master和slave1的一条数据
#master端删除01和02数据
mysql> delete from class where id=01;
Query OK, 0 rows affected (0.00 sec)mysql> delete from class where id=02;
Query OK, 0 rows affected (0.00 sec)
#数据未开启同步前,两个从服务器的数据不会改变

启动从库的同步,再次查看
MySQL [school]> select * from class;//同步开启,两个从库会同步master库执行过的sql语句;删除01和02
总结
主从复制
通过主从复制的方式同步数据,再通过读写分离提升数据库的并发负载能力
mysql支持的复制类型
mixed:混合类型的复制;
默认采用基于语句的复制,一旦发现基于语句无法精确复制时,就采用基于行复制
主从复制的核心
核心为:两个日志,三个线程;工作原理和流程
主从复制的工作过程★★★
mysql节点将改变的数据记录到二进制日志(bin log)中;
slave节点每隔一段时间会对master的二进制文件进行检测,
当数据发生变化时,会开启一个I/O线程去请求master的二进制日志;
同时master也会启动dump线程来发送二进制事件给slave的I/O线程,
I/O线程会将收到的二进制文件保存到slave节点的中继日志(relay log)中;
之后启动sql线程读取中继日志中的二进制日志,并解析成sql语句在本地逐行执行;
确保主从数据一致;
最后,I/O线程和sql线程会进入睡眠状态,等待下一次唤醒
主从复制延迟的原因有:
1.master服务器高并发,形成大量事务;slave来不及复制执行
2.网络延迟
3.主从设备硬件差异(cpu主频、内存io、硬盘io)导致
4.本来就不是同步复制而是异步复制
解决办法:
从库优化mysql参数;使用高性能主机;使用SSD磁盘;避免跨机房实现同步;
主从复制配置
关闭主、从的防火墙,防火墙自启和安全机制
主库安装ntp,从库安装ntpdate,做时间同步
主库设置为时钟源,时间层级为8
开启ntpd服务,同步为北京时间
timedatectl set-timezone Asia/Shanghai
从服务器安装ntpdate,并开启ntpd
crontabe -e设置定时任务
主服务器配置my.cnf文件,添加
server-id = 1
log-bin=master-bin
binlog_format = MIXED
log-slave-updates=true
重启mysql,并登录
给从服务器授权
grant replication slave on *.* to 'myslave'@'192.168.67.%' identified by '123456';
flush privilieges;刷新权限
show master status;查看主的状态,file和position
从服务器配置my.cnf文件,写入
server-id = 12
relay-log=relay-log-bin
relay-log-index=slave-relay-bin.index
relay_log_recovery = 1
配置同步
change master to master_host='192.168.67.12',master_user='myslave',master_passsword='123456',master_log_file='master-bin.000001',master_log_pos=603;
start slave;启动同步
show slave status\G;#查看 Slave 状态
添加修改数据,验证主从复制
读写分离
读写分离作用:解决高并发
为什么做读写分离:锁行锁表,影响使用;
读写分离:只在主服务器上写,只在从服务器上读;
程序使用数据库多,但更新少,查询多的情况下考虑使用;
利用数据库主从同步,通过读写分离来分担数据库压力,提高性能
mysql读写分离类型
1.基于程序代码内部实现
优点:性能好,不需要额外的硬件设备
缺点:需要开发人员来实现,运维做不了
2.基于中间代理层实现
mysql-proxy
altas
Amoeba是一个非常容易使用、可移植性非常强的软件
读写分离实验
主、从安装jdk1.6
修改环境变量,并刷新
安装amoeba软件
相关文章:
【MySQL】6.MySQL主从复制和读写分离
主从复制 主从复制与读写分离 通常数据库的读/写都在同一个数据库服务器中进行; 但这样在安全性、高可用性和高并发等各个方面无法满足生产环境的实际需求; 因此,通过主从复制的方式同步数据,再通过读写分离提升数据库的并发负载…...

Lucene及概念介绍
Lucene及概念介绍 基础概念倒排索引索引合并分析查询语句的构成 基础概念 Document:我们一次查询或更新的载体,对比于实体类 Field:字段,是key-value格式的数据,对比实体类的字段 Item:一个单词࿰…...

密码算法概论
基本概念 什么是密码学? 简单来说,密码学就是研究编制密码和破译密码的技术科学 例题: 密码学的三个阶段 古代到1949年:具有艺术性的科学1949到1975年:IBM制定了加密标准DES1976至今:1976年开创了公钥密…...
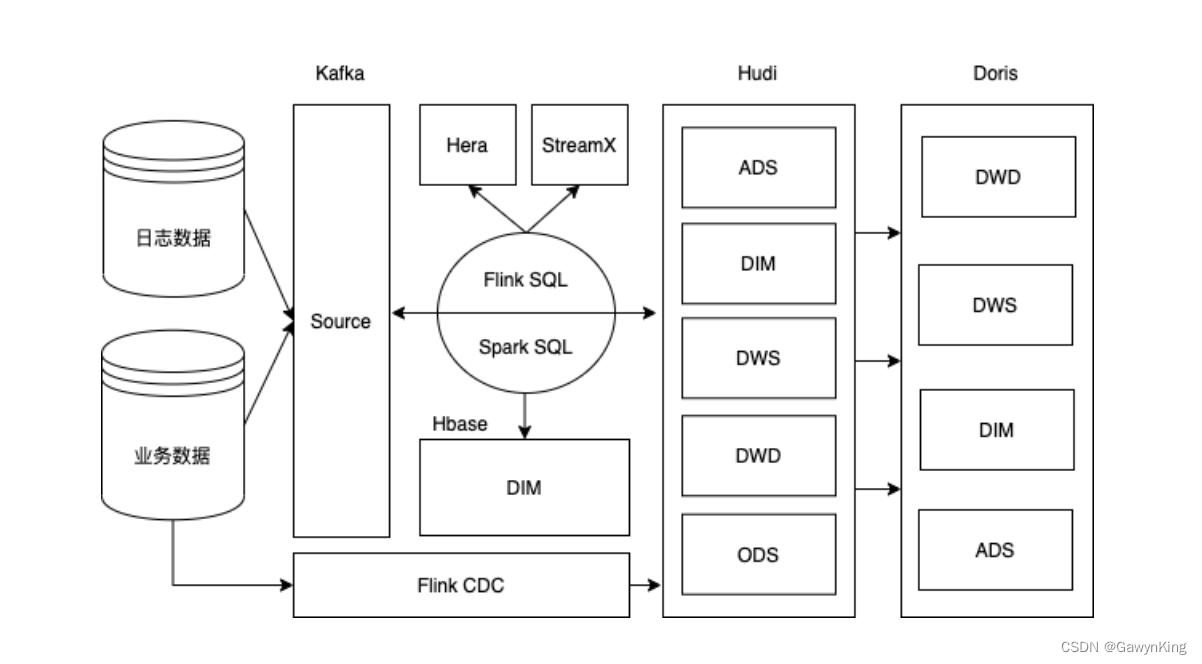
实时数仓之实时数仓架构(Hudi)
目前比较流行的实时数仓架构有两类,其中一类是以FlinkDoris为核心的实时数仓架构方案;另一类是以湖仓一体架构为核心的实时数仓架构方案。本文针对FlinkHudi湖仓一体架构进行介绍,这套架构的特点是可以基于一套数据完全实现Lambda架构。实时数…...

2022-04-15_for循环等_作业
for循环 编写程序数一下 1到 100 的所有整数中出现多少个数字9计算1/1-1/21/3-1/41/5 …… 1/99 - 1/100 的值,打印出结果求10 个整数中最大值在屏幕上输出9*9乘法口诀表二分查找 编写程序数一下 1到 100 的所有整数中出现多少个数字9 #include <stdio.h>in…...

脑机辅助推导算法
目录 一,背景 二,华容道中道 1,问题 2,告诉脑机如何编码一个正方形格子 3,让脑机汇总信息 4,观察图,得到启发式算法 5,根据启发式算法求出具体解 6,可视化 一&am…...
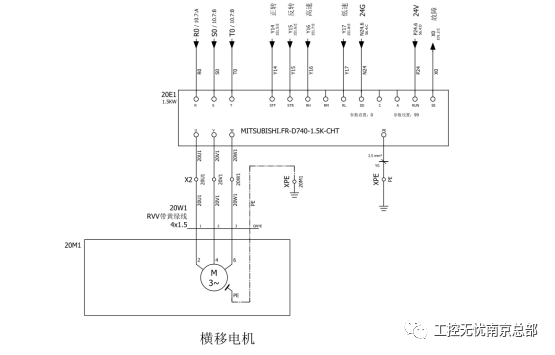
【原创教程】三菱FX PLC控制FR-E740变频器
变频器的使用 1. 使用三菱FX PLC 控制变频器时,接线图请按下图所示接线。 各个端子的说明如下: R、S、T:变频器电源,E740变频器电源位3相380V。 STF:正转启动, STF信号ON时为正转、OFF时为停止指令。 STR :反转启动,STR信号ON时为反转、OFF时为停止指令。 RH、RM、RL…...
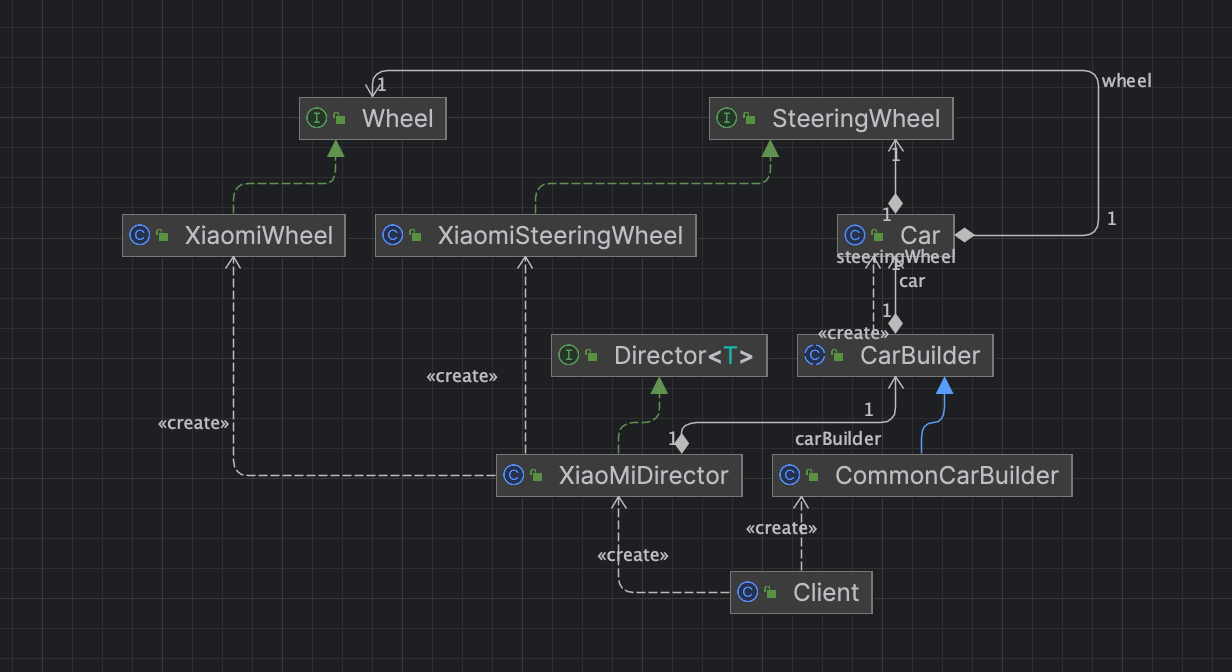
重读Java设计模式: 深入探讨建造者模式,构建复杂对象的优雅解决方案
引言 在软件开发中,有时需要构建具有复杂结构的对象,如果直接使用构造函数或者 setter 方法逐个设置对象的属性,会导致代码变得冗长、难以维护,并且容易出错。为了解决这个问题,我们可以使用建造者模式。 一、建造者…...

C语言数据结构易错知识点(6)(快速排序、归并排序、计数排序)
快速排序属于交换排序,交换排序还有冒泡排序,这个太简单了,这里就不再讲解。 归并排序和快速排序都是采用分治法实现的排序,理解它们对分支思想的感悟会更深。 计数排序属于非比较排序,在数据集中的情况下可以考虑使…...

使用 React Router v6.22 进行导航
使用 React Router v6.22 进行导航 React Router v6.22 是 React 应用程序中最常用的路由库之一,提供了强大的导航功能。本文将介绍如何在 React 应用程序中使用 React Router v6.22 进行导航。 安装 React Router 首先,我们需要安装 React Router v6…...
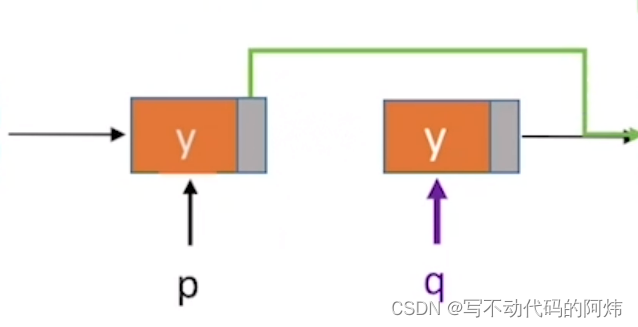
单链表的插入和删除
一、插入操作 按位序插入(带头结点): ListInsert(&L,i,e):插入操作。在表L中的第i个位置上插入指定元素e。 typedef struct LNode{ElemType data;struct LNode *next; }LNode,*LinkList;//在第i 个位置插插入元素e (带头结点) bool Li…...

全量知识系统 之“程序”详细设计 之 “絮”---开端“元素周期表”表示的一个“打地鼠”游戏
全量知识系统 之“程序”详细设计 概述-概要和纪要 序 絮(一个极简的开场白--“全量知识系统”自我介绍) 将整个“人生”的三个阶段 比作“幼稚园”三班 : 第一步【想】-- “感性”思维游戏:打地鼠 。学前教育-新生期&#x…...

【详细讲解WebView的使用与后退键处理】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...

【Linux多线程】生产者消费者模型
【Linux多线程】生产者消费者模型 目录 【Linux多线程】生产者消费者模型生产者消费者模型为何要使用生产者消费者模型生产者消费者的三种关系生产者消费者模型优点基于BlockingQueue的生产者消费者模型C queue模拟阻塞队列的生产消费模型 伪唤醒情况(多生产多消费的…...
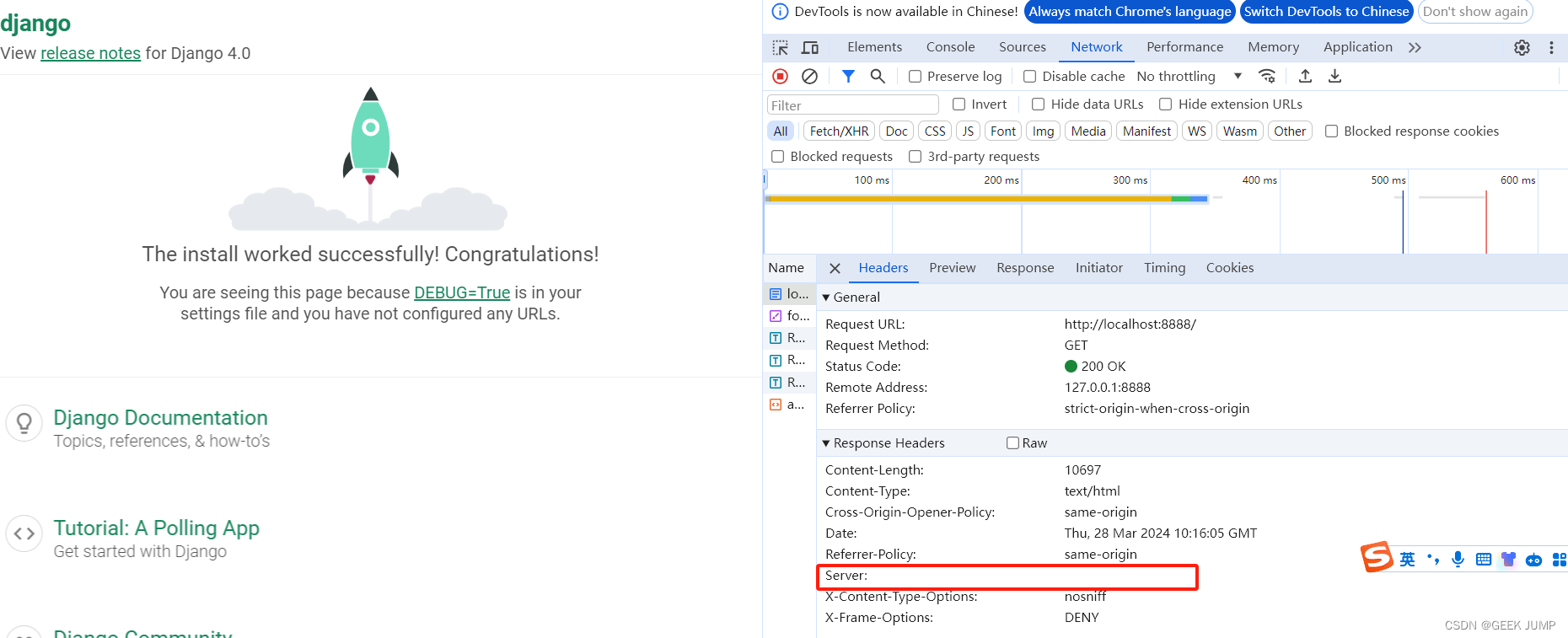
Django屏蔽Server响应头信息
一、背景 最近我们被安全部门的漏洞扫描工具扫出了一个服务端口的漏洞。这个服务本身是一个Django启动的web服务,并且除了登录页面,其它页面或者接口都需要进行登录授权才能进行访问。 漏洞扫描信息和提示修复信息如下: 自然这些漏洞如何修复,…...
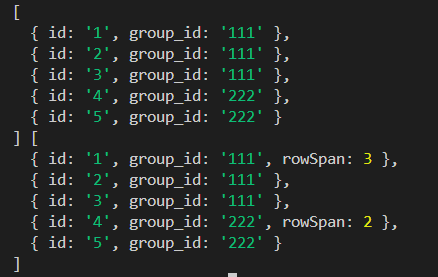
前端对数据进行分组和计数处理
js对数组数据的处理,添加属性,合并表格数据。 let data[{id:1,group_id:111},{id:2,group_id:111},{id:3,group_id:111},{id:4,group_id:222},{id:5,group_id:222} ]let tempDatadata; tempDatatempData.reduce((arr,item)>{let findarr.find(i>i…...

synchronized 和 lock
synchronized 和 Lock 都是 Java 中用于实现线程同步的机制,它们都可以保证线程安全。 # synchronized 介绍与使用 synchronized 可用来修饰普通方法、静态方法和代码块,当一个线程访问一个被 synchronized 修饰的方法或者代码块时,会自动获…...
ssh 公私钥(github)
一、生成ssh公私钥 生成自定义名称的SSH公钥和私钥对,需要使用ssh-keygen命令,这是大多数Linux和Unix系统自带的标准工具。下面,简单展示如何使用ssh-keygen命令来生成具有自定义名称的SSH密钥对。 步骤 1: 打开终端 首先,打开我…...

LangChain入门:8.打造自动生成广告文案的应用程序
在这篇技术博文中,我们将探讨如何利用LangChain框架的模板管理、变量提取和检查、模型切换以及输出解析等优势,打造一个自动生成广告文案的应用程序。 LangChain框架的优势 在介绍应用程序之前,让我们先了解一下LangChain框架的几个优势: 模板管理: 在大型项目中,文案可…...

AI如何影响装饰器模式与组合模式的选择与应用
🌈 个人主页:danci_ 🔥 系列专栏:《设计模式》《MYSQL应用》 💪🏻 制定明确可量化的目标,坚持默默的做事。 🚀 转载自热榜文章:设计模式深度解析:AI如何影响…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...

莫兰迪高级灰总结计划简约商务通用PPT模版
莫兰迪高级灰总结计划简约商务通用PPT模版,莫兰迪调色板清新简约工作汇报PPT模版,莫兰迪时尚风极简设计PPT模版,大学生毕业论文答辩PPT模版,莫兰迪配色总结计划简约商务通用PPT模版,莫兰迪商务汇报PPT模版,…...

什么是VR全景技术
VR全景技术,全称为虚拟现实全景技术,是通过计算机图像模拟生成三维空间中的虚拟世界,使用户能够在该虚拟世界中进行全方位、无死角的观察和交互的技术。VR全景技术模拟人在真实空间中的视觉体验,结合图文、3D、音视频等多媒体元素…...

小木的算法日记-多叉树的递归/层序遍历
🌲 从二叉树到森林:一文彻底搞懂多叉树遍历的艺术 🚀 引言 你好,未来的算法大神! 在数据结构的世界里,“树”无疑是最核心、最迷人的概念之一。我们中的大多数人都是从 二叉树 开始入门的,它…...

MySQL体系架构解析(三):MySQL目录与启动配置全解析
MySQL中的目录和文件 bin目录 在 MySQL 的安装目录下有一个特别重要的 bin 目录,这个目录下存放着许多可执行文件。与其他系统的可执行文件类似,这些可执行文件都是与服务器和客户端程序相关的。 启动MySQL服务器程序 在 UNIX 系统中,用…...

MyBatis-Plus 常用条件构造方法
1.常用条件方法 方法 说明eq等于 ne不等于 <>gt大于 >ge大于等于 >lt小于 <le小于等于 <betweenBETWEEN 值1 AND 值2notBetweenNOT BETWEEN 值1 AND 值2likeLIKE %值%notLikeNOT LIKE %值%likeLeftLIKE %值likeRightLIKE 值%isNull字段 IS NULLisNotNull字段…...