Spark UI
Spark UI
- Executors
- Environment
- Storage
- SQL
- Exchange
- Sort
- Aggregate
- Jobs
- Stages
- Stage DAG
- Event Timeline
- Task Metrics
- Summary Metrics
- Tasks
展示 Spark UI ,需要设置配置项并启动 History Server
# SPARK_HOME表示Spark安装目录
${SPAK_HOME}/sbin/start-history-server.sh
打开 Spark UI 先见默认 Jobs 页面
- 每个 Action 都对应一个 Job,而每个 Job 都对应着一个作业
Spark UI导航条:

| 入口页 | 内容 | 作用 |
|---|---|---|
| Jobs | Actions,数据读取/移动操作 | 作业详情概览 |
| Stages | DAG 中每个 Stages 的入口 | Stages 详细概览 |
| Storage | 分布式数据集缓存详细页 | Cache 在内存/磁盘中的发布情况 |
| Environment | 配置项,环境变量详情 | Spark 配置项是否合理 |
| Execution | 分布式运行环境/计算负载详情 | 执行计划的每个环节 |
Executors
Executors 有两个部分:Summary/Executors
- Executors:更细的粒度记录着每一个 Executor 的详情
- Summary :所有 Executors 度量指标的累计和
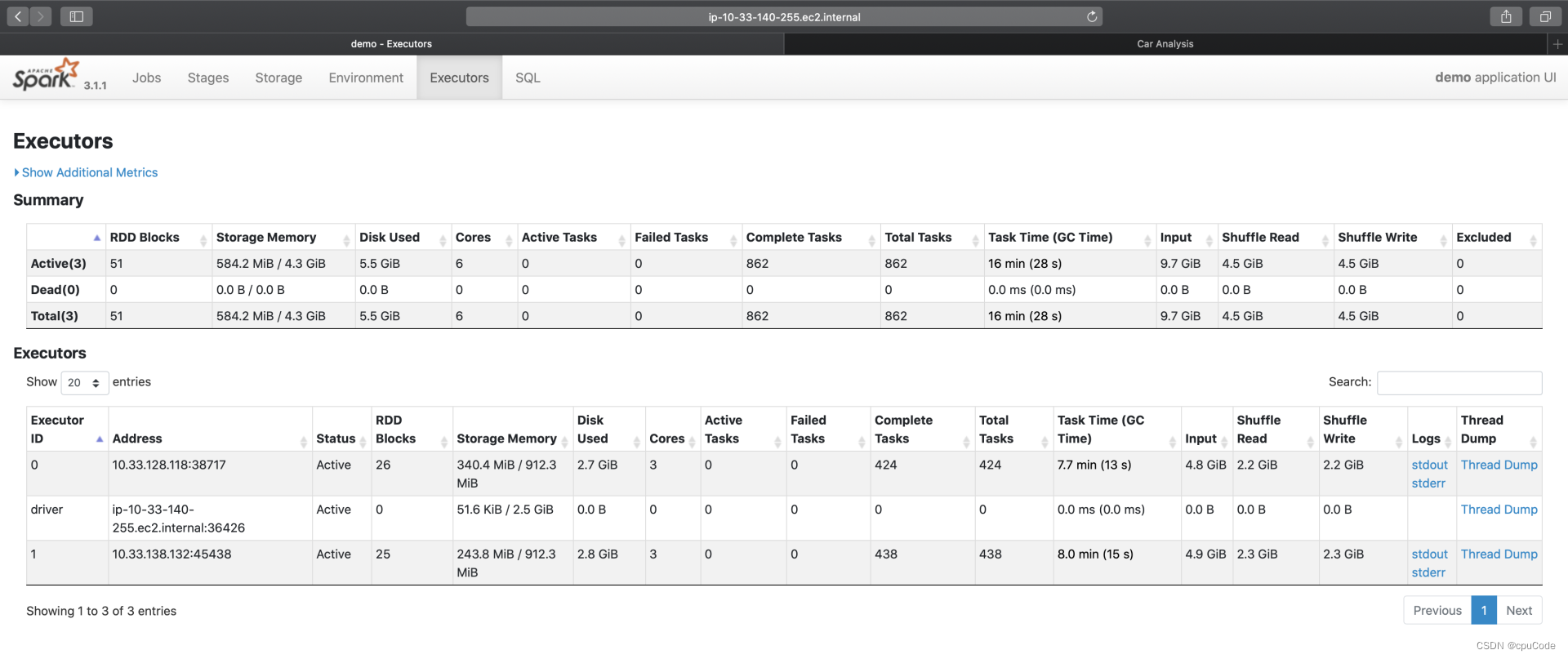
每个 Executor 的工作负载信息:
| Metrics | 含义 |
|---|---|
| RDD Blocks | 原始数据集的分区数 |
| Storage memory | Cache 的内存占用 |
| Disk Used | 计算过程中消耗的磁盘空间 |
| Cores | 计算 CPU 核数 |
| Action/Failed/Complete/Total Tasks | (活跃的/失败的/完成的/总共的)分布式任务数量 |
| Task Time(GC Time) | 任务执行时间(括号内为任务 GC 时间) |
| Input | 输入数据量大小 |
| Shuffle Read/Write | Shuffle 读写过程中消耗的数据量 |
| Logs/Thread Dump | 日志与 Core Dump |
- 根据每个 Executor 的资源消耗,能判断不同 Executors 是否存在负载不均衡
Environment
Environment 记录了各种各样的环境变量与配置项信息
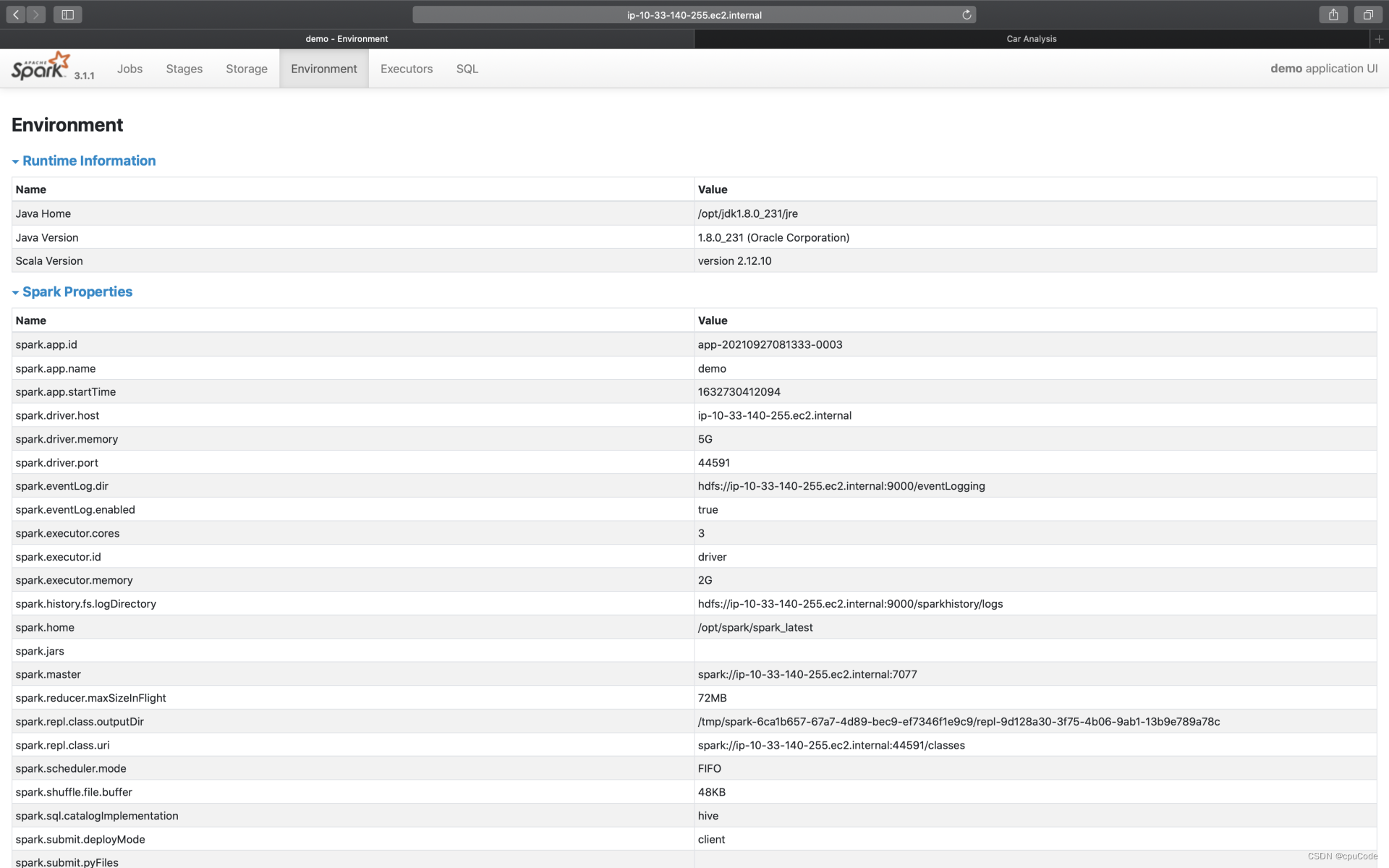
5 个环境信息:
| Metrics | 含义 |
|---|---|
| Runtime information | Java, Scala 版本号等信息 |
| Spark Properties | 所有 Spark 配置项设置 |
| Hadoop Properties | Hadoop 配置信息 |
| System Properties | 应用提交方法(spark-shell/ spark-submit) |
| Classpath Entries | Classpath 路径设置信息 |
- 根据 Spark Properties 信息,能排除是否因配置项设置而导致问题
Storage
Storage 记录了每个分布式缓存(RDD Cache、DataFrame Cache)
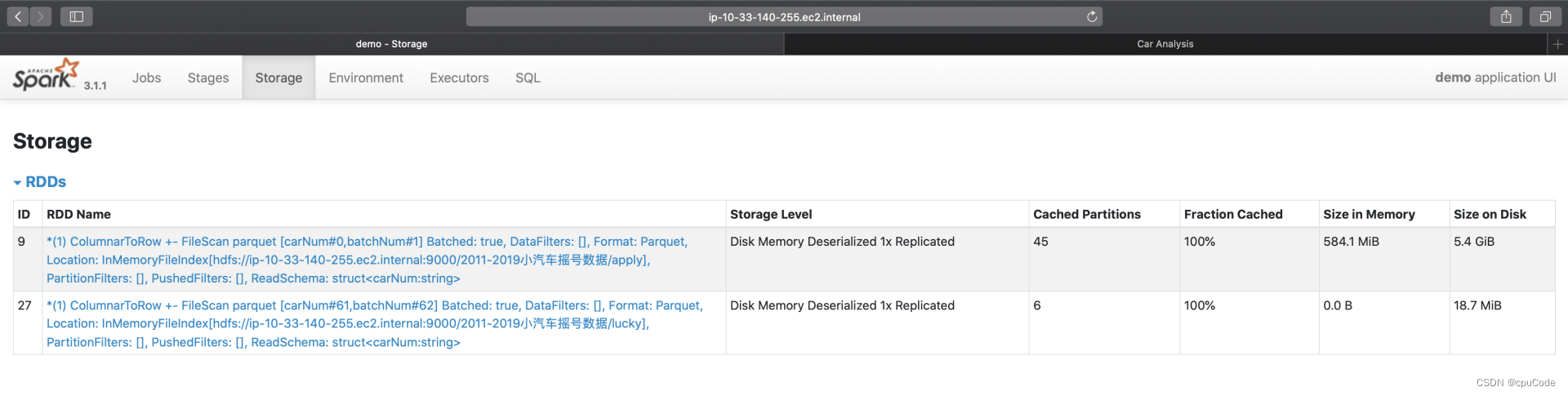
Storage 信息:
| Storage Level | 存储级别 |
|---|---|
| Cached Partitions | 已缓存分区数 |
| Fraction Cached | 缓存比例 |
| Size in Memory | 内存大小 |
| Size on Disk | 磁盘大小 |
- Cached Partitions/Fraction Cached 分别记录:数据集成功缓存的分区数量/这些缓存的分区占所有分区的比例
Fraction Cached < 100%时,说明分布式数据集没有完全缓存到内存(磁盘),这时就要注意缓存换入换出的问题
SQL
SQL 的入口页面,记录了每个 Action 对应的 Spark SQL 执行计划。点击 Description 进入二级页面,记录了每个执行计划的详细信息
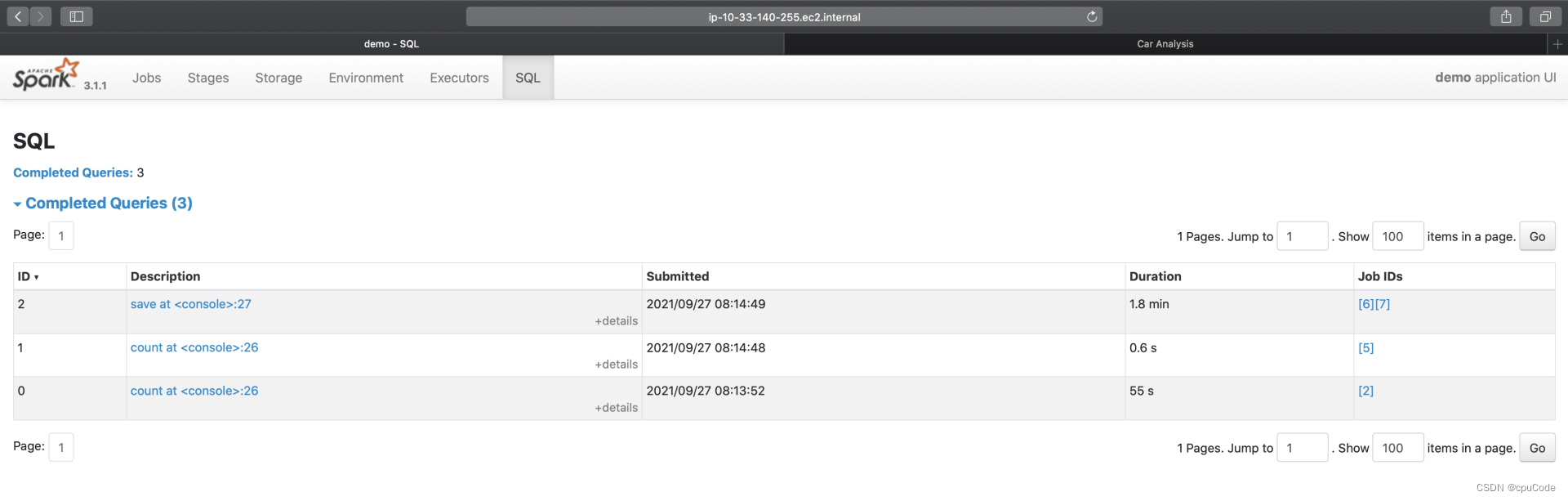
save 的执行计划 :
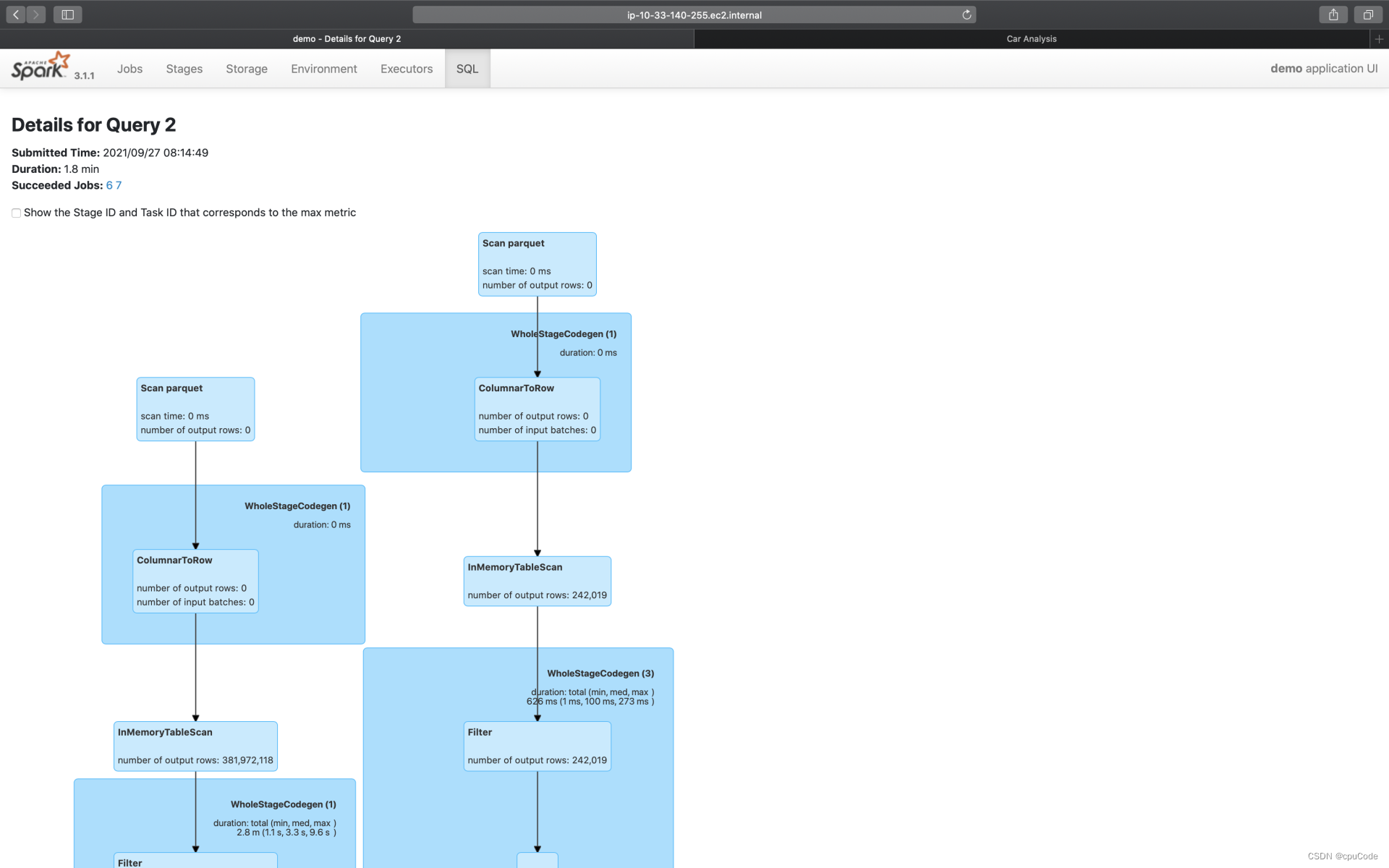
执行计划的示意图 :
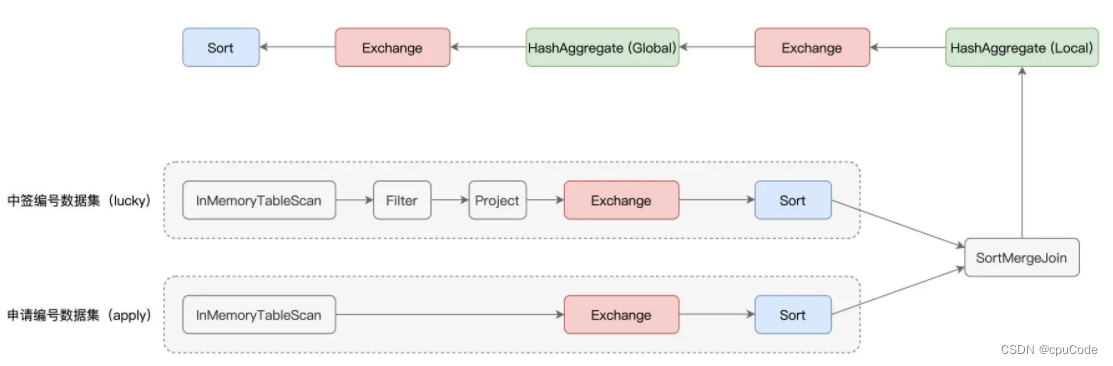
计算过程中有过滤、投影、关联、分组聚合、排序 :
- 红色部分为 Exchange,表示 Shuffle 操作
- 蓝的部分为 Sort,表示排序
- 绿色的部分为 Aggregate,表示(局部与全局的)数据聚合
Exchange
并列有两个 Exchange,对应的 SortMergeJoin 前的两个 Exchange :
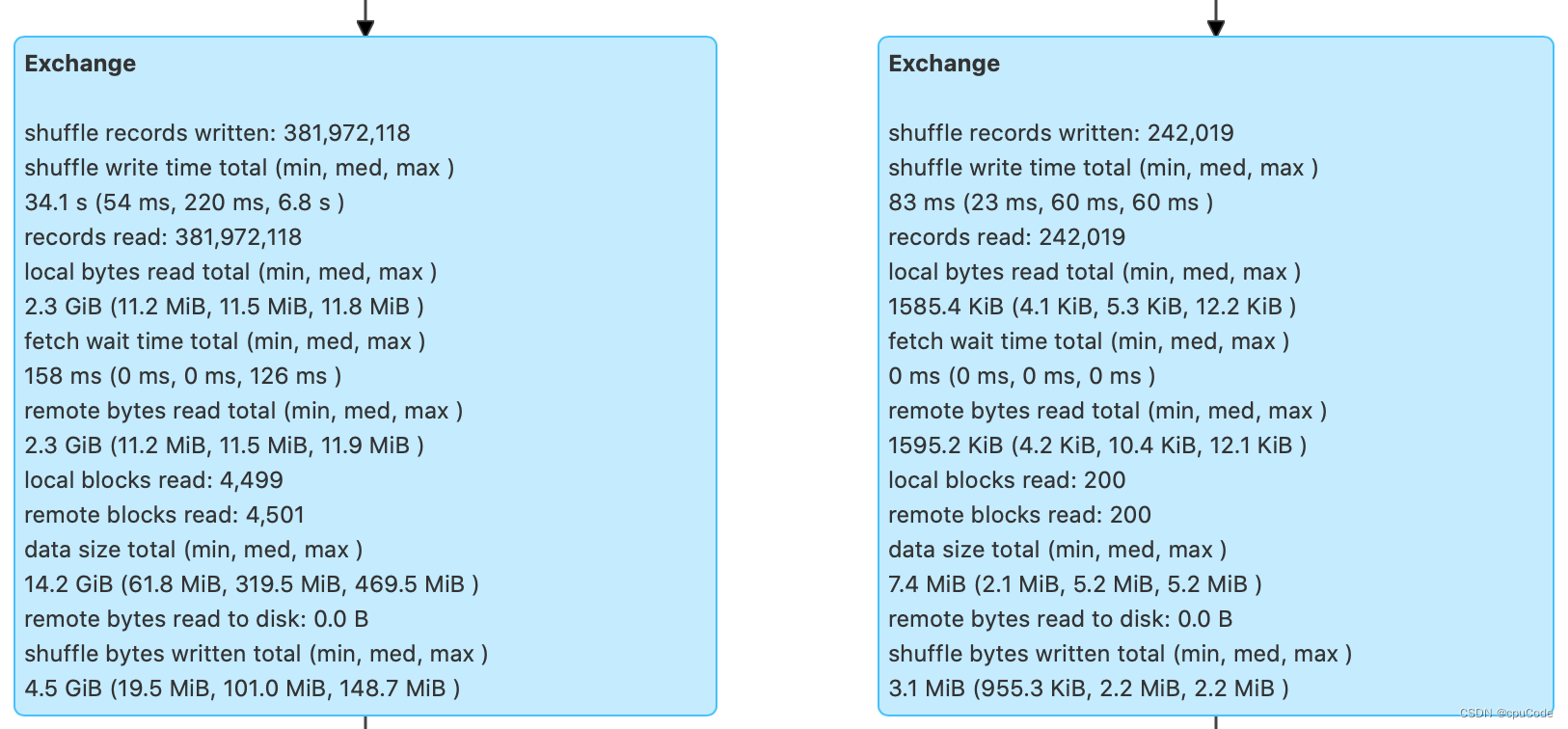
Shuffle 的计算信息:
| Shuffle records written | Shuffle Write 阶段写入的数据条目数 |
|---|---|
| Shuffle write time total | Shuffle Write 阶段花费的写入时间 |
| Records read | Shuffle Read 阶段读取的数据条目数 |
| Local bytes read total | Shuffle Read 阶段从本地节点读取的数据总量 |
| Fetch wait time total | Shuffle Read 阶段花费在网络传输上的时间 |
| Remote bytes read total | Shuffle Read 阶段跨网络,从远节点读取的数据总量 |
| Local blocks read | Shuffle Read 阶段从本地节点读取数据块数 |
| Remote blocks read | Shuffle Read 阶段跨网络,从远节点读取的数据块数 |
| Data size total | 原始数据在内存中展开后的总大小 |
| Remote bytes read to disk | Shuffle Read 阶段因数据块过大而直接落盘的情况 |
| Shuffle bytes written total | Shuffle 中间文件总大小 |
- 而过滤后的中签编号数据大小不足 10MB,对于这种大表 Join 小表,用 SortMergeJoin 不是很合理。可以使用强制广播或 AQE 让 Spark SQL 选择 BroadcastHashJoin
Sort
Sort 在运行时的内存消耗:
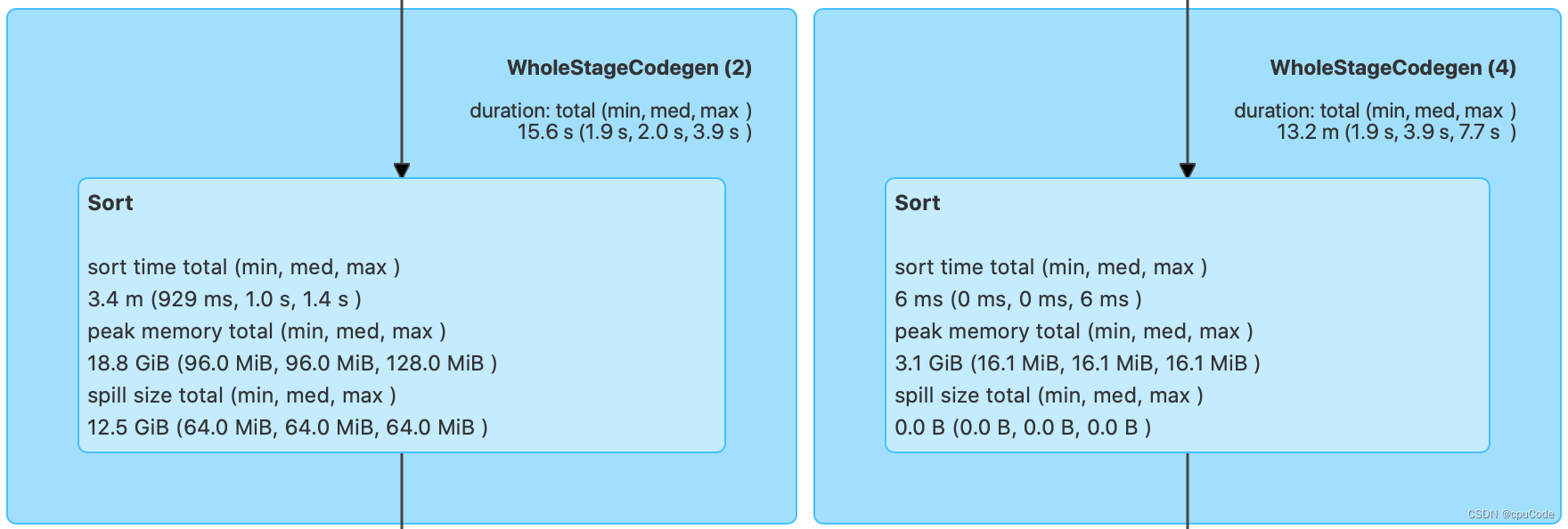
Sort 信息:
| Sort time total | 排序消耗的总时间 |
|---|---|
| Peak memory total | 内存消耗峰值 |
| Spill size total | 排序过程中溢出到磁盘的数据总量 |
- 根据
Peak memory total/Spill size total信息,能有效的设置spark.executor.memory/spark.memory.fraction/
spark.memory.storageFraction,提高性能
例子:18.8GB 的峰值消耗和 12.5GB 的磁盘溢出这两条信息,就能知道当前 3GB 的 Executor Memory 是不够的。需要调整上面的 3个参数,来加速 Sort 的执行性能
Aggregate
Aggregate 主要是内存消耗,记录Spill size(磁盘溢出)/ Peak memory total(峰值消耗)

图中:零溢出与 3.2GB 的峰值消耗,证明 3GB 的 Executor Memory 能满足
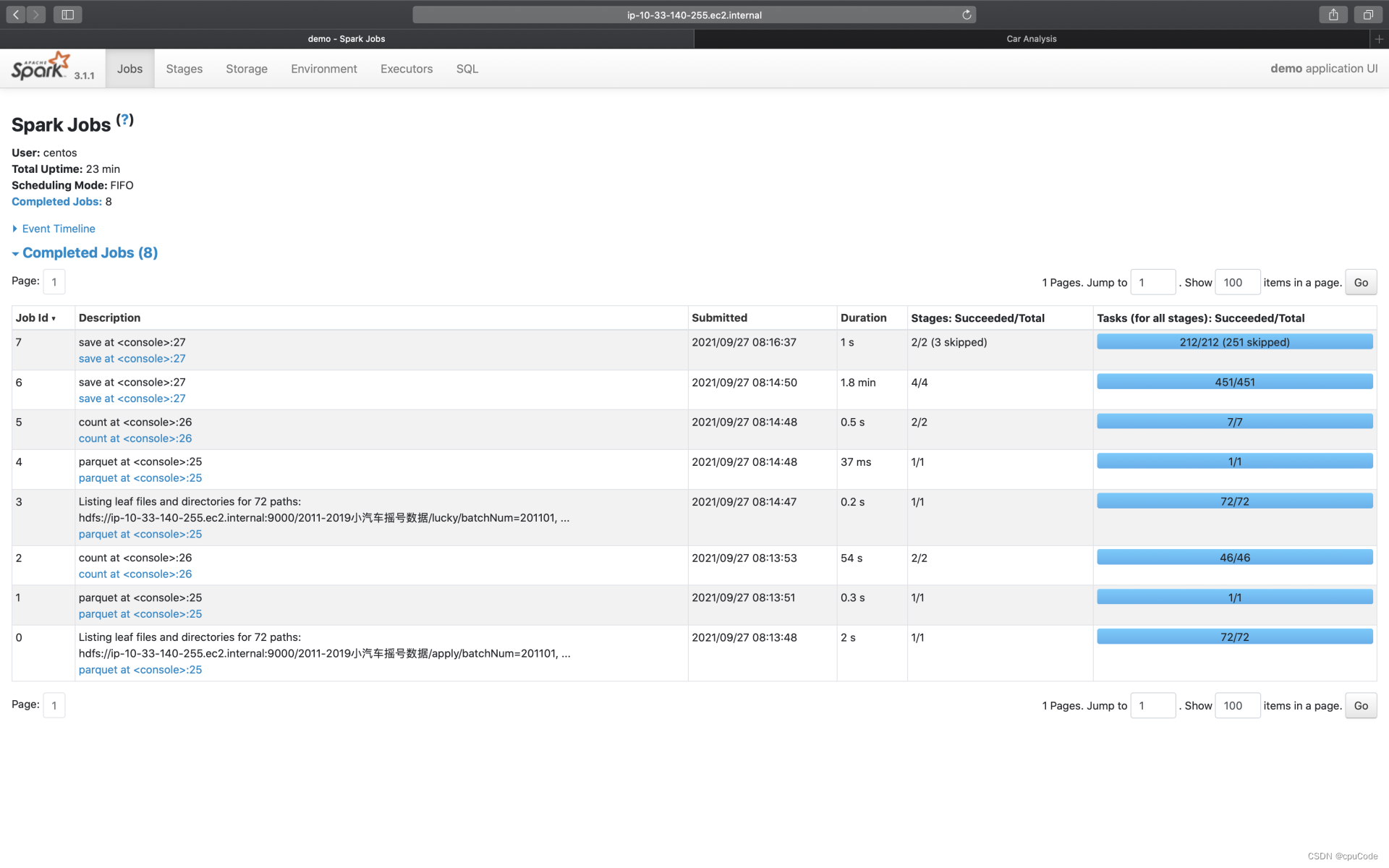
Jobs
Jobs 的入口页面记录了每个 Action 对应作业的执行情况
- 点击 Description 进入二级页面,记录了每个作业详细信息
- Jobs 详情页会显示当前 Job 的所有 Stages。每个 Stage 的执行细节能通过 Description 的跳转
Stages
Stages 记录了每一个作业的 Stages。Description 进入二级页面,记录了每个 Stage 详情页
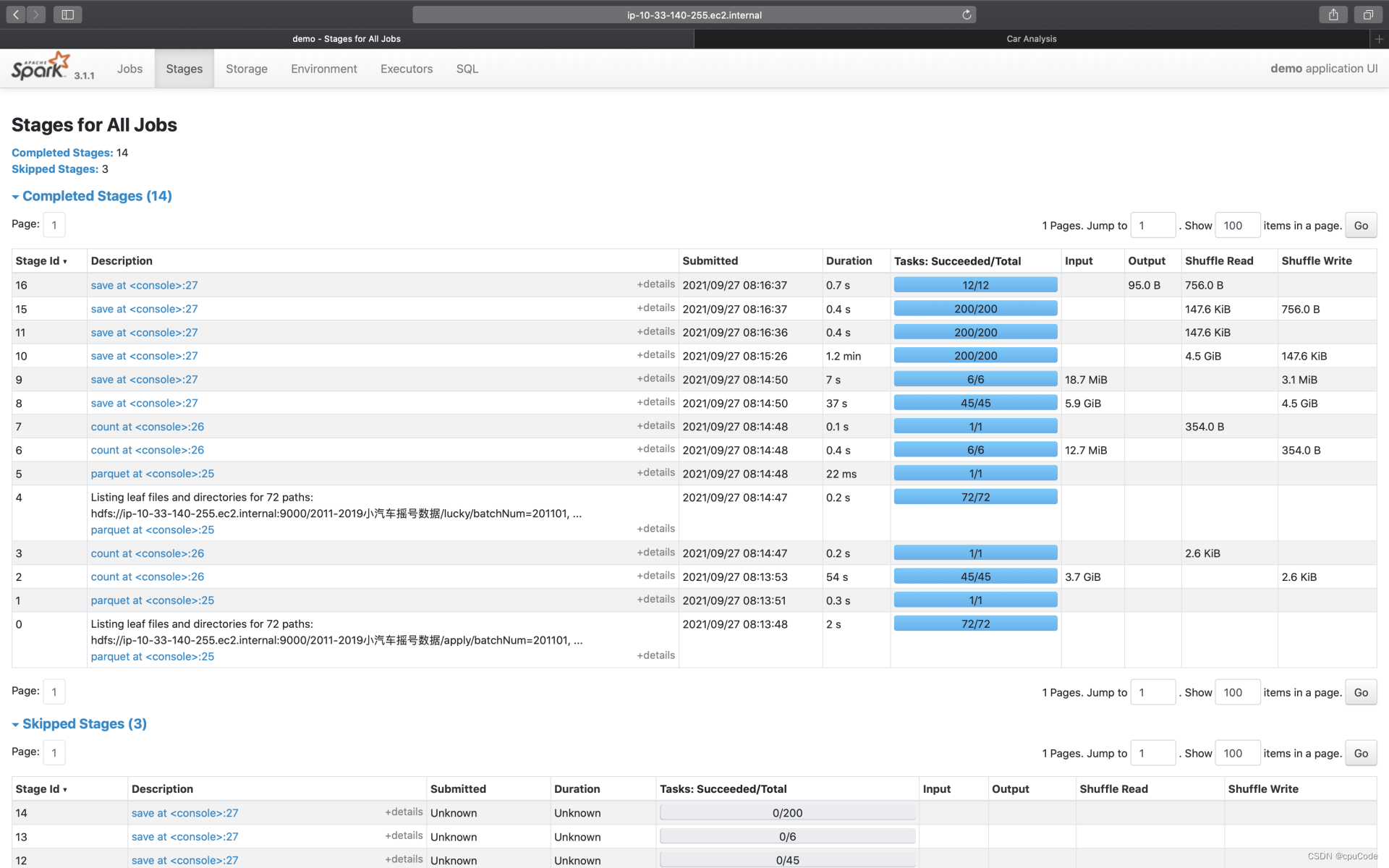
Stage 详情页包含 3 大类信息: Stage DAG、Event Timeline、Task Metrics
- Task Metrics 分为 Summary、Entry details 提供不同粒度的信息汇总
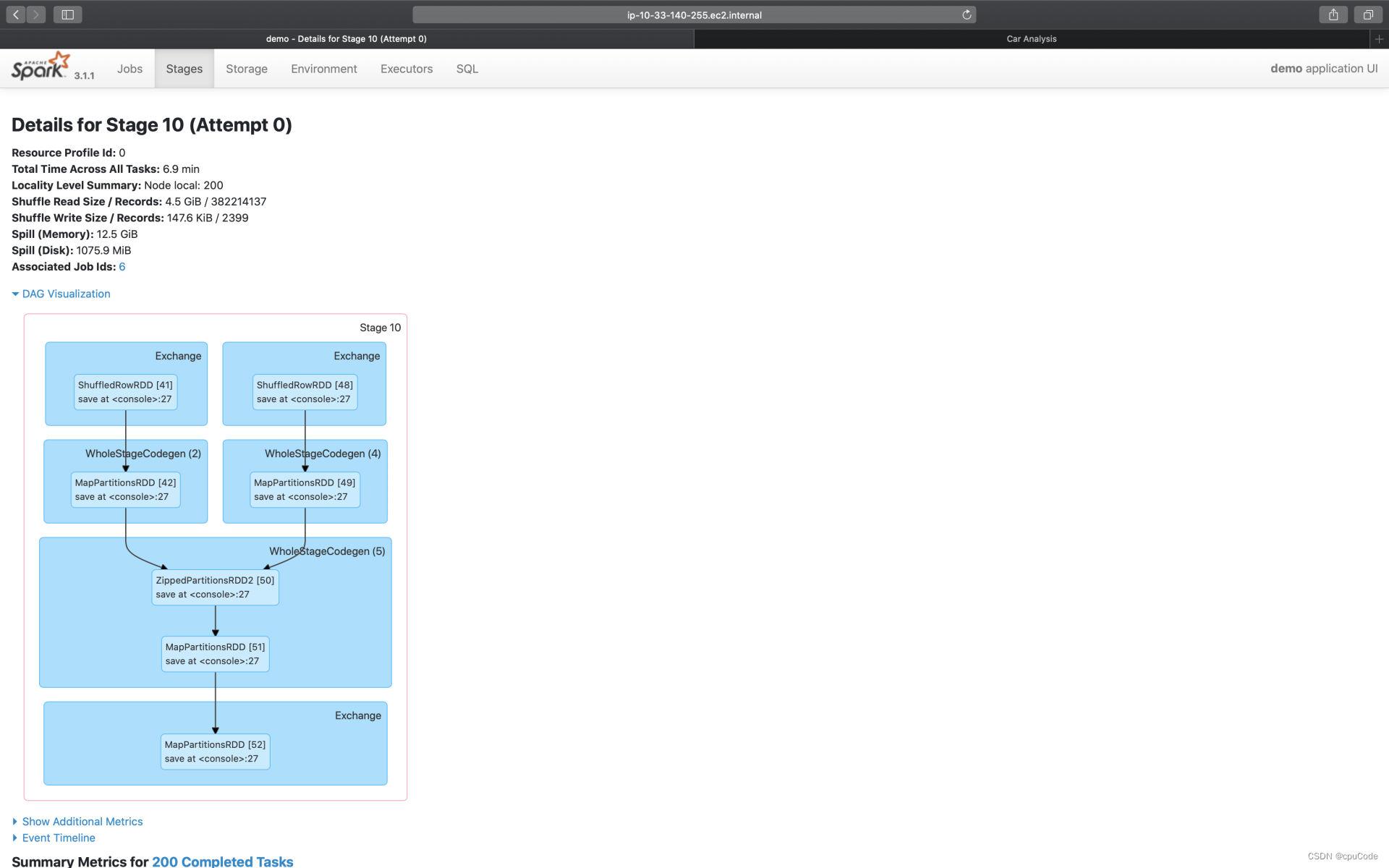
Stage DAG
点击 DAG Visualization,就能获取到当前 Stage 的 DAG Stage。 DAG 仅是 SQL 页面完整 DAG 的一个子集
Event Timeline
点击 Event Timeline ,可视化信息记录了分布式任务调度与执行过程中,不同计算环节的主要时间花销
- 图中的每个条带就代表着一个分布式任务,条带由不同的颜色构成
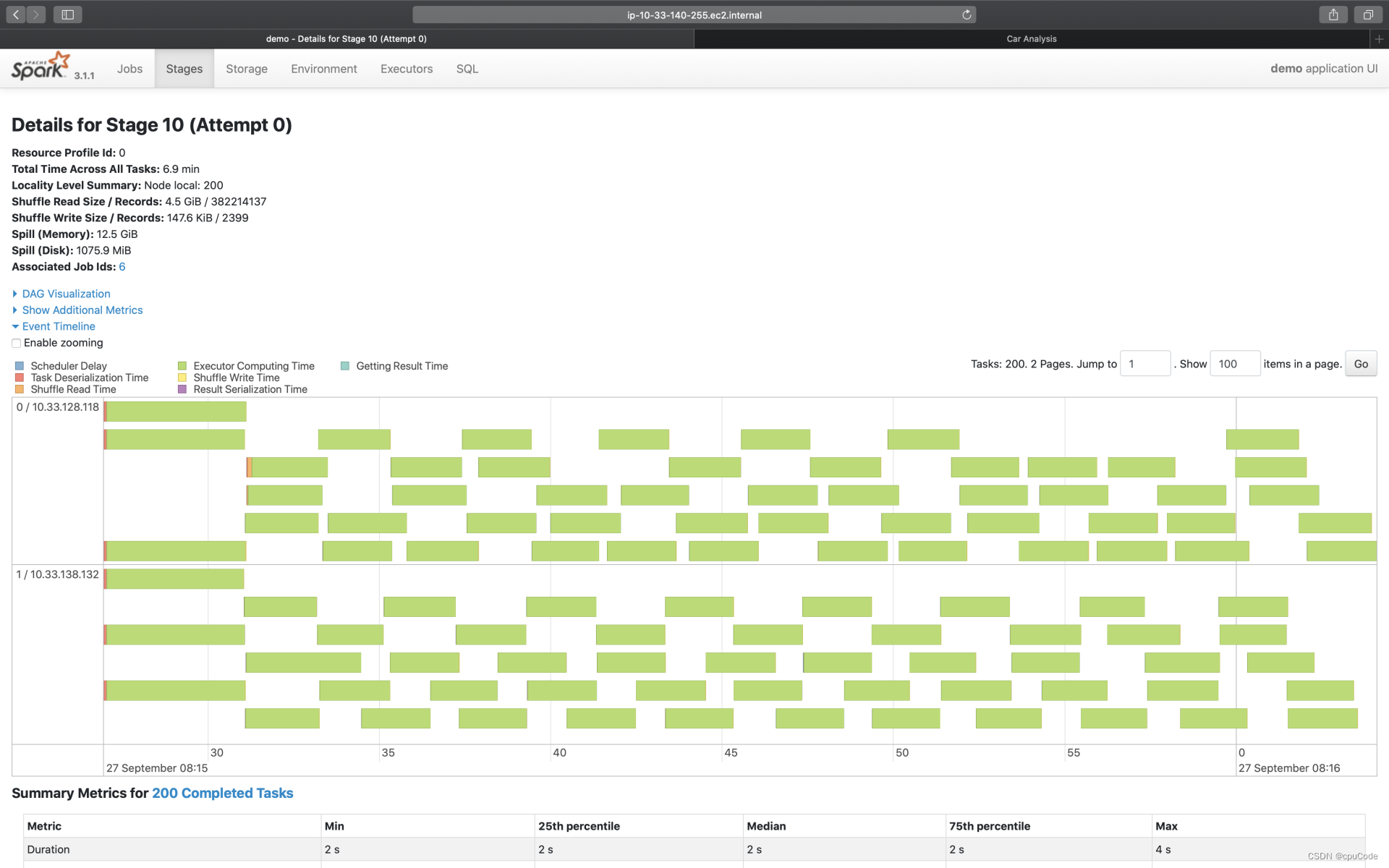
不同环节的计算时间:
| Metrics | 颜色 | 含义 |
|---|---|---|
| Scheduler Delay | 深蓝 | 调度延迟(调度系统开销) |
| Task Deserialization Time | 红色 | 任务的反序列化时间(调度系统开销) |
| Shuffle Read Time | 橙色 | Shuffle Read 时间开销 |
| Executor Computing Time | 绿色 | 计算时间 |
| Shuffle Write Time | 黄色 | Shuffle Write 时间开销 |
| Result Serialization Time | 紫色 | 任务结果的序列化时间 |
| Getting Result Time | 浅蓝 | 结果收集花费的时间 |
结合 Event Timeline,来判断作业是否存在调度开销过大、Shuffle 负载过重的问题
例子:深蓝的部分(Scheduler Delay)很多,就说明任务的调度开销很重。这时就需要参考公式:D / P ~ M / C ,来调整 CPU、内存、并行度,来减低任务的调度开销
- D 是数据集尺寸,P 为并行度
- M 是 Executor 内存,C 是 Executor 的 CPU 核数
- 波浪线 ~ 表示:等式两边的数值,要在同一量级
例子:黄色(Shuffle Write Time)/橙色(Shuffle Read Time)的面积较大,就说明任务的 Shuffle 负载很重,这时就需要考虑是否能通过Broadcast Join 来消除 Shuffle
Task Metrics
Task Metrics
- Summary Metrics : 对所有 Tasks 执行细节的统计汇总
- Tasks : 以 Task 为粒度,记录着每个分布式任务的执行细节
Summary Metrics
点击 Show Additional Metrics ,勾选 Select All ,让所有的度量指标都生效
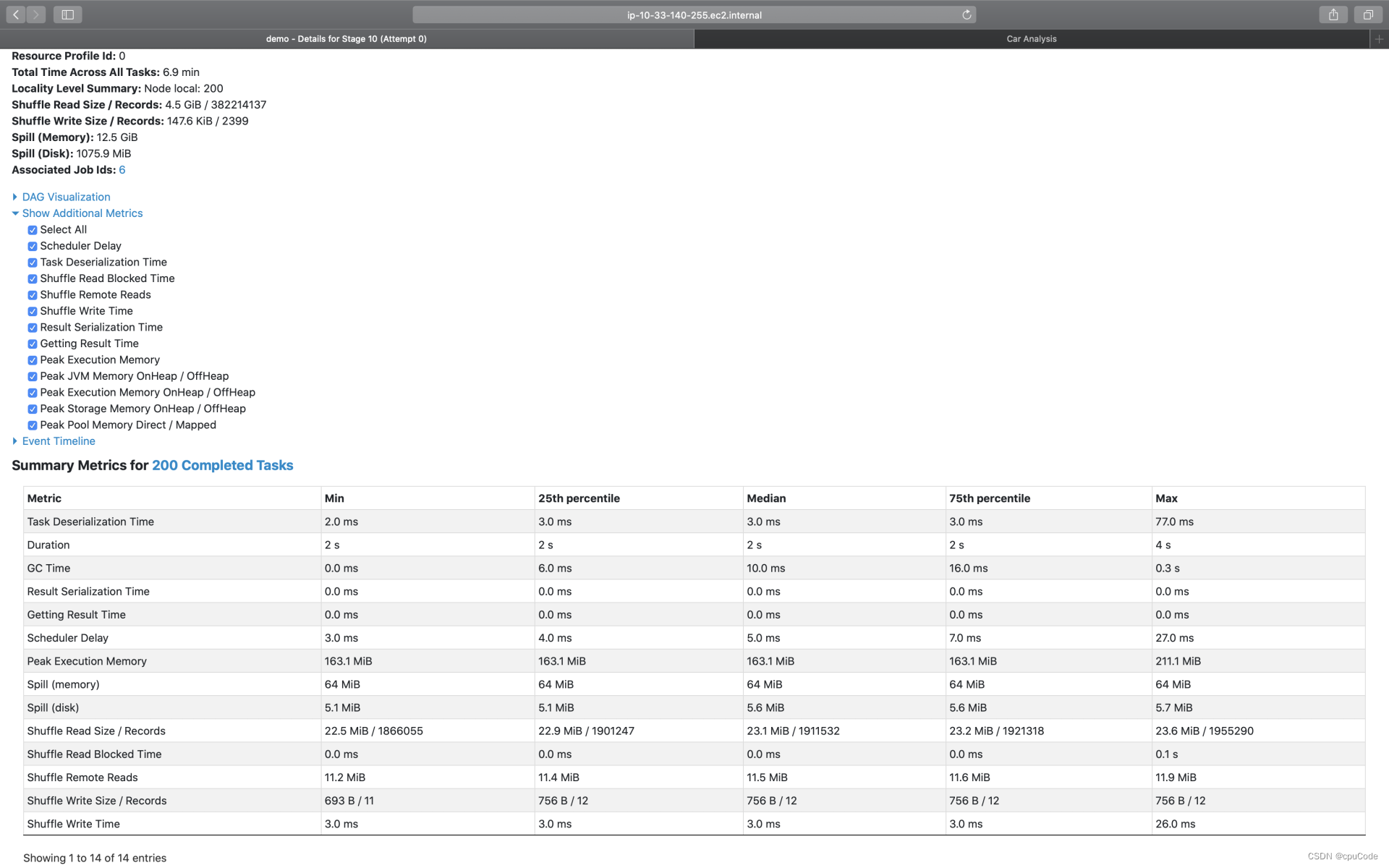
不同环节的计算时间 :
| Metrics | 含义 |
|---|---|
| Duration | Task 执行时间 |
| GC Time | 任务执行过程中, Java GC 时间 |
| Peak Execution Memory | 内存峰值消耗 |
| Spill ( Memory ) | 溢出数据的内存占用 |
| Spil (Disk) | 溢出数据的磁盘占用 |
| Shuffle Read Size/ Records | Shuffle Read 读取的数据量/条目数量 |
| Shuffle Read Blocked Time | Shuffle Read 的网络延迟 |
| Shuffle Remote Reads | Shuffle Read 跨节点、从远端节点拉取的数据量 |
| Shuffle Write Size Records | Shuffle Write 写入的数据量/条目数量 |
| Shuffle Write Time | Shuffle Write 花费的写入时间 |
Spill (溢出数据) : 因内存数据结构(PartitionedPairBuffer、AppendOnlyMap)空间受限,而腾挪出去的数据
- Spill(Memory):这块数据在内存中的存储大小
- Spill(Disk):这块数据在磁盘中的大小
Spill(Memory) / Spill(Disk)= Explosion ratio (数据膨胀系数) 。能估算它在内存中的存储大小
Tasks
Tasks度量指标 :
| Metrics | 含义 |
|---|---|
| Locality level | 本地性级别 |
| Logs | 执行日志 |
| Errors | 执行错误细节 |
- Locality level:每个 Task 会结合本地性倾向,把 Tasks 调度到合适的 Executors/计算节点,尽可能保证数据不动、代码动
- Logs : Tasks 的执行日志,记录了 Tasks 在执行过程中的运行状态
- Errors :记录了报错信息,帮助快速定位问题
相关文章:
Spark UI
Spark UIExecutorsEnvironmentStorageSQLExchangeSortAggregateJobsStagesStage DAGEvent TimelineTask MetricsSummary MetricsTasks展示 Spark UI ,需要设置配置项并启动 History Server # SPARK_HOME表示Spark安装目录 ${SPAK_HOME}/sbin/start-history-server…...
MFC基础到实战(2))
windows应用(vc++2022)MFC基础到实战(2)
目录向导和资源编辑器使用 MFC 应用程序向导创建 MFC 应用程序使用类视图管理类和 Windows 消息使用资源编辑器创建和编辑资源生成 MFC 应用程序的操作1.创建一个主干应用程序。2.了解即使在不添加你自己的任何一行代码的情况下,框架和 MFC 应用程序向导也能提供的内…...

记一次反射型XSS
记一次反射型XSS1.反射型XSS1.1.前言1.2.测试过程1.3.实战演示1.3.1.输入框1.3.2.插入代码1.3.3.跳转链接2.总结1.反射型XSS 1.1.前言 关于这个反射型XSS,利用的方式除了钓鱼,可能更多的就是自娱自乐,那都说是自娱自乐了,并且对系…...

BUUCTF-[羊城杯 2020]Bytecode
题目下载:下载 这道题是一个关于python字节码的。 补充一下相关知识:https://shliang.blog.csdn.net/article/details/119676978dis --- Python 字节码反汇编器 — Python 3.7.13 文档 手工还原参考:[原创]死磕python字节码-手工还原python源码-软件逆…...

《Uniapp入门指南:从安装到打包的全流程》
Uniapp是一款基于Vue.js的跨平台开发框架,可以快速构建出同时支持多个移动端平台和Web端的应用程序。本文将介绍Uniapp的基础知识和开发流程,帮助读者快速入门Uniapp开发。一、Uniapp的基础知识1.Uniapp的优势Uniapp的最大优势是可以快速开发同时支持多个…...

机器学习算法集成系统
版权所有:CSDN——川川菜鸟 本系统并不作为本专栏要求,这一篇自愿学习。 文章目录 本系统设计背景设计思路完整代码本系统设计背景 随着人工智能技术的不断发展,机器学习成为了人工智能领域的重要组成部分。机器学习算法能够从大量数据中发现模式、规律,并利用这些规律对新…...

scratch绘制雷达 电子学会图形化编程scratch等级考试三级真题和答案解析2022年9月
目录 scratch绘制雷达 一、题目要求 1、准备工作 2、功能实现 二、案例分析...

VRRP主备备份
1、VRRP专业术语 VRRP备份组框架图如图14-1所示: 图14-1:VRRP备份组框架图 VRRP路由器(VRRP Router):运行VRRP协议的设备,它可能属于一个或多个虚拟路由器,如SwitchA和SwitchB。虚拟路由器(Virtual Router):又称VRR…...

【软件逆向】软件破解?病毒木马?游戏外挂?
文章目录课前闲聊认识CTF什么是CTFCTF解题模式什么是逆向定义应用领域CTF中的逆向现状推荐书籍学习要点逆向工程学习基础常规逆向流程阶段一:信息收集阶段二:过保护后静态调试阶段三:结合动态调试阶段四:写解题脚本逆向例题概览1-控制台程序解题过程2-Crackme3-游戏4-移动安全C…...

curl请求常用参数和返回码
curl是一个用于传输数据的工具,支持各种协议,如HTTP、FTP、SMTP等。以下是一些常用的curl请求参数及其作用: -X, --request:指定HTTP请求方法,常见的有GET、POST、PUT、DELETE等。 -H, --header:设置HTTP请…...
:抢占式优先级和响应式优先级(NVIC_PriorityGroupConfig))
【STM32】进阶(一):抢占式优先级和响应式优先级(NVIC_PriorityGroupConfig)
1、简介 STM32(Cortex-M3)中每个中断源都有两级优先级:抢占式优先级(pre-emption priority)和子优先级(subpriority),子优先级也叫响应式优先级。 1.1 抢占式优先级 望文知义,就是优先级高的…...

LogCompilation后JIT输出文件格式解析
https://wiki.openjdk.org/display/HotSpot/LogCompilationoverview https://spotcodereviews.com/articles/optimization/2020/12/23/why-does-the-jit-continually-recompile-the-same-method.html task_queued count表示总共执行次数,iicount表示解释器执行次数…...

Linux学习第二十四节-Podman容器
一、容器的概念 容器是由一个或多个与系统其余部分隔离的进程组成的集合。我们可以理解为“集装箱”。 集装箱是打包和装运货物的标准方式。它作为一个箱子进行标记、装载、卸载,以及从一个 位置运输到另一个位置。该容器的内容与其他容器的内容隔离,…...
基于quartz实现定时任务管理系统
基于quartz实现定时任务管理系统 背景 说起定时任务框架,首先想到的是Quartz。这是定时任务的老牌框架了,它的优缺点都很明显。借助PowerJob 的readme文档的内容简单带过一下这部分。 除了上面提到,还有elastic-job-lite、quartzui也是相当…...
vue-element-admin:基于element-ui 的一套后台管理系统集成方案
文章目录一、vue-element-admin1、vue-element-admin1.1简介1.2安装2、vue-admin-template2.1简介2.2安装一、vue-element-admin 1、vue-element-admin 1.1简介 vue-element-admin是基于element-ui 的一套后台管理系统集成方案。 GitHub地址:https://github.com…...

KVM-7、KVM 虚拟机创建的几种方式
通过对 qemu-kvm、libvirt 的学习,总结三种创建虚拟机的方式: (1)通过 qemu-kvm 创建 (2)通过 virt-install 创建 (3)通过 virt-manager 创建 在使用这三种创建虚拟机前提是 宿主机必须支持 cpu 的硬件虚拟化技术(Intel 是 vmx,AMD 是svm),通过下面方式进行查看…...
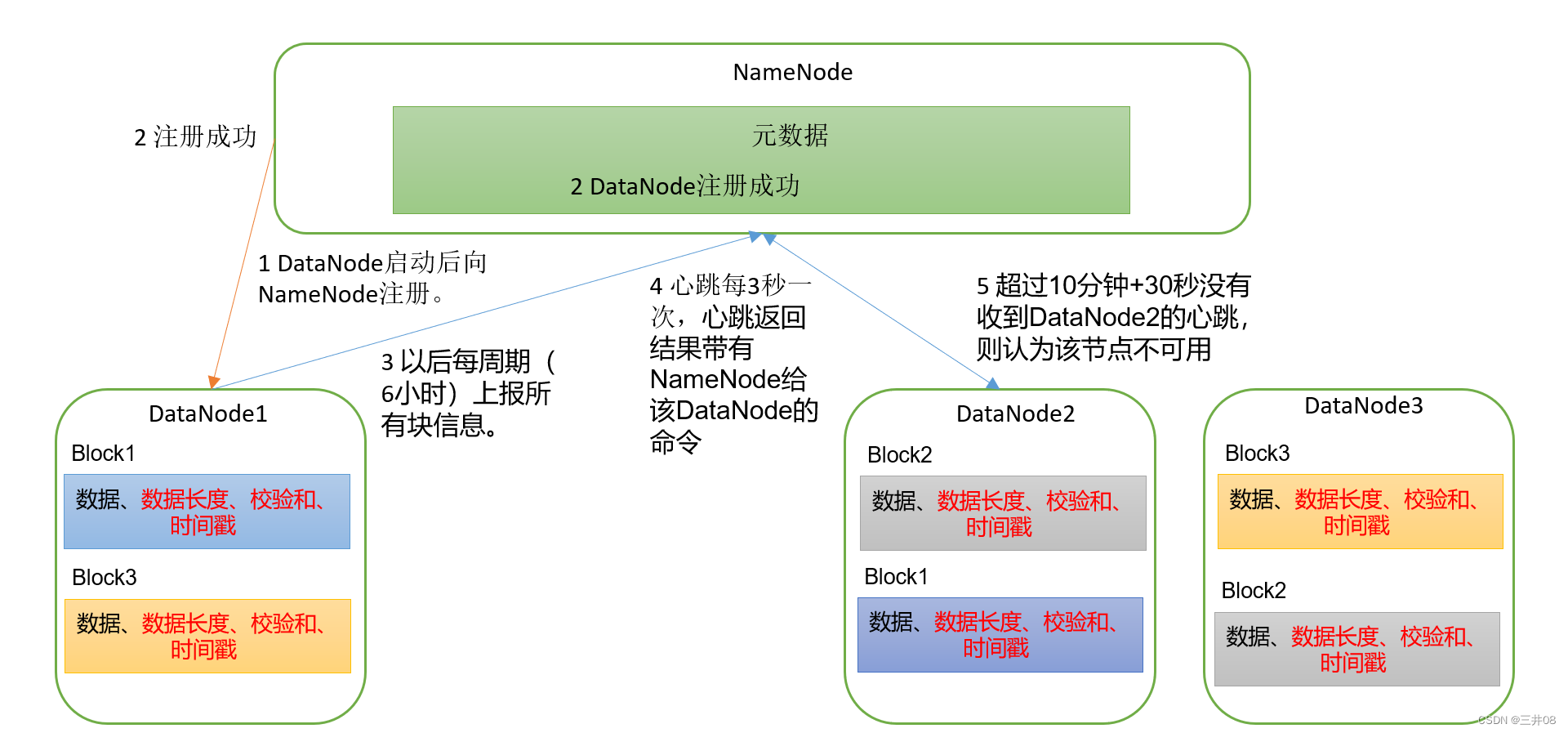
Hadoop三大框架之HDFS
一、概述HDFS产生的背景及定义HDFS产生背景随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,需要一种系统来管理多台机器上的文件,这就是分布式文件…...
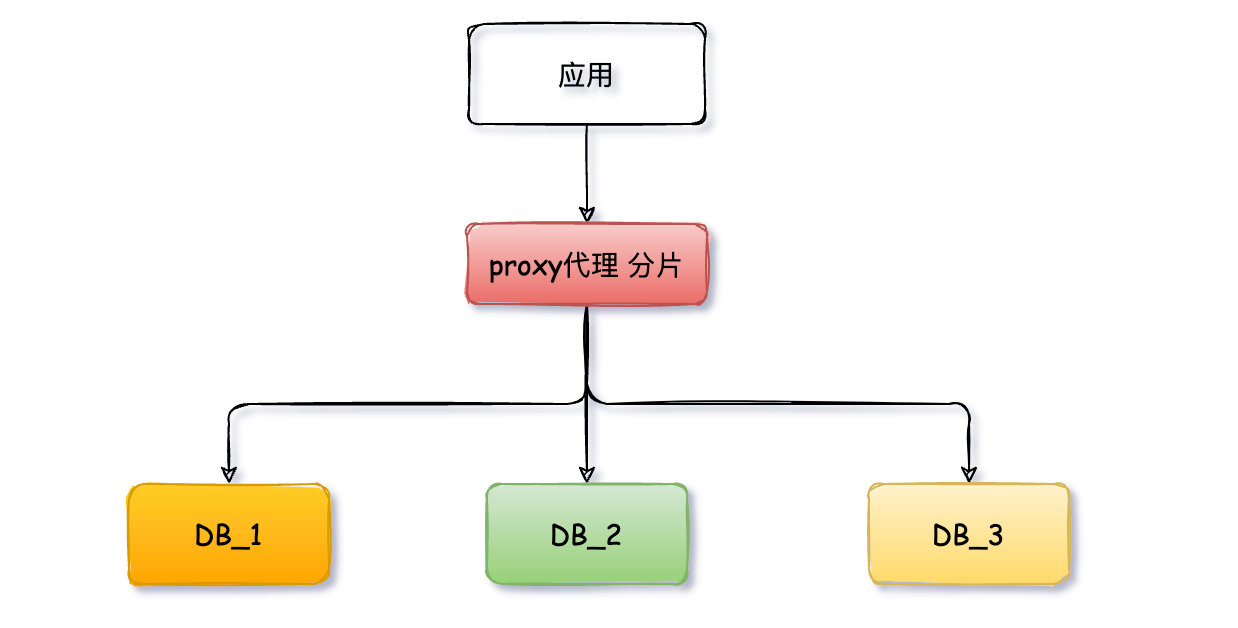
好好的系统,为什么要分库分表?
不急于上手实战 ShardingSphere 框架,先来复习下分库分表的基础概念,技术名词大多晦涩难懂,不要死记硬背理解最重要,当你捅破那层窗户纸,发现其实它也就那么回事。 什么是分库分表 分库分表是在海量数据下࿰…...
多种调度模式下的光储电站经济性最优储能容量配置分析(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
)
二分法(适用于任何题型!!!)
今天看二分法看了一天,看吐了,现在讲讲怎么做类题。 只讲两种做法(实则是可合并为一种),任何题型都可以转化为这种做法!!!是任何! 首先,设置 int left,righ…...

PNAS|收入不足对婴儿早期脑发育的影响
本文揭示了逆境在出生后最早期脑发育阶段中的关键作用。基于 Baby Steps 研究(一项正在进行的纵向研究;在一所服务于贫困与压力发生率较高家庭的初级保健门诊中采集婴儿脑电(EEG)与社会经济地位相关数据)的数据表明&am…...
)
用Python搞定雷达海杂波建模:从瑞利、威布尔到K分布的仿真对比(附完整代码)
用Python搞定雷达海杂波建模:从瑞利、威布尔到K分布的仿真对比(附完整代码) 雷达海杂波建模是雷达信号处理中的核心挑战之一。想象一下,当雷达波束扫过海面时,回波信号中不仅包含目标信息,还混杂着海面反射…...

mxbai-embed-large-v1 应用开发:从零构建智能文档检索系统
mxbai-embed-large-v1 应用开发:从零构建智能文档检索系统 1. 项目概述与核心价值 mxbai-embed-large-v1 是由 mixedbread-ai 开发的高性能文本嵌入模型,在 MTEB 基准测试中超越了 OpenAI text-embedding-3-large 等商业模型。该模型能够将文本转换为高…...

Meta2d.js完整指南:5步掌握专业级2D可视化引擎开发
Meta2d.js完整指南:5步掌握专业级2D可视化引擎开发 【免费下载链接】meta2d.js The meta2d.js is real-time data exchange and interactive web 2D engine. Developers are able to build Web SCADA, IoT, Digital twins and so on. Meta2d.js是一个实时数据响应和…...

MODSERIAL:嵌入式UART高可靠缓冲与事件驱动库
1. MODSERIAL:面向嵌入式实时系统的高可靠性串行通信缓冲库MODSERIAL 是一个专为 ARM Cortex-M 系列微控制器(尤其是基于 mbed OS 和 STM32 HAL 生态)设计的轻量级、中断安全、线程安全的串行通信增强库。其核心目标并非替代标准 HAL_UART 或…...

Z-Image-GGUF开发者案例:集成至内部CMS系统,支持运营人员一键生成Banner
Z-Image-GGUF开发者案例:集成至内部CMS系统,支持运营人员一键生成Banner 1. 项目背景与挑战 想象一下这个场景:你是一家电商公司的运营人员,明天就是“618”大促了,你需要为50个不同的商品制作Banner图。设计团队已经…...

命名实体识别工具:从技术突破到业务价值重构
命名实体识别工具:从技术突破到业务价值重构 【免费下载链接】W2NER 项目地址: https://gitcode.com/gh_mirrors/w2/W2NER 1 解锁NER效率新范式 传统NER为何在长文本中频频失效? 当面对医疗病例中"高血压引发的左心室肥厚导致劳力性呼吸困…...
)
用Python和ROS 2 Humble手把手教你写一个简易机械臂仿真器(附完整代码)
用Python和ROS 2 Humble构建2自由度机械臂仿真器:从零实现运动学与轨迹可视化 在机器人开发中,机械臂的运动控制一直是核心难点。传统实体设备的高成本和复杂调试流程让许多开发者望而却步。本文将带你用Python和ROS 2 Humble构建一个完整的2自由度机械臂…...

StarRailAssistant:崩坏星穹铁道自动化终极解决方案,如何用开源脚本解放双手?
StarRailAssistant:崩坏星穹铁道自动化终极解决方案,如何用开源脚本解放双手? 【免费下载链接】StarRailAssistant 崩坏:星穹铁道自动化 | 崩坏:星穹铁道自动锄大地 | 崩坏:星穹铁道锄大地 | 自动锄大地 | …...

双指针-15. 三数之和
文章目录1.题解2.机考代码3.知识点讲解1.res.add(Arrays.asList(nums[i], nums[l], nums[r]));2.Arrays常用方法大厂机考 / 算法题里 Arrays 只需要掌握这 5 个1. Arrays.sort(nums) —— 排序(最常用)2. Arrays.toString(nums) —— 打印数组3. Arrays.…...