Web 前端性能优化之一:性能模型及网页原理
一、RAIL 性能模型
RAIL性能模型指出了用户对不同延迟时间的感知度,以用户为中心的原则,就是要让用户满意网站或应用的性能体验。
RAIL :响应(Response)、动画(Animation)、空闲(Idle)、加载(Load)


1、响应
网站性能对于响应方面的要求是,在用户感知延迟之前接收到操作的反馈。比如用户进行了文本输入、按钮单击、表单切换及启动动画等操作后,必须在100ms内收到反馈,如果超过100ms的时间窗口,用户就会感知延迟。
看似很基本的用户操作背后,可能会隐藏着复杂的业务逻辑处理及网络请求与数据计算。对此应当将较大开销的工作放在后台异步执行,而即便后台处理要数百毫秒才能完成的操作,也应当给用户提供及时的阶段性反馈。比如在单击按钮向后台发起某项业务处理请求时,首先反馈给用户开始处理的提示,然后在处理完成的回调后反馈完成的提示。
2、动画
前端所涉及的动画不仅有炫酷的UI特效,还包括滚动和触摸拖动等交互效果,而这一方面的性能要求就是流畅。
研究表明这是由于视神经存在反应速度造成的,其值是1/24s,即当我们所见的物体移除后,该物体在我们眼中并不会立即消失,而会延续存在1/24s的时间。对动画来说,无论动画帧率有多高,最后我们仅能分辨其中的30帧,但越高的帧率会带来更好的流畅体验,因此动画要尽力达到60fps的帧率。
每一帧画面的生成都需要经过若干步骤,根据60fps帧率的计算,一帧图像的生成预算为16ms(1000ms/60≈16.66ms),除去浏览器绘制新帧的时间,留给执行代码的时间仅10ms左右。
3、空闲
完全可以利用浏览器的空闲时间处理可延迟的任务,只要让用户感受不到延迟即可。
为了更加合理地利用浏览器的空闲时间,最好将处理任务按50ms为单位分组。这么做就是保证用户在发生操作后的100ms内给出响应。
4、加载
用户感知要求我们尽量在1s内完成页面加载,如果没有完成,用户的注意力就会分散到其他事情上,并对当前处理的任务产生中断感。需要注意的是,这里在1s内完成加载并渲染出页面的要求,并非要完成所有页面资源的加载,从用户感知体验的角度来说,只要关键渲染路径完成,用户就会认为全部加载已完成。
对于其他非关键资源的加载,延迟到浏览器空闲时段再进行,是比较常见的渐进式优化策略。
二、性能优化的步骤
进行性能优化的步骤一般是:
首先可量化地评估出网站或应用的性能表现;
然后立足于网站页面响应的生命周期,分析出造成较差性能表现的原因;
最后进行技术改造、可行性分析等具体的优化实施。
1、性能测量
1、Chrome 浏览器的 Performance 功能
打开开发者工具的Performance选项卡,单击左上角的“开始评估”按钮后刷新网站,该工具便开始分析页面资源加载、渲染、请求响应等各环节耗费的时间线,据此便可分析一定程度的性能问题,比如JavaScript的执行是否会触发大量视觉变化的计算,重绘和重排(或回流)是否会被多次触发等。

2、灯塔(Lighthouse)
Lighthouse是一个开源的自动化审查网站页面性能的工具,可根据所提供的网站URL从性能、可访问性、渐进式Web应用、SEO(搜索引擎优化)等多个方面进行自动化分析,最终给出一份具有指导意义的报告。它既可以当作Chrome的扩展插件来使用,又可以在开发者工具中直接使用。

除此之外,还会经常用到的性能测试工具有PageSpeed Insights、WEBPAGETEST、Pingdom等。
2、生命周期
网站页面的生命周期,通俗地讲就是从我们在浏览器的地址栏中输入一个URL后,到整个页面渲染出来的过程。
整个过程:
- 域名解析
- 建立TCP连接
- 前后端通过HTTP进行会话
- 压缩与解压缩
- 前端的关键渲染路径等
把这些阶段拆解开来看,不仅能容易地获得优化性能的启发,而且也能为今后的前端工程师之路构建出完整的知识框架,网站页面加载的生命周期如下图所示:

3、优化方案
(1)传输资源的优化,比如图像资源,不同的格式类型会有不同的使用场景,在使用的过程中是否恰当。
(2)加载过程的优化,比如延迟加载,是否有不需要在首屏展示的非关键信息,占用了页面加载的时间。
(3)JavaScript是现代大型网站中相当“昂贵”的资源,是否进行了压缩,书写是否规范,有无考虑内存泄漏等。
(4)关键渲染路径优化,比如是否存在不必要的重绘和回流。
(5)本地存储和浏览器缓存。
三、网页访问原理
1、网络请求线程开启
浏览器接收到我们输入的URL到开启网络请求线程,这个阶段是在浏览器内部完成的。
首先是对URL的解析。
URL结构:Protocol://Host:Port/Path?Query#Fragment

解析URL后,如果是HTTP协议,则浏览器会新建一个网络请求线程去下载所需的资源,要明白这个过程需要先了解进程和线程之间的区别,以及目前主流的多进程浏览器结构。
1、进程与线程
简单来说,进程就是一个程序运行的实例,操作系统会为进程创建独立的内存,用来存放运行所需的代码和数据;而线程是进程的组成部分,每个进程至少有一个主线程及可能的若干子线程,这些线程由所属的进程进行启动和管理。由于多个线程可以共享操作系统为其所属的同一个进程所分配的资源,所以多线程的并行处理能有效提高程序的运行效率。

(1)只要某个线程执行出错,将会导致整个进程崩溃。
(2)进程与进程之间相互隔离。这保证了当一个进程挂起或崩溃的情况发生时,并不会影响其他进程的正常运行,虽然每个进程只能访问系统分配给自己的资源,但可以通过IPC机制进行进程间通信。
(3)进程所占用的资源会在其关闭后由操作系统回收。即使进程中存在某个线程产生的内存泄漏,当进程退出时,相关的内存资源也会被回收。
(4)线程之间可以共享所属进程的数据。
2、多进程浏览器

(1)浏览器主进程:一个浏览器只有一个主进程,负责如菜单栏、标题栏等界面显示,文件访问,前进后退,以及子进程管理等。
(2)GPU进程:GPU(图形处理单元)最初是为了实现3D的CSS效果而引入的,后来随着网页及浏览器在界面中的使用需求越来越普遍,Chrome便在架构中加入了GPU进程。
(3)插件进程:主进程会为每个加入浏览器的插件开辟独立的子进程,由于进程间所分配的运行资源相对独立,所以即便某个插件进程意外崩溃,也不至于对浏览器和页面造成影响。另外,出于对安全因素的考虑,这里采用了沙箱模式(即上图中虚线所标出的进程),在沙箱中运行的程序受到一些限制:不能读取敏感位置的数据,也不能在硬盘上写入数据。这样即使插件运行了恶意脚本,也无法获取系统权限。
(4)网络进程:负责页面的网络资源加载,之前属于浏览器主进程中的一个模块,最近才独立出来。
(5)渲染进程:也称为浏览器内核,其默认会为每个标签窗口页开辟一个独立的进程,负责将HTML、CSS和JavaScript等资源转为可交互的页面,其中包含多个子线程,即JS引擎线程、GUI渲染线程、事件触发线程、定时触发器线程、异步HTTP请求线程等。当打开一个标签页输入URL后,所发起的网络请求就是从这个进程开始的。另外,出于对安全性的考虑,渲染进程也被放入沙箱中。
打开Chrome任务管理器,可以从中查看到当前浏览器都启动了哪些进程:

2、建立 HTTP 请求
这个阶段的主要工作分为两部分:DNS解析和通信链路的建立。简单说就是,首先发起请求的客户端浏览器要明确知道所要访问的服务器地址,然后建立通往该服务器地址的路径。
1、DNS 解析
前面讲到的URL解析,其实仅将URL拆分为代表具体含义的字段,然后以参数的形式传入网络请求线程进行进一步处理,
首先第一步便是这里讲到的DNS解析。
其主要目的便是通过查询将URL中的Host字段转化为网络中具体的IP地址,因为域名只是为了方便帮助记忆的,IP地址才是所访问服务器在网络中的“门牌号”

首先查询浏览器自身的DNS缓存,如果查到IP地址就结束解析,由于缓存时间限制比较大,一般只有1分钟,同时缓存容量也有限制,所以在浏览器缓存中没找到IP地址时,就会搜索系统自身的DNS缓存;如果还未找到,接着就会尝试从系统的hosts文件中查找。
在本地主机进行的查询若都没获取到,接下来便会在本地域名服务器上查询。如果本地域名服务器没有直接的目标IP地址可供返回,则本地域名服务器便会采取迭代的方式去依次查询根域名服务器、COM顶级域名服务器和权限域名服务器等,最终将所要访问的目标服务器IP地址返回本地主机,若查询不到,则返回报错信息。
2、网络模型
在通过DNS解析获取到目标服务器IP地址后,就可以建立网络连接进行资源的请求与响应了。
在互联网发展初期,为了使网络通信能够更加灵活、稳定及可互操作,国际标准化组织提出了一些网络架构模型:OSI模型、TCP/IP模型。


3、TCP 连接
根据对网络模型的介绍,当使用本地主机连上网线接入互联网后,数据链路层和网络层就已经打通了,而要向目标主机发起HTTP请求,就需要通过传输层建立端到端的连接。
传输层常见的协议有TCP协议和UDP协议。
由于TCP是面向有连接的通信协议,所以在数据传输之前需要建立好客户端与服务器端之间的连接,即通常所说的“三次握手”,具体过程分为如下步骤:
(1)客户端生成一个随机数seq,假设其值为t,并将标志位SYN设为1,将这些数据打包发给服务器端后,客户端进入等待服务器端确认的状态。
(2)服务器端收到客户端发来的SYN=1的数据包后,知道这是在请求建立连接,于是服务器端将SYN与ACK均置为1,并将请求包中客户端发来的随机数t加1后赋值给ack,然后生成一个服务器端的随机数seq=k,完成这些操作后,服务器端将这些数据打包再发回给客户端,作为对客户端建立连接请求的确认应答。
(3)客户端收到服务器端的确认应答后,检查数据包中ack的字段值是否为t+1,ACK是否等于1,若都正确就将服务器端发来的随机数加1(ack=k+1),将ACK=1的数据包再发送给服务器端以确认服务器端的应答,服务器端收到应答包后通过检查ack是否等于k+1来确认连接是否建立成功。

当用户关闭标签页或请求完成后,TCP连接会进行“四次挥手”:
(1) 客户端发送指令告诉服务器端请求关闭:
由客户端先向服务器端发送FIN=M的指令,随后进入完成等待状态FIN_WAIT_1,表明客户端已经没有再向服务器端发送的数据,但若服务器端此时还有未完成的数据传递,可继续传递数据。
(2)服务器端收到请求关闭,确认数据是否完成传递,未完成则告诉服务器请等待
当服务器端收到客户端的FIN报文后,会先发送ack=M+1的确认,告知客户端关闭请求已收到,但可能由于服务器端还有未完成的数据传递,所以请客户端继续等待。
(3)服务器端确认数据传递完成,发送给客户端告诉准备关闭
当服务器端确认已完成所有数据传递后,便发送带有FIN=N的报文给客户端,准备关闭连接。
(4)客户端收到关闭操作,为确保数据正确,双方客户端再次确认后即断开连接
客户端收到FIN=N的报文后可进行关闭操作,但为保证数据正确性,会回传给服务器端一个确认报文ack=N+1,同时服务器端也在等待客户端的最终确认,如果服务器端没有收到报文则会进行重传,只有收到报文后才会真正断开连接。而客户端在发送了确认报文一段时间后,没有收到服务器端任何信息则认为服务器端连接已关闭,也可关闭客户端信息。
连接关闭的关系图如下图所示:

3、前后端的交互
当TCP连接建立好之后,便可通过HTTP等协议进行前后端的通信,但在实际的网络访问中,并非浏览器与确定IP地址的服务器之间直接通信,往往会在中间加入反向代理服务器。
1、反向代理服务器
对需要提供复杂功能的网站来说,通常单一的服务器资源是很难满足期望的。一般采用的方式是将多个应用服务器组成的集群由反向代理服务器提供给客户端用户使用,这些功能服务器可能具有不同类型,比如文件服务器、邮件服务器及Web应用服务器,同时也可能是相同的Web服务部署到多个服务器上,以实现负载均衡的效果。

反向代理服务器通常的作用如下:
负载均衡、安全防火墙、加密及SSL加速、数据压缩、解决跨域、对静态资源缓存。
2、后端处理流程
经反向代理收到请求后,具体的服务器后台处理流程大致如下:
(1)首先会有一层统一的验证环节,如跨域验证、安全校验拦截等。如果发现是不符合规则的请求,则直接返回相应的拒绝报文。
(2)通过验证后才会进入具体的后台程序代码执行阶段,如具体的计算、数据库查询等。
(3)完成计算后,后台会以一个HTTP响应数据包的形式发送回请求的前端,结束本次请求。
只要网站涉及数据交互,这个请求和响应的过程就会频繁发生,而后端处理程序的执行需要花费时间,HTTP协议保证数据交互的同时也对传输细节有所限制。这其中就存在很大的性能优化空间,比如HTTP协议版本的升级、缓存机制等。
3、HTTP 相关协议特性
HTTP是建立在传输层TCP协议之上的应用层协议,在TCP层面上存在长连接和短连接的区别。所谓长连接,就是在客户端与服务器端建立的TCP连接上,可以连续发送多个数据包,但需要双方发送心跳检查包来维持这个连接。
短连接就是当客户端需要向服务器端发送请求时,会在网络层IP协议之上建立一个TCP连接,当请求发送并收到响应后,则断开此连接。根据前面关于TCP连接建立过程的描述,我们知道如果这个过程频繁发生,就是个很大的性能耗费,所以从HTTP的1.0版本开始对于连接的优化一直在进行。
- HTTP1.0:
浏览器与服务器只保持短暂的连接,浏览器每次请求都需要 与服务器建立一个TCP连接
- HTTP1.1:
引入了长连接(TCP默认不关闭,可以被多个请求复用)
在同一个TCP连接里,客户端可以发送多个请求
多个请求按次序在服务端被处理
新增了一些请求方法、请求头和响应头
- HTTP2.0
采用二进制格式而非文本格式
完全多路复用,而非有序并阻塞的、只需要建立一个连接即 可实现并行
使用报头压缩,降低开销
服务器推送
- HTTP3.0
QUIC 基于 UDP 实现,是 HTTP/3 中的底层支撑协议,该协 议基于 UDP,又取了 TCP 中的精华,实现了即快又可靠的 协议。
4、浏览器缓存
具体的缓存策略分为两种:强缓存和协商缓存。
强缓存就是当浏览器判断出本地缓存未过期时,直接读取本地缓存,无须发起HTTP请求,此时状态为:200 from cache。在HTTP 1.1版本后通过头部的cache-control字段的max-age属性值规定的过期时长来判断缓存是否过期失效,这比之前使用expires标识的服务器过期时间更准确而且安全。
协商缓存则需要浏览器向服务器发起HTTP请求,来判断浏览器本地缓存的文件是否仍未修改,若未修改则从缓存中读取,此时的状态码为:304。具体过程是判断浏览器头部if-none-match与服务器短的e-tag是否匹配,来判断所访问的数据是否发生更改。这相比HTTP 1.0版本通过last-modified判断上次文件修改时间来说也更加准确。
具体的浏览器缓存触发逻辑如下图:

在浏览器缓存中,强缓存优于协商缓存,若强缓存生效则直接使用强缓存,若不生效则再进行协商缓存的请求,由服务器来判断是否使用缓存,如果都失效则重新向服务器发起请求获取资源。
4、关键渲染路径
当我们经历了网络请求过程,从服务器获取到了所访问的页面文件后,浏览器如何将这些HTML、CSS及JS文件组织在一起渲染出来呢?
1、构建对象模型
首先浏览器会通过解析HTML和CSS文件,来构建DOM(文档对象模型)和CSSOM(层叠样式表对象模型),为便于理解,我们以如下HTML内容文件为例,来观察文档对象模型的构建过程。

- 浏览器接收读取到的HTML文件,其实是文件根据指定编码(UTF-8)的原始字节,形如3C 62 6F 793E 65 6C 6F 2C 20 73 70…首先需要将字节转换成字符,即原本的代码字符串
- 接着再将字符串转化为W3C标准规定的令牌结构,所谓令牌就是HTML中不同标签代表不同含义的一组规则结构。
- 然后经过词法分析将令牌转化成定义了属性和规则值的对象
- 最后将这些标签节点根据HTML表示的父子关系,连接成树形结构

DOM树表示文档标记的属性和关系,但未包含其中各元素经过渲染后的外观呈现。
这便是接下来CSSOM的职责了。
与将HTML文件解析为文档对象模型的过程类似,CSS文件也会首先经历从字节到字符串,然后令牌化及词法分析后构建为层叠样式表对象模型。假设CSS文件内容如下:

最后构建的CSSOM树如图:

这两个对象模型的构建过程是会花费时间的,可以通过打开Chrome浏览器的开发者工具的性能选项卡,查看到对应过程的耗时情况:

2、渲染绘制
当完成文档对象模型和层叠样式表对象模型的构建后,所得到的其实是描述最终渲染页面两个不同方面信息的对象:一个是展示的文档内容,另一个是文档对象对应的样式规则,接下来就需要将两个对象模型合并为渲染树,渲染树中只包含渲染可见的节点,该HTML文档最终生成的渲染树如图:

渲染绘制的步骤大致如下:
(1)从所生成DOM树的根节点开始向下遍历每个子节点,忽略所有不可见的节点(脚本标记不可见、CSS隐藏不可见),因为不可见的节点不会出现在渲染树中。
(2)在CSSOM中为每个可见的子节点找到对应的规则并应用。
(3)布局阶段,根据所得到的渲染树,计算它们在设备视图中的具体位置和大小,这一步输出的是一个“盒模型”。
(4)绘制阶段,将每个节点的具体绘制方式转化为屏幕上的实际像素。
关键渲染路径执行快慢,将直接影响首屏加载时间的性能指标。
当首屏渲染完成后,用户在和网站的交互过程中,有可能通过JavaScript代码提供的用户操作接口更改渲染树的结构,一旦DOM结构发生改变,这个渲染过程就会重新执行一遍。可见对于关键渲染路径的优化影响的不仅是首屏性能,还有交互性能。
以上内容是《Web前端性能优化》的书籍的读书笔记。
相关文章:
Web 前端性能优化之一:性能模型及网页原理
一、RAIL 性能模型 RAIL性能模型指出了用户对不同延迟时间的感知度,以用户为中心的原则,就是要让用户满意网站或应用的性能体验。 RAIL :响应(Response)、动画(Animation)、空闲(Idle)、加载(Load) RAIL 性能模型 用户感知延迟的时间窗口 1…...

常用的主流好用的WEB自动化测试工具强烈推荐
在业务使用的自动化测试工具很多。有开源的,有商业化的,各有各得特色,各有各得优点!下面我就介绍几个我用过的一款非常优秀的国产自动化测试工具。在现有的自动化软件当中,都是以元素的name、id、xpath、class、tag、l…...
分享几个非常不错嵌入式开源项目,一定不要错过
大家好,我是知微! 经常有小伙伴后台私信我: 有没有好的开源项目推荐怎么样才能提升自己的编程能力 那么这篇文章就推荐几个还不错的开源项目,感兴趣的小伙伴可以学习一下! 日志库EasyLogger https://github.com/ar…...

Golang基础-4
Go语言基础 介绍 基础 数组(array) 数组声明 元素访问与修改 数组遍历 关系运算 切片创建 多维数组 介绍 本文介绍Go语言中数组(array)操作(数组声明、元素访问与修改、数组遍历、关系运算、切片创建、多维数组)等相关知识。 基础 数组 数组是具有相同数据类型的…...
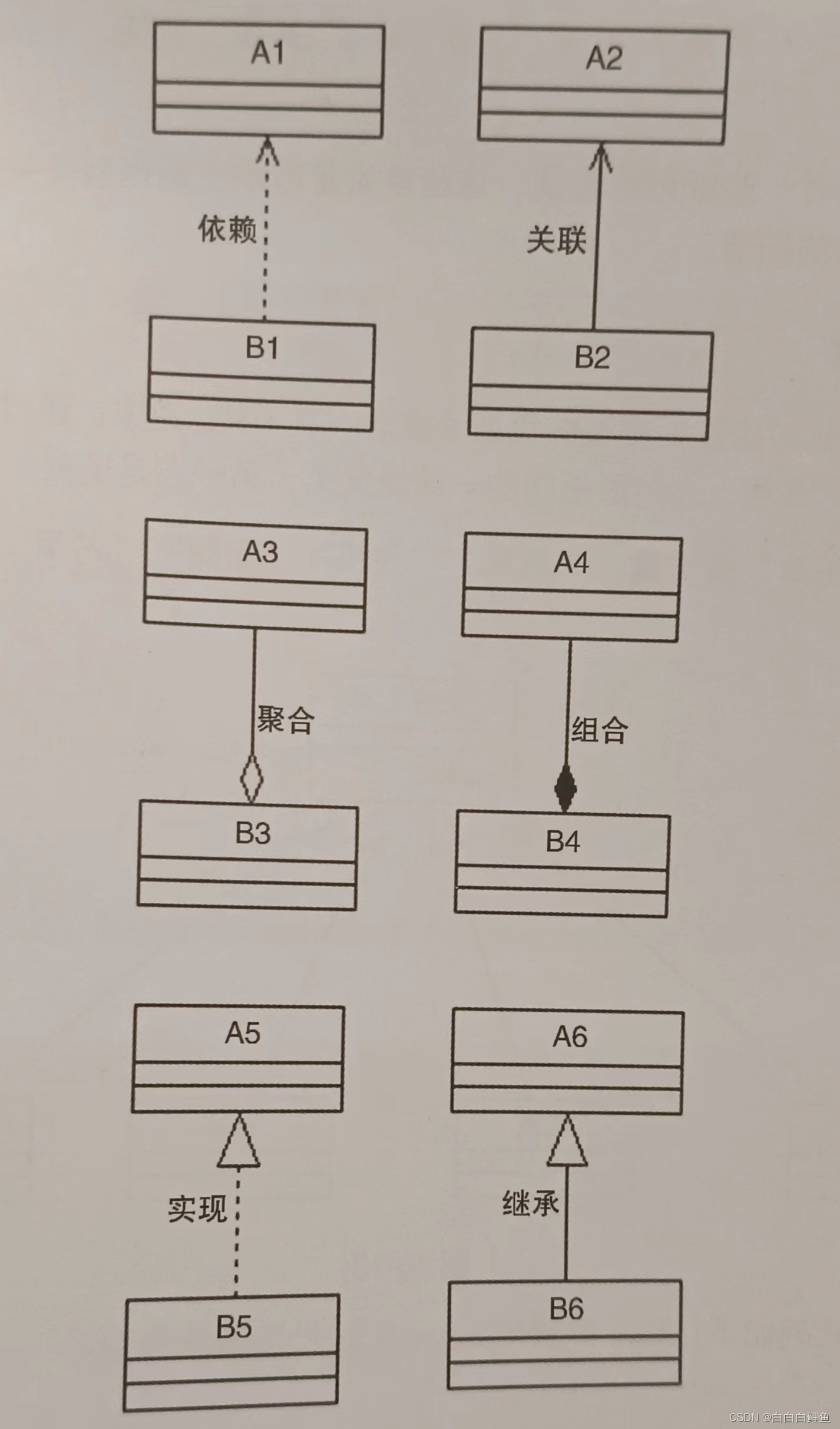
2024软件设计师备考讲义——UML(统一建模语言)
UML的概念 用例图的概念 包含 <<include>>扩展<<exted>>泛化 用例图(也可称用例建模)描述的是外部执行者(Actor)所理解的系统功能。用例图用于需求分析阶段,它的建立是系统开发者和用户反复…...

HTML——1.简介、基础、元素
一、简介 HTML(HyperText Markup Language)是一种用于创建网页的标记语言。它使用标记(tag)来描述网页的结构和内容。HTML被用于定义网页中的文本、图像、链接、多媒体以及其他元素的排列和呈现方式。 HTML文档是由一系列的HTML…...
 函数简介)
Rust 标准库:std::env::args() 函数简介
std::env::args() 是 Rust 标准库中的一个函数,它属于 std::env 模块。这个函数用于获取并返回一个迭代器,该迭代器包含了程序运行时从命令行传入的所有参数。 当你运行一个 Rust 程序并从命令行传递参数时,例如: my_rust_progr…...
【Blockchain】GameFi | NFT
Blockchain GameFiGameFi顶级项目TheSandbox:Decentraland:Axie Infinity: NFTNFT是如何工作的同质化和非同质化区块链协议NFT铸币 GameFi GameFi是游戏和金融的组合,它涉及区块链游戏,对玩家提供经济激励,…...

【Docker】搭建安全可控的自定义通知推送服务 - Bark
【Docker】搭建安全可控的自定义通知推送服务 - Bark 前言 本教程基于绿联的NAS设备DX4600 Pro的docker功能进行搭建。 简介 Bark是一款为Apple设备用户设计的开源推送服务应用,它允许开发者、程序员以及一般用户将信息快速推送到他们自己的iPhone、iPad等设备上…...
国内IP代理软件电脑版:深入解析与应用指南
随着互联网技术的快速发展,网络活动日益丰富多样,IP代理软件也因其独特的功能和优势,成为许多电脑用户不可或缺的工具。在国内,由于网络环境的复杂性和特殊性,选择一款稳定、高效的IP代理软件电脑版尤为重要。虎观代理…...

面向对象设计之开闭原则
设计模式专栏: http://t.csdnimg.cn/4Mt4u 目录 1.引言 2.如何理解“对扩展开放、对修改关闭” 3.修改代码就意味着违反开闭原则吗 4.如何做到“对扩展开放、对修改关闭” 5.如何在项目中灵活应用开闭原则 6.总结 1.引言 开闭原则(Open Closed Principle&…...

【项目技术介绍篇】若依项目代码文件结构介绍
作者介绍:本人笔名姑苏老陈,从事JAVA开发工作十多年了,带过大学刚毕业的实习生,也带过技术团队。最近有个朋友的表弟,马上要大学毕业了,想从事JAVA开发工作,但不知道从何处入手。于是࿰…...
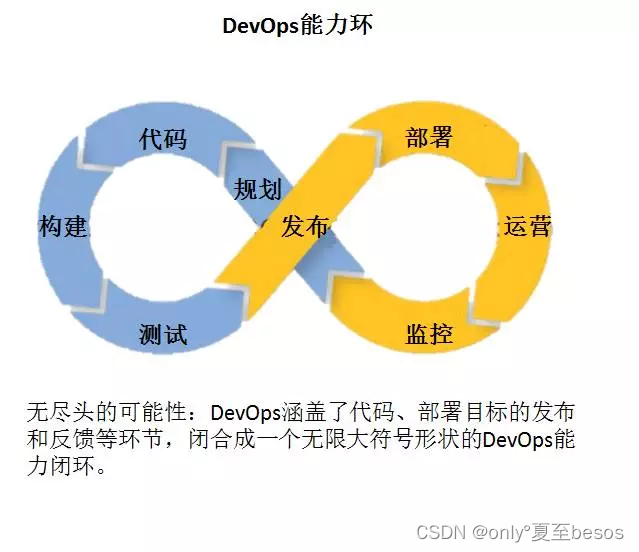
实现DevOps需要什么?
实现DevOps需要什么? 硬性要求:工具上的准备 上文提到了工具链的打通,那么工具自然就需要做好准备。现将工具类型及对应的不完全列举整理如下: 代码管理(SCM):GitHub、GitLab、BitBucket、SubV…...

Linux小程序: 手写自己的shell
注意: 本文章只是为了理解shell内部的工作原理, 所以并没有完成shell的所有工作, 只是完成了shell里的一小部分工作 #include <stdio.h> #include <unistd.h> #include <string.h> #include <stdlib.h> #include &l…...

javaSwing租户管理系统
简介 欢迎阅读本篇博客,今天我将为大家介绍一个基于Java Swing开发的租户管理系统。该系统具有登录、注册、添加租户、查询租户信息、修改租户信息、删除租户、修改密码、退出登录等功能模块,旨在提供一个便捷的租户管理解决方案。 一、项目介绍 该租…...
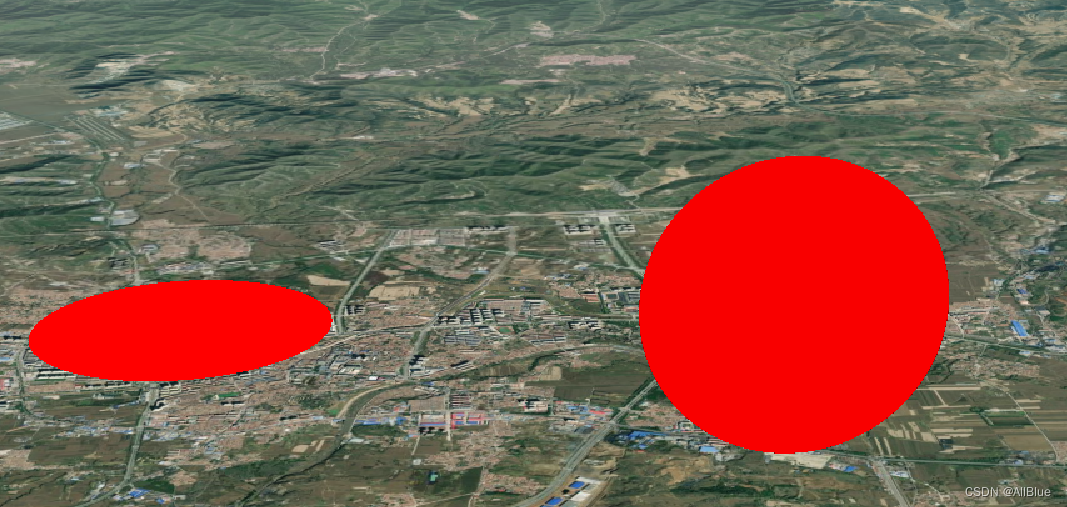
cesium实现竖立的圆
cesium中的圆是平行于地面的,想实现竖起来的圆可以使用ellipsoid,设置其中一个轴的radii值为一个很小的值,比如0.00001,则这个轴上的宽度就会非常小,看起来就是一个圆面。 一、画圆ellipse,此处也把画圆的代…...

汽车电子行业知识:智能汽车电子架构
文章目录 3.智能汽车电子架构3.1.汽车电子概念及发展3.2.汽车电子架构类型3.2.1.博世汽车电子架构3.2.2.联合电子未来汽车电子架构3.2.3.安波福汽车电子架构3.2.4.丰田汽车电子架构3.2.5.华为汽车电子架构 3.智能汽车电子架构 3.1.汽车电子概念及发展 汽车电子是车体汽车电子…...

LeetCode146:LRU缓存
leetCode:146. LRU 缓存 题目描述 请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。 实现 LRUCache 类: LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存 int get(int key) 如果关键字 key 存在于缓存中&#x…...

【Unity音游制作】你玩过节奏大师吗?(Koreographe插件导入游戏主体)【一】
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:Uni…...

高效解决Ubuntu Server 18.04.1 LTS 64bit更新gdb8.1.1到gdb12.1
文章目录 问题解决步骤 问题 因为需要用到gdb一些指令,但是gdb8.x好像存在普遍的问题,实现不了某些指令,比方说set detach-on-fork on,升级版本也没有比较好的教程 经过我不断的试错,我终于升级成功了!&a…...

别光知道Levenshtein!Python实战:用Jaro-Winkler算法搞定人名地址模糊匹配
别光知道Levenshtein!Python实战:用Jaro-Winkler算法搞定人名地址模糊匹配 在数据清洗和用户输入处理的场景中,字符串相似度计算是个绕不开的话题。当我们需要匹配"张三丰"和"张三風"时,传统的Levenshtein距离…...

线程池核心参数与拒绝策略深度解析
前言 线程池是Java并发编程中最常用的工具之一,但很多开发者只停留在“会用”层面。面试中,面试官往往通过线程池考察你对并发编程的理解深度——参数如何设置?为什么这样设置?拒绝策略如何选择? 本文将深入剖析线程池…...

深度解析Windows微信自动化:Wechaty Puppet XP零成本架构设计与实战指南
深度解析Windows微信自动化:Wechaty Puppet XP零成本架构设计与实战指南 【免费下载链接】puppet-xp Wechaty Puppet WeChat Windows Protocol 项目地址: https://gitcode.com/gh_mirrors/pu/puppet-xp 在即时通讯自动化领域,Windows平台微信机器…...

I2CLCD驱动库:HD44780字符屏的I²C轻量级嵌入式适配方案
1. I2CLCD库概述:面向嵌入式系统的字符型LCD IC适配驱动I2CLCD是一个轻量级、可移植的C语言驱动库,专为将标准HD44780兼容的字符型LCD(如1602、2004)通过IC总线接入MCU而设计。其核心价值在于消除并行接口对GPIO资源的高占用&…...

League-Toolkit:基于LCU API的英雄联盟效率工具集
League-Toolkit:基于LCU API的英雄联盟效率工具集 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League-Toolkit是一…...

5个必知技巧:让你的PT下载效率提升300%的浏览器插件指南
5个必知技巧:让你的PT下载效率提升300%的浏览器插件指南 【免费下载链接】PT-Plugin-Plus PT 助手 Plus,为 Microsoft Edge、Google Chrome、Firefox 浏览器插件(Web Extensions),主要用于辅助下载 PT 站的种子。 项…...
——基于asp+access的公司门户网站设计与实现)
asp毕业设计下载(全套源码+配套论文)——基于asp+access的公司门户网站设计与实现
基于aspaccess的公司门户网站设计与实现(毕业论文程序源码) 大家好,今天给大家介绍基于aspaccess的公司门户网站设计与实现,更多精选毕业设计项目实例见文末哦。 文章目录: 基于aspaccess的公司门户网站设计与实现&a…...

计算机毕业设计springboot彝族民族文化宣传网站 基于SpringBoot的彝族非物质文化遗产数字化展示平台 SpringBoot框架下彝族传统风俗文化传播系统
计算机毕业设计springboot彝族民族文化宣传网站l36tn9 (配套有源码 程序 mysql数据库 论文)本套源码可以先看具体功能演示视频领取,文末有联xi 可分享 在当今数字化浪潮席卷全球的背景下,少数民族文化的保护与传承面临着前所未有…...

ESFT-gate-law-lite:法律文本智能分析新工具
ESFT-gate-law-lite:法律文本智能分析新工具 【免费下载链接】ESFT-gate-law-lite ESFT-gate-law-lite是基于HuggingFace的深度学习模型,专为法律领域定制。源自deepseek-ai团队,继承ESFT-vanilla-lite优势,强大而轻量,…...

手把手教你解决Unity视频播放问题:H264编码设置与RawImage的正确用法
Unity视频播放全攻略:H264编码优化与RawImage实战解析 在Unity项目开发中,视频播放功能看似简单,却暗藏诸多技术细节。许多开发者都曾遇到过视频不同步、颜色失真或性能低下的困扰。本文将深入剖析视频播放的核心技术要点,从编码格…...