在k8s中部署高可用程序实践和资源治理
在k8s中部署高可用程序实践
- 1. 多副本部署
- 1.1. 副本数量
- 1.2. 更新策略
- 1.3. 跨节点的统一副本分布
- 1.4. 优先级
- 1.5. 停止容器中的进程
- 1.6. 预留资源
- 2. 探针
- 2.1. 活性探针(liveness probes)
- 2.2. 就绪探针(Readiness probe)
- 2.3. 启动探针
- 2.4. 外部依赖检查
- 3. 负载调整
- 3.1. HPA(HorizontalPodAutoscaler,横向资源扩缩容)
- 3.2. VPA(VerticalPodAutoscaler,纵向资源扩缩容)
- 4. 疑问和思考
- 5. 参考文档
Kubernetes 可以提供所需的编排和管理功能,以便您针对这些工作负载大规模部署容器。借助 Kubernetes 编排功能,您可以构建跨多个容器的应用服务、跨集群调度、扩展这些容器,并长期持续管理这些容器的健康状况。有了 Kubernetes,您便可切实采取一些措施来提高 IT 安全性。
高可用性(High Availability,HA)是指应用系统无中断运行的能力,通常可通过提高该系统的容错能力来实现。一般情况下,通过设置 replicas 给应用创建多个副本,可以适当提高应用容错能力,但这并不意味着应用就此实现高可用性。
众所周知,在Kubernetes环境中部署一个可用的应用程序是一件轻而易举的事。但另外一方面,如果要部署一个可容错,高可靠且易用的应用程序则不可避免地会遇到很多问题。在本文中,我们将讨论在Kubernetes中部署高可用应用程序并以简洁的方式给大家展示,本文也会重点介绍在Kubernetes部署高可用应用所需要注意的故则以及相应的方案。
1. 多副本部署
1.1. 副本数量
通常情况下,至少需要两个副本才能保证应用程序的最低高可用。但是,您可能会问,为什么单个副本无法做到高可用?问题在于 Kubernetes 中的许多实体(Node、Pod、ReplicaSet ,Deployment等)都是非持久化的,即在某些条件下,它们可能会被自动删除或者重新被创建。因此,Kubernetes 集群本身以及在其中运行的应用服务都必须要考虑到这一点。
例如,当使用autoscaler服务缩减您的节点数量时,其中一些节点将会被删除,包括在该节点上运行的 Pod。如果您的应用只有一个实例且在运行删除的节点上,此时,您可能会发现您的应用会变的不可用,尽管这时间通常是比较短的,因为对应的Pod会在新的节点上重新被创建。
一般来说,如果你只有一个应用程序副本,它的任何异常停服都会导致停机。换句话说,您必须为正在运行的应用程序保持至少两个副本,从而防止单点故障。
副本越多,在某些副本发生故障的情况下,您的应用程序的计算能力下降的幅度也就越小。例如,假设您有两个副本,其中一个由于节点上的网络问题而失败。应用程序可以处理的负载将减半(只有两个副本中的一个可用)。当然,新的副本会被调度到新的节点上,应用的负载能力会完全恢复。但在那之前,增加负载可能会导致服务中断,这就是为什么您必须保留一些副本。
当然应用层面需要注意在多副本情况下的事务一致性问题。
在k8s环境中,各个pod的高可用配置以及相关的资源高利用率治理通常是一个复杂的治理过程,并且难度很高
对于有多个副本的应用程序,最好的替代方法是配置 HorizontalPodAutoscaler 并让它管理副本的数量。本文的最后会详细描述HorizontalPodAutoscaler。
1.2. 更新策略
Deployment 的默认更新策略需要减少旧+新的 ReplicaSet Pod 的数量,其Ready状态为更新前数量的 75%。因此,在更新过程中,应用程序的计算能力可能会下降到正常水平的 75%,这可能会导致部分故障(应用程序性能下降)。
该strategy.RollingUpdate.maxUnavailable参数允许您配置更新期间可能变得不可用的Pod的最大百分比。因此,要么确保您的应用程序在 25% 的Pod不可用的情况下也能顺利运行,要么降低该maxUnavailable参数。请注意,该maxUnavailable参数已四舍五入。
默认更新策略 ( RollingUpdate)有一个小技巧:应用程序在滚动更新过程中,多副本策略依然有效,新旧版本会同时存在,一直到所有的应用都更新完毕。但是,如果由于某种原因无法并行运行不同的副本和不同版本的应用程序,那么您可以使用strategy.type: Recreate参数. 在Recreate策略下,所有现有Pod在创建新Pod之前都会被杀死。这会导致短暂的停机时间。
其他部署策略(蓝绿、金丝雀等)通常可以为 RollingUpdate 策略提供更好的替代方案。但是,我们没有在本文中考虑它们,因为它们的实现取决于用于部署应用程序的软件。
1.3. 跨节点的统一副本分布
Kubernetes 的设计理念为假设节点不可靠,节点越多,发生软硬件故障导致节点不可用的几率就越高。所以我们通常需要给应用部署多个副本,并根据实际情况调整 replicas 的值。该值如果为1 ,就必然存在单点故障。该值如果大于1但所有副本都调度到同一个节点,仍将无法避免单点故障。
为了避免单点故障,我们需要有合理的副本数量,还需要让不同副本调度到不同的节点。为此,您可以指示调度程序避免在同一节点上启动同一 Deployment 的多个 Pod:
affinity:PodAntiAffinity:preferredDuringSchedulingIgnoredDuringExecution:- PodAffinityTerm:labelSelector:matchLabels:app: testapptopologyKey: kubernetes.io/hostname
最好使用preferredDuringSchedulingaffinity而不是requiredDuringScheduling. 如果新Pod所需的节点数大于可用节点数,后者可能会导致无法启动新 Pod。尽管如此,requiredDuringScheduling当提前知道节点和应用程序副本的数量并且您需要确保两个Pod不会在同一个节点上结束时,亲和性也就会派上用场。
1.4. 优先级
priorityClassName代表的Pod优先级。调度器使用它来决定首先调度哪些 Pod,如果节点上没有剩余Pod空间,应该首先驱逐哪些 Pod。
您将需要添加多个PriorityClass(https://kubernetes.io/docs/concepts/configuration/Pod-priority-preemption/#priorityclass)类型资源并使用priorityClassName. 以下是如何PriorityClasses变化的示例:
- Cluster. Priority > 10000:集群关键组件,例如 kube-apiserver。
- Daemonsets. Priority: 10000:通常不建议将 DaemonSet Pods 从集群节点中驱逐,并替换为普通应用程序。
- Production-high. Priority: 9000:有状态的应用程序。
- Production-medium. Priority: 8000:无状态应用程序。
- Production-low. Priority: 7000:不太重要的应用程序。
- Default. Priority: 0:非生产应用程序。
设置优先级将帮助您避免关键组件的突然被驱逐。此外,如果缺乏节点资源,关键应用程序将驱逐不太重要的应用程序。
1.5. 停止容器中的进程
STOPSIGNAL中指定的信号(通常为TERM信号)被发送到进程以停止它。但是,某些应用程序无法正确处理它并且无法正常停服。对于在 Kubernetes 中运行的应用程序也是如此。
例如下面描述,为了正确关闭 nginx,你需要一个preStop这样的钩子:
lifecycle:
preStop:exec:command:- /bin/sh- -ec- |sleep 3nginx -s quit
上述的简要说明:
- sleep 3 可防止因删除端点而导致的竞争状况。
- nginx -s quit正确关闭nginx。镜像中不需要配置此行,因为 STOPSIGNAL: SIGQUIT参数默认设置在镜像中。
STOPSIGNAL的处理方式依赖于应用程序本身。实际上,对于大多数应用程序,您必须通过谷歌搜索或者其它途径来获取处理STOPSIGNAL的方式。如果信号处理不当,preStop钩子可以帮助您解决问题。另一种选择是用应用程序能够正确处理的信号(并允许它正常关闭)从而来替换STOPSIGNAL。
terminationGracePeriodSeconds是关闭应用程序的另一个重要参数。它指定应用程序正常关闭的时间段。如果应用程序未在此时间范围内终止(默认为 30 秒),它将收到一个KILL信号。因此,如果您认为运行preStop钩子和/或关闭应用程序STOPSIGNAL可能需要超过 30 秒,您将需要增加 terminateGracePeriodSeconds 参数。例如,如果来自 Web 服务客户端的某些请求需要很长时间才能完成(比如涉及下载大文件的请求),您可能需要增加它。
值得注意的是,preStop hook 有一个锁定机制,即只有在preStop hook 运行完毕后才能发送STOPSIGNAL信号。同时,在preStop钩子执行期间,terminationGracePeriodSeconds倒计时继续进行。所有由钩子引起的进程以及容器中运行的进程都将在TerminationSeconds结束后被终止。
此外,某些应用程序具有特定设置,用于设置应用程序必须终止的截止日期(例如,在Sidekiq 中的–timeout 选项)。因此,您必须确保如果应用程序有此配置,则它的值略应该低于terminationGracePeriodSeconds。
1.6. 预留资源
调度器使用 Pod的resources.requests来决定将Pod调度在哪个节点上。例如,无法在没有足够空闲(即非请求)资源来满足Pod资源请求的节点上调度Pod。另一方面,resources.limits允许您限制严重超过其各自请求的Pod的资源消耗。
一个很好的方式是设置limits等于 requests。将limits设置为远高于requests可能会导致某些节点的Pod无法获取请求的资源的情况。这可能会导致节点(甚至节点本身)上的其他应用程序出现故障。。Kubernetes 根据其资源方案为每个Pod分配一个 QoS 类。然后,K8s 使用 QoS 类来决定应该从节点中驱逐哪些 Pod。
因此,您必须同时为 CPU 和内存设置requests 和 limits。如果Linux 内核版本早于 5.4(https://engineering.indeedblog.com/blog/2019/12/cpu-throttling-regression-fix/)。在某些情况下,您唯一可以省略的是 CPU 限制(在 EL7/CentOS7 的情况下,如果要支持limits,则内核版本必须大于 3.10.0-1062.8.1.el7)。
此外,某些应用程序的内存消耗往往以无限的方式增长。一个很好的例子是用于缓存的 Redis 或基本上“独立”运行的应用程序。为了限制它们对节点上其他应用程序的影响,您可以(并且应该)为要消耗的内存量设置限制。
唯一的问题是,当应用程序达到此限制时应用程序将会被KILL。应用程序无法预测/处理此信号,这可能会阻止它们正常关闭。这就是为什么
除了 Kubernetes 限制之外,我们强烈建议使用专门针对于应用程序本身的机制来限制内存消耗,使其不会超过(或接近)在 Pod的limits.memory参数中设置的数值。
这是一个Redis配置案例,可以帮助您解决这个问题:
maxmemory 500mb # if the amount of data exceeds 500 MB...
maxmemory-policy allkeys-lru # ...Redis would delete rarely used keys
至于 Sidekiq,你可以使用 Sidekiq worker killer(https://github.com/klaxit/sidekiq-worker-killer):
require 'sidekiq/worker_killer'
Sidekiq.configure_server do |config|
config.server_middleware do |chain|# Terminate Sidekiq correctly when it consumes 500 MBchain.add Sidekiq::WorkerKiller, max_rss: 500
end
end
很明显,在所有这些情况下,limits.memory需要高于触发上述机制的阈值。
2. 探针
在 Kubernetes 中,探针(健康检查)用于确定是否可以将流量切换到应用程序(readiness probes)以及应用程序是否需要重新启动(liveness probes)。它们在更新部署和启动新Pod方面发挥着重要作用。
首先,我们想为所有探头类型提供一个建议:为timeoutSeconds参数设置一个较高的值 。一秒的默认值太低了,它将对 readiness Probe 和 liveness probes 产生严重影响。
如果timeoutSeconds太低,应用程序响应时间的增加(由于服务负载均衡,所有Pod通常同时发生)可能会导致这些Pod从负载均衡中删除(在就绪探测失败的情况下),或者,更糟糕的是,在级联容器重新启动时(在活动探测失败的情况下)。
2.1. 活性探针(liveness probes)
在实践中,活性探针的使用并不像您想象的那样广泛。它的目的是在应用程序被冻结时重新启动容器。然而,在现实生活中,应用程序出现死锁是一个意外情况,而不是常规的现象。如果应用程序出于某种原因导致这种异常的现象(例如,它在数据库断开后无法恢复与数据库的连接),您必须在应用程序中修复它,而不是“增加”基于 liveness probes 的解决方法。
虽然您可以使用 liveness probes 来检查这些状态,但我们建议默认情况下不使用 liveness Probe或仅执行一些基本的存活的探测,例如探测 TCP 连接(记住设置大一点的超时值)。这样,应用程序将重新启动以响应明显的死锁,而不会进入不停的重新启动的死循环(即重新启动它也无济于事)。
不合理的 liveness probes 配置引起的风险是非常严重的。在最常见的情况下, liveness probes 失败是由于应用程序负载增加(它根本无法在 timeout 参数指定的时间内完成)或由于当前正在检查(直接或间接)的外部依赖项的状态。
在后一种情况下,所有容器都将重新启动。
在最好的情况下,这不会导致任何结果,但在最坏的情况下,这将使应用程序完全不可用,也可能是长期不可用。如果大多数Pod的容器在短时间内重新启动,可能会导致应用程序长期完全不可用(如果它有大量副本)。一些容器可能比其他容器更快地变为 READY,并且整个负载将分布在这个有限数量的运行容器上。这最终会导致 liveness probes 超时,也将触发更多的重启。
另外,如果应用程序对已建立的连接数有限制并且已达到该限制,请确保liveness probes不会停止响应。通常,您必须为liveness probes指定一个单独的应用程序线程/进程来避免此类问题。例如,如果应用程序有11个线程(每个客户端一个线程),则可以将客户端数量限制为10个,以确保liveness probes有一个空闲线程可用。
另外,当然,不要向 liveness Probe 添加任何外部依赖项检查。
2.2. 就绪探针(Readiness probe)
事实证明,readinessProbe 的设计并不是很成功。readinessProbe 结合了两个不同的功能:
- 它会在容器启动期间找出应用程序是否可用;
- 它检查容器成功启动后应用程序是否仍然可用。
在实践中,绝大多数情况下都需要第一个功能,而第二个功能的使用频率仅与 liveness Probe 一样。配置不当的 readiness Probe 可能会导致类似于 liveness Probe 的问题。在最坏的情况下,它们最终还可能导致应用程序长期不可用。
当 readiness Probe 失败时,Pod 停止接收流量。在大多数情况下,这种行为没什么用,因为流量通常或多或少地在 Pod 之间均匀分布。因此,一般来说,readiness Probe 要么在任何地方都有效,要么不能同时在大量 Pod 上工作。在某些情况下,此类行为可能有用。但是,根据我的经验,这也主要是在某些特殊情况下才有用。
尽管如此,readiness Probe 还具有另一个关键功能:它有助于确定新创建的容器何时可以处理流量,以免将负载转发到尚未准备好的应用程序。这个 readiness Probe 功能在任何时候都是必要的。
换句话说,readiness Probe的一个功能需求量很大,而另一个功能根本不需要。startup Probe的引入解决了这一难题。它最早出现在Kubernetes 1.16中,在v1.18中成为beta版,在v1.20中保持稳定。因此,最好使用readiness Probe检查应用程序在Kubernetes 1.18以下版本中是否已就绪,而在Kubernetes 1.18及以上版本中是否已就绪则推荐使用startup Probe。同样,如果在应用程序启动后需要停止单个Pod的流量,可以使用Kubernetes 1.18+中的readiness Probe。
2.3. 启动探针
startup Probe 检查容器中的应用程序是否准备就绪。然后它将当前 Pod 标记为准备好接收流量或继续更新/重新启动部署。与 readiness Probe 不同,startup Probe 在容器启动后停止工作。
我们不建议使用 startup Probe 来检查外部依赖:它的失败会触发容器重启,这最终可能导致 Pod 处于CrashLoopBackOff状态。在这种状态下,尝试重新启动失败的容器之间的延迟可能高达五分钟。这可能会导致不必要的停机时间,因为尽管应用程序已准备好重新启动,但容器会继续等待,直到因CrashLoopBackOff而尝试重新启动的时间段结束。
如果您的应用程序接收流量并且您的 Kubernetes 版本为 1.18 或更高版本,则您应该使用 startup Probe。
另请注意,增加failureThreshold配置而不是设置initialDelaySeconds是配置探针的首选方法。这将使容器尽快可用。
2.4. 外部依赖检查
如您所知,readiness Probe 通常用于检查外部依赖项(例如数据库)。虽然这种方法理应存在,但建议您将检查外部依赖项的方法与检查 Pod 中的应用程序是否满负荷运行(并切断向其发送流量)的方法分开也是个好主意)。
您可以使用initContainers在运行主容器的 startupProbe/readinessProbe 之前检查外部依赖项。很明显,在这种情况下,您将不再需要使用 readiness Probe 检查外部依赖项。initContainers不需要更改应用程序代码。您不需要嵌入额外的工具来使用它们来检查应用程序容器中的外部依赖项。通常,它们相当容易实现:
initContainers:- name: wait-postgresimage: postgres:12.1-alpinecommand:- sh- -ec- |until (pg_isready -h example.org -p 5432 -U postgres); dosleep 1doneresources:requests:cpu: 50mmemory: 50Milimits:cpu: 50mmemory: 50Mi- name: wait-redisimage: redis:6.0.10-alpine3.13command:- sh- -ec- |until (redis-cli -u redis://redis:6379/0 ping); dosleep 1doneresources:requests:cpu: 50mmemory: 50Milimits:cpu: 50mmemory: 50Mi
3. 负载调整
3.1. HPA(HorizontalPodAutoscaler,横向资源扩缩容)
让我们考虑一种情况,如果应用程序的意外负载明显高于平时,会发生什么情况?是的,您可以手动扩展集群,但这不是我们推荐使用的方法。这就是HorizontalPodAutoscaler(HPA,https://kubernetes.io/docs/tasks/run-application/horizontal-Pod-autoscale/)的用武之地。
借助 HPA,您可以选择一个指标并将其用作触发器,根据指标的值自动向上/向下扩展集群。想象一下,在一个安静的夜晚,您的集群突然因流量大幅上升而爆炸,例如,Reddit 用户发现了您的服务,CPU 负载(或其他一些 Pod 指标)增加,达到阈值,然后 HPA 开始发挥作用。它扩展了集群,从而在大量 Pod 之间均匀分配负载。
也正是多亏了这一点,所有传入的请求都被成功处理。同样重要的是,在负载恢复到平均水平后,HPA 会缩小集群以降低基础设施成本。这听起来很不错,不是吗?
让我们看看 HPA 是如何计算要添加的副本数量的。这是官方文档中提供的公式:
d e s i r e d R e p l i c a s = c e i l [ c u r r e n t R e p l i c a s ∗ ( c u r r e n t M e t r i c V a l u e / d e s i r e d M e t r i c V a l u e ) ] desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )] desiredReplicas=ceil[currentReplicas∗(currentMetricValue/desiredMetricValue)]
现在假设:
- 当前副本数为3;
- 当前度量值为 100;
- 度量阈值为 60;
在这种情况下,结果则为3 * ( 100 / 60 ),即“大约”5 个副本(HPA 会将结果向上舍入)。因此,应用程序将获得额外的另外两个副本。当然,HPA操作还会继续:如果负载减少,HPA 将继续计算所需的副本数(使用上面的公式)来缩小集群。
另外,还有一个是我们最关心的部分。你应该使用什么指标?首先想到的是主要指标,例如 CPU 或内存利用率。如果您的 CPU 和内存消耗与负载成正比,这将起作用。但是如果 Pod 处理不同的请求呢?有些请求需要较大的 CPU 周期,有些可能会消耗大量内存,还有一些只需要最少的资源。
例如,让我们看一看RabbitMQ队列和处理它的实例。假设队列中有十条消息。监控显示消息正在稳定且定期地退出队列(按照RabbitMQ的术语)。也就是说,我们觉得队列中平均有10条消息是可以的。但是负载突然增加,队列增加到100条消息。然而,worker的CPU和内存消耗保持不变:他们稳定地处理队列,在队列中留下大约80-90条消息。
但是如果我们使用一个自定义指标来描述队列中的消息数量呢?让我们按如下方式配置我们的自定义指标:
- 当前副本数为3;
- 当前度量值为 80;
- 度量阈值为 15
因此,3 * ( 80 / 15 ) = 16。在这种情况下,HPA 可以将 worker 的数量增加到 16,并且它们会快速处理队列中的所有消息(此时 HPA 将再次减少它们的数量)。但是,必须准备好所有必需的基础架构以容纳此数量的 Pod。也就是说,它们必须适合现有节点,或者在使用Cluster Autoscaler(https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler)的情况下,必须由基础设施供应商(云提供商)提供新节点。换句话说,我们又回到规划集群资源了。
现在让我们来看看一些清单:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: php-apache
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50
这个很简单。一旦 CPU 负载达到 50%,HPA 就会开始将副本数量扩展到最多 10 个。
下面是一个比较有趣的案例:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: worker
spec:
scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: worker
minReplicas: 1
maxReplicas: 10
metrics:
- type: Externalexternal:metric:name: queue_messagestarget:type: AverageValueaverageValue: 15
请注意,在此示例中,HPA 使用自定义指标(https://kubernetes.io/docs/tasks/run-application/horizontal-Pod-autoscale/#support-for-custom-metrics)。它将根据队列的大小(queue_messages指标)做出扩展决策。鉴于队列中的平均消息数为 10,我们将阈值设置为 15。这样可以更准确地管理副本数。如您所见,与基于 CPU 的指标相比,自定义指标可实现更准确的集群自动缩放。
HPA 配置选项是多样化。例如,您可以组合不同的指标。在下面的清单中,同时使用CPU 利用率和队列大小来触发扩展决策。
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: worker
spec:
scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: worker
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 50
- type: Externalexternal:metric:name: queue_messagestarget:type: AverageValueaverageValue: 15
这种情况下,HPA又该采用什么计算算法?好吧,它使用计算出的最高副本数,而不考虑所利用的指标如何。例如,如果基于 CPU 指标的值显示需要添加 5 个副本,而基于队列大小的指标值仅给出 3 个 Pod,则 HPA 将使用较大的值并添加 5 个 Pod。
随着Kubernetes 1.18的发布,你现在有能力来定义scaleUp和scaleDown方案(https://kubernetes.io/docs/tasks/run-application/horizontal-Pod-autoscale/#support-for-configurable-scaling-behavior)。例如:
behavior:
scaleDown:stabilizationWindowSeconds: 60policies:- type: Percentvalue: 5periodSeconds: 20- type: Podsvalue: 5periodSeconds: 60selectPolicy: Min
scaleUp:stabilizationWindowSeconds: 0policies:- type: Percentvalue: 100periodSeconds: 10
正如您在上面的清单中看到的,它有两个部分。第一个 ( scaleDown) 定义缩小参数,而第二个 ( scaleUp) 用于放大。每个部分都有stabilizationWindowSeconds. 这有助于防止在副本数量持续波动时出现所谓的“抖动”(或不必要的缩放)。这个参数本质上是作为副本数量改变后的超时时间。
现在让我们谈谈这两者的策略。scaleDown策略允许您指定在type: Percent特定时间段内缩减的 Pod 百分比 。如果负载具有周期性现象,您必须做的是降低百分比并增加持续时间。在这种情况下,随着负载的减少,HPA 不会立即杀死大量 Pod(根据其公式),而是会逐渐杀死对应的Pod。此外,您可以设置type: Pods在指定时间段内允许 HPA 杀死的最大 Pod 数量 。
注意selectPolicy: Min参数。这意味着 HPA 使用影响最小 Pod 数量的策略。因此,如果百分比值(上例中的 5%)小于数字替代值(上例中的 5 个 Pod),HPA 将选择百分比值。相反,selectPolicy: Max策略会产生相反的效果。
scaleUp部分中使用了类似的参数。请注意,在大多数情况下,集群必须(几乎)立即扩容,因为即使是轻微的延迟也会影响用户及其体验。因此,在本节中StabilizationWindowsSeconds设置为0。如果负载具有循环模式,HPA可以在必要时将副本计数增加到maxReplicas(如HPA清单中定义的)。我们的策略允许HPA每10秒(periodSeconds:10)向当前运行的副本添加多达100%的副本。
最后,您可以将selectPolicy参数设置Disabled为关闭给定方向的缩放:
behavior:
scaleDown:selectPolicy: Disabled
大多数情况下,当 HPA 未按预期工作时,才会使用策略。策略带来了灵活性的同时,也使配置清单更难掌握。
最近,HPA能够跟踪一组 Pod 中单个容器的资源使用情况(在 Kubernetes 1.20 中作为 alpha 功能引入)(https://kubernetes.io/docs/tasks/run-application/horizontal-Pod-autoscale/#container-resource-metrics)。
总结:让我们以完整的 HPA 清单示例结束本段:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: worker
spec:
scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: worker
minReplicas: 1
maxReplicas: 10
metrics:
- type: Externalexternal:metric:name: queue_messagestarget:type: AverageValueaverageValue: 15
behavior:scaleDown:stabilizationWindowSeconds: 60policies:- type: Percentvalue: 5periodSeconds: 20- type: Podsvalue: 5periodSeconds: 60selectPolicy: MinscaleUp:stabilizationWindowSeconds: 0policies:- type: Percentvalue: 100periodSeconds: 10
请注意,此示例仅供参考。您将需要对其进行调整以适应您自己的操作的具体情况。
Horizontal Pod Autoscaler 简介:HPA 非常适合生产环境。但是,在为 HPA 选择指标时,您必须谨慎并尽量多的考虑现状。错误的度量标准或错误的阈值将导致资源浪费(来自不必要的副本)或服务降级(如果副本数量不够)。密切监视应用程序的行为并对其进行测试,直到达到正确的平衡。
3.2. VPA(VerticalPodAutoscaler,纵向资源扩缩容)
VPA(https://github.com/kubernetes/autoscaler/tree/master/vertical-Pod-autoscaler)分析容器的资源需求并设置(如果启用了相应的模式)它们的限制和请求。
假设您部署了一个新的应用程序版本,其中包含一些新功能,结果发现,比如说,导入的库是一个巨大的资源消耗者,或者代码没有得到很好的优化。换句话说,应用程序资源需求增加了。您在测试期间没有注意到这一点(因为很难像在生产中那样加载应用程序)。
当然,在更新开始之前,相关的请求和限制已经为应用程序设置好了。现在,应用程序达到内存限制,其Pod由于OOM而被杀死。VPA可以防止这种情况!乍一看,VPA看起来是一个很好的工具,应该是被广泛的使用的。但在现实生活中,情况并非是如此,下面会简单说明一下。
主要问题(尚未解决)是Pod需要重新启动才能使资源更改生效。在未来,VPA将在不重启Pod的情况下对其进行修改,但目前,它根本无法做到这一点。但是不用担心。如果您有一个“编写良好”的应用程序,并且随时准备重新部署(例如,它有大量副本;它的PodAntiAffinity、PodDistributionBudget、HorizontalPodAutoscaler都经过仔细配置,等等),那么这并不是什么大问题。在这种情况下,您(可能)甚至不会注意到VPA活动。
遗憾的是,可能会出现其他不太令人愉快的情况,如:应用程序重新部署得不太好,由于缺少节点,副本的数量受到限制,应用程序作为StatefulSet运行,等等。在最坏的情况下,Pod的资源消耗会因负载增加而增加,HPA开始扩展集群,然后突然,VPA开始修改资源参数并重新启动Pod。因此,高负载分布在其余的Pod中。其中一些可能会崩溃,使事情变得更糟,并导致失败的连锁反应。
这就是为什么深入了解各种 VPA 操作模式很重要。让我们从最简单的开始——“Off模式”。
Off模式:该模式所做的只是计算Pod的资源消耗并提出建议。我们在大多数情况下都使用这种模式(我们建议使用这种模式)。但首先,让我们看几个例子。
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-app-vpa
spec:
targetRef:apiVersion: "apps/v1"kind: Deploymentname: my-app
updatePolicy:updateMode: "Recreate"containerPolicies:- containerName: "*"minAllowed:cpu: 100mmemory: 250MimaxAllowed:cpu: 1memory: 500MicontrolledResources: ["cpu", "memory"]controlledValues: RequestsAndLimits
我们不会详细介绍此清单的参数:文章(https://povilasv.me/vertical-Pod-autoscaling-the-definitive-guide/)详细描述了 VPA 的功能和细节。简而言之,我们指定 VPA 目标 ( targetRef) 并选择更新策略。
此外,我们指定了 VPA 可以使用的资源的上限和下限。主要关注updateMode部分。在“重新创建”或“自动”模式下,VPA 将重新创建 Pod ,因此需要考虑由此带来的短暂停服风险(直到上述用于 Pod的 资源参数更新的补丁可用)。由于我们不想要它,我们使用“off”模式:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-app-vpa
spec:
targetRef:apiVersion: "apps/v1"kind: Deploymentname: my-app
updatePolicy:updateMode: "Off" # !!!
resourcePolicy:containerPolicies:- containerName: "*"controlledResources: ["cpu", "memory"]
VPA 开始收集指标。您可以使用kubectl describe vpa命令查看建议(只需让 VPA 运行几分钟即可):
Recommendation:Container Recommendations:Container Name: nginxLower Bound:Cpu: 25mMemory: 52428800Target:Cpu: 25mMemory: 52428800Uncapped Target:Cpu: 25mMemory: 52428800Upper Bound:Cpu: 25mMemory: 52428800
运行几天(一周、一个月等)后,VPA 建议将更加准确。然后是在应用程序清单中调整限制的最佳时机。这样,您可以避免由于缺乏资源而导致的 OOM 终止并节省基础设施(如果初始请求/限制太高)。
现在,让我们谈谈使用 VPA 的一些细节。
其他 VPA 模式:
请注意,在“Initial”模式下,VPA 在 Pod 启动时分配资源,以后不再更改它们。因此,如果过去一周的负载相对较低,VPA 将为新创建的 Pod 设置较低的请求/限制。如果负载突然增加,可能会导致问题,因为请求/限制将远低于此类负载所需的数量。如果您的负载均匀分布并以线性方式增长,则此模式可能会派上用场。
在“Auto”模式下,VPA 重新创建 Pod。因此,应用程序必须正确处理重新启动。如果它不能正常关闭(即通过正确关闭现有连接等),您很可能会捕获一些可避免的 5XX 错误。很少建议使用带有 StatefulSet 的 Auto 模式:想象一下 VPA 试图将 PostgreSQL 资源添加到生产中……
至于开发环境,您可以自由试验以找到您可以接受的(稍后)在生产中使用的资源级别。假设您想在“Initial”模式下使用 VPA,并且我们在Redis集群中使用maxmemory参数 。您很可能需要更改它以根据您的需要进行调整。问题是 Redis 不关心 cgroups 级别的限制。
换句话说,如果您的 Pod 的内存上限为 1GB,那么maxmemory 设置的是2GB ,您将面临很大的风险。但是你怎么能设置maxmemory成和limit一样呢?嗯,有办法!您可以使用 VPA 推荐的值:
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
labels:app: redis
spec:
replicas: 1
selector:matchLabels:app: redis
template:metadata:labels:app: redisspec:containers:- name: redisimage: redis:6.2.1ports:- containerPort: 6379resources:requests:memory: "100Mi"cpu: "256m"limits:memory: "100Mi"cpu: "256m"env:- name: MY_MEM_REQUESTvalueFrom:resourceFieldRef:containerName: appresource: requests.memory- name: MY_MEM_LIMITvalueFrom:resourceFieldRef:containerName: appresource: limits.memory
您可以使用环境变量来获取内存限制(并从应用程序需求中减去 10%)并将结果值设置为maxmemory。您可能需要对sed用于处理 Redis 配置的 init 容器做一些事情,因为默认的 Redis 容器映像不支持maxmemory使用环境变量进行传递。尽管如此,这个解决方案还是很实用的。
最后,我想将您的注意力转移到 VPA 一次性驱逐所有 DaemonSet Pod 的事实。我们目前正在开发修复此问题的补丁(https://github.com/kubernetes/kubernetes/pull/98307)。
最终的 VPA 建议:
“OFF”模式适用于大多数情况。您可以在开发环境中尝试“Auto”和“Initial”模式。
只有在您已经积累了大量的经验并对其进行了彻底测试的情况下,才能在生产中使用VPA。此外,你必须清楚地了解你在做什么以及为什么要这样做。
与此同时,我们热切期待 Pod 资源的热(免重启)更新功能。
请注意,同时使用 HPA 和 VPA 存在一些限制。例如,如果基于 CPU 或基于内存的指标用作触发器,则 VPA 不应与 HPA 一起使用。原因是当达到阈值时,VPA 会增加资源请求/限制,而 HPA 会添加新副本。
因此,负载将急剧下降,并且该过程将反向进行,从而导致“抖动”。官方文件(https://github.com/kubernetes/autoscaler/tree/master/vertical-Pod-autoscaler#known-limitations)更清楚地说明了现有的限制。。
4. 疑问和思考
我们分享了一些 Kubernetes 高可用部署应用的的一些建议以及相关的案例,这些机制有助于部署高可用性应用程序。我们讨论了调度器操作、更新策略、优先级、探针等方面。最后一部分我们深入讨论了剩下的三个关键主题:PodDisruptionBudget、HorizontalPodAutoscaler 和 VerticalPodAutoscaler。
问题中提到的大量案例都是基于我们生成的真实场景,如使用,请根据自生的环境进行调整。
通过本文,我们也希望读者能够根据自有的环境进行验证,能够一起分享各自的生成经验,能偶一起推进Kubernetes相关技术的发展与进步。再次也感谢读者能够花费大量的时间认真读完本文。
5. 参考文档
暂无
相关文章:

在k8s中部署高可用程序实践和资源治理
在k8s中部署高可用程序实践 1. 多副本部署1.1. 副本数量1.2. 更新策略1.3. 跨节点的统一副本分布1.4. 优先级1.5. 停止容器中的进程1.6. 预留资源 2. 探针2.1. 活性探针(liveness probes)2.2. 就绪探针(Readiness probe)2.3. 启动…...

WebView的使用与后退键处理-嵌入小程序或者 H5 页面
在使用 WebView 嵌入小程序或者 H5 页面时,通常会涉及到处理后退键的操作。在 Android 平台上,可以通过 WebView 的相关方法来实现后退键的处理。你可以按照以下步骤来实现: 在 Activity 或 Fragment 中找到 WebView 控件,并为其…...
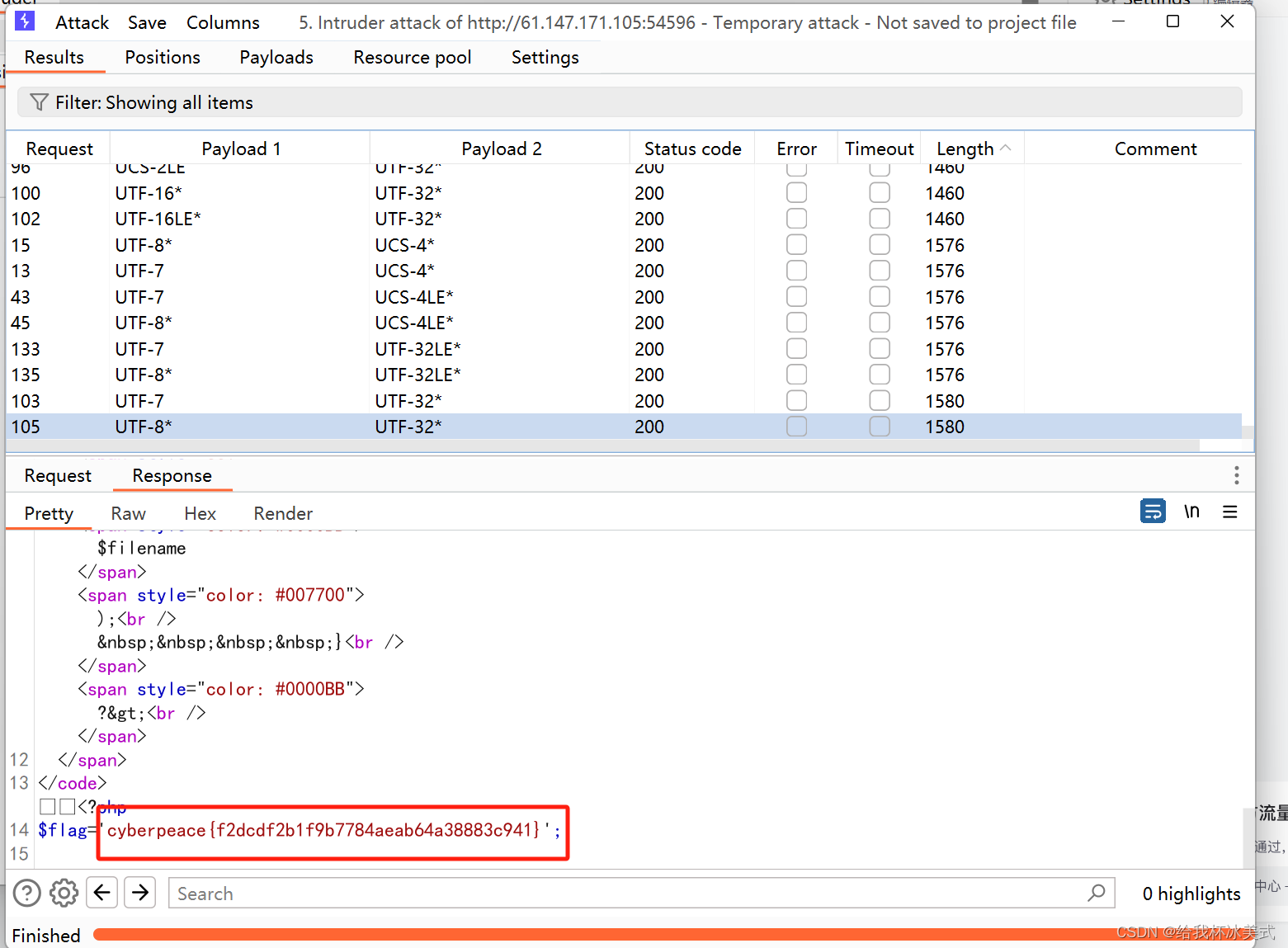
【攻防世界】file_include (PHP伪协议+过滤器)
打开题目环境: 进行PHP代码审计,发现这是一个文件包含漏洞。 我们尝试利用PHP伪协议中的 php://filter来读取 check.php 中的内容。 构造payload 并提交: 发现payload被过滤掉了,我们就需要尝试使用不同的转换器。 PHP各类转换…...
:PHY驱动)
Linux 内核中PHY子系统(网络):PHY驱动
一. 简介 PHY 子系统就是用于 PHY 设备相关内容的,分为 PHY 设备和 PHY 驱动,和 platform 总线一样,PHY 子系统也是一个设备、总线和驱动模型。 前面一篇文章学习了 PHY子系统中的 PHY设备。文章如下: Linux 内核中PHY子系统(网…...
机器学习-机器学习算法简介】)
【六 (1)机器学习-机器学习算法简介】
目录 文章导航一、机器学习二、基于学习方式的分类三、监督学习常见类型四、无监督学习常见类型五、强化学习常见分类 文章导航 【一 简明数据分析进阶路径介绍(文章导航)】 一、机器学习 机器学习是一门多领域交叉学科,涉及概率论、统计学…...

TCP服务端主动向客户端发送数据
C TCP 服务端和客户端通信的例子 在此基础上,要修改服务端代码,使其能够每秒向客户端发送当前时间,你需要添加一个循环,每次循环发送当前时间给客户端。同时,你需要在客户端代码中添加接收服务端发送的数据的逻辑。 …...
ObjectiveC-03-XCode的使用和基础数据类型
本节做为Objective-C的入门课程,笔者会从零基础开始介绍这种程序设计语言的各个方面。 术语 ObjeC:Objective-C的简称,因为完整的名称过长,后续会经缩写来代替;项目/工程:也称工程,指的是一个A…...
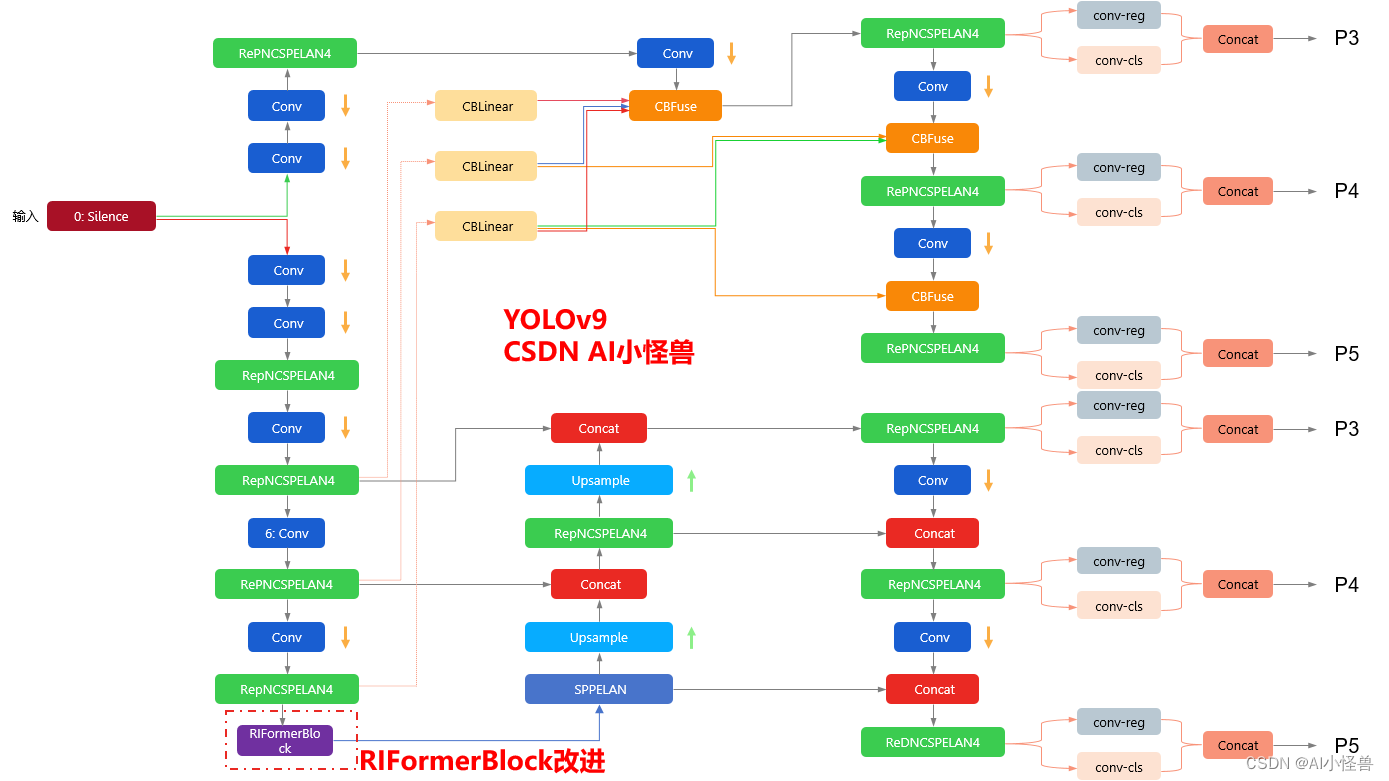
YOLOv9改进策略 :主干优化 | 无需TokenMixer也能达成SOTA性能的极简ViT架构 | CVPR2023 RIFormer
💡💡💡本文改进内容: token mixer被验证能够大幅度提升性能,但典型的token mixer为自注意力机制,推理耗时长,计算代价大,而RIFormers是无需TokenMixer也能达成SOTA性能的极简ViT架构 ,在保证性能的同时足够轻量化。 💡💡💡RIFormerBlock引入到YOLOv9,多个数…...

원클릭으로 주류 전자상거래 플랫폼 상품 상세 데이터 수집 및 접속 시연 예제 (한국어판)
클릭 한 번으로 전자상거래 플랫폼 데이터를 캡처하는 것은 일반적으로 웹 페이지에서 정보를 자동으로 추출 할 수있는 네트워크 파충류 기술과 관련됩니다.그러나 모든 형태의 데이터 수집은 해당 웹 사이트의 사용 약관 및 개인 정보 보호 정책 및 현지 법률 및 규정을 준수…...

2024年github开源top100中文
2024年github开源top100中文 动动美丽的小指头点个赞呗,感谢啦!💕💕💕😘😘😘 本文由Butterfly一键发布工具发布 语言star项目名称描述Python45670xai-org/grok-1Grok开源发布Ruby260…...
回收站删除的文件在哪里?专业恢复方法分享(最新版)
“我很想知道我从回收站删除的文件被保存在哪里了呢?我刚刚不小心清空了回收站,现在想将它们恢复,应该怎么操作呢?谁能教教我怎么从回收站恢复文件?” 回收站,作为Windows操作系统中的一个重要组件…...

什么是工时管理软件?
简而言之,工时管理软件是一种可以帮助管理者跟踪企业员工在项目和任务上花费的时间的软件。然而,工时管理软件不仅是一种收集信息的工具,它还是一种解决方案,使企业能够处理和优化不同的流程和活动,例如工资单、项目预…...
一文解析智慧城市,人工智能技术将成“智”理主要手段
长期以来,有关智慧城市的讨论主要围绕在技术进步方面,如自动化、人工智能、数据的公开以及将更多的传感器嵌入城市以使其更加智能化。实际上,智慧城市是一个关于未来的设想,其重要原因在于城市中存在各种基础设施、政治、地理、财…...
SQLBolt,一个练习SQL的宝藏网站
知乎上有人问学SQL有什么好的网站,这可太多了。 我之前学习SQL买了本SQL学习指南,把语法从头到尾看了个遍,但仅仅是心里有数的程度,后来进公司大量的写代码跑数,才算真真摸透了SQL,知道怎么调优才能最大化…...

TikTok防关联引流系统:全球多账号运营的终极解决方案
tiktok防关联引流系统介绍,tiktok防关联系统是基于tiktok生态研发的效率工具,帮你快速实现tiktok全球多账号运营,系统配备了性能强劲的安卓,防关联智能终端,可一建创建全球多国手机环境,完美满足各类app软件…...
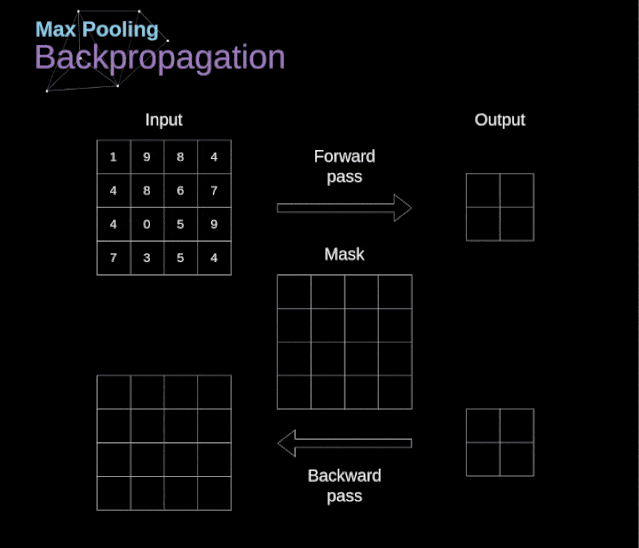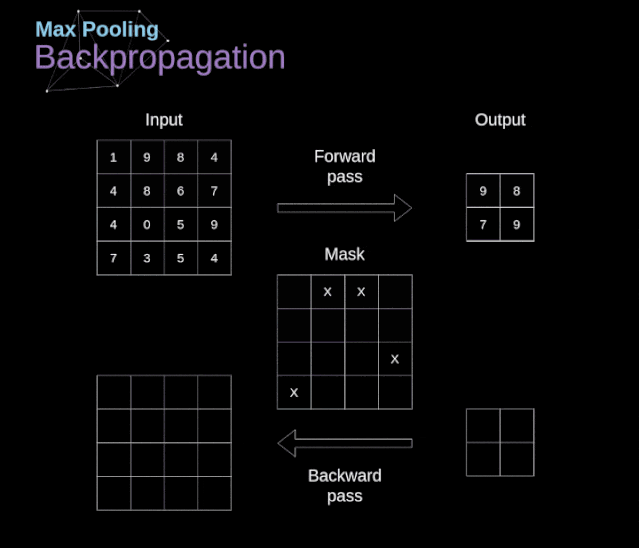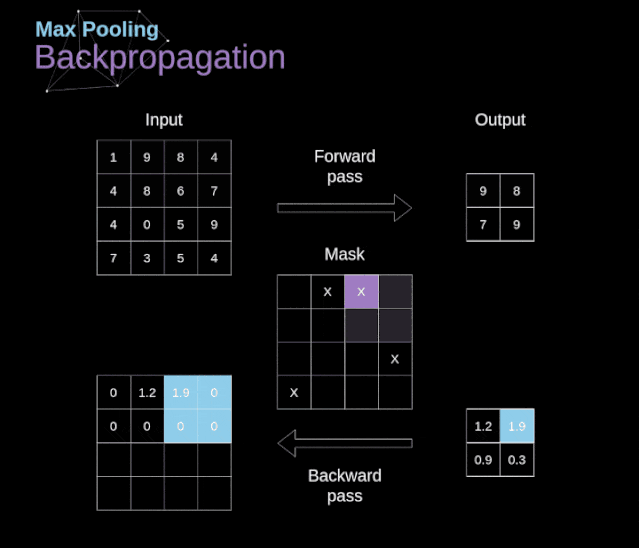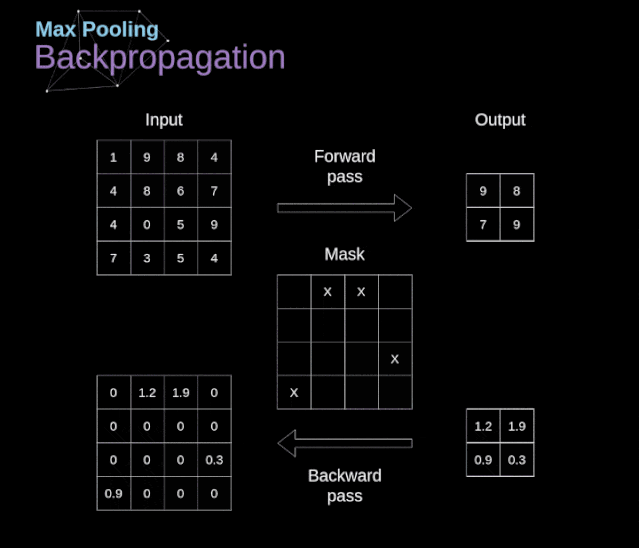
卷积神经网络(CNN)的数学原理解析
文章目录 前言 1、介绍 2、数字图像的数据结构 3、卷积 4、Valid 和 Same 卷积 5、步幅卷积 6、过渡到三维 7、卷积层 8、连接剪枝和参数共享 9、卷积反向传播 10、池化层 11、池化层反向传播 前言 本篇主要分享卷积神经网络(CNN)的数学原理解析…...
)
2024年华为OD机试真题-亲子游戏-Java-OD统一考试(C卷)
题目描述: 宝宝和妈妈参加亲子游戏,在一个二维矩阵(N*N)的格子地图上,宝宝和妈妈抽签决定各自的位置,地图上每个格子有不同的糖果数量,部分格子有障碍物。 游戏规则是妈妈必须在最短的时间(每个单位时间只能走一步)到达宝宝的位置,路上的所有糖果都可以拿走,不能走障…...

大模型显存占用分析
kvcache显存占用分析 假设序列输入长度:s,输出长度:n,数据类型以FP16来保存KV cache。 峰值显存占用:b(sn)hl2*24blh(sn) 注:b表示batch size,第一个2表示k/v cache,第二个2表示FP1…...

matlab中旋转矩阵函数
文章目录 matlab里的旋转矩阵、四元数、欧拉角四元数根据两向量计算向量之间的旋转矩阵和四元数欧拉角转旋转矩阵旋转矩阵转欧拉角旋转矩阵转四元数参考链接 matlab里的旋转矩阵、四元数、欧拉角 旋转矩阵dcmR四元数quatq[q0,q1,q2,q3]欧拉角angle[row,pitch,yaw] % 旋转矩阵…...

探讨Spring Boot的自动配置原理
Spring Boot以其简化Spring应用开发和部署的能力而广受欢迎。其中最引人注目的特性之一就是自动配置,它极大地减少了开发者需要手动编写的配置量。在本篇博客中,我们将深入探讨Spring Boot自动配置的工作原理,以及它是如何使得Spring应用的配…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

大话软工笔记—需求分析概述
需求分析,就是要对需求调研收集到的资料信息逐个地进行拆分、研究,从大量的不确定“需求”中确定出哪些需求最终要转换为确定的“功能需求”。 需求分析的作用非常重要,后续设计的依据主要来自于需求分析的成果,包括: 项目的目的…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

什么?连接服务器也能可视化显示界面?:基于X11 Forwarding + CentOS + MobaXterm实战指南
文章目录 什么是X11?环境准备实战步骤1️⃣ 服务器端配置(CentOS)2️⃣ 客户端配置(MobaXterm)3️⃣ 验证X11 Forwarding4️⃣ 运行自定义GUI程序(Python示例)5️⃣ 成功效果
苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...

水泥厂自动化升级利器:Devicenet转Modbus rtu协议转换网关
在水泥厂的生产流程中,工业自动化网关起着至关重要的作用,尤其是JH-DVN-RTU疆鸿智能Devicenet转Modbus rtu协议转换网关,为水泥厂实现高效生产与精准控制提供了有力支持。 水泥厂设备众多,其中不少设备采用Devicenet协议。Devicen…...
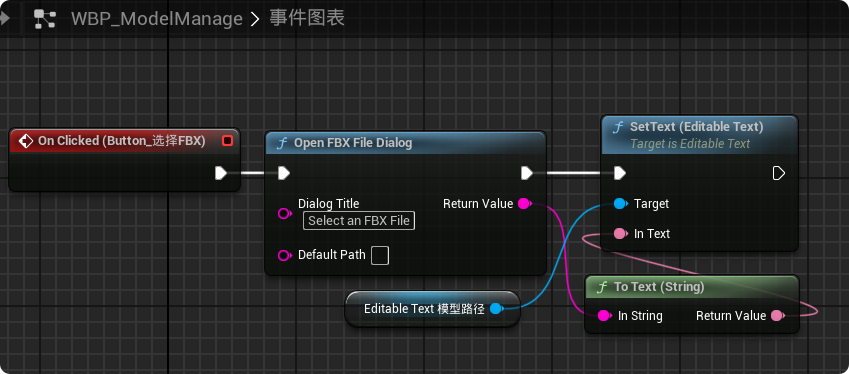
【UE5 C++】通过文件对话框获取选择文件的路径
目录 效果 步骤 源码 效果 步骤 1. 在“xxx.Build.cs”中添加需要使用的模块 ,这里主要使用“DesktopPlatform”模块 2. 添加后闭UE编辑器,右键点击 .uproject 文件,选择 "Generate Visual Studio project files",重…...
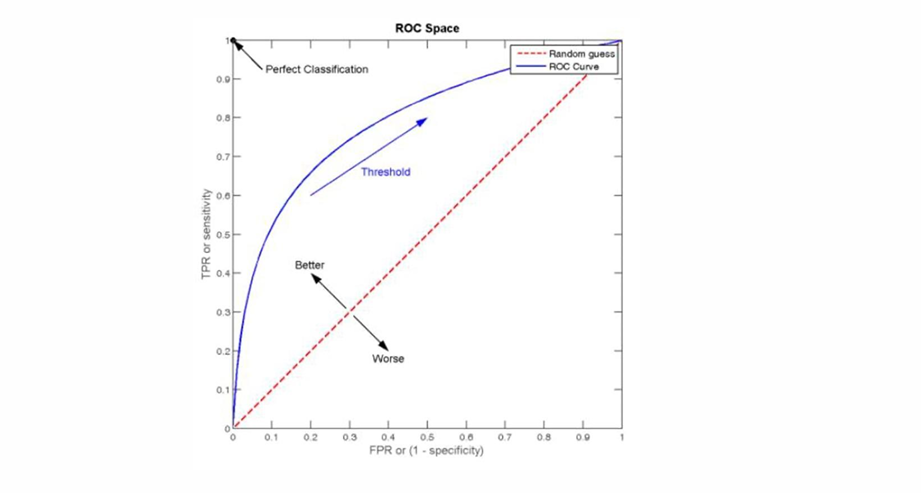
自然语言处理——文本分类
文本分类 传统机器学习方法文本表示向量空间模型 特征选择文档频率互信息信息增益(IG) 分类器设计贝叶斯理论:线性判别函数 文本分类性能评估P-R曲线ROC曲线 将文本文档或句子分类为预定义的类或类别, 有单标签多类别文本分类和多…...

6️⃣Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙
Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙 一、前言:离区块链还有多远? 区块链听起来可能遥不可及,似乎是只有密码学专家和资深工程师才能涉足的领域。但事实上,构建一个区块链的核心并不复杂,尤其当你已经掌握了一门系统编程语言,比如 Go。 要真正理解区…...