Pyspark基础入门7_RDD的内核调度
Pyspark
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下Pyspark基础入门7
#博学谷IT学习技术支持
文章目录
- Pyspark
- 前言
- 一、RDD的依赖关系
- 1 窄依赖
- 2 宽依赖
- 二、DAG和STAGE
- 三、RDD的shuffle
- 四、Job的调度流程
- 五、Spark的并行度
- 总结
前言
今天和大家分享的是Spark RDD的内核调度
一、RDD的依赖关系
RDD的依赖: 指的一个RDD的形成可能是有一个或者多个RDD得出, 此时这个RDD和之前的RDD之间产生依赖关系.
在Spark中, RDD之间的依赖关系,主要有二种依赖关系:
1 窄依赖
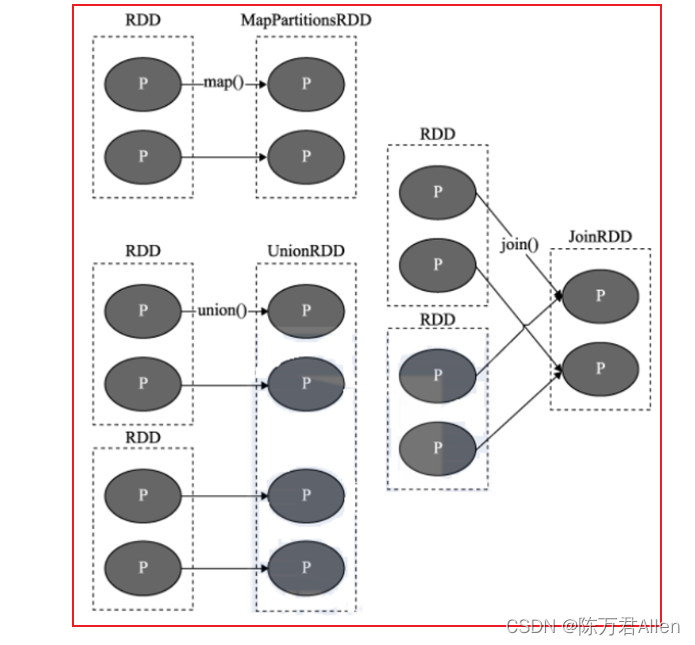
目的: 为了实现并行计算操作, 并且提高容错的能力
指的: 一个RDD上的一个分区的数据, 只能完整的交付给下一个RDD的一个分区(完全继承),不能分隔
2 宽依赖
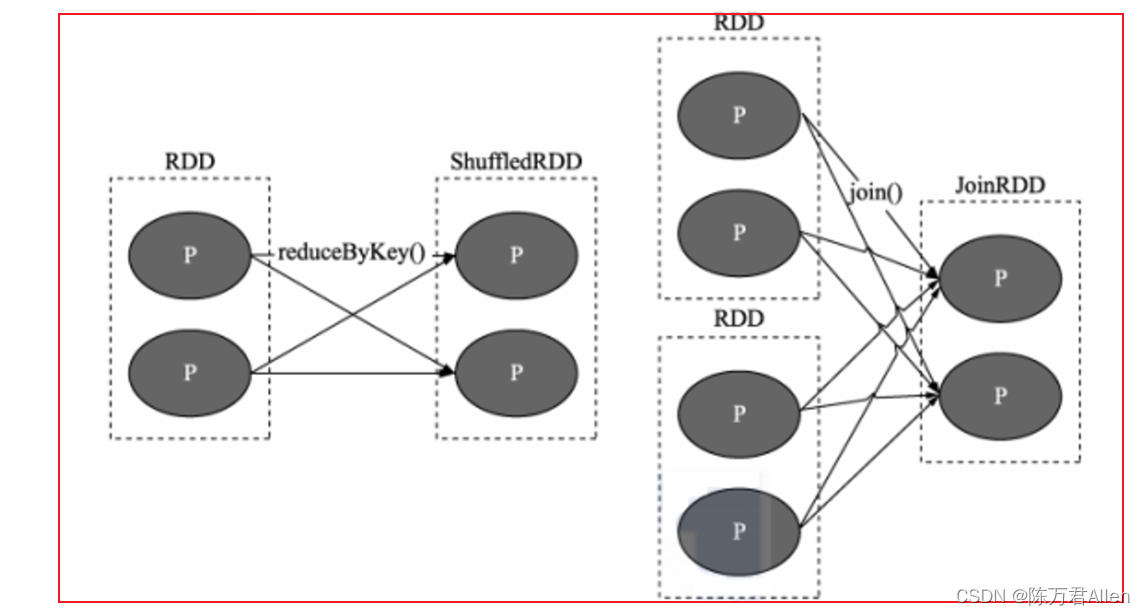
目的: 划分stage的依据
指的: 上一个RDD的某一个分区的数据被下游的一个RDD的多个分区的所接收, 中间必然存在shuffle操作(是否存在shuffle操作是判定宽窄依赖关系的重要依据)
注意: 一旦有了shuffle操作, 后续的RDD的执行必须等待前序的RDD(shuffle)执行完成,才能执行
在Spark中, 每一个算子是否会执行shuffle操作, 其实Spark在设计算子的时候, 就已经规划好了, 比如说: Map算子就不会触发shuffle, reduceByKey算子一定会触发shuffle操作
如果想知道这个算子是否会触发shuffle操作, 可以通过在运行的时候, 查看默认4040 WEB UI界面. 在界面中对应Job的DAG执行流程图中, 如果这个图被划为为了多个stage, 那么就说明这个算子会触发shuffle. 或者也可以查看这个算子源码. 一般在源码的说明信息中也会有一定的标记是否有shuffle
在实际使用中, 不需要纠结哪些算子会存在shuffle, 以需求实现为目标, 虽然shuffle的存在, 会影响一定的效率,但是以完成需求为准则, 该用那个算子, 就使用那个算子即可, 不要过分纠结
二、DAG和STAGE
DAG: 有向无环图
主要描述一段执行任务, 从开始一直往下 执行, 不允许出现回调的操作
在Spark的应用程序中, 程序中有一个action算子, 就会触发一个Job任务,所以说一个Spark应用程序中可以有多个Job任务
对于每一个Job任务, 都会产生一个DAG执行流程图
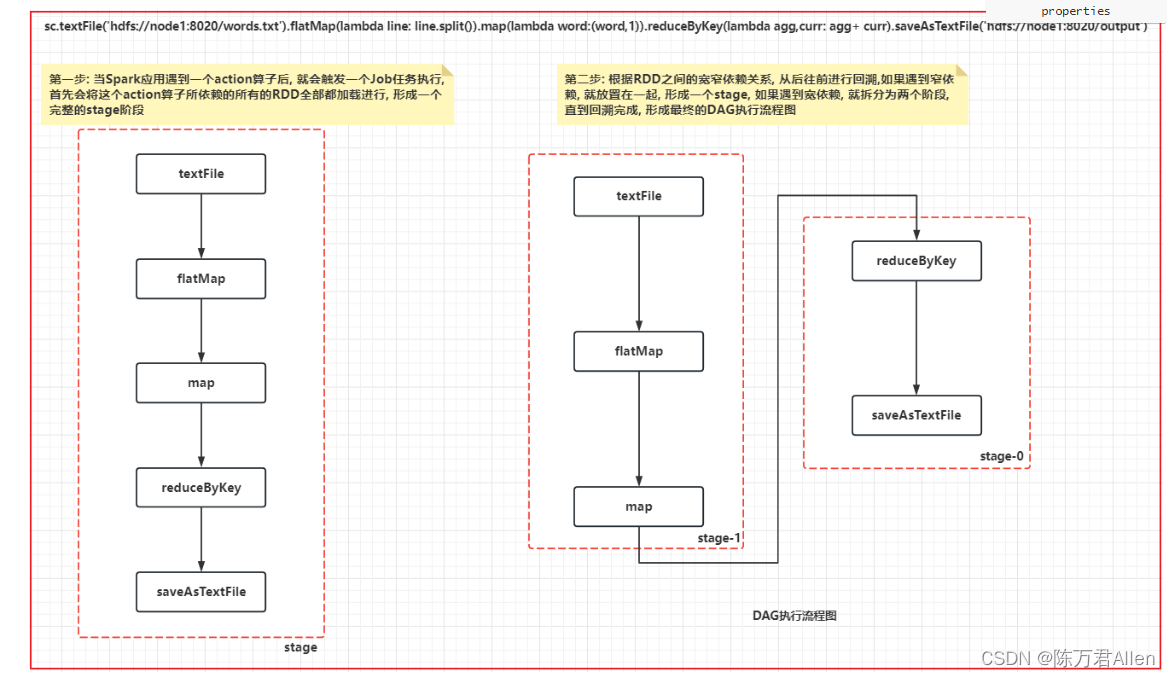
- 第一步: 当Spark应用遇到一个action算子后, 就会触发一个Job任务执行,
首先会将这个action算子所依赖的所有的RDD全部都加载进行, 形成一个完整的stage阶段 - 第二步: 根据RDD之间的宽窄依赖关系, 从后往前进行回溯,如果遇到窄依赖, 就放置在一起, 形成一个stage, 如果遇到宽依赖,
就拆分为两个阶段,直到回溯完成, 形成最终的DAG执行流程图
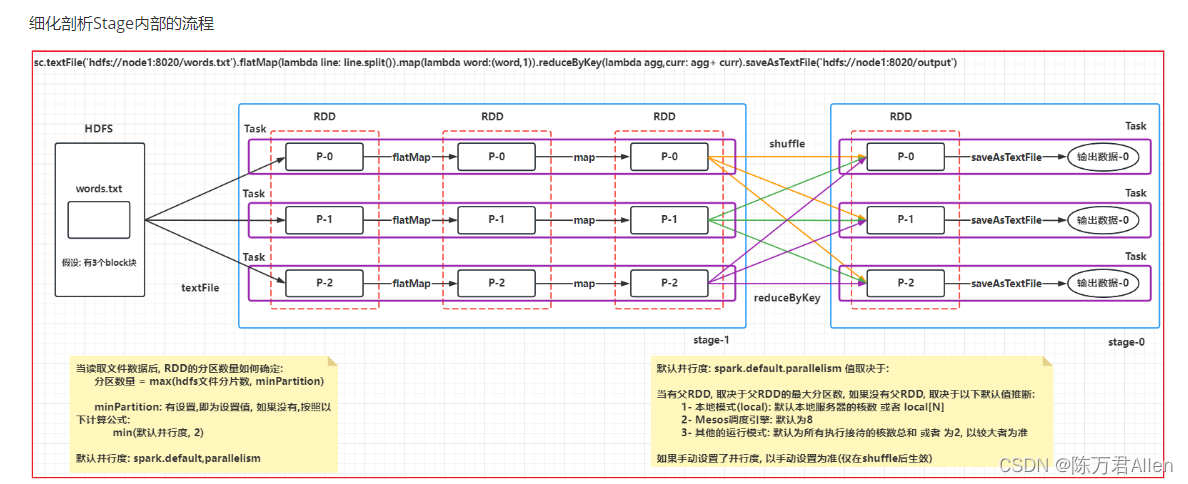
三、RDD的shuffle
在2.0版本的时候, 将Hash shuffle剔除, 将Hash Shuffle方案被Sort Shuffle
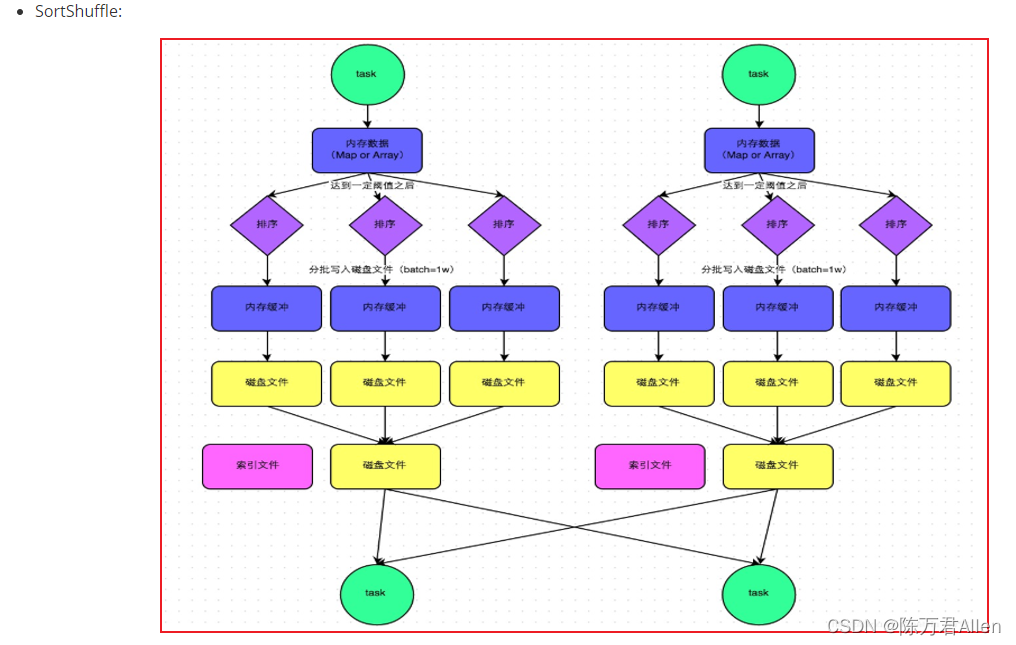
Sort Shuffle执行流程 与 MR有非常高的相似度:
每个线程(分区)处理后, 将数据写入到内存中, 当内存数据达到一定的阈值后, 触发溢写操作,在一些的时候, 需要对数据进行分区/排序, 将数据写入到磁盘上, 形成一个个文件, 当整个溢写完成后, 将多个小文件合并为一个大文件, 同时会为这个大文件提供一个索引文件, 方便下游读取对应分区的数据
Sort shuffle 存在两种运行的机制: 普通机制 和 byPass机制
普通机制:
每个线程(分区)处理后, 将数据写入到内存中, 当内存数据达到一定的阈值后, 触发溢写操作,在一些的时候, 需要对数据进行分区/排序, 将数据写入到磁盘上, 形成一个个文件, 当整个溢写完成后, 将多个小文件合并为一个大文件, 同时会为这个大文件提供一个索引文件, 方便下游读取对应分区的数据
bypass机制使用条件:
1- 上游的分区的数量不能超过200个(默认)
2- 上游不能进行提前聚合操作(提前聚合意味着要进行分组操作, 而分组的前提是要对数据进行排序, 将相关的数据放置在一起)
bypass机制: 在普通的机制基础上, 去除了排序操作
两种机制, bypass的运行效率在某些条件下, 可能要优于普通机制
四、Job的调度流程
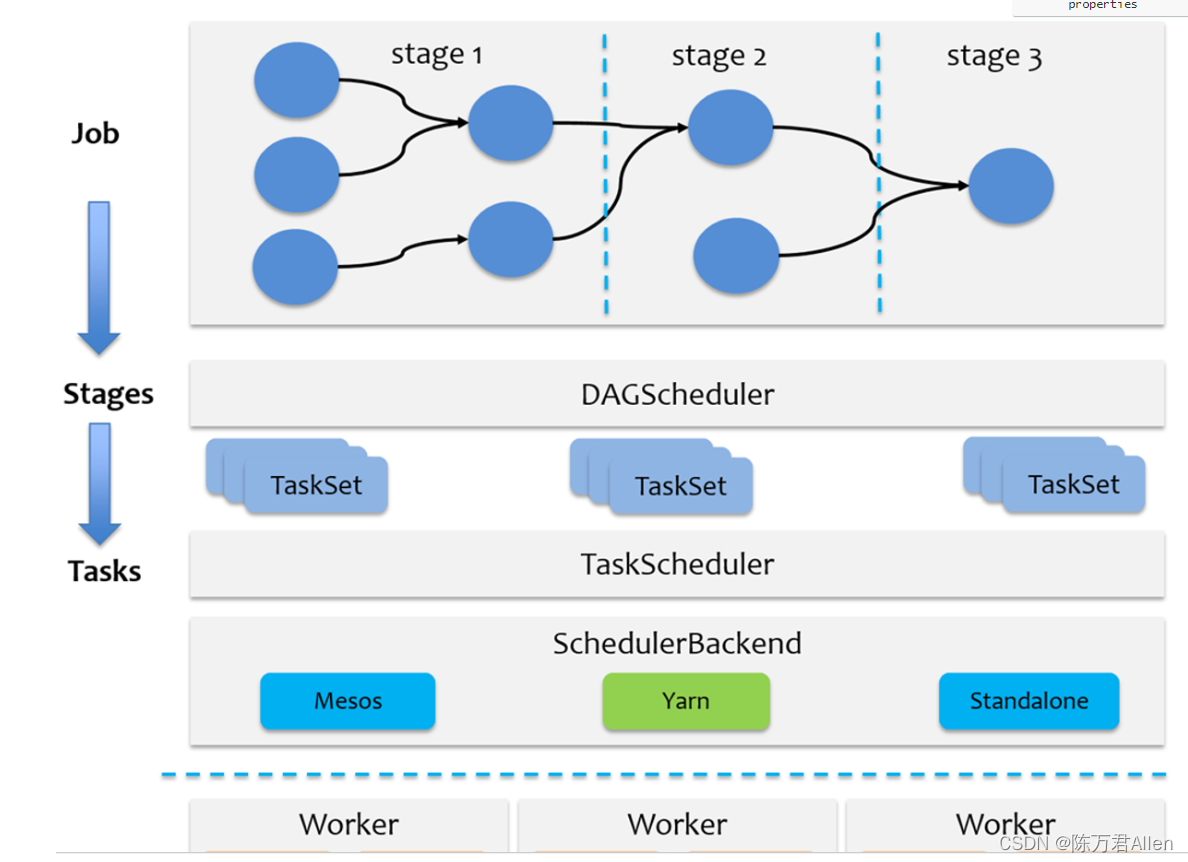
1- 当Spark应用程序启动后, 此时首先会创建SparkContext对象, 此对象在创建的时候, 底层同时也会创建DAGScheduler 和 TaskScheduler:
DAGScheduler: 负责DAG流程图生成, Stage阶段划分, 每个阶段运行多少个线程
TaskScheduler: 负责每个阶段的Task线程的分配工作, 以及将对应线程任务提交到Executor上运行
2- 遇到Action算子后,就会产生一个Job任务, SparkContext对象将任务提交到DAGScheduler,DAGScheduler接收到任务后, 就会产生一个DAG执行流程图, 划分stage,并且确定每个stage中需要运行多少个线程,将每个阶段的线程放置到一个TaskSet集合中,提交给TaskScheduler
3- TaskScheduler接收到各个阶段的TaskSet后, 开始进行任务的分配工作,确认每个线程应该运行在那个executor上(尽可能保持均衡),然后将任务提交给对应executor上(底层由调度队列), 让executor启动线程执行任务即可,阶段是一个一个的运行, 无法并行执行的
4- Driver负责监听各个executor执行状态即可, 等待任务执行完成
五、Spark的并行度
整个Spark应用中, 影响程序并行度的因素有以下两个原因:
- 1- 资源的并行度: Executor数量 和 CPU核心数 以及 内存大小
- 2- 数据的并行度: Task的线程数 和 分区数量
目的: 在合适的资源上, 运行合适的数据
当资源比较充足的时候, 但是数据的并行度无法达到, 虽然不会影响效率 但是会浪费资源
当数据的并行度充足的时候, 而资源不足, 会导致本来可以并行计算的, 变成串行执行, 影响效率
推荐值:
一个CPU上运行 2~3个线程, 一个CPU需要配置3~5GB内存, 从而充分压榨CPU性能
一个线程, 建议处理1~3GB数据, 处理时间10~20分钟, 如果想要时间减少, 那么让每一个线程处理数据量减少
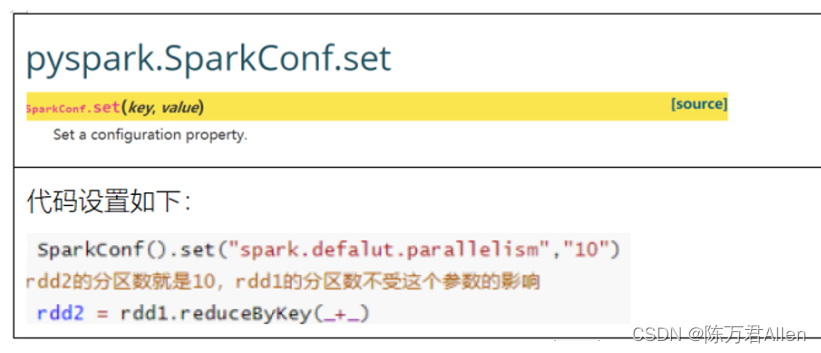
说明: 并行度设置, 需要在shuffle后生效, shuffle前的分区数量, 默认取决于初始数据源的时候确定的分区数量(上一个父RDD的分区数量)
总结
今天主要和大家分享了RDD的内核调度。
相关文章:
Pyspark基础入门7_RDD的内核调度
Pyspark 注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hi…...

C/C++每日一练(20230307)
目录 1. 国名排序 ★★ 2. 重复的DNA序列 ★★★ 3. 买卖股票的最佳时机 III ★★★ 🌟 每日一练刷题专栏 C/C 每日一练 专栏 Python 每日一练 专栏 1. 国名排序 小李在准备明天的广交会,明天有来自世界各国的客房跟他们谈生意,…...

一条SQL查询语句是如何执行的?
平时我们使用数据库,看到的通常都是一个整体。比如,你有个最简单的表,表里只有一个ID字段,在执行下面这个查询语句时: mysql> select * from T where ID10; 我们看到的只是输入一条语句,返…...
tcsh常用配置
查看当前的shell类型 在 Linux 的世界中,有着许多 shell 程序。常见的有: Bourne shell (sh) C shell (csh) TC shell (tcsh) Korn shell (ksh) Bourne Again shell (bash) 其中,最常用的就是bash和tcsh,本次文章介绍tcsh的…...

YOLOv5源码逐行超详细注释与解读(2)——推理部分detect.py
前言 前面简单介绍了YOLOv5的项目目录结构(直通车:YOLOv5源码逐行超详细注释与解读(1)——项目目录结构解析),对项目整体有了大致了解。 今天要学习的是detect.py。通常这个文件是用来预测一张图片或者一…...

什么叫个非对称加密?中间人攻击?数字签名?
非对称加密也称为公钥密码。就是用公钥来进行加密,撒子意思? 非对称加密 在对称加密中,我们只需要一个密钥,通信双方同时持有。而非对称加密需要4个密钥,来完成完整的双方通信。通信双方各自准备一对公钥和私钥。其中…...

2023.03.07 小记与展望
碎碎念系列全新改版! 以后就叫小记和展望系列 最近事情比较多,写篇博客梳理一下自己3月到5月下旬的一个规划 一、关于毕设 毕设马上开题答辩了,准备再重新修改一下开题报告,梳理各阶段目标。 毕设是在去年的大学生创新训练项目…...

MyBatis源码分析(七)MyBatis与Spring的整合原理与源码分析
文章目录写在前面一、SqlSessionFactoryBean配置SqlSessionFactory1、初识SqlSessionFactoryBean2、实现ApplicationListener3、实现InitializingBean接口4、实现FactoryBean接口5、构建SqlSessionFactory二、SqlSessionTemplate1、初始SqlSessionTemplate2、SqlSessionTemplat…...
基于声网 Flutter SDK 实现多人视频通话
前言 本文是由声网社区的开发者“小猿”撰写的Flutter基础教程系列中的第一篇。本文除了讲述实现多人视频通话的过程,还有一些 Flutter 开发方面的知识点。该系列将基于声网 Fluttter SDK 实现视频通话、互动直播,并尝试虚拟背景等更多功能的实现。 如果…...

IT服务管理(ITSM) 中的大数据
当我们谈论IT服务管理(ITSM)领域的大数据时,我们谈论的是关于两件不同的事情: IT 为业务提供的大数据工具/服务 - 对业务运营数据进行数字处理。IT 运营中的大数据 – 处理和利用复杂的 IT 运营数据。 面向业务运营的大数据服务…...
Validator校验之ValidatorUtils
注意:hibernate-validator 与 持久层框架 hibernate 没有什么关系,hibernate-validator 是 hibernate 组织下的一个开源项目 。 hibernate-validator 是 JSR 380(Bean Validation 2.0)、JSR 303(Bean Validation 1.0&…...
)
C++---背包模型---采药(每日一道算法2023.3.7)
注意事项: 本题是"动态规划—01背包"的扩展题,dp和优化思路不多赘述。 题目: 辰辰是个天资聪颖的孩子,他的梦想是成为世界上最伟大的医师。 为此,他想拜附近最有威望的医师为师。 医师为了判断他的资质&…...
Java各种锁
目录 一、读写锁(ReentrantReadWriteLock) 二、非公平锁(synchronized/ReentrantLock) 三、可重入锁/递归锁(synchronized/ReentrantLock) 四、自旋锁(spinlock) 五、乐观锁/悲观锁 六、死锁 1、死锁代码 2、死锁的检测(jps -l 与 jstack 进程号) 七、sychronized-wait…...
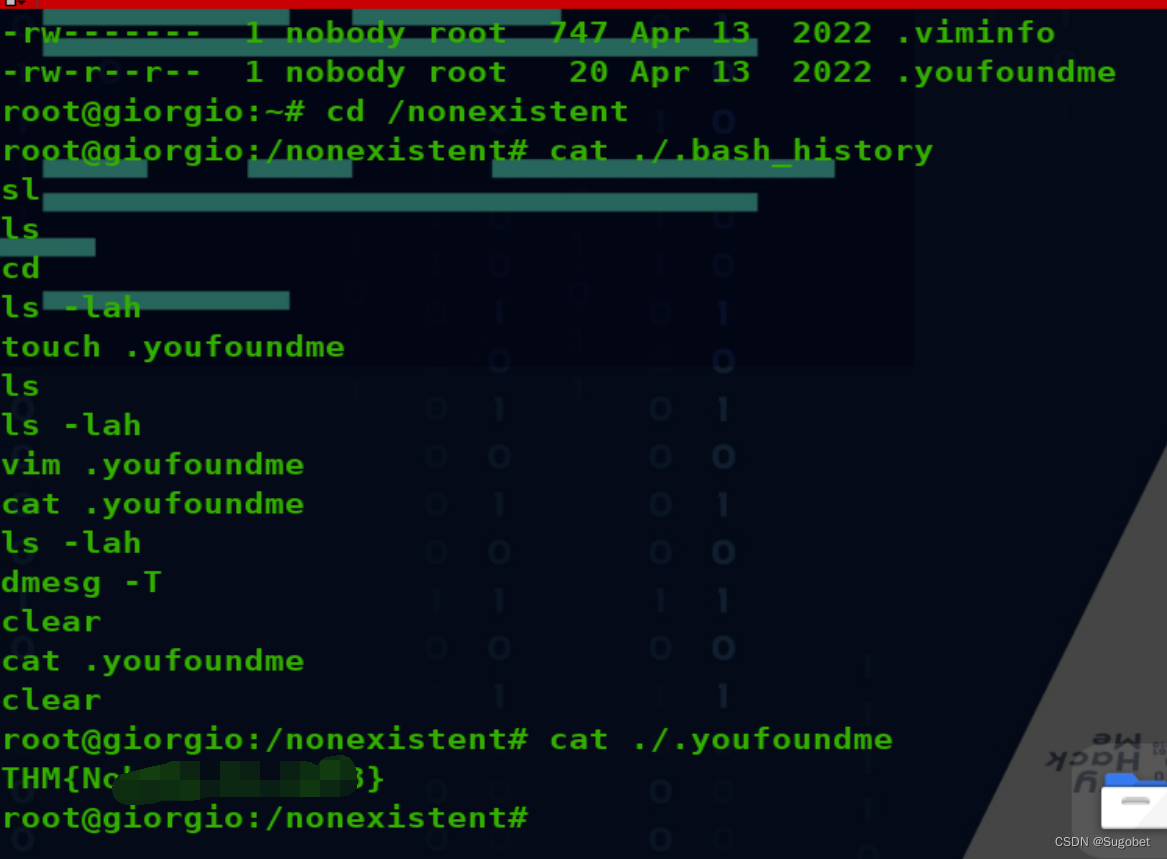
TryHackMe-Tardigrade(应急响应)
Tardigrade 您能否在此 Linux 端点中找到所有基本的持久性机制? 服务器已遭到入侵,安全团队已决定隔离计算机,直到对其进行彻底清理。事件响应团队的初步检查显示,有五个不同的后门。你的工作是在发出信号以使服务器恢复生产之前…...
导出GIS | 将EXCEL表格中坐标导出成GIS格式文件
一 前言 EXCEL是我们日常工作学习数据处理的办公软件,操作易上手,几乎人人都会用。EXCEL表格能够处理各种数据,包括经纬度坐标数据,地址数据等等。 有时因工作需要需将表格中地址数据处理为GIS格式的文件,以便能够将数…...

new set数组对象去重失败
我们知道Set是JS的一个种新的数据结构,和数组类似,和数组不同的是它可以去重,比如存入两个1或两个"123",只有1条数据会存入成功,但有个特殊情况,如果添加到set的值是引用类型,比如数组…...

Acwing: 一道关于线段树的好题(有助于全面理解线段树)
题目链接🔗:2643. 序列操作 - AcWing题库 前驱知识:需要理解线段树的结构和程序基本框架、以及懒标记的操作。 题目描述 题目分析 对区间在线进行修改和查询,一般就是用线段树来解决,观察到题目一共有五个操作&…...

DD-1/40 10-40mA型【接地继电器】
系列型号: DD-1/40接地继电器 DD-1/50接地继电器 DD-1/60接地继电器 一、 用途及工作原理 DD-1型接地继电器为瞬时动作的过电流继电器,用作小电流接地电力系统高电压三相交流发电机和电动机的接地零序过电流保护。继电器线圈接零序电流互感器(电缆式、母…...

【女神节】简单使用C/C++和Python嵌套for循环生成一个小爱心
目录 前言实现分析代码实现代码如下效果如下优化效果代码如下效果如下总结尾叙前言 女神节马上到了,有女朋友的小伙伴是不是已经精心准好礼物了呢!对于已婚男士,是不是整愁今天又该送什么礼物呢!说真的,我也整愁着,有什么要推荐么,评论留言下! 实现分析 可以先在纸上或…...

Biome-BGC生态系统模型与Python融合技术实践应用
查看原文>>> Biome-BGC生态系统模型与Python融合技术实践应用 Biome-BGC是利用站点描述数据、气象数据和植被生理生态参数,模拟日尺度碳、水和氮通量的有效模型,其研究的空间尺度可以从点尺度扩展到陆地生态系统。 在Biome-BGC模型中…...

终极PHPExcel性能优化指南:从512MB到1GB内存的突破技巧
终极PHPExcel性能优化指南:从512MB到1GB内存的突破技巧 【免费下载链接】PHPExcel ARCHIVED 项目地址: https://gitcode.com/gh_mirrors/ph/PHPExcel PHPExcel作为一款强大的PHP电子表格处理库,在处理大型数据时常常面临内存不足的挑战。本文将分…...

终极指南:如何通过awesome-hyper主题配色方案提升终端可读性
终极指南:如何通过awesome-hyper主题配色方案提升终端可读性 【免费下载链接】awesome-hyper 🖥 Delightful Hyper plugins, themes, and resources 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-hyper Hyper终端是一款基于Web技术构建的…...

TV Bro电视浏览器完全指南:如何在智能电视上享受大屏上网的终极体验
TV Bro电视浏览器完全指南:如何在智能电视上享受大屏上网的终极体验 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro TV Bro是一款专为智能电视和遥控器操作优…...
)
如何批量调整图片大小?跨境电商卖家必备效率工具(附实操教程)
一、前言:你可能低估了“图片处理”的成本 如果你在做电商(尤其是跨境、多平台),一定经历过这种情况: 同一款商品,不同平台尺寸要求完全不同一次上新几十个 SKU,每个商品多张图用 PS 一张张改…...
:mbuf、mempool、ethdev 的数据路径)
DPDK 教程(二):mbuf、mempool、ethdev 的数据路径
1 DPDK 教程(二):mbuf、mempool、ethdev 的数据路径 本文对应学习路径第二步:把“包从网卡进来到被应用消费”的主链路读成一张图。读完你应能口述:描述符环 → PMD RX → mbuf 与 mempool → 用户处理 → TX burst →…...
)
Sora 2 × YouTube双平台协同工作流:自动生成多尺寸横竖版+智能章节标记+CC字幕同步(仅需1次Prompt)
更多请点击: https://intelliparadigm.com 第一章:Sora 2 YouTube双平台协同工作流全景概览 Sora 2 作为新一代多模态生成引擎,已原生支持高保真视频结构化输出与语义时间轴标注;YouTube 则通过 Creator Studio API 和 Data API…...

Windows热键侦探:快速定位占用快捷键的终极解决方案
Windows热键侦探:快速定位占用快捷键的终极解决方案 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾经…...

RP2040微控制器实现无闪烁HDMI图形显示的核心技术与实践
1. 项目概述:当RP2040遇见HDMI对于玩惯了单片机点阵屏或者SPI接口小屏的嵌入式开发者来说,让一块像树莓派Pico这样的微控制器直接输出HDMI信号到一台标准显示器,听起来多少有点“跨界”的感觉。但正是这种将低功耗微控制器与通用高清显示接口…...

JESD204B高速串行接口技术解析与应用实践
1. JESD204B接口技术深度解析JESD204B作为第三代高速串行接口标准,正在彻底改变数据转换器与逻辑器件之间的连接方式。我在实际项目中使用过ADC16DX370和DAC38J84等多款支持JESD204B的器件,深刻体会到这种接口带来的设计变革。相比传统的LVDS或CMOS并行接…...

AI时代的“新铁饭碗”:那些机器越强、人越贵的岗位
——写给软件测试从业者的未来指南当AI能够在90秒内完成一份测试报告的初稿,当大语言模型可以自动生成覆盖边界值的测试用例,许多软件测试从业者内心都升起过一丝隐忧:我们会被取代吗?这种焦虑并非空穴来风。2025年的行业数据显示…...