【flinkx】【hdfs】【ing】Cannot obtain block length for LocatedBlock
一. 任务描述
使用flinkx去跑HDFS到HIVE的任务时,出现如下报错:
CannotObtainBlockLengthException
com.dtstack.flinkx.throwable.FlinkxRuntimeException: can't get file size from hdfs, file = hdfs://xxx/.data/540240453caeb6fe4b3f118410a05315_235_0at com.dtstack.flinkx.connector.hdfs.sink.BaseHdfsOutputFormat.getCurrentFileSize(BaseHdfsOutputFormat.java:169) ~[flinkx-connector-hdfs-1.12-SNAPSHOT.jar:?]at com.dtstack.flinkx.sink.format.BaseFileOutputFormat.checkCurrentFileSize(BaseFileOutputFormat.java:137) ~[flinkx-core-1.12-SNAPSHOT.jar:?]at com.dtstack.flinkx.sink.format.BaseFileOutputFormat.writeSingleRecordInternal(BaseFileOutputFormat.java:128) ~[flinkx-core-1.12-SNAPSHOT.jar:?]at com.dtstack.flinkx.sink.format.BaseRichOutputFormat.writeSingleRecord(BaseRichOutputFormat.java:427) ~[flinkx-core-1.12-SNAPSHOT.jar:?]at com.dtstack.flinkx.sink.format.BaseRichOutputFormat.writeRecord(BaseRichOutputFormat.java:244) ~[flinkx-core-1.12-SNAPSHOT.jar:?]at com.dtstack.flinkx.sink.format.BaseRichOutputFormat.writeRecord(BaseRichOutputFormat.java:84) ~[flinkx-core-1.12-SNAPSHOT.jar:?]at com.dtstack.flinkx.sink.DtOutputFormatSinkFunction.invoke(DtOutputFormatSinkFunction.java:117) ~[flinkx-core-1.12-SNAPSHOT.jar:?]at org.apache.flink.table.runtime.operators.sink.SinkOperator.processElement(SinkOperator.java:72) ~[flink-table-blink_2.12-1.12.7.jar:1.12.7]at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.pushToOperator(CopyingChainingOutput.java:71) ~[flink-dist_2.12-1.12.7.jar:1.12.7]at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:46) ~[flink-dist_2.12-1.12.7.jar:1.12.7]at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:26) ~[flink-dist_2.12-1.12.7.jar:1.12.7]at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:50) ~[flink-dist_2.12-1.12.7.jar:1.12.7]at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:28) ~[flink-dist_2.12-1.12.7.jar:1.12.7]at StreamExecCalc$12.processElement(Unknown Source) ~[?:?]at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.pushToOperator(CopyingChainingOutput.java:71) ~[flink-dist_2.12-1.12.7.jar:1.12.7]at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:46) ~[flink-dist_2.12-1.12.7.jar:1.12.7]at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:26) ~[flink-dist_2.12-1.12.7.jar:1.12.7]at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:50) ~[flink-dist_2.12-1.12.7.jar:1.12.7]at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:28) ~[flink-dist_2.12-1.12.7.jar:1.12.7]at org.apache.flink.streaming.api.operators.StreamSourceContexts$ManualWatermarkContext.processAndCollect(StreamSourceContexts.java:317) ~[flink-dist_2.12-1.12.7.jar:1.12.7]at org.apache.flink.streaming.api.operators.StreamSourceContexts$WatermarkContext.collect(StreamSourceContexts.java:411) ~[flink-dist_2.12-1.12.7.jar:1.12.7]at com.dtstack.flinkx.source.DtInputFormatSourceFunction.run(DtInputFormatSourceFunction.java:135) ~[flinkx-core-1.12-SNAPSHOT.jar:?]at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:110) ~[flink-dist_2.12-1.12.7.jar:1.12.7]at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:66) ~[flink-dist_2.12-1.12.7.jar:1.12.7]at org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:267) ~[flink-dist_2.12-1.12.7.jar:1.12.7]
Caused by: org.apache.hadoop.hdfs.CannotObtainBlockLengthException: Cannot obtain block length for LocatedBlock{BP-908532681-10.203.2.20-1593930010000:blk_2513177302_1108300914318; getBlockSize()=0; corrupt=false; offset=0; locs=[DatanodeInfoWithStorage[10.203.70.78:9866,DS-9aa641e8-4ce8-436b-9eaa-fd3eb676185e,DISK], DatanodeInfoWithStorage[10.203.22.205:9866,DS-cb07688e-a349-46eb-8929-71d8fd6156dd,DISK], DatanodeInfoWithStorage[10.203.34.146:9866,DS-efa9e16d-405b-4a05-8e52-0e35d681c3d2,DISK]]}at org.apache.hadoop.hdfs.DFSInputStream.readBlockLength(DFSInputStream.java:363) ~[hadoop-hdfs-client-3.2.1U20.jar:?]at org.apache.hadoop.hdfs.DFSInputStream.fetchLocatedBlocksAndGetLastBlockLength(DFSInputStream.java:270) ~[hadoop-hdfs-client-3.2.1U20.jar:?]at org.apache.hadoop.hdfs.DFSInputStream.openInfo(DFSInputStream.java:201) ~[hadoop-hdfs-client-3.2.1U20.jar:?]at org.apache.hadoop.hdfs.DFSInputStream.<init>(DFSInputStream.java:185) ~[hadoop-hdfs-client-3.2.1U20.jar:?]at org.apache.hadoop.hdfs.DFSClient.openInternal(DFSClient.java:1048) ~[hadoop-hdfs-client-3.2.1U20.jar:?]at org.apache.hadoop.hdfs.DFSClient.open(DFSClient.java:1011) ~[hadoop-hdfs-client-3.2.1U20.jar:?]at org.apache.hadoop.hdfs.DistributedFileSystem$5.doCall(DistributedFileSystem.java:359) ~[hadoop-hdfs-client-3.2.1U20.jar:?]at org.apache.hadoop.hdfs.DistributedFileSystem$5.doCall(DistributedFileSystem.java:355) ~[hadoop-hdfs-client-3.2.1U20.jar:?]at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) ~[hadoop-common-3.2.1U20.jar:?]at org.apache.hadoop.hdfs.DistributedFileSystem.open(DistributedFileSystem.java:367) ~[hadoop-hdfs-client-3.2.1U20.jar:?]at org.apache.hadoop.fs.FilterFileSystem.open(FilterFileSystem.java:164) ~[hadoop-common-3.2.1U20.jar:?]at org.apache.hadoop.fs.viewfs.ChRootedFileSystem.open(ChRootedFileSystem.java:285) ~[hadoop-common-3.2.1U20.jar:?]at org.apache.hadoop.fs.viewfs.ViewFileSystem.open(ViewFileSystem.java:500) ~[hadoop-common-3.2.1U20.jar:?]at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:912) ~[hadoop-common-3.2.1U20.jar:?]at com.dtstack.flinkx.connector.hdfs.sink.BaseHdfsOutputFormat.getCurrentFileSize(BaseHdfsOutputFormat.java:166) ~[flinkx-connector-hdfs-1.12-SNAPSHOT.jar:?]... 24 more
看报错可以得到当时任务的一些消息
文件没有了 还去获取文件
文件还在写的时候去获取文件
暂时怀疑flinkx的hdfs写操作会偶发的出现,或者当达到什么机制时后,会出现。
二、google解决方案
Usually when you see “Cannot obtain block length for LocatedBlock”, this means the file is still in being-written state, i.e., it has not been closed yet, and the reader cannot successfully identify its current length by communicating with corresponding DataNodes. There are multiple possibilities here, .e.g., there may be temporary network connection issue between the reader and the DataNodes, or the original writing failed some while ago and the under-construction replicas are somehow missing.
In general you run fsck command to get more information about the file. You can also trigger lease recovery for further debugging. Run command:
hdfs debug recoverLease -path <path-of-the-file> -retries <retrytimes>
This command will ask the NameNode to try to recover the lease for the file, and based on the NameNode log you may track to detailed DataNodes to understand the states of the replicas. The command may successfully close the file if there are still healthy replicas. Otherwise we can get more internal details about the file/block state.
当看到这个消息时:Cannot obtain block length for LocatedBlock,说明文件仍然是写的状态,即写还没有关闭,client无法成功的和datanodes通讯获取到当前文件的长度。
有以下几种可能的原因会出现这种问题:
- 可能是短暂的网络通讯问题导致client和dataNodes不能通讯 来获取到文件信息
- flink写某些文件时,写失败了并且创建副本时,副本因为一些原因丢失了。
解决:
- 可以通过run fsck相关命令获取文件更多的信息。
- 或者执行如上debug命令来请求namenode来恢复文件的租约,并且基于namenode日志可以追踪到datanode的一些细节来理解副本的状态。如果文件有健康的副本,此时会关闭文件。
三、进一步逻辑探究
1. hdfs的租约机制
ing
相关文章:

【flinkx】【hdfs】【ing】Cannot obtain block length for LocatedBlock
一. 任务描述 使用flinkx去跑HDFS到HIVE的任务时,出现如下报错: CannotObtainBlockLengthException com.dtstack.flinkx.throwable.FlinkxRuntimeException: cant get file size from hdfs, file hdfs://xxx/.data/540240453caeb6fe4b3f118410a05315_2…...
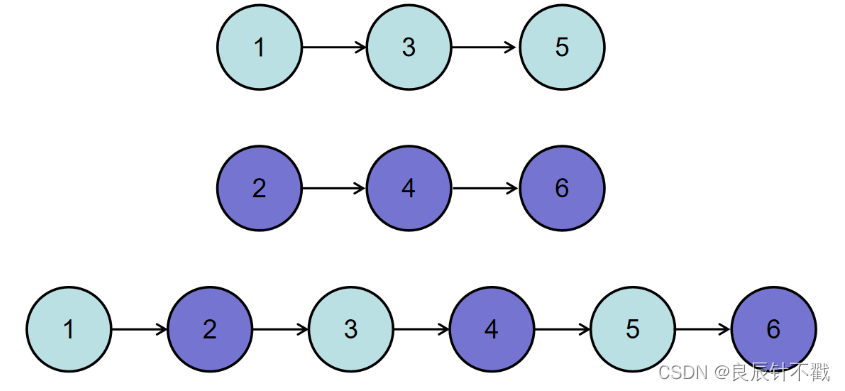
【Day6】合并两个排序链表与合并k个已排序的链表,java代码实现
前言: 大家好,我是良辰丫🚀🚀🚀,今天与大家一起做两道牛客网的链表题,好久写关于链表题的博客了,这两道题可以帮大家巩固一下链表知识,我把两道题的链接放到下面…...

Swagger PHP
PHP使用Swagger生成好看的API文档不是不可能,而是非常简单。首先本人使用Laravel框架,所以在Laravel上安装swagger-php。一、安装swagger - phpcomposer require zircote/swagger-phpswagger-php提供了命令行工具,所以可以全局安装࿰…...

谷粒商城-品牌管理-JSR303数据校验
后端在处理前端传过来的数据时,尽管前端表单已经加了校验逻辑,但是作为严谨考虑,在后端对接口传输的数据做校验也必不可少。 开启校验: 实体类上增加校验注解,接口参数前增加Valid 开启校验 package com.xxh.product.…...

Java零基础教程——数组
目录数组静态初始化数组数组的访问数组的动态初始化元素默认值规则:数组的遍历数组遍历-求和冒泡排序数组的逆序交换数组 数组就是用来存储一批同种类型数据的容器。 20, 10, 80, 60, 90 int[] arr {20, 10, 80, 60, 90}; //位置 0 1 2 3 4数组的…...
AirServer在哪下载?如何免费使用教程
苹果手机投屏到电脑mac是怎么弄?你知道多少?相信大家对苹果手机投屏到电脑mac能在电脑上操作不是很了解,下面就让coco玛奇朵带大家一起了解一下教程。AIrServer是一款ios投屏到mac的专用软件,可将iOS上的音频,视频&…...

加载sklearn covtype数据集出错 fetch_covtype() HTTPError: HTTP Error 403: Forbidden解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理…...

理论六:为什么基于接口而非实现编程?有必要为每个类定义接口么?
在上一节课中、我们讲了接口和抽象类,以及各种编程语言是如何支持、实现这两个语法概念的。今天,我们继续讲一个跟“接口”相知识点:基于接口而非实现编程。这个原则非常重要,是一种非常有效的提高代码质量的手段,在平时的开发中特别经常被用到。为了让你…...
react日常开发技巧)
(HP)react日常开发技巧
高级特性 1,protals(传送门):将子组件渲染到父组件之外。 实例场景:父组件的儿子是<Modal>组件,使用fixed定位虽然样式看着是在父组件之外了,但是打开控制台查看元素,Modal相…...

【20230211】【剑指1】搜索与回溯算法II
树的子结构递归思维:对称性递归什么是对称性递归?就是对一个对称的数据结构(这里指二叉树)从整体的对称性思考,把大问题分解成子问题进行递归,即不是单独考虑一部分(比如树的左子树),而是同时考…...
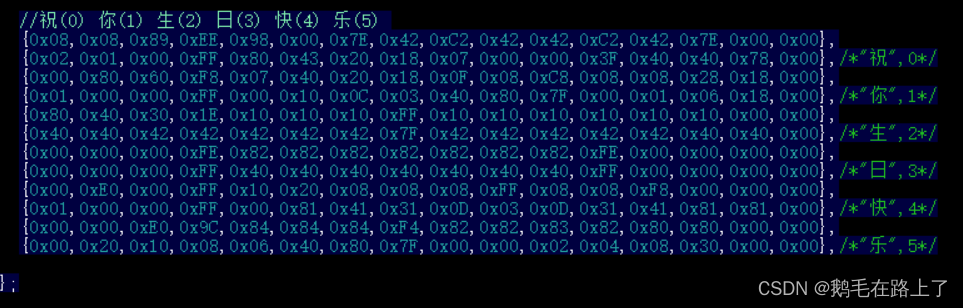
STM32F103C8T6—库函数应用I2C/SPI驱动OLED显示中文、字符串
文章目录1. I2C与SPI通信协议对比2. 四脚OLED与六脚OLED3. I2C驱动OLED显示oled.h & oled.c:汉字取模 & oledfont.h:main.c 显示示例:连线方法:4. SPI驱动OLED显示1. I2C与SPI通信协议对比 I2C(Inter-Integra…...

sql语句要注意的地方及常用查询语句
sql要注意的地方关键字不能被缩写,也不能分行小写大写不敏感,没区别使用缩进提高语句的可读性常用查询语句1.查询所有库SHOW DATABASES;2.选择数据库 use 数据库名USE myemployees;3.查看数据库中所有表show tables4.查看表中的内容 select 字段一&#…...

数组去重、伪数组和真数组的区别以及伪数组如何转换成真数组
1.数组去重 1) 利用数组的indexOf下标属性来查询。 如果找到一个 item,则返回 item 的第一次出现的位置。开始位置的索引为 0。 如果在数组中没找到指定元素则返回 -1。 function unique4(arr) {var newArr []for (var i 0; i < arr.length; i) {i…...

JavaScript内置支持类Array
<!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title>内置支持类Array</title> </head> <body bgcolor"antiquewhite"> <script type"text/javasc…...
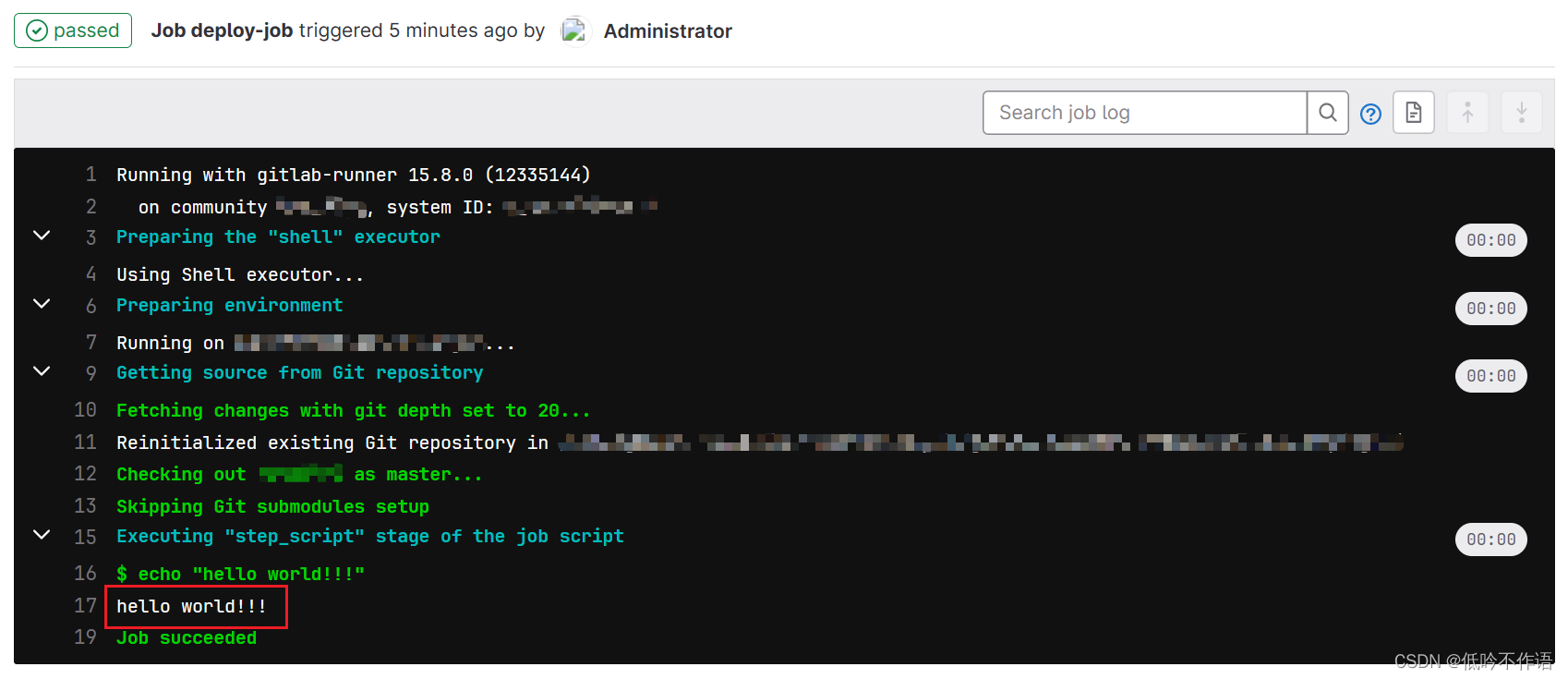
GitLab CI-CD 学习笔记
概述 1. CI/CD CI(持续集成)指开发人员一天内进行多次合并和提交代码操作,并通过自动化测试,完成构建 CD(持续部署)指每次代码更改都会自动部署到对应环境 CI/CD 结合在一起,可以加快开发团…...
K8S安装
1.创建三台centos虚拟机 使用的官方最小镜像安装 CentOS-7-x86_64-Minimal-1804.iso 建议最小硬件配置:2核CPU、2G内存、20G硬盘 master配置详情 node1和node2配置详情 三台虚拟机在安装centos的时候在网络IPV4指定DHCP,配置IPV4固定地址,保证可以访问…...
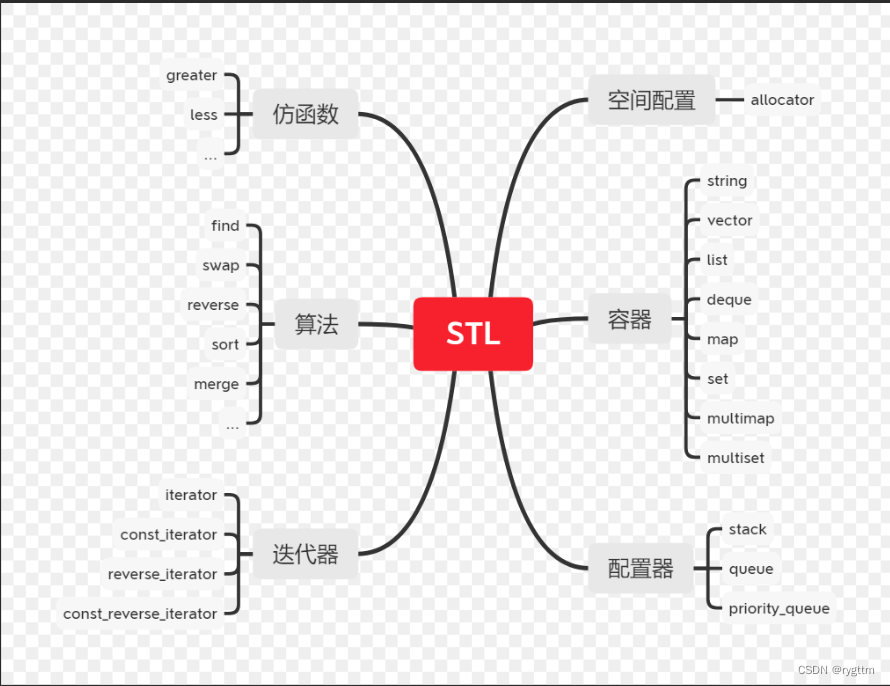
【C++】模板初阶STL简介
今天,你内卷了吗? 文章目录一、泛型编程二、函数模板(显示实例化和隐式实例化)1.函数模板格式2.单参数模板3.多参数模板4.模板参数的匹配原则三、类模板(没有推演的时机,统一显示实例化)1.类模…...
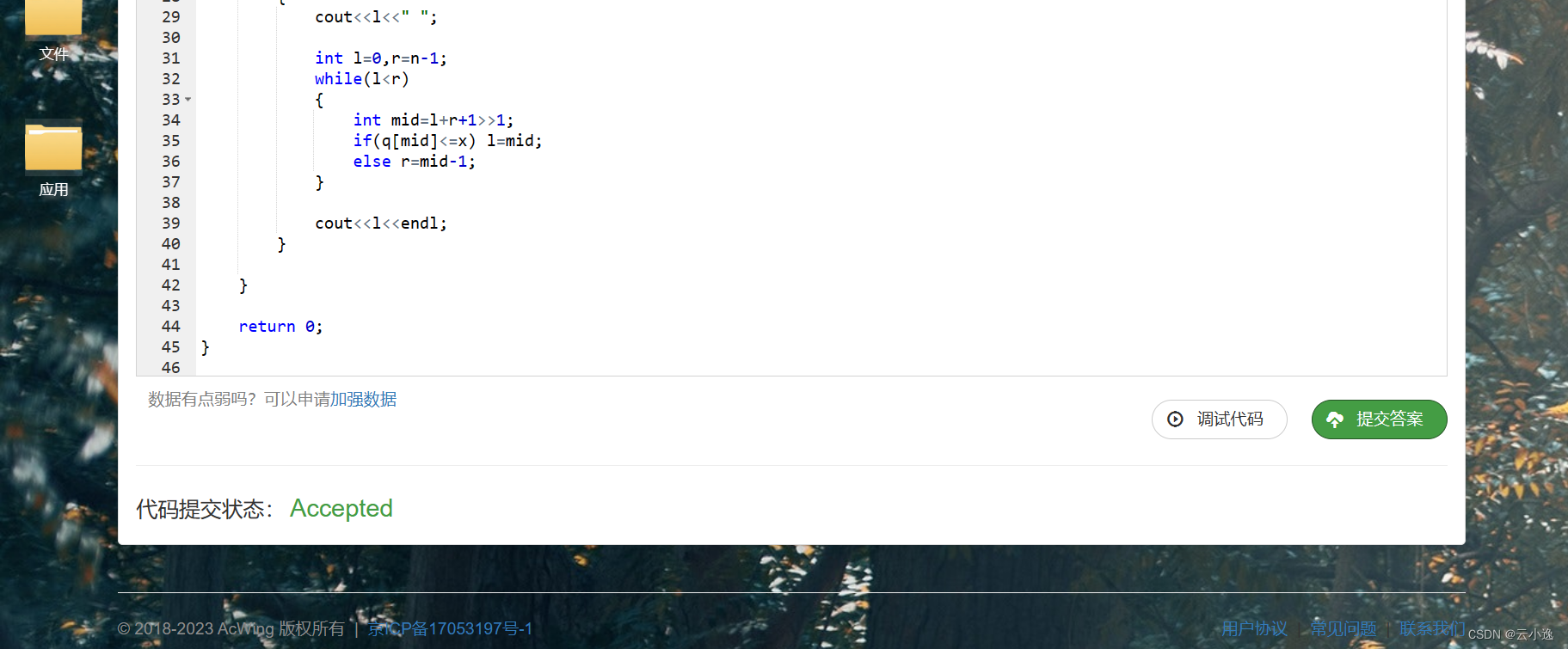
备战蓝桥杯第一天【二分查找无bug版】
🌹作者:云小逸 📝个人主页:云小逸的主页 📝Github:云小逸的Github 🤟motto:要敢于一个人默默的面对自己,强大自己才是核心。不要等到什么都没有了,才下定决心去做。种一颗树,最好的时间是十年前…...

Java集合中的Map
MapMap接口键 值 对存储键不能重复,值可以重复Map三个实现类的存储结构HashMap:Hash表链表红黑树结构 线程不安全TreeMap: 底层红黑树实现HashTable:hash表链表红黑树 线程安全HashMapHashMap常用方法HashMap<String,String>…...

【java】springboot项目启动数据加载内存中的三种方法
文章目录一、前言二、加载方式2.1、 第一种:使用PostConstruct注解(properties/yaml文件)。2.2、 第二种:使用Order注解和CommandLineRunner接口。2.3、 第三种:使用Order注解和ApplicationRunner接口。三、代码示例3.…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现企业微信功能
1. 开发环境准备 安装DevEco Studio 3.1: 从华为开发者官网下载最新版DevEco Studio安装HarmonyOS 5.0 SDK 项目配置: // module.json5 {"module": {"requestPermissions": [{"name": "ohos.permis…...

在 Spring Boot 项目里,MYSQL中json类型字段使用
前言: 因为程序特殊需求导致,需要mysql数据库存储json类型数据,因此记录一下使用流程 1.java实体中新增字段 private List<User> users 2.增加mybatis-plus注解 TableField(typeHandler FastjsonTypeHandler.class) private Lis…...
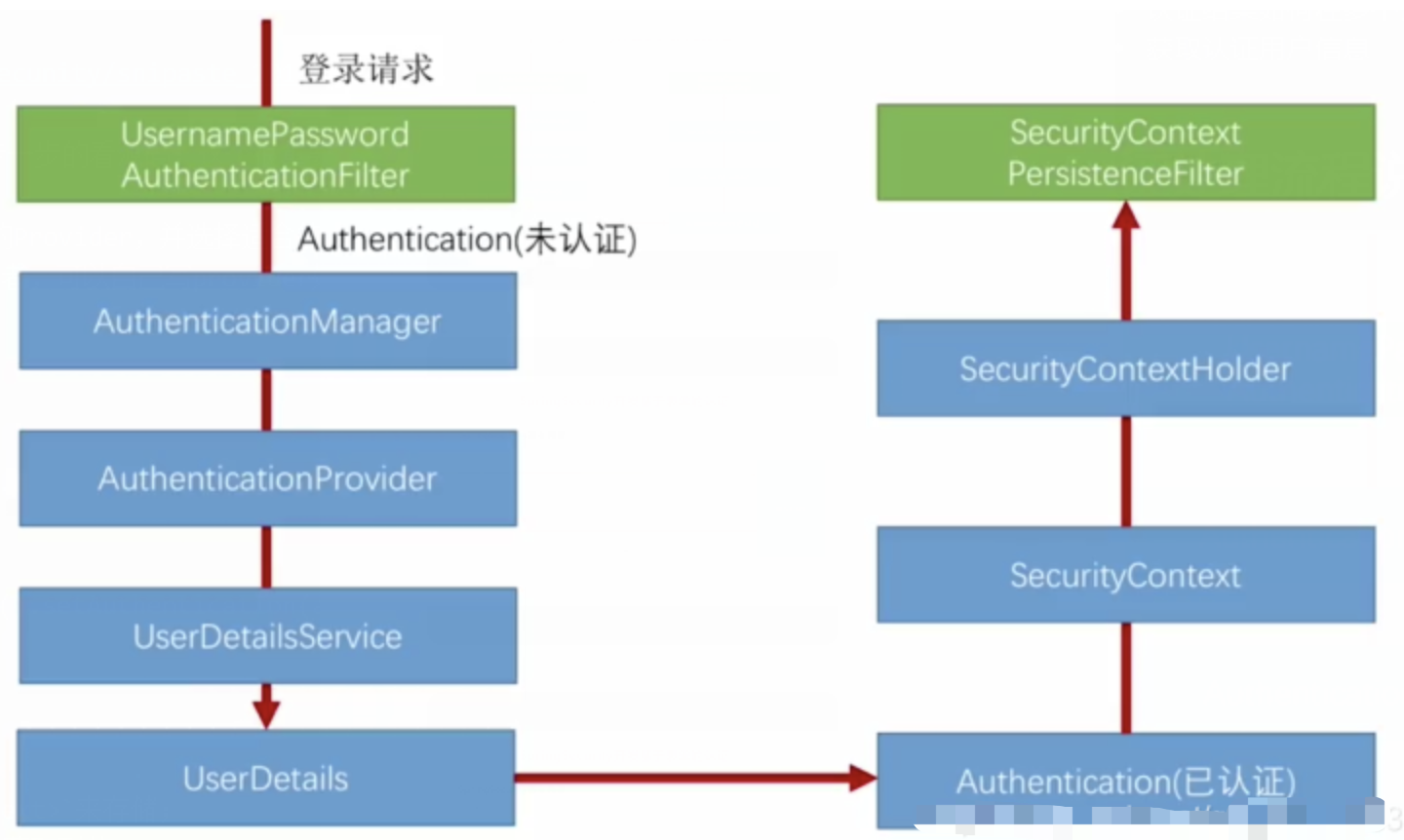
spring Security对RBAC及其ABAC的支持使用
RBAC (基于角色的访问控制) RBAC (Role-Based Access Control) 是 Spring Security 中最常用的权限模型,它将权限分配给角色,再将角色分配给用户。 RBAC 核心实现 1. 数据库设计 users roles permissions ------- ------…...
ui框架-文件列表展示
ui框架-文件列表展示 介绍 UI框架的文件列表展示组件,可以展示文件夹,支持列表展示和图标展示模式。组件提供了丰富的功能和可配置选项,适用于文件管理、文件上传等场景。 功能特性 支持列表模式和网格模式的切换展示支持文件和文件夹的层…...

《Offer来了:Java面试核心知识点精讲》大纲
文章目录 一、《Offer来了:Java面试核心知识点精讲》的典型大纲框架Java基础并发编程JVM原理数据库与缓存分布式架构系统设计二、《Offer来了:Java面试核心知识点精讲(原理篇)》技术文章大纲核心主题:Java基础原理与面试高频考点Java虚拟机(JVM)原理Java并发编程原理Jav…...
Python环境安装与虚拟环境配置详解
本文档旨在为Python开发者提供一站式的环境安装与虚拟环境配置指南,适用于Windows、macOS和Linux系统。无论你是初学者还是有经验的开发者,都能在此找到适合自己的环境搭建方法和常见问题的解决方案。 快速开始 一分钟快速安装与虚拟环境配置 # macOS/…...

Neo4j 完全指南:从入门到精通
第1章:Neo4j简介与图数据库基础 1.1 图数据库概述 传统关系型数据库与图数据库的对比图数据库的核心优势图数据库的应用场景 1.2 Neo4j的发展历史 Neo4j的起源与演进Neo4j的版本迭代Neo4j在图数据库领域的地位 1.3 图数据库的基本概念 节点(Node)与关系(Relat…...