深度学习pytorch——卷积神经网络(持续更新)
计算机如何解析图片?
在计算机的眼中,一张灰度图片,就是许多个数字组成的二维矩阵,每个数字就是此点的像素值(图-1)。在存储时,像素值通常位于[0, 255]区间,在深度学习中,像素值通常位于[0, 1]区间。

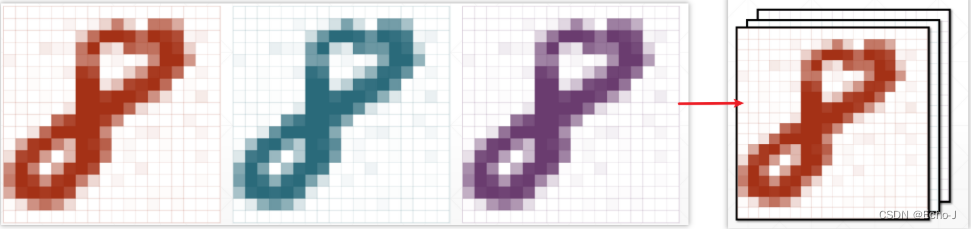
一张彩色图片,是使用三张图片叠加而成,即RGB(red green blue)(图-2)。
什么是卷积?
标准的神经网络是全连接的方式,全连接会获取更多的信息,但同时也包含着巨大的算力需求。在以前,算力完全不足以支撑如此巨大的计算量,但是又要进行处理,因此当时的人们联想到了人类观察事物的过程,即结合人眼观察事物的角度——先观察吸引我们的点,忽略不吸引我们的点,这称为局部相关性(Receptive Field)。应用到神经网络中,就出现了卷积的概念。
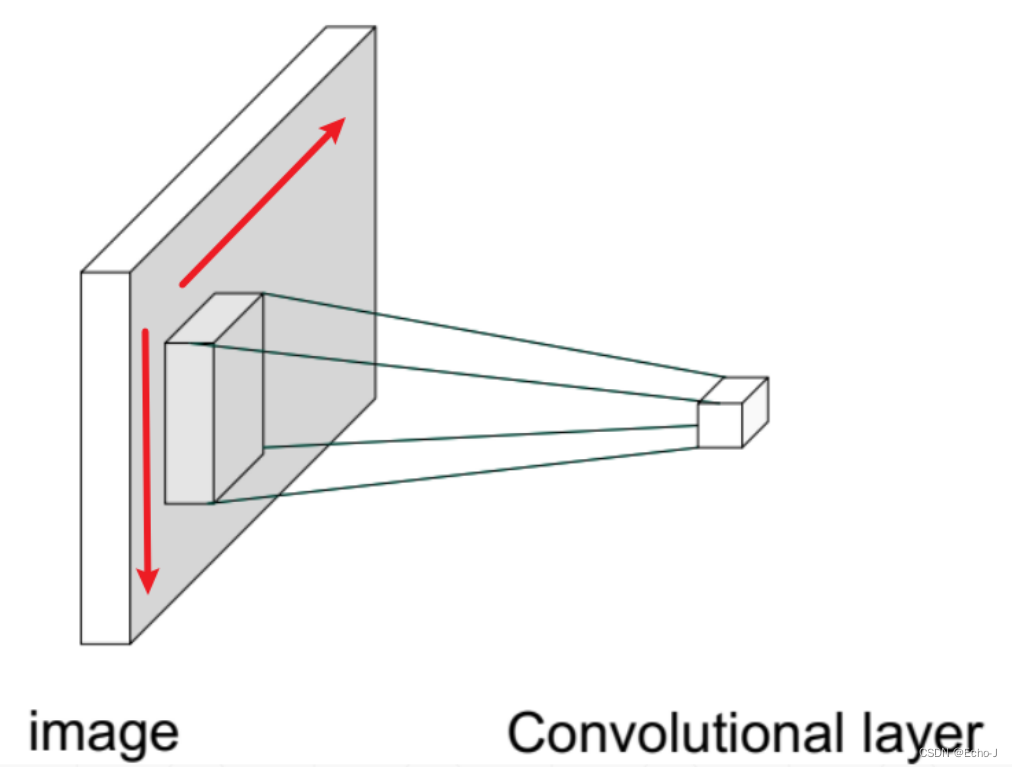
卷积操作就是先仅仅观察一部分,然后移动视野观察下一部分,这就称为卷积操作(图-3)。
表现在神经网络中就相当于只连接局部相关性的属性(假设红色的线都是相关的,其它的都断开,当然红色的线都是我自己瞎画的),如图-4所示:

表现在实例上就是图-5的情况:

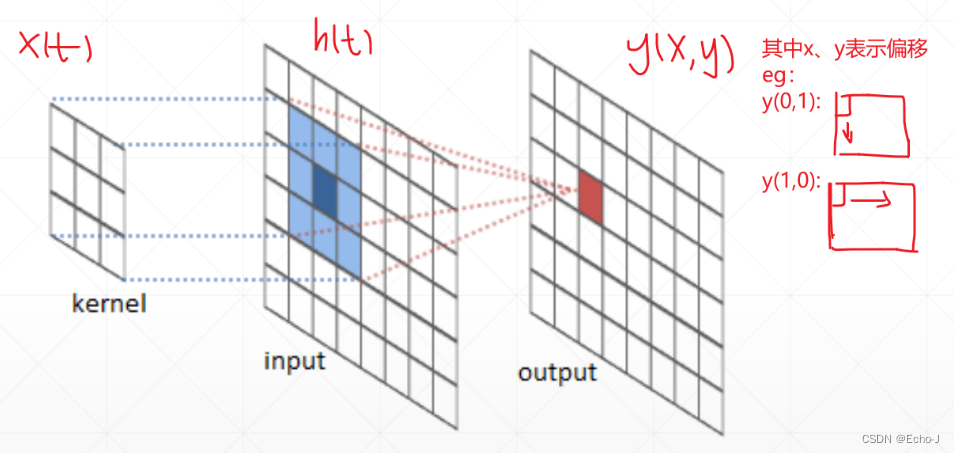
卷积的数学表示:设x(t)为输入的数据,h(t)为遍历使用的矩阵,y(t)为经过卷积计算得到的矩阵,将x(t)和h(t)进行点乘运算,将每次点成的结果进行累加得到y(t)对应元素的值(公式-1)。

宏观效果(图-6):
实例
以不同的 h(t) 进行卷积操作,会获取到不同的特征:
锐化(图-7):

模糊处理(图-8):

边缘检测(图-9):

卷积神经网络
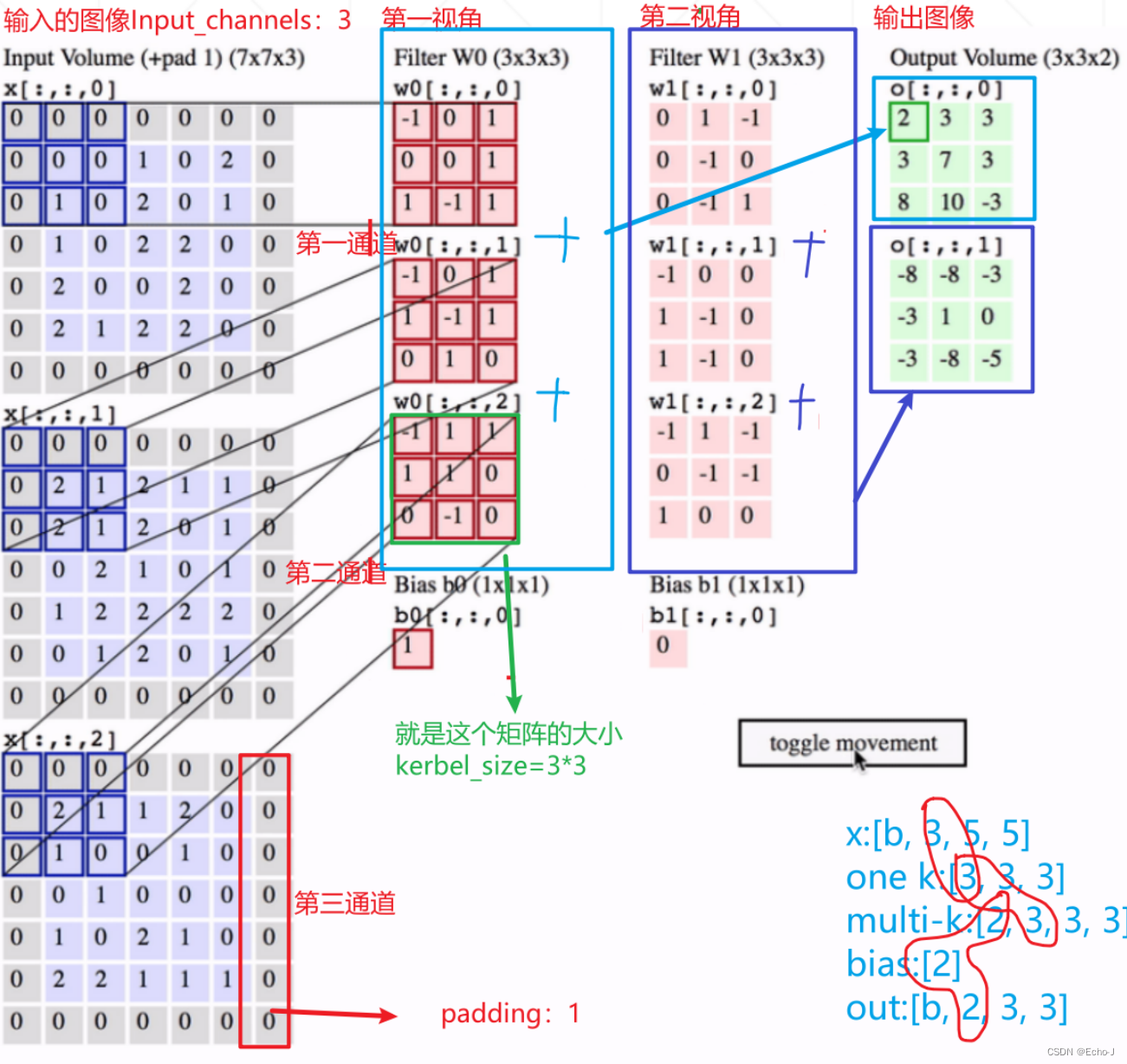
图-3 是以1个Kernel_channel进行卷积运算。以多个Kernel_channels进行卷积运算(图-10):
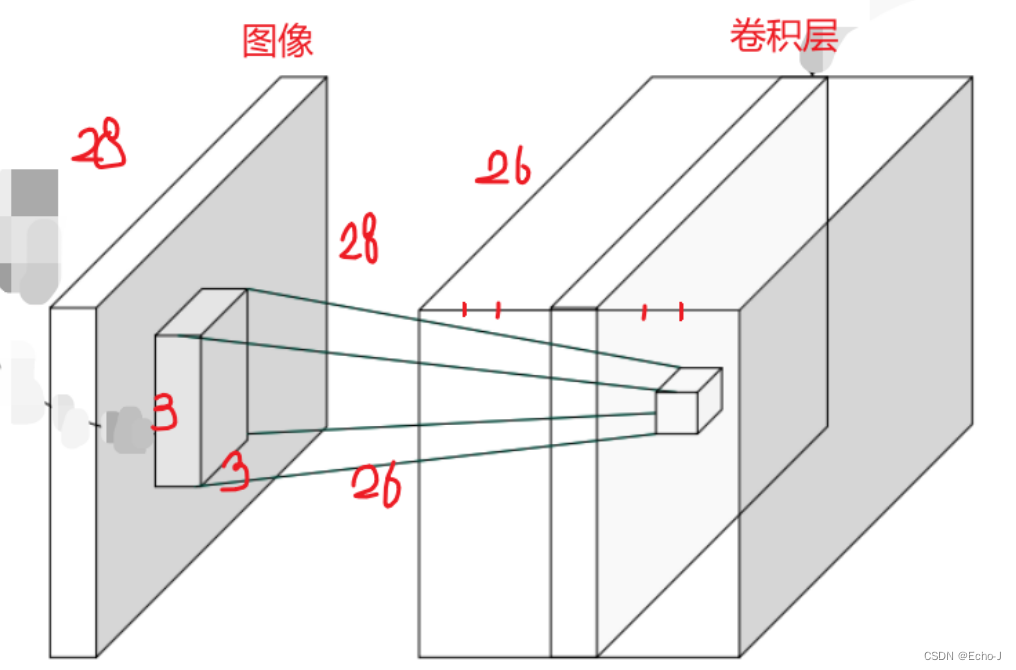
假设原来的图像是一个28*28的灰度图像,即[1, 28, 28]。使用3*3的特征矩阵以7个角度来观察这副图像,最后得到的卷积层是[7, 26, 26]。
称呼声明:
Input_channels :输入的图像的通道,彩色图像就是3,灰度图像就是1
Kernel_channels: 以多少个视角来观察图像
Kernel_size : 特征矩阵的size
Stride: 每次向下/左移动的步长
Padding: 空白的数量,补0
实例(图-11),注意右下角的标注,每个圈中的值必须相等。将同一视角不同通道得出来的矩阵进行叠加,最后会得到一个高维的特性。卷积的过程叫做特征提取。
输出图像的大小计算(公式-2):

代码示例:
# 1、
x=torch.rand(1,1,28,28) #[b,c,h,w]
layer=nn.Conv2d(1,3,kernel_size=3,stride=1,padding=0) # weight [3,1,3,3],不补零
out=layer.forward(x)
print(out.shape)
#torch.Size([1, 3, 26, 26])# 2、
layer=nn.Conv2d(1,3,kernel_size=3,stride=1,padding=1) # weight [3,1,3,3],补零
out=layer.forward(x)
print(out.shape)
#torch.Size([1, 3, 14, 14])# 3、
layer=nn.Conv2d(1,3,kernel_size=3,stride=2,padding=1) # weight [3,1,3,3],补零
out=layer.forward(x)
print(out.shape)
#torch.Size([1, 3, 14, 14])# 说明:
#现在基本不用layer.forward,而是用layer
out=layer(x) #推荐使用
print(out.shape)
#torch.Size([1, 3, 14, 14])###### inner weight $ bias #########
#直接调用
print(layer.weight)
# Parameter containing:
# tensor([[[[-0.1249, -0.3302, -0.1774],
# [-0.1542, 0.0873, 0.0282],
# [-0.0006, -0.1798, -0.1030]]],
#
#
# [[[ 0.1932, 0.3240, 0.1747],
# [-0.2188, -0.1775, -0.0652],
# [-0.1455, -0.1220, 0.0629]]],
#
#
# [[[ 0.2596, 0.3017, 0.2028],
# [-0.2629, -0.0715, 0.3267],
# [ 0.3174, -0.1441, -0.1714]]]], requires_grad=True)print(layer.weight.shape)
# torch.Size([3, 1, 3, 3])print(layer.bias.shape)
# torch.Size([3])向上/向下采样
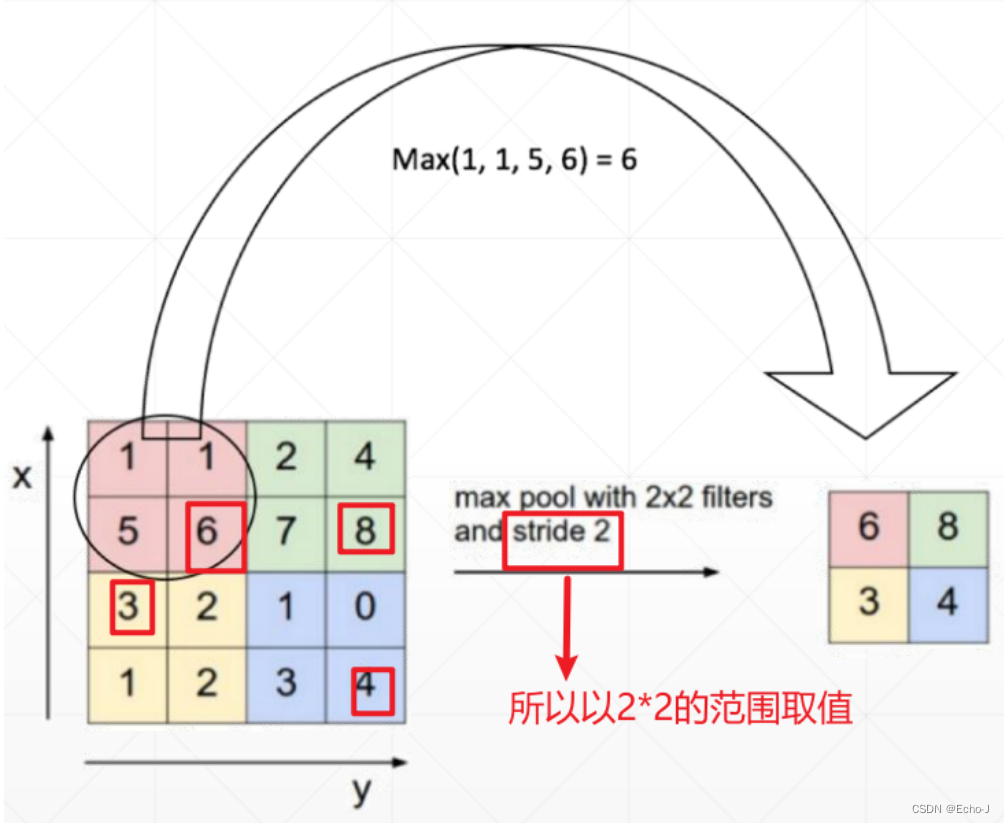
最大采样,选取最大的(图-12):
代码演示:
x=out
print(x.shape)
#torch.Size([1, 3, 14, 14])layer=nn.MaxPool2d(2,stride=2) #最大池化,2*2的滑动窗口,步长为2
out=layer(x) #推荐使用
print(out.shape)
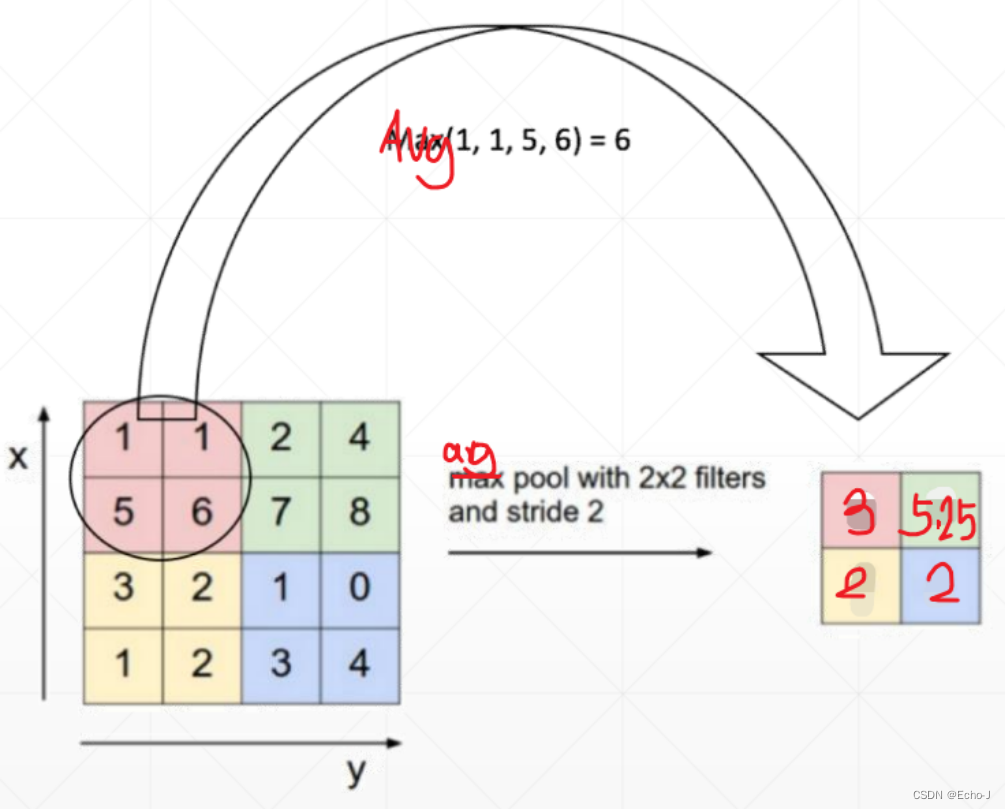
#torch.Size([1, 3, 7, 7])平均采样,选择平均值(图-13):
代码演示:
x=out
print(x.shape)
#torch.Size([1, 3, 14, 14])out=F.avg_pool2d(x,2,stride=2) #平均池化,2*2的滑动窗口,步长为2
print(out.shape)
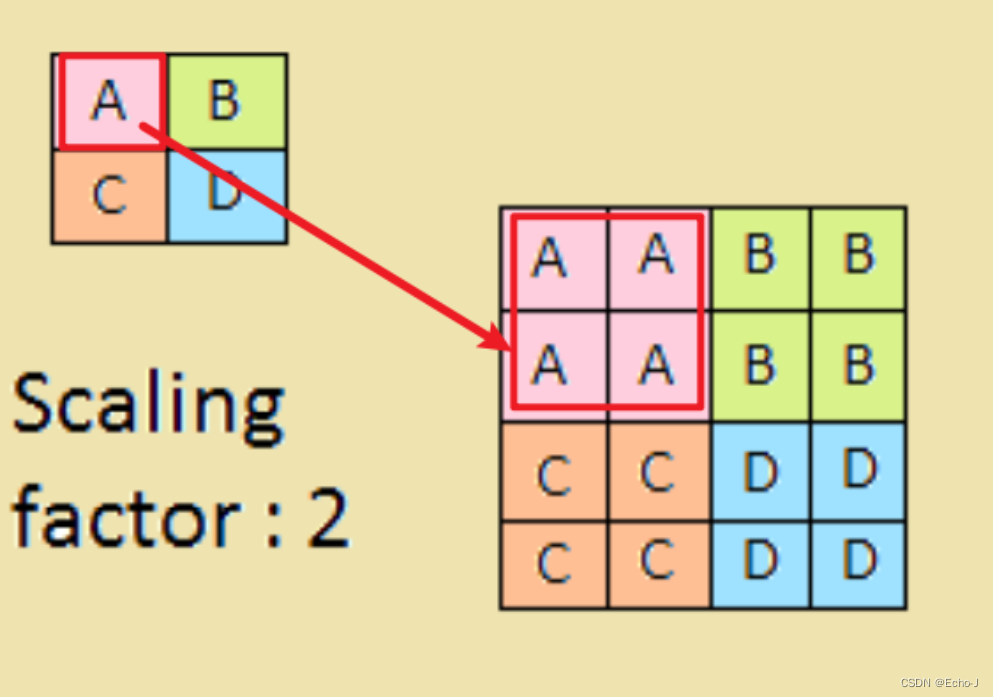
#torch.Size([1, 3, 7, 7])上采样,选取最邻近的(图-14):
代码演示:
x=out
print(out.shape)
# torch.Size([1, 3, 7, 7])
out=F.interpolate(x,scale_factor=2,mode='nearest')# 为放大倍数
print(out.shape)
# torch.Size([1, 3, 14, 14])
out=F.interpolate(x,scale_factor=3,mode='nearest')
print(out.shape)
# torch.Size([1, 3, 21, 21])扩展到卷积层:

1、输入是一个32*32的灰度图像[1, 32, 32],使用一个3*3的特征矩阵进行卷积,分别从6个角度进行卷积,步长为1,会得到一个[6,1,28,28]的图像
2、上采样-》[6,1,14,14]
3、卷积-》[16,1,10,10]
4、上采样-》[16,1,5,5]
5、全连接
6、全连接
7、高斯分布
ReLU

代码演示:
#两种方式,一种是nn.ReLU,另一种是F.relu
x=out
print(x.shape)
#torch.Size([1, 3, 7, 7])layer=nn.ReLU(inplace=True)
out=layer(x)
print(out.shape)
#torch.Size([1, 3, 7, 7])#与上面三行等价
out=F.relu(x)
print(out.shape)
#torch.Size([1, 3, 7, 7])#relu激活函数并不改变size大小相关文章:
深度学习pytorch——卷积神经网络(持续更新)
计算机如何解析图片? 在计算机的眼中,一张灰度图片,就是许多个数字组成的二维矩阵,每个数字就是此点的像素值(图-1)。在存储时,像素值通常位于[0, 255]区间,在深度学习中࿰…...
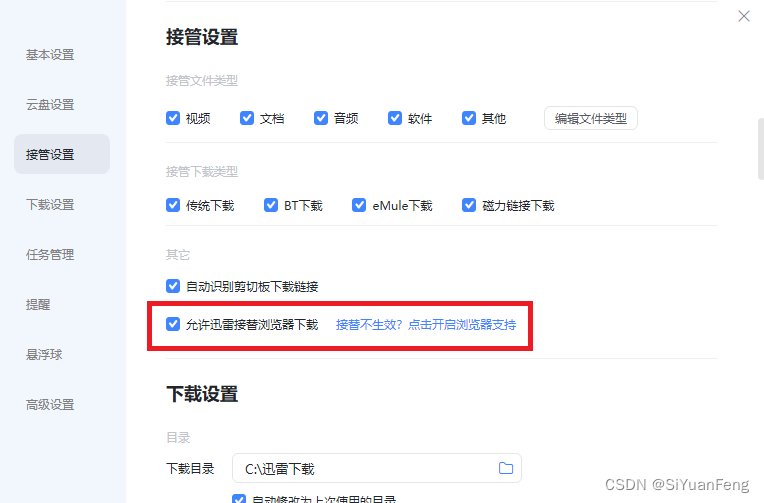
【edge浏览器无法登录某些网站,以及迅雷插件无法生效的解决办法】
edge浏览器无法登录某些网站,以及迅雷插件无法生效的解决办法 edge浏览器无法登录某些网站,但chrome浏览器可以登录浏览器插件无法使用,比如迅雷如果重装插件重装浏览器重装迅雷后仍然出现问题 edge浏览器无法登录某些网站,但chro…...

OpenHarmony无人机MAVSDK开源库适配方案分享
MAVSDK 是 PX4 开源团队贡献的基于 MavLink 通信协议的用于无人机应用开发的 SDK,支持多种语言如 C/C、python、Java 等。通常用于无人机间、地面站与通信设备的消息传输。 MAVLink 是一种非常轻量级的消息传递协议,用于与无人机(以及机载无…...
模型训练----parser.add_argument添加配置参数
现在需要配置参数来达到修改训练的方式,我现在需要新建一个参数来开关wandb的使用。 首先就是在def parse_option():函数里添加上你要使用的变量名 parser.add_argument("--open_wandb",type bool,defaultFalse,helpopen wandb) 到config文件里增加你的…...

数字未来:探索 Web3 的革命性潜力
在当今数字化的时代,Web3作为互联网的新兴范式正逐渐崭露头角,引发了广泛的关注和探讨。本文将深入探索数字未来中Web3所蕴含的革命性潜力,探讨其对社会、经济和技术的深远影响。 1. Web3:数字世界的下一个阶段 Web3是一个正在崛…...
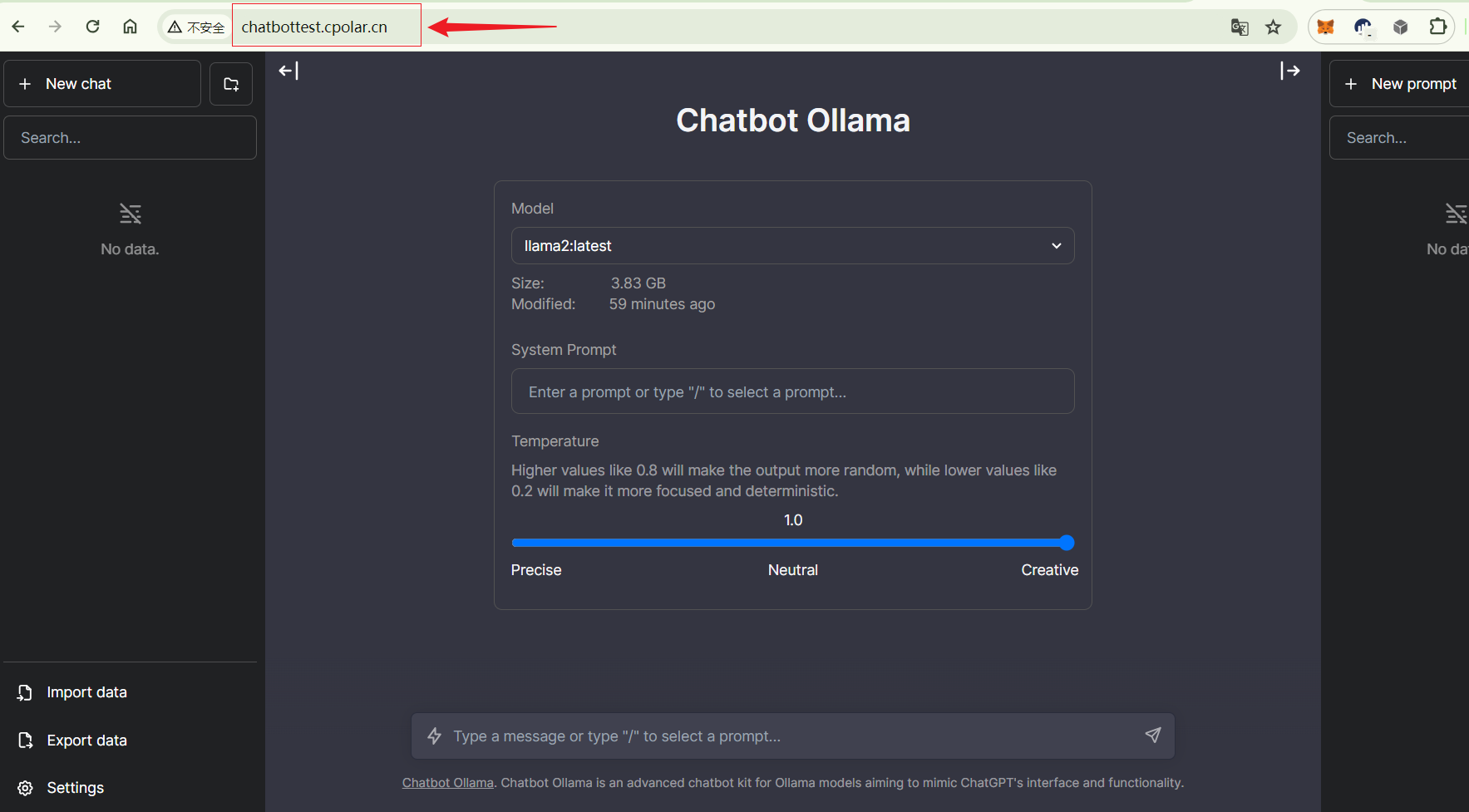
群晖NAS使用Docker部署大语言模型Llama 2结合内网穿透实现公网访问本地GPT聊天服务
文章目录 1. 拉取相关的Docker镜像2. 运行Ollama 镜像3. 运行Chatbot Ollama镜像4. 本地访问5. 群晖安装Cpolar6. 配置公网地址7. 公网访问8. 固定公网地址 随着ChatGPT 和open Sora 的热度剧增,大语言模型时代,开启了AI新篇章,大语言模型的应用非常广泛,包括聊天机…...

[选型必备基础信息] 存储器
存储芯片根据断电后是否保留存储的信息可分为易失性存储芯片(RAM)和非易失性存储芯片(ROM)。 简单说,存储类IC分为 ROM和RAM ROM:EEPROM / Flash / eMMC RAM:SRAM/SDRAM/DDR2/DDR3/DDR4/DDR5…...
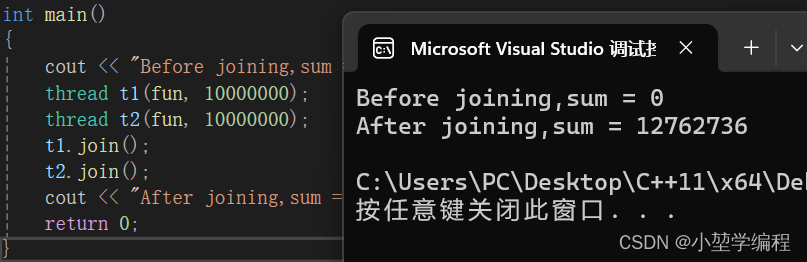
C++——C++11线程库
目录 一,线程库简介 二,线程库简单使用 2.1 传函数指针 编辑 2.2 传lamdba表达式 2.3 简单综合运用 2.4 线程函数参数 三,线程安全问题 3.1 为什么会有这个问题? 3.2 锁 3.2.1 互斥锁 3.2.2 递归锁 3.3 原子操作 3…...

机器学习 | 线性判别分析(Linear Discriminant Analysis)
1 机器学习中的建模 1.1 描述性建模 以方便的形式给出数据的主要特征,实质上是对数据的概括,以便在大量的或有噪声的数据中仍能观察到重要特征。重在认识数据的主要概貌,理解数据的重要特征。 Task:聚类分析,数据降…...

TypeScript-数组、函数类型
1.数组类型 1.1类型 方括号 let arry:number[][5,2,0,1,3,1,4] 1.2 数组泛型 let arry2:Array<number>[5,2,0,1,3,1,4] 1.3接口类型 interface makeArryRule{[index:number]:number }let arry3:makeArryRule[5,2,0,1,3,1,4] 1.4伪数组 说明: argument…...
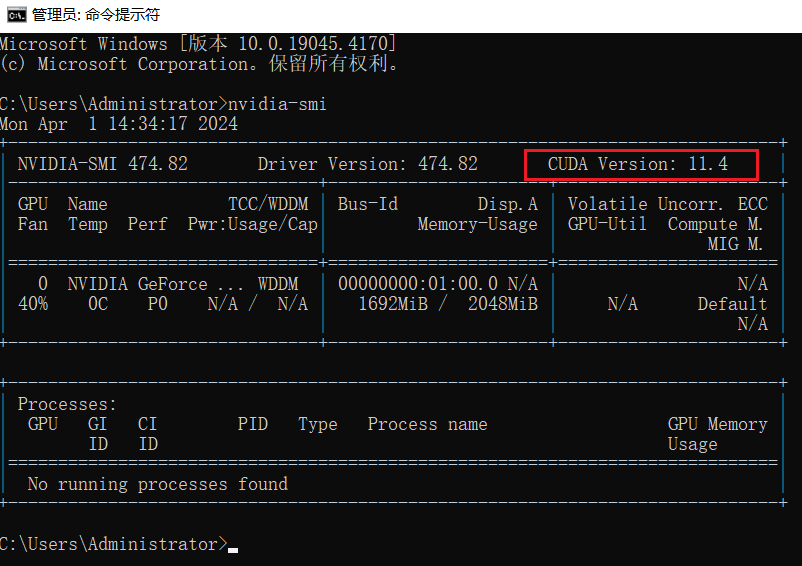
Python深度学习034:cuda的环境如何配置
文章目录 1.安装nvidia cuda驱动CMD中看一下cuda版本:下载并安装cuda驱动2.创建虚拟环境并安装pytorch的torch_cuda3.测试附录1.安装nvidia cuda驱动 CMD中看一下cuda版本: 注意: 红框的cuda版本,是你的显卡能装的最高的cuda版本,所以可以选择低于它的版本。比如我的是11…...
【论文笔记】Text2QR
论文:Text2QR: Harmonizing Aesthetic Customization and Scanning Robustness for Text-Guided QR Code Generation Abstract 二维码通常包含很多信息但看起来并不美观。stable diffusion的出现让平衡扫描鲁棒性和美观变为可能。 为了保证美观二维码的稳定生成&a…...
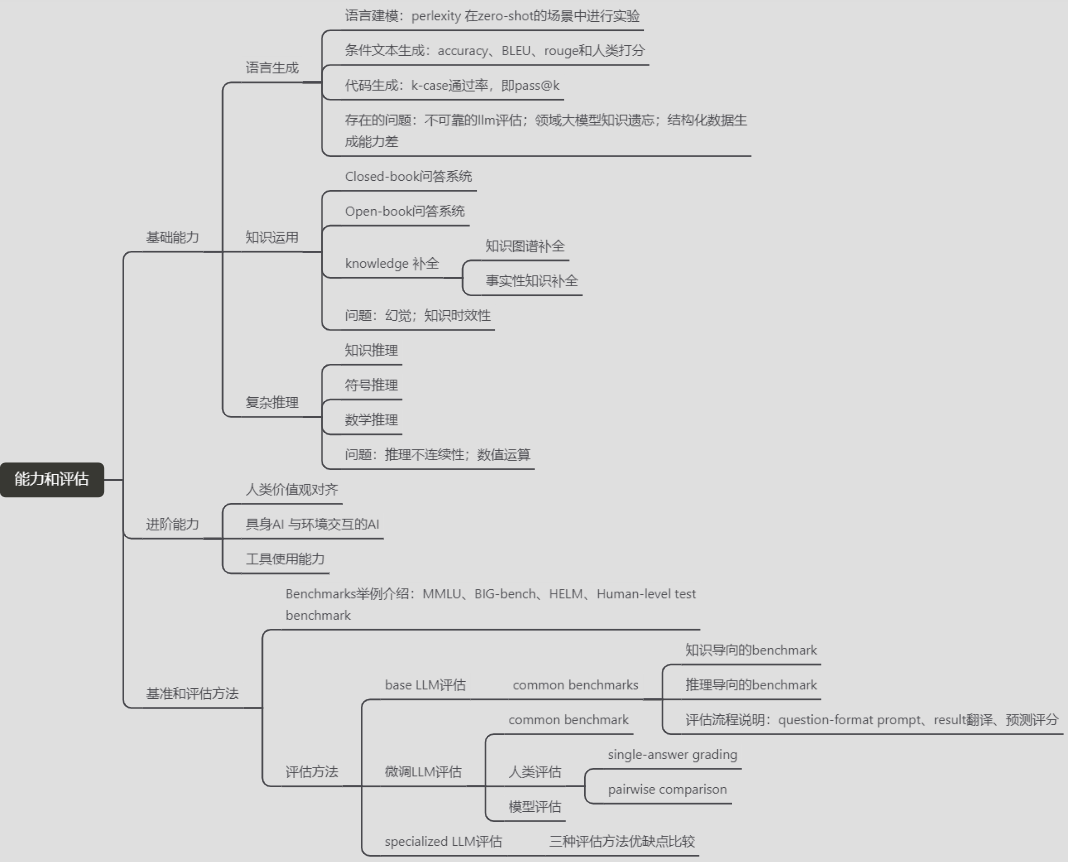
【ReadPapers】A Survey of Large Language Models
LLM-Survey的llm能力和评估部分内容学习笔记——思维导图 思维导图 参考资料 A Survey of Large Language Models论文的github仓库...

站群CMS系统
站群CMS系统是一种用于批量建立和管理网站的内容管理系统,它能够帮助用户快速创建大量的网站,并实现对这些网站的集中管理。以下是三个在使用广泛的站群CMS系统,它们各具特色,可以满足不同用户的需求。 1. Z-BlogPHP Z-BlogPHP是…...

landsat8数据产品说明
1、下载数据用户手册 手册下载网址,搜索landsat science关键词,并点击到官网下载。 2、用户手册目录 3、landsat8数据产品说明 具体说明在手册的第四章,4.1.4数据产品章节,具体描述如下: 英文意思: L8 的…...
Golang 内存管理和垃圾回收底层原理(二)
一、这篇文章我们来聊聊Golang内存管理和垃圾回收,主要注重基本底层原理讲解,进一步实战待后续文章 垃圾回收,无论是Java 还是 Golang,基本的逻辑都是基于 标记-清理 的, 标记是指标记可能需要回收的对象,…...
OpenHarmony:全流程讲解如何编写ADC平台驱动以及应用程序
ADC(Analog to Digital Converter),即模拟-数字转换器,可将模拟信号转换成对应的数字信号,便于存储与计算等操作。除电源线和地线之外,ADC只需要1根线与被测量的设备进行连接。 一、案例简介 该程序是基于…...

计算机学生求职简历的一些想法
面试真的是一件非常难的事情,因为在短短的半小时到一个小时,来判断一个同学行不行,其实是很不全面的。作为一个求职的同学应该怎么办呢?求职的同学可以提前做一些准备,其中比较重要的要数简历的编写。 简历的作用 简…...

网工内推 | 售前专场,需熟悉云计算技术,上市公司,提成高
01 神州数码 招聘岗位:售前工程师 职责描述: 1.负责所在区域华为IT产品线(服务器、存储、云、虚拟化)的售前技术支持工作,包括客户交流、方案编写、配置报价、投标支持、测试等; 2.与厂商相关人员建立和保…...
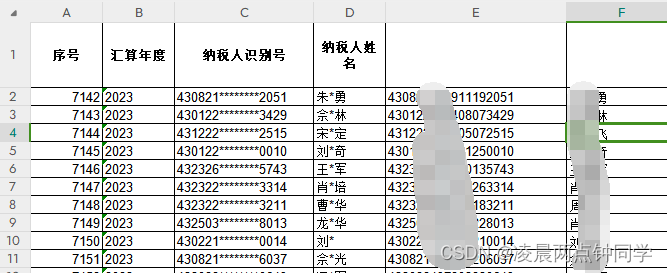
excel匹配替换脱敏身份证等数据
假如excel sheet1中有脱敏的身份证号码和姓名,如: sheet2中有未脱敏的数据数据 做法如下: 1、在sheet2的C列用公式 LEFT(A2,6)&REPT("*",8)&RIGHT(A2,4) 做出脱敏数据,用来与sheet1的脱敏数据匹配 2、在sheet…...

解决罗技鼠标宏压枪不准的5个实战方案 - 绝地求生外设优化完全指南
解决罗技鼠标宏压枪不准的5个实战方案 - 绝地求生外设优化完全指南 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在竞技射击游戏中,…...

Kaggle冠军都在用的XGBoost技巧:3个90%人不知道的细节优化
Kaggle冠军都在用的XGBoost技巧:3个90%人不知道的细节优化 在数据竞赛的战场上,XGBoost早已成为选手们的标配武器。但真正让顶级选手脱颖而出的,往往不是基础用法,而是那些藏在参数列表深处、文档角落里的高阶技巧。本文将揭示三个…...

MATLAB小白也能画BODE图:手把手教你用sym2poly搞定复杂传递函数
MATLAB小白也能画BODE图:手把手教你用sym2poly搞定复杂传递函数 在控制系统分析与设计中,Bode图是工程师最常用的频率响应分析工具之一。它能直观展示系统在不同频率下的增益和相位特性,为稳定性分析和控制器设计提供重要依据。然而对于MATLA…...
)
彻底搞懂 Java 垃圾回收(GC)
在 Java 后端开发、面试、线上性能优化、OOM 排查中,GC(垃圾回收) 都是绕不开的核心基石。很多人只知道 GC 是自动回收内存,但到底怎么回收、什么时候回收、为什么会卡顿、不同回收器区别是什么,一知半解。这篇文章我用…...
)
从CRUD到业务解构:如何优雅处理多表关联的菜品管理接口(附SQL优化小技巧)
从CRUD到业务解构:如何优雅处理多表关联的菜品管理接口(附SQL优化小技巧) 在中小型外卖系统的开发过程中,菜品管理模块往往是业务逻辑最为复杂的部分之一。不同于简单的单表CRUD操作,一个完整的菜品管理接口需要处理菜…...

【技术评审版】分布式 AI 代码智能体集群系统架构与技术方案设计文档 1 / 光子 AI
分布式 AI 代码智能体集群系统架构与技术方案设计文档 文档版本: v1.0 创建日期: 2026-03-19 文档状态: 技术评审版 保密级别: 内部机密 目录 项目概述 系统架构设计 系统模块设计 领域模型设计 业务流程设计 系统交互设计...

R语言双坐标轴实战:从base到ggplot2的5种方法对比与优化技巧
R语言双坐标轴可视化:5种方法深度解析与实战优化 1. 双坐标轴的应用场景与挑战 在科研数据可视化中,我们经常遇到需要同时展示两个量纲不同但存在关联的变量的需求。比如: 温度与降水量的季节性变化股价与交易量的关系微生物丰度与代谢物浓度…...

STM32Modbus RTU包:主从机源码,支持多寄存器写入读取,代码注释详细可读
stm32modbus RTU包主从机源码,支持单个多个寄存器的写入和读取,代码注释详细可读性强以下是一个简化的STM32 Modbus RTU主从机源码示例,用于支持单个或多个寄存器的写入和读取操作。代码中包含了详细的注释,以提高可读性。请注意&…...

别再只盯着ImageNet了!这8个无人机数据集,才是CV工程师的实战宝藏
无人机视觉实战:8个被低估的数据集与工程化解决方案 当计算机视觉遇上无人机视角,传统算法往往面临全新挑战——目标尺寸骤减、背景动态变化、拍摄角度多变。ImageNet和COCO虽为经典,却难以应对这些独特场景。本文将深入剖析8个专为无人机视觉…...

5分钟搞定 Stable Diffusion v1.5 Archive 部署:开箱即用,快速体验AI绘画魅力
5分钟搞定 Stable Diffusion v1.5 Archive 部署:开箱即用,快速体验AI绘画魅力 想亲手试试AI绘画,但被复杂的安装和环境配置劝退?今天,我来带你体验一个“傻瓜式”的解决方案。Stable Diffusion v1.5 Archiveÿ…...