Flink应用
1.免密登录
2.flink StandAlone模式
3.Flink Yarn 模式 (on per 模式,on session 模式)
Flink概述
按照Apache官方的介绍,Flink是一个对有界和无界数据流进行状态计算的分布式处理引擎和框架。通俗地讲,Flink就是一个流计算框架,主要用来处理流式数据。其起源于2010年德国研究基金会资助的科研项目“Stratosphere”,2014年3月成为Apache孵化项目,12月即成为Apache顶级项目。Flinken在德语里是敏捷的意思,意指快速精巧。其代码主要是由 Java 实现,部分代码由 Scala实现。Flink既可以处理有界的批量数据集,也可以处理无界的实时流数据,为批处理和流处理提供了统一编程模型。
Flink安装部署
本地模式
本地模式即在linux服务器直接解压flink二进制包就可以使用,不用修改任何参数,用于一些简单测试场景。
下载安装包
直接在Flink官网下载安装包,如写作此文章时最新版为flink-1.11.1-bin-scala_2.11.tgz
上传并解压至linux
[root@vm1 myapp]# pwd
/usr/local/myapp
[root@vm1 myapp]# ll
总用量 435772
-rw-r--r--. 1 root root 255546057 2月 8 02:29 flink-1.11.1-bin-scala_2.11.tgz
解压到指定目录
[root@vm1 myapp]# tar -zxvf flink-1.11.1-bin-scala_2.11.tgz -C /usr/local/myapp/flink/
启动Flink
[root@vm1 ~]# java -version
java version "1.8.0_261"
Java(TM) SE Runtime Environment (build 1.8.0_261-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.261-b12, mixed mode)
进入flink目录执行启动命令
[root@vm1 ~]# cd /usr/local/myapp/flink/flink-1.11.1/
[root@vm1 flink-1.11.1]# bin/start-cluster.sh
[root@vm1 flink-1.11.1]# jps
3577 Jps
3242 StandaloneSessionClusterEntrypoint
3549 TaskManagerRunner
执行Jps查看java进程,可以看到Flink相关进程已经启动。可以通过浏览器访问Flink的Web界面http://vm1:8081
关闭防火墙
查看linux防火墙状态
[root@vm1 ~]# systemctl status firewalld
临时关闭防火墙
[root@vm1 ~]# systemctl stop firewalld
永久关闭防火墙
[root@vm1 ~]# systemctl disable firewalld
关闭Flink
执行bin/stop-cluster.sh
集群模式
集群环境适合在生产环境下面使用,且需要修改对应的配置参数。Flink提供了多种集群模式,我们这里主要介绍standalone和Flink on Yarn两种模式。
Standalone模式
Standalone是Flink的独立集群部署模式,不依赖任何其它第三方软件或库。如果想搭建一套独立的Flink集群,不依赖其它组件可以使用这种模式。搭建一个标准的Flink集群,需要准备3台Linux机器。
Linux机器规划
节点类型 主机名 IP
Master vm1 192.168.174.136
Slave vm2 192.168.174.137
Slave vm3 192.168.174.138
在Flink集群中,Master节点上会运行JobManager(StandaloneSessionClusterEntrypoint)进程,Slave节点上会运行TaskManager(TaskManagerRunner)进程。
集群中Linux节点都要配置JAVA_HOME,并且节点之间需要设置ssh免密码登录,至少保证Master节点可以免密码登录到其他两个Slave节点,linux防火墙也需关闭。
设置免密登录
1)先在每一台机器设置本机免密登录自身
[root@vm1 ~]# ssh-keygen -t rsa
[root@vm1 ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
在本机执行ssh登录自身,不提示输入密码则表明配置成功
[root@vm1 ~]# ssh vm1
Last login: Tue Sep 29 22:23:39 2020 from vm1
在其它机器vm2、vm3执行同样的操作:
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh vm2
ssh vm3
2)设置vm1免密登录其它机器
把vm1的公钥文件拷贝到其它机器vm2、vm3上
[root@vm1 ~]# scp ~/.ssh/id_rsa.pub root@vm2:~/
[root@vm1 ~]# scp ~/.ssh/id_rsa.pub root@vm3:~/
登录到vm2、vm3,把vm1的公钥文件追加到自己的授权文件中
[root@vm2 ~]# cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
[root@vm3 ~]# cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
如果提示没有 ~/.ssh/authorized_keys目录则可以在这台机器上执行ssh-keygen -t rsa。不建议手动创建.ssh目录!
验证在vm1上ssh登录vm2、vm3是否无需密码,不需要密码则配置成功!
[root@vm1 ~]# ssh vm2
Last login: Mon Sep 28 22:31:22 2020 from 192.168.174.133
[root@vm1 ~]# ssh vm3
Last login: Tue Sep 29 22:35:25 2020 from vm1
执行exit退回到本机
[root@vm3 ~]# exit
logout
Connection to vm3 closed.
[root@vm1 ~]#
3)同样方式设置其它机器之间的免密登录
在vm2、vm3上执行同样的步骤
把vm2的公钥文件拷贝到vm1、vm3
[root@vm2 ~]# scp ~/.ssh/id_rsa.pub root@vm1:~/
[root@vm2 ~]# scp ~/.ssh/id_rsa.pub root@vm3:~/
[root@vm1 ~]# cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
[root@vm3 ~]# cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
把vm3的公钥文件拷贝到vm1、vm2
[root@vm3 ~]# scp ~/.ssh/id_rsa.pub root@vm1:~/
[root@vm3 ~]# scp ~/.ssh/id_rsa.pub root@vm2:~/
[root@vm1 ~]# cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
[root@vm2 ~]# cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
4)验证ssh免密码登录
[root@vm2 ~]# ssh vm1
[root@vm2 ~]# ssh vm3
[root@vm3 ~]# ssh vm1
[root@vm3 ~]# ssh vm2
设置主机时间同步
如果集群内节点时间相差太大的话,会导致集群服务异常,所以需要保证集群内各节点时间一致。
执行命令yum install -y ntpdate安装ntpdate
执行命令ntpdate -u ntp.sjtu.edu.cn 同步时间
Flink安装步骤
下列步骤都是先在Master机器上操作,再拷贝到其它机器(确保每台机器都安装了jdk)
解压Flink安装包
[root@vm1 myapp]# tar -zxvf flink-1.11.1-bin-scala_2.11.tgz -C /usr/local/myapp/flink/
修改Flink的配置文件flink-1.11.1/conf/flink-conf.yaml
把jobmanager.rpc.address配置的参数值改为vm1
jobmanager.rpc.address: vm1
修改Flink的配置文件flink-1.11.1/conf/workers
[root@vm1 conf]# vim workers
vm2
vm3
将vm1这台机器上修改后的flink-1.11.1目录复制到其他两个Slave节点
scp -rq /usr/local/myapp/flink vm2:/usr/local/myapp/
scp -rq /usr/local/myapp/flink vm3:/usr/local/myapp/
在vm1这台机器上启动Flink集群服务
执行这一步时确保各个服务器防火墙已关闭
进入flink目录/flink-1.11.1/bin执行start-cluster.sh
[root@vm1 ~]# cd /usr/local/myapp/flink/flink-1.11.1/
[root@vm1 flink-1.11.1]# bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host vm1.
Starting taskexecutor daemon on host vm2.
Starting taskexecutor daemon on host vm3.
查看vm1、vm2和vm3这3个节点上的进程信息
[root@vm1 flink-1.11.1]# jps
4983 StandaloneSessionClusterEntrypoint
5048 Jps
[root@vm2 ~]# jps
4122 TaskManagerRunner
4175 Jps
[root@vm3 ~]# jps
4101 Jps
4059 TaskManagerRunner
查看Flink Web UI界面,访问http://vm1:8081
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6tKRfsOg-1603003404551)(image-20201001000826062.png)]
8)提交任务执行
[root@vm1 flink-1.11.1]# bin/flink run ./examples/batch/WordCount.jar
提交任务可以在任意一台flink客户端服务器提交,本例中在vm1、vm2、vm3都可以
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AJKInteJ-1603003404554)(image-20201017200539366.png)]
停止flink集群
bin/stop-cluster.sh
10)单独启动、停止进程
手工启动、停止主进程StandaloneSessionClusterEntrypoint
[root@vm1 flink-1.11.1]# bin/jobmanager.sh start
[root@vm1 flink-1.11.1]# bin/jobmanager.sh stop
手工启动、停止TaskManagerRunner(常用于向集群中添加新的slave节点)
[root@vm1 flink-1.11.1]# bin/taskmanager.sh start
[root@vm1 flink-1.11.1]# bin/taskmanager.sh stop
Flink on YARN 模式
Flink on Yarn模式使用YARN 作为任务调度系统,即在YARN上启动运行flink。好处是能够充分利用集群资源,提高服务器的利用率。这种模式的前提是要有一个Hadoop集群,并且只需公用一套hadoop集群就可以执行MapReduce和Spark以及Flink任务,非常方便。因此需要先搭建一个hadoop集群。
Hadoop集群搭建
1)下载并解压到指定目录
从官网下载Hadoop二进制包,上传到linux服务器,并解压到指定目录。
[root@vm1 ~]# tar -zxvf hadoop-2.9.2.tar.gz -C /usr/local/myapp/hadoop/
1
2)配置环境变量
vim /etc/profile
export HADOOP_HOME=/usr/local/myapp/hadoop/hadoop-2.9.2/
export PATH=$PATH:$HADOOP_HOME/bin
执行hadoop version查看版本号
[root@vm1 hadoop]# source /etc/profile
[root@vm1 hadoop]# hadoop version
Hadoop 2.9.2
3)修改hadoop-env.sh文件
修改配置export JAVA_HOME=${JAVA_HOME}指定JAVA_HOME路径:
export JAVA_HOME=/usr/local/myapp/jdk/jdk1.8.0_261/
1
同时指定Hadoop日志路径,先创建好目录:
[root@vm1]# mkdir -p /data/hadoop_repo/logs/hadoop
1
再配置HADOOP_LOG_DIR
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
1
4)修改yarn-env.sh文件
指定JAVA_HOME路径
export JAVA_HOME=/usr/local/myapp/jdk/jdk1.8.0_261/
1
指定YARN日志目录:
[root@vm1 ~]# mkdir -p /data/hadoop_repo/logs/yarn
1
export YARN_LOG_DIR=/data/hadoop_repo/logs/yarn
1
4)修改core-site.xml
配置NameNode的地址fs.defaultFS、Hadoop临时目录hadoop.tmp.dir
NameNode和DataNode的数据文件都会存在临时目录下的对应子目录下
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://vm1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_repo</value>
</property>
</configuration>
6)修改hdfs-site.xml
dfs.namenode.secondary.http-address指定secondaryNameNode的http地址,本例设置vm2机器为SecondaryNameNode
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>vm2:50090</value>
</property>
</configuration>
7)修改yarn-site.xml
yarn.resourcemanager.hostname指定resourcemanager的服务器地址,本例设置vm1机器为hadoop主节点
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>vm1</value>
</property>
</configuration>
8)修改mapred-site.xml
[root@vm1 hadoop]# mv mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
mapreduce.framework.name设置使用yarn运行mapreduce程序
9) 配置slaves
设置vm2、vm3为Hadoop副节点
[root@vm1 hadoop]# vim slaves
vm2
vm3
10)设置免密码登录
免密配置参考前文 设置服务器间相互免密登录
11)拷贝hadoop到其它机器
将在vm1上配置好的Hadoop目录拷贝到其它服务器
[root@vm1 hadoop]# scp -r /usr/local/myapp/hadoop/ vm2:/usr/local/myapp/
[root@vm1 hadoop]# scp -r /usr/local/myapp/hadoop/ vm3:/usr/local/myapp/
12)格式化HDFS
在Hadoop集群主节点vm1上执行格式化命令
[root@vm1 bin]# pwd
/usr/local/myapp/hadoop/hadoop-2.9.2/bin
[root@vm1 bin]# hdfs namenode -format
如果要重新格式化NameNode,则需要先将原来NameNode和DataNode下的文件全部删除,否则报错。NameNode和DataNode所在目录在core-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性配置
13)启动集群
直接启动全部进程
[root@vm1 hadoop-2.9.2]# sbin/start-all.sh
也可以单独启动HDFS
sbin/start-dfs.sh
也可以单独启动YARN
sbin/start-yarn.sh
14)查看web页面
要在本地机器http访问虚拟机先关闭linux防火墙,关闭linux防火墙请参照前文
查看HDFS Web页面:
http://vm1:50070/
查看YARN Web 页面:
http://vm1:8088/cluster
15)查看各个节点进程
[root@vm1 ~]# jps
5026 ResourceManager
5918 Jps
5503 NameNode
[root@vm2 ~]# jps
52512 NodeManager
52824 Jps
52377 DataNode
52441 SecondaryNameNode
[root@vm3 ~]# jps
52307 DataNode
52380 NodeManager
52655 Jps
16)停止Hadoop集群
[root@vm1 hadoop-2.9.2]# sbin/stop-all.sh
Hadoop集群搭建完成后就可以在Yarn上运行Flink了!
Flink on Yarn的两种方式
第1种:在YARN中预先初始化一个Flink集群,占用YARN中固定的资源。该Flink集群常驻YARN 中,所有的Flink任务都提交到这里。这种方式的缺点在于不管有没有Flink任务执行,Flink集群都会独占系统资源,除非手动停止。如果YARN中给Flink集群分配的资源耗尽,只能等待YARN中的一个作业执行完成释放资源才能正常提交下一个Flink作业。
第2种:每次提交Flink任务时单独向YARN申请资源,即每次都在YARN上创建一个新的Flink集群,任务执行完成后Flink集群终止,不再占用机器资源。这样不同的Flink任务之间相互独立互不影响。这种方式能够使得资源利用最大化,适合长时间、大规模计算任务。
下面分别介绍2种方式的具体步骤。
第1种方式
不管是哪种方式,都要先运行Hadoop集群
1)启动Hadoop集群
[root@vm1 hadoop-2.9.2]# sbin/start-all.sh
2)将flink依赖的hadoop相关jar包拷贝到flink目录
[root@vm1]# cp /usr/local/myapp/hadoop/hadoop-2.9.2/share/hadoop/yarn/hadoop-yarn-api-2.9.2.jar /usr/local/myapp/flink/flink-1.11.1/lib
[root@vm1]# cp /usr/local/myapp/hadoop/hadoop-2.9.2/share/hadoop/yarn/sources/hadoop-yarn-api-2.9.2-sources.jar /usr/local/myapp/flink/flink-1.11.1/lib
还需要 flink-shaded-hadoop-2-uber-2.8.3-10.0.jar ,可以从maven仓库下载并放到flink的lib目录下。
3)创建并启动flink集群
在flink的安装目录下执行
bin/yarn-session.sh -n 2 -jm 512 -tm 512 -d
1
这种方式创建的是一个一直运行的flink集群,也称为flink yarn-session
创建成功后,可以访问hadoop任务页面,查看是否有flink任务成功运行:http://vm1:8088/cluster
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bIcGDTS0-1603003404558)(image-20201015212535158.png)]
创建成功后,flink控制台会输出web页面的访问地址,可以在web页面查看flink任务执行情况:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-91J9xKue-1603003404560)(image-20201015213139655.png)]
控制台输出http://vm2:43243 可以认为flink的Jobmanager进程就运行在vm2上,且端口是43243。指定host、port提交flink任务时可以使用这个地址+端口
4)附着到flink集群
创建flink集群后会有对应的applicationId,因此执行flink任务时也可以附着到已存在的、正在运行的flink集群
#附着到指定flink集群
[root@vm1 flink-1.11.1]# bin/yarn-session.sh -id application_1602852161124_0001
1
2
applicationId参数是上一步创建flink集群时对应的applicationId
5) 提交flink任务
可以运行flink自带的wordcount样例:
[root@vm1 flink-1.11.1]# bin/flink run ./examples/batch/WordCount.jar
在flink web页面 http://vm2:43243/ 可以看到运行记录:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZYwxhNTz-1603003404561)(image-20201015213038724.png)]
可以通过-input和-output来手动指定输入数据目录和输出数据目录:
-input hdfs://vm1:9000/words
-output hdfs://vm1:9000/wordcount-result.txt
第2种方式
这种方式很简单,就是在提交flink任务时同时创建flink集群
[root@vm1 flink-1.11.1]# bin/flink run -m yarn-cluster -yjm 1024 ./examples/batch/WordCount.jar
需要在执行上述命令的机器(即flink客户端)上配置环境变量YARN_CONF_DIR、HADOOP_CONF_DIR或者HADOOP_HOME环境变量,Flink会通过这个环境变量来读取YARN和HDFS的配置信息。
如果报下列错,则需要禁用hadoop虚拟内存检查:
Diagnostics from YARN: Application application_1602852161124_0004 failed 1 times (global limit =2; local limit is =1) due to AM Container for appattempt_1602852161124_0004_000001 exited with exitCode: -103
Failing this attempt.Diagnostics: [2020-10-16 23:35:56.735]Container [pid=6890,containerID=container_1602852161124_0004_01_000001] is running beyond virtual memory limits. Current usage: 105.8 MB of 1 GB physical memory used; 2.2 GB of 2.1 GB virtual memory used. Killing container.
修改所有hadoop机器(所有 nodemanager)的文件$HADOOP_HOME/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
重启hadoop集群再次运行
[root@vm1 hadoop-2.9.2]# sbin/stop-all.sh
[root@vm1 hadoop-2.9.2]# sbin/start-all.sh
[root@vm1 flink-1.11.1]# bin/flink run -m yarn-cluster -yjm 1024 ./examples/batch/WordCount.jar
任务成功执行,控制台输出如下。可以使用控制台输出的web页面地址vm3:44429查看任务。不过这种模式下任务执行完成后Flink集群即终止,所以输入地址vm3:44429时可能看不到结果,因为此时任务可能执行完了,flink集群终止,页面也访问不了了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XsBPibbF-1603003404563)(image-20201016000427565.png)]
上述Flink On Yarn的2种方式案例中分别使用了两个命令:yarn-session.sh 和 flink run
yarn-session.sh 可以用来在Yarn上创建并启动一个flink集群,可以通过如下命令查看常用参数:
[root@vm1 flink-1.11.1]# bin/yarn-session.sh -h
-n :表示分配的容器数量,即TaskManager的数量
-jm:设置jobManagerMemory,即JobManager的内存,单位MB
-tm:设置taskManagerMemory ,即TaskManager的内存,单位MB
-d: 设置运行模式为detached,即后台独立运行
-nm:设置在YARN上运行的应用的name(名字)
-id: 指定任务在YARN集群上的applicationId ,附着到后台独立运行的yarn session中
flink run命令既可以提交任务到Flink集群中执行,也可以在提交任务时创建一个新的flink集群,可以通过如下命令查看常用参数:
[root@vm1 flink-1.11.1]# bin/flink run -h
-m: 指定主节点(JobManger)的地址,在此命令中指定的JobManger地址优先于配置文件中的
-c: 指定jar包的入口类,此参数在jar 包名称之前
-p:指定任务并行度,同样覆盖配置文件中的值
flink run使用举例:
1)提交并执行flink任务,默认查找当前YARN集群中已有的yarn-session的JobManager
[root@vm1 flink-1.11.1]# bin/flink run ./examples/batch/WordCount.jar -input hdfs://vm1:9000/hello.txt -output hdfs://vm1:9000/result_hello
1
2)提交flink任务时显式指定JobManager的的host的port,该域名和端口是创建flink集群时控制台输出的
[root@vm1 flink-1.11.1]# bin/flink run -m vm3:39921 ./examples/batch/WordCount.jar -input hdfs://vm1:9000/hello.txt -output hdfs://vm1:9000/result_hello
1
3)在YARN中启动一个新的Flink集群,并提交任务
[root@vm1 flink-1.11.1]# bin/flink run -m yarn-cluster -yjm 1024 ./examples/batch/WordCount.jar -input hdfs://vm1:9000/hello.txt -output hdfs://vm1:9000/result_hello
Flink on Yarn集群HA
Flink on Yarn模式的HA利用的是YARN的任务恢复机制。Flink on Yarn模式依赖hadoop集群,这里可以使用前文中的hadoop集群。这种模式下的HA虽然依赖YARN的任务恢复机制,但是Flink任务在恢复时,需要依赖检查点产生的快照。快照虽然存储在HDFS上,但是其元数据保存在zk中,所以也需要一个zk集群,使用前文配置好的zk集群即可。
相关文章:

Flink应用
1.免密登录 2.flink StandAlone模式 3.Flink Yarn 模式 (on per 模式,on session 模式) Flink概述 按照Apache官方的介绍,Flink是一个对有界和无界数据流进行状态计算的分布式处理引擎和框架。通俗地讲,Flink就是一个流计算框架,主要用来处…...

C# 委托与事件 终章
C# 委托与事件 浅尝 C# 委托与事件 深入 委托 委托有什么用? 将函数作为函数的参数传递声明事件并用来注册 强类型委托 Action<T1> Func<T1, TResult>事件 希望一个类的某些成员在发生变化时能被外界观测到 CollctionChangedTextChanged 标准.Ne…...

MySQL-linux安装-万能RPM法
一、MySQL的Linux版安装 1、 CentOS7下检查MySQL依赖 1. 检查/tmp临时目录权限(必不可少) 由于mysql安装过程中,会通过mysql用户在/tmp目录下新建tmp_db文件,所以请给/tmp较大的权限。执行 : chmod -R 777 /tmp2. …...

elment UI el-date-picker 月份组件选定后提交后台页面显示正常,提交后台字段变成时区格式
需求:要实现一个日期的月份选择<el-date-picker :typeformData.dateType :value-formatdateFormat v-modelformData.leaveFactoryDateplaceholder选择月份></el-date-picker>错误示例:将日期显示类型(type)dateType或将日期绑定值的格式(val…...

基于 NGINX 的 ngx_http_geoip2 模块 来禁止国外 IP 访问网站
基于 NGINX 的 ngx_http_geoip2 模块 来禁止国外 IP 访问网站 一、安装 geoip2 扩展依赖 [rootfxkj ~]# yum install libmaxminddb-devel -y二、下载 ngx_http_geoip2_module 模块 [rootfxkj tmp]# git clone https://github.com/leev/ngx_http_geoip2_module.git三、解压模…...
)
C++经典面试题目(二十)
1、请解释运算符重载的限制。 运算符重载必须至少有一个操作数是用户自定义类型。不能改变运算符的优先级和结合性。不能创建新的运算符。不能重载以下运算符:::, .*, .*, ?:, sizeof, typeid。 2、什么是友元函数?它有什么作用? 友元函数…...

vue3+uniapp 动态渲染组件,兼容h5、app端
1.setup写在js中,使用ref绑定数据,事件和数据都需要return出去。调用数据{数据名}.value。 如果你想要通过接口动态获取组件路径,并据此动态渲染组件,你可以使用异步组件和defineAsyncComponent函数。在Vue 3中,你可以…...

CSS层叠样式表学习(2)
(大家好,今天我们将继续来学习CSS(2)的相关知识,大家可以在评论区进行互动答疑哦~加油!💕) 目录 二、CSS基础选择器 2.1 CSS选择器的作用 2.2 选择器分类 2.3 标签选择器 2.…...

【MySQL】DML的表操作详解:添加数据&修改数据&删除数据(可cv例题语句)
前言 大家好吖,欢迎来到 YY 滴MySQL系列 ,热烈欢迎! 本章主要内容面向接触过C Linux的老铁 主要内容含: 欢迎订阅 YY滴C专栏!更多干货持续更新!以下是传送门! YY的《C》专栏YY的《C11》专栏YY的…...

Docker命令及部署Java项目
文章目录 简介Docker镜像镜像列表查找镜像拉取镜像删除镜像镜像标签 Docker容器容器启动容器查看容器停止和重启后台模式和进入强制停止容器清理停止的容器容器错误日志容器别名及操作 Docker部署Java项目 简介 Docker是一种容器化技术,可以帮助开发者轻松打包应用…...

深度学习入门:从理论到实践的全面指南
深度学习入门:从理论到实践的全面指南 引言第一部分:深度学习基础第二部分:数学基础第三部分:编程和工具第四部分:构建你的第一个模型第五部分:深入学习结语 引言 大家好,这里是程序猿代码之路。…...

后端前行Vue之路(二):模版语法之插值与指令
1.概述 Vue.js的模板语法是一种将Vue实例的数据绑定到HTML文档的方法。Vue的模板语法是一种基于HTML的扩展,允许开发者将Vue实例中的数据绑定到HTML元素,以及在HTML中使用一些简单的逻辑和指令。Vue.js 基于 HTML 的模板语法允许开发者声明式地将 DOM 绑…...

Kotlin 中的类和构造方法
Kotlin 中的类与接口和 Java 中的类与接口还是有区别的。例如,Koltin 中的接口可以包含属性声明,与 Java 不同的是。Kotlin 的声明默认是 final 和 public 的。此外,嵌套的类默认并不是内部类:它们并没有包含对其它外部类的隐式引…...
)
【2024最新】vue3的基本使用(超详细)
一、Vue 3 概述 1. 为什么要学习Vue 3 Vue 3是Vue.js的最新主要版本,它带来了许多改进和新特性,包括但不限于: 性能提升:Vue 3提供了更快的渲染速度和更低的内存使用率。Composition API:引入了一个新的API…...
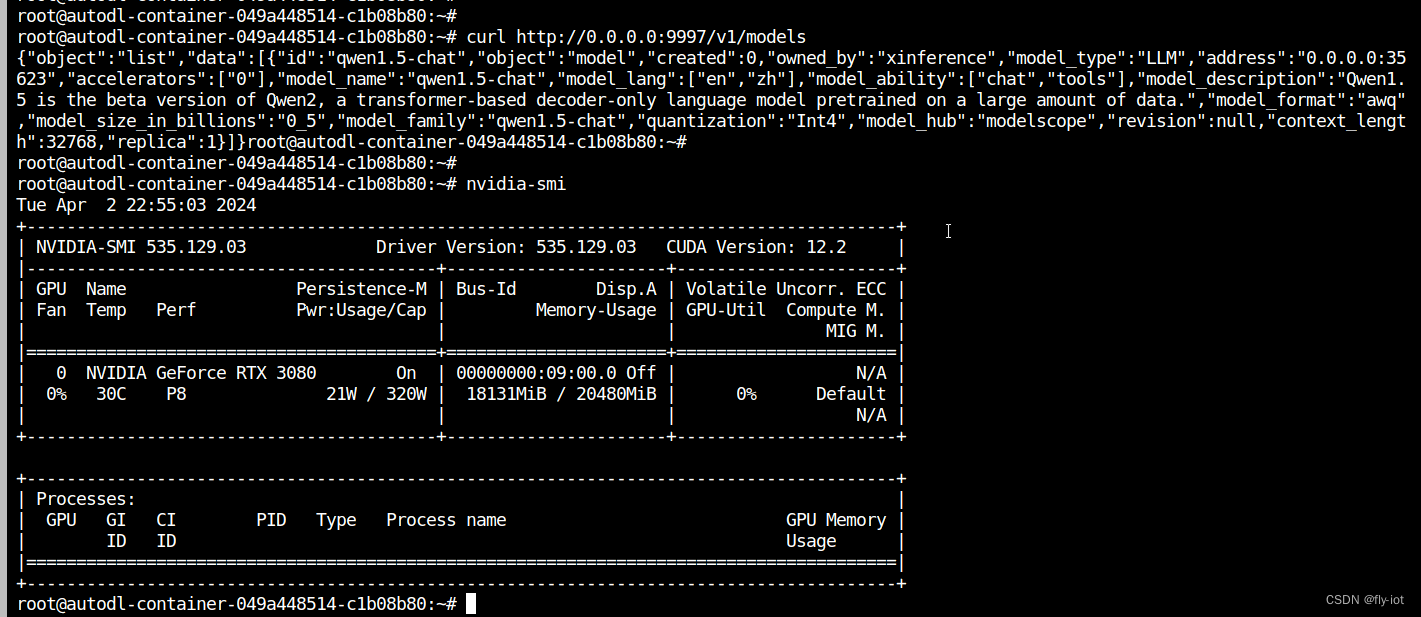
【xinference】(8):在autodl上,使用xinference部署qwen1.5大模型,速度特别快,同时还支持函数调用,测试成功!
1,关于xinference Xorbits Inference (Xinference) 是一个开源平台,用于简化各种 AI 模型的运行和集成。借助 Xinference,您可以使用任何开源 LLM、嵌入模型和多模态模型在云端或本地环境中运行推理,并创建强大的 AI 应用。 Xor…...
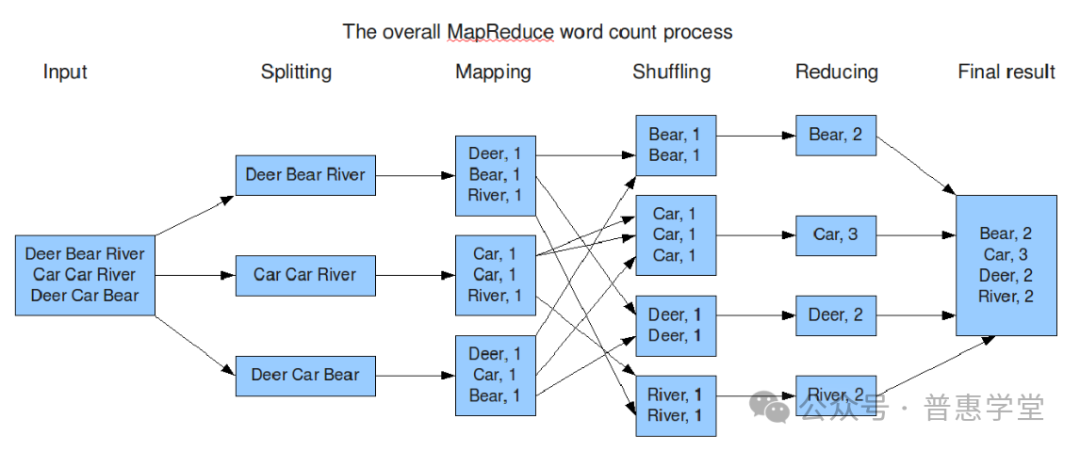
YARN集群 和 MapReduce 原理及应用
YARN集群模式 本文内容需要基于 Hadoop 集群搭建完成的基础上来实现 如果没有搭建,请先按上一篇: <Linux 系统 CentOS7 上搭建 Hadoop HDFS集群详细步骤> 搭建:https://mp.weixin.qq.com/s/zPYsUexHKsdFax2XeyRdnA 配置hadoop安装目录下的 etc…...

C++算法——滑动窗口
一、长度最小的子数组 1.链接 209. 长度最小的子数组 - 力扣(LeetCode) 2.描述 3.思路 本题从暴力求解的方式去切入,逐步优化成“滑动窗口”,首先,暴力枚举出各种组合的话,我们先让一个指针指向第一个&…...

Rust---有关介绍
目录 Rust---有关介绍变量的操作Rust 数值库:num某些基础数据类型序列(Range)字符类型单元类型 发散函数表达式(! 语句) Rust—有关介绍 得益于各种零开销抽象、深入到底层的优化潜力、优质的标准库和第三方库实现,Ru…...

vue项目双击from表单限制重复提交 添加全局注册自定义函数
第一步: 找到utils文件夹添加directive.js文件 import Vue from vue //全局防抖函数 // 在vue上挂载一个指量 preventReClick const preventReClick Vue.directive(preventReClick, {inserted: function (el, binding) {console.log(el.disabled)el.addEventListener(click,…...

WebPack的使用及属性配、打包资源
WebPack(静态模块打包工具)(webpack默认只识别js和json内容) WebPack的作用 把静态模块内容压缩、整合、转译等(前端工程化) 1️⃣把less/sass转成css代码 2️⃣把ES6降级成ES5 3️⃣支持多种模块文件类型,多种模块标准语法 export、export…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...

实战设计模式之模板方法模式
概述 模板方法模式定义了一个操作中的算法骨架,并将某些步骤延迟到子类中实现。模板方法使得子类可以在不改变算法结构的前提下,重新定义算法中的某些步骤。简单来说,就是在一个方法中定义了要执行的步骤顺序或算法框架,但允许子类…...
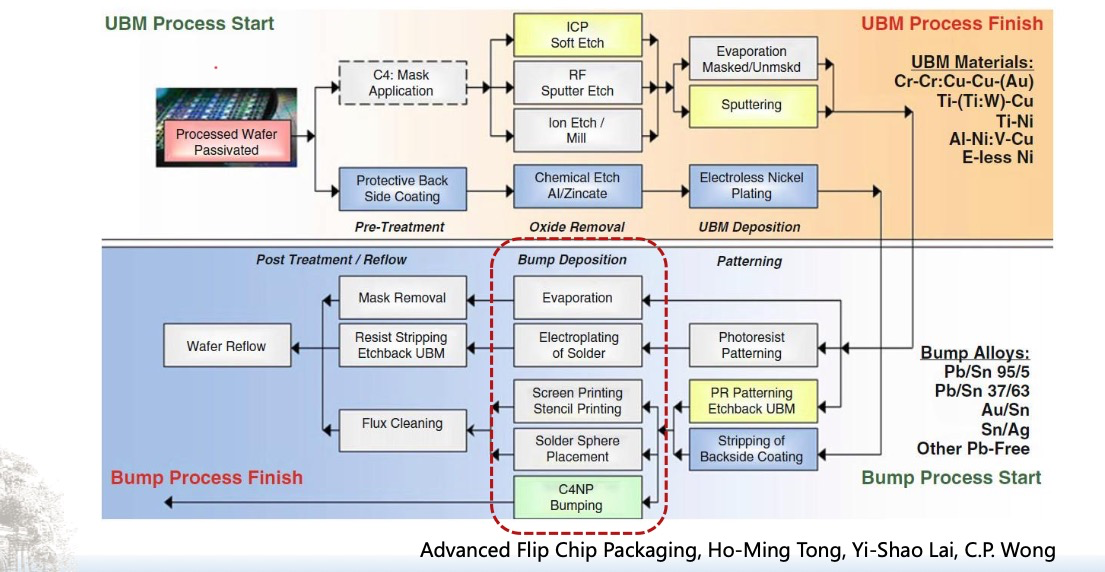
倒装芯片凸点成型工艺
UBM(Under Bump Metallization)与Bump(焊球)形成工艺流程。我们可以将整张流程图分为三大阶段来理解: 🔧 一、UBM(Under Bump Metallization)工艺流程(黄色区域ÿ…...