Java开发 - Redis初体验
前言
es我们已经在前文中有所了解,和es有相似功能的是Redis,他们都不是纯粹的数据库。两者使用场景也是存在一定的差异的,本文目的并不重点说明他们之间的差异,但会简要说明,重点还是在对Redis的了解和学习上。学完本篇,你将了解Redis的特点和作用,掌握Redis的基础用法,这将有助于你在后续的项目中更好的使用Redis。建议大家都动手和博主一起实操,莫要养成眼高手低的毛病,下面,让我们提起精神,一起开始这场Redis盛宴吧。
Redis
什么是Redis
Redis全名Remote Dictionary Server,即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
其官网:Redis
虽然Redis也是数据库,但又有别于我们所知的mysql等关系型数据库,Redis是一款基于内存的NoSQL数据存储服务,也就是非关系型的数据库,这点要搞搞清楚。
为什么使用Redis
相信大家在学习SQL的时候都有过这样的经历,往数据库插入50w条数据,然后去条件检索某些数据,效率如何?大家心里多少还是有点x数的,试想,这种暴力型操作要是出现在我们常用的一些网站和应用上,且每次请求到这么做,那该是何等的疯狂?
说到这里,其实还没有说出Redis的主要应用场景,每每想到这个,总是会跳出另一个东西:ES。算了,咱们看下面的对比吧,有对比才有伤害啊!
Redis和ES的区别
Redis使用场景
因为Redis是基于内存运行的,说起内存,你应该知道,其运行效率远高于和硬盘的交互。这也就导致了Redis运行效率非常高。
Redis同样支持将数据存储在硬盘上,支持主从和分布式使用,但在事务上有着严重不足,所以在关系比较复杂的地方就不适合使用Redis,但却可以配合关系型数据库做缓存,也就是通过复杂SQL查找到数据缓存在Redis。
此类缓存数据,我准备用一个绝对一些的词,必须是稳定型,通用型,高频次数据,比如类别,商品信息,资讯信息等。如果每次请求都会变,每个人又都不一样的数据,不太建议存储在Redis,不是不行,只是不建议,因为会占用大量的内存,造成数据的冗余,还不利于做数据同步。
ES使用场景
ES是非关系型数据库,我们通常说他是一个引擎,实时搜索引擎,他是把数据按照一定的规律存储起来,达到比关系型数据库查询效率更高的目的。
ES扩展容易,前文中曾使用了ik插件,ES同样支持主从,由于其存储的数据结构特点,所以其查询效率非常高,在微服务这种大数据形态下的表现尤为优秀,可以快速实现数据的整合,对于日志和数据分析非常友好,对于实时状态的高也并发有着极强的适应能力,且延迟也很低。
想了解ES的童鞋可以点击下面链接前往查看:Java开发 - Elasticsearch初体验
Redis安装
由于博主是Mac电脑,这里就以Mac为例,Windows没试过,Windows的童鞋可自行百度安装。
- 打开终端,输入:brew install redis
- 测试安装成功输入:redis-server,看到Redis 的启动日志则说明安装成功,通过Ctrl-C可停止此redis
- 使用 launchd 启动Redis:brew services start redis 暂停Redis:brew services stop redis 查看Redis信息:brew services info redis
其实博主觉得这么做挺麻烦的,有个东西叫:Docker Desktop

直接安装这个,Mac电脑省去了安装虚拟机的麻烦,直接在此软件内安装各种服务,不要太爽:
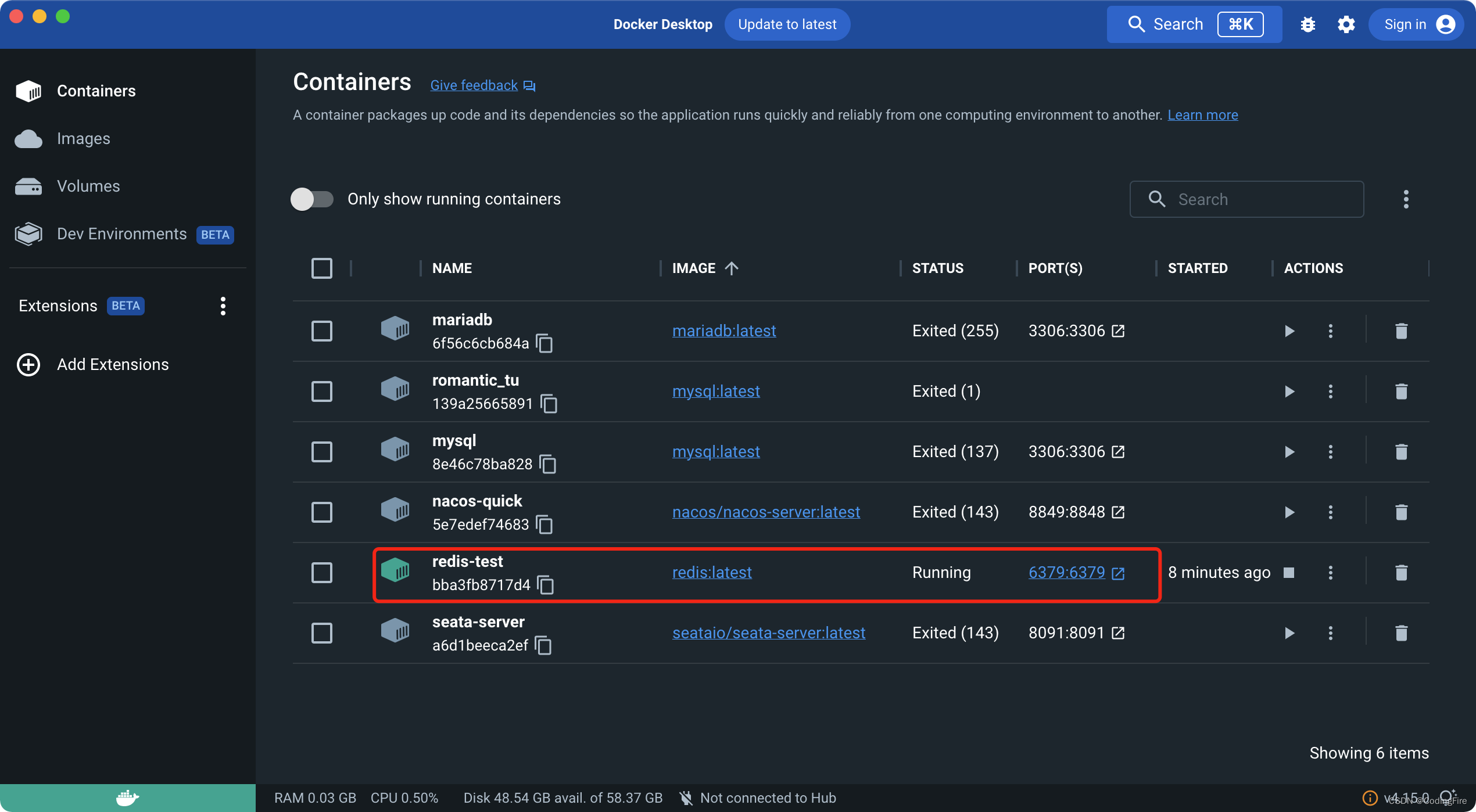
数据库,nacos,senta等都可以在这里安装并且一键启动,推荐大家去装一个,就不用每一个东西都要自己装,太麻烦了。
还有个Redis的客户端也推荐大家装一下 :

此软件在Mac上App Store是收费的,推荐安装方式如下:
brew install --cask another-redis-desktop-manager
安装后就可以找到启动图标了,Windows可在网上自行搜索,其工作页面如下:
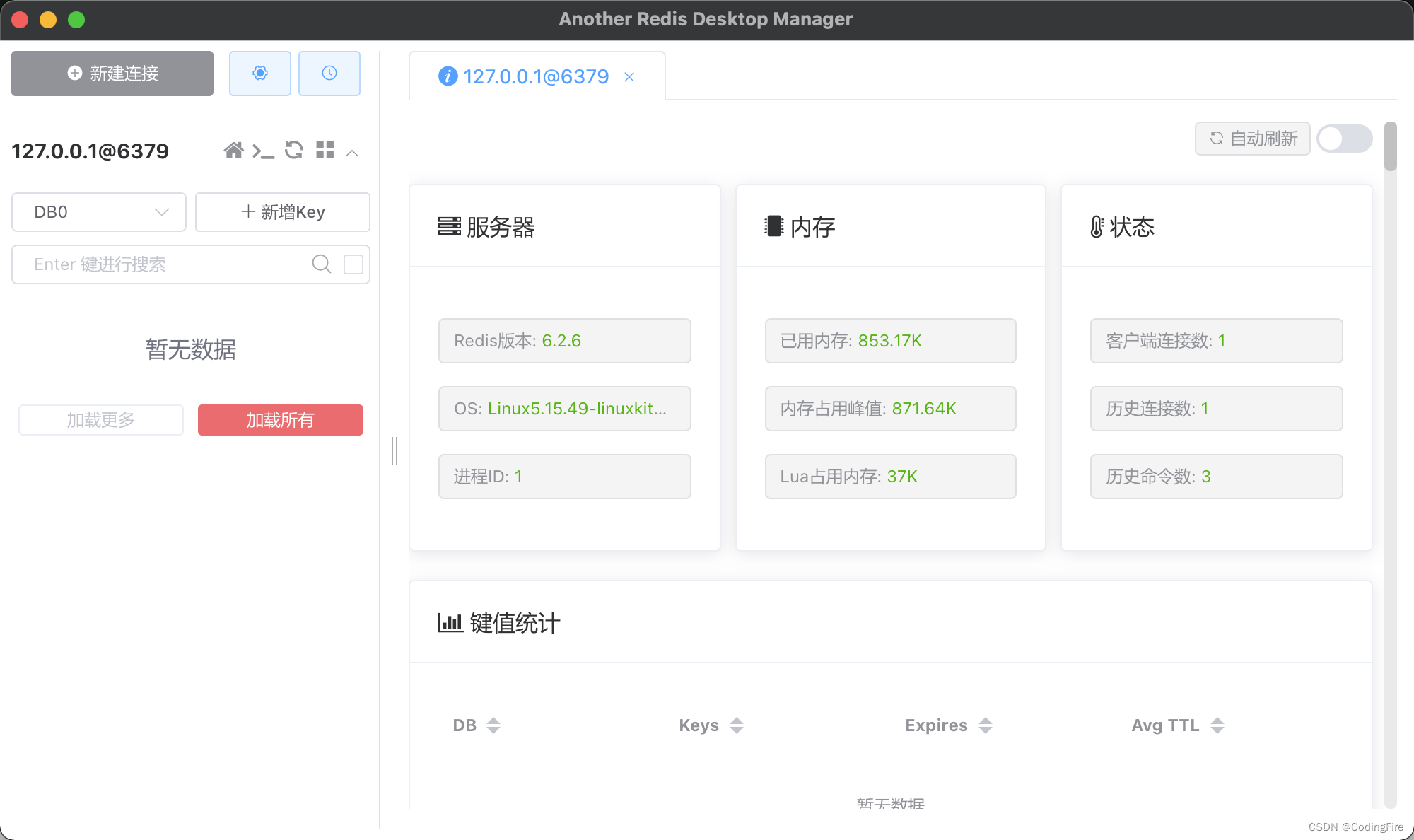
可看到目前我们是启动状态,客户端连接数是1。
最好弄好了这些东西后再来跟着学下去,这种可视化工具可以在我们调用接口时看到存储在Redis中的数据,非常方便。
Redis缓存
缓存淘汰
Redis帮助我们解决了一些三高的问题,但在访问量非常大的时候,Redis要在同一时间保存大量的数据,但Redis内存并不是无限的,一旦内存占满,可能会发生什么?降速?阻塞?宕机?都有可能,所以在连续不断的存入新数据的同时,还要将不使用的老数据及时的从内存中删除,这就需要一个淘汰策略。
好在Redis提供了这种机制,我们看看有哪些淘汰策略:
noeviction:返回错误**(默认)**
allkeys-random:所有数据中随机删除数据
volatile-random:所有过期时间的数据库中随机删除数据
volatile-ttl:删除剩余有效时间最少的数据
allkeys-lru:所有数据中删除上次使用时间最久的数据
volatile-lru:所有过期时间的数据中删除上次使用时间最久的数据
allkeys-lfu:所有数据中删除使用频率最少的
volatile-lfu:所有过期时间的数据中删除使用频率最少的
通过合理的选择以上参数配置Redis,可以有效解决这个问题,但也需要时刻监测Redis内存情况,现在的云服务做得都很好,可以提前预警通知。
缓存穿透
我们在使用Redis时,将数据库中查询出来的数据保存在Redis中,但Redis有自己的淘汰策略,所以这些数据并不会无限期保存。
正常来说,访问的请求会先去Redis中拿数据,拿不到才会去数据库中查找,再将查到的数据存储到Redis中,一旦这样的请求数量非常多的时候,数据库的压力就会变大,我们可以认为,其表现的现象即为Redis失效,没有工作,当然算是失效了,而这种情况,我们称之为缓存穿透。
开发中当然要避免缓存穿透,简单点,可以将查询回来为空的数据在Redis中存为null,防止Redis被反复穿透,但这也有缺点,比如反复更换查询关键字,反复穿透依然存在,当然,这只是特例,虽然实际中发生的概率不会太高,但还是要防范利用此情况攻击服务器的可能。
最好的做法是通过增加布隆过滤器来解决此问题,在业务进入时,提前判断用户查询的信息是否存在于数据库中,如果没有,直接返回,不再走完整的路径。
缓存击穿
缓存穿透和缓存击穿很类似,我们正常的流程是先访问Redis,Redis没有就去数据库查询,这种情况,数据库是可以查到数据的,此种现象就叫击穿,而少量的击穿并不是问题。
缓存雪崩
上面的击穿在同一时间大量发生,就变成了雪崩,数据库短时间内出现很多新的查询请求,就会发生性能问题。
这是由于Redis缓存淘汰策略把过期的数据大批量清空导致的,它本身不算异常,只是我们要避免同一时间大量的过期情况出现,所以在设置过期时间时,在基础时间上增加10分钟或30分钟以内的随机时间来解决这个问题,时间你可以自己定。
Redis持久化
存储特点
Redis是在内存中运行的,这和我们所有的软件都是一样的,内存可以保存,但Redis保存的数据却并不是在内存上,试想我们的电脑手机,关机后再打开还能恢复打开时的样子吗?这自然是不能的。
所以,为了解决断电重启等问题,Redis支持了持久化,将需要保存的数据保存在服务器硬盘上。
针对以上硬盘保存数据的特点,Redis在重新启动后恢复数据的方式有两种,我们来看看是哪两种。
RDB
RDB全称Redis Database Backup,中文名叫数据库快照,它可以将Redis数据库数据转化为二进制数据保存在硬盘上,生成一个dump.rdb的文件,想使用此恢复模式需要提前在Redis安装程序的配置文件中进行配置才能生效。
基于此模式,由于是整体Redis数据的二进制格式,所以数据恢复是整体恢复的,非常方便。但也因此存在了一个大文件的通病:读写效率不高。快照的备份不能实时进行,所以断电重启恢复只能恢复最后一次生成的rdb文件数据。可能会造成短时间的数据丢失。
AOF
AOF全称Append Only File,它的策略不是缓存数据,而是将所有命令日志备份下来,在数据丢失后,可以根据运行过的日志恢复为断电前的状态,注意一点:这种保存日志的策略也不是实时的,数据量比较大时会分批分次进行缓存。
实际中,我们一般设置1s发送一次日志,断电最多丢失1s数据。为了降低日志对内存的占用,AOF支持AOF rewrite,也就是说,如果你是删除数据,那完全没有留日志的必要,但默认时有日志的,所以,可以将这些删除操作的日志删除。
存储原理
存储原理博主简单给大家说说,想要深入了解的推荐这篇博客:Redis存储原理深入剖析 - 墨天轮
也可以自行查找。
Redis将内存划分为16384个槽,类似哈希槽,将要存储的数据的key通过CRC16算法处理,得到一个0~16383之间的值,然后将这条数据存储到对应的槽中,下次查找的时候也是通过CRC16算法处理过的数字去对应槽中查找当前key是否存在,因为有可能直接一次就找到对应key,所以这种存储查找方式效率非常高。这也是一种散列算法,和数据库主键查找的原理很类似。推荐读一下博主这篇博客:Java开发 - 数据库索引的数据结构
Redis集群
Redis我们一般说起来都会说Redis服务器,所以,Redis本质上也是一台服务器,Redis即服务器,服务器即Redis。服务器宕机,Redis肯定也好不到哪里去。如果只有一台Redis服务器,那将会面临一定的风险,比如系统崩溃。
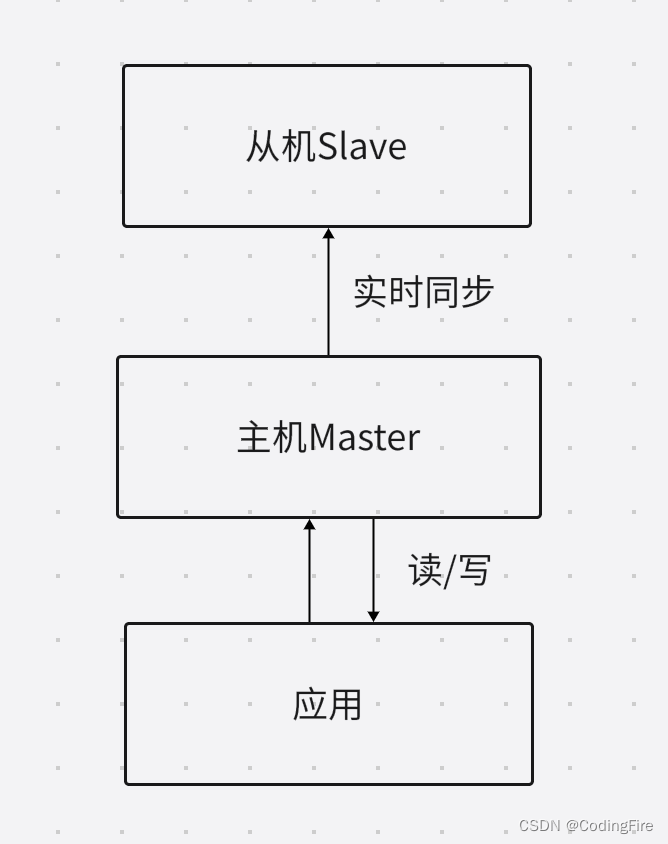
主从
为了解决单Redis服务器可能存在的问题,我们一般会使用一台备用机,这就叫做主从。主从状态下,备用机Redis会实时同步主机Redis的数据,如果主机掉线,备用机就可以起到预备队的效果。但这也存在一定的问题,主机正常工作时,从机就在那里歇着,主机累的喘不过来气,肯定不愿意,从机的钱不是也白花了吗?如下图:
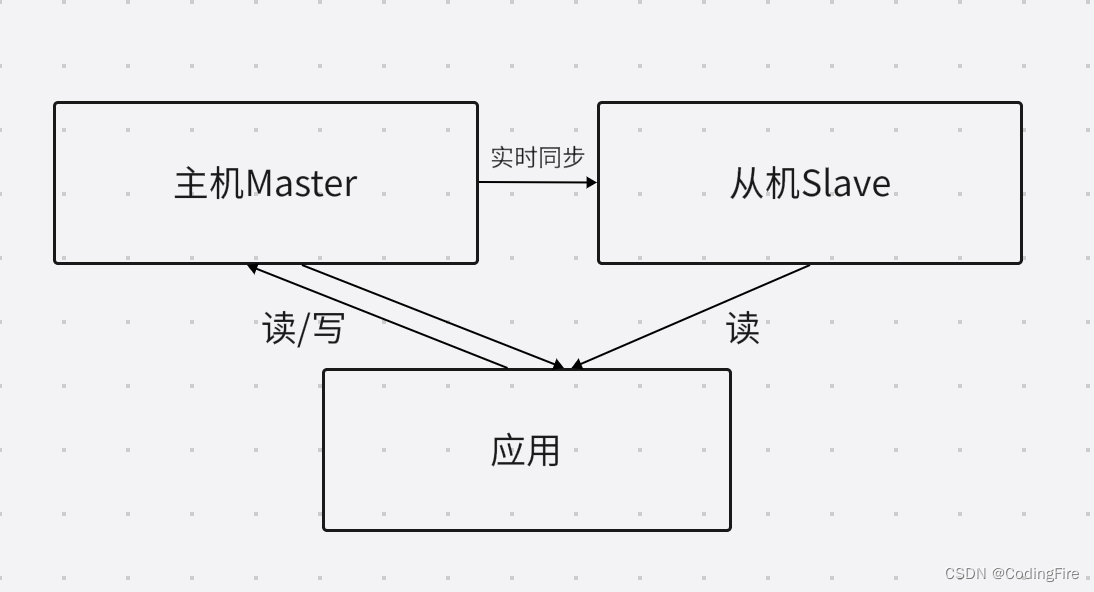
读写分离
为了解决从机不干活的问题,我们一般会将读写分离,主机可读可写,从机也可以读取,这样不仅让从机干活,还减轻了主机的压力,提高了项目运行的流畅度。如下图:
哨兵
此时,还存在一个问题,主机宕机后,需要人手动切换到从机,要是及时发现还好,要是不及时,将会造成严重的后果。这时候,我们需要一个可以自动切换到从机的机制:哨兵模式。如下图:
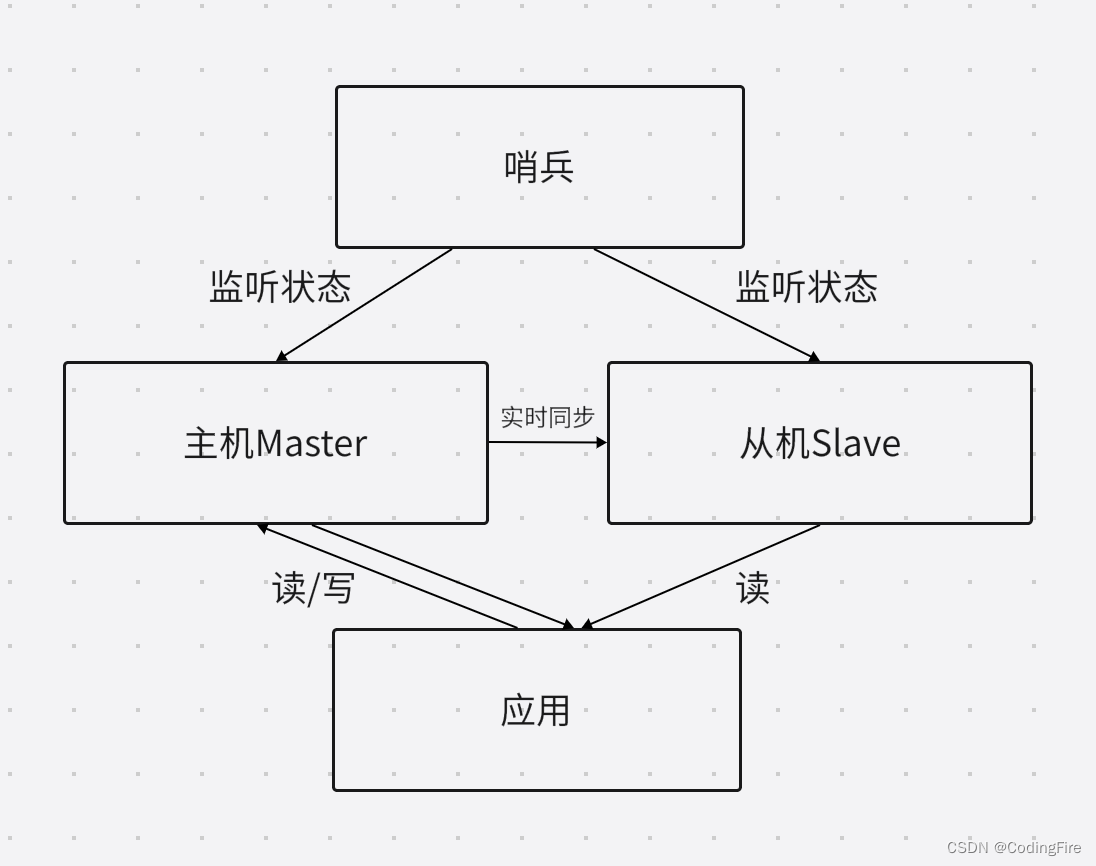
哨兵每隔固定时间向主从节点发送请求,如果节点正常相应,则说明节点正常工作,否则,将视为节点异常,启将自动切换备用机。
有时候,因为网络问题或者其他因素会导致哨兵接受请求返回异常而切换备用机,这不仅没起到保护的作用,还降低了Redis的工作效率,这时,有两种方式来解决:一是多次请求后都返回异常再切换备用机,二是采用多个哨兵的形式,当多台哨兵都认为某台机器存在异常,再切换到备用机。但是切记一点,哨兵不能和Redis在同一台服务器上,否则服务器异常哨兵也将离线。
哨兵的配置推荐看看这篇博客:Redis中的哨兵模式 - 简书
Redis基本使用
下面,我们就来看看Redis有哪些API,具体该怎么使用。在原来微服务项目中,上一篇Quartz是在stock子项目下运行的,Redis我们也在stock子项目下添加吧,你也可以选择其他模块,或者独立建一个项目也是可以的。
添加依赖
<!-- Spring Boot Data Redis:缓存 --> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId> </dependency>
请注意,博主依赖中没有添加version信息是因为主工程中对版本进行了管理,如果你单独创建的项目是需要加上版本的,其他依赖在需要时按需添加。
添加配置类
操作Redis需要使用RedisTemplate对象,我们在config包下创建RedisConfiguration类:
package com.codingfire.cloud.stock.config;import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.RedisSerializer;import java.io.Serializable;@Configuration
public class RedisConfiguration {@Beanpublic RedisTemplate<String, Serializable> redisTemplate(RedisConnectionFactory redisConnectionFactory) {RedisTemplate<String, Serializable> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(redisConnectionFactory);redisTemplate.setKeySerializer(RedisSerializer.string());redisTemplate.setValueSerializer(RedisSerializer.json());return redisTemplate;}
}
固定模式,也没啥好说的,只是需要使用这样一个实例来操作Redis。
编写测试方法
由于我们之前删除了用于测试的文件夹,还是需要新建的,选择src,新建,file:
选择test/java,新建测试类:
package com.codingfire.cloud.stock;import org.springframework.boot.test.context.SpringBootTest;@SpringBootTest
public class CloudStockApplicationTests {}
包名,路径和格式注意下,不要错了。下面我们来添加Redis的测试方法。
存储普通字符串:
package com.codingfire.cloud.stock;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import org.junit.jupiter.api.Test;import java.io.Serializable;
import java.util.concurrent.TimeUnit;@SpringBootTest
class CloudStockApplicationTests {@AutowiredRedisTemplate<String, Serializable> redisTemplate;@Testvoid testSetValue() {redisTemplate.opsForValue().set("name", "codingfire");}}
运行测试方法,成功后我们去Redis客户端看看有没有什么变化:

这个就是我们测试方法中存入的数据,表示我们已经将此字符串存入Redis中。有问题的童鞋看看自己的Redis有没有启动连接。
有存就有取,我们去把刚才存进去的字符串取出来:
@Testvoid testGetValue() {// 当key存在时,可获取到有效值// 当key不存在时,获取到的结果将是nullSerializable name = redisTemplate.opsForValue().get("name");System.out.println("get value --> " + name);}运行测试方法,查看控制台输出:
get value --> codingfire
成功从Redis取到了我们存入的数据。
不知道你注意到没,我们前面的配置类里面对Redis的存取类型做了限制:
redis存储类型很有限,不过好在string和json几乎能满足所有的需要,下面我们来存取对象类型试试:
@Testvoid testSetAdminValue() {AdminLoginDTO adminLoginDTO = new AdminLoginDTO();adminLoginDTO.setUsername("codingfire");adminLoginDTO.setPassword("123456");redisTemplate.opsForValue().set("user", adminLoginDTO);}@Testvoid testGetAdminValue() {// 当key存在时,可获取到有效值// 当key不存在时,获取到的结果将是nullSerializable user = redisTemplate.opsForValue().get("user");System.out.println("get value --> " + user);if (user != null) {AdminLoginDTO adminLoginDTO = (AdminLoginDTO) user;System.out.println("get value --> " + adminLoginDTO);}}分别运行以上存取对象类型方法,看看Redis客户端和控制台会输出什么。
存储对象后Redis客户端:
获取对象后控制台输出:
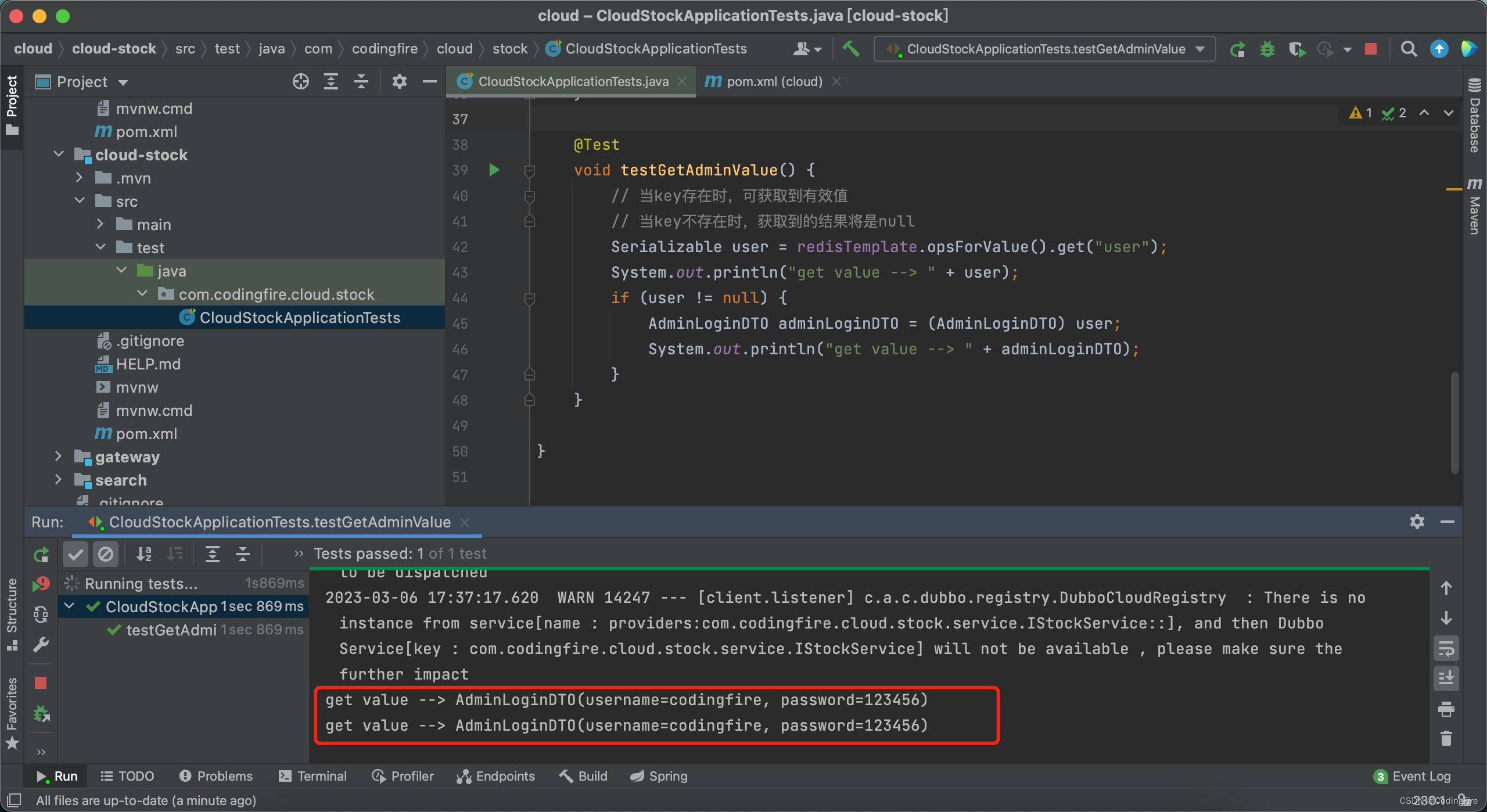
两次输出一样为什么还要强转呢?不强转你就不知道获取的对象类型,也无法直接使用序列化后对象进行数据的操作。
有添加就有删除,那么删除Redis中数据该怎么做呢:
@Testvoid testDeleteKey() {// 删除key时,将返回“是否成功删除”// 当key存在时,将返回true// 当key不存在时,将返回falseBoolean result = redisTemplate.delete("name");System.out.println("result --> " + result);}运行此测试方法查看结果:
由于Redis中存在名为name的参数,所以result为true,对象类型的删除也是一样的操作。
接下来我们设置Redis的过期时间,时间到了就自动删除,我们通过查看源码得知,set有三个参数,第二个为过期时间,第三个为时间单位:
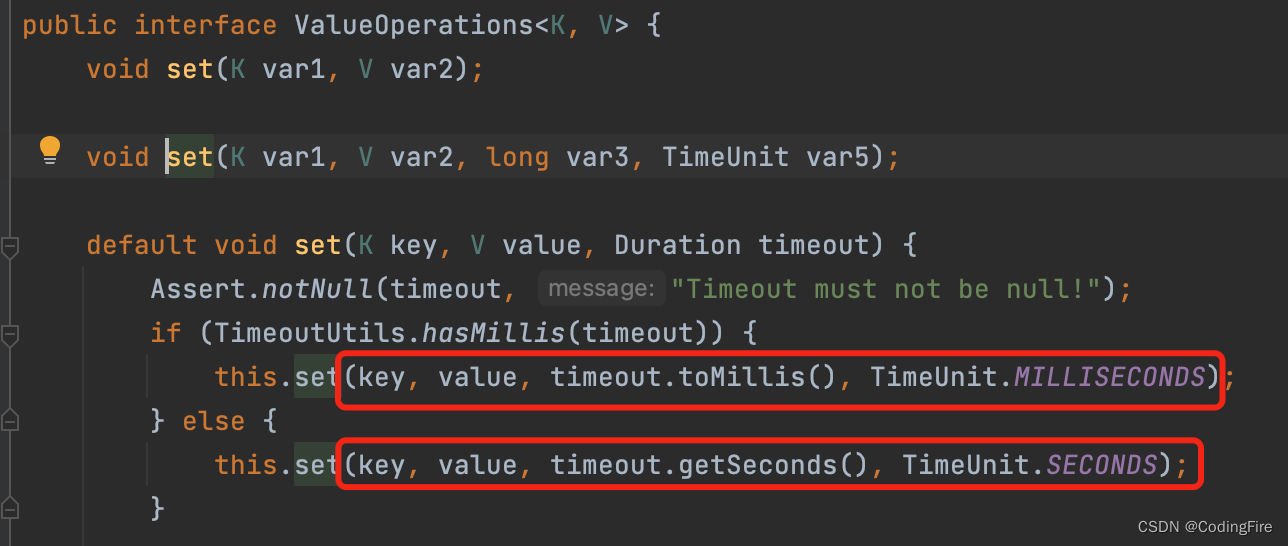
下面我来写代码:
@Testvoid testSetValueTimeout() {redisTemplate.opsForValue().set("name", "codingfire",20, TimeUnit.SECONDS);}运行测试方法,在Redis中能看到存入的数据,20s后,数据自动删除:
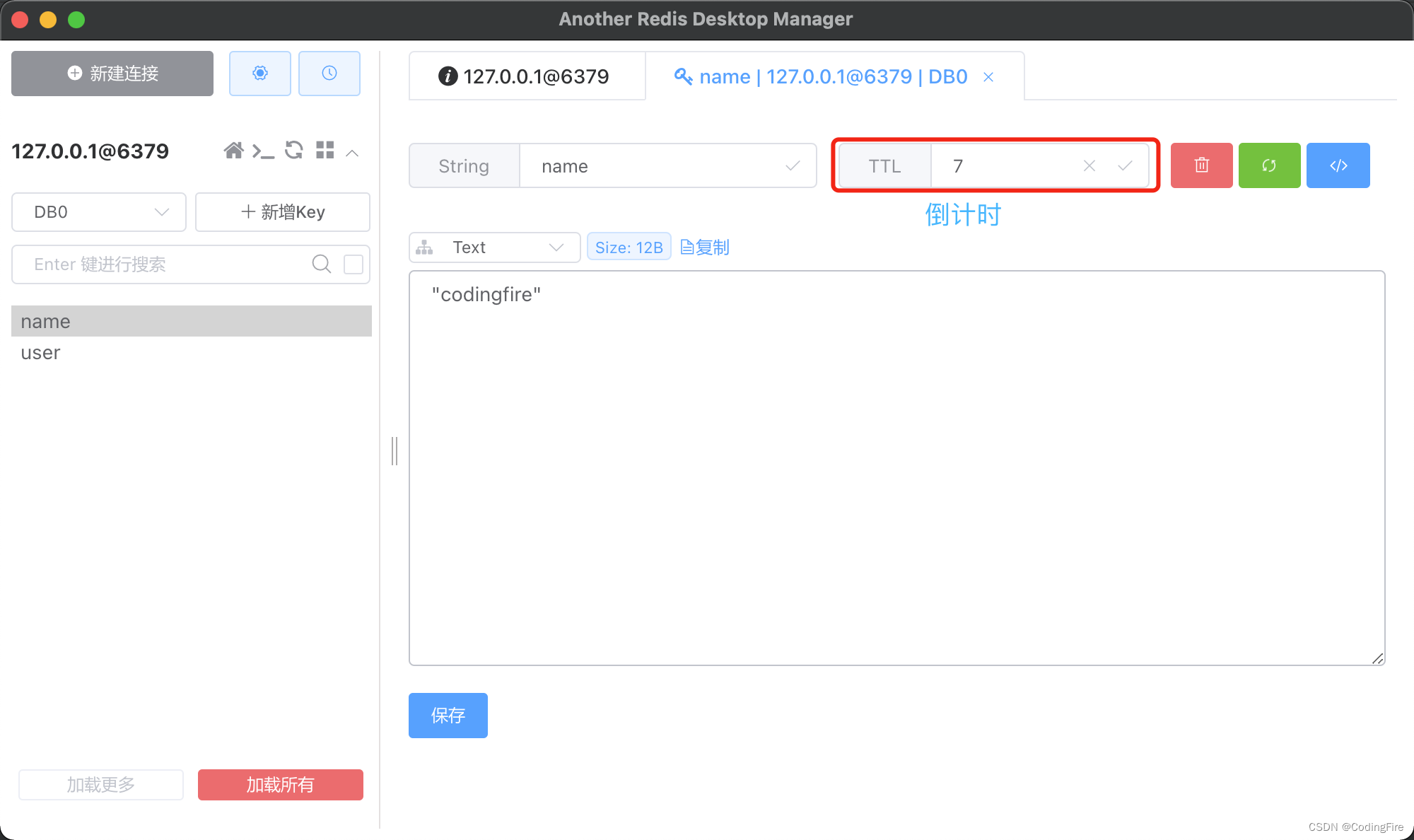
在客户端中能看到TTL,就是倒计时的意思,打开自动刷新功能,你能看见数字是在变化的。
在存储数据时还有一个特殊情况,比如分页数据,是一个数组,这该怎么存呢?Redis中ops是操作器,opsForValue可以操作普通字符串或对象类型,既然是对象,为什么不能操作数组?数组也是对象啊,博主也不死心,我们来试试看:
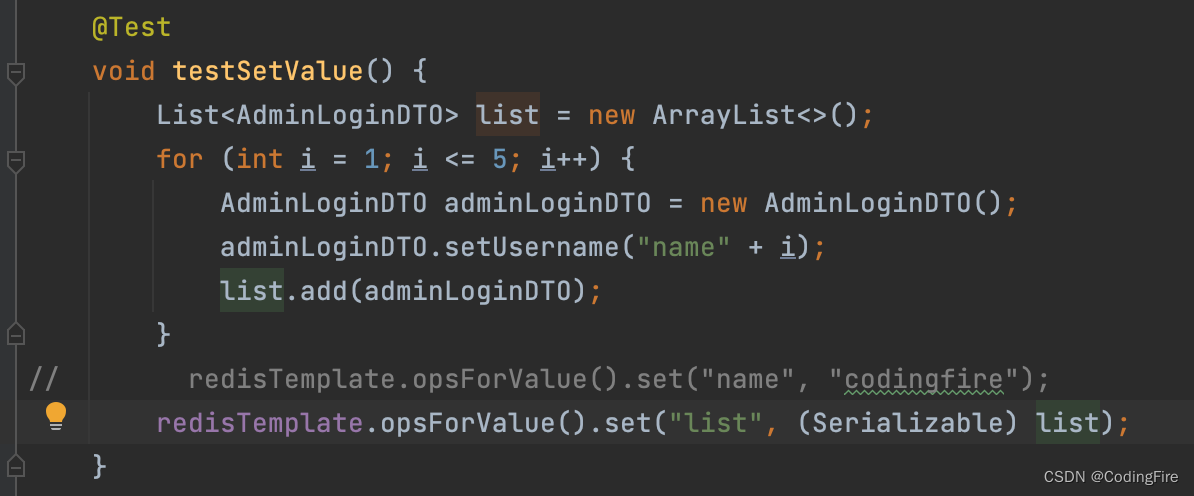

好像成功了?为了对比这两种方式存储数组的能力我们来试试ospForList存数组后是否一样:
@Testvoid testRightPushList() {// 存入List时,需要redisTemplate.opsForList()得到针对List的操作器// 通过rightPush()可以向Redis中的List追加数据// 每次调用rightPush()时使用的key必须是同一个,才能把多个数据放到同一个List中List<AdminLoginDTO> list = new ArrayList<>();for (int i = 1; i <= 5; i++) {AdminLoginDTO adminLoginDTO = new AdminLoginDTO();adminLoginDTO.setUsername("name" + i);list.add(adminLoginDTO);}String key = "UserList";for (AdminLoginDTO adminLoginDTO : list) {redisTemplate.opsForList().rightPush(key, adminLoginDTO);}}运行测试代码后查看Redis客户端数据:
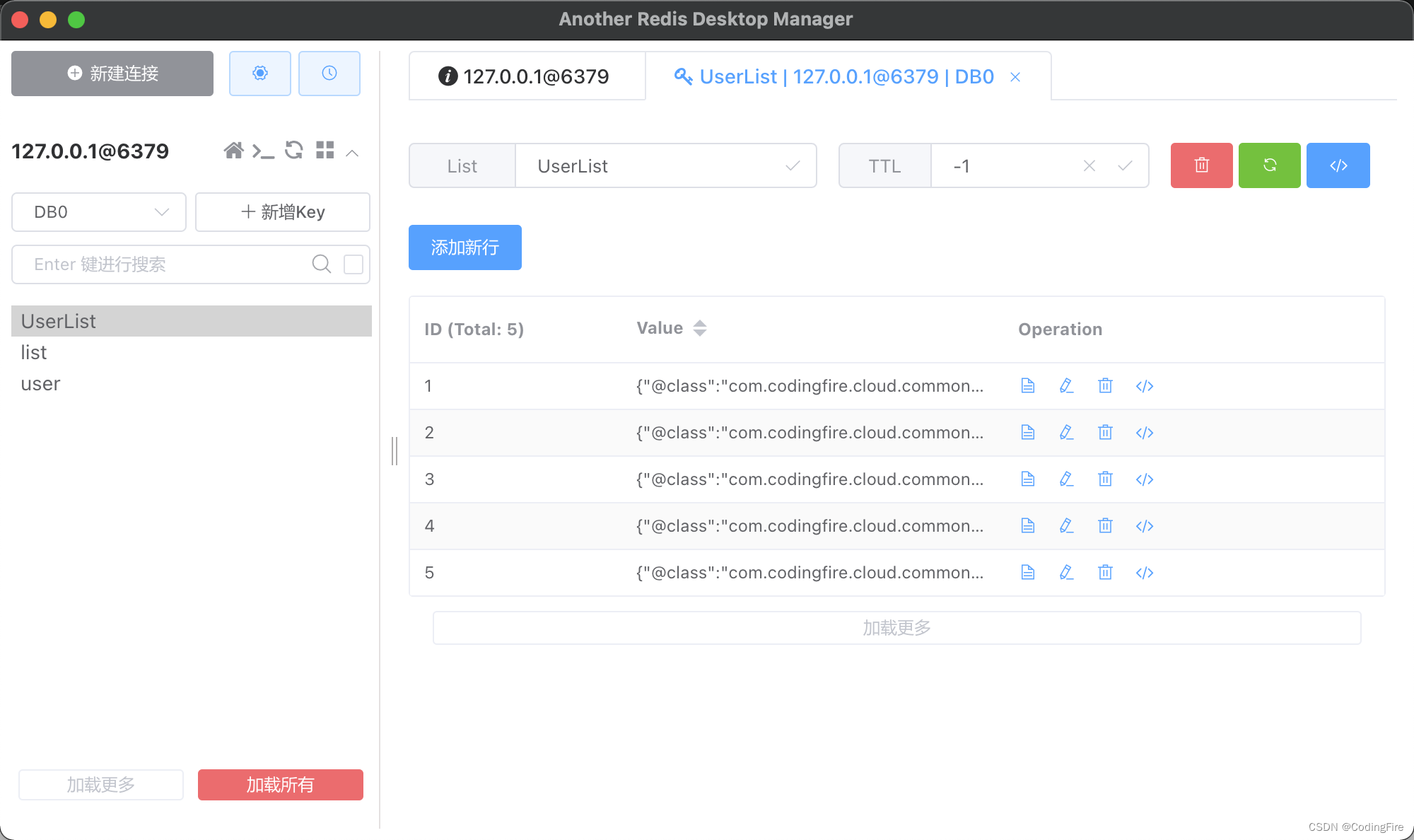
呀!数据展示的形式不一样啊,我们来获取并输出一下这两组数据,看看输出是否一样:
@Testvoid testGetListValue() {// 调用opsForList()后再调用range(String key, long start, long end)方法取出List中的若干个数据,将得到List// long start:起始下标(结果中将包含)// long end:结束下标(结果中将包含),如果需要取至最后一个元素,可使用-1作为此参数值List<Serializable> rangeList = redisTemplate.opsForList().range("UserList", 0, -1);Serializable listSer = redisTemplate.opsForValue().get("list");List<Serializable> list = (List<Serializable>) listSer;System.out.println(rangeList);System.out.println(list);for (Serializable serializable : rangeList) {System.out.println(serializable);}for (Serializable serializable : list) {System.out.println(serializable);}}运行测试方法查看控制台输出:
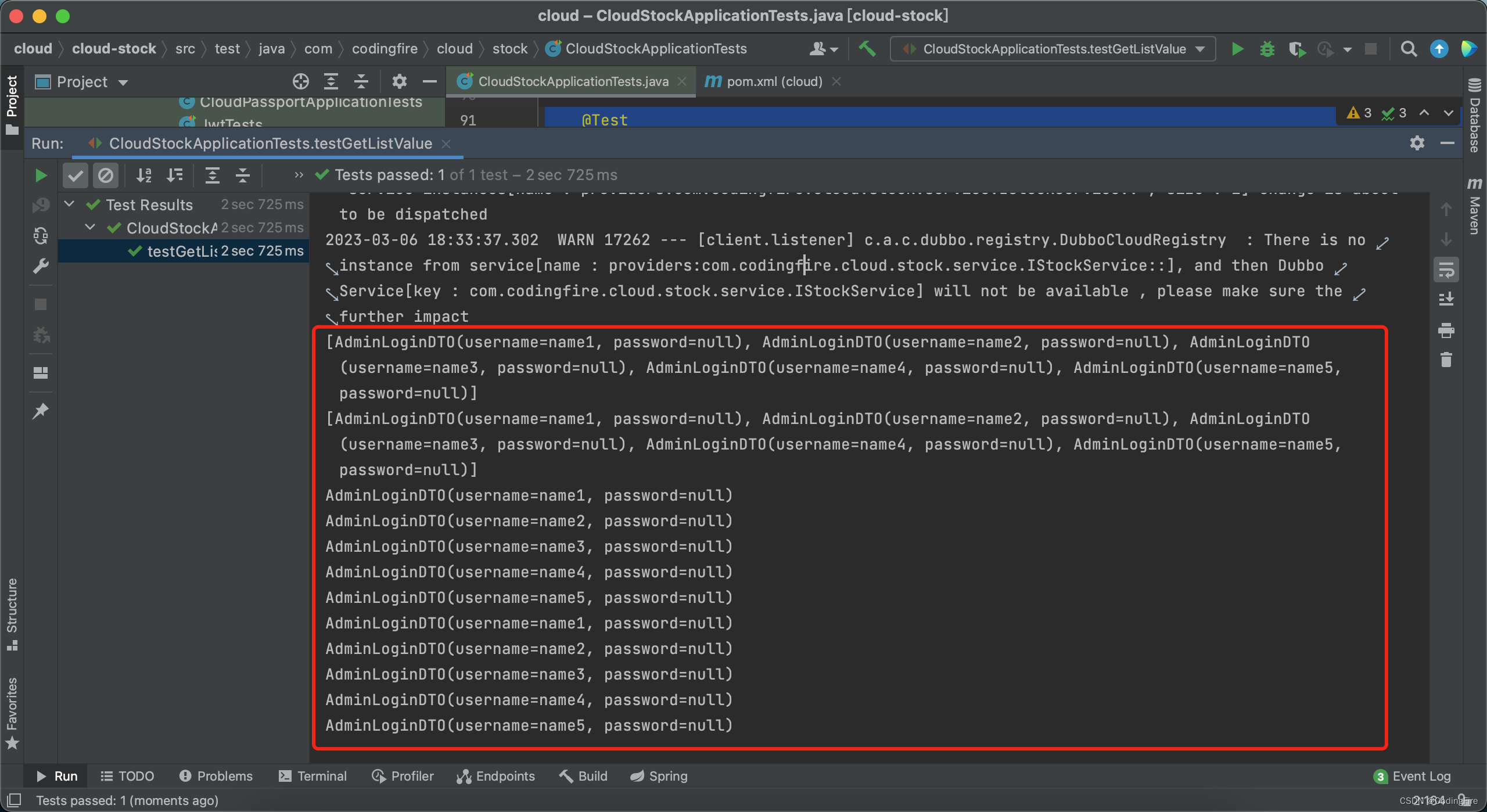
从数据库,其实并没有什么太大的差别 ,但是请仔细看博主获取两个list的代码,秘密就藏在里面,也就是说:怎么存,怎么取,不通过数组专用方法的需要强转。这就是最终结论。大家不用自己试了,博主都一一试过了,opsForxxxxx用的不对就报错了。
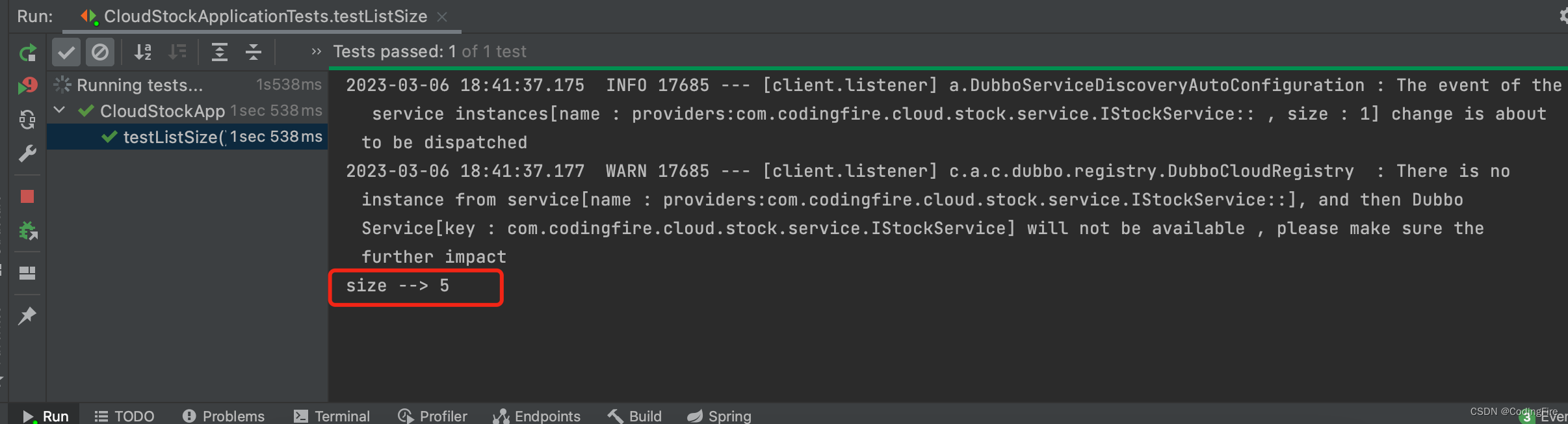
最后再补充两个方法,一个是获取数组长度,一个是获取Redis中所有key的方法,注意:获取数组长度的方法必须是通过opsForList方法存进去的,否则此方法无效,且报错,看代码:
@Testvoid testListSize() {// 获取List的长度,即List中的元素数量String key = "UserList";Long size = redisTemplate.opsForList().size(key);System.out.println("size --> " + size);}运行结果:
获取所有Redis的key:
@Testvoid testKeys() {// 调用keys()方法可以找出匹配模式的所有key// 在模式中,可以使用星号作为通配符Set<String> keys = redisTemplate.keys("*");for (String key : keys) {System.out.println(key);}}此方法对ops无影响,只获取key,查看运行结果:

对比Redis客户端中所有key值:
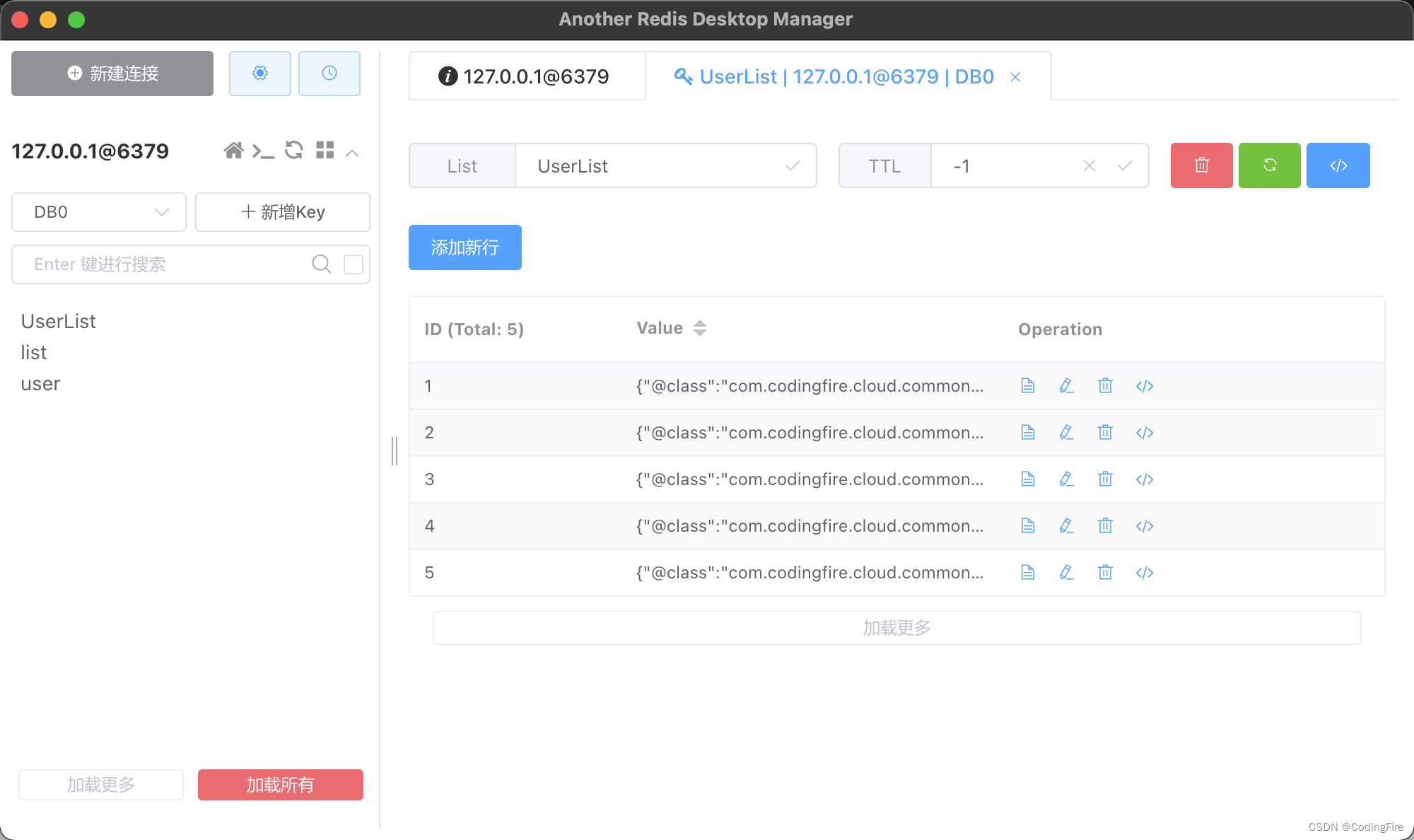
完全一致,测试成功。
最后,关于Key的使用,通常建议使用冒号区分多层次,类似URL的设计方式,例如:
- 用户列表的Key:users
:list或users - 某个用户id(001)对应用户信息的Key:users
:userId:001
但也不是绝对,可根据自己需要选择合适的组合方式,目的是使key不重复,且好理解。
到这里,Redis基础方法使用就讲解完了,但这毕竟只是基础方法,在实战中该怎么用还是个问题。下面,我们将在真实项目中去使用Redis。
Redis实战
开始前的思考
使用Redis可以提高查询效率,降低数据库的压力。基本上是用在高频查询的数据或是几乎不太会改变的数据上。所以,有些比较精密的经常需要变动的数据就不能使用Redis,比如购物类应用的创建订单,库存都属于此类数据。
所以在开始前确定哪些数据使用Redis,Redis中的数据从哪来是很重要的。关于Redis的调用,是写在业务逻辑层还是做一个单独的组件独立出来,这也是一个问题。
如果直接将访问Redis的代码写在Service中,首次开发时会很省事,但却不利于后期的维护。
如果将访问Redis的代码写的新的组件中,首次开发时会更麻烦,但有利于后期的维护。
所以你会怎么选呢?我们首先要知道,访问Redis的API都很简单,上面的基础使用大家基本应该是掌握了,也没什么难的,自定义组件虽然有利于后期维护,但代码量可能会很少,这个需要我们去衡量总体的工作量和后期的维护情况。
每一个项目都不一样,甚至有些小的项目根本不使用Redis都有可能,这并不是危言耸听,这个就教给大家自己选择了,今天,博主的目的是教会大家在项目中使用Redis。
创建Redis模块
博主准备以passport为基础,在其上使用Redis,虽然实际中不会在这么简单的模块用,不过该有的功能,博主是一步都不会省略的,照葫芦画瓢,其他的模块参照此模块就可以移植。passport是做单点登录的模块:Java开发 - 单点登录初体验(Spring Security + JWT)
没有此模块的童鞋可以先学此篇,也可以先看看博主代码,新建一个模块,照着往别的模块上面搬。
创建调用Redis接口
在passport包下创建repository包,repository下创建IPassportRedisRepository接口:
package com.codingfire.cloud.passport.repository;import com.codingfire.cloud.commons.pojo.passport.vo.AdminLoginVO;public interface IPassportRedisRepository {String KEY_ADMIN_ITEM_PREFIX = "admins:item:";// 将用户信息存入到Redis中void save(AdminLoginVO adminLoginVO);// 根据用户id获取用户信息AdminLoginVO getAdminDetailsById(Long id);
}
创建Redis实现类
在这一步之前,请大家添加Redis的依赖,并将上面代码中Redis的配置类RedisConfiguration复制到passport的config包下,在repository包下新建impl包,包下建PassportRedisRepositoryImpl实现类:
package com.codingfire.cloud.passport.repository.impl;import com.codingfire.cloud.commons.pojo.passport.vo.AdminLoginVO;
import com.codingfire.cloud.passport.repository.IPassportRedisRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Repository;
import java.io.Serializable;@Repository
public class PassportRedisRepositoryImpl implements IPassportRedisRepository {@Autowiredprivate RedisTemplate<String, Serializable> redisTemplate;@Overridepublic void save(AdminLoginVO adminLoginVO) {String key = KEY_ADMIN_ITEM_PREFIX + adminLoginVO();redisTemplate.opsForValue().set(key, adminLoginVO);}@Overridepublic AdminLoginVO getAdminDetailsById(Long id) {String key = KEY_ADMIN_ITEM_PREFIX + id;Serializable result = redisTemplate.opsForValue().get(key);if (result == null) {return null;} else {AdminLoginVO adminLoginVO = (AdminLoginVO) result;return adminLoginVO;}}
}
测试以上代码
下面在test文件夹下depassport包下新建一个测试类PassportRedisRepositoryTests:
package com.codingfire.cloud.passport;import com.codingfire.cloud.commons.pojo.passport.dto.AdminLoginDTO;
import com.codingfire.cloud.commons.pojo.passport.vo.AdminLoginVO;
import com.codingfire.cloud.passport.repository.IPassportRedisRepository;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;@SpringBootTest
class PassportRedisRepositoryTests {@AutowiredIPassportRedisRepository repository;@Testvoid testGetAdminDetailsByIdSuccessfully() {testSave();Long id = 2L;AdminLoginDTO admin = repository.getAdminDetailsById(id);System.out.println(admin);}@Testvoid testGetAdminDetailsByIdReturnNull() {Long id = -1L;AdminLoginVO adminLoginVO = repository.getAdminDetailsById(id);Assertions.assertNull(adminLoginVO);}private void testSave() {AdminLoginVO adminLoginVO = new AdminLoginVO();adminLoginVO.setId(2L);adminLoginVO.setUsername("codeliu");adminLoginVO.setPassword("123456");repository.save(adminLoginVO);}
}
运行第一个方法,先存储,后查找:
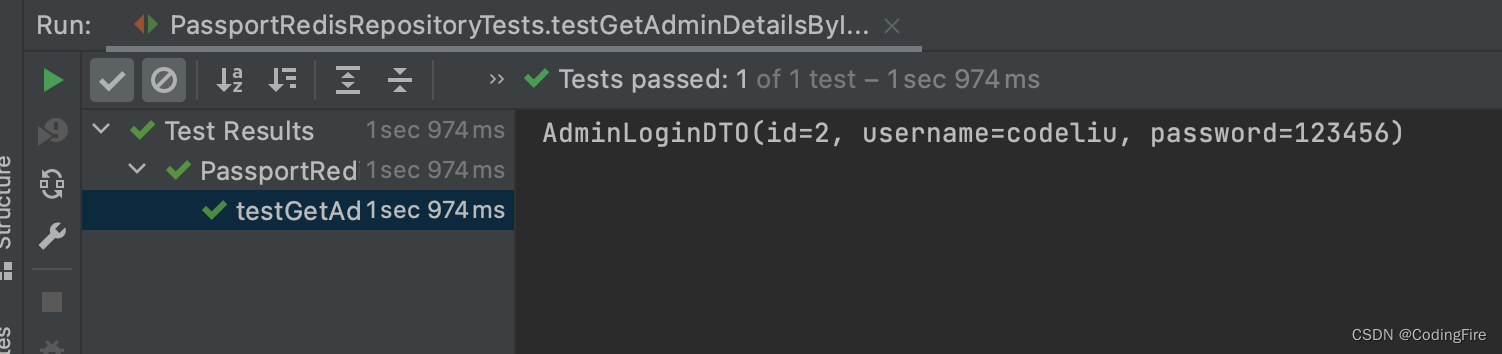
控制器输出我们存入的数据,看看Redis客户端有没有数据:
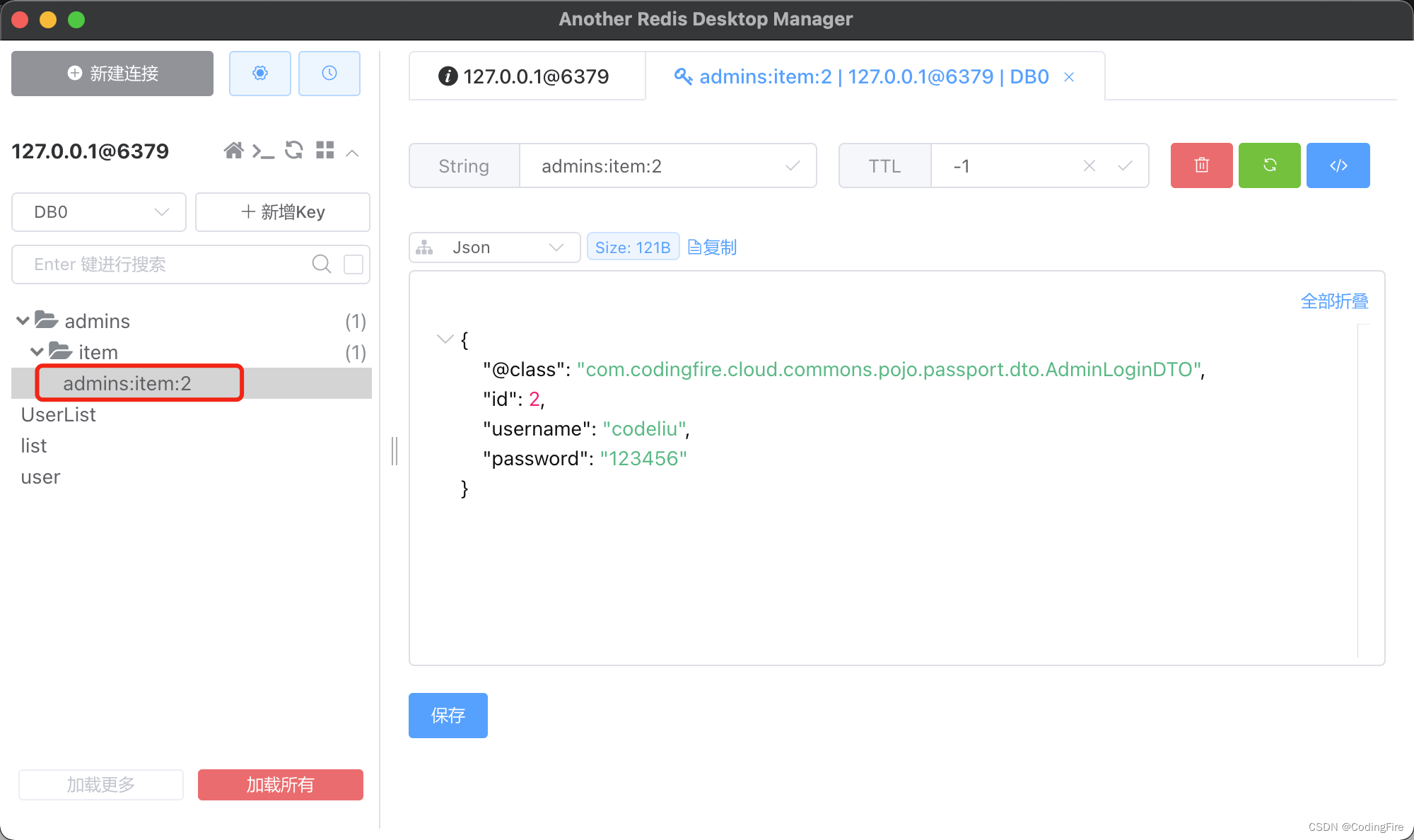
可以看到室友层级的key,这种key的命名方式我们在上面已经讲过,有利于数据分层,便于观察。
让Redis在业务中体现调用逻辑
业务逻辑思考
下面,我们结合接口的调用来做个修改,在接口的调用过程中,我们去使用Redis。我们打开IAdminService类,在里面添加一个新的方法:
AdminLoginVO getAdminDetailsById(Long id);
接着打开AdminServiceImpl类,在里面实现接口方法:
@Overridepublic AdminLoginVO getAdminDetailsById(Long id) {// ===== 以下是原有代码,只从数据库中获取数据 =====
// AdminLoginVO adminLoginVO = adminMapper.getLoginInfoByUserId(id);
// if (adminLoginVO == null) {
// throw new CloudServiceException(ResponseCode.ERR_INTERNAL_SERVER_ERROR,
// "获取用户信息失败,尝试访问的数据不存在!");
// }
// return adminLoginVO;// ===== 以下是新的业务,将从Redis中获取数据 =====// 从repsotiroy中调用方法,根据id获取缓存的数据// 判断缓存中是否存在与此id对应的key// 有:表示明确的存入过某数据,此数据可能是有效数据,也可能是null// -- 判断此key对应的数据是否为null// -- 是:表示明确的存入了null值,则此id对应的数据确实不存在,则抛出异常// -- 否:表示明确的存入了有效数据,则返回此数据即可// 无:表示从未向缓存中写入此id对应的数据,在数据库中,此id可能存在数据,也可能不存在// 从mapper中调用方法,根据id获取数据库的数据// 判断从数据库中获取的结果是否为null// 是:数据库也没有此数据,先向缓存中写入错误数据(null),再抛出异常// 将从数据库中查询到的结果存入到缓存中// 返回查询结果return null;}大家看看实现的逻辑,这个很重要。
看完后,为了保证项目能运行,我们还有两步需要做。
添加调用SQL的方法
AdminMapper添加如下方法:
AdminLoginVO getLoginInfoByUserId(Long id);
添加SQL
AdminMapper.xml添加如下SQL:
<select id="getLoginInfoByUserId" resultMap="LoginInfoResultMap">select<include refid="LoginInfoQueryFields" />from adminleft join admin_roleon admin.id = admin_role.admin_idleft join role_permissionon admin_role.role_id = role_permission.role_idleft join permissionon role_permission.permission_id = permission.idwhere id=#{id}
</select>
避免缓存穿透
在IPassportRedisRepository接口中添加如下方法:
/*** 判断是否存在id对应的缓存数据** @param id 类别id* @return 存在则返回true,否则返回false*/boolean exists(Long id);/*** 向缓存中写入某id对应的空数据(null),此方法主要用于解决缓存穿透问题** @param id 类别id*/void saveEmptyValue(Long id);在PassportRedisRepositoryImpl类中添加实现方法如下:
@Overridepublic boolean exists(Long id) {String key = KEY_ADMIN_ITEM_PREFIX + id;return redisTemplate.hasKey(key);}@Overridepublic void saveEmptyValue(Long id) {String key = KEY_ADMIN_ITEM_PREFIX + id;redisTemplate.opsForValue().set(key, null);}其实我们在上面说过,这种设置null的方法能一定程度上防止缓存反复穿透,但却并不是最好的解决办法,常规做法应该是通过布隆过滤器来做。
业务实现
@Overridepublic AdminLoginVO getAdminDetailsById(Long id) {
// ===== 以下是原有代码,只从数据库中获取数据 =====
// AdminLoginVO adminLoginVO = adminMapper.getLoginInfoByUserId(id);
// if (adminLoginVO == null) {
// throw new CloudServiceException(ResponseCode.ERR_INTERNAL_SERVER_ERROR,
// "获取用户信息失败,尝试访问的数据不存在!");
// }
// return adminLoginVO;// ===== 以下是新的业务,将从Redis中获取数据 =====log.debug("根据id({})获取用户详情……", id);// 从repository中调用方法,根据id获取缓存的数据// 判断缓存中是否存在与此id对应的keyboolean exists = redisRepository.exists(id);if (exists) {// 有:表示明确的存入过某数据,此数据可能是有效数据,也可能是null// -- 判断此key对应的数据是否为nullAdminLoginVO cacheResult = redisRepository.getAdminDetailsById(id);if (cacheResult == null) {// -- 是:表示明确的存入了null值,则此id对应的数据确实不存在,则抛出异常log.warn("在缓存中存在此id()对应的Key,却是null值,则抛出异常", id);throw new CloudServiceException(ResponseCode.ERR_INTERNAL_SERVER_ERROR,"获取用户详情失败,尝试访问的数据不存在!");} else {// -- 否:表示明确的存入了有效数据,则返回此数据即可return cacheResult;}}// 缓存中没有此id匹配的数据// 从mapper中调用方法,根据id获取数据库的数据log.debug("没有命中缓存,则从数据库查询数据……");AdminLoginVO dbResult = adminMapper.getAdminInfoByUserId(id);// 判断从数据库中获取的结果是否为nullif (dbResult == null) {// 是:数据库也没有此数据,先向缓存中写入错误数据,再抛出异常log.warn("数据库中也无此数据(id={}),先向缓存中写入错误数据", id);redisRepository.saveEmptyValue(id);log.warn("抛出异常");throw new CloudServiceException(ResponseCode.ERR_INTERNAL_SERVER_ERROR,"获取用户信息失败,尝试访问的数据不存在!");}// 将从数据库中查询到的结果存入到缓存中log.debug("已经从数据库查询到匹配的数据,将数据存入缓存……");redisRepository.save(dbResult);// 返回查询结果log.debug("返回查询到数据:{}", dbResult);return dbResult;}到这里,基于业务调用的Redis业务调用流程代码就结束了,你可以在controller中添加新的方法来调用此接口完成测试,博主不再写了。
但此时还有一个问题,我们不能让每次数据查询的时候再去存Redis,否则第一次查询的时候Redis是空的。基于此,我们需要在系统启动时就把数据存入Redis中,此法叫做缓存预热。
缓存预热
创建预热类
缓存预热需要确定哪些数据在系统启动时就存入数据,我们在Spring Boot内自定义一个组件,他需要实现实现ApplicationRunner,我们和启动类平级建一个这样的类,名字叫CachePreLoad:
package com.codingfire.cloud.passport;import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;public class CachePreLoad implements ApplicationRunner {@Overridepublic void run(ApplicationArguments args) throws Exception {System.out.println("CachePreLoad.run()");}
}
此类用于启动项目时提前预热资源,run方法是重写的启动类方法,启动时此方法会被调用,可在这里写存储Redis相关的内容。
但却不可将业务实现直接写在这个类中,为了项目代码整体的一致性,我们还将预热的业务以接口和实现的形式写在Redis单独的Repository组件内。
在写之前,为了防止童鞋们迷惑,博主需要解释一个问题,我个人也感觉使用用户模块做Redis不太恰当,应该是使用店铺列表,商品列表,品牌列表这样不太会变的数据做Redis,考虑到再加入新的表增加大家学习难度,所以才在用户表上面做文章,好在这个用户表也很简单,大家在真实场景中可以根据这里的代码转嫁到其他的业务下即可,万不可钻牛角尖。此处数据只做案例讲解使用,并非真实使用场景,但代码绝对是业务级别的。下面,我们来在Redis组件中增加预热的代码。
添加Redis操作接口
在IPassportRedisRepository接口中增加以下接口:
String KEY_ADMIN_LIST = "admins:list";/*** 将用户的列表存入到Redis中** @param admins 用户列表*/void save(List<AdminLoginVO> admins);/*** 删除Redis中各独立存储的用户数据*/void deleteAllItem();/*** 删除Redis中的用户列表* @return 如果成功删除,则返回true,否则返回false*/Boolean deleteList();实现Redis操作接口
接口增加完了,实现类报错,需要实现新增加的方法:
@Overridepublic void save(List<AdminLoginVO> admins) {for (AdminLoginVO admin : admins) {redisTemplate.opsForList().rightPush(KEY_ADMIN_LIST, admin);}}@Overridepublic void deleteAllItem() {Set<String> keys = redisTemplate.keys(KEY_ADMIN_ITEM_PREFIX + "*");redisTemplate.delete(keys);}@Overridepublic Boolean deleteList() {return redisTemplate.delete(KEY_ADMIN_LIST);}添加调用SQL方法
在IAdminMapper接口中增加方法:
@Select("select * from admin")List<AdminLoginVO> list();由于比较简单,就把SQL直接写在注解里来。
添加预热调用接口
在IAdminService接口中增加预热方法:
void preloadCache();
实现预热方法
在AdminServiceImpl实现类中实现上面的接口方法:
@Overridepublic void preloadCache() {log.debug("删除缓存中的用户列表……");redisRepository.deleteList();log.debug("删除缓存中的各独立的用户数据……");redisRepository.deleteAllItem();log.debug("从数据库查询用户列表……");List<AdminLoginVO> list = adminMapper.list();for (AdminLoginVO admin : list) {log.debug("查询结果:{}", admin);log.debug("将当前用户存入到Redis:{}", admin);redisRepository.save(admin);}log.debug("将用户列表写入到Redis……");redisRepository.save(list);log.debug("将用户列表写入到Redis完成!");}启动时预热类调用预热方法
最后一步,在预热缓存类中调用此预热方法:
package com.codingfire.cloud.passport;import com.codingfire.cloud.passport.service.IAdminService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.stereotype.Component;@Component
@Slf4j
public class CachePreLoad implements ApplicationRunner {@Autowiredprivate IAdminService adminService;@Overridepublic void run(ApplicationArguments args) throws Exception {System.out.println("CachePreLoad.run()");log.debug("准备执行缓存预热……");adminService.preloadCache();log.debug("缓存预热完成!");}
}
测试缓存预热
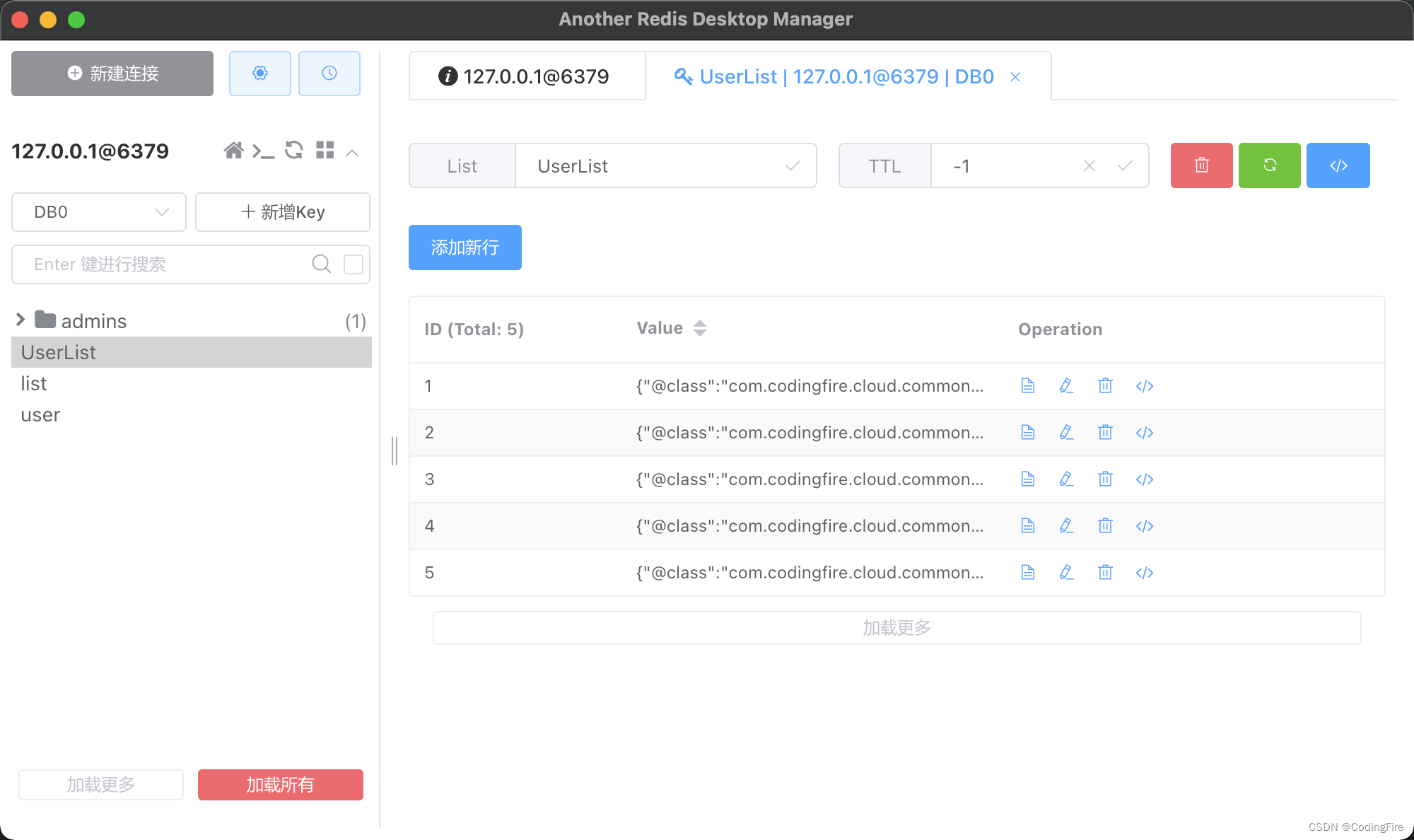
其实这一步测试是最简单的,我们什么都不需要做,直接启动项目就可以,项目启动后,我们在控制台会看到预热方法运行的输出:

下面是启动前,Redis客户端内的参数列表:
下面是项目启动后,Redis客户端内的参数列表:
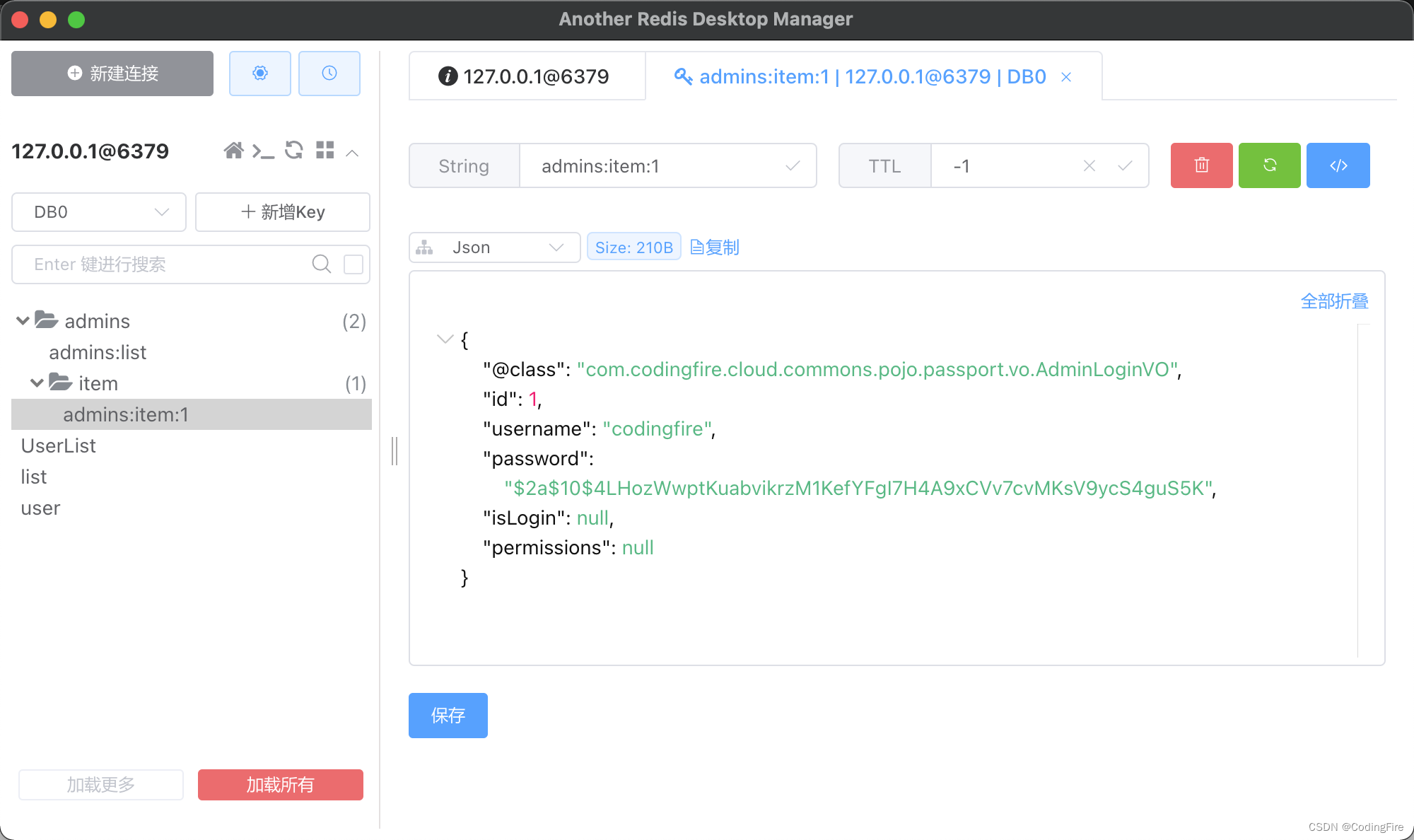
到这一步,若果你的测试结果和博主一样,那么恭喜你,你已经完成了Redis的基本学习,赶快到自己的项目中使用吧。
结语
Redis学习到这里就结束了,美中不足是少了布隆过滤器对Redis做的一个防止缓存穿透的操作,建议大家可以自己写写,后期博主会做个补充,建议大家不要等,自己动动手,也不算难。总体上,Redis整体上还算是比较简单的,用过几次其实就熟练了,很多东西都是调用API,再配合我们的业务逻辑来写。行吧,结语也不知道该写点啥,就是跟大家诉诉苦,太累了,坐的腰酸背疼,熬夜熬的眼疼,觉得写的不错,三连支持一下。
相关文章:
Java开发 - Redis初体验
前言 es我们已经在前文中有所了解,和es有相似功能的是Redis,他们都不是纯粹的数据库。两者使用场景也是存在一定的差异的,本文目的并不重点说明他们之间的差异,但会简要说明,重点还是在对Redis的了解和学习上。学完本…...

Python - 使用 pymysql 操作 MySQL 详解
目录创建连接 pymsql.connect() 方法的可传参数连接对象 conn pymsql.connect() 方法游标对象 cursor() 方法使用示例创建数据库表插入数据操作数据查询操作数据更新操作数据删除操作SQL中使用变量封装使用简单使用: import pymysqldb pymysql.connect(host,user…...
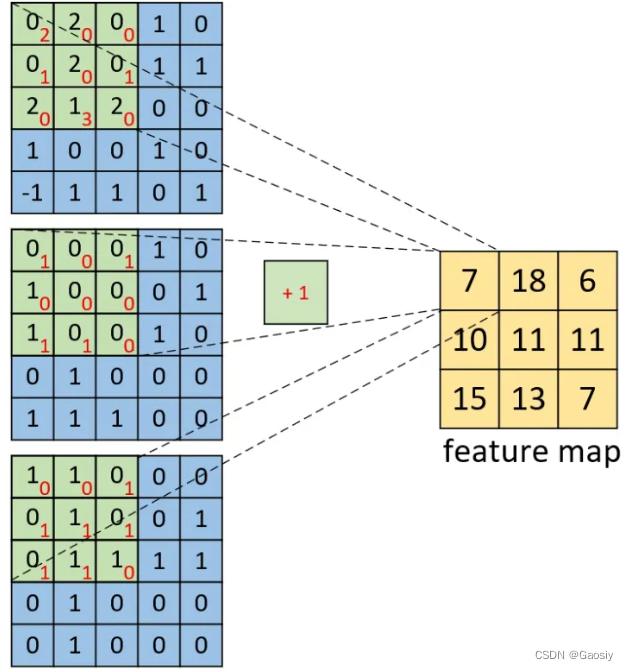
机器学习-卷积神经网络CNN中的单通道和多通道图片差异
背景 最近在使用CNN的场景中,既有单通道的图片输入需求,也有多通道的图片输入需求,因此又整理回顾了一下单通道或者多通道卷积的差别,这里记录一下探索过程。 结论 直接给出结论,单通道图片和多通道图片在经历了第一…...
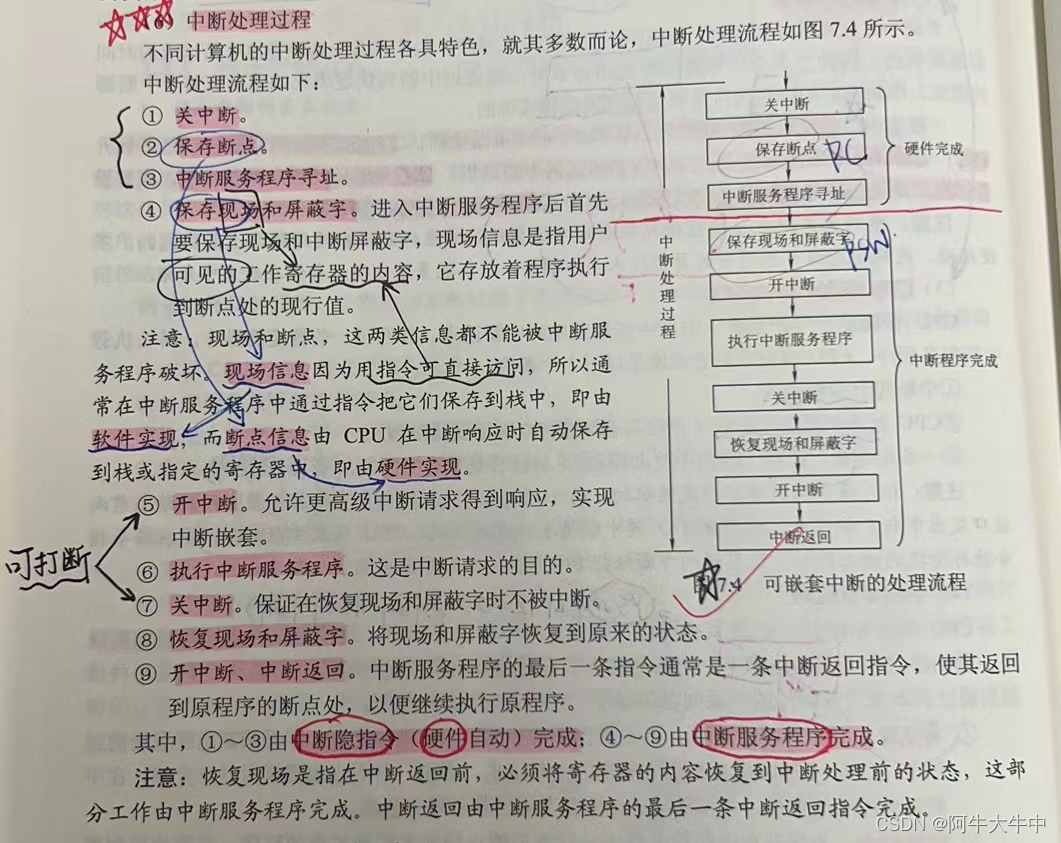
考研复试——计算机组成原理
文章目录计算机组成原理1. 计算机系统由哪两部分组成?计算机系统性能取决于什么?2. 冯诺依曼机的主要特点?3. 主存储器由什么组成,各部分有什么作用?4. 什么是存储单元、存储字、存储字长、存储体?5. 计算机…...

硬件设计 之摄像头分类(IR摄像头、mono摄像头、RGB摄像头、RGB-D摄像头、鱼眼摄像头)
总结一下在机器人上常用的几种摄像头,最近在组装机器人时,傻傻分不清摄像头的种类。由于本人知识有限,以下资料都是在网上搜索而来,按照摄像头的分类整理一下,供大家参考: 1.IR摄像头: IRinfr…...
)
PTA:C课程设计(2)
山东大学(威海)2022级大一下C习题集(2)2-5-1 字符定位函数(程序填空题)2-5-2 判断回文(程序填空题)2-6-1 数字金字塔(函数)2-6-2 使用函数求最大公约数(函数)2-6-3 使用函数求余弦函…...
第四章:面向对象编程
第四章:面向对象编程 4.1:面向过程与面向对象 面向过程(POP)与面向对象(OOP) 二者都是一种思想,面向对象是相对于面向过程而言的。面向过程,强调的是功能行为,以函数为最小单位,考虑怎么做。面向对象&…...

Linux 安装npm yarn pnpm 命令
下载安装包 node 下载地址解压压缩包 tar -Jxf node-v19.7.0-linux-x64.tar.xz -C /root/app echo "export PATH$PATH:/app/node-v16.9.0-linux-x64" >> /etc/profile source /etc/profile ln -sf /app/node-v16.9.0-linux-x64/bin/npm /usr/local/bin/ ln -…...
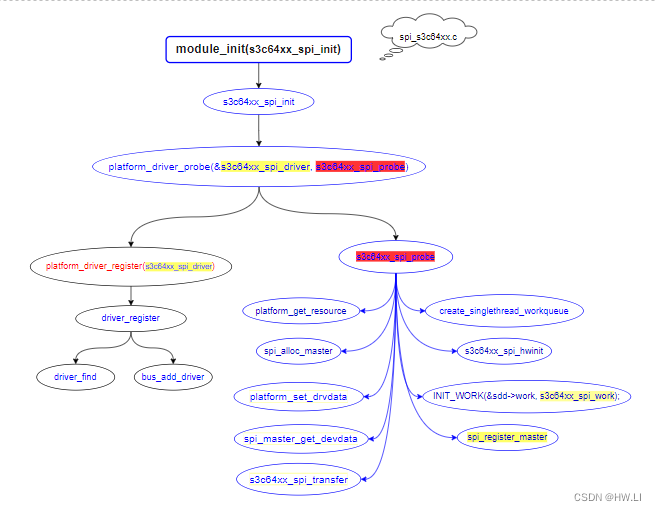
linux SPI驱动代码追踪
一、Linux SPI 框架概述 linux系统下的spi驱动程序从逻辑上可以分为3个部分: SPI Core:SPI Core 是 Linux 内核用来维护和管理 spi 的核心部分,SPI Core 提供操作接口,允许一个 spi master,spi driver 和 spi device 在 SPI Cor…...

Ls-dyna材料的相关学习笔记
Elastic Linear elastic materials -Isotropic:各向同性材料 -orthotropic 正交各向异性的 -anistropic 各向异性的...
)
Arrays方法(copyOfRange,fill)
Arrays方法 1、Arrays.copyOfRange Arrays.copyOfRange的使用方法 功能: 将数组拷贝至另外一个数组 参数: original:第一个参数为要拷贝的数组对象 from:第二个参数为拷贝的开始位置(包含) to:…...
)
AcWing - 蓝桥杯集训每日一题(DAY 1——DAY 5)
文章目录一、AcWing 3956. 截断数组(中等)1. 实现思路2. 实现代码二、AcWing 3729. 改变数组元素(中等)1. 实现思路2. 实现代码三、AcWing 1460. 我在哪?(简单)1. 实现思路2. 实现代码四、AcWin…...
)
RHCSA-文件的其他命令(3.7)
目录 文件的其他命令: 文本内容统计wc 移动和复制(cp) 移动 查找文件的路径 压缩和解压缩 .tar(归档命令) shell-命令解释器 linux中的特殊字符 查看系统上的别名:alias 历史命令(his…...

多线程update导致的mysql死锁问题处理方法
最近想起之前处理过的一个mysql 死锁问题,是在高并发下update批量更新导致的,这里探讨一下发生的原因,以及解决办法; 发生死锁的sql语句如下,其中where条件后的字段是有复合索引的。 update t_push_message_device_h…...
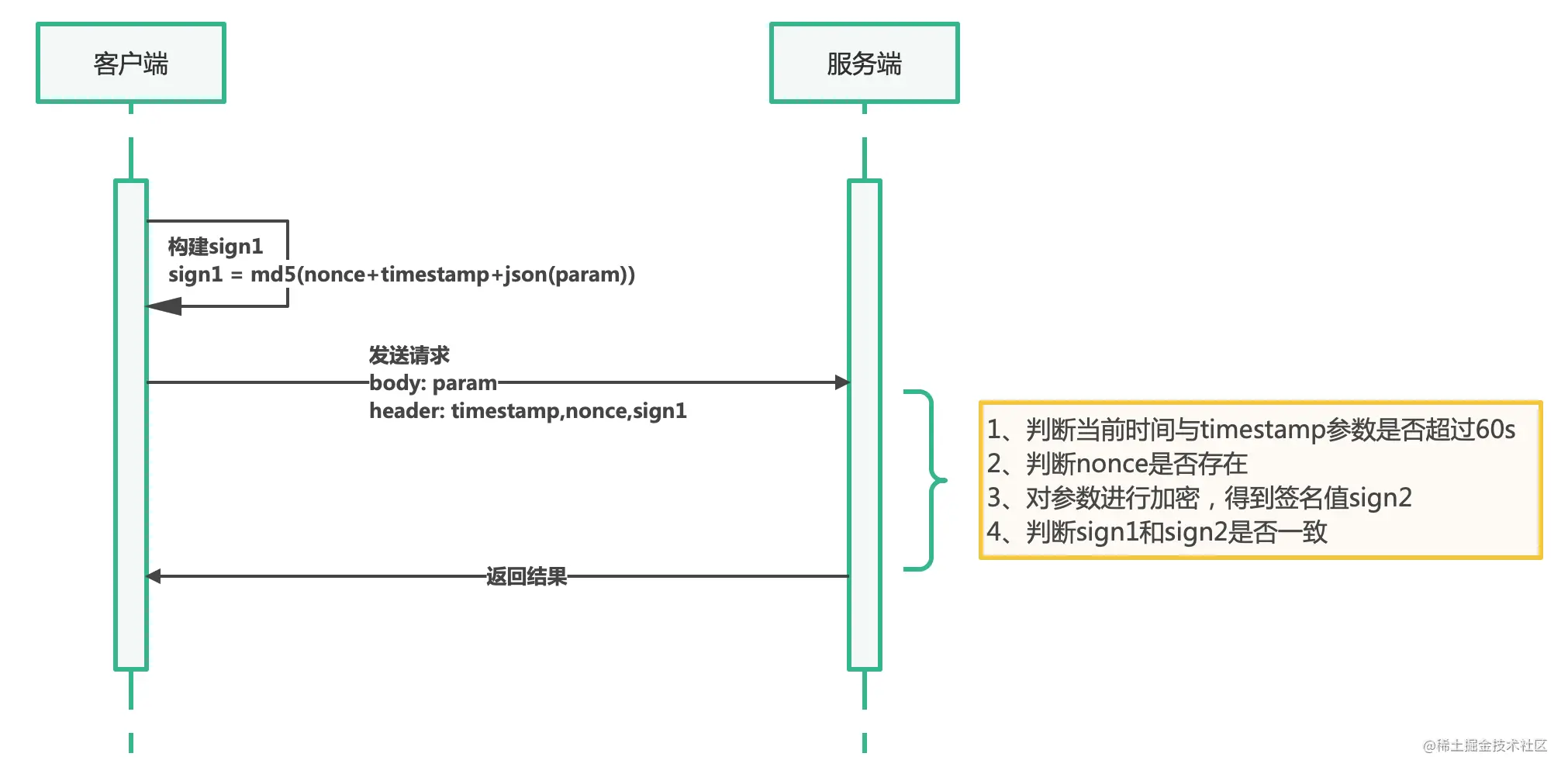
SpringBoot 如何保证接口安全?
为什么要保证接口安全对于互联网来说,只要你系统的接口暴露在外网,就避免不了接口安全问题。 如果你的接口在外网裸奔,只要让黑客知道接口的地址和参数就可以调用,那简直就是灾难。举个例子:你的网站用户注册的时候&am…...

英伟达驱动爆雷?CPU占用率过高怎么办?
又有一新驱动导致CPU占用率过高? 上周英伟达发布531.18显卡驱动,为大家带来了视频超分辨率技术,并为新发布的热门游戏《原子之心》提供支持。 但在安装新驱动后没过不久就有玩家反映,在游戏结束后会出现CPU占用率突然飙升到10%以…...
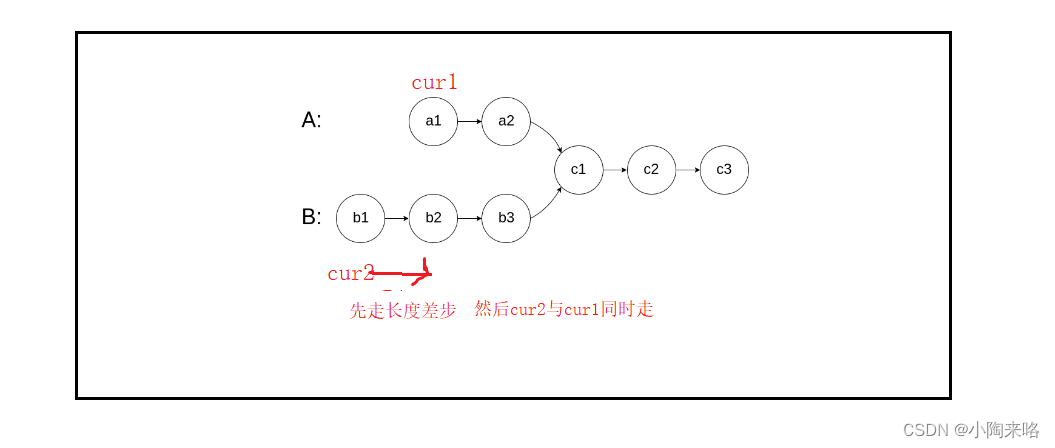
链表经典面试题【典中典】
💯💯💯链表经典面试题❗❗❗炒鸡经典,本篇带有图文解析,建议动手刷几遍。🟥1.反转链表🟧2.合并两个有序链表🟨3.链表分割🟩4.链表的回文结构🟦5.相交链表&…...

Java泛型深入
一. 泛型的概述和优势 泛型概述 泛型:是JDK5中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查。泛型的格式:<数据类型>,注意:泛型只能支持引用数据类型。集合体系的全部接口和实现类都是…...
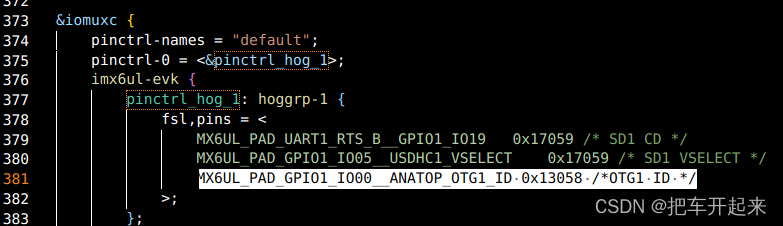
体验Linux USB 驱动
目录 一、USB OTG 二、I.MX6ULL USB 接口简介 硬件原理图 1、USB HUB 原理图 2 、USB OTG 原理图 三、使能驱动 1、打开 HID 驱动 2、 使能 USB 键盘和鼠标驱动 3 、使能 Linux 内核中的 SCSI 协议 4、使能 U 盘驱动 四、测试u盘 五、 Linux 内核自带 USB OTG USB 是…...

servlet 中的ServletConfig与servletContext
ServletConfig对象:servlet配置对象,主要把servlet的初始化参数封装到这个对象中。 一个网站中可能会存在多个servletConfig对象,一个servletConfig对象就封装了一个servlet的配置信息。 可以在web.xml中通过<init-param></init-p…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...

【C++进阶篇】智能指针
C内存管理终极指南:智能指针从入门到源码剖析 一. 智能指针1.1 auto_ptr1.2 unique_ptr1.3 shared_ptr1.4 make_shared 二. 原理三. shared_ptr循环引用问题三. 线程安全问题四. 内存泄漏4.1 什么是内存泄漏4.2 危害4.3 避免内存泄漏 五. 最后 一. 智能指针 智能指…...