Apache Hive的基本使用语法(一)
一、数据库操作
- 创建数据库
create database if not exists myhive;
- 查看数据库
use myhive;
desc database myhive;

- 创建数据库并指定hdfs存储
create database myhive2 location '/myhive2';
- 删除空数据库(如果有表会报错)
drop database myhive;
- 强制删除数据库,包含数据库下的表一起删除
drop database myhive cascade;
- 数据库和HDFS的关系
- Hive的库在HDFS上就是一个以.db结尾的目录
- 默认存储在:/user/hive/warehouse内
- 可以通过LOCATION关键字在创建的时候指定存储目录
- Hive中可以创建的表有好几种类型, 分别是:
- 内部表
- 外部表
- 分区表
- 分桶表
二、Hive SQL语法
1、表操作
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] 分区 [CLUSTERED BY (col_name, col_name, ...) 分桶 [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT DELIMITED | SERDE serde_name WITH SERDEPROPERTIES(property_name=property_value,..)] [STORED AS file_format] [LOCATION hdfs_path]
[] 中括号的语法表示可选。
| 表示使用的时候,左右语法二选一。
建表语句中的语法顺序要和语法树中顺序保持一致。
字段简单说明
- CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项 来忽略这个异常。
- EXTERNAL 外部表
- COMMENT: 为表和列添加注释。
- PARTITIONED BY 创建分区表
- CLUSTERED BY 创建分桶表
- SORTED BY 排序不常用
- ROW FORMAT DELIMITED 使用默认序列化LazySimpleSerDe 进行指定分隔符
- SERDE 使用其他序列化类 读取文件
- STORED AS 指定文件存储类型
- LOCATION 指定表在HDFS上的存储位置。
- LIKE 允许用户复制现有的表结构,但是不复制数据
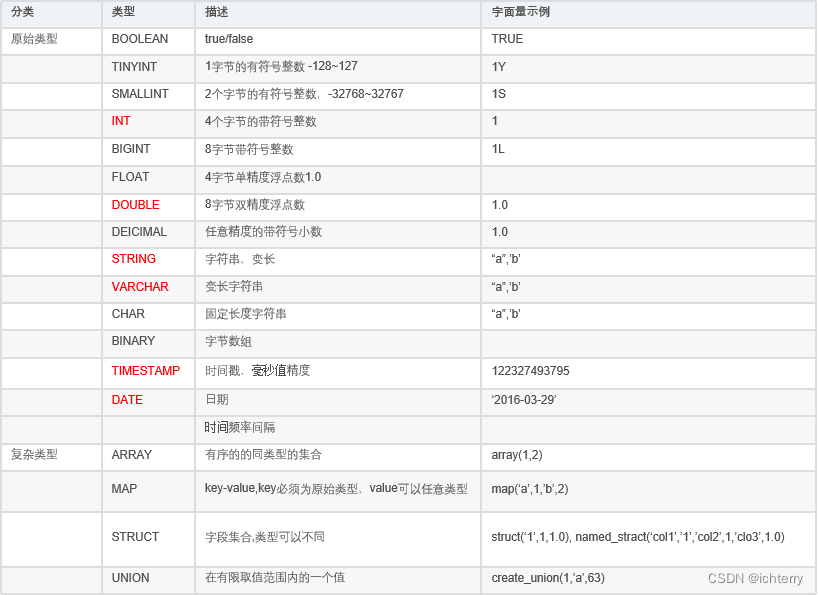
- 数据类型
- 创建表
CREATE TABLE test(id INT, name STRING, gender STRING);
- 删除表
DROP TABLE test;
2、内部表操作
- 默认创建的就是内部表,如下举例:
create database if not exists myhive;
use myhive;
create table if not exists stu2(id int,name string);
insert into stu2 values (1,"zhangsan"), (2, "lisi");
select * from stu2;
- 在HDFS上,查看表的数据存储文件

3、外部表操作
# 创建外部表
create external table test_ext(id int, name string) row format delimited fields terminated by '\t' location '/tmp/test_ext';
# 可以看到,目录/tmp/test_ext被创建
select * from test_ext #空结果,无数据
# 上传数据:
hadoop fs -put test_external.txt /tmp/test_ext/
#现在可以看数据结果
select * from test_ext
# 删除外部表(但是在HDFS中,数据文件依旧保留)
drop table test_ext;
- 内外部表转换(EXTERNAL=TRUE 外或FALSE 内,注意字母大写)
alter table stu set tblproperties('EXTERNAL'='TRUE');
4、数据加载和导出
- 先建表
CREATE TABLE myhive.test_load(dt string comment '时间(时分秒)', user_id string comment '用户ID', word string comment '搜索词',url string comment '用户访问网址'
) comment '搜索引擎日志表' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
- 数据加载方式一:基于HDFS进行load加载数据(不保留原始文件)
load data local inpath '/home/hadoop/search_log.txt' into table myhive.test_load;
search_log.txt文件内容如下:

- 数据加载方式二:将SELECT查询语句的结果插入到其它表中,被SELECT查询的表可以是内部表或外部表(保留原始文件)
INSERT INTO TABLE tbl1 SELECT * FROM tbl2;
INSERT OVERWRITE TABLE tbl1 SELECT * FROM tbl2;
- 将查询的结果导出到本地 - 使用默认列分隔符
insert overwrite local directory '/home/hadoop/export1' select * from test_load ;
- 将查询的结果导出到本地 - 指定列分隔符
insert overwrite local directory '/home/hadoop/export2' row format delimited fields terminated by '\t' select * from test_load;
- 将查询的结果导出到HDFS上(不带local关键字)
insert overwrite directory '/tmp/export' row format delimited fields terminated by '\t' select * from test_load;
- hive表数据导出
bin/hive -e "select * from myhive.test_load;" > /home/hadoop/export3/export4.txtbin/hive -f export.sql > /home/hadoop/export4/export4.txt
5、分区表
- 在大数据中,最常用的一种思想就是分治,我们可以把大的文件切割划分成一个个的小的文件,这样每次操作一个小的文件就会很容易了
同样的道理,在hive当中也是支持这种思想的,就是我们可以把大的数据,按照每天,或者每小时进行切分成一个个的小的文件,这样去操作小的文件就会容易得多了。
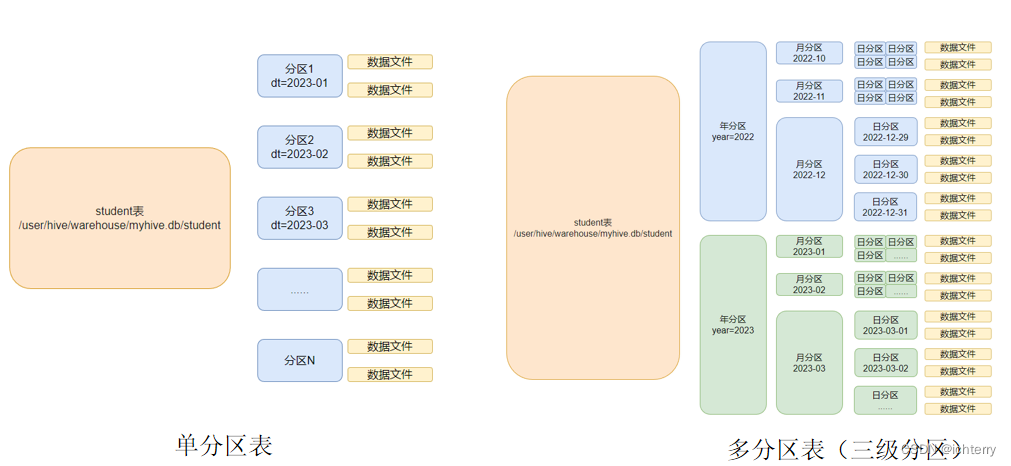
- 基本语法
create table tablename(...) partitioned by (分区列 列类型, ......) row format delimited fields terminated by ''; - 创建分区表
create table score(s_id string, c_id string, s_score int) partition by (month string) row format delimited fields terminated by '\t';
- 创建多个分区表
create table score(s_id string, c_id string, s_score int) partition by (year string,month string,day string) row format delimited fields terminated by '\t';
- 加载数据到分区表中
load data local inpath '/export/server/hivedata/score.txt' into table score partition(month='202403');
- 加载数据到多分区表中
load data local inpath '/export/server/hivedata/score.txt' into table score partition(year='2024',month='03',day='27');
- 查看分区表
show partitions score;
- 添加一个分区
alter table score add partition(month='202403');
- 同时添加多个分区
alter table score add partition(month='202403') partition(month='202402');
- 删除分区
alter table score drop partition(month='202403');
6、分桶表
- 开启分桶的自动优化(自动匹配reduce task数量和桶数量一致)
set hive.enforce.bucketing=true;
- 创建分桶表
create table course (c_id string,c_name string,t_id string) clustered by(c_id) into 3 buckets row format delimited fields terminated by '\t';
- 桶表的数据加载,由于桶表的数据加载通过load data无法执行,只能通过insert select.
所以,比较好的方式是:
- 创建一个临时表(外部表或内部表均可),通过load data加载数据进入表
- 然后通过insert select 从临时表向桶表插入数据
# 创建普通i表
create table course_common(c_id string, c_name string, t_id string) row format delimited fields terminated by '\t';
# 普通表中加载数据
load data local inpath '/export/server/hivedata/course.txt' into table course_common;
# 通过insert overwrite给桶表加载数据
insert overwrite table course select * from course_common cluster by(c_id);
- 为什么不可以用load data,必须用insert select插入数据:
- 问题就在于:如何将数据分成三份,划分的规则是什么?
- 数据的三份划分基于分桶列的值进行hash取模来决定
- 由于load data不会触发MapReduce,也就是没有计算过程(无法执行Hash算法),只是简单的移动数据而已
所以无法用于分桶表数据插入。
- Hash取模
- Hash算法是一种数据加密算法,其原理我们不去详细讨论,我们只需要知道其主要特征:
- 同样的值被Hash加密后的结果是一致的
比如字符串“hadoop”被Hash后的结果是12345(仅作为示意),那么无论计算多少次,字符串“hadoop”的结果都会是12345。
比如字符串“bigdata”被Hash后的结果是56789(仅作为示意),那么无论计算多少次,字符串“bigdata”的结果都会是56789。
- 基于如上特征,在辅以有3个分桶文件的基础上,将Hash的结果基于3取模(除以3 取余数)
那么,可以得到如下结果:
- 无论什么数据,得到的取模结果均是:0、1、2 其中一个
- 同样的数据得到的结果一致,如hadoop hash取模结果是1,无论计算多少次,字符串hadoop的取模结果都是1
跳转到《Apache Hive的基本使用语法(二)》
至此,分享结束!!!
相关文章:
Apache Hive的基本使用语法(一)
一、数据库操作 创建数据库 create database if not exists myhive;查看数据库 use myhive; desc database myhive;创建数据库并指定hdfs存储 create database myhive2 location /myhive2;删除空数据库(如果有表会报错) drop database myhive;…...

Python爬虫详解:原理、常用库与实战案例
前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:https://www.captainbed.cn/z ChatGPT体验地址 文章目录 前言引言:一、爬虫原理1. HTTP请求与响应过程2. 常用爬虫技术 二、P…...

搭建跨境电商电商独立站如何接入1688平台API接口|通过1688API接口采集商品通过链接搜索商品下单
接口设计|接口接入 对于mall项目中商品模块的接口设计,大家可以参考项目的Swagger接口文档,以Pms开头的接口就是商品模块对应的接口。 参数说明 通用参数说明 参数不要乱传,否则不管成功失败都会扣费url说明……d.cn/平台/API类型/ 平台&…...

【GlobalMapper精品教程】073:像素到点(Pixels-to-Points)从无人机图像轻松生成点云
文章目录 一、工具介绍二、生成点云三、生成正射四、生成3D模型五、注意事项一、工具介绍 Global Mapper v19引入的新的像素到点工具使用摄影测量原理,从重叠图像生成高密度点云、正射影像及三维模型。它使LiDAR模块成为已经功能很强大的的必备Global Mapper扩展功能。 打开…...

论文复现1:Mobilealoha
abstract:从人类演示中进行的模仿学习在机器人技术中表现出了令人印象深刻的表现。然而,大多数结果都集中在桌面操作上,缺乏一般有用任务所需的移动性和灵活性。在这项工作中,我们开发了一种用于模仿双手且需要全身控制的移动操纵任务的系统。我们首先推出 Mobile ALOHA,这…...

pycharm复习
目录 1.基础语法 2.判断语句 3.while循环 4.函数 5.数据容器 1.基础语法 1.字面量 2.注释: 单行注释# 多行注释" " " " " " 3.变量: 变量名 变量值 print:输出多个结果&#x…...
【SQLSERVER】批量导出所有作业或链接脚本
1.在Microsoft SQL Server Management Studio中选择–>视图(v)–>对象资源管理器详细信息(F7) 2.SSMS图形界面,左侧是“对象资源管理器”,右侧是“对象资源管理器详细信息”界面 3.左侧的“对象资源管理器”界面–>点击“SQLSserver代理”–…...

函数参数缺省和内联函数【C++】
文章目录 函数参数缺省函数参数缺省的条件和要求 内联函数内联函数的工作原理内联函数的定义方法内联函数的要求解决方法:直接在.h中定义内联函数的函数体 内联函数再Debug模式下默认是不展开的 函数参数缺省 顾名思义:可以少传一个/多个参数给函数&…...
javaWeb城市公交查询系统的设计与实现
一、选题背景 随着低碳生活的普及,人们更倾向于低碳环保的出行方式,完善公交系统无疑具有重要意义。公交是居民日常生活中最常使用的交通工具之一,伴随着我国经济繁荣和城市人口增长,出行工具的选择也变得越来越重要。政府在公共…...
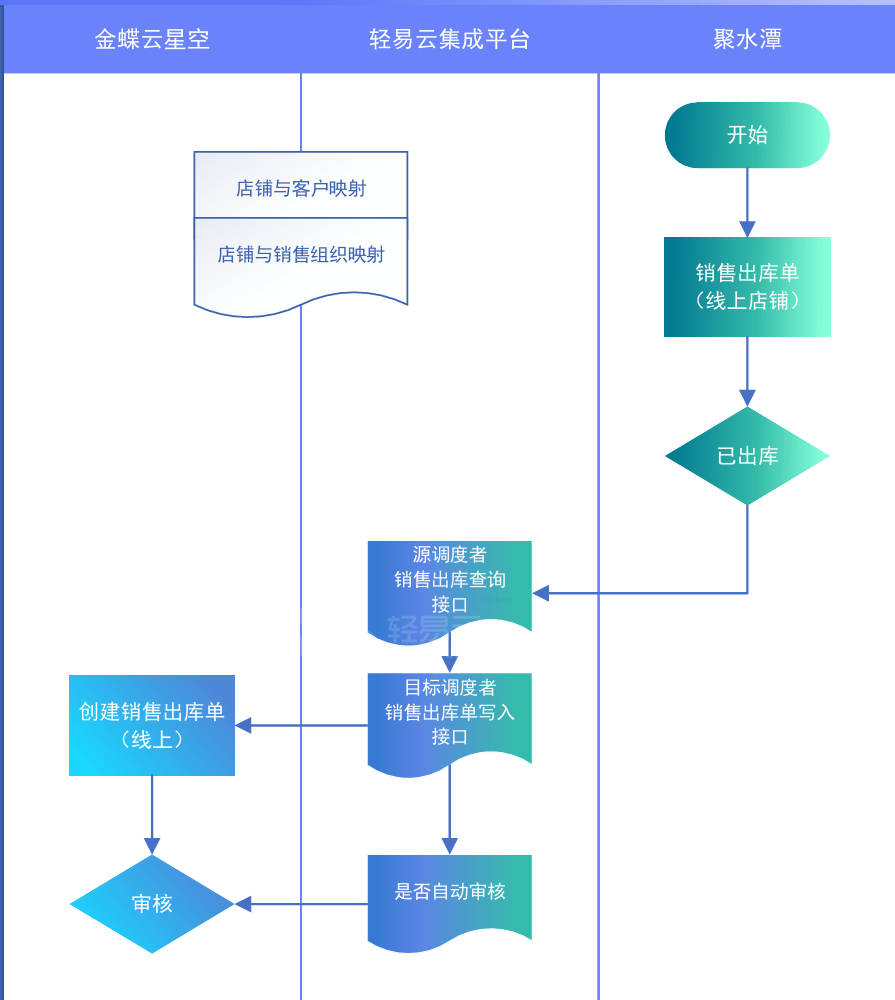
企业案例:金蝶云星空对接旺店通·企业版
某知名化妆品企业,主要专注于化妆品,护肤品等研发,销售,生产于一体化的企业。企业的业务模式涉及比较广,有2B,2C和国内外电商领域。由于对内部业务流程的连贯性和数据的准确性比较关注。财务系统用的金蝶云星空&#x…...
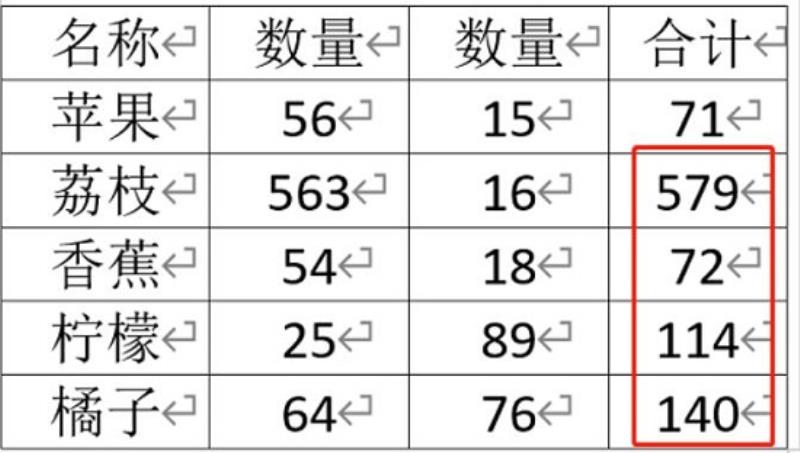
wpsword求和操作教程
wpsword求和怎么操作: 1、首先,单纯的数据是无法求和的,所以我们必须要“插入”一个“表格” 2、接着将需要求和的数据填入到表格中。 3、填完后,进入“布局”选项卡。 4、然后打开其中的“公式” 5、在其中选择求和公式“SUM”并…...

Android 手机部署whisper 模型
Whisper 是什么? “Whisper” 是一个由OpenAI开发的开源深度学习模型,专门用于语音识别任务。这个模型能够将语音转换成文本,支持多种语言,并且在处理不同的口音、环境噪音以及跨语言的语音识别方面表现出色。Whisper模型的目标是提供一个高效、准确的工具,以支持自动字幕…...

通信术语:初学者入门指南(二)
1.SAR:Synthetic Aperture Radar合成孔径雷达,是一种雷达系统,通常用于地球或行星的遥感成像。相较于传统的实孔径雷达,SAR 通过在相对较长的时间内,对来自同一地点的多个雷达反射信号进行综合处理,实现了更…...

Java中使用MQTT客户端库实现TLS/SSL加密通信的示例
以下是一个完整的Java代码示例,展示了如何使用Eclipse Paho MQTT客户端库在Java中实现TLS/SSL加密的MQTT通信。在这个示例中,我们将创建一个简单的MQTT客户端,该客户端连接到支持TLS/SSL的MQTT代理,并发布和订阅消息。 首先&…...

【m122】webrtc的比较
uint16的比较IsNewerSequenceNumber 和 u32的比较LatestTimestamp G:\CDN\WEBRTC-DEV\libwebrtc_build\src\modules\include\module_common_types_public.h/** Copyright (c) 2017 The WebRTC project authors. All Rights Reserved.** Use of this source code is governed …...

axios发送get请求但参数中有数组导致请求路径多出了“[]“的处理办法
一、情况 使用axios发送get请求携带了数组参数时,请求路径中就会多出[]字符,而在后端也会报错 二、解决办法 1、安装qs 当前项目的命令行中安装 npm install qs2、引入qs库(使用qs库来将参数对象转换为字符串) // 全局 import qs from qs Vue.proto…...
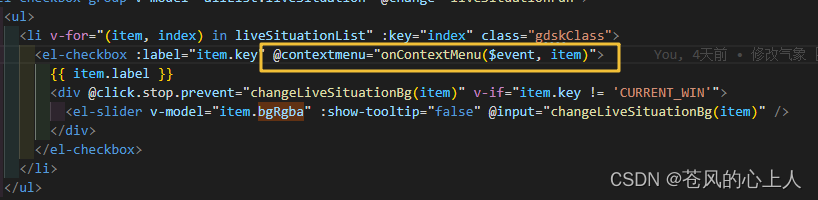
vue3的mars3d点击右键出现置顶、向下、向上等选项
效果图 下载插件 imengyu/vue3-context-menu npm i imengyu/vue3-context-menu在要使用的页面中引入一下代码 import "imengyu/vue3-context-menu/lib/vue3-context-menu.css"; import ContextMenu from "imengyu/vue3-context-menu";如果是使用在树的…...

MySQL进阶-----SQL提示与覆盖索引
目录 前言 一、SQL提示 1.数据准备 2. SQL的自我选择 3.SQL提示 二、覆盖索引 前言 MySQL进阶篇的索引部分基本上要结束了,这里就剩下SQL提示、覆盖索引、前缀索引以及单例联合索引的内容。那本期的话我们就先讲解SQL提示和覆盖索引先,剩下的内容就…...

机器学习模型之K近邻
K近邻(K-Nearest Neighbors,KNN)是一种基本的机器学习算法,它既可以用于分类问题,也可以用于回归问题。KNN算法的核心思想非常简单:一个新样本的分类或回归值取决于它与训练集中最相似的K个样本的多数类别或…...
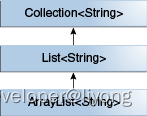
强化基础-Java-泛型基础
什么是泛型? 泛型其实就参数化类型,也就是说这个类型类似一个变量是可变的。 为什么会有泛型? 在没有泛型之前,java中是通过Object来实现泛型的功能。但是这样做有下面两个缺陷: 1 获取值的时候必须进行强转 2 没有…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...