【Golang星辰图】数据处理的航海家:征服数据海洋的航行工具
数据处理的建筑师:用Go语言中构建稳固的数据分析建筑物
前言
数据处理和分析是现代计算机科学中的关键任务之一,而Go语言作为一门现代化的编程语言,也需要强大的数据处理和分析库来支持其在这一领域的应用。本文将介绍几款优秀的数据处理和分析库,它们在Go语言中提供了高效、灵活和简单的数据操作和计算能力。
欢迎订阅专栏:Golang星辰图
文章目录
- 数据处理的建筑师:用Go语言中构建稳固的数据分析建筑物
- 前言
- 1. go-arrow
- 1.1 介绍
- 1.2 特点
- 1.3 使用示例
- 2. go-parquet
- 2.1 介绍
- 2.2 特点
- 2.3 使用示例
- 3. go-dataframe
- 3.1 介绍
- 3.2 特点
- 3.3 使用示例
- 4. go-pandas
- 4.1 介绍
- 4.2 特点
- 4.3 使用示例
- 5. go-datatable
- 5.1 介绍
- 5.2 特点
- 5.3 使用示例
- 6. go-spark
- 6.1 介绍
- 6.2 特点
- 6.3 使用示例
- 总结
1. go-arrow
1.1 介绍
go-arrow是一个用于Go语言的Apache Arrow库,它支持列式内存数据结构和计算。Apache Arrow是一种用于大数据处理的内存数据格式,具有高效的列式存储和跨语言的数据交换能力。go-arrow提供了对Arrow数据格式的读写和操作功能。
1.2 特点
- 支持高效的列式内存数据结构:go-arrow利用Apache Arrow的列式存储,可以高效地处理大规模数据集,并提供快速的数据操作和计算能力。
- 跨语言的数据交换能力:由于Apache Arrow是一种跨语言的数据格式,go-arrow可以与其他语言的Arrow库进行数据交换,方便数据在不同系统和平台之间的共享和处理。
- 简单易用的API:go-arrow提供了简洁明了的API接口,使得数据处理和分析任务变得更加简单和高效。
1.3 使用示例
package mainimport ("fmt""github.com/apache/arrow/go/arrow""github.com/apache/arrow/go/arrow/array"
)func main() {// 创建整型数组ints := []int64{1, 2, 3, 4, 5}intsData := array.NewInt64Data(ints)intsArray := array.NewInt64(intsData)// 创建字符串数组strings := []string{"apple", "banana", "cherry"}stringsData := array.NewStringData(strings)stringsArray := array.NewString(stringsData)// 创建表table := array.NewTable([]arrow.Field{{Name: "ints", Type: arrow.PrimitiveTypes.Int64},{Name: "strings", Type: arrow.BinaryTypes.String},}, []array.Interface{intsArray, stringsArray})// 打印表中的数据for i := 0; i < table.NumRows(); i++ {row := table.Row(i)intValue := row.Column(0).(*array.Int64).Value(i)strValue := row.Column(1).(*array.String).Value(i)fmt.Printf("Row %d: ints=%d, strings=%s\n", i, intValue, strValue)}
}
在上面的示例代码中,我们使用go-arrow创建了一个包含整型和字符串列的表,并打印了表中的数据。通过这个示例,您可以了解到如何使用go-arrow进行数据的创建和操作。
2. go-parquet
2.1 介绍
go-parquet是一个用于Go语言的Parquet库,它支持Parquet列式存储格式的读写。Parquet是一种高效的列式存储格式,适用于大规模数据集的存储和分析。go-parquet提供了对Parquet文件的读写和查询功能。
2.2 特点
- 高效的列式存储:go-parquet使用Parquet列式存储格式,可以高效地存储和处理大规模数据集,减少存储空间和读取时间。
- 跨语言的数据交换:Parquet是一种跨语言的存储格式,go-parquet可以与其他语言的Parquet库进行数据交换,实现数据的无缝传递和共享。
- 支持复杂数据类型:go-parquet支持多种复杂数据类型,如嵌套结构、列表、字典等,可以方便地处理复杂的数据结构。
2.3 使用示例
package mainimport ("fmt""github.com/xitongsys/parquet-go/parquet""github.com/xitongsys/parquet-go/source/local""github.com/xitongsys/parquet-go/writer"
)type Data struct {ID int32 `parquet:"name=id, type=INT32"`Name string `parquet:"name=name, type=BYTE_ARRAY"`Age int32 `parquet:"name=age, type=INT32"`Email string `parquet:"name=email, type=BYTE_ARRAY"`
}func main() {// 创建parquet写入器fw, err := local.NewLocalFileWriter("data.parquet")if err != nil {panic(err)}pw, err := writer.NewParquetWriter(fw, new(Data), 4)if err != nil {panic(err)}// 写入数据for i := 0; i < 10; i++ {data := Data{ID: int32(i),Name: fmt.Sprintf("name%d", i),Age: int32(i + 20),Email: fmt.Sprintf("email%d@example.com", i),}if err := pw.Write(data); err != nil {panic(err)}}// 关闭写入器if err := pw.WriteStop(); err != nil {panic(err)}if err := fw.Close(); err != nil {panic(err)}// 创建parquet阅读器fr, err := local.NewLocalFileReader("data.parquet")if err != nil {panic(err)}pr, err := reader.NewParquetReader(fr, new(Data), 4)if err != nil {panic(err)}// 读取数据for i := 0; i < int(pr.GetNumRows()); i++ {data := new(Data)if err := pr.Read(data); err != nil {panic(err)}fmt.Printf("Data: %+v\n", data)}// 关闭阅读器if err := pr.ReadStop(); err != nil {panic(err)}if err := fr.Close(); err != nil {panic(err)}
}
在上面的示例代码中,我们使用go-parquet创建了一个Parquet文件,并向文件中写入了一些数据。之后,我们使用go-parquet从文件中读取数据,并打印出来。通过这个示例,您可以了解到如何使用go-parquet进行Parquet文件的读写和查询。
3. go-dataframe
3.1 介绍
go-dataframe是一个用于Go语言的数据框架库,它提供了类似Pandas的数据处理和分析功能。数据框架是一种用于处理结构化数据的表格型数据结构,可以方便地进行数据的筛选、聚合、变换等操作。go-dataframe使得在Go语言中进行数据分析变得更加方便和高效。
3.2 特点
- 类似Pandas的操作:go-dataframe提供了类似Pandas的操作接口,包括数据的筛选、聚合、变换等操作,使得在Go语言中进行数据处理和分析更加方便和灵活。
- 支持多种数据类型:go-dataframe支持多种常见的数据类型,如整数、浮点数、字符串、日期等,可以处理各种类型的结构化数据。
- 高性能计算:go-dataframe采用高效的数据结构和算法,可以进行高性能的数据计算,适用于大规模数据集的处理和分析。
3.3 使用示例
package mainimport ("fmt""github.com/go-gota/gota/dataframe""github.com/go-gota/gota/series"
)func main() {// 创建数据帧data := map[string]interface{}{"name": []string{"Alice", "Bob", "Charlie"},"age": []int{25, 30, 35},"score": []float64{90.5, 85.0, 95.5},}df := dataframe.LoadMap(data)// 打印数据帧内容fmt.Println(df)// 筛选数据filter := df.Filter(dataframe.F{Colname: "age", Comparator: ">", Comparando: 25}).Subset([]string{"name", "age"})fmt.Println(filter)// 聚合数据summary := df.GroupBy("name").Aggregation([]series.Aggregation{{"age", series.Mean},{"score", series.Max},})fmt.Println(summary)
}
在上面的示例代码中,我们使用go-dataframe创建了一个数据帧,并展示了数据的筛选和聚合操作。通过这个示例,您可以了解到如何使用go-dataframe进行数据的处理和分析。
4. go-pandas
4.1 介绍
go-pandas是一个用于Go语言的Pandas库的实现,它提供了类似Pandas的数据处理和分析功能。Pandas是一个流行的Python数据分析库,它提供了灵活而高效的数据结构和数据操作接口。go-pandas在Go语言中实现了类似的功能,使得在Go语言中进行数据处理和分析更加方便和简单。
4.2 特点
- 数据结构:go-pandas提供了类似Pandas的数据结构,如Series和DataFrame,可以表示和操作结构化数据。
- 数据操作:go-pandas支持丰富的数据操作功能,包括数据的筛选、聚合、分组、排序等,可以方便地对数据进行处理和分析。
- 高性能计算:go-pandas采用了高效的底层算法和数据结构,可以进行高性能的数据计算,适用于大规模数据集的处理和分析。
4.3 使用示例
package mainimport ("fmt""github.com/go-gota/gota/dataframe"
)func main() {// 创建数据帧df := dataframe.ReadCSV("data.csv")// 打印数据帧内容fmt.Println(df)// 筛选数据filteredDf := df.Filter(dataframe.F{Colname: "age",Comparator: ">",Comparando: 30,})// 打印筛选后的结果fmt.Println(filteredDf)// 聚合数据summaryDf := df.GroupBy("name").Aggregation([]dataframe.Aggregation{{"age", dataframe.Mean},{"score", dataframe.Max},})// 打印聚合后的结果fmt.Println(summaryDf)
}
在上面的示例代码中,我们使用go-pandas读取了一个CSV文件,并展示了数据的筛选和聚合操作。通过这个示例,您可以了解到如何使用go-pandas进行数据的处理和分析。
5. go-datatable
5.1 介绍
go-datatable是一个用于Go语言的数据表格库,它提供了快速而高效的数据处理和分析功能。数据表格是一种用于处理大规模数据的二维表格数据结构,可以方便地进行数据的过滤、排序、计算等操作。go-datatable使得在Go语言中进行数据处理变得更加高效和灵活。
5.2 特点
- 高性能计算:go-datatable采用了高效的算法和数据结构,可以进行高性能的数据计算,适用于大规模数据集的处理和分析任务。
- 类似SQL的操作:go-datatable提供了类似SQL的操作接口,如过滤、排序、分组、聚合等,使得数据处理更加直观和灵活。
- 内存优化:go-datatable针对大规模数据的处理进行了内存优化,可以在有限的内存资源中高效地处理大规模的数据集。
5.3 使用示例
package mainimport ("fmt""github.com/go-gota/gota/dataframe""github.com/lawrsp/go-datatable"
)func main() {// 创建数据表格dt := datatable.NewDataTable()dt.AddColumn("name", "string")dt.AddColumn("age", "int")dt.AddColumn("score", "float64")// 添加数据dt.AddRow("Alice", 25, 90.5)dt.AddRow("Bob", 30, 85.0)dt.AddRow("Charlie", 35, 95.5)// 打印数据表格内容fmt.Println(dt)// 筛选数据filteredDt := dt.FilterByFunc(func(r datatable.Row) bool {age, _ := r.Get("age").(int)return age > 30})// 打印筛选后的结果fmt.Println(filteredDt)// 聚合数据summaryDt := dt.GroupBy("name").Aggregation([]datatable.Aggregation{{Name: "age", Func: "mean"},{Name: "score", Func: "max"},})// 打印聚合后的结果fmt.Println(summaryDt)
}
在上面的示例代码中,我们使用go-datatable创建了一个数据表格,并展示了数据的筛选和聚合操作。通过这个示例,您可以了解到如何使用go-datatable进行数据的处理和分析。
6. go-spark
6.1 介绍
go-spark是一个用于Go语言的Spark库的实现,它提供了类似Spark的分布式数据处理和分析功能。Spark是一个流行的大数据处理框架,它提供了分布式计算和内存计算能力。go-spark在Go语言中实现了类似的功能,使得在Go语言中进行大数据处理和分析更加方便和高效。
6.2 特点
- 分布式计算:go-spark提供了分布式计算和内存计算的能力,可以处理大规模的数据集和复杂的计算任务。
- 支持多种数据源:go-spark支持多种常见的数据源,如Hadoop、Kafka、Hive等,使得数据的读取和存储更加灵活和方便。
- 高性能计算:go-spark采用了高效的算法和数据结构,可以进行高性能的数据计算,适用于大规模数据集的处理和分析。
6.3 使用示例
package mainimport ("fmt""github.com/sparkgo/spark"
)func main() {// 创建Spark上下文sc := spark.NewSparkContext("local[*]", "go-spark-example")// 读取数据data := sc.TextFile("data.txt")// 过滤数据filteredData := data.Filter(func(line string) bool {return len(line) > 10})// 打印过滤后的结果filteredData.Collect().ForEach(func(line string) {fmt.Println(line)})
}
在上面的示例代码中,我们使用go-spark读取了一个文本文件,并展示了数据的过滤操作。通过这个示例,您可以了解到如何使用go-spark进行分布式数据处理和分析。
这是关于数据处理和分析库的内容,包括了go-arrow、go-parquet、go-dataframe、go-pandas、go-datatable和go-spark的介绍、特点和使用示例。以上示例代码仅展示了基本功能,具体使用时可以根据实际需求进行相应的调整和扩展。
总结
数据处理和分析是现代计算机科学中不可或缺的一部分,而在Go语言中进行数据处理和分析需要有强大的库来支持。本文介绍了几款优秀的数据处理和分析库,包括go-arrow、go-parquet和go-dataframe,它们提供了高效、灵活和简单的数据操作和计算能力。通过本文的介绍和示例代码,读者可以了解到这些库的特点和使用方法,并掌握它们在实际场景中的应用。
相关文章:

【Golang星辰图】数据处理的航海家:征服数据海洋的航行工具
数据处理的建筑师:用Go语言中构建稳固的数据分析建筑物 前言 数据处理和分析是现代计算机科学中的关键任务之一,而Go语言作为一门现代化的编程语言,也需要强大的数据处理和分析库来支持其在这一领域的应用。本文将介绍几款优秀的数据处理和…...

容器网络测试关键问题
资料问题 主要影响客户体验, 低级问题. 类似于单词拼写错误, 用词有歧义,等。 另一点是,我们的用户文档,主要偏向于技术向的描述,各种参数功能罗列。友商有比较好的最佳实践操作说明。我们后面也会都增加这样的最佳实践。golang o…...
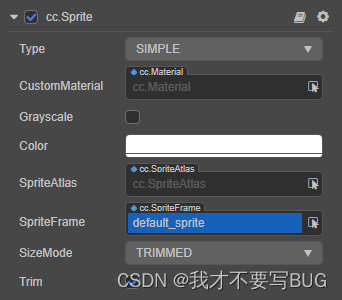
6、Cocos Creator 2D 渲染组件:Sprite 组件
Sprite 组件 Sprite(精灵)是 2D/3D 游戏最常见的显示图像的方式,在节点上添加 Sprite 组件,就可以在场景中显示项目资源中的图片。 属性功能说明Type渲染模式,包括普通(Simple)、九宫格&#x…...

算法沉淀——动态规划篇(子数组系列问题(上))
算法沉淀——动态规划篇(子数组系列问题(上)) 前言一、最大子数组和二、环形子数组的最大和三、乘积最大子数组四、乘积为正数的最长子数组长度 前言 几乎所有的动态规划问题大致可分为以下5个步骤,后续所有问题分析都…...
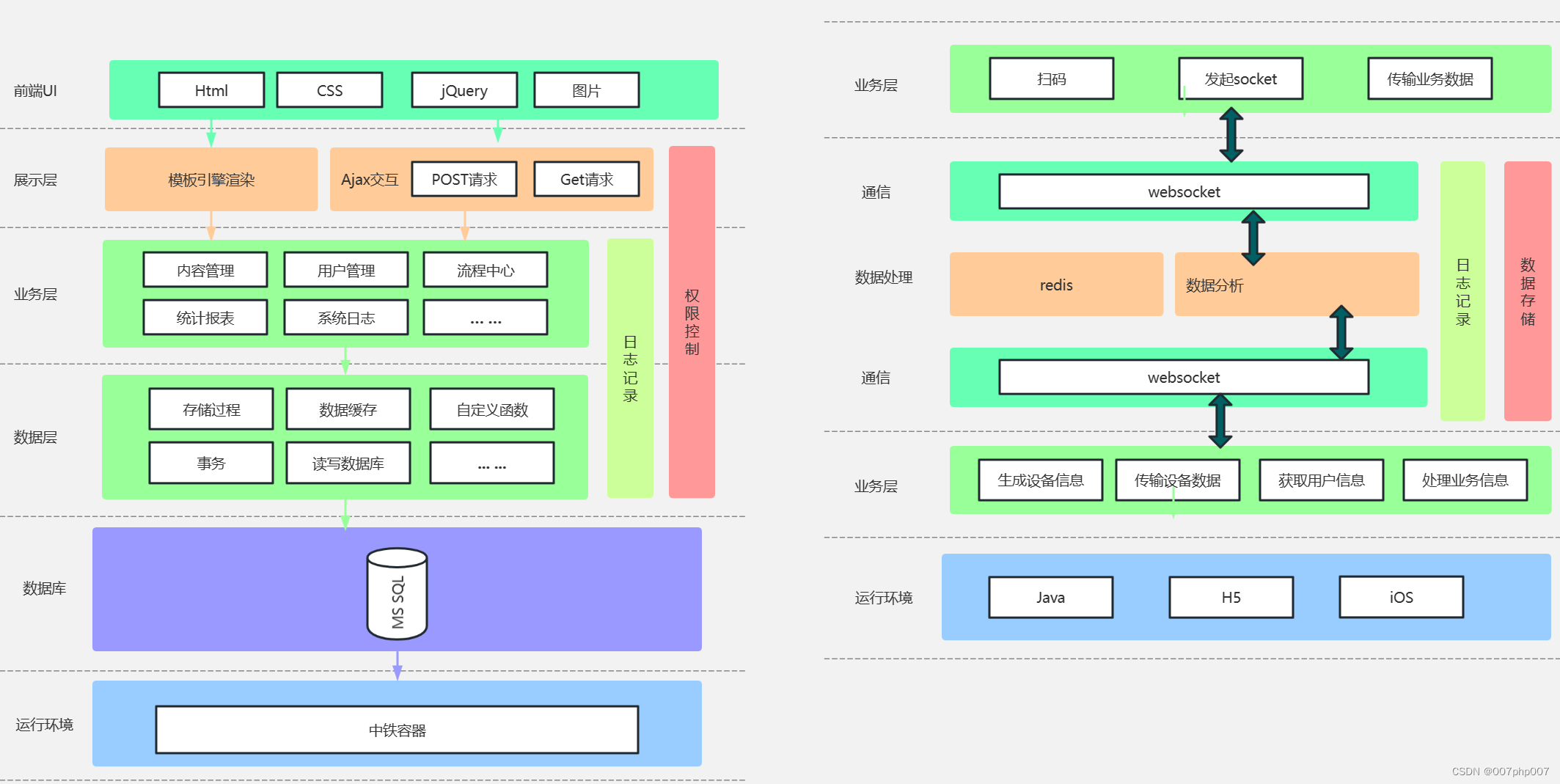
通知中心架构:打造高效沟通平台,提升信息传递效率
随着信息技术的快速发展,通知中心架构作为一种关键的沟通工具,正逐渐成为各类应用和系统中必不可少的组成部分。本文将深入探讨通知中心架构的意义、设计原则以及在实际场景中的应用。 ### 什么是通知中心架构? 通知中心架构是指通过集中管…...
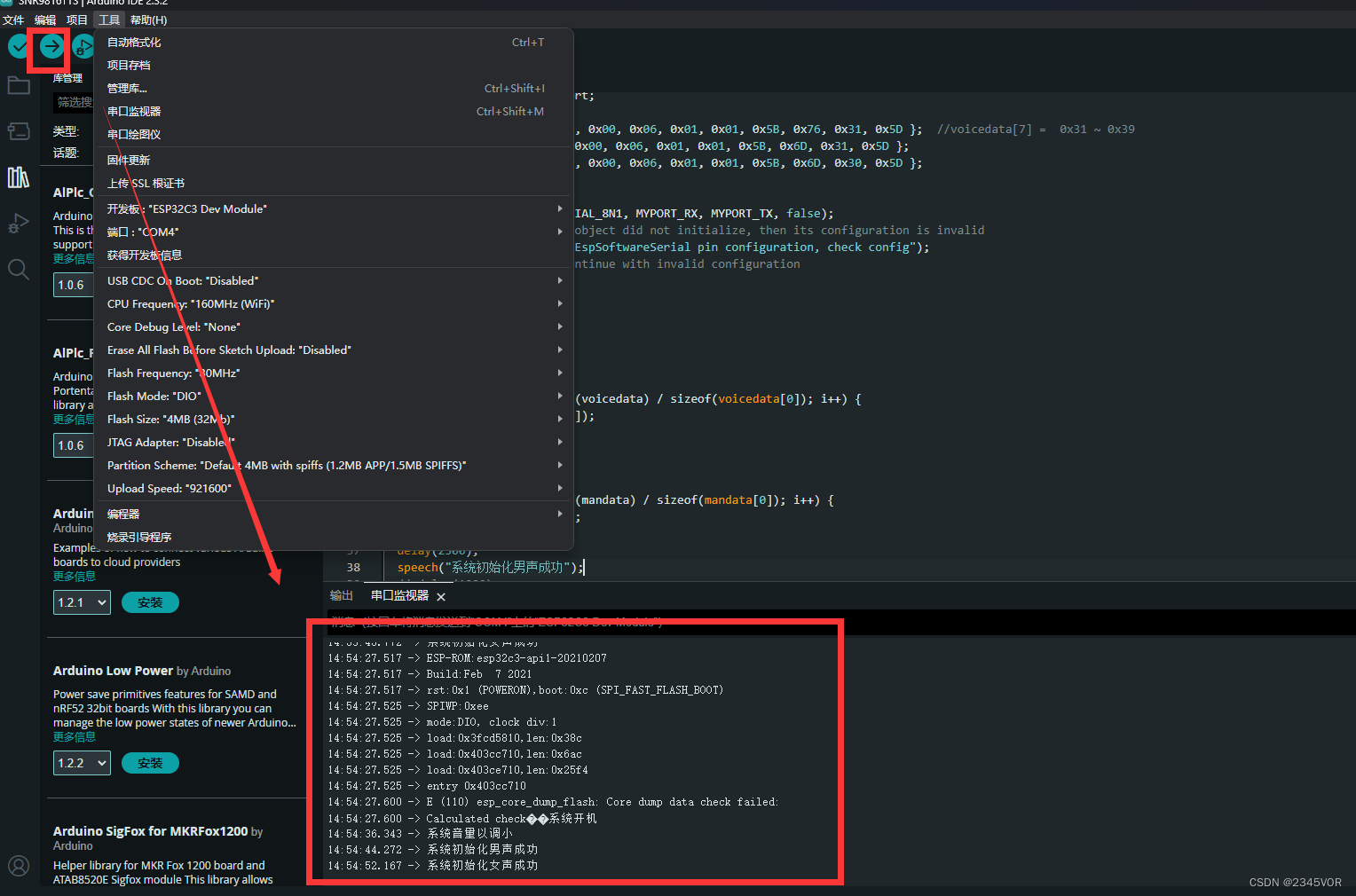
【Arduino使用SNR9816TTS模块教程】
【Arduino使用SNR9816TTS模块教程】 1.前言2. 硬件连接3. Arduino代码3.1 环境配置3.2 Arduino源码 4. 调试步骤5. 总结 1.前言 在今天的教程中,我们将详细介绍如何使用Arduino IDE开发ESP32C3与汕头新纳捷科技有限公司生产的SNR9816TTS中文人声语音合成模块进行交…...
)
牛客练习赛123(A,B,C,D)
牛客挑战赛,练习赛和小白月赛周赛不是一种东西。这玩意跟CF的div12差不多难度。而且找不到题解。所以决定不等题解补题了,直接写题解了。 比赛链接 光速签到下班,rk。感觉E可能能补掉,看情况补吧。 B题感觉之前考了两次&#x…...
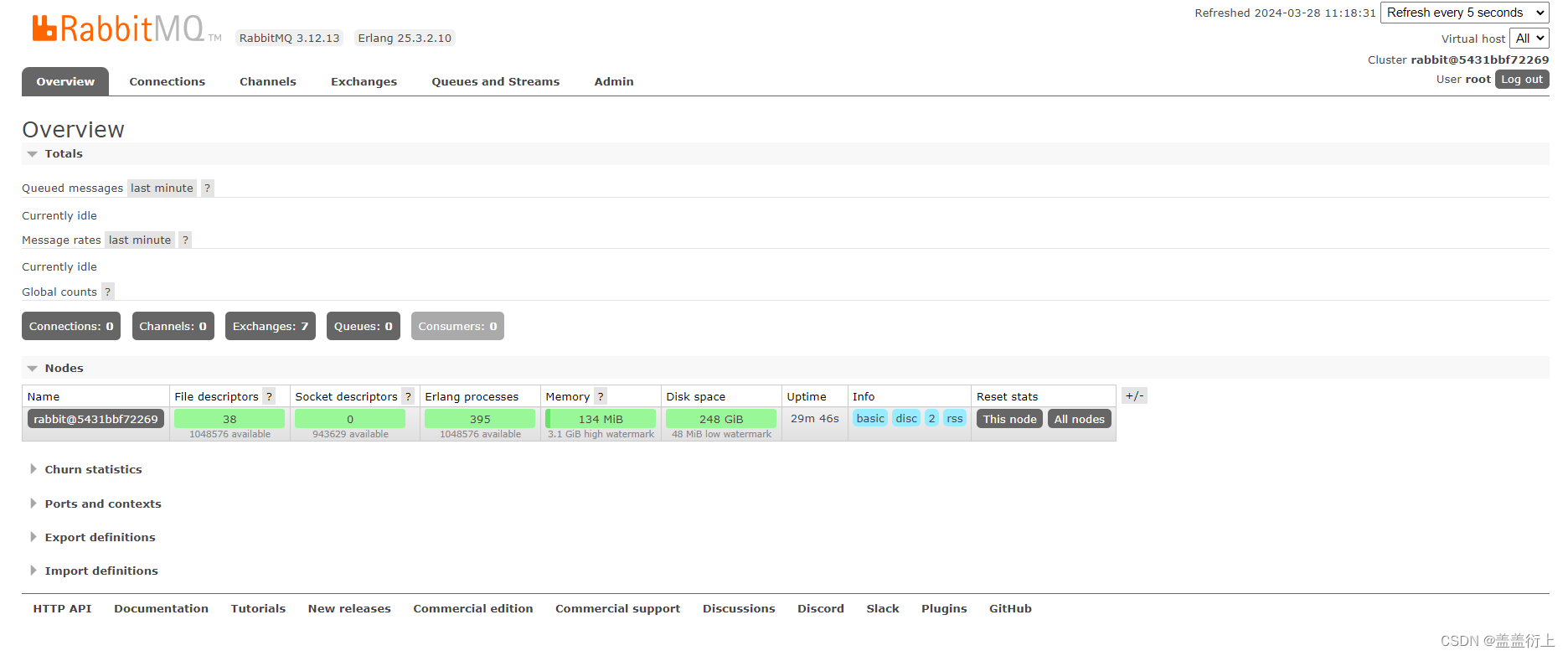
docker部署-RabbitMq
1. 参考 RabbitMq官网 docker官网 2. 拉取镜像 这里改为自己需要的版本即可,下面容器也需要同理修改 docker pull rabbitmq:3.12-management3. 运行容器 docker run \ --namemy-rabbitmq-01 \ -p 5672:5672 \ -p 15672:15672 \ -d \ --restart always \ -…...
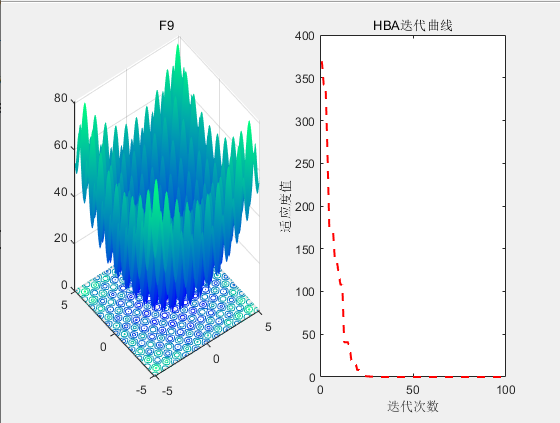
【智能算法】蜜獾算法(HBA)原理及实现
目录 1.背景2.算法原理2.1算法思想2.2算法过程 3.结果展示4.参考文献 1.背景 2021年,FA Hashim等人受到自然界中蜜獾狩猎行为启发,提出了蜜獾算法((Honey Badger Algorithm,HBA)。 2.算法原理 2.1算法思想 蜜獾以其…...
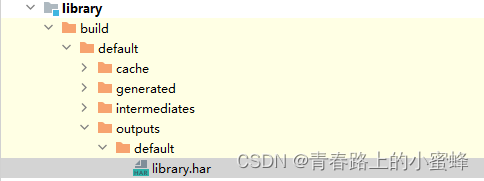
9、鸿蒙学习-开发及引用静态共享包(API 9)
HAR(Harmony Archive)是静态共享包,可以包含代码、C库、资源和配置文件。通过HAR可以实现多个模块或多个工程共享ArkUI组件、资源等相关代码。HAR不同于HAP,不能独立安装运行在设备上,只能作为应用模块的依赖项被引用。…...

[Pytorch]:PyTorch中张量乘法大全
在 PyTorch 中,有多种方法可以执行张量之间的乘法。这里列出了一些常见的乘法操作: 总结: 逐元素乘法:*ortorch.mul()矩阵乘法:ortorch.mm()ortorch.matmul()点积:torch.Tensor.dot()批量矩阵乘法ÿ…...

【软考】防火墙技术
目录 1. 概念2. 包过滤防火墙3. 应用代理网关防火墙4. 状态检测技术防火墙 1. 概念 1.防火墙(Firewall)是建立在内外网络边界上的过滤封锁机制,它认为内部网络是安全和可信赖的,而外部网络是不安全和不可信赖的。2.防火墙的作用是防止不希望的、未经授权…...

OpenHarmony实战:Makefile方式组织编译的库移植
以yxml库为例,其移植过程如下文所示。 源码获取 从仓库获取yxml源码,其目录结构如下表: 表1 源码目录结构 名称描述yxml/bench/benchmark相关代码yxml/test/测试输入输出文件,及测试脚本yxml/Makefile编译组织文件yxml/.gitat…...

嵌入式C语言--GPT通用定时器
嵌入式C语言–GPT通用定时器 嵌入式C语言--GPT通用定时器 嵌入式C语言--GPT通用定时器一. GPT基本概念二. GPT的作用三. GPT通道的四个状态四. Continuous/One-Shot模式3.1)Continuous模式3.2)One-Shot模式 一. GPT基本概念 GPT即General Purpose Timer…...

『Apisix系列』破局传统架构:探索新一代微服务体系下的API管理新范式与最佳实践
一、『Apisix安装部署』 🚀 1.1 手把手教你从零部署APISIX高性能API网关 二、『Apisix入门篇』 🚀 2.1 从零到一掌握Apache APISIX:架构解析与实战指南 三、『Apisix进阶篇』 🚀 3.1 动态负载均衡:APISIX的实战演练…...
如何在极狐GitLab 自定义 Pages 域名、SSL/TLS 证书
本文作者:徐晓伟 GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 本文主要讲述了在极狐GitLab 用户…...

React Native 应用打包
引言 在将React Native应用上架至App Store时,除了通常的上架流程外,还需考虑一些额外的优化策略。本文将介绍如何通过配置App Transport Security、Release Scheme和启动屏优化技巧来提升React Native应用的上架质量和用户体验。 配置 App Transport…...

单链表就地逆置
算法思想:构建一个带头结点的单链表L,然后访问链表中的每一个数据结点,将访问到的数据结点依此插入到L的头节点之后。 #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<stdlib.h> typedef int ElemType; typedef s…...
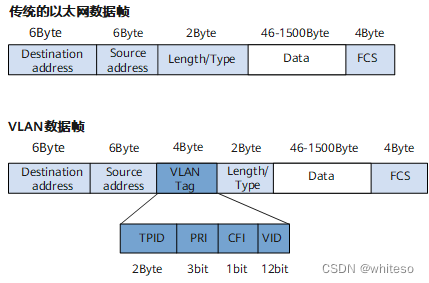
MTU/TCPMSS/VLAN/ACCESS/TRUNK/HYBRID
MTU RFC标准定义以太网的默认MTU值为1500 最小64字节是为了保证最极端的冲突能被检测到,64字节是能被检测到的最小值;最大不超过1518字节是为了防止过长的帧传输时间过长而占用共享链路太长时间导致其他业务阻塞。所以规定以太网帧大小为64~1518字节&am…...

Spring Boot的基础知识和应用
在快速发展的软件开发领域,Spring Boot已经成为了一个广受欢迎的框架,它极大地简化了Spring应用的初始搭建以及开发过程。Spring Boot遵循“约定优于配置”的原则,通过默认配置减少了开发者的配置工作量,使得开发者能够更专注于业…...

【复现】基于神经网络与ANFIS结合的自适应MPC和神经网络NN- MPC在自动驾驶车辆路径跟踪中的应用
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

IDIOMATIC VIMRC完全指南:打造属于你的高效Vim配置文件
IDIOMATIC VIMRC完全指南:打造属于你的高效Vim配置文件 【免费下载链接】idiomatic-vimrc Guidelines for sculpting your very own ~/.vimrc. 项目地址: https://gitcode.com/gh_mirrors/id/idiomatic-vimrc 想要打造一个真正高效、个性化的Vim编辑器配置吗…...

PE Tools历史版本回顾:从2002年到2018年的发展历程
PE Tools历史版本回顾:从2002年到2018年的发展历程 【免费下载链接】petools PE Tools - Portable executable (PE) manipulation toolkit 项目地址: https://gitcode.com/gh_mirrors/pe/petools PE Tools,这款经典的PE文件分析工具,自…...

跨云跨机房服务协同失效?MCP 2026编排引擎全链路诊断,5类高频故障秒级定位与修复
第一章:MCP 2026跨云跨机房协同失效的典型表征与根因图谱MCP 2026(Multi-Cloud Platform 2026)在跨云(如 AWS ↔ 阿里云 ↔ Azure)与跨物理机房(如北京IDC ↔ 深圳IDC ↔ 新加坡IDC)场景下&…...

PROJECT MOGFACE Java开发集成指南:SpringBoot微服务调用实战
PROJECT MOGFACE Java开发集成指南:SpringBoot微服务调用实战 你是不是正在开发一个Java后端应用,想给它加上点“智能”的能力?比如让系统能自动生成一段产品描述,或者分析用户上传的图片内容。以前做这些,要么得自己…...

7款免费开源字体深度评测:设计师与开发者的创新资源指南
7款免费开源字体深度评测:设计师与开发者的创新资源指南 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 在数字化设计与开发领域,开源字体正以前所未有的速度重…...

网盘资源搜索工具使用体验分享
最近在找一些学习资料和影视资源时,试用了几个网盘搜索网站,记录下使用体验,希望能帮到有同样需求的朋友。 竹云盘搜(zhuyunso.top) 这个站给我的第一印象就是简洁。打开页面就一个搜索框,没有任何弹窗广…...

REX-UniNLU与Python爬虫结合:零样本语义分析实战指南
REX-UniNLU与Python爬虫结合:零样本语义分析实战指南 1. 场景引入:当爬虫遇到语义理解 电商公司的运营小张最近遇到了一个头疼的问题:他们用爬虫收集了上万条竞品评论数据,但面对海量的文本信息,手动分析变得几乎不可…...

为什么你的Ubuntu密码策略总失效?深入解析libpam-pwquality的隐藏参数
为什么你的Ubuntu密码策略总失效?深入解析libpam-pwquality的隐藏参数 在Ubuntu服务器管理中,密码策略配置看似简单却暗藏玄机。许多运维工程师按照官方文档配置/etc/pam.d/common-password后,仍会遇到密码复杂度要求时灵时不灵的情况——有时…...
彻底清理卸载应用后的「打开方式」残留项)
Mac(六)彻底清理卸载应用后的「打开方式」残留项
1. 为什么卸载应用后「打开方式」菜单还有残留? 每次在Mac上卸载完应用,本以为可以彻底告别它,结果右键点击文件时,那个阴魂不散的「打开方式」选项还在列表里晃悠。这种情况我遇到过太多次了,特别是像Photoshop、GIMP…...