Flink 流批一体在模型特征场景的使用
摘要:本文整理自B站资深开发工程师张杨老师在 Flink Forward Asia 2023 中 AI 特征工程专场的分享。内容主要为以下四部分:
- 模型特征场景
- 流批一体
- 性能优化
- 未来展望
一、 模型特征场景
以下是一个非常简化并且典型的线上实时特征和样本的生产过程。

前面是一个 Show 和 Click ,也就是点击展现实时流,数据上报到 kafka 后在 Flink 里面进行 Join,计算完再输出到 Kafka 。再进入下一个 Flink 任务进行特征计算和样本生成,最后再输出到 Kafka 供给模型实时训练使用。目前B站大部分推荐链路的实时数据架构,基本都是这样。Kafka 的中间数据,全部都会 dump 到 Hive 或者到 Iceberg 里面去,如果要算历史的特征样本或者模型冷启动,离线侧会用 Spark 做类似的一个计算存储到 Hive 里面去,供给模型离线训练使用。
上面的链路主要对应着线上生产场景,下面的则对应着模型调研以及冷启动场景,两条链路一定是长期都存在的。

这样做会出现的一些常见问题:
-
双链路开发架构的问题
用户既要学习 Spark 又要学 Flink 。尤其是 Flink 里面很多语法和现在的 Spark 稍微有些不一样。大部分开发同学都是从离线的模型转到实时。那它其实是有比较高的学习成本,或者是比较高的转换成本。 -
计算一致性
很多 SQL 看起来虽然是一样的但是计算结果会有微小的差别,比如 Flink 支持 ANSI SQL 标准,但 Spark 我们当前版本不完全支持。用户可能离线调研时发现特征效果很好,实时一上生产后发现效果不佳,这种情况挺常见的,一番排查最终发现是自带的算子 UDF 行为不一样所引起的,需要一直在这个层面做各种兼容调整,这样其实是比较痛苦的。 -
长期运维
另外就是在特征计算库的开发,在计算引擎层面就是 UDF。我们有一些纯 Java 的 UDF ,也有一些带 JNI 的 UDF,在 Spark、Flink 引擎上都分别实现了。但是在长期看,比如说算某天说我要升级 UDF 依赖的 Tensorflow,这个对 Linux 内核版本要求也比较高,整个计算引擎依赖的环境就要跟着变化。如果是多引擎,那多引擎都要去做基础环境的升级,这个风险其实就非常大了。在我们的业务场景里,这个其实常常遇到,是个很大痛点。
二、流批一体
基于上面背景,我们采用了流批一体的方案来解决当前的问题。我们目前使用的 Flink 1.15 版本,它已经是一个比较成熟的版本。如果用 Flink 来替代 Spark 的离线场景,那实际上前面讲的问题对用户来说,都是可以解决的。

这个是基本的架构,用户的 Adhoc 或者 ETL 通过 Client 提交到 Flink 集群,资源调度我们支持 Yarn 和 K8S 。Shuffle 架构前期是使用了Flink Remote Shuffle,目前现在已经迁移到 Celeborn。最终的结果数据是写到 Kafka 或者 Hive 来支持机器学习或者一些业务分析的应用。

以下是我们对接流批一体所做的具体工作:
- 基于 Flink 1.15的版本,打通了公司内部所有的 Adhoc/ETL 调度引擎的入口,包括针对算法同学依赖的 CLI 的提交。打通现有离线体系的好处不言而喻,Flink 能立即无缝对接到当前的离线生态,我们只需要专注于引擎本身的开发。
- 第二个是支持 Flink 任务运行在实时的 k8s 或者离线的 Yarn 资源池里。目前实时的一个重要工作就是逐步迁移到 K8S,离线当前还是以 Yarn为主。
- 第三个对于实时链路,是有多种存储的,流批一体意味着批也要支持多存储。比如说实时它可能 Redis 用的比较多,离线可能大部分都是用 Hive 就可以。所以在流批一体上,这些各种 Flink 的 Connector 都对 Batch 场景进行了优化。因为在实际的使用过程中,会发现不优化的话有很多很多小问题,这个后面会大概讲一下。
- 最后一个就是协助业务迁移。目前商业化和AI推荐相当一部分的特征计算或者调研,都已经逐渐迁到 Flink Batch 上去了。

以下是语法层面我们做的一些细节点。
- 第一个就是支持 Hive Module,主要是兼容 HIVE UDF,这样既方便 Batch场 景使用,Streaming 场景收益也比较大。对于大部分用户来说,它从离线模型升级到实时模型,可能很多 UDF 尤其是系统的 UDF,是不需要去做重复的开发。
- 第二个是特征流批业务,把用户经常使用的语法进行支持。在做离线特征计算的时候,用户很常用某种语法,实时没有或者不好用,我们也都做了相应的优化。比如业务经常会用 Add Jar 来加实施资源。
- 第三个在实际使用过程中发现,对于用户来说,很多UDF流批行为也是稍微不一样的。部分UDF流批行为进行区分,不同模式需求不同,如 Now 函数 Streaming 场景是非 Deterministic,但是我们在 Batch 场景下,用户的期望是 Deterministic 的。我们做了兼容,根据版本自动会选择自己的行为,这个是语法或者 UDF 上一些很小的细节带来的一些坑。
接下来就是 Connector 的优化,也就是流批模式的兼容改造。
-
Streaming 延迟敏感,Batch 吞吐优先,默认参数大多根据 Streaming 场景定制,根据模式自适应。其实 Streaming 场景是一个延迟敏感的。大部分在线上实时流对延迟是比较敏感的。比如说他的特征计算或样本生成,写到 Kafka 里面可能配的 Count 是100条就写入,或者超时100毫秒就写出去。但是在把这个配置直接拿到批场景去使用,这个配置数值就太低了。
-
Streaming 里一些 Static 单例连接的优化,如果没有开 Restart 功能,那么在实时场景下算子的生命周期大部分场景下都是一致。Batch 场景下 Task 的生命周期是完全不一样的,算子完成后如果直接粗暴的关闭单例就会有问题。其实 Streaming 里面这种做法也是不合理的,只是 Batch 会放大这个问题,我们在这方面也是做了优化。

第三个就是做了流批的错峰资源的利用。因为流业务主要运行在 K8S 集群上,所以做 Flink 的批也希望运行在 K8S 上。K8S 上是流批共享调度器,流和批任务的行为差别还挺大的,批任务的资源占用大头 ETL 都是在晚上,白天相对资源占用较少。但是流任务完全相反,白天用的比较满,晚上用的比较少。流批天然就是错峰资源占用,因此我们也建议用户可以把一些比较占资源的补数的任务丢到半夜运行,这样能比较充分的利用资源。
但是实际白天的时候,流批还是会有一些竞争,无法完全避免。我们整个方案是基于公司内部的一个混部框架,就是在同一套 K8s 集群上,会有两套资源视图,一个是在线资源视图,他会看到所有的机器资源。另一个是混部资源视图,能看到那些剩余资源,但是这个视图的优先级是比较低的,在资源紧张的情况下会驱逐任务。比如说在线机器是 100% 资源视图,在线业务实际占用了 30% 资源,那剩下的 70% 资源可以被混部资源视图看到,两个资源视图配合两个调度器来进行调度。
下面这是一个效果,这是前段时间截图的。

图上可以看到 2 点到 6 点左右,流占用的资源是非常少的,但是这个时候批占用的资源是很大的,错峰的资源能被批利用起来。在白天的话其实批资源使用也不低,这是业务特性,可以看到机器的资源利用率大概是70%左右。因为我们设置的保护阈值在 80% 左右,如果流业务吃不到 80% 资源,剩下的都是可以被批作业占用。
除此之外,最近还做了一个事情,就是把 flink 升到了 JDK17。因为我们发现混部之后,资源瓶颈好像不在 CPU 了而是在内存了,对于低版本的 Java 进程来说,它的内存消耗是刚性的,不是很利于混部。在 JDK12 之后 Jvm 的 GC 支持了向操作系统进行内存返还,在流计算这样的大数据场景,我们觉得对性能的要求也没有高到要去考虑内存分配效率的这个程度,因此我们把 Flink 运行环境进行到了 JDK17,也开启了内存返还的功能。
从上线的数据来看,整个集群的内存节省是超过 15% ,能比较好的提升资源的利用。
三、 性能优化
接下来我们来看一下框架层面做的性能优化。
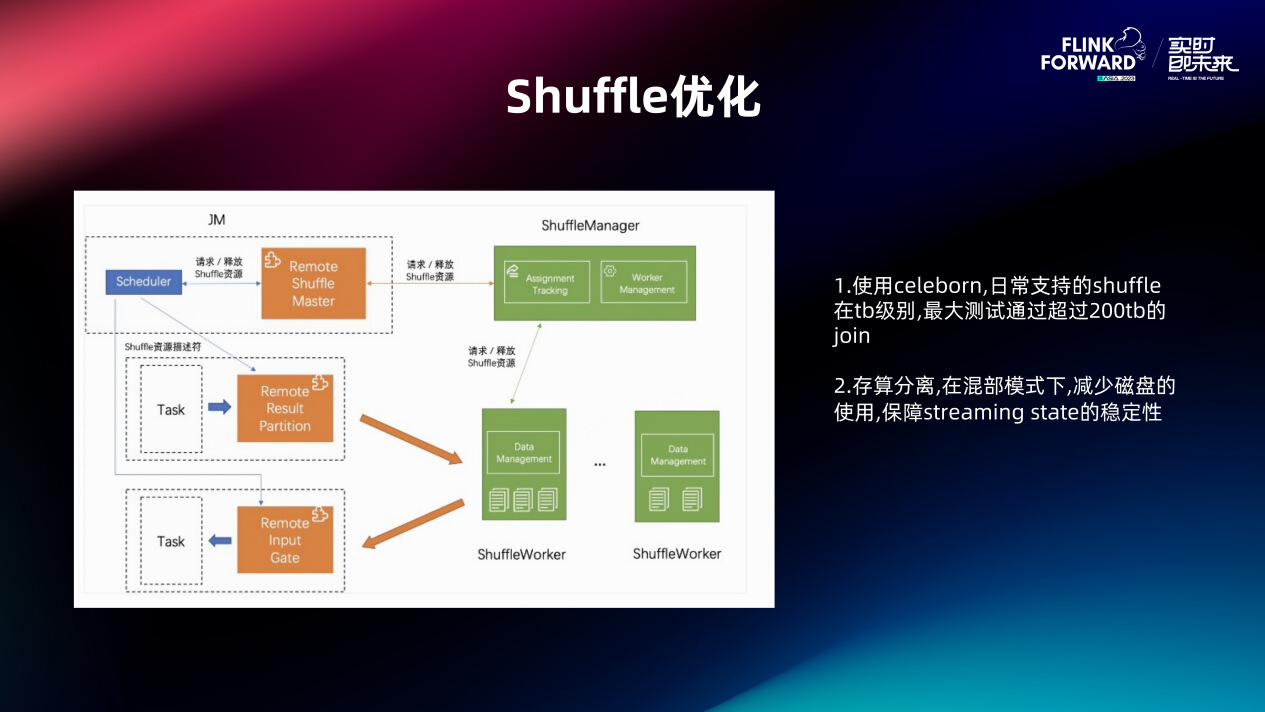
首先就是 Shuffle 的优化,业务的使用过程中,shuffle 操作是比较常见的。我们最开始用的 Flink Netty Shuffle,发现稳定性比较差,本地磁盘的 IO 压力很大,算子资源占用也比较多。我们调研下业界的一些方案,切换到了 Apache Celeborn Shuffle ,我们在80台物理机,单机 14tb 的 SSD 存储的集群上,测试存储超过200T的 Shuffle 任务,性能上看很稳定。做这个事情还有一个好处就是存算分离,前面说了我们是流批混部的架构。Streaming 本身就是存算一体的,那把批再放上来,如果它也是一个存算一体的架构,这个其实对磁盘的争抢会非常激烈,那只能做 IO 的 Cgroup 或者分盘管理,但是这个其实运维成本很高。实际上 Streaming 这块我们目前也在做 Tiered Storage,社区应该也有这个规划。我们希望在 Flink 计算上把本地的存储放到远程去,这样的话,计算的 Scala 的能力会更大。
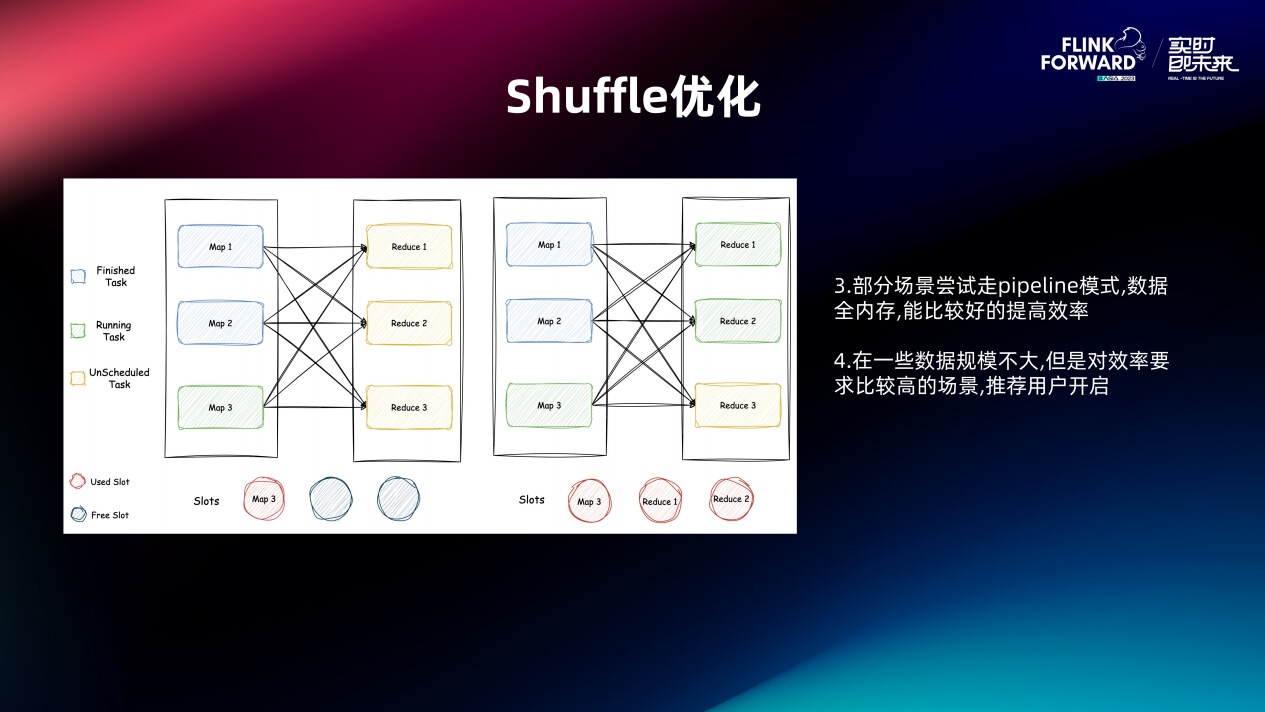
然后 Shuffle 优化的第二个点就是在部分场景尝试走 Pipeline 的模式。社区其实有一个 Hybrid 模式,介于上面两者之间,但是这个功能我们测试下来会有死锁的问题,最新的版本应该是解决了。在 Pipeline 模式下,数据是不会落盘,目前我们测下来,比如说几百G或者两三个T的场景还是能比较好的提升效率,它的效率整个来说我们是和 Presto 做一些对标,比会差一点但没有差特别多。所以这种场景我们也在推荐用户走这个 Pipeline 模式。
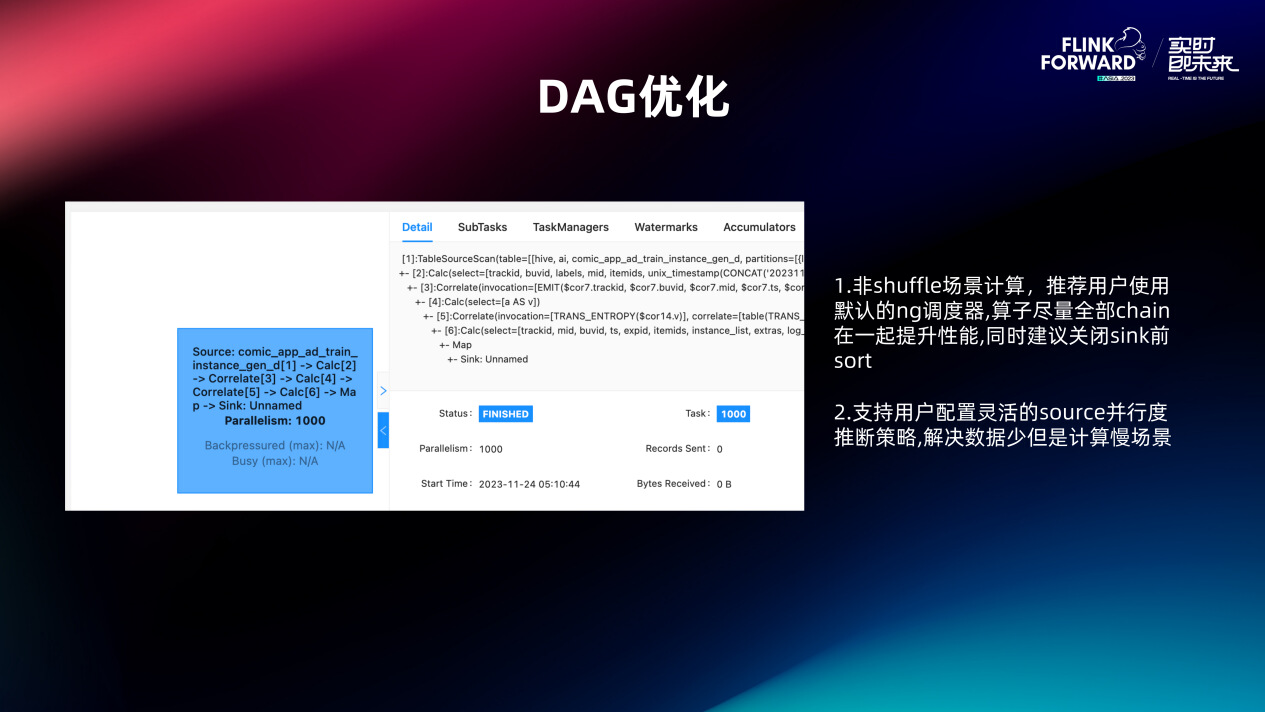
如图就是一些 DAG 的优化。直接切到 Flink 批上去之后,其实发现可能会有很多无用的 Shuffle。比如 Source 读完数据再做个 Map 计算,在这两个算子之间会加一层 Shuffle,其实完全没有必要。
很多的一些非 Shuffle 的场景,我们实际上都是推荐用户走默认的 NG 调度器。算子我们是尽量能够全部 chain 在一起的,包括 Sink 默认的 Sort 我们也关闭了,这样实际上计算上看到这个 DAG 其实就是从头串到尾的,效率非常高。
但是在有些场景下,比如说 Source 的数据不大但是计算压力非常大。比如说有些特征计算比较复杂,需要调一些 Tensorflow 库导致算起来比较慢,我们也是支持配这些灵活的策略,例如 Source 我要把它分开来,后面的计算可以做的更多,这个目前也是可以的。
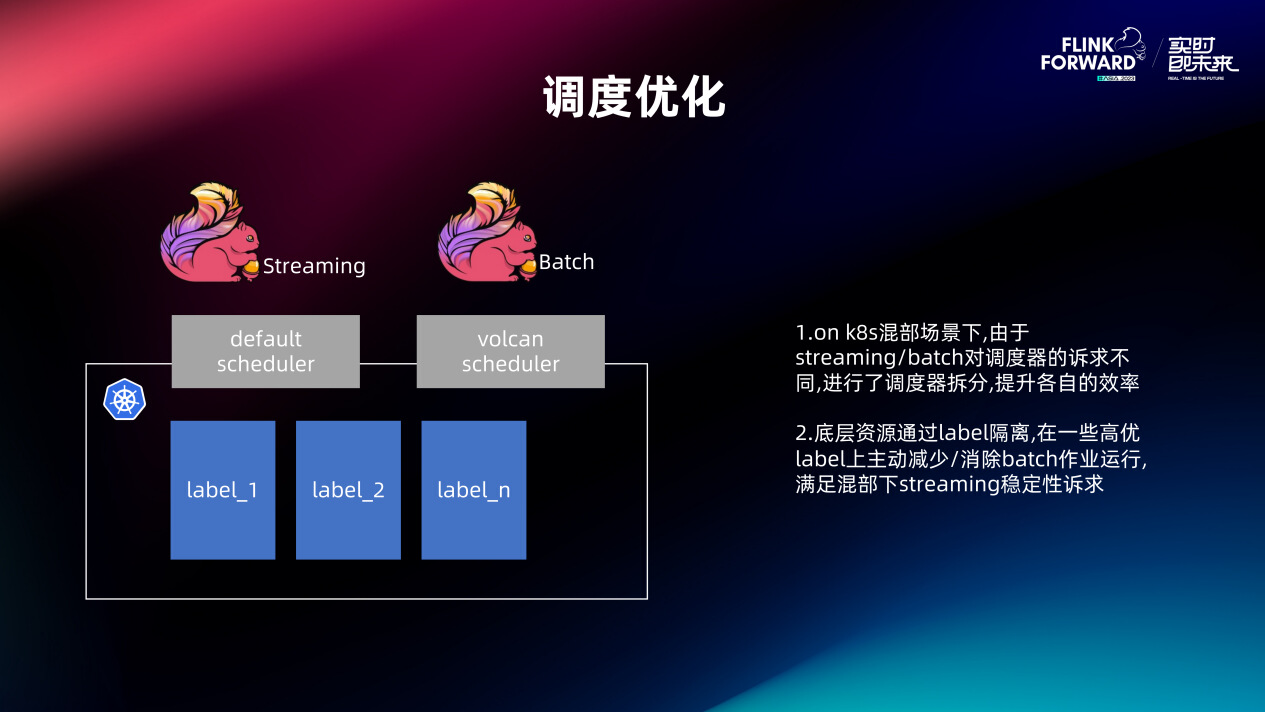
最后一个是调度层面的优化。
我们前面也说到我们采用的一个资源池下面的流批混部,错峰使用资源。调度器层面也出现了一些问题,Streaming 和 Batch 对调度器的诉求其实不同的。Streaming 是 Long Running 的,Container 调度的频率其实相对的是比较低的,吞吐要求不是很高。但是 Batch 任务不是,任务频繁运行,每次执行都是几百上千个 Container 申请,在资源紧张的情况下,它可能运行周期内也会一直持续的来申请 Container。早期我们共用一个调度器,发现 Batch 任务比较多的时候,Streaming 任务是没法申请到 Container 的,都堵在调度器线程里面。所以我们需要进行调度器的拆分, Streaming 业务我们还是用 K8s 默认的 Default Scheduler,Batch 则是换到了目前大部分公司都会选用的 Volcano 调度器。
在底层资源上,Streaming 业务采用了 K8S 的 Label 隔离,也就是物理层面隔离。但是在 Batch,我们实际上是通过 Volcano 的一些 Capacity 来进行限制,来保证整个的资源弹性。前面也说过,混部资源的优先级会比较低,在 Streaming 业务申请资源的情况下,如果整体资源不足,Batch 业务会被驱逐。
四、未来展望

-
探索更多特征场景的流批一体。目前还有部分算子例如 Interval Join 等还没办法做到流批一体,技术上难度也比较大。这两天听了一些 Apache Paimon 的分享,发现也可以试试看能不能从存储层面解决这个问题。
-
第二个就是 DAG/Shuffle 优化,提升特征样本计算性能。我们和 Spark 或者 Presto 进行了一些对比之后,目前1.15版本在一些细节的地方效果没有那么好,还有比较大的提升空间。
-
最后一个是 Flink 支持更多引擎的 UDF。业务也希望我们支持除了 Hive 还有像 Presto/Spark 这些引擎独有的 UDF 。有些纯粹的离线模型也想逐渐实时化,这个也是当前主要的迁移成本之一。
相关文章:
Flink 流批一体在模型特征场景的使用
摘要:本文整理自B站资深开发工程师张杨老师在 Flink Forward Asia 2023 中 AI 特征工程专场的分享。内容主要为以下四部分: 模型特征场景流批一体性能优化未来展望 一、 模型特征场景 以下是一个非常简化并且典型的线上实时特征和样本的生产过程。 前面…...
06-编辑器
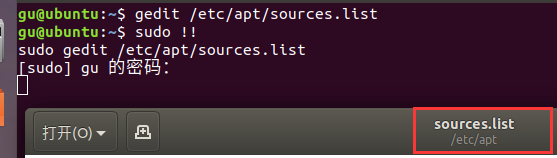
gedit编辑器 gedit是Ubuntu系统自带的编辑器,可以用来轻度编辑和记录一些内容。 在终端中我们通过以下命令打开: gedit 要打开或者新建的文件名虽然Ubuntu的图形界面也能通过gedit打开文件,但是用终端打开gedit可以动用更高的权限ÿ…...
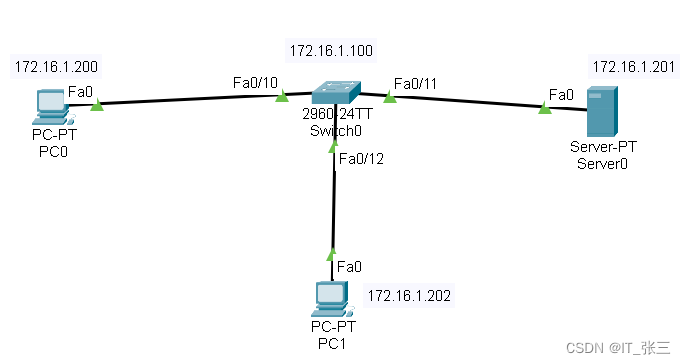
5.3.2 实验2:配置交换机端口安全
1、实验目的 通过本实验可以掌握: 交换机管理地址配置及接口配置。查看交换机的MAC地址表。配置静态端口安全、动态端口安全和粘滞端口安全的方法。 2、实验拓扑 配置交换机端口安全的实验拓扑如图所示。 配置交换机端口安全的实验拓扑 3、实验步骤 ÿ…...

【AIGC调研系列】通义千问、文心一言、抖音云雀、智谱清言、讯飞星火的特点分析
通义千问、文心一言、抖音云雀、智谱清言、讯飞星火这五款AI大模型各有特色,它们在市场上的定位和竞争策略也有所不同。 通义千问:由阿里巴巴推出,被认为是最接近ChatGPT水平的国产AI模型[7]。它不仅提供了长文档处理功能,还能够…...
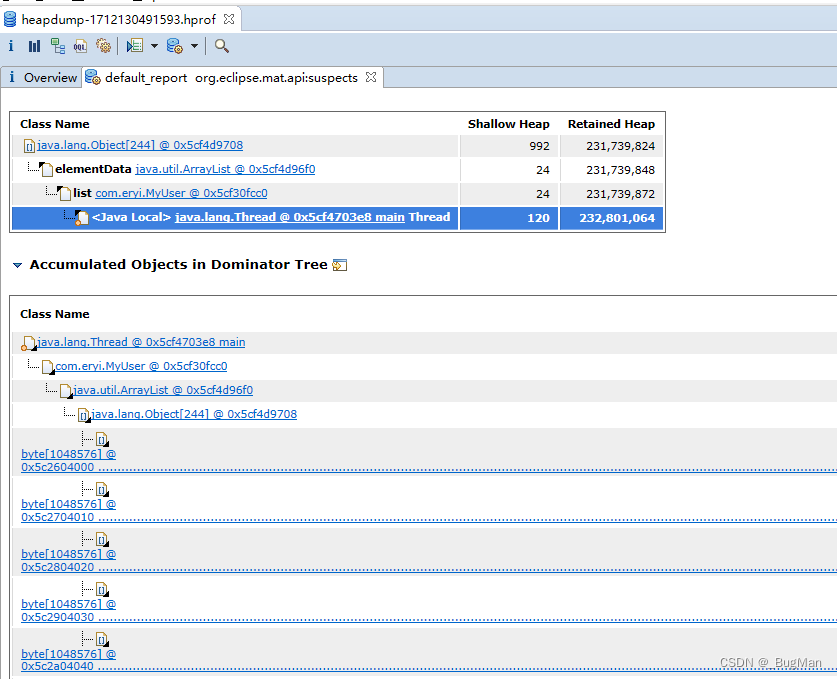
【JVM】如何定位、解决内存泄漏和溢出
目录 1.概述 2.堆溢出、内存泄定位及解决办法 2.1.示例代码 2.2.抓堆快照 2.3.分析堆快照 1.概述 常见的几种JVM内存溢出的场景如下: Java堆溢出: 错误信息: java.lang.OutOfMemoryError: Java heap space 原因:Java对象实例在运行时持…...

常见网络问题的概述
网络问题概述 网络问题可能包括视频通话延迟、应用或网络速度慢、下载缓冲、VoIP质量差和互联网连接丢失等。 这些问题可能由硬件故障、使用模式变化、安全漏洞等引起,且可能对业务运营产生严重影响。 网络问题对企业的影响 网络问题不可避免,但可以…...

说说你对数据结构-树的理解
对树 - 二叉搜索树的理解 二叉搜索树是一种常见的二叉树结构,它具有以下特点: 每个节点最多只有两个子节点,分别称为左子节点和右子节点;对于任意节点,其左子树中的所有节点均小于该节点,其右子树中的所有…...
Docker实例
华子目录 docker实例1.为Ubuntu镜像添加ssh服务2.Docker安装mysql docker实例 1.为Ubuntu镜像添加ssh服务 (1)访问https://hub.docker.com,寻找合适的Ubuntu镜像 (2)拉取Ubuntu镜像 [rootserver ~]# docker pull ubuntu:latest latest: Pulling from library/ub…...

python基础——模块【模块的介绍,模块的导入,自定义模块,*和__all__,__name__和__main__】
📝前言: 这篇文章主要讲解一下python基础中的关于模块的导入: 1,模块的介绍 2,模块的导入方式 3,自定义模块 🎬个人简介:努力学习ing 📋个人专栏:C语言入门基…...
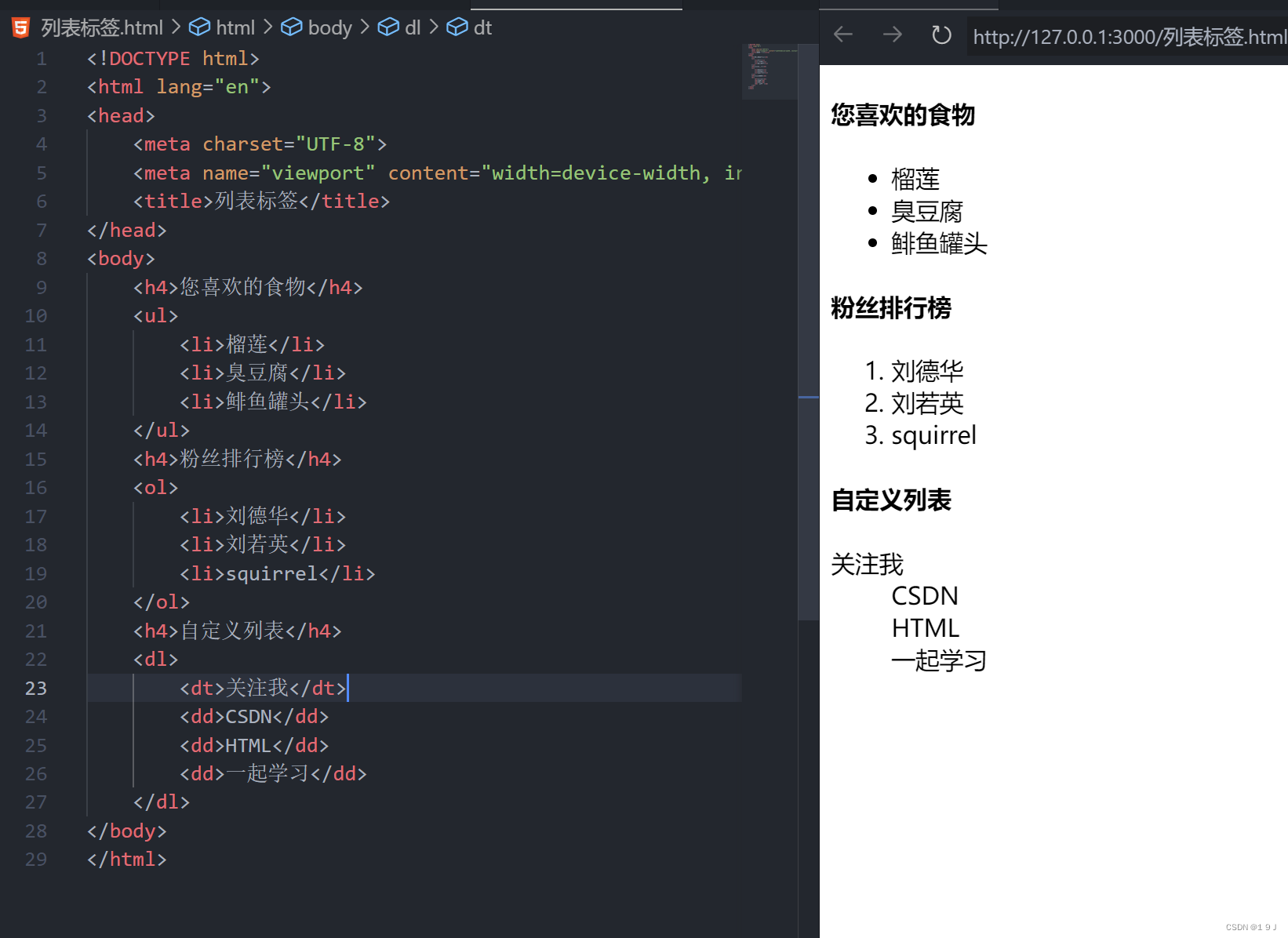
【HTML】标签学习(下.2)
(大家好哇,今天我们将继续来学习HTML(下.2)的相关知识,大家可以在评论区进行互动答疑哦~加油!💕) 目录 二.列表标签 2.1 无序列表(重点) 2.2有序列表(理解) 2.3 自定义列表(重点…...
)
os模块篇(十一)
文章目录 os.chdir(path)os.chmod(path, mode, *, dir_fdNone, follow_symlinksTrue)os.chown(path, uid, gid, *, dir_fdNone, follow_symlinksTrue)os.getcwd()os.getcwdb()os.lchflags(path, flags)os.lchmod(path, mode)os.lchown(path, uid, gid) os.chdir(path) os.chdi…...

编译amd 的 amdgpu 编译器
1,下载源码 git clone --recursive https://github.com/ROCm/llvm-project.git 2, 配置cmake cmake -G "Unix Makefiles" ../llvm \ -DLLVM_ENABLE_PROJECTS"clang;clang-tools-extra;compiler-rt" \ -DLLVM_BUILD_EXAMPLESON …...

github 多个账号共享ssh key 的设置方法
确认本机是否已有ssh key 首先确认自己系统内有没有 ssh key。 bash复制代码cd ~/.ssh ls *.pub # 列出所有公钥文件id_rsa.pub若有,确认使用当前 key 或者生成新 key,若没有,生成新 key。由于我需要登录两个帐号,所以在已经存在…...

dm8修改sysdba用户的密码
1 查看达梦数据库版本 SQL> select * from v$version;LINEID BANNER ---------- --------------------------------- 1 DM Database Server 64 V8 2 DB Version: 0x7000c 3 03134283904-20220630-163817-200052 …...

基于boost准标准库的搜索引擎项目
零 项目背景/原理/技术栈 1.介绍boost准标准库 2.项目实现效果 3.搜索引擎宏观架构图 这是一个基于Web的搜索服务架构 客户端-服务器模型:采用了经典的客户端-服务器模型,用户通过客户端与服务器交互,有助于集中管理和分散计算。简单的用户…...
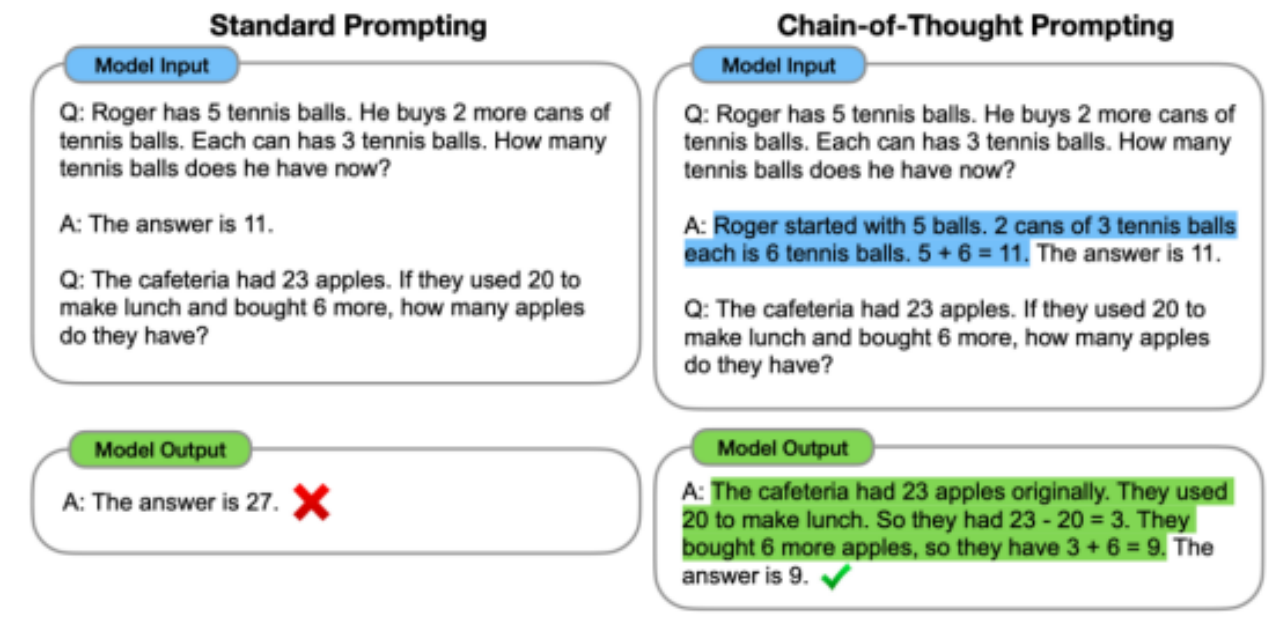
语言模型进化史(下)
由于篇幅原因,本文分为上下两篇,上篇主要讲解语言模型从朴素语言模型到基于神经网络的语言模型,下篇主要讲解现代大语言模型以及基于指令微调的LLM。文章来源是:https://www.numind.ai/blog/what-are-large-language-models 四、现…...

设计模式之旅:工厂模式全方位解析
简介 设计模式中与工厂模式相关的主要有三种,它们分别是: 简单工厂模式(Simple Factory):这不是GoF(四人帮,设计模式的开创者)定义的标准模式,但被广泛认为是工厂模式的…...

大数据时代的生物信息学:挖掘生命数据,揭示生命奥秘
在当今科技日新月异的时代,大数据如同一座蕴藏无尽宝藏的矿山,而生物信息学则是那把锐利的探矿锤,精准有力地敲击着这座“生命之矿”,揭示出隐藏在其深处的生命奥秘。随着基因测序技术的飞速进步与广泛应用,生物医学领…...

微信小程序开发【从入门到精通】——页面导航
👨💻个人主页:开发者-曼亿点 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 曼亿点 原创 👨💻 收录于专栏:…...
嵌入式|蓝桥杯STM32G431(HAL库开发)——CT117E学习笔记15:PWM输出
系列文章目录 嵌入式|蓝桥杯STM32G431(HAL库开发)——CT117E学习笔记01:赛事介绍与硬件平台 嵌入式|蓝桥杯STM32G431(HAL库开发)——CT117E学习笔记02:开发环境安装 嵌入式|蓝桥杯STM32G431(…...
三大特性之封装)
Javase(三)三大特性之封装
封装现实生活中,比如鼠标,我们知道它是全部装在一个装置里面,只暴露出一个接口能够我们充电或连接电脑,里面的设计、电路等都不暴露给我们这些使用者看,这样子能很好的保护里面的东西不被破坏。在Java中也是如此&#…...

偏振无关 宽带消色差 长波红外超透镜模型 粒子群优化算法 复现论文:2022年博士论文
偏振无关 宽带消色差 长波红外超透镜模型 粒子群优化算法 复现论文:2022年博士论文:消色差超透镜设计原理及其应用研究 论文介绍:采用各向同性的多种不同形状的超表面单元,利用庞大的数据库和粒子群优化算法,设计长波红…...
)
OpenClaw × 88API:10 分钟搭好本地网关,解决 API 超时和多渠道切换(2026 完整教程)
你可能也踩过这些坑:项目快提测了,Claude API 突然超时,重试半天还是报错想临时换一个中转站兜底,结果又要改一遍 base_url、api_key、模型名一个渠道支持 Claude,不支持 Gemini;另一个支持 GPT,…...

leetcode 困难题 1591. 奇怪的打印机 II-Strange Printer II
Problem: 1591. 奇怪的打印机 II-Strange Printer II 通过观察可以发现,像Example 2,3的最大外接矩形内包括了3和4,所以先3后4,也就是 3->4 同样的,若1的外接矩形内包括了2, 3,4,…...

RefluxJS终极部署指南:从开发到生产的完整工作流程
RefluxJS终极部署指南:从开发到生产的完整工作流程 【免费下载链接】refluxjs A simple library for uni-directional dataflow application architecture with React extensions inspired by Flux 项目地址: https://gitcode.com/gh_mirrors/re/refluxjs Re…...

AI大模型系统学习路线:零基础入门人工智能,附AI大模型学习与面试资源!【非常详细】
人工智能(AI)正在重塑全球产业格局,从自动驾驶到医疗诊断,从金融风控到内容创作,AI技术已成为21世纪的核心竞争力。对于零基础学习者而言,构建系统化的学习路径至关重要。1. 明确学习动机职业转型 …...

c++如何通过文件映射mmap在多进程间实现高性能数据共享【进阶】
mmap 多进程共享必须用 MAP_SHARED,因其确保所有进程映射同一物理页并同步回文件;MAP_PRIVATE 为写时复制,修改不共享。需 O_RDWR 打开、ftruncate 预设大小,并配合适当同步机制。为什么 mmap 在多进程共享中必须用 MAP_SHARED 而…...

Qwen2.5-14B-Instruct开源模型落地:像素剧本圣殿短视频脚本批量生成
Qwen2.5-14B-Instruct开源模型落地:像素剧本圣殿短视频脚本批量生成 1. 项目概述 像素剧本圣殿(Pixel Script Temple)是一款基于Qwen2.5-14B-Instruct深度微调的专业剧本创作工具。它将顶尖的AI推理能力与8-Bit复古美学完美融合,…...

3分钟搭建你的微信智能管家:零代码实现24小时自动回复
3分钟搭建你的微信智能管家:零代码实现24小时自动回复 【免费下载链接】WechatBot 项目地址: https://gitcode.com/gh_mirrors/wechatb/WechatBot 想要一个能帮你自动处理微信消息的智能助手吗?WechatBot微信机器人让你在3分钟内拥有一个全天候在…...

告别繁琐配置:用快马ai一键生成windows版openclaw自动化安装脚本原型
最近在折腾一个开源工具OpenClaw,发现它在Windows下的安装过程真是让人头大——各种依赖检查、环境变量配置,手动操作一不小心就出错。作为一个懒人程序员,我决定用Python写个自动化安装脚本,结果发现用InsCode(快马)平台的AI辅助…...