数据结构记录
之前记录的数据结构笔记,不过图片显示不了了
数据结构与算法(C版)
1、绪论
1.1、数据结构的研究内容
一般应用步骤:分析问题,提取操作对象,分析操作对象之间的关系,建立数学模型。
1.2、基本概念和术语
数据:是能输入计算机且能被计算机处理的各种符号的集合。
数据元素:是数据的基本单位,也可称为元素、记录、结点或顶点。
数据项:构成数据元素的最小单位。
数据对象:是性质相同的数据元素的集合,是数据的一个子集。
数据结构:是指相互之间存在一种或多种特定关系的数据元素集合。
- 逻辑结构
- 物理结构
四种基本的存储结构:顺序、链式、索引和散列存储。
数据类型(Data Type) 定义:数据类型是一组性质相同的值的集合以及定义于这个值集合上的一组操作的总称。
1.3、抽象数据类型的表示与实现

1.4、算法和算法分析
算法的定义:对特定问题求解方法和步骤的一种描述,它是指令的有限序列(每个指令表示一个或多个操作)
算法特性:
- 有穷性(算法在有穷步结束,且每一步都在有穷时间内完成)
- 确定性(算法中每一条指令必须有确切的含义,没有二义性)
- 可行性(算法是可执行的)
- 输入(一个算法有零个或多个输入)
- 输出(一个算法有一个或多个输出)
考虑算法的效率问题:
1.时间复杂度,一般情况下,不必计算所有操作的执行次数,而只考虑算法中的基本语句执行次数(比较主要的数量级),它是问题规模n的某个函数,用T(n)表示(T(n)=O(f(n)))
2.空间复杂度,算法所需存储空间的度量,记作:S(n)=O(f(n)),其中n为问题的规模(或大小),算法要占据的空间(输入/输出,指令,常数,变量等)以及要使用的辅助空间
2、线性表
2.1、线性表的定义和特点
线性表(Linear List)是具有相同特性的数据元素的一个有限序列
2.2、案例引入
多项式求和(指数相同项可以进行相加减)
图书管理系统(图书表可以看作是一个线性表,每本图书可以看作是线性表的数据元素)
2.3、线性表的类型定义
基本操作:1、InitList (&L)构造一个空的线性表;2、DestroyList (&L)销毁线性表;3、ClearList (&L)重置为空表…
2.4、线性表的顺序表示和实现
顺序存储定义:把逻辑上相邻的数据元素存储在物理上相邻的存储单元中的存储结构
地址计算公式:LOC(ai)=LOC(a1>)+(i-1)*L
2.4.1、顺序表的顺序存储表示
顺序表(元素),可以用一维数组表示顺序表

2.4.2、顺序表基本操作的实现
例如:构造一个空的顺序表L,为顺序表分配空间,存储分配失败处理,空表长度为0.
顺序表的插入,时间复杂度是O(n) (n*(n+1)/(n+1)/2)
顺序表的删除,(1、判断删除的位置是否合法(1<=i<=n);2、将欲删除的元素保留在e中;3、将第i+1至第n位的元素一次向前移动一个位置;4、表长减1,删除成功返回OK)
顺序表的删除,时间复杂度是O(n) (n*(n-1)/n/2)
小结:
线性表的逻辑结构和存储结构是一致的(连续)
- 时间复杂度:查找、插入、删除算法的平均时间复杂度为O(n)
- 空间复杂度:显然,顺序表操作算法的空间复杂度S(n)=O(1),没有占用辅助空间
优点:可存储密度大;可以随机存储表中任一元素。
缺点:在插入,删除某一元素时,需要移动大量元素;浪费存储空间;属于静态存储形式,数据元素的个数不能自由扩充。
//template <typename 类型参数>
//class 类名{
// 类成员声明
//};
//或者
//template <class 类型参数>
//class 类名{
// 类成员声明
//};
typedef int Rank; //秩
#define ListNodePosi(T) ListNode<T>* //列表节点位置template <typename T> struct ListNode { //列表节点模板类(以双向链表形式实现)// 成员T data; ListNodePosi(T) pred; ListNodePosi(T) succ; //数值、前驱、后继//构造函数ListNode() {}; //针对header和trailer的构造ListNode(T e, ListNodePosi(T) p = nullptr, ListNodePosi(T) s = nullptr) : data(e), pred(p), succ(s) {} //默认构造器//操作接口ListNodePosi(T) insertAsPred(T const& e); //紧靠当前节点之前插入新节点ListNodePosi(T) insertAsSucc(T const& e); //紧靠当前节点之后插入新节点
};
2.5 、线性表的链式表示和实现
链表=结点+数据
首元结点:开始存储第一个数据的结点;头节点则是预设的、其指针指向首元结点。
2.5.1 、单链表的定义和表示

2.5.2、单链表基本操作的实现
单链表的初始化:步骤1、生成新节点作为头节点,用头指针L指向头节点;2、将头节点的指针域置空。
单链表的销毁:从头指针开始,一次释放所有的结点。
清空链表:(链表任然存在,但是链表中无元素成为了空链表)依次释放所有节点,并将头节点指针域设置为空
结束条件:p==nullptr;循环条件:p!=nullptr.

取值-取单链表中第i个元素的内容
bool GetElem(const LinkList &L, const int &i, ElemType &e)
{if(i < 0){cerr << "out of range" << endl;return false;}Lnode *p = L->next;for (int j = 1; j < i + 1; ++j){p = p->next;if(!p){cerr << "out of range" << endl;return false;//如果此时p为空,意味着已经到达链表尾端,停止循环}}e = p->data;return true;
}
先分析下算法步骤,算法描述;对于取值、查找、删除等基本操作要熟练!
删除链表的某个结点
bool ListDelete_L(LinkList &L, int i, ElemType &e)
{LinkList p = L;int j = 0;while (p->next && j < i - 1) {p = p->next; j++;} //寻找第i个结点,并令p指向其前驱if (!(p->next) || j > i - 1) {cerr << "out of range" << endl;return false; //删除位置不合理}Lnode *q = p->next; //临时保存被删结点的地址以备释放p->next = q->next; //改变删除结点前驱结点的指针域e = q->data; //保存删除结点的数据域delete q; //释放删除结点的空间return true;
} //时间复杂度为O(n)
建立单链表,有头插法和尾插法(元素插入到链表头部还是尾部)
头插法创建单向链表
void CreateListhead(LinkList &L, int n)
{for (int i = 0; i < n; i++){Lnode *p = new Lnode; //生成新结点cin >> p->data;p->next = L->next; //插入到表头L->next = p;}
}
尾插法创建单向链表

void CreateListTail(LinkList &L, int n)
{
Lnode *r = L;for (int i = 0; i < n; i++){Lnode *p = new Lnode; //生成新结点,输入元素值cin >> p->data;p->next = nullptr; r->next = p; //插入到表尾r = p; //指向新的尾结点}
}
2.5.3、循环链表
头指针表示时间复杂度O(n),尾指针表示时间复杂度O(1)。

2.5.4、双向链表
双向链表:在单链表的每个结点里再增加一个指向其直接前驱的指针域prior,这样的链表中就形成了有两个方向不同的链,故称为双向链表。
bool ListInsert_DuL(DuLinkList &L, const int i, const ElemType &e)
{//移动指针到i处DuLnode *p = L->next;int j = 1;while (p->next && j < 1){++j;p=p->next;}if (j > i || j < 1){cerr << "out of range" << endl;return false;}//在堆区创建要插入的结点DuLnode *s = new DuLnode();s->data = e;//重新建立链表关系s->prior = p->prior; //第一步,s的前驱等于p的前驱p->prior->next = s; //第二步,用p的前驱结点的后继指向插入元素s,更改了第一条链s->next = p; //第三步,s的后继指向pp->prior = s; //第四步,p的前驱指向s,更改了第二条链return ture;
}

一些概念:
存储密度:指结点数据本身所占的存储量和整个结点占用的空间总量
因此,顺序表存储密度=1,链表存储密度一般<1
2.6、顺序表和链表的比较

2.7、线性表的应用
2.7.1、有序表
线性表的合并之两个有序链表的合并
void MergeList(LinkList &La, LinkList &Lb, LinkList &Lc)
{Lnode *pa = La->next;Lnode *pb = Lb->next;Lc = La;Lnode *pc = Lc;while (pa && pb){if (pa->data <= pb->data) //尾插法,插入元素{//pc的指针域指向小元素的地址pc->next = pa;//移动pc指针,使得pc永远都指向最后链表Lc的最后一个元素pc = pc->next;//pa的元素使用过后,要向后移动papa = pa->next;}else{//pc的指针域指向小元素的地址pc->next = pb;//移动pc指针,使得pc永远都指向最后链表Lc的最后一个元素pc = pc->next;//pb的元素使用过后,要后向移动papb = pb->next;}}//上面的while循环执行完毕后,较长的链表还会余留一段元素,这段元素的起始地址为pa或者pbpc->next = (pa ? pa : pb);//链表合并完毕,释放Lb的头结点delete Lb;
}
这个算法的复杂度为O(n),但是空间复杂度为O(1),巧妙的地方在于不需要在堆区申请新的内存空间组成合并链表。
2.7.2、有序表的合并
算法步骤[(1) 创建一个空表Lc;(2) 依次从La或Lb中摘取元素值较小的结点插入到Lc表的最后,直至其中一个表变为空为止;(3) 继续将La或Lb其中一个表的剩余结点插入在Lc表的最后。]
2.8、案例分析与实现
一元多项式的运算:实现两个多项式加、减、乘等运算
void OperatePoly(SqList &L1, SqList &L2, SqList &L3)
{for (int i = 0; i < L1.length && i < L2.length; i++){L3.elem[i] = L1.elem[i] + L2.elem[i];L3.length += 1;}if (L1.length <= L2.length){for (int j = L1.length; j < L2.length; j++){L3.elem[j] = L2.elem[j];L3.length += 1;}}else {for (int j = L2.length; j < L1.length; j++){L3.elem[j] = L1.elem[j];L3.length += 1;}}
}
稀疏多项式的相加
合并两个有序顺序表(变形)
void SequSum(SqList &L1, SqList &L2, SqList &L3)
{ElemType *p1 = L1.index;ElemType *p1_last = L1.index + L1.length - 1;ElemType *p2 = L2.index;ElemType *p2_last = L2.index + L2.length - 1;ElemType *p3 = L3.index;ElemType *p3_last = L3.index + L3.length - 1;while (p1 <= p1->last && p2 <= p2->last){if (p1->expo < p2->expo){p3->expo = p1->expo;p3->coef = p1->coef;++p1;++p3;++L3.length;}else if (p2->expo < p1->expo){p3->expo = p2->expo;p3->coef = p2->coef;++p2;++p3;++L3.length;}else{p3->expo = p1->expo; //p1->expo与p2->expo值相等p3->coef = p1->coef + p2->coef;++p1;++p2;++p3;++L3.length;}}while (p1 <= p1_last){p3->expo = p1->expo;p3->coef = p1->coef;++p1;++p3;++L3.length;}while (p2 <= p2_last){p3->expo = p2->expo;p3->coef = p2->coef;++p2;++p3;++L3.length;}
}
合并两个有序链表(变形)
void LinkSum(LinkedList &La, LinkedList &Lb, LinkedList &Lc)
{Lnode *pa = La->next; //指向空结点Lnode *pb = Lb->next;Lc = La;Lnode *pc = Lc->next;while (pa && pb){if (pa->data.expo < pb->data.expo){pc->next = pa;pc = pc->next;pa = pa->next;}else if(pa->data.expo > pb->data.expo){pc->next = pb;pc = pc->next;pb = pb->next;}else if(pa->data.expo == pb->data.expo){pa->data.coef += pb->data.coef;pc->next = pa;pc = pc->next;pa = pa->next;pb = pb->next;}}pc->next = (pa ? pa : pb);delete Lb;
}
图书管理系统 - 单链表实现
结构体定义
typedef struct Book
{string isbn;string name;float price;
} ElemType;
struct Lnode
{ElemType data;Lnode *next;
} *LinkList;
其他操作,例如对图书的添加、删除、查找等操作,和单链表基本上一样的,这里就不赘述了。不过,受到《C++ Primer》的启发,我们可以添加两个这样的函数,简化程序:
//使用read函数向ElemType的对象写入数据
istream &read(istream &in, ElemType &rhs)
{in>>rhs.isbn;in>>rhs.name;in>>rhs.price;return in;
}
//使用print函数打印ElemType对象
ostream &print(ostream &out, ElemType &rhs)
{out<<rhs.isbn<<" "<<rhs.name<<" "<<rhs.price<<endl;return out;
}
如何使用这两个函数?
//读
read(cin, L->data);
//写
print(cout, L->data);
本篇完~
3、栈和队列
3.1、 栈和队列的定义和特点
栈和队列是限定插入和删除只能在表的“端点”进行的线性表
栈——后进先出
队列——先进先出

3.1.1 栈的定义和特点
栈(stack)
插入元素到栈顶(即表尾)的操作,称为入栈。
从栈顶(即表尾)删除最后一个元素的操作,称为出栈。
3.1.2 队列的定义和特点
队列(queue)
在表一端(表尾)插入,在另一端(表头)删除
3.2 案例
十进制与八进制的转换(反向取值)
括号匹配的检验(([{}])的匹配检索)
表达式求值(数值入栈,运算符入栈)
舞伴问题(配对问题)
3.3 栈的表示和操作的实现
空栈:base==top 是栈空标志
栈满:top-base==stacksize 是栈满标志
#define MAXSIZE 100 //顺序栈的表示
typedef struct {SElemType *base; //栈底指针SELemType *top; //栈顶指针int stacksize; //栈可用最大容量
} SqStack;
顺序栈的初始化
bool InitializeStack (SqStack &S)
{S.base = new ElemType(MAXSIZE);if (!S.base){cerr << "fail to get memory" << endl;return false;}S.top = S.base;;S.stacksize = MAXSIZE;return true;
}
顺序栈的入栈
bool Push (SqStack &S, SElemType &e)
{//判断栈是否满if (S.top - S.base == S.stacksize){cerr << "full stack" << endl;return false;}*S.top = e;S.top++;return true;
}
顺序栈的出栈
bool Pop (SqStack &S, SElemType &e)
{//判断栈是否空if (S.top == S.base){cerr << "empty stack" << endl;return false;}S.top--;e = *S.top;return true;
}
链栈:运算受限的单链表,只能在链表头部进行操作

链栈的入栈(视频)
bool Push(LinkStack &S, SElemType &e)
{p = new StackNode; //生成新结点p->data = e; //将新结点数据置为ep->next = S; //将新结点插入栈顶S = p; //修改栈顶指针return true;
}
链式栈的定义
typedef struct StackNode
{ElemType data;StackNode *next;
} * LinkStack;
栈的初始化
void InitStack(LinkStack &S)
{//创建头结点S = new StackNode;S->next = nullptr;S->data = 0; //表示栈的元素个数
}
//王老师的视频中没有设置头结点
//由于ELemType等价于int,因此我设置了一个头结点,在头结点的数据域中保存栈的元素个数
压栈
void Push(LinkStack &S, const ElemType &e)
{//插入元素StackNode *temp = new StackNode;temp->data = e;temp->next = S;S = temp;++(S->data);//元素个数加一
}
弹栈
void Pop(LinkStack &S, ElemType &e)
{//删除元素StackNode *p = S;e = p->data;S->next = p->next;--(S->data);delete p;
}
创建栈
void CreatStack(LinkStack &S, const int n)
{ElemType input;for (int i = 0; i < n;++i){cin >> input;Push(S, input);}
}
获取栈的元素个数
int StackLength(LinkStack &S)
{return S->data;
}
判断栈是否为空
bool IsEmpty(LinkStack &S)
{if(!(S->next)){return true;}else {return false;}
}
3.4 栈与递归
分治法:对于一个复杂问题,分解成几个相对简单的问题
long Fact(long n)
{if (n == 0) return 1; //基本项else return n * Fact(n - 1); //归纳项
}
- 函数调用过程:调用前,系统完成:保存参数、地址、局部变量等;调用后,系统完成:释放数据等。
3.5 队列的表示和操作的实现
队列(Queue)是仅在表尾进行插入操作,在表头进行删除操作的线性表
3.5.1 队列的抽象数据类型定义
队列的物理存储可以用顺序存储结构,也可以用链式存储结构
3.5.2 队列的顺序表示和实现
#define MAXQSIZE 100 //最大队列长度
Typedef struct
{QElemType *base; //初始化的动态分配存储空间int front; //头指向int rear; //尾指向
} SqQueue;

front == rear (队空还是队满)

循环队列的初始化
bool InitQueue (SqQueue &Q)
{Q.base = new QElemType[MAXQSIZE]; //分配数组空间if (!Q.base) exit (OVERFLOW); //存储分配失败Q.front = Q.rear = 0; //头指针尾指针置为0,队列为空return true;
}
求队列的长度
int QueueLength (SqQueue &Q)
{return (Q.rear - Q.front + MAXQSIZE) % MAXQSIZE;
}
3.5.3 链队——队列的链式表示和实现
#define MAXQSIZE 100 //最大队列长度
typedef struct Qnode
{QElemType data;struct Qnode *next;
} QNode, *QueuePtr;typedef struct
{QueuePtr front; //队头指针QueuePtr rear; //队尾指针
} LinkQueue;
打印链队
void PrintQueue (LinkQueue &Q)
{Qnode *p = Q.front->next;while (p){cout << p->data << endl;p = p->next;}
}
4 串、数组和广义表
4.1 串的定义
串(String)----零个或多个任意字符组成的有限序列
子串:串中任意个连续字符组成的子序列称为该串的子串
4.2 案例引入
病毒检测(aab,aba,baa)
4.3 串的类型定义、存储结构及运算
按照存储结构划分(顺序则是顺序串,链式则是链串)
顺序存储结构
#define MAXLEN 255
typedef struct
{char ch[MAXLEN + 1]; //存储串的一维数组int length; //串的当前长度
} SString;
串的链式存储结构
#define MAXLEN 255
typedef struct
{char ch[MAXLEN + 1]; //存储串的一维数组int length; //串的当前长度char *head; //指向链串的头结点
} LString *L;
串的模式匹配算法----BF(Brute Force)算法
简单匹配算法,采用穷举法
int index_BF (SString S, SString T, int pos)
{int i = pos, j = 1;while (i <= S.length && j <= T.length){if (s.ch[i] == t.ch[j]) {+=i; ++j;} //主串和子串依次匹配下一个字符else {i = i - j + 2; j = 1;} //主串、子串指针回溯重新开始下一次匹配}if (j >= T.length) return i - T.length; //返回匹配的第一个字符的下标else return 0; //模式匹配不成功
}
时间复杂度O(n*m)
KMP算法(Knuth Morris Pratt):时间复杂度O(n+m)
void get_next(SString T, int &next[])
{int i = 1; next[1] = 0; j = 0;while (i < T.length){if (j == 0 || T.ch[i] == T.ch[j]){++i; ++j;next[i] = j;}elsej = next[j];}
}int Index_KMP(SString, SString T, int pos)
{i = pos, j = 1;while (i <= S.length && j <= T.length){if (j == 0 || S.ch[i] == T.ch[j]){i++;j++;next[i] = j;}elsej = next[j];}if (j >= T.length) return i - T.length; //匹配成功else return 0; //返回不匹配标志
}
4.4 数组
按照一定格式排列起来的,具有相同类型的数据元素集合
数组特点:结构固定——维数和维界不变
数组的基本操作:初始化、销毁、修改元素(一般没有插入和删除操作)

页、行、列三维数据进行陈列
矩阵可以描述为一个二维数组
对称矩阵

稀疏矩阵存储:非零元素很少,( <= 5%)

例如元素12,9的表示
| 1 | 2 | 12 |
|---|---|---|
| 1 | 3 | 9 |
4.5 广义表
广义表(又称为列表Lists)是n个元素的有限序列。其中一个元素是原子,或是一个广义表。

5 树和二叉树
5.1 树和二叉树的定义
非线性结构(前驱和后继并不是1:1的比例)
树是n个结点的有限集
5.1.1 树的定义

5.1.2 树的基本术语

根据树中结点的各子树有无次序可以分为:1、有序树 2、无序树。
森林:是m棵互不相交的树的集合。
5.1.3 二叉树的定义
二叉树是n个结点的有限集,或者是空集,或者由一个根节点及两棵互不相交的分别称作这个根的左子树和右子树的二叉树构成。(二叉树结构简单,规律性强)
特点:1、每个结点最多有两孩子;2、子树有左右之分,其次序不能颠倒;3、二叉树可以是空集合,根可以有空的左子树或者是空的右子树。
5.2 案例引入
数据压缩问题:将数据文件转换成0、1组成的二进制串,称之为编码。
5.3 树和二叉树的抽象数据类型定义
ADT(abstract data type) 中序遍历、先序遍历、后序遍历
5.4 二叉树的性质和存储结构
在二叉树的第i层至多有2i-1个结点,至少有1个结点;深度为k的二叉树最大结点数为2k-1,至少有k个结点
性质3:对于任何一棵二叉树(叶子数,度为2的结点数存在关系)

满二叉树:一棵深度为k的二叉树拥有结点数为2k-1,叶子结点全在最底层,满二叉树编号规则(从上到下,从左到右)
完全二叉树:深度为k的具有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号1~n的结点一一对应时,称之为完全二叉树。


二叉树顺序存储表示
#define MAXTSIZE 100 //设置最大容量
Typedef TElemType SqBiTree[MAXTSIZE]
SqBiTree bt;
利用数组进行存储(没有的分支用0来表示)
二叉树的链式存储结构

typedef struct BiNode
{TElemType data;struct BiNode *lchild, *rchild; //左右孩子指针
} BiNode, *BiTree; //嵌套递归调用
5.5 遍历二叉树和线索二叉树
5.5.1 遍历二叉树
先序遍历:若为空树,空操作;不然先访问根结点,再左结点,最后右结点。
中序遍历:若为空树,空操作;不然先访问左结点,再根结点,最后右结点。
后序遍历:若为空树,空操作;不然先访问左结点,再右结点,最后根结点。
例题:已知先序和中序序列求二叉树,先确定根节点~ 再确定左子树和右子树

前后序确定根结点,中序辨别树结构

二叉树先序遍历算法
bool PreOrderTraverse(BiTree T)
{if (T == nullptr) return true; //空二叉树else //cout << T->data << endl;{visit(T); //访问根结点PreOrderTraverse(T->lchild); //递归遍历左子树PreOrderTraverse(T->rchild); //递归遍历右子树}
}
二叉树中序遍历算法
bool PreOrderTraverse(BiTree T)
{if (T == nullptr) return true; //空二叉树else //cout << T->data << endl;{PreOrderTraverse(T->lchild); //递归遍历左子树visit(T); //访问根结点 PreOrderTraverse(T->rchild); //递归遍历右子树}
}
二叉树后序遍历算法
bool PreOrderTraverse(BiTree T)
{if (T == nullptr) return true; //空二叉树else //cout << T->data << endl;{PreOrderTraverse(T->lchild); //递归遍历左子树PreOrderTraverse(T->rchild); //递归遍历右子树visit(T); //访问根结点 }
}
中序遍历非递归算法
bool InOrderTraverse(BiTree T)
{BiTree p, q;InitStack(S);p = T;while (p || !StackEmpty(S)){if (p){Push(S, p);p = p->lchild;}else{Pop(S, q);cout << q->data;p = q->rchild;}}return true;
}
二叉树的层次遍历
利用队列的方式

void LevelOrder(BTNode *b)
{BTNode *p;SqQueue *qu;InitQueue(qu); //初始化队列enQueue(qu, b); //根结点指针进入队列while (!QueueEmpty(qu)) //队不为空,则循环{deQueue(qu, p); //出队结点pcout << p->data; //访问结点pif (p->lchild != nullptr) enQueue(qu, p->lchild); //有左孩子时将其进队if (p->rchild != nullptr) enQueue(qu, p->rchild); //有右孩子时将其进队}
}

复制二叉树
int Copy(BiTree T, BiTree &NewT)
{if (T == nullptr) //如果是空树返回0{NewT = nullptr;return 0;}else {NewT = new BiTNode;NewT->data = T->data;Copy(T->lChild, NewT->lchild);Copy(T->rchild, NewT->rchild);}
}
计算二叉树深度
int Depth(BiTree T)
{if (T == nullptr) return 0; //如果是空树返回0else{m = Depth(T->lChild);n = Depth(T->rChild);if (m > n) return(m + 1);else return(n + 1)}
}
计算二叉树结点总数
int NodeCount(BiTree T)
{if (T == nullptr) return 0;else return NodeCount(T->lchild) + NodeCount(T->rchild) + 1;
}
计算二叉树叶子结点总数
int LeafCount(BiTree T)
{if (T == nullptr) return 0;if (T->lchild == nullptr && T->rchild == nullptr) return 1;else return LeafCount(T->lchild) + LeafCount(T->rchild);
}
5.5.2 线索二叉树



改变空指针域的指向称为线索
5.6 树和森林
5.6.1 树的存储结构
结点结构和树结构的定义
typedef struct PTNode
{TElemType data;int parent; //双亲位置域
} PTNode;#define MAX_TREE_SIZE 100
typedef struct
{PTNode nodes[MAX_TREE_SIZE];int r, n; //根结点的位置和结点个数
} PTree;


5.6.2 二叉树的转换
将树转换为二叉树:(1)加线:在兄弟之间加一连线;(2)抹线:对每个结点,除了其左孩子外,去除其与其余孩子之间的关系;(3)旋转:以树的根结点为轴心,将整树顺时针旋转45°。
树变二叉树:兄弟相连留长子

森林变二叉树:树变二叉根相连
5.6.3 树和森林的遍历

5.7 哈夫曼树及其应用
5.7.1 哈夫曼树的基本概念
判断树:用于描述分类过程的二叉树

哈夫曼树(最优二叉树,更确切地说是最小的带权路径长度树)
路径:从树中一个结点到另一个结点之间的分支构成这两个结点之间的路径。结点的路径长度:两结点路径上的分支数。
-
树的路径长度(所有结点的路径总和)、权(给结点赋一个有着某种含义的数值)
-
树的带权路径长度:树中所有叶子结点的带权路径长度之和
5.7.2 哈夫曼树的构造算法

算法实现:
void CreateHuffman Tree(HuffmanTree HT, int n) //构造哈夫曼树——哈夫曼算法
{if (n <= 1) return;m = 2 * n - 1; //数组共2n-1个元素HT = new HTNode[m + 1]; //0号单元未用,HT[m]表示根结点for (int i = 1; i <= m; ++i) //将2n-1个元素的lch、rch、parent置为0{HT[i].lch = 0;HT[i].rch = 0;HT[i].parent = 0;}for (int i = 1; i <= n; ++i){cin >> HT[i].weight; //输入前n个元素的weight值}//初始化结束,下面开始建立哈夫曼树for (int i = n + 1; i <= m; i++) //合并产生n-1个结点——构造Huffman树{Select(HT, i - 1, s1, s2); //在HT[k](1<=k<=i-1)中选择两个其双亲域为0且//权值最小的结点,并返回它们在HT中的序号s1和s2HT[s1].parent = i; HT[s2].parent = i; //表示从F中删除s1,s2HT[i].lch = s1; HT[i].rch = s2; //s1,s2分别作为i的左右孩子HT[i].weight = HT[s1].weight + HT[s2].weight; //i的权值为左右孩子权值之和}
}
5.7.3 哈夫曼编码
二进制编码(A——00,B——01,C——10,D——11),但是位数太多
哈夫曼编码:利用出现概率大小决定编码长短,左0右1,根到结点经过的数字形成编码

由于没有一片树叶是另一片树叶的祖先,所以每个叶结点的编码不可能是其它叶结点编码的前缀;因为哈夫曼树的带权路径长度最短,故字符编码的总长最短。
- 性质1 哈夫曼编码是前缀码
- 性质2 哈夫曼编码是最优前缀码
void CreatHuffmanCode(HuffmanTree HT, HuffmanCode &HC, int n)
{//从叶子到根逆向求每个字符的哈夫曼编码,存储在编码表HC中HC = new char*[n + 1]; //分配n个字符编码的头指针矢量cd = new char[n]; //分配临时存放编码的动态数组空间cd[n - 1] = '\0'; //编码结束符for (int i = 1; i <= n; ++i){//逐个字符求哈夫曼编码start = n - 1;c = i;f = HT[i].parent;while (f != 0){//从叶子结点开始向上回溯,直到根结点--start; //回溯一次start向前指一个位置if (HT[f].lchild == c) cd[start] = '0'; //结点c是f的左孩子,则生成代码0else cd[start] = '1'; //结点c是f的右孩子,则生成代码1c = f; HT[f].parent; //继续向上回溯,求出第i个字符的编码}HC[i] = new char[n - start]; //为第i个字符串编码分配空间strcpy(HC[i], &cd[start]); //将求得的编码从临时空间cd复制到HC的当前行中}delete cd; //释放临时空间
} //CreatHuffanCode
6 图
6.1 图的定义和术语
图:G=(V, E),其中 V:顶点(数据元素)的有穷非空集合;E:边的有穷集合
完全图:任意两个点都有一条边相连(有向和无向)
稀疏、稠密图
网:边/弧带权的图
邻接:有边/弧相连的两个顶点之间的关系
顶点的度:与该顶点相关联的边的数目,记为TD(v)

路径:接续的边构成的顶点序列
路径长度:路径上边或弧的数目/权值之和
回路(环):第一个顶点和最后一个顶点相同的路径
简单路径:除路径起点和终点可以相同外,其余顶点均不相同的路径
简单回路(简单环):除路径起点和终点相同外,其余顶点均不相同的路径





6.2 案例引入
六度空间理论
6.3 图的类型定义
ADT:图的创建,BFS,DFS
6.4 图的存储结构
图的逻辑结构:多对多
6.4.1 邻接矩阵

邻接矩阵的存储表示:用两个数组分别存储顶点表和邻接矩阵
#define MaxInt 32767 //表示极大值,即inf
#define MVNum 100 //最大顶点数
typedef char VerTexType; //设顶点的数据类型为字符型
typedef int ArcType; //假设边的权值类型为整形typedef struct {VerTexType vexs[MVNum]; //顶点表ArcType arcs[MVNum][MVNum]; //邻接矩阵int vexnum, arcnum; //图的当前点数和边数
} AMGraph; //Adjacency Matrix Graph
算法6.1 采用邻接矩阵表示法创建无向图
bool CreateUDN(AMGraph &G)
{ //采用邻接矩阵表示法,创建无向网Gcin >> G.vexnum >> G.arcnum; //输入总顶点数,总边数for (i = 0; i < G.vexnum; ++i)cin >> G.vexs[i]; //依次输入点的信息for (i = 0; i < G.vexnum; ++i) //初始化邻接矩阵for (j = 0; j < G.vexnum; ++j)G.arcs[i][j] = MaxInt; //边的权值均置为极大值for (k = 0; k < G.arcnum; ++k) //构造邻接矩阵{cin >> v1 >> v2 >> w; //输入一条边所依附的顶点及权值i = LocateVex(G, v1);j = LocateVex(G, v2); //确定v1和v2在G中的位置G.arcs[i][j] = w; //边<v1, v2>的权值置为wG.arcs[j][i] = G.arcs[i][j]; //置<v1, v2>的对称边<v2, v1>的权值为w}return true;
}
int LocateVex(AMGraph G, VertexType u)
{int i;for (i = 0; i < G.vexnum; ++i)if (u == G.vexs[i]) return i;return -1;
}
6.4.2 邻接表
邻接表的表示法(链表)

typedef struct VNode //结点结构
{VerTexType data; //顶点信息ArcNode *firstarc; //指向第一条依附该顶点的边的指针
} VNode, AdjList[MVNum]; //AdjList表示邻接表类型#define MVNum 100 //最大顶点数
typedef struct ArcNode //边结点结构
{int adjvex; //该边所指向的顶点的位置struct ArcNode *nextarc; //指向下一条边的指针OtherInfo info; //和边相关的信息
} ArcNode;
算法6.2 采用邻接表表示法创建无向网
bool CreateUDG(ALGraph &G) //采用邻接表表示法,创建无向图G
{cin >> G.vexnum >> G.arcnum; //输入总顶点数,总边数for (int i = 0; i < G.vexnum; ++i) //输入各点,构造表头结点表{cin >> G.vertices[i].data; //输入顶点值G.vertices[i].firstarc = nullptr; //初始化表头结点的指针域}for (int k = 0; k < G.arcnum; ++k) //输入各边,构造邻接表{cin >> v1 >> v2; //输入一条边依附的两个顶点i = LocateVex(G, v1);j = LocateVex(G, v2);}p1 = new ArcNode; //生成一个新的边结点*p1p1->adjvex = j; //邻接点序号为jp1->nextarc = G.vertices[i].firstarc;G.vertices[i].firstarc = p1; //将新结点*p1插入到顶点vi的边表头部//若为有向边,则不用p2p2 = new ArcNode; //生成另一个对称的新的边结点*p2p2->adjvex = i; //邻接点序号为ip2->nextarc = G.vertices[j].firstarc;G.vertices[j].firstarc = p2; //将新结点*p2插入顶点vj的边表头部return true;
}


6.4.3 十字链表——用于有向图

6.4.4 邻接多重表(无向图的另一种链式存储结构)

6.5 图的遍历
深度优先遍历(DFS)

连通图的深度优先遍历类似于先序遍历
算法6.5 采用邻接矩阵表示图的深度优先搜索遍历
void DFS(AMGraph G, int v) { //图G为邻接矩阵类型cout << v; visited[v] = true; //访问第v个顶点for (int w = 0; w < G.vexnum; w++) //依次检查邻接矩阵v所在的行if ((G.arcs[v][w] != 0) && (!visited[w]))DFS(G, w);//w是v的邻接点,如果w未访问,则递归调用DFS
}
广度优先搜索(BFS)

算法6.7 按照广度优先非递归遍历连通图G
void BFS(Graph G, int v) { //按广度优先非递归遍历连通图Gcout << v; visited[v] = true; //访问第v个顶点InitQueue(Q); //辅助队列Q初始化,置空EnQueue(Q, v); //v进队while (!QueueEmpty(Q)) { //队列非空DeQueue(Q, u); //队头元素出队并置为ufor (w = FirstAdjVex(G, u); w >= 0; w = NextAdjVex(G, u, w))if (!visited[w]) { //w为u的尚未访问的邻接顶点cout << w; visited[w] = true;EnQueue(Q, w); //w进队} //if} //while
} //BFS
6.6 图的应用
6.6.1 最小生成树
生成树:所有顶点均由边连接在一起,但不存在回路的图

MST性质可以用于构造最小生成树
构造最小生成树的一些算法:


6.6.2 最短路径
有向图(区别于最小生成树的无向图),不需要遍历所有结点!
一、单源最短路径-用Dijkstra(迪杰斯特拉)算法
二、所有顶点间的最短路径-用Floyd(弗洛伊德)算法
Dijkstra:


Floyd:

6.6.3 拓扑排序和关键路径
拓扑排序:
例如:排课表中课程存在先后顺序。

关键路径:



7 查找
7.1 查找的基本概念
根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素或记录。
主关键字:可以唯一标识一个记录
7.2 线性表的查找
一、顺序查找(线性查找)
二、折半查找(二分或对分查找)
三、分块查找
7.2.1 顺序查找

算法7.2 时间效率分析
int Search_Seq(SSTable ST, KeyType key) {ST.R[0].key = key;for (int i = ST.length; ST.R[i].key != key; --i);return i;
}
- 时间复杂度为O(n)
- 空间复杂度:一个辅助空间-O(1)
7.2.2 折半查找
每次将待查找记录所在区间缩小一半(mid = (low + high) / 2)
算法7.3 折半查找
int Search_Bin(SSTable ST, KeyType key) {int low = 1, high = ST.length; //置区间初值while (low <= high) {mid = (low + high) / 2;if (ST.R[mid].key == key) return mid; //找到待查元素else if (key < ST.R[mid].key) //缩小查找区间high = mid - 1; //继续在前半区间进行查找else low = mid + 1; //继续在后半区间进行查找}return 0; //顺序表中不存在待查元素
} //Search_Bin

时间复杂度:O(logN) 对数级
空间复杂度:O(1)常数级
7.2.3 分块查找
例如:字典中(A~Z)分块搜索

折中方法,平均查找长度位于中间,插入删除方便,但是分块需要分别排序(块间有序,块内无序)
7.3 树表的查找
二叉排序树的操作
算法7.4 二叉排序树的递归查找
BSTree SearchBST(BSTree T, KeyType key) {if (!T || key == T->data.key) return T;else if (key < T->data.key)return SearchBST(T->lchild, key); //在左子树中继续查找else return SearchBST(T->rchild, key); //在右子树中继续查找
} //SearchBST
还有一些插入和删除操作~
7.3.1 二叉排序树
问题:如何提高形态不均衡的二叉排序树的查找效率?
解决办法:做“平衡化”处理,尽量让二叉树的形态均衡!
7.3.2 平衡二叉树

平衡因子:左子树高度-右子树高度(-1,0,1)
平衡类型的四种类型

调整原则:1)降低高度 2)保持二叉排序树性质

7.4 散列表的查找
7.4.1 散列表的基本概念
基本思想:记录的存储位置与关键字之间存在对应关系
冲突:不同的关键码映射到同一个散列地址
同义词:具有相同函数值的多个关键字
7.4.2 散列函数的构造方法



7.4.3 处理冲突的方法
-
开放定址法(开地址法)
-
链地址法(拉链法)
-
再散列法(双散列函数法)
-
建立一个公共溢出区


7.4.4 散列表的查找


8 排序
8.1 概述


8.2 插入排序
基本思想:每步将一个待排序的对象,插入到已经排好顺序的序列中
- 直接插入排序——采用顺序查找法查找插入位置

void InsertSort(SqList &L) {int i, j;for (i = 2; i < L.length; ++i) {if (L.r[i].key < L.r[i - 1].key) { //若“<”,需将L.r[i]插入到有序子表L.r[0] = L.r[i]; //复制为哨兵for (j = i - 1; L.r[0].key < L.r[j].key; --j) {L.r[j + 1] = L.r[j]; //记录后移}L.r[j + 1] = L.r[0]; //插入到正确位置}}
}
- 折半插入排序
void BInsertSort(SqList &L) {for (int i = 2; i <= L.length; ++i) { //依次插入第2~n个元素L.r[0] = L.r[i]; //当前插入元素存在“哨兵”位置int low = 1, high = i - 1; //采用二分查找法查找插入元素while (low < high) {mid = (low + high) / 2;if (L.r[0].key < L.r[mid].key) high = mid - 1;else low = mid + 1;} //循环结束,high + 1则为插入位置for (j = i - 1; j > high + 1; --j) L.r[j + 1] = L.r[j]; //移动元素L.r[high + 1] = L.r[0]; //插入到正确位置}
} //BInsertSort
- 希尔插入排序
定义增量序列,分块排序后形成有序序列
void ShellInsert(SqList &L, int dk) {//对顺序表L进行一趟增量为dk的Shell排序,dk为步长因子for (int i = dk + 1; i <= L.length; ++i)if(r[i].key < r[i - dk].key) {r[0] = r[i];for (int j = i - dk; j > 0 && (r[0].key < r[j].key); j = j -dk)r[j + dk] = r[j];r[j + dk] = r[0];}
}
8.3 交换排序
8.3.1 冒泡排序
基本思想:每趟不断将记录两两比较,并按前小后大的规则交换
void bubble_sort(SqList &L) { //冒泡排序算法int m, i, j; RedType x; //交换时临时存储for (int m = 1; m <= n - 1; m++) { //总共需要m趟for (int j = 1; j <= n - m; j++)if (L.r[j].key > L.r[j + 1]) {//发生交换x = L.r[j]; L.r[j] = L.r[j + 1]; L.r[j + 1] = x; //交换} //endif} //for
}
8.3.2 快读排序
基本思想:1、任取一个元素为中心(pivot:枢轴、中心点);2、所有比它小的元素一律放前,比它大的一律放后;3、对子表重复操作直到排序完毕
void main() { //对顺序表L快速排序QSort(L, 1, L.length);
}
void QSort(SqList &L, int low, int high) { //对顺序表L快速排序if (low < high)pivotloc = Partition(L, low, high);QSort(L, low, pivotloc - 1); //对低位递归排序QSort(L, pivotloc + 1, high); //对高位递归排序
}

8.4 选择排序
8.4.1 简单选择排序
基本思想:在待排序的数据中选出最大(小)的元素放在最终位置

8.4.2 堆排序

完全二叉树:深度为k,而且k-1层为满的二叉树


8.5 归并排序
基本思想:将两个或两个以上有序序列归并成一个有序序列

8.6 基数排序
基本思想:分配+收集
也叫桶排序或箱排序,设置若干个箱子,将关键字为k的记录放入第k个箱子,然后再按照序号将非空的连接。


8.7 各种排序方法的综合比较




相关文章:
数据结构记录
之前记录的数据结构笔记,不过图片显示不了了 数据结构与算法(C版) 1、绪论 1.1、数据结构的研究内容 一般应用步骤:分析问题,提取操作对象,分析操作对象之间的关系,建立数学模型。 1.2、基本概念和术语 数据&…...
从零到一:基于 K3s 快速搭建本地化 kubeflow AI 机器学习平台
背景 Kubeflow 是一种开源的 Kubernetes 原生框架,可用于开发、管理和运行机器学习工作负载,支持诸如 PyTorch、TensorFlow 等众多优秀的机器学习框架,本文介绍如何在 Mac 上搭建本地化的 kubeflow 机器学习平台。 注意:本文以 …...

kettle使用MD5加密增量获取接口数据
kettle使用MD5加密增量获取接口数据 场景介绍: 使用JavaScript组件进行MD5加密得到Http header,调用API接口增量获取接口数据,使用json input组件解析数据入库 案例适用范围: MD5加密可参考、增量过程可参考、调用API接口获取…...
PS入门|黑白色的图标怎么抠成透明背景
前言 抠图可以算是PS的入门必备操作,开始学习PS的小伙伴可以根据本帖子推荐一步步学习哦!但切勿心急~ 今天给小伙伴们带来:黑白色的图标抠图教程 抠图有很多种方法,但根据类型的不同,使用适当的方法很重…...
apexd 启动)
android 14 apexd分析(2)apexd 启动
1. class main进程一起启动, apexservice是他提供的binderservice,这也第二阶段的最主要的作用 /system/apex/apexd/apexd.rc?r3c8e8603c640fc41e0406ddcf981381803447cfb#1 1 service apexd /system/bin/apexd 2 interface aidl apexservice …...

微信小程序怎么制作?制作一个微信小程序需要多少钱?
随着移动互联网的快速发展,微信小程序已成为连接用户与服务的重要桥梁。它以其便捷性和易用性,为各类企业和个人提供了一个全新的展示和交易平台。那么,如何制作一个微信小程序?又需要投入多少资金呢?本文将为您提供全…...
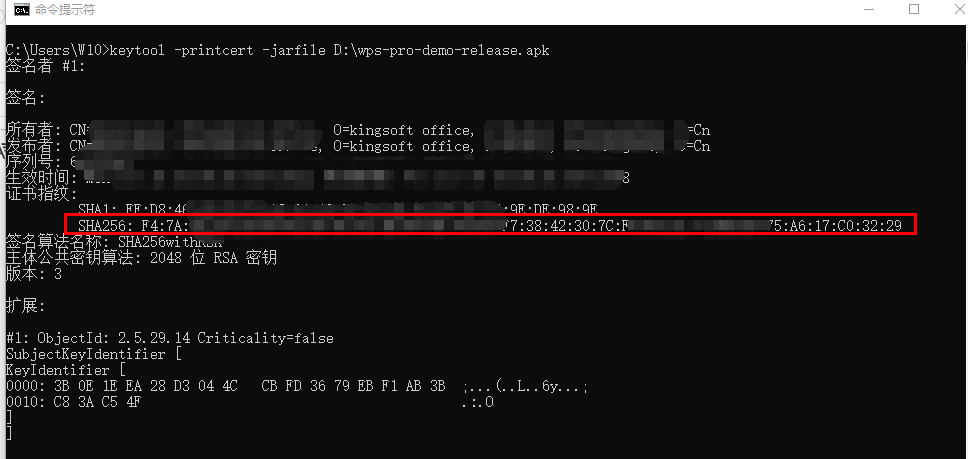
WPS二次开发专题:如何获取应用签名SHA256值
作者持续关注WPS二次开发专题系列,持续为大家带来更多有价值的WPS开发技术细节,如果能够帮助到您,请帮忙来个一键三连,更多问题请联系我(QQ:250325397) 在申请WPS SDK授权版时候需要开发者提供应用包名和签…...

Flink SQL系列之:基于Flink SQL查询Topic中序列化的Debezium数据格式字段
Flink SQL系列之:基于Flink SQL查询Topic中序列化的Debezium数据格式字段 一、表结构二、查询Topic中表的数据三、反序列化字段一、表结构 CREATE TABLE IF NOT EXISTS record_rt (id decimal(20,0) COMMENT "主键",follow_entity_type <...

【WPF应用30】WPF中的ListBox控件详解
WPF(Windows Presentation Foundation)是.NET框架的一个组成部分,用于构建桌面应用程序的用户界面。ListBox是WPF中一个非常常用的控件,用于显示一系列的项,用户可以选择单个或多个项。 1.ListBox的基本概念 ListBox…...

Chatgpt掘金之旅—有爱AI商业实战篇(二)
演示站点: https://ai.uaai.cn 对话模块 官方论坛: www.jingyuai.com 京娱AI 一、前言: 成为一名商业作者是一个蕴含着无限可能的职业选择。在当下数字化的时代,作家们有着众多的平台可以展示和推广自己的作品。无论您是对写书、文…...

AGI时代,LLM可以在AutoML哪些环节进行增强?
当下大模型技术发展如火如荼,颇有改变各行业和各领域的架势。那么对于AutoML来讲,LLM对其有哪些助力?对于这个问题,我们来问一问kimi chat,看看它怎么回答? 大型语言模型(LLM)可以在…...
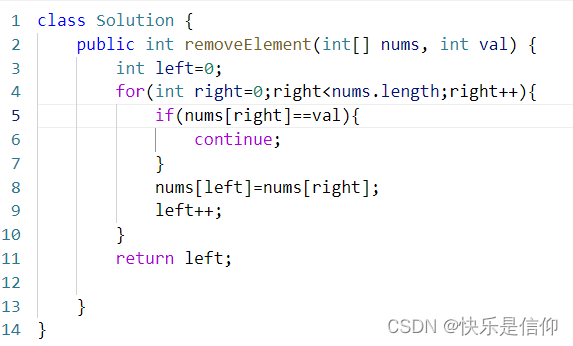
算法练习—day1
title: 算法练习—day1 date: 2024-04-03 21:49:55 tags: 算法 categories:LeetCode typora-root-url: 算法练习—day1 网址:https://red568.github.io 704. 二分查找 题目: 题目分析: 左右指针分别为[left,right],每次都取中…...
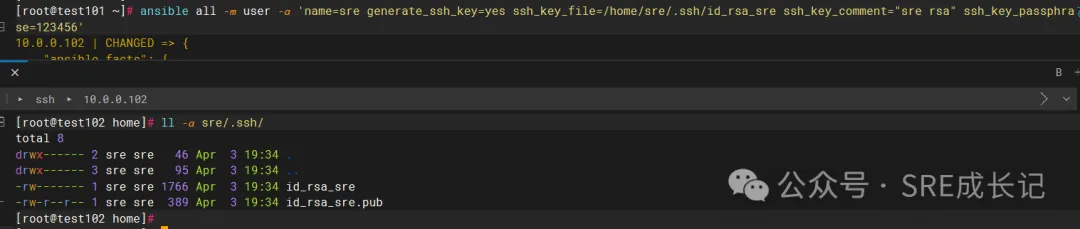
关于ansible的模块 ③
转载说明:如果您喜欢这篇文章并打算转载它,请私信作者取得授权。感谢您喜爱本文,请文明转载,谢谢。 接《关于Ansible的模块①》和《关于Ansible的模块②》,继续学习ansible的user模块。 user模块可以增、删、改linux远…...
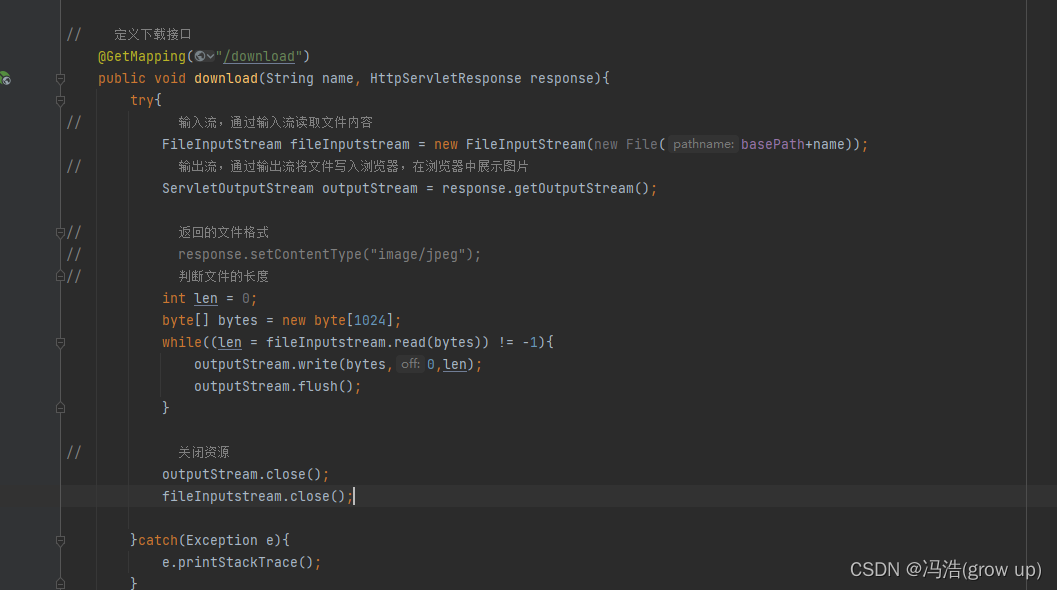
Spring Boot--文件上传和下载
文件上传和下载 前言文件上传1、以MultipartFile 接口流文件,流的名称需要和前台传过来的名称对应上2、获取到文件名称截取后缀3、为了放置文件名重复使用uuid来随机生成id后缀4、判断转存路径中是否有这个文件夹如果没有就创建5、将文件存储到转存的目录中 文件下载…...
hexo博客7:构建简单的多层安全防御体系
【hexo博客7】构建简单的多层安全防御体系 写在最前面理解全面安全策略的重要性防御常见的网络攻击1. SQL注入攻击2. 文件上传漏洞3. 跨站脚本攻击(XSS)4. 跨站请求伪造(CSRF)5. 目录遍历/本地文件包含(LFI/RFI&#x…...

《捕鱼_ue4-5输出带技能的透明通道素材到AE步骤》
《捕鱼_ue4-5输出带技能的透明通道素材到AE步骤》 2022-05-17 11:06 先看下带透明的特效素材效果1、首先在项目设置里搜索alpha,在后期处理标签设置最后一项allow through tonemapper2、在插件管理器中,搜索movie render ,加载movie render q…...
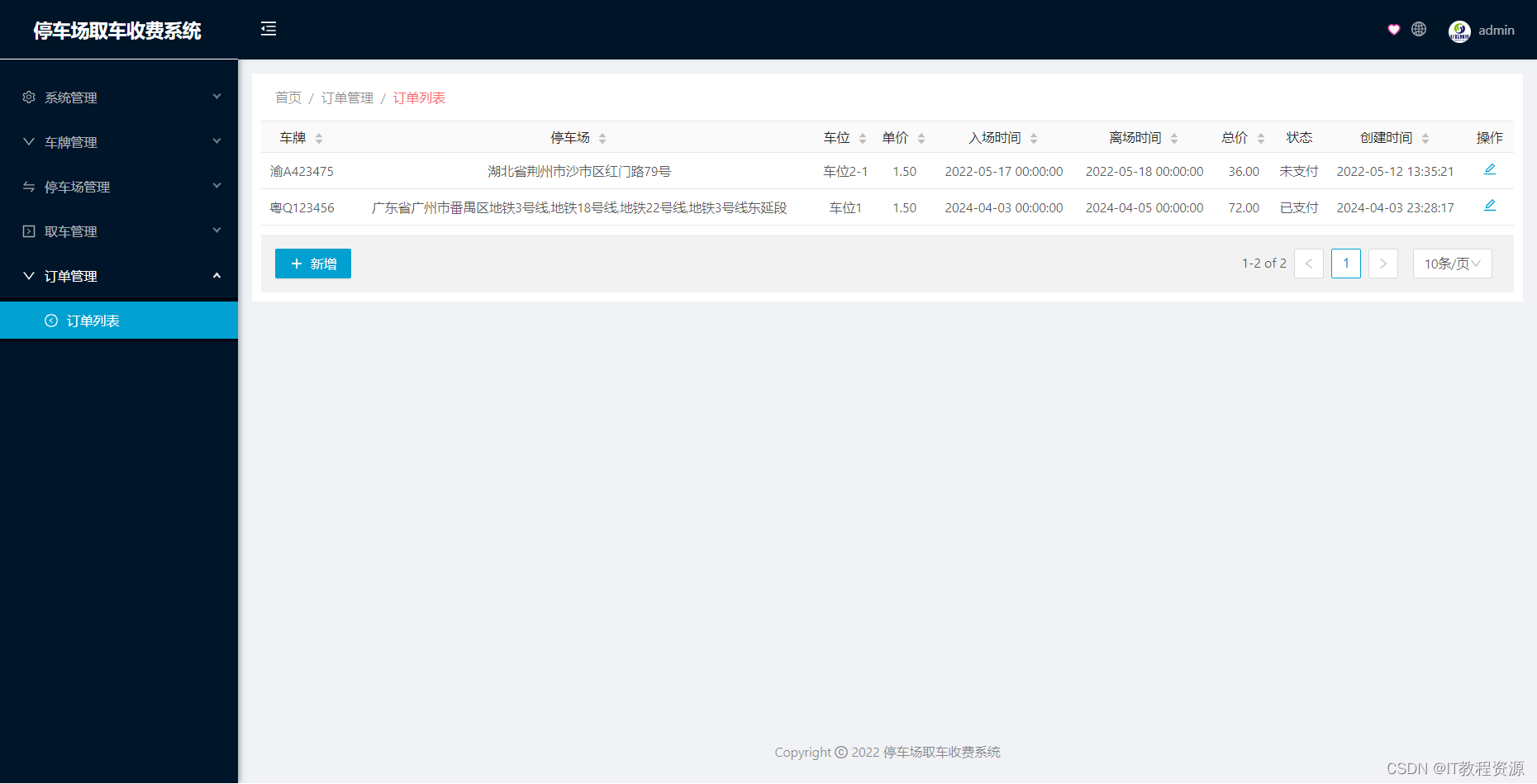
(免费分享)基于微信小程序自助停取车收费系统
本项目的开发和制作主要采用Java语言编写,SpringBoot作为项目的后端开发框架,vue作为前端的快速开发框架,主要基于ES5的语法,客户端采用微信小程序作为开发。Mysql8.0作为数据库的持久化存储。 获取完整源码: 大家点赞…...

Vue3_2024_7天【回顾上篇watch常见的后两种场景】___续
Vue3中监听多条数据的两种使用 1.watch【使用上一章写法,监听两个属性,然后执行相应操作…】 2.watchEffect【相对于使用watch,watchEffect默认页面初始加载,有点类似加配置:立即执行 immediate】 代码: …...
Gemini即将收费,GPT无需注册?GPT3.5白嫖和升级教程
🌐Gemini 即将开始收费 开发者“白嫖”的好日子到头了 - Gemini将开始收费,影响使用Google AI for Developers提供的Gemini API的用户。 - Gemini API将引入按量付费定价,需要注意新的服务条款。 - 用户需在5月2日之前停止使用Gemini API和Go…...
【协议篇:Http与Https】
1. Http 1.1 Http的定义 超文本传输协议(Hypertext Transfer Protocol,HTTP)是用于分布式、协作式和超媒体信息系统的应用层协议。它是互联网上最广泛应用的数据通信协议之一,尤其对于万维网(WWW)服务而言…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...