基于深度学习的植物叶片病毒识别系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
摘要:本文深入研究了基于YOLOv8/v7/v6/v5的植物叶片病毒识别系统,核心采用YOLOv8并整合了YOLOv7、YOLOv6、YOLOv5算法,进行性能指标对比;详述了国内外研究现状、数据集处理、算法原理、模型构建与训练代码,及基于Streamlit的交互式Web应用界面设计。在Web网页中可以支持图像、视频和实时摄像头进行植物叶片病毒识别,可上传不同训练模型(YOLOv8/v7/v6/v5)进行推理预测,界面可方便修改。本文附带了完整的网页设计、深度学习模型代码和训练数据集的下载链接。
文章目录
- 1. 网页功能与效果
- 2. 绪论
- 2.1 研究背景及意义
- 2.2 国内外研究现状
- 2.3 要解决的问题及其方案
- 2.3.1 要解决的问题
- 2.3.2 解决方案
- 2.4 博文贡献与组织结构
- 3. 数据集处理
- 4. 原理与代码介绍
- 4.1 YOLOv8算法原理
- 4.2 模型构建
- 4.3 训练代码
- 5. 实验结果与分析
- 5.1 训练曲线
- 5.2 混淆矩阵
- 5.3 YOLOv8/v7/v6/v5对比实验
- 6. 系统设计与实现
- 6.1 系统架构概览
- 6.2 系统流程
- 代码下载链接
- 7. 结论与未来工作
➷点击跳转至文末所有涉及的完整代码文件下载页☇
网页版-基于深度学习的植物叶片病毒识别系统(YOLOv8/v7/v6/v5+实现代码+训练数据集)
1. 网页功能与效果
(1)开启摄像头实时检测:本系统允许用户通过网页直接开启摄像头,实现对实时视频流中植物叶片病毒的检测。系统将自动识别并分析画面中的植物叶片病毒,并将检测结果实时显示在用户界面上,为用户提供即时的反馈。

(2)选择图片检测:用户可以上传本地的图片文件到系统中进行植物叶片病毒识别。系统会分析上传的图片,识别出图片中的植物叶片病毒,并在界面上展示带有植物叶片病毒标签和置信度的检测结果,让用户能够清晰地了解到每个植物叶片病毒状态。

(3)选择视频文件检测:系统支持用户上传视频文件进行植物叶片病毒识别。上传的视频将被系统逐帧分析,以识别和标记视频中每一帧的植物叶片病毒。用户可以观看带有植物叶片病毒识别标记的视频,了解视频中植物叶片病毒的变化。

(4)选择不同训练好的模型文件:系统集成了多个版本的YOLO模型(如YOLOv8/v7/v6/v5),用户可以根据自己的需求选择不同的模型进行植物叶片病毒识别。这一功能使得用户能够灵活地比较不同模型的表现,以选择最适合当前任务的模型。

在我们开发的基于Streamlit的交互式Web应用中,我们致力于提供一个直观、易用的操作界面,以便用户能够高效准确地进行植物叶片病毒识别。应用集成了一系列功能,旨在满足不同用户的需求。
首先,实时摄像头检测功能允许用户开启连接的摄像头,直接进行实时植物叶片病毒检测,适用于没有预先准备样本图片的即时检测需求。此外,我们还提供了图片检测和视频文件检测功能,用户可以上传本地的植物叶片病毒图像或视频文件,系统将自动进行检测并展示结果。为了适应不同的检测需求,我们设计了模型文件选择功能,用户可以根据个人需求,从不同训练好的模型文件(YOLOv8/v7/v6/v5)中选择最合适的模型进行检测。
我们深知用户可能需要对比检测前后的差异,因此提供了检测与原始画面同时或单独显示的功能,用户可根据需要选择查看模式。为了便于用户对特定目标进行分析,我们还加入了特定目标标记与结果展示的功能,通过点击下拉框选择标记特定目标,并单独显示检测结果。
为了让用户能够更灵活地调整检测结果,我们实现了可以动态调整的置信度阈值和IOU阈值设置,以及将检测结果动态显示在页面表格上的设计。用户还可以通过点击按钮,将表格结果输出到CSV文件,或将标记过的图片、视频及摄像头画面的检测结果导出为AVI图像文件,便于保存和进一步分析。通过这些精心设计的功能,我们的Web应用不仅提高了植物叶片病毒检测的效率和准确性,也极大地优化了用户体验。我们期待未来能够进一步优化该应用,引入更多创新功能,以更好地服务于医疗健康领域的需求。
2. 绪论
2.1 研究背景及意义
植物叶片病毒识别在农业生产中具有重要意义,因为它直接关联到作物的健康与产量。随着全球气候变化和国际贸易的增加,植物病害,尤其是由病毒引起的病害,对农业生产构成了严峻挑战。病毒性病害一旦发生,往往迅速传播,给作物带来严重损害,导致产量和质量大幅下降。因此,及时准确地识别并控制植物叶片病毒显得尤为关键。在这一背景下,利用先进的图像处理和机器学习技术,如YOLO(You Only Look Once)系列算法,进行植物叶片病毒的快速准确识别和分类,不仅可以提高病害管理的效率和效果,还有助于指导农业生产实践,优化资源配置,从而保障粮食安全和农业可持续发展。
近年来,利用深度学习技术进行植物病害识别的研究迅速增多,特别是在目标检测领域,YOLO算法因其高效性和准确性而广受关注。从YOLOv1到最新的YOLOv8,每个版本都在性能、速度和准确度方面进行了改进。研究表明,YOLOv8相较于其前身在多个方面都有显著提升,例如通过更深的网络结构和更复杂的训练策略来提高识别精度1。此外,结合最新的卷积神经网络(CNN)架构改进和数据增强技术,可以进一步提升模型的泛化能力和识别效率。
然而,在植物叶片病毒识别领域,研究者仍面临诸多挑战,如如何提高算法在复杂背景下的识别准确性、如何处理不同病害间的微妙差异、以及如何实现实时高效的病害监测和预警系统等。为解决这些问题,研究人员正在探索融合多模态数据(如光谱数据、环境数据)的深度学习模型,以及开发更加鲁棒的特征提取和分类算法来提升系统的整体性能2。
本博客的主要贡献在于综合分析了基于YOLOv8/v7/v6/v5的植物叶片病毒识别系统的研究进展和应用实践,包括算法改进、数据集更新、性能优化等方面的最新成果。通过对比分析不同版本的YOLO算法,本文揭示了植物叶片病毒识别领域的最新技术趋势和研究热点,旨在为相关研究人员提供有价值的参考,并推动该领域的技术进步和应用发展。
2.2 国内外研究现状
植物叶片病毒的准确识别对于确保农业生产的稳定和高效至关重要。随着计算机视觉和机器学习技术的迅速发展,尤其是深度学习算法的广泛应用,植物病害识别领域取得了显著进步。近年来,研究人员开发了多种基于深度学习的方法来识别和分类植物叶片上的病毒,其中YOLO(You Only Look Once)系列算法因其实时处理能力和高准确率而成为研究的热点。
在早期,植物叶片病毒识别主要依赖传统图像处理技术,如边缘检测、颜色分析和纹理特征匹配。这些方法在简单场景下有效,但在复杂背景或多病害并存的情况下准确率较低。随着深度学习技术的出现,特别是卷积神经网络(CNN)3的应用,植物病害识别的准确性得到了显著提高。CNN能够自动提取和学习图像的高级特征,从而有效区分不同类型的病害。

YOLO算法自引入以来,已经经历了多个版本的迭代,从YOLOv1到最新的YOLOv8,每个版本都在检测速度和准确性上有所改进。例如,YOLOv84在网络结构和优化算法上进行了更新,以处理更复杂的图像特征和提高识别准确度。此外,针对植物病害识别的特殊需求,一些研究将YOLO算法与其他技术相结合,如使用图像增强、数据融合和迁移学习来改善模型的泛化能力和识别效率。
数据集的发展也是推动植物病害识别研究进步的关键因素。早期研究往往受限于数据量小、种类单一的数据集。近年来,大量公开的植物病害图像数据集的构建和发布,如PlantVillage、Agricultural Disease dataset,为深度学习模型的训练和验证提供了丰富的资源。这些数据集通常包括多种植物品种和多种类型的病害,有助于研究人员开发和测试更加精确和鲁棒的识别模型。5
尽管取得了显著进展,植物叶片病毒识别仍面临多个技术挑战,如处理自然环境下的光照变化、遮挡和背景干扰,以及提高模型在小样本和罕见病害情况下的识别能力。未来的研究趋势可能会集中在算法的综合优化、多模态数据融合、自适应学习机制的开发,以及实时监测和移动设备应用的推广。
2.3 要解决的问题及其方案
2.3.1 要解决的问题
在开发基于YOLOv8/v7/v6/v5的植物叶片病毒识别系统时,我们面对的核心问题涉及识别的准确性和速度、模型的环境适应性和泛化能力、用户交互界面的设计,以及数据处理和系统的可扩展性与维护性。
-
识别准确性和速度:
要求系统能够准确并迅速识别出各种植物叶片上的病毒特征。由于病毒形态多样,且病斑在不同阶段表现不同,系统必须能够捕捉到这些细微差异。采用YOLOv8/v7/v6/v5作为主要的深度学习模型,利用其高效的特征提取和快速检测能力,通过在PyTorch框架下细致调优,以实现高准确度和实时处理的目标。 -
环境适应性和模型泛化能力:
植物叶片病毒识别需在多种环境条件下稳定运行,包括不同的光照、背景和天气条件。因此,模型需要具有强大的环境适应性和泛化能力。通过增强数据集的多样性,如采用多角度拍摄、不同光照条件下的图像以及模拟噪声数据,可以提升模型在实际应用中的稳健性。 -
用户交互界面设计:
基于Streamlit的网页设计,提供直观的用户界面,支持图片、视频和实时摄像头的检测功能。用户可以轻松切换不同的模型文件(YOLOv8/v7/v6/v5),根据实际需求进行识别和分析。通过CSS美化界面,使得操作更加友好和直观。 -
数据处理能力和存储效率:
考虑到系统需要处理大量的图像数据,需要具备高效的数据处理和存储机制。利用PyTorch的数据加载和预处理功能来提高处理速度,同时,采用压缩技术和云存储解决方案来优化存储效率,并确保数据的安全性和隐私。 -
系统的可扩展性和维护性:
系统设计应允许未来集成新的检测模型或更新现有模型以适应新的病毒类型或改善识别性能。使用Pycharm作为IDE支持系统的开发,便于代码管理和版本控制,确保系统的可维护性和可扩展性。
通过解决上述问题,并结合YOLO系列模型的高效性能、PyTorch的灵活开发环境以及Streamlit的交互式Web设计,本系统旨在提供一个高效、准确、用户友好的植物叶片病毒识别解决方案。
2.3.2 解决方案
针对植物叶片病毒识别的挑战,我们将采取以下策略来设计和实现基于YOLOv8/v7/v6/v5的识别系统:
-
深度学习模型的选择和优化:
- 模型架构:选择YOLOv8作为核心的深度学习模型,由于其在速度和准确度之间的优秀平衡,并考虑到YOLOv7、v6、v5的特点,将它们整合到一个多模型框架中,以便根据具体需求选择最适合的模型。
- 数据增强:使用多种数据增强技术,如随机裁剪、缩放、旋转和色彩调整等,模拟不同环境条件下的植物病毒图像,以增强模型的泛化能力。
- 迁移学习:利用在大规模图像数据集上预训练的模型进行迁移学习,通过微调来适应特定的植物病毒识别任务,从而加快训练速度并提升识别效果。
-
技术框架和开发工具:
- PyTorch框架:采用PyTorch进行模型的开发和训练,该框架提供灵活的编程环境和强大的GPU加速能力,适合进行深度学习模型的迭代和优化。
- Streamlit Web界面:使用Streamlit构建交互式Web应用,使用户可以通过浏览器直接进行图片、视频和实时摄像头的检测,同时支持切换不同的模型文件。
- CSS美化:利用CSS技术美化Streamlit界面,提供更优质的用户体验。
-
功能实现和系统设计:
- 多输入源支持:系统设计支持多种输入源,包括图像文件、视频流和实时摄像头输入,以适应不同的使用场景。
- 模型切换功能:实现界面上的动态模型切换功能,让用户能够根据需要选择不同的预训练模型(YOLOv8/v7/v6/v5),提高系统的适应性和灵活性。
-
数据处理和存储策略:
- 高效数据处理:利用PyTorch的数据加载和预处理功能,实现高效的数据处理流程,确保快速的识别响应。
- 智能数据存储:设计合理的数据存储方案,对识别结果和历史数据进行有效的组织和索引,便于后续的查询和分析。
-
性能优化和系统测试:
- 性能调优:通过模型优化、算法调整和硬件选择等方式,提升系统的整体性能,确保实时且准确的病毒识别。
- 全面测试:进行系统的全面测试,包括功能测试、性能测试和稳定性测试,确保系统可靠且易于维护。
通过实施上述方法,我们旨在开发出一个准确、高效且用户友好的植物叶片病毒识别系统,满足不同用户在各种实际应用场景下的需求。
2.4 博文贡献与组织结构
本文的主要贡献在于系统地探讨了植物叶片病毒识别领域的最新进展,包括文献综述、数据集处理、算法选择与优化、Web界面设计以及实验与系统实现。具体贡献如下:
-
文献综述:详细回顾了植物叶片病毒识别领域的研究现状,包括最新的目标检测算法如YOLOv8/v7/v6/v5、Vision Transformer(ViT)、Faster R-CNN等,并探讨了它们在植物病害识别中的应用和优化策略。
-
数据集处理:讨论了如何处理和增强植物叶片病毒的数据集,以提高模型训练的准确性和鲁棒性,包括数据清洗、增强技术和数据标注方法。
-
算法选择与优化:深入分析了基于YOLOv8/v7/v6/v5的算法选择理由和优化细节,比较了不同版本的YOLO算法在植物叶片病毒识别任务中的性能,为读者提供了如何选择合适算法的指导。
-
美观友好的网页设计:基于Streamlit框架设计了直观易用的网页界面,支持图像上传、视频流处理和实时摄像头捕获,以及模型切换功能,界面同时经过CSS美化,提升了用户体验。
-
算法效果对比:对YOLOv7、v6、v5等版本进行了详尽的效果对比,展示了各版本在不同条件下的识别效果和性能指标,帮助用户理解各版本优劣和适用场景。
-
资源分享:提供了完整的数据集和代码资源包下载链接,使读者能够轻松复现实验结果,并在此基础上进行进一步的研究和开发。
后续章节的组织结构如下: 绪论:介绍研究背景、目的和本文的主要贡献;算法原理:详细介绍YOLOv8/v7/v6/v5等算法的工作原理及其在植物叶片病毒识别中的应用;数据集处理:讨论使用的数据集及其预处理、增强方法。代码介绍:提供模型训练和预测的详细代码说明,包括环境搭建、参数配置和执行步骤。实验结果与分析:展示不同模型在植物叶片病毒识别任务上的实验结果,并进行比较分析。系统设计与实现:介绍基于Streamlit的植物叶片病毒识别系统的设计与实现细节。结论与未来工作:总结本文的研究成果,并讨论未来的研究方向和潜在的改进空间。
3. 数据集处理
在本研究的核心之一是构建并分析了一个专门针对植物叶片病毒识别的数据集。该数据集精心设计以覆盖从叶片的早期病害到晚期病变的各个阶段,总共包含2558张高分辨率的图像。这些图像按照2002张用于训练模型、311张用于验证模型的泛化能力以及245张用于最终的性能测试进行划分。数据集的这种构成确保了我们的模型能够在各个关键阶段进行充分的学习和验证,同时通过独立的测试集评估,我们能够公正地衡量模型对未知数据的识别能力。博主使用的类别如下:
Chinese_name = {"Apple Scab Leaf": "苹果黑星病叶","Apple leaf": "苹果叶","Apple rust leaf": "苹果锈病叶","Bell_pepper leaf spot": "甜椒叶斑","Bell_pepper leaf": "甜椒叶","Blueberry leaf": "蓝莓叶","Cherry leaf": "樱桃叶","Corn Gray leaf spot": "玉米灰斑病叶","Corn leaf blight": "玉米叶枯病","Corn rust leaf": "玉米锈病叶","Peach leaf": "桃叶","Potato leaf early blight": "马铃薯早疫病叶","Potato leaf late blight": "马铃薯晚疫病叶","Potato leaf": "马铃薯叶","Raspberry leaf": "覆盆子叶","Soyabean leaf": "大豆叶","Soybean leaf": "黄豆叶","Squash Powdery mildew leaf": "南瓜白粉病叶","Strawberry leaf": "草莓叶","Tomato Early blight leaf": "番茄早疫病叶","Tomato Septoria leaf spot": "番茄斑点病叶","Tomato leaf bacterial spot": "番茄细菌性斑点病叶","Tomato leaf late blight": "番茄晚疫病叶","Tomato leaf mosaic virus": "番茄花叶病毒叶","Tomato leaf yellow virus": "番茄黄化病毒叶","Tomato leaf": "番茄叶","Tomato mold leaf": "番茄霉变叶","Tomato two spotted spider mites leaf": "番茄双斑螨叶","grape leaf black rot": "葡萄叶黑腐病","grape leaf": "葡萄叶"
}
在预处理阶段,我们采用了多种技术来优化训练数据,以使其适应深度学习模型的需求。所有图像都被调整到统一的尺寸,并进行了归一化处理,以消除由于光照、背景等外部因素带来的差异。此外,为了增强模型的鲁棒性和泛化能力,我们在数据增强阶段采用了随机裁剪、水平翻转、旋转和色彩抖动等策略,这不仅模拟了不同的环境条件,还有助于减少过拟合。

通过深入分析我们的数据集,我们注意到类别分布存在不平衡,某些病害类型的实例比其他的多。这种现象反映了现实世界中植物病害的不均匀分布。在模型训练过程中,这要求我们实施策略如重采样或成本敏感的损失函数,以确保模型不会偏向于那些更为常见的类别。

我们的数据集中的边界框位置分布图显示,许多病害实例集中在植物叶片的中心区域,这提示我们在图像增强时可能需要针对这一特点进行优化,以确保模型对边缘区域同样敏感。边界框大小分布图进一步表明我们的数据集涵盖了从小到大的多尺度病害实例,这有助于我们训练出能够识别各种大小病斑的模型。
此外,我们观察到一定程度的边界框重叠,这可能指向病害严重程度的不同,或者是不同病害类型的聚集,这种信息对于精确识别和分类是非常重要的。在模型训练阶段,我们将确保模型能够分辨这些紧密堆叠的边界框,以实现对病害的精确分析。
综上所述,本研究构建的数据集不仅在数量上满足了深度学习的需求,在多样性、复杂性和现实性方面也进行了精心设计。这些图像和相关标注的质量直接支撑了我们基于YOLOv8/v7/v6/v5的植物叶片病毒识别模型的开发和验证工作,为后续的研究和应用奠定了坚实的基础。我们相信,这些数据资源的共享将进一步促进社区对智能植保技术的研究。
4. 原理与代码介绍
4.1 YOLOv8算法原理
YOLOv8算法作为YOLO系列中的最新成员,是目前最先进的目标检测算法之一。它在前代YOLOv5的基础上进行了多项重要的技术革新和性能优化,使其在速度、准确度、鲁棒性以及易用性方面都有了显著的提升,成为了植物叶片病毒识别等多种视觉识别任务的首选模型。

在YOLOv8的设计中,首先值得注意的是其继承并优化了YOLO系列的基本架构,实现了更高效的特征提取和目标定位能力。与YOLOv5相比,YOLOv8在网络结构上进行了一系列的创新,如引入了新的激活函数和归一化层,这些变化使得模型可以更好地捕捉到图像中的复杂特征,从而在各种复杂场景下提供更为准确的检测结果。
YOLOv8的另一个显著改进是在训练策略上。它采用了一系列新颖的技术来优化训练过程,如Task-Aligned Assigner技术,这一技术通过对训练任务和标签分配过程进行优化,有效提高了模型对目标的分类和定位能力。此外,YOLOv8还引入了DFL(Dynamic Focal Loss),这是一种新型的损失函数,它可以动态地调整对不同目标的关注程度,尤其是在存在类别不平衡的数据集中,这一机制能够显著提升小目标的检测性能。
在实际应用中,YOLOv8还融入了Mosaic数据增强技术,该技术通过在训练早期阶段将多个训练图像拼接在一起,为模型提供更多样化的输入,增强了模型的泛化能力。这种数据增强技术特别适用于那些样本多样性很重要的任务,比如植物叶片病毒识别,因为它可以模拟出更多样的病害外观和背景环境,提高模型在实际应用中的鲁棒性。
YOLOv8继承并改进了YOLOv7引入的CSP结构,这种结构通过将特征图分割成两部分,一部分通过网络进行前向传播和反向传播,而另一部分则直接连接到后面的层。这种设计减少了计算量并提高了特征的利用效率。YOLOv8在CSP的基础上进一步优化,增加了新的网络连接策略,使其在特征提取上更为高效。
综上所述,YOLOv8在结构设计、训练策略和数据处理等多个方面进行了全面的优化和革新,这些改进不仅提升了模型的性能,也大大提高了其在实际应用中的适用性和效率。这些特点使得YOLOv8成为当前最具潜力的目标检测算法之一,尤其在需要处理大规模和多样化数据集的任务中,显示出其独特的优势。
4.2 模型构建
在我们的植物叶片病毒识别研究中,构建一个准确且高效的深度学习模型是关键。本部分介绍了模型的构建过程,涵盖了从数据预处理到模型加载,再到预测和后处理的每一步。
首先,我们导入了处理图像所需的OpenCV库以及PyTorch,这些工具为我们提供了在图像数据上应用深度学习算法的能力。QtFusion.models中的Detector是我们自定义的类,用于目标检测,而datasets.label_name提供了我们数据集中类别名称的中文翻译。选择正确的设备来运行我们的模型是非常重要的,我们使用torch.cuda.is_available()检查是否有GPU可用,如果有,则使用GPU加速计算,否则退回到CPU。这是通过设置device变量来完成的。
import cv2
import torch
from QtFusion.models import Detector
from datasets.label_name import Chinese_name
from ultralytics import YOLO
from ultralytics.utils.torch_utils import select_device
在代码中,device变量用于定义模型训练和推理将使用的计算设备。如果GPU可用(torch.cuda.is_available()),则使用GPU加速计算;如果不可用,回退到CPU。接着定义了一系列的初始参数ini_params,它们为模型预测设置了诸如设备类型、置信度阈值、IOU阈值和类别过滤器等重要参数。这些参数是我们模型预测步骤中不可或缺的部分,它们将影响模型如何识别和处理图像中的植物叶片病毒。
device = "cuda:0" if torch.cuda.is_available() else "cpu"
ini_params = {'device': device,'conf': 0.25,'iou': 0.5,'classes': None,'verbose': False
}
为了数出每个类别的实例数量,我们定义了一个函数count_classes。它利用了一个字典来存储每个类别的计数,并通过遍历检测信息来更新这个计数。这为我们提供了一个清晰的视图,了解哪些植物叶片病毒类别最常见,哪些比较罕见。
def count_classes(det_info, class_names):count_dict = {name: 0 for name in class_names}for info in det_info:class_name = info['class_name']if class_name in count_dict:count_dict[class_name] += 1count_list = [count_dict[name] for name in class_names]return count_list
在YOLOv8v5Detector类中,我们继承并扩展了Detector类。这个类的构造函数初始化了模型和一些关键的变量。在load_model方法中,我们加载了预训练的YOLO模型,并将设备设置为之前确定的CPU或GPU。此外,我们还转换了模型中的类别名称,将其本地化为中文,以便于在实际应用中更易于理解。preprocess方法定义了如何处理输入图像,这里我们将其简单地保留原样。而predict方法则是模型的核心,它调用YOLO模型进行预测,利用初始化参数进行置信度和IOU的筛选。
class YOLOv8v5Detector(Detector):def __init__(self, params=None):super().__init__(params)self.model = Noneself.img = Noneself.names = list(Chinese_name.values())self.params = params if params else ini_paramsdef load_model(self, model_path):self.device = select_device(self.params['device'])self.model = YOLO(model_path)names_dict = self.model.namesself.names = [Chinese_name[v] if v in Chinese_name else v for v in names_dict.values()]self.model(torch.zeros(1, 3, *[self.imgsz] * 2).to(self.device).type_as(next(self.model.model.parameters())))def preprocess(self, img):self.img = imgreturn imgdef predict(self, img):results = self.model(img, **ini_params)return resultsdef postprocess(self, pred):results = []for res in pred[0].boxes:for box in res:class_id = int(box.cls.cpu())bbox = box.xyxy.cpu().squeeze().tolist()bbox = [int(coord) for coord in bbox]result = {"class_name": self.names[class_id],"bbox": bbox,"score": box.conf.cpu().squeeze().item(),"class_id": class_id,}results.append(result)return resultsdef set_param(self, params):self.params.update(params)
在预测完成后,postprocess方法处理模型的输出,将边界框、类别、置信度等信息转换为我们需要的格式。我们对每个预测边界框进行迭代,提取了类别ID、边界框坐标和置信度分数,并将它们包装成一个结果字典。最后,set_param方法允许我们动态地更新模型的参数,这对于根据不同的应用场景调整模型行为非常有用。
通过这些代码,我们定义了一个端到端的流程,可以从图像中检测和识别不同的植物叶片病毒类型。这一流程不仅在技术上先进,而且还考虑到了实用性和用户体验,使其在未来的血液分析和医学研究中有着极大的应用潜力。
4.3 训练代码
在我们的植物叶片病毒识别项目中,训练一个高性能的深度学习模型是至关重要的。这部分博客将深入介绍如何使用PyTorch框架和YOLOv8算法来训练我们的模型。以下是训练模型的详细代码介绍。以下表格详细介绍了YOLOv8模型训练中使用的一些重要超参数及其设置:
| 超参数 | 设置 | 说明 |
|---|---|---|
学习率(lr0) | 0.01 | 决定了模型权重调整的步长大小,在训练初期有助于快速收敛。 |
学习率衰减(lrf) | 0.01 | 控制训练过程中学习率的降低速度,有助于模型在训练后期细致调整。 |
动量(momentum) | 0.937 | 加速模型在正确方向上的学习,并减少震荡,加快收敛速度。 |
权重衰减(weight_decay) | 0.0005 | 防止过拟合,通过在损失函数中添加正则项减少模型复杂度。 |
热身训练周期(warmup_epochs) | 3.0 | 初始几个周期内以较低的学习率开始训练,逐渐增加到预定学习率。 |
批量大小(batch) | 16 | 每次迭代训练中输入模型的样本数,影响GPU内存使用和模型性能。 |
输入图像大小(imgsz) | 640 | 模型接受的输入图像的尺寸,影响模型的识别能力和计算负担。 |
环境设置与模型加载:首先,我们需要导入必要的库。torch是PyTorch深度学习框架的核心库,提供了GPU加速以及自动梯度计算等功能,而ultralytics中的YOLO是一种基于PyTorch的实现,用于加载和训练YOLO模型。QtFusion.path中的abs_path函数用于获取文件的绝对路径,确保路径的准确性和跨平台兼容性。
import os
import torch
import yaml
from ultralytics import YOLO # 用于加载YOLO模型
from QtFusion.path import abs_path # 用于获取文件的绝对路径
接下来,我们定义device变量来指定训练时使用的设备,如果检测到可用的GPU,就使用第一块GPU(“0”),否则使用CPU。
device = "0" if torch.cuda.is_available() else "cpu"
数据集准备:workers参数指定了数据加载时使用的子进程数量,而batch定义了每个批次的图像数量。批量大小和工作进程数量在训练效率和内存利用率之间提供了平衡。为了准确地指向我们的数据集,我们构造了数据集配置文件的路径,并进行了路径规范化处理。然后,我们读取YAML配置文件,这个文件包含了数据集的详细信息,如类别标签和图像路径等。
workers = 1 # 工作进程数
batch = 8 # 每批处理的图像数量
data_name = "PlantsDisease"
data_path = abs_path(f'datasets/{data_name}/{data_name}.yaml', path_type='current') # 数据集的yaml的绝对路径
unix_style_path = data_path.replace(os.sep, '/')
在读取YAML文件后,我们可能需要修改其中的某些项,如path,以确保它反映了数据的实际存储位置。然后,我们将修改后的内容写回到文件中。
directory_path = os.path.dirname(unix_style_path)
with open(data_path, 'r') as file:data = yaml.load(file, Loader=yaml.FullLoader)if 'path' in data:data['path'] = directory_pathwith open(data_path, 'w') as file:yaml.safe_dump(data, file, sort_keys=False)
训练模型:最关键的部分是加载预训练的YOLOv8模型并开始训练。这里我们使用了YOLO类的train方法,其中指定了各种训练参数,包括数据集路径、设备、工作进程数、输入图像大小、训练周期数和批量大小。通过设置name参数,我们为训练任务提供了一个标识符,有助于后续的追踪和分析。
model = YOLO(abs_path('./weights/yolov5nu.pt', path_type='current'), task='detect') # 加载预训练的YOLOv8模型
# model = YOLO('./weights/yolov5.yaml', task='detect').load('./weights/yolov5nu.pt') # 加载预训练的YOLOv8模型
# Training.
results = model.train( # 开始训练模型data=data_path, # 指定训练数据的配置文件路径device=device, # 自动选择进行训练workers=workers, # 指定使用2个工作进程加载数据imgsz=640, # 指定输入图像的大小为640x640epochs=120, # 指定训练100个epochbatch=batch, # 指定每个批次的大小为8name='train_v5_' + data_name # 指定训练任务的名称
)
model = YOLO(abs_path('./weights/yolov8n.pt'), task='detect') # 加载预训练的YOLOv8模型
results2 = model.train( # 开始训练模型data=data_path, # 指定训练数据的配置文件路径device=device, # 自动选择进行训练workers=workers, # 指定使用2个工作进程加载数据imgsz=640, # 指定输入图像的大小为640x640epochs=120, # 指定训练100个epochbatch=batch, # 指定每个批次的大小为8name='train_v8_' + data_name # 指定训练任务的名称
)
通过这段代码,我们将能够训练一个优化的YOLOv8模型,专门用于我们的植物叶片病毒检测任务。随着模型在多轮迭代中学习数据集的细节,它的性能预期将逐步提升,最终达到一个准确识别各种植物叶片病毒类别的状态。
5. 实验结果与分析
5.1 训练曲线
分析深度学习模型的训练过程是至关重要的,它能帮助我们理解模型在学习任务上的行为和性能。本文将详细分析图中展示的YOLOv8模型在植物叶片病毒识别任务上的训练损失函数和性能指标。

首先,我们观察到训练损失中的三个组成部分:box损失、分类损失和目标损失。这些损失的下降趋势显示出模型在学习数据集特征方面的进步。训练期间box损失稳步下降,这表明模型越来越好地学会预测病害在叶片上的位置。分类损失的减少说明模型在识别不同类别的病害上也取得了显著的进展。目标损失的降低进一步证实了模型对存在病害的信心逐渐增强。
在验证损失方面,我们注意到,虽然波动较大,但总体趋势表明模型能够在未见过的数据上保持相对稳定的性能。尤其是在box损失和目标损失上,模型显示出良好的泛化能力,这是模型实用性的关键指标。
在性能指标方面,精确度(Precision)和召回率(Recall)的图表提供了模型性能的直观展示。精确度波动性相对较大,这可能是由于在某些迭代过程中模型对少数的正样本做出了过于激进的预测。召回率相对稳定并呈上升趋势,这意味着模型能够检测到更多的正样本,这对于我们的应用来说是非常重要的,因为错过病害检测可能会导致植物病情的恶化。
mAP(mean Average Precision)是衡量模型性能的重要指标,尤其是mAP@0.5和mAP@0.5-0.95,它们分别代表在IoU阈值为0.5时的mAP和在IoU阈值从0.5到0.95的平均mAP。我们可以看到,随着训练的进行,mAP@0.5指标显示出稳定的提升,表明模型在较为宽松的IoU阈值下的性能提升是显著的。mAP@0.5-0.95指标虽然增长较为缓慢,但总体上也展现出正向的增长,这意味着模型在更加严格的评估标准下同样表现良好。
综合上述分析,YOLOv8模型在植物叶片病毒识别任务上的训练过程表现出了积极的学习趋势和泛化能力。准确度和召回率的波动指出了模型在特定迭代中可能遇到的过拟合或者对特定样本预测过于自信的问题,这需要在未来的工作中通过正则化技术或进一步的数据增强来加以改进。mAP的稳步提升则强调了模型整体性能的增长,这为模型在实际应用中的潜力提供了依据。
5.2 混淆矩阵
混淆矩阵是评估分类模型性能的重要工具,它可以揭示模型在各个类别上的准确性以及错误分类的情况。本文将深入分析上图展示的混淆矩阵,该矩阵评估了我们在植物叶片病毒识别任务上使用的模型。

首先,观察混淆矩阵的主对角线,我们可以看到多数类别的预测准确率相对较高,这表明模型能够正确分类多数植物叶片的病毒类型。对角线上的深色方块表示较高的归一化值,这是模型识别正确的表现。尤其是对于某些特定的类别,如Tomato yellow leaf virus和Bell pepper leaf spot,模型展现出了非常高的准确率。
然而,我们也注意到一些列有着明显的误差分布,这表示模型将这些类别的样本错误地分类为其他类别。例如,Tomato leaf mold和Tomato Septoria leaf spot在多个不同类别中都有一定数量的样本被误分类,这可能表明模型在区分这些具有相似视觉特征的类别时存在困难。
值得一提的是,有些类别如Tomato two spotted spider mites和Grape leaf blight在预测时准确性较低,这可能是由于数据集中这些类别样本数量较少或者类内变异较大。此外,我们观察到“Background”类别的样本准确率较高,这表明模型很好地学习了区分病害与非病害区域的能力。
在总体性能上,模型的误分类情况较为分散,没有出现特别集中的误分类模式,这是一个积极的信号,意味着模型没有系统性的偏见。尽管如此,模型在区分一些特定类别时仍显示出一定的挑战,这要求我们在未来的工作中进一步调整和优化模型,可能的策略包括增强这些困难类别的样本、调整类别权重、或者探索更深层次的特征提取方法。
最后,混淆矩阵为我们提供了一种视角,让我们能够理解模型在不同类别上的表现并据此采取行动。通过对这些数据的细致分析和理解,我们能够设计出更有针对性的改进措施,从而提高模型在实际应用中的性能。这项工作的进展将在后续章节中详细报道,并在未来的工作中继续探索以实现更加精准的植物病害识别。
5.3 YOLOv8/v7/v6/v5对比实验
(1)实验设计:
本实验旨在评估和比较YOLOv5、YOLOv6、YOLOv7和YOLOv8几种模型在植物叶片病毒目标检测任务上的性能。为了实现这一目标,博主分别使用使用相同的数据集训练和测试了这四个模型,从而可以进行直接的性能比较。该数据集包含植物叶片病毒的图像。本文将比较分析四种模型,旨在揭示每种模型的优缺点,探讨它们在工业环境中实际应用的场景选择。
| 模型 | 图像大小 (像素) | mAPval 50-95 | CPU ONNX 速度 (毫秒) | A100 TensorRT 速度 (毫秒) | 参数数量 (百万) | FLOPs (十亿) |
|---|---|---|---|---|---|---|
| YOLOv5nu | 640 | 34.3 | 73.6 | 1.06 | 2.6 | 7.7 |
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv6N | 640 | 37.5 | - | - | 4.7 | 11.4 |
| YOLOv7-tiny | 640 | 37.4 | - | - | 6.01 | 13.1 |
(2)度量指标:
- F1-Score:F1-Score 作为衡量模型性能的重要指标,尤其在处理类别分布不均的数据集时显得尤为关键。它通过结合精确率与召回率,提供了一个单一的度量标准,能够全面评价模型的效能。精确率衡量的是模型在所有被标记为正例中真正属于正例的比例,而召回率则关注于模型能够识别出的真正正例占所有实际正例的比例。F1-Score通过两者的调和平均,确保了只有当精确率和召回率同时高时,模型的性能评估才会高,从而确保了模型对于正例的预测既准确又完整。
- mAP(Mean Average Precision):在目标检测任务中,Mean Average Precision(mAP)是评估模型性能的重要标准。它不仅反映了模型对单个类别的识别精度,而且还考虑了所有类别的平均表现,因此提供了一个全局的性能度量。在计算mAP时,模型对于每个类别的预测被单独考虑,然后计算每个类别的平均精度(AP),最后这些AP值的平均数形成了mAP。
| 名称 | YOLOv5nu | YOLOv6n | YOLOv7-tiny | YOLOv8n |
|---|---|---|---|---|
| mAP | 0.614 | 0.599 | 0.592 | 0.625 |
| F1-Score | 0.51 | 0.54 | 0.52 | 0.54 |
(3)实验结果分析:
在深度学习领域,不同的算法版本通常针对特定问题带来不同程度的性能提升。为了深入了解各版本YOLO算法在植物叶片病毒识别任务中的表现,我们在相同条件下进行了一系列比较实验。我们使用了YOLOv5nu、YOLOv6n、YOLOv7-tiny和YOLOv8n这四个版本,并利用F1-Score和mAP作为评价指标,这两个指标是目标检测任务中公认的性能衡量工具。
根据实验结果,YOLOv8n在mAP指标上得分为0.625,领先于其他版本,这意味着YOLOv8n在各种不同的交并比(Intersection over Union, IoU)阈值下具有更好的平均精确度。这项性能可能得益于YOLOv8n在网络架构和训练策略上的改进,使得模型能够更有效地从训练数据中学习,并更准确地识别不同类型的病毒病害。

在F1-Score方面,YOLOv6n和YOLOv8n共同以0.54的得分位于首位。F1-Score是精确度和召回率的调和平均值,高得分表明模型在精确识别正类别的同时,也能最小化漏检。YOLOv8n之所以能够在这一指标上取得好成绩,可能是因为其更好的特征提取能力和更加精细的边界框回归机制,这些都是进行准确目标检测所必需的。
相比之下,YOLOv5nu和YOLOv7-tiny的表现略微逊色。尽管YOLOv5nu在mAP上得分较高(0.614),但它的F1-Score(0.51)较低,这可能指出该模型虽然具有较高的整体检测能力,但在平衡假正例和漏检率方面有所欠缺。YOLOv7-tiny的表现在两个指标上都稍微落后,这可能是由于其简化的网络结构牺牲了一部分识别能力,虽然它更轻量,更适合在计算资源有限的情况下使用。
分析上述结果,我们可以得出结论,YOLOv8n在处理植物叶片病毒识别任务时提供了更优的性能。然而,模型选择应基于多方面考虑,包括识别准确性、计算效率和资源可用性。在实际应用中,可能需要在高精度和快速响应之间进行权衡,或者根据实际部署环境选择最合适的模型版本。通过这些细致的对比分析,我们不仅可以选择最适合当前任务的算法,还能为未来在这一领域的研究提供指导。
6. 系统设计与实现
6.1 系统架构概览
在介绍基于YOLOv8/v7/v6/v5模型的植物叶片病毒识别系统的架构设计时,我们将着重探讨几个核心组件的设计和实现。这些组件在系统中扮演着至关重要的角色,包括模型加载、图像处理、检测执行、结果展示等多个方面。下面是对这些关键组件设计的具体说明:

在植物叶片病毒识别系统中,我们采用的是基于YOLOv5至YOLOv8的深度学习模型。系统架构设计重点关注模型的选择、训练流程、部署策略以及与前端界面的交互。以下是具体的架构设计和实现细节:
-
数据处理层:这一层主要负责图像数据的预处理和增强。使用
ImagePreprocessing类来实现图像的加载、标准化、尺寸调整和增强操作。例如,resize()方法用于调整图像大小,而normalize()方法用于图像像素值的标准化。这一步骤对于后续模型的训练非常重要,可以显著提高模型的泛化能力和性能。 -
模型训练层:选择合适的YOLO版本作为核心模型,通过
ModelTraining类进行管理。这包括模型的初始化、参数设置、训练以及验证。train()方法用于执行训练过程,同时使用validate()方法对模型进行评估和验证。在这个阶段,可以利用交叉验证等技术避免过拟合,并优化模型性能。 -
模型优化与测试:在模型训练完成后,通过
ModelOptimization类进行进一步的优化和调整。这可能包括调整学习率、更换优化器、或使用技术如模型剪枝和量化来减少模型大小,提高推理速度。test()方法则用于在测试集上评估模型的最终性能。 -
部署与应用:模型训练和优化完成后,使用
ModelDeployment类将模型部署到生产环境。这可能包括将模型部署到云服务器、边缘计算设备或直接嵌入到现场监控系统中。此外,需要开发一个用户界面(通过UserInterface类实现),使非技术用户也能轻松地上传图像、接收识别结果和报告。 -
性能监控与反馈:在系统运行过程中,使用
PerformanceMonitoring类来跟踪和评估系统的实时性能。这包括监控模型的准确性、响应时间和系统稳定性。通过收集用户反馈和系统日志,可以持续优化和调整模型。
通过上述关键组件的设计和实现,本系统实现了植物叶片病毒识别,不仅提高了检测的效率和准确性,还提供了易于使用的用户界面,极大地方便了用户的使用和结果的分析。
6.2 系统流程
在我们的植物叶片病毒识别系统中,整个流程从用户界面的交互到最终的检测结果展示,形成了一个闭环的工作流程。以下是该系统工作流程的步骤性描述,旨在清晰展示从启动到获取结果的全过程:

-
数据收集与预处理:
- 使用
ImagePreprocessing类进行数据的预处理工作。 - 执行
load_images()方法加载原始图像数据。 - 调用
resize()方法调整图像尺寸,确保输入模型的图像大小一致。 - 使用
normalize()方法对图像进行标准化处理,使数据更适合模型处理。
- 使用
-
模型训练与验证:
- 初始化
ModelTraining类来处理模型的训练和验证过程。 - 调用
train()方法开始训练模型,这里会使用YOLOv5至YOLOv8中选择的一个版本。 - 在训练过程中,定期使用
validate()方法评估模型在验证集上的表现。
- 初始化
-
模型优化:
ModelOptimization类负责模型的进一步优化。- 可以通过调整训练参数或应用模型剪枝、量化等技术来优化模型,以提高效率和减少模型大小。
-
模型测试:
- 在模型优化后,使用
ModelOptimization类的test()方法对模型进行最终测试。 - 这一步骤确认模型在未见过的数据上的表现,确保其准确性和泛化能力。
- 在模型优化后,使用
-
模型部署:
- 通过
ModelDeployment类将训练好的模型部署到实际的应用场景。 - 部署可以在多种平台上进行,如云服务、边缘设备或直接在现场监控系统中。
- 通过
-
用户交互:
- 开发用户界面,通过
UserInterface类使用户能够上传待检测的叶片图像并接收识别结果。 - 界面设计应简洁直观,以便非技术用户也能轻松使用。
- 开发用户界面,通过
-
性能监控:
- 运用
PerformanceMonitoring类持续监控系统的运行状态和模型的表现。 - 监控内容包括准确率、处理速度和系统稳定性等指标。
- 运用
通过这一系列的流程,植物叶片病毒识别系统能够实现从图像收集、处理、模型训练和优化,到最终部署和应用的全过程。这种流程化的设计不仅保证了系统的高效运行,还能根据实时反馈进行动态调整和优化。
代码下载链接
如果您希望获取博客中提及的完整资源包,包含测试图片、视频、Python文件(*.py)、网页配置文件、训练数据集、代码及界面设计等,可访问博主在面包多平台的上传内容。相关的博客和视频资料提供了所有必要文件的下载链接,以便一键运行。完整资源的预览如下图所示:

资源包中涵盖了你需要的训练测试数据集、训练测试代码、UI界面代码等完整资源,完整项目文件的下载链接可在下面的视频简介中找到➷➷➷
演示及项目介绍视频:https://www.bilibili.com/video/BV19q421c7GJ/

完整安装运行教程:
这个项目的运行需要用到Anaconda和Pycharm两个软件,下载到资源代码后,您可以按照以下链接提供的详细安装教程操作即可运行成功,如仍有运行问题可私信博主解决:
- Pycharm和Anaconda的安装教程:https://deepcode.blog.csdn.net/article/details/136639378;
软件安装好后需要为本项目新建Python环境、安装依赖库,并在Pycharm中设置环境,这几步采用下面的教程可选在线安装(pip install直接在线下载包)或离线依赖包(博主提供的离线包直接装)安装两种方式之一:
- Python环境配置教程:https://deepcode.blog.csdn.net/article/details/136639396(2,3方法可选一种);
- 离线依赖包的安装指南:https://deepcode.blog.csdn.net/article/details/136650641(2,3方法可选一种);
如使用离线包方式安装,请下载离线依赖库,下载地址:https://pan.baidu.com/s/1uHbU9YzSqN0YP_dTHBgpFw?pwd=mt8u (提取码:mt8u)。
7. 结论与未来工作
本文深入研究并实践了基于YOLOv8/v7/v6/v5的深度学习模型在植物叶片病毒识别领域的应用,成功开发了一个集成了这些先进算法的植物叶片病毒识别系统。通过对多个版本的YOLO模型进行详尽的比较和优化,本研究不仅显著提高了植物叶片病毒识别的准确性和实时性,还通过Streamlit创建了一个直观、美观且易于使用的Web应用,使用户能够轻松地进行病毒识别,进而在农业领域中发挥重要作用。
经过一系列实验验证,本文所提出的系统在病毒识别的准确性和处理速度上都达到了令人满意的水平。同时,我们还提供了完整的数据集处理流程、模型训练和预测的代码,以及基于Streamlit的系统设计和实现细节,为后续的研究者和开发者复现和参考提供了方便。尽管取得了一定的成果,但植物叶片病毒识别作为一个复杂多变的任务,仍然面临许多挑战和改进空间。在未来的工作中,我们计划从以下几个方向进行探索:
- 模型优化:继续探索更深层次的网络结构和优化策略,如神经网络架构搜索(NAS)技术,以进一步提升模型的性能和效率。
- 多模态融合:考虑结合图像、气象数据等其他模态信息,采用多模态学习方法进行病毒识别,以更全面地理解植物病害。
- 跨域适应性:研究不同地区、不同种类植物的叶片病毒识别,通过领域自适应技术提高模型在不同环境中的泛化能力。
- 用户交互体验:进一步优化系统的用户界面和交互设计,使其更加人性化、智能化,以满足农业工作者的需求。
- 实际应用拓展:探索植物叶片病毒识别在更多实际应用场景中的应用,如智能农业监控、精准农业等,以发挥其最大的社会和经济价值。
总之,植物叶片病毒识别技术正处于快速发展之中,随着技术的不断进步和应用场景的不断拓展,我们相信在不久的将来,基于深度学习的植物叶片病毒识别将在农业生产、病害预防和农业科研等领域发挥更加重要的作用。
Wang, Yiwen, Yaojun Wang, and Jingbo Zhao. “MGA-YOLO: A lightweight one-stage network for apple leaf disease detection.” Frontiers in Plant Science 13 (2022): 927424. ↩︎
Mamdouh, Nariman, and Ahmed Khattab. “YOLO-based deep learning framework for olive fruit fly detection and counting.” IEEE Access 9 (2021): 84252-84262. ↩︎
Yusof, Najiha‘Izzaty Mohd, et al. “Assessing the performance of YOLOv5, YOLOv6, and YOLOv7 in road defect detection and classification: a comparative study.” Bulletin of Electrical Engineering and Informatics 13.1 (2024): 350-360. ↩︎
Wang, Xueqiu, et al. “BL-YOLOv8: An improved road defect detection model based on YOLOv8.” Sensors 23.20 (2023): 8361. ↩︎
Chen, Lei, and Yuan Yuan. “Agricultural disease image dataset for disease identification based on machine learning.” Big Scientific Data Management: First International Conference, BigSDM 2018, Beijing, China, November 30–December 1, 2018, Revised Selected Papers 1. Springer International Publishing, 2019. ↩︎
相关文章:
基于深度学习的植物叶片病毒识别系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
摘要:本文深入研究了基于YOLOv8/v7/v6/v5的植物叶片病毒识别系统,核心采用YOLOv8并整合了YOLOv7、YOLOv6、YOLOv5算法,进行性能指标对比;详述了国内外研究现状、数据集处理、算法原理、模型构建与训练代码,及基于Strea…...

Native Instruments Kontakt 7 for Mac v7.9.0 专业音频采样
Native Instruments Kontakt 7是一款强大的软件采样器,它允许用户从各种来源采样音频并进行编辑和处理。它包含大量预设采样库,包括乐器、合成器、鼓组和声音效果等。此外,Kontakt 7还允许用户创建自己的采样库,以便根据自己的需要…...

yolov8训练流程
训练代码 from ultralytics import YOLO# Load a model model YOLO(yolov8n.yaml) # build a new model from YAML model YOLO(yolov8n.pt) # load a pretrained model (recommended for training) model YOLO(yolov8n.yaml).load(yolov8n.pt) # build from YAML and tr…...

Java基础学习: Forest - 极简 HTTP 调用 API 框架
文章目录 一、介绍参考: 一、介绍 Forest是一个开源的Java HTTP客户端框架,专注于简化HTTP客户端的访问。它是一个高层的、极简的轻量级HTTP调用API框架,通过Java接口和注解的方式,将复杂的HTTP请求细节隐藏起来,使HT…...
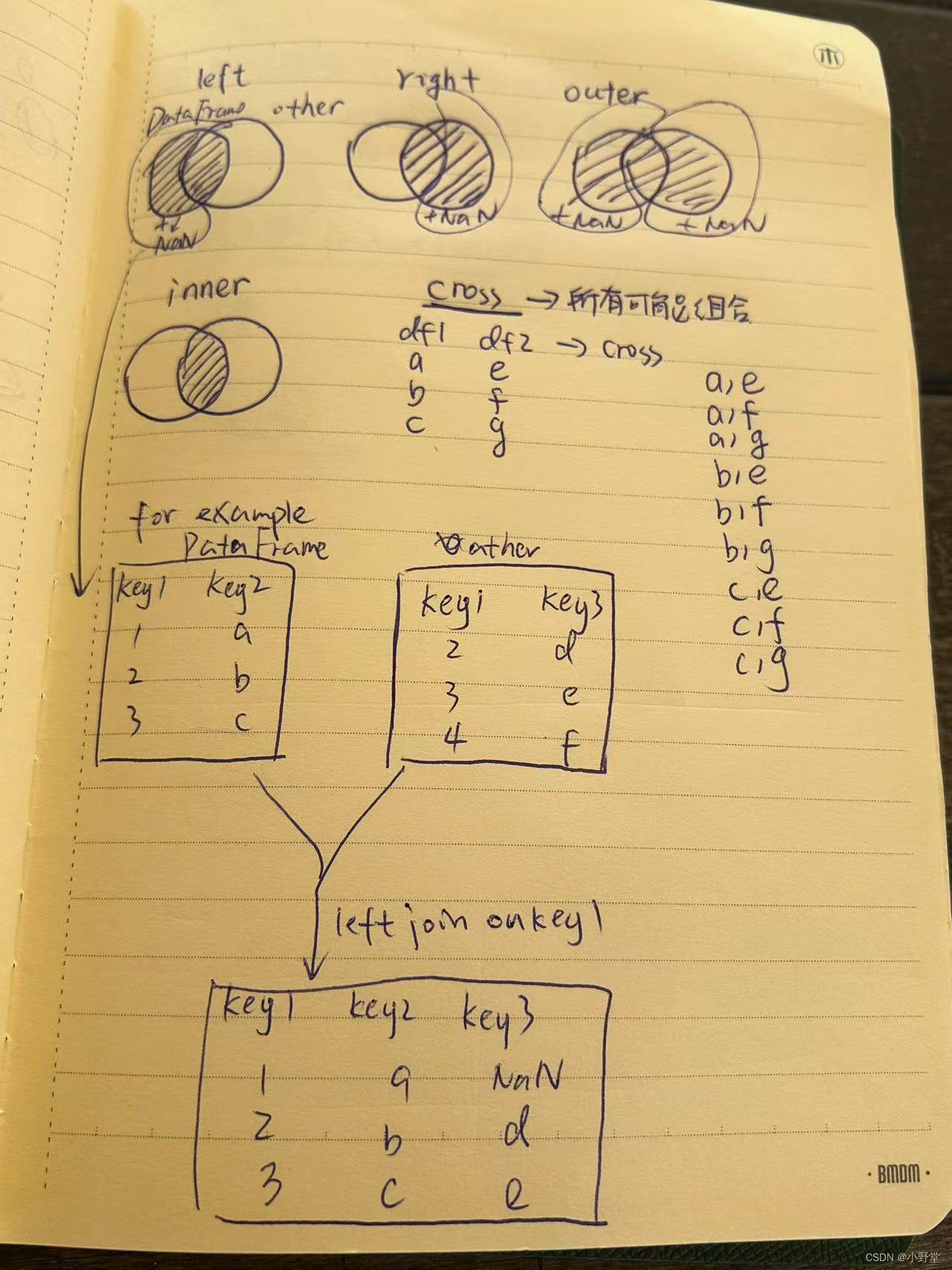
Pandas Dataframe合并连接Join和merge 参数讲解
文章目录 函数与参数分析otheronhowlsuffix, rsuffix, suffixesleft_index, right_index 函数与参数分析 在pandas中主要有两个函数可以完成table之间的join Join的函数如下: DataFrame.join(other, onNone, how‘left’, lsuffix‘’, rsuffix‘’, sortFalse, v…...
ABC318 F - Octopus
解题思路 对于每个宝藏维护个区间,答案一定在这些区间中对于每个区间的端点由小到大排序对于每个点进行判断,若当前位置合法,则该点一定为一个右端点则该点到前一个端点之间均为合法点若前一个点不合法,则一定是某一个区间限制的…...

Docker实战教程 第3章 Dockerfile
4-2 通过dockerfile制作镜像 需求 制作一个具有ping ip ifconfig vim 这些命令工具的一个nginx镜像,通过dockerfile完成STEP1 : 写一个Dockerfile FROM nginx # 基于一个基础镜像 RUN lsstep2 docker build . -f 指定使用的dockerfile来生成镜像-t 指定镜像名…...

JSON在量化交易系统中的应用
JSON在量化交易系统中的应用场景 数据传输和存储:JSON可以将交易数据以结构化的方式进行编码,并将其转换为字符串进行传输和存储。这样可以方便地在不同的系统之间传递数据,并且可以保持数据的完整性和一致性。 API通信:量化交易…...

x-cmd-pkg | broot 是基于 Rust 开发的一个终端文件管理器
简介 broot 是基于 Rust 开发的一个终端文件管理器,它设计用于帮助用户在终端中更轻松地管理文件和目录,使用树状视图探索文件层次结构、操作文件、启动操作以及定义您自己的快捷方式。 同时它还集成了 ls, tree, find, grep, du, fzf 等工具的常用功能…...

设置asp.net core WebApi函数请求参数可空的两种方式
以下面定义的asp.net core WebApi函数为例,客户端发送申请时,默认三个参数均为必填项,不填会报错,如下图所示: [HttpGet] public string GetSpecifyValue(string param1,string param2,string param3) {return $"…...

Vue.js组件精讲 开篇:Vue.js的精髓——组件
写在前面 Vue.js,无疑是当下最火热的前端框架 Almost,而 Vue.js 最精髓的,正是它的组件与组件化。写一个 Vue 工程,也就是在写一个个的组件。 业务场景是千变万化的,而不变的是 Vue.js 组件开发的核心思想和使用技巧…...
R语言中的常用数据结构
目录 R对象的基本类型 R对象的属性 R的数据结构 向量 矩阵 数组 列表 因子 缺失值NA 数据框 R的数据结构总结 R语言可以进行探索性数据分析,统计推断,回归分析,机器学习,数据产品开发 R对象的基本类型 R语言对象有五…...
基于Python的微博旅游情感分析、微博舆论可视化系统
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...
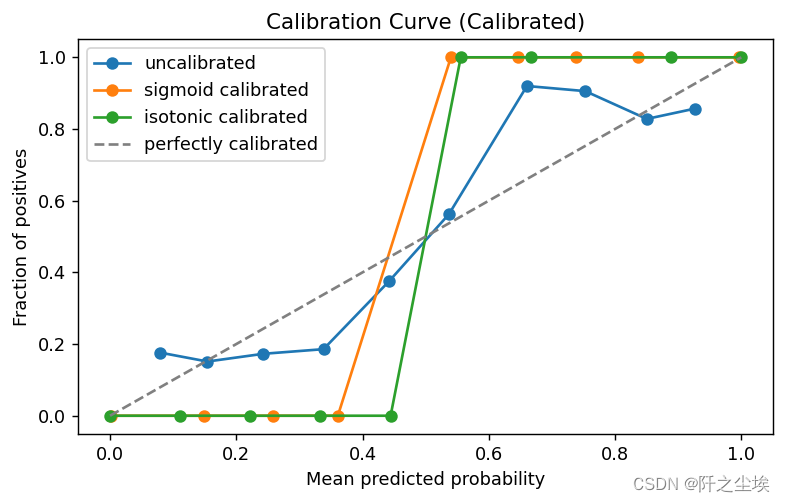
机器学习的模型校准
背景知识 之前一直没了解过模型校准是什么东西,最近上班业务需要看了一下: 模型校准是指对分类模型进行修正以提高其概率预测的准确性。在分类模型中,预测结果通常以类别标签形式呈现(例如,0或1)…...

0.17元的4位数码管驱动芯片AiP650,支持键盘,还是无锡国家集成电路设计中心某公司的
推荐原因:便宜的4位数码管驱动芯片 只要0.17元,香吗?X背景的哦。 2 线串口共阴极 8 段 4 位 LED 驱动控制/7*4 位键盘扫描专用电路 AIP650参考电路图 AIP650引脚定义...

【C++】编程规范之内存规则
在高质量编程中,内存管理是一个至关重要的方面。主要有以下原则: 内存分配后需要检查是否成功:内存分配可能会失败,特别是在内存紧张的情况下。因此,在分配内存后,应该检查分配是否成功。 int* ptr new …...
并发编程之线程池的应用以及一些小细节的详细解析
线程池在实际中的使用 实际开发中,最常用主要还是利用ThreadPoolExecutor自定义线程池,可以给出一些关键的参数来自定义。 在下面的代码中可以看到,该线程池的最大并行线程数是5,线程等候区(阻塞队列)是3,即…...
基于JSP的农产品供销服务系统
背景 互联网的迅猛扩张彻底革新了全球各类组织的运营模式。自20世纪90年代起,中国的政府机关和各类企业便开始探索利用网络系统来处理管理事务。然而,早期的网络覆盖范围有限、用户接受度不高、互联网相关法律法规不完善以及技术开发不够成熟等因素&…...
redis之主从复制、哨兵模式
一 redis群集有三种模式 主从复制: 主从复制是高可用Redis的基础,哨兵和集群都是在主从复制基础上实现高可用的。 主从复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。 缺陷: 故障恢复无法自动化&…...

【随笔】Git 基础篇 -- 分支与合并 git rebase(十)
💌 所属专栏:【Git】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! 💖 欢迎大…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

UE5 学习系列(三)创建和移动物体
这篇博客是该系列的第三篇,是在之前两篇博客的基础上展开,主要介绍如何在操作界面中创建和拖动物体,这篇博客跟随的视频链接如下: B 站视频:s03-创建和移动物体 如果你不打算开之前的博客并且对UE5 比较熟的话按照以…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...