【大模型】大模型 CPU 推理之 llama.cpp
【大模型】大模型 CPU 推理之 llama.cpp
- llama.cpp
- 安装llama.cpp
- Memory/Disk Requirements
- Quantization
- 测试推理
- 下载模型
- 测试
- 参考
llama.cpp
-
描述
The main goal of llama.cpp is to enable LLM inference with minimal setup and state-of-the-art performance on a wide variety of hardware - locally and in the cloud.
- Plain C/C++ implementation without any dependencies
- Apple silicon is a first-class citizen - optimized via ARM NEON, Accelerate and Metal frameworks
- AVX, AVX2 and AVX512 support for x86 architectures
- 1.5-bit, 2-bit, 3-bit, 4-bit, 5-bit, 6-bit, and 8-bit integer quantization for faster inference and reduced memory use
- Custom CUDA kernels for running LLMs on NVIDIA GPUs (support for AMD GPUs via HIP)
- Vulkan, SYCL, and (partial) OpenCL backend support
- CPU+GPU hybrid inference to partially accelerate models larger than the total VRAM capacity
-
官网
https://github.com/ggerganov/llama.cpp -
Supported platforms:
Mac OSLinuxWindows (via CMake)DockerFreeBSD -
Supported models:
- Typically finetunes of the base models below are supported as well.
LLaMA 🦙
LLaMA 2 🦙🦙
Mistral 7B
Mixtral MoE
Falcon
Chinese LLaMA / Alpaca and Chinese LLaMA-2 / Alpaca-2
Vigogne (French)
Koala
Baichuan 1 & 2 + derivations
Aquila 1 & 2
Starcoder models
Refact
Persimmon 8B
MPT
Bloom
Yi models
StableLM models
Deepseek models
Qwen models
PLaMo-13B
Phi models
GPT-2
Orion 14B
InternLM2
CodeShell
Gemma
Mamba
Xverse
Command-R- Multimodal models:
LLaVA 1.5 models, LLaVA 1.6 models
BakLLaVA
Obsidian
ShareGPT4V
MobileVLM 1.7B/3B models
Yi-VL
安装llama.cpp
- 下载代码
git clone https://github.com/ggerganov/llama.cpp - Build
On Linux or MacOS:
其他编译方法参考官网https://github.com/ggerganov/llama.cppcd llama.cppmake
Memory/Disk Requirements
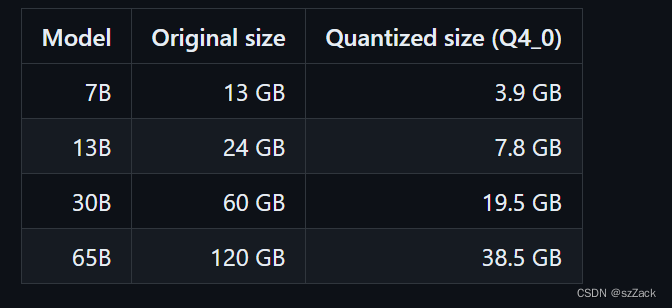
Quantization
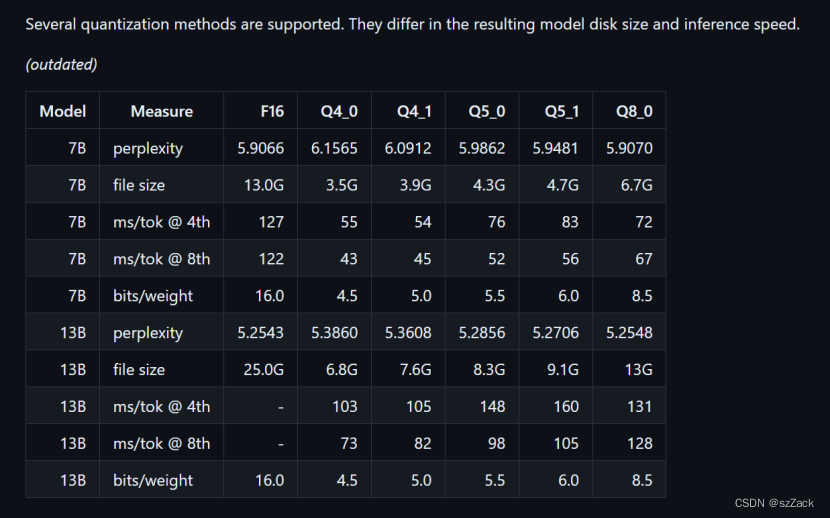
测试推理
下载模型
快速下载模型,参考: 无需 VPN 即可急速下载 huggingface 上的 LLM 模型
我这里下 qwen/Qwen1.5-1.8B-Chat-GGUF 进行测试
huggingface-cli download --resume-download qwen/Qwen1.5-1.8B-Chat-GGUF --local-dir qwen/Qwen1.5-1.8B-Chat-GGUF
测试
cd ./llama.cpp./main -m /your/path/qwen/Qwen1.5-1.8B-Chat-GGUF/qwen1_5-1_8b-chat-q4_k_m.gguf -n 512 --color -i -cml -f ./prompts/chat-with-qwen.txt
需要修改提示语,可以编辑 ./prompts/chat-with-qwen.txt 进行修改。
加载模型输出信息:
llama.cpp# ./main -m /mnt/data/llm/Qwen1.5-1.8B-Chat-GGUF/qwen1_5-1_8b-chat-q4_k_m.gguf -n 512 --color -i -cml -f ./prompts/chat-with-qwen
.txt
Log start
main: build = 2527 (ad3a0505)
main: built with cc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0 for x86_64-linux-gnu
main: seed = 1711760850
llama_model_loader: loaded meta data with 21 key-value pairs and 291 tensors from /mnt/data/llm/Qwen1.5-1.8B-Chat-GGUF/qwen1_5-1_8b-chat-q4_k_m.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = qwen2
llama_model_loader: - kv 1: general.name str = Qwen1.5-1.8B-Chat-AWQ-fp16
llama_model_loader: - kv 2: qwen2.block_count u32 = 24
llama_model_loader: - kv 3: qwen2.context_length u32 = 32768
llama_model_loader: - kv 4: qwen2.embedding_length u32 = 2048
llama_model_loader: - kv 5: qwen2.feed_forward_length u32 = 5504
llama_model_loader: - kv 6: qwen2.attention.head_count u32 = 16
llama_model_loader: - kv 7: qwen2.attention.head_count_kv u32 = 16
llama_model_loader: - kv 8: qwen2.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 9: qwen2.rope.freq_base f32 = 1000000.000000
llama_model_loader: - kv 10: qwen2.use_parallel_residual bool = true
llama_model_loader: - kv 11: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 12: tokenizer.ggml.tokens arr[str,151936] = ["!", "\"", "#", "$", "%", "&", "'", ...
llama_model_loader: - kv 13: tokenizer.ggml.token_type arr[i32,151936] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 14: tokenizer.ggml.merges arr[str,151387] = ["Ġ Ġ", "ĠĠ ĠĠ", "i n", "Ġ t",...
llama_model_loader: - kv 15: tokenizer.ggml.eos_token_id u32 = 151645
llama_model_loader: - kv 16: tokenizer.ggml.padding_token_id u32 = 151643
llama_model_loader: - kv 17: tokenizer.ggml.bos_token_id u32 = 151643
llama_model_loader: - kv 18: tokenizer.chat_template str = {% for message in messages %}{{'<|im_...
llama_model_loader: - kv 19: general.quantization_version u32 = 2
llama_model_loader: - kv 20: general.file_type u32 = 15
llama_model_loader: - type f32: 121 tensors
llama_model_loader: - type q5_0: 12 tensors
llama_model_loader: - type q8_0: 12 tensors
llama_model_loader: - type q4_K: 133 tensors
llama_model_loader: - type q6_K: 13 tensors
llm_load_vocab: special tokens definition check successful ( 293/151936 ).
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = qwen2
llm_load_print_meta: vocab type = BPE
llm_load_print_meta: n_vocab = 151936
llm_load_print_meta: n_merges = 151387
llm_load_print_meta: n_ctx_train = 32768
llm_load_print_meta: n_embd = 2048
llm_load_print_meta: n_head = 16
llm_load_print_meta: n_head_kv = 16
llm_load_print_meta: n_layer = 24
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: n_embd_k_gqa = 2048
llm_load_print_meta: n_embd_v_gqa = 2048
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-06
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 5504
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 2
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 1000000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_yarn_orig_ctx = 32768
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: model type = 1B
llm_load_print_meta: model ftype = Q4_K - Medium
llm_load_print_meta: model params = 1.84 B
llm_load_print_meta: model size = 1.13 GiB (5.28 BPW)
llm_load_print_meta: general.name = Qwen1.5-1.8B-Chat-AWQ-fp16
llm_load_print_meta: BOS token = 151643 '<|endoftext|>'
llm_load_print_meta: EOS token = 151645 '<|im_end|>'
llm_load_print_meta: PAD token = 151643 '<|endoftext|>'
llm_load_print_meta: LF token = 148848 'ÄĬ'
llm_load_tensors: ggml ctx size = 0.11 MiB
llm_load_tensors: CPU buffer size = 1155.67 MiB
...................................................................
llama_new_context_with_model: n_ctx = 512
llama_new_context_with_model: n_batch = 512
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: freq_base = 1000000.0
llama_new_context_with_model: freq_scale = 1
llama_kv_cache_init: CPU KV buffer size = 96.00 MiB
llama_new_context_with_model: KV self size = 96.00 MiB, K (f16): 48.00 MiB, V (f16): 48.00 MiB
llama_new_context_with_model: CPU output buffer size = 296.75 MiB
llama_new_context_with_model: CPU compute buffer size = 300.75 MiB
llama_new_context_with_model: graph nodes = 868
llama_new_context_with_model: graph splits = 1system_info: n_threads = 4 / 4 | AVX = 1 | AVX_VNNI = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 |
main: interactive mode on.
Reverse prompt: '<|im_start|>user
'
sampling:repeat_last_n = 64, repeat_penalty = 1.000, frequency_penalty = 0.000, presence_penalty = 0.000top_k = 40, tfs_z = 1.000, top_p = 0.950, min_p = 0.050, typical_p = 1.000, temp = 0.800mirostat = 0, mirostat_lr = 0.100, mirostat_ent = 5.000
sampling order:
CFG -> Penalties -> top_k -> tfs_z -> typical_p -> top_p -> min_p -> temperature
generate: n_ctx = 512, n_batch = 2048, n_predict = 512, n_keep = 10== Running in interactive mode. ==- Press Ctrl+C to interject at any time.- Press Return to return control to LLaMa.- To return control without starting a new line, end your input with '/'.- If you want to submit another line, end your input with '\'.system
You are a helpful assistant.
user>输入文本:What’s AI?
输出示例:
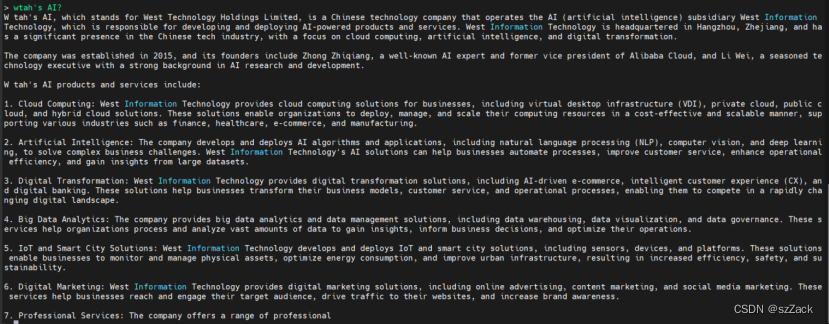
参考
- https://github.com/ggerganov/llama.cpp
相关文章:
【大模型】大模型 CPU 推理之 llama.cpp
【大模型】大模型 CPU 推理之 llama.cpp llama.cpp安装llama.cppMemory/Disk RequirementsQuantization测试推理下载模型测试 参考 llama.cpp 描述 The main goal of llama.cpp is to enable LLM inference with minimal setup and state-of-the-art performance on a wide var…...
异地组网怎么管理?
在当今信息化时代,随着企业的业务扩张和员工的分布,异地组网已经成为越来越多企业的需求。异地组网管理相对来说是一项复杂而繁琐的任务。本文将介绍一种名为【天联】的管理解决方案,帮助企业更好地管理异地组网。 【天联】组网的优势 【天联…...
Kafka参数介绍
官网参数介绍:Apache KafkaApache Kafka: A Distributed Streaming Platform.https://kafka.apache.org/documentation/#configuration...
如何利用待办事项清单提高工作效率?
你是否经常因为繁重的工作量而感到不堪重负?你是否在努力赶工期或经常忘记重要的电子邮件?你并不是特例。如何利用待办事项清单提高工作效率?这里有一个简单的方法可以帮你理清混乱并更高效地完成任务—待办事项清单。 这种类型的清单可以帮…...

力扣经典150题第二题:移除元素
移除元素问题详解与解决方法 1. 介绍 移除元素问题是 LeetCode 经典题目之一,要求原地修改输入数组,移除所有数值等于给定值的元素,并返回新数组的长度。 问题描述 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等…...

55555555555555
欢迎关注博主 Mindtechnist 或加入【Linux C/C/Python社区】一起学习和分享Linux、C、C、Python、Matlab,机器人运动控制、多机器人协作,智能优化算法,滤波估计、多传感器信息融合,机器学习,人工智能等相关领域的知识和…...
:图像形态学处理(上))
用Skimage学习数字图像处理(018):图像形态学处理(上)
本节开始讨论图像形态学处理,这是上篇,将介绍与二值形态学相关的内容,重点介绍两种基本的二值形态学操作:腐蚀和膨胀,以及三种复合二值形态学操作:开、闭和击中击不中变换。 目录 9.1 基础 9.2 基本操作…...

MySQL中 in 和 exists 区别
在MySQL中,IN和EXISTS都是用于在子查询中测试条件的操作符,但它们在处理和效率上有一些重要的区别。MySQL中的in语句是把外表和内表作hash连接,⽽exists语句是对外表作loop循环,每次loop循环再对内表进⾏查询。⼤家⼀直认为exists…...

Java基础 - 代码练习
第一题:集合的运用(幸存者) public class demo1 {public static void main(String[] args) {ArrayList<Integer> array new ArrayList<>(); //一百个囚犯存放在array集合中Random r new Random();for (int i 0; i < 100; …...
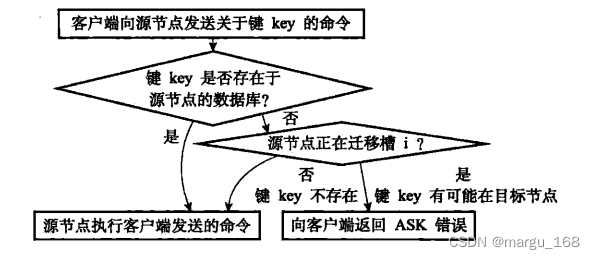
【Redis】redis集群模式
概述 Redis集群,即Redis Cluster,是Redis 3.0开始引入的分布式存储方案。实际使用中集群一般由多个节点(Node)组成,Redis的数据分布在这些节点中。集群中的节点分为主节点和从节点:只有主节点负责读写请求和集群信息的维护&#…...

基于opencv的猫脸识别模型
opencv介绍 OpenCV的全称是Open Source Computer Vision Library,是一个跨平台的计算机视觉库。OpenCV是由英特尔公司发起并参与开发,以BSD许可证授权发行,可以在商业和研究领域中免费使用。OpenCV可用于开发实时的图像处理、计算机视觉以及…...

基于注意力整合的超声图像分割信息在乳腺肿瘤分类中的应用
基于注意力整合的超声图像分割信息在乳腺肿瘤分类中的应用 摘要引言方法 Segmentation information with attention integration for classification of breast tumor in ultrasound image 摘要 乳腺癌是世界范围内女性最常见的癌症之一。基于超声成像的计算机辅助诊断&#x…...
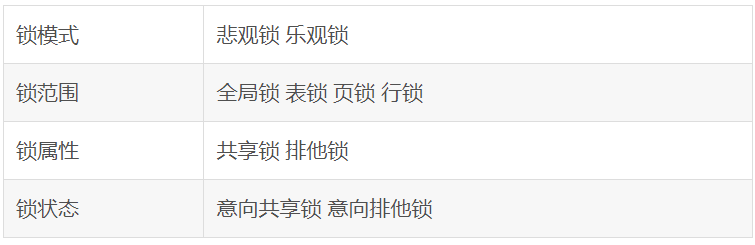
数据库重点知识(个人整理笔记)
目录 1. 索引是什么? 1.1. 索引的基本原理 2. 索引有哪些优缺点? 3. MySQL有哪几种索引类型? 4. mysql聚簇和非聚簇索引的区别 5. 非聚簇索引一定会回表查询吗? 6. 讲一讲前缀索引? 7. 为什么索引结构默认使用B…...

[技术闲聊]checklist
电路设计完成后,需要确认功能完整性,明确是否符合设计规格需求;需要确认电路设计是否功能符合但是系列项不符合设计规则,如果都没有问题,那么就可以发给layout工程师。 今天主要讲讲电路设计规则,涉及到一…...
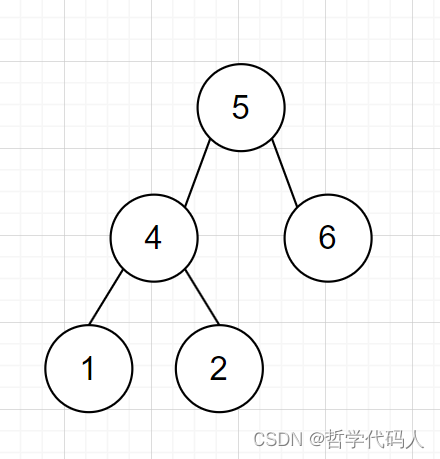
力扣刷题 二叉树的迭代遍历
题干 给你二叉树的根节点 root ,返回它节点值的 前序 遍历。 示例 1: 输入:root [1,null,2,3] 输出:[1,2,3]示例 2: 输入:root [] 输出:[]示例 3: 输入:root [1] 输…...
【二】Django小白三板斧
今日内容 静态文件配置 request对象方法初识 pycharm链接数据库(MySQL) django链接数据库(MySQL) Django ORM简介 利用ORM实现数据的增删查改 【一】Django小白三板斧 HttpResponse 返回字符串类型的数据 render 返回HTML文…...
MyBatis的基本应用
源码地址 01.MyBatis环境搭建 添加MyBatis的坐标 <!--mybatis坐标--><dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>3.5.9</version></dependency><!--mysql驱动坐…...
Day80:服务攻防-中间件安全HW2023-WPS分析WeblogicJettyJenkinsCVE
目录 中间件-Jetty-CVE&信息泄漏 CVE-2021-34429(信息泄露) CVE-2021-28169(信息泄露) 中间件-Jenkins-CVE&RCE执行 cve_2017_1000353 CVE-2018-1000861 cve_2019_1003000 中间件-Weblogic-CVE&反序列化&RCE 应用金山WPS-HW2023-RCE&复现&上线…...

使用generator实现async函数
我们先来看一下async函数是怎么使用的 const getData (sec) > new Promise((resolve) > {setTimeout(() > resolve(sec * 2), sec * 1000);})// aim to get this asycnFun by generator async function asyncFun() {const data1 await getData(1);const data2 awa…...

go并发请求url
sync.WaitGroup写法 package mainimport ("database/sql""fmt""net/http""sync""time"_ "github.com/go-sql-driver/mysql" )func main() {//开始计时start : time.Now()//链接数据库,用户名…...

安宝特方案丨XRSOP人员作业标准化管理平台:AR智慧点检验收套件
在选煤厂、化工厂、钢铁厂等过程生产型企业,其生产设备的运行效率和非计划停机对工业制造效益有较大影响。 随着企业自动化和智能化建设的推进,需提前预防假检、错检、漏检,推动智慧生产运维系统数据的流动和现场赋能应用。同时,…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...

HarmonyOS运动开发:如何用mpchart绘制运动配速图表
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在运动类应用中,运动数据的可视化是提升用户体验的重要环节。通过直观的图表展示运动过程中的关键数据,如配速、距离、卡路里消耗等,用户可以更清晰…...

搭建DNS域名解析服务器(正向解析资源文件)
正向解析资源文件 1)准备工作 服务端及客户端都关闭安全软件 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2)服务端安装软件:bind 1.配置yum源 [rootlocalhost ~]# cat /etc/yum.repos.d/base.repo [Base…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...