【详细注释+流程讲解】基于深度学习的文本分类 TextCNN
前言
这篇文章用于记录阿里天池 NLP 入门赛,详细讲解了整个数据处理流程,以及如何从零构建一个模型,适合新手入门。
赛题以新闻数据为赛题数据,数据集报名后可见并可下载。赛题数据为新闻文本,并按照字符级别进行匿名处理。整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐的文本数据。实质上是一个 14 分类问题。
赛题数据由以下几个部分构成:训练集20w条样本,测试集A包括5w条样本,测试集B包括5w条样本。
比赛地址:零基础入门NLP - 新闻文本分类_学习赛_天池大赛-阿里云天池的赛制
数据可以通过上面的链接下载。
其中还用到了训练好的词向量文件。
词向量下载链接: 百度网盘 请输入提取码 提取码: qbpr
这篇文章中使用的模型主要是CNN + LSTM + Attention,主要学习的是数据处理的完整流程,以及模型构建的完整流程。虽然还没有使用 Bert 等方案,不过如果看完了这篇文章,理解了整个流程之后,即使你想要使用其他模型来处理,也能更快实现。
1. 为什么写篇文章
首先,这篇文章的代码全部都来源于 Datawhale 提供的开源代码,我添加了自己的笔记,帮助新手更好地理解这个代码。
1.1 Datawhale 提供的代码有哪些需要改进?
Datawhale 提供的代码里包含了数据处理,以及从 0 到 1模型建立的完整流程。但是和前面提供的 basesline 的都不太一样,它包含了非常多数据处理的细节,模型也是由 3 个部分构成,所以看起来难度陡然上升。
其次,代码里的注释非常少,也没有讲解整个数据处理和网络的整体流程。这些对于新手来说,增加了理解的门槛。 在数据竞赛方面,我也是一个新人,花了一天的时间,仔细研究数据在一种每一个步骤的转化,对于一些难以理解的代码,在群里询问之后,也得到了 Datawhale 成员的热心解答。最终才明白了全部的代码。
1.2 我做了什么改进?
所以,为了减少对于新手的阅读难度,我添加了一些内容。
-
首先,梳理了整个流程,包括两大部分:数据处理和模型。
因为代码不是从上到下顺序阅读的。因此,更容易让人理解的做法是:先从整体上给出宏观的数据转换流程图,其中要包括数据在每一步的 shape,以及包含的转换步骤,让读者心中有一个框架图,再带着这个框架图去看细节,会更加了然于胸。
-
其次,除了了解了整体流程,在真正的代码细节里,读者可能还是会看不懂某一段小逻辑。因此,我在原有代码的基础之上增添了许多注释,以降低代码的理解门槛。
2. 数据处理
2.1 数据拆分为 10 份
数据首先会经过all_data2fold函数,这个函数的作用是把原始的 DataFrame 数据,转换为一个list,有 10 个元素,表示交叉验证里的 10 份,每个元素是 dict,每个dict包括 label 和 text。
首先根据 label 来划分数据行所在 index, 生成 label2id。
label2id 是一个 dict,key 为 label,value 是一个 list,存储的是该类对应的 index。
然后根据`label2id`,把每一类别的数据,划分到 10 份数据中。最终得到的数据`fold_data`是一个`list`,有 10 个元素,每个元素是 `dict`,包括 `label` 和 `text`的列表:`[{labels:textx}, {labels:textx}. . .]`。
最后,把前 9 份数据作为训练集train_data,最后一份数据作为验证集dev_data,并读取测试集test_data。
2.2 定义并创建 Vacab
Vocab 的作用是:
-
创建 词 和
index对应的字典,这里包括 2 份字典,分别是:_id2word和_id2extword。 -
其中
_id2word是从新闻得到的, 把词频小于 5 的词替换为了UNK。对应到模型输入的batch_inputs1。 -
_id2extword是从word2vec.txt中得到的,有 5976 个词。对应到模型输入的batch_inputs2。 -
后面会有两个
embedding层,其中_id2word对应的embedding是可学习的,_id2extword对应的embedding是从文件中加载的,是固定的。 -
创建 label 和 index 对应的字典。
-
上面这些字典,都是基于
train_data创建的。
3. 模型
3.1 把文章分割为句子
上上一步得到的 3 个数据,都是一个list,list里的每个元素是 dict,每个 dict 包括 label 和 text。这 3 个数据会经过 get_examples函数。 get_examples函数里,会调用sentence_split函数,把每一篇文章分割成为句子。
然后,根据vocab,把 word 转换为对应的索引,这里使用了 2 个字典,转换为 2 份索引,分别是:word_ids和extword_ids。最后返回的数据是一个 list,每个元素是一个 tuple: (label, 句子数量,doc)。其中doc又是一个 list,每个 元素是一个 tuple: (句子长度,word_ids, extword_ids)。
在迭代训练时,调用data_iter函数,生成每一批的batch_data。在data_iter函数里,会调用batch_slice函数生成每一个batch。拿到batch_data后,每个数据的格式仍然是上图中所示的格式,下面,调用batch2tensor函数。
3.2 生成训练数据
batch2tensor函数最后返回的数据是:(batch_inputs1, batch_inputs2, batch_masks), batch_labels。形状都是(batch_size, doc_len, sent_len)。doc_len表示每篇新闻有几句话,sent_len表示每句话有多少个单词。
batch_masks在有单词的位置,值为1,其他地方为 0,用于后面计算 Attention,把那些没有单词的位置的 attention 改为 0。
batch_inputs1, batch_inputs2, batch_masks,形状是(batch_size, doc_len, sent_len),转换为(batch_size * doc_len, sent_len)。
3.3 网络部分
下面,终于来到网络部分。模型结构图如下:
3.3.1 WordCNNEncoder
WordCNNEncoder 网络结构示意图如下:
1. Embedding
batch_inputs1, batch_inputs2都输入到WordCNNEncoder。WordCNNEncoder包括两个embedding层,分别对应batch_inputs1,embedding 层是可学习的,得到word_embed;batch_inputs2,读取的是外部训练好的词向量,因此是不可学习的,得到extword_embed。所以会分别得到两个词向量,将 2 个词向量相加,得到最终的词向量batch_embed,形状是(batch_size * doc_len, sent_len, 100),然后添加一个维度,变为(batch_size * doc_len, 1, sent_len, 100),对应 Pytorch 里图像的(B, C, H, W)。
2. CNN
然后,分别定义 3 个卷积核,output channel 都是 100 维。
第一个卷积核大小为[2,100],得到的输出是(batch_size * doc_len, 100, sent_len-2+1, 1),定义一个池化层大小为[sent_len-2+1, 1],最终得到输出经过squeeze()的形状是(batch_size * doc_len, 100)。
同理,第 2 个卷积核大小为[3,100],第 3 个卷积核大小为[4,100]。卷积+池化得到的输出形状也是(batch_size * doc_len, 100)。
最后,将这 3 个向量在第 2 个维度上做拼接,得到输出的形状是(batch_size * doc_len, 300)。
3.3.2 shape 转换
把上一步得到的数据的形状,转换为(batch_size , doc_len, 300)名字是sent_reps。然后,对mask进行处理。
batch_masks的形状是(batch_size , doc_len, 300),表示单词的 mask,经过sent_masks = batch_masks.bool().any(2).float()得到句子的 mask。含义是:在最后一个维度,判断是否有单词,只要有 1 个单词,那么整句话的 mask 就是 1,sent_masks的维度是:(batch_size , doc_len)。
3.3.3 SentEncoder
SentEncoder 网络结构示意图如下:
SentEncoder包含了 2 层的双向 LSTM,输入数据sent_reps的形状是(batch_size , doc_len, 300),LSTM 的 hidden_size 为 256,由于是双向的,经过 LSTM 后的数据维度是(batch_size , doc_len, 512),然后和 mask 按位置相乘,把没有单词的句子的位置改为 0,最后输出的数据sent_hiddens,维度依然是(batch_size , doc_len, 512)。
3.3.4 Attention
接着,经过Attention。Attention的输入是sent_hiddens和sent_masks。在Attention里,sent_hiddens首先经过线性变化得到key,维度不变,依然是(batch_size , doc_len, 512)。
然后key和query相乘,得到outputs。query的维度是512,因此output的维度是(batch_size , doc_len),这个就是我们需要的attention,表示分配到每个句子的权重。下一步需要对这个attetion做softmax,并使用sent_masks,把没有单词的句子的权重置为-1e32,得到masked_attn_scores。
最后把masked_attn_scores和key相乘,得到batch_outputs,形状是(batch_size, 512)。
3.3.5 FC
最后经过FC层,得到分类概率的向量。
4. 完整代码+注释
4.1 数据处理
导入包
import random
import numpy as np
import torch
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)-15s %(levelname)s: %(message)s')
查看本文全部内容,欢迎访问天池技术圈官方地址:【详细注释+流程讲解】基于深度学习的文本分类 TextCNN_天池技术圈-阿里云天池
相关文章:

【详细注释+流程讲解】基于深度学习的文本分类 TextCNN
前言 这篇文章用于记录阿里天池 NLP 入门赛,详细讲解了整个数据处理流程,以及如何从零构建一个模型,适合新手入门。 赛题以新闻数据为赛题数据,数据集报名后可见并可下载。赛题数据为新闻文本,并按照字符级别进行匿名…...

Day.21
interface MyInterface{public final static int PI 3;void show();public default void printX(){System.out.println("接口默认方法");}public static void printY(){System.out.println("接口静态方法");}}class MyClass implements MyInterface{publi…...

Spring-IoC 基于注解
基于xml方法见:http://t.csdnimg.cn/dir8j 注解是代码中的一种特殊标记,可以在编译、类加载和运行时被读取,执行相应的处理,简化 Spring的 XML配置。 格式:注解(属性1"属性值1",...) 可以加在类上…...
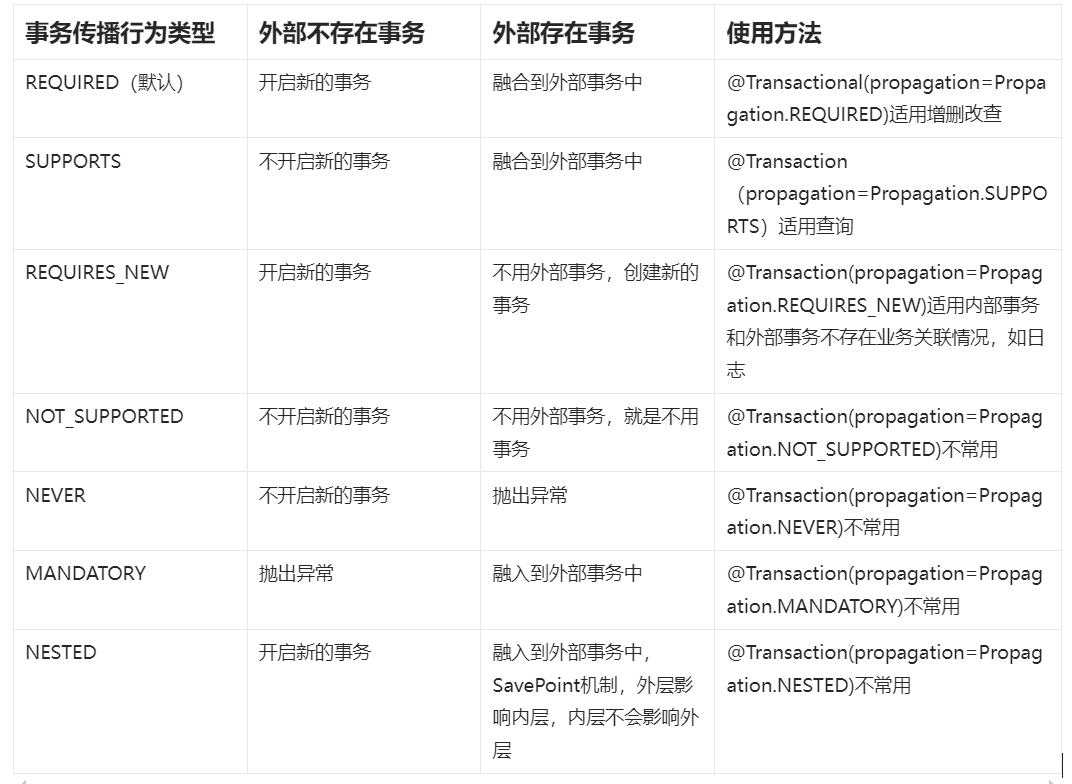
Spring声明式事务以及事务传播行为
Spring声明式事务以及事务传播行为 Spring声明式事务1.编程式事务2.使用AOP改造编程式事务3.Spring声明式事务 事务传播行为 如果对数据库事务不太熟悉,可以阅读上一篇博客简单回顾一下:MySQL事务以及并发访问隔离级别 Spring声明式事务 事务一般添加到…...

【C语言数据库】Sqlite3基础介绍
1. SQLite简介 SQLite is a C-language library that implements a small, fast, self-contained, high-reliability, full-featured, SQL database engine. SQLite is the most used database engine in the world. SQLite is built into all mobile phones and most computer…...
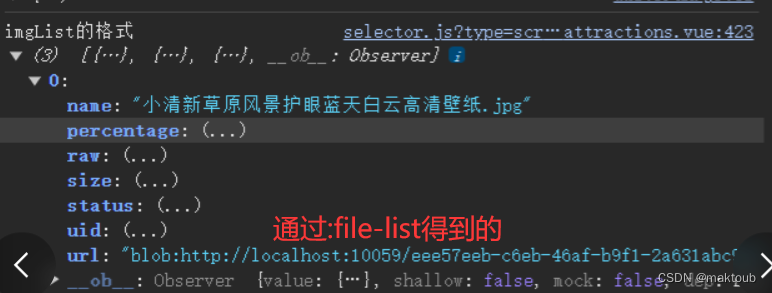
el-upload上传图片图片、el-load默认图片重新上传、el-upload初始化图片、el-upload编辑时回显图片
问题 我用el-upload上传图片,再上一篇文章已经解决了,el-upload上传图片给SpringBoot后端,但是又发现了新的问题,果然bug是一个个的冒出来的。新的问题是el-upload编辑时回显图片的保存。 问题描述:回显图片需要将默认的 file-lis…...
【拓扑空间】示例及详解1
例1 度量空间的任意两球形邻域的交集是若干球形邻域的并集 Proof: 任取空间的两个球形邻域、,令 任取,令 球形领域 例2 规定X的子集族,证明是X上的一个拓扑 Proof: 1. 2., (若干个球形邻域的并集都是的元素,元素…...

linux安装jdk8
上传到某个目录,例如:/usr/local/ tar -xvf jdk-8u144-linux-x64.tar.gz配置环境变量: export JAVA_HOME/usr/local/java export PATH$PATH:$JAVA_HOME/bin设置环境变量: source /etc/profile...
Spring重点知识(个人整理笔记)
目录 1. 为什么要使用 spring? 2. 解释一下什么是 Aop? 3. AOP有哪些实现方式? 4. Spring AOP的实现原理 5. JDK动态代理和CGLIB动态代理的区别? 6. 解释一下什么是 ioc? 7. spring 有哪些主要模块?…...

HTML基础知识详解(上)(如何想知道html的全部基础知识点,那么只看这一篇就足够了!)
前言:在学习前端基础时,必不可少的就是三大件(html、css、javascript ),而HTML(超文本标记语言——HyperText Markup Language)是构成 Web 世界的一砖一瓦,它定义了网页内容的含义和…...

如何借助Idea创建多模块的SpringBoot项目
目录 1.1、前言1.2、开发环境1.3、项目多模块结构1.4、新建父工程1.5、创建子模块1.6、编辑父工程的pom.xml文件 1.1、前言 springmvc项目,一般会把项目分成多个包:controler、service、dao、utl等,但是随着项目的复杂性提高,想复用其他一个模…...

爬虫 新闻网站 并存储到CSV文件 以红网为例 V1.0
爬虫:红网网站, 获取当月指定关键词新闻,并存储到CSV文件 V1.0 目标网站:红网 爬取目的:为了获取某一地区更全面的在红网已发布的宣传新闻稿,同时也让自己的工作更便捷 环境:Pycharm2021&#…...

CentOS 使用 Cronie 实现定时任务
CentOS 使用 Cronie 实现定时任务 文章目录 CentOS 使用 Cronie 实现定时任务一、简介二、基本使用1、常用命令2、使用示例第一步:创建脚本/home/create.sh第二步:添加定时任务第三步:重启 cronie 服务额外:查看 cronie 运行状态定…...
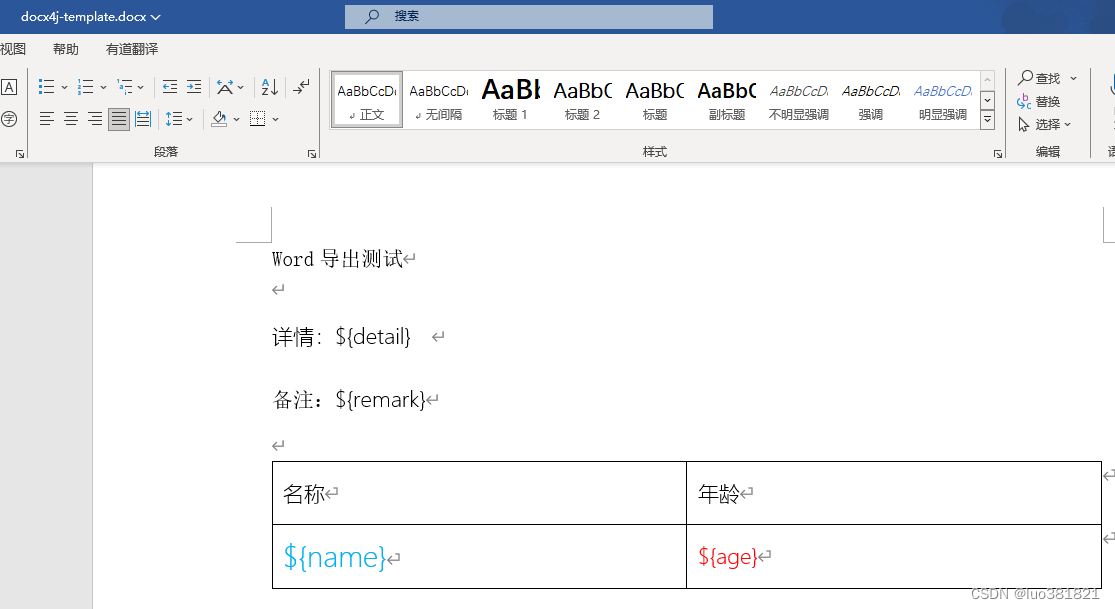
java生成word
两种方案 一、poi-tl生成word <dependency><groupId>com.deepoove</groupId><artifactId>poi-tl</artifactId><version>1.12.1</version> </dependency> public static void main(String[] args) throws Exception {String…...

C语言中的结构体:揭秘数据的魔法盒
前言 在C语言的广阔天地中,结构体无疑是一颗璀璨的明珠。它就像是一个魔法盒,能够容纳各种不同类型的数据,并按我们的意愿进行组合和排列。那么,这个魔法盒究竟有何神奇之处呢?让我们一探究竟。 一、结构体的诞生&…...

Listener
文章目录 ListenerServletContextListenerServletContextAttributeListenerHttpSessionListenerHttpSessionAttributeListenerServletRequestListenerServletRequestAttributeListenerHttpSessionBindingListenerHttpSessionActivationListener Listener Listener 监听器它是 J…...

单细胞RNA测序(scRNA-seq)SRA数据下载及fastq-dumq数据拆分
单细胞RNA测序(scRNA-seq)入门可查看以下文章: 单细胞RNA测序(scRNA-seq)工作流程入门 单细胞RNA测序(scRNA-seq)细胞分离与扩增 1. NCBI查询scRNA-seq SRA数据 NCBI地址: https…...

金蝶Apusic应用服务器 未授权目录遍历漏洞复现
0x01 产品简介 金蝶Apusic应用服务器(Apusic Application Server,AAS)是一款标准、安全、高效、集成并具丰富功能的企业级应用服务器软件,全面支持JakartaEE8/9的技术规范,提供满足该规范的Web容器、EJB容器以及WebService容器等,支持Websocket1.1、Servlet4.0、HTTP2.0…...

成都百洲文化传媒有限公司电商服务的新领军者
在当今数字化时代,电商行业正以前所未有的速度蓬勃发展。在这个大背景下,成都百洲文化传媒有限公司凭借其深厚的行业经验和精湛的专业技能,正迅速崛起为电商服务领域的新领军者。 一、专业引领,成就卓越 作为一家专注于电商服务的…...

从无到有开始创建动态顺序表——C语言实现
顺序表的概念 顺序表的底层结构是数组,对数组的封装,实现了常用的增删改查等接口。在物理结构和逻辑结构都是连续的,物理结构是指顺序表在计算机内存的存储方式,逻辑结构是我们思考的形式,顺序表和数组是类似的&#x…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...