物联网行业中,我们如何选择数据库?
在当今数字化潮流中,我们面对的不仅是海量数据,更是时间的涟漪。从生产线的传感器到金融市场的交易记录,时间序列数据成为了理解事物演变和趋势的关键。在面对这样庞大而动态的数据流时,我们需要深入了解一种强大的工具——时序数据库。时序数据库的崛起不仅是技术发展的产物,更是对时间维度数据挖掘需求的响应。
时序数据库广泛应用于物联网、工业监控、能源管理、量化金融等领域,是数字化转型的关键组成部分。本文将着眼于物联网行业,为大家介绍时序数据库的核心概念、优势及应用场景等。我们将揭开时序数据库的技术奥秘,探讨它对于数据管理和分析的深远影响,提供一种物联网数据库选型的新思路。
什么是时序数据?
时序数据是一种按时间顺序排列的数据,其主要特征是数据随时间变化而变化。时序数据往往具有时间依赖性、连续性、周期性、实时性、大规模性、异步性、多维性、不确定性等特点。时序数据的处理和分析需要专门的数据库管理系统,即时序数据库。
时序数据的应用场景有哪些?
-
生产制造与工业自动化
-
能源电力与石油化工
-
车联网与轨道交通
-
航空航天
-
物联网传感器测量(水冷、高温、地震...)
-
服务器监控(CPU、内存、磁盘...)
-
资源消耗(能源、电力...)
-
医疗健康监测(心率、血氧浓度...)
-
网络流量分析
-
零售与电子商务
-
金融市场交易
什么是时序数据库?
时序数据库全称是时间序列数据库(Time series database,TSDB),主要用于存储和处理带时间标签的时序数据。时序数据库的存储结构往往具有列式存储、索引结构和压缩算法等特点,能够最大程度地提高数据存储和检索的效率。
在时序数据库成为热点之前,时序数据通常使用 MySQL 或 PostgreSQL 等关系数据库进行处理。但随着互联网和通信技术的发展,网络中产生的时间序列数据量有了爆炸式的增长,传统的数据库已经无法处理这种万亿级的海量数据。不仅如此,现代业务对数据价值挖掘的需求已不仅停留在简单计算和绘制图表的层面上,而是需要更多精细、复杂的计算分析。
如何以一种高性能的方式记录、查询和分析如此大规模的数据,成为了一个难题。时序数据库(time-series database)应运而生。
时序数据库与传统数据库在技术上有哪些区别呢?
1. 首先,大部分时序数据库的查询场景可以认为是 OLAP(Online Analytical Processing )分析型数据库场景。具体地说,时序数据库的读取负载主要可以分为两种,一种是对指定时间序列在指定时间段内数据的查询,如查询某个设备或某支股票最新一小时的数据等;另一种是对大量数据进行统计分析,如分析某支股票、甚至是所有股票在过去一周内的平均价格。这两种场景都是典型的 OLAP 读取场景。因此,时序数据库具有大部分 OLAP 数据库的特点,如列存、会对数据做压缩、支持复杂的查询语句等,并更加注重时序数据的查询,特别是对于按时间范围的查询和聚合操作的性能。
2. 从写入负载来分析,时序数据库的场景有大量数据的实时写入,而非单行数据的写入与修改。由于时序数据库的写入负载通常很高,如每秒几百万甚至几千万条数据,所以时序数据库的存储引擎往往是基于对大量写入更加友好的 LSM Tree(Log Structured Merge Tree)。
3. 时序数据库支持很多时序场景特有的分析语句与函数。一些常见的语句与函数有:降采样、插值、滑动平均、时间滑动平均、累积和、window join、context by、pivot by 等。要高效地(往往是向量化地)支持这些查询语句并不是一件非常容易的事情。
4. 流数据的处理。对时序数据的离线分析属于批处理的范畴,而还有许多时序数据场景则可以抽象成另外一个称之为流数据的计算场景:有数据不停地产生,且需要低延时地对这些数据做即时的响应与计算。在时序领域,对于流数据的处理,以往的做法是使用 flink 等单独的流数据处理平台,这当然也能够解决问题,但会导致至少两个问题,第一是需要维护时序数据库与 flink 两套系统,使得运维成本大大提升;第二个问题则可能更加致命,那就是流数据的处理是否能够与批数据处理一致,而如果产生不一致,则可能会对业务场景带来负面影响。如果时序数据库能够推出针对时序场景的特殊流数据处理子系统,并且能够达到 “流批一体”,就可以保证批数据与流数据处理的结果完全一致。
5. 另外,时序数据库对于多变、动态的数据模型更为灵活,能够容纳不同类型和结构的时序数据,在设计上更加注重满足时序数据的特殊需求,以提供更高效灵活的存储和查询方案。传统数据库则更多面向一般性的数据存储和查询需求。
作为一种针对时序数据高度优化的垂直型数据库,时序数据库在物联网行业有广泛的应用场景(如工业制造、能源电力、航空航天、智慧交通、设备健康、智能运维、医疗保健、零售业等),通过对海量时序数据进行分析预测,企业可以获得有价值的信息,从而做出更明智的决策,获得独特的竞争优势。
物联网大数据平台数据库选型的考量因素:
物联网大数据平台在进行时序数据库选型时,会考虑哪些性能特征呢?以下为一些常见的考量因素,供大家参考~
1. 高效的分布式系统与存储功能。物联网产生的数据量巨大,因此处理系统必须是分布式的、水平扩展的。为降低成本,一个节点的处理性能必须是高效的,需要支持数据的快速写入和快速查询。
2. 数据持续稳定写入。对于物联网系统,通常数据流量呈平稳状态,因此我们可以相对准确地估算数据写入所需的资源。然而,挑战在于查询和分析阶段,尤其是即席查询,可能对系统资源造成巨大压力。因此,系统必须确保分配足够的资源,以保障数据能够顺利写入系统而不至丢失。具体而言,这要求系统采取写优先的策略,以确保对写入操作的优先满足。
3. 实时处理的框架。对于物联网场景,需要基于采集的数据做实时预警、决策,延时要控制在秒级以内。物联网数据的实时性要求数据库具备快速的数据摄取和处理能力,以支持实时监控、预警和其他实时应用场景。
4. 实时流式计算功能。支持流式数据处理,能够对连续流入的数据进行实时处理和分析,以满足物联网环境中快速变化的数据需求。实时预警或预测已经不再简单地基于单一阈值进行,而是需要对多个设备生成的数据流进行实时聚合计算。这种计算不再仅限于单一时间点,而是基于时间窗口进行,考虑了更广泛的时间范围。
5. 快速且灵活的查询能力。时序数据库提供了专门用于时序数据分析的查询能力。它包括了经过优化的函数、运算符和索引技术,通过其处理涉及时间间隔、滑动窗口和聚合等复杂查询的能力,使用户能够迅速准确地从物联网海量数据中提取有价值的指标。
6. 持续聚合。允许用户预先计算并存储不同时间间隔的聚合数据。这个特性极大地提高了常见聚合查询的性能,例如在特定时间范围内计算平均值、总和或计数。对于需要实时分析和仪表板的物联网应用,持续聚合提供了显著的性能提升。
7. 高扩展性和高可用性。由于物联网设备数量众多,数据库应该具备高度可扩展性,能够轻松应对不断增长的设备连接和数据量;同时,由于物联网环境复杂,数据库应具备容错性和高可用性,以确保即使在设备故障或网络问题的情况下,系统仍能保持稳定运行。
8. 支持云边协同。要有一套灵活的机制将边缘计算节点的数据上传到云端,根据具体需要,可以将原始数据及加工计算后的数据,或仅符合过滤条件的数据同步到云端,而且随时可以取消,更改策略。
9. 便于私有化部署。通过私有化部署,便于掌握系统的管理、配置和访问控制,确保数据安全性并满足内部隐私和合规性要求,并适应特定业务流程和工作负载。
作为 DB-Engines 排行榜上国内排名第一的时序数据库,DolphinDB 是完全自主研发的新一代的高性能分布式时序数据库,以一站式大数据方案、快速开发、性能优异、综合使用成本低著称。DolphinDB 目前广泛应用于量化金融及工业物联网领域,接下来介绍 DolphinDB 作为工业物联网数据平台的7大优势,为大家提供数据库选型参考。
1. 一站式数据解决方案
工业物联网的要求不仅包括对机器产生的工艺数据的采集,还需要进行实时计算和预警,并将结果直观地展示给操作员或直接反馈给机器。同时,对这些原始的工艺数据进行保存,以支持在线或离线查询。在积累了大量的历史数据后,可以在 DolphinDB 这一套系统内完成更为复杂的大数据挖掘,高效一体地进行整个数据处理和分析流程。
下图展示了 DolphinDB 的数据处理流程:
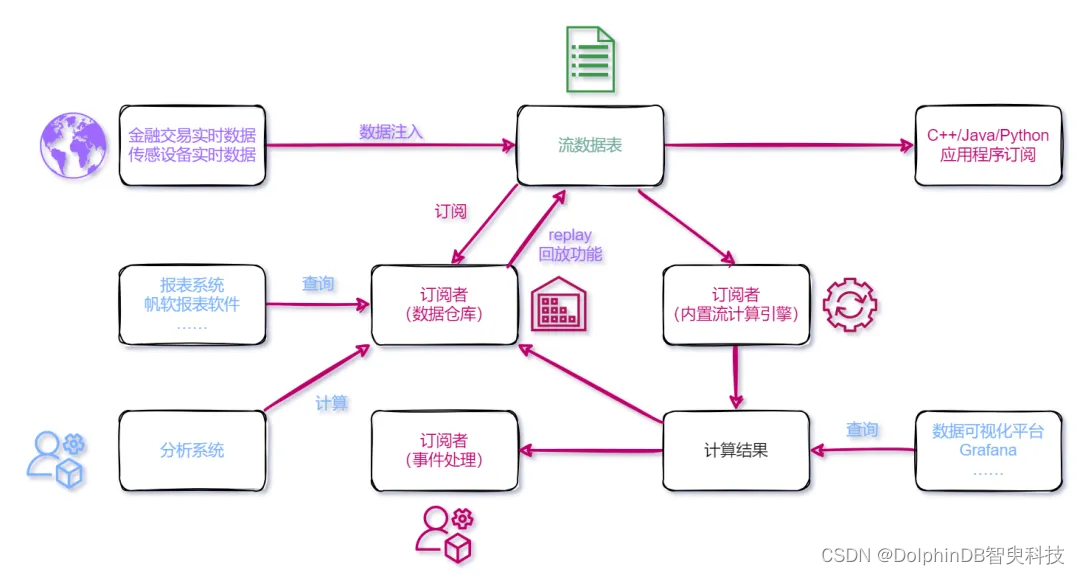
对于系统集成商或企业而言,在一套系统上进行开发和维护,无论是在开发维护还是硬件采购成本上都更为经济高效。
2. 轻量级跨平台部署
工业物联网平台的复杂性体现在多方面:从低成本的工控机(低配 PC 或嵌入式系统)到高性能的服务器或服务器集群,涵盖了边缘计算、本地平台部署以及云端平台部署。这涉及到多种操作系统,包括 Linux 和 Windows。市场上存在许多开源或商用的时序数据库,以及相关的大数据生态系统,这些组件繁多且复杂,体积庞大,对软硬件的要求也较高。尝试使用一套系统进行跨平台部署会面临巨大的挑战。
DolphinDB 是一个非常轻量级的系统,用 GNU C++开发,系统大小仅70余兆,无任何依赖,可以部署在上述任何平台上,极大节约了系统集成商的开发和维护成本。
3. 海量历史数据存储和处理
工业物联网数据采集的特点是维度高、频率高、设备数量众多,数据量巨大,且具备高时间精度。由于数据库系统的限制,企业难以充分挖掘历史数据的价值。
DolphinDB 以列式存储为特色,支持高达20%左右的数据压缩率,能够处理最高纳秒精度的时序数据。单表支持百万级别分区,通过增加节点水平扩展集群的存储和计算能力。DolphinDB 集群还支持多副本分布式存储和分布式事务机制,确保数据的高可用性和强一致性。
企业可以充分利用 DolphinDB 对长时间积累的历史数据进行深度数据挖掘和分析,如设备的预测性维护、工艺流程的改进、产品质量的提升以及制造计划的优化等。这有助于企业更全面、深入地了解生产过程,智能决策。
4. 实时流计算
物联网实时采集的数据可以通过 DolphinDB 的流计算引擎进行清洗、实时统计,并即时入库,同时通过可视化方式实时展示。DolphinDB 具备流表对偶性,可直接使用 SQL 注入和查询分析流数据。其流计算引擎基于发布-订阅-消费的模式,通过流数据表发布数据,其他数据节点或第三方应用可以通过 DolphinDB 脚本或 API 订阅消费流数据,将计算结果实时反馈给机器或操作员。
5. 丰富的函数与计算功能
DolphinDB 内置了脚本语言,可直接在数据库中进行复杂的计算和交互分析,无需数据迁移。大部分计算功能和函数都经过优化,性能远远超过其他数据库中的相同功能。
以下为一些 DolphinDB 常用的计算功能:
-
范围查询:DolphinDB 使用数据对(pair)的形式表示范围。
-
多维查询:可以针对不同列进行聚合,实现高维或低维的范围查询功能。
-
抽样查询:提供了以分区为单位的抽样查询机制,可以按照指定的比例或者数量对分区进行抽样,只需要在 where 后调用 sample 函数。
-
精度查询:DolphinDB 的时间精度达到纳秒,支持海量高精度历史数据存储,也支持把高精度大数据集聚合转换成低精度小数据集存储。同时,支持多种精度分组抽样及自定义分组。
-
插值查询:在工业领域经常会发生采集的数据缺失。DolphinDB 在查询计算时提供了4种插值方式补全数据,向前/向后取非空值填充(bfill/ffill),线性填充(lfill)和指定值填充(nullFill)。
-
聚合查询:DolphinDB 函数库非常丰富,支持以下聚合函数:atImax, atImin, avg, beta, contextCount, contextSum, contextSum2, count, corr, covar, derivative, difference, first, imax, last, lastNot, max, maxPositiveStreak, mean, med, min, mode, percentile, rank, stat,std,sum, sum2,var, wavg, wsum, zscore。
-
面板数据分组查询:DolphinDB 提供了 context by 和滑动统计函数,并对部分滑动统计函数进行了优化,最大程度地降低了重复计算。
-
对比查询:DolphinDB 的 pivot by 可用于数据透视,特别是同一时间不同列的指标对比。
-
关联查询:支持多种关联查询,包括等值连接、完全连接、交叉连接、左连接、asof join 和窗口连接。
-
机器学习与分布式计算:提供了 map-reduce,iterative map-reduce 等分布式计算框架,无需编译、部署,可以直接在线使用。同时,DolphinDB 内置了常用的拟合和分类算法,如线性回归、广义线性模型(GLM)、随机森林(Random Forest)、逻辑回归等。
除了已有的功能外,DolphinDB 提供了几种途径扩展系统功能。用户可以用脚本语言自定义函数来扩展系统功能。同时,还提供了 C++、C#、Java、Python、R、JS、Excel 等语言和系统 API ,方便与其它系统集成。
6. 综合使用成本低
工业企业的利润率通常较低,若数据平台的成本(软硬件采购、系统集成费用、维护费用及应用开发成本等)过高,将严重制约工业物联网的发展。DolphinDB 提供一站式解决方案、跨平台部署能力、强大的实时数据和海量历史数据处理能力、丰富的计算功能以及可扩展性,大幅度降低了系统的综合成本。
7. 安全可控
DolphinDB 是一个完全自主研发的分布式时序数据库,从底层的分布式文件系统和存储引擎,到数据库和核心类库,再到分布式计算引擎、脚本语言,甚至外围的开发集成环境 GUI 和集群管理工具,全部自主研发,无任何外部依赖,保证了系统的安全可控性。
DolphinDB 不仅支持 x86 和 arm 指令体系,还在适配 MIPS 指令体系,以支持龙芯等国产 CPU ,在工业物联网平台上实现了软硬件同时自主可控。
小结
在本文中,我们深入探索了时序数据库这一前沿技术,揭示了其在物联网领域的关键作用与优势。时序数据库不仅是存储时序数据的媒介,更是对数据进行深刻理解的智能引擎,为我们提供了探索和解析复杂数据的工具。时序数据库作为工业 4.0 时代的利器,打开了数据洞察与智能运维的大门。未来,时序数据库将继续在不断涌现的数据浪潮中发挥至关重要的作用,为万物互联与智慧城市开创新的可能。
相关文章:
物联网行业中,我们如何选择数据库?
在当今数字化潮流中,我们面对的不仅是海量数据,更是时间的涟漪。从生产线的传感器到金融市场的交易记录,时间序列数据成为了理解事物演变和趋势的关键。在面对这样庞大而动态的数据流时,我们需要深入了解一种强大的工具——时序数…...
openstack云计算(一)————openstack安装教程,创建空白虚拟机,虚拟机的环境准备
1、创建空白虚拟机 需要注意的步骤会截图一下,其它的基本都是下一步,默认的即可 ----------------------------------------------------------- 2、在所建的空白虚拟机上安装CentOS 7操作系统 (1)、在安装CentOS 7的启动界面中…...

Linux存储的基本管理
实验环境: 系统里添加两块硬盘 ##1.设备识别## 设备接入系统后都是以文件的形式存在 设备文件名称: SATA/SAS/USB /dev/sda,/dev/sdb ##s SATA, dDISK a第几块 IDE /dev/hd0,/dev/hd1 ##h hard VIRTIO-BLOCK /de…...

Python yield解析:深入理解生成器的魔力
Python中的yield关键字是生成器函数中非常重要的一部分,它可以使函数暂停执行并保存当前状态,同时允许生成器函数返回一个值。本文将详细介绍yield关键字的用法、特性、基本功能、高级功能、实际应用场景以及总结,帮助深入了解yield关键字的作…...

【Linux】GCCGDB
五、GCC & GDB 5.1 gcc 阶段变化命令预处理hello.c->hello.igcc -E 编译hello.i->hello.sgcc -S 汇编hello.s->hello.ogcc -c 链接hello.o->a.outgcc gcc -E hello.c -o 1.i # -o指定输出文件 gcc -E hello.c -g # -g包含提示信息 gcc -D gcc -DDebug <…...
InternLM2-Chat-1.8B 模型测试
在interStudio进行InternLM2-Chat-1.8B模型访问,进入开发机后 配置基础环境 新建conda环境并且进入 conda create -n demo python3.10 -y conda activate demo 下载pytorch等相关包 conda install pytorch2.0.1 torchvision0.15.2 torchaudio2.0.2 pytorch-cuda11.…...

Flutter 关键字
import ‘package:xxxx.dart’; //源于pub.dev (完美的相对引入) import ‘xxxx.dart’; //自定义文件(库)(参考的相对引入(填写import命令码所在文件的上级文件夹下的文件(库)相对路径))(受到import命令码所在文件的参考路径的影响) import:import不具有传递性(类似…...

Java常用API之Collections类解读
写在开头:本文用于作者学习Java常用API 我将官方文档中Collections类中所有API全测了一遍并打印了结果,日拱一卒,常看常新 addAll() 将所有指定元素添加到指定 collection 中 可以添加一个或多个元素 Testpublic void test_addAl…...
KV260 BOOT.BIN更新 ubuntu22.04 netplan修改IP
KV260 2022.2设置 BOOT.BIN升级 KV260开发板需要先更新BOOT.BIN到2022.2版本,命令如下: sudo xmutil bootfw_update -i “BOOT-k26-starter-kit-202305_2022.2.bin” 注意BOOT.BIN应包含全目录。下面是更新到2022.1 FW的示例,非更新到2022.…...

Android 代码自定义drawble文件实现View圆角背景
简介 相信大多数Android开发都会遇到一个场景,给TextView或Button添加背景颜色,修改圆角,描边等需求。一看到这样的实现效果,自然就是创建drawble文件,设置相关属性shap,color,radius等。然后将…...

C#实现Word文档转Markdown格式(Doc、Docx、RTF、XML、WPS等)
文档格式的多样性丰富了我们的信息交流手段,其中Word文档因其强大的功能性而广受欢迎。然而,在网络分享、版本控制、代码阅读及编写等方面,Markdown因其简洁、易于阅读和编辑的特性而展现出独特的优势。将Word文档转换为Markdown格式…...

信息系统架构设计-以服务为中心的企业整合实践
生命周期 业务分析服务建模架构设计系统开发 案例背景 某航空公司的信息系统已有好几十年的历史。该航空公司的主要业务系统构建于20世纪七八十年代,以IBM的主机系统为主。 近年来,该公司已经在几个主要的核心系统之间构建了用于信息集成的信息Hub(I…...

mysql知识点梳理
mysql知识点梳理 一、InnoDB引擎中的索引策略,了解过吗?二、一条 sql 执行过长的时间,你如何优化,从哪些方面入手?三、索引有哪几种类型?四、SQL 约束有哪几种呢?五、drop、delete、truncate的区…...
进行排序)
版本排序,(如果 版本 是 1,1a,1.1a, 2, 2c , 1c , 1.2a, 3 , 5b , 5)进行排序
如果 版本 是 1,1a,1.1a, 2, 2c , 1c , 1.2a, 3 , 5b , 5 对上面的进行排序 利用 VersionComparator 导入依赖 <dependency><groupId>cn.hutool</groupId…...
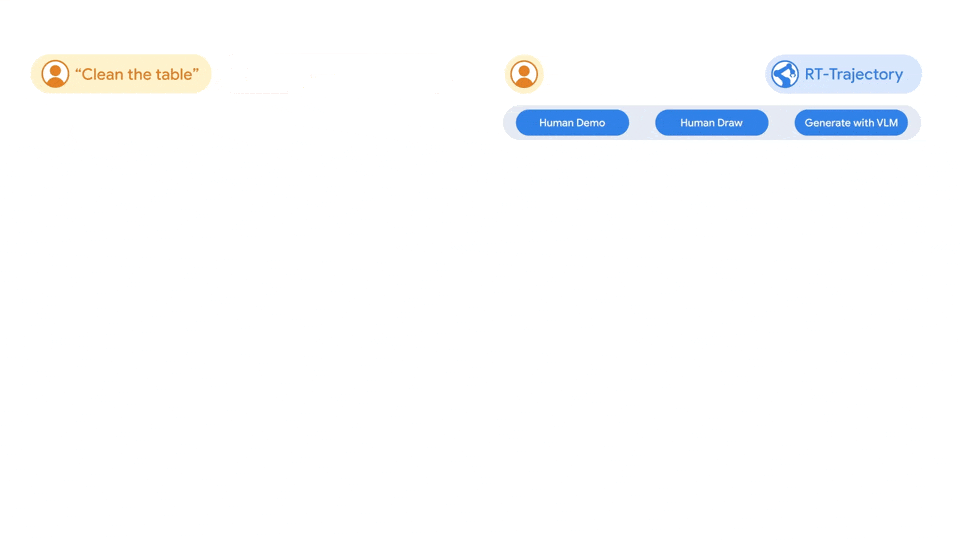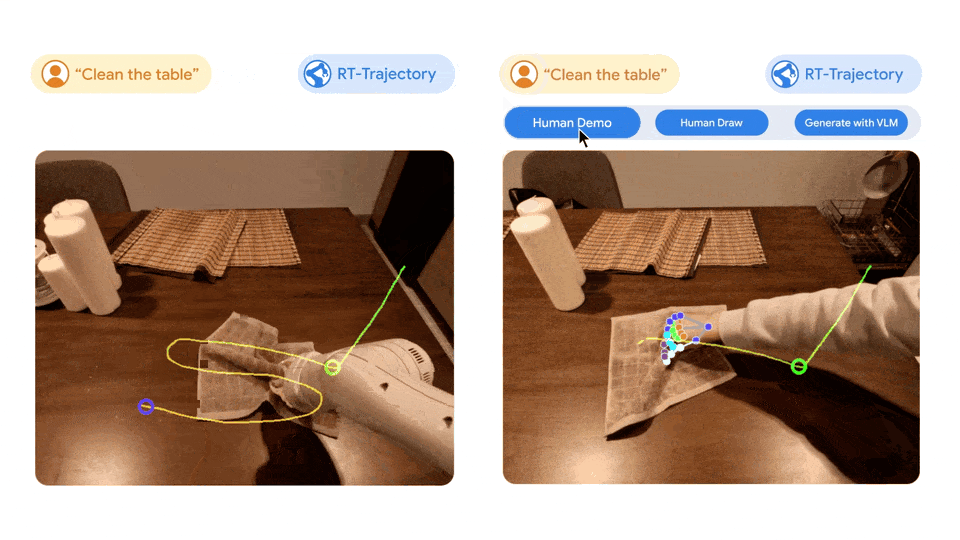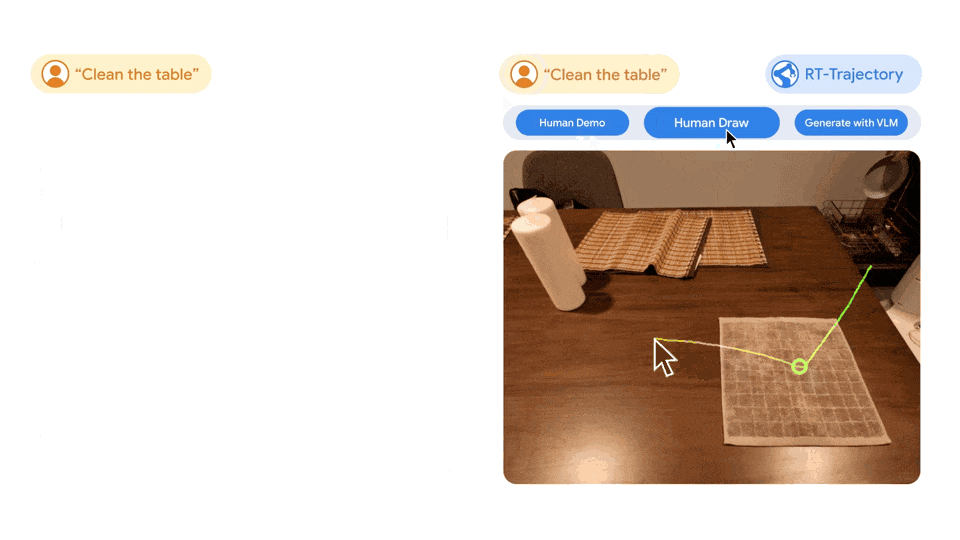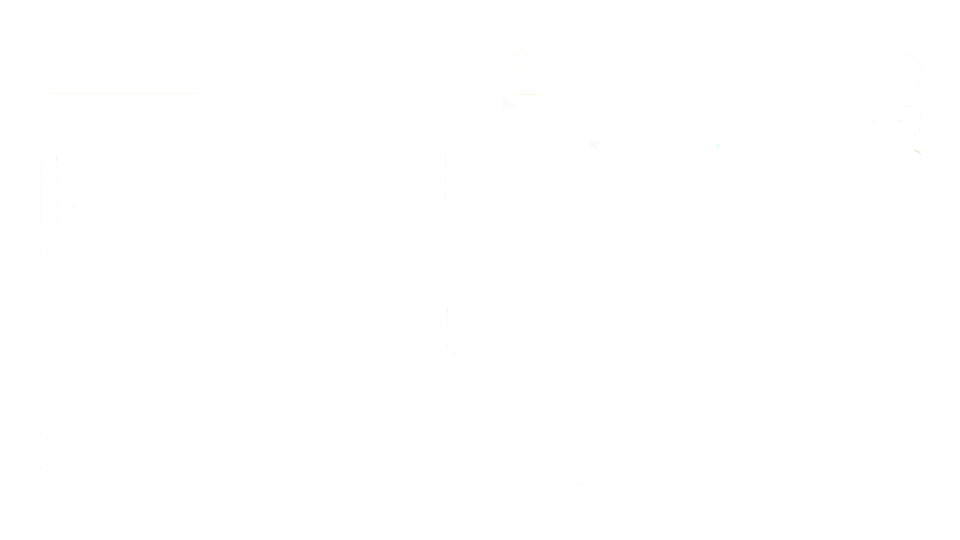
Google视觉机器人超级汇总:从RT、RT-2到AutoRT、SARA-RT、RT-Trajectory
前言 随着对视觉语言机器人研究的深入,发现Google的工作很值得深挖,比如RT-2 想到很多工作都是站在Google的肩上做产品和应用,Google真是科技进步的核心推动力,做了大量大模型的基础设施,服 故有了本文…...
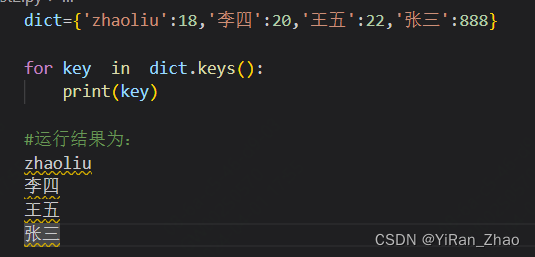
python笔记(9)Dictionary(字典)
目录 创建字典 取值 修改字典 删除 内置函数和方法 创建字典 字典键值和value用:隔开,键值是不可变的,而且必须是唯一的,值可以变,可以是任意类型 dict {key1 : value1, key2 : value2 } 1)不允许同…...

蓝桥杯嵌入式总结
用到外部时钟:UART,ADC,RTC 用到中断:UART,TIM LED_KEY: 将高低电平写入对应引脚 HAL_GPIO_WritePin(GPIOD, GPIO_PIN_2, GPIO_PIN_SET); 读取对应引脚的电平状态 HAL_GPIO_ReadPin(GPIOB,GPIO_PIN_0) UART: 发送: int fputc(int …...
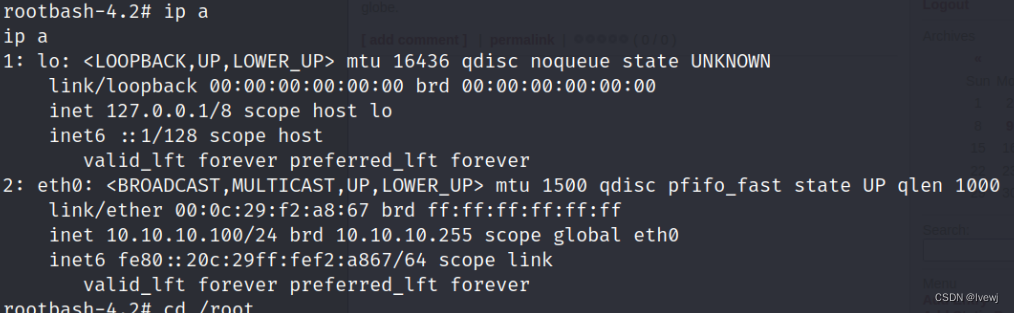
渗透测试:数据库UDF提权(linux)
目录 开头: 1.UDF提权简介: 1.1共享库文件(UDF文件)指定目录: 版本特征: 操作系统版本: 2.靶场UDF提权复现 提权前提 1.要有一个高权限的MySQL的账号 编辑 2.MySQL的权限配置secure_file_priv为空 3.必须有存放UDF文件的…...

java算法day45 | 动态规划part07 ● 70. 爬楼梯 (进阶) ● 322. 零钱兑换 ● 279.完全平方数
70. 爬楼梯 (进阶) 题目描述: 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬至多m (1 < m < n)个台阶。你有多少种不同的方法可以爬到楼顶呢? 注意:给定 n 是一个正整数。 输入描述:输入…...
HuggingFace踩坑记录-连不上,根本连不上
学习 transformers 的第一步,往往是几句简单的代码 from transformers import pipelineclassifier pipeline("sentiment-analysis") classifier("We are very happy to show you the 🤗 Transformers library.") ""&quo…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...