机器学习每周挑战——旅游景点数据分析

数据的截图,数据的说明:
# 字段 数据类型 # 城市 string # 名称 string # 星级 string # 评分 float # 价格 float # 销量 int # 省/市/区 string # 坐标 string # 简介 string # 是否免费 bool # 具体地址 string
拿到数据第一步我们先导入数据,查看一下数据的分布,类型等
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltdata = pd.read_excel("旅游景点.xlsx")
pd.set_option("display.max_columns",100)
# print(data.head())print(data.info())
print(data.isnull().sum())接下来我们来看具体的问题:
# 问题(先大概分析一下) # 1、全国景点分布 (我们分析城市的分布即可) # 2、国民出游分析 (我们可以分析评分,城市,销量之间的关系 ) # 3、景区价格分析 (我们分析价格因素)
# 问题看完之后,我们开始对数据进行预处理 # 由于星级对我们问题的分析帮助很大,所以我们无法用删除,或者众数等方式填充,因此我们用无来填充,将其划分为一个新的类别
data["星级"] = data["星级"].fillna("无")
print(data["星级"].isnull().sum())至于简介和地址,缺失数据无关紧要,这里我们可以选择用无来填充,也可以用删除来处理,为了不破坏数据的完整性,这里我选择用无来填充
data = data.fillna("无")
# print(data.isnull().sum())
# 这样我们的数据就没有了缺失值
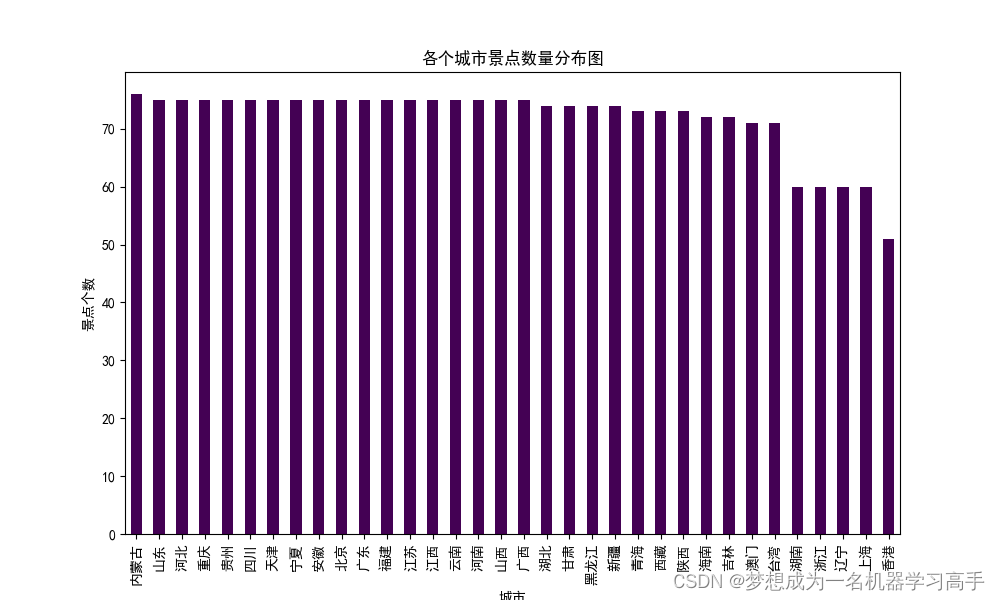
# print(data.info())# 1、全国景点分布 (我们分析城市的分布即可)
scenic = data['城市'].value_counts().sort_values(ascending=False)
plt.figure()
scenic.plot(kind='bar',stacked=False,colormap='viridis',figsize=(10,6))
plt.title("各个城市景点数量分布图")
plt.xlabel('城市')
plt.ylabel('景点个数')
# plt.show()# 2、国民出游分析 (我们可以分析评分,城市,销量之间的关系 )
# data['销量'] = data['销量'].astype(int) 这种转换类型的方法,如果有无法转换的值,则无法转换
data['评分'] = pd.to_numeric(data['评分'], errors='coerce')
data['销量'] = pd.to_numeric(data['销量'],errors='coerce')
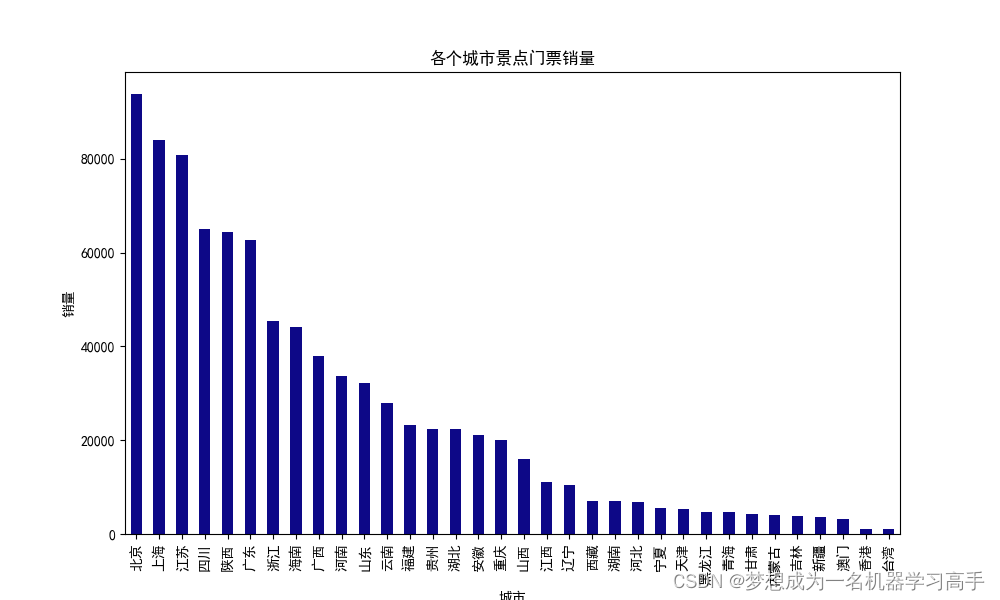
data['价格'] = pd.to_numeric(data['价格'],errors='coerce')city_sales = data.groupby('城市')['销量'].sum()
city_sales = city_sales.sort_values(ascending=False)plt.figure()
city_sales.plot(kind='bar',stacked=True,colormap='plasma',figsize=(10,6))
plt.title('各个城市景点门票销量')
plt.xlabel('城市')
plt.ylabel('销量')
# 从销量可以看出北京,上海,江苏,四川,陕西,广东的销量较高,因此,我们着重分析这六个地方的景点评分
shanghai = data[data['城市'].str.contains('上海')]
beijing = data[data['城市'].str.contains('北京')]
jiangsu = data[data['城市'].str.contains('江苏')]
sichuan = data[data['城市'].str.contains('四川')]
shanxi = data[data['城市'].str.contains('陕西')]
guangdong = data[data['城市'].str.contains('广东')]shanghai_group = shanghai.groupby('名称')['销量'].sum().reset_index()
beijing_group = beijing.groupby('名称')['销量'].sum().reset_index()
jiangsu_group = jiangsu.groupby('名称')['销量'].sum().reset_index()
sichuan_group = sichuan.groupby('名称')['销量'].sum().reset_index()
shanxi_group = shanxi.groupby('名称')['销量'].sum().reset_index()
guangdong_group = guangdong.groupby('名称')['销量'].sum().reset_index()shanghai_sort = shanghai_group.merge(shanghai[['名称','评分']].drop_duplicates(),on='名称').sort_values(by='销量', ascending=False).head(10)
beijing_sort = beijing_group.merge(beijing[['名称','评分']].drop_duplicates(),on='名称').sort_values(by='销量', ascending=False).head(10)
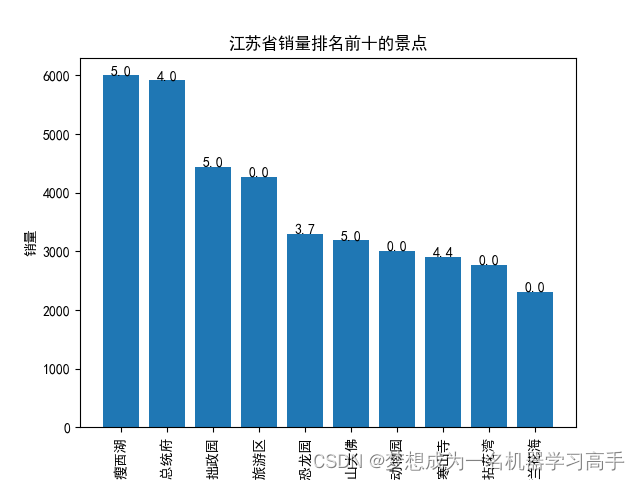
jiangsu_sort = jiangsu_group.merge(jiangsu[['名称','评分']].drop_duplicates(),on='名称').sort_values(by='销量', ascending=False).head(10)
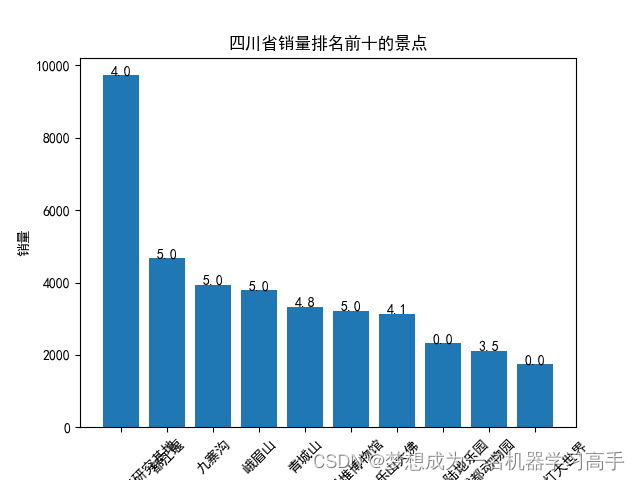
sichuan_sort = sichuan_group.merge(sichuan[['名称','评分']].drop_duplicates(),on='名称').sort_values(by='销量', ascending=False).head(10)
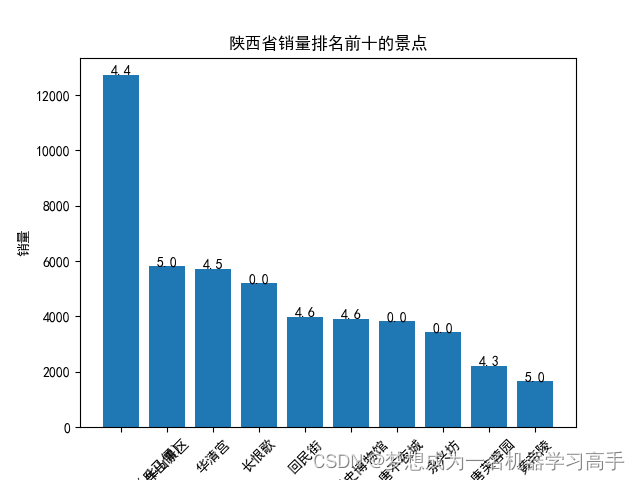
shanxi_sort = shanxi_group.merge(shanxi[['名称','评分']].drop_duplicates(),on='名称').sort_values(by='销量', ascending=False).head(10)
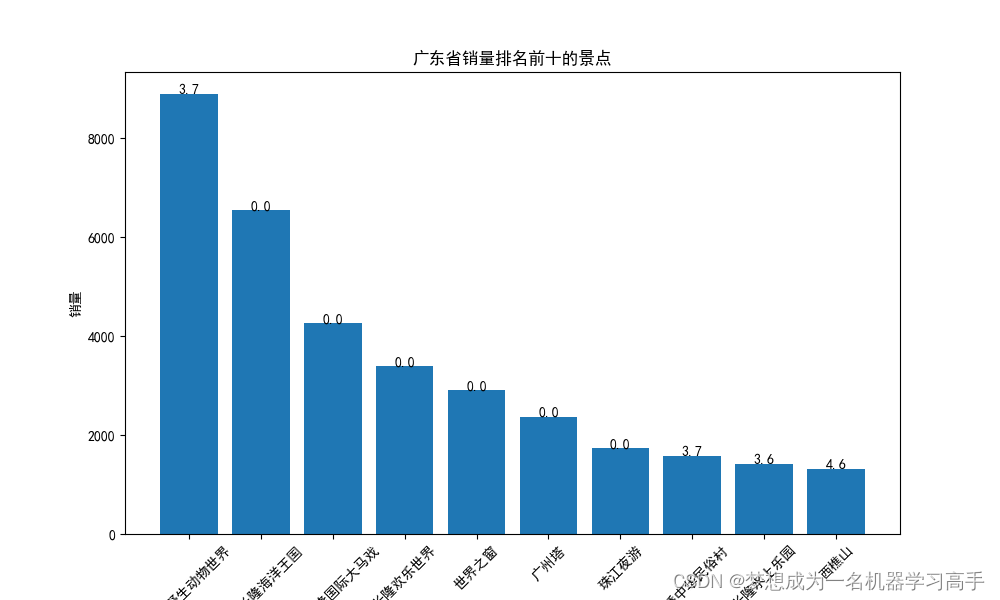
guangdong_sort = guangdong_group.merge(guangdong[['名称','评分']].drop_duplicates(),on='名称').sort_values(by='销量', ascending=False).head(10)shanghai_sort.reset_index(drop=True,inplace=True)
beijing_sort.reset_index(drop=True,inplace=True)
jiangsu_sort.reset_index(drop=True,inplace=True)
sichuan_sort.reset_index(drop=True,inplace=True)
shanxi_sort.reset_index(drop=True,inplace=True)
guangdong_sort.reset_index(drop=True,inplace=True)plt.figure()
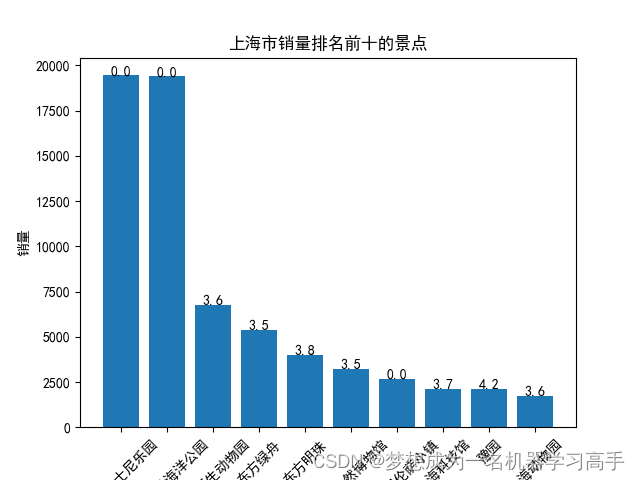
plt.bar(shanghai_sort['名称'],shanghai_sort['销量'])
for i, v in enumerate(shanghai_sort['评分']):plt.text(i, shanghai_sort['销量'][i] + 0.2, str(v), ha='center')plt.xlabel('名称')
plt.ylabel('销量')
plt.title('上海市销量排名前十的景点')
plt.xticks(rotation=45)plt.figure()
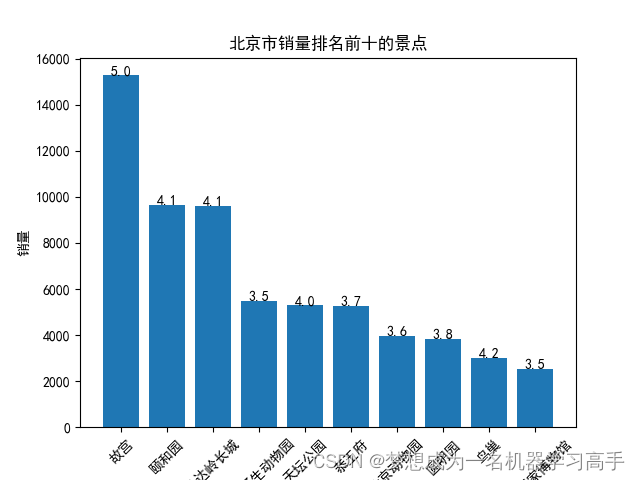
plt.bar(beijing_sort['名称'], beijing_sort['销量'])
for i, v in enumerate(beijing_sort['评分']):plt.text(i, beijing_sort['销量'][i] + 0.2, str(v), ha='center')plt.xlabel('名称')
plt.ylabel('销量')
plt.title('北京市销量排名前十的景点')
plt.xticks(rotation=45)plt.figure()
plt.bar(jiangsu_sort['名称'], jiangsu_sort['销量'])
for i, v in enumerate(jiangsu_sort['评分']):plt.text(i, jiangsu_sort['销量'][i] + 0.2, str(v), ha='center')plt.xlabel('名称')
plt.ylabel('销量')
plt.title('江苏省销量排名前十的景点')
plt.xticks(rotation='vertical')plt.figure()
plt.bar(sichuan_sort['名称'], sichuan_sort['销量'])
for i, v in enumerate(sichuan_sort['评分']):plt.text(i, sichuan_sort['销量'][i] + 0.2, str(v), ha='center')plt.xlabel('名称')
plt.ylabel('销量')
plt.title('四川省销量排名前十的景点')
plt.xticks(rotation=45)plt.figure()
plt.bar(shanxi_sort['名称'], shanxi_sort['销量'])
for i, v in enumerate(shanxi_sort['评分']):plt.text(i, shanxi_sort['销量'][i] + 0.2, str(v), ha='center')plt.xlabel('名称')
plt.ylabel('销量')
plt.title('陕西省销量排名前十的景点')
plt.xticks(rotation=45)plt.figure(figsize=(10,6))
plt.bar(guangdong_sort['名称'], guangdong_sort['销量'])
for i, v in enumerate(guangdong_sort['评分']):plt.text(i, guangdong_sort['销量'][i] + 0.2, str(v), ha='center')plt.xlabel('名称')
plt.ylabel('销量')
plt.title('广东省销量排名前十的景点')
plt.xticks(rotation=45)由此,我们结合这几个分析来回答这几个问题:
相关文章:
机器学习每周挑战——旅游景点数据分析
数据的截图,数据的说明: # 字段 数据类型 # 城市 string # 名称 string # 星级 string # 评分 float # 价格 float # 销量 int # 省/市/区 string # 坐标 string # 简介 string # 是否免费 bool # 具体地址 string拿到数据…...

开发语言漫谈-C语言
个人认为C语言是最伟大的开发语言(没有之一)。C语言开创了高级语言的新时代。比C更低级的是汇编语言,这个东西就是反人类的玩意。之后的语言或多或少都受C语言的影响。更神奇的是直到现在,C语言还有生命力。C语言的发明人丹尼斯里…...

vue3导入excel并解析excel数据渲染到表格中,纯前端实现。
需求 用户将已有的excel上传到系统,并将excel数据同步到页面的表格中进行二次编辑,由于excel数据不是最终数据,只是批量的一个初始模板,后端不需要存储,所以该功能由前端独立完成。 吐槽 系统中文件上传下载预览三部…...

Java常用API之Encoders类解读
写在开头:本文用于作者学习Java常用API 我将官方文档中Encoders类中所有API全测了一遍并打印了结果,日拱一卒,常看常新 在Spark中,Encoders类提供了一些静态方法用于创建不同数据类型的编码器。 首先,我遇到这样一个…...
java中大型医院HIS系统源码 Angular+Nginx+SpringBoot云HIS运维平台源码
java中大型医院HIS系统源码 AngularNginxSpringBoot云HIS运维平台源码 云HIS系统是一款满足基层医院各类业务需要的健康云产品。该产品能帮助基层医院完成日常各类业务,提供病患预约挂号支持、病患问诊、电子病历、开药发药、会员管理、统计查询、医生工作站和护士工…...
windows部署Jenkins并远程部署tomcat
目录 1、Jenkins官网下载Jenkins 2、安装Jenkins 3、修改Home directory 4、插件安装及系统配置 5、Tomcat安装及配置 5.1、修改配置文件,屏蔽以下代码 5.2、新增登录用户 5.3、编码格式修改 5.4、启动tomcat 6、Jenkins远程部署war包 6.1、General配置 6.2、Sourc…...
)
设计模式|责任链模式(Chain of Responsibility Pattern)
文章目录 结构优点缺点使用责任链的步骤示例有哪些知名框架采用了责任链模式责任链模式和链表有什么关联常见面试题 责任链模式(Chain of Responsibility Pattern)是一种行为设计模式,它允许你创建一个对象链。请求将沿着这个链传递ÿ…...
文件服务器之二:SAMBA服务器
文章目录 什么是SAMBASAMBA的发展历史与名称的由来SAMBA常见的应用 SAMBA服务器基础配置配置共享资源Windows挂载共享Linux挂载共享 什么是SAMBA 下图来自百度百科 SAMBA的发展历史与名称的由来 Samba是一款开源的文件共享软件,它基于SMB(Server Messa…...

20.安全性测试与评估
每年都会涉及;可能会考大题;多记!!! 典型考点:sql注入、xss; 从2个方面记: 1、测试对象的功能、性能; 2、相关设备的工作原理; 如防火墙,要了解防…...

阿里巴巴实习面经
本人bg:浙江大学,计算机研二,本科也是浙大计算机专业的。 在阿里巴巴达摩院实习,算法岗,我是去年拿到的阿里巴巴达摩院的实习offer,这个过程还是比较惊心动魄,所以我称之为惊心动魄版本…...
javaweb学习(day11-监听器Listener过滤器Filter)
一、监听器Listener 1 Listener介绍 Listener 监听器它是 JavaWeb 的三大组件之一。JavaWeb 的三大组件分别是:Servlet 程 序、Listener 监听器、Filter 过滤器 Listener 是 JavaEE 的规范,就是接口 监听器的作用是,监听某种变化(一般就是对…...
教你快速认识Java中的抽象类和接口
目录 引言 抽象类(Abstract Class) 抽象类的概念 抽象类的图标 抽象类的语法 抽象类的特点 接口(Interface) 接口的概念 接口的图标 接口的语法 接口的特点 接口的使用 接口的意义 抽象类与接口的区别 Object类 结…...
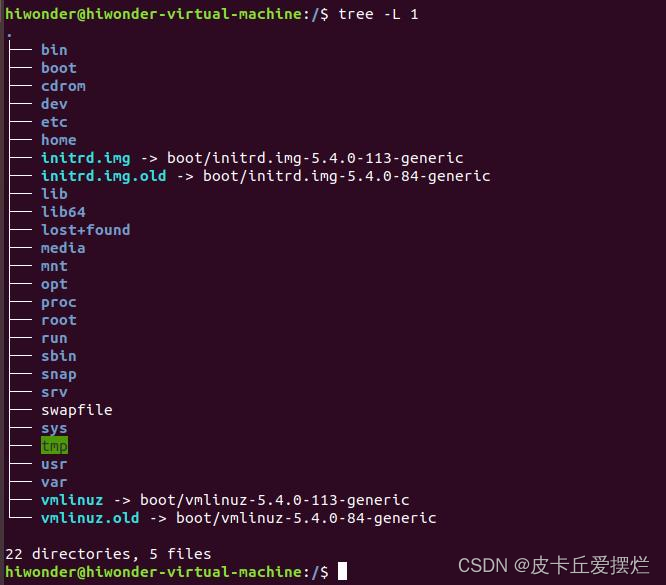
Linux第5课 Linux目录介绍
文章目录 Linux第5课 Linux目录介绍一、打开系统目录二、查看系统目录 Linux第5课 Linux目录介绍 系统目录就是指操作系统的主要文件存放的目录,目录中的文件直接影响到系统是否正常工作,了解这些目录的功能,对使用系统会有很大的帮助。 一…...

GitHub要求2FA?不慌,有它(神锁离线版)帮你!
GitHub宣布,到 2023 年底,所有用户都必须要启用双因素身份验证 (2FA),不能只用密码啦。 说实话,听到这消息小编是非常高兴的。 正如GitHub的首席安全官Mike Hanley所说,软件供应链是从开发者开始的,保护开…...
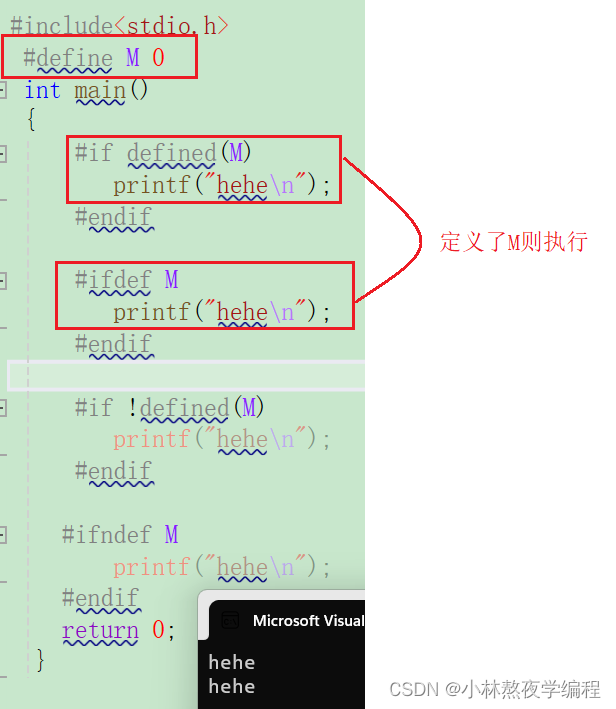
C语言第四十弹---预处理(下)
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】 预处理 1、#和## 1.1 #运算符 1.2、##运算符 2、命名约定 3、#undef 4、命令行定义 5、条件编译 6、头文件的包含 6.1、头文件被包含的方式 6.1.1、本地…...

SYS-2722音频分析仪SYS2722
181/2461/8938产品概述: Audio Precision 2722 音频分析仪是 Audio Precision 屡获殊荣的 PC 控制音频分析仪的旗舰型号,长期以来一直是音频设备设计和测试的全球公认标准。功能齐全的 SYS-2722 提供了测试转换器技术最新进展所需的无与伦比的失真和噪声…...
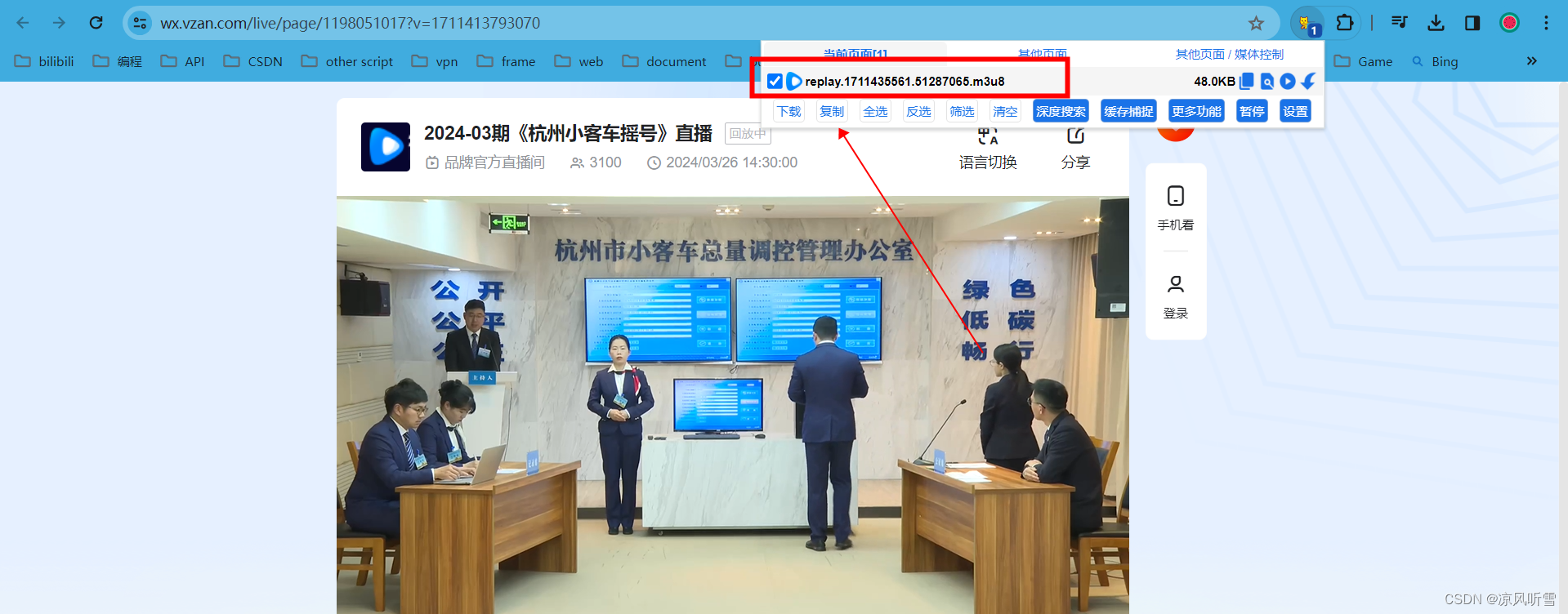
下载页面上的视频
引言:有些页面上的视频可以直接右键另存为或者F12检索元素找到视频地址打开后保存,但有些视频页面是转码后的视频,不能直接另存为视频格式,可以参考下本方法 以该页面视频为例:加载中...点击查看详情https://wx.vzan.c…...
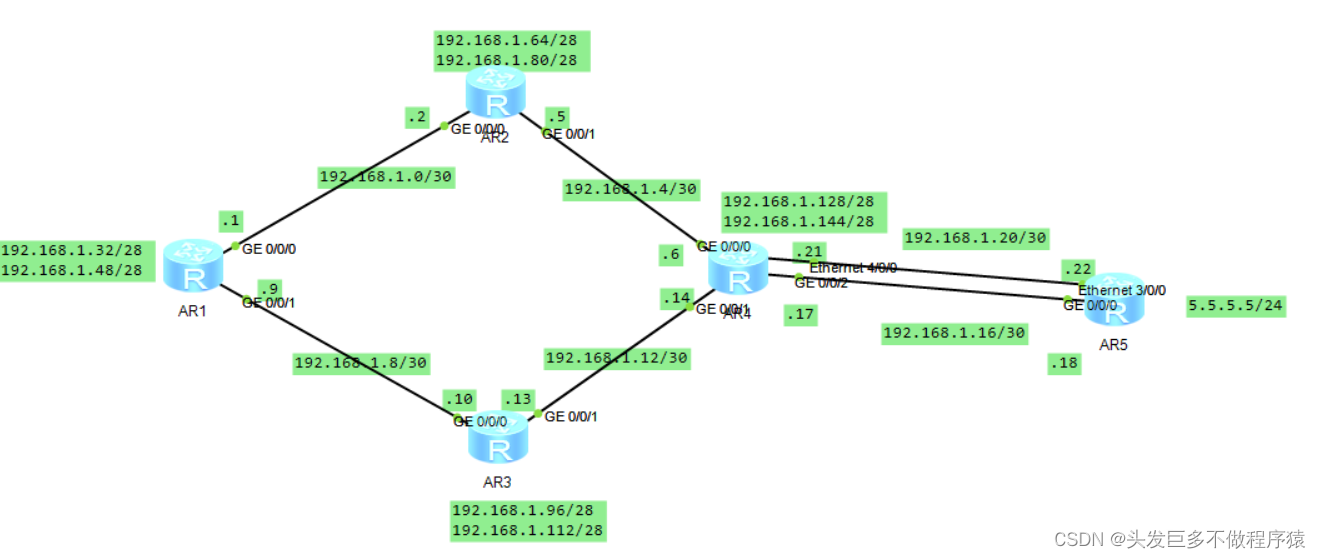
静态路由协议实验综合实验
需求: 1、除R5的换回地址已固定外,整个其他所有的网段基于192.168.1.0/24进行合理的IP地址划分。 2、R1-R4每台路由器存在两个环回接口,用于模拟连接PC的网段;地址也在192.168.1.0/24这个网络范围内。 3、R1-R4上不能直接编写到…...

qt MVC软件设计模式
在Qt中使用MVC(Model-View-Controller)软件设计模式可以帮助你将数据模型、用户界面和控制逻辑有效地分离,从而使得代码更清晰,更易于维护和扩展。以下是在Qt中使用MVC模式的一般思路: Model(模型ÿ…...

代码随想录刷题随记15-二叉树回溯
代码随想录刷题随记15-二叉树回溯 110.平衡二叉树 leetcode链接 一棵高度平衡二叉树定义为:一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。 求深度和求高度的区别: 求深度可以从上到下去查 所以需要前序遍历(中左右ÿ…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...

省略号和可变参数模板
本文主要介绍如何展开可变参数的参数包 1.C语言的va_list展开可变参数 #include <iostream> #include <cstdarg>void printNumbers(int count, ...) {// 声明va_list类型的变量va_list args;// 使用va_start将可变参数写入变量argsva_start(args, count);for (in…...