解析Apache Kafka:在大数据体系中的基本概念和核心组件
关联阅读博客文章:探讨在大数据体系中API的通信机制与工作原理
关联阅读博客文章:深入解析大数据体系中的ETL工作原理及常见组件
关联阅读博客文章:深度剖析:计算机集群在大数据体系中的关键角色和技术要点
关联阅读博客文章:深入理解HDFS工作原理:大数据存储和容错性机制解析
引言:
在当今数字化时代,数据已经成为企业成功的关键要素之一。随着数据量的不断增长和数据处理需求的不断提高,构建高效、可靠的大数据体系成为了企业面临的重要挑战之一。在这个过程中,Apache Kafka作为一个分布式流处理平台,扮演着至关重要的角色。它不仅提供了高吞吐量、低延迟的消息传输服务,还支持实时数据流处理和复杂的事件驱动架构。

概要:
从Kafka的工作原理、集群架构和应用场景三个方面对其进行深入探讨。首先,我们将介绍Kafka的基本概念和核心组件,包括Producer、Consumer、Broker等,并深入探讨其消息存储和分发机制。接着,我们将详细解析Kafka集群的架构设计,包括ZooKeeper的角色、分区和副本的管理以及故障恢复机制。最后,我们将探讨Kafka在大数据领域的应用场景,包括实时日志处理、数据管道和ETL、实时推荐系统、分布式事务处理以及流式数据处理等,并通过实际案例展示其在不同场景下的应用和价值。
1. Kafka的基本概念
在开始深入了解Kafka的工作原理之前,需要了解一些基本概念:
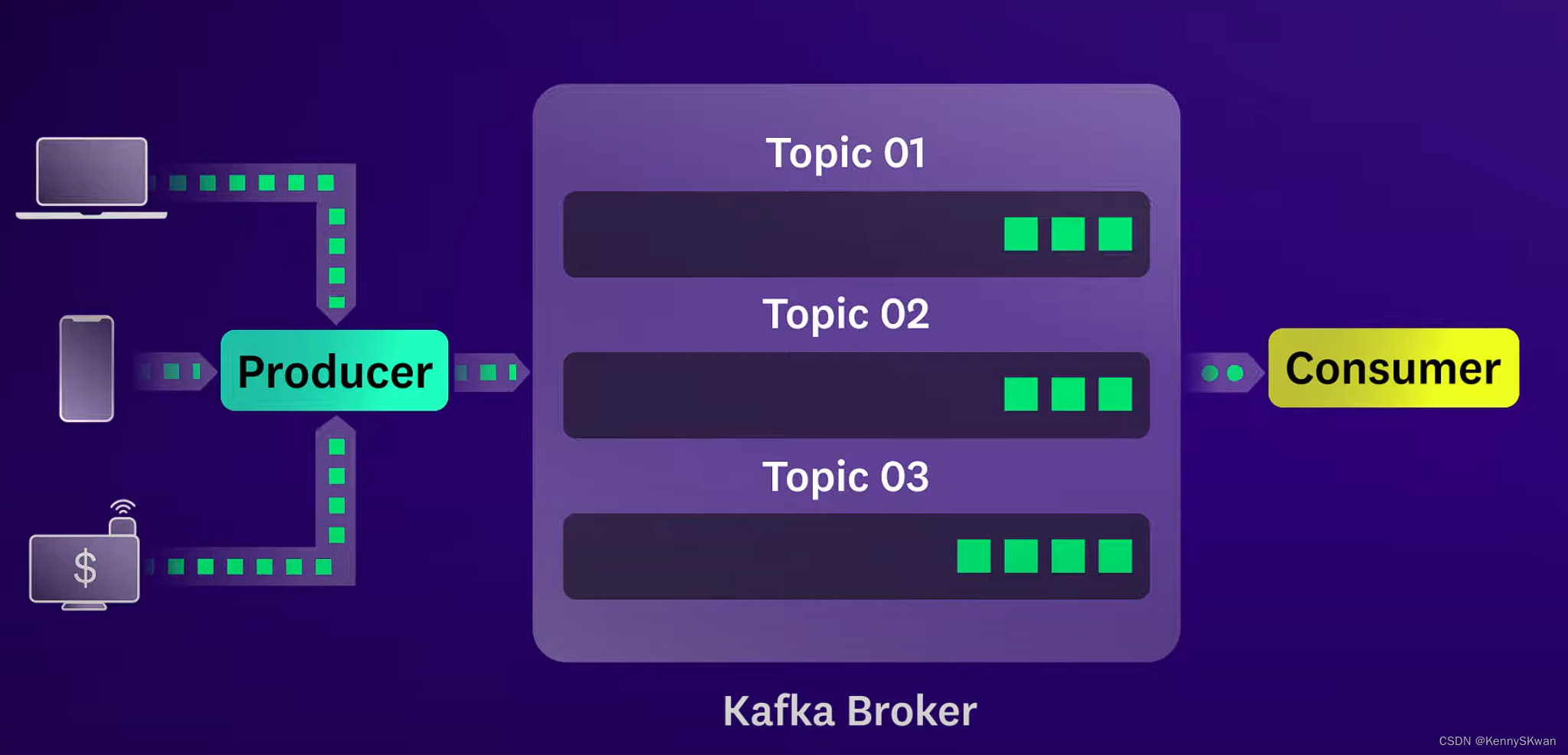
- Producer(生产者): 将数据发布到Kafka主题(Topic)的应用程序。
- Consumer(消费者): 从Kafka主题中读取数据的应用程序。
- Broker(代理): Kafka集群中的服务器,负责存储数据和处理数据传输。
- Topic(主题): 数据发布的类别或分区。
- Partition(分区): 主题被分割成多个分区,每个分区在不同的服务器上。
- Offset(偏移量): 每个消息在分区中的唯一标识。
Kafka消息存储
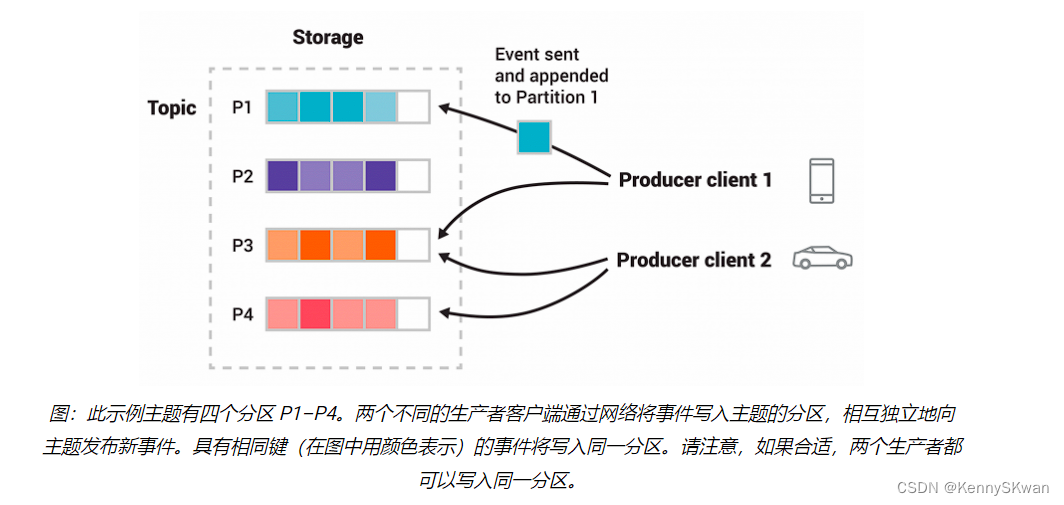
- Kafka的消息存储是基于日志的,每个主题被分成一个或多个分区,每个分区是一个有序的消息队列。消息被追加到分区的末尾,并且保留一段时间(可以配置)。这种设计使得Kafka能够处理大量数据,并支持高吞吐量。
生产者发布消息
- 当生产者发送消息到Kafka时,它们首先连接到Kafka集群的一个Broker,并根据特定的分区策略将消息发布到一个或多个主题中的分区。生产者可以选择指定消息的键,这样消息将被发送到特定的分区,或者Kafka将基于负载均衡策略自动选择分区。
消费者消费消息
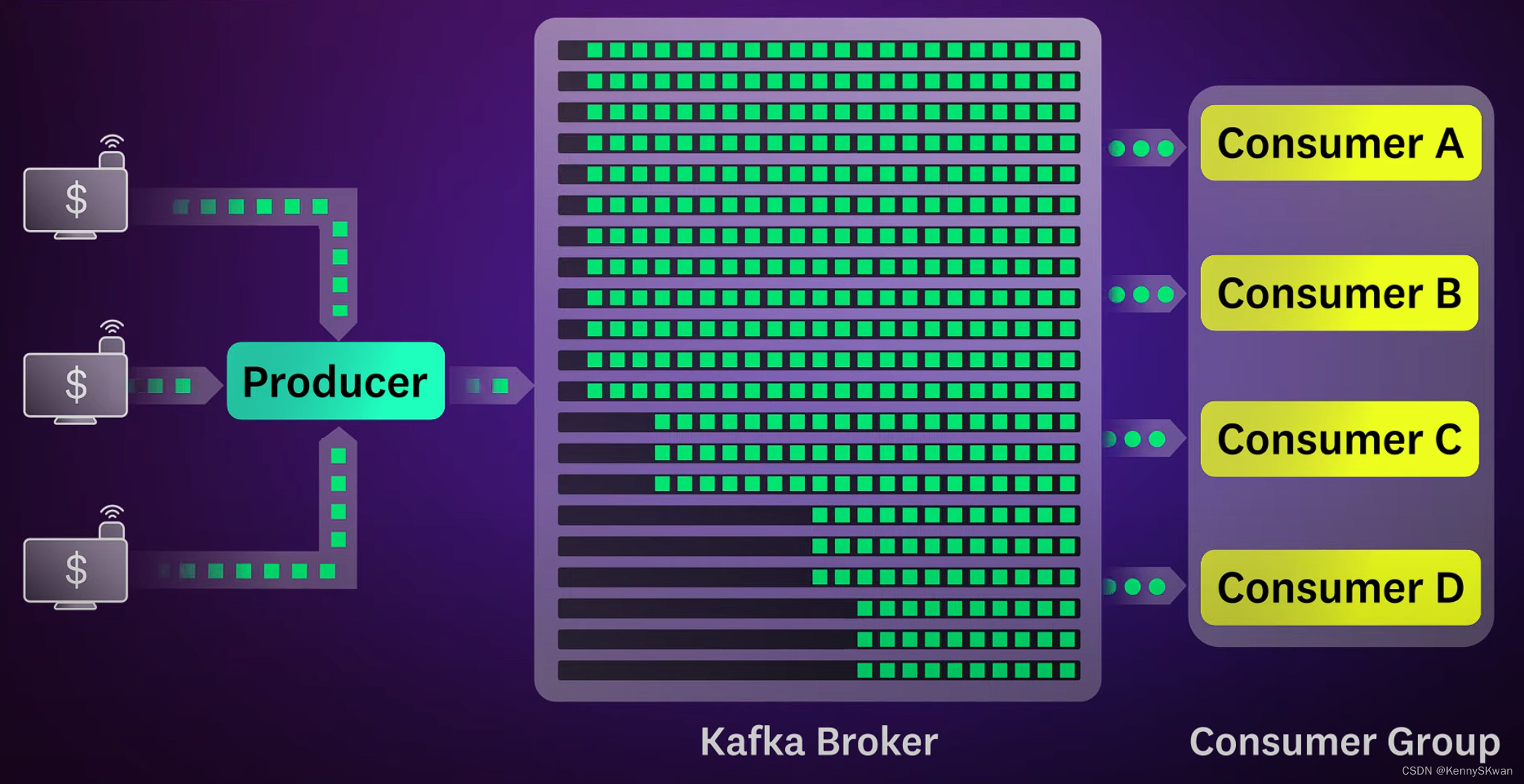
- 消费者从Kafka订阅一个或多个主题,并且会被分配到每个主题的一个或多个分区。消费者定期轮询Kafka Broker,拉取新的消息。一旦消费者拉取到消息,它们就会处理这些消息,并提交偏移量来记录自己的消费位置。
Kafka的水平扩展性
- Kafka通过分区和复制来实现水平扩展性和高可用性。分区允许数据水平分布在集群中的多个Broker上,从而允许Kafka处理大量数据。同时,Kafka通过复制每个分区到多个Broker上来提供容错性和可靠性。
2.Kafka集群组件
一个典型的Kafka集群包含以下组件:
- ZooKeeper:
ZooKeeper是一个分布式协调服务,Kafka依赖它来进行集群管理和领导者选举。ZooKeeper保存了Kafka集群的元数据(如主题、分区、副本分配等),并且监控Kafka Broker的健康状态。 - Broker:
Broker是Kafka集群中的服务器节点,负责存储和处理数据。每个Broker都是一个独立的Kafka服务器,它们共同组成了整个Kafka集群。 - Topic:
Topic是消息发布的类别或分区。在集群中,每个Topic都被分成一个或多个分区,这些分区分布在不同的Broker上。 - Partition:
Partition是Topic的子集,每个分区都是一个有序的消息队列。分区允许数据在多个Broker上进行并行处理,从而提高了吞吐量和可扩展性。
Kafka集群工作原理
- 启动:
当Kafka Broker启动时,它会向ZooKeeper注册自己的信息,包括主机名、端口号等。ZooKeeper会维护所有Broker的信息,并监控它们的健康状态。 - 元数据管理:
ZooKeeper保存了Kafka集群的元数据,包括Topic、分区、副本分配等信息。这些元数据被用来协调Broker之间的消息路由和复制。 - Leader-Follower模式:
对于每个分区,Kafka会选举出一个Broker作为Leader,并将其他Broker设置为Follower。Leader负责处理所有的读写请求,而Follower则负责复制Leader的数据。当Leader失效时,ZooKeeper会协助选举新的Leader。 - 消息发布和消费:
生产者将消息发布到指定的Topic,Kafka根据分区策略将消息分配到各个分区中。消费者从Topic订阅消息,并根据分配的分区拉取数据。Kafka会保证消息的顺序性和一致性,以及消费者的负载均衡。 - 水平扩展:
Kafka通过增加Broker节点和分区来实现水平扩展。每个Broker负责处理一部分数据和请求,从而提高了集群的吞吐量和容量。
Kafka集群的可靠性和容错性
- 副本复制:
每个分区都有多个副本,它们分布在不同的Broker上。当Leader失效时,Kafka会自动选择一个副本作为新的Leader,从而保证数据的可用性。 - ISR机制:
Kafka使用ISR(In-Sync Replicas)机制来确保副本之间的一致性。只有处于ISR中的副本才会被选举为新的Leader,这样可以防止数据丢失和不一致。 - 故障恢复:
当Broker或者分区发生故障时,Kafka会自动进行故障恢复,包括重新选举Leader和同步数据等操作。
3.Kafka在大数据的应用场景
实时日志处理
- 实时日志处理是Kafka的一个典型应用场景。许多大型互联网企业和在线服务需要实时收集、处理和分析海量日志数据,以监控系统运行状况、进行故障排查和提供用户行为分析等功能。Kafka作为一个高吞吐量、低延迟的消息队列,可以用来收集和传输日志数据,同时支持流式处理引擎(如Apache Spark、Apache Flink等)进行实时分析和计算。
数据管道和ETL
- Kafka常用于构建数据管道和ETL(Extract, Transform,Load)流程,用于将数据从源系统提取、转换和加载到目标系统中。例如,一个企业可能需要将来自各种数据源(如数据库、日志文件、传感器等)的数据集成到一个数据湖或数据仓库中,以支持数据分析和决策制定。Kafka可以作为数据管道的中间件,用来传输和缓存数据,并保证数据的可靠性和一致性。
实时推荐系统
- 实时推荐系统需要快速响应用户行为,并向用户推荐个性化的内容或产品。Kafka可以用来收集和分析用户行为数据,并将结果传输给推荐算法模型进行实时计算和推荐。通过结合Kafka与实时计算引擎(如Apache Storm、Apache Samza等),可以实现高效的实时推荐服务,提升用户体验和业务价值。
分布式事务处理
- Kafka提供了分布式事务支持,可以用来实现分布式系统中的事务性消息处理。这在金融领域、电子商务等需要确保数据一致性和可靠性的场景中尤为重要。通过Kafka的事务功能,可以实现跨多个服务和系统的原子性操作,确保数据的完整性和一致性。
流式数据处理
- Kafka与流式处理引擎(如Apache Kafka Streams、Apache Flink等)的集成,可以实现实时数据流的处理和分析。这对于实时监控、实时预测和实时反馈等场景非常有用,例如智能工厂的实时生产监控、智能交通的实时流量调度等。
Kafka的局限性
- 复杂性:Kafka的分布式特性、多种配置和调优参数使得设置、维护和操作变得复杂。
- 有限的数据保留:Kafka并不是为长期数据存储而设计的。其主要功能是实时数据处理和消息传递。
- 有限的查询能力:与数据库不同,Kafka不支持查询能力。它只是一个消息传递系统。
- 缺乏完整的安全措施:Kafka缺乏某些安全功能,例如基于角色的访问控制,并且缺乏一些更高级的安全功能。
扩展阅读:
kafka官方手册
相关文章:
解析Apache Kafka:在大数据体系中的基本概念和核心组件
关联阅读博客文章:探讨在大数据体系中API的通信机制与工作原理 关联阅读博客文章:深入解析大数据体系中的ETL工作原理及常见组件 关联阅读博客文章:深度剖析:计算机集群在大数据体系中的关键角色和技术要点 关联阅读博客文章&a…...
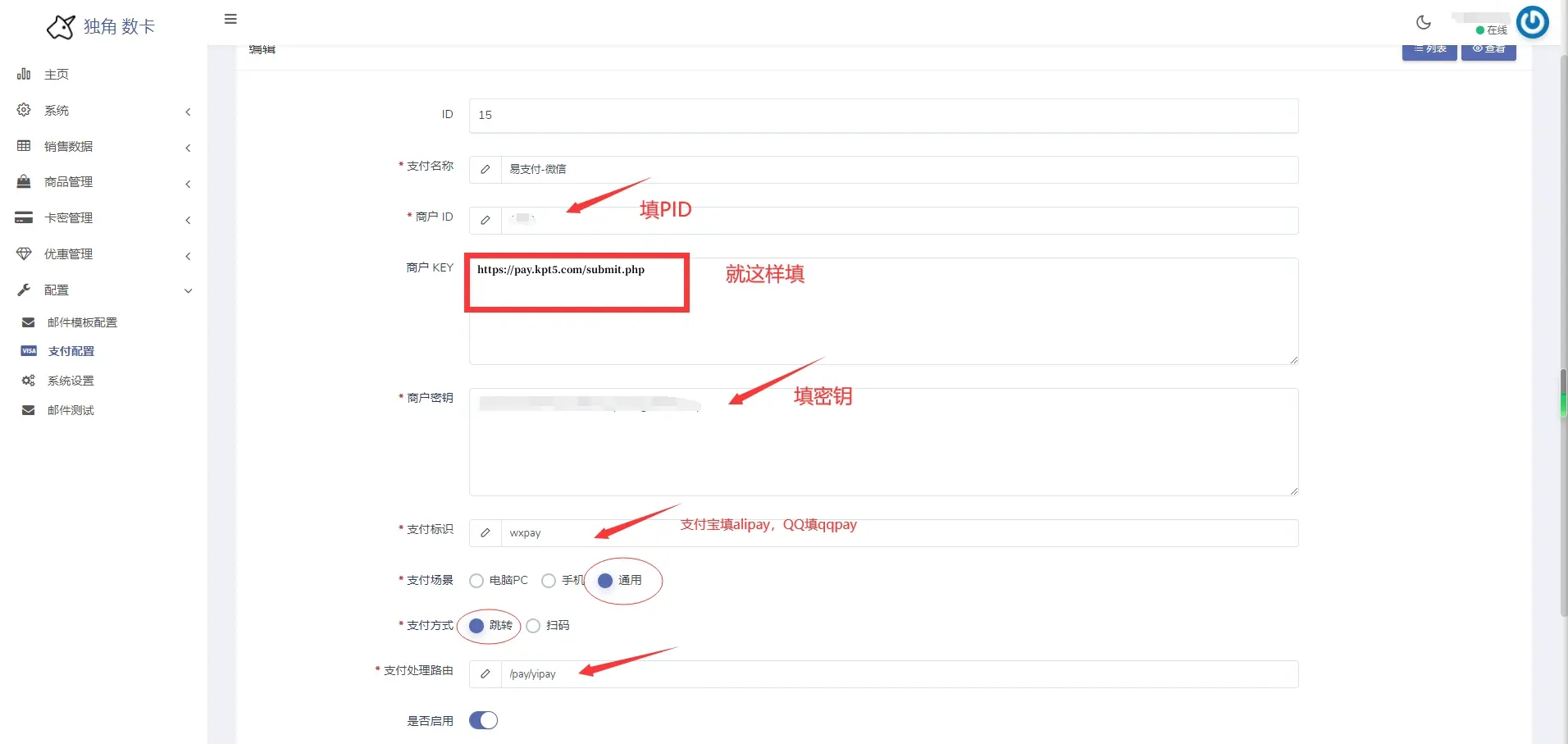
独角数卡对接码支付收款教程
1、到码支付后台找到支付配置。2、将上面的复制依次填入,具体看下图,随后点立即添加 商户ID商户PID 商户KEY异步不能为空 商户密钥商户密钥...
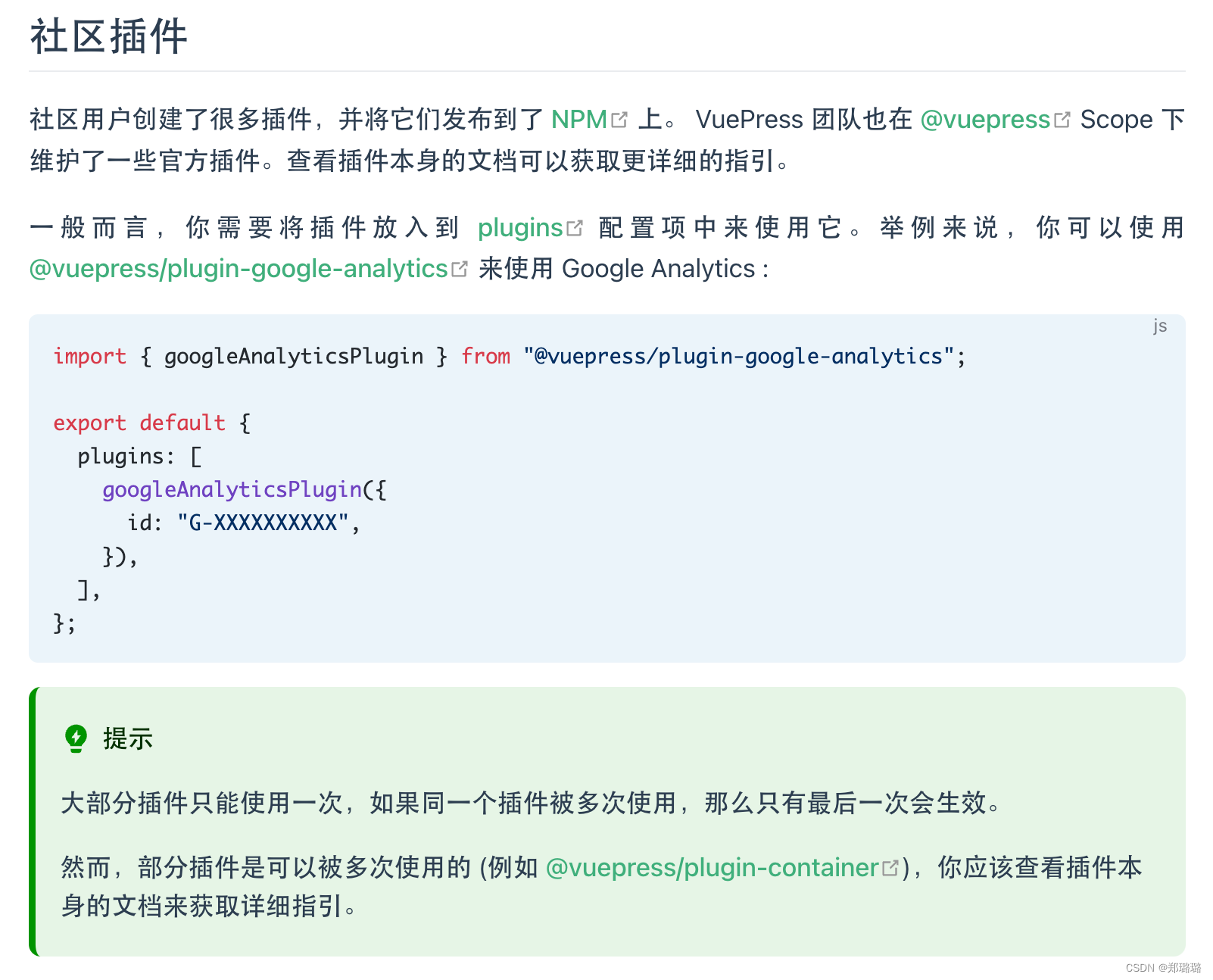
vuepress-theme-hope 添加谷歌统计代码
最近做了个网站,从 cloudflare 来看访问量,过去 30 天访问量竟然有 1.32k 给我整懵逼了,我寻思不应该呀,毕竟这个网站内容还在慢慢补充中,也没告诉别人,怎么就这么多访问?搜索了下, cloudflare 还会把爬虫的请求也就算进来,所以数据相对来说就不是很准确 想到了把 Google An…...

LabVIEW太赫兹波扫描成像系统
LabVIEW太赫兹波扫描成像系统 随着科技的不断发展,太赫兹波成像技术因其非电离性、高穿透性和高分辨率等特点,在生物医学、材料质量无损检测以及公共安全等领域得到了广泛的应用。然而,在实际操作中,封闭性较高的信号采集软件限制…...

什么是stable diffusion?
🌟 Stable Diffusion:一种深度学习文本到图像生成模型 🌟 Stable Diffusion是2022年发布的深度学习文本到图像生成模型,主要用于根据文本的描述产生详细图像。它还可以应用于其他任务,如内补绘制、外补绘制࿰…...
KeyguardClockSwitch的父类
KeyguardClockSwitch 定义在KeyguardStatusView中, mClockView findViewById(R.id.keyguard_clock_container);KeyguardClockSwitch的父类为: Class Name: LinearLayout Class Name: KeyguardStatusView Class Name: NotificationPanelView Class Name: Notificat…...
:Groovy基础)
Gradle系列(二):Groovy基础
Gradle系列(二):Groovy基础 本篇文章继续讲下Groovy一些基础的语法。 1:Map map与List的用法很像,只不过值是一个K:V的键值对。 下面是是Groovy中Map的定义: task testMap { def map [‘width’:1280,‘height’:1960] prin…...

PW1503限流芯片:可达3A限流,保障USB电源管理安全高效
在电源管理领域,开关的性能直接关系到设备的稳定性和安全性。今天,我们将详细解析一款备受关注的超低RDS(ON)开关——PW1503。它不仅具有可编程的电流限制功能,还集成了多项保护机制,为各类电子设备提供了高…...
深挖苹果Find My技术,伦茨科技ST17H6x芯片赋予产品功能
苹果发布AirTag发布以来,大家都更加注重物品的防丢,苹果的 Find My 就可以查找 iPhone、Mac、AirPods、Apple Watch,如今的Find My已经不单单可以查找苹果的设备,随着第三方设备的加入,将丰富Find My Network的版图。产…...

Web3 革命:揭示区块链技术的全新应用
随着数字化时代的不断发展,区块链技术作为一项颠覆性的创新正在改变着我们的世界。而在这一技术的进步中,Web3正逐渐崭露头角,为区块链技术的应用带来了全新的可能性。本文将探讨Web3革命所揭示的区块链技术全新应用,并展望其未来…...

[实战经验]Mybatis的mapper.xml参数#{para}与#{para, jdbcType=BIGINT}有什么区别?
在MyBatis框架中,传入参数使用#{para}和#{para, jdbcTypeBIGINT}的有什么区别呢? #{para}:这种写法表示使用MyBatis自动推断参数类型,并根据参数的Java类型自动匹配数据库对应的类型。例如,如果参数para的Java类型是Lo…...

高并发下的linux优化
针对高并发服务,对 Linux 内核和网络进行优化可以提高系统的性能和稳定性。本文将深入探讨如何对 Linux 内核和网络进行优化,包括调整内核参数、调整网络性能参数、使用 TCP/IP 协议栈加速技术、下面将介绍一些可用于优化Linux内核和网络的技术ÿ…...
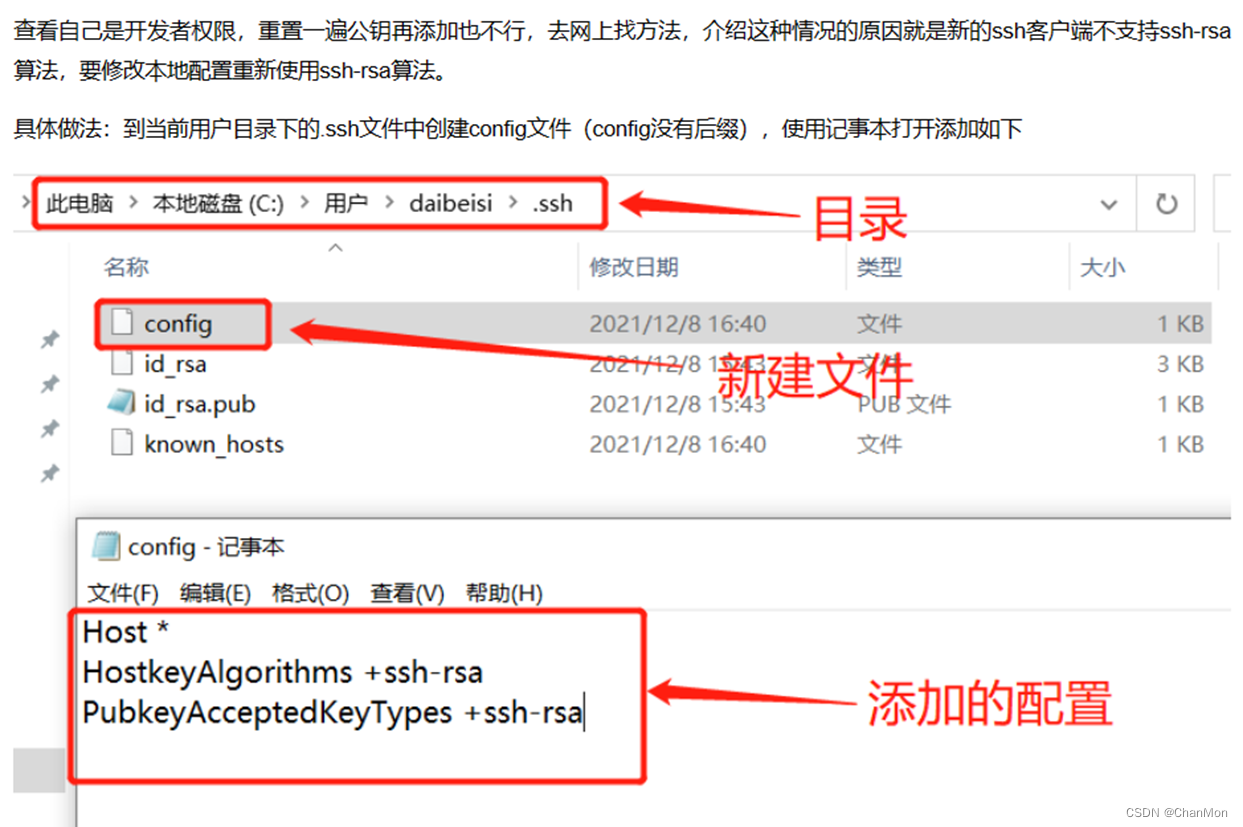
不同设备使用同一个Git账号
想要在公司和家里的电脑上用同一个git账号来pull, push代码 1. 查看原设备的用户名和邮箱 第1种方法, 依次输入 git config user.name git config user.email第2种方法, 输入 cat ~/.gitconfig2. 配置新设备的用户名和邮箱 用户名和邮箱与原设备保持…...

蓝桥杯算法题:区间移位
题目描述 数轴上有n个闭区间:D1,...,Dn。 其中区间Di用一对整数[ai, bi]来描述,满足ai < bi。 已知这些区间的长度之和至少有10000。 所以,通过适当的移动这些区间,你总可以使得他们的“并”覆盖[0, 10000]——也就是说[0, 100…...

提取word文档里面的图片
大家好,我是阿赵。 阿赵我写博客的时候的习惯是,先用word文档写好,然后再把word文档里面的图片另存,最后再在博客里面复制正文和上传图片。 而我写的文章一般配图都比较多,所以经常要做的一个功能就是另存图片…...

MybatisPlus总结
一、MyBatis回顾 (1)什么是MyBatis:MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映…...

使用 mitmproxy 抓包 grpc
昨天在本地执行 grpc 的 quick start(python版本的),我了解 grpc 内部使用的是 HTTP2,所以我就想着抓包来试试,下面就来记录一下这个过程中的探索。 注意:我的电脑上面安装了 Fiddler Classic,…...

【解决Jetson Nano 内存不足问题】纯命令行将 Conda 环境迁移到 SD 卡
前言 Jetson Nano 板载只有 16GB 的存储空间,在安装完 Ubuntu 和 Conda 环境后,剩余空间就捉襟见肘了,无法满足安装 PyTorch 等大型包的需求。此时如果你有一张SD卡,那么可以考虑将 Conda 环境迁移到 SD 卡上。 但网上的教程基本…...
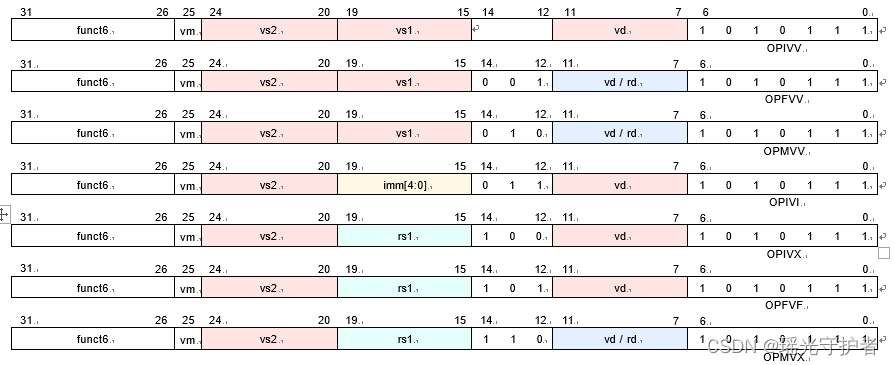
【RISC-V 指令集】RISC-V 向量V扩展指令集介绍(七)- 向量算术指令格式
1. 引言 以下是《riscv-v-spec-1.0.pdf》文档的关键内容: 这是一份关于向量扩展的详细技术文档,内容覆盖了向量指令集的多个关键方面,如向量寄存器状态映射、向量指令格式、向量加载和存储操作、向量内存对齐约束、向量内存一致性模型、向量…...
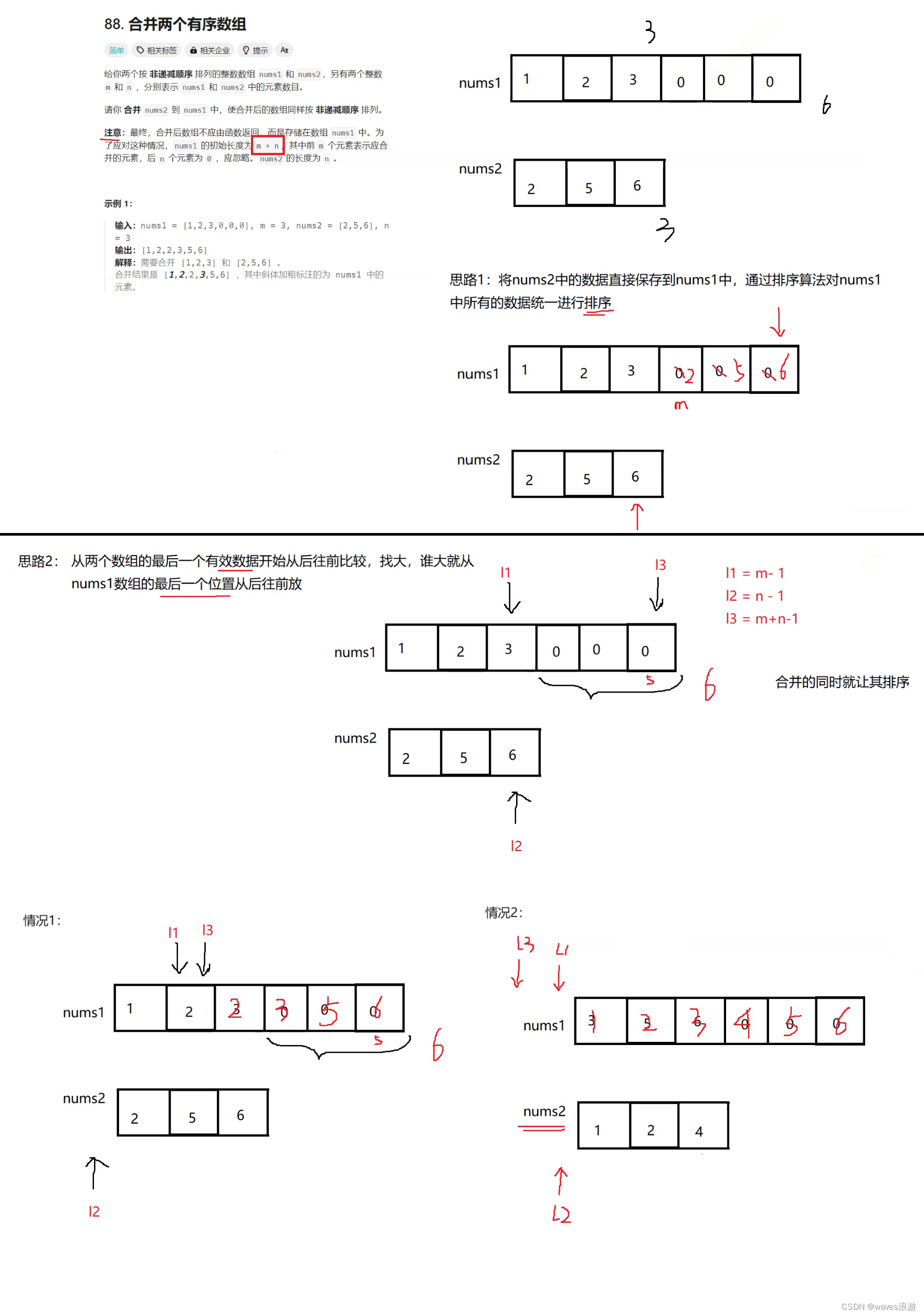
顺序表的应用
文章目录 目录1. 基于动态顺序表实现通讯录项目2.顺序表经典算法2.1 [移除元素](https://leetcode.cn/problems/remove-element/description/)2.2 [合并两个有序数组](https://leetcode.cn/problems/merge-sorted-array/description/) 3. 顺序表的问题及思考 目录 基于动态顺序…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

JS手写代码篇----使用Promise封装AJAX请求
15、使用Promise封装AJAX请求 promise就有reject和resolve了,就不必写成功和失败的回调函数了 const BASEURL ./手写ajax/test.jsonfunction promiseAjax() {return new Promise((resolve, reject) > {const xhr new XMLHttpRequest();xhr.open("get&quo…...

作为测试我们应该关注redis哪些方面
1、功能测试 数据结构操作:验证字符串、列表、哈希、集合和有序的基本操作是否正确 持久化:测试aof和aof持久化机制,确保数据在开启后正确恢复。 事务:检查事务的原子性和回滚机制。 发布订阅:确保消息正确传递。 2、性…...
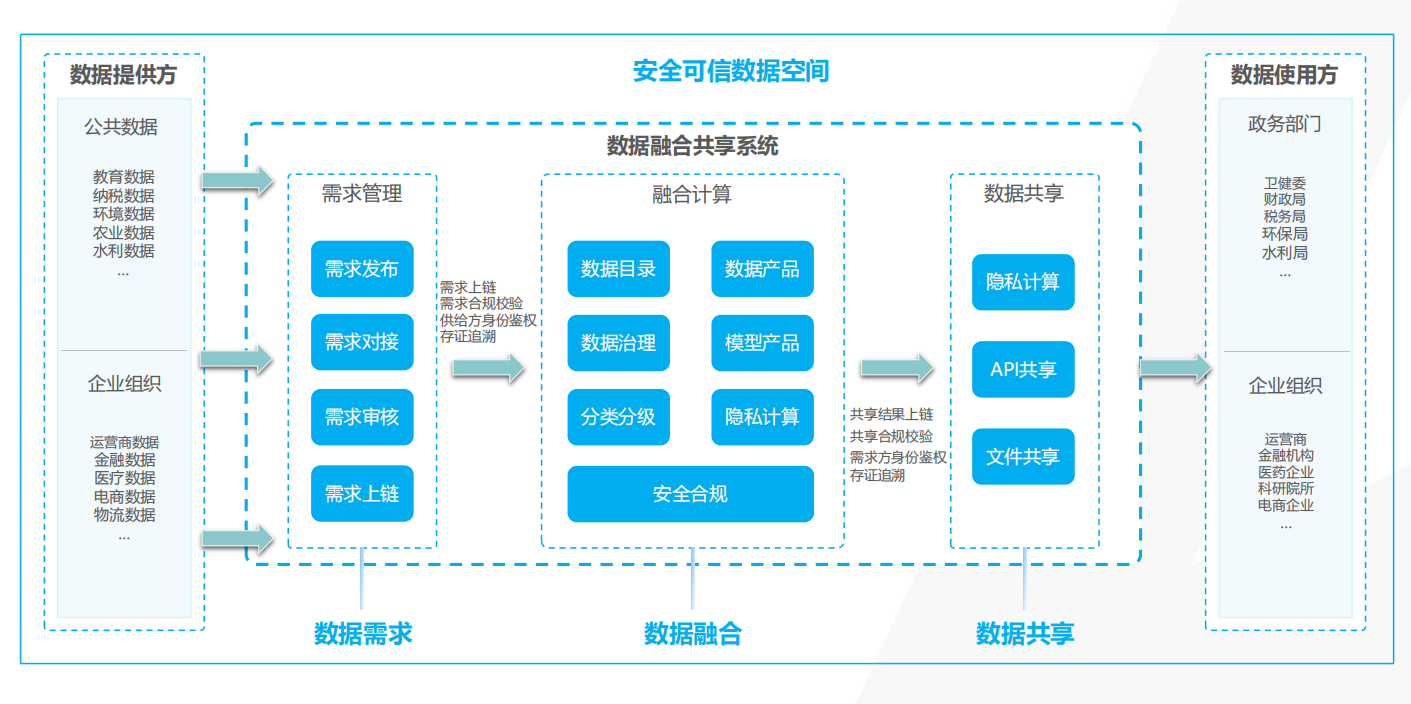
热烈祝贺埃文科技正式加入可信数据空间发展联盟
2025年4月29日,在福州举办的第八届数字中国建设峰会“可信数据空间分论坛”上,可信数据空间发展联盟正式宣告成立。国家数据局党组书记、局长刘烈宏出席并致辞,强调该联盟是推进全国一体化数据市场建设的关键抓手。 郑州埃文科技有限公司&am…...