SV学习笔记(四)
OCP Open Closed Principle 开闭原则
文章目录
- 随机约束和分布
- 为什么需要随机?
- 为什么需要约束?
- 我们需要随机什么?
- 声明随机变量的类
- 什么是约束
- 权重分布
- 集合成员和inside
- 条件约束
- 双向约束
- 约束块控制
- 打开或关闭约束
- 内嵌约束
- 随机函数
- pre_randomize 和 post_randomize
- 系统随机数函数
- 随机化个别变量
- 数组约束
- 约束数组的大小
- 约束数组的元素
- 产生唯一元素值的数组
- 随机化句柄数组
- 随机控制
- 参考资料
随机约束和分布
为什么需要随机?
- 芯片复杂度越来越高,在20年前 定向测试 已经无法满足验证的需求,而 随机测试 的比例逐渐提高。
- 定向测试能找到你认为可能存在的缺陷,而 随机测试可以找到连你都没有想到的缺陷 。
- 随机测试的环境要求比定向测试复杂,它需要激励、参考模型和在线比较。上百次的仿真不再需要人为参与,以此来提高验证效率。
- 随机测试相对于定向测试可以减少相当多的代码量,而产生的激励较定向测试也更多样。
为什么需要约束?
- 如果随机没有约束,产生有效激励的同时,还 会产生大量的无效激励 。
- 通过为随机添加约束,这种 随机自由是一种合法的随机 ,产生有效的测试激励。
- 约束不是一成不变的,为了获取期望的测试范围或期待的数值范围,约束需要“变形”。
- 随机的对象不只是一个数据,而是 有联系的变量集合 。通常这些变量集合会被封装在一个数据类里,同时需要类中声明数据之间的约束关系。因此,约束之后要产生一个随机数据的“求解器”,即在满足数据本身和数据之间约束关系的随机数值解。
- 约束不但 可以指定数据的取值范围 ,还 可以指定各个数值的随机权重分布 。
我们需要随机什么?
- 器件配置: 通过寄存器和系统信号。
- 环境配置: 随机化环境,例如合理的时钟和外部反馈信号。
- 原始输入数据: 例如MCDF数据包的长度、带宽,数据间的顺序。
- 延时: 握手信号之间的时序关系,例如valid和ready,req和ack之间的时序关系。
- 协议异常: 如果反馈信号给出异常,那么设计是否可以保持后续数据处理的稳定性。
声明随机变量的类
- 随机化是为了产生更多可能的驱动,我们倾向于将相关数据有机整理在一个类的同时,也用“rand”关键词来表明它的随机属性。
- “randc”关键词表示周期性随机,即所有可能的值都赋过值后随机才可能重复,也就好比54张扑克牌抽牌游戏,rand代表每抽完一张放回去才可以下次抽牌,randc代表没抽完一张不需要放回就抽取下一张,如果抽完了,那就全部放回再次同样规则抽取。
- rand和randc,只能声明类的变量,硬件域以及软件域的局部变量都不可以。
- 随机属性需要配合SV预定义的随机函数std::randomize()使用。即通过声明rand变量,并且在后期调用randomize()函数才可以随机化变量。
- 约束constraint也同随机变量一起在class中声明。
class packet;rand bit [31:0] src, dst, data[8];randc bit [7:0] kind;constraint c {src >10;src <15;}
endclass//----------------------------------Packet p;
initial beginp = new();//assert语句保证randomize成功,否则会报fatal(如果约束冲突,如src>15 and src<10则会随机失败)assert (p.randomize()) else $fatal(0, "Packet::randomize failed");transmit(p);
end
白话一刻
* `class packet;`:定义一个名为`packet`的类。
* `rand bit [31:0] src, dst, data[8];`:声明了三个随机变量,分别是`src`(源地址)、`dst`(目标地址)和`data`(一个包含8个元素的数组,用于存储数据)。每个变量的位宽度为32位。
* `randc bit [7:0] kind;`:声明了一个随机且唯一的变量`kind`,其位宽度为8位。`randc`意味着每次生成的`kind`值都是唯一的,直到所有可能的值都被使用完。
* `constraint c { ... }`:定义了一个约束`c`,用于限制随机变量的取值范围或关系。这里,它指定了`src`的值必须大于10且小于15。
* `Packet p;`:声明了一个`packet`类型的变量`p`。注意,这里类名`packet`的首字母是大写的,这通常表示它是一个用户定义的类型,而不是SystemVerilog的内建类型。
* `initial begin ... end`:`initial`块在仿真开始时执行一次。 + `p = new();`:创建一个新的`packet`对象,并将其赋值给变量`p`。 + `assert (p.randomize()) else $fatal(0, "Packet::randomize failed");`:调用`p`的`randomize`方法,该方法会根据类的约束随机设置`p`的成员变量的值。`assert`语句检查`randomize`是否成功。如果`randomize`失败(例如,由于约束冲突),则执行`else`部分的`$fatal`语句,导致仿真终止并输出错误消息。 + `transmit(p);`:调用一个名为`transmit`的函数(这个函数在提供的代码片段中未定义),并将随机化的数据包`p`作为参数传递。
总之,这段代码定义了一个数据包类,并展示了如何创建和随机化这个类的实例,以及如何将这个实例传递给一个函数。这对于在仿真中生成随机化的数据包场景非常有用。
什么是约束
- 约束表达式的求解是有SV的约束求解器自动完成的。
- 求解器能够选择满足约束的值,这个值是由SV的PRNG(伪随机数发生器)从一个初始值(seed)产生。只要改变种子的值,就可以改变CRT的行为。
- SV标准定义了表达式的含义以及产生的合法值,但没有规定求解器计算约束的准确顺序。也就是,不同仿真器对于同一个约束类和种子求解出的数值可能不同。
- 什么可以被约束?SV只能随机化二值数据类型,但数据位可以是二值或四值的,所以无法随机出x值和z值,也无法随机出字符串。
class date;rand bit [2:0] month; //note:rand bit [4:0] day;rand int year;constraint c_data {month inside {[1:12]};day inside {[1:31]};year inside {[2010:2030]};}}
endclass
请问:month=10,day=31,year=2020此组随机值可以产生吗?
答案:不能,因为month的声明是3位,所以不可能出现数值10,这也是经常会犯的错误,当你约束数据时,一定要与声明数据的位数相匹配。
class stim;const bit [31:0] CONGEST_ADDR = 42; //声明常数typedef enum {READ, WRITE, CONTROL} stim_e;randc stime_e kind;rand bit [31:0] len, src, dst;bit congestion_test;constraint c_stim {len < 1000;len > 0;if(congestion_test) (dst inside {[CONGEST_ADDR-100:CONGEST_ADDR+100]};src == CONGEST_ADDR;) else (src inside {0, [10:20], [100:200]};)}
endclass
权重分布
- 关键词dist可以在约束中用来产生随机数值的权重分布,这样某些值的选取机会要大于其他值。
- dist操作符带有一个值的列表以及相应的权重,中间用 := 或 😕 分开。值和权重可以是常数,也可以是变量。
- 权重不要百分比表示,权重的和也不必是100。
- := 操作符表示值的范围内的每一个值的权重是相同的, 😕 操作符表示权重要平均分到范围内的每一个值。
rand int src, dst;constraint c_dist {src dist {0:=40, [1:3]:=60;}// src=1, weight=40/220// src=2, weight=60/220// src=3, weight=60/220// src=4, weight=60/220dst dist {0:/40, [1:3]:/60;}// dst=1, weight=40/100// dst=2, weight=20/100// dst=3, weight=20/100// dst=4, weight=20/100
}
这段代码是使用SystemVerilog语言编写的,用于定义随机数生成的约束。SystemVerilog通常用于硬件描述和验证。下面我将详细解释这段代码:systemverilog
rand int src, dst;
这行代码声明了两个随机整数变量:src 和 dst。rand 关键字表示这些变量在仿真期间可以被随机化。systemverilog
constraint c_dist { src dist {0:=40, [1:3]:=60;} dst dist {0:/40, [1:3]:/60;}
}
这部分定义了一个名为 c_dist 的约束,用于控制 src 和 dst 变量的随机化分布。对于 src 变量:systemverilog
src dist {0:=40, [1:3]:=60;}
{0:=40} 表示当 src 变量取值为 0 时,其权重是 40。
{[1:3]:=60} 表示当 src 变量取值为 1、2 或 3 时,其权重是 60。
权重可以理解为生成特定值的概率或可能性。权重越高,生成该值的概率越大。对于 dst 变量:systemverilog
dst dist {0:/40, [1:3]:/60;}
{0:/40} 表示当 dst 变量取值为 0 时,其权重是 40。
{[1:3]:/60} 表示当 dst 变量取值为 1、2 或 3 时,其权重是 60。
注意,src 和 dst 的权重分布使用了不同的语法。src 使用了 := 运算符,而 dst 使用了 :/ 运算符。这实际上是一个语法错误,因为在SystemVerilog中,权重分布应该使用统一的语法。通常,你会看到 := 用于指定绝对权重,而 :/ 用于指定相对权重。但在同一个约束中混合使用这两种语法是不正确的。此外,注释部分解释了每个值的权重分布,但它似乎有些混淆,因为它似乎试图将权重与可能的取值范围相除来得到概率,但这不是正确的解释。实际上,权重是独立的数值,它们会被归一化以表示生成特定值的相对概率。正确的解释应该是:对于 src,总权重是 40 + 60 * 3 = 220。因此,src 取值为 0 的概率是 40/220,取值为 1、2 或 3 的概率是 60/220。
对于 dst,由于代码中的语法错误,我们不能直接计算权重分布。如果假设 dst 也使用绝对权重,并且语法被修正为 dst dist {0:=40, [1:3]:=60};,那么总权重将是 100(因为权重被错误地标记为相对权重)。但实际上,dst 的权重分布应该也使用绝对权重,并且总和应该与 src 一致,以便进行正确的概率计算。
为了修复这个问题,你应该选择使用绝对权重或相对权重,并确保 src 和 dst 的权重分布语法一致。如果你使用绝对权重,代码应该类似于:systemverilog
rand int src, dst; constraint c_dist { src dist {0:=40, [1:3]:=20}; // 总权重为 80 dst dist {0:=40, [1:3]:=20}; // 总权重也为 80,以保持一致性
}
这样,src 和 dst 就会有相同的权重分布,每个值都有相同的概率被选中。
集合成员和inside
- inside是常见的约束运算符,表示变量属于某个值的集合,除非还存在其他约束 ,否则随机变量在集合里取值的概率是相等的(集合里也可以是变量)。
- 可以使用 $ 符指定最大或最小值。
rand int c;
int lo, hi;
constraint c_range{c inside {[lo:hi]};
}//-------------------------------rand bit [6:0] b;
rand bit [5:0] e;
constraint c_range {b inside {[$:4], [20:$]};e inside {[$:4], [20:$]};
}
条件约束
可以通过 -> 或者 if-else来让一个约束表达式在特定条件有效。
constraint c_io {(i_space_mode) -> addr[31] == 1'b1; //i_space_mode!=0
}//--------------------------------------constraint c_io {if(i_space_mode) //i_space_mode!=0addr[31] == 1'b1;else;
}
双向约束
- 约束块不是自上而下的程序代码,它们是声明性代码,是并行的,所有的约束同时有效。
- 约束是双向的,这表示它会同时计算所有的随机变量的约束,增加或删除任何一个变量的约束都会直接或间接的影响所有相关的值的选取。
- 约束块可以声明多个,但是它们仍旧是并行的,如果对同一变量进行约束,取两者约束的交集,也就是两个约束都会生效,与写在一个约束块效果相同。
- 子类会继承父类的约束。
约束块控制
打开或关闭约束
-
一个类可以包含多个约束块,可以把不同约束块用于不同测试。
-
一般情况下,各个约束块之间的约束内容是相互协调不违背的,因此通过随机函数产生的随机数可以找到合适的解。
-
对于其他情况,例如跟胡不同需求,来选择使能哪些约束块,禁止哪些约束块,可以使用内建函数constraint_mode()打开或者关闭约束。
class packet;rand int length;constraint c_short {length inside {[1:32];}}constraint c_long {length inside {[1000:1032];}}
endclass//------------------------packet p;
initial beginp =new ();//create a long packet by disabling c_shortp.c_short.constraint_mode(0);assert(p.randomize());transmit(p);//create a short packet by disabling all constraint and then enable only c_shortp.constraint_mode(0);p.c_short.constraint_mode(1);assert(p.randomize());transmit(p);
end
内嵌约束
- 伴随着复杂的约束,它们之间会相互作用,最终产生难以预测的结果。用来使能和禁止这些约束的代码也会增加测试的复杂性。
- 经常增加或修改类的约束也可能会影响整个团队的工作,这需要考虑类的OCP原则(开放封闭原则,也就是哪些对外部开放,哪些不对外开放)。
- SV允许使用 randomize() with来增加额外的约束,这和在类里增加约束是等效的,但同时要注意类内部约束和外部约束之间应该是协调的,如果出现违背,随机数会求解失败(求解失败,不同的工具报告形式不同,有的是error,有的是warning)。
class packet;rand int length;constraint c_short {soft length inside {[1:32];}}
endclass//------------------------packet p;
initial beginp =new ();assert(p.randomize() with {length inside {[36:46];};length != 40; });transmit(p);
end
上述例子中randomize() with{}约束与c_short产生可冲突,那会不会报错呢?
答案是不会,因为c_short约束前加了soft(软约束)关键字,意义就在于当外部或子类的约束发生冲突时,其优先级降低,不会影响外部或子类的约束。
随机函数
pre_randomize 和 post_randomize
-
有时需要在调用randomize()之前或之后立即执行一些操作,例如在随机前设置一些非随机变量(上下限、条件值、权重),或者在随机化后需要计算数据的误差、分析和记录随机数据等。
-
SV提供两个预定义的void类型函数pre_randomize和post_randomize,用户可以类中定义这两个函数,分别在其中定义随机化前的行为和随机化后的行为。
-
如果某个类中定义了pre_randomize或post_randomize,那么对象在执行randomize()之前或之后会分别执行这两个函数,所以pre_randomize和post_randomize可以看做是randomize函数的回调函数(callback function)。
和之前学的语言类的知识关联起来了,好像spring框架的前置和后置
系统随机数函数
SV提供了一些常用的系统随机函数,这些系统随机函数可以直接调用来返回随机数值:
- $random()平均分布,返回32位有符号随机数。
- $urandom()平均分布,返回32位无符号随机数。
- $urandom_range()在指定范围内的平均分布。
随机化个别变量
- 在调用randomize()时可以传递变量的一个子集,这样只会随机化类里的几个变量。
- 只有参数列表里的变量才会被随机化,其他变量会被当做状态量而不会被随机化。
- 所有的约束仍然保持有效。
- 注意:类里所有没有被指定rand的变量也可以作为randomize()的参数而被随机化。
- 注意:未进行随机化的变量默认初始值为0。
class rising;byte low;rand byte med, hi;constraint up {low<med; med<hi;}
endclass//----------------------------------initial beginrising r;r =new();r.randomize(); //随机化hi和med,不改变lowr.randomize(med); //只随机化medr.randomize(low); //只随机化low
end
数组约束
约束数组的大小
- 在约束随机标量的同时,我们也可以对随机化数组进行约束。
- 多数情况下,数组的大小应该给定范围,防止生成过大体积的数组或空数组。
- 此外,还可以在约束中结合数组的其他方法sum(), product(), and(), or(), 和xor()。
class dyn_size;rand logic [31:0] d[];constraint d_size {d,size() inside {[1:10];};}
endclass
约束数组的元素
- SV可以利用foreach对数组每一个元素进行约束,和直接写出对固定大小数组的每一个元素相比,foreach更简洁。
- 针对动态数组,foreach更适合于对非固定大小数组中每个元素的约束。
class good_sum5;rand uint len[];constraint c_len{foreach (len[i]) len[i] inside {[1:255]};len.sum() < 1024;len.size() inside {[1:8]};}
endclass
产生唯一元素值的数组
如果想要产生一个随机数组,它的每一个元素值都是唯一的,如果使用randc数组,数组中的每一个元素只会独立的随机化,并不会按照我们期望的使得数组中的元素值是唯一的。
解决方案1:
rand bit [7:0] data;
constraint c_data{foreach(data[i])foreach(data[j])if(i != j) data[i] != data[j];
}
解决方案2:
class randc_data;randc bit [7:0] data[64];
endclassclass data_array;bit [7:0] data_array [64];function void pre_randomize();randc_data rcd;rcd = new();foreach (data_array[i]) beginassert(rcd.randomize());data_array[i] = rcd.val;endendfunction
endclass
“randc”关键词表示周期性随机,即所有可能的值都赋过值后随机才可能重复,也就好比54张扑克牌抽牌游戏,rand代表每抽完一张放回去才可以下次抽牌,randc代表没抽完一张不需要放回就抽取下一张,如果抽完了,那就全部放回再次同样规则抽取。
- 特别示例如下,首先“<=”代表小于等于,其次限定da.size为(3/4/5),实际不可能取到5,原因是da.size的约束体现在“da[i] <= da[i+1]”时,约束的是i和i+1为(3/4/5)。
rand bit [7:0] da[];
constraint c_da {da.size() inside {[3:5]};foreach(da[i]) da[i] <= da[i+1];
}
随机化句柄数组
-
随机句柄数组的功能是在调用其所在类的随机函数时,随机函数会随机化数组中的每一个句柄所指向的对象。因此随机句柄数组的声明一定要添加rand来表示其随机化的属性,同时在调用随机函数前要保证句柄数组中的每一个句柄元素都是非悬空的,这需要早随机化之前为每一个元素句柄构建对象。
-
如果要产生多个随机对象,那么你可能需要建立随机句柄数组。和整数数组不同,你需要在随机化前分配所有的元素,因为在随机求解器不会创建对象。使用动态数组可以按照需要分配最大数量的元素,然后再使用约束减小数组的大小。在随机化时,动态句柄数组的大小可以保持不变或减小,但不能增加。
parameter MAX_SIZE = 10;
class RandStuff;bit[1:0] value = 1;
endclassclass RandArray;rand RandStuff array[];constraint c_array {array.size() inside {[1:MAX_SIZE]};}function new();//分配最大容量array = new[MAX_SIZE];foreach (array[i]) array[i] = new();endfunction
endclass//---------------------------RandArray ra;
initial begin// 构造数组和所有对象ra = new();// 随机化数组,但可能会减小数组assert(ra.randomize());foreach(ra.array[i]) $display(ra.array[i].value);
end
- 问题1:执行ra.randomize() with {array.size=2}时,array[0].value 和 array[0].value分别是多少?
答案都是1,首先value没有加rand,所以randomize不会随机value,仍然保持为1。
- 问题2:为什么要分配最大容量?
答案是只有创建对象,并且分配最大容量,才能保证随机化时可能会碰到句柄数组悬空,无指向对象,随机会报错。
- 总结:句柄数组的随机,首先查看句柄指向的对象内有没有rand变量,其次对句柄数组按最大容量进行例化。
随机控制
- 产生事务序列的另一个方法是使用SV的randsequence结构。这对于随机安排组织原子(atomic)测试序列很有帮助。
initial beginfor (int i=0; i<15; i++) beginrandsequence (stream)stream: cfg_read := 1 | //权重不一样io_read := 2 | //权重不一样mem_read := 5; //权重不一样cfg_read: (cfg_read_task;) |(cfg_read_task;) cfg_read;mem_read: (mem_read_task;) |(mem_read_task;) mem_read;io_read: (io_read_task;) |(io_read_task;) io_read;endsequenceend
end
这是一个伪代码或特定于某个工具(如SystemVerilog)的代码片段,用于描述一种随机序列生成机制。我会逐步解释这段代码的含义。
-
initial begin
initial 是 SystemVerilog 中的一个块,它在仿真开始时就执行一次。begin … end 是定义该块范围的关键词。 -
- for (int i=0; i<15; i++) begin … end
这是一个循环结构,它将执行其内部的代码块 15 次。每次迭代,i 的值从 0 增加到 14。
-
- randsequence (stream)
randsequence 是 SystemVerilog 中用于描述随机序列的关键字。它允许用户为某个事件流(在这里是 stream)定义多个可能的随机序列。
-
- stream: cfg_read := 1 | io_read := 2 | mem_read := 5;
这定义了三个事件:cfg_read、io_read 和 mem_read,并分别为它们分配了权重。权重决定了这些事件在随机选择时出现的频率。例如,mem_read 事件出现的频率是 cfg_read 的 5 倍,是 io_read 的 2.5 倍。
-
- cfg_read: (cfg_read_task;) | (cfg_read_task;) cfg_read;
这定义了当 cfg_read 事件被选择时要执行的任务或操作。这里,cfg_read_task 被执行,然后事件流可以选择再次进入 cfg_read 状态(通过后面的 cfg_read)或者退出这个状态(因为有两个选择,但只执行一个)。
-
- mem_read: (mem_read_task;) | (mem_read_task;) mem_read;
与 cfg_read 类似,但这里是为 mem_read 事件定义的行为。
-
- io_read: (io_read_task;) | (io_read_task;) io_read;
同样,这是为 io_read 事件定义的行为。
- 总结:
这段代码描述了一个循环,该循环运行 15 次。在每次迭代中,它都会根据定义的权重随机选择一个事件(cfg_read、io_read 或 mem_read)并执行相应的任务。
每个事件都有自己的任务(cfg_read_task、mem_read_task 和 io_read_task),并且在任务执行完毕后,可以选择再次进入相同的事件或退出。
这种随机性在模拟或测试复杂系统的行为时非常有用,因为它可以模拟多种可能的执行顺序或条件。
- 我们也可以使用randcase来建立随机决策树,但它带来的问题是没有变量可供追踪调试。
initial beginint len;randcase:1: len = $urandom_range(0,2); //10%8: len = $urandom_range(3,5); //80%1: len = $urandom_range(6,7); //10%endcase$display("len=%0d", len);
end
- 总结:
- randsequence和randcase是针对轻量级的随机控制的应用。而我们可以通过定义随机类取代上述随机控制的功能,并且由于类的继承性使得后期维护代码时更加方便。
- randsequence的相关功能我们在协调激励组件和测试用例时,可能会用到。
- randcase则对应着随机约束中的dist权重约束 + if-else条件约束的组合。
参考资料
- Wenhui’s Rotten Pen
- SystemVerilog
- chipverify
相关文章:
)
SV学习笔记(四)
OCP Open Closed Principle 开闭原则 文章目录 随机约束和分布为什么需要随机?为什么需要约束?我们需要随机什么?声明随机变量的类什么是约束权重分布集合成员和inside条件约束双向约束 约束块控制打开或关闭约束内嵌约束 随机函数pre_random…...

Midjourney艺术家分享|By Moebius
Moebius,本名让吉拉德(Jean Giraud),是一位极具影响力的法国漫画家和插画师,以其独特的科幻和幻想风格而闻名于世。他的艺术作品不仅在漫画领域内受到高度评价,也为电影、时尚和广告等多个领域提供了灵感。…...

Vue - 1( 13000 字 Vue 入门级教程)
一:Vue 导语 1.1 什么是 Vue Vue.js(通常称为Vue)是一款流行的开源JavaScript框架,用于构建用户界面。Vue由尤雨溪在2014年开发,是一个轻量级、灵活的框架,被广泛应用于构建单页面应用(SPA&am…...

Vue关键知识点
watch侦听器 Vue.js 中的侦听器(Watcher)是 Vue提供的一种响应式系统的核心机制之一。 监听数据的变化,并在数据发生变化时执行相应的回调函数。 目的:数据变化能够自动更新到视图中 原理: Vue 的侦听器通过观察对象的属性&#…...

Prometheus+grafana环境搭建redis(docker+二进制两种方式安装)(四)
由于所有组件写一篇幅过长,所以每个组件分一篇方便查看,前三篇 Prometheusgrafana环境搭建方法及流程两种方式(docker和源码包)(一)-CSDN博客 Prometheusgrafana环境搭建rabbitmq(docker二进制两种方式安装)(二)-CSDN博客 Prometheusgrafana环境搭建m…...
)
宝塔面板安装nginx流媒体服务器(http-flv)
前文介绍了使用nginx搭建流媒体服务器,实现了hls切片方式播放,不过延迟较长。本文采用nginx搭建支持http-flv方式的流媒体服务器,用以测试期性能。 目录 一、服务器操作系统安装 二、在控制台安装宝塔面板...
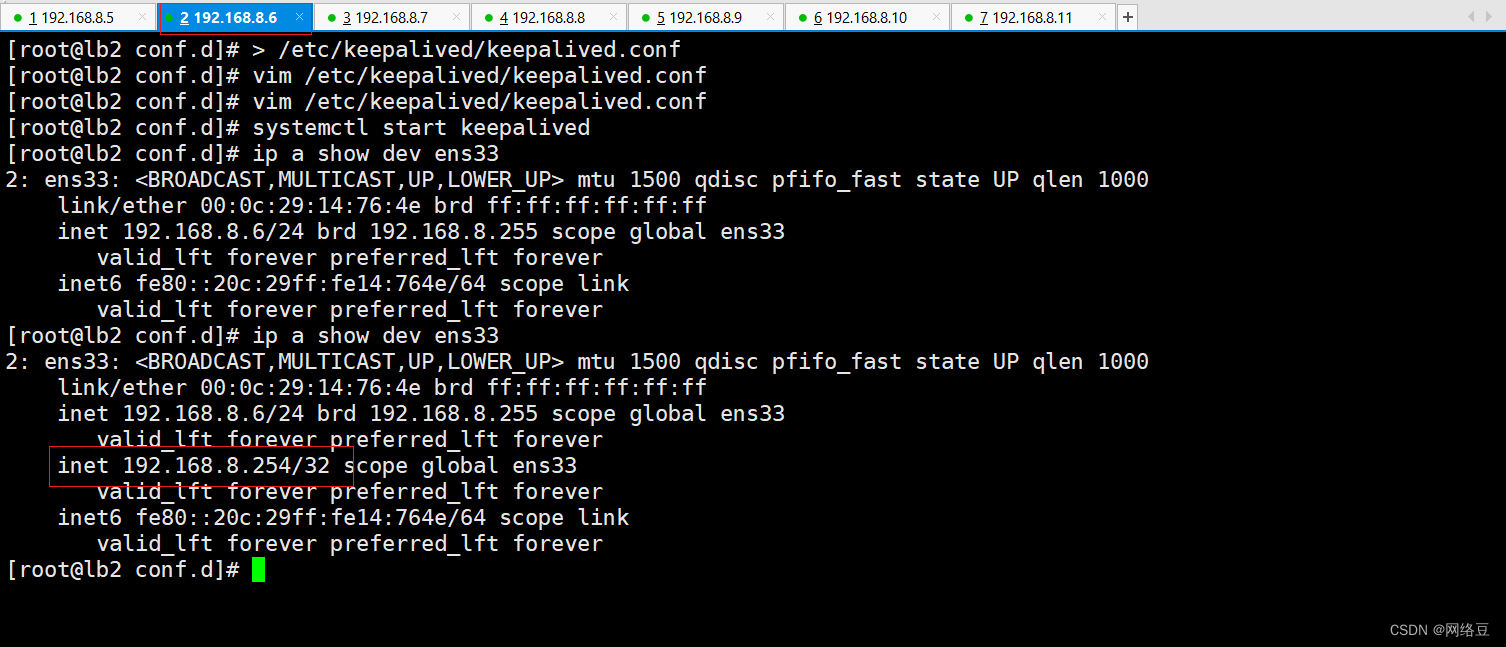
LNMP环境:揭秘负载均衡与高可用性设计
lb1: 192.168.8.5 lb2: 192.168.8.6 web1:192.168.8.7 web2:192.168.8.8 php-fpm: 192.168.8.9 mysql: 192.168.8.10 nfs:192.168.8.11 分别插入镜像 8.5-8.8 分别安装nginx,并设置启动 8.9 安装php 8.10 安装mysql 先配置一台web服务器然后同步 设置网站根目录 cp -…...
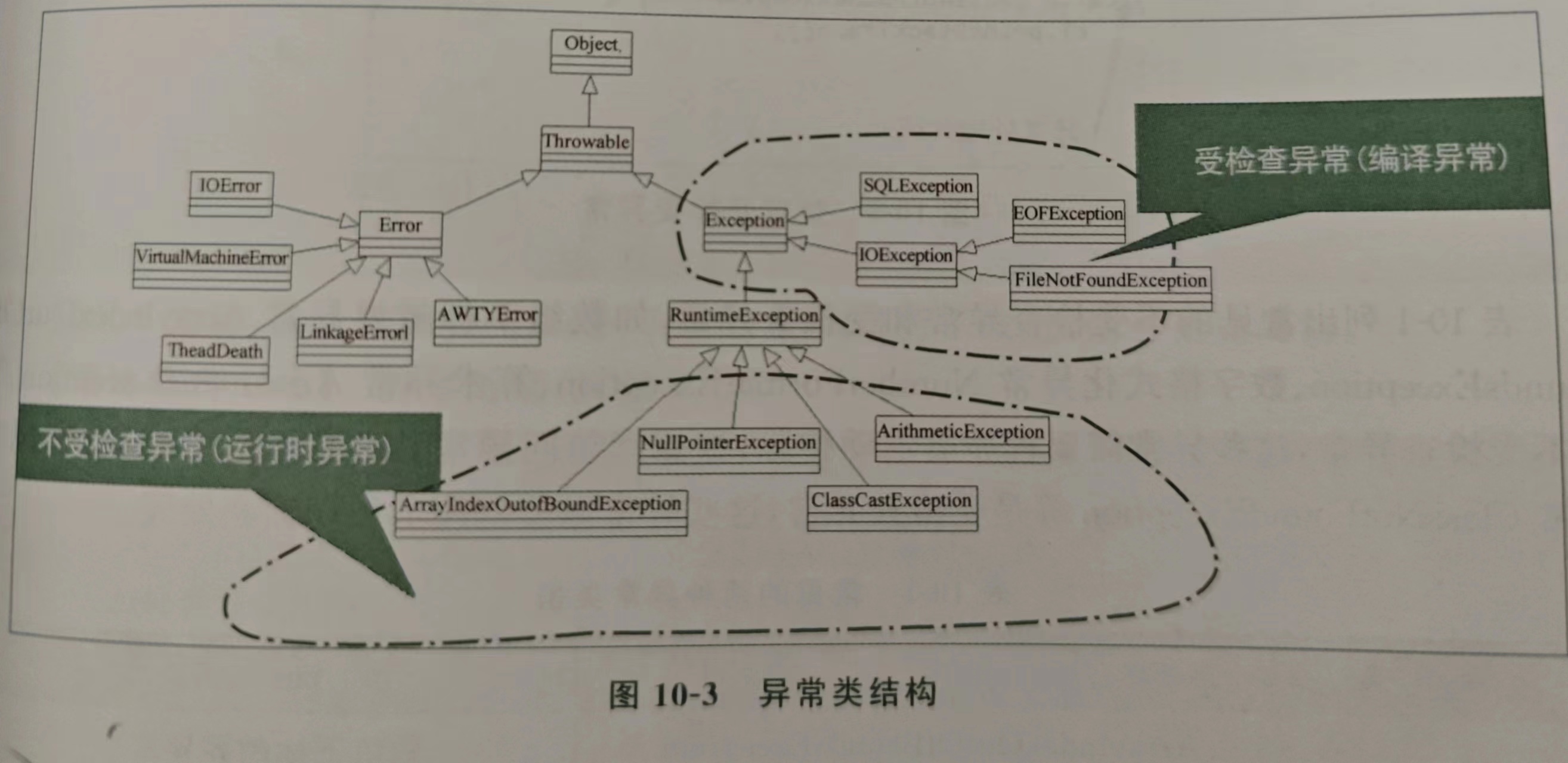
深入理解Java异常处理机制(day20)
异常处理 异常处理是程序运行过程产生的异常情况进行恰当的处理技术 在计算机编程里面,异常的情况比所我们所想的异常情况还要多。 Java里面有两种异常处理方式; 1.利用trycatchfinaly语句处理异常,优点是分开了处理异常代码和程序正常代码…...
Docker实战教程 第1章 Linux快速入门
2-1 Linux介绍 为什么要学Linux 三个不得不学习 课程需要:Docker开发最好在Linux环境下。 开发需要:作为一个后端程序员,是必须要掌握Linux的,这是找工作的基础门槛。 运维需要:在服务器端,主流的大型服…...

java数据结构与算法刷题-----LeetCode172. 阶乘后的零
java数据结构与算法刷题目录(剑指Offer、LeetCode、ACM)-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/123063846 文章目录 数学:阶乘的10因子个数数学优化:思路转变为求5的倍数…...
掌握数据相关性新利器:基于R、Python的Copula变量相关性分析及AI大模型应用探索
在工程、水文和金融等各学科的研究中,总是会遇到很多变量,研究这些相互纠缠的变量间的相关关系是各学科的研究的重点。虽然皮尔逊相关、秩相关等相关系数提供了变量间相关关系的粗略结果,但这些系数都存在着无法克服的困难。例如,…...
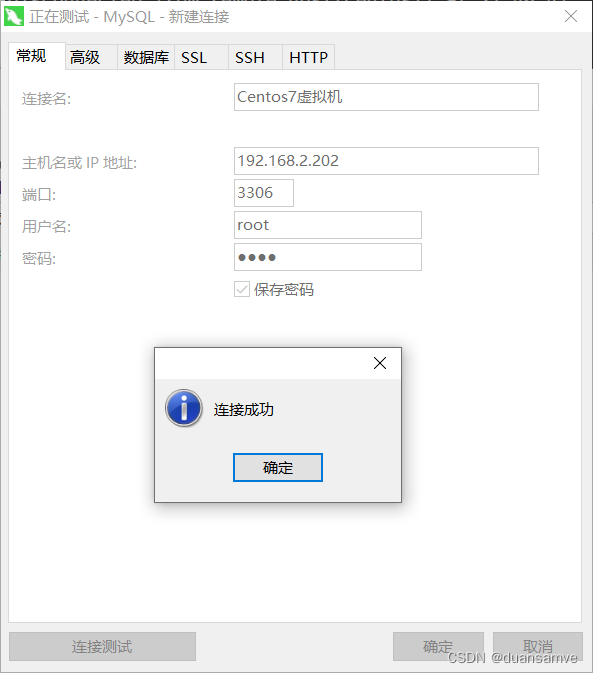
Centos7环境下安装MySQL8详细教程
1、下载mysql安装包 下载哪个版本,首先需要确定一下系统的glibc版本,使用如下命令: rpm -qa | grep glibc 2、检查是否安装过mysql ps:因为以前用yum安装过,所以先用yum卸载。如果不是此方式或者没安装过则跳过…...

趣学前端 | 综合一波CSS选择器的用法
背景 最近睡前习惯翻会书,重温了《HTML5与CSS 3权威指南》。这本书,分上下两册,之前读完了上册,下册基本没翻过。为了对得起花过的每一分钱,决定拾起来近期读一读。 CSS 选择器 在CSS3中,提倡使用选择器…...

数据库 06-04 恢复
01 一.事务故障 二.系统 三.磁盘 02. 重点是稳定存储器 组成...

基于MPPT的风力机发电系统simulink建模与仿真
目录 1.课题概述 2.系统仿真结果 3.核心程序与模型 4.系统原理简介 4.1风能与风力发电机模型 4.2风力机功率特性与最大功率点 4.3 MPPT 5.完整工程文件 1.课题概述 基于MPPT的风力机发电系统simulink建模与仿真。MPPT使用S函数编写实现。基于最大功率点跟踪(…...

GD32F30x IO 复用问题
1.PE9 复用PWM 引脚 需要使能 gpio_pin_remap_config(GPIO_TIMER0_FULL_REMAP,ENABLE);...
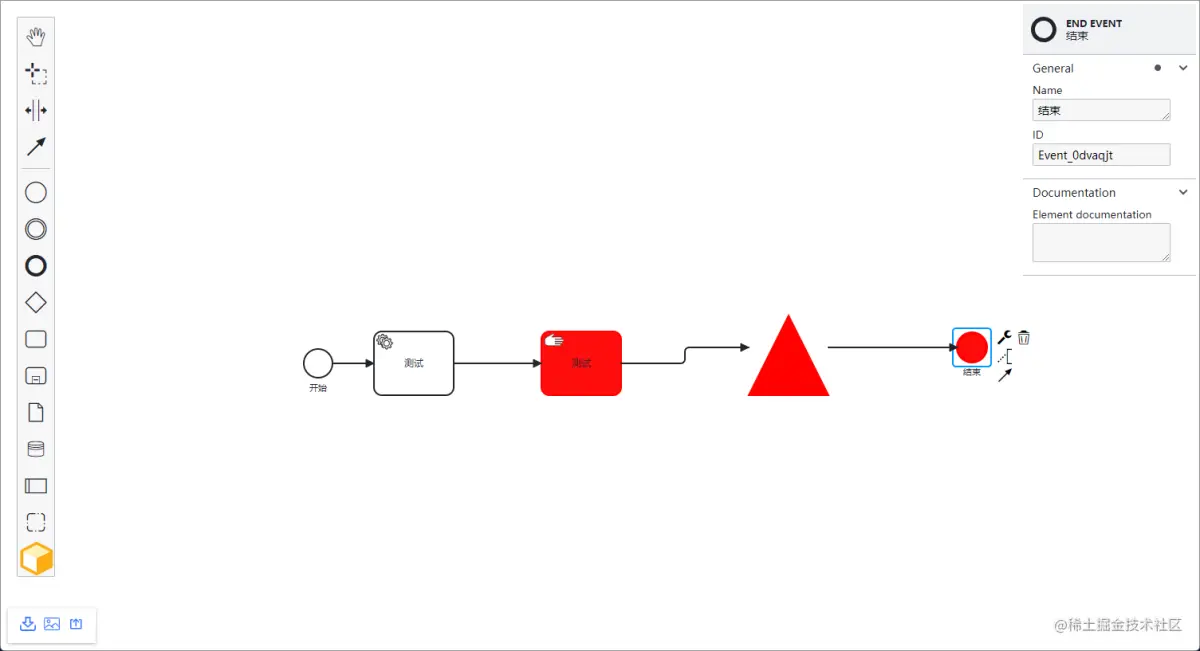
BPMNJS 在原生HTML中的引入与使用
BPMNJS 在HTML中的引入与使用 在网上看到的大多是基于vue使用BPMN的示例或者教程,竟然没有在HTML使用的示例,有也是很简单的介绍核心库的引入和使用,并没有涉及到扩展库。于是简单看了下,真的是一波三折,坎坎坷坷。不…...

HarmonyOS 应用开发之通过数据管理服务实现数据共享静默访问
场景介绍 典型跨应用访问数据的用户场景下,数据提供方会存在多次被拉起的情况。 为了降低数据提供方拉起次数,提高访问速度,OpenHarmony提供了一种不拉起数据提供方直接访问数据库的方式,即静默数据访问。 静默数据访问通过数据…...

ubuntu强密码支持
接到新需求,欧盟需要ubuntu使用强密码,网络上找到一个包可以增加ubuntu密码增强机制,以下是调试过程。 sudo apt-get install libpam-pwquality 然后,编辑位于/etc/pam.d/目录中的common-password文件: sudo vim /et…...

C语言中文分词 Friso的使用教程
Friso是使用C语言开发的一款高性能中文分词器,使用流行的mmseg算法实现。完全基于模块化设计和实现,可以很方便的植入到其他程序中,例如:MySQL,PHP等。同时支持对UTF-8/GBK编码的切分。 官方地址:https://…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...

探索Selenium:自动化测试的神奇钥匙
目录 一、Selenium 是什么1.1 定义与概念1.2 发展历程1.3 功能概述 二、Selenium 工作原理剖析2.1 架构组成2.2 工作流程2.3 通信机制 三、Selenium 的优势3.1 跨浏览器与平台支持3.2 丰富的语言支持3.3 强大的社区支持 四、Selenium 的应用场景4.1 Web 应用自动化测试4.2 数据…...

Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement
Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement 1. LAB环境2. L2公告策略2.1 部署Death Star2.2 访问服务2.3 部署L2公告策略2.4 服务宣告 3. 可视化 ARP 流量3.1 部署新服务3.2 准备可视化3.3 再次请求 4. 自动IPAM4.1 IPAM Pool4.2 …...

全面解析数据库:从基础概念到前沿应用
在数字化时代,数据已成为企业和社会发展的核心资产,而数据库作为存储、管理和处理数据的关键工具,在各个领域发挥着举足轻重的作用。从电商平台的商品信息管理,到社交网络的用户数据存储,再到金融行业的交易记录处理&a…...

深入理解 React 样式方案
React 的样式方案较多,在应用开发初期,开发者需要根据项目业务具体情况选择对应样式方案。React 样式方案主要有: 1. 内联样式 2. module css 3. css in js 4. tailwind css 这些方案中,均有各自的优势和缺点。 1. 方案优劣势 1. 内联样式: 简单直观,适合动态样式和…...