ES入门十四:分词器
我们存储到ES中数据大致分为以下两种:
- 全文本,例如文章内容、通知内容
- 精确值,如实体Id
在对这两类值进行查询的时候,精确值类型会比较它们的二进制,其结果只有相等或者不想等。而对全文本类型进行等值比较是不太实现的,一般我们只会比较两个文本是否相似。根据上一讲的内容我们知道,要比较两个文本类型是否相似,使用相关性评分来评估的。而要得到相关性评分,我们就需要对全文本进行分词处理,然后得到统计数据才能进行评估
在es中,负责处理文本分词的是分词器,本文我们就来学习ES中分词器的组成和部分分词器的特性。
分词(Analysis)与分词器
分词是将全文本转换为一系列单词的过程,这些单词称为term或者token,而这个过程称为分词。
分词是通过**分词器(Analyzer)来实现的,**比如用于中文分词的IK分词器等。当然你也可以实现自己的分词器,例如可以简单将全文本以空格来实现分词。ES内置来一些常用的分词器,如果不能满足你的需求,你可以安装第三方的分词器或者定制化你自己的分词器。
**除了在写入的时候对数据进行分词,在对全文本进行查询的时候也需要使用相同的分词器对检索内存进行分析。例如,**查询Java Book的时候会分为java 和book两个单词,如下如所示: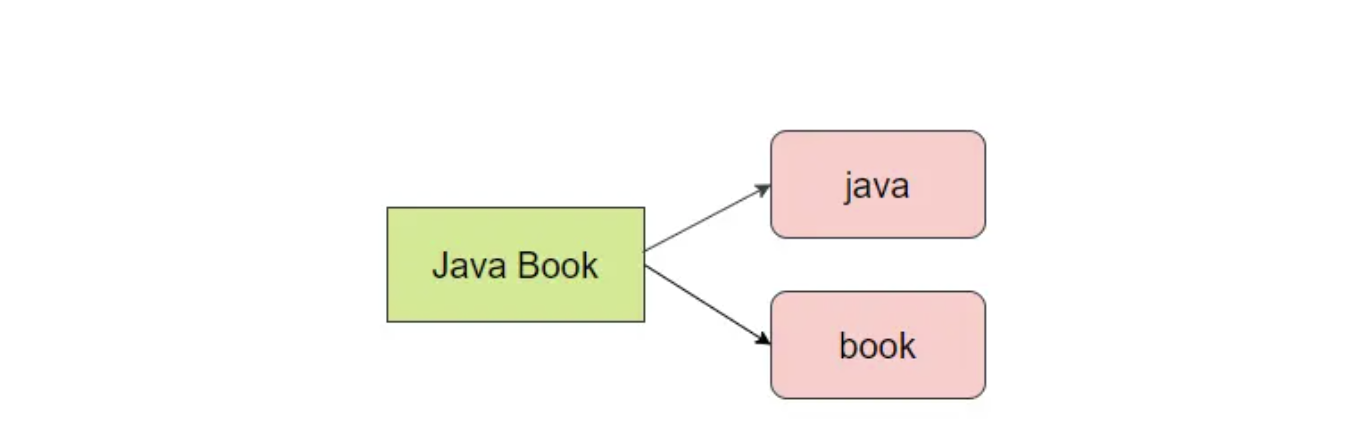
分词器的组成
分词器主要由 3 部分组成。
- Character Filter:注意对原文本进行格式处理,比如去除html标签
- Tokenizer:按照指定规则对文本进行切分,比如按空格来切分单词,同时页负责标记出每个单词的顺序、位置以及单词在原文本中开始和结束的偏移量
- Token Filter:对切分后的单词进行处理,如转换为小写、删除停顿词、增加同义词、词干化等
如下图就是分词器工作的流程,需要进行分词的文本依次通过Character Filter、Tokenizer、Token Filter,最后得出切分后的词项: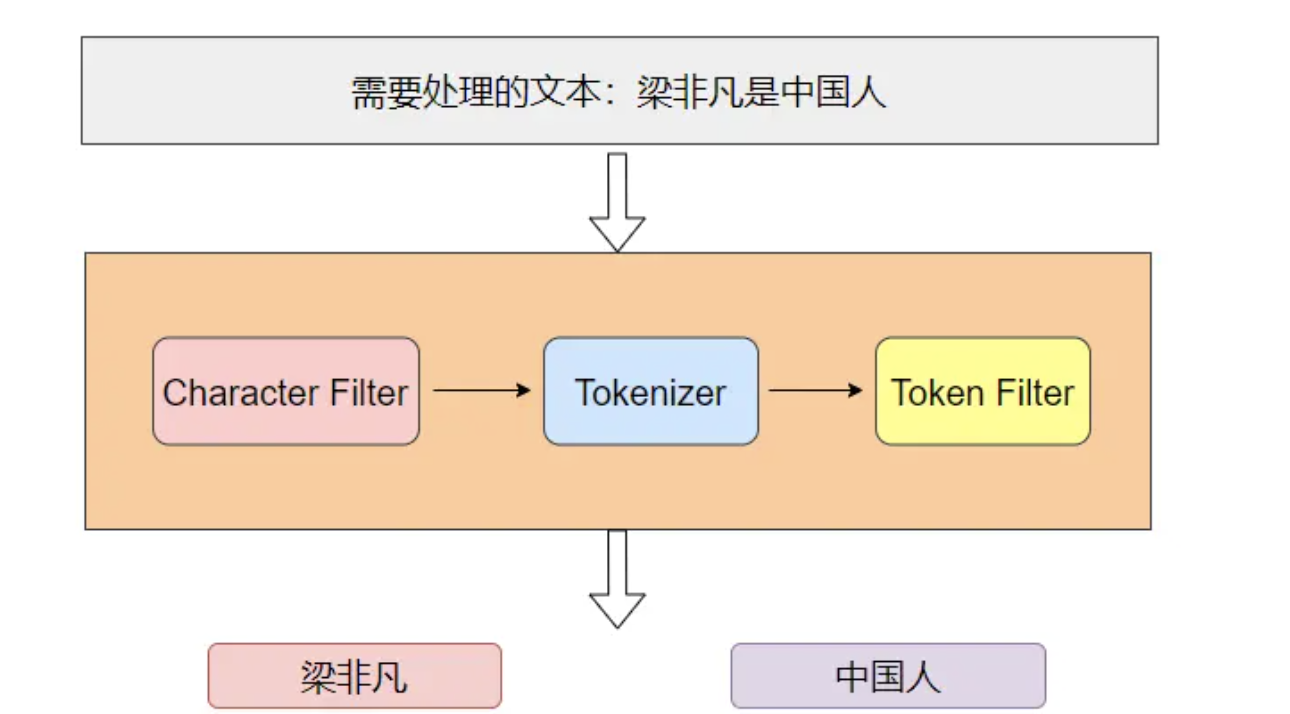
ES内置的分词器
为了方便用户使用,Es为用户提供了多个内置的分词器,常见的有以下8种。
- Standard Analyzer:这个是默认的分词器,使用Unicode文本分割算法,将文本按单词切分并且转换为小写
- Simple Analyzer:按照非字母切分并且进行小写处理
- Stop Analyzer:与 Simple Analyzer 类似,但增加了停用词过滤(如 a、an、and、are、as、at、be、but 等)。
- Whitespace Analyzer:使用空格对文本进行切分,并不进行小写转换
- Pattern n Analyzer;使用正则表达式切分,默认使用 \W+ (非字符分隔)。支持小写转换和停用词删除。
- Keyword Analyzer:不进行分词
- Language Analyzer:提供了多种常见语言的分词器。如 Irish、Italian、Latvian 等。
- Customer Analyzer:自定义分词器
下面我们通过讲解Standard Analyzer来进一步熟悉分词器的工作流程,但在这之前我要先介绍一个Es提供的API:_analyze。
_analyze Api是一个非常有用的工具,它可以帮助我们查看分词器是如何工作的。_analyze API 提供了 3 种方式来查看分词器是如何工作的。
- 使用 _analyze API 时可以直接指定 Analyzer 来进行测试,示例如下:
GET _analyze
{"analyzer": "standard","text": "Your cluster could be accessible to anyone."
}# 结果
{"tokens": [{"token": "your","start_offset": 0,"end_offset": 4,"type": "<ALPHANUM>","position": 0},{"token": "cluster","start_offset": 5,"end_offset": 12,"type": "<ALPHANUM>","position": 1}......]
}
如上示例,在这段代码中我们可以看到它将text的内容用standard分词器进行分词,text的内容按单词进行了切分并且your转为了小写。
- 对指定的索引进行测试,示例如下:
# 创建和设置索引
PUT my-index
{"mappings": {"properties": {"my_text": {"type": "text","analyzer": "standard" # my_text字段使用了standard分词器}}}
}GET my-index/_analyze
{"field": "my_text", # 直接使用my_text字段已经设置的分词器"text": "Is this déjà vu?"
}# 结果:
{"tokens": [{"token": "is","start_offset": 0,"end_offset": 2,"type": "<ALPHANUM>","position": 0},......]
}- 组合 tokenizer、filters、character filters 进行测试,示例如下:
GET _analyze
{"tokenizer": "standard", # 指定一个tokenizer"filter": [ "lowercase", "asciifolding" ], # 可以组合多个token filter# "char_filter":"html_strip", 可以指定零个Character Filter"text": "java app"
}从上面的示例可以看到,tokenizer使用了standard而token filter使用了lowercase和ascillfolding来对text的内容进行切分。用户可以组合一个tokenizer、零个或者多个token filter、零个或者多个character filter。
Standard Analyzer
Standard Analyzer 是 ES 默认的分词器,它会将输入的内容按词切分,并且将切分后的词进行小写转换,默认情况下停用词(Stop Word)过滤功能是关闭的。
可以试一下下面这个例子:
GET _analyze
{"analyzer": "standard", # 设定分词器为 standard"text": "Your cluster could be accessible to anyone."
}# 结果
{"tokens": [{"token": "your","start_offset": 0,"end_offset": 4,"type": "<ALPHANUM>","position": 0},{"token": "cluster","start_offset": 5,"end_offset": 12,"type": "<ALPHANUM>","position": 1} ......]
}如上示例,从其结果中可以看出,单词You做了小写转换,停用词be没有被去掉,并且返回结果里记录了这个单词在原文本中的开始偏移量、结束偏移以及这个词出现的位置
自定义分词器
除了使用内置的分词器外,我们还可以通过组合 Tokenizer、Filters、Character Filters 来自定义分词器。其用例如下:
PUT my-index-001
{"settings": {"analysis": {"char_filter": { # 自定义char_filter"and_char_filter": {"type": "mapping","mappings": ["& => and"] # 将 '&' 转换为 'and'}},"filter": { # 自定义 filter"an_stop_filter": {"type": "stop","stopwords": ["an"] # 设置 "an" 为停用词}},"analyzer": { # 自定义分词器为 custom_analyzer"custom_analyzer": {"type": "custom",# 使用内置的html标签过滤和自定义的my_char_filter"char_filter": ["html_strip", "and_char_filter"],"tokenizer": "standard",# 使用内置的lowercase filter和自定义的my_filter"filter": ["lowercase", "an_stop_filter"]}}}}
}GET my-index-001/_analyze
{"analyzer": "custom_analyzer","text": "Tom & Gogo bought an orange <span> at an orange shop"
}你可以在 Kibana 中运行上述的语句并且查看结果是否符合预期,Tom 和 Gogo 将会变成小写,而 & 会转为 and,an 这个停用词和这个 html 标签将会被处理掉,但 at 不会。
ES 的内置分词器可以很方便地处理英文字符,但对于中文却并不那么好使,一般我们需要依赖第三方的分词器插件才能满足日常需求。
中文分词器
中文分词不像英文分词那样可以简单地以空格来分隔,而是要分成有含义的词汇,但相同的词汇在不同的语境下有不同的含义。社区中有很多优秀的分词器,这里列出几个日常用得比较多的。
- analysis-icu是官方的插件,其将Lucene ICU module融入到es中。使用ICU函数库来处理提供处理Unicode的工具
- IK:支持自定义词典和词典热更新
- THULAC:其安装和使用官方文档中有详细的说明,本文就不再赘述了
analysis-icu分词器
analysis-icu 是官方的插件,项目在这里。ICU 的安装如下:
# 进入脚本目录,参见ES 简介和安装一节我们把es安装在ES/es_node1# 有3个节点的需要分别进入3个节点目录进行安装 !!!!!cd ES/es_node1bin/elasticsearch-plugin install https://artifacts.elastic.co/downloads/elasticsearch-plugins/analysis-icu/analysis-icu-7.13.0.zip# 如果安装出错,并且提示你没有权限,请加上sudo:sudo bin/elasticsearch-plugin install https://artifacts.elastic.co/downloads/elasticsearch-plugins/analysis-icu/analysis-icu-7.13.0.zipICU 的用例如下:
POST _analyze
{ "analyzer": "icu_analyzer","text": "Linus 在90年代开发出了linux操作系统"
}# 结果
{"tokens" : [......{"token" : "开发","start_offset" : 11,"end_offset" : 13,"type" : "<IDEOGRAPHIC>","position" : 4},{"token" : "出了","start_offset" : 13,"end_offset" : 15,"type" : "<IDEOGRAPHIC>","position" : 5},{"token" : "linux","start_offset" : 15,"end_offset" : 20,"type" : "<ALPHANUM>","position" : 6}......]
}通过在 Kibana 上运行上述查询语句,可以看到结果与 Standard Analyzer 是不一样的,同样你可以将得出的结果和下面的 IK 分词器做一下对比,看看哪款分词器更适合你的业务。更详细的 ICU 使用文档可以查看:ICU 文档
IK分词器
IK 的算法是基于词典的,其支持自定义词典和词典热更新。下面来安装 IK 分词器插件:
# 有3个节点的需要分别进入3个节点目录进行安装 !!!!!cd ES/es_node1# 如果因为没有权限而安装失败的话,使用sudo ./bin/elasticsearch-plugin install url 来安装./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.13.0/elasticsearch-analysis-ik-7.13.0.zip在每个节点执行完上述指令后,需要重启服务才能使插件生效。重启后,可以在 Kibana 中测试一下 IK 中文分词器的效果了。
POST _analyze
{ "analyzer": "ik_max_word","text": "Linus 在90年代开发出了linux操作系统"
}POST _analyze
{ "analyzer": "ik_smart","text": "Linus 在90年代开发出了linux操作系统"
}如上示例可以看到,IK 有两种模式:ik_max_word 和 ik_smart,它们的区别可总结为如下(以下是 IK 项目的原文)。
- ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、人、民、共和国、共和、和、国国、国歌”,会穷尽各种可能的组合,适合 Term Query。
- ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国、国歌”,适合 Phrase 查询。
关于 IK 分词器插件更详细的使用信息,你可以参考 IK 项目的文档。
相关文章:
ES入门十四:分词器
我们存储到ES中数据大致分为以下两种: 全文本,例如文章内容、通知内容精确值,如实体Id 在对这两类值进行查询的时候,精确值类型会比较它们的二进制,其结果只有相等或者不想等。而对全文本类型进行等值比较是不太实现…...

汇编——SSE打包整数
SSE也可以进行整数向量的加法,示例如下: ;sse_integer.asm extern printfsection .datadummy db 13 align 16pdivector1 dd 1dd 2dd 3dd 4pdivector2 dd 5dd 6dd 7dd 8fmt1 db "Packed Integer Vector 1: %d, %d, %d, %d",…...
)
动态规划(2)
动态规划(2) 文章目录 动态规划(2)1、聪明的寻宝人2、基因检测3、药剂稀释4、找相似串 1、聪明的寻宝人 #include <iostream> using namespace std; void MaxValue(int values[], int weights[], int n, int m) {int dp[21…...

JetBrains IDE 2024.1 发布 - 开发者工具
JetBrains IDE 2024.1 (macOS, Linux, Windows) - 开发者工具 CLion, DataGrip, DataSpell, Fleet, GoLand, IntelliJ IDEA, PhpStorm, PyCharm, Rider, RubyMine, WebStorm 请访问原文链接:JetBrains IDE 2024.1 (macOS, Linux, Windows) - 开发者工具࿰…...

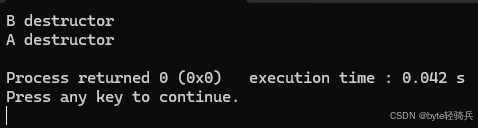
C++ 构造函数中的参数顺序
描述: 未初始化的参数必须在初始化参数之前 正确 ✓ 写法: mother(const char* food, const char* lastName"无姓", const char* firstName "无名" ); 错误❌写法: mother(const char* lastName"无姓", …...

Git Flow困境逃脱指南
本来来自极狐GitLab 资源中心,原文链接:https://resources.gitlab.cn/articles/020183ba-cfc0-4917-b901-248acdcfc92f。 GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab ÿ…...

MySQL的sql_mode模式简介
前言 今天同事使用数据库时报错,排查问题时发现配置文件里的sql_mode配置被人注释了,所以通过查询资料对这个配置进行了下了解。 介绍 mysql为了支持在不同的环境下运行,允许我们给它设置不同的运行模式(sql_mode)。 不同的运行模式&#…...

性能优化-如何爽玩多线程来开发
前言 多线程大家肯定都不陌生,理论滚瓜烂熟,八股天花乱坠,但是大家有多少在代码中实践过呢?很多人在实际开发中可能就用用Async,new Thread()。线程池也很少有人会自己去建,默认的随便用用。在工作中大家对…...
非关系型数据库-----------Redis的主从复制、哨兵模式
目录 一、redis群集有三种模式 1.1主从复制、哨兵、集群的区别 1.1.1主从复制 1.1.2哨兵 1.1.3集群 二、主从复制 2.1主从复制概述 2.2主从复制的作用 ①数据冗余 ②故障恢复 ③负载均衡 ④高可用基石 2.3主从复制流程 2.4搭建redis主从复制 2.4.1环境准备 2.4…...

使用docx4j转换word为pdf处理中文乱码问题
word转pdf 实现方法 mavendocx4j版本自己酌情升级 实现方法 import org.docx4j.Docx4J; import org.docx4j.fonts.IdentityPlusMapper; import org.docx4j.fonts.Mapper; import org.docx4j.fonts.PhysicalFonts; import org.docx4j.openpackaging.packages.WordprocessingMLP…...

【引子】C++从介绍到HelloWorld
C从介绍到HelloWorld 一、C的介绍1. 简介2. 应用场景3. C的标准4. C的运行过程 二、Visual Studio的安装1. 什么是Visual Studio2. Visual Studio的安装 三、完成HelloWorld1.…...
Django检测到会话cookie中缺少HttpOnly属性手工复现
一、漏洞复现 会话cookie中缺少HttpOnly属性会导致攻击者可以通过程序(JS脚本等)获取到用户的cookie信息,造成用户cookie信息泄露,增加攻击者的跨站脚本攻击威胁。 第一步:复制URL:http://192.168.43.219在浏览器打开,…...

2024数字城市建设博览会:一站式平台,满足多元需求
2024数字城市建设博览会:引领未来城市发展的风向标 2024年,一场前所未有的盛会——数字城市建设博览会暨交流大会,将在雄安这座未来之城拉开帷幕。本次大会不仅是数字经济全产业链的精英集结,更是一场汇聚了众多优质项目和丰富客…...
iOS 17.5系统或可识别并禁用未知跟踪器,苹果Find My技术应用越来越合理
苹果公司去年与谷歌合作,宣布将制定新的行业标准来解决人们日益关注的跟踪器隐私问题。苹果计划在即将发布的 iOS 17.5 系统中加入这项提升用户隐私保护的新功能。 科技网站 9to5Mac 在苹果发布的 iOS 17.5 开发者测试版内部代码中发现了这项反跟踪功能的蛛丝马迹…...

关于搭建elk日志平台
我这边是使用docker compose进行的搭建 所以在使用的时候 需要自行提前安装docker以及dockercompose环境 或者从官网下载对应安装包也可以 具体文章看下一章节:【ELK】搭建elk日志平台(使用docker-compose),并接入springboot项目...
【全套源码教程】基于SpringBoot+MyBatis+Vue的流浪动物救助网站的设计与实现
目录 前言 需求分析 可行性分析 技术实现 后端框架:Spring Boot 持久层框架:MyBatis 前端框架:Vue.js 数据库:MySQL 功能介绍 前台界面功能介绍 动物领养及捐赠 宠物论坛 公告信息 商品页面 寻宠服务 个人中心 购…...
Word wrap在计算机代表的含义(自动换行)
“Word wrap”是一个计算机术语,用于描述文本处理器在内容超过容器边界时自动将超出部分转移到下一行的功能。在多种编程语言和文本编辑工具中,都有实现这一功能的函数或选项。 在编程中,例如某些编程语言中的wordwrap函数,能够按…...

室友打团太吵?一条命令让它卡死
「作者主页」:士别三日wyx 「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者 「推荐专栏」:更多干货,请关注专栏《网络安全自学教程》 SYN Flood 1、hping3实现SYN Flood1.1、主机探测1.2、扫描端…...

RabbitMQ3.13.x之八_RabbitMQ中数据文件和目录位置
RabbitMQ3.13.x之_RabbitMQ中数据文件和目录位置 文章目录 RabbitMQ3.13.x之_RabbitMQ中数据文件和目录位置1. 概述2. 覆盖位置1. 路径和目录名称限制2.所需的文件和目录权限 3. 环境变量4. Linux、macOS、BSD上的默认位置5. Windows上的默认位置6. 通用二进制构建默认值 1. 概…...
仿抖音短视频直播带货刷一刷商城社交电商源码系统小程序APP开发
系统功能介绍 一、短视频与社交功能 短视频浏览与互动 用户可以浏览仿抖音风格的短视频,包括评论、点赞、进入视频发布者的主页,以及加关注等功能。系统会显示用户关注的好友列表,方便用户快速查看好友发布的视频。用户还可以浏览同城视频&…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...
【C++特殊工具与技术】优化内存分配(一):C++中的内存分配
目录 一、C 内存的基本概念 1.1 内存的物理与逻辑结构 1.2 C 程序的内存区域划分 二、栈内存分配 2.1 栈内存的特点 2.2 栈内存分配示例 三、堆内存分配 3.1 new和delete操作符 4.2 内存泄漏与悬空指针问题 4.3 new和delete的重载 四、智能指针…...

车载诊断架构 --- ZEVonUDS(J1979-3)简介第一篇
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...
EasyRTC音视频实时通话功能在WebRTC与智能硬件整合中的应用与优势
一、WebRTC与智能硬件整合趋势 随着物联网和实时通信需求的爆发式增长,WebRTC作为开源实时通信技术,为浏览器与移动应用提供免插件的音视频通信能力,在智能硬件领域的融合应用已成必然趋势。智能硬件不再局限于单一功能,对实时…...

【Redis】Redis从入门到实战:全面指南
Redis从入门到实战:全面指南 一、Redis简介 Redis(Remote Dictionary Server)是一个开源的、基于内存的键值存储系统,它可以用作数据库、缓存和消息代理。由Salvatore Sanfilippo于2009年开发,因其高性能、丰富的数据结构和广泛的语言支持而广受欢迎。 Redis核心特点:…...

统计按位或能得到最大值的子集数目
我们先来看题目描述: 给你一个整数数组 nums ,请你找出 nums 子集 按位或 可能得到的 最大值 ,并返回按位或能得到最大值的 不同非空子集的数目 。 如果数组 a 可以由数组 b 删除一些元素(或不删除)得到,…...