java单元测试批处理数据模板【亿点点日志配合分页以及多线程处理】
文章目录
- 引入
- 相关资料
- 环境准备
- 分页查询处理,减少单次批量处理的数据量级
- 补充亿点点日志,更易观察
- 多线程优化查询_切数据版
- 多线程_每个线程都分页处理
引入
都说后端开发能顶半个运维,我们经常需要对大量输出进行需求调整,很多时候sql语句已经无法吗,满足我们的需求,此时就需要使用我们熟悉的 java语言结合单元测试写一些脚本进行批量处理。
相关资料
案例代码获取
视频讲解:
- 利用分页处理数据量较大的情况
- 补充亿点点日志
环境准备
可直接使用我分享的工程:
案例代码获取
我这里准备了一个10000条数据的的user表,和对应的一个springboot工程:
@Slf4j
@SpringBootTest(classes = MyWebDemoApplication.class,// 配置端口启动,否则获取失败webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class BatchDemo {@Autowiredprivate UserMapper userMapper;}
分页查询处理,减少单次批量处理的数据量级
当我们的数据量很大,并且单个对象也很大时,如果一次查出所有待处理的数据,往往会把我们的对象给撑爆,这时我们可以利用分页的思想将数据拆分,分页去处理
- 已知数据量总数的分页批处理模板
/*** 分页查询处理,减少单次批量处理的数据量级* 当前已知数据量总数*/
@Test
public void test1() {// 预定义参数int page = 0;int pageSize = 5000;// 获取总数Integer total = userMapper.selectCount(null);// 计算页数int pages = total / pageSize;if (total % pageSize > 0) {pages++;}// 开始遍历处理数据for (; page < pages; page++) {List<User> users = userMapper.selectList(Wrappers.<User>lambdaQuery().last(String.format("LIMIT %s,%s", page * pageSize, pageSize)));users.forEach(user -> {/// 进行一些数据组装操作});/// 批量 修改/插入 操作User lastUser = users.get(users.size() - 1);log.info("最后一个要处理的用户的ID为:{},名字:{}", lastUser.getId(), lastUser.getNickName());}}
上面展示的是已知数据量总数的情况,有时候我们是未知总量的,此时可以采用如下写法
- 未知数据量总数的分页批处理模板
/*** 未知总数的写法*/
@Test
public void test2() {// 预定义参数int page = 0;int pageSize = 500;// 开始遍历处理数据for (; ; ) {List<User> users = userMapper.selectList(Wrappers.<User>lambdaQuery().last(String.format("LIMIT %s,%s", (page++) * pageSize, pageSize)));users.forEach(user -> {/// 进行一些数据组装操作});/// 批量 修改/插入 操作if (CollUtil.isNotEmpty(users)) {User lastUser = users.get(users.size() - 1);log.info("最后一个要处理的用户的ID为:{},名字:{}", lastUser.getId(), lastUser.getNickName());}if (users.size() < pageSize) {break;}}
}
这里每次输出循环的最后一条数据,帮助我们验证结果:

补充亿点点日志,更易观察
良好的日志输出能够帮助我们实时了解脚本的运行情况,很多时候每次循环内部都会处理一个耗时操作,这里用已知总数的情况添加日志如下:
- 起始展示待处理数据总量,总页数,每页条数
- 每页开始展示当前进度,每页结束暂时,耗时,已处理条数,失败数,最后一条数据信息等
- 循环内部,每分钟输出一次日志
- 处理完毕输出总耗时,总条数,失败数,失败数据id集合等
/*** 补充亿点点日志*/
@Test
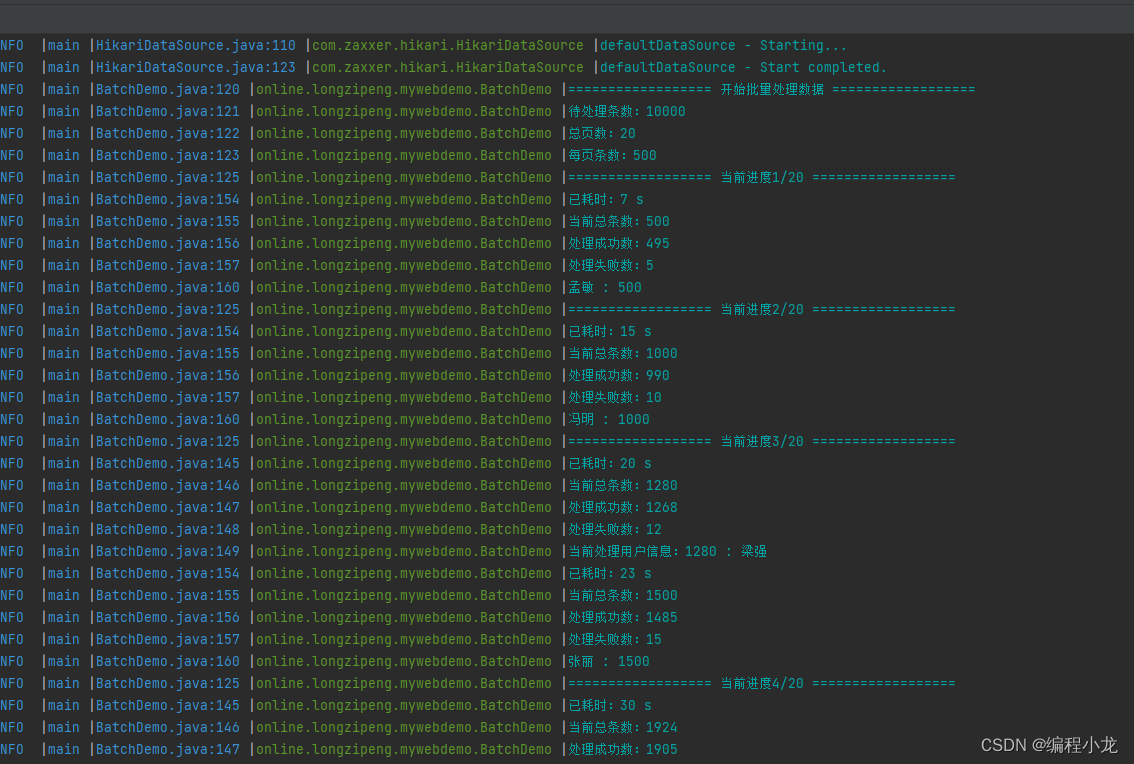
public void test3() {// 预定义参数int page = 1;int pageSize = 500;// 获取总数Integer total = userMapper.selectCount(null);// 计算页数int pages = total / pageSize;if (total % pageSize > 0) {pages++;}// 总处理条数int count = 0;// 成功处理数int countOk = 0;// 处理失败记录List<Integer> wrongIds = new ArrayList<>();// 已过分钟数int countMinute = 1;long start = System.currentTimeMillis();// 开始遍历处理数据log.info("================== 开始批量处理数据 ==================");log.info("待处理条数:{}", total);log.info("总页数:{}", pages);log.info("每页条数:{}", pageSize);for (; page < pages; page++) {log.info("================== 当前进度{}/{} ==================", page, pages);List<User> users = userMapper.selectList(Wrappers.<User>lambdaQuery().last(String.format("LIMIT %s,%s", (page - 1) * pageSize, pageSize)));for (User user : users) {/// 进行一些数据组装操作if (user.getId() % 99 == 0) {wrongIds.add(user.getId());} else {countOk++;}count++;/// 模拟耗时操作try {Thread.sleep(10);} catch (InterruptedException e) {throw new RuntimeException(e);}// 每分钟输出一次日志if ((System.currentTimeMillis() - start) / 1000 / 60 > countMinute) {log.info("已耗时:{} s", (System.currentTimeMillis() - start) / 1000);log.info("当前总条数:{}", count);log.info("处理成功数:{}", countOk);log.info("处理失败数:{}", wrongIds.size());log.info("当前处理用户信息:{} : {}", user.getId(), user.getNickName());countMinute++;}}/// 批量 修改/插入 操作log.info("已耗时:{} s", (System.currentTimeMillis() - start) / 1000);log.info("当前总条数:{}", count);log.info("处理成功数:{}", countOk);log.info("处理失败数:{}", wrongIds.size());if (CollUtil.isNotEmpty(users)) {User user = users.get(users.size() - 1);log.info("{} : {}", user.getNickName(), user.getId());}}log.info("========================== 运行完毕 ==========================");log.info("总耗时:{} s", (System.currentTimeMillis() - start) / 1000);log.info("总处理条数:{}", count);log.info("处理成功数:{}", countOk);log.info("处理失败数:{}", wrongIds.size());log.info("处理失败数据id集合:{}", wrongIds);
}
效果如下
多线程优化查询_切数据版
多核CPU才能真正意义上的并行,不然就是宏观并行,微观串行 o(╥﹏╥)o,大家得看下自己的cpu,当然,如果有很多阻塞IO,单核进行切换线程也是能够提高性能的
这里开5个线程,将数据按线程数进行拆分,代码如下:
/*** 多线程优化查询,【切数据版 ,按线程数量切割数据,直接处理】* + 需要程序进行大量计算* + 数据库能承受较大并发* + 多核CPU才能真正意义上的并行,不然就是宏观并行,微观串行 o(╥﹏╥)o*/
@Test
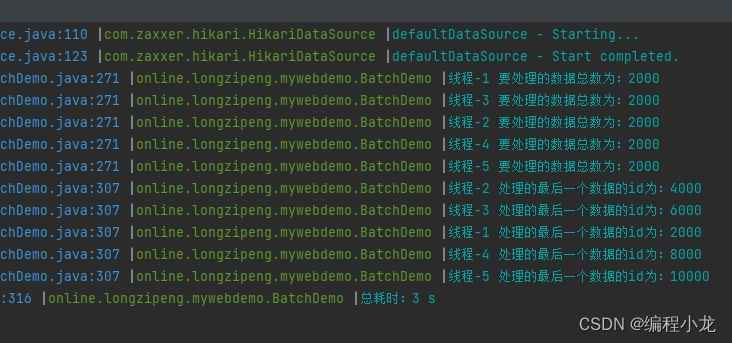
public void test4() {// 预定义参数int threadNum = 5;long start = System.currentTimeMillis();// 获取总数Integer total = userMapper.selectCount(null);// 创建线程池,这里为了简便操作直接用Executors创建,推荐自行集成配置线程池ExecutorService executorService = Executors.newFixedThreadPool(threadNum);// 设置信号标,用于等待所有线程执行完CountDownLatch countDownLatch = new CountDownLatch(threadNum);// 计算线程需要处理的数据量的递增步长int threadTotalStep = total / threadNum;// 判断是否有余数,如果有多出的数据,补给最后一个线程int more = total % threadNum;// 开启 threadNum 个线程处理数据for (int i = 0; i < threadNum; i++) {int finalI = i;executorService.execute(() -> {int current = threadTotalStep * finalI;/// 如果有余数,最后一次计算得补充余数if (more > 0 && finalI == threadNum - 1) {current += more;}List<User> users = userMapper.selectList(Wrappers.<User>lambdaQuery().last(String.format("LIMIT %s,%s", current, threadTotalStep)));users.forEach(user -> {/// 进行一些数据组装操作/// 进行一些耗时操作try {Thread.sleep(1);} catch (InterruptedException e) {throw new RuntimeException(e);}});/// 批量 修改/插入 操作User user = users.get(users.size() - 1);log.info("线程-{} 处理的最后一个数据的id为:{}", finalI + 1, user.getId());countDownLatch.countDown();});}try {countDownLatch.await();executorService.shutdown();log.info("总耗时:{} s", (System.currentTimeMillis() - start) / 1000);} catch (InterruptedException e) {throw new RuntimeException(e);}
}
执行结果如下:
多线程_每个线程都分页处理
如果单个线程处理数据量也很大,此时每个线程都可补充分页进行处理,如下
/*** 多线程优化查询,【分页版,先按数量切数据,再在每个线程中分页处理数据】* + 需要程序进行大量计算* + 数据库能承受较大并发* + 多核CPU才能真正意义上的并行,不然就是宏观并行,微观串行 o(╥﹏╥)o*/
@Test
public void test5() {// 预定义参数int threadNum = 5; // 线程数int pageSize = 500; // 每页处理条数long start = System.currentTimeMillis();// 获取总数Integer total = userMapper.selectCount(null);// 创建线程池,这里为了简便操作直接用Executors创建,推荐自行集成配置线程池ExecutorService executorService = Executors.newFixedThreadPool(threadNum);// 设置信号标,用于等待所有线程执行完CountDownLatch countDownLatch = new CountDownLatch(threadNum);// 计算线程需要处理的数据量的递增步长int threadTotalStep = total / threadNum;// 判断是否有余数,如果有多出的数据,补给最后一个线程int more = total % threadNum;// 开启 threadNum 个线程处理数据for (int i = 0; i < threadNum; i++) {int finalI = i;executorService.execute(() -> {/// 数据总数就是 数据总数步长int threadTotal = threadTotalStep;// 获取上一个线程最终行数int oldThreadCurrent = threadTotalStep * finalI;/// 如果有余数,最后一次计算得补充余数if (more > 0 && finalI == threadNum - 1) {threadTotal += more;}log.info("线程-{} 要处理的数据总数为:{}", finalI + 1, threadTotal);// 计算页数int pages = threadTotal / pageSize;if (threadTotal % pageSize > 0) {pages++;}// 统计数量,当等于线程总总数时退出循环,避免重复计数int handleCount = 0;// 获取最后一个userUser lastUser = new User();// 开始遍历处理数据for (int page = 0; page < pages; page++) {List<User> users = userMapper.selectList(Wrappers.<User>lambdaQuery().last(String.format("LIMIT %s,%s", page * pageSize + oldThreadCurrent, pageSize)));for (User user : users) {handleCount++;if (handleCount == threadTotal) {break;}/// 模拟真正的逻辑处理,耗时操作try {Thread.sleep(1);} catch (InterruptedException e) {throw new RuntimeException(e);}}/// 批量 修改/插入 操作if (CollUtil.isNotEmpty(users)) {lastUser = users.get(users.size() - 1);}}log.info("线程-{} 处理的最后一个数据的id为:{}", finalI + 1, lastUser.getId());countDownLatch.countDown();});}try {countDownLatch.await();executorService.shutdown();log.info("总耗时:{} s", (System.currentTimeMillis() - start) / 1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}
相关文章:
java单元测试批处理数据模板【亿点点日志配合分页以及多线程处理】
文章目录引入相关资料环境准备分页查询处理,减少单次批量处理的数据量级补充亿点点日志,更易观察多线程优化查询_切数据版多线程_每个线程都分页处理引入 都说后端开发能顶半个运维,我们经常需要对大量输出进行需求调整,很多时候…...
【数据结构】模拟实现 堆
堆数据结构是一种数组对象,它可以被看作一颗完全二叉树的结构(数组是完全二叉树),堆是一种静态结构。堆分为最大堆和最小堆。最大堆:每个父结点都大于孩子结点。最小堆:每个父结点都小于孩子结点。堆的优势…...
Go语言学习的第三天--上部分(基础用法)
前两天经过不断度娘,与对up主的跟踪学习了解了go的历史,今天开始了go的基础!!本章主要是go 的注释、变量及常量的梳理一、注释不管什么语言都有自己的注释,go也不例外 !!单行注释 // 多行注释 …...
linux面试基础篇
题目目录1.简述DNS分离解析的工作原理,关键配置2.apache有几种工作模式,分别简述两种工作模式及其优缺点?3.写出172.0.0.38/27 的网络id与广播地址4.写出下列服务使用的传输层协议(TCP/UDP)及默认端口5.在局域网想获得…...
黑马程序员提高变成
这里写目录标题函数模板1.2.2 函数模板注意事项1.2.3 函数模板案例调用规则类模板与函数模板区别类模板与继承类模板成员函数类外实现#pragma once类模板与友元案例重新定义【】stl2.2 STL基本概念STL六大组件容器算法迭代器初识vectorvector容器嵌套容器string容器string赋值操…...

MySQL5种索引类型
MySQL的类型主要有五种:主键索引、唯一索引、普通索引、空间索引、全文索引 有表: CREATE TABLE t1 ( id bigint unsigned NOT NULL AUTO_INCREMENT, u1 int unsigned NOT NULL DEFAULT 0, u2 int unsigned NOT NULL DEFAULT 0, u3 varchar(20) NOT NU…...

uniapp封装缓存方法,支持类似cookie具有过期时间
1、定义CacheManage类,有set和get方法 class CacheManage {set() {},get() {} }set用来设置缓存,get用来获取缓存 2、完善set业务逻辑 大概逻辑如下: 1、将接收params参数,包含key、data、unit、time key 缓存字段,…...
Jfrog 搭建本地maven仓库以及上传Android库
Jfrog 下载 安装包下载地址:Download Artifactory OSS | JFrog 如果是想下载之前的版本,可以点击上面的Get code source ,如果是最新版本,直接点下面的下载就好。下面以Linux安装为例。 Jfrog安装 对于Linux而言,其实…...
日报周报月报工作总结生成器【智能文案生成器】
日报周报月报工作总结生成器【智能文案生成器】 天天写日报,我真的快奔溃了! 摸了一天鱼,下班还要写日报; 划了一周的水,周末还要写周报; 啊啊啊啊… 在职场上,尤其是互联网公司里,…...

linux日志管理工具logrotate配置
linux日志管理工具logrotate配置logrotate介绍logrotate配置讲解主配置文件解释(/etc/logrotate.conf)logrotete 命令参数添加配置以添加一个nginx配置为例强制启动配置logrotate介绍 logrotate是centos自带工具,其他操作系统可能需要自行安装。logrotate用来进行日…...

[ C++ ] 设计模式——单例模式
目录 1.设计模式: 2.单例模式 饿汉模式 懒汉模式 饿汉模式和懒汉模式的优缺点 1.设计模式: 设计模式(Design Pattern)是一套被反复使用,多数人只晓得,经过分类的,代码设计经验的总结。为什么会产生设计模式这样的…...
HACKTHEBOX——Help
nmap可以看到对外开放了22,80,3000端口可以看到80端口和3000端口都运行着http服务,先从web着手切入TCP/80访问web提示无法连接help.htb,在/etc/hosts中写入IP与域名的映射打开只是一个apache default页面,没什么好看的使用gobuster扫描网站目…...
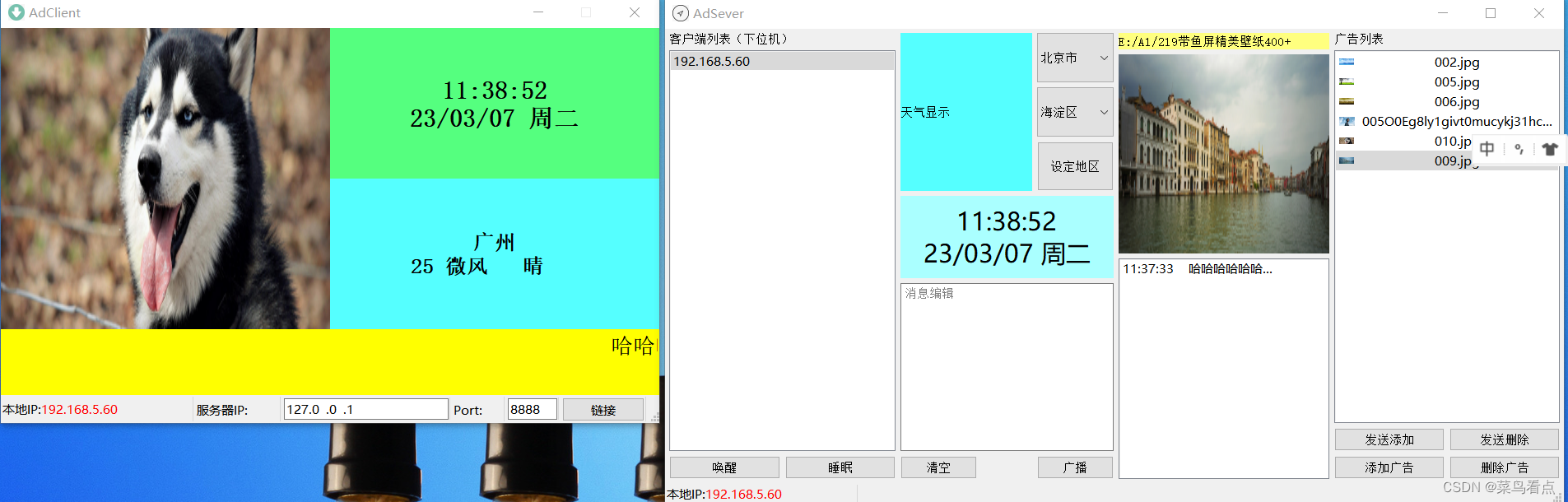
Qt广告机客户端(下位机)
目录功能结构adClient.promain.cppadclient.h 客户端adclient.cpp 客户端addate.h 时间处理addate.cpp 时间处理adsocket.h 客户端Socket处理adsocket.cpp 客户端Socket处理weather.h 天气信息处理weather.cpp 天气信息处理rollmassege.h 滚动信息处理rollmassege.cpp 滚动信息…...

JavaScript新手学习手册-基础代码(二)
与上篇博客相接 一:函数: 案例:通过函数实现绝对值的输出 方法一: function absoluate(x){if(x>0){return x;}else{ return -x;}} 在控制台调用函数 方法二: var demo1 function(x){if(x>0){return x;}els…...
wireshark 抓包使用记录
文章目录前言wireshark 抓包使用记录一、wireshark的基础使用二、wireshark的常用功能1、开始混杂模式2、过滤器操作2.1、抓包过滤器2.2、显示过滤器3、时间格式显示4、统计流量图5、标记显示6、导出数据包7、增加、隐藏、删除显示列前言 如果您觉得有用的话,记得给…...

pd dataframe 读取处理 有合并单元格的excel方式
from pathlib import Path import openpyxl 拆分所有的合并单元格,并赋予合并之前的值。 由于openpyxl并没有提供拆分并填充的方法,所以使用该方法进行完成 def unmerge_and_fill_cells(worksheet): all_merged_cell_ranges list( worksheet.merged_…...
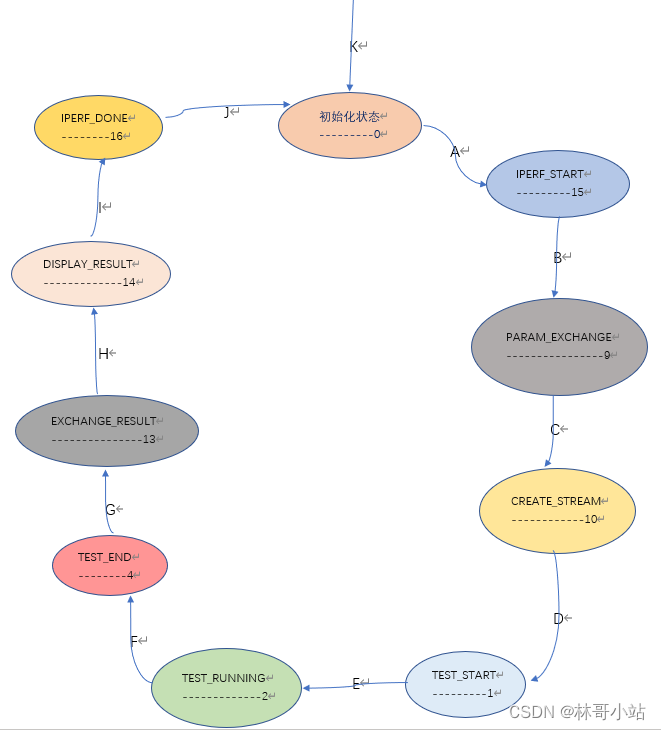
七,iperf3源代码分析:状态机及状态转换过程--->运行正向TCP单向测试时的服务端代码
本文目录一、测试用命令二、iperf3状态机中各个状态解析三、iperf3状态机迁移分析K-初始化测试对象(NA--->初始化状态):A-服务器端测试对象开始运行(初始化状态--->IPERF_START状态):B-建立控制连接(初始化状态-…...

【网络篇】----- 传输层协议 之 UDP(协议格式,协议特性和编程影响三方面详细分析)
文章目录 前言1、UDP协议2、协议格式 2.1、协议格式模型2.2、字段分析3.协议特性4.编程影响总结前言 1、UDP协议 UDP协议,又名数据报传输协议,是传输层协议之一!!! 在TCP/IP五层模型中,在传输层中ÿ…...

【基于STM32的多功能台灯控制】
基于STM32的多功能台灯控制 在之前一篇博文中已出过智能台灯相关的介绍,在这里对之前的模块以及功能上进行了优化和功能上的改进,需源码或实物可私【创作不易-拒绝白嫖】 功能说明 1、按键模式多功能台灯在设计上使用了4个按键分别做为 按键1模式的切换…...

Mac 编译x264源码No working C compiler found 错误
在mac上编译x264源码时,报错No working C compiler found 。网上找了一圈方案也无法解决 只能硬着头皮看configure这个脚本,通过一步一步抽丝拨茧终于是在mac上可以编译了。 这里只当记录一下,为后续同学遇到同样问题提供一个辅助解决方案。…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

接口自动化测试:HttpRunner基础
相关文档 HttpRunner V3.x中文文档 HttpRunner 用户指南 使用HttpRunner 3.x实现接口自动化测试 HttpRunner介绍 HttpRunner 是一个开源的 API 测试工具,支持 HTTP(S)/HTTP2/WebSocket/RPC 等网络协议,涵盖接口测试、性能测试、数字体验监测等测试类型…...