《数据解构》HashMap源码解读
👑作者主页:Java冰激凌
📖专栏链接:数据结构
目录
了解HashMap
HashMap的构造
两个参数的构造方法
一个参数的构造方法
不带参数的构造方法
哈希表初始化的长度
HashMap源码中的成员
Pt
Get
了解HashMap
首先我们要明确 什么是HashMap?
HashMap 是一个用于存储(Key - Value)键值对的集合 每一个键值对也称为Entry ,这些键值对被均匀的分布在了一个存储的table数组当中
本文讨论的HashMap是基于JDK8 的源码~
面试题
HashMap底层的数据结构是什么?
是一个特殊的数组
Hash表示什么?
散列表 一个用于存储(Key - Value)键值对的集合 每一个键值对也称为Entry ,这些键值对被均匀的分布在了一个存储的table数组当中
HashMap的构造
HashMap的构造也是有多种形式的
两个参数的构造方法
//public HashMap (int,float)public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);}这个构造方法 是传入两个参数 第一个参数为初始化哈希表的长度 第二个参数是手动指定负载因子
我们着重来观察一下这个代码 我们进入方法 是非常有趣的
static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}这个代码是干啥的呢? 写的花里胡哨的 可其实 这个可是非常有趣的 这个是我们传入的初始化的长度 这个方法会帮我们转换为2的最小次幂 我们来解读一下 举例我们传入cap为10
static final int tableSizeFor(int cap) {//cap = 10int n = cap - 1;// 9 00000000 00000000 00000000 00001001n |= n >>> 1;//n>>>1 00000000 00000000 00000000 00001100//n 00000000 00000000 00000000 00001001//|= 00000000 00000000 00000000 00001101//我们现在看还不是很明显 我们再做一个n |= n >>> 2;// n 00000000 00000000 00000000 00001101//n>>>2 00000000 00000000 00000000 00001111//n 00000000 00000000 00000000 00001111//发现了什么吗?我们可以观察到 其实每次做 都是在复制当前前几位1 //当这个操作都做完之后 我们可以得到我们会变成什么样子//也就是 当前的最前一位的1 后面都变为了1 如此操作我们便可以做到完成//找到2的最小次幂 那么为什么要使用位运算呢?这个问题我们就不讨论了 //计算时cup做位运算效率很高 并且哈希表是本身就是为了快n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }

一个参数的构造方法
//public HashMap(int)public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);}这个构造方法是传入一个参数 传入的参数为初始化哈希表的长度 我们也可以发现 在指定长度后 是调用了我们的带有两个参数的构造方法 其中的 initialCapacity 是我们指定的初始化的长度 DEFAULT_LOAD_FACTOR 是默认的负载因子 其中 在源码中 默认的负载因子的大小为0.75f(对的 float类型!)

不带参数的构造方法
public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}这是我们不带参数的构造方法 其中 会默认指定loadFactor(负载系数)为0.75以及其他字段 都为默认值 其中 值得注意到的是 HashMap的默认初始化数组的大小不是10 也不是 20 而是
16 那么为什么会是16呢?
哈希表初始化的长度
这是我们刚刚没有提及到的 我们在手动设定哈希表长度的时候 真的会是以我们手动设置的长度来构造哈希表的长度的吗?
HashMap表的默认初始化长度为16 并且每次拓展 或者手动指定初始化长度的时候 长度 必须是2次幂
默认初始化长度为何会是16呢?并且为何又要是2次幂呢?
之所以我们选择16来作为默认的初始化长度 是为了服务Key映射到index的Hash算法
从Key映射到HashMap数组对应的位置 我们都需要借助到一个Hash函数
这个Hash函数就是用来计算能够尽量避免哈希碰撞的长度的
并且初始化为16 更加符合Hash算法分布均匀的要求
那么我们如何可以实现一个分布比较均匀的Hash函数呢?
此时 我们就需要利用到另一个函数 HashCode 这个HashCode是利用Key的
HashCode来确定在哈希表中映射的位置
那么 是不是把Key的HashCode值和HashMap的长度进行取余运算?
漏漏漏 大漏特漏 虽然说取余的方式很简单快捷 但是效率是比较低的 显然 我们哈希表出
现之初就是为了提高效率的 这个操作反而有点背道而行了,所以 HashMap采用了位运
算的方式
面试题
通过new HashMap(10)创建对象 此时HashMap底层的数组长度是多少?
16 不管你传进去什么数字,返回的一定是大于等于该数字的最小2的幂次,
那么为什么是2次幂? 我们需要对于这个进行长篇大论了 等我们讲完put之后会讲解的
HashMap源码中的成员

我们去源码中寻找HashMap的特殊的 数组 我们发现 在整个HashMap中只有一个数组 就是table
但是我们同时也发现了 在我们的构造方法以及创建的时候 并没有去初始化数组的大小
面试题
为何没有在初始化或者构造方法中对数组进行初始化
等到我们看到put中会发现 是在put方法中进行的初始化 那么为何要在put中才进行初始化呢 其实这是一个叫做懒加载的机制 是从技术底层帮我们避免了一些资源浪费 假设我们有以下的代码 如果对于map不进行使用 假设我们没有加入懒加载这个机制 就会造成资源的浪费 其中相同的技术也在List中也使用到了 (懒加载在Spring中也会经常的使用到 一定要了解到这个概念)

Put
put是HashMap中的插入方法 将指定值与此映射中的指定键关联 如果映射之前包含键的映射 则替换旧值(如果存在相同的值 会被覆盖)
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}我们可以看到 put是有返回值的 这个返回值为V类型 然后我们进入putVal中查看
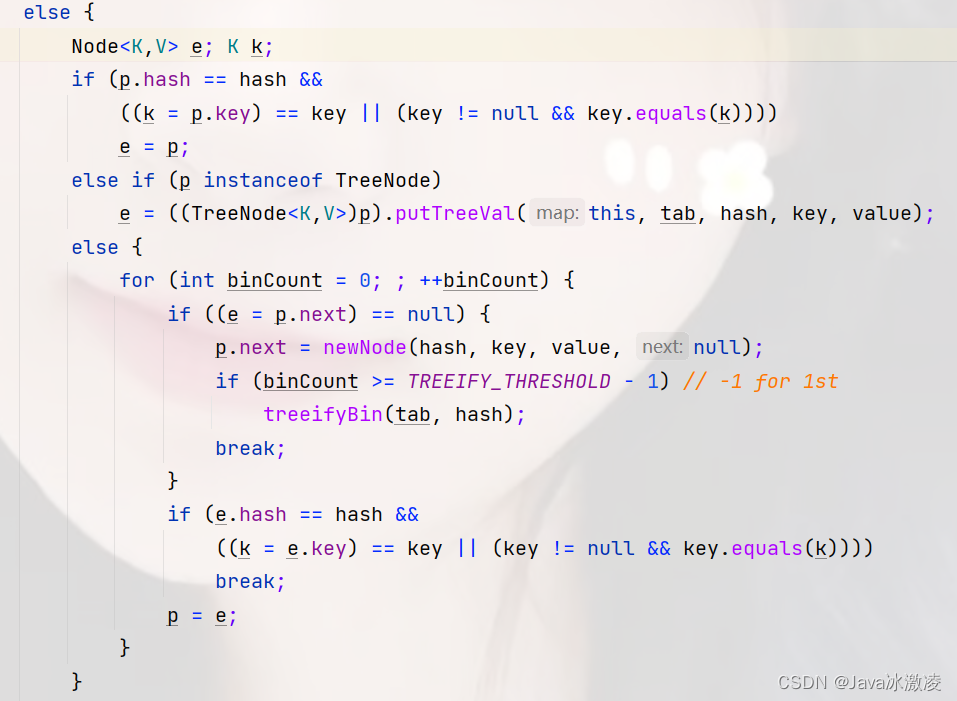
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;}代码相当的长 我们将代码分割几个部分来进行分析
这个判断的意思就是为了查看 如果数组为null 或者数组中有效元素个数为0 那么我们进入resize方法
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve orderNode<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}又是超级长的代码 不过没瓜系 我们还是分开来解读
首先 进入方法 oldTab = table = null(因为我们的table当前为空)
所以 oldCap = 0 然后我们进入判断 判断中 oldCap为0 我们将newCap与newThr都赋值为默认值
之后我们对于table进行了初始化
可以啦
以上这个代码 都不用看 因为我们现在在进行初始化 为何不需要看这些代码呢 因为这些代码都是在考虑扩容的代码 我们此时不会涉及到扩容 所以这些代码暂时不用理会 (ps:看了一天的源码 我总结出一个道理 看源码不能一行一行去读 而要去寻找重点 如果一行一行代码去读 )
好的我们又回到了put方法中 我们看当前红框中的代码 这是一个如果当前位置为空 我们便将key以及value插入 但是我们的注意力 要放到hash方法中
也就是当初put传入的这个hash值 这个值是如何计算出来的呢?
面试题
HashMap中的Key能不能为null?如果为null 则下标为多少?
我们以上的源码可以解释这个问题 是可以为null的 且只能有一个为nill的Key 下标为0
如果Key == null 那么直接返回hash = 0
我们还是将注意力 放到这里
假设不为空的话 它的下标是如何计算的?
首先要通过我们的HashCode来计算一个哈希值 然后我们还要异或h>>>16位
面试题
HashMap中秋hash值的时候用到了扰动函数 为什么要这么做呢?
先说结论 为了减少Hash冲突发生的可能性
我们来具体举例一下
return (h = gril.hashCode() ^ (h >>> 16)
//假设girl的hash值是
//00101101 00101101 10100111 00101101
那么我们假设HashMap的长度为16 也就是下标为0-15
计算这个的hashMap值也很简单 我们计算下标
//00101101 00101101 10100111 00101101
//00000000 00000000 00000000 00001111
其实也就是取出最后四位嘛 直接后四位进行计算就好啦
//00000000 00000000 00000000 00000010
我们再假设 woman的hash值是这样的
//00111111 11101101 11100111 10111101
计算下标的话
//00000000 00000000 00000000 00001111
//00000000 00000000 00000000 00000010
我们可以发现 最后计算出的下标是相同的 这就是为何要加入扰动函数 扰动函数是干啥的呢?也就是说 全球60亿人 有很多人的眼睛可能是一样的 但是如果加上这些人的其他特征 那么就变得不一样了 因为世界人相同的人只有一个下面我们便到了 插入重复元素
这个代码也是比较复杂的 直接一句话 如果当前下标没有元素 直接插入 如果有元素 我们进行尾插(在JDK1.7之前 是头插)
那么我们如何插入 是怎么放的 此处我们不得不提到一个哈希冲突
面试题
Hash冲突发生之后怎么解决?
线性探测法:for循环找一下旁边有没有空位
链式地址法:实际上就是在同一个节点下面加
链地址法怎么理解 假设你在坐火车 你拿着的票的位置已经坐了一个小姐姐 你该怎么办 总不能直接坐到人家小姐姐身上把(滑稽)此时我们可以加入一个上下铺的方式往后依次走
我们来看一下这个 这个红框中的是 计算负载因子 如果超过负载因子 进行扩容 并且 当一定的要求满足的时候 会转变为链表加红黑树
面试题
HashMap链表转红黑树的条件
链表的深度必须大于等于8
数组的长度必须大于等于64








final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve orderNode<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}
扩容的细节还是在于 扩容会进行扩容为2的次幂
面试题
HashMap为什么线程不安全?
JDK1.7之前
·put的时候会造成数据丢失
·扩容的时候 头插法会造成死循环
JDK1.8
·put的时候会造成数据丢失
·扩容的时候 头插改成了尾插 不会出现循环
(这也可能是一部分为何要在JDK1.8之后将HashMap改为尾插法的原因之一)
Get
使用Get方法根据Key来查找Value的时候,发生了什么呢?
首先会把输入的Key做一次Hash映射,得到对应的index 之后会去当前index下标去寻找节点是否存在 如果存在即返回V即可 get的原理是比较简单的 没有put如此的繁琐
用了10+小时来分析源码 已经吐了~知识点很多 融入文章才能看懂 有不足之处也希望多多指出 😢
相关文章:
《数据解构》HashMap源码解读
👑作者主页:Java冰激凌 📖专栏链接:数据结构 目录 了解HashMap HashMap的构造 两个参数的构造方法 一个参数的构造方法 不带参数的构造方法 哈希表初始化的长度 HashMap源码中的成员 Pt Get 了解HashMap 首先我们要明…...

Databend 开源周报 第 83 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.com 。Whats New探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。Support for WebHDFSHDFS 是大数…...
Spring | 基础
1. IOC和DI IOC:控制反转,其思想是反转资源获取的方向,传统的资源查找方式要求组件向容器发起请求查找资源,作为回应,容器适时的返回资源。而应用了 IOC 之后,则是**容器主动地将资源推送给它所管理的组件…...

windows7安装sql server 2000安装步骤 及安装过程中遇到的问题和解决方式
提示:文章写完后windows7安装sql server 2000安装步骤 及安装过程中遇到的问题和解决方式, 文章目录一、ms sql server 2000是什么?版本简介:**特点:****优点:**二、步骤1.下载安装包及Sq4补丁包2.安装 ms …...

Python 开发-批量 FofaSRC 提取POC 验证
数据来源 学习内容和目的: ---Request 爬虫技术,lxml 数据提取,异常护理,Fofa 等使用说明---掌握利用公开或 0day 漏洞进行批量化的收集及验证脚本开发Python 开发-某漏洞 POC 验证批量脚本---glassfish存在任意文件读取在默认4…...

Linux系统中部署软件
目录 1.Mysql 2.Redis 3.ZooKeeper 声明 致谢 1.Mysql 参考:CentOS7安装MySQL 补充: ① 执行:rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022 再执行:yum -y install mysql-community-server ② mysql…...

PHP常用框架介绍与比较
HP是一种广泛应用于Web开发的编程语言。随着互联网的快速发展,PHP的应用场景变得越来越广泛,从简单的网站到复杂的Web应用程序都可以使用PHP来开发。为了更好地组织和管理PHP代码,开发人员经常会使用框架来提高开发效率和代码质量。 本文将介绍一些常用的PHP框架,并进行简…...

Umi + React + Ant Design Pro 项目实践(一)—— 项目搭建
学习一下 Umi、 Ant Design 和 Ant Design Pro 从 0 开始创建一个简单应用。 首先,新建项目目录: 在项目目录 D:\react\demo 中,安装 Umi 脚手架: yarn create umi # npm create umi安装成功: 接下来,…...
)
MySQL知识点总结(1)
目录 1、sql、DB、DBMS分别是什么,他们之间的关系? 2、什么是表? 3、SQL语句怎么分类呢? 4、导入数据 5、什么是sql脚本呢? 6、删除数据库 7、查看表结构 8、表中的数据 10、查看创建表的语句 11、简单的查询…...
)
day45第九章动态规划(二刷)
今日任务 70.爬楼梯(进阶)322.零钱兑换279.完全平方数 70.爬楼梯(进阶) 题目链接: https://leetcode.cn/problems/climbing-stairs/description/ 题目描述: 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不…...
第十四届蓝桥杯第三期模拟赛原题与详解
文章目录 一、填空题 1、1 找最小全字母十六进制数 1、1、1 题目描述 1、1、2 题解关键思路与解答 1、2 给列命名 1、2、1 题目描述 1、2、2 题解关键思路与解答 1、3 日期相等 1、3、1 题目描述 1、3、2 题解关键思路与解答 1、4 乘积方案数 1、4、1 题目描…...
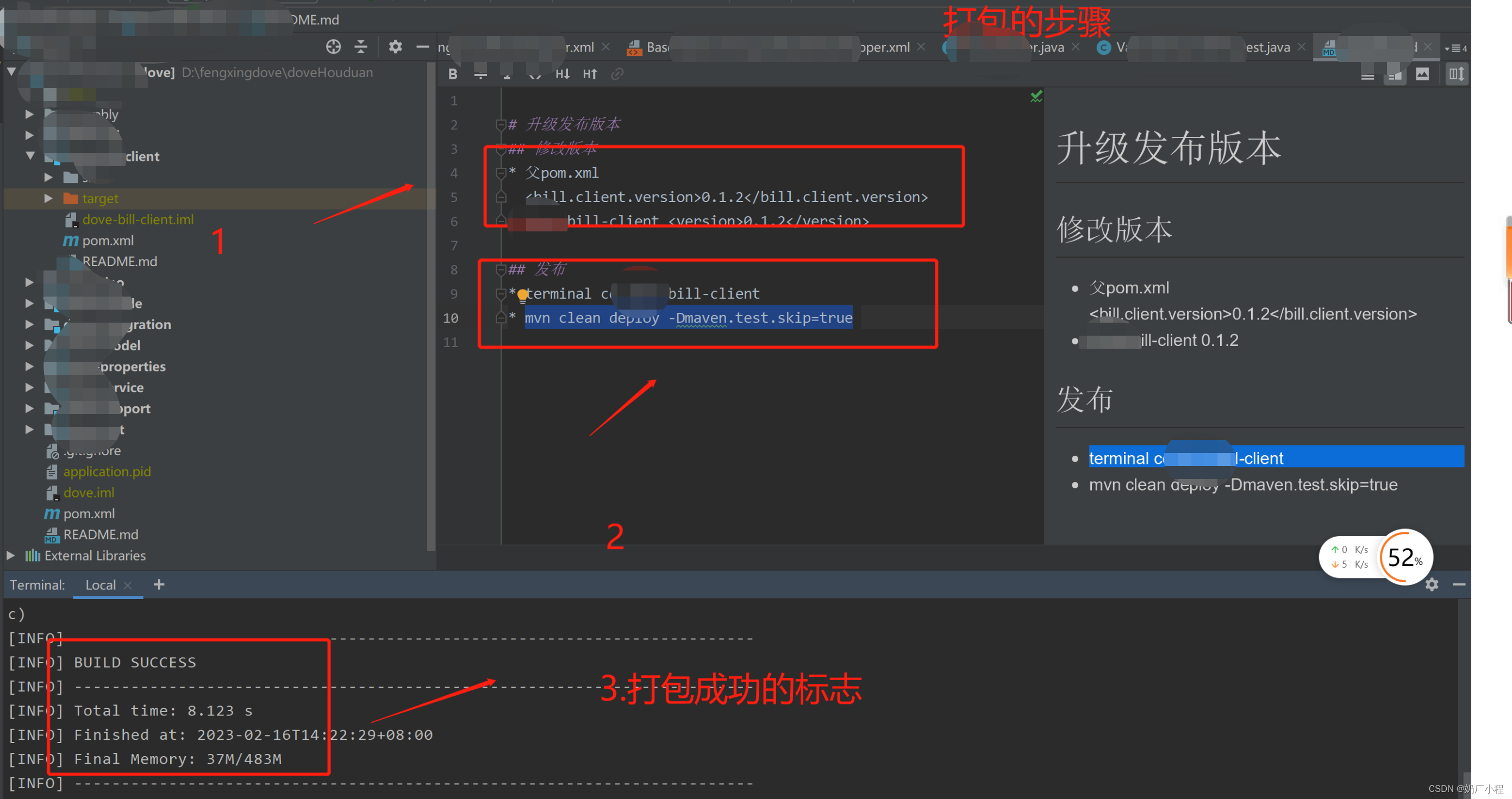
client打包升级
目录 前言 一、client如何打包升级? 二、使用步骤 1.先进行改版本 2.执行打包升级命令 总结 前言 本文章主要记录一下,日常开发中,常需要进行打包升级的步骤。 一、client如何打包升级? # 升级发布版本 ## 修改版本 * 父p…...

Blazor_WASM之3:项目结构
Blazor_WASM之3:项目结构 Blazor WebAssembly项目模板可选两种,Blazor WebAssemblyAPP及Blazor WebAssemblyAPP-Empty 如果使用Blazor WebAssemblyAPP模板,则应用将填充以下内容: 一个 FetchData 组件的演示代码,该…...

OperWrt 包管理系统02
文章目录 OperWrt 包管理系统OPKG简介OPKG的工作原理OPKG命令介绍软件包的更新、安装、卸载和升级等功能软件包的信息查询OPKG配置文件说明OPKG包结构(.ipk)OPKG演示案例OperWrt 包管理系统 OPKG简介 OPKG(Open/OpenWrt Package)是一个轻量快速的软件包管理系统,是 IPKG…...
人人都学会APP开发 提高就业竞争力 简单实用APP应用 安卓浏览器APP 企业内部通用APP制作 制造业通用APP
安卓从2009年开始流程于手机、平板,已经是不争的非常强大生产力工具,更为社会创造非常高的价值,现在已经是202X年,已经十几年的发展,安卓平台已经无所不在。因此建议人人都学学APP制作,简易入门,…...

【自然语言处理】从词袋模型到Transformer家族的变迁之路
从词袋模型到Transformer家族的变迁之路模型名称年份描述Bag of Words1954即 BOW 模型,计算文档中每个单词出现的次数,并将它们用作特征。TF-IDF1972对 BOW 进行修正,使得稀有词得分高,常见词得分低。Word2Vec2013每个词都映射到一…...
LIME: Low-light Image Enhancement viaIllumination Map Estimation
Abstract当人们在低光条件下拍摄图像时,图像通常会受到低能见度的影响。除了降低图像的视觉美感外,这种不良的质量还可能显著降低许多主要为高质量输入而设计的计算机视觉和多媒体算法的性能。在本文中,我们提出了一种简单而有效的微光图像增…...

源码指标编写1000问4
4.问: 哪位老师把他改成分析家的,组合公式:猎庄敢死队别样红(凤翔) {猎庄敢死队} rsv:(c-llv(l,9))/(hhv(h,9)-llv(l,9))100; stickline(1,50,50,1,0),pointdot,Linethick2,colorff00; k:sma(rsv,3,1); d:sma(k,3,1); rsv1:(hhv(h,9.8)-c)/(hhv(h,9.8)-llv(l,9.8))1…...

Golang中GC和三色屏障机制【Golang面试必考】
文章目录Go v1.3 标记—清楚(mark and sweep)方法Go V1.5 三色标记法三色标记过程无STW的问题强弱三色不变式插入写屏障Go V1.8的三色标记法混合写屏障机制混合写屏障场景场景1:对象被一个堆对象删除引用,成为栈对象的下游场景2:对象被一个栈对象删除引用࿰…...
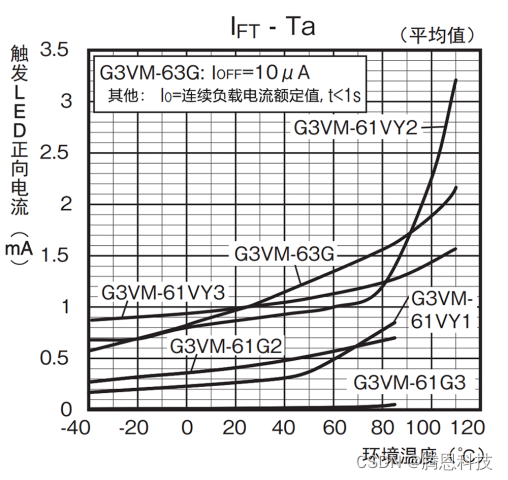
MOS FET继电器(无机械触点继电器)设计输入侧电源时的电流值概念
设计输入侧电源时的问题 机械式继电器、MOS FET继电器分别具有不同的特长。基于对MOS FET继电器所具小型及长寿命、静音动作等优势的需求,目前已经出现了所用机械式继电器向MOS FET继电器转化的趋势。 但是,由于机械式继电器与MOS FET继电器在产品结构…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...

DiscuzX3.5发帖json api
参考文章:PHP实现独立Discuz站外发帖(直连操作数据库)_discuz 发帖api-CSDN博客 简单改造了一下,适配我自己的需求 有一个站点存在多个采集站,我想通过主站拿标题,采集站拿内容 使用到的sql如下 CREATE TABLE pre_forum_post_…...

webpack面试题
面试题:webpack介绍和简单使用 一、webpack(模块化打包工具)1. webpack是把项目当作一个整体,通过给定的一个主文件,webpack将从这个主文件开始找到你项目当中的所有依赖文件,使用loaders来处理它们&#x…...
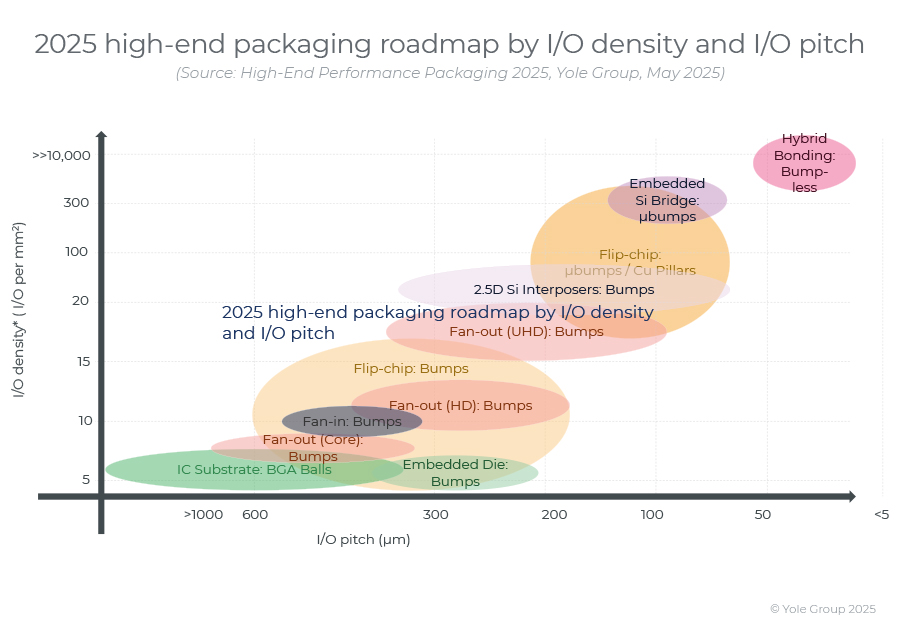
高端性能封装正在突破性能壁垒,其芯片集成技术助力人工智能革命。
2024 年,高端封装市场规模为 80 亿美元,预计到 2030 年将超过 280 亿美元,2024-2030 年复合年增长率为 23%。 细分到各个终端市场,最大的高端性能封装市场是“电信和基础设施”,2024 年该市场创造了超过 67% 的收入。…...

深度解析云存储:概念、架构与应用实践
在数据爆炸式增长的时代,传统本地存储因容量限制、管理复杂等问题,已难以满足企业和个人的需求。云存储凭借灵活扩展、便捷访问等特性,成为数据存储领域的主流解决方案。从个人照片备份到企业核心数据管理,云存储正重塑数据存储与…...

el-amap-bezier-curve运用及线弧度设置
文章目录 简介示例线弧度属性主要弧度相关属性其他相关样式属性完整示例链接简介 el-amap-bezier-curve 是 Vue-Amap 组件库中的一个组件,用于在 高德地图 上绘制贝塞尔曲线。 基本用法属性path定义曲线的路径,可以是多个弧线段的组合。stroke-weight线条的宽度。stroke…...