数据同步工具Sqoop
- 大数据Hadoop之——数据同步工具Sqoop
- Sqoop基本原理及常用方法
1 概述
Apache Sqoop(SQL-to-Hadoop)项目旨在协助RDBMS(Relational Database Management System:关系型数据库管理系统)与Hadoop之间进行高效的大数据交流。用户可以在 Sqoop 的帮助下,轻松地把关系型数据库的数据导入到 Hadoop 与其相关的系统 (如HBase和Hive)中;同时也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。
Sqoop是一个在结构化数据和Hadoop之间进行批量数据迁移的工具,结构化数据可以是MySQL、Oracle等RDBMS。Sqoop底层用MapReduce程序实现抽取、转换、加载,MapReduce天生的特性保证了并行化和高容错率,而且相比Kettle等传统ETL工具,任务跑在Hadoop集群上,减少了ETL服务器资源的使用情况。在特定场景下,抽取过程会有很大的性能提升。
Sqoop的导入和导出功能是通过基于Map Task(只有map)的MapReduce作业实现的。所以它是一种批处理方式进行数据传输,难以实现实时的数据进行导入和导出。
官网:sqoop.apache.org/ 官方文档:sqoop.apache.org/docs/1.99.7… GitHub:github.com/apache/sqoo…
1.1 功能
- (超详细)数据转换工具Sqoop的实战
import : RDBMS–>Hadoop
- 将数据从关系型数据库或大型主机导入到Hadoop平台,导入进程中的输入内容是数据库表或主机数据集。对于数据库,Sqoop将逐行读取表格到Hadoop。对于主机数据集,Sqoop将从每个主机数据集读取记录到HDFS。导入过程的输出是一组文件,其中包含导入的表或数据集的副本。导入过程是并行执行的。因此,输出将在多个文件中产生。
export: Hadoop – > RDBMS
- 将数据从Hadoop平台导出到关系数据库或大型主机,Sqoop的导出过程会并行地从HDFS读取所需数据,将它们解析为记录,如果导出到数据库,则将它们作为新行插入到目标数据库表中,如果导出到大型主机,则直接形成数据集,供外部应用程序或用户使用。
用户使用Sqoop时,只需要通过简单的命令进行操作,Sqoop会自动化数据传输中的大部分过程。Sqoop使用MapReduce导入和导出数据,提供并行操作和容错功能。 在使用Sqoop的过程中,用户可以定制导入、导出过程的大多数方面,可以控制导入的特定行范围或列,也可以为数据的基于文件的表示以及所使用的文件格式指定特定的分隔符和转义字符。
1.2 特点
-
优点:它可以将跨平台的数据进行整合。
-
缺点:它不是很灵活。
-
并行处理
Sqoop充分利用了MapReduce的并行特点,以批处理的方式加快数据的传输,同时也借助MapReduce实现了容错。
-
适用性高
通过JDBC接口和关系型数据库进行交互,理论上支持JDBC接口的数据库都可以使用Sqoop和Hadoop进行数据交互。
-
使用简单
用户通过命令行的方式对Sqoop进行操作,一共只有15条命令。其中13条命令用于数据处理,操作简单,用户可以轻松地完成Hadoop与RDBMS的数据交互。
1.3 CDH部署Sqoop
- CDH6.3.2集群部署5—添加sqoop
2 架构
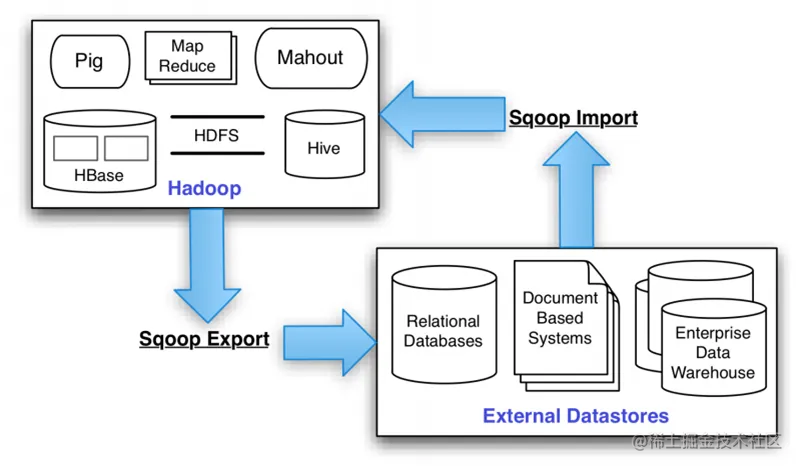
sqoop的底层实现是mapreduce,所以sqoop依赖于hadoop,sqoop将导入或导出命令翻译成MapReduce程序来实现,在翻译出的MapReduce 中主要是对InputFormat和OutputFormat进行定制。
2.1 数据导入(RDBMS->Haoop)
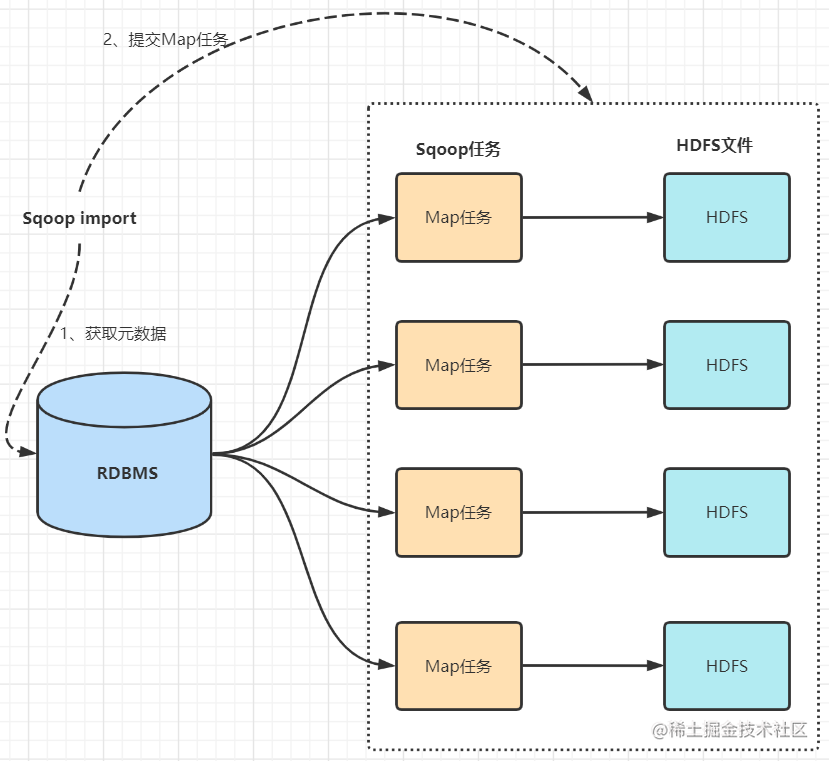
- sqoop会通过jdbc来获取需要的数据库的元数据信息,例如:导入的表的列名,数据类型。
- 这些数据库的数据类型会被映射成为java的数据类型,根据这些信息,sqoop会生成一个与表名相同的类用来完成序列化工作,保存表中的每一行记录。
- sqoop开启MapReduce作业
- 启动的作业在input的过程中,会通过jdbc读取数据表中的内容,这时,会使用sqoop生成的类进行序列化。
- 最后将这些记录写到hdfs上,在写入hdfs的过程中,同样会使用sqoop生成的类进行反序列化。
2.2 数据导出(Haoop->RDBMS)
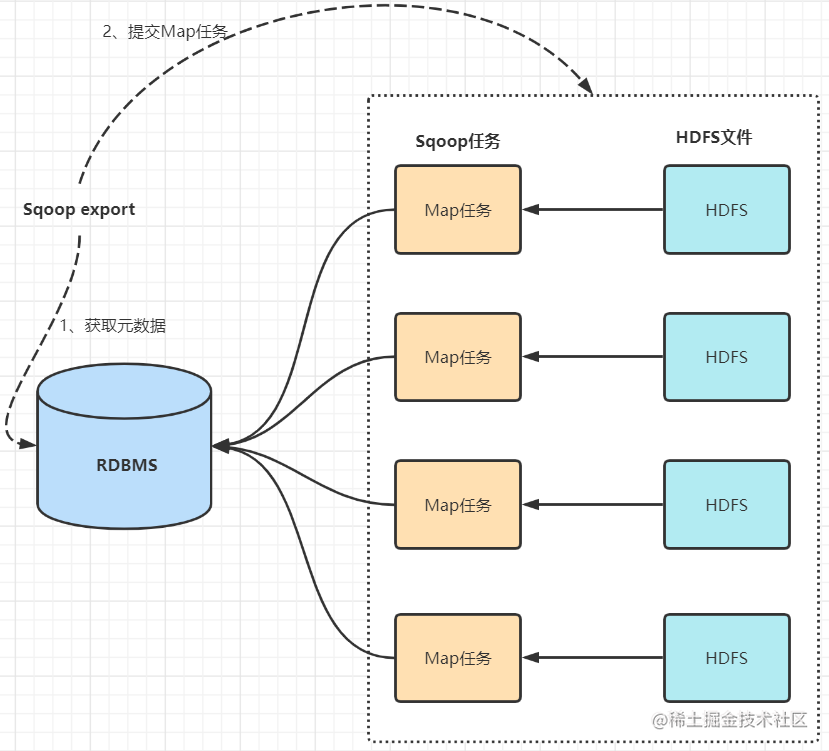
- 首先sqoop通过jdbc访问关系型数据库获取需要导出的信息的元数据信息
- 根据获取的元数据信息,sqoop生成一个Java类,用来承载数据的传输,该类必须实现序列化
- 启动MapReduce程序
- sqoop利用生成的这个类,并行从hdfs中获取数据
- 每个map作业都会根据读取到的导出表的元数据信息和读取到的数据,生成一批insert 语句,然后多个map作业会并行的向MySQL中插入数据。
3 Sqoop常用命令及参数
- Sqoop常用命令及参数
3.1 常用命令
| 序号 | 命令 | 类 | 说明 |
|---|---|---|---|
| 1 | import | ImportTool | 将数据导入到集群 |
| 2 | export | ExportTool | 将集群数据导出 |
| 3 | codegen | CodeGenTool | 获取数据库中某张表数据生成Java并打包Jar |
| 4 | createhive-table | CreateHiveTableTool | 创建Hive表 |
| 5 | eval | EvalSqlTool | 查看SQL执行结果 |
| 6 | importall-tables | ImportAllTablesTool | 导入某个数据库下所有表到HDFS中 |
| 7 | job | JobTool | 用来生成一个sqoop的任务,生成后,该任务并不执行,除非使用命令执行该任务。 |
| 8 | list-databases | ListDatabasesTool | 列出所有数据库名 |
| 9 | list-tables | ListTablesTool | 列出某个数据库下所有表 |
| 10 | merge | MergeTool | 将HDFS中不同目录下面的数据合在一起,并存放在指定的目录中 |
| 11 | metastore | MetastoreTool | 记录sqoop job的元数据信息,如果不启动metastore实例,则默认的元数据存储目录为:~/.sqoop,如果要更改存储目 录,可以在配置文件sqoopsite.xml中进行更改。 |
| 12 | help | HelpTool | 打印sqoop帮助信息 |
| 13 | version | VersionTool | 打印sqoop版本信息 |
3.2 常用参数
所谓公用参数,就是大多数命令都支持的参数。
3.2.1 公用参数 – 数据库连接
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | –connect | 连接关系型数据库的URL |
| 2 | –connection-manager | 指定要使用的连接管理类 |
| 3 | –driver | Hadoop根目录 |
| 4 | –help | 打印帮助信息 |
| 5 | –password | 连接数据库的密码 |
| 6 | –username | 连接数据库的用户名 |
| 7 | –verbose | 在控制台打印出详细信息 |
3.2.2 公用参数 – import
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | –enclosed-by | 给字段值前加上指定的字符 |
| 2 | –escaped-by | 对字段中的双引号加转义符 |
| 3 | –fields-terminated-by | 设定每个字段是以什么符号作为结束,默认为逗号 |
| 4 | –lines-terminated-by | 设定每行记录之间的分隔符,默认是\n |
| 5 | –mysql-delimiters | Mysql默认的分隔符设置,字段之间以逗号分隔,行之间以\n分隔,默认转义符是\,字段值以单引号包裹 |
| 6 | –optionally-enclosed-by | 给带有双引号或单引号的字段值前后加上指定字符 |
Import的控制参数,常见Import的控制参数有如下几个:
| Argument | Description |
|---|---|
| –append | 通过追加的方式导入到HDFS |
| –as-avrodatafile | 导入为 Avro Data 文件格式 |
| –as-sequencefile | 导入为 SequenceFiles文件格式 |
| –as-textfile | 导入为文本格式 (默认值) |
| –as-parquetfile | 导入为 Parquet 文件格式 |
| –columns | 指定要导入的列 |
| –delete-target-dir | 如果目标文件夹存在,则删除 |
| –fetch-size | 一次从数据库读取的数量大小 |
| -m,–num-mappers | n 用来指定map tasks的数量,用来做并行导入 |
| e,–query | 指定要查询的SQL语句 |
| –split-by | 用来指定分片的列 |
| –table | 需要导入的表名 |
| -target-dir | HDFS 的目标文件夹 |
| –where | 用来指定导入数据的where条件 |
| -z,–compress | 是否要压缩 |
| –compression-codec | 使用Hadoop压缩 (默认是 gzip) |
3.2.3 公用参数 – export
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | –input-enclosed-by | 对字段值前后加上指定字符 |
| 2 | –input-escaped-by | 对含有转移符的字段做转义处理 |
| 3 | –input-fields-terminated-by | 字段之间的分隔符 |
| 4 | –input-lines-terminated-by | 行之间的分隔符 |
| 5 | –input-optionally-enclosed-by | 给带有双引号或单引号的字段前后加上指定字符 |
3.2.4 公用参数 – hive
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | –hive-delims-replacement | 用自定义的字符串替换掉数据中的\r\n和\013\010等字符 |
| 2 | –hive-drop-import-delims | 在导入数据到hive时,去掉数据中的\r\n\013\010这样的字符 |
| 3 | –map-column-hive | 生成hive表时,可以更改生成字段的数据类型 |
| 4 | –hive-partition-key | 创建分区,后面直接跟分区名,分区字段的默认类型为string |
| 5 | –hive-partition-value | 导入数据时,指定某个分区的值 |
| 6 | –hive-home | hive的安装目录,可以通过该参数覆盖之前默认配置的目录 |
| 7 | –hive-import | 将数据从关系数据库中导入到hive表中 |
| 8 | –hive-overwrite | 覆盖掉在hive表中已经存在的数据 |
| 9 | –create-hive-table | 默认是false,即,如果目标表已经存在了,那么创建任务失败。 |
| 10 | –hive-table | 后面接要创建的hive表,默认使用MySQL的表名 |
| 11 | –table | 指定关系数据库的表名 |
3.2.5 import参数
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | –append | 将数据追加到HDFS中已经存在的DataSet中,如果使用该参数,sqoop会把数据先导入到临时文件目录,再合并。 |
| 2 | –as-avrodatafile | 将数据导入到一个Avro数据文件中 |
| 3 | –as-sequencefile | 将数据导入到一个sequence文件中 |
| 4 | –as-textfile | 将数据导入到一个普通文本文件中 |
| 5 | –boundary-query | 边界查询,导入的数据为该参数的值(一条sql语句)所执行的结果区间内的数据。 |
| 6 | –columns <col1, col2, col3> | 指定要导入的字段 |
| 7 | –direct | 直接导入模式,使用的是关系数据库自带的导入导出工具,以便加快导入导出过程。 |
| 8 | –direct-split-size | 在使用上面direct直接导入的基础上,对导入的流按字节分块,即达到该阈值就产生一个新的文件 |
| 9 | –inline-lob-limit | 设定大对象数据类型的最大值 |
| 10 | –m或–num-mappers | 启动N个map来并行导入数据,默认4个。 |
| 11 | –query或–e | 将查询结果的数据导入,使用时必须伴随参–target-dir,–hive-table,如果查询中有where条件,则条件后必须加上$CONDITIONS关键字 |
| 12 | –split-by | 按照某一列来切分表的工作单元,不能与–autoreset-to-one-mapper连用(请参考官方文档) |
| 13 | –table | 关系数据库的表名 |
| 14 | –target-dir | 指定HDFS路径 |
| 15 | –warehouse-dir | 与14参数不能同时使用,导入数据到HDFS时指定的目录 |
| 16 | –where | 从关系数据库导入数据时的查询条件 |
| 17 | –z或–compress | 允许压缩 |
| 18 | –compression-codec | 指定hadoop压缩编码类,默认为gzip(Use Hadoop codec default gzip) |
| 19 | –null-string | string类型的列如果null,替换为指定字符串 |
| 20 | –null-non-string | 非string类型的列如果null,替换为指定字符串 |
| 21 | –check-column | 作为增量导入判断的列名 |
| 22 | –incremental | mode:append或lastmodified |
| 23 | –last-value | 指定某一个值,用于标记增量导入的位置 |
3.2.6 export参数
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | –direct | 利用数据库自带的导入导出工具,以便于提高效率 |
| 2 | –export-dir | 存放数据的HDFS的源目录 |
| 3 | -m或–num-mappers | 启动N个map来并行导入数据,默认4个 |
| 4 | –table | 指定导出到哪个RDBMS中的表 |
| 5 | –update-key | 对某一列的字段进行更新操作 |
| 6 | –update-mode | updateonly allowinsert(默认) |
| 7 | –input-null-string | 请参考import该类似参数说明 |
| 8 | –input-null-non-string | 请参考import该类似参数说明 |
| 9 | –staging-table | 创建一张临时表,用于存放所有事务的结果,然后将所有事务结果一次性导入到目标表中,防止错误。 |
| 10 | –clear-staging-table | 如果第9个参数非空,则可以在导出操作执行前,清空临时事务结果表 |
3.3 常用参数
| 参数 | 说明 |
|---|---|
| –connect | 连接关系型数据库的URL |
| –username | 连接数据库的用户名 |
| –password | 连接数据库的密码 |
| –driver | JDBC的driver class |
| –query或–e <> | 将查询结果的数据导入,使用时必须伴随参–target-dir,–hcatalog-table,如果查询中有where条件,则条件后必须加上C O N D I T I O N S 关 键 字 。 如 果 使 用 双 引 号 包 含 s q l , 则 CONDITIONS关键字。如果使用双引号包含sql,则CONDITIONS关键字。如果使用双引号包含sql,则CONDITIONS前要加上\以完成转义:$CONDITIONS |
| –hcatalog-database | 指定HCatalog表的数据库名称。如果未指定,default则使用默认数据库名称。提供 --hcatalog-database不带选项–hcatalog-table是错误的。 |
| –hcatalog-table | 此选项的参数值为HCatalog表名。该–hcatalog-table选项的存在表示导入或导出作业是使用HCatalog表完成的,并且是HCatalog作业的必需选项。 |
| –create-hcatalog-table | 此选项指定在导入数据时是否应自动创建HCatalog表。表名将与转换为小写的数据库表名相同。 |
| –hcatalog-storage-stanza ‘stored as orc tblproperties (“orc.compress”=“SNAPPY”)’ \ | 建表时追加存储格式到建表语句中,tblproperties修改表的属性,这里设置orc的压缩格式为SNAPPY |
| -m | 指定并行处理的MapReduce任务数量。-m不为1时,需要用split-by指定分片字段进行并行导入,尽量指定int型。 |
| –split-by id | 如果指定-split by, 必须使用$CONDITIONS关键字, 双引号的查询语句还要加\ |
| –hcatalog-partition-keys 或 --hcatalog-partition-values | keys和values必须同时存在,相当于指定静态分区。允许将多个键和值提供为静态分区键。多个选项值之间用,(逗号)分隔。比如:–hcatalog-partition-keys year,month,day 和 --hcatalog-partition-values 1999,12,31 |
| –null-string ‘\N’ 或 --null-non-string ‘\N’ | 指定mysql数据为空值时用什么符号存储,null-string针对string类型的NULL值处理,–null-non-string针对非string类型的NULL值处理 |
| –hive-drop-import-delims | 设置无视字符串中的分割符(hcatalog默认开启) |
| –fields-terminated-by ‘\t’ | 设置字段分隔符 |
4 Sqoop抽取的两种方式
对于Mysql数据的采集,通常使用Sqoop来进行。
通过Sqoop将关系型数据库数据到Hive有两种方式,一种是原生Sqoop API,一种是使用HCatalog API。两种方式略有不同。
HCatalog方式与Sqoop方式的参数基本都是相同,只是个别不一样,都是可以实现Sqoop将数据抽取到Hive。
4.1 区别
4.1.1 数据格式区别
Sqoop方式支持的数据格式较少,HCatalog支持的数据格式多,包括RCFile, ORCFile, CSV, JSON和SequenceFile等格式。
4.1.2 数据覆盖
Sqoop方式允许数据覆盖,HCatalog不允许数据覆盖,每次都只是追加。
4.1.3 字段名
Sqoop方式比较随意,不要求源表和目标表字段相同(字段名称和个数都可以不相同),它抽取的方式是将字段按顺序插入,比如目标表有3个字段,源表有一个字段,它会将数据插入到Hive表的第一个字段,其余字段为NULL。但是HCatalog不同,源表和目标表字段名需要相同,字段个数可以不相等,如果字段名不同,抽取数据的时候会报NullPointerException错误。HCatalog抽取数据时,会将字段对应到相同字段名的字段上,哪怕字段个数不相等。
4.2 Sqoop的方式
sqoop import \
--hive-import \
--connect 'jdbc:mysql://localhost:3306/test' \
--username 'root' \
--password '123456789' \
--query " select order_no from driver_action where \$CONDITIONS" \
--hive-database test \
--hive-table driver_action \
--hive-partition-key pt \
--hive-partition-value 20190901 \
--null-string '' \
--null-non-string '' \
--num-mappers 1 \
--target-dir /tmp/test \
--delete-target-dir
4.3 HCatalog方式
sqoop import \
--connect jdbc:mysql://localhost:3306/test\
--username 'root' \
--password 'root' \
--query "SELECT order_no FROM driver_action WHERE \$CONDITIONS" \
--hcatalog-database test \
--hcatalog-table driver_action \
--hcatalog-partition-keys pt \
--hcatalog-partition-values 20200104 \
--hcatalog-storage-stanza 'stored as orcfile tblproperties ("orc.compress"="SNAPPY")' \
--num-mappers 1
4.4 针对不同字段名,想要使用HCatalog方式将数据插入,可以使用下面的方式
sqoop import \
--connect jdbc:mysql://localhost:3306/test\
--username 'root' \
--password 'root' \
--query "SELECT order_no_src as order_no_target FROM driver_action WHERE \$CONDITIONS" \
--hcatalog-database test \
--hcatalog-table driver_action \
--hcatalog-partition-keys pt \
--hcatalog-partition-values 20200104 \
--hcatalog-storage-stanza 'stored as orc tblproperties ("orc.compress"="SNAPPY")' \
--num-mappers 1
5 Sqoop导入实战
- Sqoop简介以及使用
- sqoop操作示例
5.1 Mysql到Hive
- sqoop导入mysql数据到Hive的各种方案
- Sqoop将MySQL数据增量导入Hive示例
- sqoop导oracle数据到hive中并动态分区
- sqoop 将mysql表导入到hive分区表
Sqoop连接MySQL需要MySQL的jar包,上传到Sqoop的lib目录下,CDH下Sqoop目录:/opt/cloudera/parcels/CDH-6.3.2.xxxxxxx/lib/sqoop/lib。
测试Sqoop能否连接到MySQL,查看存在的数据库:
sqoop list-databases --connect jdbc:mysql://192.168.0.161:3306/ --username root --password 123456
将关系型数据的表结构复制到hive中,只是复制表的结构,表中的内容没有复制过去。
sqoop create-hive-table -connect jdbc:mysql://localhost:3306/sample -table student -username root -password 123456 -hive-table test
其中–table student为 MySQL 中的数据库 sample中的表–hive-table test为 hive中新建的表名称。
指定分区:
#!/bin/shsqoop import \
--connect jdbc:oracle:thin:@127.0.0.1:1521:orcl \
--username test \
--password 123456 \
--columns "viewTime,userid,page_url,referrer_url,ip" \
--hive-partition-key "dt" \
--hive-partition-value "2018" \
--query "SELECT viewTime,userid,page_url,referrer_url,ip from page_view WHERE 1=1 and \$CONDITIONS" \
--hive-table test.page_view \
--hive-drop-import-delims \
--target-dir "/data/test/page_view" \
--hive-overwrite \
--null-string '\\N' \
--null-non-string '\\N' \
--hive-import;
在使用sqoop导入数据的时候可以指定分区,但是--hive-partition-key和--hive-partition-value选项只能指定一个参数,可以使用--hcatalog-partition-keys和--hcatalog-partition-values选项指定多个分区字段,用逗号分隔。
导入分区表:
sqoop import \
--connect jdbc:mysql://single:3306/retail_db \
--driver com.mysql.jdbc.Driver \
--username root \
--password kb10 \
--query "select order_id,order_status from orders where
order_date>='2014-07-02' and order_date<'2014-07-03' and \$CONDITIONS" \
--hive-import \
--hive-database sqooptest \
--hive-table order_partition \
--hive-partition-key 'order_date' \
--hive-partition-value '2014-07-02' \
-m 1
Sqoop将MySQL数据增量导入Hive示例脚本:
#!/bin/bashexport sqoop_home=/usr/bin/sqoop-- 判断有无传参,有传参使用传参
if [ $# -eq 1 ]
then datestr=$1
elsedatestr=`date -d '-1 day' +%Y -%m-%d`
fistart_time=`date +%Y-%m-%d`
year_stat=`date +%Y`
month_stat=`date +%m` jdbc_url='jdbc:mysql://hadoop01:3306/nev'
username='root'
password='123456'${sqoop_home} import \
--connect ${jdbc_url} \
--username ${username} --password ${password} \
--query "SELECT
id,create_date_time,session_id,sid,create_time,seo_source,seo_keywords,
ip,area,country,province,city,origin_channel,user AS user_match,
manual_time,begin_time,end_time,last_customer_msg_time_stamp,
last_agent_msg_time_stamp,reply_msg_count,msg_count,browser_name,os_info,
'${start_time}' AS starts_time
FROM web_chat_ems_${year_stat}_${month_stat}
WHERE create_time BETWEEN '${datestr} 00:00:00' AND '${start_time} 00:00:00' and \$CONDITIONS" \
--hcatalog-database itcast_ods \
--hcatalog-table web_chat_ems \
--hive-partition-key starts_time \
--hive-partition-value ${datestr} \
-m 100 \
--split-by idwait${sqoop_home} import \
--connect ${jdbc_url} \
--username ${username} --password ${password} \
--query "SELECT
wcte.id,
wcte.referrer,
wcte.from_url,
wcte.landing_page_url,
wcte.url_title,
wcte.platform_description,
wcte.other_params,
wcte.history,
'${start_time}' AS start_time
FROM
(SELECT *
FROM web_chat_ems_${year_stat}_${month_stat}
WHERE create_time BETWEEN '${datestr} 00:00:00' AND '${start_time} 00:00:00') tmp
JOIN web_chat_text_ems_${year_stat}_${month_stat} wcte ON tmp.id = wcte.id and \$CONDITIONS" \
--hcatalog-database itcast_ods \
--hcatalog-table web_chat_text_ems \
--hive-partition-key start_time \
--hive-partition-value ${datestr} \
-m 100 \
--split-by id
5.2 mysql数据导入数据仓库Hive的各种方案
采用sqoop向hive中导入原始数据形成ODS层,之后可以在原始数据的基础上进行增量备份数据(定时同步)或者通过canal解析binlog(实时同步)日志进行同步数据。
5.2.1 sqoop向hive中导数据的原理
sqoop在向hive中导入数据时,是先将数据上传到hdfs中,然后创建表,最后再将hdfs中的数据load到表目录下。
我们采用sqoop直接导入hive并自动创建hive表,产生的是hive内部表。
可以通过查看表的位置信息识别(desc formatted table_name;):
-
内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),由hive自身管理
-
外部表的存储位置可以自定义,由HDFS管理,
-
删除内部表会直接删除元数据(metadata)及存储数据;
-
删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除。
5.2.2 sqoop导入hive的具体种类
sqoop导入数据到hive其实细分很多种情况:
全量备份(初次导入原始数据)
1.先将数据导入hdfs中,然后在hive中自己建内部表,将数据load进hive中(load完之后hdfs中的数据就会消失)
2.先将数据导入hdfs,然后自己建hive外部表,设置location hdfs的路径,做数据关联(源数据路径不变)
3.将数据直接导入已创建好的hive表中(需要你手动建表)
4.将数据导入hive中,hive表不存在,导入的时候自动创建hive表
5.表如果过多,可以考虑使用import-all-tables工具一次性全库导入,导入的同时自动生成表,但是必须满足以下条件:5.1.每个表必须具有主键或使用--autoreset-to-one-mapper选项。5.2.会导入每张表的所有列。5.3.使用默认拆分列,不能使用WHERE条件
增量备份(后续在原始数据的基础上做数据同步)
1.Append方式,以唯一id为依据,在指定值的基础上导入新数据
2.lastModify方式,以最后修改时间为依据,同步指定时间节点之后修改的数据
5.2.3 sqoop导入的一些参数说明
--hive-import 插入数据到hive当中,使用hive的默认分隔符
--hive-overwrite 重写插入
--create-hive-table 建表,如果表已经存在,该操作会报错!
--hive-table [table] 设置到hive当中的表名
--hive-drop-import-delims 导入到hive时删除 \n, \r, and \01
--hive-delims-replacement 导入到hive时用自定义的字符替换掉 \n, \r, and \01
--hive-partition-key hive分区的key
--hive-partition-value hive分区的值
--map-column-hive 类型匹配,sql类型对应到hive类型
--direct 是为了利用某些数据库本身提供的快速导入导出数据的工具,比如mysql的mysqldump
性能比jdbc更好,但是不知大对象的列,使用的时候,那些快速导入的工具的客户端必须的shell脚本的目录下
--columns <列名> 指定列
-z, –compress 打开压缩功能
–compression-codec < c > 使用Hadoop的压缩,默认为gzip压缩
–fetch-size < n > 从数据库一次性读入的记录数
–as-avrodatafile 导入数据格式为avro
–as-sequencefile 导入数据格式为sqeuqncefile
–as-textfile 导入数据格式为textfile
--as-parquetfile 导入数据格式为parquet
--query 'select * from test_table where id>10 and $CONDITIONS' \ ($CONDITIONS必须要加上就相当于一个配置参数,sql语句用单引号,用了SQL查询就不能加参数--table )
--target-dir /sqoop/emp/test/ \ (指定导入的目录,若不指定就会导入默认的HDFS存储路径:/user/root/XXX.)
--delete-target-dir (如果指定目录存在就删除它,一般都是用在全量导入,增量导入的时候加该参数会报错)
--fields-terminated-by '\n' \ (指定字段分割符为',')
--null-string '\\N' \ (string类型空值的替换符(Hive中Null用\n表示))
--null-non-string '\\N' \ (非string类型空值的替换符)
--split-by id \ (根据id字段来切分工作单元实现哈希分片,从而将不同分片的数据分发到不同 map 任务上去跑,避免数据倾斜。)
-m 3 (使用3个mapper任务,即进程,并发导入)
一般RDBMS的导出速度控制在60~80MB/s,每个 map 任务的处理速度5~10MB/s 估算,即 -m 参数一般设置4~8,表示启动 4~8 个map 任务并发抽取。
5.2.4 实际导入代码,已亲测,可直接复制执行(记得换自己的数据库连接)
# 全量备份(将数据导入到HDFS指定目录)
sqoop import --connect jdbc:mysql://11.25.57.18:3306/usercenter_test \
--username root --password 123456 \
--query 'select * from useradmin where id>10 and $CONDITIONS' \
--target-dir /user/root/test/ \
--delete-target-dir \
--fields-terminated-by '\t' \
--hive-drop-import-delims \
--null-string '\\N' \
--null-non-string '\\N' \
--split-by id \
-m 1# 全量备份(导入已有的hive表)
sqoop import --connect jdbc:mysql://11.25.57.18:3306/usercenter_test \
--username root --password 123456 --table useradmin \
--hive-import \
--hive-database test \
--hive-table useradmin \
--fields-terminated-by '\t' \
--hive-overwrite \
--null-string '\\N' \
--null-non-string '\\N' \
--split-by id \
-m 1 # 全量备份(hive表不存在,导入时自动创建hive表)
sqoop import --connect jdbc:mysql://11.25.57.18:3306/usercenter_test \
--username root --password 123456 --table users \
--hive-import \
--hive-database test1 \
--create-hive-table \
--fields-terminated-by '\t' \
--null-string '\\N' \
--null-non-string '\\N' \
--split-by id \
-m 1 # 全库导入
sqoop import-all-tables "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \
--connect jdbc:mysql://11.25.57.18:3306/usercenter_test \
--username root \
--password 123456 \
--hive-import \
--hive-overwrite \
--hive-database original_usercenter_test \
--fields-terminated-by '\t' \
--exclude-tables 'drop_table' \
--as-parquetfile #--exclude-tables 'drop_table' \ (此参数可以 exclude掉不需要import的表(多个表逗号分隔))
#--create-hive-table \ (不能和as-parquetfile共用)
#--direct \ (只支持文本格式,不能和as-parquetfile共用)
#--as-textfile \# 增量备份lastmodified模式不支持直接导入Hive表(但是可以使用导入HDFS的方法,只不过--target-dir设置成Hive table在HDFS中的关联位置即可)
sqoop import --connect jdbc:mysql://11.25.57.18:3306/usercenter_test \
--username root --password 123456 --table useradmin \
--target-dir /user/hive/warehouse/test.db/useradmin \
--null-string '\\N' \
--null-non-string '\\N' \
--split-by id \
-m 1 \
--fields-terminated-by '\t' \
--hive-drop-import-delims \
--incremental lastmodified \
--check-column CreateTime \
--last-value '2019-06-04 14:29:01' \
--append# 增量备份append模式,可以增量的导入hive表
sqoop import --connect jdbc:mysql://11.25.57.18:3306/usercenter_test \
--username root --password 123456 --table useradmin \
--hive-import \
--hive-database test \
--hive-table useradmin \
--hive-drop-import-delims \
--fields-terminated-by '\t' \
--null-string '\\N' \
--null-non-string '\\N' \
--incremental append \
--check-column id \
--last-value 18 \
--split-by id \
-m 1
5.3 导入数据到orc格式hive指定分区表中
- 【sqoop】导入数据到orc格式hive指定分区表中
Sqoop需要依赖HCatalog的lib,所以需要配置环境变量$HCAT_HOME,一般从hive目录下即可找到hcatalog的相关路径
- hive/lib中将hive-hcatalog-core-1.2.2.jar复制到sqoop/lib下
cp $HIVE_HOME/lib/hive-shims* $SQOOP_HOME/lib/- 在/etc/profile文件中添加
export HCATALOG_HOME=${HIVE_HOME}/hcatalog
下面的脚本中需要赋值的变量
${IP} mysql所在的服务器IP
${USERNAME} mysql用户名
${PWD} mysql密码
$MYSQLTABLE mysql表
${date_field} 表中的时间字段
${partition_name} hive中需要加入的分区字段名
${partition_value} hive分区值
5.3.1 sqoop创建并导入数据到hive orc表
sqoop import \
--connect jdbc:mysql://$IP:3306/$MYSQLDB \
--username $USERNAME \
--password $PWD \
--table $MYSQLTABLE \
--driver com.mysql.jdbc.Driver \
--hcatalog-database intelligentCoal \
--create-hcatalog-table \
--hcatalog-table t_user_orc \
--where "date_format(${date_field},'%Y-%m-%d')='${partition_value}' and \$CONDITIONS" \
--hcatalog-partition-keys ${partition_name} \
--hcatalog-partition-values ${partition_value} \
--hcatalog-storage-stanza 'stored as orc tblproperties ("orc.compress"="SNAPPY")' \
-m 1
where选项根据需求自行添加或者不加,不加where的效果和 --where “1=1 and $CONDITIONS” \ 一样
5.3.2 sqoop导入数据到已存在的hive orc表
sqoop import \
--connect jdbc:mysql://$IP:3306/$MYSQLDB \
--username $USERNAME \
--password $PWD \
--table $MYSQLTABLE \
--driver com.mysql.jdbc.Driver \
--hcatalog-database intelligentCoal \
--hcatalog-table t_user_orc \
--where "date_format(${date_field},'%Y-%m-%d')='${partition_value}' and \$CONDITIONS" \
--hcatalog-partition-keys ${partition_name} \
--hcatalog-partition-values ${partition_value} \
--hcatalog-storage-stanza 'stored as orc tblproperties ("orc.compress"="SNAPPY")' \
-m 1
若不指定字段类型,MySQL中的varchar数据抽取至hive中也会是varchar类型,但是varchar类型在hive中操作会出现各种问题
1.抽取时长文本、含有特殊字符的文本抽取不全
2.hive操作orc表varchar类型的字段造成乱码
解决:抽取数据时指定字段类型(xxx是你要改成String类型的column)
-map-column-hive xxx=String,xxxx=String
connect JDBC连接信息 username JDBC验证用户名 password JDBC验证密码 table 要导入的源表名 driver 指定JDBC驱动 create-hcatalog-table 指定需要创建表,若不指定则默认不创建,注意若指定创建的表已存在将会报错 hcatalog-table 要导出的目标表名 hcatalog-storage-stanza 指定存储格式,该参数值会拼接到create table的命令中。默认:stored as rcfile hcatalog-partition-keys 指定分区字段,多个字段请用逗号隔开(hive-partition-key的加强版) hcatalog-partition-values 指定分区值,多分区值请用逗号隔开(hive-partition-value的加强)
5.4 HCatalog方式与Sqoop方式两者的区别
(1)数据格式
Sqoop方式支持的数据格式较少,HCatalog支持的较多,比如Sqoop方式不支持ORC格式的表,但是HCatalog支持。
(2)数据增加形式
Sqoop方式允许数据覆盖,HCatalog不允许数据覆盖,每次都只是追加。
(3)字段一致性
Sqoop方式比较随意,不要求源表和目标表字段相同(字段名称和个数都可以不相同),它抽取的方式是将字段按顺序插入,比如目标表有三个字段,源表只有一个字段,它会将数据插入到Hive表的第一个字段,其余字段为NULL。但是HCatalog不同,源表和目标表字段名需要相同,字段个数可以不相等,如果字段名不同,抽取数据的时候会报NullPointerException错误。HCatalog抽取数据时,会将字段对应到相同字段名的字段上,哪怕字段个数不相等。
6 Sqoop优化
6.1 -m与split-by的优化
- 小量数据时(200M左右) :最好使用一个map,快且减少小文件。
- 大量数据时:要特别考虑数据的特征,对于split- by最完美的情况是有一个:均匀分布的数字(如自增列)或时间字段,且这个字段还有索引(最好字段是int、tinyin),这样在抽取时使得并发的每个sq1处理相近的数据量,并且sqoop附加的where条件可以使用索引。
- split-by id,-m 2, 数据量1-100。第 一个mapper:(0,50]第二个mapper: (50, 100],对于m要综合考虑数据量、I0、源数据库的性能、集群的资源等等。一种简单的考虑是最大不超过yarn.上分配给这个用户的vcore个数,最小“数据量/m”要够一个128MB的文件。如果条件允许可以先设置一个值跑着试试,然后观察源数据库负载、集群I0以及运行时长等,再进行相应调整。
6.2 --fetch-size n
一次取mysq1中批量读取的数据条数。建议优化如下:
- 考虑一条数据的量。(如果2个字段和200个字段的–fetch-size不能一样)
- 考虑数据库的性能
- 考虑网络速度
- 最好的状态是一 次–fetch-si ze能满足一个mapper
附录A:Sqoop与DataX对比
A.1 Sqoop特点
Sqoop主要特点:
- 可以将关系型数据库中的数据导入hdfs、hive或者hbase等hadoop组件中,也可将hadoop组件中的数据导入到关系型数据库中;
- sqoop在导入导出数据时,充分采用了map-reduce计算框架,根据输入条件生成一个map-reduce作业,在hadoop集群中运行。采用map-reduce框架同时在多个节点进行import或者export操作,速度比单节点运行多个并行导入导出效率高,同时提供了良好的并发性和容错性;
- 支持insert、update模式,可以选择参数,若内容存在就更新,若不存在就插入;
- 对国外的主流关系型数据库支持性更好。
A.2 DataX特点
DataX主要特点:
- 异构数据库和文件系统之间的数据交换;
- 采用Framework + plugin架构构建,Framework处理了缓冲,流控,并发,上下文加载等高速数据交换的大部分技术问题,提供了简单的接口与插件交互,插件仅需实现对数据处理系统的访问;
- 数据传输过程在单进程内完成,全内存操作,不读写磁盘,也没有IPC;
- 开放式的框架,开发者可以在极短的时间开发一个新插件以快速支持新的数据库/文件系统。
A.3 Sqoop与DataX的区别
Sqoop与DataX的区别如下:
- sqoop采用map-reduce计算框架进行导入导出,而datax仅仅在运行datax的单台机器上进行数据的抽取和加载,速度比sqoop慢了许多;
- sqoop只可以在关系型数据库和hadoop组件之间进行数据迁移,而在hadoop相关组件之间,比如hive和hbase之间就无法使用sqoop互相导入导出数据,同时在关系型数据库之间,比如mysql和oracle之间也无法通过sqoop导入导出数据。
- 与之相反,datax能够分别实现关系型数据库hadoop组件之间、关系型数据库之间、hadoop组件之间的数据迁移;
- sqoop是专门为hadoop而生,对hadoop支持度好,而datax可能会出现不支持高版本hadoop的现象;
- sqoop只支持官方提供的指定几种关系型数据库和hadoop组件之间的数据交换,而在datax中,用户只需根据自身需求修改文件,生成相应rpm包,自行安装之后就可以使用自己定制的插件;
相关文章:
数据同步工具Sqoop
大数据Hadoop之——数据同步工具SqoopSqoop基本原理及常用方法 1 概述 Apache Sqoop(SQL-to-Hadoop)项目旨在协助RDBMS(Relational Database Management System:关系型数据库管理系统)与Hadoop之间进行高效的大数据交…...

Kafka 版本
kafka-2.11-2.1.1 : Kafka 1.0.0 后,Kafka 版本命名规则从 4 位到 3 位Kafka版本号是 2.1.1前 2 : 大版本号 (MajorVersion)中 1 : 小版本号或次版本号 (Minor Version)后 1 : 修订版本号 (Patch) Kafka 0.7 最早开源版本 : 只提供最基础的消息队列功…...
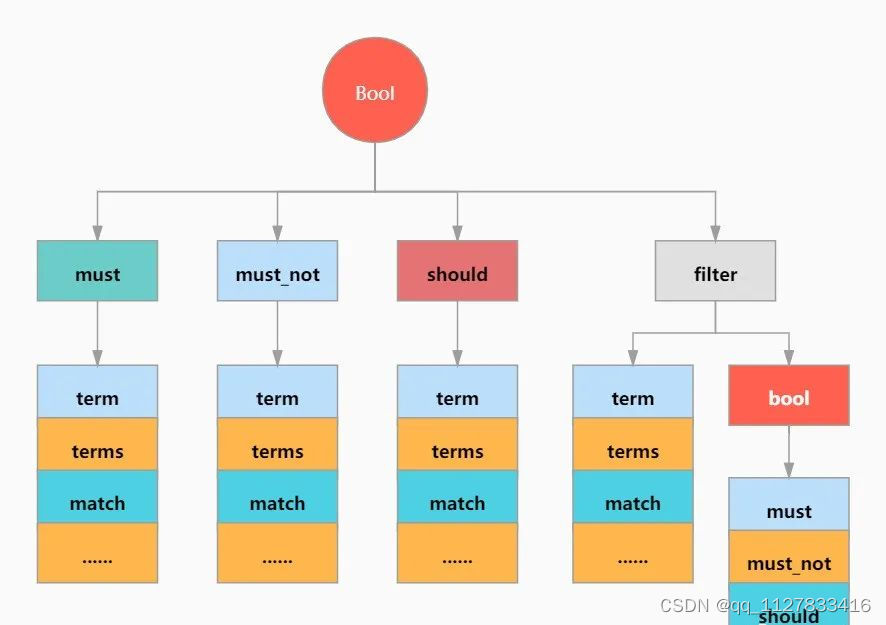
ElasticSearch 在Java中的各种实现
ES JavaAPI的相关体系: 词条查询 所谓词条查询,也就是ES不会对查询条件进行分词处理,只有当词条和查询字符串完全匹配时,才会被查询到。 等值查询-term 等值查询,即筛选出一个字段等于特定值的所有记录。 【SQL】 s…...
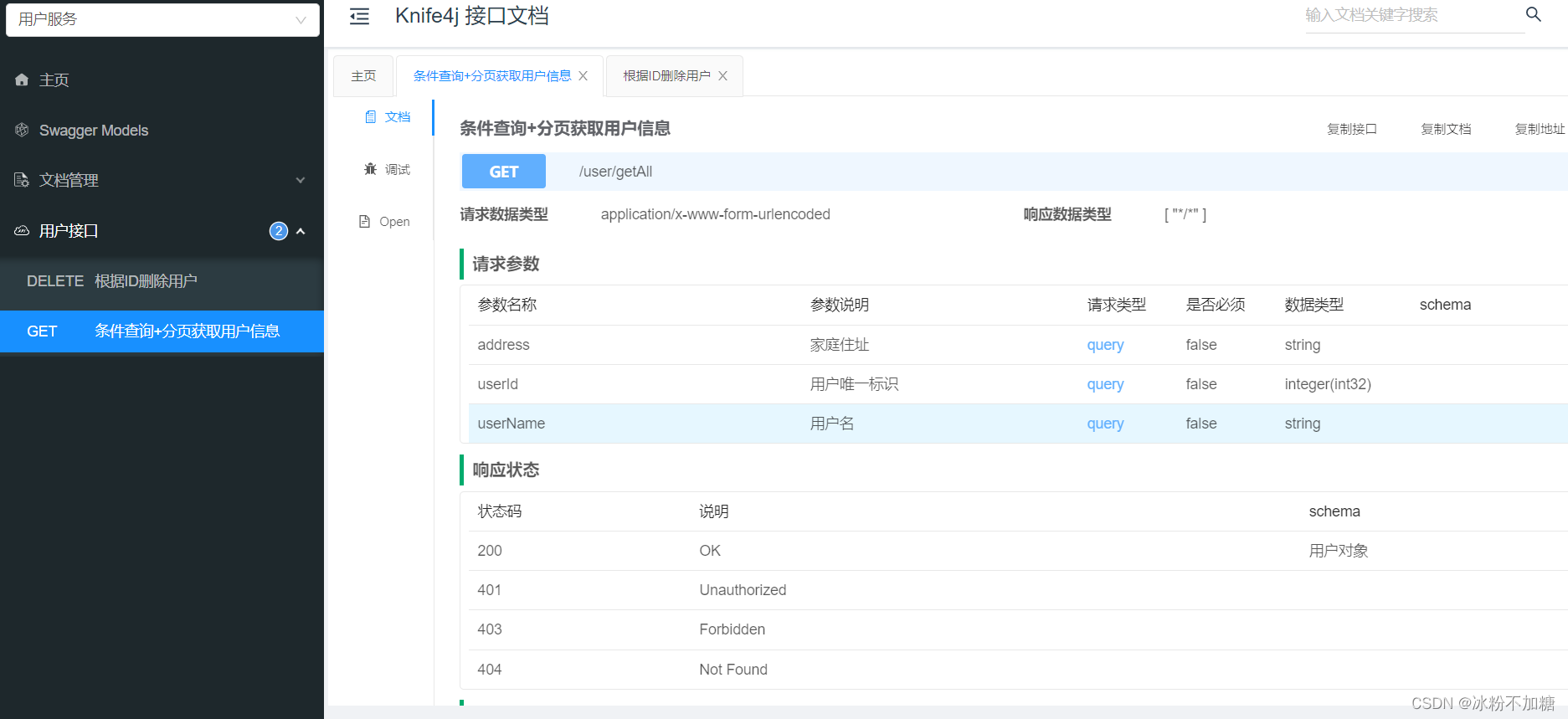
SpringBoot整合Knife4j
文章目录前言一、Knife4j是什么?二、使用步骤1.导入依赖2.编写配置文件3.编写controller和实体类4.测试总结前言 接上篇整合Swagger链接奉上http://t.csdn.cn/9mXSu 一、Knife4j是什么? 官方文档:https://doc.xiaominfo.com/ knife4j可以理解…...

MyISAM和InnoDB存储引擎的区别
目录前言存储引擎区别事务外键表单的存储数据查询效率数据更新效率如何选择前言 MyISAM和InnoDB是使用MySQL最常用的两种存储引擎,在5.5版本之前默认采用MyISAM存储引擎,从5.5开始采用InnoDB存储引擎。 存储引擎 存储引擎是:数据库管理系统…...

SpringMVC自定义处理多种日期格式的格式转换器
package cn.itcast.utils;import org.springframework.core.convert.converter.Converter;import java.text.DateFormat;import java.text.SimpleDateFormat;import java.util.Date;/*** 把字符串转换日期*/public class StringToDateConverter implements Converter<String…...
NYUv2生成边界GT(1)
看了cityscape和NYUv2生成边界GT的代码后,因为自己使用的是NYUv2数据集,所以需要对自己的数据集进行处理。CASENet生成边界GT所使用的代码是MATLAB,所以又重新看了一下MATLAB的代码,并进行修改,生成了自己的边界代码。…...
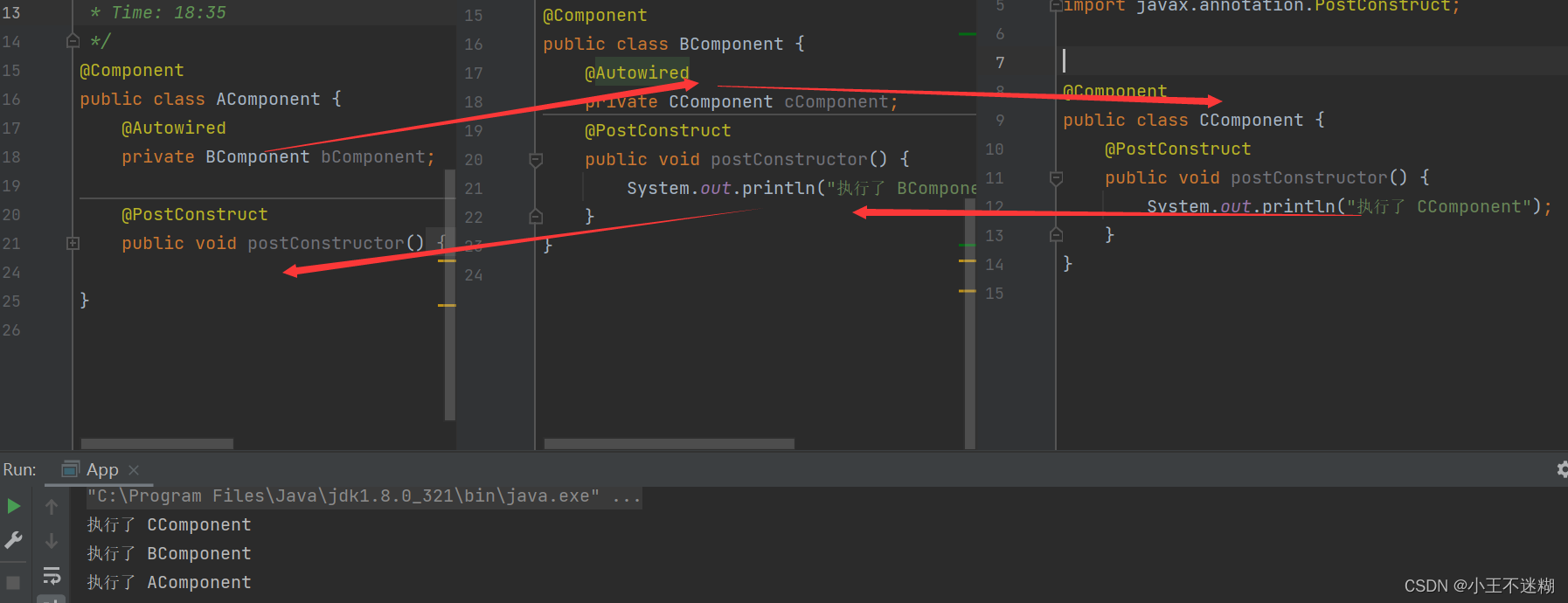
Spring基本概念与使用
文章目录一、Spring概念1.容器2.IoC3.DI4.Ioc与DI的关系二、Spring创建与使用1.Maven2.添加Spring框架支持注:国内的Maven源配置3.简单实例(1)创建一个Bean对象。(2)将Bean对象存储到Spring当中(3ÿ…...

安恒信息java实习面经
目录1.Java ME、EE、SE的区别,Java EE相对于SE多了哪些东西?2.jdk与jre的区别3.说一下java的一些命令,怎么运行一个jar包4.简单说一下java数据类型及使用场景5.Map跟Collection有几种实现?6.面向对象的特性7.重载和重写的区别8.重…...

第八章:枚举类与注解
第八章:枚举类与注解 8.1:枚举类的使用 类的对象只有有限个,确定的。我们称此类为枚举类。当需要定义一组常量是,强烈建议使用枚举类。如果枚举类中只有一个对象,则可以作为单例模式的实现方式。 如何定义枚举类 …...
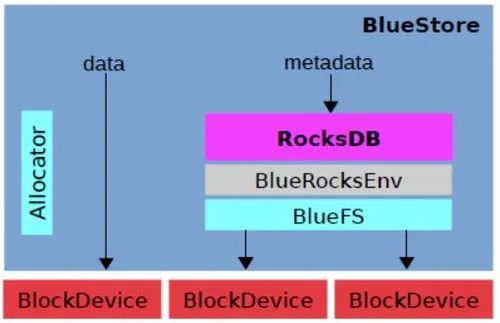
Ceph介绍
分布式存储概述 常用的存储可以分为DAS、NAS和SAN三类 DAS:直接连接存储,是指通过SCSI接口或FC接口直接连接到一台计算机上,常见的就是服务器的硬盘NAS:网络附加存储,是指将存储设备通过标准的网络拓扑结构ÿ…...

remove 和 erase 的区别
remove 和 erase 的区别 以容器vector来说明remove和erase的区别 在STL中,vector容器也提供了remove()和erase()函数,用于从vector中删除元素。虽然这两个函数都可以实现删除元素的功能,但是它们之间还是有一些区别的。 remove() remove(…...
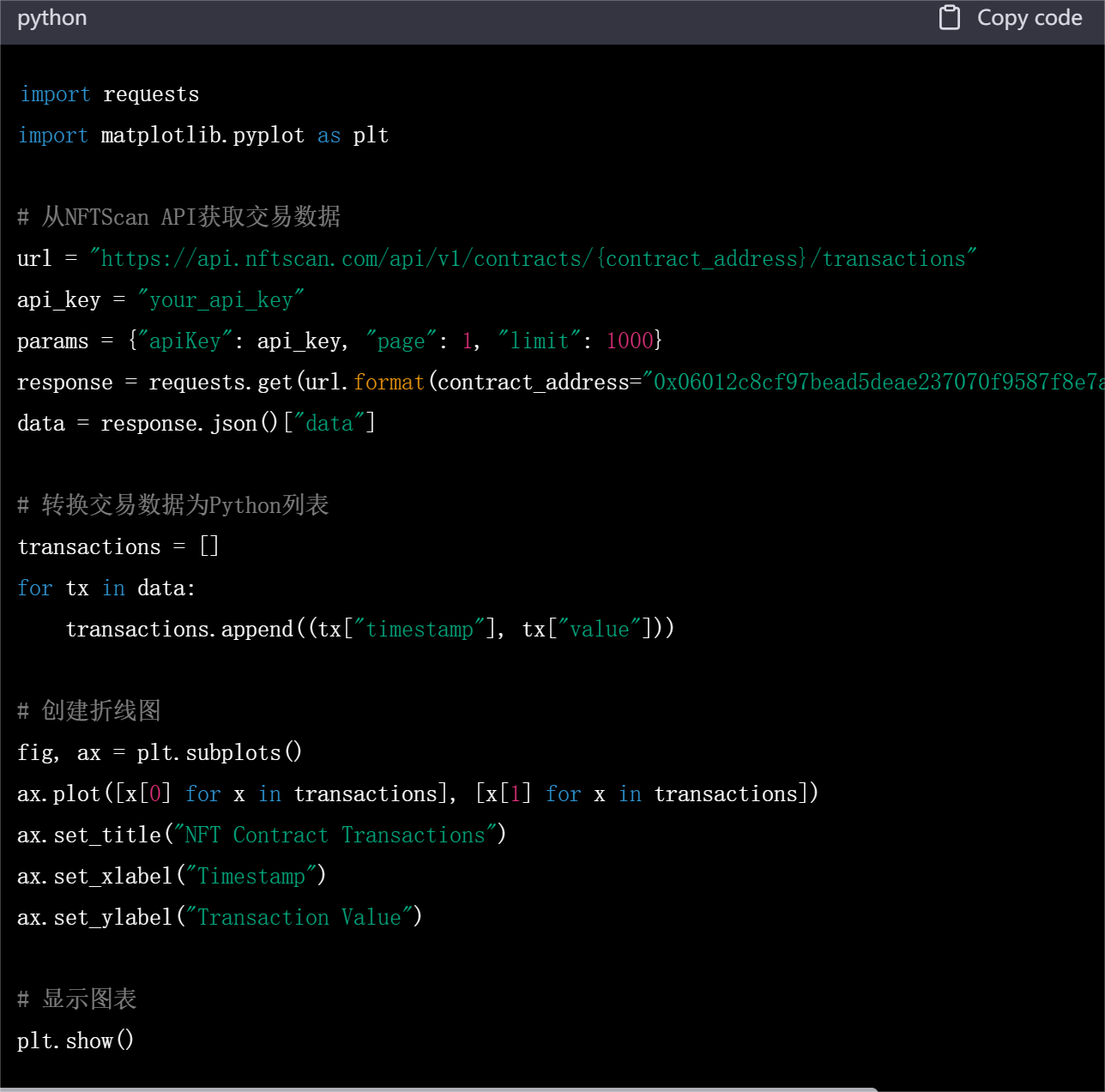
NFTScan:怎么使用 NFT API 开发一个 NFT 数据分析平台?
对很多开发者来说,在 NFT 数据海洋中需要对每个 NFT 进行索引和筛选是十分困难且繁琐的,NFT 数据获取仍是一大问题。而数据平台提供的 API 使得开发者可以通过接口获取区块链上 NFT 的详细信息,并对其进行分析、处理、统计和可视化。在本篇文…...

ECOLOY直接更换流程表单后导致历史流程中数据为空白的解决方案
用户反馈流历史流程打开是空白了没有内容。 一、问题调查分析: 工作流“XX0204 员工培训协议审批流程”workflowId37166产生的7个具体流程中,创建日期为2021年的4个具体流程原先引用的数据库表单应该是“劳动合同签订审批表”(formtable_main_190)&…...

mysql中的共享锁,排他锁,间隙锁,意向锁及死锁机制
一、前言(以下均为读完 高性能Mysql第四版 后的个人理解,建议阅读,挺不错的)在写锁机制前先简单贴出mysql InnoDB引擎中的事务特性与隔离级别:事务的ACID标准(1)原子性-atomicity:一个事务作为一个不可分割…...
SpringBoot整合MybatisPlus
文章目录前言一、MybatisPlus是什么?二、使用步骤1.导入依赖2.编写配置文件3.编写Controller和实体类4.编写持久层接口mapper5.启动类加包扫描注解6.测试总结前言 本篇记录一下SpringBoot整合MybatisPlus 一、MybatisPlus是什么? MyBatis-Plusÿ…...

中电金信Gien享汇・大数据专题|金融行业数据架构及模型演进
本期嘉宾 陈子刚 中电金信商业分析事业部华南区总经理 毕业于复旦大学,硕士研究生;拥有16年以上金融行业商业智能领域从业经验;曾就职于中国工商银行、Teradata、东亚银行,服务于平安银行、广发银行、招商银行、广东农信、招商…...

Cadence Allegro 导出Design Cross Section报告详解
⏪《上一篇》 🏡《上级目录》 ⏩《下一篇》 目录 1,概述2,Design Cross Section作用3,Design Cross Section示例4,Component Report导出方法4.1,方法14.2,方法2B站关注“硬小二”浏览更多演示视频 1,概述 <...
【LeetCode】剑指 Offer 23. 链表中环的入口节点 p139 -- Java Version
题目链接:https://leetcode.cn/problems/c32eOV/ 1. 题目介绍(23. 链表中环的入口节点) 给定一个链表,返回链表开始入环的第一个节点。 从链表的头节点开始沿着 next 指针进入环的第一个节点为环的入口节点。如果链表无环&#x…...

LeetCode-96. 不同的二叉搜索树
题目来源 96. 不同的二叉搜索树 递归 1.我们要知道二叉搜索树的性质,对于一个二叉搜索树,其 【左边的节点值 < 中间的节点值 < 右边的节点值】,也就是说,对于一个二叉搜索树,其中序遍历之后形成的数组应该是一…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...