【NLP】多标签分类【下】
文章目录
- 简介
- 个人博客与相关链接
- 1 实验数据与任务说明
- 2 模型介绍
- 2.1 Transformer
- Transformer能做什么?
- 2.2 Hugging Face
- Hugging Face的Transformers库
- 社区支持和资源
- 预训练模型的应用
- 2.3 T5模型(Text-To-Text Transfer Transformer)
- T5的核心理念
- T5的架构和训练方法
- T5在多标签分类任务中的运用
- 3 实验步骤
- 3.1 数据预处理
- 3.2 模型训练与测试
- 模型选择
- 参数设置
- 3.3 结果转化与评估
- 4 代码与实验
- 4.1 数据预处理
- 4.2 模型训练与预测
- 自定义批处理函数
- 自定义Dataset
- 自定义LightningModule
- 训练与预测函数
- 保存结果以及任务启动
- 4.3 结果转化与模型评估
- 5 实验结果
简介
在《【NLP】多标签分类》系列的上一篇文章中,我们深入探讨了三种机器学习方法:Binary Relevance (BR)、Classifier Chains (CC) 以及 Label Powerset (LP),旨在解决多标签分类的挑战。这些方法各展所长,为我们提供了不同角度解析和处理多标签问题的视角。继先前对这些机器学习方法的详尽分析之后,本篇文章转向更为先进的解决策略——专注于序列生成方法,并以Transformer模型的一种变体,即T5预训练模型为核心,进行实验探索。
本文将不仅详细介绍如何利用T5模型对多标签分类任务进行微调,而且还将通过实验对比,展现其相较于之前讨论的传统方法在性能上的优势和潜在应用价值。通过精心设计的实验和深入的结果分析,揭示序列生成方法特别是Transformer架构的强大能力和灵活性。
个人博客与相关链接
本文相关代码和数据集已同步上传github: issey_Kaggle/MultiLabelClassification at main · iceissey/issey_Kaggle (github.com)
本文代码(Notebook)已公布至kaggle: Transformer-Multi-Label-Classification (kaggle.com)
博主个人博客链接:issey的博客 - 愿无岁月可回首
1 实验数据与任务说明
数据来源:Multi-Label Classification Dataset (kaggle.com)
任务说明:
- 背景:NLP——多标签分类数据集。
- 内容:该数据集包含6个不同的标签(计算机科学、物理学、数学、统计学、定量生物学、定量金融),用于根据摘要和标题对研究论文进行分类。 标签列中的值1表示该标签属于该论文,每篇论文可以有多个标签为1。
2 模型介绍
2.1 Transformer
Transformer模型自从2017年由Vaswani等人在论文《Attention Is All You Need》中首次提出以来,已经证明了其在多种自然语言处理任务上的强大能力。尽管本文不会深入讲解Transformer的详细架构及其组成模块,我们仍然强烈推荐感兴趣的读者参考原始论文以获得全面的理解。
Transformer能做什么?
Transformer的创新之处在于其独特的自注意力机制,使其能够在处理文本时更有效地捕捉长距离依赖关系。这一特性不仅提高了处理速度,还提升了模型对文本的理解深度,打开了自然语言处理领域的新篇章。以下是Transformer在NLP领域的一些关键应用:
- 文本分类:Transformer能够理解复杂的文本结构和语义,使其在文本分类任务上表现优异,包括情感分析、主题识别等。
- 机器翻译:由于其强大的语言模型能力,Transformer模型已成为机器翻译领域的主导技术,提供了更加流畅和准确的翻译结果。
- 文本摘要:Transformer模型能够理解和提取文本的关键信息,生成准确且连贯的摘要,无论是抽取式还是生成式摘要。
- 问答系统:利用其深度理解能力,Transformer能够从大量文本中提取答案,为问答系统提供强有力的支持。
- 语言生成:Transformer的变体,如GPT系列,已经展示了在生成文本、编写代码等任务上的卓越能力,推动了创造性文本生成和自动编程的新发展。
2.2 Hugging Face
在深入探讨如何将Transformer模型应用于多标签分类任务之前,让我们先了解一下Hugging Face。作为一个致力于推进机器学习技术民主化的开源社区和公司,Hugging Face为研究者和开发者们提供了丰富的预训练模型库及相关工具,极大地简化了NLP任务的开发流程。
官网链接:Hugging Face – The AI community building the future.
Hugging Face的Transformers库
作为一个广泛使用的Python库,Hugging Face的Transformers库集合了数百种预训练的Transformer模型,支持轻松应用于文本分类、文本生成、问答等多种NLP任务。该库的一个主要优势是其提供了统一的接口,让不同的Transformer模型,比如BERT、GPT-2、RoBERTa等,在几乎不需修改代码的情况下就能互相替换使用。
社区支持和资源
Hugging Face不仅提供预训练模型,还维护着一个充满活力的社区,社区成员在此分享经验、解决方案及最佳实践。这样的平台为初学者和专家提供了交流与学习的机会,进一步推动了NLP领域的发展。更进一步,Hugging Face也提供了模型共享平台,允许研究者和开发者上传及分享自己训练的模型,进一步增强了社区资源。
预训练模型的应用
对于多标签分类任务而言,Hugging Face的Transformers库开辟了一个既简单又强大的途径,以便利用最先进的模型。用户可根据自身任务需求选择合适的预训练模型,并通过微调(fine-tuning)的方式使其适应具体的多标签分类任务,从而大幅度降低了模型开发和训练的时间及资源消耗。在接下来的部分中,我们会详细展示这一过程的实现,包括模型的选择、数据准备、训练以及性能评估等关键步骤。
2.3 T5模型(Text-To-Text Transfer Transformer)
本节将介绍我们在本次实验中使用的预训练模型T5,全称为Text-To-Text Transfer Transformer。T5模型以其创新性著称,其设计理念是将所有自然语言处理(NLP)任务转化为一个统一的文本到文本的格式。这种独特的通用性使得T5成为解决多标签分类等复杂任务的理想选择。
T5的核心理念
T5模型的设计核心在于将各种NLP任务统一到一个简单的框架中:接受文本输入并产生文本输出。这意味着无论是进行文本分类、翻译,还是处理更为复杂的多标签分类和问答任务,T5模型都以相同的方法处理,极大地提升了模型的灵活性和适用范围。
T5的架构和训练方法
T5遵循了经典的Encoder-Decoder架构,但在训练策略上进行了创新。它首先在大量文本数据上进行预训练,掌握语言的广泛知识,然后在特定任务的数据集上进行微调(fine-tuning)。这种结合预训练和微调的方法使T5在许多NLP任务上取得了卓越的表现。
T5在多标签分类任务中的运用
在多标签分类任务中,T5模型将任务视为一个文本到文本的转换问题:它将文章内容作为输入,并输出一系列的标签作为分类结果。这种方法简化了任务的处理流程,并允许T5利用其预训练阶段学到的丰富语言知识,以提升任务的处理效率和分类准确性。
3 实验步骤
本实验的主要步骤包括:1)数据预处理。2)模型训练与测试。3)结果转化与评估。
3.1 数据预处理
正如前一节所述,T5模型以序列生成的形式处理任务,即接收文本输入并产生文本输出。因此,我们需要将原始数据转换成符合这一格式的形式,以便模型能够有效处理。以下是我们的原始数据格式示例:
| 文本内容 | 计算机科学 | 物理 | 数学 | 统计学 | 定量生物学 | 定量金融学 |
|---|---|---|---|---|---|---|
| 这是一个文本示例。 | 1 | 0 | 0 | 1 | 0 | 0 |
为了将这些数据转换为适合序列生成任务的格式,我们需要将标签(即标记为1的类别)转化为一串文本标签,如下所示:
示例:
| 文本内容 | 标签 |
|---|---|
| 这是一个文本示例。 | 计算机科学;统计学 |
注意:标签之间可以使用其他符号进行隔开,本例中使用的是分号(;)。我们的目标是将标记为1的标签拼接成一条文本数据,以便模型可以将这些标签作为生成任务的一部分来处理。
3.2 模型训练与测试
模型选择
模型名称:T5-Small
模型链接:google-t5/t5-small · Hugging Face
参数设置
batch_size = 16
epochs = 5
learning_rate = 2e-5
3.3 结果转化与评估
在使用T5模型完成多标签分类任务后,我们会得到模型生成的文本序列作为输出。这些输出序列以文本形式列出了预测的标签,例如:
| 预测标签 |
|---|
| 统计学;定量生物学;定量金融学 |
为了对模型的性能进行评估,并使用我们在上篇文章中介绍的多标签分类评估方法,必须先将这些文本格式的标签转换回原始数据的格式,即将每个标签对应到它们各自的分类列上,并用0或1表示其是否被预测为该类。转换后的格式如下所示:
| 计算机科学 | 物理 | 数学 | 统计学 | 定量生物学 | 定量金融学 |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 1 | 1 |
在这个转换过程中,我们首先将每个预测的标签字符串分割为单独的标签(在本例中,我们使用分号";"作为分隔符)。然后,我们检查每个原始标签列,并将其与分割后的标签进行匹配,如果预测中包含某个标签,则在相应的列中标记为1;如果不包含,则标记为0。这样,我们就能得到一个与原始数据格式相匹配的矩阵,便于我们采用上篇文章中介绍的评估方法来量化模型的性能。
4 代码与实验
该部分强烈建议搭配Kaggle使用,见"相关链接"部分。(如果觉得有帮助,可以顺便在Kaggle点个赞谢谢)
4.1 数据预处理
将原始的多标签分类数据集转换为适用于T5模型的格式。具体来说,我们将文章的标题和摘要合并为一个单独的文本输入,并将标记为1的多个标签合并为一个分号分隔的标签字符串。最终,这一预处理步骤将生成一个清晰的文本到文本格式,为T5模型的训练做好准备。
DataPreprocessing.py
import pandas as pd"""准备数据"""
input_csv = "../../../archive/train.csv"
data = pd.read_csv(input_csv)
print(len(data))
label_columns = data.columns[-6:] # 提取labels列
print(label_columns)data['text'] = data['TITLE'] + " " + data['ABSTRACT'] # 准备text
print(data['text'].head())data['labels'] = data[label_columns].apply(lambda x: '; '.join(x.index[x == 1]), axis=1)
print(data['labels'])
# Displaying the updated dataset
preprocessed_data = data[['text', 'labels']]
print(preprocessed_data.head())# 存储为新的 CSV 文件
output_path = "../../../archive/preprocessed_data.csv"
preprocessed_data.to_csv(output_path, index=False)
4.2 模型训练与预测
本次仍然使用了Pytorch以及Pytorch lightning作为实验框架,关于Pytorch lightning的使用方法请自行查阅官网。
Pytorch lightning: Welcome to ⚡ PyTorch Lightning — PyTorch Lightning 2.2.1 documentation
该部分对应文件名:Transformer.py
自定义批处理函数
def collate_fn(batch):"""自定义批处理函数"""texts = [item['text'] for item in batch]labels = [item['labels'] for item in batch]# 使用 tokenizer 对文本和标签进行编码,最大长度512encoding = tokenizer(texts, padding=True, truncation=True, max_length=512, return_tensors="pt")# 使用 tokenizer 的 target_tokenizer 对标签进行编码with tokenizer.as_target_tokenizer():labels_encoding = tokenizer(labels, padding=True, truncation=True, max_length=512, return_tensors="pt")# 将标签中的 pad token 替换为 -100,这是 T5 模型的要求labels_encoding["input_ids"][labels_encoding["input_ids"] == tokenizer.pad_token_id] = -100return {'input_ids': encoding['input_ids'],'attention_mask': encoding['attention_mask'],'labels': labels_encoding['input_ids']}
自定义Dataset
class T5Dataset(Dataset):"""自定义数据集"""def __init__(self, dataset):self.dataset = datasetdef __getitem__(self, idx):item = self.dataset[idx]return {'text': item['text'],'labels': item['labels']}def __len__(self):return len(self.dataset)
自定义LightningModule
class T5FineTuner(pl.LightningModule):"""自定义LightningModule"""def __init__(self, train_dataset, val_dataset, test_dataset, learning_rate=2e-5):super(T5FineTuner, self).__init__()self.validation_loss = []self.model = T5ForConditionalGeneration.from_pretrained('t5-small')self.learning_rate = learning_rate # 微调self.train_dataset = train_datasetself.val_dataset = val_datasetself.test_dataset = test_datasetself.prediction = []def forward(self, input_ids, attention_mask, labels=None):output = self.model(input_ids=input_ids,attention_mask=attention_mask,labels=labels)return outputdef configure_optimizers(self):return AdamW(self.model.parameters(), lr=self.learning_rate)def train_dataloader(self):train_loader = DataLoader(dataset=self.train_dataset, batch_size=batch_size, collate_fn=collate_fn,shuffle=True)return train_loaderdef val_dataloader(self):val_loader = DataLoader(dataset=self.val_dataset, batch_size=batch_size, collate_fn=collate_fn,shuffle=False)return val_loaderdef test_dataloader(self):test_loader = DataLoader(dataset=self.test_dataset, batch_size=batch_size, collate_fn=collate_fn,shuffle=False)return test_loaderdef training_step(self, batch, batch_idx):input_ids = batch['input_ids']attention_mask = batch['attention_mask']labels = batch['labels']output = self(input_ids, attention_mask, labels)loss = output.lossself.log('train_loss', loss, prog_bar=True, logger=True, on_step=True, on_epoch=True) # 将loss输出在控制台return lossdef validation_step(self, batch, batch_idx):input_ids = batch['input_ids']attention_mask = batch['attention_mask']labels = batch['labels']output = self(input_ids, attention_mask, labels)loss = output.lossself.log('val_loss', loss, prog_bar=False, logger=True, on_step=True, on_epoch=True)return lossdef test_step(self, batch, batch_idx):input_ids = batch['input_ids']attention_mask = batch['attention_mask']self.model.eval()# 生成输出序列generated_ids = self.model.generate(input_ids=input_ids, attention_mask=attention_mask)# 将生成的token ids转换为文本generated_texts = [tokenizer.decode(generated_id, skip_special_tokens=True, clean_up_tokenization_spaces=True)for generated_id in generated_ids]# 返回解码后的文本# print(generated_texts)self.prediction.extend(generated_texts)
训练与预测函数
def test(model, fast_run):trainer = pl.Trainer(fast_dev_run=fast_run)trainer.test(model)test_result = model.prediction# print(type(test_result))for text in test_result[:10]:print(text)return test_resultdef train(fast_run):# 增加回调最优模型checkpoint_callback = ModelCheckpoint(monitor='val_loss', # 监控对象为'val_loss'dirpath='../../archive/log/T5FineTuner_checkpoints', # 保存模型的路径filename='Models-{epoch:02d}-{val_loss:.2f}', # 最优模型的名称save_top_k=1, # 只保存最好的那个mode='min' # 当监控对象指标最小时)# 设置日志保存的路径log_dir = "../../archive/log"logger = TensorBoardLogger(save_dir=log_dir, name="T5FineTuner_logs")# Trainer可以帮助调试,比如快速运行、只使用一小部分数据进行测试、完整性检查等,# 详情请见官方文档https://lightning.ai/docs/pytorch/latest/debug/debugging_basic.html# auto自适应gpu数量trainer = pl.Trainer(max_epochs=epochs, log_every_n_steps=10, accelerator='gpu', devices="auto", fast_dev_run=fast_run,callbacks=[checkpoint_callback], logger=logger)model = T5FineTuner(train_dataset, valid_dataset, test_dataset, learning_rate)trainer.fit(model)return model
保存结果以及任务启动
当在Kaggle上进行操作时,请注意,直接使用load_dataset函数从CSV文件加载数据集可能会导致错误。为了避免这个问题,推荐先使用pandas库将CSV文件读入为DataFrame,之后再将其转换为适合模型训练的格式。具体的代码实现和操作可以参考Kaggle笔记本中的相关部分。
def save_to_csv(test_dataset, predictions, filename="../../archive/test_predictions.csv"):with open(filename, mode='w', newline='', encoding='utf-8') as file:writer = csv.writer(file)writer.writerow(['text', 'true_labels', 'pred_labels'])for item, pred_label in zip(test_dataset, predictions):text = item['text']true_labels = item['labels']writer.writerow([text, true_labels, pred_label])if __name__ == '__main__':data = load_dataset('csv', data_files={'train': '../../archive/preprocessed_data.csv'})["train"]# 分割数据集为训练集和测试+验证集train_testvalid = data.train_test_split(test_size=0.3, seed=42)# 分割测试+验证集为测试集和验证集test_valid = train_testvalid['test'].train_test_split(test_size=0.5, seed=42)# 现在我们有了训练集、验证集和测试集train_dataset = train_testvalid['train']valid_dataset = test_valid['train']test_dataset = test_valid['test']# 打印各个数据集的大小print("Training set size:", len(train_dataset))print("Validation set size:", len(valid_dataset))print("Test set size:", len(test_dataset))# 准备Datasettrain_dataset = T5Dataset(train_dataset)valid_dataset = T5Dataset(valid_dataset)test_dataset = T5Dataset(test_dataset)# print(train_dataset.__len__())# print(train_dataset[0])# 初始化分词器tokenizer = T5Tokenizer.from_pretrained('t5-small')# 装载dataLoadertrain_dataloader = DataLoader(dataset=train_dataset, batch_size=batch_size,collate_fn=collate_fn, shuffle=True, drop_last=True)# 查看装载情况for i, batch in enumerate(train_dataloader):print(f"Batch {i + 1}")print("Input IDs:", batch['input_ids'])print("Input IDs shape:", batch['input_ids'].shape)print("Attention Mask:", batch['attention_mask'])print("Attention Mask shape:", batch['attention_mask'].shape)print("Labels:", batch['labels'])print("\n")if i == 0:breakfast_run = Truemodel = train(fast_run)# model = T5FineTuner.load_from_checkpoint(# "../../archive/log/T5FineTuner_checkpoints/model-epoch=09-val_loss=0.32.ckpt",# train_dataset=train_dataset, val_dataset=valid_dataset,# test_dataset=test_dataset)pre_texts = test(model, fast_run)save_to_csv(test_dataset, pre_texts)
4.3 结果转化与模型评估
Estimate.py
import pandas as pd
from sklearn.preprocessing import MultiLabelBinarizer
from sklearn.metrics import precision_score, recall_score, f1_score, accuracy_score
import numpy as npdef convert_labels(label_str):return label_str.split(';') if label_str else []def clean_label(label):return label.strip()# 读取提供的 CSV 文件
file_path = "../../archive/test_predictions.csv"
data = pd.read_csv(file_path)
# print(data.head())# 提取并转换真实标签和预测标签
true_labels = [convert_labels(label_str) for label_str in data['true_labels']]
pred_labels = [convert_labels(label_str) for label_str in data['pred_labels']]
# 使用清理后的标签重新创建真实标签和预测标签列表
true_labels_cleaned = [list(map(clean_label, label_list)) for label_list in true_labels]
pred_labels_cleaned = [list(map(clean_label, label_list)) for label_list in pred_labels]# 使用 MultiLabelBinarizer 对标签进行独热编码
mlb = MultiLabelBinarizer()
mlb.fit(true_labels_cleaned + pred_labels_cleaned)
y_true = mlb.transform(true_labels_cleaned)
y_pred = mlb.transform(pred_labels_cleaned)print("Transformer(T5) Accuracy =", accuracy_score(y_true, y_pred))
print("Transformer(T5) Precision (micro-average) =", precision_score(y_true, y_pred, average='micro'))
print("Transformer(T5) Recall (micro-average) =", recall_score(y_true, y_pred, average='micro'))
print("Transformer(T5) F1 Score (micro-average) =", f1_score(y_true, y_pred, average='micro'))print("\nAnother way to calculate accuracy:")
# 计算每一列的准确率
column_accuracies = np.mean(y_true == y_pred, axis=0)
# 为每列准确率添加列名
column_accuracy_with_labels = list(zip(mlb.classes_, column_accuracies))
# 计算列准确率的均值
mean_column_accuracy = np.mean(column_accuracies)for acc in column_accuracy_with_labels:print(acc)
# print(column_accuracy_with_labels)
print("Average accuracy = ", mean_column_accuracy)
5 实验结果
本节汇总并比较了上篇和下篇文章中各种实验的结果。我们采用了几种不同的算法来处理多标签分类问题,包括Binary Relevance(BR)与Random Forest组合、Classifier Chains(CC)与Random Forest组合、Label Powerset(LP)与Random Forest组合、LP与SVM组合,以及使用了Transformer(T5)模型的序列生成方法。
通过对比准确率(Accuracy)、微观精确度(Precision_micro)、微观召回率(Recall_micro)和微观F1分数(F1_micro)这四个关键性能指标,我们发现:
- 使用基于Random Forest的BR、CC和LP方法可以得到相对较好的预测性能。
- 当LP与SVM组合使用时,性能有所提高,特别是在召回率和F1分数方面。
- 最为显著的是,Transformer(T5)模型尤其在准确率、召回率和F1分数上达到了最高值。
具体数值如下所示:
| Algorithms | Acc | P r e m i c r o Pre_{micro} Premicro | R e m i c r o Re_{micro} Remicro | F 1 m i c r o F1_{micro} F1micro |
|---|---|---|---|---|
| BR(RandomForest) | 0.4477 | 0.8038 | 0.4978 | 0.6149 |
| CC(RandomForest) | 0.4787 | 0.8012 | 0.5277 | 0.6363 |
| LP(RandomForest) | 0.5349 | 0.7179 | 0.5889 | 0.6470 |
| LP(SVM) | 0.5914 | 0.7368 | 0.7245 | 0.7306 |
| Transformer(T5) | 0.6427 | 0.7994 | 0.7840 | 0.7916 |
从结果中我们可以得出结论,Transformer模型在处理复杂的多标签分类任务时,展现出了其强大的能力。这也表明了序列到序列模型,在NLP领域的广泛应用潜力和有效性。
相关文章:
【NLP】多标签分类【下】
文章目录 简介个人博客与相关链接1 实验数据与任务说明2 模型介绍2.1 TransformerTransformer能做什么? 2.2 Hugging FaceHugging Face的Transformers库社区支持和资源预训练模型的应用 2.3 T5模型(Text-To-Text Transfer Transformer)T5的核…...

HWOD:密码强度等级
一、知识点 回车键的ASCII码是10 如果使用EOF,有些用例不通过 二、题目 1、描述 密码按如下规则进行计分,并根据不同的得分为密码进行安全等级划分。 一、密码长度: 5 分: 小于等于4 个字符 10 分: 5 到7 字符 25 分: 大于等于8 个字符 二、字母: 0…...

期货学习笔记-MACD指标学习2
MACD底背离把握买入多单的技巧 底背离的概念及特征 底背离指的是MACD指标与价格低点之间的对比关系,这里需要明白的是MACD指标的涨跌动能和价格形态衰竭形态之间的关系,如果市场价格创新低而出现衰竭形态同时也有底背离形态的出现,此时下跌…...

5G智慧港口简介(一)
引言 港口作为交通运输的枢纽,在促进国际贸易和地区发展中起着举足轻重的作用,全球贸易中约 90% 的贸易由海运业承载,作业效率对于港口至关重要。在“工业 4.0”、“互联网 +”大发展的时代背景下,港口也在进行数字化、全自动的转型升级。随着全球 5G 技术浪潮的到来,华为…...
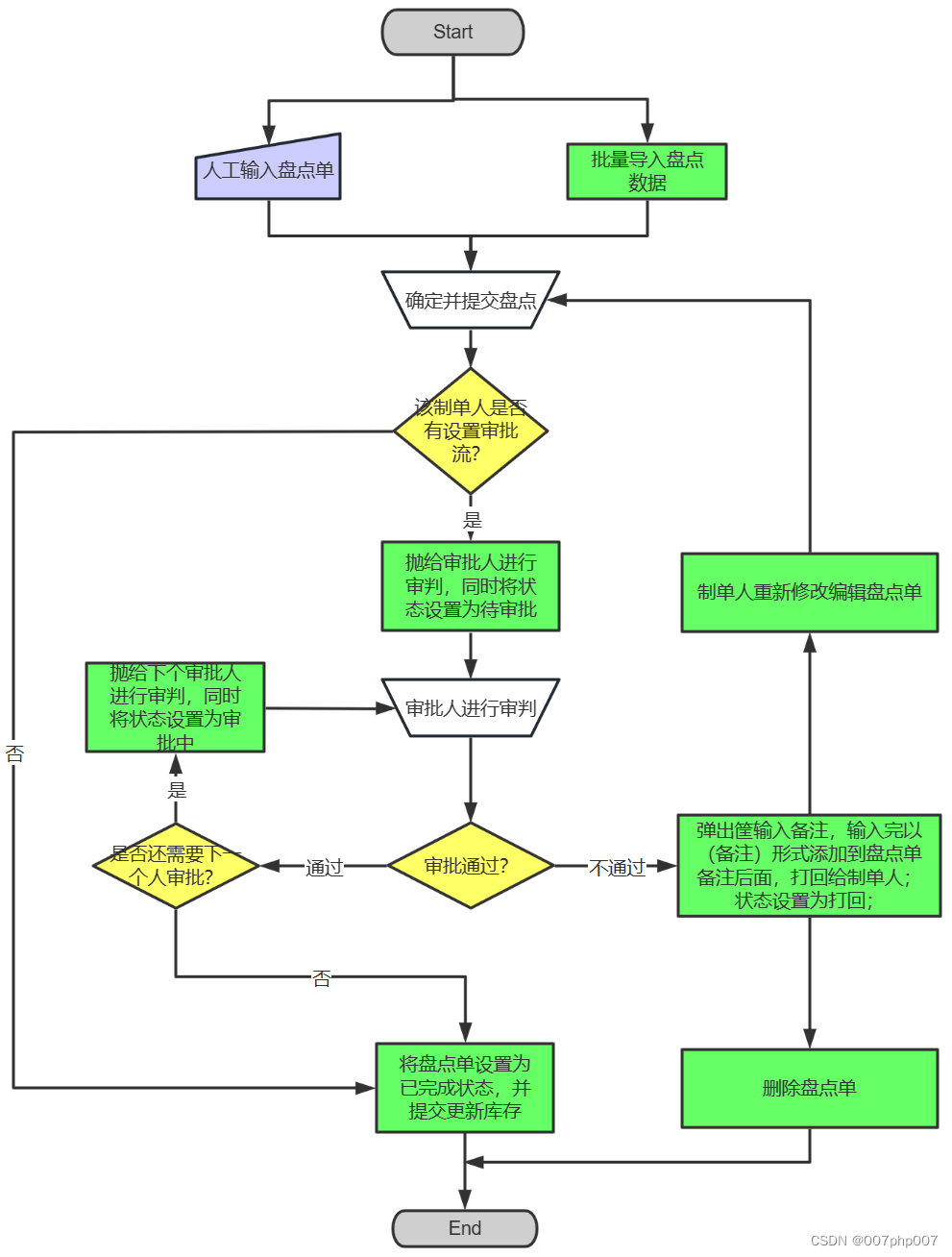
订单中台架构:打造高效订单管理系统的关键
在现代商业环境下,订单管理对于企业来说是至关重要的一环。然而,随着业务规模的扩大和多渠道销售的普及,传统的订单管理方式往往面临着诸多挑战,如订单流程复杂、信息孤岛、数据不一致等问题。为了应对这些挑战并抓住订单管理的机…...
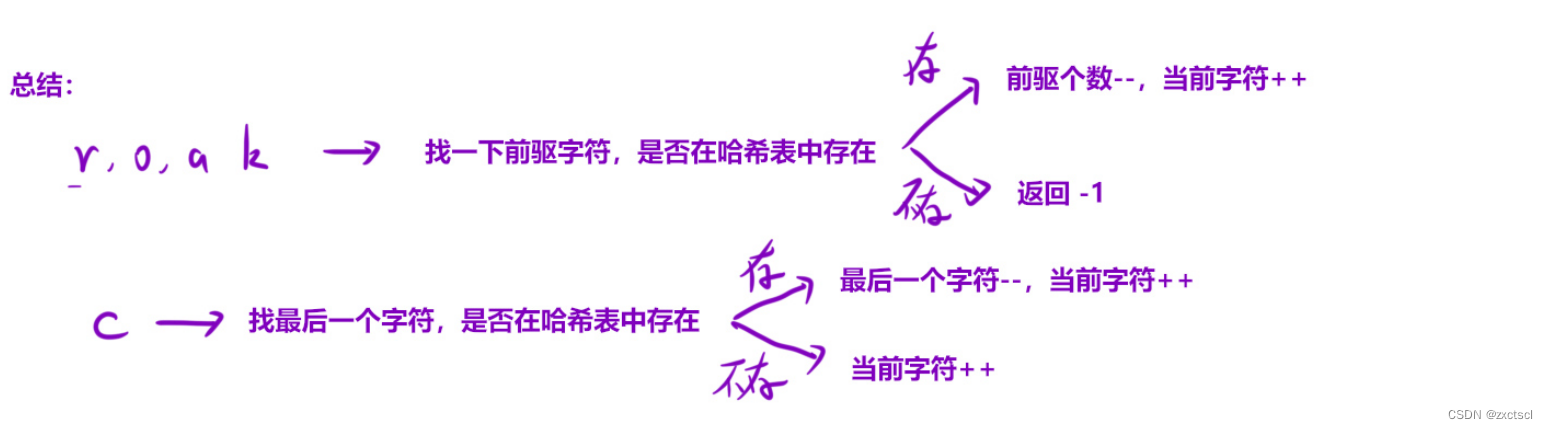
【算法】模拟
个人主页 : zxctscl 如有转载请先通知 题目 前言1. 1576. 替换所有的问号1.1 分析1.2 代码 2. 495. 提莫攻击2.1 分析2.2 代码 3. 6. Z 字形变换3.1 分析3.2 代码 4. 38. 外观数列4.1 分析4.2 代码 5. 1419. 数青蛙5.1 分析5.2 代码 前言 模拟算法就是根据题目所给…...

电力综合自动化系统对电力储能技术的影响有哪些?
电力综合自动化系统对电力储能技术的影响主要体现在以下几个方面: 提高能源利用效率:电力综合自动化系统通过优化调度和能量管理,可以实现储能设备的有效利用,提高能源利用效率。在电力系统中,储能设备可以有效地平抑风…...

Compose UI 之 Card 卡片组件
Card Card 是用于显示带有圆角和可选阴影的矩形内容容器。它通常用于构建用户界面,并可以包含标题、文本、图像、按钮等元素,表示界面上的可交互元素,我们称它是 “卡片”。 Card 使用的一些经典的场景: 列表数据,例如 新闻列表,产品列表等。信息提示框,使用 Card 组件…...
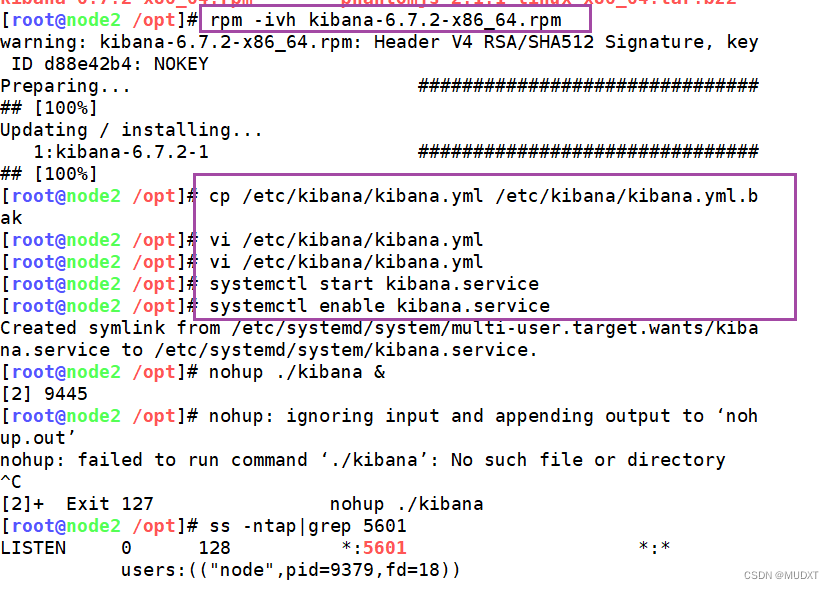
ELK日志
...

WPF Pack
在WPF中,Pack URI(Uniform Resource Identifier)是一种特殊格式的统一资源标识符,用于定位和访问应用程序内部或外部的各种资源,如XAML文件、图像、样式、字体等。这种机制允许开发者以标准化、平台无关的方式引用和打…...

计算两个时间段的差值
计算两个时间段的差值 运行效果: 代码实现: #include<stdio.h>typedef struct {int h; // 时int m; // 分int s; // 秒 }Time;void fun(Time T[2], Time& diff) {int sum_s[2] { 0 }; for (int i 0; i < 1; i) { // 统一为秒数sum_s[…...
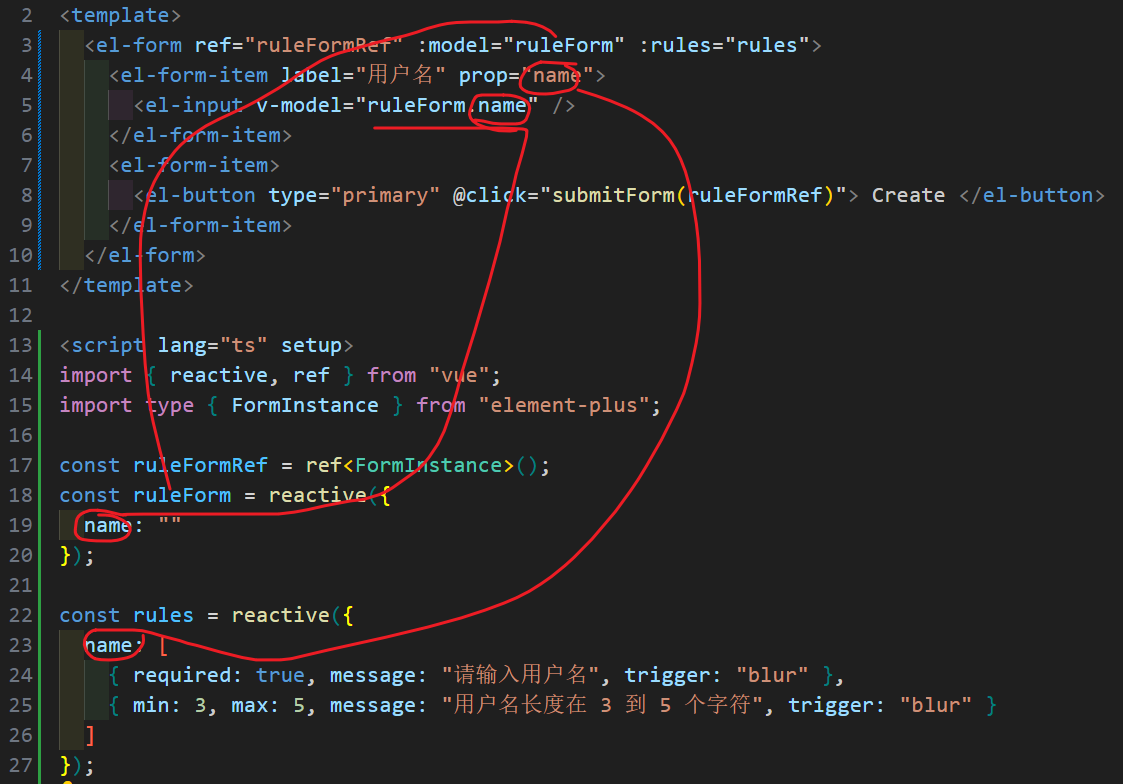
Element Plus 表单校验
原理 为 rules 属性传入约定的验证规则,并将 form-Item 的 prop 属性设置为需要验证的特殊键值:model和:rules中字段的名称需要一致 示例: <template><el-form ref"ruleFormRef" :model"ruleForm" :rules"rules&q…...
java实现TCP交互
服务器端 import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; import java.io.PrintWriter; import java.net.ServerSocket; import java.net.Socket; import java.util.PriorityQueue; import java.util.Scanner;public class TCP_Serv…...

学习云计算HCIE选择誉天有什么优势?
誉天云计算课程优势实战性强 课程注重实践操作,通过实际案例和实验操作,让学员深入了解云计算的应用场景和实际操作技能。课程内容全面 涵盖所有云计算涉及的IT基础知识、服务器、存储、网络等方面的基础知识,开源操作系统Linux,开…...
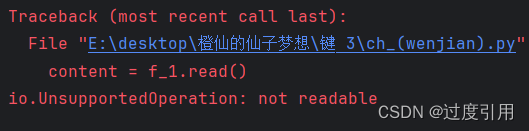
python之文件操作与管理
1、文件操作 通过open()操作,来创建文件对象,下面是open()函数语法如下: open(file,mode r,buffering -1 , encoding None ,errors None , newline None,closefd True,opener …...

大厂Java笔试题之对完全数的处理
题目:完全数(Perfect number),又称完美数或完备数,是一些特殊的自然数。 它所有的真因子(即除了自身以外的约数)的和(即因子函数),恰好等于它本身。 例如&…...

【Redis深度解析】揭秘Cluster(集群):原理、机制与实战优化
Redis Cluster是Redis官方提供的分布式解决方案,通过数据分片与节点间通信机制,实现了水平扩展、高可用与数据容灾。本文将深入剖析Redis Cluster的工作原理、核心机制,并结合实战经验分享优化策略,为您打造坚实可靠的Redis分布式…...

【JAVA基础篇教学】第六篇:Java异常处理
博主打算从0-1讲解下java基础教学,今天教学第五篇: Java异常处理。 异常处理是Java编程中重要的一部分,它允许开发人员在程序运行时检测和处理各种错误情况,以保证程序的稳定性和可靠性。在Java中,异常被表示为对象&am…...
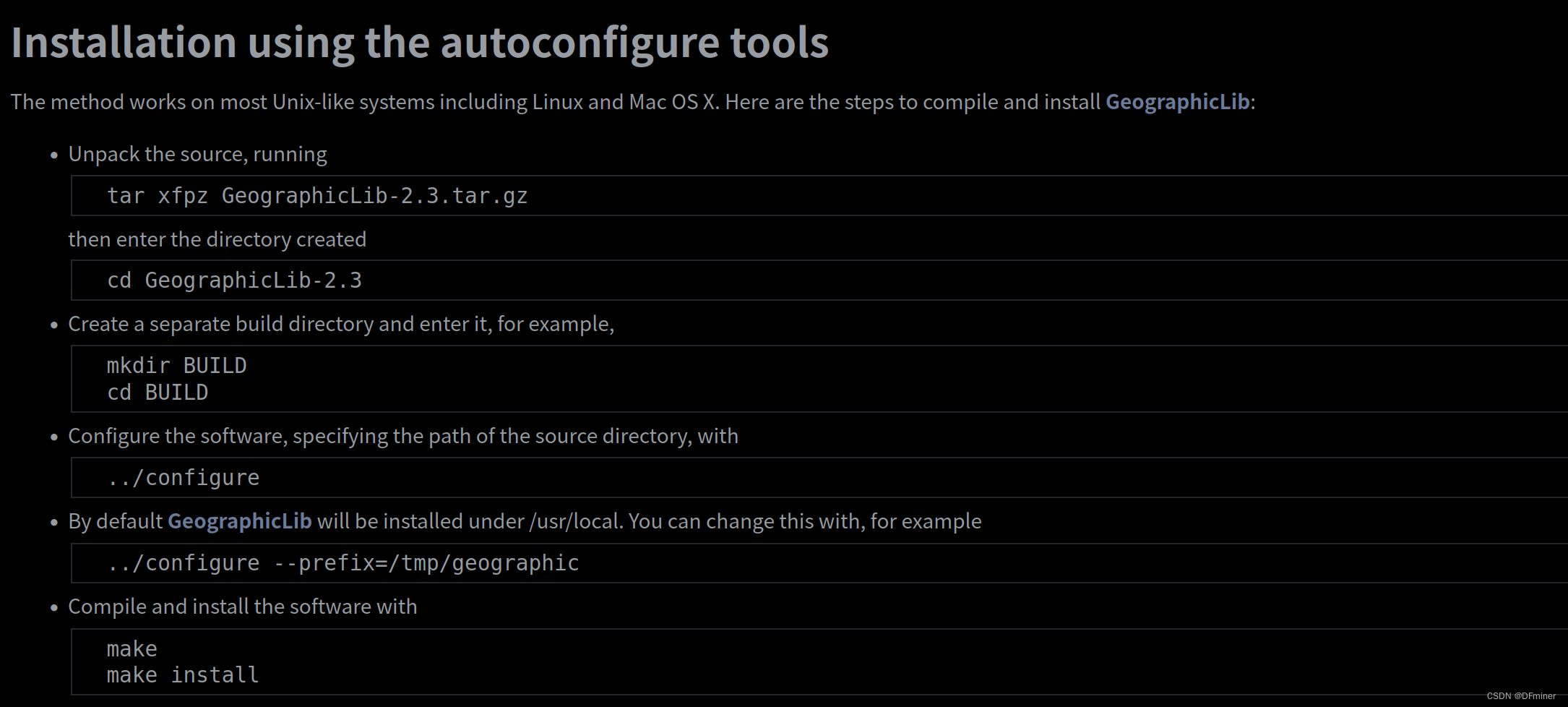
【ubuntu20.04】安装GeographicLib
下载地址 GeographicLib: Installing GeographicLib 我们是ubuntu20.04 ,所以下载第一个 GeographicLib-2.3.tar.gz 接着跟着官方步骤安装,会出错!!!!马的 官方错误示例:tar xfpz Geographi…...
 Vue-Router的使用与配置)
从0开始搭建基于VUE的前端项目(四) Vue-Router的使用与配置
版本 vue-router 3.6.5 (https://v3.router.vuejs.org/zh/) 安装 安装要指定版本,默认安装的4版本的 npm install vue-router3.6.5代码实现 在src目录下创建router目录 router/index.js import Vue from vue import Router from vue-routerVue.use(Router)con…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...

Selenium常用函数介绍
目录 一,元素定位 1.1 cssSeector 1.2 xpath 二,操作测试对象 三,窗口 3.1 案例 3.2 窗口切换 3.3 窗口大小 3.4 屏幕截图 3.5 关闭窗口 四,弹窗 五,等待 六,导航 七,文件上传 …...