第6章 6.3.1 正则表达式的语法(MATLAB入门课程)
讲解视频:可以在bilibili搜索《MATLAB教程新手入门篇——数学建模清风主讲》。
MATLAB教程新手入门篇(数学建模清风主讲,适合零基础同学观看)_哔哩哔哩_bilibili
正则表达式可以由一般的字符、转义字符、元字符、限定符等元素组成,下面我们介绍MATLAB的正则表达式中一些常用的语法规则。
一、元字符
正则表达式中的元字符是一些特殊字符,它们具有特定的含义,用于匹配具有某种共同特征的单个字符,是实现灵活匹配的关键。
(1).: 元字符.用于匹配任何单个字符,且能连续使用。

上面代码的输出结果为:[8 20 31 49]。这四个数字表示在原字符串 str 中,与正则表达式's...t'匹配的子字符串的起始位置。
如果我们想同时得到结束的位置,则可以给两个返回值:

大多数情况下,我们更希望直接得到正则表达式匹配到的文本,而不是它们对应的位置。为此,我们可以在regexp函数中添加一个输入参数'match':

需要注意的是,regexp函数在匹配时默认是区分大小写的。如果想进行不区分大小写的匹配,可以使用regexpi函数:

(2)[c1c2c3]: 匹配包含在方括号中的任意一个字符(可包含转义字符)。另外,如果方括号中存在特殊字符(例如表示任意字符的元字符.),则它会被当作普通字符来处理。

(3)[^c1c2c3]: 匹配不包含在方括号中的任意一个字符,相当于[c1c2c3]表示的字符的补集。

观察上面代码返回的结果,我们得到了一个包含六个元素的字符串数组。值得注意的是,第三个元素是" shot",这是一个以空格开头的字符串。这是因为空格字符也是除了's'之外的任意字符之一,所以它也符合正则表达式'[^s]...t'的条件。
如果我们希望同时排除以空格或者's'开头的字符串,那么我们可以在中括号中加入一个空格,即将正则表达式修改为'[^s ]...t'。这样执行匹配会得到以下结果:

(4)[c1-c2]: 匹配从c1到c2范围内的任意单个字符(即从c1到c2的Unicode编码范围内的字符)。例如,[1-6]等价于[123456],意味着它将匹配数字'1'到'6'中的任意一个;再举个例子,[h-m]等价于[hijklm],它会匹配字母'h'到'm'中的任意一个。

(5)\s: 匹配单个空白字符,例如常见的空格( )、换行符(\n)、水平制表符(\t)、回车符(\r)等。(注意:\s的写法类似于转义字符,实际上它是正则表达式中的元字符)
注意,MATLAB官网在介绍\s时,认为它等同于[ \f\n\r\t\v],实际上这里的描述并不完全准确,我们可以通过下面的代码获取它能匹配的所有空白字符的Unicode编码:

(6)\S: 匹配单个非空白字符,可以理解为\s的补集,意味着它将匹配除了\s能识别的25个空白字符之外的任何其他字符。

(7)\d: 匹配单个数字字符。
注意,MATLAB官网认为\d等同于[0-9],实际上这个描述并不完全准确。我们可以通过类似于\s中的代码来获取所有能够被\d识别的数字字符的Unicode编码。大家只需要将 regexp函数中的正则表达式由'\s'修改为'\d'即可。
运行这段代码会返回一个包含370个元素的向量。这个向量中的前十个元素分别对应字符'0'到'9'的Unicode编码(48到57),即我们日常使用的阿拉伯数字。后面的360个元素代表一些特殊的数字体系,这些字符在中英文语境下的使用频率较低,仅供了解即可。
(8)\D: 匹配单个非数字字符,可以理解为\d的补集。

(9)\w:匹配单个的数字、字母(无论大小写)或者下划线。
值得注意的是,这里的“字母”并不局限于英文字符集中的a-z和A-Z,而是扩展到了所有语言中的字母字符。因此,中文汉字也能被\w所识别。实际上,MATLAB的官网上有这样的描述:对于英语字符集,\w等同于[a-zA-Z_0-9]。然而,这一描述仅限于英文语境。在更广泛的多语言环境中,\w的匹配范围要广泛得多。
(10)\W:匹配单个的非数字、非字母(无论大小写)且非下划线的字符。这包括标点符号、空白字符、控制字符以及其他特殊字符,可以视为\w的补集。

至此,我们已经深入探讨了使用频率较高的十个元字符。这些元字符在正则表达式中发挥着至关重要的作用。此外,MATLAB官网上还给出了两组不常用的元字符:\oN或\o{N}、\xN或\x{N},它们分别与八进制和十六进制的数值表示形式有关,使用频率很低。
另外有一个要注意的地方:元字符.可以匹配任意单个字符,那么如何匹配'.'字符本身?答案是使用\.或者[.]进行匹配。

二、限定符
限定符(也称为量词)是正则表达式中用于精确控制字符在文本中出现次数的工具。它们为正则表达式的匹配提供了更加精准的控制。下表截取自MATLAB官网,介绍了六种限定符及其示例(注意:下表某些示例并不准确,大家可以暂时忽略,或者听配套的讲解视频):

下面,让我们通过三个具体的例子来深入理解限定符在正则表达式中的应用。
例1:匹配手机号码

上面代码中,s是一个包含三个元素的字符串数组,我们构造了一个正则表达式来匹配连续出现的11位数字。另外,我们使用的正则表达式是'[0-9]{11}',绝大多数情况下,你也可以使用'\d{11}'替代,这样更为简洁。最终返回的结果c1是一个元胞数组,里面有三个数据,每个数据分别表示s中对应元素匹配的结果。
接下来,请大家思考下面两个问题:
(1) 能否修改上方的正则表达式来同时匹配座机号码?
只需要将正则表达式修改为'[0-9]{3}-?[0-9]{8}'或者'\d{3}-?\d{8}'就能够匹配到座机号码。因为字符'-'出现的次数是0次或者1次,因此我们可以使用'-?'进行匹配。
(2) 这个正则表达式是否存在漏洞?
确实存在潜在的漏洞。例如,如果字符串中包含类似于圆周率这样的长数字序列(如“3.14159265358”),则正则表达式可能会错误地匹配其中的一部分数字。尽管这种情况在实际应用中可能较少见到,但仍然需要注意正则表达式的精确性和适用性。为了避免这种误匹配,我们可以根据具体的应用场景进一步细化正则表达式的规则,也可以对匹配后的结果进行进一步的筛选。
例2:匹配QQ邮箱
最一般的QQ邮箱的格式为“QQ号@qq.com”,其中QQ号是一个5到10位的数字。为了从文本中提取这种格式的邮箱,我们可以编写一个正则表达式来匹配它。
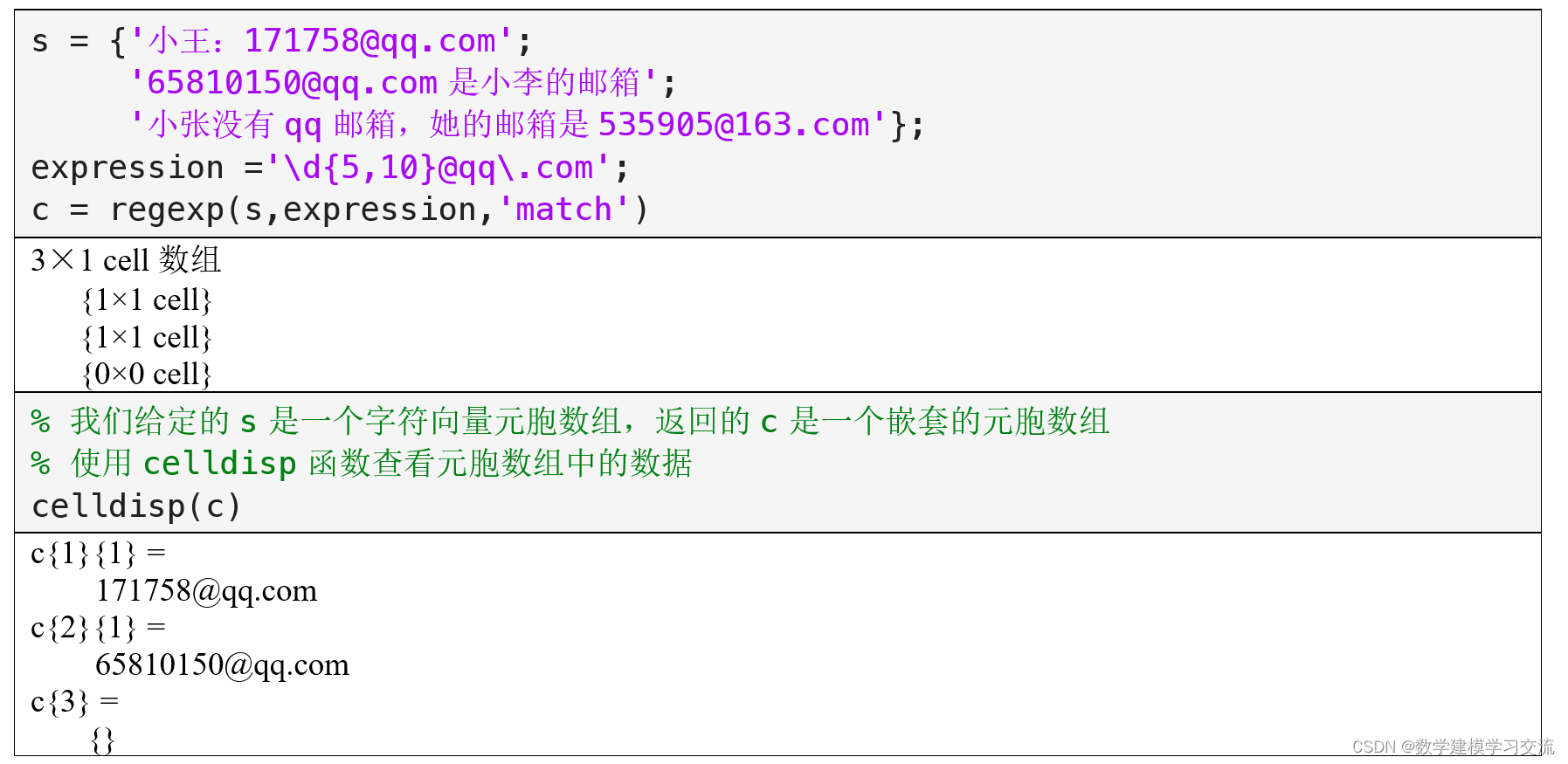
此外,QQ邮箱还提供了英文邮箱格式,QQ的英文邮箱规则如下:必须以英文字母开头,邮箱前缀(即@符号之前的字符)的长度为3至18,且只能包括大小写英文字母、数字和下划线,并使用@qq.com结尾。请重新写一段正则表达式来匹配QQ的英文邮箱。

例3:匹配英文单词
s是一个字符串标量,它用来保存一段英文,请从s中提取出所有的英文单词。

另外,有些英文单词比较特殊,例如sixty-three和don't。现在请你思考:上面的代码能正确匹配这两种单词吗?如果不能应如何修改代码?

事实上,最下面的这种方法也存在漏洞,我们来看一个比较特殊的例子:

可以看到,第5个单词被匹配为world',多了一个单引号'。要想解决这个问题,我们可以考虑对ss使用strip(ss,"'")命令,这样就能去掉这个多余的单引号。
当然,使用正则表达式也能修复这一漏洞,这需要用到正则表达式的条件运算符|:


另外,我们也可以使用下面这两种正则表达式,得到的结果和s1完全相同:
s3 = regexp(s,"[a-zA-Z]+(['-][a-zA-Z]+|['-]{0})",'match')
s4 = regexp(s,"[a-zA-Z]+(['-][a-zA-Z]+|)",'match')
另外,如果我们希望匹配字符'|'、'*'、'+'和'?'本身,我们可以使用\|、\*、\+和\?,也可以使用[|]、[*]、[+]和[?],这和匹配字符'.'的方式相同。

此外,我们可以利用成对的英文小括号来明确区分正则表达式的不同部分,这不仅使得正则表达式的结构变得更加清晰,而且也便于理解和修改。例如,上面的例子中,你可以把正则表达式改写为'(\|)(\*+)(\+)',这样改动后得到的匹配结果与原来完全一致。值得注意的是,通过这种添加小括号的方式,我们实际上创建了正则表达式中的捕获组。在这个例子中,我们定义了三个捕获组:第一个捕获组用于匹配'|'字符,第二个捕获组匹配一个或多个'*'字符,而第三个捕获组则匹配'+'字符。在后续内容中,我们将详细介绍捕获组的相关知识和它们的应用。
当然,如果我们需要匹配小括号'('和')'本身,同样可以通过使用\(和\)来实现,或者将它们置于方括号内(即[(]和[)]),这些方法都是通用的。例如我们要匹配包含小括号的数学表达式:

三、模式
模式用于控制限定符的匹配策略,MATLAB的正则表达式支持三种模式:贪婪(Greedy)模式、懒惰(Lazy)模式和独占(Possessive)模式。这些模式对于精确控制匹配行为至关重要。让我们通过一个实际例子来探讨模式的应用及其重要性。
假设我们有一个字符串标量s,其中包含了两个网址,我们希望通过正则表达式'www.*com'分别匹配这两个网址,然而返回的结果却不是我们期望得到的:

在此例中,由于MATLAB的正则表达式默认采用贪婪模式,*限定符尽可能地匹配更多字符,直到找到字符串中的最后一个com。因此,从第一个www到最后一个com之间的整个字符串都被匹配了。
为了能够分别匹配每一个网址,我们应该采用懒惰模式。懒惰模式通过在限定符后面添加一个问号?来实现,使得正则表达式匹配尽可能少的字符。一旦找到符合条件的匹配项,它就会停止当前的匹配过程,然后开始下一次匹配。这样,从第一个www开始,到遇到的第一个com结束,完成第一次匹配;随后MATLAB继续执行第二次匹配,从而实现了对两个网址的分别匹配:

再来举一个例子帮助大家理解正则表达式中的贪婪模式和懒惰模式:

拓展:独占模式(本部分内容涉及到底层的算法知识,初学者仅需了解即可)
在深入了解贪婪模式和懒惰模式后,我们已经见识到了正则表达式在字符匹配中的灵活性,这两种模式能够满足绝大多数复杂的匹配需求。然而,面对极大规模的文本处理的应用场景时,正则表达式的匹配效率成为关键考虑因素。特别是在贪婪模式下,可能有大量的回溯操作来寻找匹配结果,某些时候这会导致匹配效率急剧下降,这种现象被称为“回溯陷阱”。
独占模式的引入,正是为了应对这一挑战。作为正则表达式的第三种模式,独占模式提供了一种更高效的匹配策略。它与贪婪模式类似,尽可能匹配更多字符,但关键的区别在于一旦进行匹配,就不会释放任何字符,即便这可能导致整个匹配失败。这种策略显著减少了回溯操作的需求,提高了匹配的效率。
在MATLAB中,独占模式通过在限定符的后面添加一个加号+来实现。现在,我们通过一个具体的例子来演示独占模式在实际应用中的性能优势。假设我们需要在一个非常长的字符串中匹配特定的模式。为此,我们人为构造了一个很长的字符串标量cc,其中包含从1到10000的数字,然后重复数字序列cc两次,并插入了两个英文字段:

对于本例题,我们发现使用独占模式进行匹配的执行时间比贪婪模式少,这是因为独占模式避免了不必要的回溯,从而减少了计算量。然而,这种模式也有其局限性,尤其是在某些场合下,可能无法成功匹配到期望的数据。
独占模式的一个主要局限性在于,一旦开始匹配,它不会放弃已匹配的字符,即使这意味着整个表达式的匹配会因此失败。这种“一往无前”的匹配策略,在某些情况下可能会导致匹配失败。考虑以下示例:

在这个例子中,使用贪婪模式能够成功匹配整个字符串"1111111a1",因为.*允许匹配任何字符直到字符串的末尾,然后通过回溯找到最后一个"1"来完成匹配。相反,当我们尝试使用独占模式进行匹配时,结果是一个空的字符串数组。这是因为独占模式下的.*+匹配了所有字符,包括最后一个"1",由于独占模式下不会释放任何已匹配的字符,因此正则表达式会因为缺少最后的"1"而导致匹配失败。
因此,尽管独占模式在提高匹配性能方面展现出了显著优势,特别是在处理大规模数据时能够有效减少回溯,从而加快匹配速度,它的使用却需慎重。这是因为独占模式的“一次匹配,不回头”的特性可能限制了其在某些场景下的适用性。确保它适合于特定的匹配需求是使用独占模式的关键。
实际上,在大多数正则表达式的应用场景中,贪婪模式和懒惰模式已经足够应对绝大部分的匹配需求。贪婪模式通过尽可能多地匹配字符,而懒惰模式则提供了更为精细的控制,允许匹配尽可能少的字符。这两种模式在灵活性和易用性方面都优于独占模式,使得它们成为日常使用中更为常见的选择。
总之,了解各种模式的特点和适用场景,可以帮助程序开发者更加精准地控制匹配行为,优化正则表达式的性能,并确保匹配结果符合预期。在选择使用哪一种模式时,评估匹配需求的具体情况是至关重要的,这不仅关乎匹配效率,也影响到最终匹配结果的准确性。
四、分组运算
在处理文本数据时,我们经常遇到只需提取特定部分信息的情况。这就需要运用到分组运算,它允许我们在匹配过程中将关注点集中于文本的特定片段。以一个实际的例子为例,假设我们需要从一段文本中提取学生的姓名。根据目前所学知识可通过以下方式编写代码:

虽然这种方法可以达到目的,但它需要额外的步骤来删除不需要的文本内容,显得有些繁琐。为了简化这一过程,我们可以利用正则表达式的分组运算功能,直接在匹配时提取我们关注的文本片段。
使用分组运算来提取特定的文本内容既简单又高效,只需遵循以下两个步骤:
(1)创建捕获组:通过将希望单独提取的文本内容用英文小括号()括起来,我们便创建了一个捕获组。这个捕获组会在匹配过程中单独提取匹配到的文本。
(2)修改regexp函数的参数:在调用regexp函数时,将它的第三个输入参数设置为'tokens'。这样才会返回捕获组定义的特定部分。
以上述例子为例,我们通过分组运算来直接提取姓名信息:

每个元胞内包含一个由捕获组(\w*)匹配到的姓名字符串。如果需要的话,你也可以将这个元胞数组转换成字符串数组类型:

此外,有同学可能会想:能否在单个正则表达式中创建多个捕获组来匹配不同的信息?答案是肯定的。例如,如果我们想同时匹配这三名同学的姓名和昵称,可以这样做:

在这个例子中,通过在正则表达式中定义两个捕获组,我们成功地同时匹配了每个学生的姓名和昵称。regexp函数返回了一个包含三个元素的元胞数组,表示匹配成功了三次。每个元胞中的数据都是包含两个元素的字符串数组,分别对应两个捕获组匹配到的姓名和昵称。当然,如果你希望将匹配结果保存到更方便操作的字符串数组中,可以这样做:

这样,我们便得到了一个3×2的字符串数组,每行包含一名学生的姓名和昵称。
接下来,我们介绍两个拓展的知识点,尽管它们的使用频率较低,但它们给正则表达式的分组运算提供了额外的灵活性和控制能力。
拓展一:同时使用多个参数返回不同类型的匹配结果
在处理文本数据时,有时候我们不仅需要提取与捕获组匹配的特定文本,还需要同时获得整个匹配的文本。MATLAB的regexp函数支持这种需求,允许通过同时指定'tokens'和'match'参数来实现,这样就能在单一函数调用中返回多种类型的匹配结果。例如:

当然,两个参数的顺序可以互换,返回的结果将相应地调整顺序以匹配参数的排列顺序。
拓展二:非捕获组
在之前的内容中,我们学习了如何通过使用英文小括号()创建捕获组,这种方式允许我们单独提取匹配的文本内容,并通过'tokens'参数进行匹配。然而,在某些情况下,我们可能需要用到小括号但又不希望捕获这部分的匹配内容。这时,我们可以利用(?:expr)来创建非捕获组,其中expr代表我们希望匹配但不捕获的正则表达式部分。例如:

五、定位点
定位点也被称为锚点,它们使得正则表达式能够精确地与文本的开头或结尾匹配,从而实现更为精细的匹配控制。下面我们介绍两种使用频率较高的定位点:

它们的使用方法非常简单,我们先举几个简单的例子:

另外,定位符^(表示开头)和$(表示结尾)也能同时使用:

在第一个例子中,由于字符串s中的开头数字和结尾字母之间还包含了其他的字符,因此正则表达式无法找到完全符合条件的匹配项,返回了一个空数组。
此外,有同学可能会回想起我们在前一章学习的两个函数:startsWith和endsWith。这两个函数与正则表达式中的定位符^(表示开头)和$(表示结尾)确实有着相似的功能。让我们通过一个具体的例子来探讨它们之间的联系:提取出所有以元音字母开头的单词。

上面这段代码通过正则表达式'^[aeiouAEIOU].*'成功地筛选出了以元音字母开头的单词,并将匹配结果重新拼接到一个字符串数组中。
作为对比,我们同样可以使用startsWith函数来实现这一功能,这提供了一个更为直接且易于理解的方法:
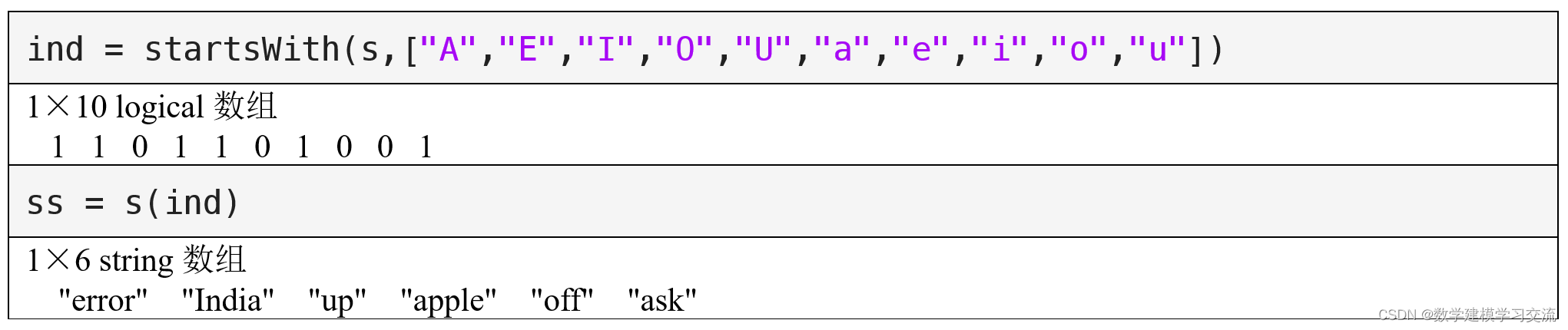
通过指定元音字母列表作为startsWith函数的第二个参数,我们可以快速得到同样的结果。这种方法不仅代码更为简洁,而且在表达意图上更加直观。
六、正则表达式中其他的高级语法
至此,我们已经介绍完MATLAB的正则表达式中一些基础和常用的语法规则,涵盖了元字符、限定符、模式、分组运算和定位点等关键概念。然而,正则表达式中还有一些高级语法我们没有介绍,例如环顾断言、动态表达式、搜索标志等。对于绝大多数的文本处理任务,掌握我们目前所学的知识点就足够了,对高级语法感兴趣的同学请参考MATLAB的官网:
正则表达式- MATLAB & Simulink- MathWorks 中国
点击下方的CSDN专栏阅读下一篇文章:
MATLAB入门课程专栏
相关文章:
第6章 6.3.1 正则表达式的语法(MATLAB入门课程)
讲解视频:可以在bilibili搜索《MATLAB教程新手入门篇——数学建模清风主讲》。 MATLAB教程新手入门篇(数学建模清风主讲,适合零基础同学观看)_哔哩哔哩_bilibili 正则表达式可以由一般的字符、转义字符、元字符、限定符等元素组…...
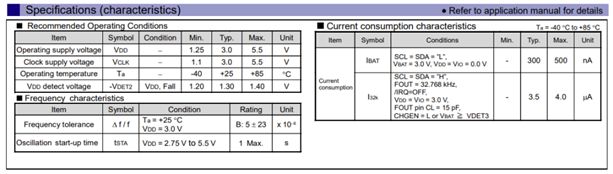
RX8130CE为用户提供带复位延迟和主备电管理的解决方案
实时时钟作为设备的精确时钟来源,其作用如同人的心脏,为设备提供准确稳定的心跳.而便携式设备由于应用场景多变,所以对内部元器件要求也相对较高,这就对作为核心器件的实时时钟模块提出不少挑战。EPSON实时钟模块产品线拥有丰富的…...

JS文件导出变量
如果 config.js 文件中有多个变量要导出,你可以按照以下步骤进行: 1. 在 config.js 文件中定义多个变量,并使用 export 导出它们。 // config.js const baseUrl "http://localhost:8081"; const apiKey "your_api_key&quo…...

已知私钥和密文,如何用python进行RSA解密
要使用Python进行RSA解密,你可以使用pycryptodome库。下面是一个简单的示例,展示了如何使用已知的私钥和密文进行RSA解密: 首先,确保你已经安装了pycryptodome库。如果没有安装,你可以通过运行pip install pycryptodome来安装它。 然后,你可以使用以下代码进行RSA解密:…...

vue2-vue3面试
v-text/v-html/v-once/v-show/v-if/v-for/v-bind/v-on beforeCreate() 已有DOM节点:可以data选项:不可以虚拟DOM节点:不可以 created():掌握 已有DOM节点:可以data选项:可以虚拟DOM节点:不可以 beforeMount…...

jmeter生成随机数的详细步骤及使用方式
Apache JMeter 是一个用于测试性能的开源工具,它可以模拟多种类型的负载并测量应用程序的性能。在 JMeter 中生成随机数可以通过使用预定义的函数来实现。以下是生成随机数的详细步骤及使用方式: 安装 JMeter: 首先,你需要在你的计…...

速盾:为什么会出现高防cdn?它适合哪些行业?
随着互联网的不断发展和普及,网络安全问题也变得日益突出。由于互联网的特性,许多企业和组织的在线业务往往面临来自网络攻击的威胁,如DDoS攻击、恶意爬虫等。为了保护在线业务的正常运行和用户数据的安全,高防CDN应运而生。 高防…...

GB∕T 25058-2019 信息安全技术 网络安全等级保护实施指南
GB∕T 25058-2019 信息安全技术 网络安全等级保护实施指南...
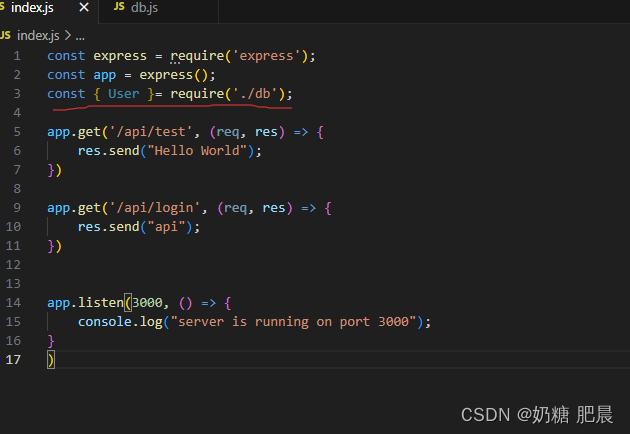
使用Nodejs + express连接数据库mongoose
文章目录 先创建一个js文档安装 MongoDB 驱动程序:引入 MongoDB 模块:设置数据库连接:新建一个表试试执行数据库操作:关闭数据库连接: 前面需要准备的内容可看前面的文章: Express框架搭建项目 node.js 简单…...

朗致集团面试-Java架构师
总结 三轮面试,第一轮是逻辑测试性格测试,第二轮是技术面试(面试官-刘老师),第三轮是CTO面试(面试官-屠老师)。如果第三轮面试通过,考官会问你薪资意向,如果满意的话HR就…...

Ubuntu 23.10 搜狗拼音输入法闪屏解决
问题与解决 Ubuntu 23.10下安装搜狗拼音输入法并且使用搜狗输入法时,会闪屏。站内有人说可以换使用Xorg作为桌面服务,然后使用基于X11的桌面,其实可以不用那么麻烦,只需要设置QT的环境变量QT_QPA_PLATFORMxcb,然后重新…...
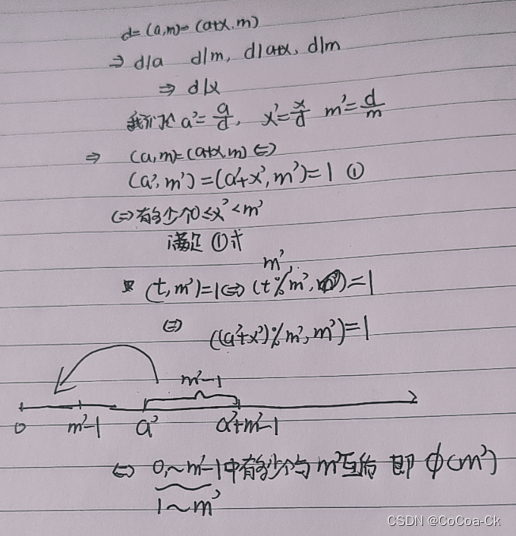
备战蓝桥杯---刷杂题2
显然我们直接看前一半,然后我们按照斜行看,我们发现斜行是递增的,而同一行从左向右也是递增的,因此我们可以直接二分,同时我们发现对称轴的数为Ck,2k. 我们从16斜行枚举即可 #include<bits/stdc.h> using name…...
.[[backup@waifu.club]].svh勒索病毒数据怎么处理|数据解密恢复
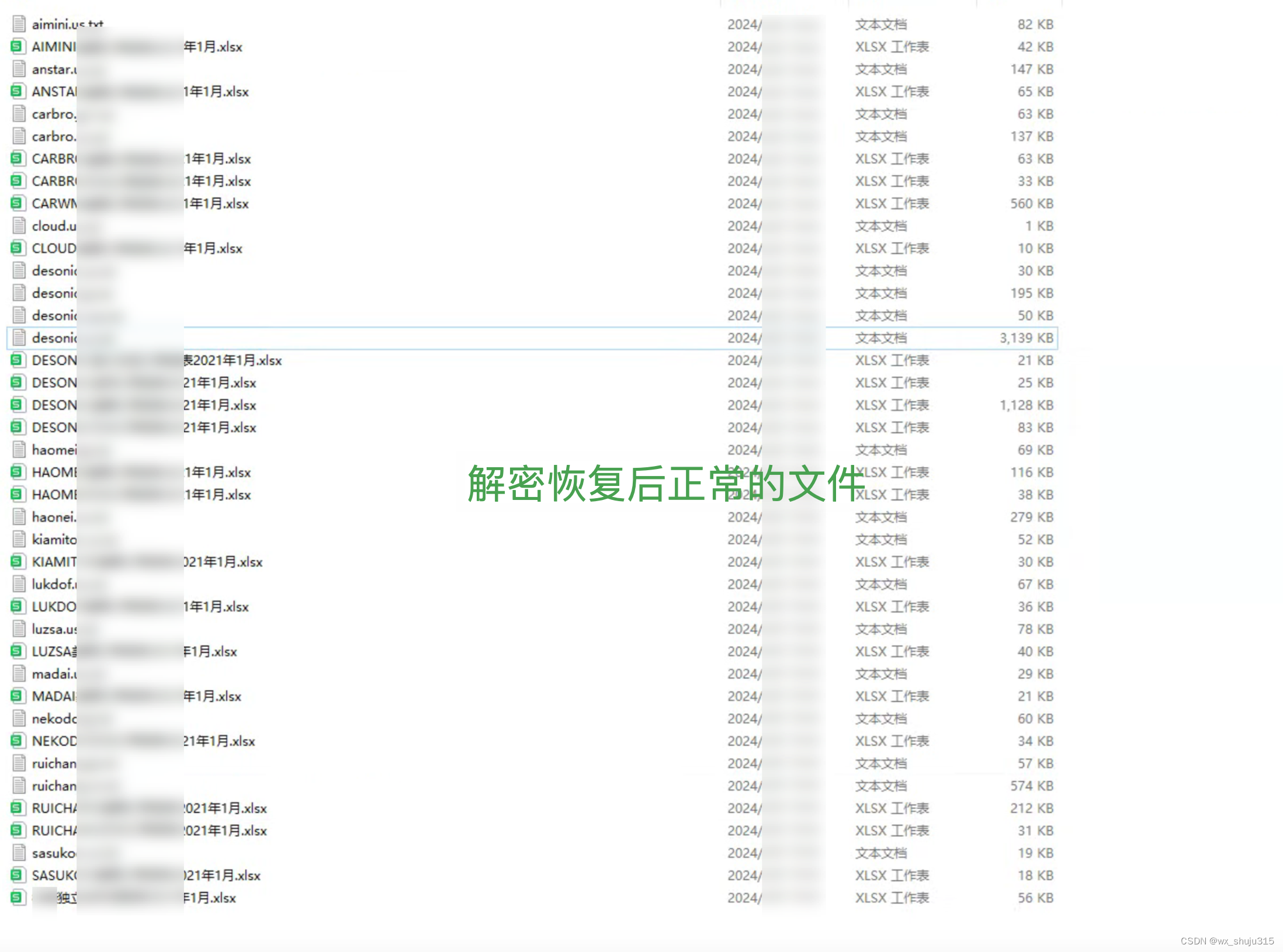
尊敬的读者: 近年来,随着信息技术的迅猛发展,网络安全问题日益凸显,其中勒索病毒成为了一大威胁。.[[backupwaifu.club]].svh、.[[MyFilewaifu.club]].svh勒索病毒就是其中之一,它以其独特的传播方式和恶劣的加密手段…...
)
SpringFramework实战指南(八)
SpringFramework实战指南(八) 5.1 场景设定和问题复现5.2 解决技术代理模式5.1 场景设定和问题复现 准备AOP项目 项目名:spring-aop-annotation pom.xml <dependencies><!--spring context依赖--><!--当你引入Spring Context依赖之后,表示将Spring的基础依赖…...
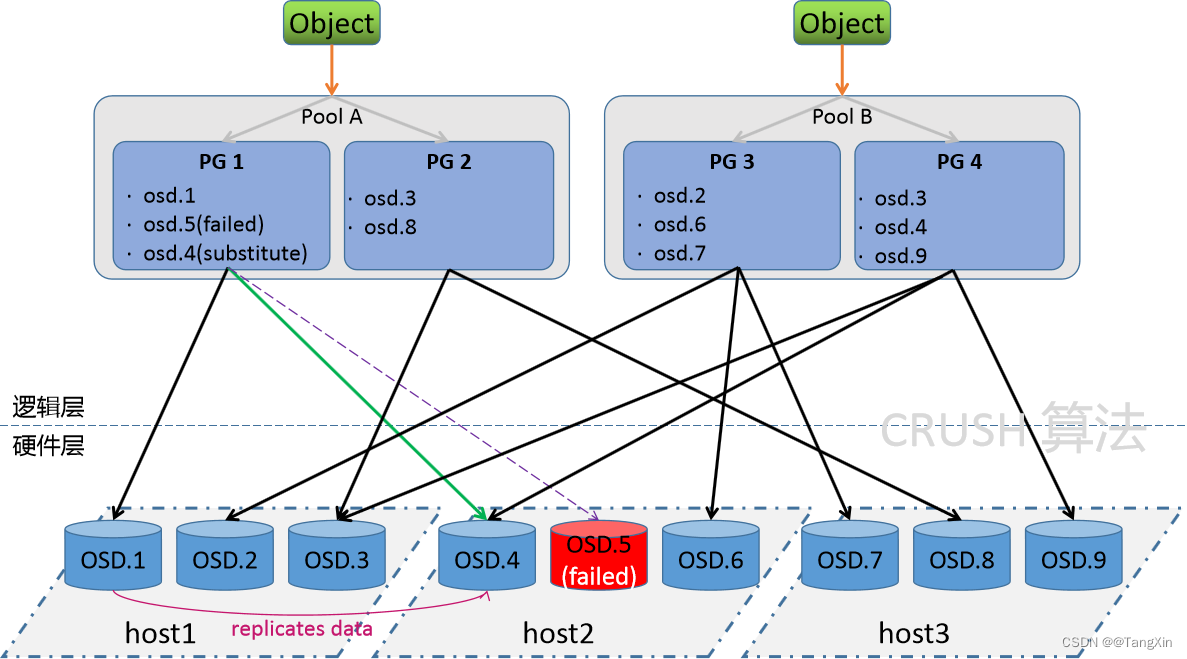
Ceph学习 -4.Ceph组件介绍
文章目录 1.Ceph组件介绍1.1 组件介绍1.2 流程解读1.2.1 综合效果图1.2.2 数据存储逻辑 1.3 小结 1.Ceph组件介绍 学习目标:这一节,我们从组件介绍、流程解读、小结三个方面来学习。 1.1 组件介绍 无论是想向云平台提供 Ceph 对象存储和 Ceph 块设备服务…...
)
Python100个库分享第13个—awesome-slugify(处理Unicode)
目录 专栏导读库的介绍库的安装基础用法1:用‘-’连接基础用法1:汉字转拼音用‘-’连接有个类似的库 —python-slugify安装总结 专栏导读 🌸 欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双手 🏳️…...

01 SQL基础 -- 初识数据库与安装
一、初识数据库 数据库是将大量数据保存起来,通过计算机加工而成的可以进行高效访问的数据集合。该数据集合称为数据库(Database, DB)。用来管理数据库的计算机系统称为数据库管理系统(Database Management System, DBMS) 1.1 DBMS 的种类 DBMS 主要通过数据的保存格式…...

PyTorch搭建Autoformer实现长序列时间序列预测
目录 I. 前言II. AutoformerIII. 代码3.1 Encoder输入3.1.1 Token Embedding3.1.2 Temporal Embedding 3.2 Decoder输入3.3 Encoder与Decoder3.3.1 初始化3.3.2 Encoder3.3.3 Decoder IV. 实验 I. 前言 前面已经写了很多关于时间序列预测的文章: 深入理解PyTorch中…...
FFmpeg: 简易ijkplayer播放器实现--06封装打开和关闭stream
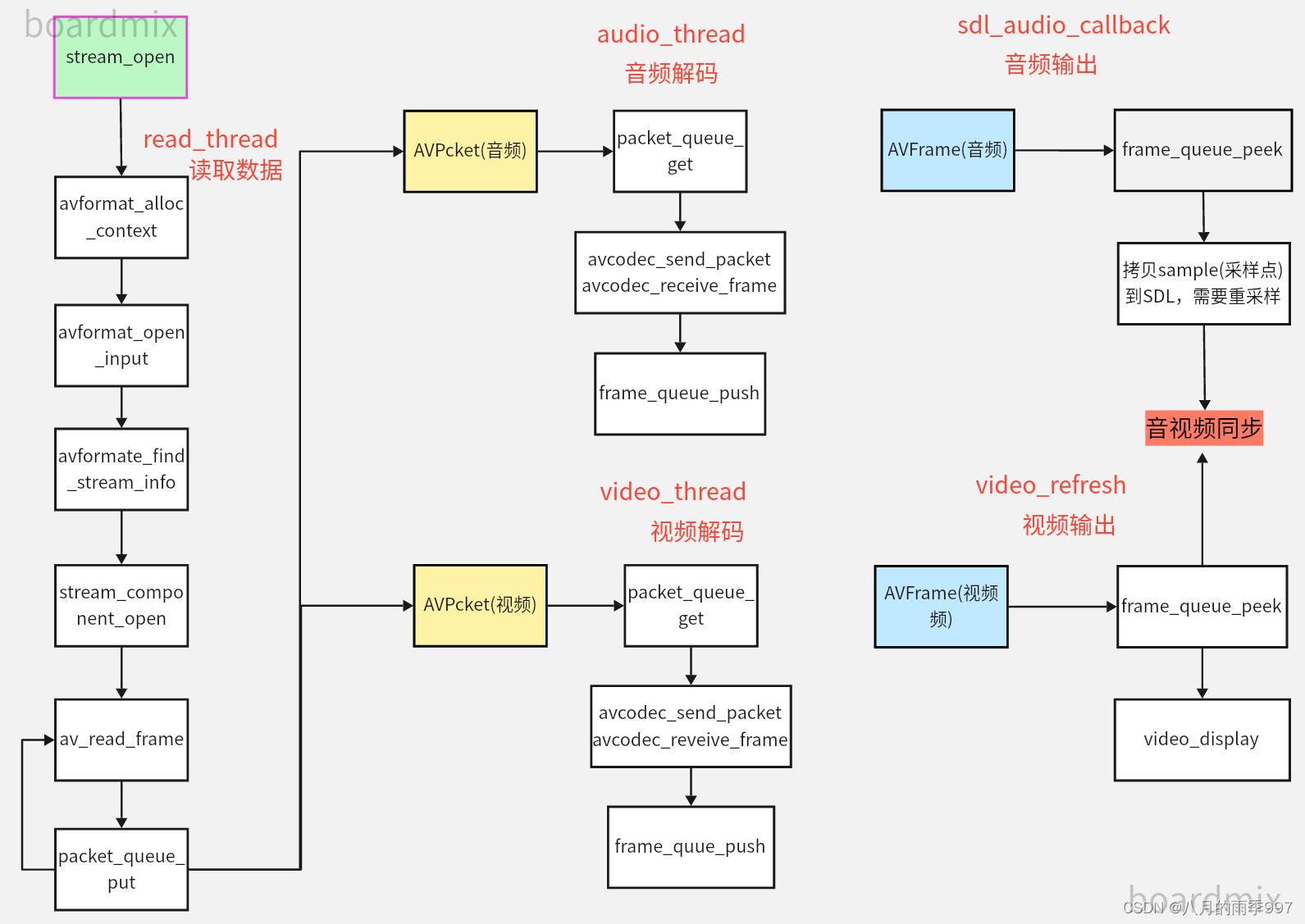
文章目录 流程图stream openstream close 流程图 stream open 初始化SDL以允许⾳频输出;初始化帧Frame队列初始化包Packet队列初始化时钟Clock初始化音量创建解复用读取线程read_thread创建视频刷新线程video_refresh_thread int FFPlayer::stream_open(const cha…...
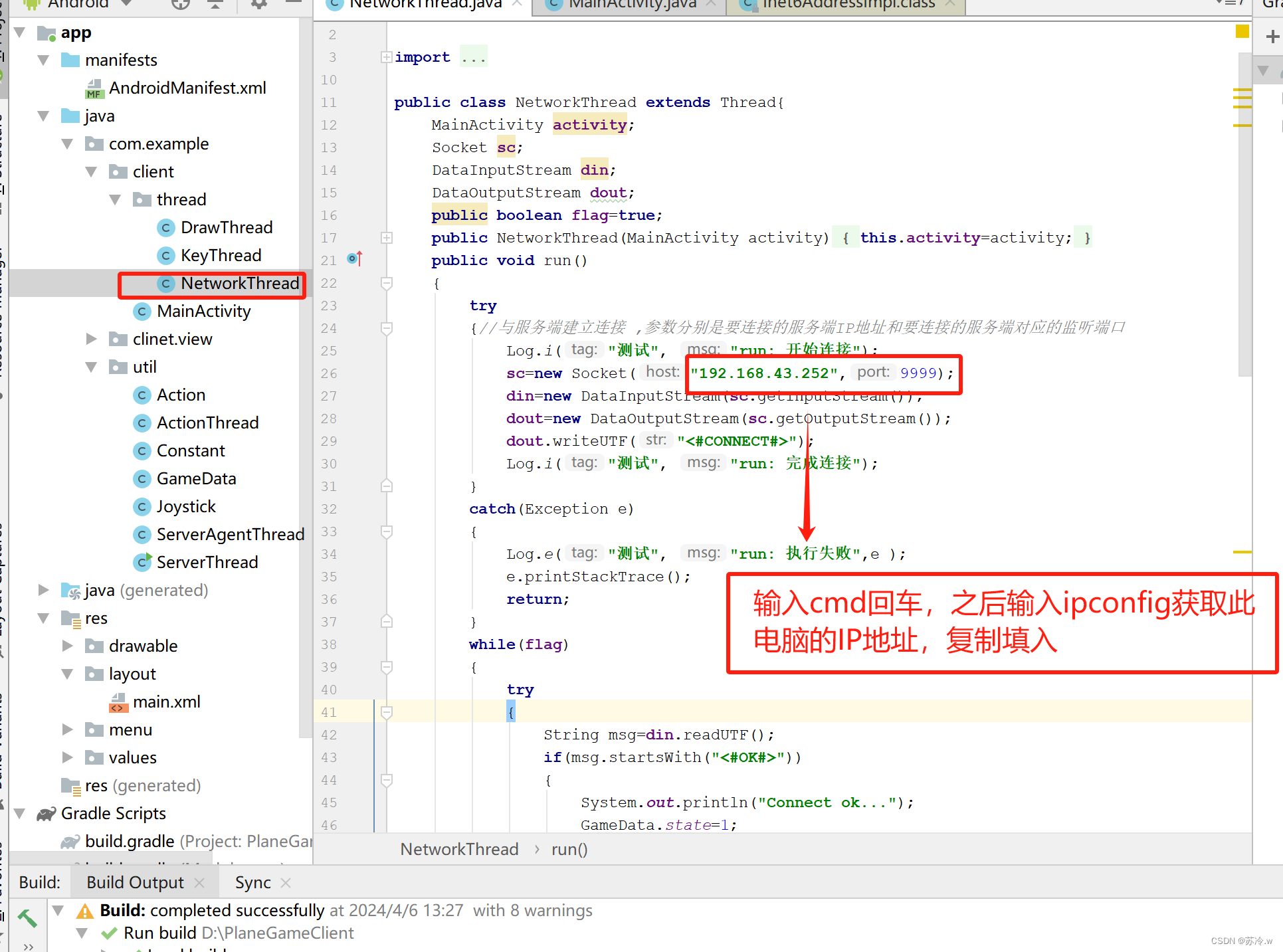
使用Android完成案例教学
目录 题目:完成在Android平台下2个玩家分别利用2个手机连接在同一局域网下通过滑动摇杆分别使红飞机和黄飞机移动的开发。(全代码解析) 题目:完成在Android平台下2个玩家分别利用2个手机连接在同一局域网下通过滑动摇杆分别使红飞…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...

STM32HAL库USART源代码解析及应用
STM32HAL库USART源代码解析 前言STM32CubeIDE配置串口USART和UART的选择使用模式参数设置GPIO配置DMA配置中断配置硬件流控制使能生成代码解析和使用方法串口初始化__UART_HandleTypeDef结构体浅析HAL库代码实际使用方法使用轮询方式发送使用轮询方式接收使用中断方式发送使用中…...
零知开源——STM32F103RBT6驱动 ICM20948 九轴传感器及 vofa + 上位机可视化教程
STM32F1 本教程使用零知标准板(STM32F103RBT6)通过I2C驱动ICM20948九轴传感器,实现姿态解算,并通过串口将数据实时发送至VOFA上位机进行3D可视化。代码基于开源库修改优化,适合嵌入式及物联网开发者。在基础驱动上新增…...