结合文本的目标检测:Open-GroundingDino训练自己的数据集
1、简单介绍
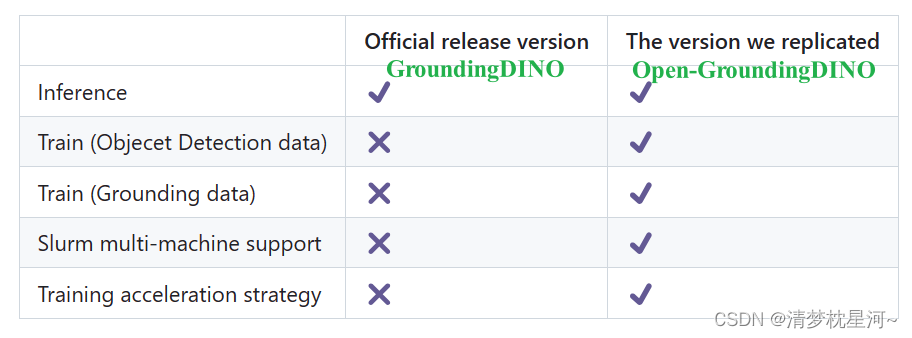
Open-GroundingDino是GroundingDino的第三方实现训练流程的代码,因为官方GroundingDino没有提供训练代码,只提供了demo推理代码。
关于GroundingDino的介绍可以看论文:https://arxiv.org/pdf/2303.05499.pdf
GroundingDino的Github网址:https://github.com/IDEA-Research/GroundingDINO
Open-GroundingDino的Github网址: https://github.com/longzw1997/Open-GroundingDino/tree/main
要跑起来Open-GroundingDino,需要解决环境安装,数据集制作,网络配置等问题,下面大致从这几个方面进行介绍。
2、训练Open-GroundingDino
2.1、环境安装
建议把GroundingDino下载下来,把环境装好,再来装Open-GroundingDino,最好可以先跑通GroundingDino的demo再来弄Open-GroundingDino,我之前跑推理的时候先弄的Open-GroundingDino结果环境有问题,缺少编译代码,没有生成groundingdino库。
关于cuda、pytorch的环境安装就不具体介绍了。主要是安装好显卡驱动(别太老,至少能CUDA12及以下),然后是conda环境安装pytorch,这直接去pytorch官网安装就行,装完了测试一下显卡能不能被调用。可以就接着装相关的库。
git clone https://github.com/IDEA-Research/GroundingDINO.git
cd GroundingDINO/
编译GroundingDino,本质和 python setup.py develop 是一样的
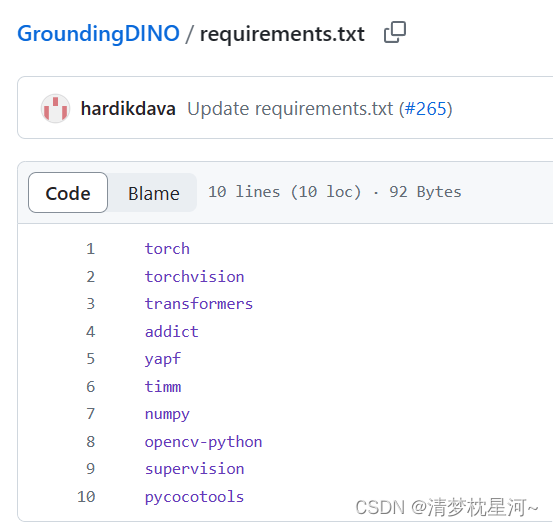
pip install -e .
执行上面的命令会自动安装 requirements.txt里的库,这个也可以手动安装
上面基本上就完成了 GroundingDino 的环境安装,可以开始测试环境可不可以用,跑一下demo,注意下载好预训练模型
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py \
-c groundingdino/config/GroundingDINO_SwinT_OGC.py \
-p weights/groundingdino_swint_ogc.pth \
-i image_you_want_to_detect.jpg \
-o "dir you want to save the output" \
-t "chair"[--cpu-only] # open it for cpu mode
或
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py \
-c groundingdino/config/GroundingDINO_SwinT_OGC.py \
-p ./groundingdino_swint_ogc.pth \
-i .asset/cat_dog.jpeg \
-o logs/1111 \
-t "There is a cat and a dog in the image ." \
--token_spans "[[[9, 10], [11, 14]], [[19, 20], [21, 24]]]"[--cpu-only] # open it for cpu mode
预训练模型下载:
mkdir weights
cd weights
wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
cd ..
或者找网址直接下载也行
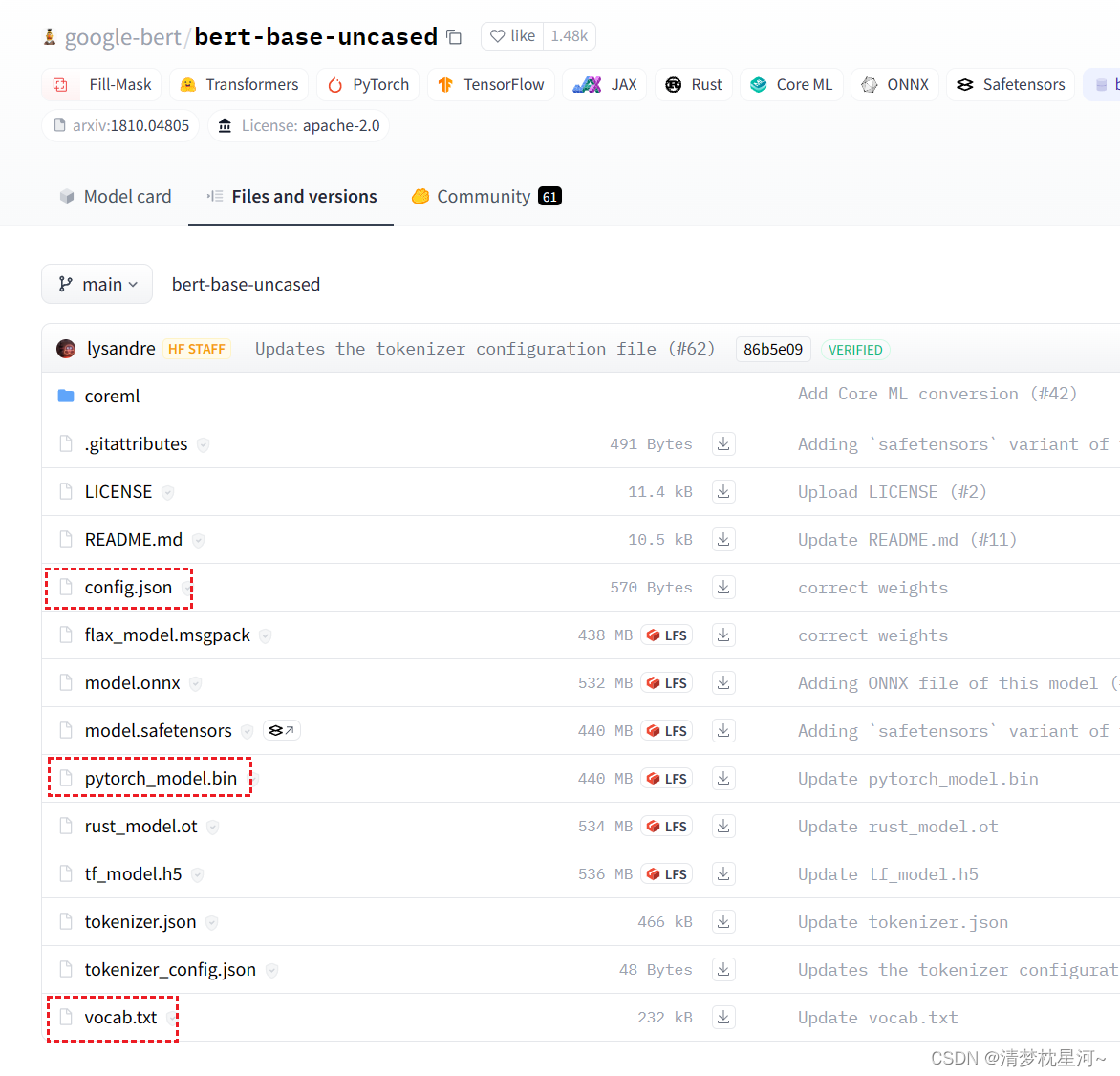
还有文本解码的 bert-base-uncased 也需要下载,网址:https://huggingface.co/google-bert/bert-base-uncased/tree/main
主要下载以下几个文件,把路径加到 text_encoder_type,关于推理可以看我上一篇:
Open-GroundingDino和GroundingDino的推理流程实现
上面是在 GroundingDino 中的环境安装和推理准备,后续需要在Open-GroundingDino中安装环境操作:
git clone https://github.com/longzw1997/Open-GroundingDino.git && cd Open-GroundingDino/
pip install -r requirements.txt
cd models/GroundingDINO/ops
python setup.py build install
python test.py
cd ../../..
再把 预训练模型 和 bert的文本模型路径 也加到 Open-GroundingDino 基本上就完成了环境安装。
2.2、数据集制作
不说细节了,主要是一些注意的地方。官方给的数据集格式:
# For OD
{"filename": "000000391895.jpg", "height": 360, "width": 640, "detection": {"instances": [{"bbox": [359.17, 146.17, 471.62, 359.74], "label": 3, "category": "motorcycle"}, {"bbox": [339.88, 22.16, 493.76, 322.89], "label": 0, "category": "person"}, {"bbox": [471.64, 172.82, 507.56, 220.92], "label": 0, "category": "person"}, {"bbox": [486.01, 183.31, 516.64, 218.29], "label": 1, "category": "bicycle"}]}}
{"filename": "000000522418.jpg", "height": 480, "width": 640, "detection": {"instances": [{"bbox": [382.48, 0.0, 639.28, 474.31], "label": 0, "category": "person"}, {"bbox": [234.06, 406.61, 454.0, 449.28], "label": 43, "category": "knife"}, {"bbox": [0.0, 316.04, 406.65, 473.53], "label": 55, "category": "cake"}, {"bbox": [305.45, 172.05, 362.81, 249.35], "label": 71, "category": "sink"}]}}# For VG
{"filename": "014127544.jpg", "height": 400, "width": 600, "grounding": {"caption": "Homemade Raw Organic Cream Cheese for less than half the price of store bought! It's super easy and only takes 2 ingredients!", "regions": [{"bbox": [5.98, 2.91, 599.5, 396.55], "phrase": "Homemade Raw Organic Cream Cheese"}]}}
{"filename": "012378809.jpg", "height": 252, "width": 450, "grounding": {"caption": "naive : Heart graphics in a notebook background", "regions": [{"bbox": [93.8, 47.59, 126.19, 77.01], "phrase": "Heart graphics"}, {"bbox": [2.49, 1.44, 448.74, 251.1], "phrase": "a notebook background"}]}}
我实践后的理解是,上面两种格式是独立的,就是你可以整一个OD格式的jsonl,也可以整一个VG格式的jsonl,然后可以把这几种格式的数据集放到一起训练,写到数据集配置文件 datasets_mixed_odvg.json:
{"train": [{"root": "path/V3Det/","anno": "path/V3Det/annotations/v3det_2023_v1_all_odvg.jsonl","label_map": "path/V3Det/annotations/v3det_label_map.json","dataset_mode": "odvg"},{"root": "path/LVIS/train2017/","anno": "path/LVIS/annotations/lvis_v1_train_odvg.jsonl","label_map": "path/LVIS/annotations/lvis_v1_train_label_map.json","dataset_mode": "odvg"},{"root": "path/Objects365/train/","anno": "path/Objects365/objects365_train_odvg.json","label_map": "path/Objects365/objects365_label_map.json","dataset_mode": "odvg"},{"root": "path/coco_2017/train2017/","anno": "path/coco_2017/annotations/coco2017_train_odvg.jsonl","label_map": "path/coco_2017/annotations/coco2017_label_map.json","dataset_mode": "odvg"},{"root": "path/GRIT-20M/data/","anno": "path/GRIT-20M/anno/grit_odvg_620k.jsonl","dataset_mode": "odvg"}, {"root": "path/flickr30k/images/flickr30k_images/","anno": "path/flickr30k/annotations/flickr30k_entities_odvg_158k.jsonl","dataset_mode": "odvg"}],"val": [{"root": "path/coco_2017/val2017","anno": "config/instances_val2017.json","label_map": null,"dataset_mode": "coco"}]
}
但是。验证集的格式必须使用COCO格式,因为代码采用的是COCO数据集的计算方法。这就是Open-GroundingDino给出的数据集制作方法。
在实践过程中发现的问题:
①给出的格式不够清晰 是不是可以把 OD、VG 在一个数据集中生成,既有detection内容又有grounding内容;
②只给了一条数据集格式,当有两张图的时候数据集格式是怎样的不清楚,我一开始是直接列表里面放字典,字典之间用逗号隔开,我转化了v3det数据集后发现不是这样的,之所以一开始没这么做,是因为v3det的数据集比较大,操作之后不好打开,不好看格式,太吃内存了。
实际上的格式是一个字典挨着一个字典:
{
}{
}{
}
}{
}
而且自己生成的时候尽量采用提供的格式,不然训练时读数据容易报 jsondecodeerror,参考tools/v3det2odvg.py,使用jsonlines 库生成 jsonl文件,训练集最好是这样,采用如下格式将个人的数据信息生成对应格式的数据集。
metas = []
instance_list = []
instance_list.append({"bbox": bbox_xyxy,"label": label - 1, # make sure start from 0"category": category})metas.append({"filename": img_info["file_name"],"height": img_info["height"],"width": img_info["width"],"detection": {"instances": instance_list}})with jsonlines.open(args.output, mode="w") as writer:writer.write_all(metas)
报错信息:json.decoder.JSONDecodeError:Expecting property name enclosed in double quotes: line 1 column 2 (char 1),这是训练时读取ODVG格式数据集的函数, 在datasets/odvg.py里面
def _load_metas(self, anno):with open(anno, 'r')as f:self.metas = [json.loads(line) for line in f]
验证集直接采用COCO格式就行了,这个格式比较清晰,可以找到的信息也多。
完成数据集制作,接下来是网络配置。
2.3、网络配置
网络训练需要配置好网络参数和数据集信息才能开始训练,配置文件:
config/cfg_odvg.py # for backbone, batch size, LR, freeze layers, etc.
config/datasets_mixed_odvg.json # support mixed dataset for both OD and VG
第一个是网络结构配置文件:
data_aug_scales = [480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800]
data_aug_max_size = 1333
data_aug_scales2_resize = [400, 500, 600]
data_aug_scales2_crop = [384, 600]
data_aug_scale_overlap = None
batch_size = 4
modelname = 'groundingdino'
backbone = 'swin_T_224_1k'
position_embedding = 'sine'
pe_temperatureH = 20
pe_temperatureW = 20
return_interm_indices = [1, 2, 3]
enc_layers = 6
dec_layers = 6
pre_norm = False
dim_feedforward = 2048
hidden_dim = 256
dropout = 0.0
nheads = 8
num_queries = 900
query_dim = 4
num_patterns = 0
num_feature_levels = 4
enc_n_points = 4
dec_n_points = 4
two_stage_type = 'standard'
two_stage_bbox_embed_share = False
two_stage_class_embed_share = False
transformer_activation = 'relu'
dec_pred_bbox_embed_share = True
dn_box_noise_scale = 1.0
dn_label_noise_ratio = 0.5
dn_label_coef = 1.0
dn_bbox_coef = 1.0
embed_init_tgt = True
dn_labelbook_size = 91
max_text_len = 256
text_encoder_type = "bert-base-uncased"
use_text_enhancer = True
use_fusion_layer = True
use_checkpoint = True
use_transformer_ckpt = True
use_text_cross_attention = True
text_dropout = 0.0
fusion_dropout = 0.0
fusion_droppath = 0.1
sub_sentence_present = True
max_labels = 50 # pos + neg
lr = 0.0001 # base learning rate
backbone_freeze_keywords = None # only for gdino backbone
freeze_keywords = ['bert'] # for whole model, e.g. ['backbone.0', 'bert'] for freeze visual encoder and text encoder
lr_backbone = 1e-05 # specific learning rate
lr_backbone_names = ['backbone.0', 'bert']
lr_linear_proj_mult = 1e-05
lr_linear_proj_names = ['ref_point_head', 'sampling_offsets']
weight_decay = 0.0001
param_dict_type = 'ddetr_in_mmdet'
ddetr_lr_param = False
epochs = 15
lr_drop = 4
save_checkpoint_interval = 1
clip_max_norm = 0.1
onecyclelr = False
multi_step_lr = False
lr_drop_list = [4, 8]
frozen_weights = None
dilation = False
pdetr3_bbox_embed_diff_each_layer = False
pdetr3_refHW = -1
random_refpoints_xy = False
fix_refpoints_hw = -1
dabdetr_yolo_like_anchor_update = False
dabdetr_deformable_encoder = False
dabdetr_deformable_decoder = False
use_deformable_box_attn = False
box_attn_type = 'roi_align'
dec_layer_number = None
decoder_layer_noise = False
dln_xy_noise = 0.2
dln_hw_noise = 0.2
add_channel_attention = False
add_pos_value = False
two_stage_pat_embed = 0
two_stage_add_query_num = 0
two_stage_learn_wh = False
two_stage_default_hw = 0.05
two_stage_keep_all_tokens = False
num_select = 300
batch_norm_type = 'FrozenBatchNorm2d'
masks = False
aux_loss = True
set_cost_class = 1.0
set_cost_bbox = 5.0
set_cost_giou = 2.0
cls_loss_coef = 2.0
bbox_loss_coef = 5.0
giou_loss_coef = 2.0
enc_loss_coef = 1.0
interm_loss_coef = 1.0
no_interm_box_loss = False
mask_loss_coef = 1.0
dice_loss_coef = 1.0
focal_alpha = 0.25
focal_gamma = 2.0
decoder_sa_type = 'sa'
matcher_type = 'HungarianMatcher'
decoder_module_seq = ['sa', 'ca', 'ffn']
nms_iou_threshold = -1
dec_pred_class_embed_share = Truematch_unstable_error = True
use_ema = False
ema_decay = 0.9997
ema_epoch = 0
use_detached_boxes_dec_out = False
use_coco_eval = True
dn_scalar = 100
根据教程,主要是做如下修改:
- use_coco_eval = True
+ use_coco_eval = False
+ label_list=['dog', 'cat', 'person']
把 use_coco_eval改为 False,把自己训练集的类别 加进去 label_list。
然后是 datasets_mixed_odvg.json 文件:
{"train": [{"root": "mypath/mydata/","anno": "path/mydata/annotations/mydata_v1_all_od.jsonl","label_map": "path/mydata/annotations/my_label_map.json","dataset_mode": "odvg"},{"root": "path/mydata/images/my_images/","anno": "path/mydata/annotations/my_vg.jsonl","dataset_mode": "odvg"}],"val": [{"root": "path/mydata/val","anno": "config/instances_val.json","label_map": null,"dataset_mode": "coco"}]
}
把个人数据集的 图片路径 jsonl 文件路径,labelmap路径加进去,就可以了,后面可以开始训练
2.4、开始训练
训练命令:
sh train_dist.sh
train_dist.sh的内容如下:
GPU_NUM=$1
CFG=$2
DATASETS=$3
OUTPUT_DIR=$4
NNODES=${NNODES:-1}
NODE_RANK=${NODE_RANK:-0}
PORT=${PORT:-29500}
MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}# Change ``pretrain_model_path`` to use a different pretrain.
# (e.g. GroundingDINO pretrain, DINO pretrain, Swin Transformer pretrain.)
# If you don't want to use any pretrained model, just ignore this parameter.python -m torch.distributed.launch --nproc_per_node=${GPU_NUM} main.py \--output_dir ${OUTPUT_DIR} \-c ${CFG} \--datasets ${DATASETS} \--pretrain_model_path /path/to/groundingdino_swint_ogc.pth \--options text_encoder_type=/path/to/bert-base-uncased
上面是多卡的,单卡命令:
python -m torch.distributed.launch --nproc_per_node=1 main.py \--output_dir ./my_output \-c config/cfg_odvg.py \--datasets ./config/datasets_mixed_odvg.json \--pretrain_model_path /path/to/groundingdino_swint_ogc.pth \--options text_encoder_type=/path/to/bert-base-uncased
--pretrain_model_path 是预训练模型路径,--options text_encoder_type是bert文本解码模型路径。
跑起来的界面:
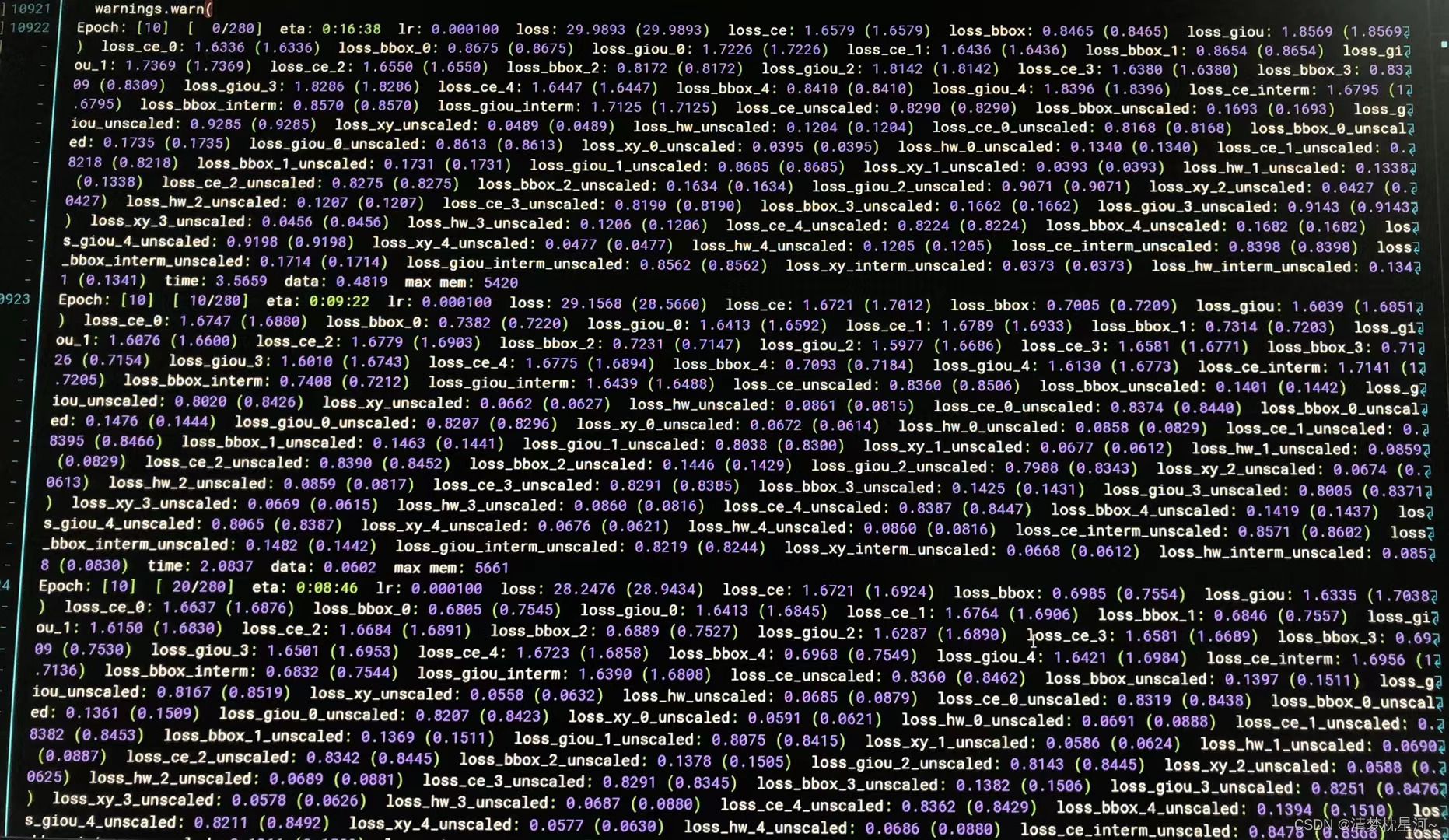
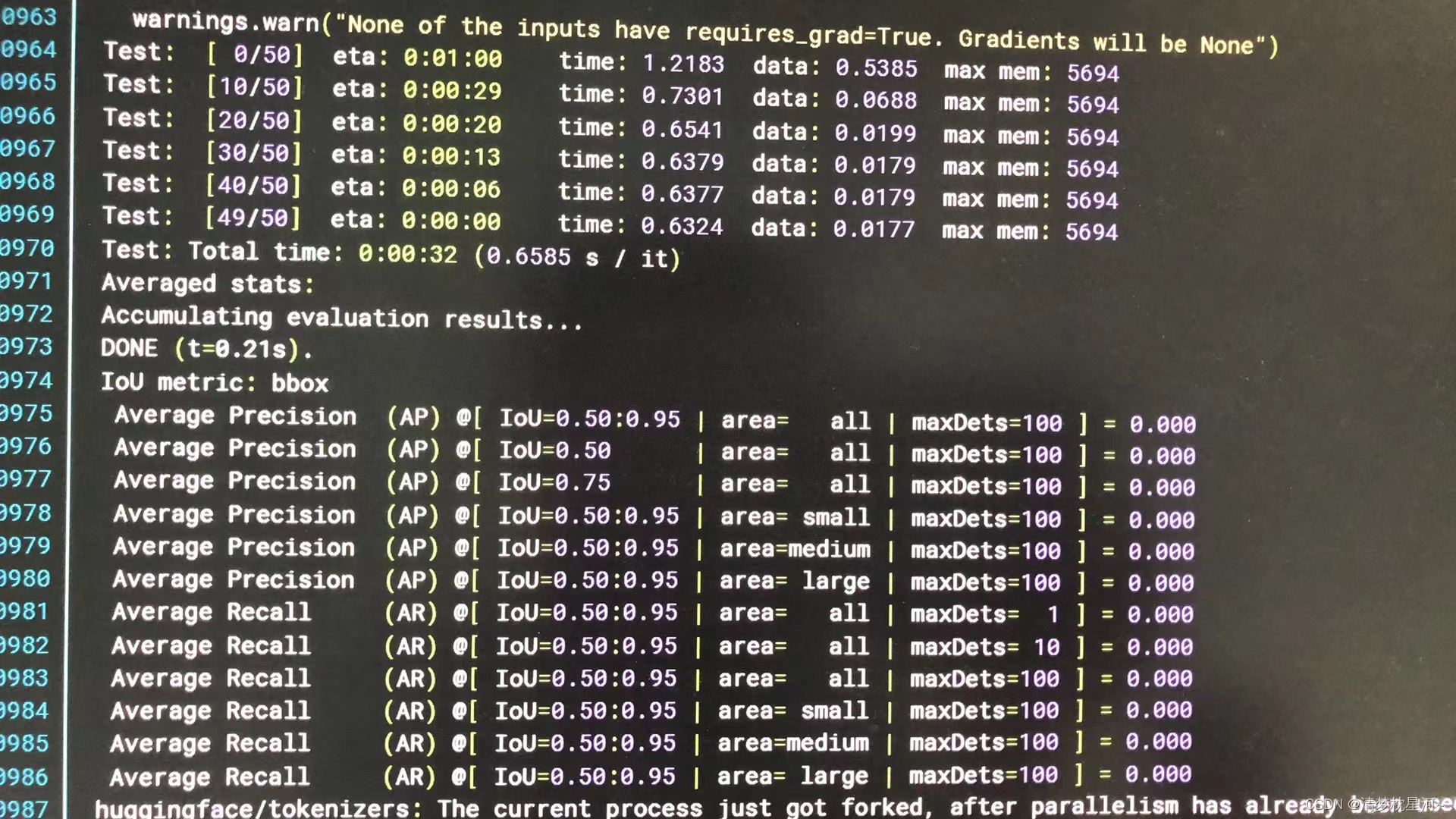
但是,我碰到一个问题,就是训练过程中的验证阶段没有精度指标,基本上是0,不知道怎么回事,是因为没采用预训练模型吗?希望碰到类似问题的一同交流一下,或者跑起来结果正常的,也希望能一起交流一下,非常感谢!
相关文章:
结合文本的目标检测:Open-GroundingDino训练自己的数据集
1、简单介绍 Open-GroundingDino是GroundingDino的第三方实现训练流程的代码,因为官方GroundingDino没有提供训练代码,只提供了demo推理代码。 关于GroundingDino的介绍可以看论文:https://arxiv.org/pdf/2303.05499.pdf GroundingDino的G…...

分布式锁-redission锁的MutiLock原理
5.5 分布式锁-redission锁的MutiLock原理 为了提高redis的可用性,我们会搭建集群或者主从,现在以主从为例 此时我们去写命令,写在主机上, 主机会将数据同步给从机,但是假设在主机还没有来得及把数据写入到从机去的时…...

MySQL索引、B+树相关知识汇总
MySQL索引、B树相关知识汇总 一、有一个查询需求,MySQL中有两个表,一个表1000W数据,另一个表只有几千数据,要做一个关联查询,如何优化?1、为关联字段建立索引二、小表驱动大表 二、b树和b树的区别1、更高的…...
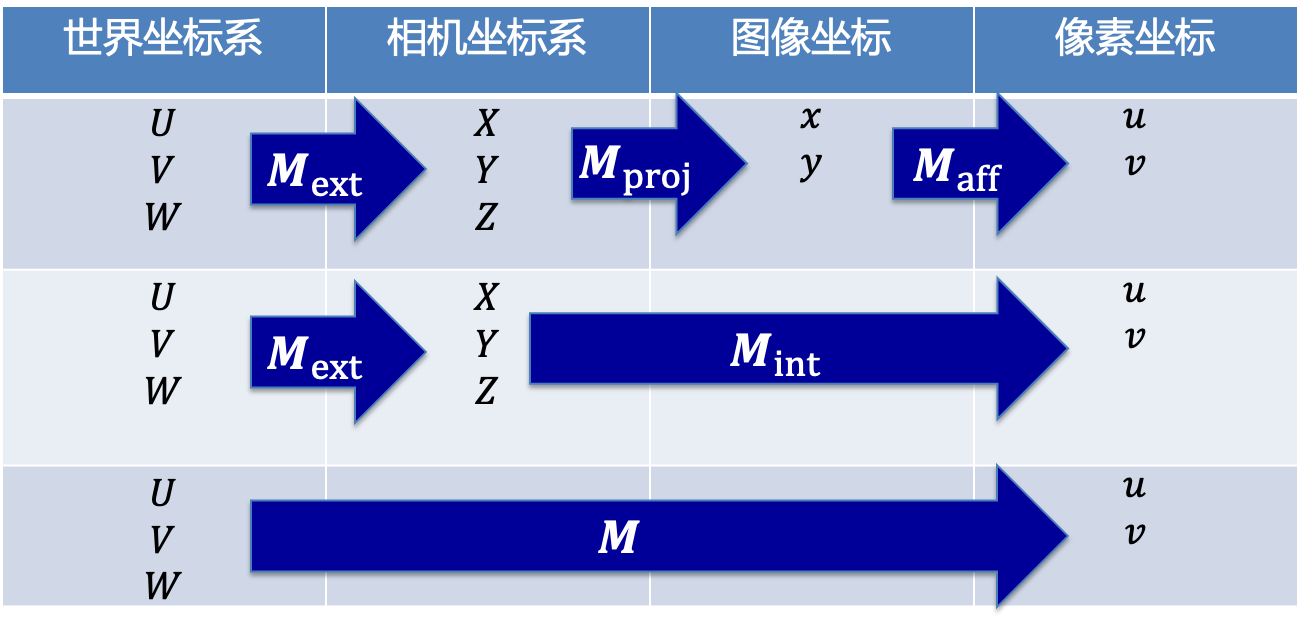
相机模型浅析
相机模型 文章目录 相机模型四个坐标系针孔相机模型世界坐标系到相机坐标系相机坐标系到图像坐标系图像坐标到像素坐标 四个坐标系 ①世界坐标系:是客观三维世界的绝对坐标系,也称客观坐标系。因为数码相机安放在三维空间中,我们需要世界坐标…...
国芯科技(C*Core)双芯片汽车安全气囊解决方案
汽车安全气囊是20世纪汽车上的十大发明之一,是目前汽车的法定标准配置,成为汽车驾乘人员生命安全的保护神。随着人们对汽车安全性要求的进一步提高,已形成前排驾驶员气囊、前排副驾驶员气囊、前排侧气囊、后排侧气囊、膝部气囊、安全气帘等等…...

牛客周赛 Round 39(A,B,C,D,E,F,G)
比赛链接 官方题解(视频) B题是个贪心。CD用同余最短路,预处理的完全背包,多重背包都能做,比较典型。E是个诈骗,暴力就完事了。F是个线段树。G是个分类大讨论,出题人钦定的本年度最佳最粪 题目…...

解锁区块链技术的潜力:实现智能合约与DApps
在数字时代,区块链技术正迅速成为重塑多个行业的革命性力量。从金融服务到供应链管理,再到数字身份验证,区块链提供了一种去中心化、安全和透明的数据处理方式。在本文中,我们将深入探讨区块链技术,特别是智能合约和去…...

MAC OS关闭SIP(navicat 无法保存密码)
最近安装navicat(16.3.7)时,安装后无法保存密码,保存密码会报错如下: 因为用的破解版,一开始是打不开的,用自带的修复软件修复后就可以打开了,但是保存密码就会报错,按照网上的一些操作 1、卸载…...

阿里云服务器带宽价格全解析,附报价单
阿里云服务器公网带宽怎么收费?北京地域服务器按固定带宽计费一个月23元/M,按使用流量计费0.8元/GB,云服务器地域不同实际带宽价格也不同,阿里云服务器网aliyunfuwuqi.com分享不同带宽计费模式下带宽收费价格表: 公网…...
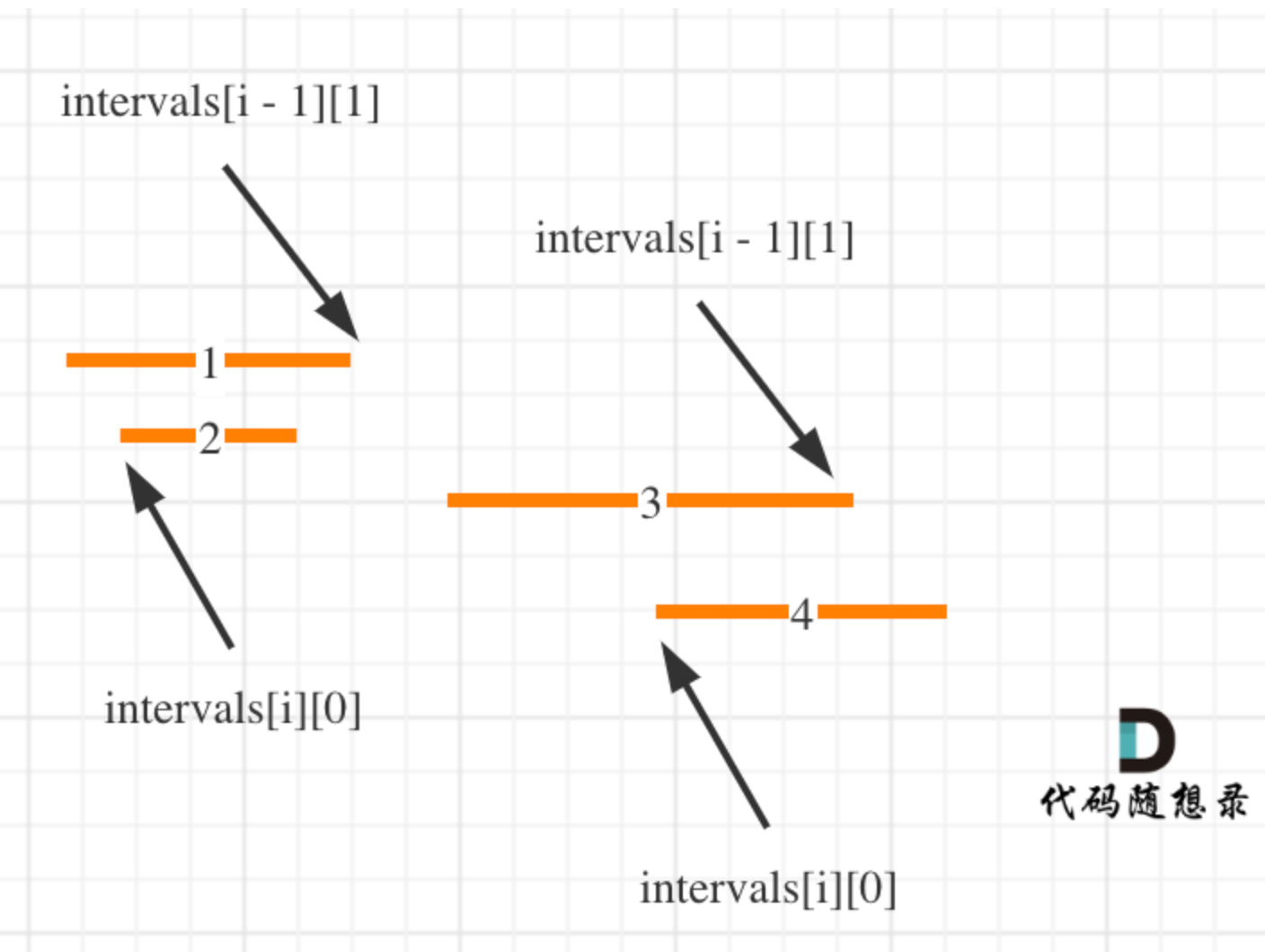
Day36|贪心算法part05:435. 无重叠区间、763.划分字母区间、56. 合并区间
435. 无重叠区间 有了上题射气球的因子,这题也就有思路了,反正无脑排序就行了: 首先将所有区间按照end的大小从小到大排序;选取最早end为起始x_end遍历所有区间,如果该区间的start比end大(可重叠…...

棋牌室计时吧台计费收费灯控管理系统软件操作流程
棋牌室计时吧台计费收费灯控管理系统软件操作流程 一、前言 以下软件操作教程以,佳易王棋牌桌球计时计费管理系统软件灯控版V17.87为例说明 软件文件下载可以点击最下方官网卡片——软件下载——试用版软件下载 该计时计费软件可以是棋牌和桌球混合同时计时计费 …...

【实践篇】RabbitMQ实现队列延迟功能汇总
前言 记录下RabbitMQ实现延迟队列功能的所有实践内容。 前期准备,需要安装好docker、docker-compose的运行环境。 一、安装RabbitMQ 开启RabbitMQ的WEB管理功能。-CSDN博客 二、实现延迟队列的两种方式 RabbitMQ实现延迟队列的两种方式。-CSDN博客 三、实践文…...

EditPlus来啦(免费使用!)
hello,我是小索奇 今天推荐一款编辑器,是索奇学习JavaSE时入手滴,非常好用哈,小索奇还是通过老杜-杜老师入手滴,相信很多人也是通过老杜认识嘞,来寻找破解版或者准备入手这个间接使用的编辑器~ EditPlus是…...

蓝桥杯22年第十三届省赛-数组切分|线性DP
题目链接: 蓝桥杯2022年第十三届省赛真题-数组切分 - C语言网 (dotcpp.com) 1.数组切分 - 蓝桥云课 (lanqiao.cn) 这道题C语言网数据会强一些。 说明: 对于一个切分的子数组,由于数组是1-N的一个排列,所以每个数唯一 可以用子…...
小米汽车:搅动市场的鲶鱼or价格战砧板上的鱼肉?
3月28日晚,备受关注的小米汽车上市发布会召开,小米集团董事长雷军宣布小米SU7正式发布。小米汽车在带飞股价的同时,二轮订购迅速售尽。 图一:小米集团股价 雷军口中“小米汽车迈出的第一步,也是人生最后一战的开篇”&a…...

Docker 学习笔记(五):梳理 Docker 镜像知识,附带 Commit 方式提交镜像副本,安装可视化面板 portainer
一、前言 记录时间 [2024-4-10] 前置文章: Docker学习笔记(一):入门篇,Docker概述、基本组成等,对Docker有一个初步的认识 Docker学习笔记(二):在Linux中部署Docker&…...
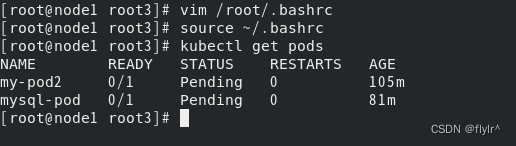
K8S node节点执行kubectl get pods报错
第一个问题是由第二个问题产生的,第二个问题也是最常见的 网上找的都是从master节点把文件复制过来,这样确实可以解决,但是麻烦,有一个node节点还好,如果有多个呢?每个都复制吗?下面是我从外网…...

C++简单日志系统
需求描述 日志等级:定义一个枚举类型 LogLevel,包含至少四个等级:DEBUG、INFO、WARNING、ERROR。日志记录:实现一个 Logger 类,包含以下功能: 一个静态方法 log,接受 LogLevel 和一个字符串作为…...

MySQL基础练习题:习题21-25
这部分主要是为了帮助大家回忆回忆MySQL的基本语法,数据库来自于MySQL的官方简化版,题目也是网上非常流行的35题。这些基础习题基本可以涵盖面试中需要现场写SQL的问题。 列出在部门sales工作的员工的姓名,假定不知道销售部的部门编号 sele…...

全面的网络流量监控
流量监控指的是对数据流进行的监控,通常包括出数据、入数据的速度、总流量。通过网络流量监控,组织可以确保只有业务关键型流量通过网络传输,并限制不需要的网络流量,从而提高网络效率,又可以防止停机、减少 MTTR、帮助…...

3分钟搞定!让Windows资源管理器秒显iPhone照片缩略图的终极方案
3分钟搞定!让Windows资源管理器秒显iPhone照片缩略图的终极方案 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 还在…...

K8s调度器踩坑记:明明内存还剩7G,为啥说我Insufficient memory?一个配置项引发的‘血案’
K8s调度器内存分配迷思:当剩余7G内存遭遇"Insufficient memory"错误 凌晨三点,当告警铃声第17次响起时,我盯着监控面板上那刺眼的红色错误提示陷入了沉思——集群明明显示7G空闲内存,为什么调度器坚持认为没有足够资源部…...
)
保姆级教程:在Ubuntu20.04上从零跑通TurtleBot3的SLAM仿真(避坑ROS Noetic环境配置)
从零到一:Ubuntu 20.04下TurtleBot3 SLAM仿真实战指南 第一次接触ROS和SLAM时,面对复杂的依赖关系和晦涩的错误提示,很多初学者往往在环境配置阶段就放弃了。本文将带你穿越这片"雷区",用最直观的方式在Ubuntu 20.04上搭…...

避开这些坑!STM32G431的ADC测量结果总跳变?CT117E-M4平台调试心得分享
STM32G431 ADC测量跳变问题全解析:从硬件设计到软件优化的实战指南 当你在CT117E-M4平台上第一次看到ADC读数像心跳图一样上下波动时,那种感觉就像在玩电子版的"打地鼠"——明明输入电压稳定,显示值却跳个不停。这不是简单的配置错…...

部署本地AI大模型--ollma
下载链接: 1.官网:在Windows上下载《Ollama 2.github:Release v0.21.0 ollama/ollama 前言:为什么选择 Ollama Ollama 是一款专为本地运行大模型打造的开源工具,它把复杂的环境配置、依赖管理和模型量化过程都封装…...

DS4Windows终极指南:3步让PlayStation手柄在Windows上完美运行
DS4Windows终极指南:3步让PlayStation手柄在Windows上完美运行 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PC游戏无法识别你的PlayStation手柄而烦恼吗?…...

2026届毕业生推荐的十大降AI率工具实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 若要降低AIGC(AI生成内容)的检测概率,得从文本特征着手。…...
)
保姆级教程:用STM32CubeMX+Keil5驱动AS5045磁编码器(附Modbus调试精灵配置)
基于STM32CubeMX与Keil5的AS5045磁编码器全流程开发指南 在工业自动化与机器人控制领域,高精度角度检测是不可或缺的基础功能。AS5045作为一款通过RS485接口输出绝对位置信息的磁旋转编码器,以其12位分辨率(4096步/转)和Modbus通信…...

别再手动拖拽了!Matlab画图时用xlim函数精准控制X轴范围的3个实战技巧
别再手动拖拽了!Matlab画图时用xlim函数精准控制X轴范围的3个实战技巧 每次用Matlab画完图,你是不是也习惯性地用鼠标拖拽坐标轴来调整显示范围?这种操作不仅效率低下,还难以保证多张图表的一致性。今天我们就来彻底解决这个问题—…...

DeepXDE终极指南:10分钟掌握科学机器学习核心库
DeepXDE终极指南:10分钟掌握科学机器学习核心库 【免费下载链接】deepxde A library for scientific machine learning and physics-informed learning 项目地址: https://gitcode.com/gh_mirrors/de/deepxde DeepXDE是一款强大的科学机器学习库,…...