【Redis】redis面试相关积累
Redis到底是多线程还是单线程?
Redis 在设计上是单线程的,这意味着 Redis 服务器在任何给定时刻只能执行一个命令。然而,这并不意味着 Redis 无法利用多核 CPU,因为 Redis 使用了一些技术来提高性能和并发性,例如非阻塞 I/O 和事件驱动模型。
具体来说,Redis 使用了以下技术来提高性能:
事件驱动模型: Redis 使用了基于事件驱动的事件循环(event loop)来管理网络连接和处理命令请求。在事件驱动模型下,Redis 服务器在主线程上轮询事件,并异步处理请求,从而实现高效的并发处理。
非阻塞 I/O: Redis 使用了非阻塞 I/O 模型来处理网络 I/O 操作。这意味着 Redis 服务器在等待网络数据时不会阻塞整个线程,而是可以同时处理其他任务,从而提高了并发性能。
虽然 Redis 主要是单线程的,但它通过使用事件驱动模型和非阻塞 I/O 等技术,使得它能够实现高并发和高性能的特性。这也是 Redis 能够成为一个高性能的内存数据库和缓存系统的重要原因之一。
Redis缓存穿透、瞬间并发、缓存雪崩及解决方法
Redis 缓存穿透、缓存并发和缓存雪崩是常见的缓存相关问题,它们会影响系统的性能和稳定性。下面我会逐一介绍这些问题以及解决方法:
缓存穿透(Cache Penetration): 缓存穿透是指恶意或者恶意的查询使得缓存无法命中,导致大量的请求直接访问数据库或其他持久化存储,从而使系统的负载增加。解决方法包括:
- 使用布隆过滤器(Bloom Filter)等数据结构对查询进行预先过滤,排除掉不存在的数据,从而减轻对数据库的压力。
- 对于查询为空的情况,也可以将空值缓存起来,并设置一个较短的过期时间,防止频繁查询相同不存在的数据。
缓存并发(Cache Concurrency): 缓存并发是指大量的并发请求同时访问同一个热点数据,导致缓存服务器压力过大,甚至引起雪崩效应。解决方法包括:
- 使用分布式锁来保护缓存数据的读写操作,确保在同一时间只有一个请求能够更新缓存数据。
- 对热点数据进行缓存预热,提前加载热门数据到缓存中,以减少并发请求对缓存服务器的冲击。
缓存雪崩(Cache Avalanche): 缓存雪崩是指在缓存失效后,大量的请求同时涌入数据库或其他持久化存储,导致系统的负载剧增。解决方法包括:
- 使用不同的过期时间,对缓存数据进行随机化设置过期时间,避免大量缓存同时失效。
- 实现自动容错机制,当缓存失效时,通过限流或者降级等手段来保护后端服务不被击垮。
- 使用缓存预热,确保在缓存失效前能够提前加载热门数据到缓存中,减少请求对后端服务的冲击。
综合来说,对于缓存相关问题,需要综合考虑预热、过期时间设置、并发控制、限流、降级等多种手段来保护系统的稳定性和性能。
Redis有哪些数据结构?
字符串String、字典Hash、列表List、集合Set、有序集合SortedSet。
如果你是Redis中高级用户,还需要加上下面几种数据结构HyperLogLog、Geo、Pub/Sub。
Redis中的分布式锁
Redis 分布式锁通常基于以下两种方式实现:
基于 SETNX 和 EXPIRE 实现分布式锁:
客户端尝试通过 SETNX 命令在 Redis 中设置一个特定的键作为锁,并设置一个过期时间来防止锁被永久持有。
如果 SETNX 命令返回 1(表示设置成功),则客户端获得锁;如果返回 0(表示键已存在,即锁已被其他客户端持有),则客户端无法获得锁。
当客户端持有锁时,可以执行操作,并在操作完成后通过 DEL 命令释放锁。
基于 Redlock 算法实现分布式锁:
Redlock 是一种基于多个 Redis 节点实现的分布式锁算法,它通过在多个 Redis 实例上设置相同的锁来确保分布式环境下的锁的一致性。
客户端尝试在多个 Redis 实例上依次进行锁的设置,并设置相同的过期时间和相同的随机值作为锁的值。
当客户端获得多个 Redis 实例上的锁时,即认为客户端获得了锁;如果在某个 Redis 实例上无法获得锁,则客户端需要释放之前获得的锁,并等待一段时间后重试。
无论是基于 SETNX 和 EXPIRE 的简单实现方式还是基于 Redlock 算法的更为复杂的实现方式,Redis 分布式锁都可以有效地解决分布式环境下的并发访问问题。但需要注意的是,Redis 分布式锁也存在一些问题和限制,如死锁、锁竞争、锁误删等,需要在使用时进行适当的考虑和处理。
假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如果将它们全部找出来?
如果该机器是生产环境正在对外提供服务,不建议使用keys * pattern的方法进行查询,可能会使服务器卡顿,而出现事故。
测试环境使用keys指令可以扫出指定模式的key列表:keys he*
一般生产服务器建议使用Scan命令,例如:SCAN 0 MATCH aaa* COUNT 5 表示从游标0开始查询aaa开头的key,每次返回5条,但是这个5条不一定,只是给Redis打了个招呼,具体返回数量看Redis。
如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
这个时候需要说明redis关键的一个特性:redis的单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。
使用过Redis做异步队列么,你是怎么用的?
一般使用list结构作为队列,rpush生产消息,lpop消费消息。当lpop没有消息的时候,要适当sleep一会再重试。
如果对方追问可不可以不用sleep呢?list还有个指令叫blpop,在没有消息的时候,它会阻塞住直到消息到来。
如果对方追问能不能生产一次消费多次呢?使用pub/sub主题订阅者模式,可以实现1:N的消息队列。
如果对方追问pub/sub有什么缺点?在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如rabbitmq等。redis中pub/sub缺陷
redis如何实现延时队列?
Redis 可以通过有序集合(Sorted Set)实现延时队列。延时队列是一种常见的队列模式,用于延迟处理任务或消息,即任务或消息在被发送到队列后,并不立即被消费者处理,而是在一定的延迟时间后再进行处理。
下面是如何使用 Redis 实现延时队列的基本步骤:
将任务作为有序集合的成员存储,成员的分数表示任务的执行时间(通常是 Unix 时间戳),并且确保分数越小的成员排在集合的前面。任务的内容可以是任务ID、任务类型、任务参数等信息。
生产者将任务添加到有序集合中,使用 ZADD 命令设置任务的执行时间作为成员的分数。
消费者通过轮询或者定时任务,从有序集合中获取当前时间之前的所有任务,即执行时间小于当前时间的任务,使用 ZRANGEBYSCORE 命令获取。
消费者处理获取到的任务,执行相应的操作。
完成任务处理后,可以根据需要将任务从有序集合中移除,避免任务被重复处理。
如果有大量的key需要设置同一时间过期,一般需要注意什么
如果大量的key过期时间设置的过于集中,到过期的那个时间点,redis可能会出现短暂的卡顿现象。一般需要在时间上加一个随机值,使得过期时间分散一些。
Redis如何做持久化的?
RDB做镜像全量持久化,AOF做增量持久化。
RDB持久化也分两种:SAVE和BGSAVE。
SAVE是阻塞式的RDB持久化,当执行这个命令时redis的主进程把内存里的数据库状态写入到RDB文件中,直到该文件创建完毕的这段时间内redis将不能处理任何命令请求;而BGSAVE属于非阻塞式的持久化,它会创建一个子进程专门去把内存中的数据库状态写入RDB文件里,同时主进程还可以处理来自客户端的命令请求。但子进程基本是复制的父进程,这等于两个相同大小的redis进程在系统上运行,会造成内存使用率的大幅增加。
AOF的持久化是通过命令追加、文件写入和文件同步三个步骤实现的。
当reids开启AOF后(redis备份方式默认是RDB),
服务端每执行一次写操作(如set、sadd、rpush)就会把该条命令追加到一个单独的AOF缓冲区的末尾,这就是命令追加;
然后把AOF缓冲区的内容写入AOF文件里。看上去第二步就已经完成AOF持久化了那第三步是干什么的呢?这就需要从系统的文件写入机制说起:一般我们现在所使用的操作系统,为了提高文件的写入效率,都会有一个写入策略,即当你往硬盘写入数据时,操作系统不是实时的将数据写入硬盘,而是先把数据暂时的保存在一个内存缓冲区里,等到这个内存缓冲区的空间被填满或者是超过了设定的时限后才会真正的把缓冲区内的数据写入硬盘中。也就是说当redis进行到第二步文件写入的时候,从用户的角度看是已经把AOF缓冲区里的数据写入到AOF文件了,但对系统而言只不过是把AOF缓冲区的内容放到了另一个内存缓冲区里而已,之后redis还需要进行文件同步把该内存缓冲区里的数据真正写入硬盘上才算是完成了一次持久化。而何时进行文件同步则是根据配置的appendfsync来进行:appendfsync有三个选项:always、everysec和no:
Pipeline有什么好处,为什么要用pipeline?
Redis Pipeline 是一种高效的批量命令执行机制,能够显著提高 Redis 客户端和服务器之间的通信效率,并且通过保证原子性操作,确保了数据的一致性和可靠性。使用redis-benchmark进行压测的时候可以发现影响redis的QPS峰值的一个重要因素是pipeline批次指令的数目。
redis-benchmark -t set,get -q -n 100000 -P 16
在这个示例中:
-t set,get:指定测试的命令类型为 set 和 get。
-q:安静模式,只输出总体结果。
-n 100000:指定每个命令的请求数量为 100000。
-P 16:指定 pipeline 的长度为 16,即一次发送 16 条命令。
Redis的同步机制了解么?
Redis可以使用主从同步,从从同步。第一次同步时,主节点做一次bgsave,并同时将后续修改操作记录到内存buffer,待完成后将rdb文件全量同步到复制节点,复制节点接受完成后将rdb镜像加载到内存。加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。
是否使用过Redis集群,集群的原理是什么?
Redis Sentinal着眼于高可用,在master宕机时会自动将slave提升为master,继续提供服务。
Redis Cluster着眼于扩展性,在单个redis内存不足时,使用Cluster进行分片存储。
用redis有哪些好处?
1.速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
2.支持丰富数据类型,支持string,list,set,sorted set,hash
3.支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
4.丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
redis相比memcached有哪些优势?
- memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
- redis的速度比memcached快很多
- redis可以持久化其数据
Memcache与Redis的区别都有哪些?
- 存储方式 :Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。 Redis 提供了持久化功能,可以将数据存储到磁盘上,保证数据的持久性。
- 数据支持类型: Memcache对数据类型支持相对简单。 Redis有复杂的数据类型。这意味着 Redis 可以更灵活地存储和操作数据,支持更多复杂的数据结构。
- 使用底层模型不同: 它们之间底层实现方式 以及与客户端之间通信的应用协议不一样。 Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
- 复制和高可用: Redis 支持主从复制和 Sentinel(哨兵)机制,可以实现数据的复制和自动故障转移,提高了系统的可用性和容错性。而 Memcached 没有内置的复制和高可用机制,需要通过其他手段来实现。
- 事务支持: Redis 支持事务(Transaction),可以将一系列命令打包在一个事务中执行,保证原子性操作。而 Memcached 不支持事务操作。
- 发布订阅: Redis 支持发布订阅(Pub/Sub)模式,可以实现消息的发布和订阅,用于构建消息队列、实时通信等功能。而 Memcached 不支持发布订阅功能。
- Lua 脚本支持: Redis 支持使用 Lua 脚本编写复杂的原子性操作,可以在服务器端执行脚本,提高了执行效率和安全性。而 Memcached 不支持脚本执行功能。
redis常见性能问题和解决方案:
- Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照。
- Master AOF持久化,如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度。
Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化,如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。 - Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
- Redis主从复制的性能问题,为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内
为什么redis需要把所有数据放到内存中?
Redis 将数据存储在内存中是为了提高性能和降低访问延迟,这种内存存储的特性使得 Redis 成为了一个高性能的内存数据库和缓存系统。同时通过异步的方式将数据写入磁盘。所以redis具有快速和数据持久化的特征。如果不将数据放在内存中,磁盘I/O速度为严重影响redis的性能。在内存越来越便宜的今天,redis将会越来越受欢迎。如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值。
redis是单进程单线程的
redis利用队列技术将并发访问变为串行访问,消除了传统数据库串行控制的开销。
Redis 是一个单进程单线程的系统。这意味着 Redis 服务器在任何给定时刻只能执行一个命令,而且 Redis 服务器在处理一个命令时不会切换到其他线程。这种单线程的设计有以下几个优点:
- 简单高效: 单线程模型简化了 Redis 的设计和实现,使得 Redis 更加轻量级和高效。
- 避免竞态条件: 单线程模型避免了多线程并发访问共享数据时可能出现的竞态条件和数据同步问题,提高了系统的稳定性和可靠性。
- 原子操作: Redis 使用原子操作来处理数据,保证了命令的原子性,即命令要么全部执行成功,要么全部执行失败。
- 事件驱动模型: Redis 使用事件驱动模型来处理网络连接和命令请求,通过非阻塞 I/O 和事件循环机制实现了高性能的网络通信。
虽然 Redis 是单进程单线程的系统,但通过事件驱动模型和非阻塞 I/O 等技术,它可以实现高并发和高性能的特性。这种设计使得 Redis 成为一个高效的内存数据库和缓存系统,适用于各种需要快速读写操作的场景。
redis的并发竞争问题如何解决?
Redis为单进程单线程模式,采用队列模式将并发访问变为串行访问。Redis本身没有锁的概念,Redis对于多个客户端连接并不存在竞争,但是在Jedis客户端对Redis进行并发访问时会发生连接超时、数据转换错误、阻塞、客户端关闭连接等问题,这些问题均是由于客户端连接混乱造成。对此有2种解决方法:
1).客户端角度,为保证每个客户端间正常有序与Redis进行通信,对连接进行池化,同时对客户端读写Redis操作采用内部锁synchronized。
2).服务器角度,利用setnx实现锁。
注:对于第一种,需要应用程序自己处理资源的同步,可以使用的方法比较通俗,可以使用synchronized也可以使用lock;第二种需要用到Redis的setnx命令,但是需要注意一些问题。
redis事物的了解CAS (check-and-set 操作实现乐观锁 )?
在 Redis 中,CAS(Check-and-Set)操作通常与乐观锁一起使用,用于实现并发控制。乐观锁是一种基于版本控制的并发控制机制,它通过比较数据的版本号或者时间戳等标识来检测数据是否被其他客户端修改过,从而避免并发访问时可能出现的数据冲突和竞态条件。
在 Redis 中,CAS 操作通常使用 WATCH、MULTI 和 EXEC 命令组合使用,具体步骤如下:
使用 WATCH 命令监视一个或多个键,当执行 WATCH 命令后,Redis 会将指定的键添加到监视列表中,并在事务执行过程中监视这些键。
使用 MULTI 命令开启一个事务块,所有在 MULTI 和 EXEC 之间的命令都将被打包到一个事务中,Redis 会将这些命令一起执行。
在事务块中执行一系列读取数据和更新数据的操作,不提交事务。
在执行事务块中的命令之前,如果有其他客户端修改了被监视的键,则事务将被中止,Redis 会回滚事务并取消所有已执行的命令。
如果事务块中的命令执行过程中没有发生被监视键的修改,则可以继续提交事务,使用 EXEC 命令提交事务。
CAS 操作的核心思想是,在事务执行过程中监视被修改的键,如果在事务执行期间这些键发生了修改,则事务会被中止,从而保证了数据的一致性和并发控制。通过组合使用 WATCH、MULTI 和 EXEC 命令,可以实现 CAS 操作的功能,确保数据的原子性和一致性。
在实际应用中,可以根据具体的业务场景和需求,使用 CAS 操作来处理并发访问时可能出现的数据冲突和竞态条件,保证系统的稳定性和可靠性。
redis持久化两种种方式
1.快照(RDB)
缺省情况情况下,Redis把数据快照存放在磁盘上的二进制文件中,文件名为dump.rdb。你可以配置Redis的持久化策略,例如数据集中每N秒钟有超过M次更新,就将数据写入磁盘;或者你可以手工调用命令SAVE或BGSAVE。
工作原理:
. Redis forks.
. 子进程开始将数据写到临时RDB文件中。
. 当子进程完成写RDB文件,用新文件替换老文件。
. 这种方式可以使Redis使用copy-on-write技术。
2.(日志) AOF
快照模式并不健壮,当系统停止,或者无意中Redis被kill掉,最后写入Redis的数据就会丢失。这对某些应用也许不是大问题,但对于要求高可靠性的应用来说,Redis就不是一个合适的选择。Append-only文件模式是另一种选择。你可以在配置文件中打开AOF模式。
redis 最适合的场景
Redis最适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能,跟传统意义上的持久化有比较大的差别,那么可能大家就会有疑问,似乎Redis更像一个加强版的Memcached,那么何时使用Memcached,何时使用Redis呢?如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点:
1 、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
2 、Redis支持数据的备份,即master-slave模式的数据备份。
3 、Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
-
缓存: Redis 最常见的用途之一是作为缓存层,用于存储频繁访问的数据,加速数据的读取和响应时间。由于 Redis 具有快速的读写能力和丰富的数据结构,适用于存储各种类型的缓存数据,如页面缓存、数据库查询结果缓存、会话缓存等。
-
会话存储: Redis 可以用作会话存储,将用户会话信息存储在内存中,提供快速的会话访问和管理。这对于需要在分布式环境中共享会话状态或处理高并发访问的应用程序特别有用。
-
消息队列: Redis 提供了发布订阅(Pub/Sub)功能和列表(List)数据结构,可以实现简单的消息队列系统。通过将消息发布到 Redis 中的频道,并订阅该频道的客户端可以接收到消息,实现了解耦和异步通信。
-
计数器和排行榜: Redis 提供了原子性操作和计数器数据结构,可以用来实现各种计数器功能,如网站访问量统计、点赞计数、商品库存管理等。同时,有序集合(Sorted Set)数据结构可以用来实现排行榜功能,根据分数进行排名和排序。
-
实时数据分析: Redis 支持复杂的数据结构和原子性操作,可以用来存储和处理实时数据,如实时日志处理、实时监控和实时统计等场景。
-
分布式锁: Redis 提供了分布式锁功能,可以用来实现分布式系统中的并发控制和资源竞争问题,保证共享资源的访问安全和一致性。
总的来说,Redis 适用于需要高性能、低延迟、高并发访问的场景,尤其适合于需要频繁读写操作和复杂数据结构的应用。需要根据具体的业务需求和系统特点来选择合适的使用场景。
更多关于redis的知识分享,请前往博客主页。编写过程中,难免出现差错,敬请指出
相关文章:

【Redis】redis面试相关积累
Redis到底是多线程还是单线程? Redis 在设计上是单线程的,这意味着 Redis 服务器在任何给定时刻只能执行一个命令。然而,这并不意味着 Redis 无法利用多核 CPU,因为 Redis 使用了一些技术来提高性能和并发性,例如非阻…...
【Linux】进程的状态(运行、阻塞、挂起)详解,揭开孤儿进程和僵尸进程的面纱,一篇文章万字讲透!!!!进程的学习②
目录 1.进程排队 时间片 时间片的分配 结构体内存对齐 偏移量补充 对齐规则 为什么会有对齐 2.操作系统学科层面对进程状态的理解 2.1进程的状态理解 ①我们说所谓的状态就是一个整型变量,是task_struct中的一个整型变量 ②.状态决定了接下来的动作 2.2运行状态 2.…...
前端js基础知识(八股文大全)
一、js的数据类型 值类型(基本类型):数字(Number)、字符串(String)、布尔(Boolean)、对空(Null)、未定义(Undefined)、Symbol,大数值类型(BigInt) 引用数据类型:对象(Object)、数组…...
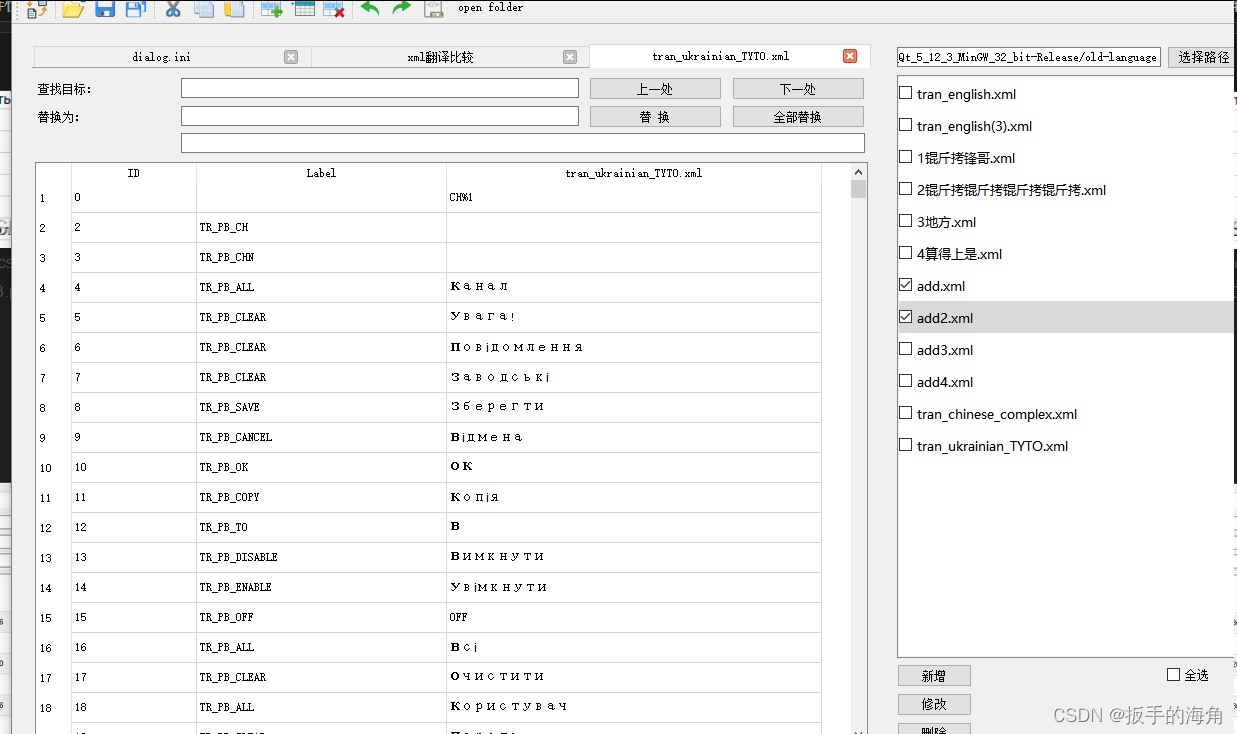
316_C++_xml文件解析成map,可以放到表格上 + xml、xlsx文件互相解析
xml文件例如: <?xml version"1.0" encoding"UTF-8" standalone"yes"?> <TrTable> <tr id"0" label"TR_PB_CH" text"CH%2"/> <tr id"4" label"TR_PB_CHN"…...
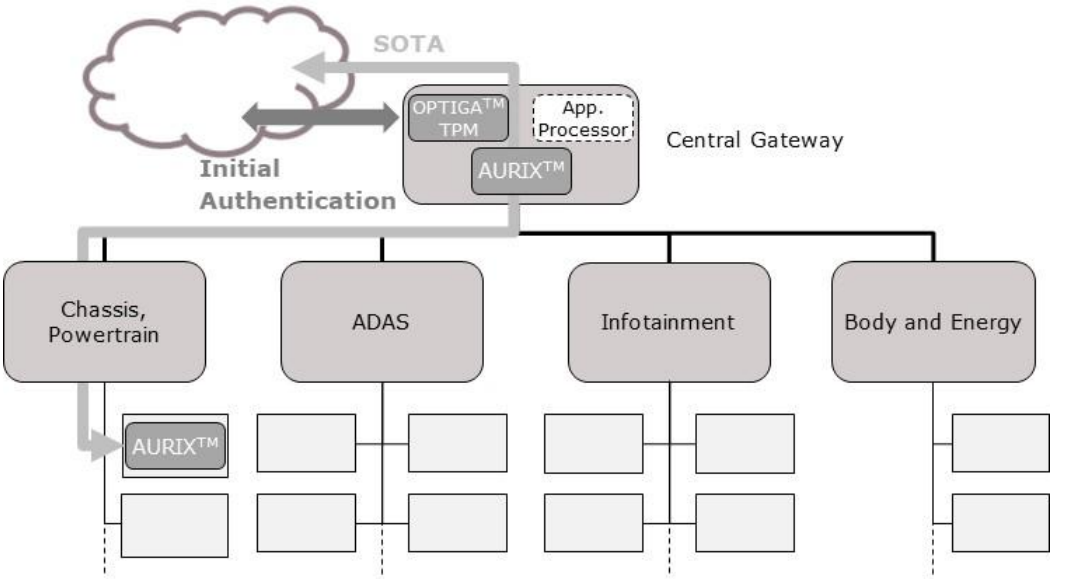
未来汽车硬件安全的需求(2)
目录 4.汽车安全控制器 4.1 TPM2.0 4.2 安全控制器的硬件保护措施 5. EVITA HSM和安全控制器结合 6.小结 4.汽车安全控制器 汽车安全控制器是用于汽车工业安全关键应用的微控制器。 他们的保护水平远远高于EVITA HSM。今天的典型应用是移动通信,V2X、SOTA、…...

html+javascript,用date完成,距离某一天还有多少天
图片展示: html代码 如下: <style>* {margin: 0;padding: 0;}.time-item {width: 500px;height: 45px;margin: 0 auto;}.time-item strong {background: orange;color: #fff;line-height: 100px;font-size: 40px;font-family: Arial;padding: 0 10px;margin-right: 10px…...
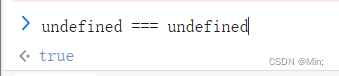
跟bug较劲的第n天,undefined === undefined
前情提要 场景复现 看到这张图片,有的同学也许不知道这个冷知识,分享一下,是因为我在开发过程中踩到的坑,花了三小时排查出问题的原因在这,你们说值不值。。。 我分享下我是怎么碰到的这个问题,下面看代码…...

数据结构_基于链表的通讯录
顺序表的源代码需要略作修改,如下 将数据类型改为通讯录的结构体。注释掉打印,查找的函数。 SList.h #define _CRT_SECURE_NO_WARNINGS 1#include<stdio.h> #include<stdlib.h> #include<assert.h> #include"Contact.h"ty…...

jenkins+gitlab配置
汉化 1、安装Localization: Chinese (Simplified)插件 (此处我已安装) (安装完成后重启jenkins服务即可实现汉化) 新增用户权限配置 1、安装插件 Role-based Authorization Strategy 2、全局安全配置 3、配置角色权限 4、新建…...
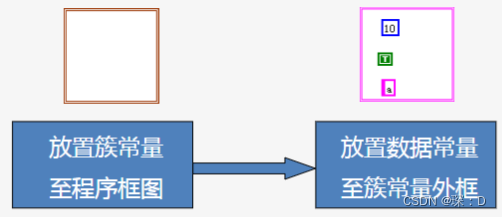
【Labview】虚拟仪器技术
一、背景知识 1.1 虚拟仪器的定义、组成和应用 虚拟仪器的特点 虚拟仪器的突出特征为“硬件功能软件化”,虚拟仪器是在计算机上显示仪器面板,将硬件电路完成信号调理和处理功能由计算机程序完成。 虚拟仪器的组成 硬件软件 硬件是基础,负责将…...

IvorySQL 3.2原理解析|与Oracle 12c XML函数兼容性的实现机制
[发行日期:2024年4月11日] IvorySQL 3.2基于PostgreSQL 16.2,引入了多种Oracle XML函数的全面兼容性功能,同时修复了多个问题,更多信息请参考文档网站。 >>>新版本体验链接: https://docs.ivorysql.org/cn…...
SpringBoot + Dobbo + nacos
SpringBoot Dobbo nacos 一、nacos https://nacos.io/zh-cn/docs/quick-start.html 1、下载安装包 https://github.com/alibaba/nacos/releases/下载后在主目录下,创建一个logs的文件夹:用来存日志 2、启动nacos 在bin目录下打开cmd运行启动命令&a…...
)
学习笔记-微服务基础(黑马程序员)
框架 spring cloudspring cloud alibaba Eureka eureka-server 注册中心 eureka-client 客户端每30s发送心跳服务 服务消费者服务提供者 server 依赖 <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-star…...

每日Bug汇总--Day05
Bug汇总—Day05 一、项目运行报错 二、项目运行Bug 1、**问题描述:**前端将从后台查询的数据作为参数进行get请求,参数为空 原因分析: 这种写法可能只支全局的参数调用方法的传参响应 代码实现 if (this.jishiName) {this.$http({url…...

docker、ctr、crictl命令对比
命令dockerctr(containerd)crictl(kubernetes)查看运行的容器docker psctr task ls/ctr container lscrictl ps查看镜像docker imagesctr image lscrictl images查看容器日志docker logs无crictl logs查看容器数据信息docker insp…...
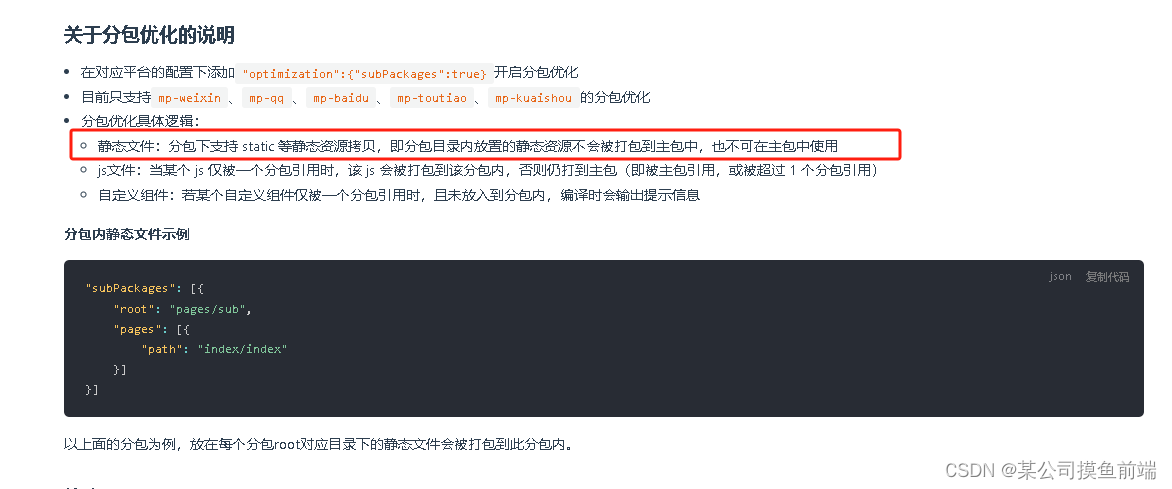
uniapp 编译后分包下静态图片404问题解决方案
如上图官方说明: 在分包下建立一个static文件夹即可: 分包内代码引用图片 <image src"/分包名称/img/图片名称"></image> <image src"/dataView/img/图片名称"></image>...

第十二届蓝桥杯大赛软件赛省赛Java 大学 B 组题解
1、ASC public class Main {public static void main(String[] args) {System.out.println(...
关于openai和chatgpt、gpt-4、PyTorch、TensorFlow 两者和Transformers的关系
近两年,随着人工智能的火爆,不论通过哪个渠道,相信我们都听说过openai、gpt等这类名词,那么它们到底是什么意思,请看下文。 openai:是一家人工智能公司; openai-api:是openai提供的api…...

C 共用体
共用体是一种特殊的数据类型,允许您在相同的内存位置存储不同的数据类型。您可以定义一个带有多成员的共用体,但是任何时候只能有一个成员带有值。共用体提供了一种使用相同的内存位置的有效方式。 定义共用体 为了定义共用体,您必须使用 u…...

智能合约:未来数字经济的基石
智能合约是一种自动执行交易的计算机协议,它以代码形式规定了交易双方的权利和义务,具有高度的可靠性和安全性。随着数字经济的发展,智能合约的重要性日益凸显,将成为未来数字经济的基石。 首先,智能合约在金融领域的应…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

如何配置一个sql server使得其它用户可以通过excel odbc获取数据
要让其他用户通过 Excel 使用 ODBC 连接到 SQL Server 获取数据,你需要完成以下配置步骤: ✅ 一、在 SQL Server 端配置(服务器设置) 1. 启用 TCP/IP 协议 打开 “SQL Server 配置管理器”。导航到:SQL Server 网络配…...
QT开发技术【ffmpeg + QAudioOutput】音乐播放器
一、 介绍 使用ffmpeg 4.2.2 在数字化浪潮席卷全球的当下,音视频内容犹如璀璨繁星,点亮了人们的生活与工作。从短视频平台上令人捧腹的搞笑视频,到在线课堂中知识渊博的专家授课,再到影视平台上扣人心弦的高清大片,音…...
0609)
书籍“之“字形打印矩阵(8)0609
题目 给定一个矩阵matrix,按照"之"字形的方式打印这个矩阵,例如: 1 2 3 4 5 6 7 8 9 10 11 12 ”之“字形打印的结果为:1,…...

「Java基本语法」变量的使用
变量定义 变量是程序中存储数据的容器,用于保存可变的数据值。在Java中,变量必须先声明后使用,声明时需指定变量的数据类型和变量名。 语法 数据类型 变量名 [ 初始值]; 示例:声明与初始化 public class VariableDemo {publi…...

VUE3 ref 和 useTemplateRef
使用ref来绑定和获取 页面 <headerNav ref"headerNavRef"></headerNav><div click"showRef" ref"buttonRef">refbutton</div>使用ref方法const后面的命名需要跟页面的ref值一样 const buttonRef ref(buttonRef) cons…...