深度学习500问——Chapter07:生成对抗网络(GAN)(2)
文章目录
7.2 GAN的生成能力评价
7.2.1 如何客观评价GAN的生成能力
7.2.2 Inception Score
7.2.3 Mode Score
7.2.5 Wasserstein distance
7.2.6 Fréchet Inception Distance (FID)
7.2.7 1-Nearest Neighbor classifier
7.2.8 其他评价方法
7.3 其他常见的生成式模型有哪些
7.3.1 什么是自回归模型:pixelRNN于pixelCNN
7.3.2 什么是VAE
7.4 GAN的改进和优化
7.4.1 如何生成指定类型的图像——条件GAN
7.4.2 CNN与GAN——DCGAN
7.4.3 如何理解GAN中的输入随机噪声
7.4.4 GAN为什么容易训练崩溃
7.4.5 WGAN如何解决训练崩溃问题
7.4.6 WGAN-GP:带有梯度正则的WGAN
7.4.7 LSGAN
7.4.8 如何尽量避免GAN的训练崩溃问题
7.2 GAN的生成能力评价
7.2.1 如何客观评价GAN的生成能力
最常见的评价GAN的方法就是主观评价。主观评价需要花费大量人力物力,且存在以下问题:
- 评价带有主观色彩,有些bad case没看到很容易造成误判。
- 如果一个GAN过拟合了,那么生成的样本会非常真实,人类主观评价得分会非常高,可是这并不是一个好的GAN。
因此,就有许多学者提出了GAN的客观评价方法。
7.2.2 Inception Score
对于一个在ImageNet训练良好的GAN,其生成的样本丢给Inception网络进行测试的时候,得到的判别概率应该具有如下特性:
- 对于同一个类别的图像,其输出的概率分布应该趋向于一个脉冲分布。可以保证生成样本的准确性。
- 对于所有类别,其输出的概率分布应该趋向于一个均匀分布,这样才不会出现mode dropping等,可以保证生成样本的多样性。
因此,可以设计如下指标:
根据前面分析,如果是一个训练良好的GAN,趋近于脉冲分布,
趋近于均匀分布。二者KL散度会很大。Inception Score自然就高。实际实验表明,Inception Score和人的主观判别趋向一致。IS的计算没有用到真实数据,具体值取决于模型M的选择。
特点:可以一定程度上衡量生成样本的多样性和准确性,但是无法检测过拟合。Mode Score也是如此。不推荐在和ImageNet数据集差别比较大的数据上使用。
7.2.3 Mode Score
Mode Score作为Inception Score的改进版本,添加了关于生成样本和真实样本预测的概率分布相似性度量的一项。具体公式如下:
对于kernel MMD值的计算,首先需要选择一个核函数,这个核函数把样本映射到再生希尔伯特空间(Reproducing Kernel Hilbert Space, RKHS),RKHS相比于欧几里得空间有许多优点,对于函数内积的计算是完备的。将上述公式展开即可得到下面的计算公式:
MMD值越小,两个分布越接近。
特点:可以一定程度上衡量模型生成图像的优劣性,计算代价小。推荐使用。
7.2.5 Wasserstein distance
Wasserstein distance在最优传输问题中通常也叫做推土机问题。这个距离的介绍在WGAN中有详细讨论。公式如下:
Wasserstein distanced可以衡量两个分布之间的相似性。距离越小,分布越相似。
特点:如果特征空间选择合适的话,会有一定的效果。但是计算复杂度为太高。
7.2.6 Fréchet Inception Distance (FID)
FID距离计算真实样本、生成样本在特征空间之间的距离。首先利用Inception网络来提取特征,然后使用高斯模型对特征空间进行建模。根据高斯模型的均值和协方差来进行距离计算。具体公式如下:
分别代表协方差和均值。
特点:尽管只计算了特征空间的前两阶矩,但是鲁棒,且计算高效。
7.2.7 1-Nearest Neighbor classifier
使用留一法,结合1-NN分类器(别的也行)计算真实图片,生成图像的精度。如果二者接近,则精度接近50%,否则接近0%。对于GAN的评价问题,作者分别用正样本的分类精度,生成样本的分类精度去衡量生成样本的真实性、多样性。
- 对于真实样本
,进行1-NN分类的时候,如果生成的样本越真实,则真实样本空间
将被生成的样本
包围,那么
- 对于生成的样本
特点:理想的度量指标,且可以检测过拟合。
7.2.8 其他评价方法
AIS、KDE方法也可以用于评价GAN,但这些方法不是model agnostic metrics。也就是说,这些评价指标的计算无法只利用:生成的样本、真实的样本来计算。
7.3 其他常见的生成式模型有哪些
7.3.1 什么是自回归模型:pixelRNN于pixelCNN
自回归模型通过对图像数据的概率分布进行显式建模,并利用极大似然估计优化模型。具体如下:
上述公式很好理解,给定条件下,所有
的概率乘起来就是图像数据的分布。如果使用RNN对上述依然关系建模,就是pixelRNN。如果使用CNN,则是pixelCNN。具体如下[5]:
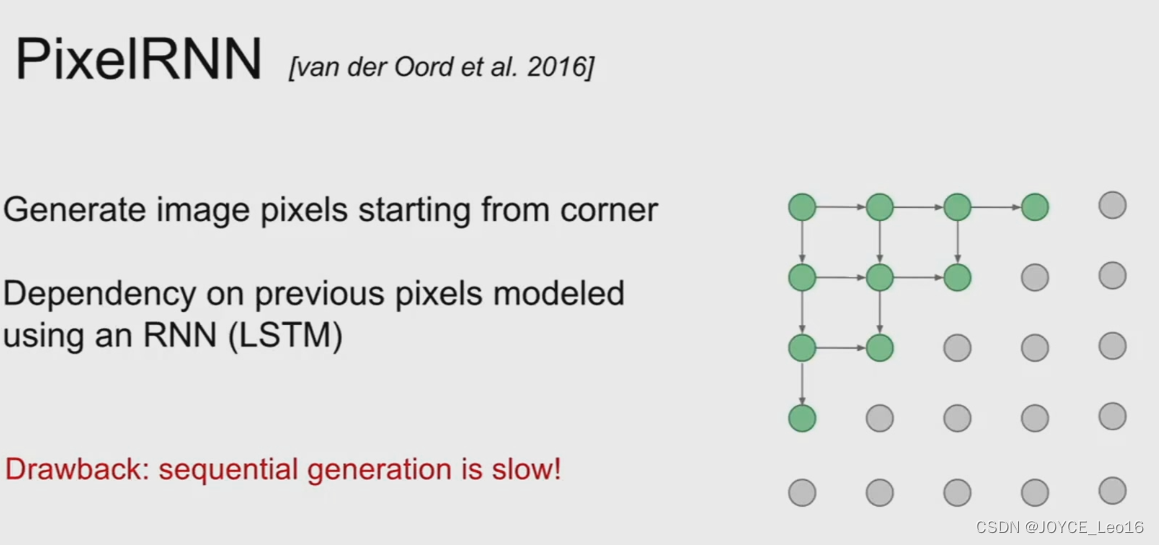
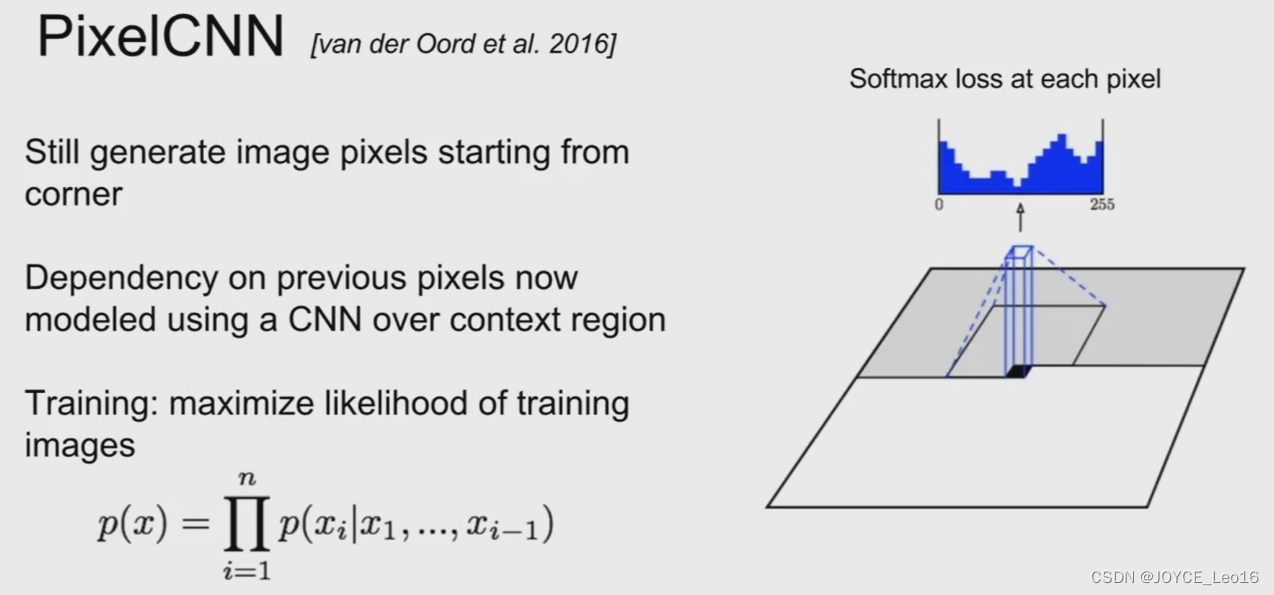
显然,不论是对于pixelCNN还是pixelRNN,由于像素值是一个个生成的。速度会很慢。语音领域大火的WaveNet就是一个典型的自回归模型。
7.3.2 什么是VAE
PixelCNN/RNN定义了一个易于处理的密度函数,我们可以直接优化训练数据的似然;对于变分自编码器我们将定义一个不易处理的密度函数,通过附加的隐变量对密度函数进行建模。VAE原理图如下[6]:

在VAE中,真实样本通过神经网络计算出均值方差(假设隐变量服从正态分布),然后通过采样得到采样变量
并进行重构。VAE和GAN均是学习了隐变量
到真实数据分布的映射。但是和GAN不同的是:
- GAN的思路比较粗暴,使用一个判别器去度量分布转换模块(即生成器)生成分布与真实数据分布的距离。
- VAE则没有那么直观,VAE通过约束隐变量
服从正态分布以及重构数据实现了分布转换映射
生成式模型对比:
- 自回归模型通过对概率分布显式建模来生成数据。
- VAE和GAN均是:假设隐变量
,实现隐变量分布
的转换。
- GAN使用判别器去度量映射
7.4 GAN的改进和优化
7.4.1 如何生成指定类型的图像——条件GAN
条件生成对抗网络(CGAN,Conditional Generative Adversarial Networks)作为一个GAN的改进,其一定程度上解决了GAN生成结果的不确定性。
如果在Mnist数据集上训练原始GAN,GAN生成的图像是完全不确定的,具体生成的是数字1,还是2,还是几,根本不可控。为了让生成的数字可控,我们可以把数据集做一个切分,把数字0~9的数据集分别拆分开训练9个模型,不过这样太麻烦了,也不现实。因为数据集拆分不仅仅是分类麻烦,更主要在于,每一个类别的样本少,拿去训练GAN很有可能导致欠拟合。因此,CGAN应运而生了。
我们先看一下CGAN的网络结构:

从结构图中可以看到,对于生成器Generator,其输入不仅仅是随机噪声的采样,还有欲生成图像的标签信息。比如对mnist数据生成,就是一个one-hot向量,某一维度为1则表示生成某个数字的图片。同样地,判别器的输入也包括样本的标签。这样就使得判别器核生成器可以学习到样本和标签之间的联系。
Loss如下:
Loss设计和原始GAN基本一致,只不过生成器、判别器的输入数据是一个条件分布。在具体编程实现时只需要对随机噪声采样和输入条件
做一个级联即可。
7.4.2 CNN与GAN——DCGAN
前面我们聊的GAN都是基于简单的神经网络构建的。可是对于视觉问题,如果使用原始的基于DNN的GAN,则会出现许多问题。如果输入GAN的随机噪声为100维的随机噪声,输出图像为 大小。也就是说,要将100维的信息映射为65536维。如果单纯用DNN来实现,那么整个模型参数会非常巨大,而且学习难度很大(低纬度映射到高纬度需要添加许多信息)。因此,DCGAN就出现了。
具体而言,DCGAN将传统GAN的生成器、判别器均采用GAN实现,且使用了一下tricks:
- 将pooling层convolutions替代,其中,在discriminator上用strided convolutions替代,在generator上用fractional-strided convolutions替代。
- 在generator和discriminator上都使用batchnorm。
- 移除全连接层,global pooling增加了模型的稳定性,但伤害了收敛速度。
- 在generator的除了输出层外的所有层使用ReLU,输出层采用tanh。
- 在discriminator的所有层上使用LeakyReLU。
网络结构图如下:

7.4.3 如何理解GAN中的输入随机噪声
为了了解输入随机噪声每一个维度代表的含义,作者做了一个非常有趣的工作,即在隐空间上,假设知道哪几个变量控制着某个物体,那么将这几个变量挡住是不是就可以将生成图片中的某个物体消失?
论文中的实验是这样的:首先,生成150张图片,包括有窗户的和没有窗户的,然后使用一个逻辑斯谛回归函数来进行分类,对于权重不为0的特征,认为它和窗户有关。将其挡住,得到新的生成图片,结果如下:

此外,将几个输入噪声进行算数运算,可以得到语义上进行算数运算的非常有趣的结果,类似于word2vec。

7.4.4 GAN为什么容易训练崩溃
所谓GAN的训练崩溃,指的是训练过程中,生成器和判别器存在一方压倒另一方的情况。
GAN原始判别器的Loss在判别器达到最优的时候,等价于最小化生成分布与真实分布之间的JS散度,由于随机生成分布很难与真实分布有不可忽略的重叠以及JS散度的突变特性,使得生成器面临梯度消失的问题;
可是如果不把判别器训练到最优,那么生成器优化的目标就失去了意义。因此需要我小心的平衡二者,要把判别器训练的不好也不坏才行。否则就会出现训练崩溃,得不到想要的结果。
7.4.5 WGAN如何解决训练崩溃问题
WGAN作者提出了使用Wasserstein距离,以解决GAN网络训练过程难以判断收敛性的问题。Wasserstein距离定义如下:
通过最小化Wasserstein距离,得到了WGAN的Loss:
- WGAN生成器Loss:
- WGAN判别器Loss:
从公式上GAN似乎总是让人摸不着头脑,在代码实现上来说,其实就以下几点:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
7.4.6 WGAN-GP:带有梯度正则的WGAN
实际实验过程中发现,WGAN没有那么好用,主要原因在于WGAN带有梯度截断。梯度截断将导致判别网络趋向于一个二值网络,造成模型容量的下降。于是作者提出使用梯度惩罚来替代梯度裁剪。公式如下:
由于上式是对每一个梯度进行惩罚,所以不适合使用BN,因为它会引入不同batch中不同样本的相互依赖关系。如果需要的话,可以选择Layer Normalization。实际训练过程中,就可以通过Wasserstein距离来度量模型收敛程度了:

上图纵坐标是Wasserstein距离,横坐标是迭代次数。可以看出,随着迭代的进行,Wasserstein距离趋于收敛,生成图像也趋于稳定。
7.4.7 LSGAN
LSGAN(Least Squares GAN)这篇文章主要针对标准GAN的稳定性和图片生成质量不高做了一个改进。作者将原始GAN的交叉熵损失采用最小二乘损失替代。
LSGAN的Loss:
实际实现的时候非常简单,最后一层去掉sigmoid,并且计算Loss的时候用平方误差即可。之所以这么做,作者在原文给出了一张图,交叉熵与最小二乘损失对比图:
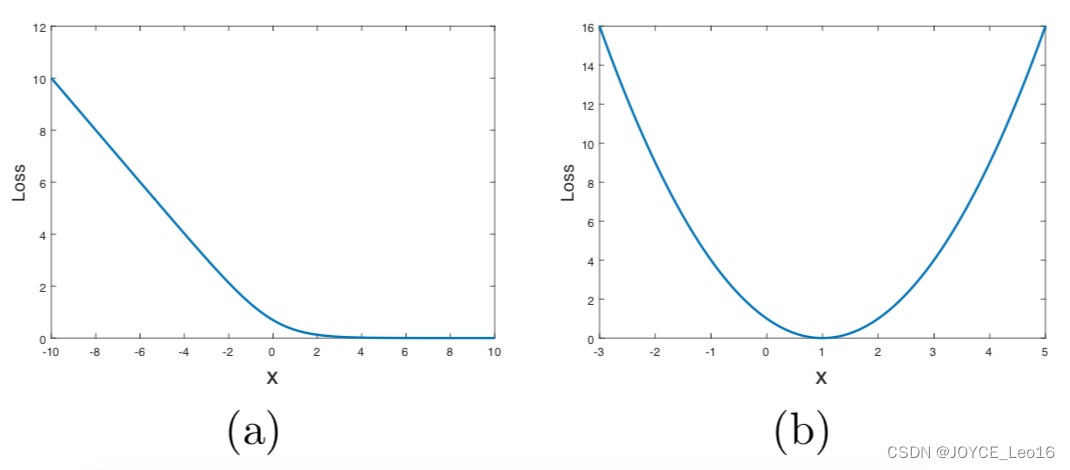
上面是作者给出的基于交叉熵损失以及最小二乘损失的Loss函数。横坐标代表Loss函数的输入,纵坐标代表输出的Loss值。可以看出,随着输入的增大,sigmoid交叉熵损失很快趋于0,容易导致梯度饱和问题。如果使用右边的Loss设计,则只在x=0点处饱和。因此使用LSGAN可以很好的解决交叉熵损失的问题。
7.4.8 如何尽量避免GAN的训练崩溃问题
- 归一化图像输入到(-1,1)之间;Generator最后一层使用tanh激活函数。
- 生成器的Loss采用:min(log 1-D)。因为原始的生成器Loss存在梯度消失问题;训练生成器的时候,考虑反转标签,real=fake,fake=real。
- 不要在均匀分布上采样,应该在高斯分布上采样。
- 一个Mini-batch里面必须只有正样本,或者负样本。不要混在一起;如果用不了Batch Norm,可以用Instance Norm。
- 避免稀疏梯度,即少用ReLU,MaxPool。可以用LeakyReLU替代ReLU,下采样可以用Average Pooling或者Convolution + stride替代。上采样可以用PixelShuffle,ConvTranspose2d + stride。
- 平滑标签或者给标签添加噪声;平滑标签,即对正样本,可以使用0.7-1.2的随机数替代;对于负样本,可以使用0-0.3的随机数替代。给标签加噪声:即训练判别器的时候,随机翻转部分样本的标签。
- 如果可以,请用DCGAN或者混合模型:KL + GAN,VAE + GAN。
- 使用LSGAN,WGAN-GP。
- Generator使用Adam,Discriminator使用SGD。
- 尽快发现错误;比如:判别器Loss为0,说明训练失败了;如果生成器Loss稳步下降,说明判别器没发挥作用。
- 不要试着通过比较生成器,判别器Loss的大小来解决训练过程中的模型坍塌问题。比如:While Loss D > Loss A: Train D While Loss A > Loss D: Train A。
- 如果有标签,请尽量利用标签信息来训练。
- 给判别器的输入加一些噪声,给G的每一层加一些人工噪声。
- 多训练判别器。尤其是在加了噪声的时候。
- 对于生成器,在训练、测试的时候使用Dropout。
相关文章:
深度学习500问——Chapter07:生成对抗网络(GAN)(2)
文章目录 7.2 GAN的生成能力评价 7.2.1 如何客观评价GAN的生成能力 7.2.2 Inception Score 7.2.3 Mode Score 7.2.5 Wasserstein distance 7.2.6 Frchet Inception Distance (FID) 7.2.7 1-Nearest Neighbor classifier 7.2.8 其他评价方法 7.3 其他常见的生成式模型有哪些 7.…...

A13 STM32_HAL库函数 之 HAL-ETH通用驱动 -- B -- 所有函数的介绍及使用
A13 STM32_HAL库函数 之 HAL-ETH通用驱动 -- B -- 所有函数的介绍及使用 1 通用定时器(TIM)预览1.11 HAL_ETH_TxCpltCallback1.12 HAL_ETH_RxCpltCallback1.13 HAL_ETH_ErrorCallback1.14 HAL_ETH_ReadPHYRegister1.15 HAL_ETH_WritePHYRegister1.16 HAL…...
Qotom Q720G5英特尔赛扬处理器N4000高性价比无风扇迷你电脑5网口软路由防火墙
在数字时代,迷你电脑已经成为高效、灵活的解决方案,无论是个人用户还是企业用户,都能从中受益。Qotom Q720G5 无风扇迷你电脑就是这样一款强大的选择,它不仅可以作为软路由、防火墙和路由器,还有着更多的潜力等待发掘。…...

如何了解数字化和信息化的区别?
在数字化浪潮席卷全球的今天,企业如何乘风破浪、实现转型升级? 数字化和信息化,这两个看似相似却各有千秋的概念,一直被人们拿来对比。 下面就来讲一讲我的理解: 从简单了说: “信息化”可以理解为传统数…...
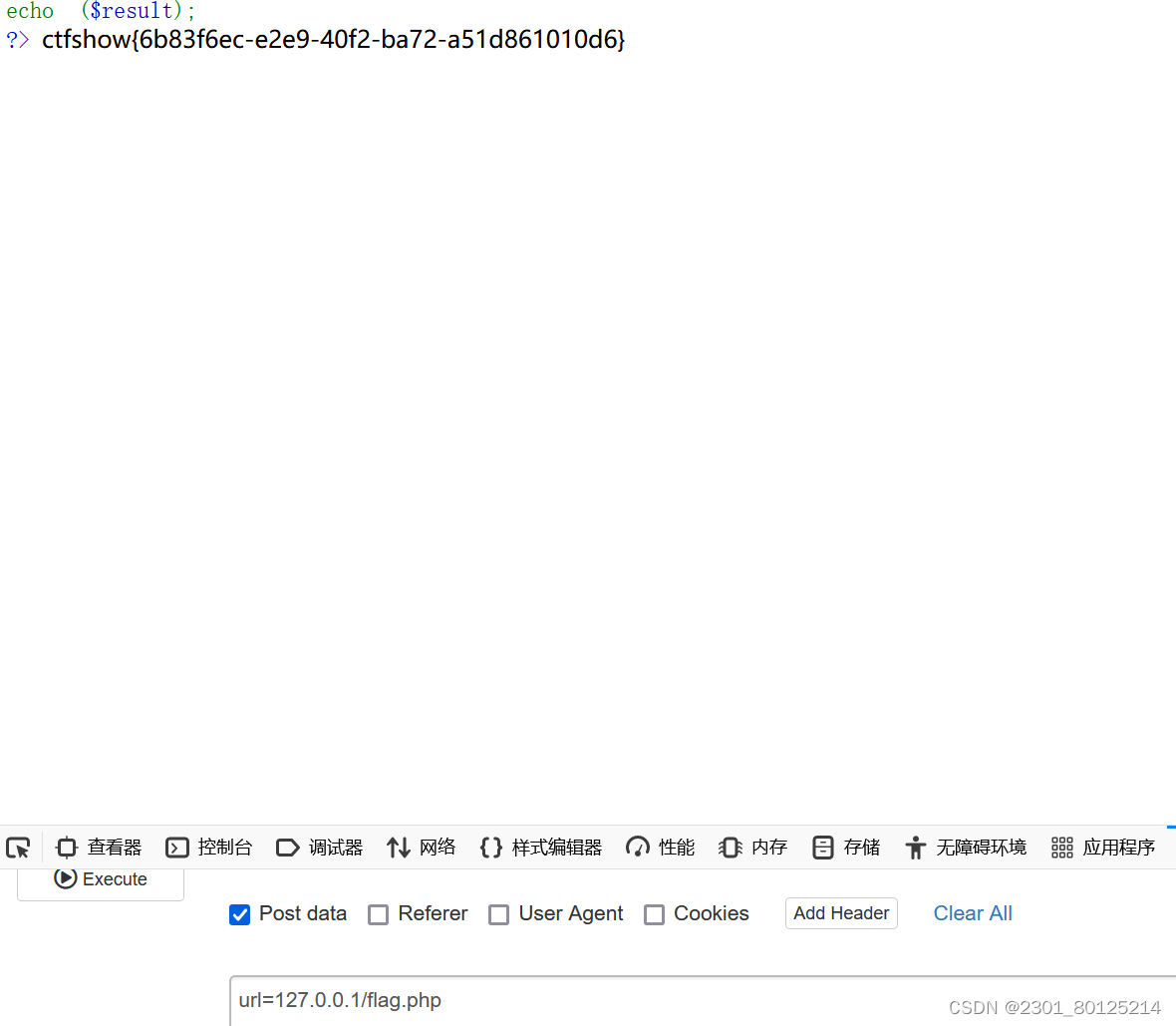
CTF-SHOW SSRF
web351 存在一个flag.php页面,访问会返回不是本地用户的消息,那肯定是要让我们以本地用户去访问127.0.0.1/flag.php web352 代码中先判断是否为HTTP或https协议,之后判断我们传入的url中是否含有localhost和127.0.0,如果没有则…...
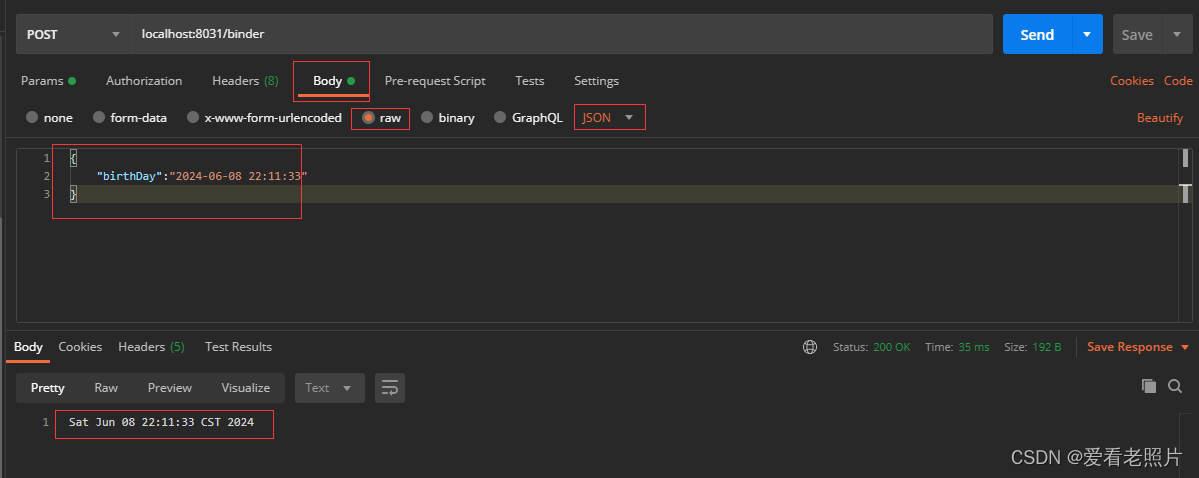
客户端传日期格式字段(String),服务端接口使用java.util.Date类型接收报错问题
客户端传日期格式字段(string),服务端接口使用java.util.Date类型接收报错问题 问题演示第1种:客户端以URL拼接的方式传值第2种:客户端以body中的form-data方式提交第3种 客户端以Body中的json方式提交 问题解决(全局解…...

【Python面试题收录】什么是堆?什么是栈?栈和堆的区别是什么?
一、堆和栈的定义 (1)堆(Heap) 数据结构:堆是一种特殊的完全二叉树,满足父节点的值总是大于或等于(大根堆)其子节点的值。也可以是总是小于或等于(小根堆)其…...

5-云原生监控体系-Grafana-使用配置文件实现自动化导入Dashboard
文章目录 1. 介绍(此文档使用的版本 grafana-enterprise-10.0.3-1)2. 清空之前的实验数据3. 使用配置文件方式配置 Datasource3.1. 创建配置文件3.2. 重启服务并检查是否生效4. 使用配置文件方式配置 Dashboard4.1. 创建配置文件5. 配置 Dashboard JSON 文件5.1. 下载 JSON 文…...
Ollama、FastGPT大模型RAG结合使用案例
参考: https://ollama.com/download/linux https://doc.fastai.site/docs/intro/ https://blog.csdn.net/m0_71142057/article/details/136738997 https://doc.fastgpt.run/docs/development/custom-models/m3e/ Ollama作为后端大模型加载运行 FastGPT作为前端页面聊天集成RA…...

夯实智慧新能源数据底座,TiDB Serverless 在 Sandisolar+ 的应用实践
本文介绍了 SandiSolar通过 TiDB Serverless 构建智慧新能源数据底座的思路与实践。作为一家致力于为全球提供清洁电力解决方案的新能源企业,SandiSolar面临着处理大量实时数据的挑战。为了应对这一问题,SandiSolar选择了 TiDB Serverless 作为他们的数据…...
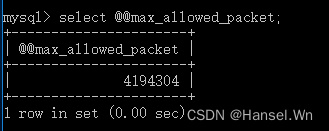
MySQL数据库max_allowed_packet参数
如上图所示的报错,我在提交接口的时候出现了这个错误: MySqlConnector.MySqlException:Error submitting 4MB packet;ensure max_allowed_packet is greater than 4MB.在MySQL数据库中,有一个参数叫max_allowed_packet,这个参数会…...

Day98:云上攻防-云原生篇K8s安全Config泄漏Etcd存储Dashboard鉴权Proxy暴露
目录 云原生-K8s安全-etcd(Master-数据库)未授权访问 etcdV2版本利用 etcdV3版本利用 云原生-K8s安全-Dashboard(Master-web面板)未授权访问 云原生-K8s安全-Configfile鉴权文件泄漏 云原生-K8s安全-Kubectl Proxy不安全配置 知识点: 1、云原生-K8s安全-etcd未…...

JUC下面常见的锁
这里写目录标题 1、ReentrantLock2、Semaphore3、CountDownLatch4、CyclicBarrier 1、ReentrantLock ReentrantLock 是属于独占模式, 即同一时刻只允许一个线程获取锁。 2、Semaphore Semaphore 属于共享模式,synchronized 和 ReentrantLock 都是一次只…...

Uniapp+基于百度智能云完成AI视觉功能(附前端思路)
本博客使用uniapp百度智能云图像大模型中的AI视觉API(本文以物体检测为例)完成了一个简单的图像识别页面,调用百度智能云API可以实现快速训练模型并且部署的效果。 uniapp百度智能云AI视觉页面实现 先上效果图实现过程百度智能云Easy DL训练图…...

Android 软件盘的弹出和消失的监听
监听接口 OnKeyboardListener.java public interface OnKeyboardListener {void onKeyboardHidden();void onKeyboardShow(int keyboardHeight);} KeyBoardUtil.java public class KeyBoardUtil {private final static String TAG "KeyBoardUtil";public PopupWi…...
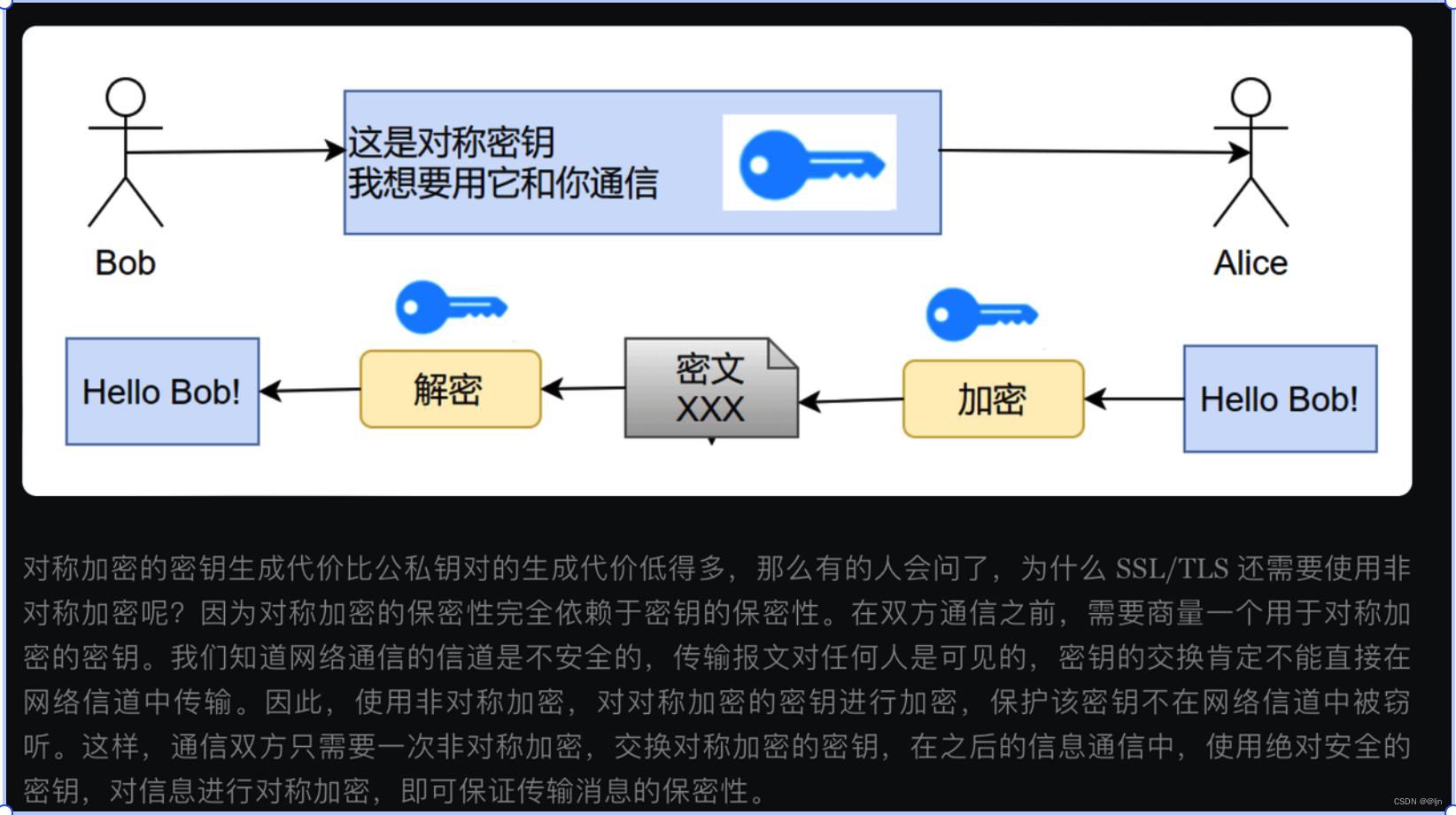
通俗易懂HTTP和HTTPS区别
HTTP:超文本传输协议,它是使用一种明文的方式发送我们的内容,没有任何的加密,例如我们要在网页上输入账号密码,如果使用HTTP协议,账号密码就可能会被暴露,默认端口是80. HTTPS:是HT…...
)
【ZZULIOJ】1061: 顺序输出各位数字(Java)
目录 题目描述 输入 输出 样例输入 Copy 样例输出 Copy 提示 code 题目描述 输入一个不大于10的9次方的正整数,从高位开始逐位分割并输出各位数字。 输入 输入一个正整数n,n是int型数据 输出 依次输出各位上的数字,每一个数字后面有一个空格…...
java数据结构与算法刷题-----LeetCode260. 只出现一次的数字 III
java数据结构与算法刷题目录(剑指Offer、LeetCode、ACM)-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/123063846 文章目录 与运算取末尾1分组 与运算取末尾1分组 解题思路:时间…...

AWS被误扣费了,怎么解决?
有时在使用aws时,可能会无意中被AWS扣费,对于如何处理这个问题,作为aws的合作伙伴,接下来由九河云进行讲解: (1)审查账单:首先,您需要仔细审查AWS账单,了解具…...

再传IPO消息,SHEIN的上市为何充满变数?
据《金融时报》援引消息人士报道,SHEIN正在等待北京监管部门的批准,以推进在纽约或伦敦的重磅上市。 几乎每隔一段时间,SHEIN即将上市的消息就会成为媒体关注的焦点,但每一次报道都“没有下文”,再加上SHEIN官方的“拒…...

如何用React Hooks与Context模式构建Conductor前端状态管理系统
如何用React Hooks与Context模式构建Conductor前端状态管理系统 【免费下载链接】conductor Conductor is a microservices orchestration engine. 项目地址: https://gitcode.com/gh_mirrors/condu/conductor Conductor是Netflix开源的微服务编排引擎,其前端…...

终极指南:如何使用Conductor微服务编排平台解决跨服务工作流难题
终极指南:如何使用Conductor微服务编排平台解决跨服务工作流难题 【免费下载链接】conductor Conductor is a microservices orchestration engine. 项目地址: https://gitcode.com/gh_mirrors/condu/conductor Conductor是Netflix开源的微服务编排引擎&…...

Alpamayo-R1-10B效果对比:Alpamayo-R1-10B vs Wayve LINGO-1轨迹精度评测
Alpamayo-R1-10B效果对比:Alpamayo-R1-10B vs Wayve LINGO-1轨迹精度评测 1. 项目背景与评测目标 自动驾驶技术的发展已经进入深水区,视觉-语言-动作(VLA)模型作为新一代自动驾驶系统的核心组件,其性能直接影响着车辆…...

DeOldify图像上色效果展示:舞蹈剧照黑白底片AI还原舞台灯光效果
DeOldify图像上色效果展示:舞蹈剧照黑白底片AI还原舞台灯光效果 1. 引言:当黑白记忆遇见彩色魔法 你有没有翻看过家里的老相册?那些泛黄的黑白照片里,藏着多少被时光褪色的故事。特别是那些记录着精彩瞬间的舞蹈剧照,…...

SpringBoot实战:Kaptcha验证码集成与前后端交互全流程解析
1. 为什么需要验证码? 验证码是现代Web应用中必不可少的安全组件。简单来说,它的核心作用就是区分人类用户和自动化程序。想象一下,如果没有验证码,恶意程序可以轻松地批量注册账号、刷票、暴力破解密码,甚至发起DDoS攻…...
基于STM32的IIC接口移植实战)
0.91寸OLED彩屏(SSD1306驱动)基于STM32的IIC接口移植实战
0.91寸OLED彩屏(SSD1306驱动)基于STM32的IIC接口移植实战 最近在做一个需要小型显示界面的项目,选来选去,发现0.91寸的OLED彩屏是个不错的选择。它尺寸小巧,功耗低,显示效果又很清晰。不过,从网…...

【深度解析】Nacos连接故障:127.0.0.1:9848端口拒绝访问的排查与修复
1. 问题现象与初步分析 最近在部署若依微服务项目时,遇到了一个典型的Nacos连接问题:gateway服务启动时报错"拒绝连接: /127.0.0.1:9848"。这个错误看似简单,但背后涉及Nacos的多种连接机制和配置优先级问题。让我想起去年在另一个…...

规则引擎可视化避坑指南:从Blender到React-Diagram的交互设计踩坑实录
规则引擎可视化交互设计实战:从Blender到React-Diagram的深度解构 当我们需要构建一个类Blender或Unreal引擎的可视化规则编辑器时,往往会陷入技术选型与交互设计的双重迷宫。本文将分享如何基于React-Diagram构建企业级规则引擎可视化系统的完整方法论&…...

openwrt ipv6与v4共存relay情况下ping6不通问题解决
有些校园网虽然开了slaac无状态,但仍然有监权机制。需要ipv4拨号。否则v6也不通。一个路由器下面的多个设备并不想多次拨号。按照前辈们的做法只分配/64的v6网络用relay就行了。尤其是openwrt22以后wan上的master也不用ssh。跑题了。^_^解决方案是用ndppd。下面是完…...

突破限制:OpenCore Legacy Patcher全流程指南——让旧Mac重获新生
突破限制:OpenCore Legacy Patcher全流程指南——让旧Mac重获新生 【免费下载链接】OpenCore-Legacy-Patcher 体验与之前一样的macOS 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是一款开源工具&…...