神经网络解决回归问题(更新ing)
神经网络应用于回归问题
- 优势是什么???
- 生成数据集:
- 通用神经网络拟合函数
- 调整不同参数对比结果
- 初始代码结果
- 调整神经网络结构
- 调整激活函数
- 调整迭代次数
- 增加早停法
- 变量归一化处理
- 正则化系数调整
- 学习率调整
- 总结ing
- fnn.py进行计算:
- 破案了。。
优势是什么???
神经网络是处理回归问题的强大工具,它们能够学习输入数据和输出之间的复杂关系。
神经网络提供了一种灵活且强大的框架,用于建模和预测回归问题。通过 适当的 网络结构、训练策略和正则化技术,可以有效地从数据中学习并做出准确的预测。
在实际应用中,选择合适的网络架构和参数对于构建一个高效的回归模型至关重要。
所以说,虽然神经网络是处理回归问题的强大工具,但是也存在很多问题,需要我们掌握很多方法技巧才能建立一个高效准确的回归模型:(实际上,掌握这些技巧的使用方法其实仍然无法把模型训练的很好,构建一个好的模型最重要的其实是对这个问题本质的理解)
- 正则化(Regularization): 为了防止过拟合,可以在损失函数中添加正则化项,如L1或L2正则化。
- Dropout: 这是一种技术,可以在训练过程中随机地丢弃一些神经元的激活,以减少模型对特定神经元的依赖。
- 批量归一化(Batch Normalization): 通过对每一层的输入进行归一化处理,可以加速训练过程并提高模型的稳定性。
- 早停(Early Stopping): 当验证集上的性能不再提升时,停止训练以避免过拟合。
- 超参数调整(Hyperparameter Tuning): 通过调整网络结构(如层数、每层的神经元数量)和学习率等超参数,可以优化模型的性能。
生成数据集:
输入数据:
X 1 = 100 × N ( 1 , 1 ) X_{1} = 100 \times \mathcal{N}(1, 1) X1=100×N(1,1)
X 2 = N ( 1 , 1 ) 10 X_{2} = \frac{\mathcal{N}(1, 1) }{10} X2=10N(1,1)
X 3 = 10000 × N ( 1 , 1 ) X_{3} = 10000 \times \mathcal{N}(1, 1) X3=10000×N(1,1)
输出数据 Y Y Y和 Y 1 Y_1 Y1:
Y = 6 X 1 − 3 X 2 + X 3 2 + ϵ Y = 6X_{1} - 3X_2 + X_3^2 + \epsilon Y=6X1−3X2+X32+ϵ
Y 1 = X 1 ⋅ X 2 − X 1 X 3 + X 3 X 2 + ϵ 1 Y_1 = X_1 \cdot X_2 - \frac{X_1}{X_3} + \frac{X_3}{X_2} + \epsilon_1 Y1=X1⋅X2−X3X1+X2X3+ϵ1
其中, ϵ 1 \epsilon_1 ϵ1 是均值为0,方差为0.1的正态分布噪声。
请注意,这里的 N ( μ , σ 2 ) {N}(\mu, \sigma^2) N(μ,σ2) 表示均值为 μ \mu μ ,方差为 σ 2 \sigma^2 σ2的正态分布。
下面是生成数据集的代码:
# 生成测试数据
import numpy as np
import pandas as pd
# 训练集和验证集样本总个数
sample = 2000
train_data_path = 'train.csv'
validate_data_path = 'validate.csv'
predict_data_path = 'test.csv'# 构造生成数据的模型
X1 = np.zeros((sample, 1))
X1[:, 0] = np.random.normal(1, 1, sample) * 100
X2 = np.zeros((sample, 1))
X2[:, 0] = np.random.normal(2, 1, sample) / 10
X3 = np.zeros((sample, 1))
X3[:, 0] = np.random.normal(3, 1, sample) * 10000# 模型
Y = 6 * X1 - 3 * X2 + X3 * X3 + np.random.normal(0, 0.1, [sample, 1])
Y1 = X1 * X2 - X1 / X3 + X3 / X2 + np.random.normal(0, 0.1, [sample, 1])# 将所有生成的数据放到data里面
data = np.zeros((sample, 5))
data[:, 0] = X1[:, 0]
data[:, 1] = X2[:, 0]
data[:, 2] = X3[:, 0]
data[:, 3] = Y[:, 0]
data[:, 4] = Y1[:, 0]# 将data分成测试集和训练集
num_traindata = int(0.8*sample)# 将训练数据保存
traindata = pd.DataFrame(data[0:num_traindata, :], columns=['x1', 'x2', 'x3', 'y', 'y1'])
traindata.to_csv(train_data_path, index=False)
print('训练数据保存在: ', train_data_path)# 将验证数据保存
validate_data = pd.DataFrame(data[num_traindata:, :], columns=['x1', 'x2', 'x3', 'y', 'y1'])
validate_data.to_csv(validate_data_path, index=False)
print('验证数据保存在: ', validate_data_path)# 将预测数据保存
predict_data = pd.DataFrame(data[num_traindata:, 0:-2], columns=['x1', 'x2', 'x3'])
predict_data.to_csv(predict_data_path, index=False)
print('预测数据保存在: ', predict_data_path)通用神经网络拟合函数
要根据生成的数据集建立回归模型应该如何实现呢?对于这样包含非线性的方程,直接应用通用的神经网络模型可能效果并不好,就像这样:
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import pandas as pdclass FNN(nn.Module):def __init__(self,Arc,func,device):super(FNN, self).__init__() # 调用父类的构造函数self.func = func # 定义激活函数self.Arc = Arc # 定义网络架构self.device = deviceself.model = self.create_model().to(self.device)# print(self.model)def create_model(self):layers = []for ii in range(len(self.Arc) - 2): # 遍历除最后一层外的所有层layers.append(nn.Linear(self.Arc[ii], self.Arc[ii + 1], bias=True))layers.append(self.func) # 添加激活函数if ii < len(self.Arc) - 3: # 如果不是倒数第二层,添加 Dropout 层layers.append(nn.Dropout(p=0.1))layers.append(nn.Linear(self.Arc[-2], self.Arc[-1], bias=True)) # 添加最后一层return nn.Sequential(*layers)def forward(self,x):out = self.model(x)return outif __name__ == "__main__":# 定义网络架构和激活函数Arc = [3, 10, 20, 20, 20, 10, 2]func = nn.ReLU() # 选择ReLU激活函数device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 根据是否有GPU来选择设备# 创建FNN模型实例model = FNN(Arc, func, device)# 定义损失函数和优化器criterion = nn.MSELoss() # 均方误差损失函数optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器# 训练数据train_data_path = 'train.csv'train_data = pd.read_csv(train_data_path)features = np.array(train_data.iloc[:, :-2])labels = np.array(train_data.iloc[:, -2:])#转换成张量inputs_tensor = torch.from_numpy(features).float().to(device) # 转换为浮点张量labels_tensor = torch.from_numpy(labels).float().to(device) # 如果标签是数值型数loss_history = []# 训练模型for epoch in range(20000):optimizer.zero_grad() # 清空之前的梯度outputs = model(inputs_tensor) # 前向传播loss = criterion(outputs, labels_tensor) # 计算损失loss_history.append(loss.item()) # 将损失值保存在列表中loss.backward() # 反向传播optimizer.step() # 更新权重if epoch % 1000 == 0:print('epoch is', epoch, 'loss is', loss.item(), )import matplotlib.pyplot as pltloss_history = np.array(loss_history)plt.plot(loss_history)plt.xlabel = ('epoch')plt.ylabel = ('loss')plt.show()torch.save(model, 'model\entire_model.pth')
应用这个代码得到的损失随迭代次数变化曲线如图:

这损失值也太大了!!!
那么应该如何修改神经网络模型使其损失函数降低呢?
修改神经网络:考虑归一化和早停
早停方法是跟这位大佬学习的:
早停方法
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, StandardScalerfrom pytorchtools import EarlyStoppingclass FNN(nn.Module):def __init__(self,Arc,func,device):super(FNN, self).__init__() # 调用父类的构造函数self.func = func # 定义激活函数self.Arc = Arc # 定义网络架构self.device = deviceself.model = self.create_model().to(self.device)# print(self.model)def create_model(self):layers = []for ii in range(len(self.Arc) - 2): # 遍历除最后一层外的所有层layers.append(nn.Linear(self.Arc[ii], self.Arc[ii + 1], bias=True))layers.append(self.func) # 添加激活函数if ii < len(self.Arc) - 3: # 如果不是倒数第二层,添加 Dropout 层layers.append(nn.Dropout(p=0.1))layers.append(nn.Linear(self.Arc[-2], self.Arc[-1], bias=True)) # 添加最后一层return nn.Sequential(*layers)def forward(self,x):out = self.model(x)return outif __name__ == "__main__":# 定义网络架构和激活函数Arc = [3, 10, 20, 20, 20, 20, 20, 20, 10, 2]func = nn.ReLU() # 选择ReLU激活函数device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 根据是否有GPU来选择设备# 创建FNN模型实例model = FNN(Arc, func, device)# 定义损失函数和优化器criterion = nn.MSELoss() # 均方误差损失函数optimizer = optim.Adam(model.parameters(), lr=1e-4) # 使用Adam优化器# 训练数据train_data_path = 'train.csv'train_data = pd.read_csv(train_data_path)feature = np.array(train_data.iloc[:, :-2])label = np.array(train_data.iloc[:, -2:])# 对特征进行Z得分归一化feature_scaler = StandardScaler()features = feature_scaler.fit_transform(feature)features_means = feature_scaler.mean_features_stds = feature_scaler.scale_# 对标签进行Z得分归一化label_scaler = StandardScaler()labels = label_scaler.fit_transform(label)label_means = torch.tensor(label_scaler.mean_).float().to(device)label_stds = torch.tensor(label_scaler.scale_).float().to(device)#转换成张量inputs_tensor = torch.from_numpy(features).float().to(device) # 转换为浮点张量labels_tensor = torch.from_numpy(labels).float().to(device) # 如果标签是数值型数label_tensor = torch.from_numpy(label).float().to(device) # 如果标签是数值型数loss_history = []# parser.add_argument('--patience', default=20, type=int, help='patience')early_stopping = EarlyStopping(patience=20, verbose=True)# 训练模型for epoch in range(2000):optimizer.zero_grad() # 清空之前的梯度output = model(inputs_tensor) # 前向传播# 反归一化outputs = (output * label_stds) + label_meansloss = criterion(outputs, label_tensor) # 计算损失loss_history.append(loss.item()) # 将损失值保存在列表中loss.backward() # 反向传播optimizer.step() # 更新权重if epoch % 100 == 0:print('epoch is', epoch, 'loss is', loss.item(), )early_stopping(loss, model)if early_stopping.early_stop:print("early stopping")breakimport matplotlib.pyplot as pltloss_history = np.array(loss_history)plt.plot(loss_history)plt.xlabel = ('epoch')plt.ylabel = ('loss')plt.show()torch.save(model, 'model\entire_model.pth')
运行结果是这样的:

损失值还是特别大。。。。。
调整不同参数对比结果
应用这些方法技巧之后,损失值其实变化并没有很大,那到底应该怎么处理才可以呢?
难道是输入输出之间的关系太复杂了??
我重新调整输入输出关系,去掉噪点:
sample = 3000
X1 = np.zeros((sample, 1))
X1[:, 0] = np.random.normal(1, 1, sample)
X2 = np.zeros((sample, 1))
X2[:, 0] = np.random.normal(2, 1, sample)
X3 = np.zeros((sample, 1))
X3[:, 0] = np.random.normal(3, 1, sample)# 模型
Y = 60 * X1 - 300 * X2 + X3 * 560
直接用这个线性的公式
初始代码结果
运行fnn_easy.py:
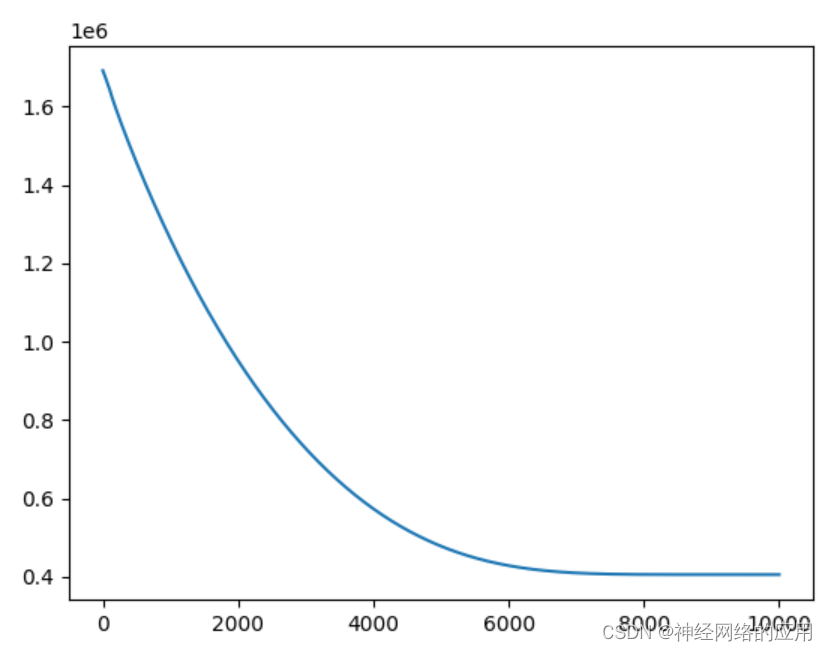
输出结果:::
epoch is 0 loss is 1691248.25
epoch is 1000 loss is 1261221.5
epoch is 2000 loss is 951328.4375
epoch is 3000 loss is 727150.8125
epoch is 4000 loss is 573457.9375
epoch is 5000 loss is 478112.90625
epoch is 6000 loss is 428555.1875
epoch is 7000 loss is 409844.65625
epoch is 8000 loss is 405917.53125
epoch is 9000 loss is 405627.59375
Test loss: 869377.875
调整神经网络结构
神经网络结构[3, 20, 20, 20, 20, 20, 2],增加层数或者神经元数量
变成这个样子:
Arc = [3, 10, 20, 20, 20, 20, 20, 20, 20, 20, 1]
输出结果::
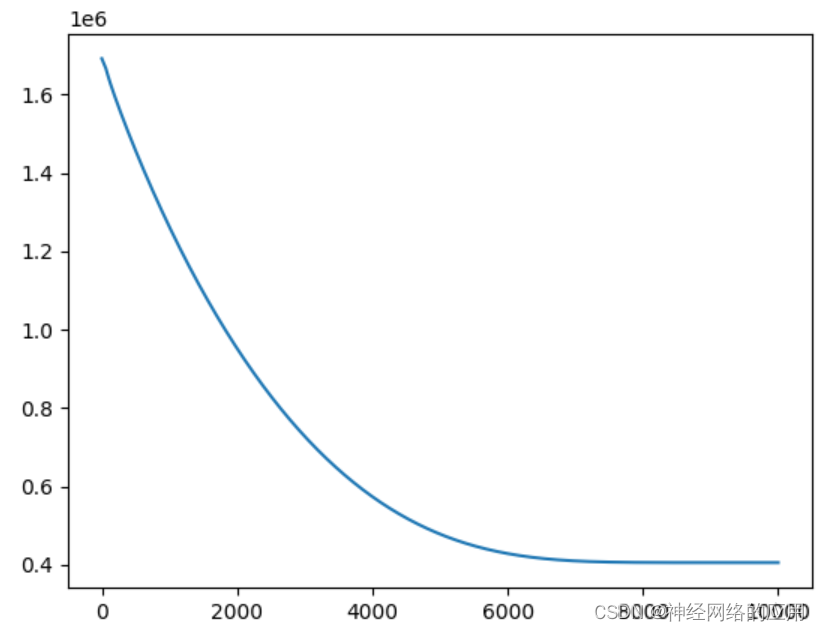
迭代7000次感觉就平缓了??
epoch is 0 loss is 1691888.625
epoch is 1000 loss is 1262176.625
epoch is 2000 loss is 952115.4375
epoch is 3000 loss is 727737.125
epoch is 4000 loss is 573853.3125
epoch is 5000 loss is 478343.09375
epoch is 6000 loss is 428659.3125
epoch is 7000 loss is 409874.03125
epoch is 8000 loss is 405920.875
epoch is 9000 loss is 405627.6875
Test loss: 869377.0625
测试集损失好大,感觉训练集过拟合了??但是这过拟合损失值怎么还这么大啊
改了网络结构,几乎没有变化。。。。。
/(ㄒoㄒ)/~~
调整激活函数
尝试sigmond、tanh、relu激活函数
- relu结果:
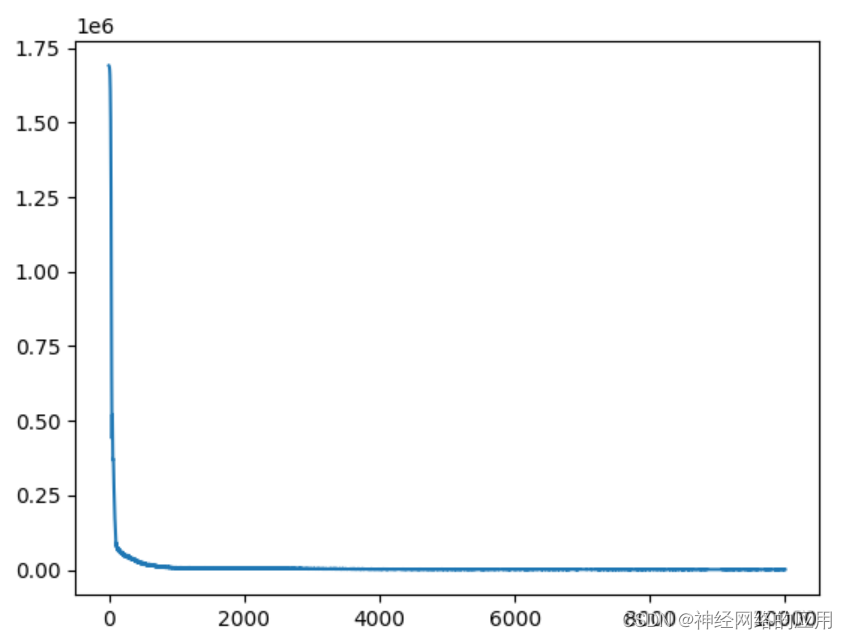
训练集损失值下降的这么快!!!但是到后面怎么基本不变了呀?
epoch is 0 loss is 1691534.125
epoch is 1000 loss is 7115.28857421875
epoch is 2000 loss is 4782.103515625
epoch is 3000 loss is 2784.762451171875
epoch is 4000 loss is 2546.99072265625
epoch is 5000 loss is 1512.3265380859375
epoch is 6000 loss is 1262.20556640625
epoch is 7000 loss is 1113.3638916015625
epoch is 8000 loss is 979.3409423828125
epoch is 9000 loss is 995.0311279296875
Test loss: 637214.0
训练集的损失值降低了,但是测试集损失值怎么还是这么高????
- 换成tanh试试::
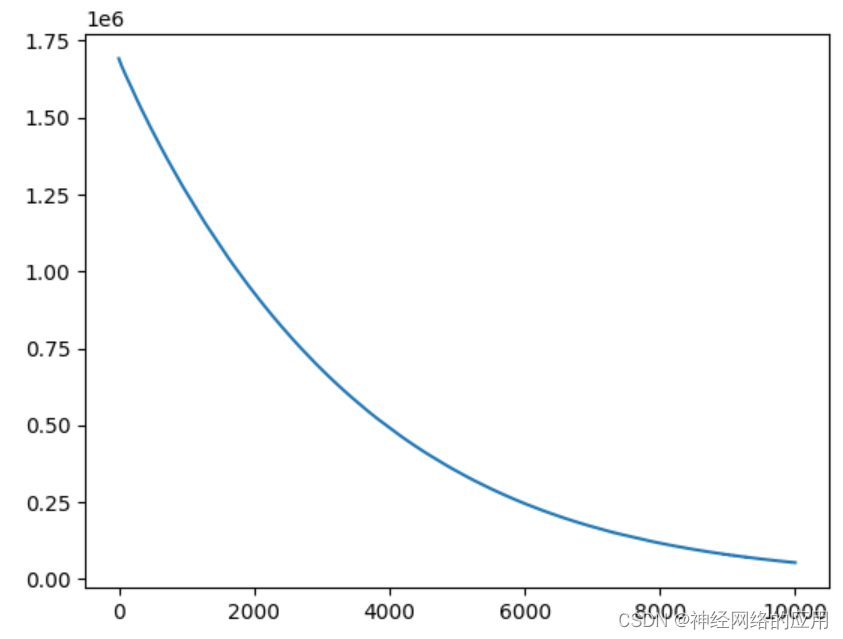
训练集损失值下降的比较平缓
epoch is 0 loss is 1691698.125
epoch is 1000 loss is 1255924.75
epoch is 2000 loss is 930623.8125
epoch is 3000 loss is 681349.75
epoch is 4000 loss is 492137.4375
epoch is 5000 loss is 350489.28125
epoch is 6000 loss is 246078.875
epoch is 7000 loss is 170598.15625
epoch is 8000 loss is 117428.3203125
epoch is 9000 loss is 79978.34375
Test loss: 704667.75
测试集损失值和训练的差不多,但是还是太大了吧。。/(ㄒoㄒ)/~~
调整迭代次数
从10000改到100000
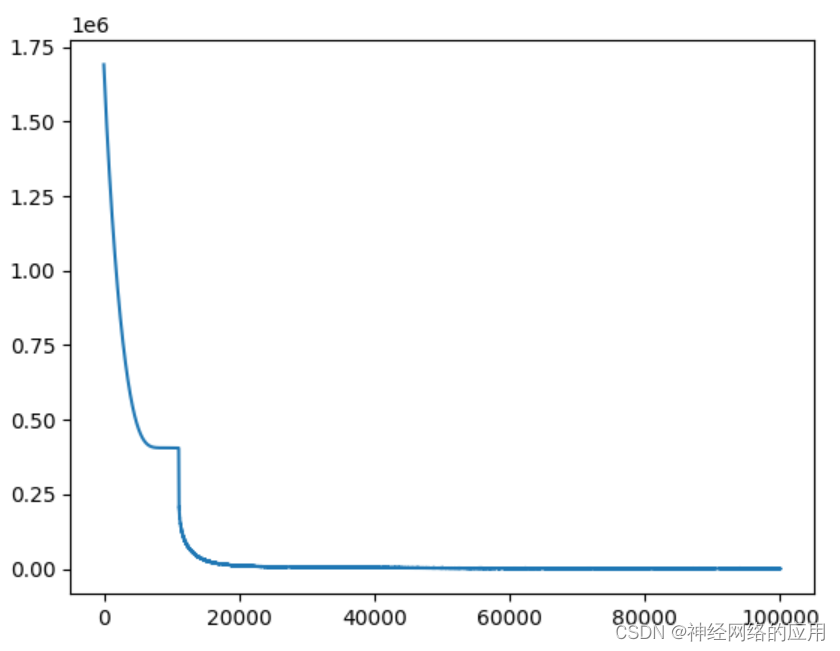
……
epoch is 96000 loss is 817.8455200195312
epoch is 97000 loss is 888.3745727539062
epoch is 98000 loss is 938.8643798828125
epoch is 99000 loss is 741.688232421875
Test loss: 644070.5
增加早停法
似乎没有必要,因为损失值一直很大
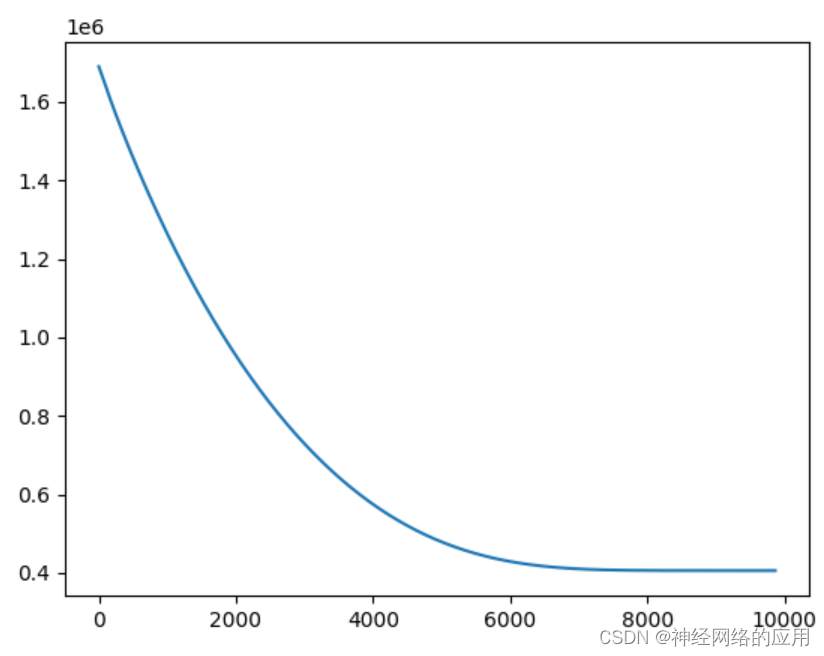
…
Validation loss decreased (405623.906250 --> 405623.906250). Saving model ...
…
EarlyStopping counter: 39 out of 40
EarlyStopping counter: 40 out of 40
early stopping
Test loss: 869326.5625
早停几乎没有起作用。基本也是迭代到10000才停下来
变量归一化处理
这里输入数据在同一数量级,其实不需要进行归一化处理。
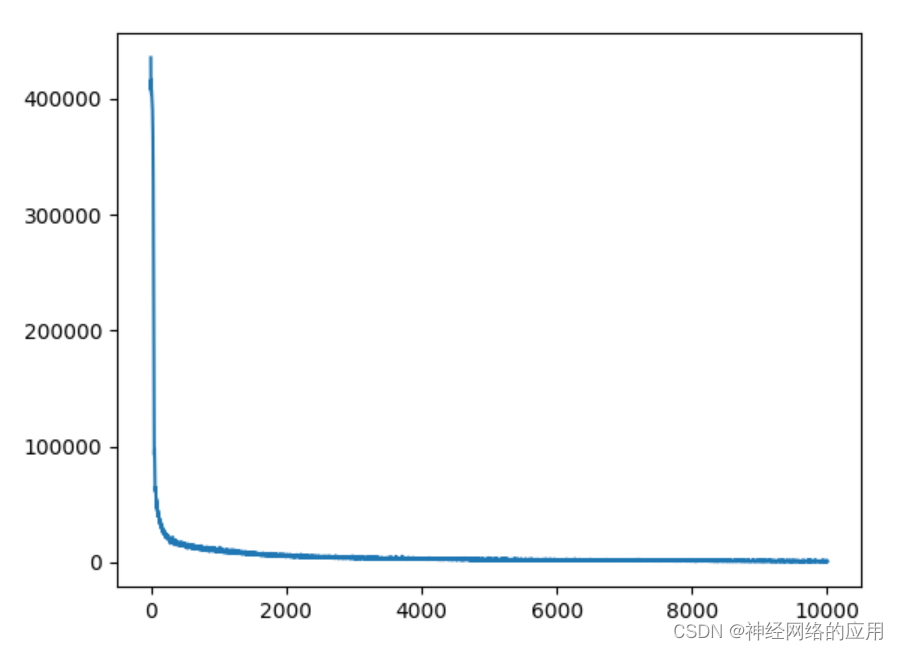
epoch is 0 loss is 435491.9375
epoch is 1000 loss is 10410.7548828125
epoch is 2000 loss is 5559.599609375
epoch is 3000 loss is 4180.0361328125
epoch is 4000 loss is 2995.7177734375
epoch is 5000 loss is 1987.0074462890625
epoch is 6000 loss is 2300.583251953125
epoch is 7000 loss is 1547.3831787109375
epoch is 8000 loss is 1220.7880859375
epoch is 9000 loss is 1113.998779296875
Test loss: 847746.5625
看起来训练集的损失值很小了,但是测试集损失值这么大,应该是过拟合了。为啥损失值这么大还会过拟合/(ㄒoㄒ)/~~
正则化系数调整
考虑增加正则化系数,使用Dropout,
正则化应该很有必要,试试看哈、系数0.1→0.3
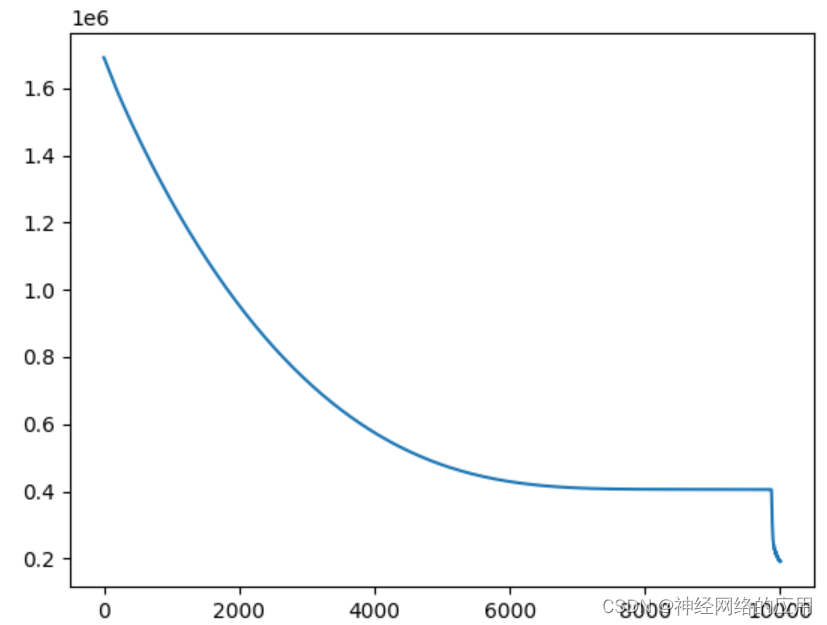
epoch is 0 loss is 1691138.75
epoch is 1000 loss is 1263657.625
epoch is 2000 loss is 953652.375
epoch is 3000 loss is 728953.6875
epoch is 4000 loss is 574693.625
epoch is 5000 loss is 478837.53125
epoch is 6000 loss is 428884.21875
epoch is 7000 loss is 409937.78125
epoch is 8000 loss is 405928.15625
epoch is 9000 loss is 405627.78125
Test loss: 603928.75
系数→0.5试试看
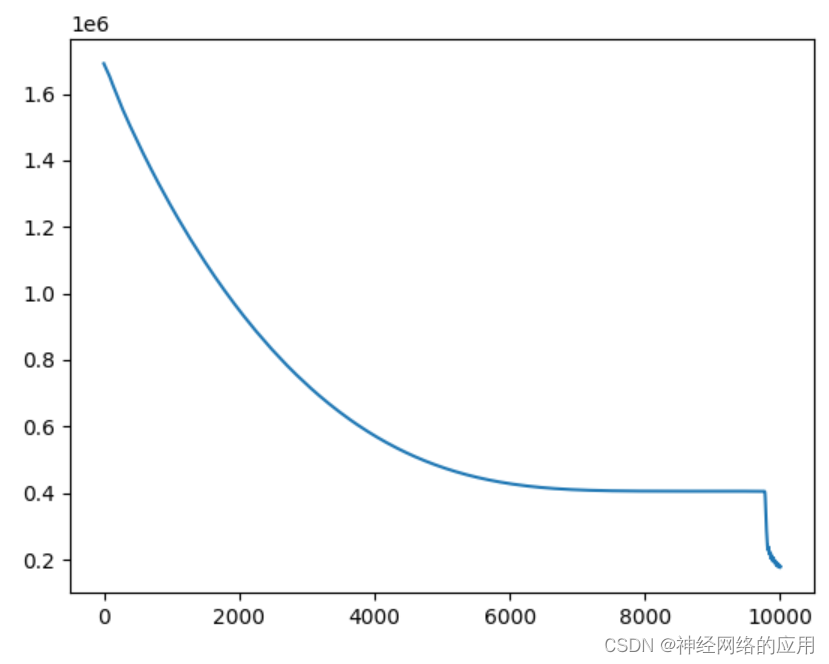
epoch is 0 loss is 1690641.875
epoch is 1000 loss is 1259986.5
epoch is 2000 loss is 950166.9375
epoch is 3000 loss is 726251.125
epoch is 4000 loss is 572842.4375
epoch is 5000 loss is 477752.59375
epoch is 6000 loss is 428392.0
epoch is 7000 loss is 409798.75
epoch is 8000 loss is 405912.375
epoch is 9000 loss is 405627.96875
Test loss: 616781.9375
和0.3似乎没什么变化,那么把epoch变大一点看看:
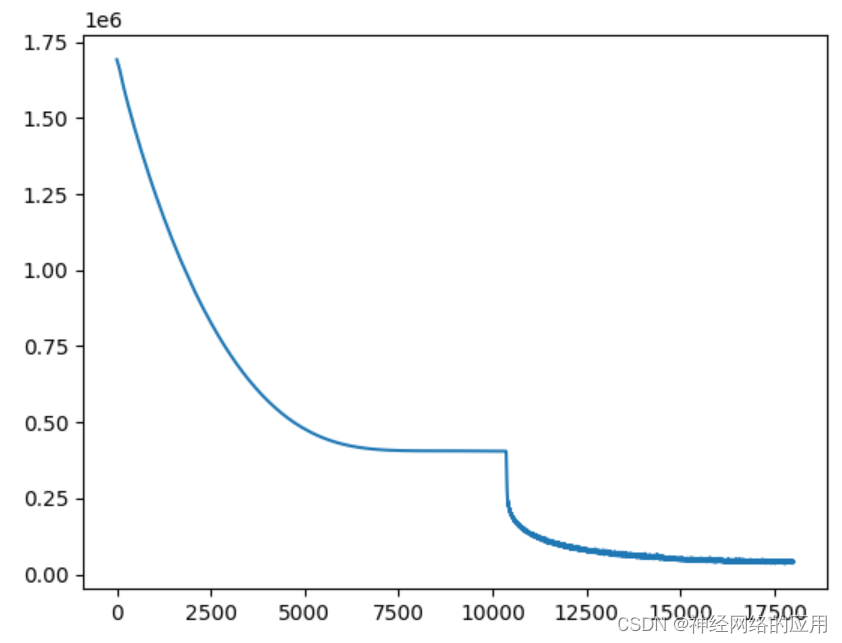
epoch is 0 loss is 1691865.875
epoch is 1000 loss is 1259460.75
epoch is 2000 loss is 949569.0625
epoch is 3000 loss is 725770.8125
epoch is 4000 loss is 572510.1875
epoch is 5000 loss is 477556.375
epoch is 6000 loss is 428302.96875
epoch is 7000 loss is 409773.96875
epoch is 8000 loss is 405909.4375
epoch is 9000 loss is 405625.90625
epoch is 10000 loss is 405623.9375
epoch is 11000 loss is 132178.5
epoch is 12000 loss is 88326.0703125
epoch is 13000 loss is 72454.6640625
epoch is 14000 loss is 58360.8125
epoch is 15000 loss is 50380.35546875
epoch is 16000 loss is 44466.1875
epoch is 17000 loss is 43652.4765625
Test loss: 758716.4375
不如不增加epoch,损失值更大了。
学习率调整
尝试调整学习率,直接加入自适应调整学习率,也还是不行
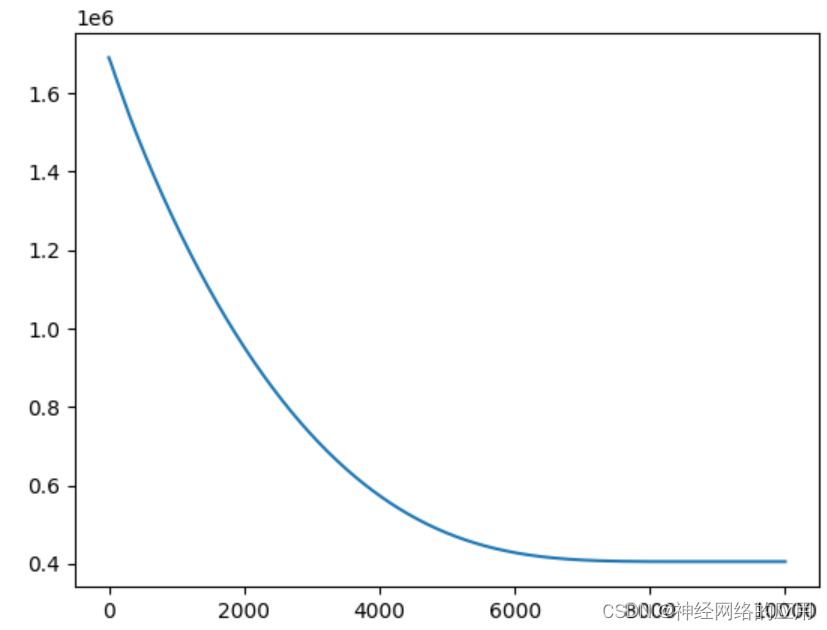
Epoch 8370: reducing learning rate of group 0 to 5.1200e-09.
epoch is 9000 loss is 405878.09375
Epoch 9001, Current Learning Rate: 5.120000000000003e-09
Test loss: 851336.625
还是不行。。。。。。。。。。所以到底应该怎么调整啊?????
总结ing
| 调整方法 | 训练损失值 |
|---|---|
| 调整神经网络结构 | 405627 |
| 调整激活函数relu | 995 |
| 调整激活函数tanh | 79978 |
| 调整迭代次数 | 741 |
| 增加早停法 | 405623 |
| 变量归一化处理 | 1113 |
| 正则化系数调整 | 405627 |
| 学习率调整 | 405878 |
从上表可以看出,合适的激活函数、增加迭代次数、对变量进行归一化处理会降低训练集的损失值。
增加迭代次数,训练集损失值降低效果最明显,但是也同时增加了过拟合风险
可以看到relu激活函数的效果比较好,训练集损失值较小
对变量进行归一化处理,
| 调整方法 | 测试损失值 |
|---|---|
| 调整神经网络结构 | 869377 |
| 调整激活函数relu | 637214 |
| 调整激活函数tanh | 704667 |
| 调整迭代次数 | 644070 |
| 增加早停法 | 869326 |
| 变量归一化处理 | 847746 |
| 正则化系数调整 | 603928 |
| 学习率调整 | 851336 |
提高正则化的系数,可以尽量避免过拟合,所以在测试集里的损失值是最低的,泛化效果较好一些。如果测试集损失值比训练集损失值差太多,一定要加入正则化。
调整合适的激活函数也能降低测试集的损失值。
增加迭代次数也能降低测试集的损失值。但是增加迭代次数会提高计算成本,我这里是10000次增加到100000次,运算时间增加了很长时间。
fnn.py进行计算:
输出结果是
epoch is 99970 loss is 1.0438059568405151
Epoch 99971, Current Learning Rate: 0.01
epoch is 99980 loss is 2.225820541381836
Epoch 99981, Current Learning Rate: 0.01
epoch is 99990 loss is 0.6199669241905212
Epoch 99991, Current Learning Rate: 0.01
Test loss: 828622.4375
训练集几乎没有损失,但是测试集是什么鬼????损失值这么大!!!
破案了。。
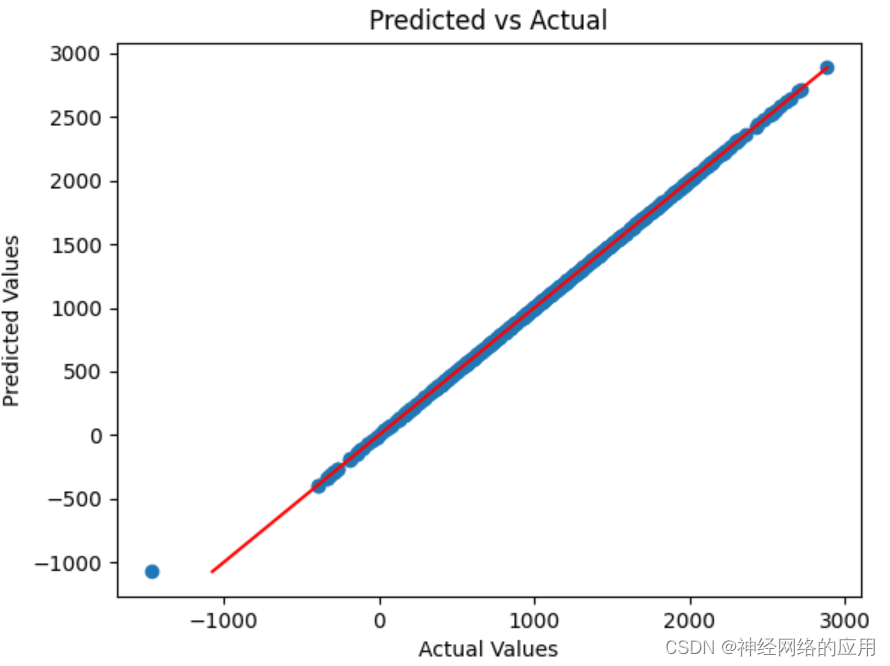
绘制 validate_outputs(预测值)和 validate_labels_tensor(真实值)
测试集损失值这么大,原来是有异常值!!!!
不是模型没有很好地学习到数据的特征,或者在验证集上过拟合了。。而是有异常值。
MSE 损失函数的一个优点是它能够惩罚较大的预测误差,因为误差的平方会随着误差的增加而显著增加。然而,它也有缺点,比如对于异常值比较敏感,因为较大的误差会对总体 MSE 有更大的影响。
我用的就是均方误差(MSE)损失函数,,,难怪算的损失值一直这么大。。
import matplotlib.pyplot as plt# 假设 validate_outputs 和 validate_labels_tensor 都是一维张量
# 并且它们的形状相同,即每个预测值对应一个真实值# 绘制散点图,其中 x 轴是真实值,y 轴是预测值
plt.scatter(validate_labels_tensor.cpu().numpy(), validate_outputs.cpu().numpy())# 添加标题和轴标签
plt.title('Predicted vs Actual')
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')# 绘制 y=x 线,表示完美的预测
plt.plot([validate_labels_tensor.min().cpu().numpy(), validate_labels_tensor.max().cpu().numpy()], [validate_labels_tensor.min().cpu().numpy(), validate_labels_tensor.max().cpu().numpy()], color='red')# 显示图表
plt.show()

相关文章:
神经网络解决回归问题(更新ing)
神经网络应用于回归问题 优势是什么???生成数据集:通用神经网络拟合函数调整不同参数对比结果初始代码结果调整神经网络结构调整激活函数调整迭代次数增加早停法变量归一化处理正则化系数调整学习率调整 总结ingfnn.py进行计算&am…...

【小红书校招场景题】12306抢票系统
1 坐过高铁吧,有抢过票吗。你说说抢票系统对于后端开发人员而言会有哪些情况? 对于后端开发人员来说,开发和维护一个高铁抢票系统(如中国的12306)会面临一系列的挑战和情况。这些挑战主要涉及系统的性能、稳定性、数据…...
)
Spring(三)
1. Spring单例Bean是不是线程安全的? Spring单例Bean默认并不是线程安全的。由于多个线程可能访问同一份Bean实例,当Bean的内部包含了可变状态(mutable state)即有可修改的成员变量时,就可能出现线程安全问题。Spring容器不会自动…...

使用element-plus中的表单验证
标签页代码如下: // 注意:el-form中的数据绑定不可以用v-model,要使用:model <el-form ref"ruleFormRef" :rules"rules" :model"userTemp" label-width"80px"><el-row :gutter"20&qu…...

flinksql
Flink SQL 是 Apache Flink 项目中的一个重要组成部分,它允许开发者使用标准的 SQL 语言来处理流数据和批处理数据。Flink SQL 提供了一种声明式的编程范式,使得用户能够以一种简洁、高效且易于理解的方式来表达复杂的数据处理逻辑。 ### 背景 Flink SQL 的设计初衷是为了简…...

Dockerfile中 CMD和ENTRYPOINT的区别
在 Dockerfile 中,CMD 和 ENTRYPOINT 都用于指定容器启动时要执行的命令。它们之间的主要区别是: - CMD 用于定义容器启动时要执行的命令和参数,它设置的值可以被 Dockerfile 中的后续指令覆盖,包括在运行容器时传递的参数。如果…...

【TC3xx芯片】TC3xx芯片的总线内存保护
前言 广义上的内存保护,包括<<【TC3xx芯片】TC3xx芯片MPU介绍>>一文介绍的MPU(常规狭义上的内存保护),<<【TC3xx芯片】TC3xx芯片的Endinit功能详解>>一文中介绍的寄存器的EndInit保护,<<【TC3xx芯片】TC3xx芯片ACCEN寄存器保护详解>>一…...
抖音小店选品必经五个阶段,看你到哪一步了,直接决定店铺爆单率
大家好,我是电商笨笨熊 新手选品必经的阶段就是迷茫期,不知道怎么选品,在哪里选品,选择什么样的品; 而有些玩家也会在进入店铺后疯狂选品,但是上架的商品没有销量; 而这些都是每个玩家都要经…...
ML在骨科手术术前、书中、术后方法应用综述【含数据集】
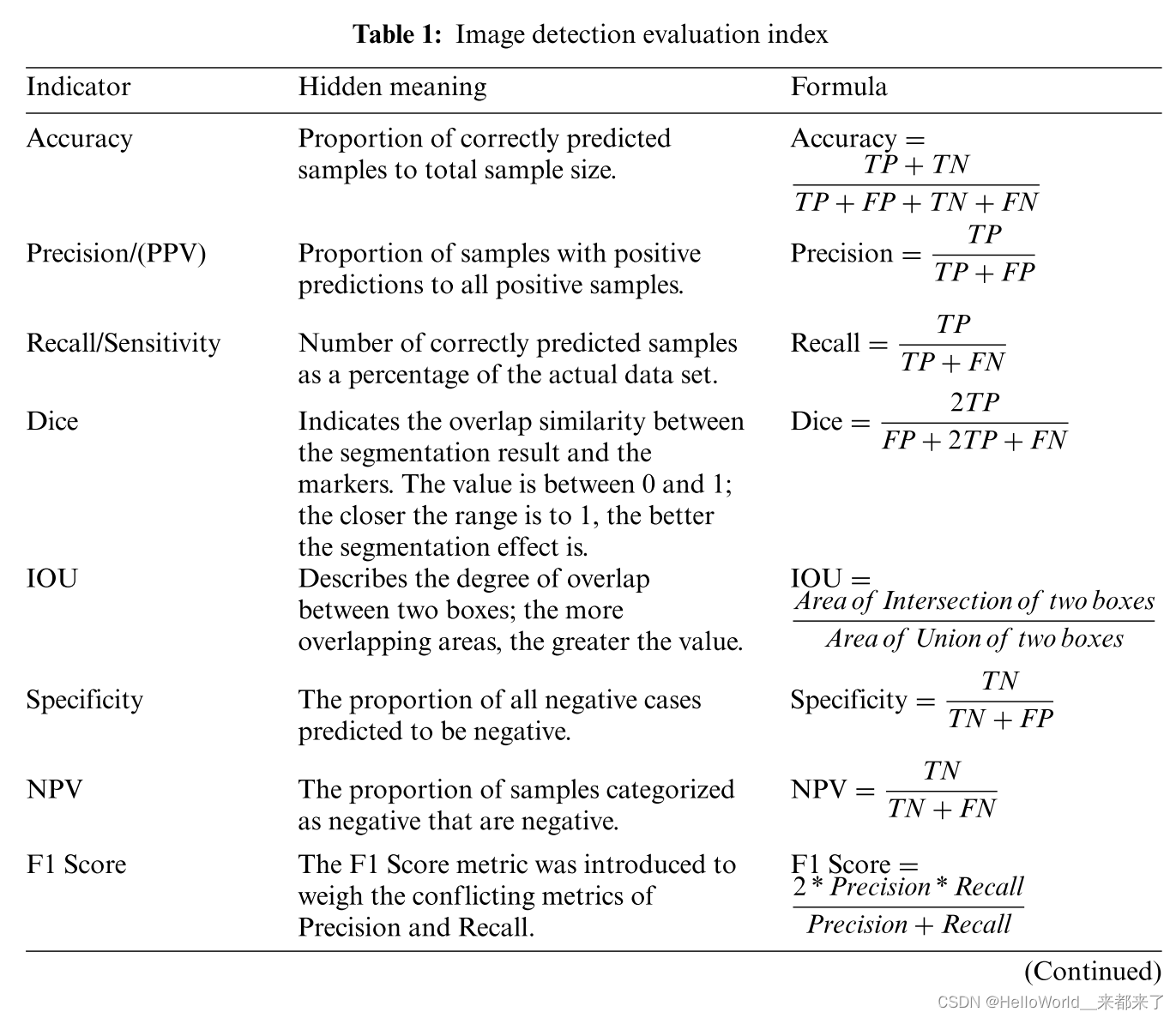
达芬奇V手术机器人 近年来,人工智能(AI)彻底改变了人们的生活。人工智能早就在外科领域取得了突破性进展。然而,人工智能在骨科中的应用研究尚处于探索阶段。 本文综述了近年来深度学习和机器学习应用于骨科图像检测的最新成果,描述了其贡献、优势和不足。以及未来每项研究…...

vue3-video-play 在安卓上正常播放,在ios上不能播放,问题解决
1.ios上autoplay需要静音,在播放后再打开声音 <vue3videoPlay v-if"!isComponent" v-bind"options" :playsinline"playsinline"></vue3videoPlay>let playsinline computed(() > {if (props.isComponent) {return}o…...
【C++类和对象】上篇
💞💞 前言 hello hello~ ,这里是大耳朵土土垚~💖💖 ,欢迎大家点赞🥳🥳关注💥💥收藏🌹🌹🌹 💥个人主页&#x…...

微信订阅号环境搭建及开发者工具下载
目录 一、注册订阅号 1.1 选择注册 2.2 选择订阅号注册 1.3 登录进入主页面 编辑 1.4 可以进行自定义菜单 1.5 我们重点关注公众平台测试账号 编辑 1.6 自定义一个域名 1.7 用自己的微信扫描这个二维码 编辑 1.8 点击修改,并自定义个域名 二、开发…...

Failed to resolve ‘bss.myhuaweicloud.com‘ ([Errno -2] Name or service not know
Failed to resolve ‘bss.myhuaweicloud.com’ ([Errno -2] Name or service not know 解決方案: 修改/etc/resolv.conf文件来指定DNS服务器,例如添加Google的公共DNS服务器: nameserver 8.8.8.8 nameserver 8.8.4.4...
)
大厂基础面试题(之二)
Q1:flex布局 Flex布局容器属性包括: flex-direction: 定义主轴的方向,决定flex容器中的子元素的排列方式 flex-wrap:设置子元素是否换行 flex-flow:是flex-direction和flex-wrap的简写形式,用于设置容器的排…...
swiftui macOS实现加载本地html文件
import SwiftUI import WebKitstruct ContentView: View {var body: some View {VStack {Text("测试")HTMLView(htmlFileName: "localfile") // 假设你的本地 HTML 文件名为 index.html.frame(minWidth: 100, minHeight: 100) // 设置 HTMLView 的最小尺寸…...

科技云报道:大模型加持后,数字人“更像人”了吗?
科技云报道原创。 北京冬奥运AI 虚拟人手语主播、杭州亚运会数字人点火、新华社数字记者、数字航天员小诤…当随着越来越多数字人出现在人们生活中,整个数字人行业也朝着多元化且广泛的应用方向发展,快速拓展到不同行业、不同场景。 面向C端࿰…...

轻松驾驭时间流:MYSQL日期与时间函数的实用技巧
🌈 个人主页:danci_🔥 系列专栏:《MYSQL应用》💪🏻 制定明确可量化的目标,坚持默默的做事。 轻松驾驭时间流:MYSQL日期与时间函数的实用技巧 MYSQL日期时间函数是数据库操作中不可…...
如何在极狐GitLab 使用Docker 仓库功能
本文作者:徐晓伟 GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 本文主要讲述了如何在[极狐GitLab…...
streamlit 大模型前段界面
结合 langchain 一起使用的工具,可以显示 web 界面 pip install streamlit duckduckgo-search 运行命令 streamlit run D:\Python_project\NLP\大模型学习\test.py import os from dotenv import load_dotenv from langchain_community.llms import Tongyi load…...
K8s 命令行工具
文章目录 K8s 命令行工具kubectl 工具在任意节点使用kubectl方式创建对象命令显示和查找资源更新资源修补资源编辑资源Scale 资源删除资源查看pod信息节点相关操作 K8s 命令行工具 在搭建集群的时候,我们通过yum 下载了kubeadm kubelet kubectl 三个命令行工具&…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

Webpack性能优化:构建速度与体积优化策略
一、构建速度优化 1、升级Webpack和Node.js 优化效果:Webpack 4比Webpack 3构建时间降低60%-98%。原因: V8引擎优化(for of替代forEach、Map/Set替代Object)。默认使用更快的md4哈希算法。AST直接从Loa…...
【Post-process】【VBA】ETABS VBA FrameObj.GetNameList and write to EXCEL
ETABS API实战:导出框架元素数据到Excel 在结构工程师的日常工作中,经常需要从ETABS模型中提取框架元素信息进行后续分析。手动复制粘贴不仅耗时,还容易出错。今天我们来用简单的VBA代码实现自动化导出。 🎯 我们要实现什么? 一键点击,就能将ETABS中所有框架元素的基…...