SQLite的PRAGMA 声明
PRAGMA 语句是特定于 SQLite 的 SQL 扩展,用于 修改 SQLite 库的操作或查询 SQLite 库 内部(非表)数据。PRAGMA声明使用相同的 接口作为其他 SQLite 命令(例如 SELECT、INSERT)但 在以下重要方面有所不同:
- pragma 命令特定于 SQLite,并且是 与任何其他 SQL 数据库引擎不兼容。
- 将来可能会删除特定的 pragma 语句并添加其他语句 SQLite的版本。不能保证向后兼容性。
- 如果发出未知的编译指示,则不会生成任何错误消息。 未知的编译指示被简单地忽略。这意味着如果 Pragma 语句 库不会通知用户这一事实。
- 某些编译指示在 SQL 编译阶段生效,而不是 执行阶段。这意味着如果使用 C 语言 sqlite3_prepare()、sqlite3_step()、sqlite3_finalize() API(或包装器中的类似 API) 接口),编译指示可以在 sqlite3_prepare() 调用期间运行, 而不是像普通 SQL 语句那样在 sqlite3_step() 调用期间。 或者,编译指示可能会像往常一样在 sqlite3_step() 期间运行 SQL 语句。编译指示是否在 sqlite3_prepare() 期间运行 或 sqlite3_step() 取决于编译指示和特定版本 的 SQLite。
- SQL 语句的 EXPLAIN 和 EXPLAIN QUERY PLAN 前缀 仅影响语句在 sqlite3_step() 期间的行为。 这意味着在 sqlite3_prepare() 期间生效的 PRAGMA 语句的行为方式相同,无论 不是它们以“解释”开头。
用于 SQLite 的 C 语言 API 提供了 SQLITE_FCNTL_PRAGMA 文件控件,该控件为 VFS 实现提供了 有机会添加新的 PRAGMA 语句或覆盖 内置 PRAGMA 语句。
PRAGMA 命令语法
pragma-stmt: 隐藏
pragma-value: 隐藏
签名号码: 显示
编译指示可以采用零个参数,也可以采用一个参数。参数可能是 在括号中,也可以用等号将其与 pragma 名称分开。 这两种语法产生相同的结果。 在许多编译指示中,参数是布尔值。布尔值可以是以下项之一:
1 是 真 开
0 否 假 关
关键字参数可以选择出现在引号中。 (例如:“yes” [FALSE]。一些编译指示 将字符串文本作为其参数。当 pragma 采用关键字时 参数,它通常也需要一个数字等价物。 例如,“0”和“否”的意思相同,“1”和“是”也是如此。 查询设置的值时,许多编译指示返回数字 而不是关键字。
杂注在杂注名称之前可能有一个可选的架构名称。 schema-name 是 ATTACH-ed 数据库的名称 或 main 和 TEMP 数据库的 “main” 或 “temp”。如果可选 省略架构名称,假定为“main”。在某些编译指示中,架构 名称毫无意义,只是被忽略。在下面的文档中, 架构名称有意义的编译指示显示 “模式。”前缀。
PRAGMA函数
返回结果且无副作用的 PRAGMA 可以是 作为表值函数从普通 SELECT 语句访问。 对于每个参与的 PRAGMA,相应的表值函数 与PRAGMA同名,前缀为7个字符的“pragma_”。 PRAGMA 参数和架构(如果有)将作为参数传递给 table-value 函数,架构作为可选的最后一个参数。
例如,有关索引中列的信息可以是 使用index_info编译指示读取,如下所示:
PRAGMA index_info('idx52');
或者,可以使用以下方法读取相同的内容:
SELECT * FROM pragma_index_info('idx52');
表值函数格式的优点是查询 可以只返回 PRAGMA 列的子集,可以包含 WHERE 子句, 可以使用聚合函数,表值函数可以只是 联接中的多个数据源之一。 例如,若要获取架构中所有索引列的列表,一个 可以查询:
SELECT DISTINCT m.name || '.' || ii.name AS 'indexed-columns'FROM sqlite_schema AS m,pragma_index_list(m.name) AS il,pragma_index_info(il.name) AS iiWHERE m.type='table'ORDER BY 1;
附注事项:
-
表值函数仅适用于内置 PRAGMA,而不适用于 PRAGMA 使用 SQLITE_FCNTL_PRAGMA 文件控件定义。
-
表值函数仅适用于返回结果和 没有副作用。
-
此功能可用于实现信息架构,方法是首先使用
然后在该架构中创建实现官方信息架构的 VIEW 使用表值 PRAGMA 函数的表。ATTACH ':memory:' AS 'information_schema';
-
添加了 PRAGMA 功能的表值函数 在 SQLite 版本 3.16.0 (2017-01-02) 中。SQLite 的早期版本 无法使用此功能。
PRAGMA列表
- analysis_limit
- application_id
- auto_vacuum
- automatic_index
- busy_timeout
- cache_size
- cache_spill
case_sensitive_like¹- cell_size_check
- checkpoint_fullfsync
- collation_list
- compile_options
count_changes¹data_store_directory¹- data_version
- database_list
default_cache_size¹- defer_foreign_keys
empty_result_callbacks¹- 编码
- foreign_key_check
- foreign_key_list
- foreign_keys
- freelist_count
full_column_names¹- fullfsync
- function_list
- hard_heap_limit
- ignore_check_constraints
- incremental_vacuum
- index_info
- index_list
- index_xinfo
- integrity_check
- journal_mode
- journal_size_limit
- legacy_alter_table
- legacy_file_format
- locking_mode
- max_page_count
- mmap_size
- module_list
- 优化
- page_count
- page_size
- parser_trace²
- pragma_list
- query_only
- quick_check
- read_uncommitted
- recursive_triggers
- reverse_unordered_selects
- schema_version³
- secure_delete
- short_column_names¹
- shrink_memory
- soft_heap_limit
- 统计³
- 同步
- table_info
- table_list
- table_xinfo
- temp_store
- temp_store_directory¹
- 线程
- trusted_schema
- user_version
- vdbe_addoptrace²
- vdbe_debug²
- vdbe_listing²
- vdbe_trace²
- wal_autocheckpoint
- wal_checkpoint
- writable_schema³
笔记:
- 名称
被划掉的 Pragma 将被弃用。不要使用它们。它们存在 为了历史兼容性。 - 这些编译指示仅在使用非标准的构建中可用 编译时选项。
- 这些编译指示用于测试 SQLite,不推荐使用 用于应用程序。
普拉格玛analysis_limit;
PRAGMA analysis_limit = N;
查询或更改近似 ANALYZE 设置的限制。 这是 通过 ANALYZE 命令在每个索引中检查的行。 如果省略参数 N,则分析极限 保持不变。 如果限制为零,则禁用分析限制,并禁用 ANALYZE 命令将检查每个索引的所有行。 如果 N 大于零,则分析限设置为 N 后续的 ANALYZE 命令将停止分析 每个索引在检查了大约 N 行之后。 如果 N 是负数或整数值以外的值, 然后编译指示的行为就像省略了 N 参数一样。 在所有情况下,返回的值都是使用的新分析限值 用于后续的 ANALYZE 命令。
此编译指示可用于帮助 ANALYZE 命令更快地运行 在大型数据库上。分析结果不那么好 当只检查每个索引的一部分,但结果是 通常足够好。将 N 设置为 100 或 1000 允许 ANALYZE 命令运行速度非常快,即使在数 GB 上也是如此 数据库文件。这种编译指示在组合时特别有用 使用 PRAGMA 优化。
本编译指示已在 SQLite 版本 3.32.0 (2020-05-22) 中添加。 当前实现仅使用 N 值 - 高阶位被静默忽略。未来版本 的 SQLite 可能会开始使用高阶位。
PRAGMA 架构。application_id;
PRAGMA 架构。application_id = 整数 ;
application_id PRAGMA 用于查询或设置 32 位 位于偏移量处的有符号 big-endian “应用程序 ID” 整数 68 进入数据库头。使用 SQLite 作为其应用程序文件格式的应用程序应将应用程序 ID 整数设置为 一个唯一的整数,以便 file(1) 等实用程序可以确定特定的 文件类型,而不仅仅是报告“SQLite3 数据库”。列表 通过查阅 SQLite 源存储库中的 magic.txt 文件,可以查看分配的应用程序 ID。
另请参阅user_version编译指示。
PRAGMA 架构。auto_vacuum;
PRAGMA 架构。auto_vacuum = 0 |无 |1 |完整 |2 |增量;
查询或设置数据库中的自动抽真空状态。
自动吸尘的默认设置为 0 或“无”, 除非使用 SQLITE_DEFAULT_AUTOVACUUM 编译时选项。 “无”设置表示自动吸尘被禁用。 当禁用自动清空功能并从数据库中删除数据时, 数据库文件的大小保持不变。未使用的数据库文件 页面被添加到“自由列表”中,并重新用于后续插入。所以 不会丢失任何数据库文件空间。但是,数据库文件不会 收缩。在此模式下,可以使用 VACUUM 命令重建整个数据库文件,并 从而回收未使用的磁盘空间。
当自动清空模式为 1 或“已满”时,自由列表页面为 移动到数据库文件的末尾,数据库文件被截断 在每次交易提交时删除自由列表页面。 但请注意,自动清空只会截断自由列表页面 从文件。自动清空不会对数据库进行碎片整理,也不会对数据库进行碎片整理。 以 VACUUM 命令的方式重新打包单个数据库页。事实上,因为 它在文件中移动页面,自动真空实际上可以 使碎片化变得更糟。
只有当数据库存储了一些 允许每个数据库页的附加信息 向后追溯到其引用。因此,自动吸尘必须 在创建任何表之前打开。这是不可能的 在创建表后启用或禁用自动清空。
当自动真空的值为 2 或“增量”时,则额外的 执行自动清空所需的信息存储在数据库文件中 但是自动清空不会在每次提交时自动发生,因为它 与 auto_vacuum=full 一起执行。在增量模式下,单独的incremental_vacuum编译指示必须 被调用以导致自动真空发生。
数据库连接可以在完全连接和增量连接之间切换 自动真空模式。但是,从 “none”到“full”或“incremental”只有在数据库出现时才会出现 是新的(无表 尚未创建)或运行 VACUUM 命令。自 更改自动吸尘模式,首先使用auto_vacuum编译指示进行设置 新的所需模式,然后调用 VACUUM 命令 重新组织整个数据库文件。从“完整”更改为 “增量”回到“无”总是需要运行 VACUUM,甚至 在空数据库上。
当调用不带参数的auto_vacuum编译指示时,它 返回当前auto_vacuum模式。
普拉格玛automatic_index;
PRAGMA automatic_index = 布尔值;
查询、设置或清除自动索引功能。
从版本 3.7.17 (2013-05-20) 开始,默认情况下启用自动索引, 但这在SQLite的未来版本中可能会发生变化。
普拉格玛busy_timeout;
PRAGMA busy_timeout = 毫秒;
查询或更改繁忙超时的设置。 此编译指示是 sqlite3_busy_timeout() C 语言的替代方案 接口,可作为编译指示与语言一起使用 不提供对 sqlite3_busy_timeout() 的直接访问的绑定。
每个数据库连接只能有一个繁忙的处理程序。此 PRAGMA 设置繁忙的处理程序 对于该进程,可能会覆盖任何以前设置的忙碌处理程序。
PRAGMA 架构。cache_size;
PRAGMA 架构。cache_size = 页;
PRAGMA 架构。cache_size = -千字节;
查询或更改建议的最大数据库磁盘页数 SQLite将立即保存在每个打开的数据库文件的内存中。是否 是否尊重此建议由应用程序定义的页面缓存自行决定。 SQLite内置的默认页面缓存支持请求, 但是,替代应用程序定义的页面缓存实现 可以选择以不同的方式解释建议的缓存大小 或者一起忽略它。 默认建议的缓存大小为 -2000,即缓存大小 限制为 2048000 字节的内存。 可以使用 SQLITE_DEFAULT_CACHE_SIZE 编译时选项更改默认建议的缓存大小。 TEMP 数据库的默认建议缓存大小为 0 页。
如果参数 N 为正数,则设置建议的缓存大小 到 N。如果参数 N 为负数,则 缓存页数调整为将 使用大约 abs(N*1024) 字节的内存,基于当前 页面大小。SQLite会记住页面缓存中的页数, 而不是使用的内存量。因此,如果您使用 一个负数,然后更改页面大小(使用 PRAGMA page_size 命令),然后更改最大缓存量 内存将随着页面大小的变化而上升或下降。
向后兼容性说明:负 N 的cache_size的行为 在版本 3.7.10 (2012-01-16) 之前有所不同。在 在早期版本中,设置了缓存中的页数 到 N 的绝对值。
当您使用cache_size编译指示更改缓存大小时, 更改仅在当前会话中持续存在。缓存大小恢复 设置为关闭并重新打开数据库时的默认值。
默认页面缓存实现不分配 一次性获得全部缓存内存。缓存内存 根据需要以较小的块进行分配。page_cache 设置是内存量的(建议)上限 缓存可以使用,而不是它将一直使用的内存量。 这是默认页面缓存实现的行为,但应用程序定义的页面缓存是免费的 如果它愿意,可以采取不同的行为。
普拉格玛cache_spill;
PRAGMA cache_spill=布尔值;
PRAGMA 架构。cache_spill=N;
cache_spill编译指示启用或禁用寻呼机的功能 将脏缓存页溢出到数据库文件的中间 交易。默认情况下,Cache_spill处于启用状态,大多数应用程序都处于启用状态 应该保持这种状态,因为缓存溢出通常是有利的。 但是,缓存溢出具有获取数据库文件的 EXCLUSIVE 锁的副作用。因此,一些应用程序 具有大型长时间运行的事务可能希望禁用缓存溢出 为了防止应用程序获得独占锁 直到事务 COMMITs.
此编译指示的“PRAGMA cache_spill=N”形式设置了最小值 发生溢出所需的缓存大小阈值。页数 缓存中必须同时超过cache_spill阈值和最大缓存 尺寸由 PRAGMA cache_size 声明设置,以便溢出至 发生。
此编译指示的“PRAGMA cache_spill=boolean”形式适用 跨连接到数据库连接的所有数据库。但是 本声明的“PRAGMA cache_spill=N”形式仅适用于 “main”架构或任何其他架构被指定为 陈述。
PRAGMA case_sensitive_like = 布尔值;
LIKE 运算符的默认行为是忽略大小写 用于 ASCII 字符。因此,默认情况下,“a”与“A”一样是 真。case_sensitive_like编译指示安装新的应用程序定义 区分大小写或不区分大小写的 LIKE 函数 关于case_sensitive_like编译指示的价值。 禁用case_sensitive_like时,默认的 LIKE 行为为 表示。启用case_sensitive_like后,大小写变为 重要。因此,例如,“a”和“A”一样是假的,但“a”像“a”一样仍然是真的。
此编译指示使用 sqlite3_create_function() 重载 LIKE 和 GLOB 函数,它们可能会覆盖以前的实现 应用程序注册的 LIKE 和 GLOB。这个杂烩 仅更改 SQL LIKE 运算符的行为。它没有 更改 sqlite3_strlike() C 语言接口的行为, 这始终不区分大小写。
警告:如果数据库在 架构,例如在 CHECK 约束、表达式索引或部分索引的 WHERE 子句中,则 使用此 PRAGMA 可以更改 LIKE 运算符的定义 导致数据库显示为已损坏。PRAGMA integrity_check 将报告错误。数据库并没有真正损坏 将 LIKE 的行为改回原样 这是定义架构并填充数据库的时候 将清除问题。如果 LIKE 的使用只发生在索引中, 然后可以通过运行 REINDEX 来清除问题。不过 不鼓励使用case_sensitive_like编译指示。
此编译指示已弃用并存在 仅用于向后兼容。新应用 应避免使用此编译指示。较旧的应用程序应停止使用 尽早使用此编译指示。可以省略此编译指示 当使用SQLITE_OMIT_DEPRECATED编译SQLite时,从构建中。
PRAGMA cell_size_check
PRAGMA cell_size_check = 布尔值;
cell_size_check编译指示启用或禁用额外的健全性 在最初从磁盘读取数据库 B 树页时检查它们。 启用单元大小检查后,可以更早地检测到数据库损坏 并且不太可能“传播”。但是,有一个小性能 点击进行额外的检查,因此单元格大小检查被关闭 默认情况下。
PRAGMA checkpoint_fullfsync
PRAGMA checkpoint_fullfsync = 布尔值;
查询或更改检查点操作的 fullfsync 标志。 如果设置了此标志,则使用F_FULLFSYNC同步方法 在支持F_FULLFSYNC的系统上的检查点操作期间。 checkpoint_fullfsync标志的默认值 已关闭。只有 Mac OS-X 支持F_FULLFSYNC。
如果设置了 fullfsync 标志,则F_FULLFSYNC同步 方法用于所有同步操作,并且 checkpoint_fullfsync 设置无关紧要。
普拉格玛collation_list;
返回为当前定义的排序规则序列的列表 数据库连接。
普拉格玛compile_options;
此编译指示返回以下情况下使用的编译时选项的名称 构建 SQLite,每行一个选项。省略“SQLITE_”前缀 从返回的选项名称中。另请参阅 sqlite3_compileoption_get() C/C++ 接口和 sqlite_compileoption_get() SQL 函数。
普拉格玛count_changes;
PRAGMA count_changes = 布尔值;
查询或更改 count-changes 标志。通常,当 未设置 count-changes 标志、INSERT、UPDATE 和 DELETE 语句 不返回任何数据。设置 count-changes 时,每个命令 返回由一个整数值组成的单行数据 - 命令插入、修改或删除的行数。这 返回的更改计数不包括任何插入、修改 或触发器执行的删除,自动进行的任何更改 通过外键操作或更新器引起的更新。
获取行更改计数的另一种方法是使用 sqlite3_changes() 或 sqlite3_total_changes() 接口。 不过,有一个微妙的不同。当 INSERT、UPDATE 或 DELETE 使用 INSTEAD OF 触发器对视图运行, count_changes编译指示报告视图中的行数 触发触发器,而 sqlite3_changes() 和 sqlite3_total_changes() 则没有。
此编译指示已弃用并存在 仅用于向后兼容。新应用 应避免使用此编译指示。较旧的应用程序应停止使用 尽早使用此编译指示。可以省略此编译指示 当使用SQLITE_OMIT_DEPRECATED编译SQLite时,从构建中。
普拉格玛data_store_directory;
PRAGMA data_store_directory = '目录名称';
查询或更改全局sqlite3_data_directory值 变量,Windows 操作系统接口后端使用它来 确定使用相对数据库指定的数据库文件的存储位置 路径。
更改data_store_directory设置是不安全的。 如果另一个线程,切勿更改data_store_directory设置 在应用程序中同时运行任何SQLite接口。 这样做会导致未定义的行为。更改data_store_directory 设置写入sqlite3_data_directory全局 变量,并且该全局变量不受互斥锁保护。
此功能是为没有操作系统的 WinRT 提供的 读取或更改当前工作目录的机制。 不鼓励在任何其他上下文中使用此编译指示,并且可能 在将来的版本中不允许使用。
此编译指示已弃用并存在 仅用于向后兼容。新应用 应避免使用此编译指示。较旧的应用程序应停止使用 尽早使用此编译指示。可以省略此编译指示 当使用SQLITE_OMIT_DEPRECATED编译SQLite时,从构建中。
PRAGMA 架构。data_version;
“PRAGMA data_version”命令指示 数据库文件已修改。 在内存中保存数据库内容的交互式程序 在屏幕上显示数据库内容可以使用 PRAGMA data_version 命令来确定他们是否需要刷新和重新加载内存 或更新屏幕显示。
由 2 返回的整数值 从同一连接调用“PRAGMA data_version” 如果将更改提交到数据库,则情况会有所不同 通过过渡期间的任何其他连接。 对于所做的提交,“PRAGMA data_version”值保持不变 在同一数据库连接上。 “PRAGMA data_version”的行为对于所有数据库都是相同的 连接,包括单独进程中的数据库连接 和共享缓存数据库连接。
“PRAGMA data_version”值是每个 数据库连接,以及两个并发调用返回的 SO 值 在单独的数据库连接上的“PRAGMA data_version”是 即使基础数据库相同,也经常不同。 只有比较“PRAGMA data_version”值才有意义 由同一数据库连接在两个不同的点返回 时间。
普拉格玛database_list;
此编译指示的工作方式类似于查询,为每个数据库返回一行 附加到当前数据库连接。 第二列是主数据库文件的“main”,即“temp” 用于存储 TEMP 对象的数据库文件,或 其他数据库文件的 ATTACHed 数据库。 第三列是数据库文件本身的名称,或者为空 字符串(如果数据库未与文件关联)。
PRAGMA 架构。default_cache_size;
PRAGMA 架构。default_cache_size = 页数;
此编译指示查询或设置建议的最大页数 将按打开的数据库文件分配的磁盘缓存。 这个编译指示和cache_size的区别在于 此处设置的值在数据库连接之间保持不变。 默认缓存大小的值存储在 4 字节中 big-endian 整数位于 数据库文件。
此编译指示已弃用并存在 仅用于向后兼容。新应用 应避免使用此编译指示。较旧的应用程序应停止使用 尽早使用此编译指示。可以省略此编译指示 当使用SQLITE_OMIT_DEPRECATED编译SQLite时,从构建中。
PRAGMA defer_foreign_keys
PRAGMA defer_foreign_keys = 布尔值;
当 PRAGMA defer_foreign_keys开启时, 所有外键约束的强制执行被延迟到 最外层的事务已提交。defer_foreign_keys pragma 默认为 OFF,因此仅在以下情况下延迟外键约束 它们被创建为“可延迟的初始延迟”。这 defer_foreign_keys编译指示在每个位置自动关闭 COMMIT 或 ROLLBACK。因此,defer_foreign_keys编译指示必须是 为每笔交易单独启用。这个杂烩是 当然,只有在启用外键约束时才有意义。
sqlite3_db_status(db,SQLITE_DBSTATUS_DEFERRED_FKS,...) C语言接口可以在事务期间用于确定 如果存在延迟和未解析的外键约束。
普拉格玛empty_result_callbacks;
PRAGMA empty_result_callbacks = 布尔值;
查询或更改 empty-result-callbacks 标志。
empty-result-callbacks 标志仅影响 sqlite3_exec() API。 通常,当清除空结果回调标志时, 提供给 sqlite3_exec() 的回调函数不会被调用 对于返回零行数据的命令。当空结果回调时 在这种情况下设置,回调函数正好调用一次, 第三个参数设置为 0 (NULL)。这是为了启用程序 使用 sqlite3_exec() API 检索列名,即使 查询不返回任何数据。
此编译指示已弃用并存在 仅用于向后兼容。新应用 应避免使用此编译指示。较旧的应用程序应停止使用 尽早使用此编译指示。可以省略此编译指示 当使用SQLITE_OMIT_DEPRECATED编译SQLite时,从构建中。
PRAGMA 编码;
PRAGMA 编码 = 'UTF-8';
PRAGMA 编码 = 'UTF-16';
PRAGMA 编码 = 'UTF-16le';
PRAGMA 编码 = 'UTF-16be';
在第一种形式中,如果主数据库已经 created,则此编译指示返回 主数据库,'UTF-8', 'UTF-16le' (little-endian UTF-16 encoding) 或 'UTF-16be' (big-endian UTF-16 encoding)。如果主 数据库尚未创建,则返回的值为 将用于创建主数据库的文本编码,如果 它是由此会话创建的。
这种编译器的第二到第五种形式 设置创建主数据库时使用的编码 它是由此会话创建的。字符串“UTF-16”被解释 作为“使用本机字节排序的 UTF-16 编码”。事实并非如此 可以在数据库的文本编码之后更改数据库的文本编码 创建,任何这样做的尝试都将被默默地忽略。
如果未首先使用此编译指示设置编码, 然后是用于创建主数据库的编码 默认为由用于打开连接的 API 确定的 API。
为数据库设置编码后,无法更改该编码。
由 ATTACH 命令创建的数据库始终使用相同的编码 作为主数据库。尝试使用不同的 ATTACH 数据库 来自“main”数据库的文本编码将失败。
PRAGMA 架构。foreign_key_check;
PRAGMA 架构。foreign_key_check(表名);
foreign_key_check编译指示检查数据库或表 称为“table-name”,用于违反的外键约束。foreign_key_check pragma 为每个外键冲突返回一行输出。 每个结果行中有四列。 第一列是包含 REFERENCES 的表的名称 第。第二列是行的 rowid,该行 包含无效的 REFERENCES 子句,如果子表是 WITHOUT ROWID 表,则为 NULL。第三列是名称 引用的表。第四列是 失败的特定外键约束。第四列 在foreign_key_check的输出中,编译指示与 foreign_key_list Pragma 输出中的第一列。 指定“table-name”时,唯一的外键约束 选中的是由 REFERENCES 子句创建的 table-name 的 CREATE TABLE 语句。
PRAGMA foreign_key_list(表名);
此编译指示为 CREATE TABLE 语句中的 REFERENCES 子句创建的每个外键约束返回一行 表“table-name”。
普拉格玛foreign_keys;
PRAGMA foreign_keys = 布尔值;
查询、设置或清除外键约束的实施。
此编译指示是事务中的无操作;外键约束 只有在没有挂起的 BEGIN 或 SAVEPOINT 时,才能启用或禁用强制执行。
更改foreign_keys设置会影响 所有发言稿都已准备好 使用数据库连接,包括在 设置已更改。使用旧版 sqlite3_prepare() 接口准备的任何现有语句都可能因SQLITE_SCHEMA错误而失败 更改foreign_keys设置后。
从 SQLite 版本 3.6.19 开始,默认设置为 foreign 密钥强制执行为 OFF。但是,这种情况在未来可能会改变 发布 SQLite。外键强制执行的默认设置 可以在编译时使用 SQLITE_DEFAULT_FOREIGN_KEYS 预处理器宏指定。为了尽量减少将来的问题,应用程序应 根据应用程序的要求设置外键强制标志 并且不依赖于默认设置。
PRAGMA 架构。freelist_count;
返回数据库文件中未使用的页数。
普拉格玛full_column_names;
PRAGMA full_column_names = 布尔值;
查询或更改full_column_names标志。这面旗帜一起 用 short_column_names 标志确定 SQLite 为 SELECT 语句的结果列分配名称的方式。 结果列按顺序应用以下规则进行命名:
-
如果结果上有 AS 子句,则 该列是 AS 子句的右侧。
-
如果结果是一个通用表达式,而不仅仅是 源表列, 然后,结果的名称是表达式文本的副本。
-
如果 short_column_names 编译指示为 ON,则 result 是源表列的名称,不带 源表名称前缀:COLUMN。
-
如果编译指示 short_column_names 和 full_column_names 都关闭,则情况 (2) 适用。
-
结果列的名称是源表的组合 和源列名称:TABLE。列
此编译指示已弃用并存在 仅用于向后兼容。新应用 应避免使用此编译指示。较旧的应用程序应停止使用 尽早使用此编译指示。可以省略此编译指示 当使用SQLITE_OMIT_DEPRECATED编译SQLite时,从构建中。
PRAGMA fullfsync
PRAGMA fullfsync = 布尔值;
查询或更改 fullfsync 标志。此标志 确定是否使用F_FULLFSYNC同步方法 在支持它的系统上。fullfsync 标志的缺省值 已关闭。只有 Mac OS X 支持F_FULLFSYNC。
另见checkpoint_fullfsync。
普拉格玛function_list;
此编译指示返回 SQL 函数列表 数据库连接已知。结果的每一行 描述单个 SQL 函数的单个调用签名。 某些 SQL 函数在结果集中将具有多行 如果它们可以(例如)使用不同数量的 参数或可以接受各种编码的文本。
PRAGMA hard_heap_limit
PRAGMA hard_heap_limit=N
此编译指示调用 sqlite3_hard_heap_limit64() 接口 参数 N,如果指定了 N,并且 N 是正整数, 小于当前硬堆限制。 hard_heap_limit 编译指示始终返回相同的整数 这将由 sqlite3_hard_heap_limit64(-1) C 语言返回 功能。也就是说,它总是返回硬的值 在此 PRAGMA 施加的任何更改后设置的堆限制。
此编译指示只能降低堆限制,而不能提高堆限制。 必须使用 C 语言接口 sqlite3_hard_heap_limit64() 提高堆限制。
另请参阅soft_heap_limit编译指示。
PRAGMA ignore_check_constraints = 布尔值;
此编译指示启用或禁用 CHECK 约束的强制执行。 默认设置为 off,这意味着 CHECK 约束为 默认强制执行。
PRAGMA 架构。incremental_vacuum(N);
PRAGMA 架构。incremental_vacuum;
incremental_vacuum编译指示会导致多达 N 页 从自由列表中删除。数据库文件被截断 相同的数量。如果出现以下情况,则incremental_vacuum编译指示不起作用 数据库未处于 auto_vacuum=incremental 模式 或者如果免费列表中没有页面。如果自由列表上的页面少于 N 页,或者 N 页小于 1,或者 如果省略“(N)”参数,则整个 自由列表被清除。
PRAGMA 架构。index_info(索引名称);
此编译指示为命名索引中的每个键列返回一行。 键列是在 CREATE INDEX 索引语句或 UNIQUE 约束或 PRIMARY KEY 约束中实际命名的列,该列 创建了索引。索引条目通常还包含辅助条目 指向要编制索引的表行的列。辅助 索引列不由index_info编译指示显示,但它们是 由 index_xinfo Pragma 列出。
index_info编译指示的输出列如下所示:
- 列在索引中的排名。(0 表示最左边。
- 要编制索引的表中列的排名。 值 -1 表示 rowid,值 -2 表示正在使用表达式。
- 要编制索引的列的名称。此列为 NULL 如果列是 rowid 或表达式。
如果没有名为 index-name 的索引,但存在具有该名称的 WITHOUT ROWID 表,则 SQLite 版本 3.30.0 on 2019-10-04) 这个编译指示返回 WITHOUT ROWID 表的 PRIMARY KEY 列(当它们被使用时) 在底层 B 树的记录中,也就是说 删除了重复的列。
PRAGMA 架构。index_list(表名);
此编译指示为与 给定的表。
index_list编译指示的输出列如下所示:
- 分配给每个索引的序列号,用于内部跟踪 目的。
- 索引的名称。
- 如果索引为 UNIQUE,则为“1”,如果不是,则为“0”。
- “c”,如果索引是由 CREATE INDEX 语句创建的, “u”(如果索引是由 UNIQUE 约束创建的),或者 “pk”,如果索引是由 PRIMARY KEY 约束创建的。
- 如果索引是部分索引,则为“1”,如果不是“0”。
PRAGMA 架构。index_xinfo(索引名称);
此编译指示返回有关索引中每一列的信息。 与此 index_info 编译指示不同,此编译指示返回有关 索引中的每一列,而不仅仅是键列。 (键列是在 CREATE INDEX 索引语句或 UNIQUE 约束或 PRIMARY KEY 约束中实际命名的列,该列 创建了索引。辅助列是需要的附加列 找到与每个索引条目对应的表条目。
index_xinfo 编译指示的输出列如下所示:
- 列在索引中的排名。(0 表示最左边。 关键列位于辅助列之前。
- 要编制索引的表中列的排名,如果为 -1,则为 -1 index-column 是要编制索引的表的 rowid,-2 如果索引位于表达式上。
- 要编制索引的列的名称,如果索引列为 NULL,则为 NULL 是要编制索引的表的 rowid 或表达式。
- 如果索引列按相反 (DESC) 顺序排序,则为 1 index 和 0,否则。
- 用于比较索引列中的值的排序规则序列的名称。
- 如果索引列是键列,则为 1,如果索引列为 0,则为 0 是辅助列。
如果没有名为 index-name 的索引,但存在具有该名称的 WITHOUT ROWID 表,则 SQLite 版本 3.30.0 on 2019-10-04) 这个编译指示返回 WITHOUT ROWID 表的列(当它们被使用时) 在底层 B 树的记录中,也就是说 首先删除重复的 PRIMARY KEY 列,然后是数据列。
PRAGMA 架构。integrity_check;
PRAGMA 架构。integrity_check(N)
PRAGMA 模式。integrity_check(表名)
此编译指示执行低级格式设置和一致性检查 数据库。integrity_check编译指示查找:
- 不按顺序排列的表或索引条目
- 格式错误的记录
- 缺少页面
- 缺少或多余的索引条目
- UNIQUE、CHECK 和 NOT NULL 约束错误
- 自由列表的完整性
- 数据库中多次使用或根本不使用的部分
如果integrity_check编译指示发现问题,则返回字符串 (作为多行,每行一列)描述 问题。在分析退出之前,Pragma integrity_check 最多返回 N 个错误,默认为 N 个 到 100。如果编译指示integrity_check未发现错误,则 返回值为“ok”的单行。
通常的情况是检查整个数据库文件。然而 如果参数为 TABLENAME,则仅对 命名的表及其关联的索引。 这称为“部分完整性检查”。因为只有 检查数据库,错误,例如文件的未使用部分或重复 无法检测到两个或多个表对文件的同一部分的使用。 自由列表仅在 部分完整性检查 TABLENAME 是否sqlite_schema或其之一 别名。添加了对部分完整性检查的支持 版本 3.33.0 (2020-08-14)。
PRAGMA integrity_check未发现 FOREIGN KEY 错误。 使用 PRAGMA foreign_key_check 命令查找 FOREIGN KEY 约束。
另请参阅 PRAGMA quick_check 命令,该命令执行大部分 检查PRAGMA integrity_check但运行速度要快得多。
PRAGMA 架构。journal_mode;
PRAGMA 架构。journal_mode = 删除 |TRUNCATE (截断) |坚持 |内存 |瓦尔 |关闭
此编译指示查询或设置数据库的日志模式 与当前数据库连接关联。
此编译指示的第一种形式查询当前日记 数据库的模式。当省略数据库时, 查询“main”数据库。
第二种形式更改了“数据库”的日记模式 或者,如果省略了“database”,则用于所有附加的数据库。 将返回新的日志模式。如果日志模式 无法更改,则返回原始日志模式。
DELETE 日记模式是正常行为。在 DELETE 中 模式下,回滚日志将在每次结束时删除 交易。事实上,删除操作是导致 要提交的事务。 (有关更多详细信息,请参阅标题为“SQLite 中的原子提交”的文档。
TRUNCATE 日记模式通过截断来提交事务 将日志回滚为零长度,而不是将其删除。在许多 系统,截断文件比删除文件快得多,因为 不需要更改包含目录。
PERSIST 日志模式可防止回滚日志 在每次事务结束时被删除。取而代之的是标头 的日志被零覆盖。这将防止其他 回滚日志的数据库连接。The PERSIST 日记模式在以下平台上用作优化 删除或截断文件比覆盖要昂贵得多 文件的第一个块,带零。参见:PRAGMA journal_size_limit 和 SQLITE_DEFAULT_JOURNAL_SIZE_LIMIT。
MEMORY 日志模式将回滚日志存储在 易失性 RAM。这样可以节省磁盘 I/O,但会以牺牲数据库为代价 安全与诚信。如果使用 SQLite 的应用程序在 设置 MEMORY 日志模式时事务的中间, 那么数据库文件很可能会损坏。
WAL 日记模式使用预写日志,而不是 回滚日志来实现事务。WAL 日记模式 是持久的;设置后,它保持有效 跨多个数据库连接,并在关闭和 重新打开数据库。WAL 日记模式下的数据库 只能通过 SQLite 版本 3.7.0 访问 (2010-07-21) 或更高版本。
OFF 日志模式将完全禁用回滚日志。 从未创建过回滚日志,因此永远不会有回滚 要删除的日志。OFF 日志模式禁用原子 SQLite的提交和回滚功能。ROLLBACK 命令 不再有效;它以未定义的方式运行。申请必须 避免在日志模式关闭时使用 ROLLBACK 命令。 如果应用程序崩溃 在事务中间,当 OFF 日记模式为 设置,则数据库文件很可能会损坏。没有日记,就没有办法 以下部分完成操作的声明 约束错误。这也可能使数据库处于损坏状态 州。例如,如果重复的条目导致 CREATE UNIQUE INDEX 语句中途失败, 它将留下一个部分创建的,因此是损坏的索引。 因为关闭日记 模式允许使用普通 SQL 破坏数据库文件, 启用SQLITE_DBCONFIG_DEFENSIVE时,它将被禁用。
请注意,内存中数据库的journal_mode是 MEMORY 或 OFF,不能更改为其他值。 尝试将内存中数据库的journal_mode更改为 除 MEMORY 或 OFF 以外的任何设置都将被忽略。另请注意 当事务处于活动状态时,无法更改journal_mode。
PRAGMA 架构。journal_size_limit
PRAGMA 架构。journal_size_limit = N ;
如果数据库连接以独占锁定模式或持久日志模式 (PRAGMA journal_mode=persist) 运行,则 提交事务后,回滚日志文件可能会保留在 文件系统。这提高了后续事务的性能 由于覆盖现有文件比追加到文件更快, 但它也消耗 文件系统空间。在进行大型交易(例如真空)之后, 回滚日志文件可能会占用非常大的空间。
同样,在 WAL 模式下,预写日志文件不会被截断 遵循检查站。相反,SQLite 重用现有文件 对于后续的 WAL 条目,因为覆盖比追加更快。
journal_size_limit编译指示可用于限制 rollback-journal 和 WAL 文件剩余 在事务或检查点之后的文件系统中。 每次提交事务或重置 WAL 文件时,SQLite 比较回滚日志文件或 WAL 文件的大小 文件系统达到大小限制 由此编译指示设置,如果日志或 WAL 文件更大 它被截断到极限。
上面列出的编译指示的第二种形式用于设置新的限制 指定数据库的字节数。负数表示没有限制。 要始终将回滚日志和 WAL 文件截断到其最小大小, 将journal_size_limit设置为零。 上面列出的编译指示的第一种和第二种形式都返回一个 包含单个整数列的结果行 - 日志的值 大小限制(以字节为单位)。默认日志大小限制为 -1(无限制)。可以使用SQLITE_DEFAULT_JOURNAL_SIZE_LIMIT预处理器宏来更改 编译时的默认日志大小限制。
此编译指示仅在先前指定的单个数据库上运行 添加到编译指示名称(如果未指定数据库,则在“main”数据库上。 无法更改所有附加数据库的日志大小限制 使用单个 PRAGMA 语句。必须单独设置大小限制 每个附加的数据库。
普拉格玛legacy_alter_table;
PRAGMA legacy_alter_table = 布尔值
此编译指示设置或查询legacy_alter_table的值 旗。当此标志处于打开状态时,ALTER TABLE RENAME 命令(用于更改表的名称)将按原样工作 在 SQLite 3.24.0 (2018-06-04) 及更早版本中。更具体地说, 当此标志亮起时 ALTER TABLE RENAME 命令仅重写初始匹配项 CREATE TABLE 语句以及任何关联的 CREATE INDEX 和 CREATE TRIGGER 语句中的表名。对 表未修改,包括:
- 对触发器和视图正文中的表的引用。
- 对原始 CHECK 约束中的表的引用 CREATE TABLE 语句。
- 对部分索引的 WHERE 子句中的表的引用。
此编译指示的默认设置为 OFF,这意味着所有 对架构中任意位置的表的引用将转换为新名称。
此编译指示是作为旧程序的解决方法提供的 包含预期不完整行为的代码 在旧版本的 SQLite 中找到的 ALTER TABLE RENAME。 新应用程序应将此标志保持关闭状态。
为了与较旧的虚拟表实现兼容, 在运行 sqlite3_module.xRename 方法时,此标志暂时打开。sqlite3_module.xRename 方法完成后,将还原此标志的值。
也可以打开和关闭旧版 alter 表行为 使用 sqlite3_db_config() 接口的 SQLITE_DBCONFIG_LEGACY_ALTER_TABLE 选项。
旧版 alter 表行为是每个连接的设置。把 此功能的打开或关闭会影响数据库连接中的所有附加数据库文件。 该设置不会保留。在一个连接中更改此设置 不会影响任何其他连接。
普拉格玛legacy_file_format;
此编译指示不再起作用。它已经成为一个禁忌。 以前由 PRAGMA 提供的功能legacy_file_format 现在可以使用 sqlite3_db_config() C 语言界面的 SQLITE_DBCONFIG_LEGACY_FILE_FORMAT 选项。
PRAGMA 架构。locking_mode;
PRAGMA 架构。locking_mode = 正常 |独家
此编译指示设置或查询数据库连接锁定模式。 锁定模式为 NORMAL 或 EXCLUSIVE。
在 NORMAL 锁定模式下(默认值,除非在编译时被覆盖 使用 SQLITE_DEFAULT_LOCKING_MODE),数据库连接 在每次读取结束时解锁数据库文件 或 写入事务。当锁定模式设置为 EXCLUSIVE 时, 数据库连接从不释放文件锁。第一次 以 EXCLUSIVE 模式读取数据库,获取共享锁,并 举行。第一次写入数据库时,独占锁是 获得并持有。
在 EXCLUSIVE 模式下通过连接获取的数据库锁可能是 通过关闭数据库连接或将 使用此编译指示将锁定模式恢复为 NORMAL,然后访问 数据库文件(用于读取或写入)。只需将锁定模式设置为 NORMAL 是不够的 - 锁要等到下次才会释放 将访问数据库文件。
将锁定模式设置为 EXCLUSIVE 有三个原因。
- 应用程序希望阻止其他进程 访问数据库文件。
- 减少了对文件系统操作的系统调用次数, 可能会导致性能小幅提升。
- 可以在 EXCLUSIVE 模式下访问 WAL 数据库,而无需 使用共享内存。 (附加信息)
当 locking_mode 编译指示指定特定数据库时, 例如:
PRAGMA主。locking_mode=排他性;
然后,锁定模式仅适用于命名数据库。如果没有 数据库名称限定符位于“locking_mode”关键字之前,然后 锁定模式应用于所有数据库,包括任何新的数据库 由后续 ATTACH 命令添加的数据库。
“temp”数据库(其中存储了 TEMP 表和索引) 内存中数据库始终使用独占锁定模式。临时数据库和内存数据库的锁定模式不能 被改变。默认情况下,所有其他数据库都使用正常锁定模式 并受到此编译指示的影响。
如果首次进入 WAL 日志模式时锁定模式为 EXCLUSEIVE,则锁定模式无法更改为 正常,直到退出 WAL 日志模式。 如果首次进入 WAL 时锁定模式为 NORMAL 日志模式,则锁定模式可以在 NORMAL 和 EXCLUSIVE 并随时返回,无需退出 WAL 日志模式。
PRAGMA 架构。max_page_count;
PRAGMA 架构。max_page_count = N;
查询或设置数据库文件中的最大页数。 编译指示的两种形式都返回最大页数。第二个 表单尝试修改最大页数。最大页数 计数不能减少到当前数据库大小以下。
PRAGMA 架构。mmap_size;
PRAGMA 架构。mmap_size=N
查询或更改设置的最大字节数 除了单个数据库上的内存映射 I/O。第一种形式 (不带参数)查询当前限制。第二个 形式(带有数值参数)设置指定 数据库,或者对于所有数据库(如果可选数据库名称为 省略。在第二种形式中,如果省略数据库名称,则 设置的 limit 将成为所有数据库的默认限制 通过后续 ATTACH 语句添加到数据库连接中。
参数 N 是数据库文件的最大字节数 将使用内存映射的 I/O 进行访问。如果 N 为零,则 内存映射 I/O 被禁用。如果 N 为负数,则极限 还原为由最新 sqlite3_config(SQLITE_CONFIG_MMAP_SIZE) 确定的默认值,或还原为编译 时间默认值由SQLITE_DEFAULT_MMAP_SIZE确定,如果不是 已设置开始时间限制。
PRAGMA mmap_size 声明永远不会增加金额 用于内存映射 I/O 的地址空间 由 SQLITE_MAX_MMAP_SIZE 编译时选项设置的硬限制, 也不是第二个参数在启动时设置的硬限制 sqlite3_config(SQLITE_CONFIG_MMAP_SIZE)
内存映射 I/O 区域的大小在以下情况下无法更改 内存映射的 I/O 区域处于活动状态,以避免取消映射 从正在运行的 SQL 语句中排出内存。出于这个原因, 如果先mmap_size不为零,则mmap_size编译指示可能是无操作 并且还有其他 SQL 语句在同一数据库连接上并发运行。
普拉格玛module_list;
此编译指示返回在数据库连接中注册的虚拟表模块的列表。
PRAGMA优化;
PRAGMA优化(MASK);
PRAGMA 模式.optimize;
PRAGMA schema.optimize(掩码);
尝试优化数据库。所有架构都在 前两种形式,在后者中仅优化指定的架构 二。
实现最佳的长期查询性能,而无需 对应用程序模式和 SQL 进行详细的工程分析, 建议应用程序运行“PRAGMA optimize”(不带参数) 就在关闭每个数据库连接之前。长时间运行的应用程序 设置一个计时器以每隔一次运行“PRAGMA optimize”也可能受益 几个小时。
这种编译通常是无操作的或几乎是这样,并且非常快。 但是,如果 SQLite 感觉 执行数据库优化(例如运行 ANALYZE 或创建新索引)将提高未来查询的性能,然后 可以完成一些数据库 I/O。想要限制金额的应用程序 的工作可以设置一个计时器,如果编译指示持续太久,该计时器将调用 sqlite3_interrupt()。 或者,从 SQLite 3.32.0 开始,应用程序可以使用 PRAGMA analysis_limit=N 来做一些小的 N(几百或几千)的值来限制深度 的分析。
预计此编译指示执行的优化的详细信息 随着时间的推移而改变和改进。应用程序应预料到这一点 此编译指示将在将来的版本中执行新的优化。
可选的 MASK 参数是要执行的优化的位掩码:
-
调试模式。实际上不执行任何优化 而是为每个优化返回一行文本 这本来可以做到的。默认情况下处于关闭状态。
-
对可能受益的表运行 ANALYZE。默认情况下处于打开状态。 有关其他信息,请参阅下文。
-
(尚未实施)记录使用情况和性能 当前会话中的信息 数据库文件,以便它可以“优化” 编译指示由将来的数据库连接运行。
-
(尚未实施)创建可能对最近的查询有帮助的索引。
默认的 MASK 是并且始终应0xfffe。0xfffe掩码意味着 执行上面列出的所有优化,调试模式除外。如果是新的 将来会添加默认情况下应该关闭的优化,这些 新的优化将被赋予 0x10000 或更大的掩码。
查看所有本来可以完成的优化,而实际上 执行这些操作,运行“PRAGMA optimize(-1)”。仅使用 ANALYZE 优化,运行“PRAGMA optimize(0x02)”。
确定何时运行分析
在当前实现中,当且仅当 以下所有情况都是正确的:
-
设置了 MASK 位0x02。
-
查询计划器sqlite_stat1对一个 或 在生存期的某个时间点,表的更多索引 当前连接。
-
表的一个或多个索引当前未分析,或者表中的行数增加了 25 倍或更多 自上次运行 ANALYZE 以来。
分析表的规则可能会在 将来的版本。
PRAGMA 架构。page_count;
返回数据库文件中的总页数。
PRAGMA 架构。page_size;
PRAGMA 架构。page_size = 字节;
查询或设置数据库的页面大小。页面 大小必须是介于 512 和 65536(含)之间的 2 次方。
创建新数据库时,SQLite 会将页面大小分配给 基于平台和文件系统的数据库。多年来, 默认页面大小几乎总是 1024 字节,但开始 使用 SQLite 版本 3.12.0 (2016-03-29), 默认页面大小增加到 4096。 对于大多数应用程序,建议使用默认页面大小。
指定新的页面大小不会更改页面大小 马上。相反,新的页面大小将被记住并被使用 在首次创建数据库时设置页面大小(如果确实如此) 发布page_size编译指示时尚不存在,或者在 下一个在同一数据库连接上运行的 VACUUM 命令 而不在 WAL 模式下。
可以使用SQLITE_DEFAULT_PAGE_SIZE编译时选项 更改分配给新数据库的默认页面大小。
PRAGMA parser_trace = 布尔值;
如果 SQLite 已使用SQLITE_DEBUG编译时进行编译 选项,则可以使用parser_trace编译指示来打开跟踪 用于 SQLite 内部使用的 SQL 解析器。 此功能用于调试 SQLite 本身。
此编译指示旨在用于调试 SQLite 本身。它 仅当 SQLITE_DEBUG 编译时选项时可用 被使用。
普拉格玛pragma_list;
此编译指示返回 PRAGMA 命令列表 数据库连接已知。
普拉格玛query_only;
PRAGMA query_only = 布尔值;
query_only编译指示在以下情况下阻止数据库文件上的数据更改 启用。启用此编译指示后,任何尝试 CREATE、DELETE、 DROP、INSERT 或 UPDATE 将导致SQLITE_READONLY错误。 但是,该数据库不是真正的只读数据库。您仍然可以运行 检查点或 COMMIT 和 sqlite3_db_readonly() 例程的返回值不受影响。
PRAGMA 架构。quick_check;
PRAGMA 架构。quick_check(N)
PRAGMA 模式。quick_check(表名)
编译指示类似于 integrity_check,只是它不验证 UNIQUE 约束,并且不验证 索引内容与表内容匹配。通过跳过 UNIQUE 和索引一致性检查,quick_check能够运行得更快。 PRAGMA quick_check 在 O(N) 时间内运行,而 PRAGMA integrity_check 需要 O(NlogN) 时间,其中 N 是 数据库。否则,这两个编译指示是相同的。
普拉格玛read_uncommitted;
PRAGMA read_uncommitted = 布尔值;
查询、设置或清除 READ UNCOMMITTED 隔离。默认隔离 SQLite 的级别是 SERIALIZABLE。任何进程或线程都可以选择 READ UNCOMMITTED 隔离,但仍将使用 SERIALIZABLE 在共享公共页面和架构缓存的连接之间。 使用 sqlite3_enable_shared_cache() API 启用缓存共享。 默认情况下,缓存共享处于禁用状态。
有关其他信息,请参阅 SQLite 共享缓存模式。
普拉格玛recursive_triggers;
PRAGMA recursive_triggers = 布尔值;
查询、设置或清除递归触发器功能。
更改recursive_triggers设置会影响 所有发言稿都已准备好 使用数据库连接,包括在 设置已更改。使用旧版 sqlite3_prepare() 接口准备的任何现有语句都可能因SQLITE_SCHEMA错误而失败 更改recursive_triggers设置后。
在 SQLite 版本 3.6.18 (2009-09-11) 之前, 不支持递归触发器。 SQLite的行为总是像这个编译指示一样 设置为 OFF。 版本 3.6.18 中添加了对递归触发器的支持 但为了兼容性,最初默认关闭。递归的 在SQLite的未来版本中,触发器可能会默认打开。
触发器的递归深度具有硬上限,由 SQLITE_MAX_TRIGGER_DEPTH编译时选项和运行时 由 sqlite3_limit(db,SQLITE_LIMIT_TRIGGER_DEPTH,...) 设置的限制。
普拉格玛reverse_unordered_selects;
PRAGMA reverse_unordered_selects = 布尔值;
启用后,此 PRAGMA 会导致许多 SELECT 语句没有 一个 ORDER BY 子句,以相反的顺序发出它们的结果 他们通常会。这可以帮助调试以下应用程序: 对结果顺序做出无效的假设。 reverse_unordered_selects编译指示适用于大多数 SELECT 语句, 但是,查询规划器有时可能会选择一种算法,该算法是 不容易反转,在这种情况下,输出将出现在相同的 无论reverse_unordered_selects设置如何,都可以订购。
SQLite 表示没有 如果 SELECT 省略 ORDER BY,则保证结果的顺序 第。即便如此,结果的顺序也不会从 1 改变 运行到下一个,许多应用程序错误地依赖于 在任意输出顺序上,无论该顺序恰好是什么。然而 有时,新版本的SQLite将包含优化器增强功能 这将导致查询的输出顺序没有 ORDER BY 子句 转移。当这种情况发生时,依赖于某个 输出顺序可能会出现故障。通过运行应用程序多个 禁用和启用此编译指示的次数,其中 应用程序对输出顺序做出错误的假设可以是 及早发现并修复,减少问题 这可能是由于链接到不同版本的 SQLite 引起的。
PRAGMA 架构。schema_version;
PRAGMA 架构。schema_version = 整数 ;
编译指示将获得或设置schema_version 数据库标头中偏移量为 40 处的 schema-version 整数的值。
SQLite 在 架构更改。当每个 SQL 语句运行时,架构版本为 选中以确保架构自 SQL 以来未更改 声明已准备就绪。 通过使用“PRAGMA schema_version=N”来颠覆这种机制 更改schema_version的值 可能会导致 SQL 语句使用过时的架构运行, 这可能导致不正确的答案和/或数据库损坏。 阅读schema_version总是安全的,但将 schema_version可能会导致问题。出于这个原因,尝试 要更改 schema_version 的值是无声的无操作,当 数据库连接。
警告:滥用此编译指示可能会导致数据库损坏。
出于本编译指示的目的,考虑使用 VACUUM 命令 架构更改,因为 VACUUM 通常会更改“根页面” sqlite_schema表中条目的值。
另请参阅 application_id 编译指示 和 user_version 编译指示。
PRAGMA 架构。secure_delete;
PRAGMA 架构。secure_delete = 布尔值|快
查询或更改安全删除设置。当secure_delete是 开启,SQLite 会用零覆盖已删除的内容。默认值 secure_delete 的设置由 SQLITE_SECURE_DELETE 编译时选项确定,通常处于关闭状态。的偏移设置 secure_delete通过减少 CPU 周期数来提高性能 以及磁盘 I/O 的数量。 希望避免离开的应用程序 删除或更新内容后的取证跟踪应启用 在执行删除或更新之前secure_delete编译指示,否则 删除或更新后运行 VACUUM。
secure_delete的“快速”设置(大约在 2017-08-01 添加) 是介于“开”和“关”之间的中间设置。 当secure_delete设置为“快速”时, SQLite只有在这样做时才会用零覆盖已删除的内容 不会增加 I/O 的数量。换句话说,“快” 设置使用更多的 CPU 周期,但不使用更多的 I/O。 这具有从 b 树页面中清除所有旧内容的效果, 但在 freelist 页面上留下了取证痕迹。
当有附加的数据库和没有数据库时 在编译指示中指定,则所有数据库都有其安全删除 设置已更改。 新附加数据库的安全删除设置是该设置 评估 ATTACH 命令时的主数据库。
当多个数据库连接共享同一缓存时,将 一个数据库连接上的 secure-delete 标志会为他们更改它 都。
限度:secure_delete编译指示仅导致删除的内容被清除 从普通桌子。如果虚拟表将内容存储在影子表中,则从虚拟表中删除内容会这样做 不一定从影子表中删除取证痕迹。 特别是 FTS3 和 FTS5 虚拟表 与 SQLite 捆绑在一起可能会在其影子表中留下取证痕迹 即使启用了 secure_delete 编译指示。
普拉格玛short_column_names;
PRAGMA short_column_names = 布尔值;
查询或更改 short-column-names 标志。此标志影响 SQLite 命名 SELECT 语句返回的数据列的方式。 有关完整的详细信息,请参阅full_column_names编译指示。
此编译指示已弃用并存在 仅用于向后兼容。新应用 应避免使用此编译指示。较旧的应用程序应停止使用 尽早使用此编译指示。可以省略此编译指示 当使用SQLITE_OMIT_DEPRECATED编译SQLite时,从构建中。
普拉格玛shrink_memory
此编译指示会导致调用它的数据库连接 通过调用 sqlite3_db_release_memory() 来释放尽可能多的内存。
PRAGMA soft_heap_limit
PRAGMA soft_heap_limit=N
此编译指示调用 sqlite3_soft_heap_limit64() 接口 参数 N,如果指定了 N 并且是非负整数。 soft_heap_limit 编译指示始终返回相同的整数 这将由 sqlite3_soft_heap_limit64(-1) C 语言返回 功能。
另请参阅hard_heap_limit pragma。
PRAGMA统计数据;
此编译指示返回有关表和 指标。返回的信息在测试期间用于帮助 验证查询计划器是否正常运行。格式 并且此编译指示的含义可能会从一个版本中发生变化 到下一个。由于其波动性,行为和输出 此编译指示的格式是故意未记录的。
此编译指示的预期用途仅用于测试和验证 SQLite的。本编译指示如有更改,恕不另行通知,并且不会 推荐供应用程序使用。
PRAGMA 架构。同步;
PRAGMA 架构。同步 = 0 |关闭 |1 |正常 |2 |完整 |3 |额外;
查询或更改“synchronous”标志的设置。 第一个(查询)窗体将返回同步设置作为 整数。第二种形式更改同步设置。 各种同步设置的含义如下:
额外 (3)
EXTRA synchronous 类似于 FULL,加上目录 包含回滚日记在取消链接后同步该日记 以 DELETE 模式提交事务。EXTRA提供额外的 如果提交紧随其后的是断电,则耐久性。
完整 (2)
当同步为 FULL (2) 时,SQLite 数据库引擎将 使用 VFS 的 xSync 方法确保所有内容都是安全的 在继续之前写入磁盘表面。 这可确保操作系统崩溃或电源故障将 不会损坏数据库。 FULL 同步非常安全,但速度也较慢。FULL 是 非 WAL 模式时最常用的同步设置。
普通 (1)
当 synchronous 为 NORMAL (1) 时,SQLite 数据库 引擎在最关键的时刻仍会同步,但频率较低 比在 FULL 模式下。有一个非常小的(尽管不是零)机会 在错误的时间发生电源故障可能会损坏旧文件系统上 journal_mode=DELETE 中的数据库。WAL 模式不会损坏,synchronous=NORMAL 并且可能 DELETE 模式在现代文件系统上也是安全的。WAL 模式始终保持一致 使用 synchronous=NORMAL,但 WAL 模式确实会失去持久性。事务 在 WAL 模式下提交 synchronous=NORMAL 可能会回滚以下内容 断电或系统崩溃。事务在应用程序中是持久的 无论同步设置或日志模式如何,都会崩溃。 synchronous=NORMAL 设置是大多数应用程序的不错选择 在 WAL 模式下运行。
关闭 (0)
在同步关闭 (0) 的情况下,SQLite 继续而不同步 一旦它将数据移交给操作系统。 如果运行SQLite的应用程序崩溃,数据将是安全的,但是 如果操作系统损坏,数据库可能会损坏 在写入该数据之前崩溃或计算机断电 到磁盘表面。另一方面,提交可以是 同步关闭时幅度更快。
在 WAL 模式下,当同步为 NORMAL (1) 时,WAL 文件为 在每个检查点和数据库文件之前同步 在完成每个检查点和 WAL 文件后同步 当 WAL 文件在 检查点,但在大多数事务期间不执行同步操作。 在 WAL 模式下使用 synchronous=FULL 时,另外 WAL 文件的同步操作在每次事务提交后进行。 每个事务之后的额外 WAL 同步有助于确保 在断电期间,事务是持久的。交易是 无论是否与提供的额外同步一致 synchronous=FULL。 如果持久性不是问题,则 synchronous=NORMAL 通常为 在 WAL 模式下都需要。
TEMP 架构始终具有 synchronous=OFF,因为 的 TEMP 是短暂的,预计不会在停电后幸存下来。 尝试更改 TEMP 的同步设置是 默默地忽略了。
另请参阅 fullfsync 和 checkpoint_fullfsync 编译指示。
PRAGMA 架构。table_info(表名);
此编译指示为每个普通列返回一行 在命名表中。 结果集中的列包括:“name”(其名称);“类型” (如果给定数据类型,否则 '');“notnull”(无论列是否 可以是 NULL);“dflt_value”(列的默认值); 和“pk”(对于不属于主键的列,任为零, 或主键中列的从 1 开始的索引)。
“cid”一栏不应被理解为超过 “在当前结果集中排名”。
在table_info注释中命名的表也可以是视图。
此编译指示不显示有关生成的列或隐藏列的信息。使用 PRAGMA table_xinfo 获取更完整的列表 包含生成列和隐藏列的列。
普拉格玛table_list;
PRAGMA 架构。table_list;
PRAGMA table_list(表名);
此编译指示返回有关架构中的表和视图的信息, 每行输出一个表。table_list编译指示首次出现 在 SQLite 版本 3.37.0 (2021-11-27) 中。自最初发布以来 table_list编译指示返回的列包括下面列出的列。 SQLite 的未来版本可能会添加 输出。
- schema:显示表或视图的架构 (例如“main”或“temp”)。
- name:表或视图的名称。
- type:对象的类型 - “table”、“view”、 “shadow”(用于影子表)或“virtual”用于虚拟表。
- ncol:表中的列数,包括生成的列和隐藏列。
- wr:如果表是 WITHOUT ROWID 表,则为 1,如果不是,则为 0。
- strict:如果表是 STRICT 表,则为 1,如果不是,则为 0。
- 在将来的版本中可能会添加其他列。
默认行为是显示所有架构中的所有表。如果架构名称出现在编译指示之前,则只有其中的表 将显示一个架构。如果提供了 table-name 参数,则 仅返回有关该表的信息。
PRAGMA 架构。table_xinfo(表名);
此编译指示为命名表中的每列返回一行, 包括生成的列和隐藏的列。 输出具有与 PRAGMA table_info plus 相同的列 一列,“隐藏”,其值表示普通列 (0), 动态或存储的生成列(2 或 3), 或虚拟表 (1) 中的隐藏列。其所针对的行 对于PRAGMA table_info省略的字段,此字段为非零。
普拉格玛temp_store;
PRAGMA temp_store = 0 |默认 |1 |文件 |2 |记忆;
查询或更改“temp_store”参数的设置。 当 temp_store 为 DEFAULT (0) 时,编译时 C 预处理器宏SQLITE_TEMP_STORE用于确定临时表和索引的位置 被存储。什么时候 temp_store是 MEMORY (2) 保留临时表和索引 就好像它们在纯内存数据库中一样。 当temp_store为 FILE (1) 时,将存储临时表和索引 在文件中。temp_store_directory编译指示可用于指定 指定 FILE 时包含临时文件的目录。更改temp_store设置时, 所有现有的临时表、索引、触发器和视图都是 立即删除。
库编译时 C 预处理器符号SQLITE_TEMP_STORE可以覆盖此编译指示设置。 下表总结了 SQLITE_TEMP_STORE预处理器宏和 temp_store 编译指示:
SQLITE_TEMP_STORE 普拉格玛
temp_store用于
TEMP 表和索引的存储0 任何 文件 1 0 文件 1 1 文件 1 2 记忆 2 0 记忆 2 1 文件 2 2 记忆 3 任何 记忆
普拉格玛temp_store_directory;
PRAGMA temp_store_directory = '目录名称';
查询或更改 sqlite3_temp_directory 全局的值 变量,许多操作系统接口后端都使用它来 确定临时表和索引的存储位置。
更改temp_store_directory设置时,所有现有的临时 数据库中的表、索引、触发器和查看器连接 发出的 pragma 将立即删除。在 练习,temp_store_directory应在第一次之后立即设置 进程的数据库连接已打开。如果temp_store_directory 对于一个数据库连接进行更改,而其他数据库连接则发生更改 在同一进程中打开,则行为未定义且 可能是不可取的。
更改temp_store_directory设置是非线程安全的。 如果另一个线程,切勿更改temp_store_directory设置 在应用程序中同时运行任何SQLite接口。 这样做会导致未定义的行为。更改temp_store_directory 设置写入sqlite3_temp_directory全局 变量,并且该全局变量不受互斥锁保护。
值 directory-name 应括在单引号中。 若要将目录恢复为默认值,请将 directory-name 设置为 一个空字符串,例如,PRAGMA temp_store_directory = ''。一 如果找不到或找不到 directory-name,则会引发错误 写。
临时文件的默认目录取决于操作系统。一些 操作系统接口可以选择忽略此变量并将临时变量放在 与指定目录不同的其他目录中的文件 这里。从这个意义上说,这种实用主义只是建议性的。
此编译指示已弃用并存在 仅用于向后兼容。新应用 应避免使用此编译指示。较旧的应用程序应停止使用 尽早使用此编译指示。可以省略此编译指示 当使用SQLITE_OMIT_DEPRECATED编译SQLite时,从构建中。
PRAGMA螺纹;
PRAGMA 线程数 = N;
查询或更改 sqlite3_limit(db,SQLITE_LIMIT_WORKER_THREADS,...) 限制的值 当前数据库连接。此限制设置了上限 关于预准备语句的辅助线程数 允许启动以协助查询。默认限制为 0 除非使用 SQLITE_DEFAULT_WORKER_THREADS 编译时选项进行更改。当限制为零时,这意味着没有 将启动辅助线程。
此编译指示是围绕 sqlite3_limit(db,SQLITE_LIMIT_WORKER_THREADS,...) 接口的精简包装器。
普拉格玛trusted_schema;
PRAGMA trusted_schema = 布尔值;
trusted_schema设置是每个连接的布尔值 确定 SQL 函数和虚拟表是否 未经安全审计的视图允许运行, 触发器,或架构的表达式,例如 CHECK 约束、DEFAULT 子句、生成的列、表达式索引和/或部分索引。也可以使用 sqlite3_db_config(db,SQLITE_DBCONFIG_TRUSTED_SCHEMA,...) C 语言界面。
为了保持向后兼容性,此设置是 默认情况下为 ON。关闭它有好处,而且大多数 如果关闭,应用程序将不受影响。出于这个原因, 鼓励所有应用程序在每个 一旦打开该连接,数据库连接。
-DSQLITE_TRUSTED_SCHEMA=0 编译时选项将导致 此设置默认为 OFF。
PRAGMA 架构。user_version;
PRAGMA 架构。user_version = 整数 ;
user_version编译指示将获得或设置 数据库标头中偏移量为 60 处的 user-version 整数的值。user-version 是一个整数,即 可供应用程序使用,以他们想要的方式使用。SQLite的 不使用用户版本本身。
另请参阅 application_id 编译指示和schema_version编译指示。
PRAGMA vdbe_addoptrace = 布尔值;
如果 SQLite 已使用SQLITE_DEBUG编译时进行编译 选项,则可以使用vdbe_addoptrace编译指示来完成 VDBE 操作码在代码生成期间创建时显示。 此功能用于调试 SQLite 本身。有关详细信息,请参阅 VDBE 文档 信息。
此编译指示旨在用于调试 SQLite 本身。它 仅当 SQLITE_DEBUG 编译时选项时可用 被使用。
PRAGMA vdbe_debug = 布尔值;
如果 SQLite 已使用SQLITE_DEBUG编译时进行编译 选项,则vdbe_debug pragma 是其他三个的简写 仅调试编译指示:vdbe_addoptrace、vdbe_listing 和 vdbe_trace。 此功能用于调试 SQLite 本身。有关详细信息,请参阅 VDBE 文档 信息。
此编译指示旨在用于调试 SQLite 本身。它 仅当 SQLITE_DEBUG 编译时选项时可用 被使用。
PRAGMA vdbe_listing = 布尔值;
如果 SQLite 已使用SQLITE_DEBUG编译时进行编译 选项,则可以使用vdbe_listing编译指示来导致一个完整的 要在标准输出中显示的虚拟机操作码列表 因为每个语句都被计算。 在列表打开的情况下,打印程序的全部内容 就在开始执行之前。声明 在打印列表后正常执行。 此功能用于调试 SQLite 本身。有关详细信息,请参阅 VDBE 文档 信息。
此编译指示旨在用于调试 SQLite 本身。它 仅当 SQLITE_DEBUG 编译时选项时可用 被使用。
PRAGMA vdbe_trace = 布尔值;
如果 SQLite 已使用SQLITE_DEBUG编译时进行编译 选项,则可以使用vdbe_trace编译指示来导致虚拟机 操作码在评估时打印在标准输出上。 此功能用于调试 SQLite。有关详细信息,请参阅 VDBE 文档 信息。
此编译指示旨在用于调试 SQLite 本身。它 仅当 SQLITE_DEBUG 编译时选项时可用 被使用。
普拉格玛wal_autocheckpoint;
PRAGMA wal_autocheckpoint=N;
此编译指示查询或设置预写日志自动检查点间隔。 启用预写日志(通过journal_mode编译指示)后,检查点将在任何时候自动运行 预写日志的长度等于或超过 N 页。 将自动检查点大小设置为零或负值 关闭自动检查点。
这个编译指示是 sqlite3_wal_autocheckpoint() C 接口的包装器。 所有自动检查点都是被动的。
默认情况下,自动检查点处于启用状态,并有一个间隔 1000 或 SQLITE_DEFAULT_WAL_AUTOCHECKPOINT。
PRAGMA 架构。wal_checkpoint;
PRAGMA 架构。wal_checkpoint(被动);
PRAGMA 架构。wal_checkpoint(已满);
PRAGMA 架构。wal_checkpoint(重新启动);
PRAGMA 架构。wal_checkpoint(截断);
如果启用了预写日志(通过journal_mode编译指示), 此编译指示会导致检查点操作在数据库数据库上运行,如果省略数据库,则在所有附加的数据库上运行。如果禁用了预写日志模式,则此编译指示是 无害的无操作。
调用此 没有参数的 pragma 等价于调用 sqlite3_wal_checkpoint() C 接口。
使用参数调用此编译指示等效于使用与参数对应的第 3 个参数调用 sqlite3_wal_checkpoint_v2() C 接口:
被动
检查尽可能多的帧,无需等待任何数据库 读者或作家完成。如果日志中的所有帧都同步数据库文件 被检查。此模式与调用 sqlite3_wal_checkpoint() C 接口相同。busy-handler 回调从不被调用 这种模式。
满
此模式阻止 (调用 busy-handler 回调) 直到没有 数据库编写器和所有读者都在从最新的数据库中读取 快照。然后,它会检查日志文件中的所有帧并同步 数据库文件。FULL 阻止并发写入器 运行,但读者可以继续。
重新启动
此模式的工作方式与 FULL 相同,只是在之后添加了 检查它阻止的日志文件(调用 busy-handler 回调) 直到所有读取器都完成日志文件。这确保了 下一个要写入数据库文件的客户端将重新启动日志文件 从一开始。RESTART 阻止并发写入器 运行,但允许读者继续。
截断
此模式的工作方式与 RESTART 相同,使用 此外,WAL 文件在成功时被截断为零字节 完成。
wal_checkpoint 编译指示返回一行,其中包含三个 整数列。第一列通常为 0,但将是 1 如果 RESTART 或 FULL 或 TRUNCATE 检查点被阻止完成, 例如,因为另一个线程或进程处于活动状态 使用数据库。换言之,如果 对 sqlite3_wal_checkpoint_v2() 的等效调用将返回 SQLITE_OK 或 1,如果等效调用返回 SQLITE_BUSY。 第二列是已修改的页面数 写入预写日志文件。 第三列是预写日志文件中的页数 已成功移回数据库文件,网址为 检查站的结论。 如果没有,则第二列和第三列为 -1 预写日志,例如,如果在数据库上调用了此编译指示 非 WAL 模式的连接。
PRAGMA writable_schema = 布尔值;
PRAGMA writable_schema = 复位
当此编译指示打开时,SQLITE_DBCONFIG_DEFENSIVE标志 熄灭,则sqlite_schema表 可以使用普通的 UPDATE、INSERT 和 DELETE 语句进行更改。如果参数为“RESET”,则模式编写为 禁用(如“PRAGMA writable_schema=OFF”),此外, 架构已重新加载。警告:滥用此编译指示很容易导致 数据库文件损坏。
相关文章:

SQLite的PRAGMA 声明
PRAGMA 语句是特定于 SQLite 的 SQL 扩展,用于 修改 SQLite 库的操作或查询 SQLite 库 内部(非表)数据。PRAGMA声明使用相同的 接口作为其他 SQLite 命令(例如 SELECT、INSERT)但 在以下重要方面有所不同: …...
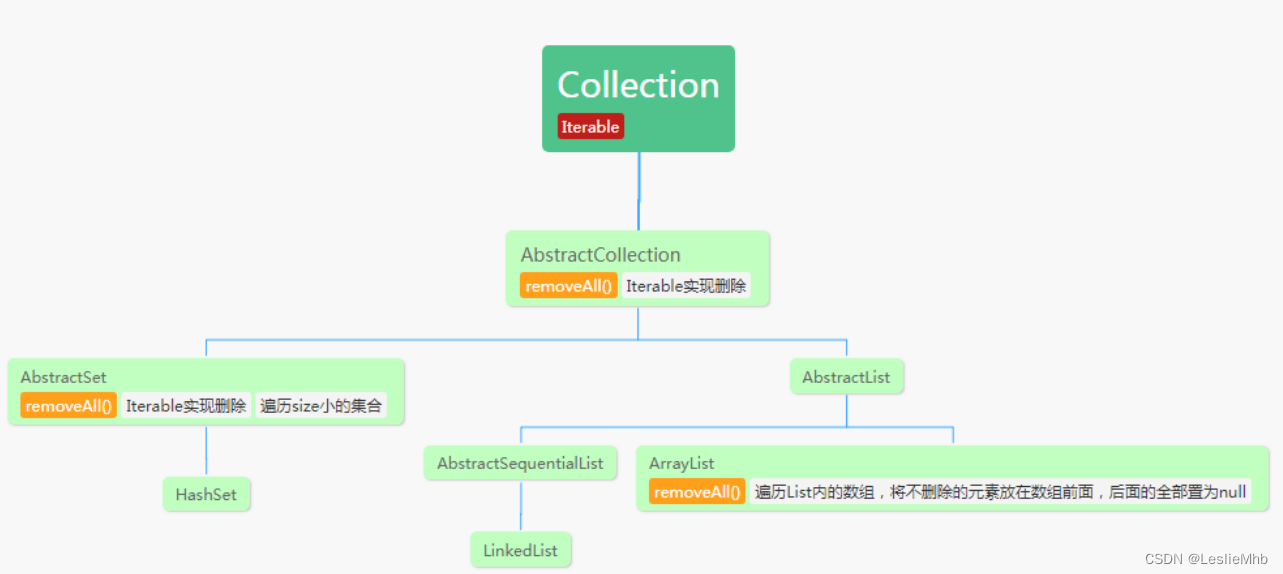
使用ArrayList.removeAll(List list)导致的机器重启
背景 先说一下背景,博主所在的业务组有一个核心系统,需要同步两个不同数据源给过来的数据到redis中,但是每次同步之前需要过滤掉一部分数据,只存储剩下的数据。每次同步的数据与需要过滤掉的数据量级大概在0-100w的数据不等。 由…...

如何在项目中使用uni-ui组件库
1、安装uni-ui npm i dcloudio/uni-ui 2、组件自动引用 配置easycom 使用 npm 安装好 uni-ui 之后,需要配置 easycom 规则,让 npm 安装的组件支持 easycom 打开项目根目录下的 pages.json 并添加 easycom 节点: // pages.json {"e…...
)
redis的过期策略和内存淘汰机制(redis篇)
分享并学习一下redis的过期策略和内存淘汰机制 在平时的工作或者学习中,即便自己没有实打实的用过redis。但是能有对这方面的思考,再结合一些实际场景和理论,那么我相信自己或者你都会越来越厉害的。 首先,我们需要认清为啥redis要…...
)
Java中Runnable和Callable有什么不同?(企业真题)
Java中Runnable和Callable有什么不同? 与之前的方式的对比:与Runnable方式的对比的好处 call()可以有返回值,更灵活 call()可以使用throws的方式处理异常,更灵活 Callable使用了泛型参数,可以指明具体的call()的返回值…...
图机器学习导论
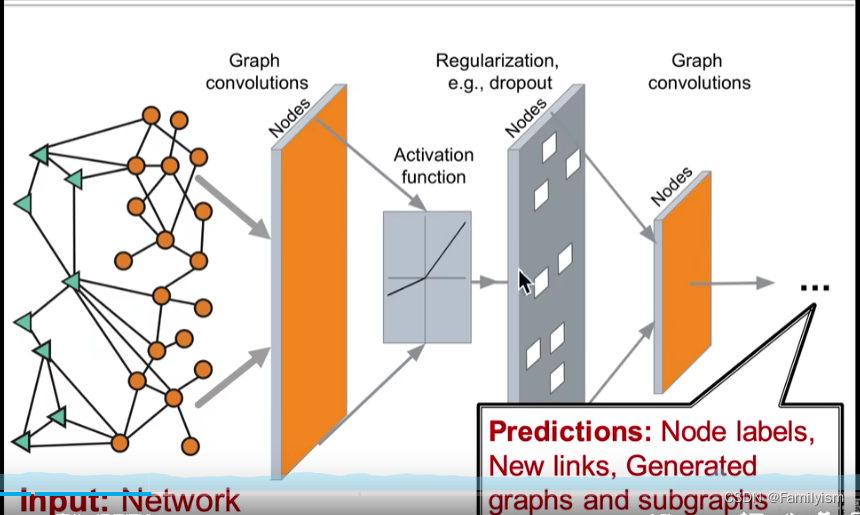
图:描述关系数据的通用语言,起源于哥尼斯堡七桥问题 传统的机器学习:数据样本之间独立同分布,简单拟合数据边界,在传统的机器学习中,每个数据样本彼此无关。传统的神经网络,只能处理简单的表格、…...

地推网推拉新平台哪家强?一文清楚告诉你
在当今这个充满副业的时代,地推网推拉新平台的寻找与对接成为了许多人关注的焦点。那么,我们应该如何找到那些既靠谱又有潜力的拉新项目呢? 经过深入研究和全网检索,我为大家盘点了5个值得一试地推网推拉新平台。 尤其是“聚小推…...
Day:004(4) | Python爬虫:高效数据抓取的编程技术(数据解析)
XPath工具 浏览器-元素-CtrlF 浏览器-控制台- $x(表达式) Xpath helper (安装包需要科学上网) 问题 使用离线安装包 出现 程序包无效 解决方案 使用修改安装包的后缀名为 rar,解压文件到一个文件夹,再用 加载文件夹的方式安装即可 安装 python若使用…...
 只出现一次的数字(81)反转字符串)
(80) 只出现一次的数字(81)反转字符串
文章目录 1. 每日一言2. (80) 只出现一次的数字2.1 解题思路2.2 代码 3. (81)反转字符串3.1 解题思路3.2 代码 4. 结语 1. 每日一言 生活是一场即兴表演,值得庆幸的是我们总是有所感受,并且将一直感受下去。 2. (80) 只出现一次的数字 题目链接&#x…...
基于拉格朗日分布算法的电动汽车充放电调度MATLAB程序
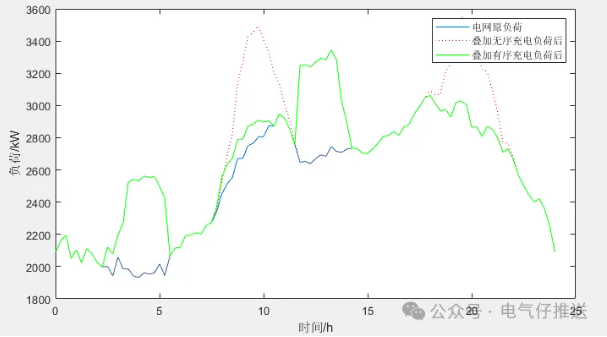
微❤关注“电气仔推送”获得资料(专享优惠) 程序简介 该模型主要做的是基于拉格朗日分布算法的电动汽车充放电调度模型。利用蒙特卡洛模拟法模拟出电动汽车负荷曲线,并求解出无序充电功率曲线和有序充电曲线,该模型在电动汽车个…...
【Linux 学习】进程优先级和命令行参数!
1. 什么是优先级? 指定进程获取某种资源(CPU)的先后顺序; Linux 中优先级数字越小,优先级越高; 1.1 优先级和权限的区别? 权限 : 能不能做 优先级: 已经能了,但是获…...

Git删除未跟踪的文件Untracked files
在 Git 中,要删除未跟踪的文件(Untracked files),你可以使用 git clean 命令。请注意,这个命令会从你的工作目录中永久删除这些文件,因此在执行之前请确保你不再需要这些文件或已经妥善备份。 以下是如何使…...

S7-1200PLC控制V90伺服通过FB284实现位置控制的方法
S7-1200PLC控制V90伺服通过FB284实现位置控制的方法 通过西门子报文111和FB284功能块 在V-ASSISTANT中将V90 PN设置控制模式为"基本位置控制(EPOS)" V90 PN与PLC采用PROFINET RT通信方式并使用西门子报文111。 在博途中V90 PN的设备视图中更改报文为:报文111 安装…...
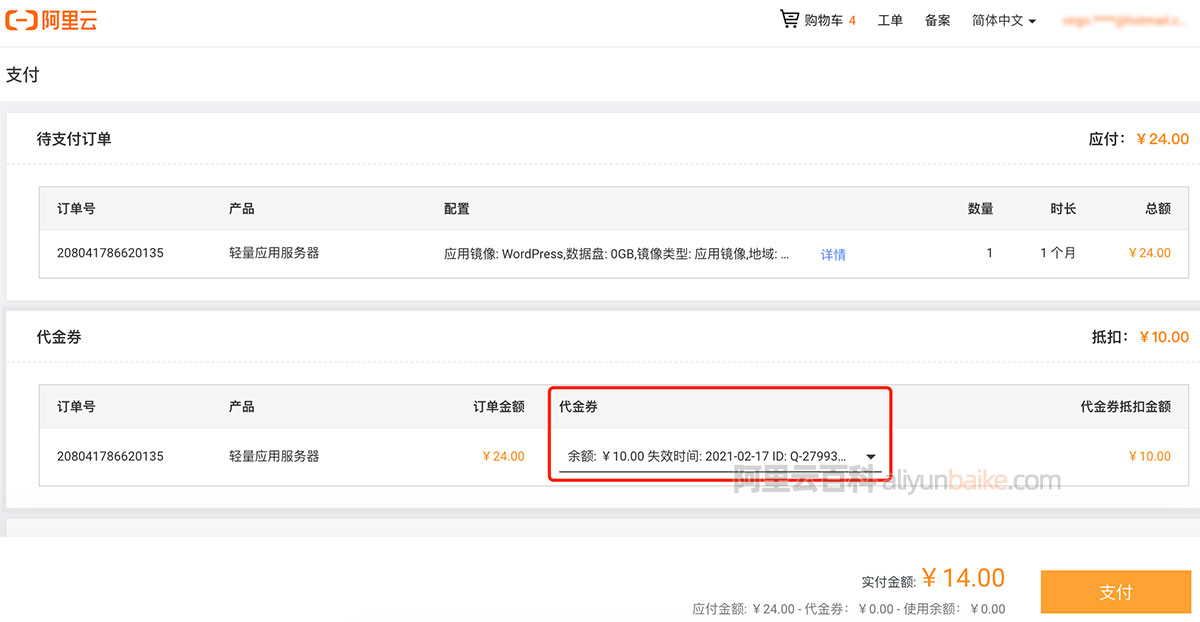
2024年阿里云优惠券领取和使用方法
阿里云优惠代金券领取入口,阿里云服务器优惠代金券、域名代金券,在领券中心可以领取当前最新可用的满减代金券,阿里云百科aliyunbaike.com分享阿里云服务器代金券、领券中心、域名代金券领取、代金券查询及使用方法: 阿里云优惠券…...
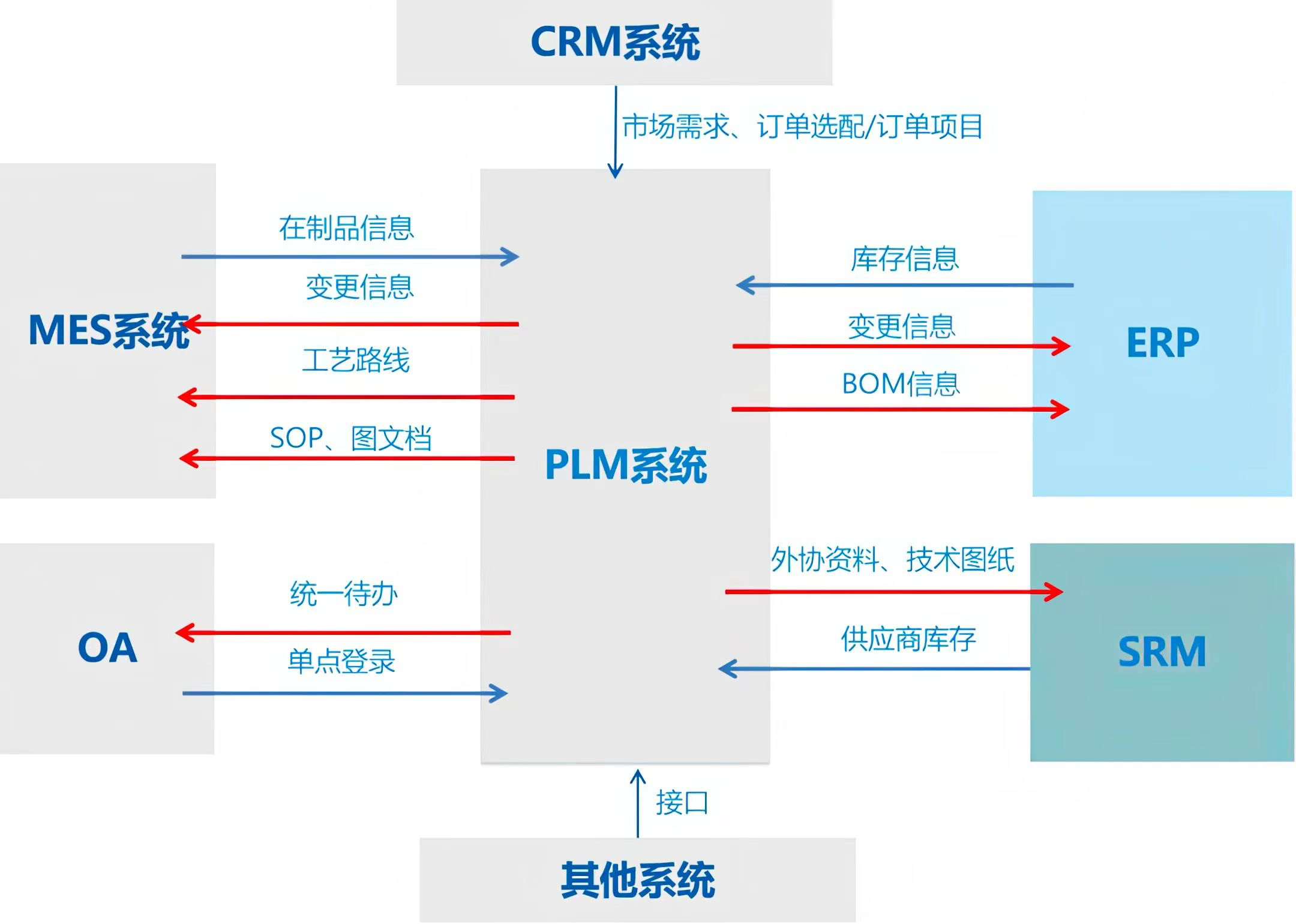
工业项目中你连PLM系统都没见过?
什么是 PLM 软件? PLM 软件是用于管理全球供应链中产品或服务全生命周期环节的解决方案。它包括从物料、零部件、产品、文档、规定、工程变更单到质量工作流的数据管理。 PLM 的发展历史 从最初的产品设计管理到如今的数字化转型和智能化生产,PLM 在不断…...
【QT入门】 Qt自定义控件与样式设计之QPushButton实现鼠标悬浮按钮弹出对话框
往期回顾: 【QT入门】 Qt自定义控件与样式设计之qss选择器-CSDN博客 【QT入门】 Qt自定义控件与样式设计之QLineEdit的qss使用-CSDN博客 【QT入门】Qt自定义控件与样式设计之QPushButton常用qss-CSDN博客 【QT入门】 Qt自定义控件与样式设计之QPushButton实现鼠标悬…...
C盘变红怎么办?免费的系统C盘清理方法,C盘空间占用克星
百夫说:分享免费又好用的工具,是一件快乐的事情。 正文: 起因:C盘报警,系统变慢 立即下载XX系统清理大师,搜索出垃圾数据近30G,开心的点击“一键清理”,结果提示要收费:…...

简述VPS 与 Apache 搭建网站方式对比:新手科普指南
在互联网时代,拥有一个网站对于个人、企业以及组织来说已经成为了必备的一项资源。然而,对于新手来说,如何搭建一个网站可能是一个挑战。在这篇文章中,我将探讨两种常见的搭建网站的方式:使用虚拟专用服务器࿰…...

js获取年月份
一、date 如何使用、如何获取年月日时分秒、时间戳、如何获取指定日期的时间戳或周几 1..Date 对象用于处理日期和时间。 创建 Date 对象的语法: var myDatenew Date() 获取年月日时分秒: // 格式化日对象 const getNowDate () > {let date new …...

Promise常用方法及区别
一、实例方法 let _fun new Promise((resolve, reject) > {reject("失败!"); }); /* resolve:异步操作成功时调用的回调函数。 reject:异步操作失败时调用的回调函数。 */ _fun.then(res > { // 成功console.log(res: , re…...
)
ADC0809模数转换实战:如何用51单片机+LCD1602搭建简易电压表(附完整代码)
51单片机与ADC0809模数转换实战:打造高精度LCD电压表 1. 项目背景与核心器件解析 在电子测量领域,电压表是最基础也最常用的工具之一。传统指针式电压表虽然直观,但精度和功能扩展性有限。而基于51单片机与ADC0809的数字电压表,不…...
)
保姆级教程:在ROS Noetic下用DWA算法让无人机在已知地图里自动巡航(附完整配置文件)
无人机自主导航实战:ROS Noetic中DWA算法的深度配置与避坑指南 当你在Gazebo仿真环境中看着无人机缓缓升起,准备开始它的首次自主飞行时,那种期待与忐忑交织的感觉,想必每个ROS开发者都深有体会。本文将从实战角度出发,…...

AI辅助开发:让快马智能生成带安全验证的路由器手机登录界面
最近在做一个路由器管理后台的移动端登录页面,需要实现192.168.1.1这个常见路由器地址的手机端登录功能。作为一个前端开发者,我发现用AI辅助开发可以大大提升效率,特别是处理安全验证这类复杂逻辑时。下面分享下我的实践过程。 需求分析 首先…...

收藏备用!小白程序员必看:从基础到进阶,彻底吃透Prompt与提示工程
本文将从基础入门到进阶实操,全面拆解Prompt的核心知识点,涵盖概念定义、分类维度、核心要素、工作原理,以及可直接套用的实用提示工程方法。全程避开晦涩术语,用程序员易懂的表述搭配具体案例,适配刚接触大模型的小白…...

北海本地人私藏的美食哪家好
在北海这座滨海城市,海鲜饮食的日常逻辑始终围绕着“活鲜”二字展开。本地食客习惯于清晨去渔港挑海鲜,或选择街边老店加工,追求的是食材本身的呼吸感与原味。而近年来,随着游客流量增长,海鲜餐饮的消费场景发生着结构…...

3分钟掌握:如何在Windows上直接安装Android应用的终极方案
3分钟掌握:如何在Windows上直接安装Android应用的终极方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经遇到过这样的情况:手机上有…...

数字人表情驱动:ARKit blend shape中文对照与实战解析
1. ARKit blend shape基础概念解析 第一次接触ARKit的blend shape功能时,我也被这些英文术语搞得晕头转向。简单来说,blend shape就像是我们小时候玩的橡皮泥,通过调整不同部位的形状来改变整体表情。ARKit定义了52个标准面部动作单元&#…...

Win11Debloat完整指南:如何一键清理Windows系统,提升51%性能的免费神器
Win11Debloat完整指南:如何一键清理Windows系统,提升51%性能的免费神器 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other …...

高效图像压缩:MozJPEG从入门到精通
高效图像压缩:MozJPEG从入门到精通 【免费下载链接】mozjpeg Improved JPEG encoder. 项目地址: https://gitcode.com/gh_mirrors/mo/mozjpeg 在数字媒体传播中,图像体积与加载速度始终是开发者面临的核心矛盾。传统JPEG压缩算法受限于基础编码框…...
)
dfs经典例题——迷宫问题(利用二维数组优化方向判断)
思路:首先关于方向问题,我们可以设定一个默认方向,比如先默认向右,触底向下,然后再是向左向上。只需要平行在dfs函数中即可,每次递归会自动依次按照if条件进行合适方向的查找初始量:地图数组&am…...