python-pytorch使用日志0.5.007
python-pytorch使用日志
- 1. optimizer.zero_grad()和model.zero_grad()的区别
- 2. cbow和skip-gram的训练数据格式
- 3. 获取cbow和skip-gram训练后的中文词向量
- 4. 获取到词向量后可以做什么
- 5. 余弦相似度结果的解释
1. optimizer.zero_grad()和model.zero_grad()的区别
都是清空模型的梯度参数,如果模型中有多个model训练时,建议使用model.zero_grad();如果只有一个模型训练optimizer.zero_grad()和model.zero_grad()意义都一样
2. cbow和skip-gram的训练数据格式
cbow格式
data1 = []
for i in range(2, len(raw_text) - 2):context = [raw_text[i - 2], raw_text[i - 1],raw_text[i + 1], raw_text[i + 2]]target = raw_text[i]data1.append((context, target))
cbow最终格式
[([‘从零开始’, ‘Zookeeper’, ‘高’, ‘可靠’], ‘开源’), ([‘Zookeeper’, ‘开源’, ‘可靠’, ‘分布式’], ‘高’), ([‘开源’, ‘高’, ‘分布式’, ‘一致性’], ‘可靠’), ([‘高’, ‘可靠’, ‘一致性’, ‘协调’], ‘分布式’), ([‘可靠’, ‘分布式’, ‘协调’, ‘服务’], ‘一致性’)]
skip-gram格式
data3 = []
window_size1=2
for i,word in enumerate(raw_text):target = raw_text[i]contexts=raw_text[max(i - window_size1, 0): min(i + window_size1 + 1, len(raw_text))]for context in contexts:if target!=context:data3.append((context,target))
data3,len(data3)或者类似于def create_skipgram_dataset(sentences, window_size=4):data = [] # 初始化数据for sentence in sentences: # 遍历句子sentence = sentence.split() # 将句子分割成单词列表for idx, word in enumerate(sentence): # 遍历单词及其索引# 获取相邻的单词,将当前单词前后各 N 个单词作为相邻单词for neighbor in sentence[max(idx - window_size, 0): min(idx + window_size + 1, len(sentence))]:if neighbor != word: # 排除当前单词本身# 将相邻单词与当前单词作为一组训练数据data.append((neighbor, word))return data
skip-gram最终格式
([(‘Zookeeper’, ‘从零开始’),
(‘开源’, ‘从零开始’),
(‘从零开始’, ‘Zookeeper’),
(‘开源’, ‘Zookeeper’),
(‘高’, ‘Zookeeper’),
(‘从零开始’, ‘开源’),
(‘Zookeeper’, ‘开源’),
(‘高’, ‘开源’),
(‘可靠’, ‘开源’),
(‘Zookeeper’, ‘高’),
(‘开源’, ‘高’),
(‘可靠’, ‘高’),
(‘分布式’, ‘高’),
(‘开源’, ‘可靠’)])
3. 获取cbow和skip-gram训练后的中文词向量
前提是需要使用中文去训练搭建的模型,可以参考
https://blog.csdn.net/Metal1/article/details/132886936
https://blog.csdn.net/L_goodboy/article/details/136347947
如果使用pytorch的Embeding的模型,获取的就是embeding层
class SkipGramModel(nn.Module):def __init__(self, vocab_size, embedding_dim):super(SkipGramModel, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.linear = nn.Linear(embedding_dim, vocab_size)def forward(self, center_word):embedded = self.embedding(center_word)output = self.linear(embedded)
"""
输出每个词的嵌入向量
for word, idx in word_to_idx.items(): print(f"{word}: {model.embedding.weight[:,idx].detach().numpy()}")
"""
如果使用原生的写的模型,获取的就是第一层的线性层
import torch.nn as nn # 导入 neural network
class SkipGram(nn.Module):def __init__(self, voc_size, embedding_size):super(SkipGram, self).__init__()# 从词汇表大小到嵌入层大小(维度)的线性层(权重矩阵)self.input_to_hidden = nn.Linear(voc_size, embedding_size, bias=False) # 从嵌入层大小(维度)到词汇表大小的线性层(权重矩阵)self.hidden_to_output = nn.Linear(embedding_size, voc_size, bias=False) def forward(self, X): # 前向传播的方式,X 形状为 (batch_size, voc_size) # 通过隐藏层,hidden 形状为 (batch_size, embedding_size)hidden = self.input_to_hidden(X) # 通过输出层,output_layer 形状为 (batch_size, voc_size)output = self.hidden_to_output(hidden) return output
"""
输出每个词的嵌入向量
for word, idx in word_to_idx.items(): print(f"{word}: {model.input_to_hidden .weight[:,idx].detach().numpy()}")
"""
4. 获取到词向量后可以做什么
“具有相同上下文的词语包含相似的语义”,使得语义相近的词在映射到欧式空间后中具有较高的余弦相似度。
-
语义相似性度量:词向量能够将语义上相近的词映射到向量空间中相近的位置。因此,可以通过计算两个词向量的余弦相似度或欧氏距离来度量它们之间的语义相似性。这在诸如词义消歧、同义词替换等任务中非常有用。
-
文本分类与情感分析:在文本分类任务(如新闻分类、电影评论情感分析)中,词向量可以作为特征输入到分类器中。通过将文本中的每个词表示为向量,并聚合这些向量(例如,通过取平均值或求和),可以得到整个文本的向量表示,进而用于分类或情感分析。
-
命名实体识别:在命名实体识别(NER)任务中,词向量可以帮助模型识别文本中的特定类型实体(如人名、地名、组织机构名等)。通过将词向量与序列标注模型(如BiLSTM-CRF)结合使用,可以提高NER的性能。
-
问答系统:在问答系统中,词向量可以用于表示问题和答案的语义信息。通过计算问题和答案的词向量之间的相似度,可以找出与问题最匹配的答案。
-
机器翻译:在机器翻译任务中,词向量可以用于捕捉源语言和目标语言之间的语义对应关系。通过训练跨语言的词向量表示(如跨语言词嵌入),可以实现更准确的翻译结果。
-
文本生成:在文本生成任务(如文本摘要、对话生成等)中,词向量可以作为生成模型的输入或隐层表示。通过利用词向量中的语义信息,模型可以生成更自然、更相关的文本内容。
-
知识图谱与实体链接:在知识图谱构建和实体链接任务中,词向量可以用于表示实体和概念之间的语义关系。通过将实体和概念映射到向量空间,可以方便地进行实体识别和关系推理。
5. 余弦相似度结果的解释
余弦相似度的结果范围通常在-1到1之间,这个范围可以用来解释两个向量之间的相似程度
-
值为1:当余弦相似度为1时,表示两个向量完全重合,即它们指向的方向完全相同,这意味着两个向量代表的文本或概念在语义上几乎完全相同。
-
值为-1:当余弦相似度为-1时,表示两个向量完全相反,即它们指向的方向完全相反。在文本相似度的上下文中,这通常意味着两个文本在语义上非常对立或相反。
-
值为0:当余弦相似度为0时,表示两个向量正交,即它们之间的夹角为90度。在文本相似度的语境中,这通常意味着两个文本在语义上没有直接的联系或相似性。
-
值在0到1之间:当余弦相似度在0和1之间时,表示两个向量之间的夹角小于90度,但不完全重合。数值越接近1,表示两个向量在方向上的相似性越高,即两个文本在语义上的相似性越高。
-
值在-1到0之间:当余弦相似度在-1和0之间时,表示两个向量之间的夹角大于90度但小于180度。数值越接近-1,表示两个向量在方向上的对立性越高,即两个文本在语义上的对立性越高
如
其中trained_vector_dic是通过模型获取的词向量字典
余弦相似度
trained_vector_dic={}
for word, idx in word_to_idx.items(): # 输出每个词的嵌入向量trained_vector_dic[word]=model.embedding.weight[idx]import torch
import torch.nn.functional as F
cosine_similarity1 = F.cosine_similarity(torch.tensor(trained_vector_dic["保持数据"].unsqueeze(0)), torch.tensor(trained_vector_dic["打印信息"]).unsqueeze(0))
print(cosine_similarity1)
"""
结果如下,表名不相似
tensor([-0.0029])
"""
点积相似度
dot_product = torch.dot(torch.tensor(trained_vector_dic["保持数据"]), torch.tensor(trained_vector_dic["打印信息"]))
x_length = torch.norm(torch.tensor(trained_vector_dic["保持数据"]))
y_length = torch.norm(torch.tensor(trained_vector_dic["打印信息"]))
similarity = dot_product / (x_length * y_length)
print(similarity)
"""
结果如下,表名不相似,与余弦结果一致
tensor([-0.0029])
"""
相关文章:

python-pytorch使用日志0.5.007
python-pytorch使用日志 1. optimizer.zero_grad()和model.zero_grad()的区别2. cbow和skip-gram的训练数据格式3. 获取cbow和skip-gram训练后的中文词向量4. 获取到词向量后可以做什么5. 余弦相似度结果的解释 1. optimizer.zero_grad()和model.zero_grad()的区别 都是清空模…...
itop4412编译内核时garbage following instruction -- `dmb ish‘ 解决方案
王德法 没人指导的学习路上磕磕绊绊太耗费时间了 今天编译4412开发板源码时报 garbage following instruction – dmb ish’ 以下是解决方案: 1.更新编译器 sudo apt-get install gcc-arm-linux-gnueabi 更新后修改Makefile 中编译器路径如下图 2.你以为更新完就可…...
(学习日记)2024.04.16:UCOSIII第四十四节:内存管理
写在前面: 由于时间的不足与学习的碎片化,写博客变得有些奢侈。 但是对于记录学习(忘了以后能快速复习)的渴望一天天变得强烈。 既然如此 不如以天为单位,以时间为顺序,仅仅将博客当做一个知识学习的目录&a…...

微信小程序Skyline模式下瀑布长列表优化成虚拟列表,解决内存问题
微信小程序长列表,渲染的越多就会导致内存吃的越多。特别是长列表的图片组件和广告组件。 为了解决内存问题,所以看了很多人的资料,都不太符合通用的解决方式,很多需要固定子组件高度,但是瀑布流是无法固定的…...

大语言模型LLM《提示词工程指南》学习笔记03
文章目录 大语言模型LLM《提示词工程指南》学习笔记03链式提示思维树检索增强生成自动推理并使用工具自动提示工程师Active-Prompt方向性刺激提示Program-Aided Language ModelsReAct框架Reflexion多模态思维链提示方法基于图的提示大语言模型LLM《提示词工程指南》学习笔记03 …...
)
239. 奇偶游戏(带权值并查集,邻域并查集,《算法竞赛进阶指南》)
239. 奇偶游戏 - AcWing题库 小 A 和小 B 在玩一个游戏。 首先,小 A 写了一个由 0 和 1 组成的序列 S,长度为 N。 然后,小 B 向小 A 提出了 M 个问题。 在每个问题中,小 B 指定两个数 l 和 r,小 A 回答 S[l∼r] 中…...
程序员做副业,AI头条,新赛道
大家好,我是老秦,6年编程,自由职业3年,今天继续更新副业内容。 在当今信息爆炸的时代,副业赚钱已成为许多人增加收入的重要途径。其中,AI头条模式以其独特的优势,吸引了越来越多的写作者加入。…...

Redis: 内存回收
文章目录 一、过期键删除策略1、惰性删除2、定时删除3、定期删除4、Redis的过期键删除策略 二、内存淘汰策略1、设置过期键的内存淘汰策略2、全库键的内存淘汰策略 一、过期键删除策略 1、惰性删除 顾名思义并不是在TTL到期后就立即删除,而是在访问一个key的时候&…...

【刷题篇】回溯算法(三)
文章目录 1、全排列2、子集3、找出所有子集的异或总和再求和4、全排列 II5、电话号码的字母组合6、括号生成 1、全排列 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 class Solution { public:vector<vector<i…...
-导入表)
pe格式从入门到图形化显示(八)-导入表
文章目录 前言一、什么是Windows PE格式中的导入表?二、解析导入表并显示1.导入表的结构2.解析导入表3.显示导入表 前言 通过分析和解析Windows PE格式,并使用qt进行图形化显示 一、什么是Windows PE格式中的导入表? 在Windows中࿰…...
模型转换为TensorFlow(Lite)模型)
如何将Paddle(Lite)模型转换为TensorFlow(Lite)模型
模型间的相互转换在深度学习应用中很常见,paddlelite和TensorFlowLite是移动端常用的推理框架,有时候需要将模型在两者之间做转换,本文将对转换方法做说明。 环境准备 建议使用TensorFlow2.14,PaddlePaddle 2.6 docker pull te…...
最新Zibll子比主题V7.1版本源码 全新推出开心版
源码下载地址:Zibll子比主题V7.1.zip...

响应式布局(其次)
响应式布局 一.响应式开发二.bootstrap前端开发框架1.原理2.优点3.版本问题4.使用(1)创建文件夹结构(2)创建html骨架结构(3)引入相关样式(4)书写内容 5.布局容器(已经划分…...

arhtas idea plugin 使用手册
arthas idea plugin 使用文档 语雀...
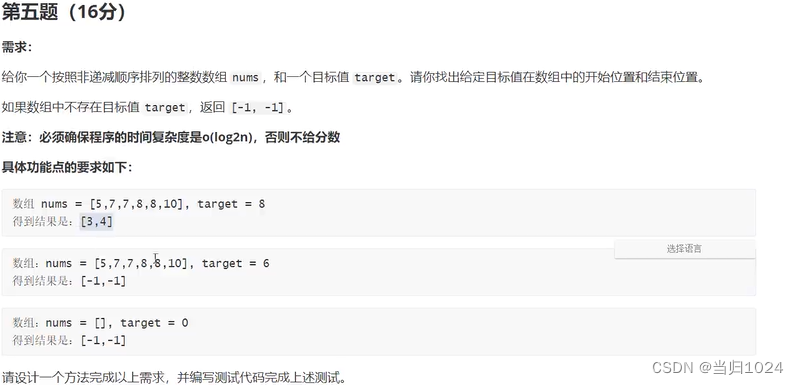
数组算法——查询位置
需求 思路 使用二分查找找到第一个值,以第一个值作为界限,分为左右两个区间在左右两个区间分别使用二分查找找左边的7,:找到中间位置的7之后,将中间位置的7作为结束位置,依次循环查找,知道start>end,返回…...

【解决leecode打不开的问题】使用chrome浏览器和其他浏览器均打不开leecode
问题描述: 能进入leetcode力扣官网但是对某些栏目加载不出来,比如学习栏目能完成加载、题库栏目不能加载。 解决方法一:cookies缓存问题 首先尝试删除浏览器cookie缓存。 因为以下原因: Cookies损坏或过期:有些网站…...
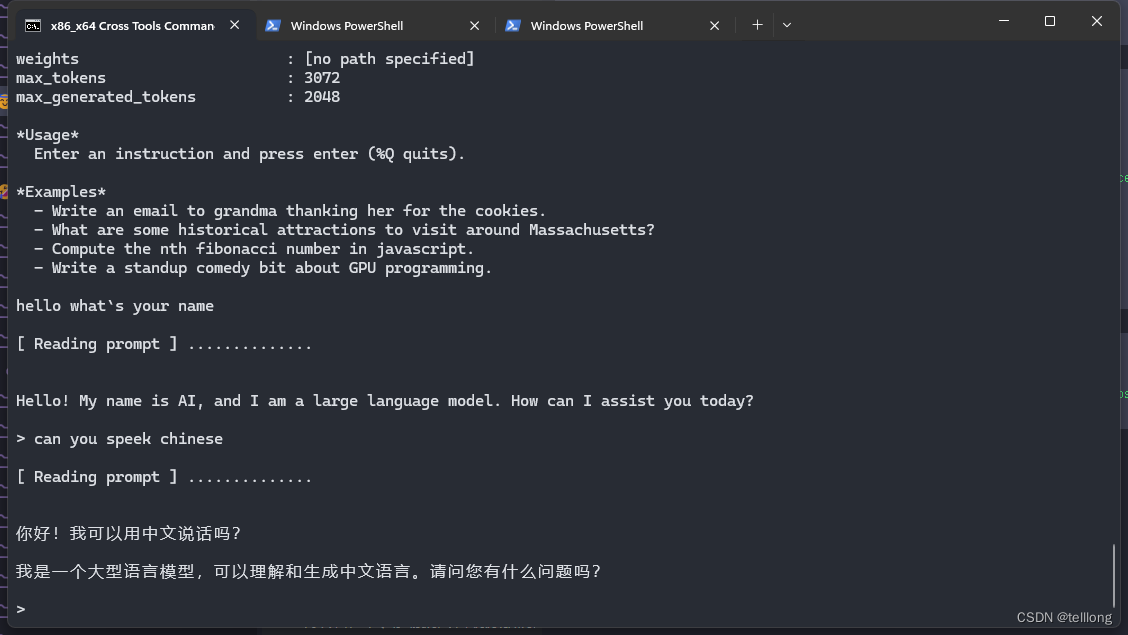
尝试在手机上运行google 最新开源的gpt模型 gemma
Gemma介绍 Gemma简介 Gemma是谷歌于2024年2月21日发布的一系列轻量级、最先进的开放语言模型,使用了与创建Gemini模型相同的研究和技术。由Google DeepMind和Google其他团队共同开发。 Gemma提供两种尺寸的模型权重:2B和7B。每种尺寸都带有经过预训练&a…...
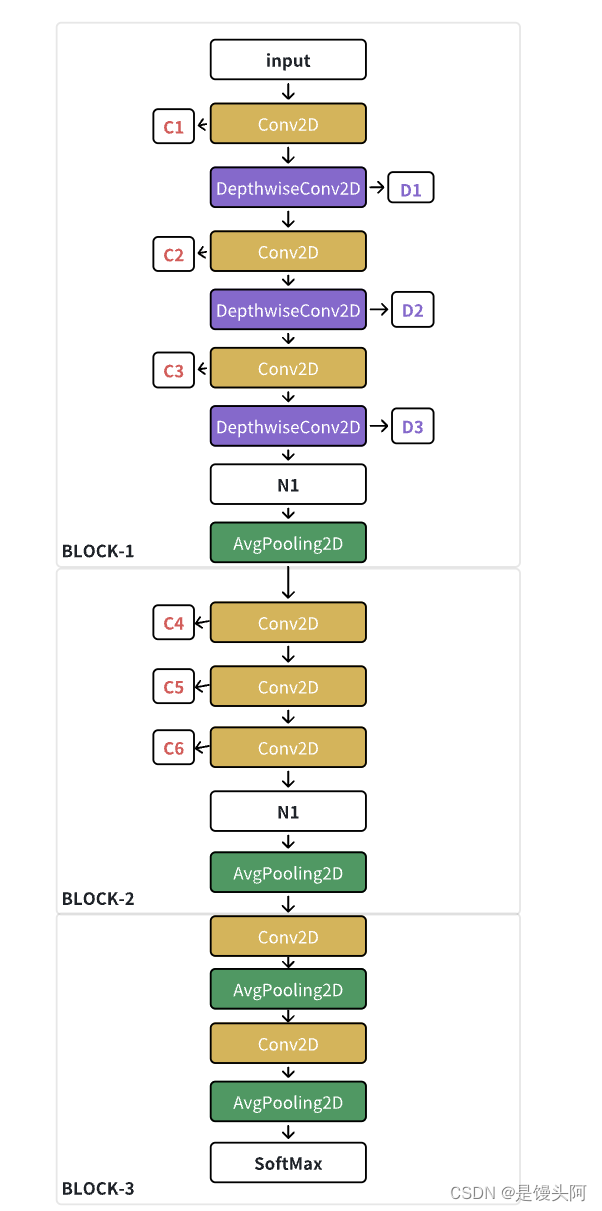
56、巴利亚多利德大学、马德里卡洛斯三世研究所:EEG-Inception-多时间尺度与空间卷积巧妙交叉堆叠,终达SOTA!
本次讲解一下于2020年发表在IEEE TRANSACTIONS ON NEURAL SYSTEMS AND REHABILITATION ENGINEERING上的专门处理EEG信号的EEG-Inception模型,该模型与EEGNet、EEG-ITNet、EEGNex、EEGFBCNet等模型均是专门处理EEG的SOTA。 我看到有很多同学刚入门,不太会…...
ORA-00600: internal error code, arguments: [krbcbp_9]
解决方案 1、清理过期 2、control_file_record_keep_time 修改 恢复时间窗口 RMAN (Recovery Manager) 是 Oracle 数据库的备份和恢复工具。在 RMAN 中,可以使用“恢复窗口”的概念来指定数据库可以恢复到的时间点。这个时间点是基于最近的完整备份或增量备份。 …...
uni-app实现分页--(2)分页加载,首页下拉触底加载更多
业务逻辑如下: api函数升级 定义分页参数类型 组件调用api传参...

解锁硬件潜能:Universal x86 Tuning Utility 让你的电脑性能全面释放
解锁硬件潜能:Universal x86 Tuning Utility 让你的电脑性能全面释放 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility …...

c++如何处理文件路径中由于不规范的连续斜杠导致的路径解析错误【避坑】
std::filesystem::path 对多个斜杠不自动归一,C://foo 被误解析为 UNC 导致 parent_path() 等行为异常;应优先使用 lexically_normal() 归一化,它安全、标准、不访问文件系统,可将 C://temp///log.txt 变为 C:/temp/log.txt。Wind…...

Bootstrap中.d-none类在不同分辨率下的高级用法
.d-none 单独使用会在所有尺寸下隐藏元素,因其含 !important 会覆盖无 !important 的响应式显示类;正确做法是避免混用,改用纯响应式组合如 .d-md-block .d-lg-flex。为什么 .d-none 在某些断点下不生效?Bootstrap 的 .d-none 是个…...

jQuery - 获取并设置 CSS 类
jQuery - 获取并设置 CSS 类 学习笔记 CSS 类(Class)是控制元素样式的关键。jQuery 提供了一组简洁的方法来动态地添加、移除、切换和检查 CSS 类,这是实现交互效果(如高亮、显示/隐藏、状态切换)最常用的手段。 一、核…...

golang如何实现群聊功能_golang群聊功能实现策略
使用 gorilla/websocket 实现群聊需维护连接 map 并加锁广播,排除自身连接避免重复消息;启用心跳与读写超时机制处理断连;消息持久化推荐 Redis Stream 分层存储,配合 seq 去重保障时序一致性。用 net/http gorilla/websocket 建…...

解锁学术新秘籍:书匠策AI,期刊论文的智能导航员
在学术的浩瀚海洋中,每一位研究者都像是勇敢的航海家,驾驶着知识的航船,探索未知的领域。而期刊论文,作为学术交流的重要载体,不仅是研究成果的展示窗口,更是推动学科进步的强劲动力。然而,撰写…...

解锁学术新境界:书匠策AI——期刊论文创作的智慧灯塔
在学术探索的浩瀚海洋中,每一位研究者都如同勇敢的航海家,怀揣着对知识的渴望,驾驭着思维的航船,不断追寻着真理的彼岸。而在这漫长的旅途中,一篇高质量的期刊论文,无疑是那指引方向的灯塔,照亮…...
_kaic)
ssm社区物业信息管理系统小程序(文档+源码)_kaic
系统实现登录模块的实现系统的登录窗口是用户的入口,用户只有在登录成功后才可以进入访问。通过在登录提交表单,后台处理判断是否为合法用户,进行页面跳转,进入系统中去。登录合法性判断过程:用户输入账号和密码后&…...

你的 Vue v-model,VuReact 会编译成什么样的 React 代码?
VuReact 是一个能将 Vue 3 代码编译为标准、可维护 React 代码的工具。今天就带大家直击核心:Vue 中常见的 v-model 指令经过 VuReact 编译后会变成什么样的 React 代码? 前置约定 为避免示例代码冗余导致理解偏差,先明确两个小约定&#x…...

终极SI4735 Arduino收音机开发实战:从零构建你的数字广播接收系统
终极SI4735 Arduino收音机开发实战:从零构建你的数字广播接收系统 【免费下载链接】SI4735 SI473X Library for Arduino 项目地址: https://gitcode.com/gh_mirrors/si/SI4735 在物联网和智能硬件快速发展的今天,如何快速搭建一个功能全面的广播接…...