Linux系统——Elasticsearch企业级日志分析系统
目录
前言
一、ELK概述
1.ELK简介
2.ELK特点
3.为什么要使用ELK
4.完整日志系统基本特征
5.ELK工作原理
6.Elasticsearch介绍
6.1Elasticsearch概述
6.2Elasticsearch核心概念
7.Logstash介绍
7.1Logstash简介
7.2Logstash主要组件
8.Kibana介绍
8.1Kibana简介
8.2Kibana主要功能
二、ELFK集群部署
1.环境准备
2.ELK Elasticsearch集群部署
2.1Node1和Node2节点
3.安装Elasticsearch-head插件
4.插入索引
4.安装Logstash
4.1测试Logstash
5.定义Logstash配置文件
6.安装Kiabana
6.1验证Kiabana
6.2Apache服务器日志通过Kiabana显示
7.部署配置Filebeat
7.1部署Filebeat
7.2配置Logstash
前言
日志服务器
- 提高安全性
- 集中存放日志
- 缺陷:对日志的分析困难
ELK日志分析系统
- Elasticsearch
- Logstash
- Kibana
一、ELK概述
1.ELK简介
ELK平台是一个开源的分布式搜索和分析引擎,有一套完整的日志集中处理解决方案,最初由Elastic公司开发。Elasticsearch基于Apache Lucene搜索引擎构建,提供了一个分布式、RESTful的接口,可以快速地存储、搜索和分析大量数据。将 ElasticSearch、Logstash 和 Kiabana 三个开源工具配合使用, 完成更强大的用户对日志的查询、排序、统计需求。它被广泛用于实时搜索、日志分析、数据可视化等领域。
- ElasticSearch:是基于Lucene(一个全文检索引擎的架构)开发的分布式存储检索引擎,用来存储各类日志。
- Elasticsearch 是用 Java 开发的,可通过 RESTful Web 接口,让用户可以通过浏览器与 Elasticsearch 通信。
- Elasticsearch是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大容量的日志数据,也可用于搜索许多不同类型的文档。
- Kiabana:Kibana 通常与 Elasticsearch 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 提供图形化的 web 界面来浏览 Elasticsearch 日志数据,可以用来汇总、分析和搜索重要数据。
- Logstash:作为数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置,一般会发送给 Elasticsearch。
- Logstash 由 Ruby 语言编写,运行在 Java 虚拟机(JVM)上,是一款强大的数据处理工具, 可以实现数据传输、格式处理、格式化输出。Logstash 具有强大的插件功能,常用于日志处理。
- 相对 input(数据采集) filter(数据过滤) output(数据输出)
可添加其他组件:
Filebeat:轻量级的开源日志文件数据搜集器。通常在需要采集数据的客户端安装 Filebeat,并指定目录与日志格式,Filebeat 就能快速收集数据,并发送给 logstash 进或是直接发给 Elasticsearch 存储,性能上相比运行于 JVM 上的 logstash 优势明显,是对它的替代。常应用于 EFLK 架构当中。
filebeat 结合 logstash 带来好处:
- 通过 Logstash 具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,从而减轻 Elasticsearch 持续写入数据的压力
- 从其他数据源(例如数据库,S3对象存储或消息传递队列)中提取
- 将数据发送到多个目的地,例如S3,HDFS(Hadoop分布式文件系统)或写入文件
- 使用条件数据流逻辑组成更复杂的处理管道
- 缓存/消息队列(redis、kafka、RabbitMQ等):可以对高并发日志数据进行流量削峰和缓冲,这样的缓冲可以一定程度的保护数据不丢失,还可以对整个架构进行应用解耦。
- Fluentd:是一个流行的开源数据收集器。由于 logstash 太重量级的缺点,Logstash 性能低、资源消耗比较多等问题,随后就有 Fluentd 的出现。相比较 logstash,Fluentd 更易用、资源消耗更少、性能更高,在数据处理上更高效可靠,受到企业欢迎,成为 logstash 的一种替代方案,常应用于 EFK 架构当中。在 Kubernetes 集群中也常使用 EFK 作为日志数据收集的方案。
- 在 Kubernetes 集群中一般是通过 DaemonSet 来运行 Fluentd,以便它在每个 Kubernetes 工作节点上都可以运行一个 Pod。 它通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
2.ELK特点
- 分布式:Elasticsearch允许数据在多个节点上分布存储,实现高可用性和横向扩展。
- 实时性:Elasticsearch能够实时地索引数据,并且搜索操作也是实时的,适用于需要快速数据检索的场景。
- 多功能性:除了文本搜索,Elasticsearch还支持结构化数据的存储和检索,可以用于各种不同类型的数据分析任务。
- 易用性:Elasticsearch提供了简单易用的RESTful API,使得开发人员可以方便地与其交互,并且具有丰富的客户端库和插件支持。
总的来说,Elasticsearch是一个功能强大且灵活的搜索和分析引擎,被广泛应用于各种大数据场景中。
3.为什么要使用ELK
日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
往往单台机器的日志我们使用grep、awk等工具就能基本实现简单分析,但是当日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用 grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
4.完整日志系统基本特征
- 收集:能够采集多种来源的日志数据
- 传输:能够稳定的把日志数据解析过滤并传输到存储系统
- 存储:存储日志数据
- 分析:支持 UI 分析
- 警告:能够提供错误报告,监控机制
5.ELK工作原理
- 在所有需要收集日志的服务器上部署Logstash,将日志进行集中化管理;或者先将日志进行集中化管理在日志服务器上,在日志服务器上部署 Logstash。
- Logstash 收集日志,将日志格式化并输出到 Elasticsearch 群集中。
- Elasticsearch 对格式化(Logstash)后的数据进行索引和存储。
- Kibana 从 ES 群集中查询数据生成图表,并进行前端数据的展示。
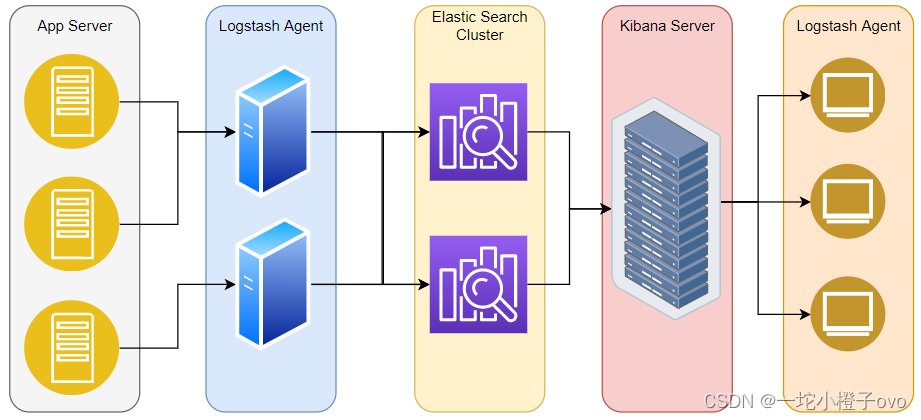
- App Server(应用服务器):如Nginx、Tomcat、微服务
- Logstash Agent:收集引擎,可对日志进行集中处理
- Elastic Search Cluster:日志分析集群,日志分析
- Kibana Server:可视化界面展示日志
- Browser:客户端可以通过登录平台查看或对日志进行操作
logstash作为日志搜集器,从数据源采集数据,并对数据进行过滤,格式化处理,然后交由Elasticsearch存储,kibana对日志进行可视化处理。
6.Elasticsearch介绍
6.1Elasticsearch概述
Elasticsearch提供了一个分布式多用户能力的全文搜索引擎
6.2Elasticsearch核心概念
- 接近实时
- 集群:有分布式一定有集群
- 节点:集群中某一台服务器
- 索引:索引(库)→索引(表)→文档(记录)
- 分片和副本:分片:索引分片,每一个分片都是独立的索引;副本:索引副本
补充知识:Elasticsearch 是用 Java 开发的,可通过 RESTful Web 接口,让用户可以通过浏览器与 Elasticsearch 通信。
RESTful apiRESTful api:GET获取文档、POST创建文档、PUT更新文档、DELETE删除文档、GET搜索值
7.Logstash介绍
7.1Logstash简介
- 一款强大的数据处理工具
- 可实现数据传输、格式处理、格式化输出
- 数据输入、数据加工(过滤、改写等)以及数据输出
数据输入收集日志、数据过滤(数据处理)、数据输出给Elasticsearch
7.2Logstash主要组件
- Shipper:日志收集者
- Indexer:存储
- Broker:负责连接多个日志收集者,还需要负责搜素和存储,相当于中间传话人
- Search and Storage:搜索和存储
- Web Interface:基于Web展示数据界面

Logstash:数据输入(Input)、数据过滤(Filter)、数据输出(Output)
8.Kibana介绍
8.1Kibana简介
- 一个针对Elasticsearch的开源分析及可视化平台
- 搜索、查看存储在Elasticsearch索引中的数据
- 通过各种图表进行高级数据分析
8.2Kibana主要功能
- Elasticsearch无缝之集成
- 整合数据,复杂数据分析
- 让更多团队成员受益
- 接口灵活,分享更容易
- 配置简单,可视化多数据源
- 简单数据导出
二、ELFK集群部署
Node1:192.168.241.11(Elasticsearch Kibana)
Node2:192.168.241.22(Elasticsearch)
Apache:192.168.241.23(Logstash Apache)
1.环境准备
systemctl stop firewalld
setenforce 02.ELK Elasticsearch集群部署
2.1Node1和Node2节点
vim /etc/hosts
tail -n2 /etc/hosts
192.168.241.11 node1
192.168.241.22 node2rpm -ivh elasticsearch-5.5.0.rpm
systemctl daemon-reload
systemctl enable elasticsearch.service
Created symlink from /etc/systemd/system/multi-user.target.wants/elasticsearch.service to /usr/lib/systemd/system/elasticsearch.service.cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml_bakvim /etc/elasticsearch/elasticsearch.ymlgrep -v "^#" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-elk-cluster
#17--取消注释,指定集群名字
node.name: node1
#23--取消注释,指定节点名字
#node2机器与其不一致 该项为node2
path.data: /data/elk_data
#33--取消注释,指定数据存放路径
path.logs: /var/log/elasticsearch
#37--取消注释,指定日志存放路径
bootstrap.memory_lock: false
#43--取消注释,改为在启动的时候不锁定内存
network.host: 0.0.0.0
#55--取消注释,设置监听地址,0.0.0.0代表所有地址
http.port: 9200
#59--取消注释,ES 服务的默认监听端口为9200
discovery.zen.ping.unicast.hosts: ["node1", "node2"]
#68--取消注释,集群发现通过单播实现,指定要发现的节点 node1、node2mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data/
#创建数据存放路径并授权systemctl start elasticsearch.service
#启动elasticsearch是否成功开启
netstat -antp|grep 9200
tcp6 0 0 :::9200 :::* LISTEN 8472/java
#大概要等待十几秒 耐心等待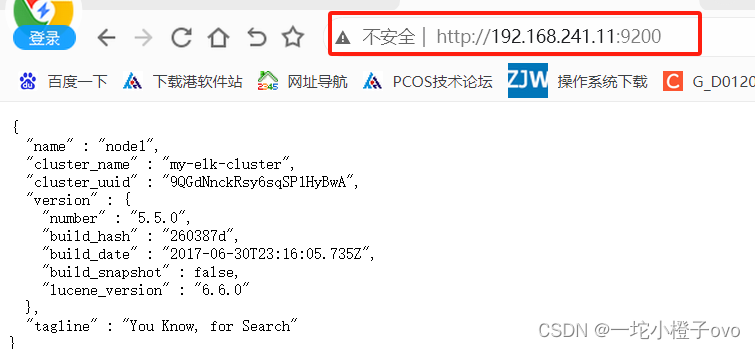
查看节点信息,出现该界面表示成功部署Elasticsearch节点
3.安装Elasticsearch-head插件
Node1:192.168.241.11
Elasticsearch 在 5.0 版本后,Elasticsearch-head 插件需要作为独立服务进行安装,需要使用npm工具(NodeJS的包管理工具)安装。
安装 Elasticsearch-head 需要提前安装好依赖软件 node 和 phantomjs。
node:是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
phantomjs:是一个基于 webkit 的JavaScriptAPI,可以理解为一个隐形的浏览器,任何基于 webkit 浏览器做的事情,它都可以做到。
#编译安装Node
[root@node1 opt]#yum install gcc gcc-c++ make -y
[root@node1 opt]#ls
elasticsearch-5.5.0.rpm node-v8.2.1.tar.gz rh
[root@node1 opt]#tar zxvf node-v8.2.1.tar.gz
[root@node1 opt]#ls
elasticsearch-5.5.0.rpm node-v8.2.1 node-v8.2.1.tar.gz rh
[root@node1 opt]#cd node-v8.2.1/
[root@node1 node-v8.2.1]#./configure
[root@node1 node-v8.2.1]#make -j 2 && make install#安装Phantomjs(前端的框架)
[root@node1 node-v8.2.1]#cd /opt
[root@node1 opt]#tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/local/src/
[root@node1 opt]#cd /usr/local/src/phantomjs-2.1.1-linux-x86_64/bin/
[root@node1 bin]#ls
phantomjs
[root@node1 bin]#cp phantomjs /usr/local/bin/
[root@node1 bin]#cd /opt/
[root@node1 opt]#ls
elasticsearch-5.5.0.rpm node-v8.2.1.tar.gz rh
node-v8.2.1 phantomjs-2.1.1-linux-x86_64.tar.bz2#安装Elasticsearch-head 数据可视化工具
[root@node1 opt]#rz -E
rz waiting to receive.
[root@node1 opt]#ls
elasticsearch-5.5.0.rpm node-v8.2.1.tar.gz
elasticsearch-head.tar.gz phantomjs-2.1.1-linux-x86_64.tar.bz2
node-v8.2.1 rh
[root@node1 opt]#tar zxvf elasticsearch-head.tar.gz -C /usr/local/src/
[root@node1 opt]#cd /usr/local/src/elasticsearch-head/
[root@node1 elasticsearch-head]#ls
Dockerfile package.json
Dockerfile-alpine package-lock.json
elasticsearch-head.sublime-project plugin-descriptor.properties
Gruntfile.js proxy
grunt_fileSets.js README.textile
index.html _site
LICENCE src
node_modules test
[root@node1 elasticsearch-head]#npm install #修改Elasticsearch主配置文件
[root@node1 elasticsearch-head]#vim /etc/elasticsearch/elasticsearch.yml
[root@node1 elasticsearch-head]#tail -n2 /etc/elasticsearch/elasticsearch.yml
http.cors.enabled: true
#开启跨域访问支持,默认为 false
http.cors.allow-origin: "*"
#指定跨域访问允许的域名地址为所有
[root@node1 ~]#systemctl restart elasticsearch.servic
[root@node1 elasticsearch-head]#npm run start &
#必须在解压后的 elasticsearch-head 目录下启动服务,进程会读取该目录下的 gruntfile.js 文件,否则可能启动失败。
[1] 47416
[root@node1 elasticsearch-head]#
> elasticsearch-head@0.0.0 start /usr/local/src/elasticsearch-head
> grunt serverRunning "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
[root@node1 elasticsearch-head]#lsof -i:9100
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
grunt 47426 root 12u IPv4 37928 0t0 TCP *:jetdirect (LISTEN)
如果看到群集健康值为 green 绿色,代表群集很健康。
4.插入索引
[root@node1 ~]#curl -X PUT 'localhost:9200/index-demo1/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
{"_index" : "index-demo1","_type" : "test","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 2,"failed" : 0},"created" : true
}#通过命令插入一个测试索引,索引为 index-demo,类型为 test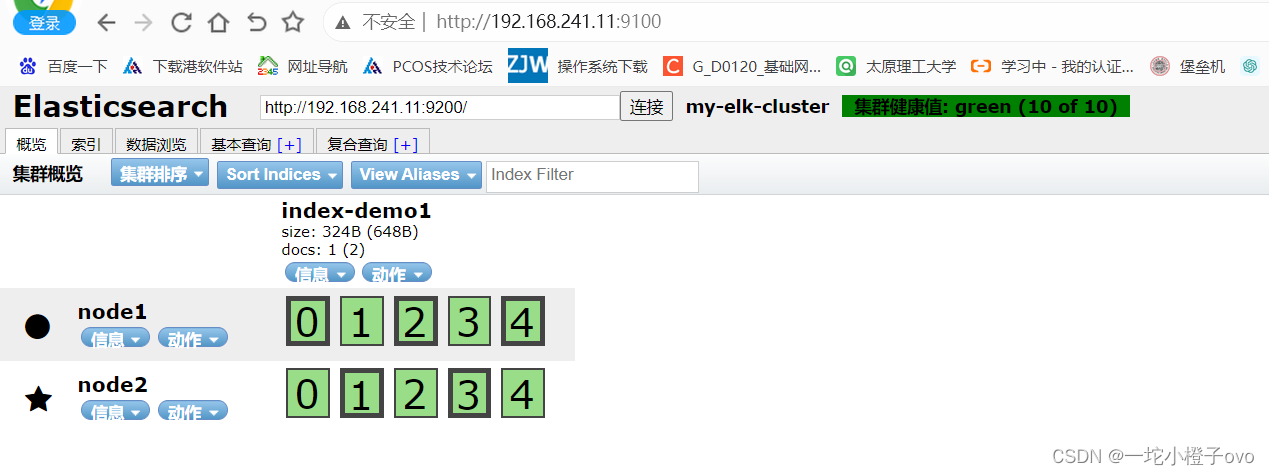
浏览器访问 http://192.168.10.13:9100/ 查看索引信息,可以看见索引默认被分片5个,并且有一个副本。
点击“数据浏览”,会发现在node1上创建的索引为 index-demo,类型为 test 的相关信息。

4.安装Logstash
Logstash 一般部署在需要监控其日志的服务器。在本案例中,Logstash 部署在 Apache 服务器上,用于收集 Apache 服务器的日志信息并发送到 Elasticsearch。
Logstash:192.168.241.23
[root@logstash opt]#ls
logstash-5.5.1.rpm rh
[root@logstash opt]#rpm -ivh logstash-5.5.1.rpm
[root@logstash opt]#java -version
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)
[root@logstash opt]#ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
[root@logstash opt]#yum install httpd -y
[root@logstash opt]#systemctl start logstash.service
[root@logstash opt]#systemctl enable logstash.service
Created symlink from /etc/systemd/system/multi-user.target.wants/logstash.service to /etc/systemd/system/logstash.service.
4.1测试Logstash
| 选项 | 含义 |
|---|---|
| -f | 通过这个选项可以指定 Logstash 的配置文件,根据配置文件配置 Logstash 的输入和输出流。 |
| -e | 从命令行中获取,输入、输出后面跟着字符串,该字符串可以被当作 Logstash 的配置(如果是空,则默认使用 stdin 作为输入,stdout 作为输出)。 |
| -t | 测试配置文件是否正确,然后退出。 |
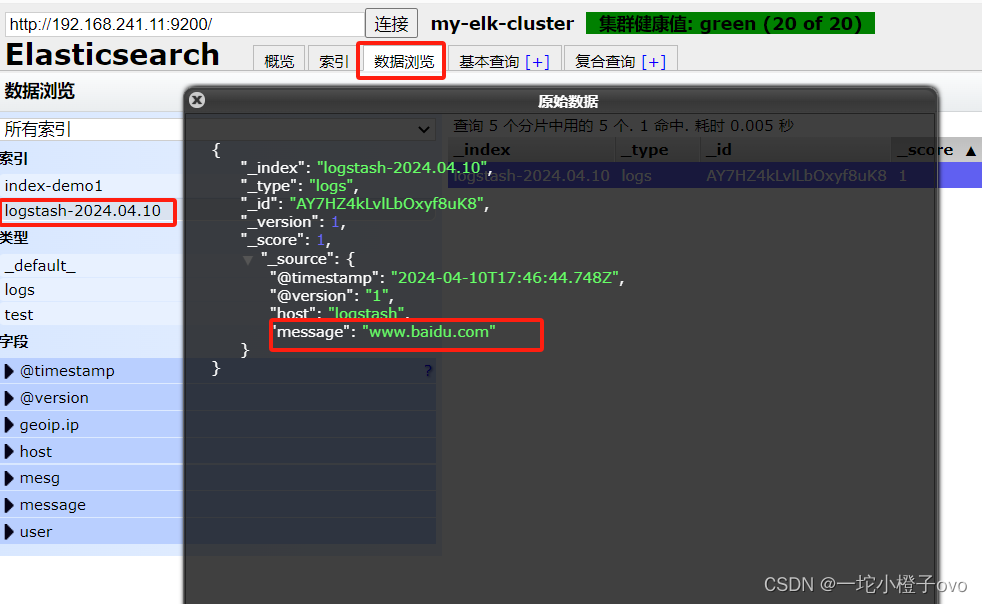
[root@logstash opt]#logstash -e 'input { stdin{} } output { stdout{} }'

www.baidu.com为键入值;2024-04-10T17:42:29.650Z logstash www.baidu.com为输出结果
Ctrl +C 退出
[root@logstash opt]#logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }'
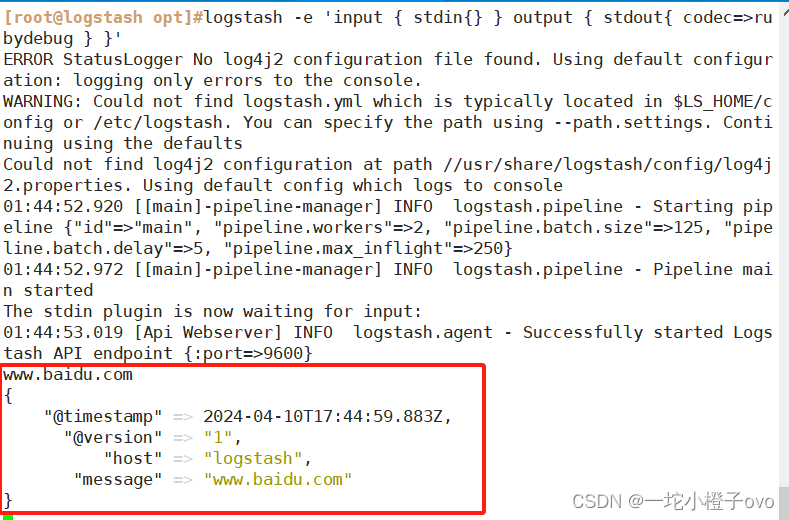
www.baidu.com键入内容;
输出结果:
{
"@timestamp" => 2024-04-10T17:44:59.883Z,
"@version" => "1",
"host" => "logstash",
"message" => "www.baidu.com"
}
[root@logstash opt]#logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.241.11:9200"] } }'
键入www.baidu.com,输出结果在浏览器的可视化页面
结果不在标准输出显示,而是发送至 Elasticsearch 中,可浏览器访问 http://192.168.10.13:9100/ 查看索引信息和数据浏览。

5.定义Logstash配置文件
Logstash 配置文件基本由三部分组成:input、output 以及 filter(可选,根据需要选择使用)。
- input:表示从数据源采集数据,常见的数据源如Kafka、日志文件等
- filter:表示数据处理层,包括对数据进行格式化处理、数据类型转换、数据过滤等,支持正则表达式
- output:表示将Logstash收集的数据经由过滤器处理之后输出到Elasticsearch。
[root@logstash opt]#cd /etc/logstash/conf.d/
[root@logstash conf.d]#ls
[root@logstash conf.d]#vim system.conf
[root@logstash conf.d]#cat system.conf
input {file{path =>"/var/log/messages"#指定要收集的日志的位置type =>"system"#自定义日志类型标识start_position =>"beginning"#表示从开始处收集}
}
output {elasticsearch {#输出到 elasticsearchhosts => [ "192.168.241.11:9200" ]#指定elasticsearch 服务器的地址和端口index =>"system-%{+YYYY.MM.dd}"#指定输出到 elasticsearch 的索引格式}
}
[root@logstash conf.d]#chmod +r /var/log/messages
#修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch 中。
[root@logstash conf.d]#systemctl restart logstash.service 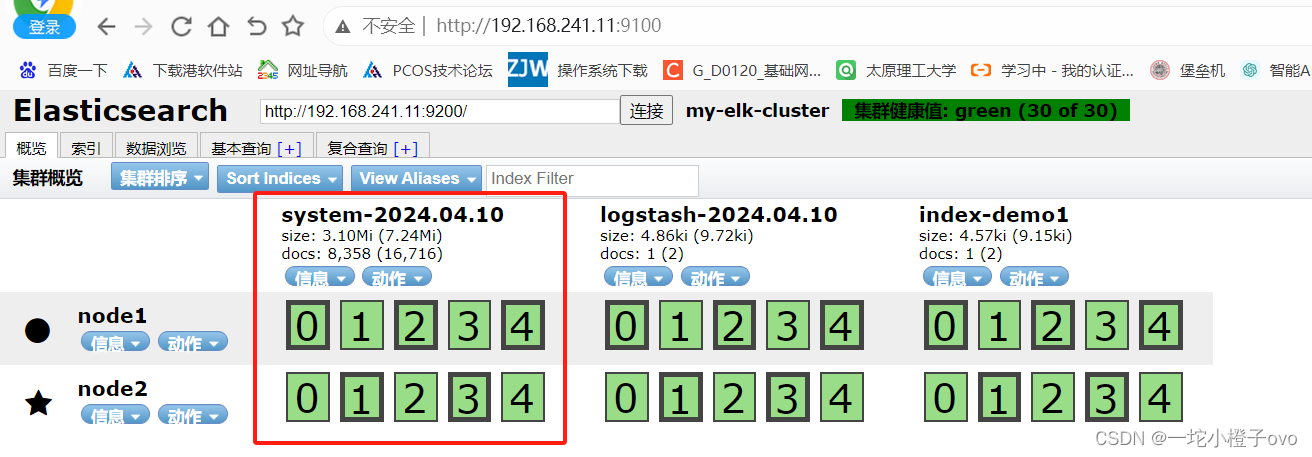

6.安装Kiabana
部署在Node1节点服务器上:192.168.241.11
[root@node1 opt]#ls
elasticsearch-5.5.0.rpm node-v8.2.1 rh
elasticsearch-head.tar.gz node-v8.2.1.tar.gz
kibana-5.5.1-x86_64.rpm phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@node1 opt]#rpm -ivh kibana-5.5.1-x86_64.rpm
[root@node1 opt]#cp /etc/kibana/kibana.yml /etc/kibana/kibana.yml_bak
[root@node1 opt]#vim /etc/kibana/kibana.yml
[root@node1 opt]#grep -v "^#" /etc/kibana/kibana.yml
server.port: 5601
#2--取消注释,Kiabana 服务的默认监听端口为5601
server.host: "0.0.0.0"
#7--取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址
elasticsearch.url: "http://192.168.241.11:9200"
#21--取消注释,设置和 Elasticsearch 建立连接的地址和端口
kibana.index: ".kibana"
#30--取消注释,设置在 elasticsearch 中添加.kibana索引
[root@node1 opt]#systemctl start kibana.service
[root@node1 opt]#systemctl enable kibana.service
Created symlink from /etc/systemd/system/multi-user.target.wants/kibana.service to /etc/systemd/system/kibana.service.
[root@node1 opt]#netstat -antp|grep 5601
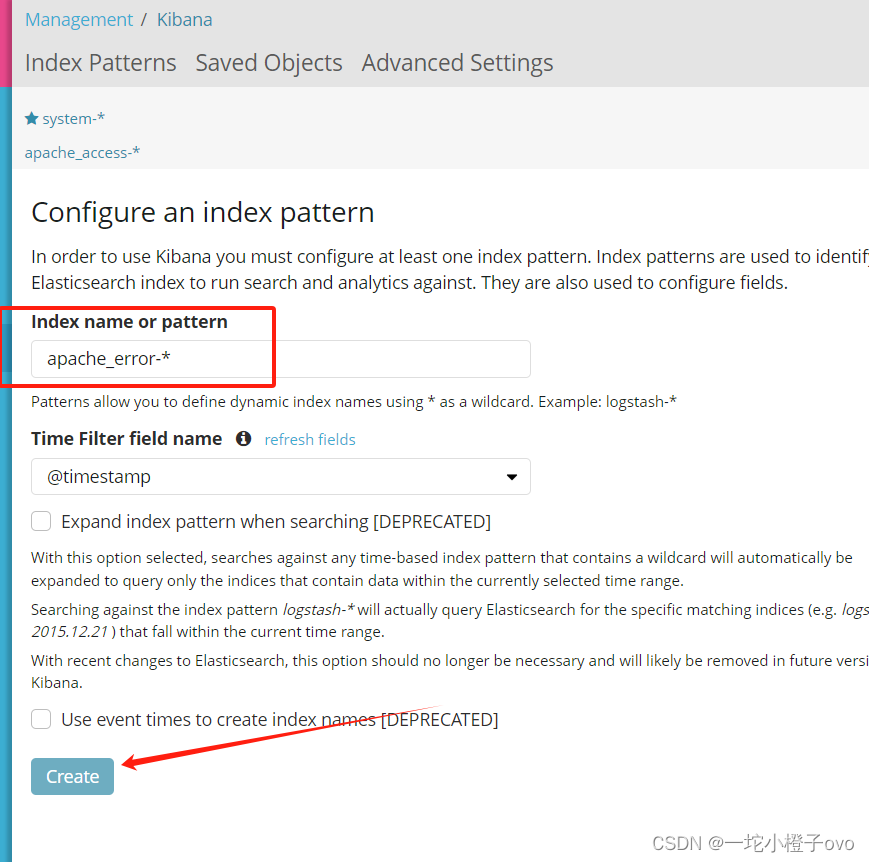
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 2801/node 6.1验证Kiabana
第一次登录需要添加一个 Elasticsearch 索引:
输入:system-* #在索引名中输入之前配置的 Output 前缀“system”

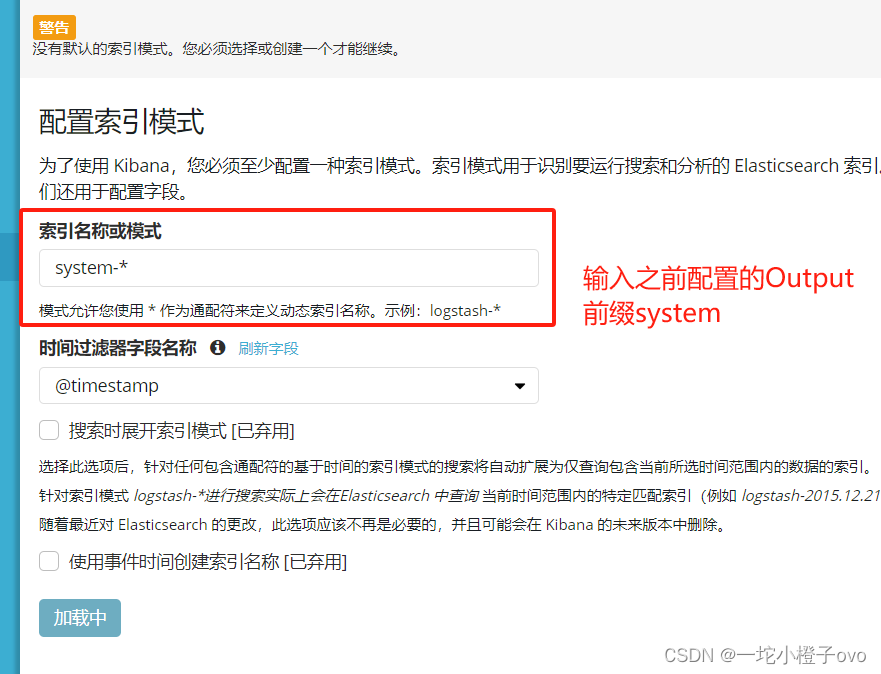
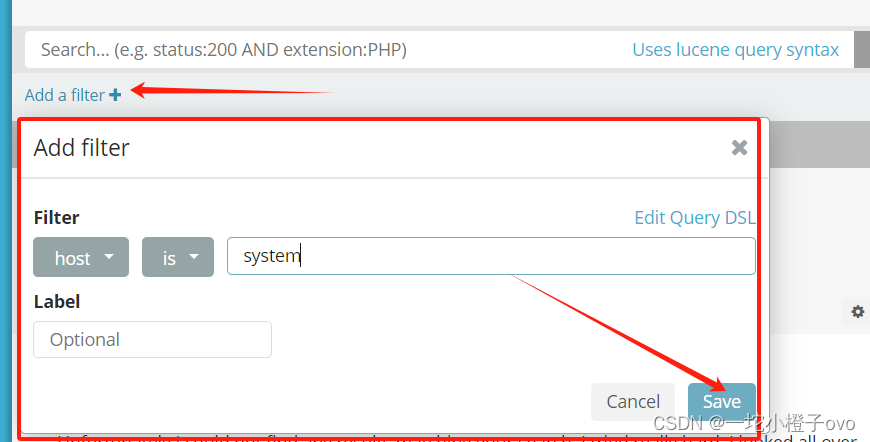

单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。
数据展示可以分类显示,在“Available Fields”中的“host”,然后单击 “add”按钮,可以看到按照“host”筛选后的结果
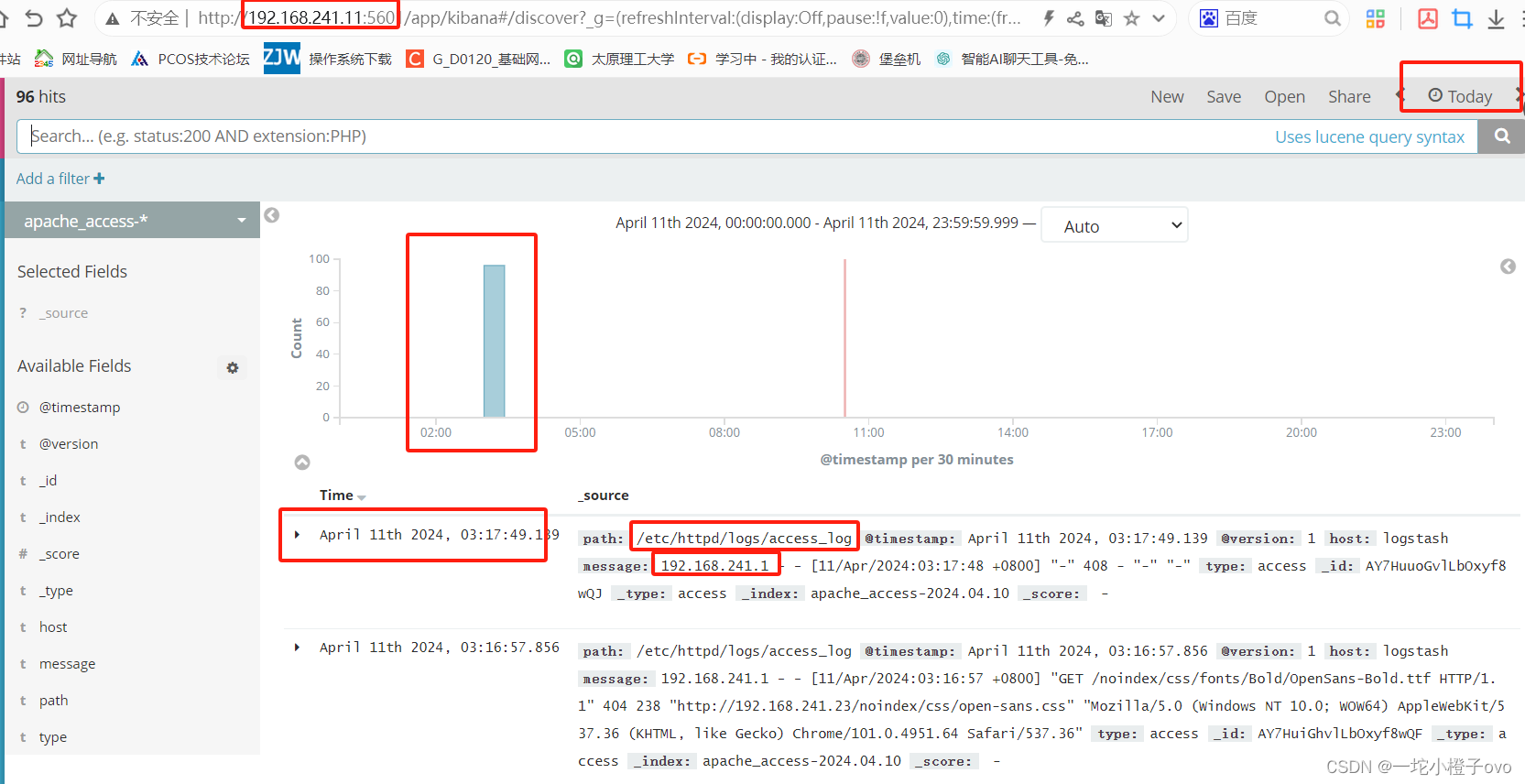
6.2Apache服务器日志通过Kiabana显示
[root@logstash ~]#vim /etc/logstash/conf.d/apache_log.conf
[root@logstash ~]#cat /etc/logstash/conf.d/apache_log.conf
input {file{path => "/etc/httpd/logs/access_log"#apache服务的访问日志路径type => "access"#访问日志start_position => "beginning"#从头开始}file{path => "/etc/httpd/logs/error_log"#apache服务的错误日志路径type => "error"#错误日志start_position => "beginning"#开始位置从头开始}
}
output {if [type] == "access" {#判断类型为访问日志elasticsearch {#指定与es建立连接的iphosts => ["192.168.241.11:9200"]index => "apache_access-%{+YYYY.MM.dd}"#索引为apache的_access的日期}}if [type] == "error" {# 判断类型为错误日志elasticsearch {hosts => ["192.168.241.11:9200"]index => "apache_error-%{+YYYY.MM.dd}"}}
}
[root@logstash ~]#cd /etc/logstash/conf.d/
[root@logstash conf.d]#/usr/share/logstash/bin/logstash -f apache_log.conf
#加载配置文件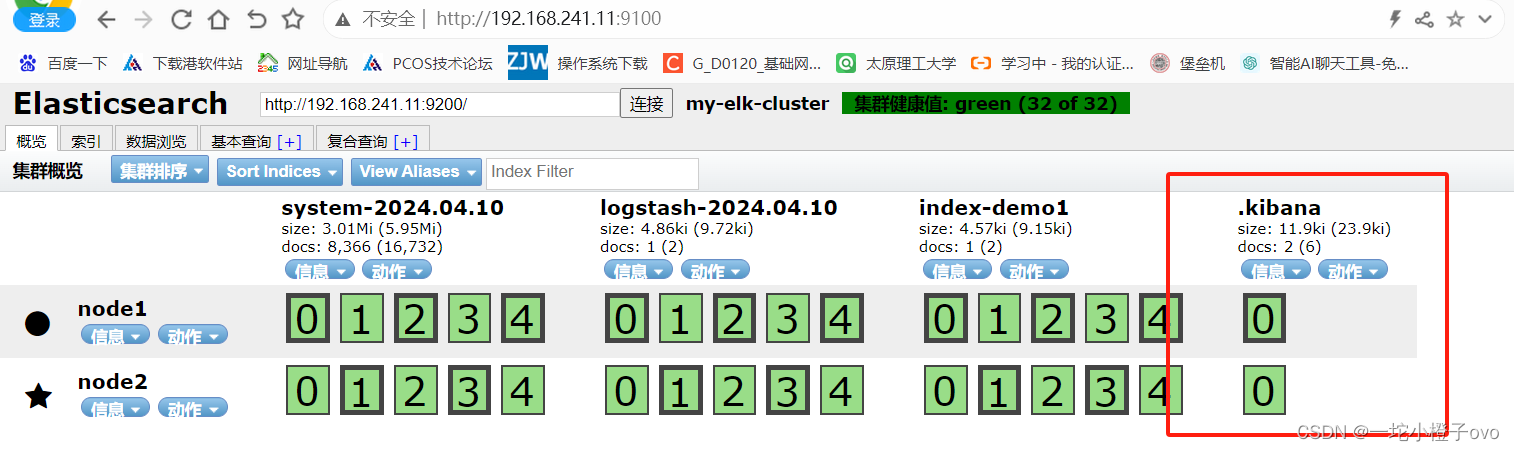
浏览器访问http://192.168.241.11/测试刷新日志文件,否则可能没有日志同步到ES
访问Apache页面
[root@logstash ~]#systemctl start httpd
[root@logstash ~]#systemctl status httpd


浏览器访问http://192.168.241.11:9100查看索引是否创建
访问http://192.168.241.11:5601
-
点击左下角有个management选项---index patterns---create index pattern
-
----分别创建apache_error-* 和 apache_access-* 的索引



就可以在DIscover查看访问日志啦!
7.部署配置Filebeat
Filebeat是一个轻量级收集日志的工具
如果是千万级访问量的话,需要使用redis和kafka进行配合使用
7.1部署Filebeat
[root@filebeat opt]#ls
filebeat-6.6.1-x86_64.rpm rh
[root@filebeat opt]#rpm -ivh filebeat-6.6.1-x86_64.rpm
[root@filebeat opt]#cd /usr/share/filebeat/
[root@filebeat filebeat]#ls
bin kibana LICENSE.txt module NOTICE.txt README.md
[root@filebeat ~]#cd /etc/filebeat/
[root@filebeat filebeat]#ls
fields.yml filebeat.reference.yml filebeat.yml modules.d
[root@filebeat filebeat]#cp filebeat.yml{,_bak}
[root@filebeat filebeat]#ls
fields.yml filebeat.yml modules.d
filebeat.reference.yml filebeat.yml_bak
[root@filebeat filebeat]#vim filebeat.yml
[root@filebeat filebeat]#systemctl start filebeat.service
[root@filebeat filebeat]#systemctl enable filebeat.service
Created symlink from /etc/systemd/system/multi-user.target.wants/filebeat.service to /usr/lib/systemd/system/filebeat.service.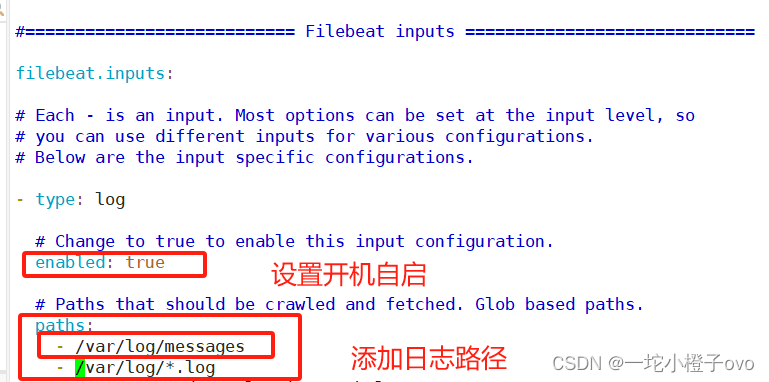

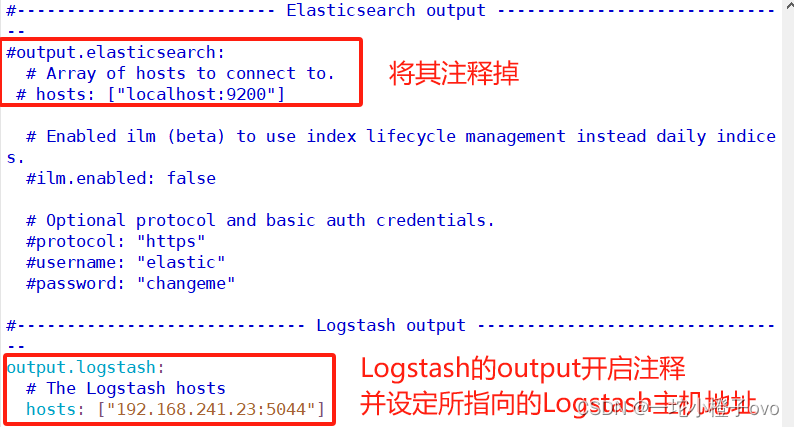
7.2配置Logstash
[root@logstash opt]#cd /etc/logstash/conf.d/
[root@logstash conf.d]#ls
apache_log.conf system.conf
[root@logstash conf.d]#vim filebeat_logstash.conf
[root@logstash conf.d]#cat filebeat_logstash.conf
input {beats {port => "5044"}
}
output {elasticsearch {hosts => ["192.168.241.11:9200"]index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"}stdout {codec => rubydebug}
}
[root@logstash conf.d]#systemctl restart logstash.service
[root@logstash conf.d]#logstash -f filebeat_logstash.conf 登入Elasticsearch可视化工具进行查看http://192.168.241.11:9100
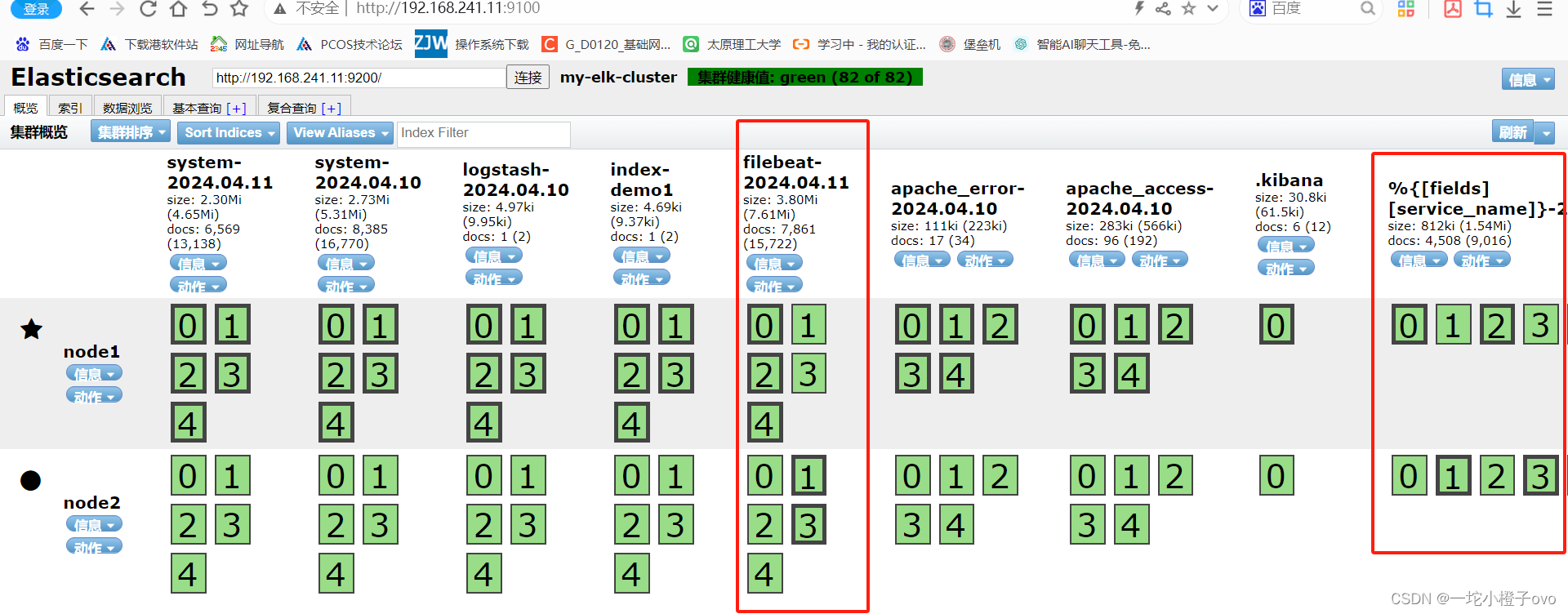

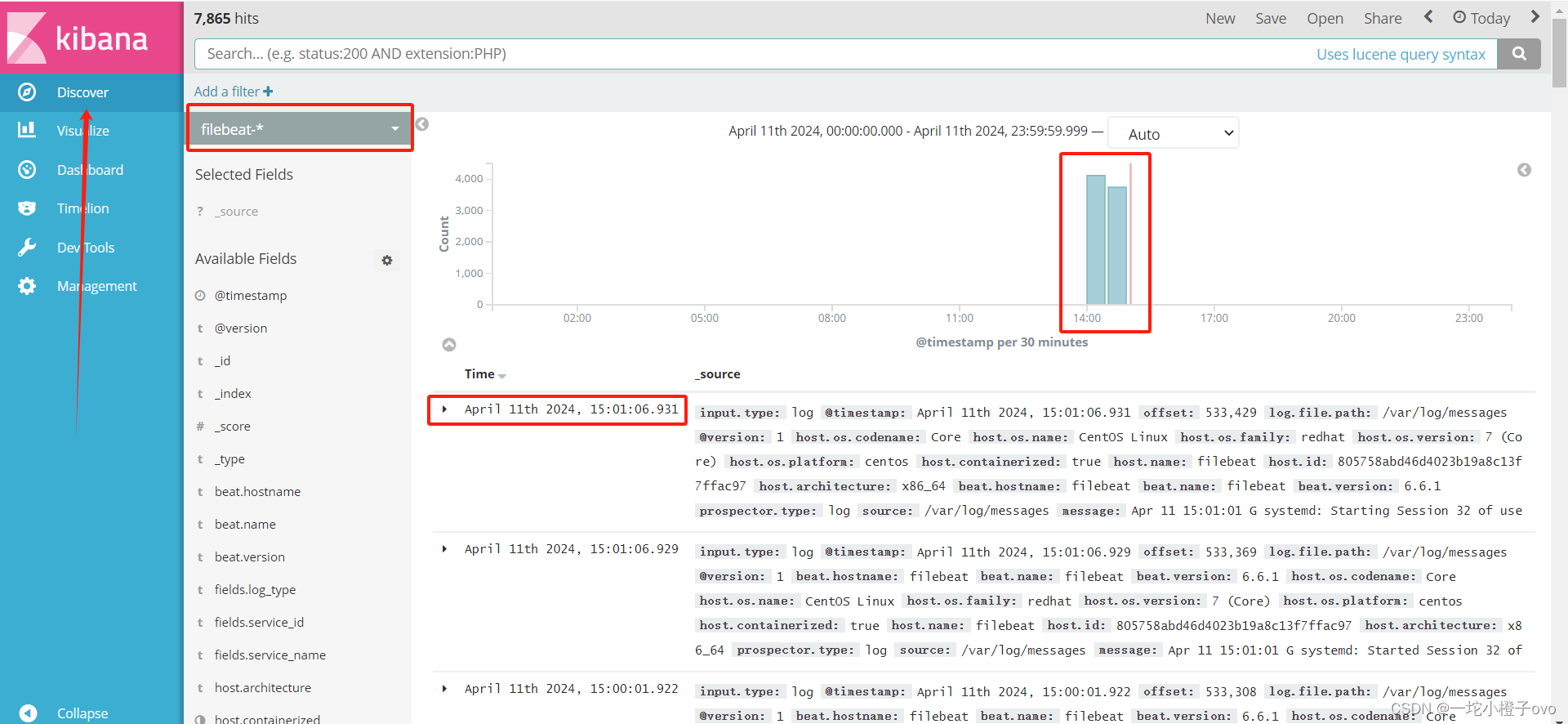
这里可以查看Filebeat的实时日志
相关文章:
Linux系统——Elasticsearch企业级日志分析系统
目录 前言 一、ELK概述 1.ELK简介 2.ELK特点 3.为什么要使用ELK 4.完整日志系统基本特征 5.ELK工作原理 6.Elasticsearch介绍 6.1Elasticsearch概述 6.2Elasticsearch核心概念 7.Logstash介绍 7.1Logstash简介 7.2Logstash主要组件 8.Kibana介绍 8.1Kibana简介 …...
多协议接入视频汇聚EasyCVR平台vs.RTSP安防视频EasyNVR平台:设备分组的区别
EasyCVR视频融合云平台则是旭帆科技TSINGSEE青犀旗下支持多协议接入的视频汇聚融合共享智能平台。平台可支持的接入协议比EasyNVR丰富,包括主流标准协议,有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海…...

Spring Security Oauth2 之 理解OAuth 2.0授权流程
1. Oauth 定义 1.1 角色 OAuth定义了四个角色: 资源所有者 一个能够授权访问受保护资源的实体。当资源所有者是一个人时,它被称为最终用户。 资源服务器 托管受保护资源的服务器能够使用访问令牌接受和响应受保护的资源请求。 客户 代表资源所有…...

mysql题目4
tj11: select count(*) 员工总人数 from tb_dept a join tb_employee b on a.deptnob.deptno where a.dname 市场部...
GFS部署实验
目录 1、部署环境 编辑 2、更改节点名称 3、准备环境 4、磁盘分区,并挂载 5. 做主机映射--/etc/hosts/ 6. 复制脚本文件 7. 执行脚本完成分区 8. 安装客户端软件 1. 安装解压源包 2. 创建gfs 3. 安装 gfs 4. 开启服务 9、 添加节点到存储信任池中 1…...
最前沿・量子退火建模方法(1) : subQUBO讲解和python实现
前言 量子退火机在小规模问题上的效果得到了有效验证,但是由于物理量子比特的大规模制备以及噪声的影响,还没有办法再大规模的场景下应用。 这时候就需要我们思考,如何通过软件的方法怎么样把大的问题分解成小的问题,以便通过现在…...
如何在Linux部署MeterSphere并实现公网访问进行远程测试工作
文章目录 前言1. 安装MeterSphere2. 本地访问MeterSphere3. 安装 cpolar内网穿透软件4. 配置MeterSphere公网访问地址5. 公网远程访问MeterSphere6. 固定MeterSphere公网地址 前言 MeterSphere 是一站式开源持续测试平台, 涵盖测试跟踪、接口测试、UI 测试和性能测试等功能&am…...
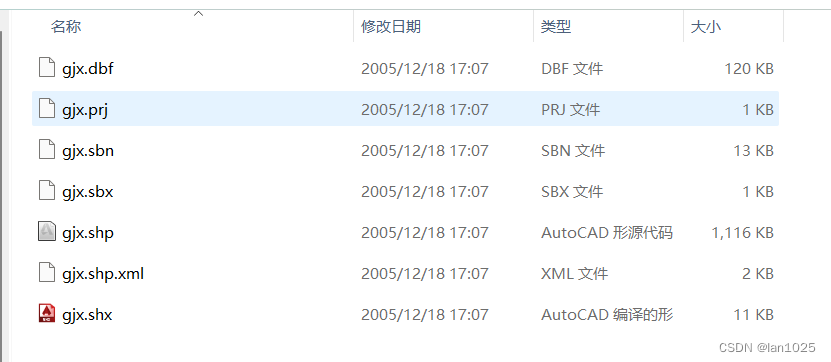
postgis导入shp数据时“dbf file (.dbf) can not be opened.“
作者进行矢量数据导入数据库中出现上述报错 导致报错原因 导入的shp文件路径太深导入的shp文件名称或路径中有中文将需要导入数据的shp 文件、dbf 文件、prj 等文件放在到同一个文件夹内,且名字要一致;导入失败: 导入成功:...
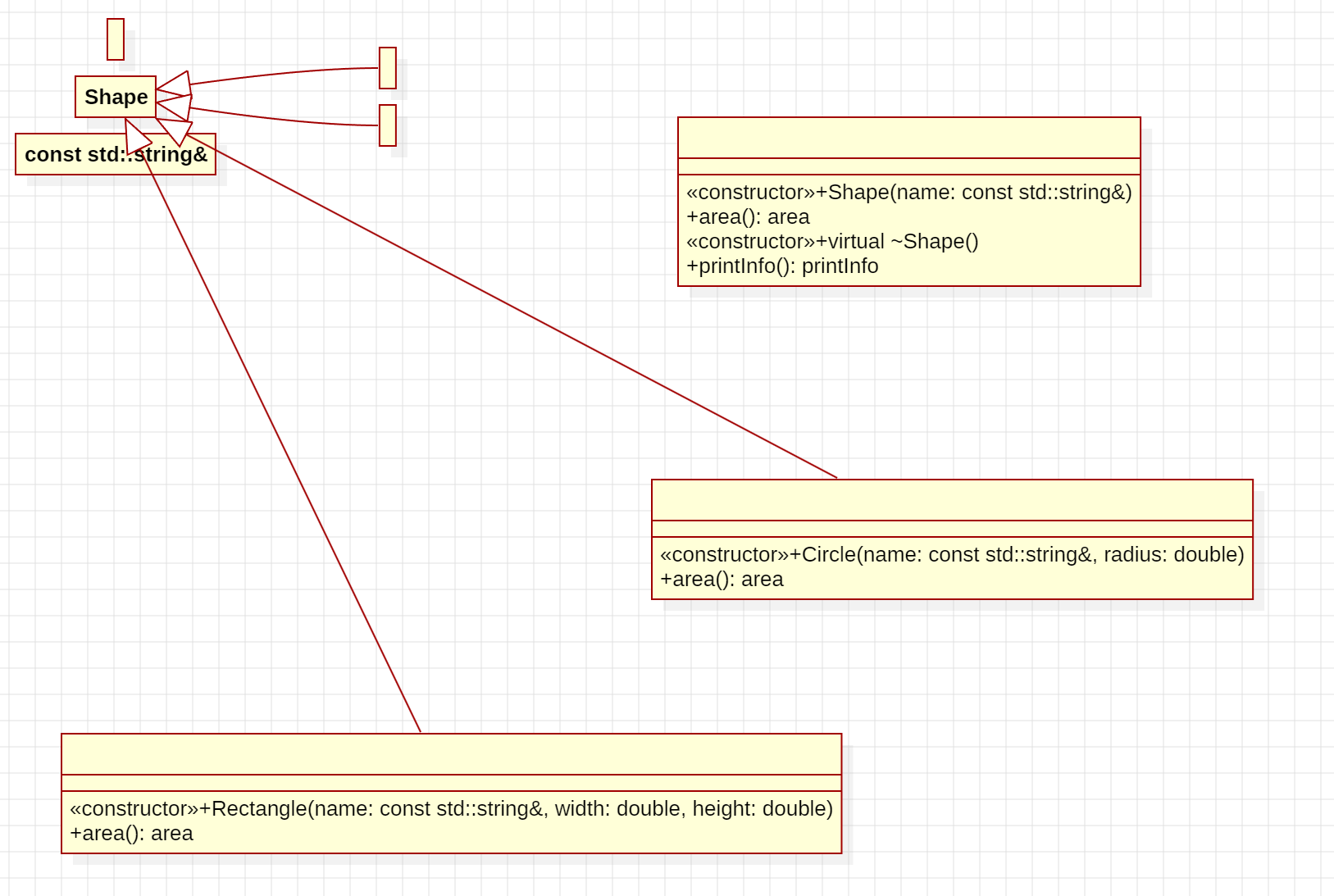
StarUML笔记之从C++代码生成UML图
StarUML笔记之从C代码生成UML图 —— 2024-04-14 文章目录 StarUML笔记之从C代码生成UML图1.安装C插件2.准备好一个C代码文件放某个路径下3.点击Reverse Code选择项目文件夹4.拖动(Class)到中间画面可以形成UML5.另外一种方式:双击Type Hierarchy,然后…...
和strlen)
sizeof()和strlen
一、什么是sizeof() sizeof()是一个在C和C中广泛使用的操作符,用于计算数据类型或变量所占内存的字节数。它返回一个size_t类型的值,表示其操作数所占的字节数。 在使用时,sizeof()可以接收一个数据类型作为参数,也可以接收一个…...

Python学习笔记13 - 元组
什么是元组 元组的创建方式 为什么要将元组设计为不可变序列? 元组的遍历...
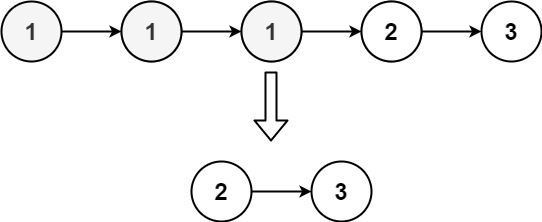
[leetcode]remove-duplicates-from-sorted-list-ii
. - 力扣(LeetCode) 给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。 示例 1: 输入:head [1,2,3,3,4,4,5] 输出:[1,2,5]示例 2&…...

共享内存和Pytorch中的Dataloader结合
dataloader中通常使用num_workers来指定多线程来进行数据的读取。可以使用共享内存进行加速。 代码地址:https://github.com/POSTECH-CVLab/point-transformer/blob/master/util/s3dis.py 文章目录 1. 共享内存和dataloader结合1.1 在init中把所有的data存储到共享内…...
分享 WebStorm 2024 激活的方案,支持JetBrains全家桶
大家好,欢迎来到金榜探云手! WebStorm公司简介 JetBrains 是一家专注于开发工具的软件公司,总部位于捷克。他们以提供强大的集成开发环境(IDE)而闻名,如 IntelliJ IDEA、PyCharm、和 WebStorm等。这些工具…...
Android OOM问题定位、内存优化
一、OOM out of memory:简称OOM,内存溢出,申请的内存大于剩余的内存而抛出的异常。 对于Android平台,广义的OOM主要是以下几种类型 JavaNativeThread 线程数的上限默认为32768,部分华为设备的限制是500通常1000左右…...
)
棋盘(c++题解)
题目描述 有一个m m的棋盘,棋盘上每一个格子可能是红色、黄色或没有任何颜色的。你现在要从棋盘的最左上角走到棋盘的最右下角。 任何一个时刻,你所站在的位置必须是有颜色的(不能是无色的) ,你只能向上、下、 左、右…...
滑动窗口例题
一、209:长度最小的子数组 209:长度最小的子数组 思路:1、暴力解法:两层for循环遍历,当sum > target时计算子数组长度并与result比较,取最小的更新result。提交但是超出了时间限制。 class Solution {public int minSubArray…...

智过网:注册安全工程师注册有效期与周期解析
在职业领域,各种专业资格认证不仅是对从业者专业能力的认可,也是保障行业安全、规范发展的重要手段。其中,注册安全工程师证书在安全生产领域具有举足轻重的地位。那么,注册安全工程师的注册有效期是多久呢?又是几年一…...

腐蚀Rust 服务端搭建架设个人社区服务器Windows教程
腐蚀Rust 服务端搭建架设个人社区服务器Windows教程 大家好我是艾西,一个做服务器租用的网络架构师也是游戏热爱者。最近在steam发现rust腐蚀自建的服务器以及玩家还是非常多的,那么作为服务器供应商对这商机肯定是不会放过的哈哈哈! 艾西这…...

蓝桥杯备赛:考前注意事项
考前注意事项 1、DevCpp添加c11支持 点击 工具 - 编译选项 中添加: -stdc112、万能头文件 #include <bits/stdc.h>万能头文件的缺陷:y1 变量 在<cmath>中用过了y1变量。 #include <bits/stdc.h> using namespace std;// 错误示例 …...
—东方仙盟)
酒店门锁V10SDK接口说明-幽冥大陆(一百23)—东方仙盟
相关文件系统环境C# :NET.20,NET3.5,NET4,NET4.5,NET 5.0C:VS2005,VS2012,VS2015操作系统:未来之窗VOSWEB:CHROME43核心代码完整代码using System; using System.Collections.Generic; using System.Text; using System.Collections.Specialized;using System.Windo…...

如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南
如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAss…...

Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器
Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook的触控板和鼠标之间切换时࿰…...

如何快速掌握Avidemux:新手完整入门指南与5个核心技巧
如何快速掌握Avidemux:新手完整入门指南与5个核心技巧 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款功能强大且完全开源的专业视频编辑工具,专为快速剪辑、…...

如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗
如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗 【免费下载链接】react-native-bottom-sheet-behavior react-native wrapper for android BottomSheetBehavior 项目地址: https://gitcode.com/gh_mirrors/re/react-native-bottom…...

PostgreSQL Merge Join 大白话详解
用生活中最直观的例子,彻底搞懂 Merge Join 是什么、为什么快、什么时候用。一、先从生活场景开始 场景一:两摞乱序试卷找同学 期末考试,老师手里有两摞试卷: A 摞:数学试卷,500 份,乱序堆放B 摞…...

ClojureDocs性能优化技巧:5个关键策略提升文档网站响应速度 [特殊字符]
ClojureDocs性能优化技巧:5个关键策略提升文档网站响应速度 🚀 【免费下载链接】clojuredocs clojuredocs.org web app 项目地址: https://gitcode.com/gh_mirrors/cl/clojuredocs ClojureDocs作为社区驱动的Clojure文档网站,其性能优…...
)
【仅限首批200家认证用户】DeepSeek v3.2.1重复检测私有化部署补丁包(含GPU内存泄漏热修复+增量扫描加速模块)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力…...

Meteor-Files新手教程:从安装到实现第一个文件上传功能的完整步骤
Meteor-Files新手教程:从安装到实现第一个文件上传功能的完整步骤 【免费下载链接】Meteor-Files 🚀 Upload files via DDP or HTTP to ☄️ Meteor server FS, AWS, GridFS, DropBox or Google Drive. Fast, secure and robust. 项目地址: https://gi…...

抖音内容自动化采集与管理的技术实现方案
抖音内容自动化采集与管理的技术实现方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批量下载工具&am…...