分布式结构化数据表Bigtable
文章目录
- 设计动机与目标
- 数据模型
- 行
- 列
- 时间戳
- 系统架构
- 主服务器
- Chubby作用
- 子表服务器
- SSTable结构
- 子表实际组成
- 子表地址组成
- 子表数据存储及读/写操作
- 数据压缩
- 性能优化
- 局部性群组(Locality groups)
- 压缩
- 布隆过滤器
- Bigtable是Google开发的基于GFS和Chubby的分布式存储系统。Google的很多数据,包括Web索引、卫星图像数据等在内的海量结构化和半结构化数据,都存储在Bigtable中。
设计动机与目标
Google设计Bigtable的动机:
- 需要存储的数据种类繁多
- 海量的服务请求
- 商用数据库无法满足Google的需求
Bigtable应达到的基本目标
- 广泛的适用性:Bigtable是为了满足一系列Google产品而并非特定产品的存储要求。
- 很强的可扩展性:根据需要随时可以加入或撤销服务器
- 高可用性:确保几乎所有的情况下系统都可用
- 简单性:底层系统的简单性既可以减少系统出错的概率,也为上层应用的开发带来便利
数据模型
- Bigtable是一个分布式多维映射表,表中的数据通过一个行关键字、一个列关键字以及一个时间戳进行索引
- Bigtable的存储逻辑可以表示为: ( r o w : s t r i n g , c o l u m n : s t r i n g , t i m e : i n t 64 ) → s t r i n g (row:string, column:string, time:int64)→string (row:string,column:string,time:int64)→string
- Bigtable数据的存储格式
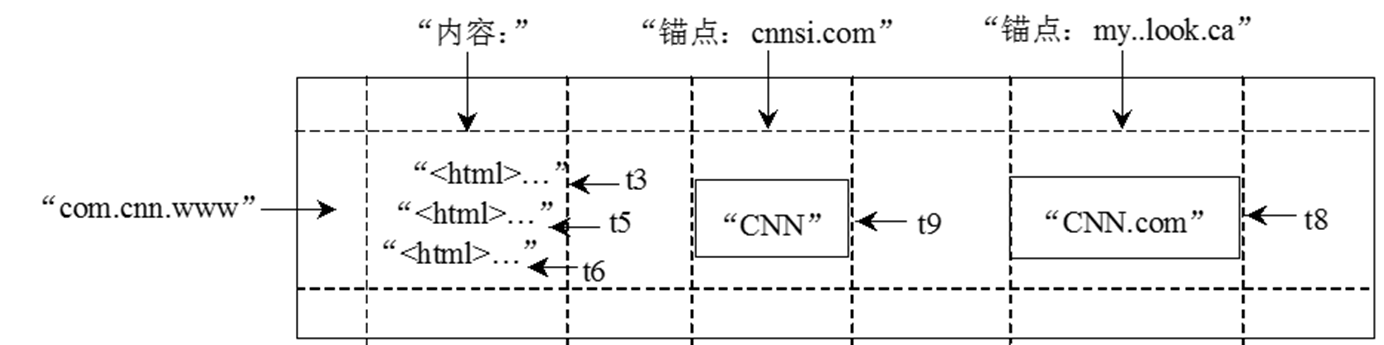
行
- Bigtable的行关键字可以是任意的字符串,但是大小不能够超过64KB
- 表中数据都是根据行关键字进行排序的,排序使用的是词典序
- 同一地址域的网页会被存储在表中的连续位置
- 倒排便于数据压缩,可以大幅提高压缩率
列
- 将其组织成所谓的列族
- 族名必须有意义,限定词则可以任意选定
- 组织的数据结构清晰明了,含义也很清楚
- 族同时也是Bigtable中访问控制的基本单元
时间戳
- Google的很多服务比如网页检索和用户的个性化设置等都需要保存不同时间的数据,不同的数据版本必须通过时间戳来区分。
- Bigtable中的时间戳是64位整型数,具体的赋值方式可以用户自行定义
系统架构
- Bigtable是三个云计算组件基础之上构建的
- WorkQueue是一个分布式的任务调度器,用来处理分布式系统队列分组和任务调度
- GFS是Google的分布式文件系统,在Bigtable中GFS主要用来存储子表数据以及一些日志文件
- Chubby提供锁服务。Chubby在Bigtable中的三大主要作用:选取并保证同一时间内只有一个主服务器;获取子表的位置信息;保存Bigtable的模式信息及访问控制列表。
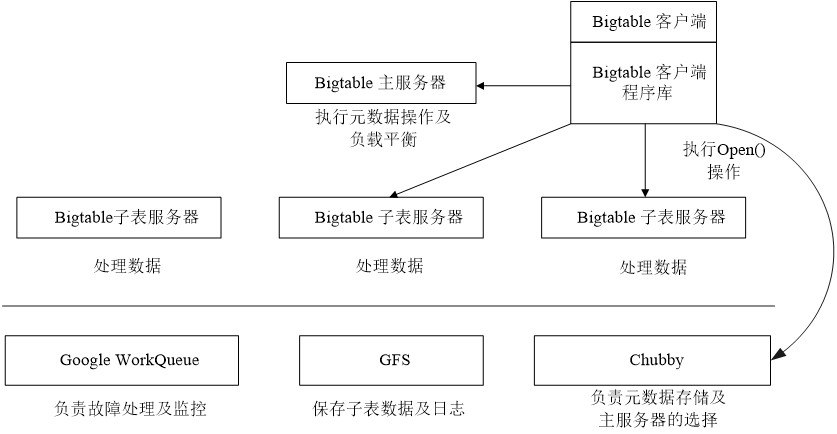
- Bigtable主要由三个部分组成:客户端程序库、一个主服务器和多个子表服务器。
- 客户访问Bigtable服务时,首先要利用其库函数执行 O p e n ( ) Open() Open()操作来打开一个锁(实际上获取文件目录),锁打开以后客户端就可以和子表服务器进行通信。客户端主要与子表服务器通信,几乎不和主服务器进行通信,使得主服务器的负载大大降低。
- 主服务主要进行一些元数据的操作以及子表服务器之间的负载调度问题,实际的数据是存储在子表服务器上的。
主服务器
-
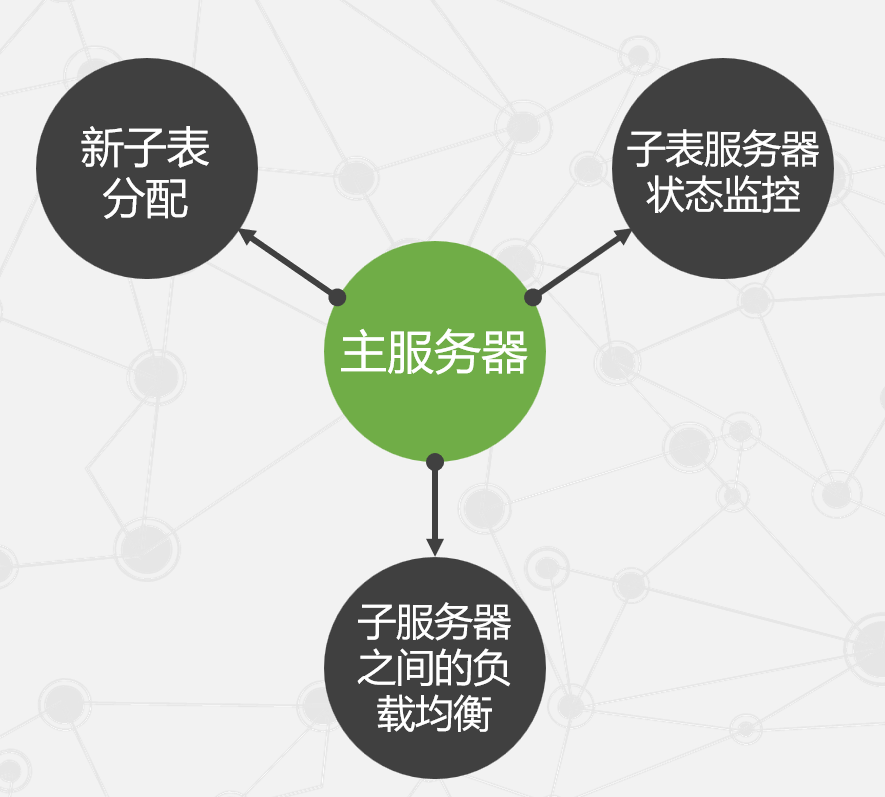
主服务器的主要作用
-
Bigtable的主服务主要负责子表的管理和分配。当新的子表产生,例如通过创建新表、表合并或子表分裂,主服务器会将它们分配给有足够空间的子表服务器。对于由主服务器直接发起的操作(如创建新表和表合并),主服务器能自动检测新子表的产生。而由子表服务器发起的操作(如子表分裂)则需要子服务器在完成后通知主服务器。
-
为了系统的可扩展性,主服务器需监控子表服务器的状态,包括新服务器的加入和现有服务器的撤销。这通过使用Chubby来实现,其中子表服务器在初始化时会从Chubby获取一个独占锁,并将基本信息保存在一个叫做服务器目录的特定位置。主服务器可以通过这个目录获取最新的子表服务器信息和分配情况。
-
主服务器还定期检查每个子表服务器的锁状态,以确定其健康状况。如果检测到锁丢失或无响应,主服务器将尝试获取锁来判断是Chubby服务出现问题还是子表服务器本身有故障。如果是后者,主服务器将停用该子表服务器,并把其上的子表转移给其他服务器。
-
此外,主服务器还会在检测到子表服务器负载过重时,进行负载均衡操作。
Chubby作用
- 当某个主服务器到时退出后,管理系统就会指定一个新的主服务器,这个主服务器的启动需要经历以下四个步骤:
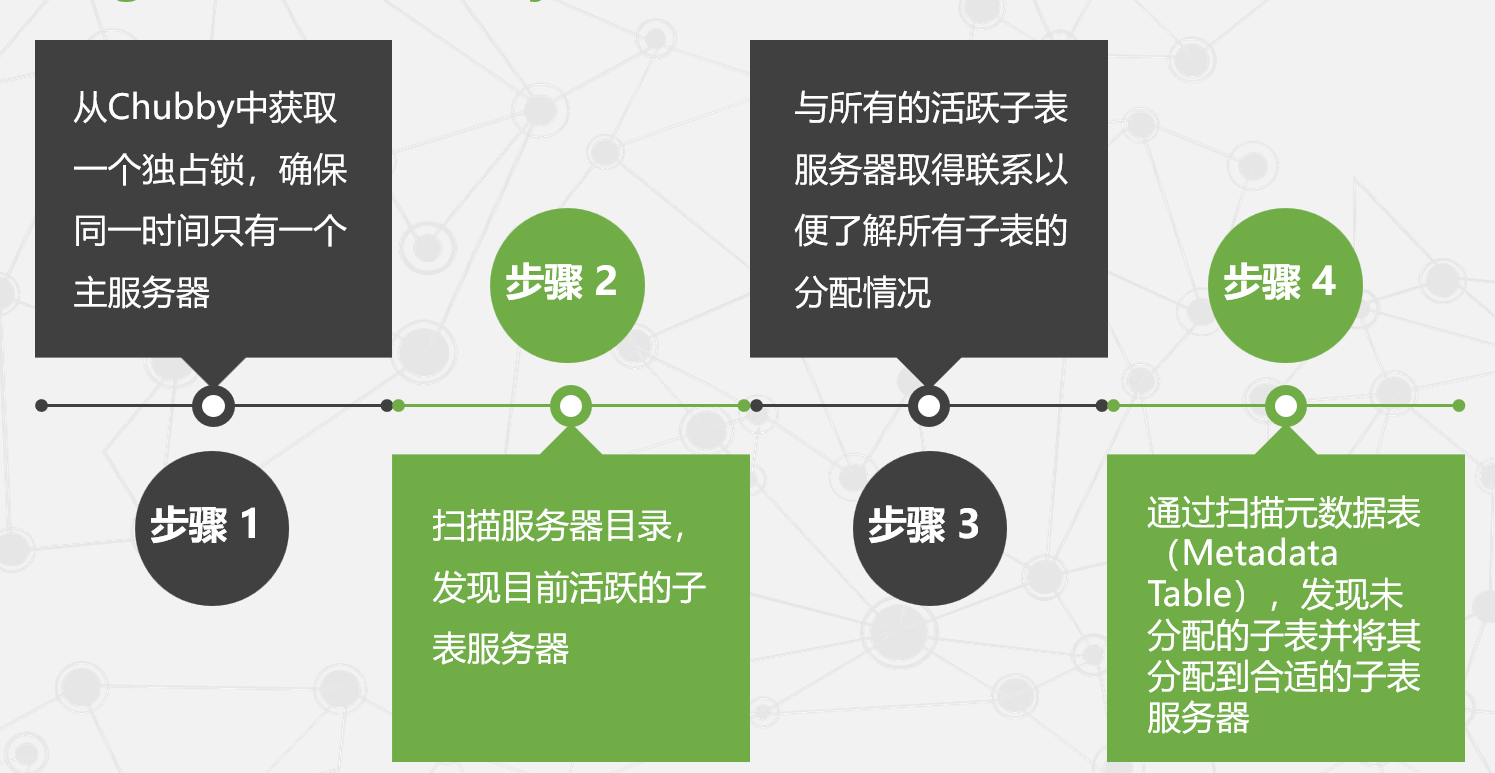
- 从Chubby中获取一个独占锁,确保同一时间只有一个主服务器。
- 扫描服务器目录,发现目前活跃的子表服务器。
- 与所有的活跃子表服务器取得联系,了解所有子表的分配情况。
- 通过扫描元数据表(Metadata Table),发现未分配的子表并将其分配到合适的子表服务器。如果元数据表未分配,则首先需要将根子表(Root Tablet)加入未分配的子表中。
- 子表保存其他所有元数据子表的信息,确保扫描能够发现所有未分配的子表
子表服务器
- Bigtable中实际的数据都是以子表的形式保存在子表服务器上的,客户一般也只和子表服务器进行通信。
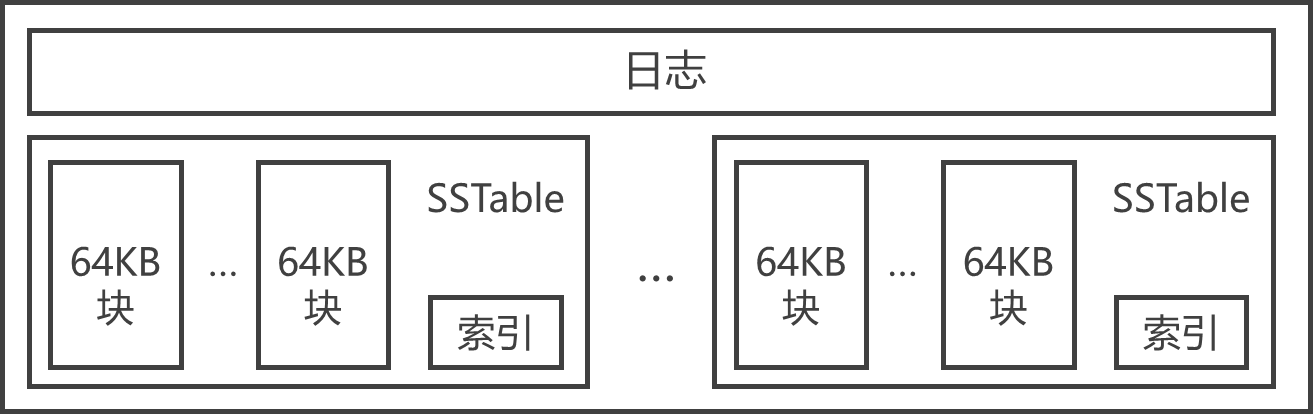
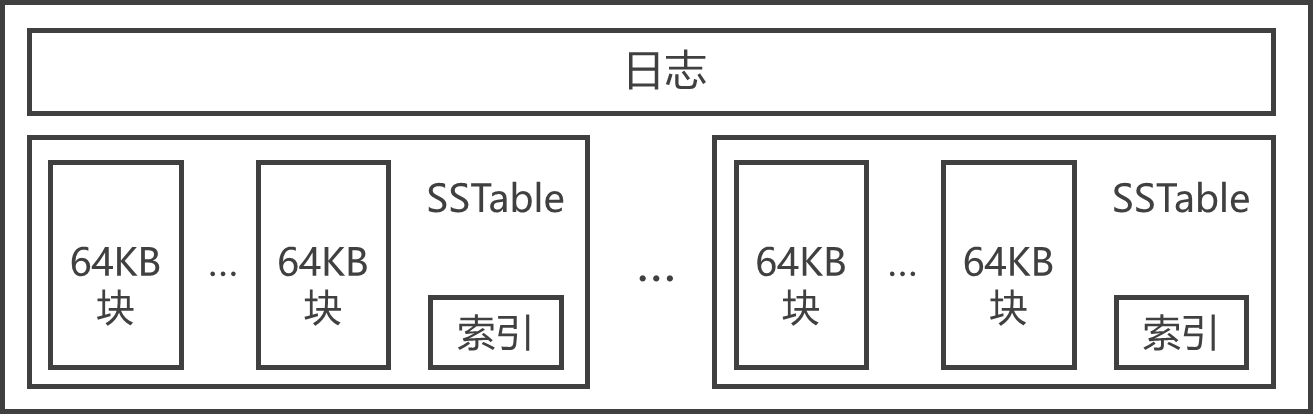
SSTable结构
- SSTable是Google为Bigtable设计的内部数据存储格式。所有的SSTable文件都存储在GFS上,用户可以通过键来查询相应的值。

- SSTable中的数据被划分成一个个的块(Block),每个块的大小是可以设置的,一般设置为64KB。
- SSTable结尾的索引(Index),保存SSTable中块的位置信息,在SSTable打开时索引会被加载进内存,用户在查找某个块时首先在内存中查找块的位置信息,然后在硬盘上直接找到这个块,这种查找方法速度非常快。
- 由于每个SSTable一般都不是很大,用户还可以选择将其整体加载进内存,这样查找起来会更快。
子表实际组成
- 不同子表的SSTable可以共享
- 每个子表服务器上仅保存一个日志文件
- Bigtable规定将日志的内容按照键值进行排序
- 每个子表服务器上保存的子表数量可以从几十到上千不等,通常情况下是100个左右
子表地址组成
-
Bigtable系统的内部采用的是一种类似B+树的三层查询体系。
-
所有的子表地址都被记录在元数据表中,元数据表也是由一个个的元数据子表组成

-
Bigtable存储系统利用一个元数据表来记录所有子表的地址信息。这个元数据表由多个元数据子表组成,其中有一个特殊的子表称为根子表,它是元数据表的首条记录,包含了其他所有元数据子表的地址。同时,根子表的信息也被存储在Chubby中的一个文件里。
-
当需要查询特定子表的位置时,系统首先从Chubby获取根子表的地址,通过这个地址读取到所需元数据子表的位置,最后从元数据子表中找到目标子表的具体地址。除了包含子表地址的元数据外,元数据表还储存了用于调试和分析的其他信息,如事件日志等。
-
为提升访问效率和减少开销,Bigtable采用了缓存和预取技术。
- 缓存技术:子表的地址信息被缓存在客户端,使得客户在查询时可以直接利用缓存信息进行地址查找,避免了不必要的网络通信。如果遇到缓存为空或信息过时的情况,客户端会进行相应的网络通信来更新地址信息:缓存为空需进行三次网络通信,而缓存过时则需六次。
- 预取技术则:在每次访问元数据表时,不仅读取当前所需的子表元数据,而是额外读取多个子表的元数据,从而减少未来访问元数据表的次数。
子表数据存储及读/写操作
- 较新的数据存储在内存中一个称为内存表(Memtable)的有序缓冲里,较早的数据则以SSTable格式保存在GFS中。
读和写操作有很大的差异性
- 在进行写操作前,系统会先检查用户是否有权限进行操作(通过查询Chubby中的访问控制列表完成)。一旦用户被认证,写入的数据首先记录到提交日志中,以便在需要时恢复数据。这些记录被称为重做记录,它们记录了最新的数据变更。数据一旦成功记录在提交日志后,会立即写入内存表中。
- 读操作时,首先要通过认证,之后读操作就要结合内存表和SSTable文件来进行,因为内存表和SSTable中都保存了数据。

数据压缩
- 在Bigtable中有三种形式的数据压缩,分别是次压缩(Minor Compaction)、合并压缩(Merging Compaction)和主压缩(Major Compaction)。
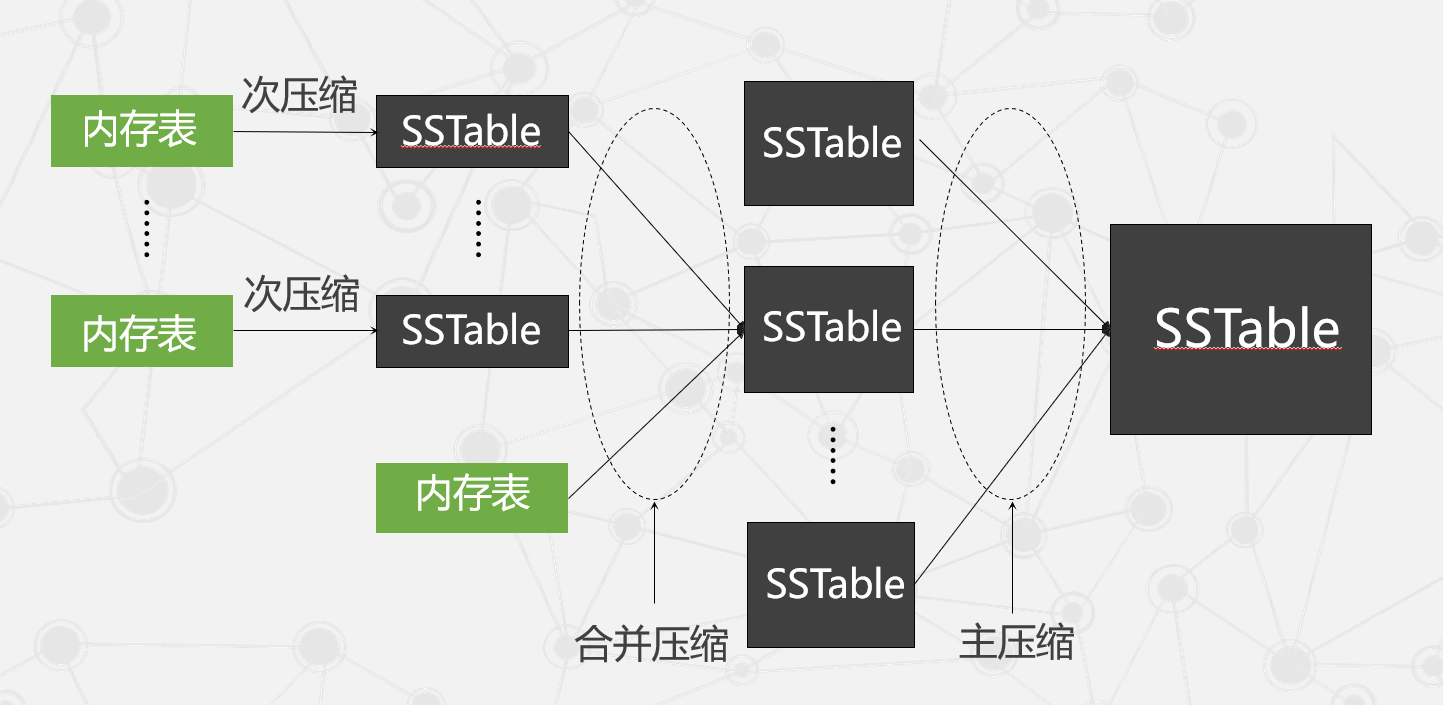
- 每次旧内存表停止使用时都会进行一个次压缩操作,产生SSTable。由于读操作要使用SSTable,数量过多的SSTable显然会影响读的速度。因此Bigtable会定期地执行一次合并压缩操作,将一些已有的SSTable和现有的内存表一并进行一次压缩。
- 主压缩是合并压缩的一种,只不过它将所有的SSTable一次性压缩成一个大的SSTable文件。主压缩也是定期执行的,执行一次主压缩之
后可以保证将所有的被压缩数据彻底删除,既回收空间又能保证敏感数据的安全性(因为这些敏感数据被彻底删除)
性能优化
局部性群组(Locality groups)
- Bigtable还允许用户个人在基本操作基础上对系统进行一些优化
- Bigtable允许用户将原本并不存储在一起的数据以列族为单位,根据需要组织在一个单独的SSTable中,以构成一个局部性群组。(实际上是数据库中垂直分区技术的应用)

- 通过设置局部性群组用户可以只看自己感兴趣的内容,对某个用户来说的大量无用信息无须读取。
- 对于较小的且被经常读取的局部性群组,用户可以将其SSTable文件直接加载进内存,可以明显地改善读取效率。
压缩
- 压缩可以有效地节省空间,Bigtable中的压缩被应用于很多场合。首先压缩可以被用在构成局部性群组的SSTable中,可以选择是否对个人的局部性群组的SSTable进行压缩。
- 利用Bentley & McIlroy方式(BMDiff)在大的扫描窗口将常见的长串进行压缩
- 采取Zippy技术进行快速压缩,它在一个16KB大小的扫描窗口内寻找重复数据,
布隆过滤器
- Bigtable向用户提供一种称为布隆过滤器的数学工具。布隆过滤器是巴顿•布隆在1970年提出的,实际上它是一个很长的二进制向量和一系列随机映射函数,在读操作中确定子表的位置时非常有用。
- 优点:布隆过滤器的速度快,省空间;不会将一个存在的子表判定为不存在
- 缺点:在某些情况下它会将不存在的子表判断为存在
相关文章:
分布式结构化数据表Bigtable
文章目录 设计动机与目标数据模型行列时间戳 系统架构主服务器Chubby作用子表服务器SSTable结构子表实际组成子表地址组成子表数据存储及读/写操作数据压缩 性能优化局部性群组(Locality groups)压缩布隆过滤器 Bigtable是Google开发的基于GFS和Chubby的…...

langchain 加载 csv,json
csv from langchain_community.document_loaders.csv_loader import CSVLoaderloader CSVLoader(file_pathdata/专业描述.csv, csv_args{delimiter: ,,quotechar: ",fieldnames: [专业, 描述] }, encodingutf8, source_column专业)data loader.load() print(data)quote…...
)
Java-常见面试题收集(十三)
二十二 Redis 1 Redis 作用 Redis,全称Remote Dictionary Server,即远程字典服务,是一个开源的使用ANSI C语言编写的、支持网络的、基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。它主要用于缓存数据的计算…...

第二证券策略:股指预计维持震荡格局 关注汽车、工程机械等板块
第二证券指出,指数自今年2月份阶段低点反弹以来,3月份持续高位整理。进入4月份之后面对年报和一季报的双重财报发表期,预计指数短期保持高位整理概率比较大。前期缺乏成绩支撑的概念股或有回落的危险,主张重视成绩稳定、估值低、分…...
hcia datacom课程学习(6):路由与路由表基础
1.路由的作用 不同网段的设备互相通信需要具有路由功能的设备进行转发 具有路由功能的设备不一定是路由器,交换机可以有路由功能,同样的,路由器也可以有交换功能,像家里常用的路由器就是集路由功能和交换功能于一体的 2.路由相…...
AI PC元年,华为的一张航海图、一艘渡轮和一张船票
今天,从学术研究者到产业投资者,无不认为大模型掀起了一场人工智能的完美风暴。 所谓“完美风暴”,指的是一项新技术的各个要素,以新的方式互相影响、彼此加强,组合在一起形成了摧枯拉朽般的力量。 而我们每个人&#…...
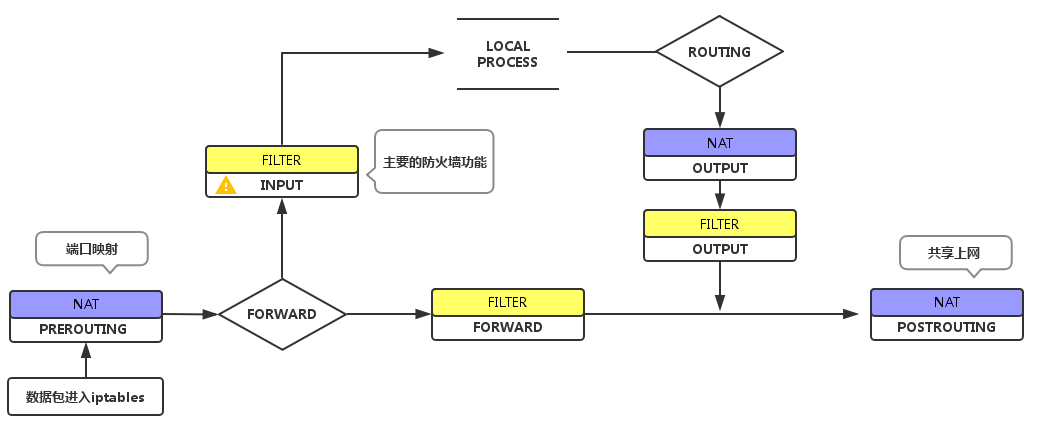
NAT技术
网络技术深似海呀,一段时间不用又忘。 是什么 NAT技术是网络防火墙技术的一部分,可以作用在linux防火墙或者设备防火墙,NAT技术可以实现地址和端口的转换,主要还是为了网络连通性。 作用 存在以下三个IP,A(10.234.…...

新能源汽车“价格战”之后,充电桩主板市场将会怎样?
2024年2月底,国内新能源汽车市场开启了一场前所未有的“价格战”↓ 比亚迪率先抛出“王炸”车型——秦PLUS荣耀版和驱逐舰05荣耀版,起售价低至7.98万元,打响了价格战的“第一枪”,引爆了平静的汽车市场。 “电比油低”就此拉开序…...
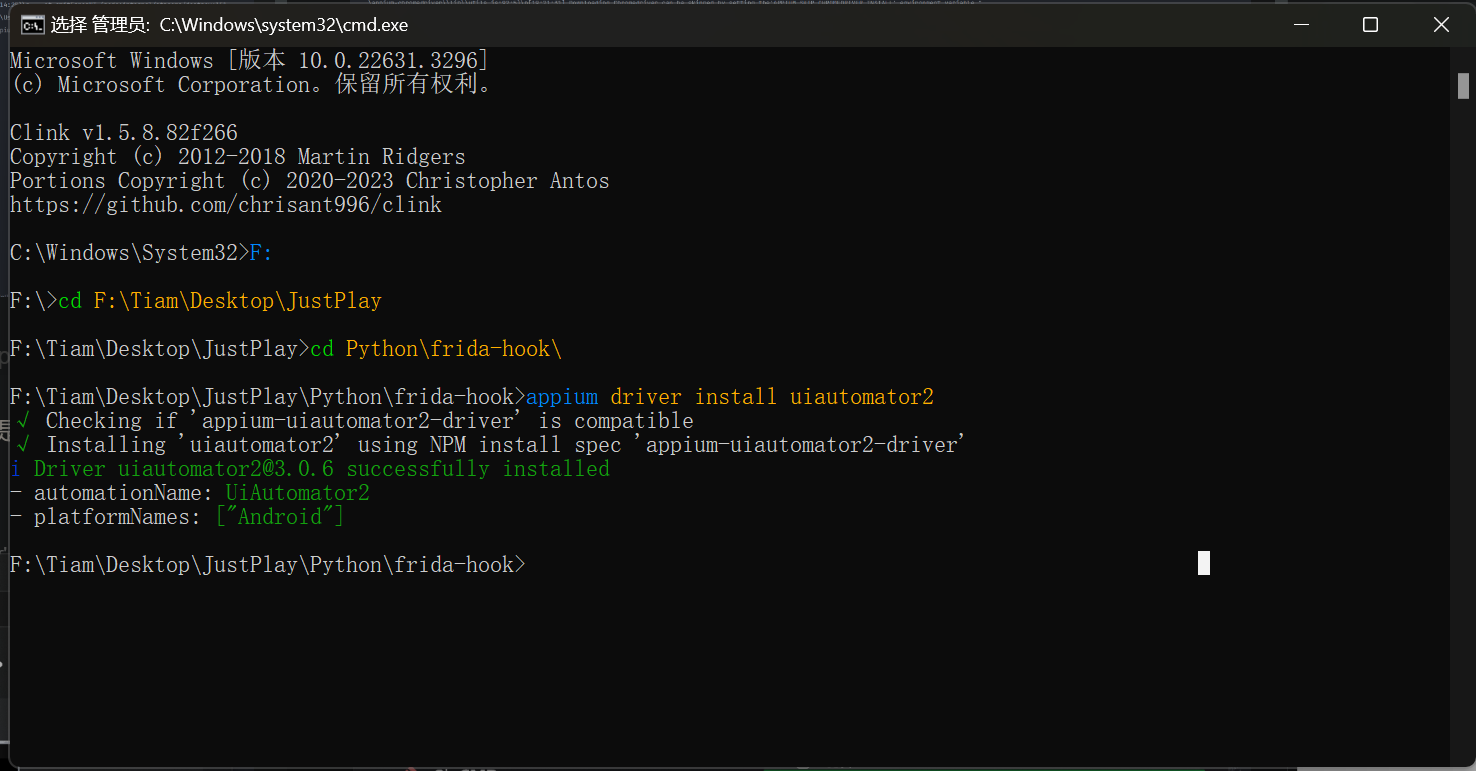
appium driver install uiautomator2 安装失败
报错 Installing ‘uiautomator2’ using NPM install spec ‘appium-uiautomator2-driver’ Error: Encountered an error when installing package: npm command ‘install --save-dev --no-progress --no-audit --omitpeer --save-exact --global-style --no-package-lock…...
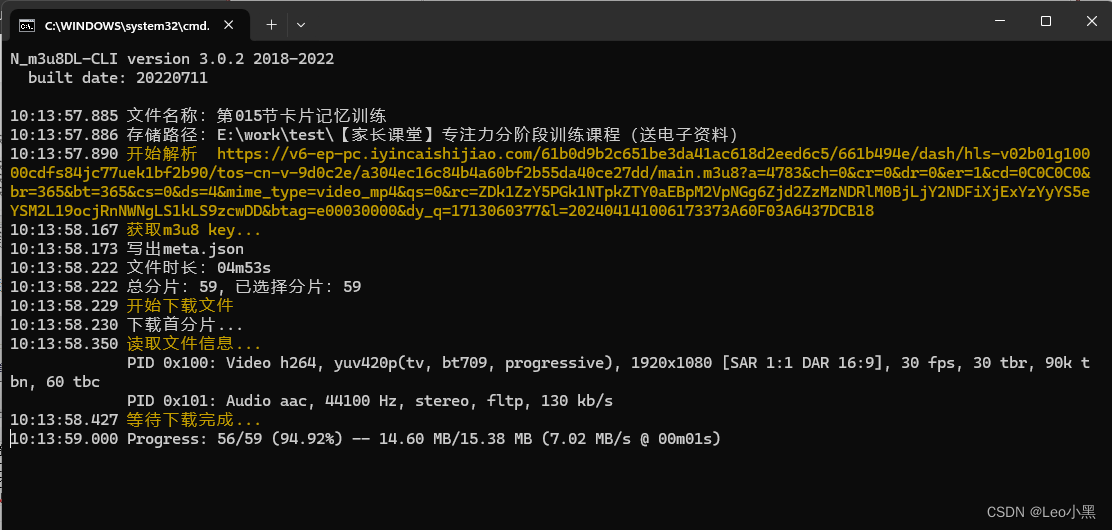
学浪已购买视频怎么下载到本地?
许多学习者在学浪购买了丰富的课程,然而,一些课程存在时间限制,使得学习者希望将其下载并永久保存。在这里,我们将介绍一款名为小浪助手的工具,它能够帮助你轻松将学浪已购买的视频下载到本地,让学习变得更…...

k8s-pod设置执行优先级
Pod的优先级管理是Kubernetes调度中的一个重要特性,通过PriorityClass(优先级类)的设置,我们可以为Pod指定不同的优先级,从而在资源有限的情况下更精细地调整调度顺序 什么是PriorityClass? PriorityClass是…...

const修饰指针
const修饰指针 常量指针 特点为指针的指向可以改,但是指针指向的值不可以修改 int a 10; int b 20; const int *p &a; *p 20; //错误,指针的指向的值不可更改 p &b; //正确 指针常量 特点是指针的指向不可以改,指针指向的值…...

php关于序列化r的指向
在PHP中,序列化字符串的索引是根据序列化过程中值的出现顺序来确定的。每个值(包括数组的键和值)在序列化字符串中都会被赋予一个顺序索引。为了理解这个顺序,我们需要知道以下几点: 序列化时,数组的键和值…...

从0到1实现RPC | 11 丰富测试案例
测试案例主要针对服务消费者consumer,复杂逻辑都在consumer端。 常规int类型,返回User对象 参数类型转换,主要实现逻辑都在TypeUtils工具类中。 测试方法重载,同名方法,参数不同 方法签名的实现,主要逻辑…...

在前端开发中用到了哪些设计模式?
在前端开发中用到了哪些设计模式? 1.单例模式2.观察者模式3.工厂模式4.适配器模式5.装饰器模式6.命令模式7.迭代器模式8.组合模式9.策略模式10.发布订阅模式 1.单例模式 确保一个类只有一个实例,提供一个全局访问点,vue就是一个单例模式&…...

ES6 的解构赋值
解构赋值(Destructuring assignment)是一种方便快捷的方式,可以从对象或数组中提取数据,并将数据赋值给变量。解构赋值是ES6中一项强大且常用的特性. 1. 基本数组解构 首先,让我们看看如何对数组进行解构赋值。假设我…...

蓝桥杯物联网竞赛_STM32L071KBU6_全部工程及国赛省赛真题及代码
包含stm32L071kbu6全部实验工程、源码、原理图、官方提供参考代码及国、省赛真题及代码 链接:https://pan.baidu.com/s/1pXnsMHE0t4RLCeluFhFpAg?pwdq497 提取码:q497...

关于UCG游戏平台的一些思考
UCG游戏平台,全称User Generated Content,即用户生成内容。它涵盖了所有玩家可以自主编辑的部分,包含并不限于换装、捏脸、关卡摆放等内容。 UCG概念在最近又火了起来,但这个模式出现的并不早。早在10多年前,war3编辑器…...
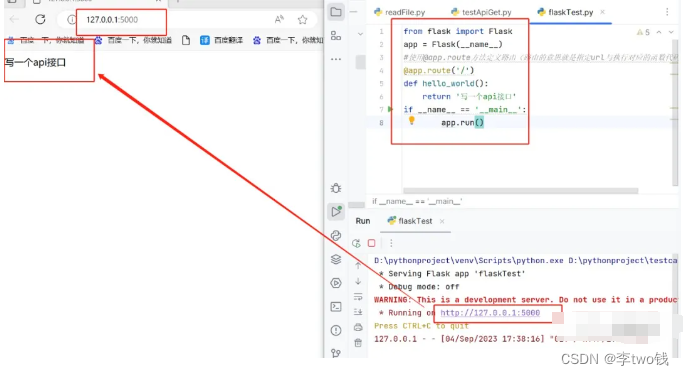
一起学习python——基础篇(20)
前言,之前经常从网上找一些免费的接口来测试,有点受制于人的感觉。想了想还不如直接写一个接口,这样方便自己测试。自己想返回什么格式就返回什么样子,不用担心服务报错,因为自己就可以完全掌控。然后宿舍二哥告诉我py…...

云服务器安装Mysql、MariaDB、Redis、tomcat
前置工作 进入根目录 cd / 创建java文件夹 mkdir java 进入java文件夹 cd java 上传压缩包 rz 压缩包 Mysql 1.下载并安装MySQL官方的 Yum Repository wget http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm rpm -ivh mysql-community-release-el7-5.noa…...

Llama-3.2V-11B-cot多轮对话效果展示:复杂技术问题拆解与解答
Llama-3.2V-11B-cot多轮对话效果展示:复杂技术问题拆解与解答 最近在测试各种大模型时,我特意找了一个比较“刁钻”的场景:让模型来解答一个复杂的系统设计问题。这类问题通常不是一两句话能说清的,它需要模型有很强的逻辑推理能…...

AI算法Excel可视化终极指南:如何用电子表格深度解析人工智能原理
AI算法Excel可视化终极指南:如何用电子表格深度解析人工智能原理 【免费下载链接】ai-by-hand-excel 项目地址: https://gitcode.com/gh_mirrors/ai/ai-by-hand-excel 你是否曾被复杂的AI算法公式和抽象概念困扰,想要找到一种更直观的学习方式&a…...

终极GitHub加速指南:3分钟让你的下载速度飙升100倍
终极GitHub加速指南:3分钟让你的下载速度飙升100倍 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub GitHub作为全球最大…...

《Origin画百图》之矩阵散点图进阶:从数据洞察到模型诊断
1. 矩阵散点图在数据科学中的进阶价值 第一次接触矩阵散点图时,我只把它当作一个简单的可视化工具。直到在一次房价预测项目中,我发现这个看似基础的图表竟然能帮我发现数据中的多重共线性问题,才真正意识到它的威力。矩阵散点图就像数据科学…...

哈尔滨全屋定制厂家:值得信赖的筛选逻辑深度解析
哈尔滨全屋定制厂家筛选逻辑深度解析:5步找到值得信赖的本地品牌 “哈尔滨全屋定制厂家选择,不是看广告多响,而是这5个筛选逻辑能帮你避开90%的坑”。对于准备在哈尔滨做全屋定制的业主来说,选对厂家直接决定了最终效果与性价比&…...

为什么你的asyncio服务内存永不释放?深入CPython asyncio循环引用链,给出4行补丁级解决方案!
第一章:Shell脚本的基本语法和命令Shell脚本是Linux/Unix系统自动化任务的核心工具,以可执行文本文件形式存在,由Bash等Shell解释器逐行解析执行。其语法简洁但严谨,强调空格、换行与引号的正确使用。脚本结构与执行方式 每个Shel…...

熵权法背后的信息论:为什么你的特征权重计算总不准?
熵权法的信息论本质:从数学原理到权重计算的精准控制 当我们需要从海量数据中提取关键特征时,如何科学地确定每个特征的权重?熵权法作为一种客观赋权方法,其核心思想源自信息论中的熵概念。但许多实践者发现,直接套用标…...

Cesium 视角控制全攻略:禁用鼠标交互的多种方法
1. 为什么需要禁用Cesium鼠标交互? 在开发基于Cesium的三维地理信息系统时,我们经常会遇到需要限制用户视角操作的场景。比如在展示固定路线的飞行演示时,如果允许用户随意旋转地图,可能会打乱预设的动画效果;在嵌入式…...

运维实战:Z-Image-Turbo_Sugar脸部Lora模型在Linux生产环境的持续部署与监控
运维实战:Z-Image-Turbo_Sugar脸部Lora模型在Linux生产环境的持续部署与监控 作为一名在AI和智能硬件领域摸爬滚打了十多年的工程师,我见过太多“模型跑得欢,运维跑断腿”的场景。一个模型在开发者的笔记本上可能表现完美,但一旦…...

零服务器生产环境监控与日志管理终极指南:保障Web应用稳定运行的10个关键策略
零服务器生产环境监控与日志管理终极指南:保障Web应用稳定运行的10个关键策略 【免费下载链接】zero Zero is a web server to simplify web development. 项目地址: https://gitcode.com/gh_mirrors/ze/zero Zero Server是一款革命性的Web服务器,…...