《经典论文阅读2》基于随机游走的节点表示学习—Deepwalk算法
word2vec使用语言天生具备序列这一特性训练得到词语的向量表示。而在图结构上,则存在无法序列的难题,因为图结构它不具备序列特性,就无法得到图节点的表示。deepwalk 的作者提出:可以使用在图上随机游走的方式得到一串序列,然后再根据得到游走序列进行node2vec的训练,进而获取得到图节点的表示。本质上deepwalk和word2vec师出同门(来自同一个思想),deepwalk算法的提出为图结构学习打开了新的天地。
1. 前言
目前主流算法可大致分为两类:walk-based 的图嵌入算法(GE,Graph Emebdding )和 message-passing-based 的图神经网络算法(GNN)。
- GE类算法主要包括有
deepwalk、metapath2vec; - 基于消息传递机制的图神经网络算法的经典论文则是GCN,GAT等。
因为内容过多,本期讲解分两期,第一期首先介绍GE类算法,第二期介绍图神经网络算法。GE类的算法经典的还属deepwalk,所以本期首先围绕deepwalk这篇论文进行介绍。
接触过word2vec 的同学都知道,word2vec的思想一改往日的one-hot囧境,将每个word映射成一个高维向量,这些学习到的的vector便具备了一定的特性,可以直接在下游任务中使用。有关word2vec这里不再叙述,更详细内容可以参考我之前的文章。
但是如果想得到图结构中顶点表示该怎么办呢?毕竟图结构与语言序列不同,图上的一个顶点可能有很多个连接点,而文本序列则是单线条,如下图所示,可以看出图结构与文本序列有着非常大的差异。
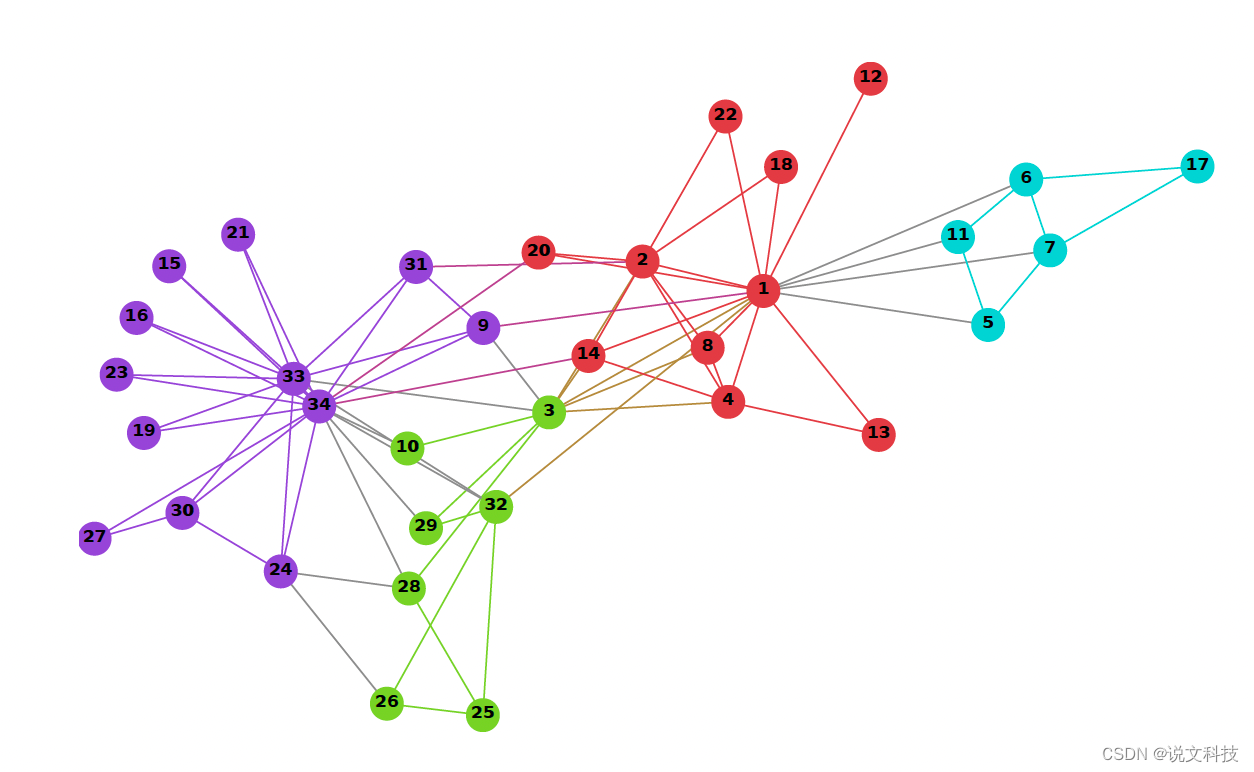
那就没有办法去解决图节点的表示学习了吗?
当然不是!而且方法还有很多,聪明的前辈们提出了一种叫做『deepwalk』的算法,这个算法着实让我惊艳。本质上说,deepwalk算法是基于图上的word2vec,而启发作者的其实是:由于二者数据分布(自然语言的词频和随机游走得到子图的节点的频率)存在一定的相似性。

所以说,很多精妙的想法不是凭空造出来的,背后其实是有数据统计支撑的。
2. 思想
文本序列虽然只是一个序列,但是我们可以想象有一张巨大的由各个单词组成的图,我们随机从图上连接几个顶点就组成了一句话。例如『论文解析之deepwalk』其实就是从一张偌大的图中挑选出这么几个单词组成的一句话,如下图所示:
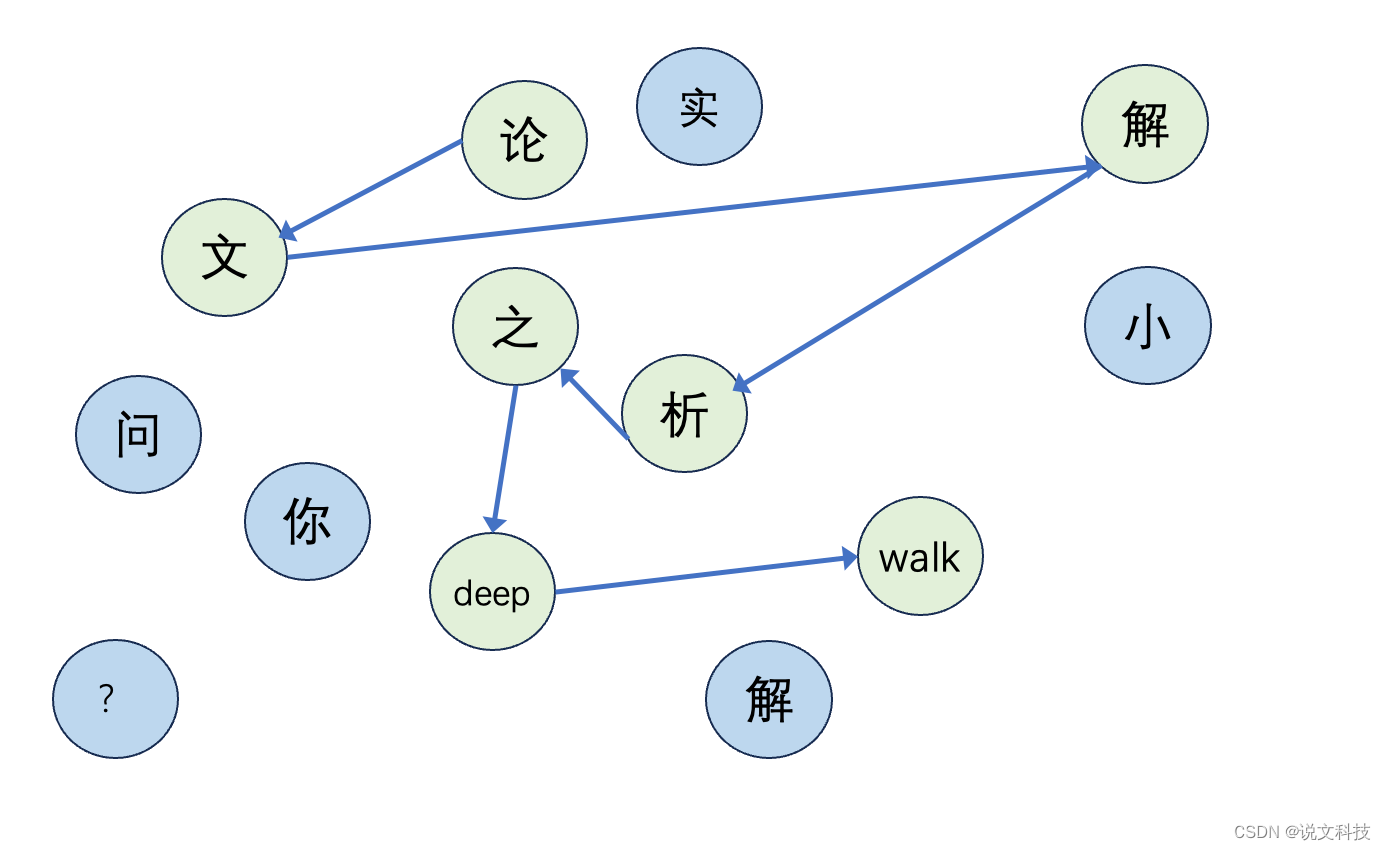
那么对于其它的图,我们也可以这么做。即:从一张大图上随机游走,这样便得到了一串序列。将这得到的序列便可以利用word2vec的方法来学习节点的表示了。
想法是不是很精妙?真的很精妙!其实我们自己在解决问题的时候,也需要抱着这样的『转换』思想,如果直接求A不成,那么能否利用已有的知识求A?这再次说明问题的转化能力是一个非常重要的能力。
既然问题已经得到了转化,接下来的工作就比较简单了,可以直接利用word2vec中的算法(如Skip gram算法)去训练得到图节点的embedding。
3. 模型
3.1 模型构造
deepwalk 算法主要包含两部分:第一部分是random walk generator;第二部分是一个更新程序。

- 采样方法
deepwalk中的采样方法其实是非常简单的均匀采样。下文中介绍到了这一采样算法:

step1. 首先随机采样一个节点作为此次walk的根节点。
step2. 接着从采样序列的最后一个节点的邻居中再随机选一个节点
step3. 直到采样序列的最大长度达成。
本文采取的实验参数是:将每个节点都做一次根节点,随机游走可以达到最长的长度为t。 对应的算法伪代码如下所示:

- 更新程序
在得到随机游走的序列后,便可以使用word2vec算法获取节点的embedding了。deepwalk算法使用的是SkipGram算法。SkipGram算法的思想很简单,就是利用当前词去预测周围词。具体来看Skip-Gram 的算法伪代码。

p ( u k ∣ ϕ ( v j ) p(u_k | \phi(v_j) p(uk∣ϕ(vj) 其实就是求在 v j v_j vj 这个顶点出现的条件下,顶点 u k u_k uk出现的概率,思想就是这么简单。那么损失函数也很好定义,直接取log后再取负数即可。但这里有个小trick点,(其实这个点也是训练word2vec 中的一个关键点),就是计算 p ( u k ∣ ϕ ( v j ) ) p(u_k|\phi(v_j)) p(uk∣ϕ(vj))时,我们一般都是用softmax来计算这个概率,softmax的计算公式是
p ( x j ) = e x p ( x j ) ∑ i n e x p ( x i ) p(x_j) = \frac{exp(x_j)}{\sum_i^n{exp(x_i)}} p(xj)=∑inexp(xi)exp(xj)
但是词表的大小一般都是上万起步,如果要逐项计算 e x p ( x i ) exp(x_i) exp(xi),则非常浪费计算资源,那么有没有可以解决这个问题的方法呢?聪明的前辈们已经替我们想到了解决方法,那就是使用:负采样或者Hierarchical softmax方法。本文的作者使用的是HIerarchical softmax。因为skip gram算法在之前的文章中已经分析过,这里直接跳过。接下来我就再花费大家的一点时间来给大家介绍一下这个Hierarchical softmax。
3.2 Skip Gram
有兴趣的请翻前文。
3.3 Hierarchical softmax
这个Hierarchical softmax的算法思想其实非常简单,一言以蔽之:能否减少分类节点的个数(其实本质上也是负采样,只不过利用了完全二叉树去实现这个负采样的过程)。
例如:假设一部词典一共有8个单词,那么就可以构建一个如下所示的二叉树。
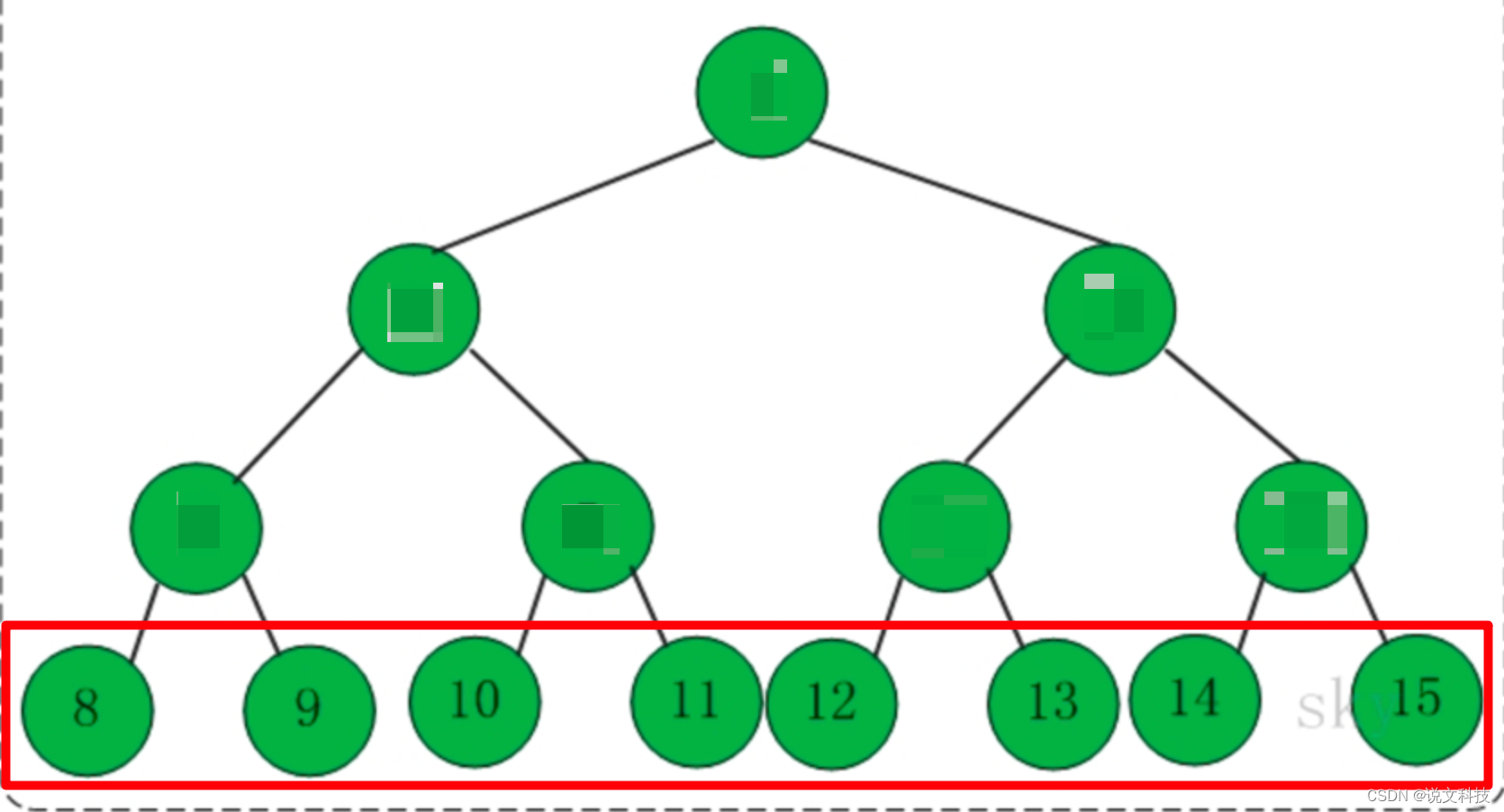
其中:
- 叶子节点与每个单词对应。
那么求上下文单词 u k u_k uk在条件 v j v_j vj出现时的概率这一问题就转化成了到达这个叶子节点的概率问题。 而到达每个叶子节点的概率是唯一的(因为路径各不相同)。那么之前的这个式子 p ( u k ∣ ϕ ( v j ) p(u_k | \phi(v_j) p(uk∣ϕ(vj) 就可以转化成由下面这个式子去求解:
∏ i m ( p ( y i ∣ v j ) ) \prod_i^m(p(y_i|v_j)) i∏m(p(yi∣vj))
其中, y i y_i yi的取值范围为{0,1},这里的m其实就是这棵二叉树的深度,也就是 l o g V log V logV向上取整。比如这里就是 l o g 8 = 3 log8=3 log8=3。
这么一套操作下来之后,就可以把原本一个线性的复杂度时间O(v)降到了O(logV),厉害吧!原文给出了一个比较直观的例子,用于理解Hierarchical softmax,如下:
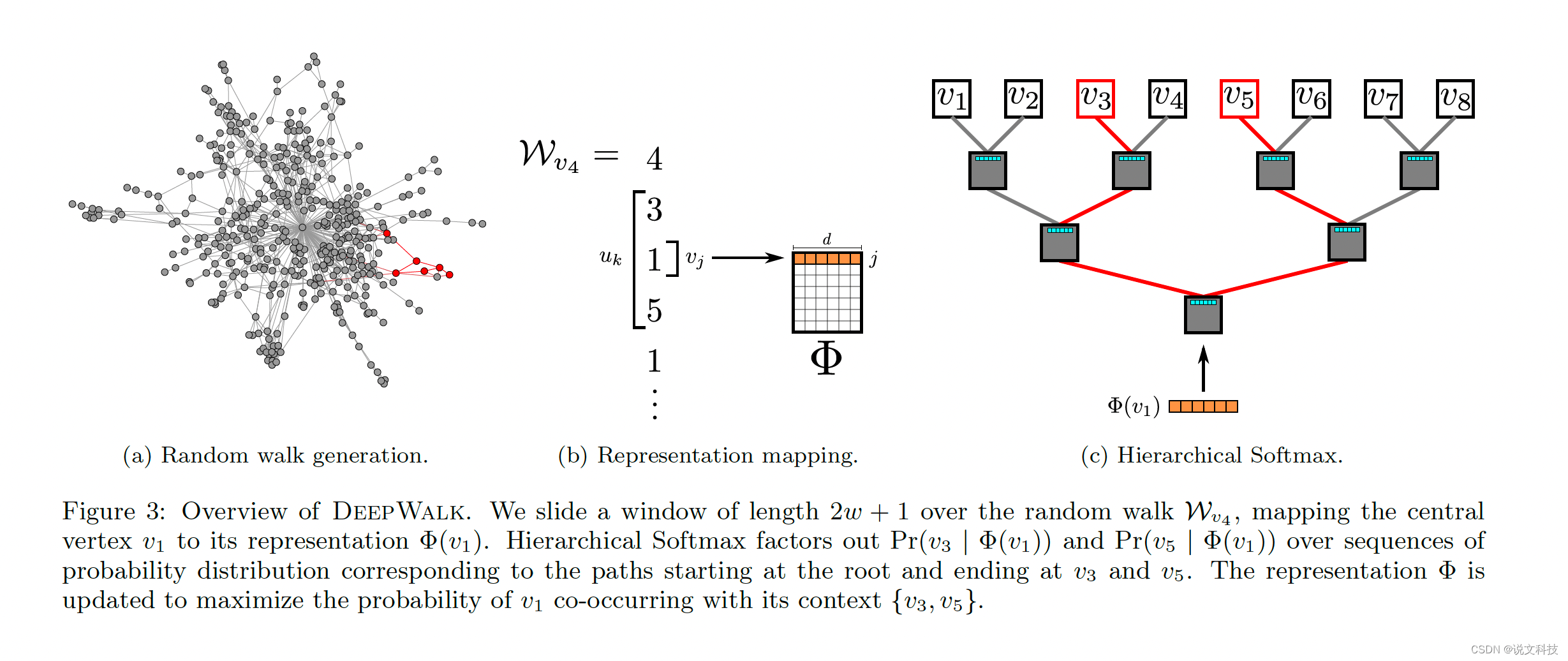
在求得这个概率之后,就可以转头去做优化了。
优化算法
deepwalk 论文的作者采取的是 SGD(stochastic gradient descent )优化损失。这里没有什么好介绍的,直接跳过了。到此为止,整个算法的核心内容已经介绍完毕了。接下来看看这个算法的实际效果如何?
3. 实际效果
deepwalk论文作者给出了一个效果示例图,如下图所示:
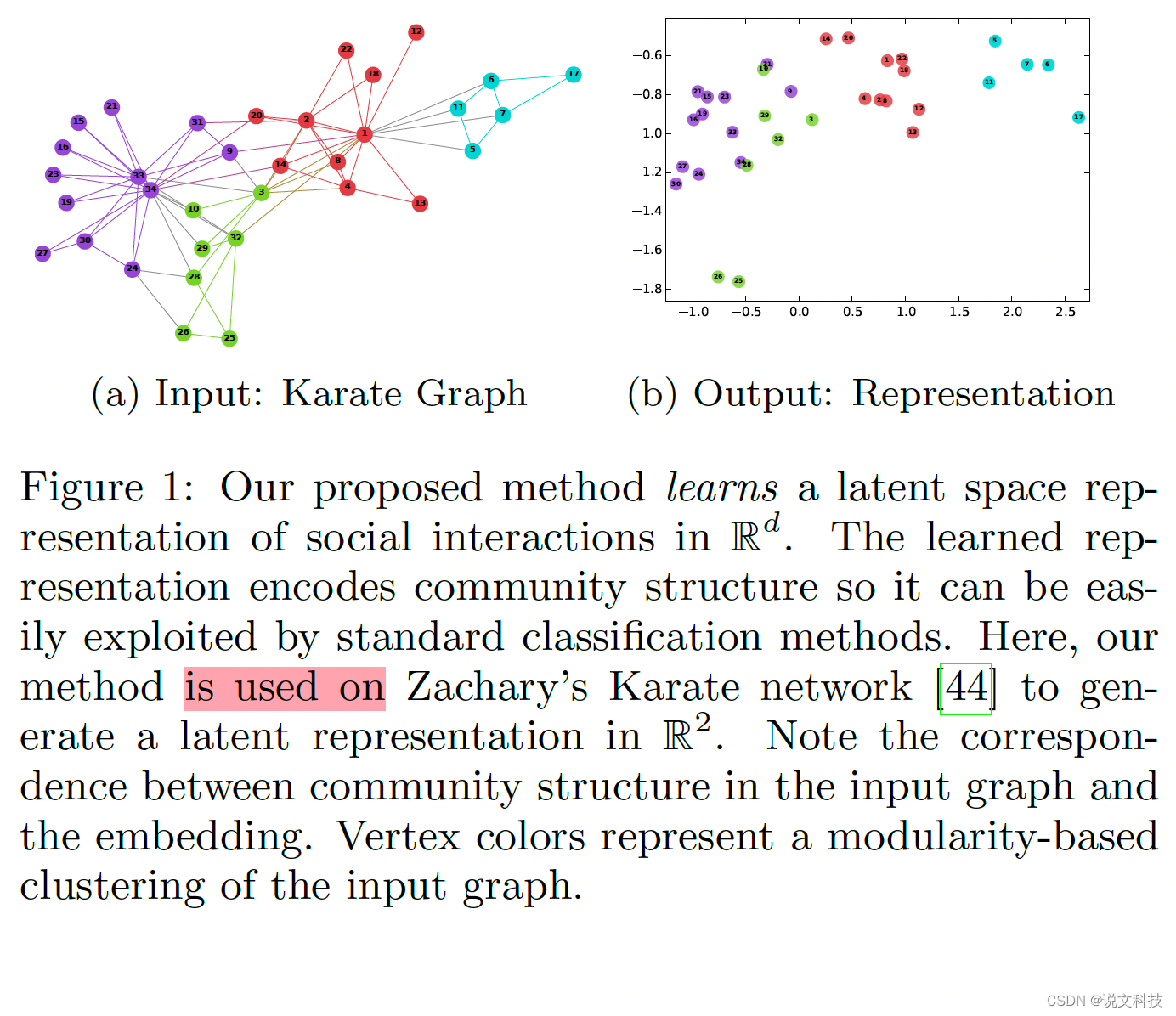
左侧是一个图结构信息,右侧是根据学习到的embedding得到的一个二维展示,可以看出图结构和节点表示几乎能够一一对应起来(顶点的颜色表示输入图对一个基于模块的聚类)。
4. 发现
文章中提出了许多非常有意思的知识。坦白讲,在没有仔细看这篇文章之前,有一些知识点我是不了解的,比如「zipf's laws」。
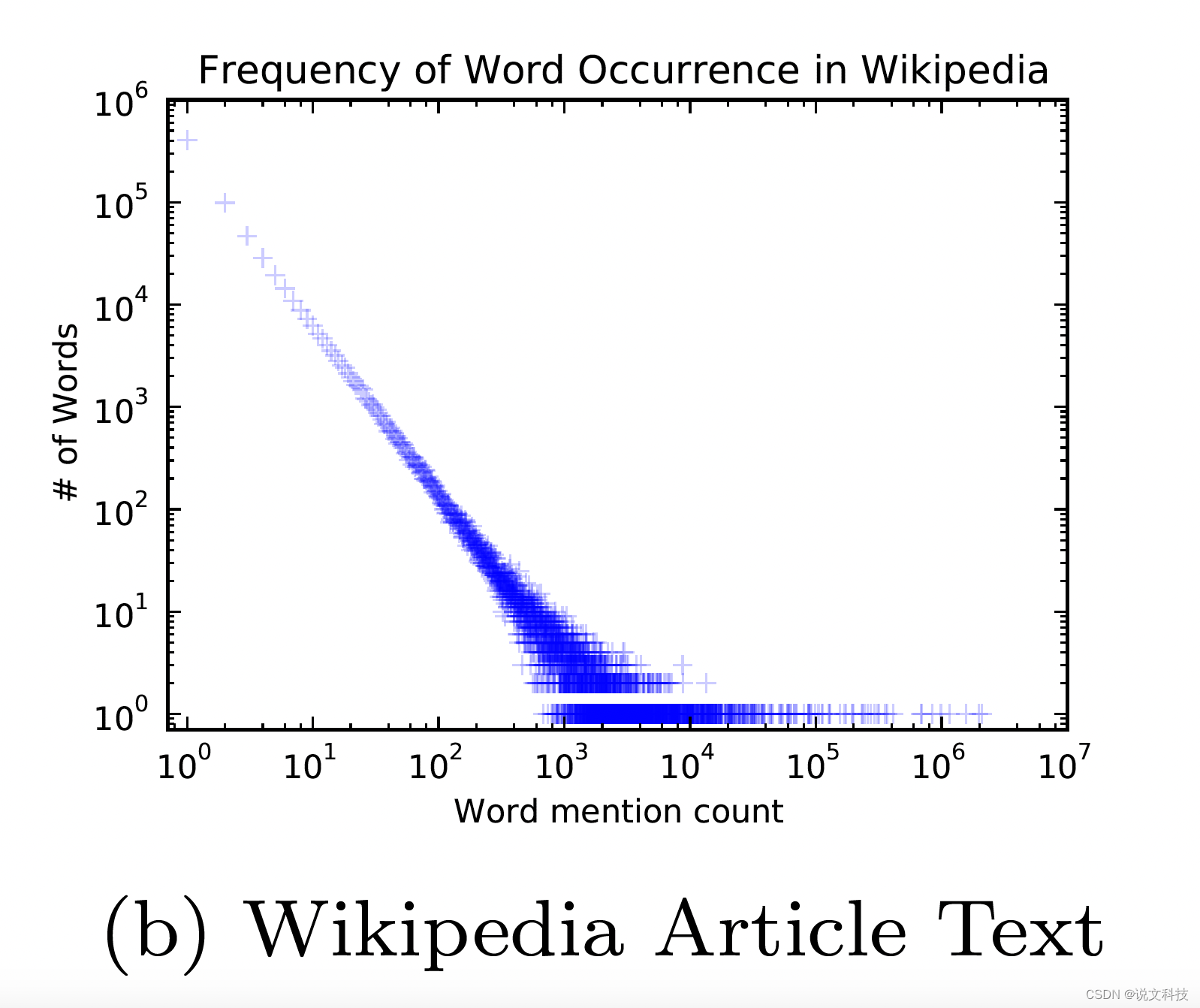
4.1 zipf’s law
zipfs'law,又称齐夫定律,这是一个经验定律。该定律表示:一个单词的排名 r r r和这个单词的出现频率 p p p成反比,也即 r ∗ p = k r*p = k r∗p=k。用图像表示则是如下这个样子:
y=1/x 这个函数的图像长这样:
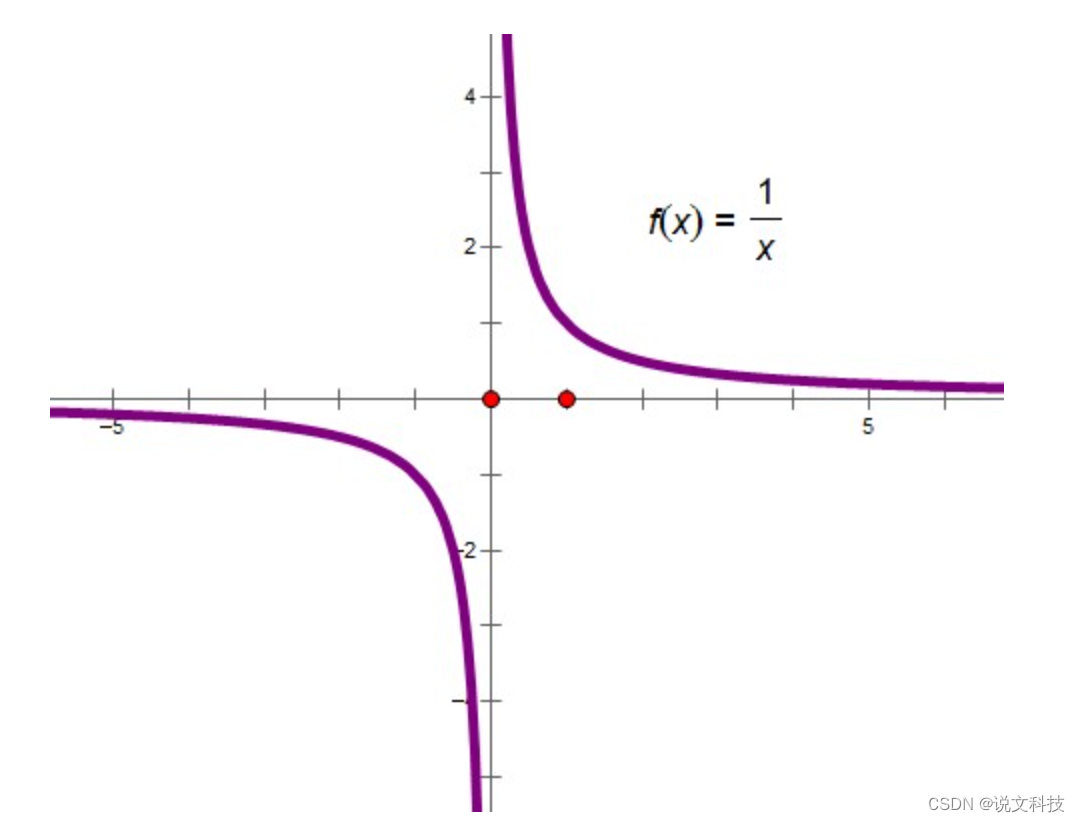
(齐夫定律的图像要稍微直一些)。作者发现,如果原始图的顶点服从齐夫定律,那么根据随机游走选出来的子图的频次也会满足齐夫定律。

这个时候作者就想到,如果满足齐夫定律的自然语言可以用语言模型建模,那么用随机游走方式得到的子图是否也可以通过语言模型来建模呢?于是接着有了后面使用SkipGram算法训练embedding,才有了这篇论文的诞生。
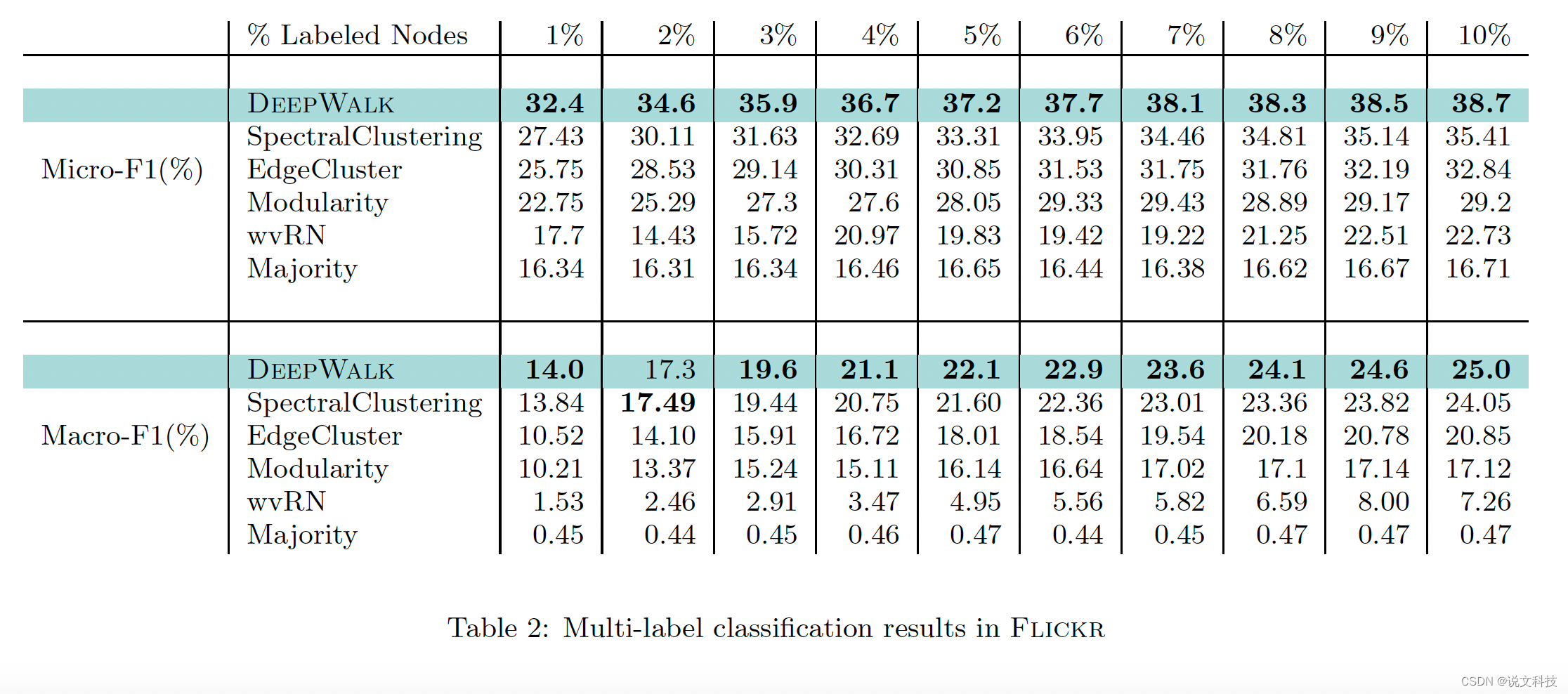
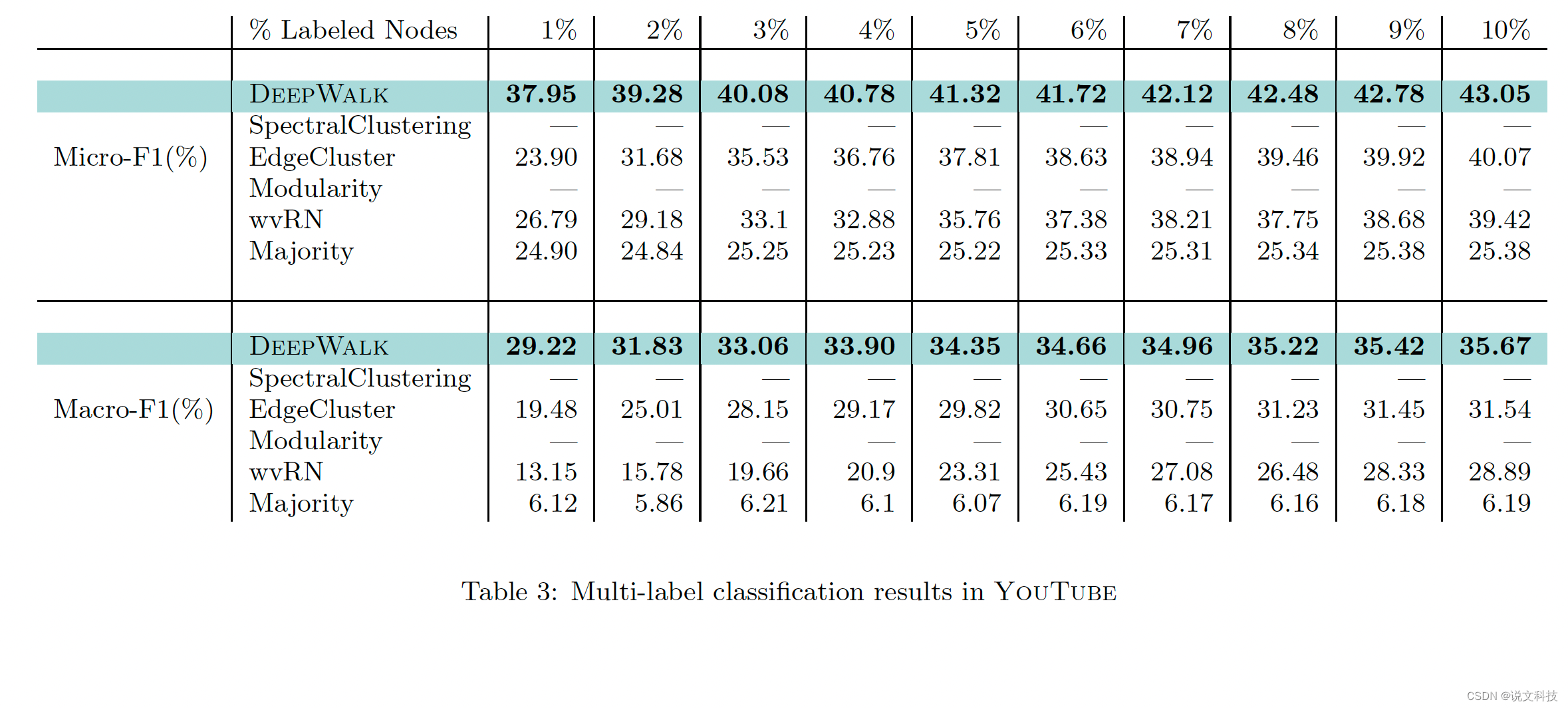
5. 实验效果
最后,作者给出了deepwalk算法在三个数据集上的多标签分类实验效果,如下所示。总结成一个词:惊艳!
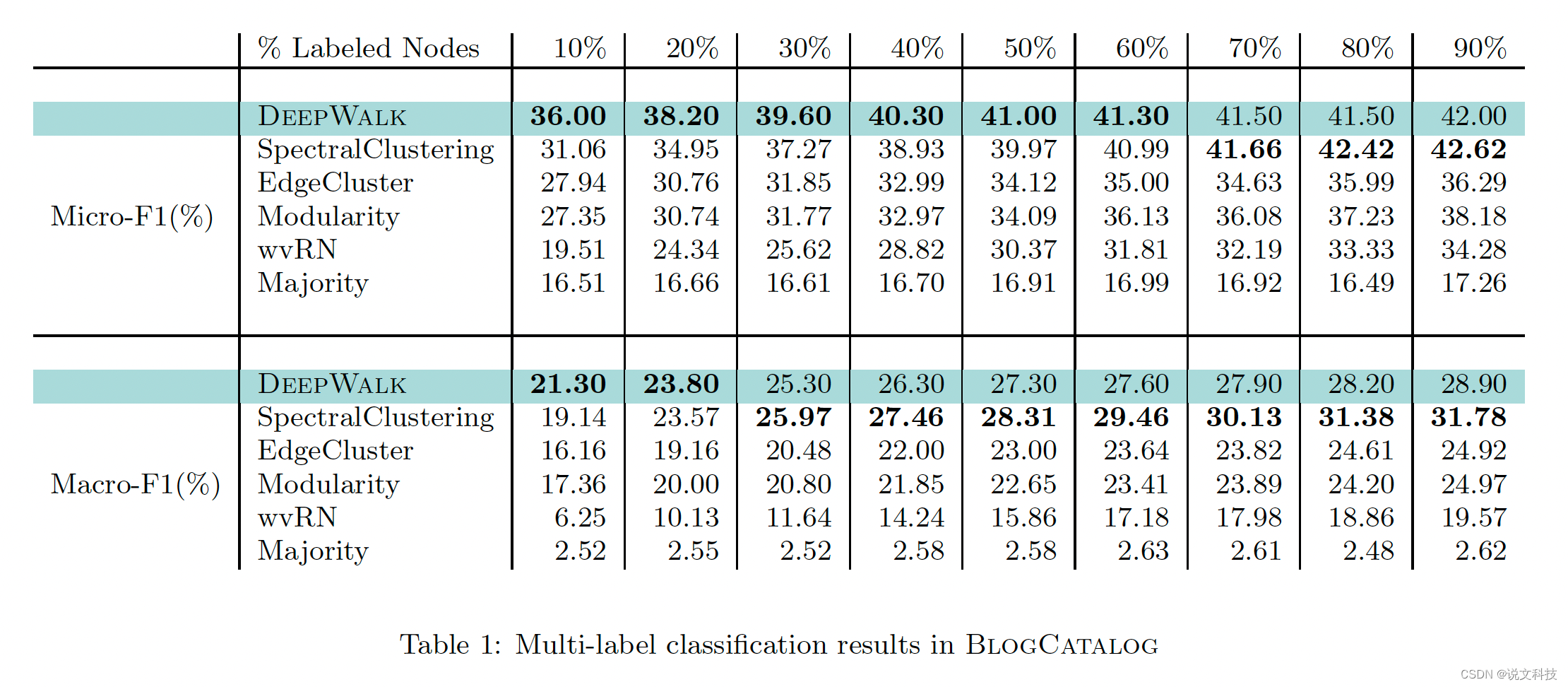
好了,到此第二期的经典论文阅读的第一部分工作已经结束,后面再围绕metapath2vec进行介绍。高质量分享实属不易,期待各位同学们的评论和赞赏哟。

相关文章:
《经典论文阅读2》基于随机游走的节点表示学习—Deepwalk算法
word2vec使用语言天生具备序列这一特性训练得到词语的向量表示。而在图结构上,则存在无法序列的难题,因为图结构它不具备序列特性,就无法得到图节点的表示。deepwalk 的作者提出:可以使用在图上随机游走的方式得到一串序列&#x…...

Java实现二叉树(下)
1.前言 http://t.csdnimg.cn/lO4S7 在前文我们已经简单的讲解了二叉树的基本概念,本文将讲解具体的实现 2.基本功能的实现 2.1获取树中节点个数 public int size(TreeNode root){if(rootnull){return 0;}int retsize(root.left)size(root.right)1;return ret;}p…...

Hello 算法10:搜索
https://www.hello-algo.com/chapter_searching/binary_search/ 二分查找法 给定一个长度为 n的数组 nums ,元素按从小到大的顺序排列,数组不包含重复元素。请查找并返回元素 target 在该数组中的索引。若数组不包含该元素,则返回 -1 。 # 首…...

常见分类算法详解
在机器学习和数据科学的广阔领域中,分类算法是至关重要的一环。它广泛应用于各种场景,如垃圾邮件检测、图像识别、情感分析等。本文将深入剖析几种常见的分类算法,帮助读者理解其原理、优缺点以及应用场景。 一、K近邻算法(K-Nea…...

推送恶意软件的恶意 PowerShell 脚本看起来是人工智能编写的
威胁行为者正在使用 PowerShell 脚本,该脚本可能是在 OpenAI 的 ChatGPT、Google 的 Gemini 或 Microsoft 的 CoPilot 等人工智能系统的帮助下创建的。 攻击者在 3 月份的一次电子邮件活动中使用了该脚本,该活动针对德国的数十个组织来传播 Rhadamanthy…...

微服务之Consul 注册中心介绍以及搭建
一、微服务概述 1.1单体架构 单体架构(monolithic structure):顾名思义,整个项目中所有功能模块都在一个工程中开发;项目部署时需要对所有模块一起编译、打包;项目的架构设计、开发模式都非常简单。 当项…...

MES生产管理系统:私有云、公有云与本地化部署的比较分析
随着信息技术的迅猛发展,云计算作为一种新兴的技术服务模式,已经深入渗透到企业的日常运营中。在众多部署方式中,私有云、公有云和本地化部署是三种最为常见的选择。它们各自具有独特的特点和适用场景,并在不同程度上影响着企业的…...

【core analyzer】core analyzer的介绍和安装详情
目录 🌞1. core和core analyzer的基本概念 🌼1.1 coredump文件 🌼1.2 core analyzer 🌞2. core analyzer的安装详细过程 🌼2.1 方式一 简单但不推荐 🌼2.2 方式二 推荐 🌻2.2.1 安装遇到…...

个人练习之-jenkins
虚拟机环境搭建(买不起服务器 like me) 重点: 0 虚拟机防火墙关闭 systemctl stop firewalld.service systemctl disable firewalld.service 1 (centos7.6)网络配置 (vmware 编辑 -> 虚拟网络编辑器 -> 选择NAT模式 ->NAT设置查看网关) vim /etc/sysconfig/network-sc…...
初探vercel托管项目
文章目录 第一步、注册与登录第二步、本地部署 在个人网站部署的助手vercel,支持 Github部署,只需简单操作,即可发布,方便快捷! 第一步、注册与登录 进入vercel【官网】,在右上角 login on,可登…...
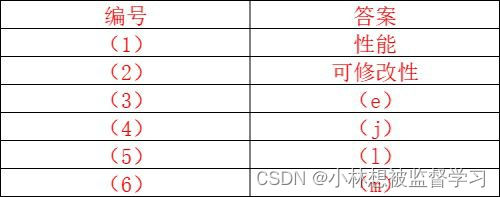
软考 - 系统架构设计师 - 质量属性例题 (2)
问题1: 、 问题 2: 系统架构风险:指架构设计中 ,潜在的,存在问题的架构决策所带来的隐患。 敏感点:指为了实现某个质量属性,一个或多个构件所具有的特性 权衡点:指影响多个质量属性…...

基于Python豆瓣电影数据可视化分析系统的设计与实现
大数据可视化项目——基于Python豆瓣电影数据可视化分析系统的设计与实现 2024最新项目 项目介绍 本项目旨在通过对豆瓣电影数据进行综合分析与可视化展示,构建一个基于Python的大数据可视化系统。通过数据爬取收集、清洗、分析豆瓣电影数据,我们提供了…...
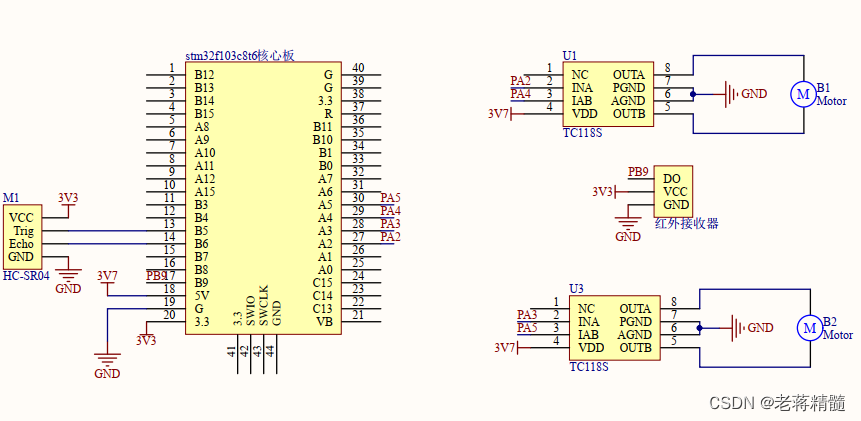
【已开源】基于stm32f103的爬墙小车
基于stm32f103的遥控器无线控制爬墙小车,实现功能为可平衡在竖直墙面上,并进行移动和转向,具有超声波防撞功能。 直接上: 演示视频如:哔哩哔哩】 https://b23.tv/BzVTymO 项目说明: 在这个项目中&…...

PCL 基于马氏距离KMeans点云聚类
文章目录 一、简介二、算法步骤三、代码实现四、实现效果参考资料一、简介 在诸多的聚类方法中,K-Means聚类方法是属于“基于原型的聚类”(也称为原型聚类)的方法,此类方法均是假设聚类结构能通过一组原型刻画,在现实聚类中极为常用。通常情况下,该类算法会先对原型进行初始…...
libVLC 视频窗口上叠加透明窗口
很多时候,我们需要在界面上画一些三角形、文字等之类的东西,我们之需要重写paintEvent方法,比如像这样 void Widget::paintEvent(QPaintEvent *event) 以下就是重写的代码。 void Widget::paintEvent(QPaintEvent *event) {//创建QPainte…...
MySQL基础入门上篇
MySQL基础 介绍 mysql -uroot -p -h127.0.0.1 -P3306项目设计 具备数据库一定的设计能力和操作数据的能力。 数据库设计DDL 定义 操作 显示所有数据库 show databases;创建数据库 create database db02;数据库名唯一,不能重复。 查询是否创建成功 加入一些…...

Docker搭建FFmpeg
FFmpeg 是一套可以用来记录、转换数字音频、视频,并能将其转化为流的完整解决方案。FFmpeg 包含了领先的音视频编解码库libavcodec,可以用于各种视频格式的转换。 应用场景包括: 视频转换:把视频从一种格式转换成另一种格式。视…...

Hudi-ubuntu环境搭建
hudi-ubuntu环境搭建 运行 1.编译Hudi #1.把maven安装包上传到服务器 # 官网下载安装包 https://archive.apache.org/dist/maven/maven-3/ scp -r D:\Users\zh\Desktop\Hudi\compressedPackage\apache-maven-3.6.3-bin.tar.gz zhangheng10.8.4.212:/home/zhangheng/hudi/com…...

Hive进阶Day05
一、HDFS分布式文件存储系统 1-1 HDFS的存储机制 按块(block)存储 hdfs在对文件数据进行存储时,默认是按照128M(包含)大小进行文件数据拆分,将不同拆分的块数据存储在不同datanode服务器上 拆分后的块数据会被分别存储在不同的服…...
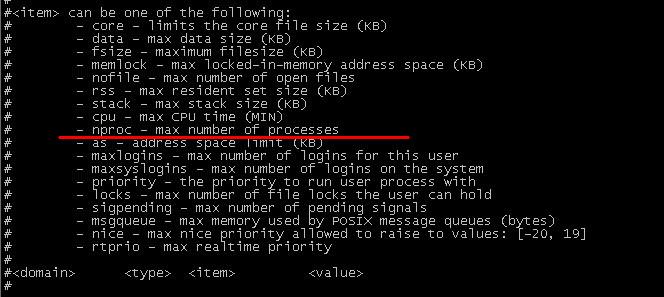
ssh爆破服务器的ip-疑似肉鸡
最近发现自己的ssh一直有一些人企图使用ssh暴力破解的方式进行密码破解.就查看了一下,真是网络安全太可怕了. 大家自己的服务器密码还是要设置好,管好,做好最基本的安全措施,不然最后只能沦为肉鸡. ssh登陆日志可以在/var/log下看到,ubuntu的话为auth.log,centos为secure文件 查…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

力扣-35.搜索插入位置
题目描述 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 class Solution {public int searchInsert(int[] nums, …...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...