实习僧网站的实习岗位信息分析
目录
- 背景描述
- 数据说明
- 数据集来源
- 问题描述
- 分析目标以及导入模块
- 1. 数据导入
- 2. 数据基本信息和基本处理
- 3. 数据处理
- 3.1 新建data_clean数据框
- 3.2 数值型数据处理
- 3.2.1 “auth_capital”(注册资本)
- 3.2.2 “day_per_week”(每周工作天数)
- 3.2.3 “num_employee”(公司规模)
- 3.2.4 “time_span”(实习月数)
- 3.2.5 “wage”(每天工资)
- 3.3 时间数据处理
- 3.3.1 “est_date”(公司成立日期)
- 3.3.2 “job_deadline”(截止时间)
- 3.3.3 “released_time”(发布时间)
- 3.3.4 “update_time”(更新时间)
- 3.4 字符型数据处理
- 3.4.1 “city”(城市)处理
- 3.4.2 “com_class”(公司和企业类型)处理
- 3.4.3 “com_logo”(公司logo)、“industry”(行业)也暂时不处理
- 4. 数据分析
- 4.1 数据基本情况
- 4.2 城市与职位数量
- 4.3 薪资
- 4.3.1 平均薪资
- 4.3.2 薪资与城市
- 4.4 学历
- 4.4.1 数据挖掘、机器学习算法的学历要求
- 4.4.2 学历与薪资
- 4.5 行业
- 4.6 公司
- 4.6.1 公司与职位数量、平均实习月薪
- 4.6.2 公司规模与职位数量
- 4.6.3 公司规模与实习月薪
- 4.6.4 公司实习期长度
- 4.6.5 企业成立时间
- 5. 给小E挑选实习公司
- 6. logo拼图
- 附录
背景描述
主要对“实习僧网站”招聘数据挖掘、机器学习的实习岗位信息进行分析。数据主要来自“数据挖掘”、“机器学习”和“算法”这3个关键词下的数据。由于原始数据还比较脏,本文使用pandas进行数据处理和分析,结合seaborn和pyecharts包进行数据可视化。
数据说明
准备数据集以及一个空文件
1.datamining.csv
2.machinelearning.csv
3.mlalgorithm.csv
4.data_clean.csv(空文件,以便清洗后存放干净数据)
数据集来源
https://github.com/Alfred1984/interesting-python/tree/master/shixiseng
问题描述
该数据主要用于“实习僧网站”招聘数据挖掘、机器学习的实习岗位信息进行分析
分析目标以及导入模块
1.由于小E想要找的实习公司是机器学习算法相关的工作,所以只对“数据挖掘”、“机器学习”、“算法”这三个关键字进行了爬取;
2.因此,分析目标就是国内公司对机器学习算法实习生的需求状况(仅基于实习僧网站),以及公司相关的分析。
1. 数据导入

2. 数据基本信息和基本处理



3. 数据处理
3.1 新建data_clean数据框

3.2 数值型数据处理
3.2.1 “auth_capital”(注册资本)




3.2.2 “day_per_week”(每周工作天数)


3.2.3 “num_employee”(公司规模)


3.2.4 “time_span”(实习月数)


3.2.5 “wage”(每天工资)

3.3 时间数据处理
3.3.1 “est_date”(公司成立日期)


3.3.2 “job_deadline”(截止时间)


3.3.3 “released_time”(发布时间)

3.3.4 “update_time”(更新时间)


3.4 字符型数据处理
3.4.1 “city”(城市)处理



3.4.2 “com_class”(公司和企业类型)处理



3.4.3 “com_logo”(公司logo)、“industry”(行业)也暂时不处理

4. 数据分析
4.1 数据基本情况

4.2 城市与职位数量





4.3 薪资
4.3.1 平均薪资

4.3.2 薪资与城市



4.4 学历
4.4.1 数据挖掘、机器学习算法的学历要求


4.4.2 学历与薪资


4.5 行业




4.6 公司
4.6.1 公司与职位数量、平均实习月薪
4.6.2 公司规模与职位数量

4.6.3 公司规模与实习月薪

4.6.4 公司实习期长度

4.6.5 企业成立时间




5. 给小E挑选实习公司


6. logo拼图



附录
导入模块
!pip install pyecharts==0.5.6
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import pyecharts
plt.style.use('ggplot')
%matplotlib inline
from pylab import mpl
#mpl.rcParams['font.sans-serif'] = ['SimHei'] #解决seaborn中文字体显示问题
plt.rc('figure', figsize=(10, 10)) #把plt默认的图片size调大一点
1. 数据导入
data_dm = pd.read_csv("datamining.csv")
data_ml = pd.read_csv("machinelearning.csv")
data_al = pd.read_csv("mlalgorithm.csv")
data = pd.concat([data_dm, data_ml, data_al], ignore_index = True)
2. 数据基本信息和基本处理
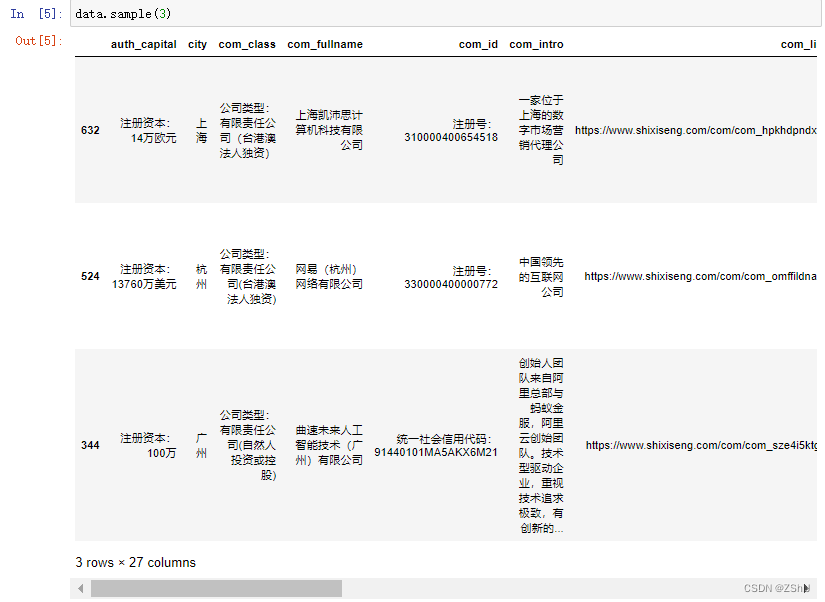
data.sample(3)
data.loc[666]
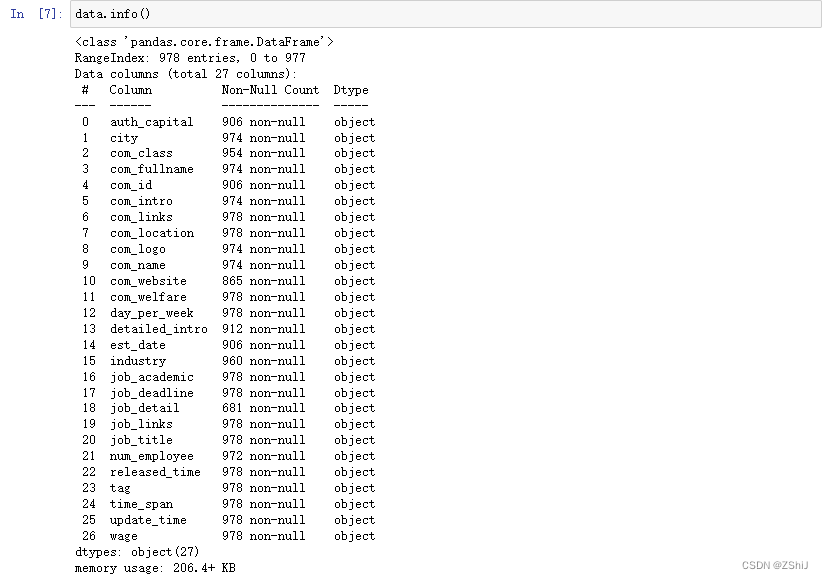
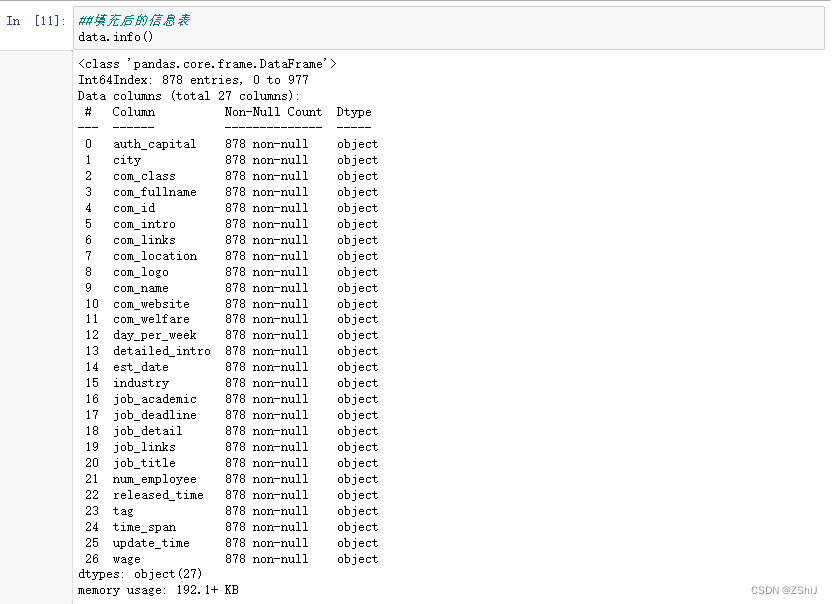
data.info()
data.drop_duplicates(subset='job_links', inplace=True)
data.shape
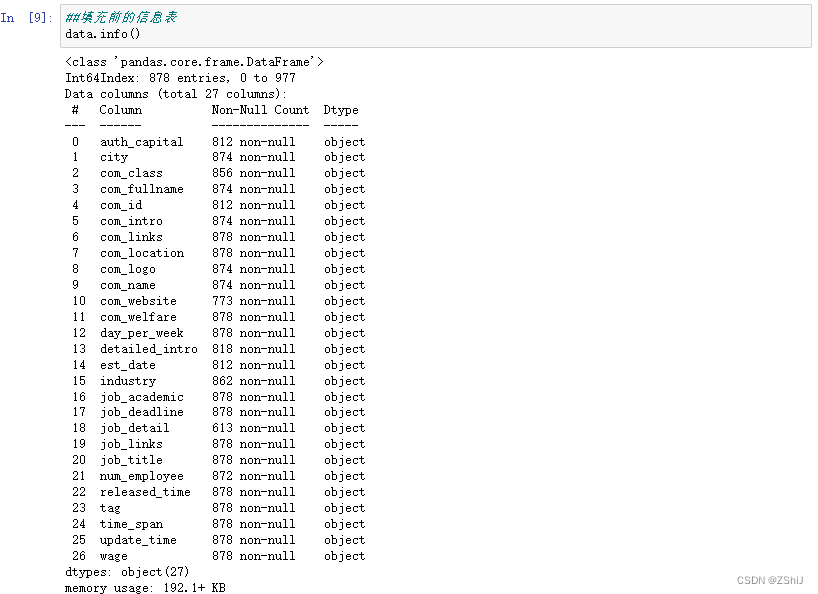
##填充前的信息表
data.info()
####将所有缺失值均补为'无')
data=data.fillna('无')##填充后的信息表
data.info()
*3. 数据处理
3.1 新建data_clean数据框
data_clean = data.drop(['com_id', 'com_links', 'com_location', 'com_website', 'com_welfare', 'detailed_intro', 'job_detail'], axis = 1)
3.2 数值型数据处理
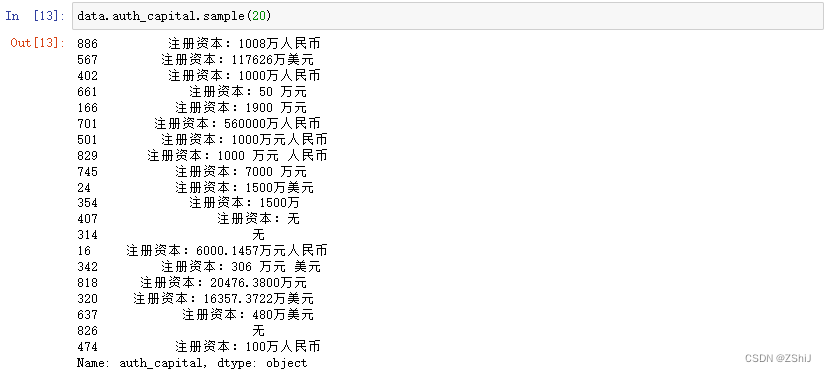
3.2.1 “auth_capital”(注册资本)
data.auth_capital.sample(20)
auth_capital = data['auth_capital'].str.split(':', expand = True)
auth_capital.sample(5)
auth_capital['num'] = auth_capital[1].str.extract('([0-9.]+)', expand=False).astype('float')
auth_capital.sample(5)
auth_capital[1].str.split('万', expand = True)[1].unique()
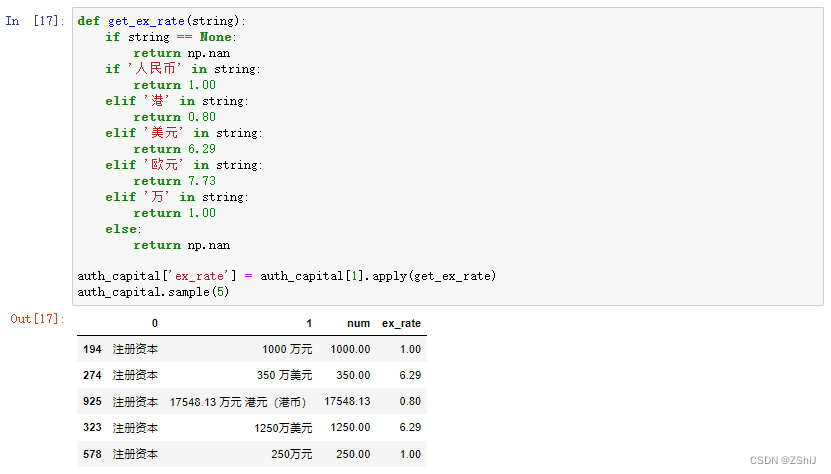
def get_ex_rate(string):if string == None:return np.nanif '人民币' in string:return 1.00elif '港' in string:return 0.80elif '美元' in string:return 6.29elif '欧元' in string:return 7.73elif '万' in string:return 1.00else:return np.nanauth_capital['ex_rate'] = auth_capital[1].apply(get_ex_rate)
auth_capital.sample(5)
data_clean['auth_capital'] = auth_capital['num'] * auth_capital['ex_rate']
data_clean['auth_capital'].head() ##此方法用于返回数据帧或序列的前n行(默认值为5)。
3.2.2 “day_per_week”(每周工作天数)
data.day_per_week.unique()
data_clean.loc[data['day_per_week'] == '2天/周', 'day_per_week'] = 2
data_clean.loc[data['day_per_week'] == '3天/周', 'day_per_week'] = 3
data_clean.loc[data['day_per_week'] == '4天/周', 'day_per_week'] = 4
data_clean.loc[data['day_per_week'] == '5天/周', 'day_per_week'] = 5
data_clean.loc[data['day_per_week'] == '6天/周', 'day_per_week'] = 6
3.2.3 “num_employee”(公司规模)
data.num_employee.unique()
data_clean.loc[data['num_employee'] == '少于15人', 'num_employee'] = '小型企业'
data_clean.loc[data['num_employee'] == '15-50人', 'num_employee'] = '小型企业'
data_clean.loc[data['num_employee'] == '50-150人', 'num_employee'] = '小型企业'
data_clean.loc[data['num_employee'] == '150-500人', 'num_employee'] = '中型企业'
data_clean.loc[data['num_employee'] == '500-2000人', 'num_employee'] = '中型企业'
data_clean.loc[data['num_employee'] == '2000人以上', 'num_employee'] = '大型企业'
data_clean.loc[data['num_employee'] == '5000人以上', 'num_employee'] = '大型企业'
data_clean.loc[data['num_employee'].isna(), 'num_employee'] = np.nan
3.2.4 “time_span”(实习月数)
data.time_span.unique()
mapping = {}
for i in range(1,19):mapping[str(i) + '个月'] = i
print(mapping)
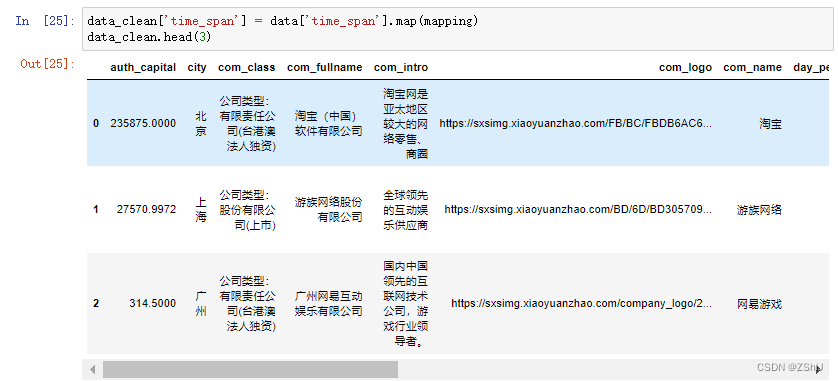
data_clean['time_span'] = data['time_span'].map(mapping)
data_clean.head(3)
3.2.5 “wage”(每天工资)
data['wage'].sample(5)
data_clean['average_wage'] = data['wage'].str.extract('([0-9.]+)-([0-9.]+)/天', expand=True).astype('int').mean(axis = 1)
data_clean['average_wage'].head()
3.3 时间数据处理
3.3.1 “est_date”(公司成立日期)
data['est_date'].sample(5)
data_clean['est_date'] = pd.to_datetime(data['est_date'].str.extract('成立日期:([0-9-]+)', expand=False))
data_clean['est_date'].sample(5)
3.3.2 “job_deadline”(截止时间)
data['job_deadline'].sample(5)
data_clean['job_deadline'] = pd.to_datetime(data['job_deadline'])
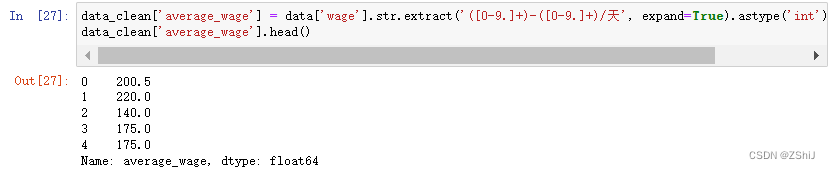
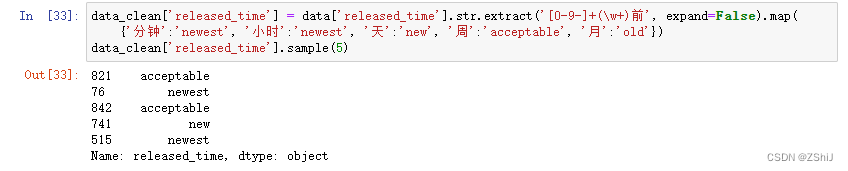
3.3.3 “released_time”(发布时间)
data['released_time'].sample(5)
data_clean['released_time'] = data['released_time'].str.extract('[0-9-]+(\w+)前', expand=False).map({'分钟':'newest', '小时':'newest', '天':'new', '周':'acceptable', '月':'old'})
data_clean['released_time'].sample(5)
3.3.4 “update_time”(更新时间)
data['update_time'].sample(5)
data_clean['update_time'] = pd.to_datetime(data['update_time'])
3.4 字符型数据处理
3.4.1 “city”(城市)处理
data['city'].unique()
data_clean.loc[data_clean['city'] == '成都市', 'city'] = '成都'
data_clean.loc[data_clean['city'].isin(['珠海市', '珠海 深圳', '珠海']), 'city'] = '珠海'
data_clean.loc[data_clean['city'] == '上海漕河泾开发区', 'city'] = '上海'
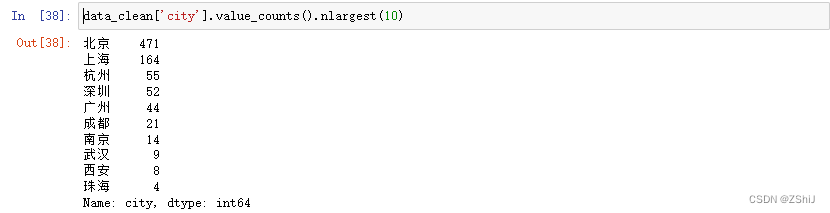
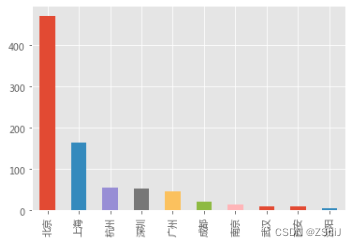
#招聘实习生前10的城市
data_clean['city'].value_counts().nlargest(10)
data_clean['city'].value_counts().nlargest(10).plot(kind = 'bar')
3.4.2 “com_class”(公司和企业类型)处理
list(data['com_class'].unique())
def get_com_type(string):if string == None:return np.nanelif ('非上市' in string) or ('未上市' in string):return '股份有限公司(未上市)'elif '股份' in string:return '股份有限公司(上市)'elif '责任' in string:return '有限责任公司'elif '外商投资' in string:return '外商投资公司'elif '有限合伙' in string:return '有限合伙企业'elif '全民所有' in string:return '国有企业'else:return np.nan
com_class = data['com_class'].str.split(':', expand = True)
com_class['com_class'] = com_class[1].apply(get_com_type)
com_class.sample(5)
data_clean['com_class'] = com_class['com_class']
3.4.3 “com_logo”(公司logo)、“industry”(行业)也暂时不处理
data_clean = data_clean.reindex(columns=['com_fullname', 'com_name', 'job_academic', 'job_links', 'tag','auth_capital', 'day_per_week', 'num_employee', 'time_span','average_wage', 'est_date', 'job_deadline', 'released_time','update_time', 'city', 'com_class', 'com_intro', 'job_title','com_logo', 'industry'])
data_clean.to_csv('data_clean.csv', index = False)
4. 数据分析
4.1 数据基本情况
data_clean.sample(3)
data_clean.info()
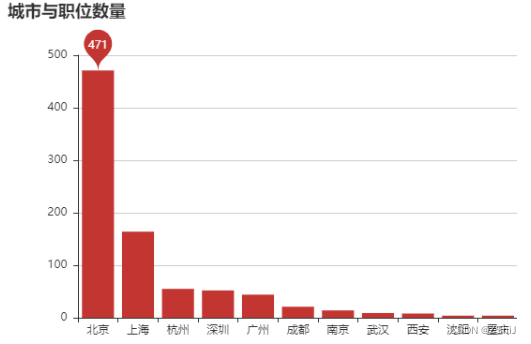
4.2 城市与职位数量
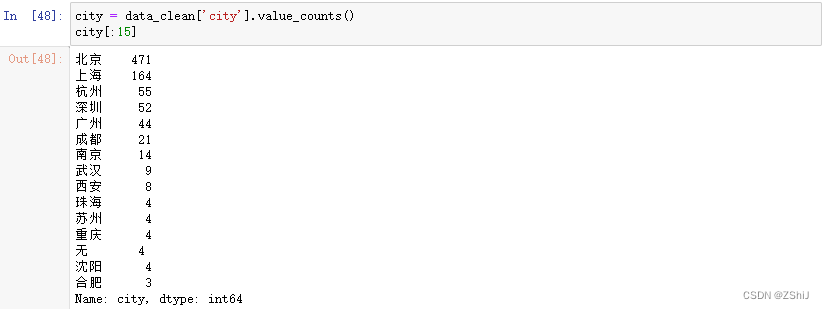
city = data_clean['city'].value_counts()
city[:15]
bar = pyecharts.Bar('城市与职位数量')
bar.add('', city[:15].index, city[:15].values, mark_point=["max"])
bar
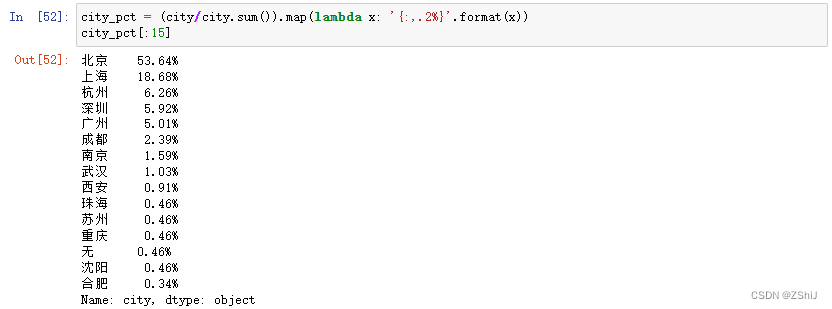
city_pct = (city/city.sum()).map(lambda x: '{:,.2%}'.format(x))
city_pct[:15]
(city/city.sum())[:5].sum()
data_clean.loc[data_clean['city'] == '杭州', 'com_name'].value_counts()[:5]
def topN(dataframe, n=5):counts = dataframe.value_counts()return counts[:n]
data_clean.groupby('city').com_name.apply(topN).loc[list(city_pct[:15].index)]
4.3 薪资
4.3.1 平均薪资
data_clean['salary'] = data_clean['average_wage'] * data_clean['day_per_week'] * 4
data_clean['salary'].mean()
4.3.2 薪资与城市
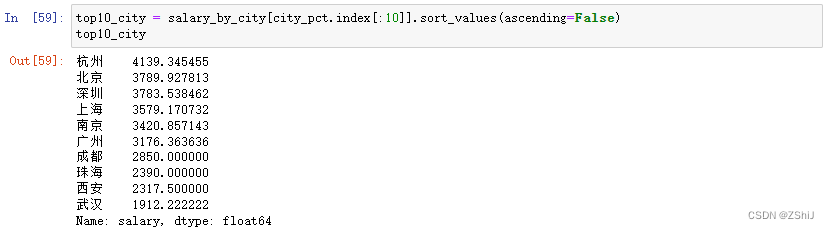
salary_by_city = data_clean.groupby('city')['salary'].mean()
salary_by_city.nlargest(10)
top10_city = salary_by_city[city_pct.index[:10]].sort_values(ascending=False)
top10_city
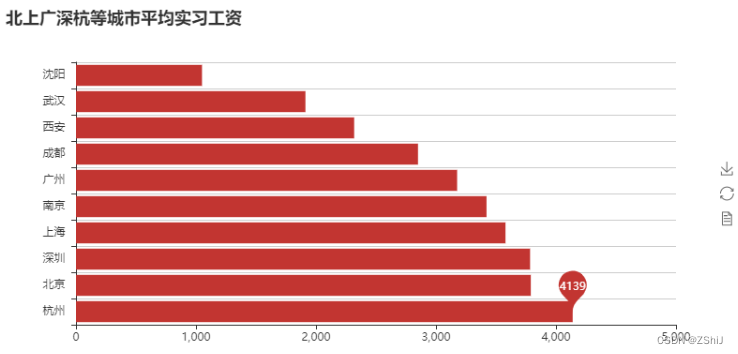
bar = pyecharts.Bar('北上广深杭等城市平均实习工资')
bar.add('', top10_city.index, np.round(top10_city.values, 0), mark_point=["max"], is_convert=True)
bar
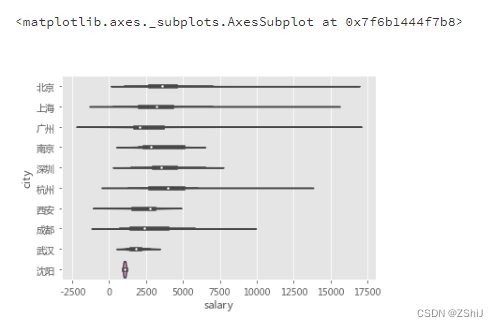
top10_city_box = data_clean.loc[data_clean['city'].isin(top10_city.index),:]
sns.violinplot(x ='salary', y ='city', data = top10_city_box)
4.4 学历
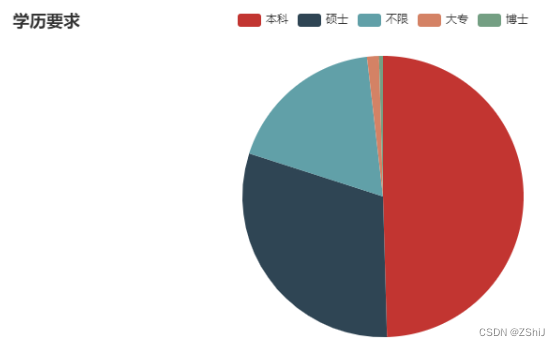
4.4.1 数据挖掘、机器学习算法的学历要求
job_academic = data_clean['job_academic'].value_counts()
job_academic
pie = pyecharts.Pie("学历要求")
pie.add('', job_academic.index, job_academic.values)
pie
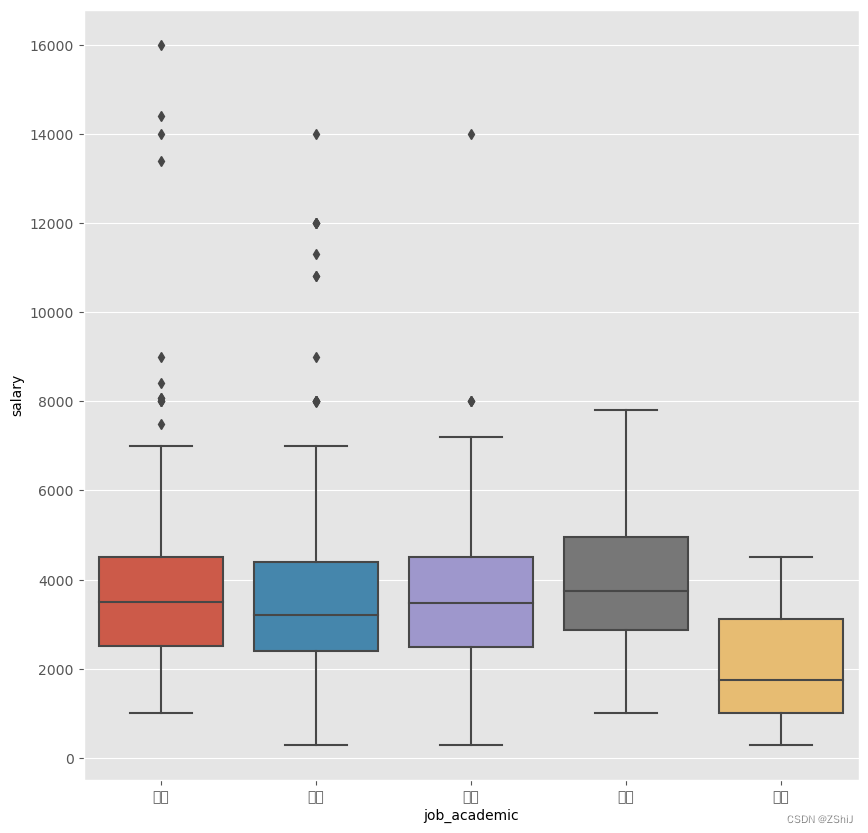
4.4.2 学历与薪资
data_clean.groupby(['job_academic'])['salary'].mean().sort_values()
sns.boxplot(x="job_academic", y="salary", data=data_clean)
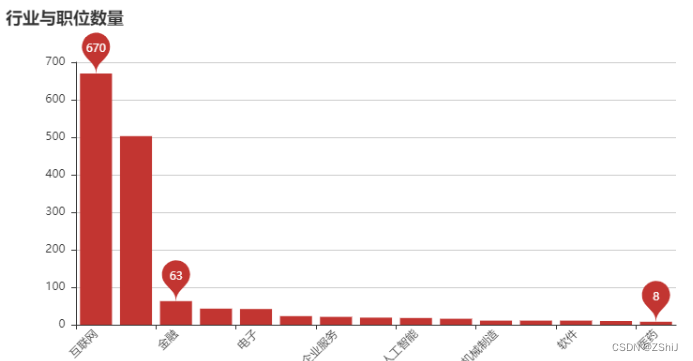
4.5 行业
data_clean['industry'].sample(5)
industry = data_clean.industry.str.split('/|,|,', expand = True)
industry_top15 = industry.apply(pd.value_counts).sum(axis = 1).nlargest(15)
bar = pyecharts.Bar('行业与职位数量')
bar.add('', industry_top15.index, industry_top15.values, mark_point=["max","min","average"], xaxis_rotate=45)
bar
4.6 公司
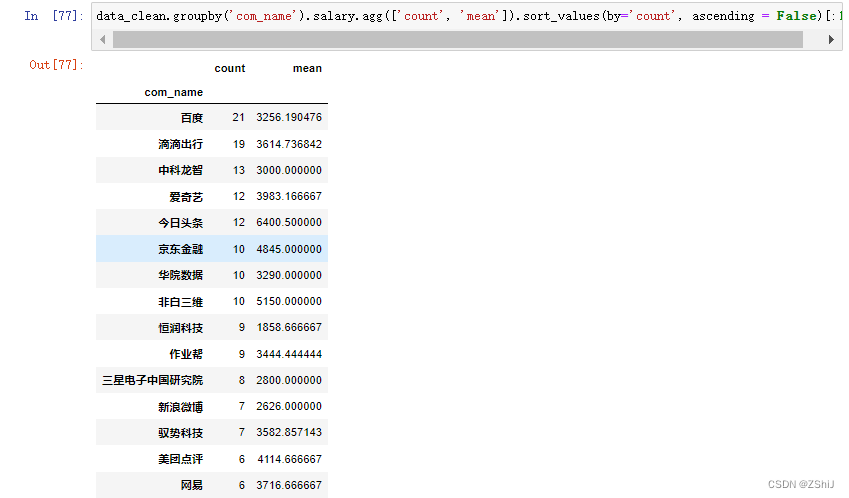
4.6.1 公司与职位数量、平均实习月薪
data_clean.groupby('com_name').salary.agg(['count', 'mean']).sort_values(by='count', ascending = False)[:15]
4.6.2 公司规模与职位数量
data_clean['num_employee'].value_counts()
4.6.3 公司规模与实习月薪
data_clean.groupby('num_employee')['salary'].mean()
4.6.4 公司实习期长度
data_clean['time_span'].value_counts()
data_clean['time_span'].mean()
4.6.5 企业成立时间
est_date = data_clean.drop_duplicates(subset='com_name')
import warnings
warnings.filterwarnings('ignore')
est_date['est_year'] = pd.DatetimeIndex(est_date['est_date']).year
num_com_by_year = est_date.groupby('est_year')['com_name'].count()
line = pyecharts.Line("每年新成立的公司数量变化")
line.add("", num_com_by_year.index, num_com_by_year.values, mark_line=["max", "average"])
line
scale_VS_year = est_date.groupby(['num_employee', 'est_year'])['com_name'].count()
scale_VS_year_s = scale_VS_year['小型企业'].reindex(num_com_by_year.index, fill_value=0)
scale_VS_year_m = scale_VS_year['中型企业'].reindex(num_com_by_year.index, fill_value=0)
scale_VS_year_l = scale_VS_year['大型企业'].reindex(num_com_by_year.index, fill_value=0)line = pyecharts.Line("新成立的企业与规模")
line.add("小型企业", scale_VS_year_s.index, scale_VS_year_s.values, is_label_show=True)
line.add("中型企业", scale_VS_year_m.index, scale_VS_year_m.values, is_label_show=True)
line.add("大型企业", scale_VS_year_l.index, scale_VS_year_l.values, is_label_show=True)
line
5. 给小E挑选实习公司
E_data = data_clean.loc[(data_clean['city'] == '深圳') & (data_clean['job_academic'] != '博士') & (data_clean['time_span'].isin([1,2,3])) & (data_clean['salary'] > 3784) & (data_clean['released_time'] == 'newest'), :]
E_data['com_name'].unique()
data.loc[E_data.index, ['job_title', 'job_links']]
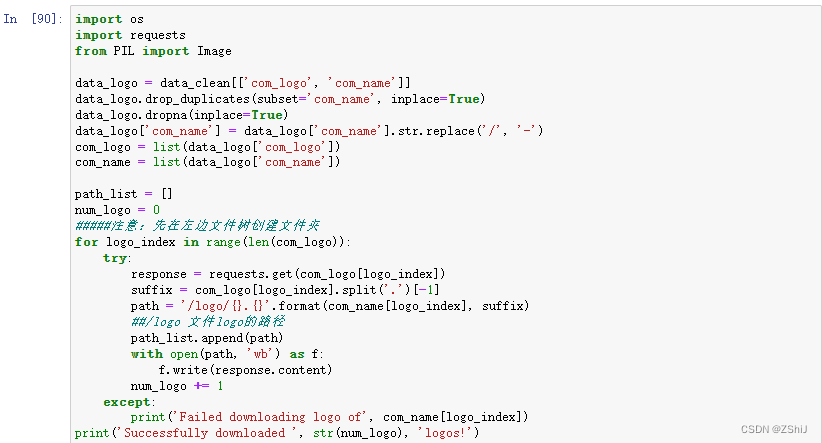
6. logo拼图
import os
import requests
from PIL import Imagedata_logo = data_clean[['com_logo', 'com_name']]
data_logo.drop_duplicates(subset='com_name', inplace=True)
data_logo.dropna(inplace=True)
data_logo['com_name'] = data_logo['com_name'].str.replace('/', '-')
com_logo = list(data_logo['com_logo'])
com_name = list(data_logo['com_name'])path_list = []
num_logo = 0
#####注意:先在左边文件树创建文件夹
for logo_index in range(len(com_logo)):try:response = requests.get(com_logo[logo_index])suffix = com_logo[logo_index].split('.')[-1]path = 'logo/{}.{}'.format(com_name[logo_index], suffix)##logo 文件logo的路径path_list.append(path)with open(path, 'wb') as f:f.write(response.content)num_logo += 1except:print('Failed downloading logo of', com_name[logo_index])
print('Successfully downloaded ', str(num_logo), 'logos!')
x = y = 0
line = 20
NewImage = Image.new('RGB', (128*line, 128*line))
for item in path_list:try:img = Image.open(item)img = img.resize((128, 128), Image.ANTIALIAS)NewImage.paste(img, (x * 128, y * 128))x += 1except IOError:print("第%d行,%d列文件读取失败!IOError:%s" % (y, x, item))x -= 1if x == line:x = 0y += 1if (x + line * y) == line * line:break
##注:先在左侧文件上传一jpg(建议纯白)
NewImage.save("test.JPG") ##test.JPG是自己创建图片的路径
##显示生成的logo拼图
import matplotlib.image as mpimg # mpimg 用于读取图片lena = mpimg.imread('test.JPG') # 读取和代码处于同一目录下的 lena.png
# 此时 lena 就已经是一个 np.array 了,可以对它进行任意处理
lena.shape #(512, 512, 3)plt.imshow(lena) # 显示图片
plt.axis('off') # 不显示坐标轴
plt.show()
相关文章:
实习僧网站的实习岗位信息分析
目录 背景描述数据说明数据集来源问题描述分析目标以及导入模块1. 数据导入2. 数据基本信息和基本处理3. 数据处理3.1 新建data_clean数据框3.2 数值型数据处理3.2.1 “auth_capital”(注册资本)3.2.2 “day_per_week”(每周工作天数…...
C语言中局部变量和全局变量是否可以重名?为什么?
可以重名 在C语言中, 局部变量指的是定义在函数内的变量, 全局变量指的是定义在函数外的变量 他们在程序中的使用方法是不同的, 当重名时, 局部变量在其所在的作用域内具有更高的优先级, 会覆盖或者说隐藏同名的全局变量 具体来说: 局部变量的生命周期只在函数内部,如果出了…...
小程序中配置scss
找到:project.config.json 文件 setting 模块下添加: "useCompilerPlugins": ["sass","其他的样式类型"] 配置完成后,重启开发工具,并新建文件 结果:...

ZYNQ-Vitis(SDK)裸机开发之(四)PS端MIO和EMIO的使用
目录 一、ZYNQ中MIO和EMIO简介 二、Vivado中搭建block design 1.配置PS端MIO: 2.配置PS端EMIO: 三、Vitis中新建工程进行GPIO控制 1. GPIO操作头文件gpio_hdl.h: 2.GPIO操作源文件gpio_hdl.c: 3.main函数进行调用 例程开发…...
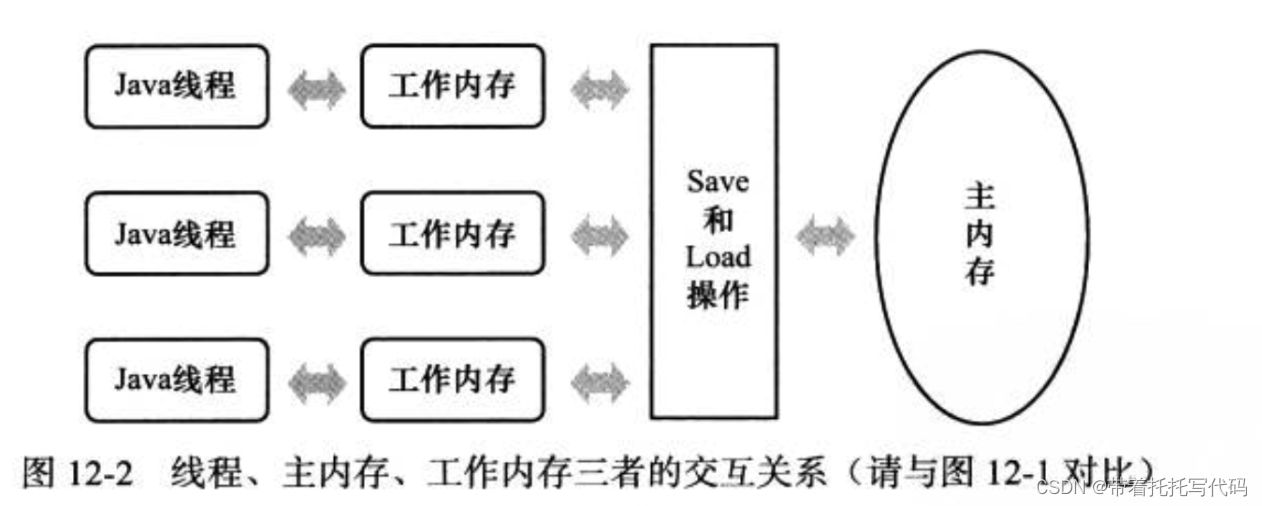
聊聊jvm中内存模型的坑
jvm线程的内存模型 看图,简单来说线程中操作的变量是副本。在并发情况下,如果数据发生变更,副本的数据就变为脏数据。这个时候就会有并发问题。 参考:https://www.cnblogs.com/yeyang/p/12580682.html 怎么解决并发问题 解决的…...
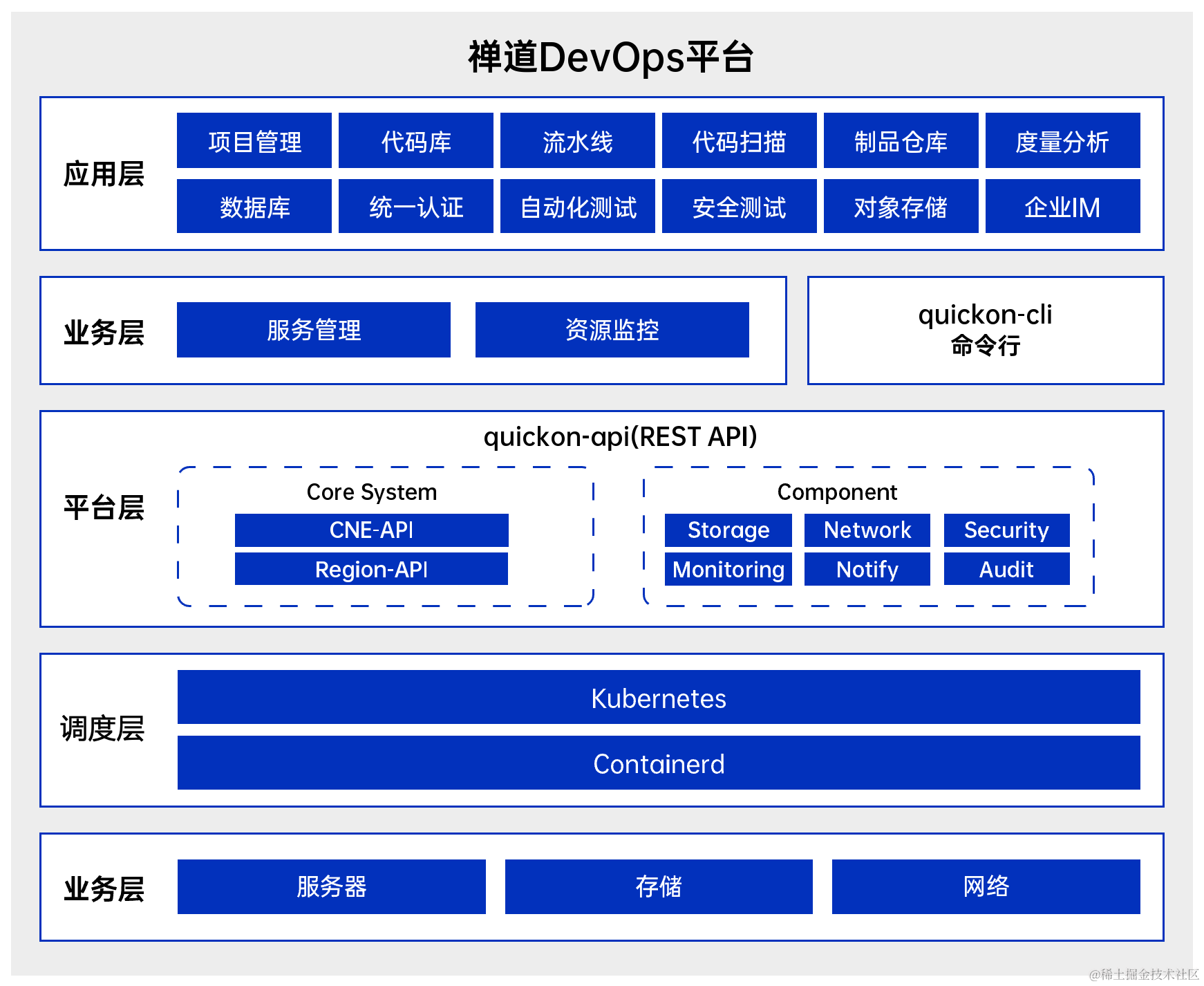
DevOps已死?2024年的DevOps将如何发展
随着我们进入2024年,DevOps也发生了变化。新兴的技术、变化的需求和发展的方法正在重新定义有效实施DevOps实践。 IDC预测显示,未来五年,支持DevOps实践的产品市场继续保持健康且快速增长,2022年-2027年的复合年增长率࿰…...

appium控制手机一直从下往上滑动
用于使用Appium和Selenium WebDriver在Android设备上滚动设置应用程序的界面。具体来说,它通过WebDriverWait和expected_conditions等待元素出现,然后使用ActionChains移动到该元素并执行滚动动作。在setUp中,它初始化了Appium的WebDriver和c…...

为什么光伏探勘测绘需要无人机?
随着全球对可再生能源需求的不断增长,光伏产业也迎来了快速发展的机遇。光伏电站作为太阳能发电的主要形式之一,其建设前期的探勘测绘工作至关重要。在这一过程中,无人机技术的应用正逐渐展现出其独特的优势。那么,为什么光伏探勘…...
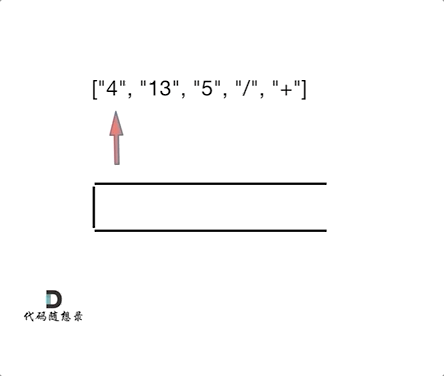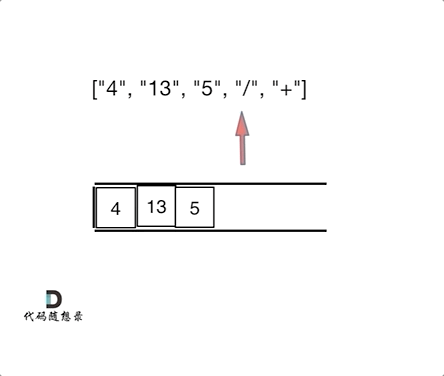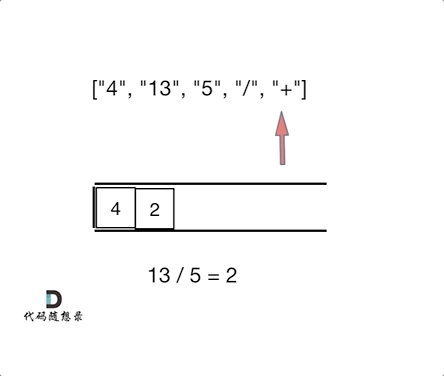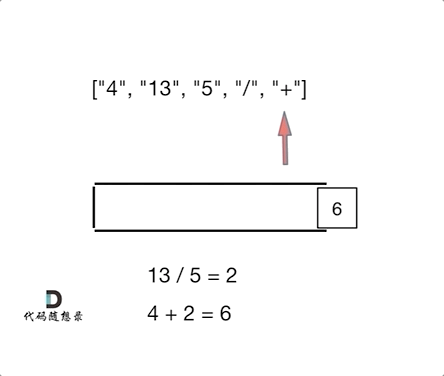
day10 | 栈与队列 part-2 (Go) | 20 有效的括号、1047 删除字符串中的所有相邻重复项、150 逆波兰表达式求值
今日任务 20 有效的括号 (题目: . - 力扣(LeetCode))1047 删除字符串中的所有相邻重复项 (题目: . - 力扣(LeetCode))150 逆波兰表达式求值 (题目: . - 力扣(LeetCode)) 20 有效的括号 题目: . - 力扣&…...
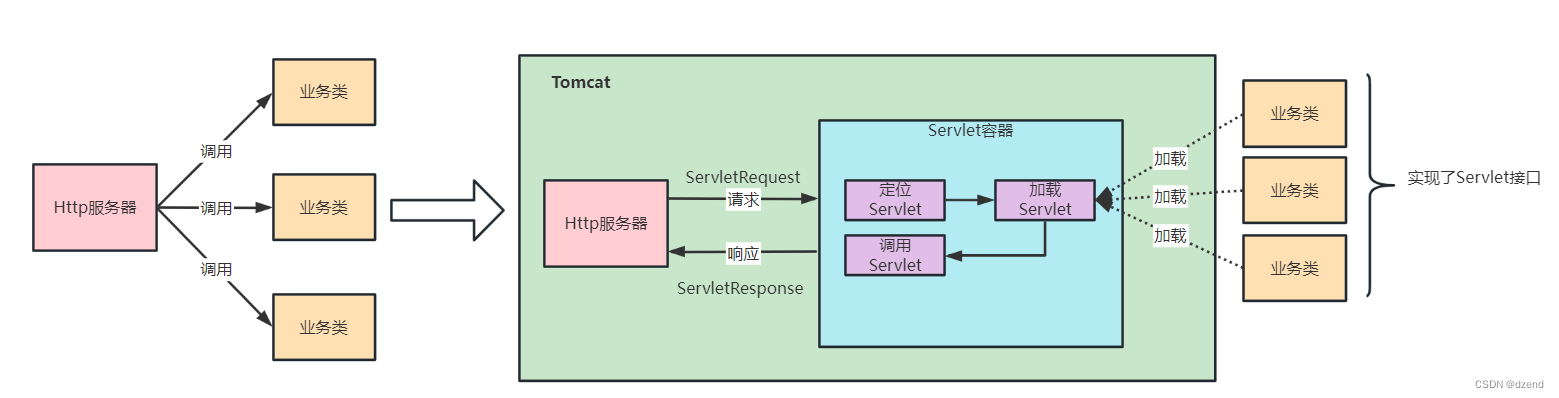
深入解析Tomcat的工作流程
tomcat解析 Tomcat是一个广泛使用的开源Servlet容器,用于托管Java Web应用程序。理解Tomcat的工作流程对于开发人员和系统管理员来说是非常重要的。本文将深入探讨Tomcat的工作原理,包括请求处理、线程池管理、类加载、以及与Web服务器之间的通信。 ###…...
【web网页制作】html+css旅游家乡山西主题网页制作(3页面)【附源码】
山西旅游网页目录 涉及知识写在前面一、网页主题二、网页效果Page1、景点介绍Page2、酒店精选|出行攻略Page3、景色欣赏 三、网页架构与技术3.1 脑海构思3.2 整体布局3.3 技术说明书 四、网页源码4.1 主页模块源码4.2 源码获取方式 作者寄语 涉及知识 山西旅游主题网页制作&am…...

系统参数指标:QPS、TPS、PV、UV等
QPS QPS:Queries Per Second 是每秒查询率,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,即每秒的响应请求数,也即是最大吞吐能力。 TPS TPS:Tra…...

一入鸿蒙深似海,从此Spring是路人:鸿蒙开发面试题
详细内容请参考最新的官方鸿蒙文档,不保证时效性 写得不对的地方请多多指点,本文仅代表个人所学知识范围 联系方式QQ 1219723557,可一同交流学习 欢迎补充,希望能做一个汇总版本出来 1. 网络编程基本知识(较为简单&…...
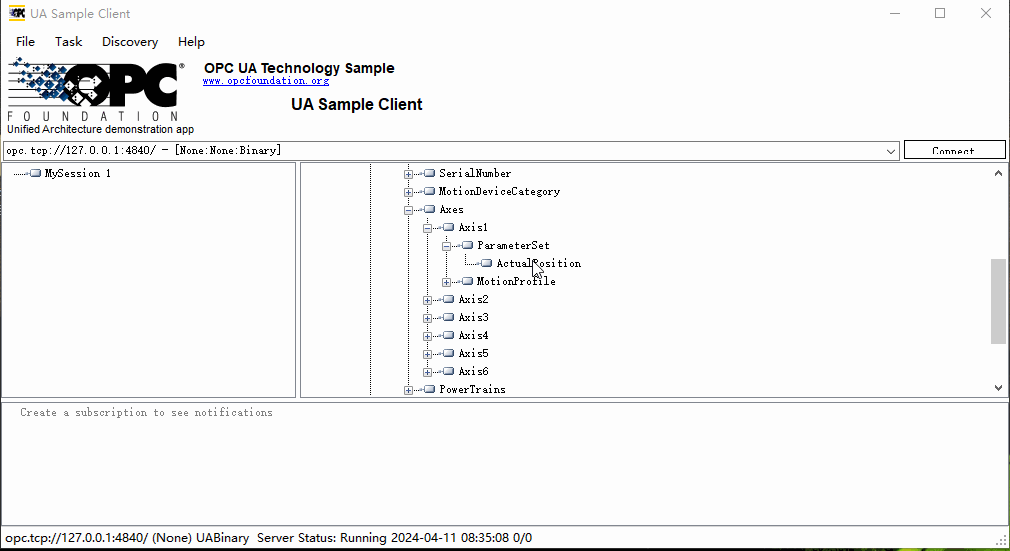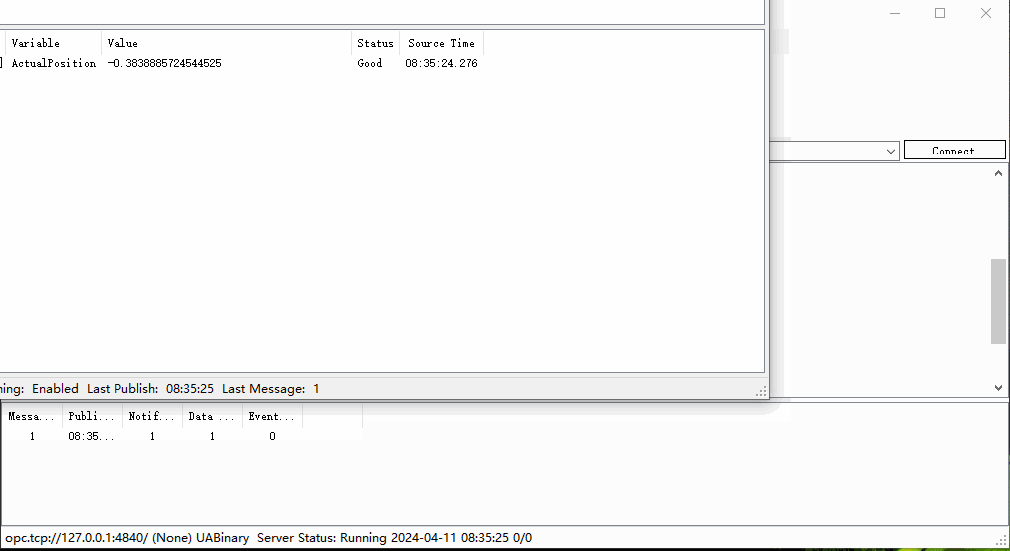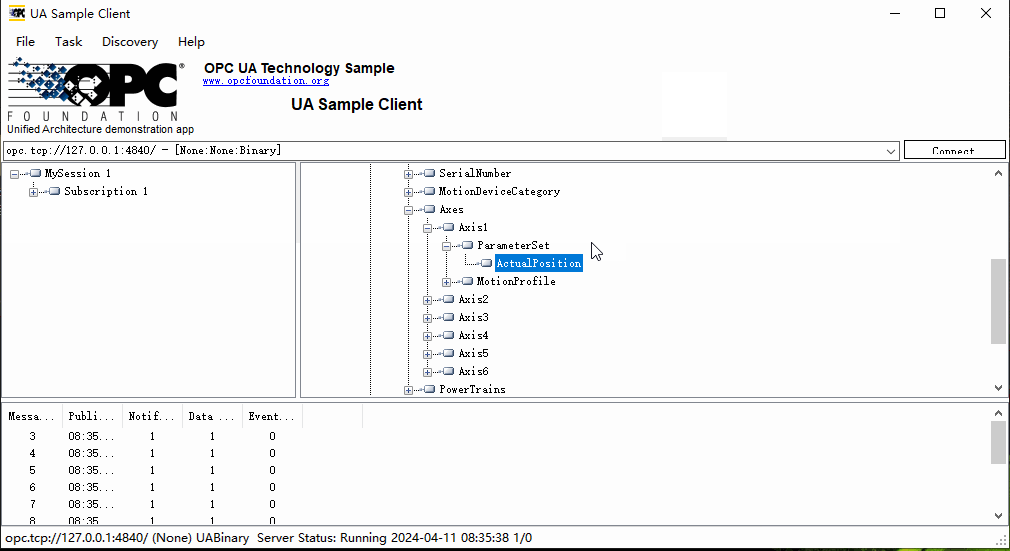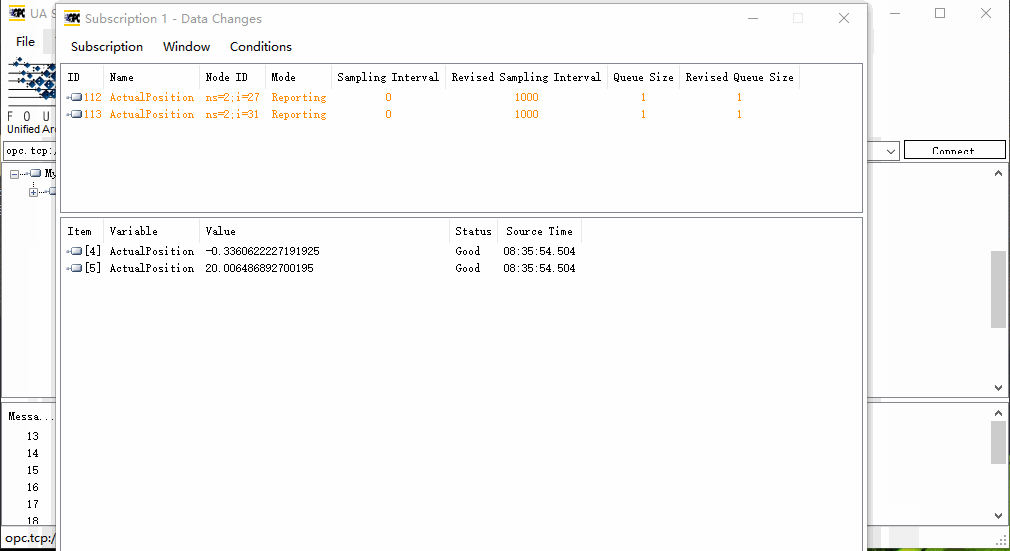
【Python】使用OPC UA创建数据服务器
目录 准备工作服务器设置创建或获取节点设置节点值启动服务器查看服务器客户端总结 在工业自动化和物联网(IoT)领域,OPC UA(开放平台通信统一架构)已经成为一种广泛采用的数据交换标准。它提供了一种安全、可靠且独立于…...

JavaScript(六)-高级篇
文章目录 作用域局部作用域全局作用域作用域链JS垃圾回收机制闭包变量提升 函数进阶函数提升函数参数动态参数多余参数 箭头函数 解构赋值数组解构对象解构 遍历数组forEach方法(重点)构造函数深入对象创建对象的三种方式构造函数实例成员 & 静态成员…...

速盾:游戏cdn什么意思
CDN(Content Delivery Network)是指内容分发网络,它是由一组位于世界各地的服务器组成的网络,用于将内容有效地传输给用户。游戏CDN,顾名思义,就是用于游戏内容分发的网络。 在传统的网络传输模式中&#…...
)
数据库-Redis(11)
目录 51.什么是Redis事务? 52.Redis事务相关命令? 53.Redis事务的三个阶段?...
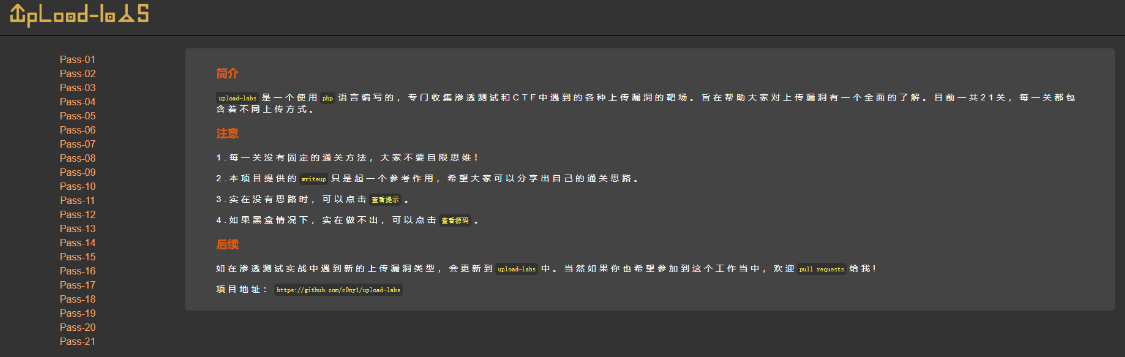
【网安小白成长之路】6.pikachu、sql-labs、upload-labs靶场搭建
🐮博主syst1m 带你 acquire knowledge! ✨博客首页——syst1m的博客💘 🔞 《网安小白成长之路(我要变成大佬😎!!)》真实小白学习历程,手把手带你一起从入门到入狱🚭 &…...
(七)C++自制植物大战僵尸游戏关卡数据加载代码讲解
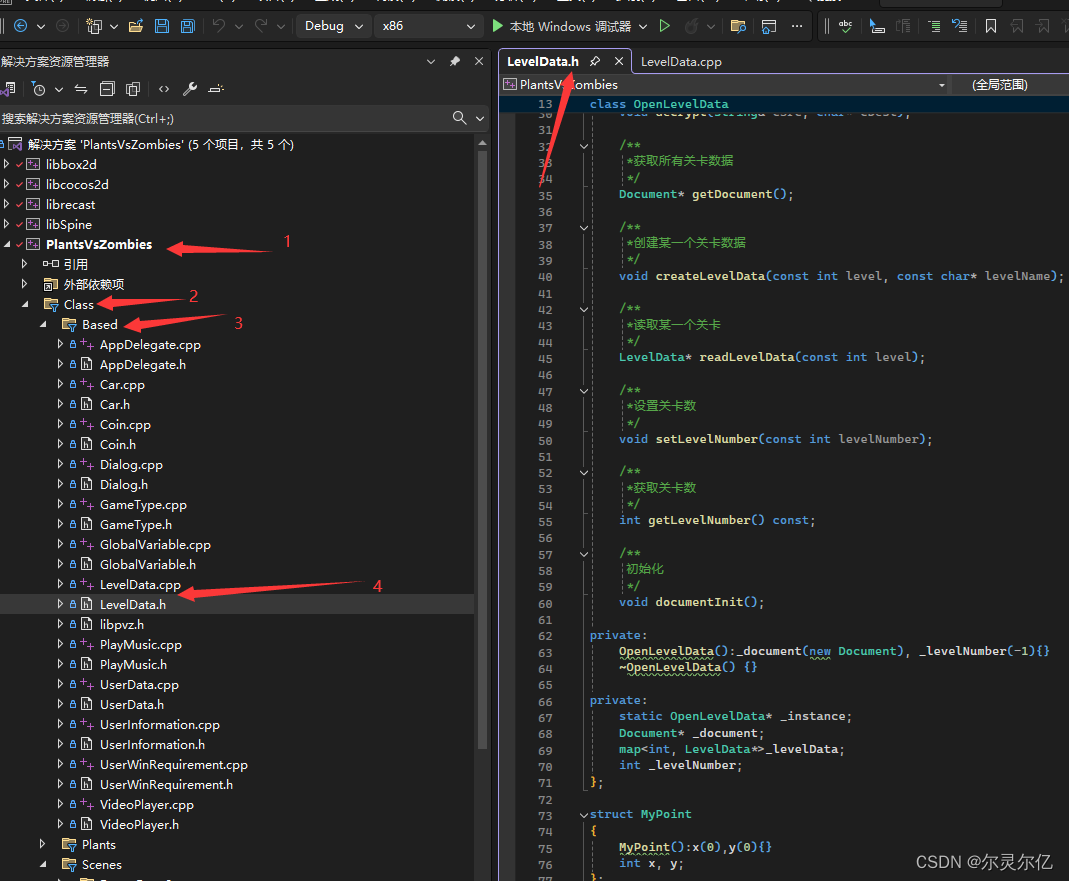
植物大战僵尸游戏开发教程专栏地址http://t.csdnimg.cn/xjvbb 打开LevelData.h和LevelData.cpp文件。文件位置如下图所示。 LevelData.h 此头文件中定义了两个类,分别是OpenLevelData、LevelData,其中OpenLevelData用于加载文件数据。LevelData解析数据…...

wpf下RTSP|RTMP播放器两种渲染模式实现
技术背景 在这篇blog之前,我提到了wpf下播放RTMP和RTSP渲染的两种方式,一种是通过控件模式,另外一种是直接原生RTSP、RTMP播放模块,回调rgb,然后在wpf下渲染,本文就两种方式做个说明。 技术实现 以大牛直…...

C++高精度算法的简单实现
一、基本原理1、存储方式采用数字记录高精度数字,数组的第一个元素存储数据长度,比如记录数字为1024示例如下:2、计算方式采用模拟立竖式计算,比如加法的计算流程,如下图所示10249000:这里只给出加法的计算…...

如何用Project Graph快速构建思维导图?终极跨平台节点图绘制指南
如何用Project Graph快速构建思维导图?终极跨平台节点图绘制指南 【免费下载链接】project-graph A node-based visual tool for organizing thoughts and notes in a non-linear way. 项目地址: https://gitcode.com/gh_mirrors/pr/project-graph 还在为项目…...

基于SpringBoot的广西特色水果电商平台的设计与实现
本课题的选题依据及研究意义 一、选题依据和意义 (一)选题依据 随着互联网经济的深入发展,电子商务在推动全球经济发展中发挥了重要作用。其中生鲜电商已成为农产品销售的重要渠道。广西作为我国热带水果的重要产区,对其传统水果产…...

Unity 5.6移动VR开发与单通道渲染优化指南
1. Unity 5.6移动VR开发环境配置1.1 Daydream原生支持解析Unity 5.6首次实现了对Daydream平台的原生支持,这标志着移动VR开发进入新阶段。与传统的插件式集成不同,原生支持直接内置于引擎核心,带来三个显著优势:性能提升ÿ…...

【NotebookLM图书馆学研究实战指南】:20年图情专家亲授AI时代知识管理新范式
更多请点击: https://codechina.net 第一章:NotebookLM图书馆学研究的范式革命 传统图书馆学研究长期依赖人工文献综述、卡片目录索引与线性知识组织方式,而NotebookLM的引入正从根本上重构知识发现、关联与推理的底层逻辑。作为Google推出的…...

英雄联盟智能助手Seraphine:如何用3个核心功能提升你的排位胜率
英雄联盟智能助手Seraphine:如何用3个核心功能提升你的排位胜率 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 你是否曾在英雄联盟排位赛中因为BP阶段手忙脚乱而错失先机?是否因为不了…...
)
零基础转行网安:3个月学习路线+就业方向(2026最新)
零基础转行网安:3 个月学习路线 就业方向(2026 最新) 最近刷到很多小白在问: “2026 年零基础还能转行网安吗?”“没有学历、没有基础、不会代码,多久能找到工作?”“网上教程杂乱,…...

构建本地化多链资产追踪器:从API聚合到数据可视化实践
1. 项目概述与核心价值最近在折腾一个挺有意思的小工具,起因是发现很多朋友在管理自己的数字资产时,尤其是那些基于区块链的Token,常常会陷入一种“信息孤岛”的状态。钱包地址散落在各处,不同链上的资产变动需要一个个去浏览器查…...

Linux驱动调试利器:debugfs接口设计与实现详解
1. 项目概述:为什么我们需要debugfs?在Linux内核驱动的开发与调试过程中,我们常常面临一个核心痛点:如何在不重启系统、不重新编译驱动、甚至不借助复杂外部工具的情况下,实时地窥探驱动内部的状态、修改关键参数&…...

最新英语作文批改APP测评 适合学生党写作提分的实用指南
一、当前英语作文批改工具的共性痛点我们团队做了5年英语作文批改领域的内容产出,前后调研过近20款市面上的主流工具,发现行业内的共性痛点其实一直没得到很好的解决:对学生来说,多数工具只能改表层语法错误,不会结合写…...