Kafka 硬件和操作系统
目录
一. 前言
二. Kafka 硬件和操作系统(Hardware and OS)
2.1. 操作系统(OS)
2.2. 磁盘和文件系统(Disks and Filesystem)
一. 前言
Kafka 是 I/O 密集型而非计算密集型的框架,所以对 CPU 的需求是各个指标里最宽松的,消耗CPU 的点主要在于消息的压缩和解压缩。一个 Kafka Broker 节点往往要承载许多个 Topic Partition 并与许多个 Producer/Consumer 交互,所以并行度(核心/线程数)要比单核性能(频率)更重要。
一般来讲单节点 8C/16T,主频 2GHz 以上(按 Broadwell 架构计)就可以满足小型生产环境,负载比较重的集群可以配到 12C/24T 甚至 16C/32T。注意根据 CPU 规格的不同,Broker 的num.network.threads 和 num.io.threads 参数也要适当改变。
二. Kafka 硬件和操作系统(Hardware and OS)
原文引用:We are using dual quad-core Intel Xeon machines with 24GB of memory.
You need sufficient memory to buffer active readers and writers. You can do a back-of-the-envelope estimate of memory needs by assuming you want to be able to buffer for 30 seconds and compute your memory need as write_throughput*30.
我们使用的是具有 24GB 内存的双四核 Intel Xeon 机器。
您需要足够的内存来缓冲活动的读写器。假设您希望能够缓冲30秒,并将您的内存需求计算为write_throughput*30,您可以对内存需求进行粗略估计。
原文引用:The disk throughput is important. We have 8x7200 rpm SATA drives. In general disk throughput is the performance bottleneck, and more disks is better. Depending on how you configure flush behavior you may or may not benefit from more expensive disks (if you force flush often then higher RPM SAS drives may be better).
磁盘吞吐量很重要。我们有 8x7200 rpm SATA 驱动器。一般来说,磁盘吞吐量是性能瓶颈,磁盘越多越好。根据您配置刷新行为的方式,您可能会从更昂贵的磁盘中受益,也可能不会从中受益(如果您经常强制刷新,则 RPM 更高的 SAS 驱动器可能会更好)。
2.1. 操作系统(OS)
原文引用:Kafka should run well on any unix system and has been tested on Linux and Solaris.
We have seen a few issues running on Windows and Windows is not currently a well supported platform though we would be happy to change that.
Kafka 应该在任何 unix 系统上都能很好地运行,并且已经在 Linux 和 Solaris 上进行了测试。
我们在 Windows 上看到了一些问题,Windows 目前不是一个受支持的平台,尽管我们很乐意改变这一点。
原文引用:It is unlikely to require much OS-level tuning, but there are three potentially important OS-level configurations:
- File descriptor limits: Kafka uses file descriptors for log segments and open connections. If a broker hosts many partitions, consider that the broker needs at least (number_of_partitions)*(partition_size/segment_size) to track all log segments in addition to the number of connections the broker makes. We recommend at least 100000 allowed file descriptors for the broker processes as a starting point. Note: The mmap() function adds an extra reference to the file associated with the file descriptor fildes which is not removed by a subsequent close() on that file descriptor. This reference is removed when there are no more mappings to the file.
- Max socket buffer size: can be increased to enable high-performance data transfer between data centers as described here.
- Maximum number of memory map areas a process may have (aka vm.max_map_count). See the Linux kernel documentation. You should keep an eye at this OS-level property when considering the maximum number of partitions a broker may have. By default, on a number of Linux systems, the value of vm.max_map_count is somewhere around 65535. Each log segment, allocated per partition, requires a pair of index/timeindex files, and each of these files consumes 1 map area. In other words, each log segment uses 2 map areas. Thus, each partition requires minimum 2 map areas, as long as it hosts a single log segment. That is to say, creating 50000 partitions on a broker will result allocation of 100000 map areas and likely cause broker crash with OutOfMemoryError (Map failed) on a system with default vm.max_map_count. Keep in mind that the number of log segments per partition varies depending on the segment size, load intensity, retention policy and, generally, tends to be more than one.
它不太可能需要太多的操作系统级别调整,但有三种潜在的重要操作系统级别配置:
- 文件描述符限制:Kafka 对日志段和开放连接使用文件描述符。如果一个 Broker 托管许多分区,那么除了 Broker 建立的连接数之外,还需要考虑该 Broker 至少需要(number_of_disparations)*(partition_size/segment_size) 来跟踪所有日志段。我们建议至少100000个允许的文件描述符作为 Broker 进程的起点。注意:mmap() 函数为与文件描述符过滤器相关联的文件添加了一个额外的引用,该文件描述符过滤器不会被该文件描述符的后续close() 删除。当不再有到该文件的映射时,将删除此引用。
- 最大套接字缓冲区大小:可以增加以实现数据中心之间的高性能数据传输,如本文所述。
- 进程可能具有的内存映射区域的最大数量(也称为 vm.max_map_count)。请参阅 Linux 内核文档。在考虑 Broker 可能具有的最大分区数时,您应该密切关注此操作系统级别的属性。默认情况下,在许多 Linux 系统上,vm.max_map_count 的值约为65535。每个分区分配的日志段都需要一对索引/时间索引文件,每个文件占用1个映射区域。换句话说,每个日志段使用2个 map 区域。因此,每个分区至少需要2个映射区域,只要它承载一个日志段即可。也就是说,在一个 Broker 上创建50000个分区将导致100000个映射区域的分配,并可能导致具有默认 vm.max_map_count 的系统上出现 OutOfMemoryError(映射失败)的Broker 崩溃。请记住,每个分区的日志段数因段大小、负载强度、保留策略而异,通常情况下往往不止一个。
2.2. 磁盘和文件系统(Disks and Filesystem)
原文引用:We recommend using multiple drives to get good throughput and not sharing the same drives used for Kafka data with application logs or other OS filesystem activity to ensure good latency. You can either RAID these drives together into a single volume or format and mount each drive as its own directory. Since Kafka has replication the redundancy provided by RAID can also be provided at the application level. This choice has several tradeoffs.
我们建议使用多个驱动器以获得良好的吞吐量,而不是与应用程序日志或其他操作系统文件系统活动共享用于 Kafka 数据的相同驱动器以确保良好的延迟。您可以将这些驱动器 RAID 到一个卷中,也可以格式化并将每个驱动器装载为自己的目录。由于 Kafka 具有复制功能,RAID 提供的冗余也可以在应用程序级别提供。这个选择有几个折衷方案。
原文引用:If you configure multiple data directories partitions will be assigned round-robin to data directories. Each partition will be entirely in one of the data directories. If data is not well balanced among partitions this can lead to load imbalance between disks.
如果配置多个数据目录,分区将被分配给数据目录。每个分区都将完全位于其中一个数据目录中。如果分区之间的数据没有很好地平衡,这可能会导致磁盘之间的负载不平衡。
原文引用:RAID can potentially do better at balancing load between disks (although it doesn't always seem to) because it balances load at a lower level. The primary downside of RAID is that it is usually a big performance hit for write throughput and reduces the available disk space.
RAID 可能在平衡磁盘之间的负载方面做得更好(尽管它似乎并不总是这样),因为它在较低级别上平衡负载。RAID 的主要缺点是,它通常会对写入吞吐量造成很大的性能影响,并减少可用磁盘空间。
原文引用:Another potential benefit of RAID is the ability to tolerate disk failures. However our experience has been that rebuilding the RAID array is so I/O intensive that it effectively disables the server, so this does not provide much real availability improvement.
RAID 的另一个潜在好处是能够容忍磁盘故障。然而,我们的经验是,重建 RAID 阵列是 I/O 密集型的,它会有效地禁用服务器,因此这并不能提供太多实际的可用性改进。
相关文章:

Kafka 硬件和操作系统
目录 一. 前言 二. Kafka 硬件和操作系统(Hardware and OS) 2.1. 操作系统(OS) 2.2. 磁盘和文件系统(Disks and Filesystem) 一. 前言 Kafka 是 I/O 密集型而非计算密集型的框架,所以对 CP…...

Kolla-ansible部署OpenStack集群
0. OpenStack 部署 系统要求 单机部署最低配置: 2张网卡8G内存40G硬盘空间 主机系统: CentOS Stream 9Debian Bullseye (11)openEuler 22.03 LTSRocky Linux 9- Ubuntu Jammy (22.04) 官方不再支持CentOS 7作为主机系统,我这里使用的是R…...

SHARE 203S PRO:倾斜摄影相机在地灾救援中的应用
在地质灾害的紧急关头,救援队伍面临的首要任务是迅速而准确地掌握灾区的地理信息。这时,倾斜摄影相机成为了救援测绘的利器。SHARE 203S PRO,这款由深圳赛尔智控科技有限公司研发的五镜头倾斜摄影相机,以其卓越的性能和功能&#…...
(附R语言和python代码实现))
MATLAB算法实战应用案例精讲-【数模应用】中介效应分析(补充篇)(附R语言和python代码实现)
目录 前言 几个高频面试题目 中介效应分析与路径分析的区别 1.中介效应分析 2.路径分析 注意事项...
Day96:云上攻防-云原生篇Docker安全系统内核版本漏洞CDK自动利用容器逃逸
目录 云原生-Docker安全-容器逃逸&系统内核漏洞 云原生-Docker安全-容器逃逸&docker版本漏洞 CVE-2019-5736 runC容器逃逸(需要管理员配合触发) CVE-2020-15257 containerd逃逸(启动容器时有前提参数) 云原生-Docker安全-容器逃逸&CDK自动化 知识点࿱…...

python botos s3 aws
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/s3.html AWS是亚马逊的云服务,其提供了非常丰富的套件,以及支持多种语言的SDK/API。本文针对其S3云储存服务的Python SDK(boto3)的使用进行介绍。 …...
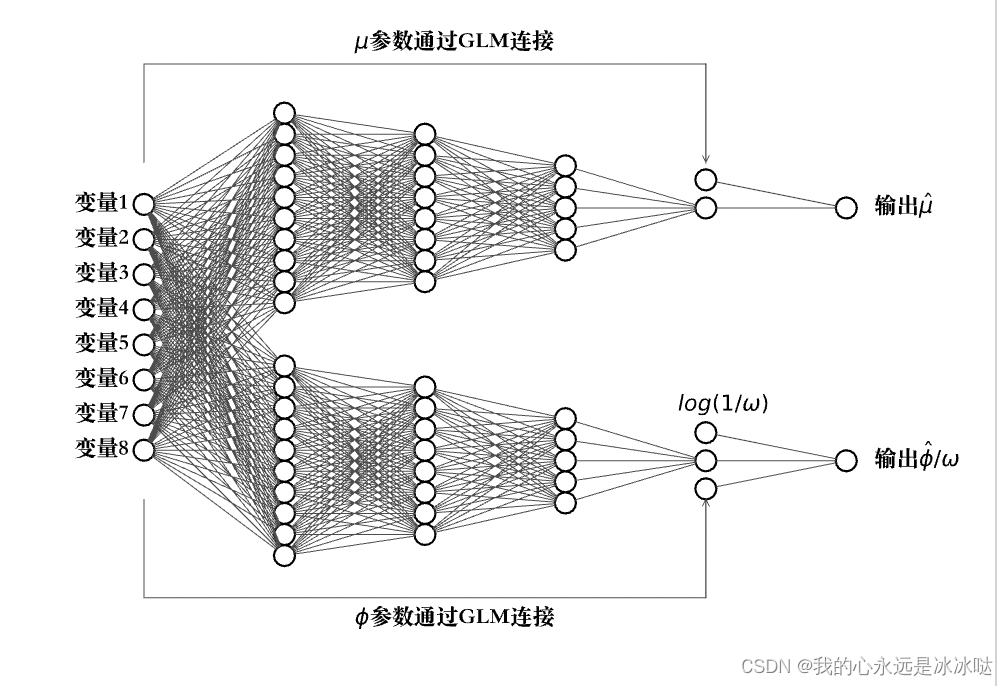
python画神经网络图
代码1(画神经网络连接图) from math import cos, sin, atan import matplotlib.pyplot as plt # 注意这里并没有用到这个networkx这个库,完全是根据matploblib这个库来画的。 class Neuron():def __init__(self, x, y,radius,nameNone):self.x xself.y …...

Bash 编程精粹:从新手到高手的全面指南之逻辑控制
在 Unix 和 Linux 系统中,Bash(Bourne-Again Shell)是一种广泛使用的 shell,提供了强大的脚本编程能力。本文将详细介绍 Bash 脚本中的逻辑控制结构,包括条件判断、分支选择、循环控制以及退出控制等内容。 条件判断&…...
Ansible 实战之自定义插件)
自动化运维(三十)Ansible 实战之自定义插件
Ansible 自定义插件允许你扩展其功能,以满足特定的自动化需求。Ansible 支持多种类型的插件开发,如动态库存、查找、回调、过滤器、变量等。这里我们将通过实例,介绍如何开发、部署和使用一个自定义插件。 开发自定义查找插件 查找插件用于在 Ansible 任务中动态获取数据。…...

实习僧网站的实习岗位信息分析
目录 背景描述数据说明数据集来源问题描述分析目标以及导入模块1. 数据导入2. 数据基本信息和基本处理3. 数据处理3.1 新建data_clean数据框3.2 数值型数据处理3.2.1 “auth_capital”(注册资本)3.2.2 “day_per_week”(每周工作天数…...
C语言中局部变量和全局变量是否可以重名?为什么?
可以重名 在C语言中, 局部变量指的是定义在函数内的变量, 全局变量指的是定义在函数外的变量 他们在程序中的使用方法是不同的, 当重名时, 局部变量在其所在的作用域内具有更高的优先级, 会覆盖或者说隐藏同名的全局变量 具体来说: 局部变量的生命周期只在函数内部,如果出了…...
小程序中配置scss
找到:project.config.json 文件 setting 模块下添加: "useCompilerPlugins": ["sass","其他的样式类型"] 配置完成后,重启开发工具,并新建文件 结果:...

ZYNQ-Vitis(SDK)裸机开发之(四)PS端MIO和EMIO的使用
目录 一、ZYNQ中MIO和EMIO简介 二、Vivado中搭建block design 1.配置PS端MIO: 2.配置PS端EMIO: 三、Vitis中新建工程进行GPIO控制 1. GPIO操作头文件gpio_hdl.h: 2.GPIO操作源文件gpio_hdl.c: 3.main函数进行调用 例程开发…...
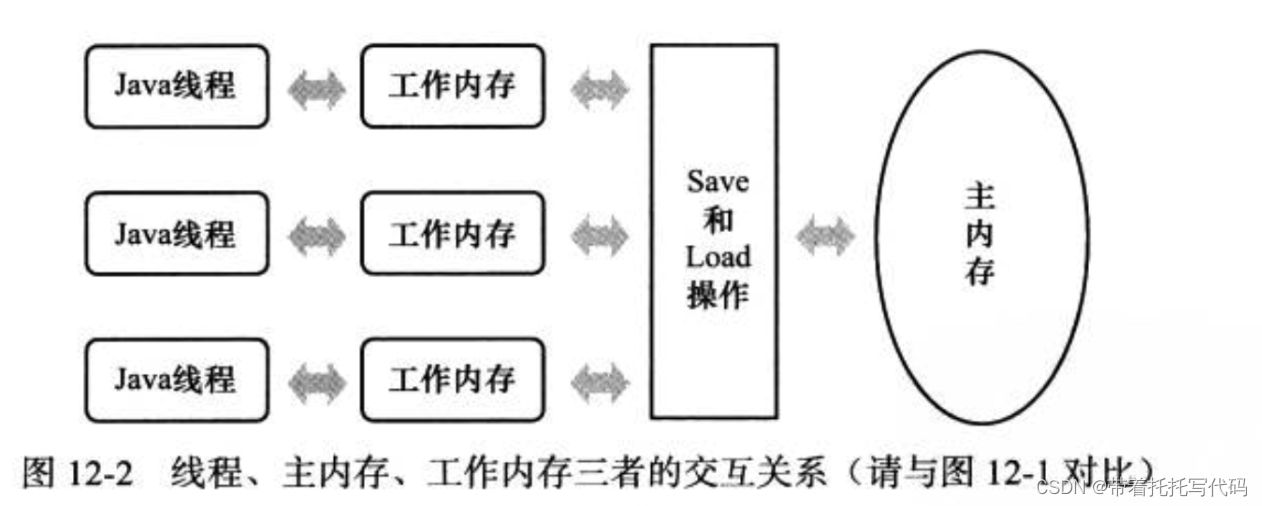
聊聊jvm中内存模型的坑
jvm线程的内存模型 看图,简单来说线程中操作的变量是副本。在并发情况下,如果数据发生变更,副本的数据就变为脏数据。这个时候就会有并发问题。 参考:https://www.cnblogs.com/yeyang/p/12580682.html 怎么解决并发问题 解决的…...
DevOps已死?2024年的DevOps将如何发展
随着我们进入2024年,DevOps也发生了变化。新兴的技术、变化的需求和发展的方法正在重新定义有效实施DevOps实践。 IDC预测显示,未来五年,支持DevOps实践的产品市场继续保持健康且快速增长,2022年-2027年的复合年增长率࿰…...

appium控制手机一直从下往上滑动
用于使用Appium和Selenium WebDriver在Android设备上滚动设置应用程序的界面。具体来说,它通过WebDriverWait和expected_conditions等待元素出现,然后使用ActionChains移动到该元素并执行滚动动作。在setUp中,它初始化了Appium的WebDriver和c…...

为什么光伏探勘测绘需要无人机?
随着全球对可再生能源需求的不断增长,光伏产业也迎来了快速发展的机遇。光伏电站作为太阳能发电的主要形式之一,其建设前期的探勘测绘工作至关重要。在这一过程中,无人机技术的应用正逐渐展现出其独特的优势。那么,为什么光伏探勘…...
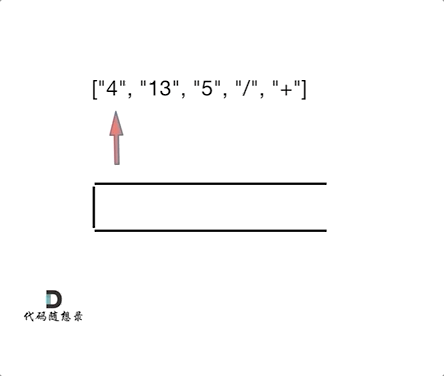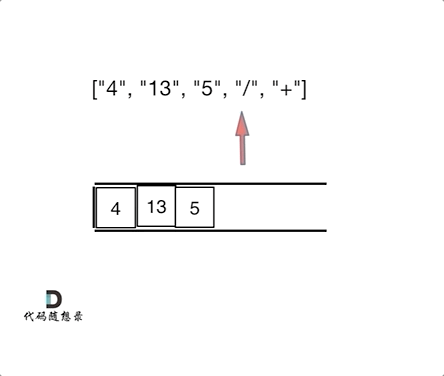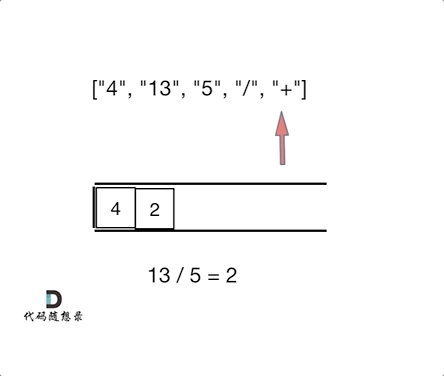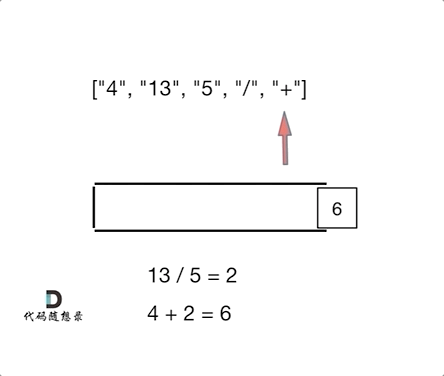
day10 | 栈与队列 part-2 (Go) | 20 有效的括号、1047 删除字符串中的所有相邻重复项、150 逆波兰表达式求值
今日任务 20 有效的括号 (题目: . - 力扣(LeetCode))1047 删除字符串中的所有相邻重复项 (题目: . - 力扣(LeetCode))150 逆波兰表达式求值 (题目: . - 力扣(LeetCode)) 20 有效的括号 题目: . - 力扣&…...
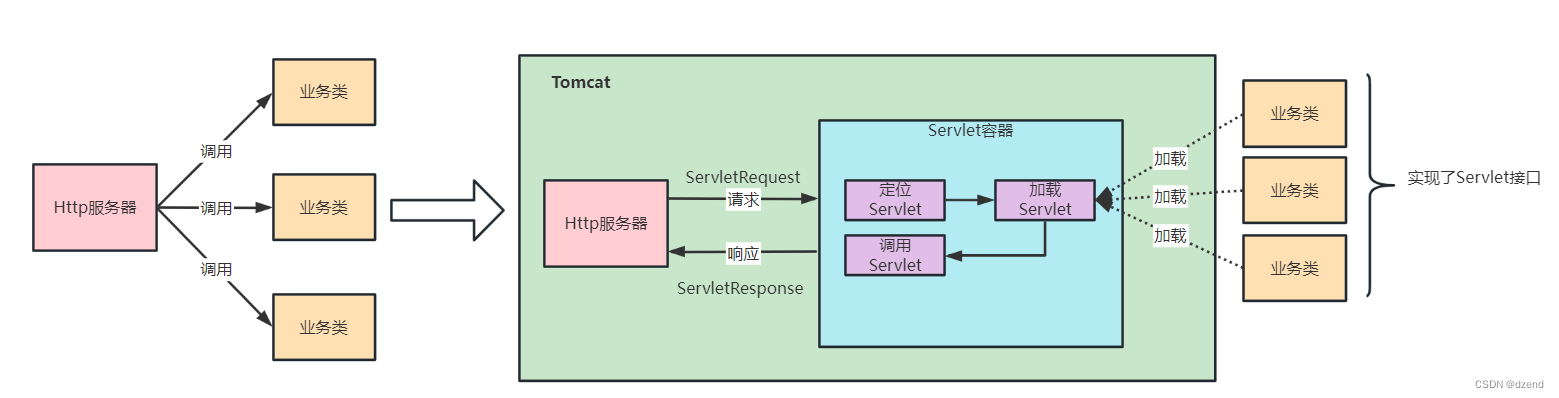
深入解析Tomcat的工作流程
tomcat解析 Tomcat是一个广泛使用的开源Servlet容器,用于托管Java Web应用程序。理解Tomcat的工作流程对于开发人员和系统管理员来说是非常重要的。本文将深入探讨Tomcat的工作原理,包括请求处理、线程池管理、类加载、以及与Web服务器之间的通信。 ###…...
【web网页制作】html+css旅游家乡山西主题网页制作(3页面)【附源码】
山西旅游网页目录 涉及知识写在前面一、网页主题二、网页效果Page1、景点介绍Page2、酒店精选|出行攻略Page3、景色欣赏 三、网页架构与技术3.1 脑海构思3.2 整体布局3.3 技术说明书 四、网页源码4.1 主页模块源码4.2 源码获取方式 作者寄语 涉及知识 山西旅游主题网页制作&am…...

别再死记硬背了!用这5个真实项目案例,彻底搞懂Python函数参数与返回值
别再死记硬背了!用这5个真实项目案例,彻底搞懂Python函数参数与返回值 函数是Python编程的基石,但很多初学者在学完基础语法后,面对实际项目依然无从下手。本文将通过5个真实开发场景,带你从"会用"到"懂…...

如何安全备份微信聊天记录:PyWxDump工具使用全指南
如何安全备份微信聊天记录:PyWxDump工具使用全指南 【免费下载链接】PyWxDump 删库 项目地址: https://gitcode.com/GitHub_Trending/py/PyWxDump 你是否曾因误删重要微信对话而懊悔不已?是否想永久保存珍贵聊天记录却不知从何下手?Py…...

Kafka Connect集群部署踩坑实录:从单机到高可用的完整配置与监控方案
Kafka Connect生产级部署实战:高可用架构设计与监控体系构建 当数据管道成为企业核心基础设施时,Kafka Connect的稳定性直接关系到业务连续性。去年某电商大促期间,因单点故障导致数据同步延迟6小时的教训仍历历在目——这正是我们需要深入探…...
)
告别Demo!用EMQX和Java模拟真实物联网设备上报数据流(Windows本地开发环境)
告别Demo!用EMQX和Java构建真实物联网数据流模拟方案 在物联网开发中,最令人头疼的莫过于缺乏真实设备进行测试。想象一下,当你精心设计的平台等待设备接入时,硬件团队却告诉你"下周才能交付原型机"。这种等待不仅拖延进…...

3个按键冲突场景,Hitboxer如何帮你重获游戏控制权?
3个按键冲突场景,Hitboxer如何帮你重获游戏控制权? 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的游戏对战中,因为同时按下W和S键而突然卡住?或…...

Seraphine:英雄联盟智能BP助手与战绩查询工具完整指南
Seraphine:英雄联盟智能BP助手与战绩查询工具完整指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟的对局中,BP(禁选英雄)阶段往往是决定胜负的关…...

JetBrains IDE试用期重置终极指南:简单三步实现30天无限续杯
JetBrains IDE试用期重置终极指南:简单三步实现30天无限续杯 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经在项目开发的关键时刻,突然看到JetBrains IDE弹出"评估期已结束…...

手机号归属地查询系统:3步构建可视化定位工具
手机号归属地查询系统:3步构建可视化定位工具 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_mirrors/lo/l…...

告别手动框选!用SUSTechPOINTS的V键批量标注,5分钟搞定一帧点云
解锁SUSTechPOINTS的V键批量标注:点云处理效率革命 在自动驾驶与机器人研发领域,点云标注是构建高精度感知模型的基础环节,但传统逐帧手动标注方式往往成为项目进度的瓶颈。我曾参与过一个城市级点云数据集标注项目,团队最初采用常…...

立体孪生全域可视,实现仓储人货动线全周期透明管控
立体孪生全域可视,实现仓储人货动线全周期透明管控副标题:动态三维实时还原库区人员、物资、车辆立体态势,运用库区无感定位、跨货架跨镜长距跟踪、身体指纹在岗确权,出入库、巡检、值守、调度全程透明可追溯一、方案总览现代规模…...