C++11 新特性:新增算法
C++11 在标准库中引入了一系列新的算法,这些新增的算法使我们的代码写起来更简洁方便。
下面是 C++11 中新增加的一些重要算法的简要描述和使用方法:
1、非修改序列操作
std::all_of:检查范围内的所有元素是否都满足指定的谓词。std::any_of:检查范围内是否存在满足指定谓词的元素。std::none_of:检查范围内是否没有元素满足指定的谓词。std::find_if_not:在范围内查找不满足指定谓词的第一个元素,这个算法和已经存在的std::find_if是相反的。
代码示例
以下的示例代码用来演示使用上面这些算法检查容器中元素的属性。
#include <iostream>
#include <vector>
#include <algorithm>int main() {// 初始化一个整数向量std::vector<int> numbers = {2, 4, 6, 8, 10, 12};// 检查所有元素是否都是偶数bool allEven = std::all_of(numbers.begin(), numbers.end(), [](int x) {return x % 2 == 0;});std::cout << "All elements are even: " << std::boolalpha << allEven << std::endl;// 检查是否存在大于10的元素bool anyGreaterThanTen = std::any_of(numbers.begin(), numbers.end(), [](int x) {return x > 10;});std::cout << "Any element greater than 10: " << anyGreaterThanTen << std::endl;// 检查是否没有元素小于0bool noneLessThanZero = std::none_of(numbers.begin(), numbers.end(), [](int x) {return x < 0;});std::cout << "No elements less than 0: " << noneLessThanZero << std::endl;// 查找第一个不是偶数的元素auto it = std::find_if_not(numbers.begin(), numbers.end(), [](int x) {return x % 2 == 0;});if (it != numbers.end()) {std::cout << "First element not even: " << *it << std::endl;} else {std::cout << "All elements are even" << std::endl;}return 0;
}输出:
All elements are even: true
Any element greater than 10: true
No elements less than 0: true
All elements are even2、修改序列操作
std::copy_if:复制满足指定条件的元素到另一个容器。std::move:将元素从一个容器移动到另一个容器(move),而非拷贝(copy)。std::move_backward:类似std::move,但是从范围的末尾开始操作,适合某些特定的容器操作。
代码示例
#include <iostream>
#include <vector>
#include <algorithm>int main() {std::vector<int> numbers = {1, 6, 3, 8, 5, 7, 2, 9};std::vector<int> copied;std::vector<int> moved(8); // 预分配空间以便使用std::move_backward// 1. 使用std::copy_if复制所有大于5的元素std::copy_if(numbers.begin(), numbers.end(), std::back_inserter(copied), [](int n) { return n > 5; });std::cout << "Copied elements: ";for (auto n : copied) std::cout << n << " ";std::cout << "\n";// 2. 使用std::move将numbers的元素移动到另一个向量std::vector<int> movedNumbers(std::make_move_iterator(numbers.begin()), std::make_move_iterator(numbers.end()));std::cout << "Moved elements: ";for (auto n : movedNumbers) std::cout << n << " ";std::cout << "\nOriginal vector (now empty elements): ";for (auto n : numbers) std::cout << n << " "; // 注意:numbers的元素现在处于未定义状态std::cout << "\n";// 3. 使用 std::move_backward,移动前 6 个元素std::move_backward(movedNumbers.begin(), std::next(movedNumbers.begin(), 6), moved.end());std::cout << "Elements after move_backward: ";for (auto n : moved) std::cout << n << " ";std::cout << "\n";return 0;
}
输出:
Copied elements: 6 8 7 9
Moved elements: 1 6 3 8 5 7 2 9
Original vector (now empty elements): 1 6 3 8 5 7 2 9
Elements after move_backward: 0 0 1 6 3 8 5 7
注意第 2 步操作,我们使用 make_move_iterator 创建两个 move_iterator,如果使用下面这个语句:
std::vector<int> copiedNumbers(numbers.begin(), numbers.end());
将不会使用移动方式,而是将数值拷贝到 copiedNumbers。
3、排序和相关操作
std::is_partitioned:检查给定范围是否被分割成两个满足特定条件的子序列。std::partition_copy:根据谓词将元素分割并复制到两个不同的容器。std::partition_point:找到分割序列的分界点。
代码示例
#include <iostream>
#include <vector>
#include <algorithm>
#include <iterator>int main() {std::vector<int> numbers = {1, 9, 3, 8, 5, 7, 2, 6};// 先对向量进行分区std::partition(numbers.begin(), numbers.end(), [](int n) { return n > 5; });std::cout << "Partitioned: ";for(auto n : numbers) std::cout << n << " ";std::cout << std::endl;// 检查是否已分区bool partitioned = std::is_partitioned(numbers.begin(), numbers.end(), [](int n) { return n > 5; });std::cout << "Is partitioned: " << std::boolalpha << partitioned << "\n";std::vector<int> less_than_6, greater_than_5;// 复制分区元素std::partition_copy(numbers.begin(), numbers.end(), std::back_inserter(greater_than_5), std::back_inserter(less_than_6),[](int n) { return n > 5; });std::cout << "Elements greater than 5: ";for (auto n : greater_than_5) std::cout << n << " ";std::cout << "\nElements not greater than 5: ";for (auto n : less_than_6) std::cout << n << " ";std::cout << "\n";// 查找分区点auto partitionPoint = std::partition_point(numbers.begin(), numbers.end(), [](int n) { return n > 5; });std::cout << "Partition point at: " << *partitionPoint << "\n";return 0;
}
输出:
Partitioned: 6 9 7 8 5 3 2 1
Is partitioned: true
Elements greater than 5: 6 9 7 8
Elements not greater than 5: 5 3 2 1
Partition point at: 5
4、数值操作
std::iota:在给定范围内填充递增序列,从而生成有序序列。
代码示例
std::iota定义在<numeric>头文件中。
#include <iostream>
#include <vector>
#include <numeric> // 包含 std::iotaint main() {std::vector<int> numbers(10); // 创建一个大小为10的vector// 使用std::iota填充numbers,使其元素从0开始递增std::iota(numbers.begin(), numbers.end(), 0);// 输出填充后的vectorstd::cout << "The vector contains: ";for(int n : numbers) {std::cout << n << " ";}std::cout << std::endl;// 用std::iota生成另一个序列,此时起始值为10std::iota(numbers.begin(), numbers.end(), 10);// 输出新的序列std::cout << "After reassigning, the vector contains: ";for(int n : numbers) {std::cout << n << " ";}std::cout << std::endl;return 0;
}
输出:
The vector contains: 0 1 2 3 4 5 6 7 8 9
After reassigning, the vector contains: 10 11 12 13 14 15 16 17 18 19
5、堆操作
std::is_heap:检查给定范围是否形成一个堆。std::is_heap_until:找到给定范围中不满足堆性质的第一个位置。std::make_heap、std::push_heap、std::pop_heap、std::sort_heap:虽然这些函数在 C++11 之前就存在,但 C++11 对它们进行了优化和改进,提高了与新特性的兼容性。
#include <iostream>
#include <vector>
#include <algorithm>int main() {// 初始化一个未排序的整数向量std::vector<int> numbers = {4, 1, 3, 5, 2, 9, 7, 8, 6};// 使用std::make_heap将向量转换为最大堆std::make_heap(numbers.begin(), numbers.end());std::cout << "After make_heap, numbers: ";for(int n : numbers) {std::cout << n << " ";}std::cout << std::endl;// 检查是否为堆bool isHeap = std::is_heap(numbers.begin(), numbers.end());std::cout << "Is the vector a heap? " << std::boolalpha << isHeap << std::endl;// 向堆中添加新元素numbers.push_back(10);std::push_heap(numbers.begin(), numbers.end()); // 重新调整为堆std::cout << "After push_heap, numbers: ";for(int n : numbers) {std::cout << n << " ";}std::cout << std::endl;// 从堆中移除根元素std::pop_heap(numbers.begin(), numbers.end()); // 将最大元素移至末尾numbers.pop_back(); // 实际移除元素std::cout << "After pop_heap, numbers: ";for(int n : numbers) {std::cout << n << " ";}std::cout << std::endl;// 对堆进行排序std::sort_heap(numbers.begin(), numbers.end());std::cout << "After sort_heap, numbers: ";for(int n : numbers) {std::cout << n << " ";}std::cout << std::endl;// 使用std::is_heap_until找到不是堆的第一个位置auto heapEnd = std::is_heap_until(numbers.begin(), numbers.end());std::cout << "The range is a heap until element: ";std::cout << (heapEnd - numbers.begin()) << std::endl;return 0;
}
输出:
After make_heap, numbers: 9 8 7 6 2 3 4 5 1
Is the vector a heap? true
After push_heap, numbers: 10 9 7 6 8 3 4 5 1 2
After pop_heap, numbers: 9 8 7 6 2 3 4 5 1
After sort_heap, numbers: 1 2 3 4 5 6 7 8 9
The range is a heap until element: 1
6、最小/最大操作
std::minmax:同时返回给定值中的最小值和最大值。std::minmax_element:返回给定范围中的最小元素和最大元素的迭代器。
代码示例
#include <iostream>
#include <algorithm>
#include <vector>int main() {// 使用std::minmax对一组值进行操作auto result = std::minmax({1, 3, 5, 7, 9, 2, 4, 6, 8, 0});std::cout << "The min value is: " << result.first << std::endl;std::cout << "The max value is: " << result.second << std::endl;// 使用std::minmax_element对容器中的元素进行操作std::vector<int> numbers = {1, 3, 5, 7, 9, 2, 4, 6, 8, 0};auto minmaxPair = std::minmax_element(numbers.begin(), numbers.end());if (minmaxPair.first != numbers.end() && minmaxPair.second != numbers.end()) {std::cout << "The smallest element in the vector is: " << *minmaxPair.first << std::endl;std::cout << "The largest element in the vector is: " << *minmaxPair.second << std::endl;}return 0;
}
输出将显示:
The min value is: 0
The max value is: 9
The smallest element in the vector is: 0
The largest element in the vector is: 9
总结
这些新增的算法增强了 C++ 的标准库,为开发者提供了更多的工具来编写高效和简洁的代码。
通过利用这些算法,可以减少手写的代码量,同时也可以保证代码的性能和可读性。
相关文章:

C++11 新特性:新增算法
C11 在标准库中引入了一系列新的算法,这些新增的算法使我们的代码写起来更简洁方便。 下面是 C11 中新增加的一些重要算法的简要描述和使用方法: 1、非修改序列操作 std::all_of:检查范围内的所有元素是否都满足指定的谓词。std::any_of&a…...
c/c++普通for循环学习
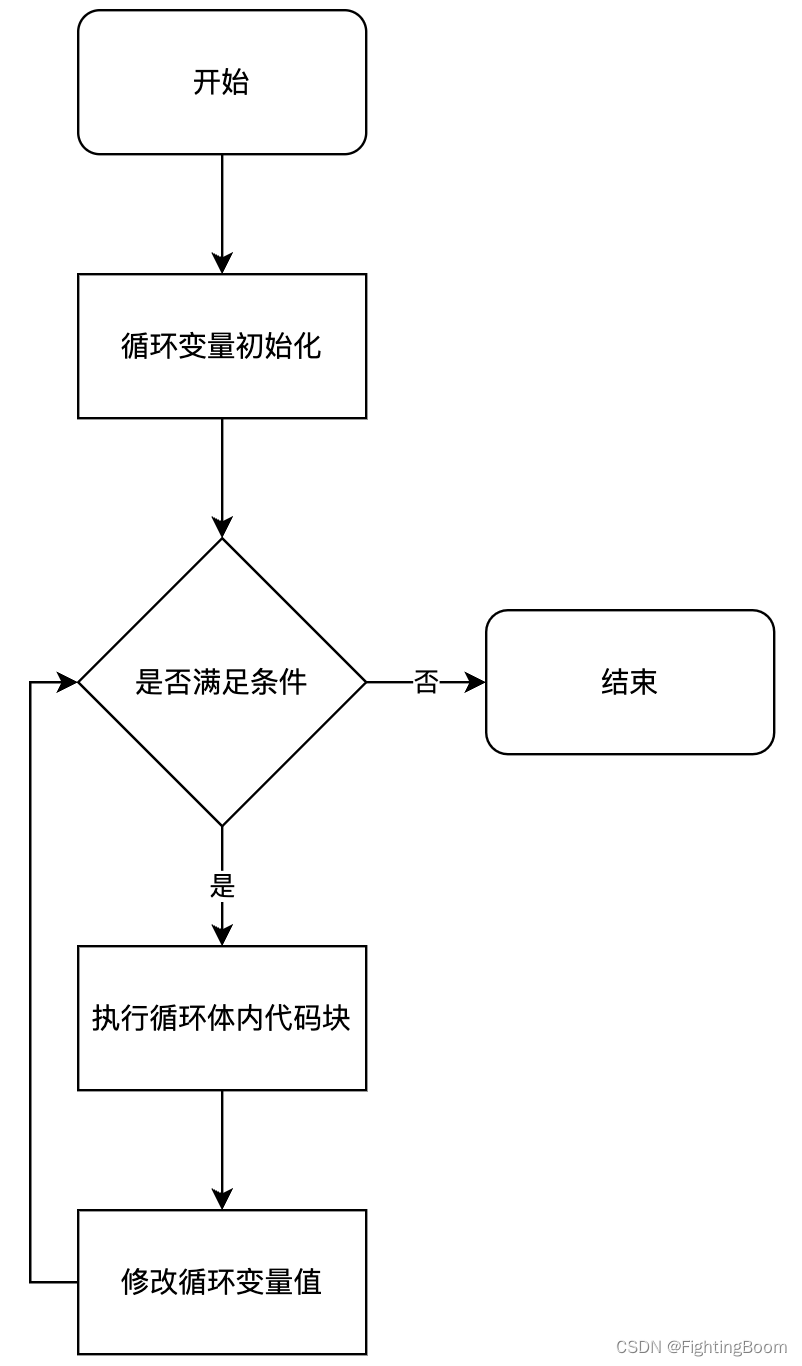
学习一下 for 循环的几种不同方式,了解一下原理及差异 完整的测试代码参考 GitHub :for 循环测试代码 1 常用形态 对于 for 循环来说,最常用的形态如下 for (表达式1; 表达式2; 表达式3) {// code }流程图如下: 编写测试代码…...
操作系统组成部分
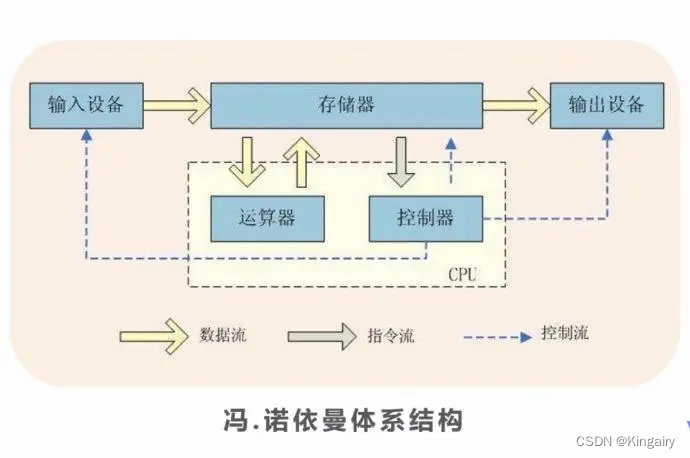
从1946年诞生第一台电子计算机。 冯诺依曼结构 冯诺依曼是:数字计算机的数制采用二进制;计算机应该按照程序顺序执行。 常见的操作系统有三种类型 单用户单任务操作系统:只支持一个用户和一个任务的执行,如DOS;单用…...

深入理解DES算法:原理、实现与应用
title: 深入理解DES算法:原理、实现与应用 date: 2024/4/14 21:30:21 updated: 2024/4/14 21:30:21 tags: DES加密对称加密分组密码密钥管理S盒P盒安全性分析替代算法 DES算法简介 历史 DES(Data Encryption Standard)算法是由IBM研发&…...

# 达梦sql查询 Sql 优化
达梦sql查询 Sql 优化 文章目录 达梦sql查询 Sql 优化注意点测试数据单表查询 Sort 语句优化优化过程 多表关联SORT 优化函数索引的使用 注意点 关于优化过程中工具的选用,推荐使用自带的DM Manage,其它工具在查看执行计划等时候不明确在执行计划中命中…...

Linux下SPI驱动:SPI设备驱动简介
一. 简介 Linux下的SPI 驱动框架和 I2C 很类似,都分为主机控制器驱动和设备驱动,主机控制器也就是 SOC的 SPI 控制器接口,SPI设备驱动也就是所操作的SPI设备的驱动。 本文来学习一下Linux下SPI设备驱动。 二. Linux下SPI驱动:SP…...

【简明图文教程】Node.js的下载、安装、环境配置及测试
文章目录 前言下载Node.js安装Node.js配置Node.js配置环境变量测试后言 前言 本教程适用于小白第一次从零开始进行Node.js的下载、安装、环境配置及测试。 如果你之前已经安装过了Node.js或删除掉了Node.js想重新安装,需要先参考以下博客进行处理后,再根…...

共模电感饱和与哪些参数有关?这些参数是如何影响共模电感的?
在做一个变频器项目,遇到一个问题,在30Hz重载超过一定1小时,CE测试结果超出限制,查找原因最终发现EMI filter内的共模电感加热,fail现象可以复现。最终增大Y电容把问题解决了。由此问题引申出一个问题,到底…...
儿童护眼台灯怎么选?五款必选的高口碑护眼台灯推荐
儿童台灯,想必大家都不会陌生了,是一种学生频繁使用的小灯具,一般指放在桌面用的有底座的电灯。随着近年来儿童青少年的视力急速下滑,很多家长都会选择给孩子选择一款合适的护眼台灯,以便孩子夜晚学习能有个好的照明环…...

前端小技巧之轮播图
文章目录 功能htmlcssjavaScript图片 设置了一点小难度,不理解的话,是不能套用的哦!!! (下方的圆圈与图片数量不统一,而且宽度是固定的) 下次写一些直接套用的,不整这些麻…...
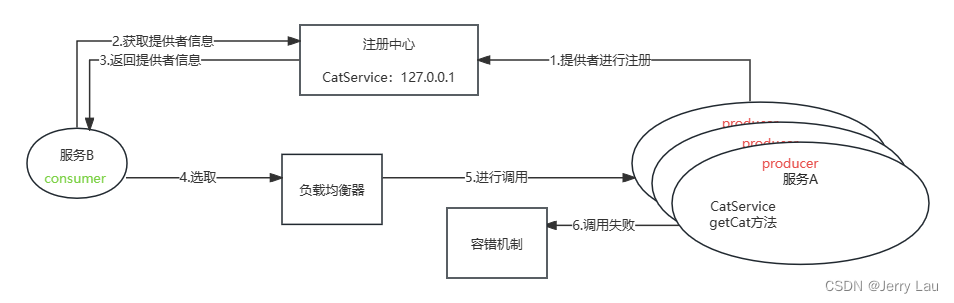
手动实现简易版RPC(上)
手动实现简易版RPC(上) 前言 什么是RPC?它的原理是什么?它有什么特点?如果让你实现一个RPC框架,你会如何是实现?带着这些问题,开始今天的学习。 本文主要介绍RPC概述以及一些关于RPC的知识,为…...
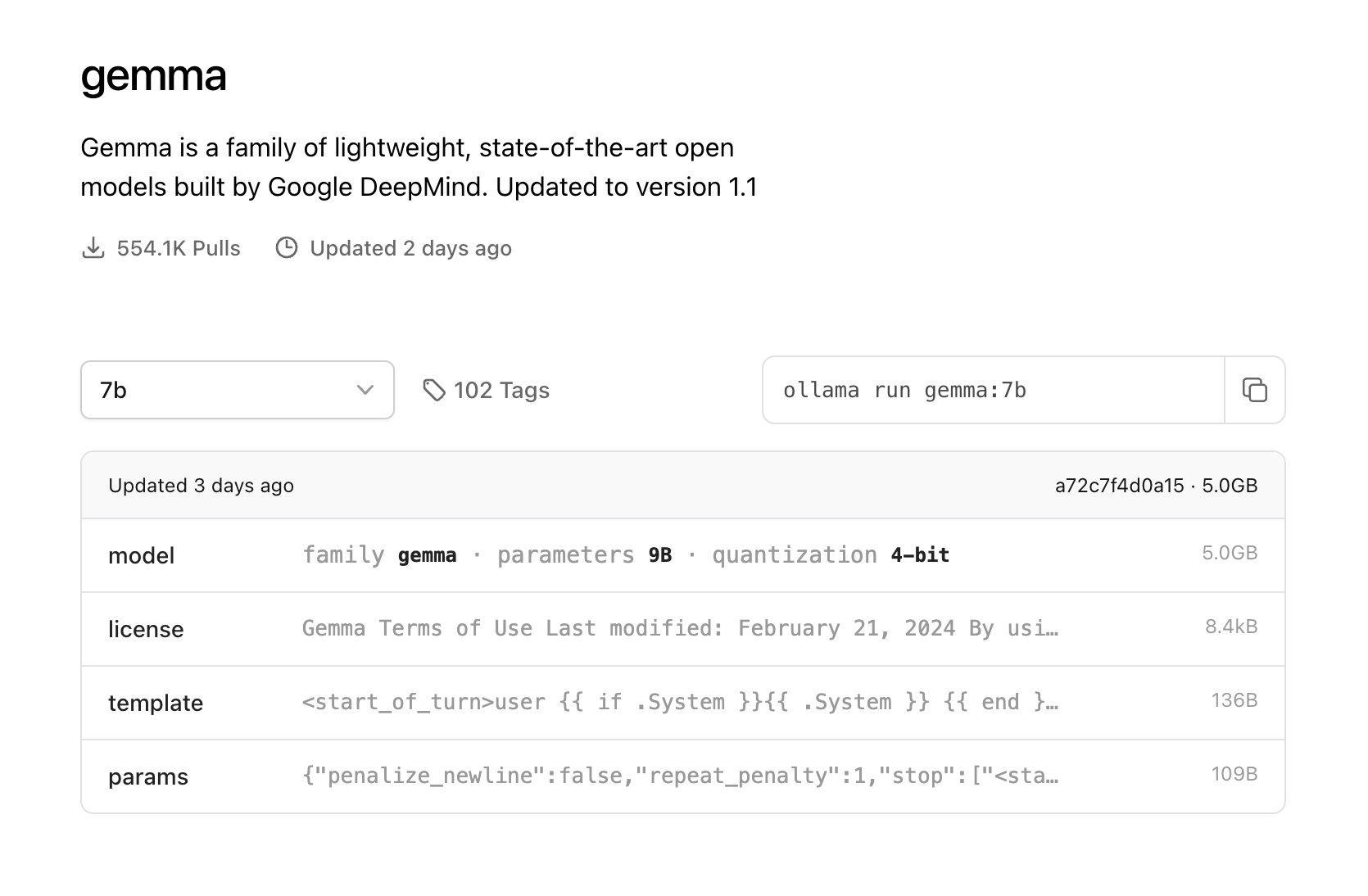
大语言模型总结整理(不定期更新)
《【快捷部署】016_Ollama(CPU only版)》 介绍了如何一键快捷部署Ollama,今天就来看一下受欢迎的模型。 模型简介gemmaGemma是由谷歌及其DeepMind团队开发的一个新的开放模型。参数:2B(1.6GB)、7Bÿ…...
)
关于npm和yarn的使用(自己的问题记录)
目录 一 npm 和 yarn 的区别 二 npm 和 yarn 常用命令对比 1. 初始化项目 2. 安装所有依赖包 3. 安装某个依赖包 4.安装某个版本的依赖包 5. 更新依赖包 5. 移除依赖包 三 package.json中 devDependencies 和 dependencies 的区别。 四 npm安装包时,…...
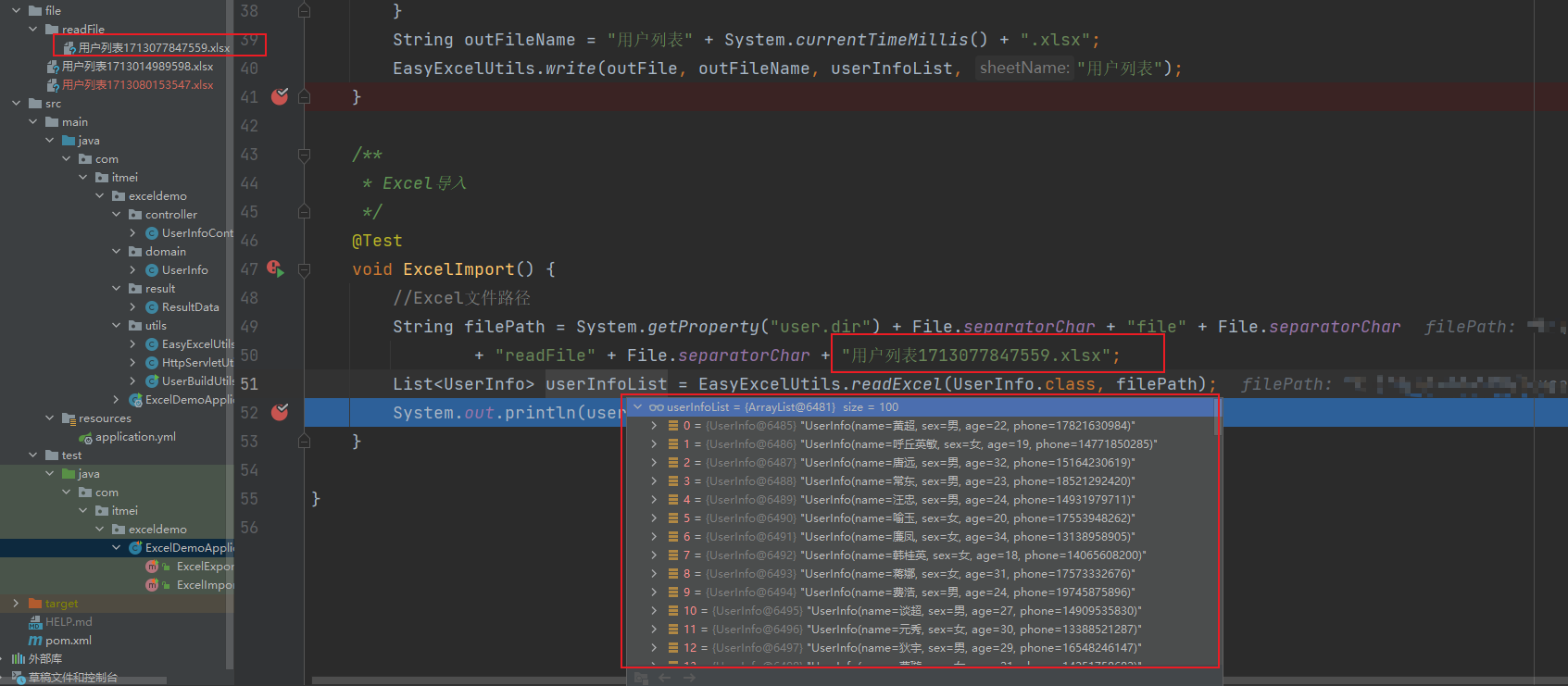
Web端Excel的导入导出Demo
📚目录 📚简介:✨代码的构建:💭Web端接口Excel操作🚀下载接口🚀导入读取数据接口 🏡本地Excel文件操作⚡导出数据🌈导入读取数据 📚简介: 使用阿里巴巴开源组件Easy Exce…...
Java日期正则表达式(附Demo)
目录 前言1. 基本知识2. Demo 前言 对于正则匹配,在项目实战中运用比较广泛 原先写过一版Python相关的:ip和端口号的正则表达式 1. 基本知识 对于日期的正则相对比较简单 以下是一些常见的日期格式及其对应的正则表达式示例: 年-月-日&a…...

基于LabVIEW的CAN通信系统开发案例
基于LabVIEW的CAN通信系统开发案例 介绍了基于LabVIEW开发的CAN通信系统,该系统主要用于汽车行业的数据监控与分析。通过对CAN通信协议的有效应用,实现了车辆控制系统的高效信息交换与实时数据处理,从而提升了车辆性能的检测与优化能力。 项…...
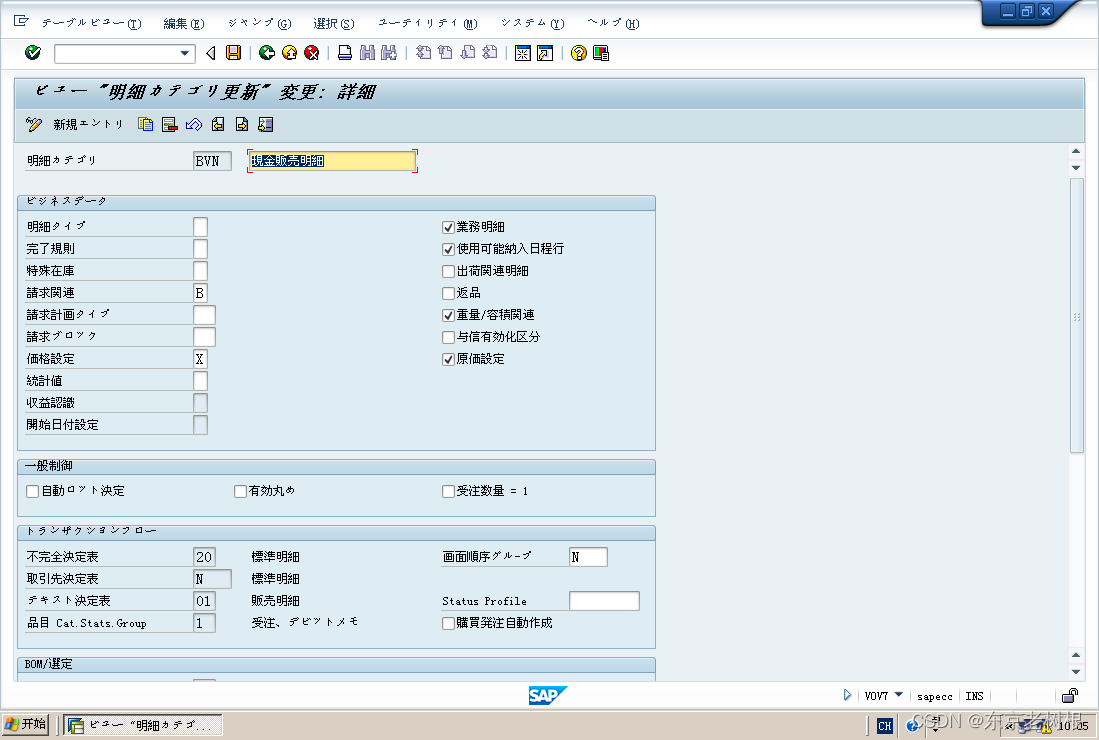
SAP SD学习笔记07 - 紧急发注(急单),现金贩卖,贩卖传票Type/ 明细Category 及其Customize
上面讲SAP中主干流程的时候,还有后面讲一括处理的时候,都用的是 OR 标准受注。 SAP SD学习笔记01 - 简单走一遍SD的流程:受注,出荷,请求_怎么学好sd模块-CSDN博客 下面开始讲一些稀奇古怪的非标准流程。 当然&#x…...

(六)C++自制植物大战僵尸游戏关卡数据讲解
植物大战僵尸游戏开发教程专栏地址http://t.csdnimg.cn/xjvbb 游戏关卡数据文件定义了游戏中每一个关卡的数据,包括游戏类型、关卡通关奖励的金币数量、僵尸出现的波数、每一波出现僵尸数量、每一波僵尸出现的类型等。根据不同的游戏类型,定义了不同的通…...
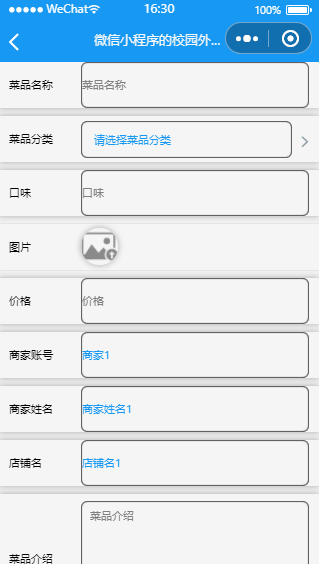
Java基于微信小程序的校园外卖平台设计与实现,附源码
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...
)
渗透工具及其知识库(个人笔记)
1.IP搜寻 查看kali网段: ip addr 、 ifconfig namp:nmap -sP xxx.xxx.xxx.0/24 netdiscover:netdiscover xxx.xxx.xxx.0/24 arp:arp-scan -l 2.端口扫描 粗略扫描:nmap <IP> 深度扫描: …...

数据库AI方向探索-MCP原理解析DB方向实战
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

如何用UI For Docker轻松管理数据卷:持久化存储的完整指南
如何用UI For Docker轻松管理数据卷:持久化存储的完整指南 【免费下载链接】ui-for-docker A web interface for Docker, formerly known as DockerUI. This repo is not maintained 项目地址: https://gitcode.com/gh_mirrors/ui/ui-for-docker UI For Dock…...

YOLO12入门必看:位置感知器与FlashAttention推理加速原理图解
YOLO12入门必看:位置感知器与FlashAttention推理加速原理图解 1. YOLO12模型概述 1.1 新一代目标检测架构 YOLO12是2025年发布的最新一代目标检测模型,代表了计算机视觉领域的重要突破。这个模型采用了全新的注意力为中心架构,在保持实时推…...

【ArUco GridBoard实战】从生成到高精度位姿估计全流程解析
1. ArUco GridBoard技术解析与应用场景 在工业视觉和机器人定位领域,精确的位姿估计是核心需求。ArUco GridBoard作为一种特殊的标记板,相比单个ArUco标记具有显著优势。我曾在多个工业项目中实测发现,使用5x7的GridBoard在3cm2cm的限定尺寸下…...

RMBG-2.0部署避坑指南:常见问题解决方案
RMBG-2.0部署避坑指南:常见问题解决方案 1. 引言 最近RMBG-2.0这个开源背景去除模型确实火得不行,效果确实惊艳,精确到发丝级别的抠图能力让很多开发者跃跃欲试。但在实际部署过程中,不少朋友都遇到了各种坑:环境配置…...

Qwen3-14B虚拟机开发环境:在VMware Ubuntu中部署与测试模型
Qwen3-14B虚拟机开发环境:在VMware Ubuntu中部署与测试模型 1. 前言:为什么选择虚拟机开发环境 在AI模型开发过程中,环境隔离是个常见需求。虚拟机提供了一个完美的沙盒环境,既能避免污染主机系统,又能方便地进行各种…...

计算机视觉——疲劳检测、基于DNN的年龄性别预测
一、疲劳检测(基于 dlib 的人脸检测与 68 点关键点定位)1.1摘要疲劳检测是一类通过分析人体行为(如眼睛闭合、头部姿态、打哈欠等)来判断个体是否处于疲劳或注意力不集中的技术。它在驾驶员监控、驾驶安全、课堂学员状态检测、远程…...

AHT20传感器数据不准?可能是你的CRC校验没做对!一个真实案例的排查与修复
AHT20传感器数据异常?CRC校验可能是你忽略的关键环节 当你在嵌入式项目中集成AHT20温湿度传感器时,是否遇到过数据偶尔跳变或明显失真的情况?这个问题困扰过不少开发者,而解决方案往往藏在一个容易被忽视的细节里——CRC校验。让我…...

OpenClaw对接Qwen3-4B-Thinking-2507-GPT-5-Codex-Distill-GGUF实战:3步完成本地模型调用
OpenClaw对接Qwen3-4B-Thinking-2507-GPT-5-Codex-Distill-GGUF实战:3步完成本地模型调用 1. 为什么选择本地模型对接? 去年冬天,当我第一次尝试用OpenClaw自动化处理周报时,发现调用云端API不仅响应慢,还频繁遇到限…...

G-Helper终极指南:5分钟精通华硕笔记本性能调校
G-Helper终极指南:5分钟精通华硕笔记本性能调校 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar, an…...