Hibernate入门经典与注解式开发大全
本博文主要讲解介绍Hibernate框架,ORM的概念和Hibernate入门,相信你们看了就会使用Hibernate了!
什么是Hibernate框架? Hibernate是一种ORM框架,全称为 Object_Relative DateBase-Mapping,在Java对象与关系数据库之间建立某种映射,以实现直接存取Java对象!
为什么要使用Hibernate? 既然Hibernate是关于Java对象和关系数据库之间的联系的话,也就是我们MVC中的数据持久层->在编写程序中的DAO层...
首先,我们来回顾一下我们在DAO层写程序的历程吧:
在DAO层操作XML,将数据封装到XML文件上,读写XML文件数据实现CRUD 在DAO层使用原生JDBC连接数据库,实现CRUD 嫌弃JDBC的ConnectionStatementResultSet等对象太繁琐,使用对原生JDBC的封装组件-->DbUtils组件 我们来看看使用DbUtils之后,程序的代码是怎么样的:
public class CategoryDAOImpl implements zhongfucheng.dao.CategoryDao {
@Override
public void addCategory(Category category) {
QueryRunner queryRunner = new QueryRunner(Utils2DB.getDataSource());
String sql = "INSERT INTO category (id, name, description) VALUES(?,?,?)";
try {
queryRunner.update(sql, new Object[]{category.getId(), category.getName(), category.getDescription()});
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
@Override
public Category findCategory(String id) {
QueryRunner queryRunner = new QueryRunner(Utils2DB.getDataSource());
String sql = "SELECT * FROM category WHERE id=?";
try {
Category category = (Category) queryRunner.query(sql, id, new BeanHandler(Category.class));
return category;
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
@Override
public List<Category> getAllCategory() {
QueryRunner queryRunner = new QueryRunner(Utils2DB.getDataSource());
String sql = "SELECT * FROM category";
try {
List<Category> categories = (List<Category>) queryRunner.query(sql, new BeanListHandler(Category.class));
return categories;
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
其实使用DbUtils时,DAO层中的代码编写是很有规律的。
当插入数据的时候,就将JavaBean对象拆分,拼装成SQL语句 当查询数据的时候,用SQL把数据库表中的列组合,拼装成JavaBean对象 也就是说:javaBean对象和数据表中的列存在映射关系!如果程序能够自动生成SQL语句就好了....那么Hibernate就实现了这个功能!
简单来说:我们使用Hibernate框架就不用我们写很多繁琐的SQL语句,从而简化我们的开发!
ORM概述
在介绍Hibernate的时候,说了Hibernate是一种ORM的框架。那什么是ORM呢?ORM是一种思想
O代表的是Objcet R代表的是Relative M代表的是Mapping ORM->对象关系映射....ORM关注是对象与数据库中的列的关系
Hibernate快速入门 学习一个框架无非就是三个步骤:
引入jar开发包 配置相关的XML文件 熟悉API 引入相关jar包 我们使用的是Hibernate3.6的版本
hibernate3.jar核心 + required 必须引入的(6个) + jpa 目录 + 数据库驱动包
编写对象和对象映射 编写一个User对象->User.java
public class User {
private int id;
private String username;
private String password;
private String cellphone;
//各种setter和getter
}
编写对象映射->User.hbm.xml。一般它和JavaBean对象放在同一目录下
我们是不知道该XML是怎么写的,可以搜索一下Hibernate文件夹中后缀为.hbm.xml。看看它们是怎么写的。然后复制一份过来
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<!--
This mapping demonstrates content-based discrimination for the
table-per-hierarchy mapping strategy, using a formula
discriminator.
-->
<hibernate-mapping
package="org.hibernate.test.array">
<class name="A" lazy="true" table="aaa">
<id name="id">
<generator class="native"/>
</id>
<key column="a_id"/>
<list-index column="idx"/>
<one-to-many class="B"/>
</class>
<class name="B" lazy="true" table="bbb">
<id name="id">
<generator class="native"/>
</id>
</class>
</hibernate-mapping>
在上面的模板上修改~下面会具体讲解这个配置文件!
<!--在domain包下-->
<hibernate-mapping package="zhongfucheng.domain">
<!--类名为User,表名也为User-->
<class name="User" table="user">
<!--主键映射,属性名为id,列名也为id-->
<id name="id" column="id">
<!--根据底层数据库主键自动增长-->
<generator class="native"/>
</id>
<!--非主键映射,属性和列名一一对应-->
<property name="username" column="username"/>
<property name="cellphone" column="cellphone"/>
<property name="password" column="password"/>
</class>
</hibernate-mapping>
如果使用Intellij Idea生成的Hibernate可以指定生成出主配置文件hibernate.cfg.xml,它是要放在src目录下的
如果不是自动生成的,我们可以在Hibernate的hibernate-distribution-3.6.0.Final\project\etc这个目录下可以找到
它长得这个样子:
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<property name="connection.url."/>
<property name="connection.driver_class"/>
<property name="connection.username"/>
<property name="connection.password"/>
<!-- DB schema will be updated if needed -->
<!-- <property name="hbm2ddl.auto">update</property> -->
</session-factory>
</hibernate-configuration>
通过上面的模板进行修改,后面会有对该配置文件进行讲解!
<hibernate-configuration>
<!-- 通常,一个session-factory节点代表一个数据库 -->
<session-factory>
<!-- 1\. 数据库连接配置 -->
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql:///zhongfucheng</property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">root</property>
<!--
数据库方法配置, hibernate在运行的时候,会根据不同的方言生成符合当前数据库语法的sql
-->
<property name="hibernate.dialect">org.hibernate.dialect.MySQL5Dialect</property>
<!-- 2\. 其他相关配置 -->
<!-- 2.1 显示hibernate在运行时候执行的sql语句 -->
<property name="hibernate.show_sql">true</property>
<!-- 2.2 格式化sql -->
<property name="hibernate.format_sql">true</property>
<!-- 2.3 自动建表 -->
<property name="hibernate.hbm2ddl.auto">create</property>
<!--3\. 加载所有映射-->
<mapping resource="zhongfucheng/domain/User.hbm.xml"/>
</session-factory>
</hibernate-configuration>
测试
package zhongfucheng.domain;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
import org.hibernate.classic.Session;
/**
* Created by ozc on 2017/5/6.
*/
public class App {
public static void main(String[] args) {
//创建对象
User user = new User();
user.setPassword("123");
user.setCellphone("122222");
user.setUsername("nihao");
//获取加载配置管理类
Configuration configuration = new Configuration();
//不给参数就默认加载hibernate.cfg.xml文件,
configuration.configure();
//创建Session工厂对象
SessionFactory factory = configuration.buildSessionFactory();
//得到Session对象
Session session = factory.openSession();
//使用Hibernate操作数据库,都要开启事务,得到事务对象
Transaction transaction = session.getTransaction();
//开启事务
transaction.begin();
//把对象添加到数据库中
session.save(user);
//提交事务
transaction.commit();
//关闭Session
session.close();
}
}
值得注意的是:JavaBean的主键类型只能是int类型,因为在映射关系中配置是自动增长的,String类型是不能自动增长的。如果是你设置了String类型,又使用了自动增长,那么就会报出下面的错误!
Caused by: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'zhongfucheng.user' does
执行完程序后,Hibernate就为我们创建对应的表,并把数据存进了数据库了
我们看看快速入门案例的代码用到了什么对象吧,然后一个一个讲解
public static void main(String[] args) {
//创建对象
User user = new User();
user.setPassword("123");
user.setCellphone("122222");
user.setUsername("nihao");
//获取加载配置管理类
Configuration configuration = new Configuration();
//不给参数就默认加载hibernate.cfg.xml文件,
configuration.configure();
//创建Session工厂对象
SessionFactory factory = configuration.buildSessionFactory();
//得到Session对象
Session session = factory.openSession();
//使用Hibernate操作数据库,都要开启事务,得到事务对象
Transaction transaction = session.getTransaction();
//开启事务
transaction.begin();
//把对象添加到数据库中
session.save(user);
//提交事务
transaction.commit();
//关闭Session
session.close();
}
相关类
Configuration 配置管理类:主要管理配置文件的一个类
它拥有一个子类AnnotationConfiguration,也就是说:我们可以使用注解来代替XML配置文件来配置相对应的信息
configure方法 configure()方法用于加载配置文件
加载主配置文件的方法
如果指定参数,那么加载参数的路径配置文件 如果不指定参数,默认加载src/目录下的hibernate.cfg.xml
buildSessionFactory方法 buildSessionFactory()用于创建Session工厂
SessionFactory SessionFactory-->Session的工厂,也可以说代表了hibernate.cfg.xml这个文件...hibernate.cfg.xml的就有 这么一个节点
openSession方法 创建一个Session对象
getCurrentSession方法 创建Session对象或取出Session对象
Session Session是Hibernate最重要的对象,Session维护了一个连接(Connection),只要使用Hibernate操作数据库,都需要用到Session对象
通常我们在DAO层中都会有以下的方法,Session也为我们提供了对应的方法来实现!
public interface IEmployeeDao {
void save(Employee emp);
void update(Employee emp);
Employee findById(Serializable id);
List<Employee> getAll();
List<Employee> getAll(String employeeName);
List<Employee> getAll(int index, int count);
void delete(Serializable id);
}
更新操作
我们在快速入门中使用到了save(Objcet o)方法,调用了这个方法就把对象保存在数据库之中了。Session对象还提供着其他的方法来进行对数据库的更新
session.save(obj); 【保存一个对象】 session.update(obj); 【更新一个对象】 session.saveOrUpdate(obj); 【保存或者更新的方法】
没有设置主键,执行保存; 有设置主键,执行更新操作; 如果设置主键不存在报错! 我们来使用一下update()方法吧....既然是更新操作了,那么肯定需要设置主键的,不设置主键,数据库怎么知道你要更新什么。将id为1的记录修改成如下:
user.setId(1);
user.setPassword("qwer");
user.setCellphone("1111");
user.setUsername("zhongfucheng");
主键查询
通过主键来查询数据库的记录,从而返回一个JavaBean对象
session.get(javaBean.class, int id); 【传入对应的class和id就可以查询】 session.load(javaBean.class, int id); 【支持懒加载】 User重写toString()来看一下效果:
User user1 = (User) session.get(User.class, 1);
System.out.println(user1);
HQL查询
HQL:hibernate query language 即hibernate提供的面向对象的查询语言
查询的是对象以及对象的属性【它查询的是对象以及属性,因此是区分大小写的!】。
SQL:Struct query language 结构化查询语言
查询的是表以及列【不区分大小写】 HQL是面向对象的查询语言,可以用来查询全部的数据!
Query query = session.createQuery("FROM User");
List list = query.list();
System.out.println(list);
当然啦,它也可以传递参数进去查询
Query query = session.createQuery("FROM User WHERE id=?");
//这里的?号是从0开始的,并不像JDBC从1开始的!
query.setParameter(0, user.getId());
List list = query.list();
System.out.println(list);
QBC查询
QBC查询: query by criteria 完全面向对象的查询
从上面的HQL查询,我们就可以发现:HQL查询是需要SQL的基础的,因为还是要写少部分的SQL代码....QBC查询就是完全的面向对象查询...但是呢,我们用得比较少
我们来看一下怎么使用吧:
//创建关于user对象的criteria对象
Criteria criteria = session.createCriteria(User.class);
//添加条件
criteria.add(Restrictions.eq("id", 1));
//查询全部数据
List list = criteria.list();
System.out.println(list);
本地SQL查询
有的时候,如果SQL是非常复杂的,我们不能靠HQL查询来实现功能的话,我们就需要使用原生的SQL来进行复杂查询了!
但是呢,它有一个缺陷:它是不能跨平台的...因此我们在主配置文件中已经配置了数据库的“方言“了。
我们来简单使用一下把:
//将所有的记录封装成User对象存进List集合中
SQLQuery sqlQuery = session.createSQLQuery("SELECT * FROM user").addEntity(User.class);
List list = sqlQuery.list();
System.out.println(list);
beginTransaction方法
开启事务,返回的是一个事务对象....Hibernate规定所有的数据库操作都必须在事务环境下进行,否则报错!
Hibernate注解开发
在Hibernate中我们一般都会使用注解,这样可以帮助我们大大简化hbm映射文件的配置。下面我就来为大家详细介绍。
PO类注解配置
首先肯定是搭建好Hibernate的开发环境啦,我在此也不过多赘述,读者自行实践。接着在src目录下创建一个cn.itheima.domain包,并在该包下创建一个Book实体类,由于Book实体类中写有注解配置,所以就不用编写那个映射配置文件啦!
@Entity // 定义了一个实体
@Table(name="t_book",catalog="hibernateTest")
public class Book {
@Id // 这表示一个主键
// @GeneratedValue 相当于native主键生成策略
@GeneratedValue(strategy=GenerationType.IDENTITY) // 相当于identity主键生成策略
private Integer id; // 主键
@Column(name="c_name", length=30, nullable=true)
private String name;
@Temporal(TemporalType.TIMESTAMP) // 是用来定义日期类型
private Date publicationDate; // 出版日期
@Type(type="double") // 允许你去指定Hibernate里面的一些类型
private Double price; // 价格,如果没有添加注解,也会自动的生成在表中
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Date getPublicationDate() {
return publicationDate;
}
public void setPublicationDate(Date publicationDate) {
this.publicationDate = publicationDate;
}
public Double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
}
下面我就来详细说一下Book实体类中的注解。
@Entity:声明一个实体。
@Table:来描述类与表之间的对应关系。
@Entity // 定义了一个实体
@Table(name="t_book",catalog="hibernateTest")
public class Book {
......
}
@id:声明一个主键。
@GeneratedValue:用它来声明一个主键生成策略。默认情况是native主键生成策略。可以选择的主键生成策略有:AUTO、IDENTITY、SEQUENCE
@Id // 这表示一个主键
// @GeneratedValue 相当于native主键生成策略
@GeneratedValue(strategy=GenerationType.IDENTITY) // 相当于identity主键生成策略
private Integer id; // 主键
@Column:定义列。
@Column(name="c_name", length=30, nullable=true)
private String name;
注意:对于PO类中所有属性,如果你不写注解,默认情况下也会在表中生成对应的列,列的名称就是属性的名称,列的类型也即属性的类型。 @Temporal:声明日期类型。
@Temporal(TemporalType.TIMESTAMP) // 是用来定义日期类型
private Date publicationDate; // 出版日期
日期类型可以选择的有:
* TemporalType.DATA:只有年月日。
* TemporalType.TIME:只有小时分钟秒。
* TemporalType.TIMESTAMP:有年月日小时分钟秒。
@Type:可允许你去指定Hibernate里面的一些类型。
@Type(type="double") // 允许你去指定Hibernate里面的一些类型
private Double price; // 价格,如果没有添加注解,也会自动的生成在表中
最后我们在src目录下创建一个cn.itheima.test包,在该包下编写一个HibernateAnnotationTest单元测试类,并在该类中编写一个用于测试PO类的注解开发的方法:
public class HibernateAnnotationTest {
// 测试PO的注解开发
@Test
public void test1() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
Book b = new Book();
b.setName("情书");
b.setPrice(56.78);
b.setPublicationDate(new Date());
session.save(b);
session.getTransaction().commit();
session.close();
}
}
现在来思考两个问题:
如果主键生成策略我们想使用UUID类型呢? 如何设定类的属性不在表中映射? 这两个问题我们一起解决。废话不多说,直接上例子。在cn.itheima.domain包下再编写一个Person实体类,同样使用注解配置。
@Entity
@Table(name="t_person", catalog="hibernateTest")
public class Person {
// 生成UUID的主键生成策略
@Id
@GenericGenerator(name="myuuid", strategy="uuid") // 声明一种主键生成策略(uuid)
@GeneratedValue(generator="myuuid") // 引用uuid主键生成策略
private String id;
@Type(type="string") // 允许你去指定Hibernate里面的一些类型
private String name;
@Transient
private String msg; // 现在这个属性不想生成在表中
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getMsg() {
return msg;
}
public void setMsg(String msg) {
this.msg = msg;
}
}
最后在HibernateAnnotationTest单元测试类中编写如下一个方法:
public class HibernateAnnotationTest {
// 测试uuid的主键生成策略及不生成表中映射
@Test
public void test2() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
Person p = new Person();
p.setName("李四");
p.setMsg("这是一个好人");
session.save(p);
session.getTransaction().commit();
session.close();
}
}
至此,两个问题就解决了。 注意:对于我们以上讲解的关于属性配置的注解,我们也可以在其对应的getXxx方法去使用。
Hibernate关联映射——一对多(多对一) 仍以客户(Customer)和订单(Order)为例来开始我的表演。 在src目录下创建一个cn.itheima.oneToMany包,并在该包编写这两个实体类:
客户(Customer)类
// 客户 ---- 一的一方
@Entity
@Table(name="t_customer")
public class Customer {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id; // 主键
private String name; // 姓名
// 描述客户可以有多个订单
/*
* targetEntity="...":相当于<one-to-many >
*/
@OneToMany(targetEntity=Order.class,mappedBy="c")
private Set<Order> orders = new HashSet<Order>();
public Set<Order> getOrders() {
return orders;
}
public void setOrders(Set<Order> orders) {
this.orders = orders;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
订单(Order)类
// 订单 ---- 多的一方
@Entity
@Table(name="t_order")
public class Order {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id;
private Double money;
private String receiverInfo; // 收货地址
// 订单与客户关联
@ManyToOne(targetEntity=Customer.class)
@JoinColumn(name="c_customer_id") // 指定外键列
private Customer c; // 描述订单属于某一个客户
public Customer getC() {
return c;
}
public void setC(Customer c) {
this.c = c;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Double getMoney() {
return money;
}
public void setMoney(Double money) {
this.money = money;
}
public String getReceiverInfo() {
return receiverInfo;
}
public void setReceiverInfo(String receiverInfo) {
this.receiverInfo = receiverInfo;
}
}
这儿用到了@OneToMany和@ManyToOne这两个注解。 以上两个实体类编写好之后,可以很明显的看出我们不需要写它们对应的映射配置文件了,是不是很爽呢!接下来,我就要编写测试程序测试一下了。现在我的需求是保存客户时,顺便保存订单,对于这种情况我们需要在Customer类中配置cascade操作,即配置cascade="save-update",配置的方式有两种,下面我细细说来:
第一种方式,可以使用JPA提供的注解。 那么@OneToMany注解就应修改为:
@OneToMany(targetEntity=Order.class,mappedBy="c",cascade=CascadeType.ALL)
private Set<Order> orders = new HashSet<Order>();
第二种方式,可以使用Hibernate提供的注解。 那么@OneToMany注解就应修改为:
@OneToMany(targetEntity=Order.class,mappedBy="c")
@Cascade(CascadeType.SAVE_UPDATE)
private Set<Order> orders = new HashSet<Order>();
两种方式都可以,口味任君选择,不过我倾向于第二种方式。 接下来在HibernateAnnotationTest单元测试类中编写如下方法进行测试:
public class HibernateAnnotationTest {
// 测试one-to-many注解操作(保存客户时级联保存订单)
@Test
public void test3() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 1.创建一个客户
Customer c = new Customer();
c.setName("叶子");
// 2.创建两个订单
Order o1 = new Order();
o1.setMoney(1000d);
o1.setReceiverInfo("武汉");
Order o2 = new Order();
o2.setMoney(2000d);
o2.setReceiverInfo("天门");
// 3.建立关系
c.getOrders().add(o1);
c.getOrders().add(o2);
// 4.保存客户,并级联保存订单
session.save(c);
session.getTransaction().commit();
session.close();
}
}
这时运行以上方法,会发现虽然客户表的那条记录插进去了,但是订单表就变成这个鬼样了:
订单表中没有关联客户的id,这是为什么呢?原因是我们在Customer类中配置了mappedBy=”c”,它代表的是外键的维护由Order方来维护,而Customer不维护,这时你在保存客户时,级联保存订单,是可以的,但是不能维护外键,所以,我们必须在代码中添加订单与客户之间的关系。所以须将test3方法修改为:
public class HibernateAnnotationTest {
// 测试one-to-many注解操作(保存客户时级联保存订单)
@Test
public void test3() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 1.创建一个客户
Customer c = new Customer();
c.setName("叶子");
// 2.创建两个订单
Order o1 = new Order();
o1.setMoney(1000d);
o1.setReceiverInfo("武汉");
Order o2 = new Order();
o2.setMoney(2000d);
o2.setReceiverInfo("天门");
// 3.建立关系
// 原因:是为了维护外键,不然的话,外键就不能正确的生成!!!
o1.setC(c);
o2.setC(c);
// 原因:是为了进行级联操作
c.getOrders().add(o1);
c.getOrders().add(o2);
// 4.保存客户,并级联保存订单
session.save(c);
session.getTransaction().commit();
session.close();
}
}
这时再测试,就没有任何问题啦!
扩展
Hibernate注解@Cascade中的DELETE_ORPHAN已经过时了,如下:
可使用下面方案来替换过时方案:
Hibernate关联映射——多对多 以学生与老师为例开始我的表演,我是使用注解完成这种多对多的配置。使用@ManyToMany注解来配置多对多,只需要在一端配置中间表,另一端使用mappedBy表示放置外键的维护权。 在src目录下创建一个cn.itheima.manyToMany包,并在该包编写这两个实体类:
学生类
@Entity
@Table(name="t_student")
public class Student {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id;
private String name;
@ManyToMany(targetEntity=Teacher.class)
// @JoinTable:使用@JoinTable来描述中间表,并描述中间表中外键与Student、Teacher的映射关系
// joinColumns:它是用来描述Student与中间表的映射关系
// inverseJoinColumns:它是用来描述Teacher与中间表的映射关系
@JoinTable(name="s_t", joinColumns={@JoinColumn(name="c_student_id",referencedColumnName="id")}, inverseJoinColumns={@JoinColumn(name="c_teacher_id")})
private Set<Teacher> teachers = new HashSet<Teacher>();
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Set<Teacher> getTeachers() {
return teachers;
}
public void setTeachers(Set<Teacher> teachers) {
this.teachers = teachers;
}
}
老师类
@Entity
@Table(name="t_teacher")
public class Teacher {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id;
private String name;
@ManyToMany(targetEntity=Student.class, mappedBy="teachers") // 代表由对方来维护外键
private Set<Student> students = new HashSet<Student>();
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Set<Student> getStudents() {
return students;
}
public void setStudents(Set<Student> students) {
this.students = students;
}
}
接下来,我就要编写测试程序测试一下了。 从上面可看出我们将外键的维护权利交由Student类来维护,现在我们演示保存学生时,将老师也级联保存,对于这种情况我们需要在Student类中配置cascade操作,即配置cascade=”save-update”,如下:
@JoinTable(name="s_t", joinColumns={@JoinColumn(name="c_student_id",referencedColumnName="id")}, inverseJoinColumns={@JoinColumn(name="c_teacher_id")})
@Cascade(CascadeType.SAVE_UPDATE)
private Set<Teacher> teachers = new HashSet<Teacher>();
接下来在HibernateAnnotationTest单元测试类中编写如下方法进行测试:
public class HibernateAnnotationTest {
// 测试多对多级联保存(保存学生时同时保存老师)
@Test
public void test4() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
// 1.创建两个老师
Teacher t1 = new Teacher();
t1.setName("Tom");
Teacher t2 = new Teacher();
t2.setName("Fox");
// 2.创建两个学生
Student s1 = new Student();
s1.setName("张丹");
Student s2 = new Student();
s2.setName("叶紫");
// 3.学生关联老师
s1.getTeachers().add(t1);
s1.getTeachers().add(t2);
s2.getTeachers().add(t1);
s2.getTeachers().add(t2);
// 保存学生同时保存老师
session.save(s1);
session.save(s2);
session.getTransaction().commit();
session.close();
}
}
运行以上方法,一切正常。 接着我们测试级联删除操作。见下图: 这里写图片描述
可在HibernateAnnotationTest单元测试类中编写如下方法进行测试:
public class HibernateAnnotationTest {
// 测试多对多级联删除(前提是建立了双向的级联)
@Test
public void test5() {
Session session = HibernateUtils.openSession();
session.beginTransaction();
Student s = session.get(Student.class, 1);
session.delete(s);
session.getTransaction().commit();
session.close();
}
}
参考文章
https://segmentfault.com/a/1190000009707894
https://www.cnblogs.com/hysum/p/7100874.html
http://c.biancheng.net/view/939.html
https://www.runoob.com/
https://blog.csdn.net/android_hl/article/details/53228348
本文由 mdnice 多平台发布
相关文章:

Hibernate入门经典与注解式开发大全
本博文主要讲解介绍Hibernate框架,ORM的概念和Hibernate入门,相信你们看了就会使用Hibernate了! 什么是Hibernate框架? Hibernate是一种ORM框架,全称为 Object_Relative DateBase-Mapping,在Java对象与关系数据库之间建…...
蓝桥杯之注意事项
1.特殊求解的地方 2.一些数学公式 比如二叉树求全深度数值那道题 3.掌握有关库函数 #include<algorithm> 包含sort()函数【排列函数】C sort()排序详解-CSDN博客,next_permutation()函数【求解全排列问题】求解数组大小sizeof(arr…...

ES6 全详解 let 、 const 、解构赋值、剩余运算符、函数默认参数、扩展运算符、箭头函数、新增方法,promise、Set、class等等
目录 ES6概念ECMAScript6简介ECMAScript 和 JavaScript 的关系ES6 与 ECMAScript 2015 的关系 1、let 、 const 、var 区别2、变量解构赋值1、数组解构赋值2、对象解构赋值3、字符串的解构赋值 3、展开剩余运算符1、**展开运算符(...)**2、**剩余运算符(...)** 4、函数的拓展函…...
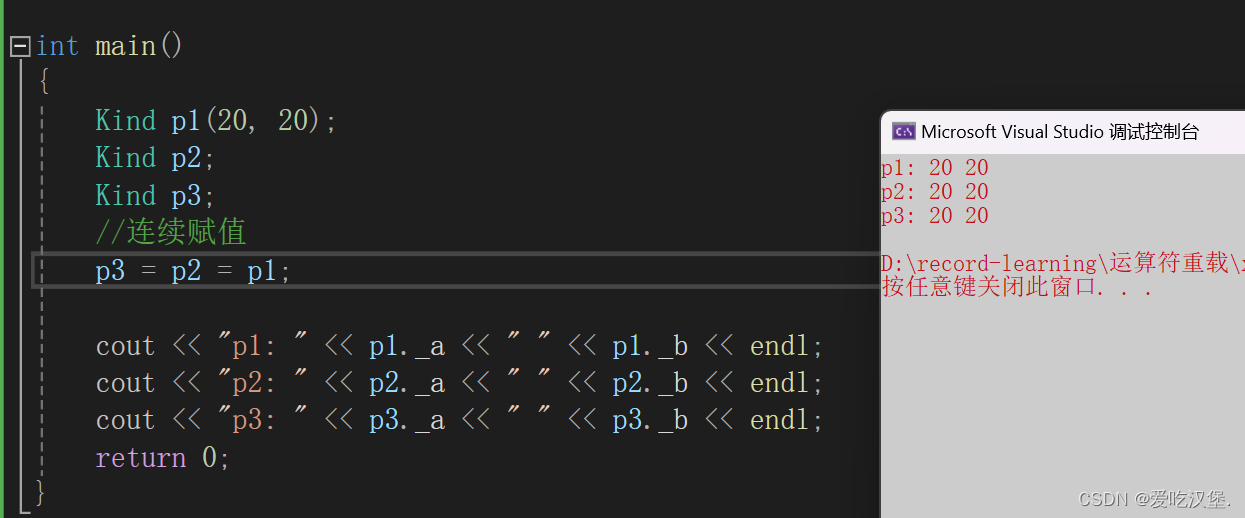
c++ - 类的默认成员函数
文章目录 前言一、构造函数二、析构函数三、拷贝构造函数四、重载赋值操作符五、取地址及const取地址操作符重载 前言 默认成员函数是编译器自动生成的,也可以自己重写,自己重写之后编译器就不再生成,下面是深入了解这些成员函数。 一、构造…...
)
Java哈希查找(含面试大厂题和源码)
哈希查找(Hash Search)是一种基于哈希表(Hash Table)的数据查找方法。哈希表通过使用哈希函数将键(Key)映射到表中的位置来存储数据,从而实现快速的数据访问。哈希查找的效率通常取决于哈希函数…...

c++中常用库函数
大小写转换 islower/isupper函数 char ch1 A; char ch2 b;//使用islower函数判断字符是否为小写字母 if(islower(ch1)){cout << ch1 << "is a lowercase letter." << end1; } else{cout << ch1 << "is not a lowercase lette…...
Scrapy框架 进阶
Scrapy框架基础Scrapy框架进阶 【五】持久化存储 命令行:json、csv等管道:什么数据类型都可以 【1】命令行简单存储 (1)语法 Json格式 scrapy crawl 自定义爬虫程序文件名 -o 文件名.jsonCSV格式 scrapy crawl 自定义爬虫程…...
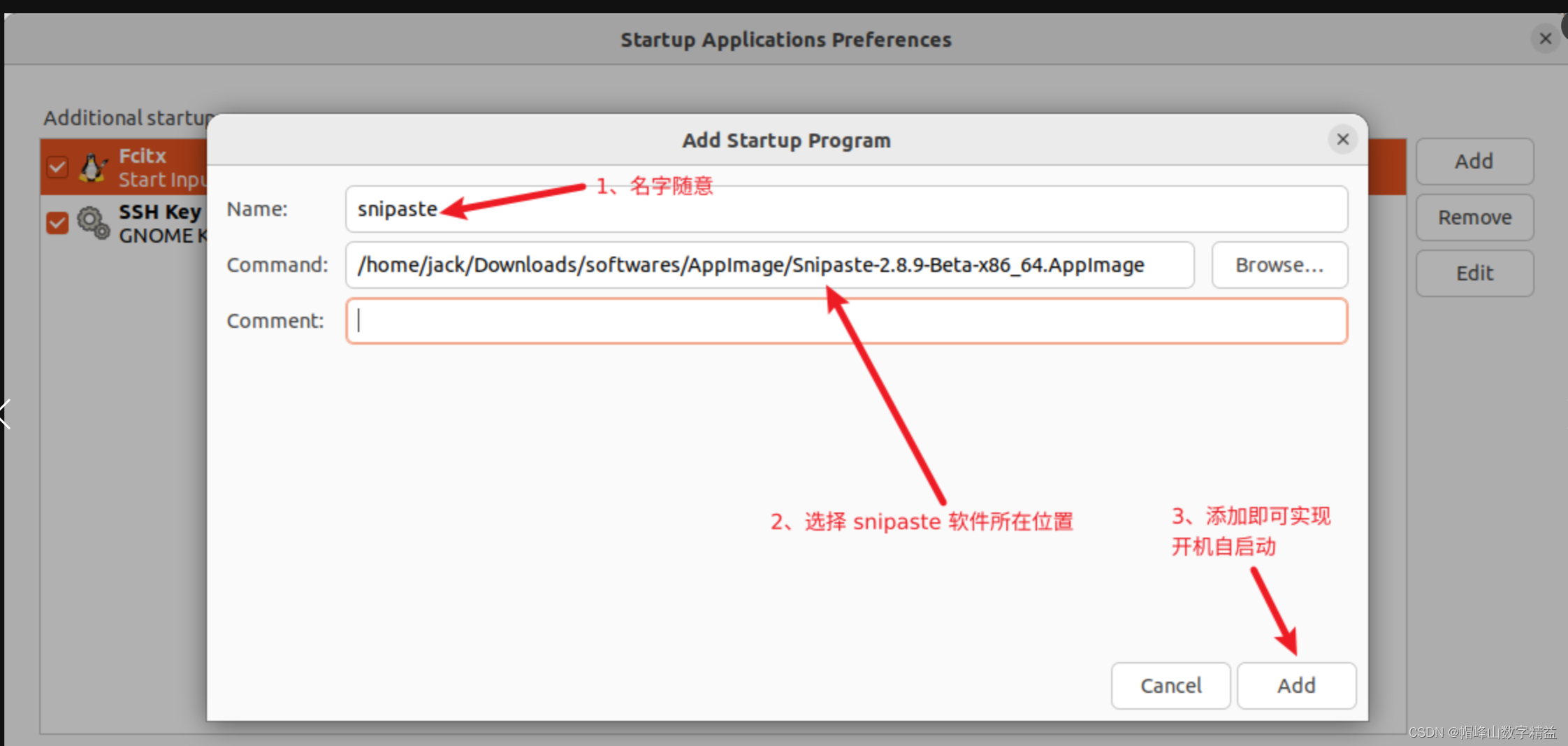
ubuntu22安装snipaste
Ubuntu 22.04 一、Snipaste 介绍和下载 Snipaste 官网下载链接: Snipaste Downloads 二、安装并使用 Snipaste # 1、进入Snipaste-2.8.9-Beta-x86_64.AppImage 目录(根据自己下载目录) cd /home/jack/Downloads/softwares/AppImage# 2、Snipaste-2.8.9-…...
spring-cloud微服务openfeign
Spring Cloud openfeign对Feign进行了增强,使其支持Spring MVC注解,另外还整合了Ribbon和Nacos,从而使得Feign的使用更加方便 优势,openfeign可以做到使用HTTP请求远程服务时就像洞用本地方法一样的体验,开发者完全感…...
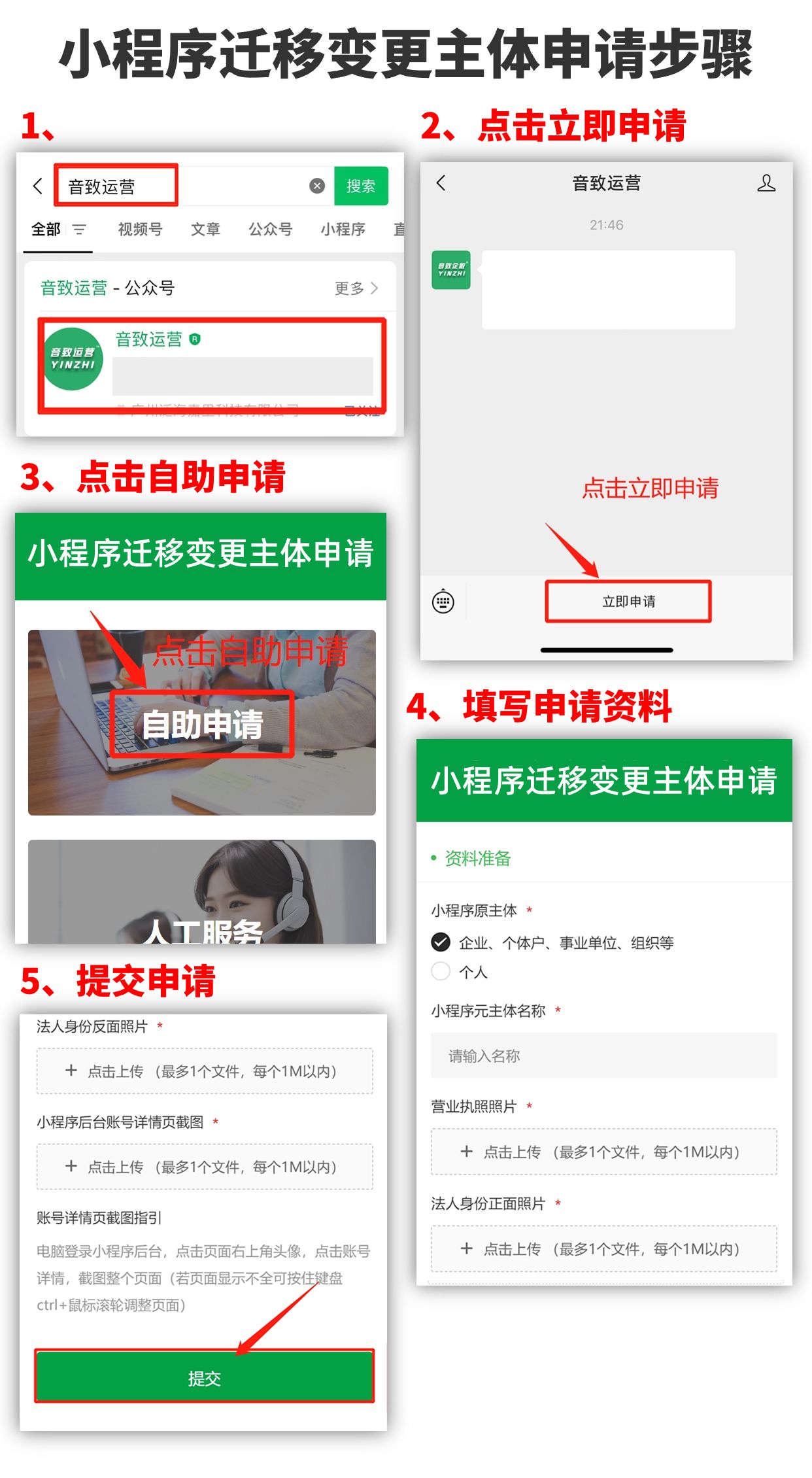
小程序变更主体需要多久?
小程序迁移变更主体有什么作用?小程序迁移变更主体的好处有很多哦!比如可以获得更多权限功能、公司变更或注销时可以保证账号的正常使用、收购账号后可以改变归属权或使用权等等。小程序迁移变更主体的条件有哪些?1、新主体必须是企业主体&am…...

19 Games101 - 笔记 - 相机与透镜
**19 ** 相机与透镜 目录 摘要一 照相机主要部分二 小孔成像与视场(FOV)三 曝光(Exposure)四 景深(Depth of Field)总结 摘要 虽说照相机与透镜属于相对独立的话题,但它们的确是计算机图形学当中的一部分知识。在过往的十多篇笔记中,我们学习的都是如…...

Flink入门学习 | 大数据技术
⭐简单说两句⭐ ✨ 正在努力的小新~ 💖 超级爱分享,分享各种有趣干货! 👩💻 提供:模拟面试 | 简历诊断 | 独家简历模板 🌈 感谢关注,关注了你就是我的超级粉丝啦! &…...

Arthas实战教程:定位Java应用CPU过高与线程死锁
引言 在Java应用开发中,我们可能会遇到CPU占用过高和线程死锁的问题。本文将介绍如何使用Arthas工具快速定位这些问题。 准备工作 首先,我们创建一个简单的Java应用,模拟CPU过高和线程死锁的情况。在这个示例中,我们将编写一个…...

HTML制作跳动的心形网页
作为一名码农 也有自己浪漫的小心思嗷~ 该网页 代码整体难度不大 操作性较强 祝大家都幸福hhhhh 效果成品: 全部代码: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <HTML><HEAD><TITLE> 一个…...
如何在Odoo 17 销售应用中使用产品目录添加产品
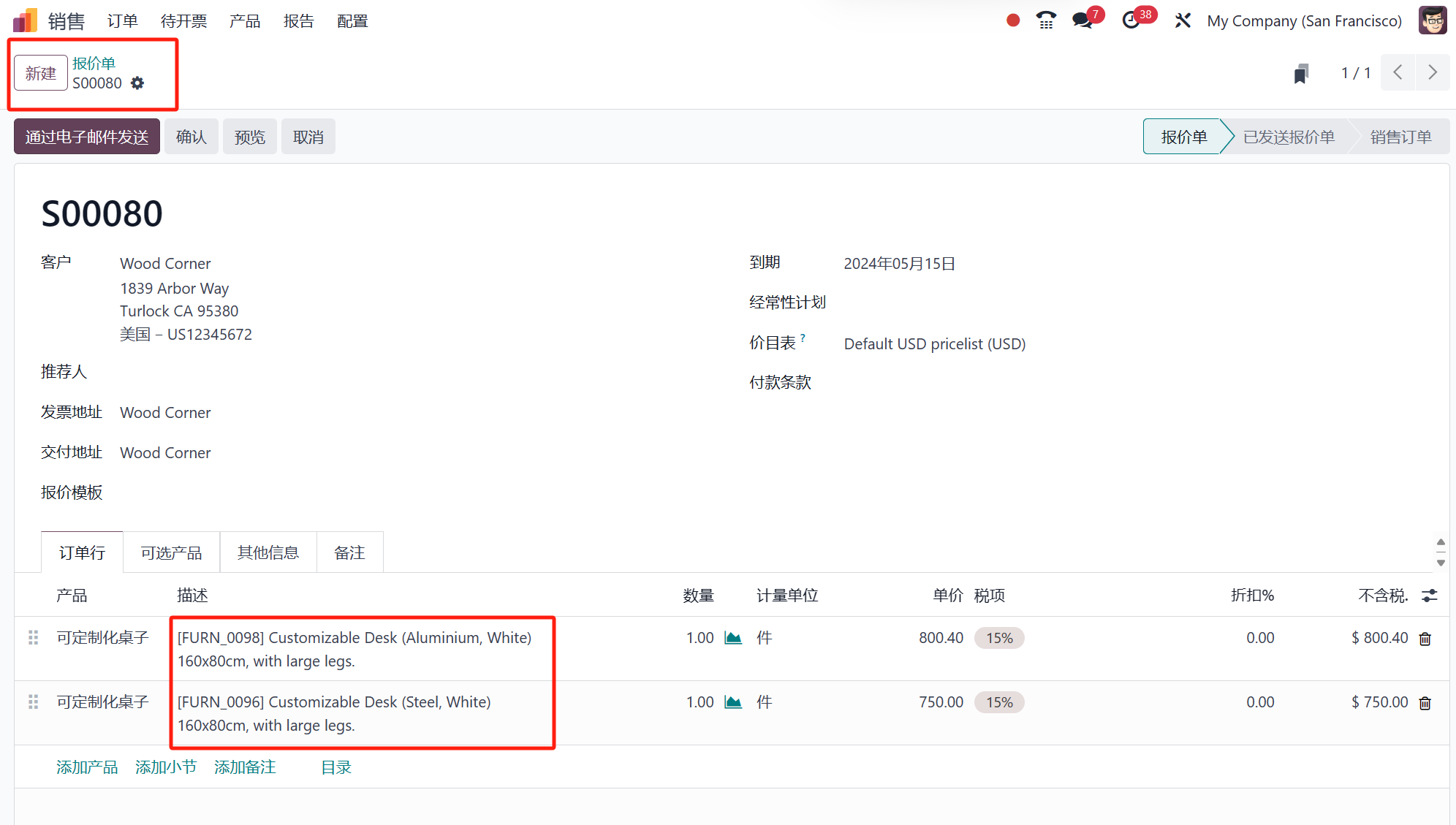
Odoo,作为一个知名的开源ERP系统,发布了其第17版,新增了多项功能和特性。Odoo 17包中的一些操作简化了,生产力提高了,用户体验也有了显著改善。为了为其用户提供新的和改进的功能,Odoo不断进行改进和增加新…...

为什么pdf拆分出几页之后大小几乎没有变化
PDF 文件的大小在拆分出几页之后几乎没有变化可能有几个原因: 图像压缩: 如果 PDF 文件中包含图像,而这些图像已经被压缩过,拆分后的页面依然会保留这些压缩设置,因此文件大小可能不会显著变化。 文本和矢量图形: PDF 文件中的文…...
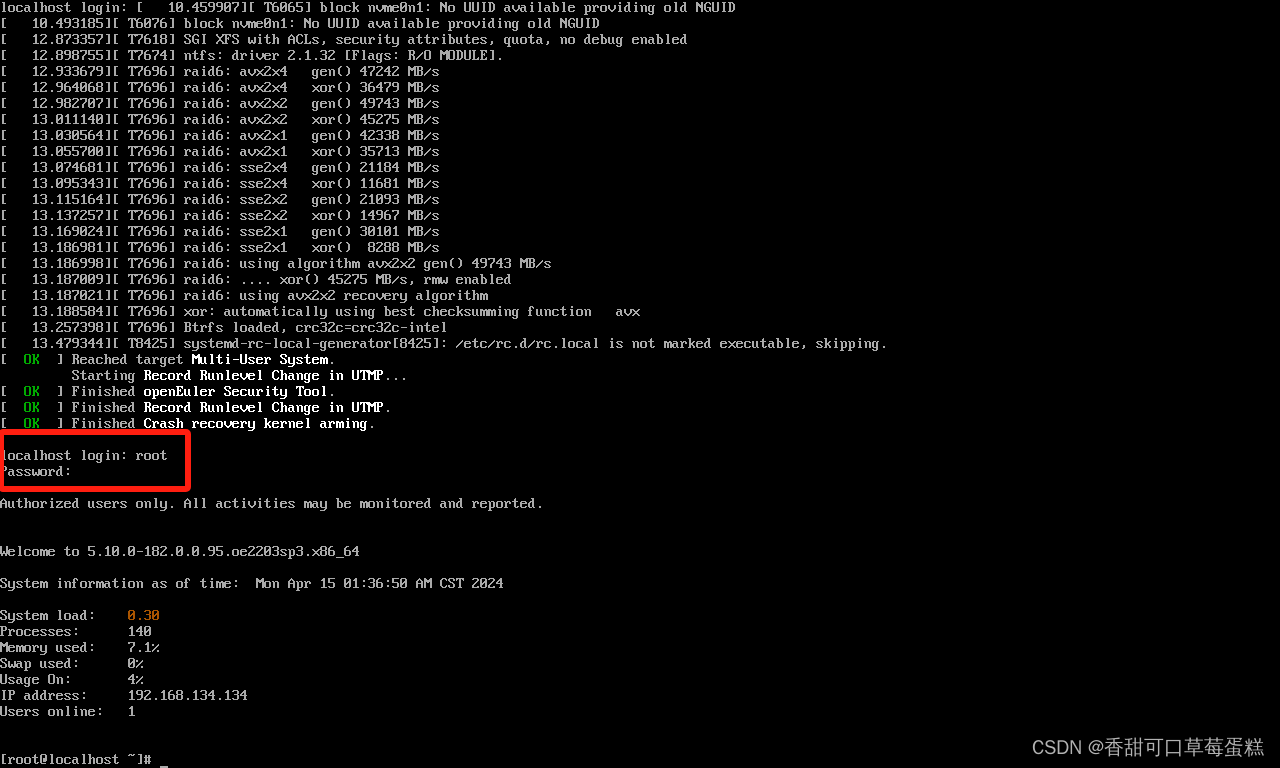
如何在 VM 虚拟机中安装 OpenEuler 操作系统保姆级教程(附链接)
一、VMware Workstation 虚拟机 若没有安装虚拟机的可以参考下篇文章进行安装: 博客链接https://eclecticism.blog.csdn.net/article/details/135713915 二、OpenEuler 镜像 点击链接前往官网 官网 选择第一个即可 三、安装 OpenEuler 打开虚拟机安装 Ctrl …...

(六)PostgreSQL的组织结构(3)-默认角色和schema
PostgreSQL的组织结构(3)-默认角色和schema 基础信息 OS版本:Red Hat Enterprise Linux Server release 7.9 (Maipo) DB版本:16.2 pg软件目录:/home/pg16/soft pg数据目录:/home/pg16/data 端口:57771 默认角色 Post…...

DockerFile定制镜像
dockerfile 简介 Dockerfile 是⼀个⽤来构建镜像的⽂本⽂件,⽂本内容包含了⼀条条构建镜像所需的指令和 说明,每条指令构建⼀层,最终构建出⼀个新的镜像。 docker镜像的本质是⼀个分层的⽂件系统 centos的iso镜像⽂件是包含bootfs和rootfs…...

Java8中JUC包同步工具类深度解析(Semaphore,CountDownLatch,CyclicBarrier,Phaser)
个人主页: 进朱者赤 阿里非典型程序员一枚 ,记录平平无奇程序员在大厂的打怪升级之路。 一起学习Java、大数据、数据结构算法(公众号同名) 引言 在Java中,并发编程一直是一个重要的领域,而JDK 8中的java.u…...

GA/T 1400视图库实战:从零部署Easy1400平台到设备级联全流程解析
1. 初识GA/T 1400与Easy1400平台 第一次接触GA/T 1400标准时,我完全被各种专业术语绕晕了。简单来说,这是一套专门针对视频监控领域的行业标准,规定了视频图像信息在采集、传输、存储等环节的技术要求。而Easy1400就是基于这个标准开发的一套…...

独立开发者如何借助Taotoken多模型能力打造全能AI助手应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken多模型能力打造全能AI助手应用 对于独立开发者或小型工作室而言,构建一个功能全面的AI助手…...

罗技PUBG鼠标宏终极教程:告别压枪烦恼,轻松提升射击稳定性
罗技PUBG鼠标宏终极教程:告别压枪烦恼,轻松提升射击稳定性 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求…...
,全程复制粘贴即可)
从0到1:手把手教你搭建VSCode(附避坑指南,拒绝报错),全程复制粘贴即可
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

3步掌握yfinance:从金融数据获取到智能分析的完整指南
3步掌握yfinance:从金融数据获取到智能分析的完整指南 【免费下载链接】yfinance Download market data from Yahoo! Finances API 项目地址: https://gitcode.com/GitHub_Trending/yf/yfinance yfinance是一个强大的Python库,能够轻松从Yahoo! F…...

期权交易基础框架:模块化设计与Python实现指南
1. 项目概述:一个为期权交易者打造的“乐高积木”底座如果你在量化交易或者期权策略开发领域摸爬滚打过一段时间,大概率会遇到一个共同的痛点:策略想法很多,但把它们变成可回测、可实盘、可管理的代码,却要耗费大量的“…...

Linux内存使用分析与泄漏排查
Linux内存使用分析与泄漏排查内存问题往往不像磁盘满那样直观,也不像进程崩溃那样立刻可见。很多服务在内存异常初期仍然可以运行,只是响应逐渐变慢、交换开始活跃、最终被系统回收或触发 OOM。中级 Linux 工程师需要掌握的,不只是看“还剩多…...

AI模型GUI开发实战:从架构设计到部署的完整指南
1. 项目概述:一个为AI模型打造的图形化交互界面最近在GitHub上看到一个挺有意思的项目,叫GrahamMiranda-AI/openclaw-model-gui。光看名字,就能猜个八九不离十:这大概率是一个为某个名为“OpenClaw”的AI模型配套开发的图形用户界…...

【ElevenLabs匈牙利语音实战指南】:2024最新API调用、音色微调与本地化合规避坑全解析
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs匈牙利语音支持概览与本地化价值定位 ElevenLabs 自 2024 年 3 月起正式引入匈牙利语(hu-HU)语音合成支持,成为其首批覆盖的中东欧语言之一。该能力依托于…...

OpenClaw-Subcortex:轻量级自动化任务编排与执行框架详解
1. 项目概述与核心价值最近在折腾一些自动化工具,发现一个挺有意思的项目叫openclaw-subcortex。乍一看这个名字,可能有点摸不着头脑,又是“爪子”又是“皮层下”的,感觉像是什么生物或者神经科学的东西。但实际上,这是…...