如何在OceanBase v4.2 中快速生成随机数据
在使用传统数据库如 MySQL 和 Oracle 时,由于缺乏多样化的随机数据生成方案,或者实现成本过高,构造随机数据的开发成本受到了影响。OceanBase在老版本中虽然有相应的解决方案,但语法复杂和性能较差等问题仍然存在。
现在,OceanBase v4.2 实现了简洁、高效且批量的随机数据插入操作。以下是一个 SQL 示例,它可向 t1 表中批量插入 100 行数据,每行均包含四个随机数值以及一个随机生成的字符串。
create table t1 (c1 varchar(10), c2 bigint, c3 bigint, c4 bigint, c5 bigint);insert into t1 select randstr(10, random()) c1,random() c2,zipf(1, 100, random(3)),normal(0, 1, random()),uniform(1, 100, random())
from table(generator(100));select * from t1;背景
我们在实践中发现,功能测试、压力测试、PoC 等等场景下都会涉及到随机数据生成,OceanBase v4.2 之前的版本存在两类问题:
- 随机函数种类少,不支持数据分布控制,需要手写 UDF 或 PL 包。
- 多行数据生成时,需要用 CONNECT BY 或 CTE,它们不仅语法复杂,而且数据行数较多时存在性能问题
下面用两个场景来说明我们亟需更好用的接口。
场景一:OceanBase 测试。
OceanBase 拥有大量的 mysqltest 测试用例,但这些用例中创建的表一般都不超过百行数据,导致一些潜在场景覆盖不到。为了增加覆盖率,我们需要给表中灌入更多数据,但在 v4.2 版之前这并不是一件容易事:
- insert into values 方法手工构造 values 很费劲,有多少行数据就要构造多少组值。
- insert into select 方法构造多行数据需要使用复杂的语法,并且性能不高,导致很少有工程师使用。
- 需要测试数据倾斜场景时,必须手工构造倾斜值,最后设计出来的 case 倾斜值的 NDV 大部分都是1、2 或者3,测试效果大打折扣。
- 需要测试长字符串场景时,只能使用 repeat、lpad、rpad 这类函数来构造长字符串,这些方法构造出来的字符串很有规律,通过存储层 lz、zstd 等压缩算法处理后占用空间会很小,也可能导致测试效果不尽人意。
场景二:OceanBase PoC。
两年前,我的一个同事在周末从 PoC 现场给我打电话咨询如何生成 1000 万行数据插入到数据库中,我给他介绍了 CTE 法和 CONNECT BY 法,但这两个方法都因为性能太差用不起来。最后他使用了“手工倍增法”:
Create table t1 (c1 bigint);
Insert into t1 values (1);
Insert into t1 select * from t1; // 现在 t1 包含 2 行数据
Insert into t1 select * from t1; // 现在 t1 包含4行数据
Insert into t1 select * from t1; // 现在 t1 包含8行数据
Insert into t1 select * from t1; // 现在 t1 包含16行数据
…
Insert into t1 select * from t1; // 现在 t1 包含65536行数据
…为了让传统 MySQL 客户快速的体验 OceanBase 极速的性能,我们可以在 QuickStart 中让他构建一个十万行的表来体验极速查询性能。构建十万行数据,无论是 insert into values 方法,还是“手工倍增法”,导数体验都很糟糕。
OceanBase v4.2 提供了全新的多行数据导入功能,彻底解决了上述痛点。它包含如下特性:
- 简洁易记的导数语法。
- 支持任意长度的随机字符串生成函数。
- 支持分布函数,轻松构造倾斜数据。
- Oracle 模式下引入原生内置随机函数,解决 PL 包性能不足问题。
OceanBase v4.2 随机行数据生成方法
随机数
为 MySQL 和 Oracle 模式统一增加了一套原生函数,提供完善的功能和最好的性能。
- 无论 MySQL 还是 Oracle 模式,都增加同名函数,丰富了函数种类。
- 无论 MySQL 还是 Oracle 模式,都提供原生内置函数,性能最优。
- 随机函数支持传入种子值,使得随机序列可复现,对测试友好。
1. 随机函数。
RANDOM([N]):随机生成一个 64 位整数。N 是整数,为随机种子,可选。
RANDSTR(N, gen):随机生成长度为 N 的字符串,gen 为随机方法,可选值为:
-
- RANDOM
- NORMAL - 生成的字符串服从正态分布
- UNIFORM - 生成的字符串服从均匀分布
- ZIPF - 生成的字符串服从齐夫分布
- 任意常数 - 生成同一个字符串

2.分布控制。
NORMAL(<mean> , <stddev> , <gen>):正态分布(高斯分布),返回一个符合正态分布(normal distribution,又称高斯分布)的浮点数。
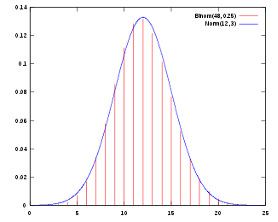
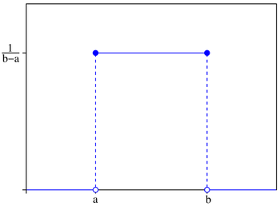
UNIFORM(<min> , <max> , <gen>):均匀分布,返回一个符合均匀分布(uniform distribution)的整数或浮点数。
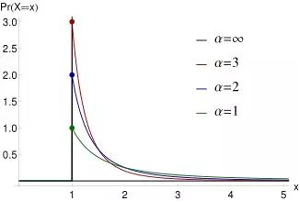
ZIPF(<s> , <N> , <gen>):齐夫分布,返回一个符合齐夫分布(zipf distribution)的整数。齐普夫定律是语言学专家Zipf在研究英文单词出现的频率时,发现如果把单词出现的频率按由大到小的顺序排列,则每个单词出现的频率与它的名次的常数次幂存在简单的反比关系,这种分布就称为Zipf定律,它表明在英语单词中,只有极少数的词被经常使用,而绝大多数词很少被使用。实际上,包括汉语在内的许多国家的语言都有这种特点。这个定律后来在很多领域得到了同样的验证,例如著名的28定律。
随机函数部分,我们在已有的 rand() 浮点随机数函数基础上,引入了直接生成整数值的 random() 函数,直接生成随机字符串的 randstr() 函数。同时,还引入了 normal、uniform、zipf 等几个分布控制函数,这使得我们能轻松控制生成数据的分布规律。
关于生成器表达式是一个比较新的概念,特别说明如下:
- 每个随机分布函数都需要一个生成器表达式(gen)作为其最后一个参数。生成器表达式可以是常量或变量:
- 如果是常量,则随机分布函数的结果是常量。
- 如果是变量,则随机分布函数的结果是可变的。
- 任何可转换为64位整数的表达式都可以用作生成器表达式。
- 任何随机分布函数的随机性都直接与其生成器表达式的随机性相关。对于大多数实际目的,random() 函数是随机生成整数值的最佳选择。
- 由数据生成函数生成的序列不能保证有序且没有间隙。这是因为数字可能会以并行的方式、不同步地生成。
行数据生成
Table function是一种在SQL语言中使用的函数,它能够返回一张数据表作为结果。与传统的SQL函数只能返回标量值不同,table function 可以返回多行、多列的数据集。 我们新增 generator 函数,并允许在 table function 中调用它,最终返回 N 行数据。语法为:table(generator(N));
N 是一个大于等于0的64位正整数。
使用举例:
OceanBase(TEST@TEST)>SELECT COUNT(*) FROM TABLE(GENERATOR(100000));
+----------+
| COUNT(*) |
+----------+
| 100000 |
+----------+
1 row in set (0.02 sec)select normal(0, 1, random()) from table(generator(5));
+------------------------+
| NORMAL(0, 1, RANDOM()) |
|------------------------|
| 0.227384164 |
| 0.9945290748 |
| -0.2045078571 |
| -1.594607893 |
| -0.8213296842 |
+------------------------+select randstr(1, zipf(1, 5, random())) str from table(generator(5));
+------------------------+
| str |
|------------------------|
| A |
| D |
| A |
| A |
| C |
+------------------------+
table generator 也可以和其它表做 join:
OceanBase(admin@test)>create table t1 (c1 bigint);
Query OK, 0 rows affected (0.18 sec)OceanBase(admin@test)>insert into t1 values (1), (2);
Query OK, 2 rows affected (0.03 sec)
Records: 2 Duplicates: 0 Warnings: 0OceanBase(admin@test)>select c1, random(1) from t1, table(generator(3));
+------+----------------------+
| c1 | random(1) |
+------+----------------------+
| 1 | -6753783847308464280 |
| 2 | -6707106347154343346 |
| 1 | -899926183391115878 |
| 2 | -8835543475904200562 |
| 1 | -2750444335953844424 |
| 2 | 7588216632478230601 |
+------+----------------------+
6 rows in set (0.00 sec)OceanBase(admin@test)>explain select c1, random(1) from t1, table(generator(3));
+--------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------+
| ================================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------------------------ |
| |0 |NESTED-LOOP JOIN CARTESIAN | |398 |14 | |
| |1 | FUNCTION_TABLE |FUNC_TABLE1|199 |1 | |
| |2 | MATERIAL | |2 |2 | |
| |3 | TABLE SCAN |t1 |2 |2 | |
| ================================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [random(1)]), filter(nil), rowset=256 |
| conds(nil), nl_params_(nil), batch_join=false |
| 1 - output(nil), filter(nil) |
| value(generator(3)) |
| 2 - output([t1.c1]), filter(nil), rowset=256 |
| 3 - output([t1.c1]), filter(nil), rowset=256 |
| access([t1.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t1.__pk_increment]), range(MIN ; MAX)always true |
+--------------------------------------------------------------------+
19 rows in set (0.00 sec)OceanBase(admin@test)>select /*+ parallel(2) */ c1, random(1) from t1, table(generator(3));
+------+----------------------+
| c1 | random(1) |
+------+----------------------+
| 1 | -6753783847308464280 |
| 2 | -6707106347154343346 |
| 1 | -899926183391115878 |
| 2 | -8835543475904200562 |
| 1 | -2750444335953844424 |
| 2 | 7588216632478230601 |
+------+----------------------+
6 rows in set (0.00 sec)OceanBase(admin@test)>explain select /*+ parallel(2) */ c1, random(1) from t1, table(generator(3));
+--------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------+
| ================================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------------------------ |
| |0 |NESTED-LOOP JOIN CARTESIAN | |398 |14 | |
| |1 | FUNCTION_TABLE |FUNC_TABLE1|199 |1 | |
| |2 | MATERIAL | |2 |2 | |
| |3 | PX COORDINATOR | |2 |2 | |
| |4 | EXCHANGE OUT DISTR |:EX10000 |2 |2 | |
| |5 | PX BLOCK ITERATOR | |2 |1 | |
| |6 | TABLE SCAN |t1 |2 |1 | |
| ================================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [random(1)]), filter(nil), rowset=256 |
| conds(nil), nl_params_(nil), batch_join=false |
| 1 - output(nil), filter(nil) |
| value(generator(3)) |
| 2 - output([t1.c1]), filter(nil), rowset=256 |
| 3 - output([t1.c1]), filter(nil), rowset=256 |
| 4 - output([t1.c1]), filter(nil), rowset=256 |
| dop=2 |
| 5 - output([t1.c1]), filter(nil), rowset=256 |
| 6 - output([t1.c1]), filter(nil), rowset=256 |
| access([t1.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t1.__pk_increment]), range(MIN ; MAX)always true |
+--------------------------------------------------------------------+
26 rows in set (0.00 sec)无论是否开启并行执行,Table Generator 都是使用单线程来生成数据。不过不用担心性能问题,目前向存储层插入数据的过程才是瓶颈,单线程生成数据不是瓶颈。
性能评测
在 OceanBase 中,我们对比了 Connect By、Recursive CTE 和 Table Generator 生成行数据性能,每行包含一列整数。生成 1000 万行数据,Table Generator 只需 2 秒,完全满足日常需求。
| Oracle Mode Connect By | MySQL ModeRecursive CTE | Table Generator | |
| 生成1w行数据耗时 | 0.02s | 0.83s | 0.002s |
| 生成10w行数据耗时 | 0.18s | 10s+(timeout) | 0.02s |
| 生成100w行数据耗时 | Out Of Memory | 10s+(timeout) | 0.21s |
| 生成1000w行数据耗时 | Out Of Memory | 10s+(timeout) | 2.05s |
最佳实践
在了解基本概念后,下面给出一些常见的随机数据生成场景,以展示基本用法。
有主键表随机数据生成
推荐搭配 sequence 对象:
create table t1 (c1 bigint primary key, c2 bigint);
create sequence s1 cache 1000000 noorder;
Insert into t1 select s1.nextval, random() from table(generator(1000));
Insert into t1 select s1.nextval, random() from table(generator(1000));
Note:为了尽可能提高生成数据的性能,sequence cache 大小不要低于 100 万。
千万行级别的随机数据生成
推荐配合使用 OceanBase 4.1 推出“旁路导入”功能,以获得最高的性能。只需要添加append enable_parallel_dml parallel(8) hint 即可,此处使用了并行度8:
create table t1 (c1 bigint, c2 varchar(10));
Insert /*+ append enable_parallel_dml parallel(8) */ into t1 select random(), randstr(10, random()) from table(generator(10000000));
Note:考虑到 OceanBase 4.2 版本旁路导入的最佳实践,建议用一条 insert 语句完成单表全部数据插入,不要拆成多条 insert 来做。
生成包含多个宏块的数据
为了测试包含多个宏块的场景,我们需要插入大量的数据。但是偶尔我们会发现,即使插入了大量行,OceanBase 凭借其强大的压缩能力,把这些数据都给压缩没了。即使插入了数十万行,还装不满一个宏块。
Oracle 模式下为了解决这个问题,我们可以在建表时加上 NOCOMPRESS属性,这样,插入很少的数据就能装满一个宏块。例如:
create table t1 (c1 bigint, c2 varchar(10000)) NOCOMPRESS;
Insert /* append enable_parallel_dml parallel(8) */ into t1 select random(), repeat('a', 10000) from table(generator(10000000));MySQL 模式下没有 NOCOMPRESS 选项,可以使用 randstr() 来生成足够长的随机串避免压缩。
create table t1 (c1 bigint, c2 varchar(10000));
Insert /* append enable_parallel_dml parallel(8) */ into t1 select random(), randstr(1000, random()) from table(generator(10000000));测试并行执行场景推荐使用本方法,有助于提前暴露数据切分相关问题。
倾斜数据生成
我们可以让数据符合正态分布或 zipf 分布,这样就能构造出数据倾斜。例如下面随机生成 20 行数据,zipf 分布可以让小数字出现的频率更高:
OceanBase(TEST@TEST)>select zipf(1, 20, random()) from table(generator(20));
+---------------------+
| ZIPF(1,20,RANDOM()) |
+---------------------+
| 0 |
| 0 |
| 4 |
| 5 |
| 12 |
| 4 |
| 16 |
| 1 |
| 2 |
| 9 |
| 0 |
| 0 |
| 0 |
| 1 |
| 3 |
| 7 |
| 11 |
| 13 |
| 1 |
| 1 |
+---------------------+
20 rows in set (0.00 sec)
Note: zipf 生成的数字的分布的特点是小数字出现频率高,大数字出现频率低。
长短不一的字符串生成
OceanBase(TEST@TEST)>select randstr(1+zipf(1, 20, random()), random()) from table(generator(20));
+-----------------------------------------+
| RANDSTR(1+ZIPF(1,20,RANDOM()),RANDOM()) |
+-----------------------------------------+
| 1E |
| VM |
| wxYJ |
| zoBaL |
| IhaZW |
| 8z6jaVWxG92vs1kx |
| roDKzcJ2JS |
| IVwBKZsvix8z |
| 8D |
| UTM |
| 9alknanS |
| rSxQ9kD4lm |
| 9 |
| 9MXuz |
| r |
| i1c |
| nE16vM52jW |
| XG1 |
| bSdeZi |
| 2TuvyPMVSf |
+-----------------------------------------+
20 rows in set (0.00 sec)批量插入单词
一些场景下,我们希望插入的字符串有一定规律,不要长得像乱码。比如,插入的内容是字典里的单词。可以通过预先构造一个单词表解决这个问题:
OceanBase(admin@test)>create table t1 (c1 int, c2 varchar(10));
Query OK, 0 rows affected (0.168 sec)OceanBase(admin@test)>insert into t1 values (0, 'hello'), (1, 'world'), (2, 'movie');
Query OK, 3 rows affected (0.011 sec)
Records: 3 Duplicates: 0 Warnings: 0OceanBase(admin@test)>create table t2 (c1 varchar(10));
Query OK, 0 rows affected (0.160 sec)OceanBase(admin@test)>insert /*+ parallel(3) enable_parallel_dml */ into t2 select b.c2 from table(generator(1000)) a, t1 b where b.c1 = random() % 3;
Query OK, 1000 rows affected (0.015 sec)
Records: 1000 Duplicates: 0 Warnings: 0插入部分 null 值
在数据集中掺入 null 值,常能有效暴露一些潜在 bug。MySQL 模式中可以用 if 来实现在随机数中掺 null,Oracle 模式下,可以用 decode 来实现。下面的例子里,都以 10% 的概率生成 null 值:
OceanBase(admin@test)>select if(random(4) % 10 = 0, null, random(4)) from table(generator(10));
+-----------------------------------------+
| if(random(4) % 10 = 0, null, random(4)) |
+-----------------------------------------+
| 5267436225003336391 |
| NULL |
| -851690886662571060 |
| 1738617244330437274 |
| -8073957877497551694 |
| 885116094377146851 |
| -8183226488433301506 |
| 6294187330509591201 |
| -8511555461190104804 |
| 4732822798680798032 |
+-----------------------------------------+
10 rows in set (0.000 sec)
OceanBase(TEST@TEST)>select decode(mod(random(4),10), 0, null, random(4)) from table(generator(10));
+--------------------------------------------+
| DECODE(MOD(RANDOM(4),10),0,NULL,RANDOM(4)) |
+--------------------------------------------+
| 5267436225003336391 |
| NULL |
| -851690886662571060 |
| 1738617244330437274 |
| -8073957877497551694 |
| 885116094377146851 |
| -8183226488433301506 |
| 6294187330509591201 |
| -8511555461190104804 |
| 4732822798680798032 |
+--------------------------------------------+
10 rows in set (0.002 sec)mysqltest 中如何生成稳定的随机数据
Mysqltest 要求数据必须稳定,否则每次回归的结果都不一样。我们只需要传入一个常数种子(seed)到随机函数中就可以保证每次插入到表中的数据是一样的。所谓 seed 就是给 random() 函数传入一个任意的常量值,seed 相同,每次执行输出的结果都相同。例如下面的例子中,3 就是 seed。
create table t1 (c1 int);
Insert into t1 select random(3) from table(generator(1000));加速数据插入
配合并行DML(PDML)可以加速数据插入速度:
create table t1 (c1 int, c2 int);
Insert /*+ parallel(4) enable_parallel_dml */ into t1 select random(), random() from table(generator(10000000));如果没有事务要求,也可以搭配上旁路导入功能,导数性能可以更高:
create table t1 (c1 int, c2 int);
Insert /*+ append parallel(4) enable_parallel_dml */ into t1 select random(), random() from table(generator(10000000));
Note:OceanBase v4.2 版本的旁路导入功能还不支持事务,我们计划在未来版本里添加事务支持。
附录:OceanBase 老版本随机数据生成方法
随机数
随机数生成针对Oracle和MySQL提供了不同的方法。
针对Oracle,提供了DBMS_RANDOM 包,示例如下:
OceanBase(TEST@TEST)>create table t1 (c1 int);
inQuery OK, 0 rows affected (0.350 sec)OceanBase(TEST@TEST)>insert into t1 values (1),(2);
Query OK, 2 row affected (0.054 sec)OceanBase(TEST@TEST)>SELECT DBMS_RANDOM.value FROM t1;
+-----------------------------------------+
| DBMS_RANDOM.VALUE |
+-----------------------------------------+
| .7399915858834366379526638344258521027 |
| .49582434020991574649964366641874399825 |
+-----------------------------------------+
2 rows in set (0.001 sec)OceanBase(TEST@TEST)>SELECT DBMS_RANDOM.random FROM t1;
+--------------------+
| DBMS_RANDOM.RANDOM |
+--------------------+
| -1829272250 |
| -302482048 |
+--------------------+
2 rows in set (0.001 sec)OceanBase(TEST@TEST)>SELECT DBMS_RANDOM.string('u', 10) FROM t1;
+----------------------------+
| DBMS_RANDOM.STRING('U',10) |
+----------------------------+
| CXYOOFFTAK |
| ISQXVGILZS |
+----------------------------+
2 rows in set (0.003 sec)OceanBase(TEST@TEST)>SELECT DBMS_RANDOM.string('l', 10) FROM t1;
+----------------------------+
| DBMS_RANDOM.STRING('L',10) |
+----------------------------+
| tesckgmuhd |
| qumsrewisr |
+----------------------------+
2 rows in set (0.006 sec)OceanBase(TEST@TEST)>SELECT DBMS_RANDOM.normal() FROM t1;
+--------------------------------------------+
| DBMS_RANDOM.NORMAL() |
+--------------------------------------------+
| -.3707362774912783852056768030439781065643 |
| -.661863938694328133730598207745367381443 |
+--------------------------------------------+
2 rows in set (0.002 sec)而对于MySQL,则提供了rand() 函数,示例如下:
OceanBase(admin@test)>create table t1 (c1 int);
Query OK, 0 rows affected (0.143 sec)OceanBase(admin@test)>insert into t1 values (1),(2);
Query OK, 2 rows affected (0.014 sec)
Records: 2 Duplicates: 0 Warnings: 0OceanBase(admin@test)>select rand() from t1;
+---------------------+
| rand() |
+---------------------+
| 0.3246343818722613 |
| 0.20731560718949474 |
+---------------------+
2 rows in set (0.005 sec)可以看到,MySQL 模式下随机函数种类太少(云平台客户大部分使用的是 MySQL 模式)。虽然 Oracle 包提供的随机函数是比较丰富的,但目前因为实现缘故,在大批量数据插入场景使用 DBMS_RANDOM 包有比较大的性能开销。
行数据生成
为了生成 1000 行数据,老版本的 OceanBase 使用如下方法:
对于Oracle,使用Connect By方法,示例如下:
OceanBase(TEST@TEST)>SELECT COUNT(*) FROM(SELECT * FROM dual CONNECT BY LEVEL <= 100000) a;
+----------+
| COUNT(*) |
+----------+
| 100000 |
+----------+
1 row in set (0.16 sec)对于MySQL,使用Recursive CTE方法,示例如下:
OceanBase(admin@test)>WITH RECURSIVE cte1 (n) AS (SELECT 1 UNION ALL SELECT n+1 FROM cte1 WHERE n < 10000 )SELECT COUNT(*) FROM cte1;
+----------+
| COUNT(*) |
+----------+
| 10000 |
+----------+
1 row in set (0.79 sec)可以看到:语法的确是比较复杂,记起来不容易,两个方法的实现性能也不太良好。
相关文章:
如何在OceanBase v4.2 中快速生成随机数据
在使用传统数据库如 MySQL 和 Oracle 时,由于缺乏多样化的随机数据生成方案,或者实现成本过高,构造随机数据的开发成本受到了影响。OceanBase在老版本中虽然有相应的解决方案,但语法复杂和性能较差等问题仍然存在。 现在…...

nvm node.js的安装
说明:部分但不全面的记录 因为过程中没有截图,仅用于自己的学习与总结 过程中借鉴的优秀博客 可以参考 1,npm install 或者npm init vuelatest报错 2,了解后 发现是nvm使用的版本较低,于是涉及nvm卸载 重新下载最新版本的nvm 2…...

【Docker】安装Redis、Nginx
1、安装redis mkdir -p /docker/redis mkdir -p /docker/redis/data touch /docker/redis/redis.conf touch /docker/redis/redis.bash编辑配置文件 vim /docker/redis/redis.conf # Redis配置文件# Redis默认不是以守护进程的方式运行,可以通过该配置项修改&…...

RK3568 UBUNTU修改网卡名称
RK3568 UBUNTU系统有两个网卡,ETH0和ETH1,于设备机壳丝印ETH1、ETH2无法对应,于是百度了一下相关的修改办法,有修改设备树的等等,挑了一个最简单,验证通过 #第1步,将原网卡关闭ip …...

【华为OD机试C++】统计字符
《最新华为OD机试题目带答案解析》:最新华为OD机试题目带答案解析,语言包括C、C++、Python、Java、JavaScript等。订阅专栏,获取专栏内所有文章阅读权限,持续同步更新! 文章目录 描述输入描述输出描述示例代码描述 输入一行字符,分别统计出包含英文字母、空格、数字和其它…...

百货商场用户画像描绘and价值分析(下)
目录 内容概述数据说明技术点主要内容4 会员用户画像和特征字段创造4.1 构建会员用户基本特征标签4.2 会员用户词云分析 5 会员用户细分和营销方案制定5.1 会员用户的聚类分析及可视化5.2 对会员用户进行精细划分并分析不同群体带来的价值差异 内容概述 本项目内容主要是基于P…...
spring-cloud微服务gateway
核心部分:routes(路由), predicates(断言),filters(过滤器) id:可以理解为是这组配置的一个id值,请保证他的唯一的,可以设置为和服务名一致 uri:可以理解为是通过条件匹配之后需要路由到&…...
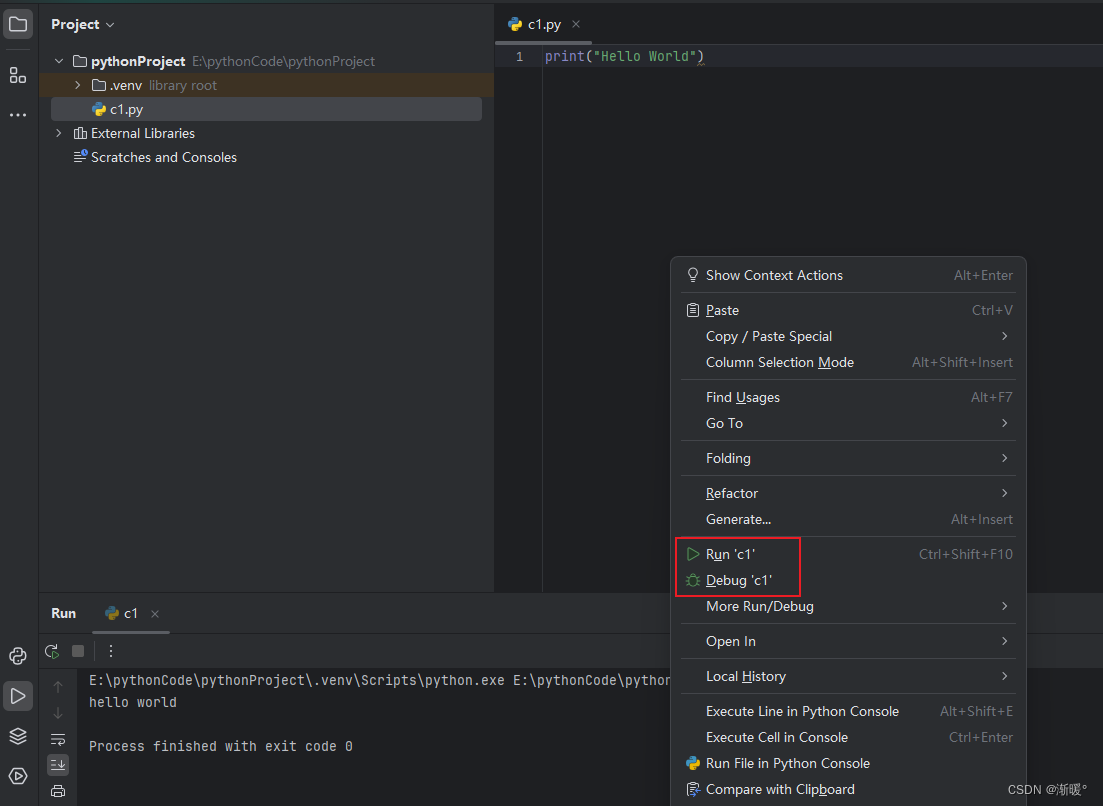
【python】在pycharm创建一个新的项目
双击打开pycharm,选择create new project 选择create,后进入项目 右键项目根目录,选择new一个新的python file 随意命名一下 输入p 然后后面就会出现智能补全提示,此时轻敲一下tab,代码就写好了,非常的方便 右键执行一下代码,下面两个直接运行和debug运行都是可以的 小结 …...
----用函数实现斐波那契数列(第二遍))
java小作业(9)----用函数实现斐波那契数列(第二遍)
代码: public class Main {public static void main(String[] args) {int n 20; // 你可以更改这个值来计算和输出前n个斐波那契数for (int i 0; i < n; i) {System.out.print(fibonacci(i) " ");}}public static int fibonacci(int n) {if (n <…...
部署项目的时候的一些错误
项目打jar包,找不到资源,连接不上数据库 项目打包后无法运行 直接在idea运行可以 解决方法:pom文件中增加(配置文件如果是yml,写yml) <resources><resource><directory>src/main/java&…...
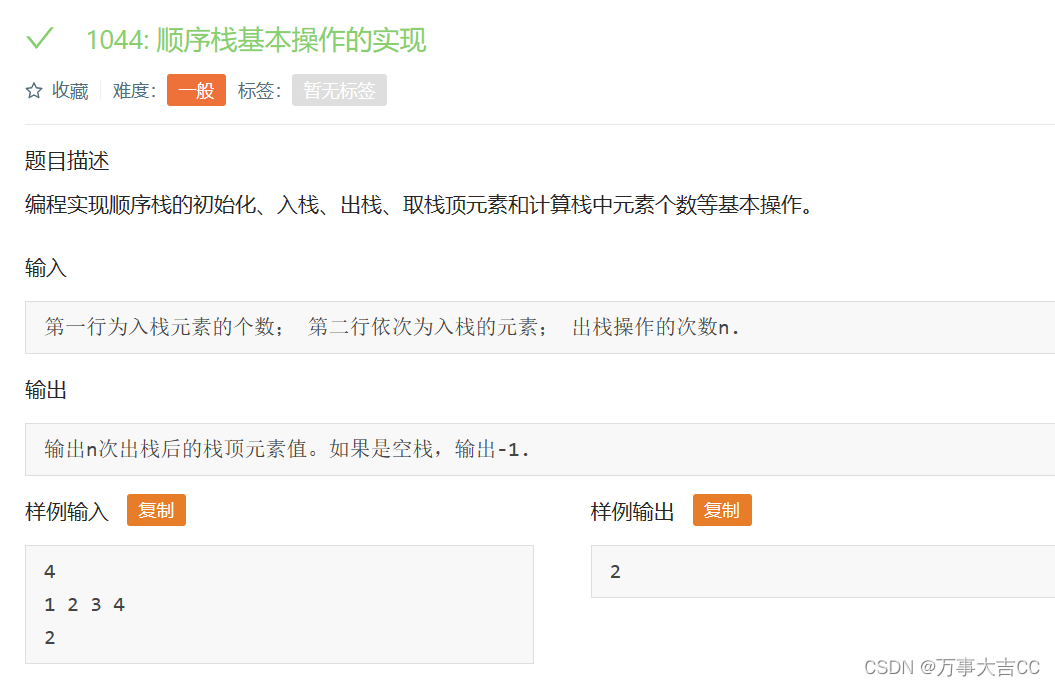
1044: 顺序栈基本操作的实现
解法: #include<iostream> #include<stack> using namespace std; int main() {int n, a, k;stack<int> sk;cin >> n;while (n--) {cin >> a;sk.push(a);}cin >> k;while (k--) {sk.pop();}if (!sk.empty()) {cout << s…...
)
微信小程序(总结)
1、wx.createSelectorQuery 在微信小程序中,wx.createSelectorQuery 是用于创建一个 SelectorQuery 对象的方法,而 this.createSelectorQuery 是在组件中获取元素的方法。 使用 wx.createSelectorQuery 创建的 SelectorQuery 对象可以用于获取页面中的…...
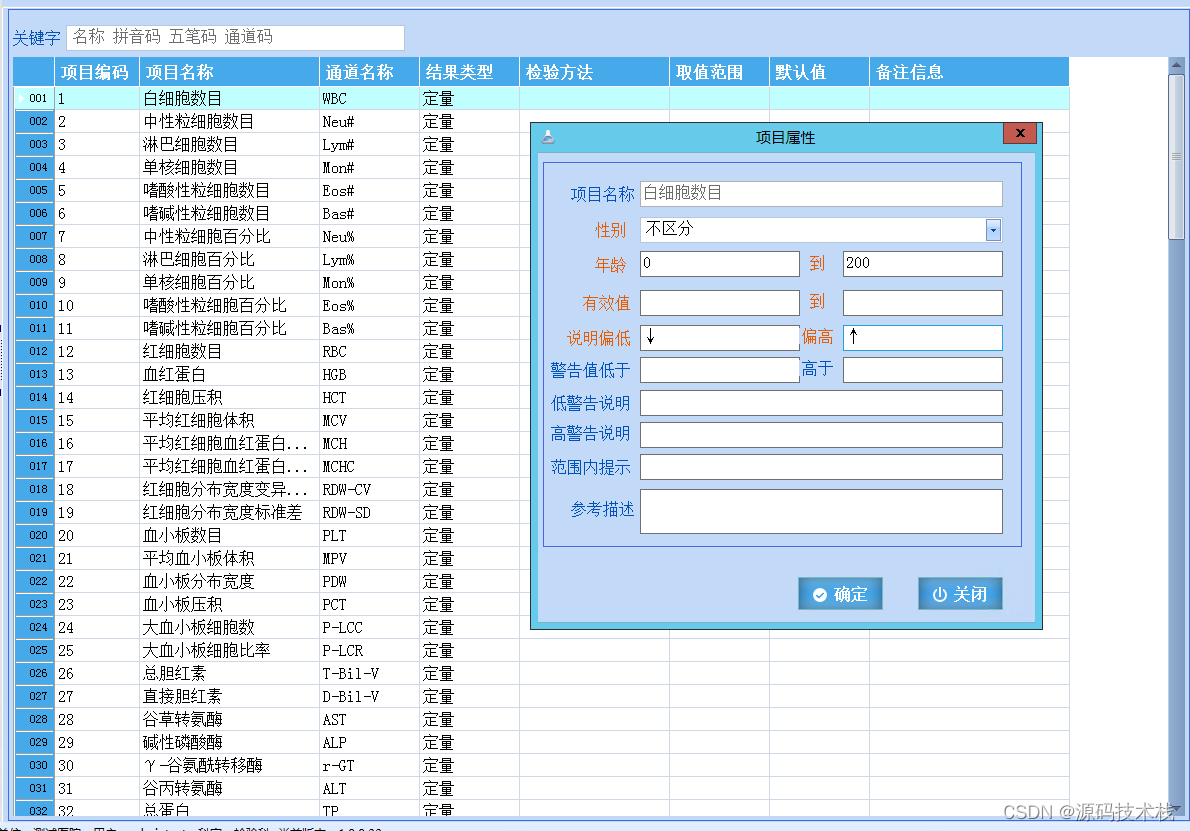
C#医学实验室/检验信息管理系统(LIS系统)源码
目录 检验系统的总体目标 LIS主要包括以下功能: LIS是集:申请、采样、核收、计费、检验、审核、发布、质控、耗材控制等检验科工作为一体的信息管理系统。LIS系统不仅是自动接收检验数据,打印检验报告,系统保存检验信息的工具&a…...

Linux驱动编程-module_platform_driver注册platform_driver
使用platform总线驱动模式编写Linux驱动时,需要注册platform_driver(用于跟.dts文件的platform_device匹配)。下面介绍2种常用注册platform_driver方法: 1、module_init()、module_exit() /* 定义平台drv,通过.name来…...
论文解读 --- 《针对PowerShell脚本的有效轻量级去混淆和语义感知攻击检测》
开篇 今天我们继续来解读安全行业优秀论文,通过学习他人的智慧成果,可以不断丰富我们的安全视野,使用它山之石来破解自身的难题。 这次要解读的论文为《Effective and Light-Weight Deobfuscation and Semantic-Aware Attack Detection for…...

在Spring Boot实战中碰到的拦截器与过滤器是什么?
在Spring Boot实战中,拦截器(Interceptors)和过滤器(Filters)是两个常用的概念,它们用于在应用程序中实现一些通用的逻辑,如日志记录、权限验证、请求参数处理等。虽然它们都可以用于对请求进行…...

数据可视化基础与应用-04-seaborn库人口普查分析--如何做人口年龄层结构金字塔
总结 本系列是数据可视化基础与应用的第04篇seaborn,是seaborn从入门到精通系列第3篇。本系列主要介绍基于seaborn实现数据可视化。 参考 参考:我分享了一个项目给你《seaborn篇人口普查分析–如何做人口年龄层结构金字塔》,快来看看吧 数据集地址 h…...

软考之【系统架构设计师】
系统架构设计师 根据原人事部、原信息产业部文件(国人部发[2003]39号)文件规定,计算机软件资格考试纳入全国专业技术人员职业资格证书制度的统一规划,实行统一大纲、统一试题、统一标准、统一证书的考试办法,每年举行…...

LigaAI x 极狐GitLab,共探 AI 时代研发提效新范式
近日,LigaAI 和极狐GitLab 宣布合作,双方将一起探索 AI 时代的研发效能新范式,提供 AI 赋能的一站式研发效能解决方案,让 AI 成为中国程序员和企业发展的新质生产力。 软件研发是一个涉及人员多、流程多、系统多的复杂工程&#…...

如何看待2023年图灵奖
目录 1.概述 2.计算复杂性理论 3.随机性和伪随机性 4.学术生涯和领导力 1.概述 图灵奖(Turing Award),全称A.M.图灵奖(ACM A.M Turing Award),是由计算机领域的最高学术机构——美国计算机协会…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

【算法训练营Day07】字符串part1
文章目录 反转字符串反转字符串II替换数字 反转字符串 题目链接:344. 反转字符串 双指针法,两个指针的元素直接调转即可 class Solution {public void reverseString(char[] s) {int head 0;int end s.length - 1;while(head < end) {char temp …...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

Redis:现代应用开发的高效内存数据存储利器
一、Redis的起源与发展 Redis最初由意大利程序员Salvatore Sanfilippo在2009年开发,其初衷是为了满足他自己的一个项目需求,即需要一个高性能的键值存储系统来解决传统数据库在高并发场景下的性能瓶颈。随着项目的开源,Redis凭借其简单易用、…...