ElasticSearch nested 字段多关键字搜索,高亮全部匹配关键字的处理
ElasticSearch nested 字段多关键字搜索,高亮全部匹配关键字的处理
环境介绍
ElasticSearch 版本号: 6.7.0
需求说明
用户会传入多个关键字去ES查询ElasticSearch nested 字段 的多个字段,要求在返回的结果中被搜索的字段需要高亮所有匹配的关键字。例如同时通过上海和策划关键字,再 工作经历的列表中的工作内容和公司名称中搜索。如果有人员的工作经历中这两个关键字上海和策划都可以匹配到,那么返回的结果中同时高亮这上海和策划关键字
分析调研
基础的ElasticSearch nested 字段的高亮实现搜可以参考https://blog.csdn.net/weixin_48990070/article/details/120342597 这篇笔记。
问题点1
对于同一个nested 字段支持在一个nested Query 用不同的关键字来搜索,但对于should 查询只会高亮其中匹配的一个关键字,而不是全部。引入如果多关键字直接是任意满足的关系,则之后高亮匹配的其中的一个关键字,这个与不满足需求。
问题点2
那就把关键字拆分为多个nested Query ,一个关键字对应一个nested Query 。但这个方法一样可以搜索,但对于同一个nested字段的nested Query 默认的inner_hits 属性只能出现在一个nested Query中,不允许同一个nested字段的不同nested Query 都指定inner_hits ,如果一定要这么做,那么就会得到一个查询错误的提示,提示如下:
"reason": {"type": "illegal_argument_exception","reason": "[inner_hits] already contains an entry for key [trackRecordList]"}
如果只在一个关键字的nested Query指定inner_hits,那么最终的高亮结果只会有该nested Query的高亮,还是不满足要求。
问题点3
通过AI询问得知inner_hits 有个name 属性可以解决问题点2的情况,可以通过设置inner_hits不同的name 属性值来达到对同一个nested字段用不同nested Query 来做多关键字的高亮效果,但是这样里又出现了两个新的问题。
1、inner_hits 有个name 属性值不能重复,否则一样出问题点2的错误提示。
2、高亮 结果是按照inner_hits 有个name 属性值分组展示的,不像非nested会给一个最终多个关键字都高亮的结果。
转换下问题就是:
1、要根据关键字自动生成不重复inner_hits 有个name 属性值
2、对于同字段的高亮结果,要做高亮内容的合并。
因此只要解决了上面两个问题,就可以完成业务的需求了。
最终解决方案
问题1解决方案
在将查询参数转换为ES Query语句的处理中,用Map来缓存每个nested字段的当前有几个nested Query,通过累计数量,来自动生成每个nested Query中的inner_hits 有个name 属性名,例如名称为 nested字段名+“-”+自增序号
因此就不能再使用静态方法来构建查询语句了,得用构建器了,下面就是构建器的部分实现
public class EsQueryBuilder {// 存储嵌套字段及其累计值的映射private Map<String, IntAccumulator> accNestedFieldMap = new HashMap<>();// 无需嵌套高亮的字段集合private Set<String> noNestedHighlightFields = new HashSet<>();// 关键词分组列表private List<PageSearchKeywordGroupParameter> keywordGroupList ;// 是否开启高亮显示private boolean isHighlight = false;// 主查询构建器private BoolQueryBuilder mainQueryBuilder;//存储嵌套字段及其高亮构建器private Map<NestedQueryBuilder,InnerHitBuilder> nestedQueryBuilderHighlightMap = new HashMap<>();/*** 构造方法* @param keywordGroupList 搜索关键字组* @param isHighlight 是否高亮*/public EsQueryBuilder(List<PageSearchKeywordGroupParameter> keywordGroupList,boolean isHighlight) {this.keywordGroupList = keywordGroupList;this.isHighlight = isHighlight;this.mainQueryBuilder = new BoolQueryBuilder();//补充嵌套字段初始累加器EsQueryFieldEnum.getNestedFieldList().forEach(item->{accNestedFieldMap.put(item.getFieldConfig().getMainField(),new IntAccumulator(0));});}/*** 向当前的查询构建器中添加条件。这个方法会遍历关键字组列表(keywordGroupList)中的每一个项目,* 并根据是否标记为排除条件,将关键字添加到查询的必须条件(must)或者必须不条件(mustNot)中。* @return EsQueryBuilder 返回当前的查询构建器实例,允许链式调用。*/public EsQueryBuilder addCondition() {keywordGroupList.forEach(item->{// 只处理非空关键字的项目if(StringUtils.isNotBlank(item.getKeyword())){// 根据是否为排除条件,选择添加到must或mustNot中if(BooleanUtils.isTrue(item.getIsExclude())){mainQueryBuilder.mustNot(buildQueryBuilder(item));}else{mainQueryBuilder.must(buildQueryBuilder(item));}}});return this;}/*** 为所有内容添加高亮显示条件的查询构建器。* 该方法遍历关键字组列表,对非排除条件的关键字进行全文搜索设置,并根据关键字是否为排除条件,添加相应的查询条件。* @return EsQueryBuilder 当前查询构建器实例,支持链式调用。*/public EsQueryBuilder addConditionForAllContentHighlight() {// 遍历关键字组列表,过滤掉设置为排除条件的关键字,对剩余的关键字进行全文搜索设置keywordGroupList.stream()// 过滤掉设置为排除条件的关键字.filter(item->BooleanUtils.isNotTrue(item.getIsExclude())).peek(item->{// 设置搜索类型为全文搜索,清空子类型设置item.setSearchType(EsQueryTypeEnum.ALL.value());item.setSearchSubType(null);}).forEach(item->{// 根据关键字是否为排除条件,添加相应的查询条件if(StringUtils.isNotBlank(item.getKeyword())){if(BooleanUtils.isTrue(item.getIsExclude())){// 如果是排除条件,则添加到must not查询条件中mainQueryBuilder.mustNot(buildQueryBuilder(item));}else{// 如果不是排除条件,则添加到must查询条件中mainQueryBuilder.must(buildQueryBuilder(item));}}});return this;}/*** 嵌套字段高亮处理**/private void highlightNestedQuery() {if(!nestedQueryBuilderHighlightMap.isEmpty()){nestedQueryBuilderHighlightMap.forEach(NestedQueryBuilder::innerHit);}}/*** 为查询添加过滤条件。* 这个方法允许用户指定一个过滤条件,并将其应用到当前的查询构建器中。* @param queryBuilder 过滤条件的查询构建器。这是一个已经构建好的查询条件,将作为过滤条件添加到主查询中。* @return 返回当前的EsQueryBuilder实例,允许链式调用。*/public EsQueryBuilder filterCondition(QueryBuilder queryBuilder) {// 为主查询添加过滤条件mainQueryBuilder.filter(queryBuilder);return this;}/*** 构建查询条件* @return org.elasticsearch.search.builder.SearchSourceBuilder*/public SearchSourceBuilder build() {SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//查询条件searchSourceBuilder.query(mainQueryBuilder);return searchSourceBuilder;}/*** 构建查询条件(支持高亮)* @return org.elasticsearch.search.builder.SearchSourceBuilder*/public SearchSourceBuilder buildWithHighlight() {SearchSourceBuilder searchSourceBuilder = build();if(isHighlight){//补充非嵌套字段的高亮highlightNestedQuery();//非嵌套高亮searchSourceBuilder.highlighter(EsHighlightUtils.buildNotNestHighlightBuilder(noNestedHighlightFields));}return searchSourceBuilder;}/*** 构建查询构建器。* 该方法根据传入的参数生成一个对应的查询条件构建器,主要用于处理专家页面的搜索关键词分组参数。* @param parameter 搜索参数,包含需要搜索的关键词和其他搜索条件。* @return 返回构建好的查询条件构建器对象。*/private QueryBuilder buildQueryBuilder(PageSearchKeywordGroupParameter parameter){// 初始化一个布尔类型的查询条件构建器,用于后续添加各种查询条件BoolQueryBuilder keywordQueryBuilder = new BoolQueryBuilder();// 根据参数生成对应的查询类型枚举,用于确定如何构建查询条件EsQueryTypeEnum queryTypeEnum = generateQueryTypeEnum(parameter);// 调用查询类型枚举中定义的添加条件处理器,处理当前搜索参数,并将其添加到查询条件构建器中queryTypeEnum.getAddConditionHandler().handle(this,keywordQueryBuilder,parameter.getKeyword());return keywordQueryBuilder;}/*** 根据关键词和字段枚举生成查询条件。* @param keyword 关键词,用于构建查询条件。* @param fieldEnum 字段枚举,包含字段配置信息,用于指定要查询的字段。* @param highlight 是否高亮处理。* @return org.elasticsearch.index.query.QueryBuilder 查询构建器,用于构建Elasticsearch的查询语句。*/private QueryBuilder generateCondition(String keyword, EsQueryFieldEnum fieldEnum, boolean highlight){EsQueryFieldConfigDTO fieldConfigDTO = fieldEnum.getFieldConfig();// 构建基于关键词的基本查询条件BoolQueryBuilder boolQueryBuilder = EsQueryBuilderUtils.generateFieldQueryBuilder(keyword,true, fieldConfigDTO.getSearchFieldList());if(BooleanUtils.isTrue(fieldConfigDTO.getIsNested())){// 如果是嵌套类型字段,则使用NestedQueryBuilder来处理NestedQueryBuildernestedQueryBuilder = new NestedQueryBuilder(fieldConfigDTO.getMainField(), boolQueryBuilder, ScoreMode.Avg);if(highlight && isHighlight){// 如果需要高亮显示,则为嵌套类型字段设置高亮处理String innerHitName = generateInnerHitName(fieldEnum);InnerHitBuilder innerHitBuilder = EsHighlightUtils.buildNestHighlightBuilder(innerHitName,fieldConfigDTO.getSearchFieldList());nestedQueryBuilderHighlightMap.put(nestedQueryBuilder,innerHitBuilder);}return nestedQueryBuilder;}else{// 对于非嵌套类型字段,处理高亮显示的逻辑if(highlight && isHighlight){// 收集非嵌套类型的高亮字段noNestedHighlightFields.addAll(fieldConfigDTO.getSearchFieldList());}return boolQueryBuilder;}}/*** 生成嵌套查询的innerHit名称* @param fieldEnum* @return java.lang.String**/private String generateInnerHitName(EsQueryFieldEnum fieldEnum){IntAccumulator accumulator = accNestedFieldMap.get(fieldEnum.getFieldConfig().getMainField());accumulator.accumulate(1);return fieldEnum.getFieldConfig().getMainField()+"-"+accumulator.getValue();}/*** 向查询构建器中添加公司名称条件。* @param esQueryBuilder ES查询构建器,用于生成特定的ES查询条件。* @param keywordQueryBuilder 关键词查询构建器,用于组合不同的查询条件。* @param keyword 用户输入的关键词,用于匹配公司名称。*/public static void addCompanyNameCondition(EsQueryBuilder esQueryBuilder,BoolQueryBuilder keywordQueryBuilder,String keyword) {// 根据关键词和字段类型(当前公司名称),生成查询条件,并添加到关键词查询构建器中keywordQueryBuilder.should(esQueryBuilder.generateCondition(keyword,EsQueryFieldEnum.CURRENT_COMPANY,true));// 根据关键词和字段类型(履历中的公司名称),生成查询条件,并添加到关键词查询构建器中keywordQueryBuilder.should(esQueryBuilder.generateCondition(keyword,EsQueryFieldEnum.TRACK_RECORD_COMPANY,true));}}
其他相关代码:
定义一个适用Lambda表达式的接口
/*** Es 搜索条件处理器*/
@FunctionalInterface
public interface IEsQueryConditionHandler {/*** 处理Es搜索条件* @param esQueryBuilder* @param keywordQueryBuilder* @param keyword* @return void*/void handle(EsQueryBuilder esQueryBuilder, BoolQueryBuilder keywordQueryBuilder,String keyword);
}定义搜索字段的枚举
/*** 专家库ES查询字段枚举*/
public enum EsQueryFieldEnum {/*** 当前公司*/CURRENT_COMPANY(10,"当前公司", EsQueryFieldConfigDTO.builder().mainField("companyInfo").isNested(false).searchFieldList(List.of("companyInfo.companyName")).build()),/*** 工作经历公司*/TRACK_RECORD_COMPANY(20,"工作经历公司", EsQueryFieldConfigDTO.builder().mainField("trackRecordList").isNested(true).searchFieldList(List.of("trackRecordList.companyName","trackRecordList.companyOtherName")).build()),;/*** 嵌套字段列表*/private static final List<EsQueryFieldEnum> NESTED_FIELD_LIST = Stream.of(EsQueryFieldEnum.values()).filter(item->item.fieldConfig.getIsNested()).collect(Collectors.toList());EsQueryFieldEnum(Integer value, String description,EsQueryFieldConfigDTO fieldConfig){this.value =value;this.description = description;this.fieldConfig = fieldConfig;}private final Integer value;private final String description;private final EsQueryFieldConfigDTO fieldConfig;public Integer value() {return this.value;}public String getDescription() {return this.description;}public EsQueryFieldConfigDTO getFieldConfig() {return fieldConfig;}/*** 获取嵌套字段列表*/public static List<EsQueryFieldEnum> getNestedFieldList() {return NESTED_FIELD_LIST;}}定义搜索类型的枚举
/*** ES查询类型枚举**/
public enum EsQueryTypeEnum {/*** 公司*/COMPANY(20,"公司", EsQueryBuilder::addCompanyNameCondition),;EsQueryTypeEnum(Integer value, String description,IEsQueryConditionHandler addConditionHandler){this.value =value;this.description = description;this.addConditionHandler = addConditionHandler;}private final Integer value;private final String description;private final IEsQueryConditionHandler addConditionHandler;public Integer value() {return this.value;}public String getDescription() {return this.description;}public IEsQueryConditionHandler getAddConditionHandler() {return addConditionHandler;}public static EsQueryTypeEnum resolve(Integer statusCode) {for (EsQueryTypeEnum status : values()) {if (status.value.equals(statusCode)) {return status;}}return null;}}
使用方法
SearchSourceBuilder searchSourceBuilder = queryBuilder// 增加关键字查询条件条件.addCondition()// 组合条件过滤.filterCondition(EsQueryHandler.getAdvancedSearchQueryBuilder(searchParameter))//生成查询语句.build();
// 获取总条数
Integer total = EsService.countBySearch(searchSourceBuilder);//重新生成高亮查询语句
searchSourceBuilder = queryBuilder.buildWithHighlight();
//补充排序规则
EsQueryHandler.setSearchSortRule(searchSourceBuilder,searchParameter.getSortType());
// 从第几页开始
searchSourceBuilder.from(searchParameter.getOffset());
// 每页显示多少条
searchSourceBuilder.size(searchParameter.getLimit());
//分页搜索
List<EsAllInfoDTO> allInfoList = EsService.listByPageSearch(searchSourceBuilder);
问题2解决方案
合并高亮的处理,这个问题实际就是:对于一个字符串a,存在多个字符串a1,a2,a3,并且a1,a2,a3再过滤掉<em>和</em> 字符后是相同的字符串。现在需要将字符串a,a1,a2,a3 合并为一个字符串fa。合并后的字符串需要满足:
1、fa过滤掉<em>和</em> 字符后同a相同
2、所有在a1,a2,a3被<em>和</em>包围的子字符串,在fa同样被<em>和</em>包围
另外要保证一个点是原始的字符串a不能本身就有<em>或</em> 这些字符串,这个可以通过对数据源头进行过滤就可以了。比如使用Jsonp 过滤。
合并高亮字符串的具体的实现算法如下:
/*** Es高亮工具类*/
public class EsHighlightUtils {public static final String emBegin = "<em>";public static final String emEnd = "</em>";private static final String emRegex = "(?i)<em>|</em>";private static final int emBeginLen = emBegin.length();private static final int emEndLen = emEnd.length();/*** 将字符串数组中的字符串合并,并在特定位置添加增强标签(<em></em>)。* @param stringList 字符串数组,数组中所有字符串如果去除"<em>" 和"</em>"后必定是相同的字符串。* @return 合并后的字符串,增强了指定的字符串片段。*/public static String mergeStrWithEmTags(List<String> stringList) {// 移除原始字符串中的所有em标签,获取干净的源字符串String sourceStr = stringList.get(0).replaceAll(emRegex, "");// 使用StringBuilder来操作源字符串,以便高效地添加em标签StringBuilder sourceBuilder = new StringBuilder(sourceStr);// 初始化一个布尔数组,用于标记哪些字符需要增强boolean[] emFlags = new boolean[sourceStr.length()];// 填充布尔数组,标记需要增强的字符位置fillEmFlags(stringList, emFlags);// 根据标记,在相应位置添加em标签addEmFlags(sourceBuilder, emFlags);return sourceBuilder.toString();}/*** 为给定的字符串数组中的每个字符串设置强调标志数组。* 该方法会查找每个字符串中所有"<em>"开头和"</em>"结尾的包围结构,* 并将这些包围结构在原字符串中的对应部分在标志数组中设置为true。* @param stringList 字符串数组,包含需要处理的字符串。* @param emFlags 增强标志数组,与字符串数组对应,用于标记特定部分。*/private static void fillEmFlags(List<String> stringList, boolean[] emFlags) {// 遍历字符串数组,为每个字符串设置强调标志for(int j = 0; j< stringList.size(); j++){String str = stringList.get(j);// 查找每个字符串中"<em>"的起始位置int beginIndex = str.indexOf(emBegin);int cumulativeOffset = 0;int noEmLen = 0;int endIndex = 0;while(beginIndex != -1){//计算没有增强的字符串长度noEmLen = endIndex>0?Math.max(beginIndex - (endIndex + emEndLen),0):beginIndex;// 查找"<em>"后的"</em>"位置endIndex = str.indexOf(emEnd,beginIndex+emBeginLen);if(endIndex==-1){// 如果找不到结束标签,则跳出循环break;}// 计算被包围的子字符串长度int emSubLength = endIndex - beginIndex - emBeginLen;// 更新累计偏移量,跳过未增强的字符串cumulativeOffset = cumulativeOffset+ noEmLen;// 将被包围的子字符串在标志数组中对应的元素设置为truefor(int i=0;i<emSubLength;i++){emFlags[cumulativeOffset + i] = true;}// 更新累计偏移量,为处理下一个"<em>"做准备cumulativeOffset = cumulativeOffset + emSubLength;// 计算下一个"<em>"标签的起始位置beginIndex = endIndex + emEndLen;// 继续查找下一个"<em>"beginIndex = str.indexOf(emBegin,beginIndex);}}}/*** 向源字符串中插入增强标签。* 根据给定的增强标志数组(emFlags),在源字符串(sourceBuilder)中插入开始(emBegin)和结束(emEnd)标签。* 当emFlags中的元素为true时,表示字符串的这个位置需要被增强* @param sourceBuilder 被插入标签的源字符串的StringBuilder对象。* @param emFlags 增强标志数组,true表示字符串的这个位置需要被增强。*/private static void addEmFlags(StringBuilder sourceBuilder, boolean[] emFlags) {// 初始化是否开始插入标签的标志和累计偏移量boolean startEm = false;int cumulativeOffset = 0 ;// 遍历增强标志数组,根据标志插入相应的标签for (boolean emFlag : emFlags) {if (emFlag) {// 当前位置需要插入开始标签if (!startEm) {// 第一次需要插入开始标签,进行插入操作并更新累计偏移量startEm = true;sourceBuilder.insert(cumulativeOffset, emBegin);cumulativeOffset += emBeginLen;}// 无论是否第一次,只要需要插入开始标签,累计偏移量就需要增加cumulativeOffset++;} else {// 当前位置需要插入结束标签if (startEm) {// 已经开始插入标签,进行插入操作并更新累计偏移量sourceBuilder.insert(cumulativeOffset, emEnd);cumulativeOffset += emEndLen;}// 标记不再插入开始标签startEm = false;// 累计偏移量增加cumulativeOffset++;}}// 如果遍历结束时正在插入开始标签,插入结束标签if(startEm){sourceBuilder.insert(cumulativeOffset,emEnd);}}/*** 构建嵌套的高亮 InnerHitBuilder* @param name* @param fields* @return org.elasticsearch.index.query.InnerHitBuilder*/public static InnerHitBuilder buildNestHighlightBuilder(String name, Collection<String> fields) {if(CollectionUtils.isEmpty(fields)){return null;}InnerHitBuilder innerHitBuilder = StringUtils.isBlank(name)?new InnerHitBuilder():new InnerHitBuilder(name);HighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.preTags(emBegin).postTags(emEnd);//设置高亮的方法highlightBuilder.highlighterType("plain");//设置分段的数量不做限制highlightBuilder.numOfFragments(0);for(String field:fields){highlightBuilder.field(field);}innerHitBuilder.setHighlightBuilder(highlightBuilder);return innerHitBuilder;}/*** 构建非嵌套的高亮 HighlightBuilder* @param fields* @return org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder*/public static HighlightBuilder buildNotNestHighlightBuilder(Collection<String> fields) {HighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.preTags(emBegin).postTags(emEnd);//设置高亮的方法highlightBuilder.highlighterType("plain");//设置分段的数量不做限制highlightBuilder.numOfFragments(0);for(String field:fields){highlightBuilder.field(field);}return highlightBuilder;}
}
修改https://blog.csdn.net/weixin_48990070/article/details/120342597 这篇笔记中的替换高亮处理的代码,思路为每次只合并找到的第一个高亮内容,将它和当前的原始内容合并,并将合并后的内容替换掉原始内容。重复这个动作知道所有高亮的内容都被合并到当前的原始内容中。
/*** 替换嵌套高亮的值* @param sourceObj* @param nestedEle* @param highlightEle* @return void*/private void replaceInnerHighlightValue(JsonObject sourceObj, JsonElement nestedEle, JsonElement highlightEle){if(nestedEle==null || highlightEle==null){return ;}//获取源对象中的嵌套字段名称JsonObject nestedObj= nestedEle.getAsJsonObject();String innerFieldName = nestedObj.get("field").getAsString();//获取当前对象匹配的源对象中的偏移位置int innerFieldOffset = nestedObj.get("offset").getAsInt();//获取源对象JsonObject findSourceObj = GsonUtils.getJsonObjectForArray(sourceObj,innerFieldName,innerFieldOffset);if(findSourceObj==null){return ;}//替换高亮的部分log.debug("高亮的部分:{}",highlightEle);JsonObject highlightObj = highlightEle.getAsJsonObject();highlightObj.entrySet().forEach((h)->{//合并高亮字段对应的原值String highlightValue = h.getValue().getAsString();JsonObject currentSourceObj = findSourceObj;String[] keyNames = StringUtils.split(h.getKey(),".");//循环到倒数第二层,获取待替换字段值对象for(int i=0;i<keyNames.length-2;i++){String keyName = keyNames[i+1];currentSourceObj = currentSourceObj.get(keyName).getAsJsonObject();}//获取最后一层的字段名称String lastFieldName = keyNames[keyNames.length-1];//获取高亮字段对应的原值String sourceValue = currentSourceObj.get(lastFieldName).getAsString();//合并原值和高亮增强的值String mergedValue = EsHighlightUtils.mergeStrWithEmTags(List.of(sourceValue, highlightValue));//替换最后一层对象的指定字段的值GsonUtils.replaceFieldValue(currentSourceObj,lastFieldName, mergedValue);});log.debug("替换后的高亮的部分{}",findSourceObj);}
相关文章:

ElasticSearch nested 字段多关键字搜索,高亮全部匹配关键字的处理
ElasticSearch nested 字段多关键字搜索,高亮全部匹配关键字的处理 环境介绍 ElasticSearch 版本号: 6.7.0 需求说明 用户会传入多个关键字去ES查询ElasticSearch nested 字段 的多个字段,要求在返回的结果中被搜索的字段需要高亮所有匹配的关键字。…...

python_31-32
目录 1.进程 2.同步进程: 3.守护进程: 1.进程 # ### 进程 process import os,time""" # ps -aux 查看进程号 # ps -aux | grep 2784 过滤查找2784这个进程# 强制杀死进程 kill -9 进程号# 获取当前进程号 res os.getpid() print(res)…...
关于机器学习/深度学习的一些事-答知乎问(四)
如何评估和量化深度学习的可解释性问题? 针对深度学习模型,评估指标能够全面衡量模型是否满足可解释性。与分类的评估指标(准确度、精确度和召回率)一样,模型可解释性的评估指标应能从特定角度证明模型的性能。但是&a…...
[spring] Spring Boot REST API - 项目实现
Spring Boot REST API - 项目实现 书接上文 Spring Boot REST API - CRUD 操作,一些和数据库相关联的注解在 [spring] spring jpa - hibernate CRUD 主要的 layer 如下: #mermaid-svg-QE1PR1gyrkz4XIT0 {font-family:"trebuchet ms",verdana…...
)
ELK之Filebeat实用配置及批量部署(部署200+可用)
跟我之前Zabbix-agent批量部署脚本Linux and Windows(部署300可用)文章的套路一样,在使用该脚本前,请先准备好安装包及配置好安装包的资源下载点,由于我这边是纯内网,所以我就找了一个NAS做了共享目录&…...

用odin实现的资源复制编辑器
用odin实现了一个资源复制编辑器,使用要安装odin,功能是把要复制的资源路径一个个添加设置,点copy能把列表里的资源全部复制,支持目录复制到目录,文件复制到目录,文件复制替换。提升效率,让自己…...

linux监控文件操作行为
linux监控文件操作行为 使用 auditd 系统 auditd 是Linux系统的一个安全和审计系统,它能够跟踪系统上发生的安全相关事件。要使用 auditd 来监控文件,你需要首先确保 auditd 已经安装并且运行在你的系统上。 然后,你可以使用 auditctl 命令…...
)
单链表接口函数的实现(增删查改)
一、单链表的实现形式以及接口函数的声明 #include<stdio.h> #include<stdlib.h> #include<assert.h> typedef int DataType ;typedef struct SListNode {DataType data;struct SListNode* next; }SLTNODE; void SLTPrint(SLTNODE* phead);//打印链表 SLTNO…...
超低功耗Sub-1G收发芯片DP32RF002 M0内核(G)FSK/OOK 无线收发机的32位SoC芯片
产品概述 DP32RF002是深圳市动能世纪科技有限公司研制的基于ARMCortex-MO内核的超低功耗 高性能的、单片集成(G)FSK/OOK 无线收发机的32位SoC芯片。工作于200 ~960MHz范围内,支持灵活可设的数据包格式,支持自动应答和自动重发功能,支持跳频…...

uniapp_微信小程序_NaN
一、定义 isNaN() 函数用于检查一个值是否为 NaN。它接受一个参数,该参数可以是任何 JavaScript 数据类型,包括数字、字符串、对象等。如果参数是 NaN,或者不能被转换为数字,则 isNaN() 返回 true;否则返回 false。 …...
1043: 利用栈完成后缀表达式的计算
解法: #include<iostream> #include<stack> using namespace std; int main() {char a;stack<int> sk;while (cin >> a && a ! #) {if (a > 0 && a < 9) {sk.push(a - 0);}else {int num2 sk.top();sk.pop();int n…...
初学ELK - elk部署
一、简介 ELK是3个开源软件组合,分别是 Elasticsearch ,Logstash,Kibana Elasticsearch :是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自…...

[Java EE] 计算机工作原理与操作系统简明概要
1. 计算机工作原理 1.1 生活中常见的计算机 计算机分为通用计算机和专用计算机,计算机并不单单指的是电脑,还有我们平时使用的手机,ipad,智能手表等终端设备都是计算机.还有我们用户不常见的计算机,比如服务器. 还有许多嵌入式设备(针对特定场景定制的"专用计算机"…...
【尚硅谷】Git与GitLab的企业实战 学习笔记
目录 第1章 Git概述 1. 何为版本控制 2. 为什么需要版本控制 3. 版本控制工具 4. Git简史 5. Git工作机制 6. Git和代码托管中心 第2章 Git安装 第3章 Git常用命令 1. 设置用户签名 1.1 基本语法 1.2 案例实操 2. 初始化本地库 2.1 基本语法 2.2 案例实操 3. 查…...
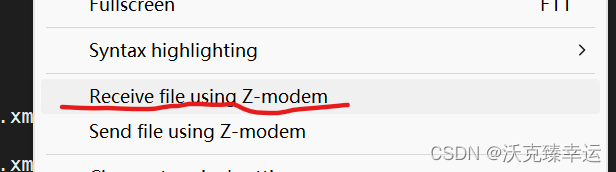
如何在MobaXterm上使用rz命令
1、首先输入命令和想下载的文件,如下图: 2、按住ctrl鼠标右键,选择如下选项: 上传命令是rz,选择Receive...... 下载命令是sz,选择Send...... 3、我这里是要把Linux上的文件下载到我的本地window磁盘&…...
【计算机考研】408网课汇总+资源分享
408王道的视频就比较通俗易懂 王道的教材非常契合408的大纲,是专门为408大纲而编写的,而教材是方方面面都讲解的透彻。 建议王道为主,网络搜索为辅! 王道中讲解不清楚,看不懂的知识点,可以尝试在网络上进…...
如何在OceanBase v4.2 中快速生成随机数据
在使用传统数据库如 MySQL 和 Oracle 时,由于缺乏多样化的随机数据生成方案,或者实现成本过高,构造随机数据的开发成本受到了影响。OceanBase在老版本中虽然有相应的解决方案,但语法复杂和性能较差等问题仍然存在。 现在…...

nvm node.js的安装
说明:部分但不全面的记录 因为过程中没有截图,仅用于自己的学习与总结 过程中借鉴的优秀博客 可以参考 1,npm install 或者npm init vuelatest报错 2,了解后 发现是nvm使用的版本较低,于是涉及nvm卸载 重新下载最新版本的nvm 2…...

【Docker】安装Redis、Nginx
1、安装redis mkdir -p /docker/redis mkdir -p /docker/redis/data touch /docker/redis/redis.conf touch /docker/redis/redis.bash编辑配置文件 vim /docker/redis/redis.conf # Redis配置文件# Redis默认不是以守护进程的方式运行,可以通过该配置项修改&…...

RK3568 UBUNTU修改网卡名称
RK3568 UBUNTU系统有两个网卡,ETH0和ETH1,于设备机壳丝印ETH1、ETH2无法对应,于是百度了一下相关的修改办法,有修改设备树的等等,挑了一个最简单,验证通过 #第1步,将原网卡关闭ip …...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...
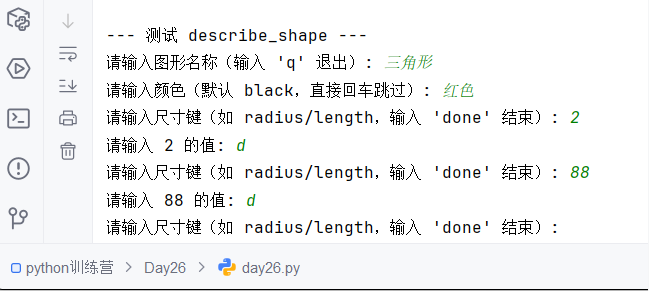
Python训练营-Day26-函数专题1:函数定义与参数
题目1:计算圆的面积 任务: 编写一个名为 calculate_circle_area 的函数,该函数接收圆的半径 radius 作为参数,并返回圆的面积。圆的面积 π * radius (可以使用 math.pi 作为 π 的值)要求:函数接收一个位置参数 radi…...

Neo4j 完全指南:从入门到精通
第1章:Neo4j简介与图数据库基础 1.1 图数据库概述 传统关系型数据库与图数据库的对比图数据库的核心优势图数据库的应用场景 1.2 Neo4j的发展历史 Neo4j的起源与演进Neo4j的版本迭代Neo4j在图数据库领域的地位 1.3 图数据库的基本概念 节点(Node)与关系(Relat…...

Flask和Django,你怎么选?
Flask 和 Django 是 Python 两大最流行的 Web 框架,但它们的设计哲学、目标和适用场景有显著区别。以下是详细的对比: 核心区别:哲学与定位 Django: 定位: "全栈式" Web 框架。奉行"开箱即用"的理念。 哲学: "包含…...

PCA笔记
✅ 问题本质:为什么让矩阵 TT 的行列式为 1? 这个问题通常出现在我们对数据做**线性变换(旋转/缩放)**的时候,比如在 PCA 中把数据从原始坐标系变换到主成分方向时。 📌 回顾一下背景 在 PCA 中ÿ…...

【QT】qtdesigner中将控件提升为自定义控件后,css设置样式不生效(已解决,图文详情)
目录 0.背景 1.解决思路 2.详细代码 0.背景 实际项目中遇到的问题,描述如下: 我在qtdesigner用界面拖了一个QTableView控件,object name为【tableView_electrode】,然后【提升为】了自定义的类【Steer_Electrode_Table】&…...