暴力破解密码自动阻断
1 re模块
re 模块是 Python 中用于正则表达式操作的模块。正则表达式(Regular Expression)是一种强大的文本处理工具,它使用一种特殊的字符序列来表示字符串中的模式,并可以通过模式匹配、查找、替换等操作对文本进行高效处理。
1.1 导入模块
python import re
1.2 编译正则表达式
使用 re.compile() 函数可以编译一个正则表达式,返回一个正则表达式对象。
python pattern = re.compile(r'\d+') # 匹配一个或多个数字
1.3 匹配操作
1.3.1 re.match()
从字符串的起始位置匹配一个模式,如果匹配成功,返回一个匹配对象;否则返回 None。
match = re.match(r'\d+', '123abc') # 匹配成功,返回匹配对象 print(match.group()) # 输出:123
1.3.2 re.search()
扫描整个字符串,返回第一个成功匹配的匹配对象。如果字符串中没有匹配项,则返回 None。
match = re.search(r'\d+', 'abc123def') # 匹配成功,返回匹配对象 print(match.group()) # 输出:123
1.3.3 re.findall()
找到字符串中所有匹配项,并返回一个包含所有匹配项的列表。
matches = re.findall(r'\d+', 'abc123def456') # 返回列表 ['123', '456'] print(matches)
1.3.4 re.finditer()
找到字符串中所有匹配项,并返回一个迭代器,每个迭代元素是一个匹配对象。
matches = re.finditer(r'\d+', 'abc123def456') for match in matches: print(match.group()) # 分别输出:123 和 456
1.4 替换操作
re.sub() 函数用于在字符串中查找匹配正则表达式的部分,并用新的字符串替换它们。
new_string = re.sub(r'\d+', 'NUMBER', 'abc123def456') # 替换数字为 'NUMBER' print(new_string) # 输出:abcNUMBERdefNUMBER
1.5 分割操作
re.split() 函数按照正则表达式的模式分割字符串。
parts = re.split(r'\d+', 'abc123def456') # 按照数字分割字符串 print(parts) # 输出:['abc', 'def', '']
1.6 正则表达式语法
正则表达式语法包括字符集、元字符、量词等,用于构建匹配模式。例如:
-
\d匹配任意数字 -
\.匹配点字符(由于点在正则表达式中是特殊字符,所以需要使用反斜杠进行转义) -
*匹配前面的子表达式零次或多次 -
+匹配前面的子表达式一次或多次 -
?匹配前面的子表达式零次或一次 -
{n}匹配确定的 n 次 -
{n,}匹配至少 n 次 -
{n,m}匹配至少 n 次,但不超过 m 次 -
^匹配字符串的开始 -
$匹配字符串的结束 -
[...]字符集,匹配方括号中的任意字符 -
[^...]否定字符集,匹配不在方括号中的任意字符 -
|或者,匹配 | 两侧的任意一项 -
( )捕获括号,用于分组和提取匹配部分 -
\转义字符,用于匹配特殊字符或转义序列
1.7 案例
案例 1:基础匹配
import re # 定义一个简单的正则表达式,匹配数字
pattern = re.compile(r'\d+') # 定义一个字符串
text = "我有10个苹果和5个橙子" # 使用re.search()进行匹配
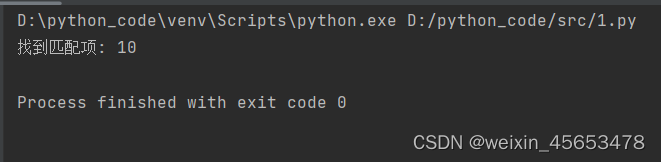
match = re.search(pattern, text) # 如果匹配成功,输出匹配到的内容
if match: print("找到匹配项:", match.group()) # 输出:找到匹配项: 10
else: print("未找到匹配项")
效果
案例 2:使用边界符匹配完整单词
import re # 匹配完整的单词 "apple"
pattern = re.compile(r'\bapple\b') # 定义一个包含单词 "apple" 的字符串
text = "I like apples and apple pie." # 使用re.findall()查找所有匹配项
matches = re.findall(pattern, text) # 输出所有匹配到的单词
print("找到匹配项:", matches) # 输出:找到匹配项['apple']
效果

案例 3:使用非贪婪匹配
import re # 使用非贪婪匹配,尽可能少地匹配字符
pattern = re.compile(r'<.*?>') # 匹配像 <a> 或 <div> 这样的标签 text = "<html><head><title>Test</title></head><body><p>Hello, world!</p></body></html>" # 使用re.findall()查找所有匹配项
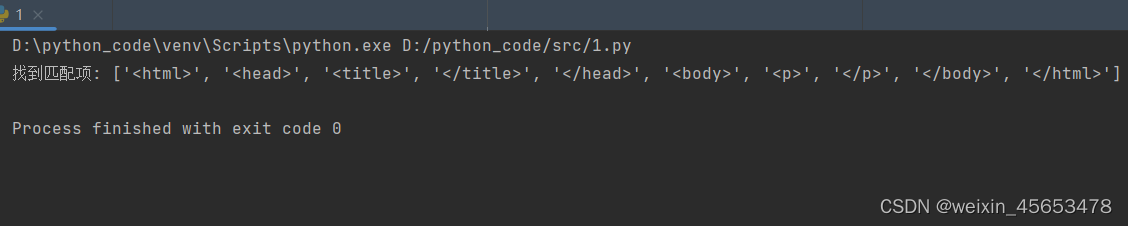
matches = re.findall(pattern, text) # 输出所有匹配到的标签
print("找到匹配项:", matches) # 输出:找到匹配项: ['<html>', '<head>', '<title>', '</title>', '</head>', '<body>', '<p>', '</p>', '</body>', '</html>']
效果
案例 4:使用re.match()从字符串开始处匹配
import re # 使用re.match()从字符串开始处匹配数字
pattern = re.compile(r'\d+') text1 = "123开始的地方"
text2 = "开始的地方123" # 尝试匹配text1
match1 = re.match(pattern, text1)
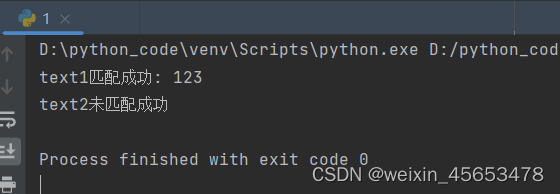
if match1: print("text1匹配成功:", match1.group()) # 输出:text1匹配成功: 123
else: print("text1未匹配成功") # 尝试匹配text2
match2 = re.match(pattern, text2)
if match2: print("text2匹配成功:", match2.group())
else: print("text2未匹配成功") # 输出:text2未匹配成功
效果
案例 5:使用re.sub()替换字符串中的模式
import re # 使用re.sub()替换字符串中的数字为 'NUMBER'
pattern = re.compile(r'\d+') text = "我有3个苹果和2个橙子"
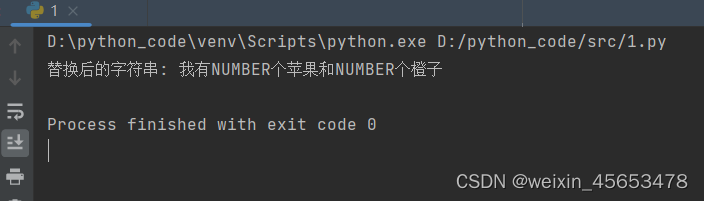
new_text = re.sub(pattern, 'NUMBER', text) # 输出替换后的字符串
print("替换后的字符串:", new_text) # 输出:替换后的字符串: 我有NUMBER个苹果和NUMBER个橙子
效果
案例 6:使用标志位
import re # 使用IGNORECASE标志位忽略大小写进行匹配
pattern = re.compile(r'python', re.IGNORECASE) text = "Python is a great programming language. I love python."
matches = re.findall(pattern, text) # 输出所有匹配到的单词,忽略大小写
print("找到匹配项:", matches) # 输出:找到匹配项: ['Python', 'python']
效果

案例 7:使用分组和提取
import re # 使用分组提取日期中的年、月、日
pattern = re.compile(r'(\d{4})-(\d{2})-(\d{2})') text = "我的生日是2023-09-17"
match = re.search(pattern, text) if match: year, month, day = match.groups() print(f"年份: {year}, 月份: {month}, 日期: {day}") # 输出:年份: 2023, 月份: 09, 日期: 17
else: print("未找到匹配项")
效果

2 subprocess模块
subprocess 模块是 Python 中用于创建新的进程,连接到它们的输入/输出/错误管道,并获取它们的返回码的模块。这个模块提供了一个高级接口来启动子进程,并收集它们的输出。
2.1 基本使用
subprocess 模块中的几个常用函数包括:
-
subprocess.run():运行命令并等待完成,返回一个CompletedProcess实例。 -
subprocess.Popen():更底层的接口,用于启动进程并返回一个Popen对象,通过这个对象可以进一步与子进程交互。
2.2 案例
示例 1:使用 subprocess.run() 运行命令
import subprocess # 运行命令并等待完成 result = subprocess.run(['ls', '-l'], capture_output=True, text=True) # 输出命令执行结果 print(result.stdout) # 捕获的标准输出 print(result.stderr) # 捕获的标准错误输出 print(result.returncode) # 返回码,0通常表示成功
效果
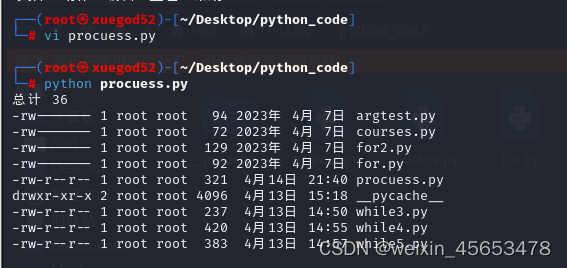
示例 2:使用 subprocess.Popen() 与进程交互
import subprocess # 使用 Popen 创建进程
p = subprocess.Popen(['ping', '-c', '4', 'www.google.com'], stdout=subprocess.PIPE, stderr=subprocess.PIPE) # 等待进程完成并获取输出
stdout, stderr = p.communicate() # 解码输出为字符串
stdout_str = stdout.decode('utf-8')
stderr_str = stderr.decode('utf-8') # 输出结果
print('返回码:', p.returncode)
print('标准输出:', stdout_str)
print('标准错误:', stderr_str)
效果

3 linux日志分析
/var/log/cron 记录系统的定时任务 /var/log/cups 打印信息的日志 /var/log/message 记录的系统重要信息的日志 /var/log/btmp 登录失败 /var/log/lastlog 最后一次登录 /var/log/wtmp 成功登录记录 /var/log/secure 登录日志 /var/log/utmp 目前登录用户的信息
hosts黑名单 /etc/hosts.deny hosts白名单 /etc/hosts.allow
登录成功 Accepted password for root from 192.168.135.130 port 53776 ssh2
登录失败 Failed password for root from 192.168.135.130 port 42404 ssh2
4 linux日志分析技巧
日志分析常见命令
find grep awk sed cat tail head
分析命令
#显示最后十条日志记录 tail -f messages

#显示最后100条日志记录 tail -100f messages

#从第五行开始的日志记录 tail -n-+5 messages

#搜索存在root的字符串 [root@xuegod61 log]# cat /etc/passwd | grep "root" root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin
#显示rot前后5行 cat /etc/passwd | grep -C 5 "root"

#显示匹配行以及其前的 5 行 cat /etc/passwd | grep -B 5 "root"
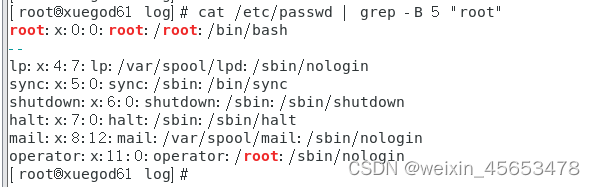
#匹配行以及其后的 5 行 cat /etc/passwd | grep -A 5 "root"

从第10行开始,显示5行,也就是说显示10~15行 cat /etc/passwd | tail -n +10 | head -n 5

只显示/etc/passwd下的账户
cat /etc/passwd | awk -F ':' '{print $1}

/var/log/secure
定位有多少个ip在爆破主机的root账号
grep "Failed password for root" /var/log/secure | awk '{print $11}' | sort | uniq -c | sort -nr
登录成功的ip有哪些
grep "Accepted" /var/log/secure | awk '{print $11}' | sort | uniq -c | sort -nr

5 linux黑白名单设置
配置格式
服务:地址:允许/封禁
服务: ssh ftp smb telnet 关键字(all)禁止or运行所有服务
all:192.168.0.10:deny(全封)
all:192.168.0.10:allow(加白) 地址:
192.168.0.10
192.168.0.10/24(整个C段封掉)
192.168.0.*(整个C段封掉)
192.168.0.(整个C段封掉)
6项目梳理
怎么实现暴力破解自动阻断
1、打开安全日志
2、对安全日志进行实时监控
3、解析日志每一行的内容,找出正在爆破的ip
4、设置一个阈值 超过阈值之后 直接封禁(把他的ip放入黑名单中)
7项目实现
代码
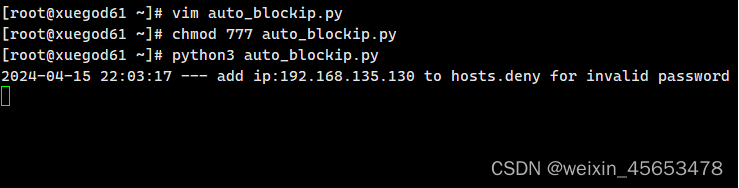
新建auto_blockip.py
#!/usr/bin/env python3
import re
import subprocess
import time
logFile = '/var/log/secure'
hostDeny = '/etc/hosts.deny'
# 允许的密码错误次数,大于该次数,直接拉黑
passwd_wrong_num = 1
# 获取已经加入黑名单的ip,转成字典
def getDenies():deniedDict = {}list = open(hostDeny).readlines()for ip in list:group = re.search(r'(\d+\.\d+\.\d+\.\d+)', ip)if group:deniedDict[group[1]] = '1'return deniedDict
# 监控方法
def monitorLog(logFile):# 统计密码错误次数tempIp = {}# 已拉黑ip名单deniedDict = getDenies()# 读取安全日志popen = subprocess.Popen('tail -f ' + logFile, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=True)# 开始监控while True:# 1s10次吧time.sleep(0.1)# 按行读line = popen.stdout.readline().strip()if line:# Invalid user: 不合法的用户名的, 直接拉黑group = re.search(r'Invalid user \w+ from (\d+\.\d+\.\d+\.\d+)', str(line))# 理论上,and后面的不用判断,已经在黑名单里面的,secure日志里,直接是refused connect from XXXXif group and not deniedDict.get(group[1]):subprocess.getoutput('echo \'sshd:{}\' >> {}'.format(group[1], hostDeny))deniedDict[group[1]] = '1'time_str = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))print('{} --- add ip:{} to hosts.deny for invalid user'.format(time_str, group[1]))continue
# 用户名合法 密码错误的group = re.search(r'Failed password for \w+ from (\d+\.\d+\.\d+\.\d+) ', str(line))if group:ip = group[1]# 统计错误次数if not tempIp.get(ip):tempIp[ip] = 1else:tempIp[ip] = tempIp[ip] + 1# 密码错误次数大于阈值的时候,直接拉黑if tempIp[ip] > passwd_wrong_num and not deniedDict.get(ip):del tempIp[ip]subprocess.getoutput('echo \'sshd:{}\' >> {}'.format(ip, hostDeny))deniedDict[ip] = '1'time_str = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))print('{} --- add ip:{} to hosts.deny for invalid password'.format(time_str, ip))
if __name__ == '__main__':monitorLog(logFile)
效果
查看黑名单
[root@xuegod61 ~]# vim /etc/hosts.deny

相关文章:
暴力破解密码自动阻断
1 re模块 re 模块是 Python 中用于正则表达式操作的模块。正则表达式(Regular Expression)是一种强大的文本处理工具,它使用一种特殊的字符序列来表示字符串中的模式,并可以通过模式匹配、查找、替换等操作对文本进行高效处理。 …...
【华为】Telnet实验配置
【华为】Telnet 实验配置 应用场景三种认证方式配置注意事项拓扑无认证(None)交换机配置顺序Telnet ServerTelnet Client测试 密码认证(Password)配置顺序Telnet ServerTelnet Client测试 AAA认证(scheme)配…...
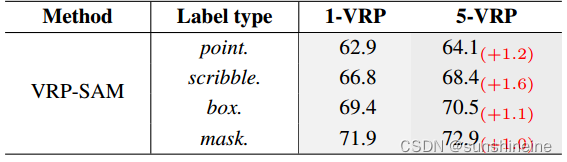
SAM功能改进VRP-SAM论文解读VRP-SAM: SAM with Visual Reference Prompt
现已总结SAM多方面相关的论文解读,具体请参考该专栏的置顶目录篇 一、总结 1. 简介 发表时间:2024年3月30日 论文: 2402.17726.pdf (arxiv.org)https://arxiv.org/pdf/2402.17726.pdf代码: syp2ysy/VRP-SAM (github.com)htt…...

MySQL truncate table 与 delete 清空表的区别和坑
拓展阅读 MySQL View MySQL truncate table 与 delete 清空表的区别和坑 MySQL Ruler mysql 日常开发规范 MySQL datetime timestamp 以及如何自动更新,如何实现范围查询 MySQL 06 mysql 如何实现类似 oracle 的 merge into MySQL 05 MySQL入门教程࿰…...
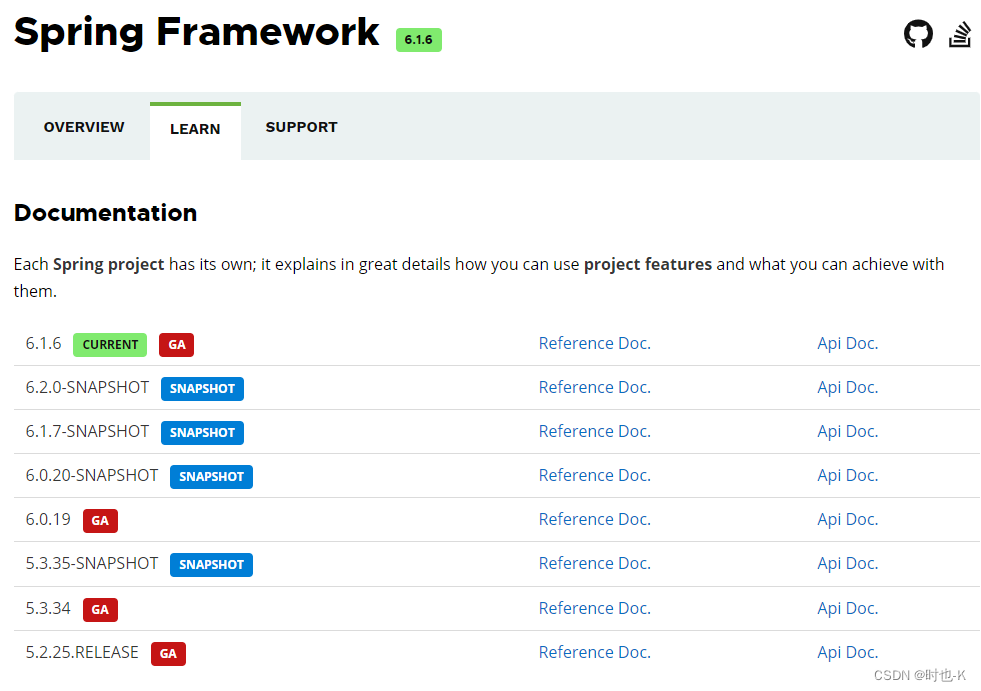
Spring GA、PRE、SNAPSHOT 版本含义及区别
GA:General Availability: 正式发布的版本,推荐使用(主要是稳定),与maven的releases类似; PRE: 预览版,内部测试版。主要是给开发人员和测试人员测试和找BUG用的,不建议使用; SNAPSHOT: 快照…...

一文看懂标准版和Pro版的区别
在CRMEB的众多产品中,有这样两款产品经常被拿来比较,它们就是CRMEB的标准版和Pro版商城系统,今天,我们就来盘一下这两款系统之间究竟有哪些不同。 1、Pro版系统性能更卓越 CRMEB Pro版采用Tp6 SwooleRedis高性能框架开发&#x…...

腾讯云服务器价格表(腾讯云服务器报价表)
腾讯云服务器提供了多种类型的产品,以满足不同用户的需求,其价格因产品类型、配置和使用时长等因素而有所不同。以下是根据最近的信息整理的腾讯云服务器价格表概览,但请注意,实际价格可能会有所变动,建议用户在购买前…...

试试把GPT和Suno结合起来用(附免费GPT)
什么是GPT GPT(生成预训练变换器)是由OpenAI开发的一种先进的人工智能模型,它能够理解和生成人类语言。通过大量的数据训练,GPT模型不仅能够撰写文章、编写代码,还能创作诗歌和故事。而现在,这种技术已经扩…...
SpringBoot修改菜品模块开发
需求分析与设计 一:产品原型 在菜品管理列表页面点击修改按钮,跳转到修改菜品页面,在修改页面回显菜品相关信息并进行修改,最后点击保存按钮完成修改操作。 修改菜品原型: 二:接口设计 通过对上述原型图…...

Rust开发笔记 | 系统编程的守护神
在如今这个信息技术不断发展的时代,系统编程语言演进的步伐从未停歇。Rust,作为现代化的系统编程语言,正凭借其出色的性能、安全性和并发处理能力赢得编程界的广泛赞誉。有别于传统的系统编程语言,Rust在保证高性能的同时…...
dcoker+nginx解决前端本地开发跨域
步骤 docker 拉取nginx镜像跑容器 并配置数据卷nginx.conf nginx.conf文件配置 这里展示server server {listen 80;listen [::]:80;server_name localhost;#access_log /var/log/nginx/host.access.log main;location / {# 当我们访问127.0.0.1:8028就会跳转到ht…...

基于云开发和微信小程序的爱宠家系统
基于云开发和微信小程序的爱宠家系统 “Development of PetCare Home System based on Cloud Computing and WeChat Mini Program” 完整下载链接:基于云开发和微信小程序的爱宠家系统 文章目录 基于云开发和微信小程序的爱宠家系统摘要第一章 系统概述1.1 研究背景1.2 研究目…...
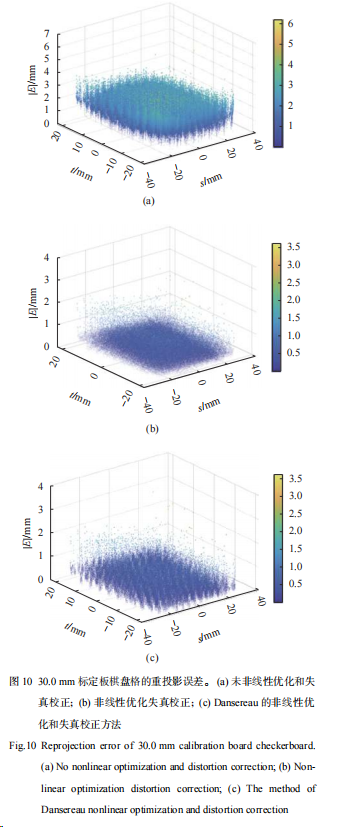
光场相机建模与畸变校正改进方法
摘要:光场相机作为一种新型的成像系统,可以直接从一次曝光的图像中得到三维信息。为了能够更充分有效地利用光场数据包含的角度和位置信息,完成更加精准的场景深度计算,从而提升光场相机的三维重建的精度,需要实现精确…...
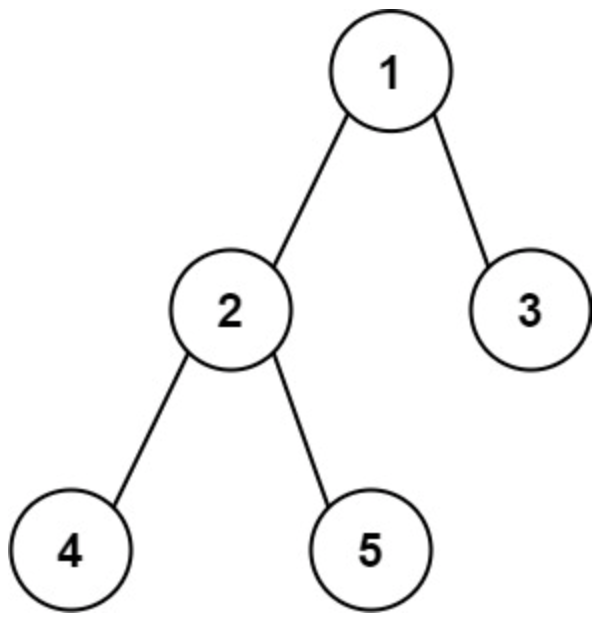
面试算法-173-二叉树的直径
题目 给你一棵二叉树的根节点,返回该树的 直径 。 二叉树的 直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也可能不经过根节点 root 。 两节点之间路径的 长度 由它们之间边数表示。 示例 1: 输入:root [1,2,3,4,…...

Python Typing模块
Python Typing模块 常用类型 类型说明int,long,float整型,长整形,浮点型bool,str布尔型,字符串类型List, Tuple, Dict, Set列表,元组,字典, 集合Iterable,Iterator可迭代类型,迭代器类型Generator生成器类型 后三行需要从typing…...

【鸿蒙开发】饿了么页面练习
0. 整体结构 整体划分3部分。店铺部分,购物车部分,金额统计部分。使用 Stack 把3部分堆叠 0.1 整体页面 Index.ets 修改 Index.ets ,使用堆叠布局,并居底部对齐 import { ElShop } from ../components/ElShop import { ElShopp…...

鸿蒙开发学习笔记第一篇--TypeScript基础语法
目录 前言 一、ArkTS 二、基础语法 1.基础类型 1.布尔值 2.数字 3.字符串 4.数组 5.元组 6.枚举 7.unkown 8.void 9.null和undefined 10.联合类型 2.条件语句 1.if语句 1.最简单的if语句 2.if...else语句 3.if...else if....else 语句 2.switch语句 5.函数…...
)
Java基础知识总结(55)
(2) ArrayList和LinkedList的区别 1、ArrayList和LinkedList都实现了List接口2、ArrayList和LinkedList都是非线程安全的,因此在多线程环境下可能会出现出现不同步的情况3、ArrayList底层实现是数组,LinkedList底层实现是双向链表…...

python爬虫 - 爬取微博热搜数据
文章目录 python爬虫 -爬取微博热搜数据1. 第一步:安装requests库和BeautifulSoup库2. 第二步:获取爬虫所需的header和cookie3. 第三步:获取网页4. 第四步:解析网页5. 第五步:分析得到的信息,简化地址6. 第…...

Pytorch-张量形状操作
😆😆😆感谢大家的观看😆😆 🌹 reshape 函数 transpose 和 permute 函数 view 和 contigous 函数 squeeze 和 unsqueeze 函数 在搭建网络模型时,掌握对张量形状的操作是非常重要的ÿ…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

C++ 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

Python 高效图像帧提取与视频编码:实战指南
Python 高效图像帧提取与视频编码:实战指南 在音视频处理领域,图像帧提取与视频编码是基础但极具挑战性的任务。Python 结合强大的第三方库(如 OpenCV、FFmpeg、PyAV),可以高效处理视频流,实现快速帧提取、压缩编码等关键功能。本文将深入介绍如何优化这些流程,提高处理…...

Unity VR/MR开发-VR开发与传统3D开发的差异
视频讲解链接:【XR马斯维】VR/MR开发与传统3D开发的差异【UnityVR/MR开发教程--入门】_哔哩哔哩_bilibili...
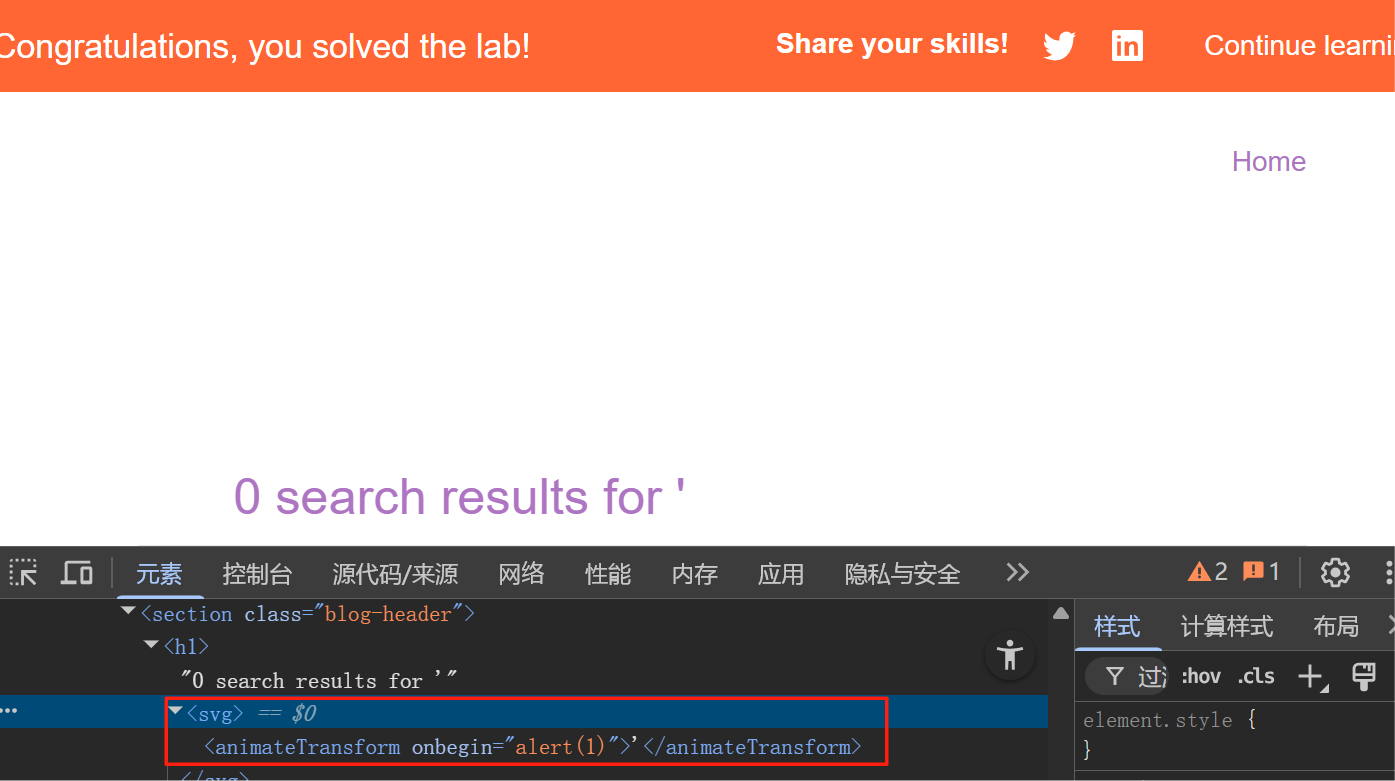
渗透实战PortSwigger Labs指南:自定义标签XSS和SVG XSS利用
阻止除自定义标签之外的所有标签 先输入一些标签测试,说是全部标签都被禁了 除了自定义的 自定义<my-tag onmouseoveralert(xss)> <my-tag idx onfocusalert(document.cookie) tabindex1> onfocus 当元素获得焦点时(如通过点击或键盘导航&…...
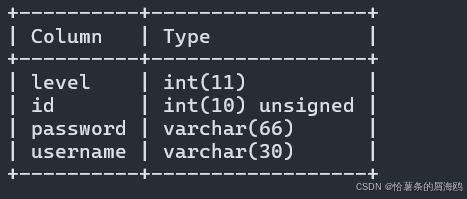
SQL注入篇-sqlmap的配置和使用
在之前的皮卡丘靶场第五期SQL注入的内容中我们谈到了sqlmap,但是由于很多朋友看不了解命令行格式,所以是纯手动获取数据库信息的 接下来我们就用sqlmap来进行皮卡丘靶场的sql注入学习,链接:https://wwhc.lanzoue.com/ifJY32ybh6vc…...
Linux入门(十五)安装java安装tomcat安装dotnet安装mysql
安装java yum install java-17-openjdk-devel查找安装地址 update-alternatives --config java设置环境变量 vi /etc/profile #在文档后面追加 JAVA_HOME"通过查找安装地址命令显示的路径" #注意一定要加$PATH不然路径就只剩下新加的路径了,系统很多命…...