NLP问答系统:使用 Deepset SQUAD 和 SQuAD v2 度量评估
目录
一、说明
二、Deepset SQUAD是个啥?
三、问答系统(QA系统),QA系统在各行业的应用及基本原理
3.1 医疗
3.2 金融
3.3 顾客服务
3.4 教育
3.5 制造业
3.6 法律
3.7 媒体
3.8 政府
四、在不同行业使用QA系统的基本原理
五、关于 Deepset deepset/minilm-uncased-squad2 模型
5.1 以下是如何使用 deepset/minilm-uncased-squad2 的一些示例:
5.2 以下是对 deepset/minilm-uncased-squad2 的一些见解:
5.3 以下是使用 deepset/minilm-uncased-squad2 的一些优点:
5.4 以下是使用 deepset/minilm-uncased-squad2 的一些缺点:
六、关于 SQuAD v2 指标
6.1 以下是有关 SQuAD v2 指标的一些关键见解:
6.2 以下是如何使用 SQuAD v2 指标的一些示例:
七、使用 Deepset minilm-uncased-squad2 模型和 SQuAD v2 指标评估进行问答
7.1 第 1 步 — 安装
7.2 第 2 步 — 构建问答管道
7.3 第 3 步 — 打印问答模型的详细信息
7.4 第 4 步 — 设置问答的上下文
7.5 第 5 步 — 使用问答管道检查 QA
7.6 第 6 步 — 使用 SQuAD v2 指标进行评估
一、说明
在本文中,我们将研究使用 Deepset 的 SQUAD2 模型进行问答以及使用 SQuAD v2 指标评估模型,我们将使用 model — deepset/minilm-uncased-squad2。
我们将按以下顺序讨论这些主题:
1. 问答系统(QA系统),QA系统在各行业的应用及基本原理
2. 关于 Deepset minilm-uncased-squad2 模型
3. 关于 SQuAD v2 指标
4. 使用 Deepset minilm-uncased-squad2 模型和 SQuAD v2 指标评估进行问答 [应用人工智能]
二、Deepset SQUAD是个啥?
Deepset SQUAD是一个基于深度学习的阅读理解任务,旨在回答关于给定段落的问题。该任务基于斯坦福大学发布的SQuAD(Stanford Question Answering Dataset)数据集,该数据集包含一系列问题和与之对应的答案,以及相关的段落文本。
Deepset SQUAD通常指的是使用深度学习方法(如Transformer模型)在SQuAD数据集上进行训练和评估,以实现阅读理解任务。通过给定一个问题和一个相关的段落文本,模型需要预测出最可能的答案。
在训练过程中,模型会学习理解文本语境、定位关键信息以及生成准确的答案。这种模型可以在各种领域和应用中发挥作用,例如智能客服、搜索引擎优化、信息检索等。
Deepset SQUAD任务的成功取决于模型的能力去理解和推理文本信息,因此需要大规模的数据集和强大的深度学习模型来取得良好的性能。近年来,随着Transformer模型(如BERT、RoBERTa、BERT-large等)的发展,Deepset SQUAD任务在自然语言处理领域取得了显著的进展。
三、问答系统(QA系统),QA系统在各行业的应用及基本原理
问答系统(QA 系统)是自然语言处理 (NLP) 系统,经过训练可以以全面和信息丰富的方式回答问题。QA系统用于各种行业,包括:
3.1 医疗
QA 系统可用于为患者提供有关其病情、治疗方案和药物的信息。QA系统还可用于帮助医疗保健专业人员诊断疾病并制定治疗计划。
例如,患者可以向 QA 系统询问特定疾病的症状、不同治疗方案的风险和益处或特定药物的副作用。医疗保健专业人员可以向 QA 系统询问有关特定疾病的最新研究或针对特定患者的最有效治疗计划的信息。
3.2 金融
QA 系统可用于为投资者提供有关股票、债券和其他金融产品的信息。QA系统还可用于帮助金融分析师做出投资决策和开发财务模型。
例如,投资者可以向 QA 系统询问特定公司的财务业绩、投资特定资产类别的风险和回报,或分配投资组合的最佳方式。金融分析师可以向 QA 系统询问有关最新经济趋势、特定事件对股票市场的影响或对特定金融产品进行建模的最佳方式的信息。
3.3 顾客服务
QA系统可用于回答客户有关产品和服务的问题。QA 系统还可用于帮助客户服务代表解决客户问题并提供更好的客户支持。
例如,客户可以向 QA 系统询问特定产品的功能和优势、如何使用特定产品或特定产品的退货政策。客户服务代表可以向 QA 系统询问有关客户帐户、客户订单状态或解决客户问题的最佳方法的信息。
3.4 教育
QA 系统可用于为学生提供有关其课程作业的信息,回答他们有关课程材料的问题,并帮助他们准备考试。QA 系统还可用于帮助教师创建和提供教育内容。
例如,学生可以向 QA 系统询问教科书中特定章节中的关键概念、解决特定数学问题所涉及的步骤或为即将到来的考试学习的最佳方式。教师可以向 QA 系统询问有关特定主题的信息、帮助创建课程计划或对其教材的反馈。
3.5 制造业
QA 系统可用于为员工提供有关制造过程、产品规格和质量控制程序的信息。
3.6 法律
QA 系统可用于为律师提供有关判例法、法规和法规的信息。
3.7 媒体
QA系统可用于为记者提供有关时事、新闻报道和感兴趣主题的背景信息。
3.8 政府
QA 系统可用于为公民提供有关政府服务、计划和政策的信息。
四、在不同行业使用QA系统的基本原理
QA 系统用于各种行业,因为它们提供了许多好处,包括:
- 便利性:QA系统可用于快速轻松地回答问题,而无需搜索多个信息来源。
- 准确性:QA 系统在大型文本和代码数据集上进行训练,这使它们能够为问题提供准确且信息丰富的答案。
- 个性化:QA系统可以根据用户的需求进行个性化设置,以便他们能够提供相关且有用的答案。
- 可扩展性:QA 系统可以扩展以处理大量问题,使其成为客户支持或客户服务是关键组成部分的行业的理想选择。
总体而言,QA 系统是一种强大的工具,可用于提高各行各业的效率、生产力和客户满意度。
随着 QA 系统的不断改进,我们可以期待在未来看到它们以更具创新性和令人兴奋的方式使用。
现在我们已经对 QA 系统及其在各个行业的应用有了相当的了解,让我们深入了解 Deepset SQUAD 问答模型。
五、关于 Deepset deepset/minilm-uncased-squad2 模型
deepset/minilm-uncased-squad2 是 Deepset 的问答 (QA) 模型,它基于 Microsoft 的 MiniLM-L12-H384-uncased 语言模型。它是在 SQuAD 2.0 数据集上训练的,该数据集是一个大规模的数据集,其中包含有关维基百科文章的人工生成的问题和答案。
deepset/minilm-uncased-squad2 在 SQuAD 2.0 开发集上获得了 76.19% 的精确匹配 (EM) 分数和 79.49% 的 F1 分数。这些结果与该数据集上最先进的 QA 模型相当。
deepset/minilm-uncased-squad2 是 QA 任务的不错选择,因为它是:
- 准确:它在 SQuAD 2.0 数据集上取得了最先进的结果。
- 高效:它基于高效的 MiniLM-L12-H384 无大小写语言模型。
- 易于使用:它可作为预训练模型使用,可以轻松加载并在各种编程语言中使用。
deepset/minilm-uncased-squad2 可用于各种 QA 任务,例如:
- 回答有关维基百科条目的问题。
- 回答有关客户支持文章的问题。
- 回答有关产品文档的问题。
- 回答有关新闻文章的问题。
- 回答有关任何其他类型的文本内容的问题。
5.1 以下是如何使用 deepset/minilm-uncased-squad2 的一些示例:
- 客户支持代表可以使用 deepset/minilm-uncased-squad2 来回答客户有关产品或服务的问题。
- 记者可以使用 deepset/minilm-uncased-squad2 来研究新闻文章的主题。
- 学生可以使用 deepset/minilm-uncased-squad2 来学习考试或学习新主题。
- 研究人员可以使用 deepset/minilm-uncased-squad2 为研究项目收集信息。
5.2 以下是对 deepset/minilm-uncased-squad2 的一些见解:
- 它是 QA 任务的不错选择,因为它准确、高效且易于使用。
- 它可用于各种 QA 任务,例如回答有关维基百科文章、客户支持文章、产品文档和新闻文章的问题。
- 它可用于提高各种行业的效率、生产力和客户满意度,例如医疗保健、金融、客户服务、教育和制造。
5.3 以下是使用 deepset/minilm-uncased-squad2 的一些优点:
- 它是一个预训练的模型,因此您不需要从头开始训练它。这可以为您节省大量时间和资源。
- 它可以通过 Hugging Face Transformers 库获得,该库是一个流行且支持良好的开源库,用于自然语言处理 (NLP) 任务。
- 它易于使用,即使您不是 NLP 专家。
5.4 以下是使用 deepset/minilm-uncased-squad2 的一些缺点:
- 它是一个大型模型,因此运行速度可能很慢且占用大量内存。
- 它是在文本和代码数据集上训练的,因此它可能不太擅长回答有关其他类型数据(例如图像或视频)的问题。
- 它不是免费使用的。
总体而言,deepset/minilm-uncased-squad2 是一个功能强大且用途广泛的 QA 模型,可用于各种任务。对于需要可靠和准确的 QA 模型的企业和组织来说,这是一个不错的选择。
六、关于 SQuAD v2 指标
SQuAD v2 指标是自然语言处理 (NLP) 任务(如问答和文本摘要)广泛使用的评估指标。它基于斯坦福问答数据集 (SQuAD),这是一个关于维基百科文章的人类生成的问题和答案的大规模数据集。
SQuAD v2 指标衡量两件事:
· 完全匹配 (EM):模型的答案与人工生成的答案完全匹配的问题百分比。
· F1 分数:精确度和召回率的加权平均值,其中精确度是模型正确答案的百分比,召回率是模型找到的人工生成答案的百分比。
为了计算 SQuAD v2 指标,使用逐字匹配算法将模型的答案与人工生成的答案进行比较。如果模型的答案与人工生成的答案完全匹配,则该问题将计为完全匹配。否则,将使用 F1 评分算法对模型的答案进行评分。
SQuAD v2 指标是衡量 NLP 模型在问答和文本摘要任务上的整体性能的良好指标。 但是,需要注意的是,SQuAD v2 指标只是性能的一种衡量标准,不应孤立地用于评估 NLP 模型。
6.1 以下是有关 SQuAD v2 指标的一些关键见解:
·SQuAD v2 指标是一个具有挑战性的指标,因为它要求模型生成既符合事实又符合语言流利的答案。
·SQuAD v2 指标广泛用于评估 NLP 模型,因此它是比较不同模型性能的好方法。
·SQuAD v2 指标并不完美,因为它可能会被生成事实正确但语言不流利的答案的模型所愚弄。
总体而言,SQuAD v2 指标是评估 NLP 模型在问答和文本摘要任务中性能的宝贵工具。但是,将 SQuAD v2 指标与其他指标(例如人工评估)结合使用非常重要,以全面了解 NLP 模型的性能。
6.2 以下是如何使用 SQuAD v2 指标的一些示例:
·正在开发新问答系统的公司可以使用 SQuAD v2 指标来评估其系统在标准数据集上的性能。
·正在开发新的文本摘要算法的研究人员可以使用 SQuAD v2 指标将其算法的性能与其他最先进的算法进行比较。
·正在学习机器学习课程的学生可以使用 SQuAD v2 指标来评估其问答模型在家庭作业中的性能。
现在我们已经了解了 QA 系统、QA 系统在各个行业的应用、Deepset SQUAD 模型和用于评估的 SQuAd 指标
现在让我们深入了解使用 SQUAD 模型进行问答,使用 SQuAd V2 指标评估 SQUAD 模型
七、使用 Deepset minilm-uncased-squad2 模型和 SQuAD v2 指标评估进行问答
7.1 第 1 步 — 安装
pip 安装以下软件包和系统依赖项:
- 库:transformers、evaluate
!pip install transformers
!pip install evaluate7.2 第 2 步 — 构建问答管道
我们将使用模型“deepset/minilm-uncased-squad2”
import transformers#Set to avoid warning messages.
transformers.logging.set_verbosity_error()from transformers import pipelinequestion_answer = pipeline("question-answering",model="deepset/minilm-uncased-squad2")7.3 第 3 步 — 打印问答模型的详细信息
此步骤用于深入了解模型配置的每个细节,包括网络、其层、编码器、解码器、注意力头、激活函数、超参数、QA 参数、转换器版本等,
#Print Details of the Question Answering Model
print("Checkpoint used: ", question_answer.model.config)
7.4 第 4 步 — 设置问答的上下文
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400">#Set Up Context for Question Answering Model to Answer Questions</span>
context=<span style="color:#c41a16">"""In a recent survey conducted by the government,
public sector employees were asked to rate their level
of satisfaction with the department they work at.
The results revealed that NASA was the most popular
department with a satisfaction rating of 95%.One NASA employee, John Smith, commented on the findings,
stating, "I'm not surprised that NASA came out on top.
It's a great place to work with amazing people and
incredible opportunities. I'm proud to be a part of
such an innovative organization.The results were also welcomed by NASA's management team,
with Director Tom Johnson stating, "We are thrilled to
hear that our employees are satisfied with their work at NASA.
We have a talented and dedicated team who work tirelessly
to achieve our goals, and it's fantastic to see that their
hard work is paying off.The survey also revealed that the
Social Security Administration had the lowest satisfaction
rating, with only 45% of employees indicating they were
satisfied with their job. The government has pledged to
address the concerns raised by employees in the survey and
work towards improving job satisfaction across all departments.
"""</span></span></span>7.5 第 5 步 — 使用问答管道检查 QA
#Question Answering Check 1
print("\n Question 1:")
answer=question_answer( question="Which department had the highest level of Satisfaction Rating?",context=context)
print(answer)输出为
问题 1: {'score': 0.7639074921607971, 'start': 179, 'end': 183, 'answer': 'NASA'}
答案是正确的,让我们根据提供的上下文检查更多问题。
问答 - 检查 2
#Question Answering Check 2
print("\n Question 2:")
answer=question_answer( question="Which department had the lowest level of Satisfaction Rating?",context=context)
print(answer)输出为
问题 2: {'score': 0.6433295011520386, 'start': 855, 'end': 885, 'answer': '社会保障局'}
答案是正确的..
让我们再检查一个问题
问答 — 勾选 3
#Question Answering Check 3
print("\n Question 3:")
answer=question_answer( question="What did Tom Johnson state on the findings?",context=context)
print(answer)输出为
问题 3: {'score': 0.07185160368680954, 'start': 596, 'end': 676, 'answer': '我们很高兴听到我们的员工对他们在 NASA 的工作感到满意'}
我们可以尝试根据提供的上下文来试验问题。
7.6 第 6 步 — 使用 SQuAD v2 指标进行评估
在此步骤中,我们将使用 SQuAD v2 指标评估模型
精确匹配 (EM)
F1 分数
根据提供的上下文,对于问题
社会保障局的满意度是多少?
假设预期的人类反应将是
“社保局满意度为45%”
模型预测答案为
“社会保障局的满意度为50%”,“
社会保障局的满意度为30%”,“
提供的上下文不提供问题的答案”
而模型对问题的回答是 45%,如前所述
让我们使用 SQuAD v2 指标评估问答模型。
精确匹配,F1 分数
#Evaluate Model using SQuAD V2 Metrics
from evaluate import load
squad_metric = load("squad_v2")correct_answer="The satisfaction rating of Social Security Administration is 45%"predicted_answers=["45%","The satisfaction rating of Social Security Administration is 50%","The satisfaction rating of Social Security Administration is 30%","Context provided does not provide the answer for the question"]cum_predictions=[]
cum_references=[]
for i in range(len(predicted_answers)):#Use the input format for predictionspredictions = [{'prediction_text':predicted_answers[i],'id': str(i),'no_answer_probability': 0.}]cum_predictions.append(predictions[0])#Use the input format for naswersreferences = [{'answers': {'answer_start': [1],'text': [correct_answer]},'id': str(i)}]cum_references.append(references[0])results = squad_metric.compute(predictions=predictions,references=references)print("F1 is", results.get('f1')," for answer :", predicted_answers[i])#Compute for cumulative Results
cum_results=squad_metric.compute(predictions=cum_predictions,references=cum_references)
print("\n Cumulative Results : \n",cum_results)输出为

相关文章:
NLP问答系统:使用 Deepset SQUAD 和 SQuAD v2 度量评估
目录 一、说明 二、Deepset SQUAD是个啥? 三、问答系统(QA系统),QA系统在各行业的应用及基本原理 3.1 医疗 3.2 金融 3.3 顾客服务 3.4 教育 3.5 制造业 3.6 法律 3.7 媒体 3.8 政府 四、在不同行业使用QA系统的基本原理 五、关于…...

php开发中如何防止抓包工具伪造请求
要防止抓包工具伪造请求,采取一系列的技术和策略来增强应用程序的安全性。以下是一些关键步骤和最佳实践: 1. 使用HTTPS 确保应用程序使用HTTPS协议进行通信。HTTPS通过TLS/SSL加密客户端和服务器之间的数据传输,这使得抓包工具捕获到的数据…...
密码学 | 椭圆曲线数字签名方法 ECDSA(下)
目录 10 ECDSA 算法 11 创建签名 12 验证签名 13 ECDSA 的安全性 14 随机 k 值的重要性 15 结语 ⚠️ 原文:Understanding How ECDSA Protects Your Data. ⚠️ 写在前面:本文属于搬运博客,自己留着学习。同时,经过几…...
拟态个人主页UI源码
拟态个人主页 效果图源代码领取源码 效果图 PC端 移动端 源代码 index.php <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><title>孤客 |佩恩</title><meta name"keywords" co…...

移动硬盘无法打开?别慌!这里有救星!
移动硬盘作为现代生活中重要的数据存储工具,承载着我们大量的文件和数据。然而,有时我们会遇到移动硬盘无法打开的情况,这往往让人焦虑不已。那么,当移动硬盘无法打开时,我们应该如何应对呢? 移动硬盘无法打…...
windows下已经创建好了虚拟环境,但是切换不了的解决方法
用得多Ubuntu,今天用Windows重新更新anaconda出问题,重新安装之后,打开pycharm发现打开终端之后,刚开始是ps的状态,后面试了网上改cmd的方法,终端变成c盘开头了 切换到虚拟环境如下:目前的shell…...
Java反序列化基础-类的动态加载
类加载器&双亲委派 什么是类加载器 类加载器是一个负责加载器类的对象,用于实现类加载的过程中的加载这一步。每个Java类都有一个引用指向加载它的ClassLoader。而数组类是由JVM直接生成的(数组类没有对应的二进制字节流) 类加载器有哪…...

课堂行为动作识别数据集
一共8884张图片 xml .txt格式都有 Yolo可直接训练 已跑通 动作类别一共8类。 全部为教室监控真实照片,没有网络爬虫滥竽充数的图片,可直接用来训练。以上图片均一一手工标注,标签格式为VOC格式。适用于YOLO算法、SSD算法等各种目标检测算法…...

【数据库】MVCC
MVCC是一种用来解决读写冲突的无锁并发控制,也就是为事务分配单项增长的时间戳,为每个修改保存一个版本,版本与事务时间戳关联,读操作只读该事务开始前的数据库的快照 MVCC,全称Multi-Version Concurrency Control&am…...

快速排序题目SelectK问题
力扣75.颜色分类 给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。 我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。 必须在不使用库内置的 sor…...

es6解构赋值
ES6解构赋值是一种简洁的为变量赋值的方式,它允许我们从数组或对象中提取值并赋给对应的变量。 解构赋值在ES6中被引入,主要目的是为了简化代码,提高代码的可读性。以下是解构赋值的基本用法: 数组解构:当我们需要从数…...
Jenkins上面使用pnpm打包
问题 前端也想用Jenkins的CI/CD工作流。 步骤 Jenkins安装NodeJS插件 安装完成,记得重启Jenkins。 全局配置nodejs Jenksinfile pipeline {agent anytools {nodejs "18.15.0"}stages {stage(Check tool version) {steps {sh node -vnpm -vnpm config…...

设计编程网站集:动物,昆虫,蚂蚁养殖笔记
入门指南 区分白蚁与蚂蚁 日常生活中,人们常常会把白蚁与蚂蚁搞混淆,其实这两者是有很大区别的,养殖方式差别也很大。白蚁主要食用木质纤维,会给家庭房屋带来较大危害,而蚂蚁主要采食甜食和蛋白质类食物,不…...
)
面经学习(众智宏图实习)
个人评价 难度还是有的,中等难度吧,可能是因为项目使用的是物流项目,该项目本来就比较庞大难度比较高,流的八股文我真的是一点不会,还需要加强,reidis的多路io复用模型没有深问,要是问了就寄了&…...

DataGrip2024安装包(亲测可用)
目录 一、软件简介 二、软件下载 一、软件简介 DataGrip是由JetBrains公司开发的一款强大的关系数据库集成开发环境(IDE),专为数据库开发人员和数据库管理员设计。它提供了一个统一的界面,用于管理和开发各种关系型数据库&#x…...
【InternLM 实战营第二期-笔记4】XTuner 微调个人小助手认知
书生浦语是上海人工智能实验室和商汤科技联合研发的一款大模型,很高兴能参与本次第二期训练营,我也将会通过笔记博客的方式记录学习的过程与遇到的问题,并为代码添加注释,希望可以帮助到你们。 记得点赞哟(๑ゝω╹๑) XTuner 微调个人小助手…...
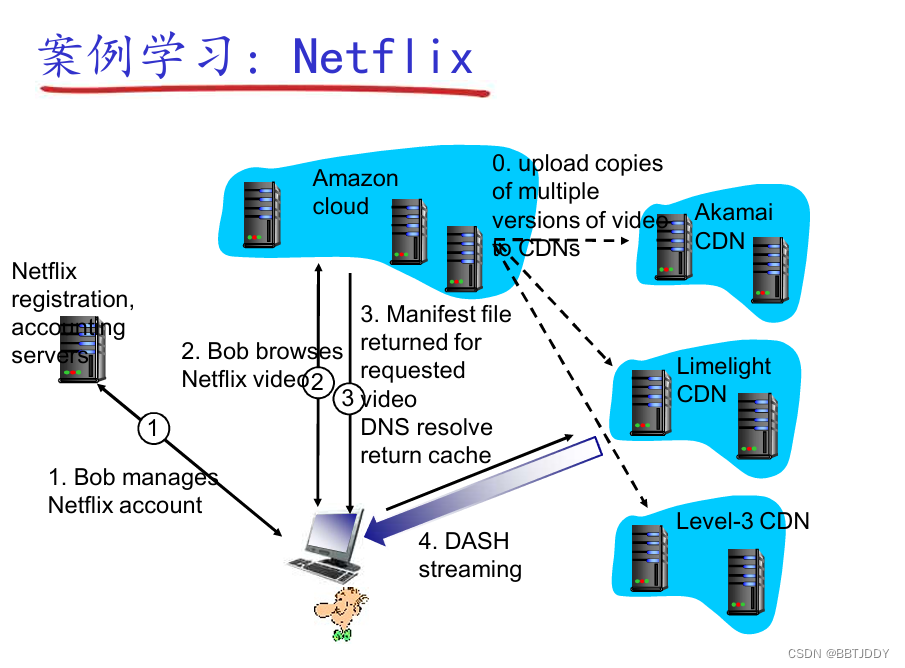
<计算机网络自顶向下> CDN
视频服务挑战 规模性异构性:不同用户有不同的能力(比如有线接入和移动用户;贷款丰富和受限用户)解决方法是:分布式的应用层面的基础设施CDN 多媒体:视频 视频是固定速度显示的一系列图像的序列ÿ…...

【Git教程】(十二)工作流之项目设置 — 何时使用工作流,工作流的结构,项目设置概述、执行过程及其实现 ~
Git教程 工作流之项目设置 1️⃣ 何时使用工作流2️⃣ 工作流的结构3️⃣ 概述4️⃣ 使用要求5️⃣ 执行过程及其实现5.1 基于项目目录创建一个新的版本库5.2 以文件访问的方式共享版本库5.3 用 Git daemon 来共享版本库5.4 用 HTTP 协议来共享版本库5.5 用 SSH 协议来共享版…...

Java 排序算法
冒泡排序 冒泡排序(Bubble Sort)是一种简单的排序算法,它通过重复地遍历要排序的数列,比较相邻元素的大小并交换位置,使得较大的元素逐渐向数列的末尾移动。 以下是Java实现的冒泡排序代码: public stat…...
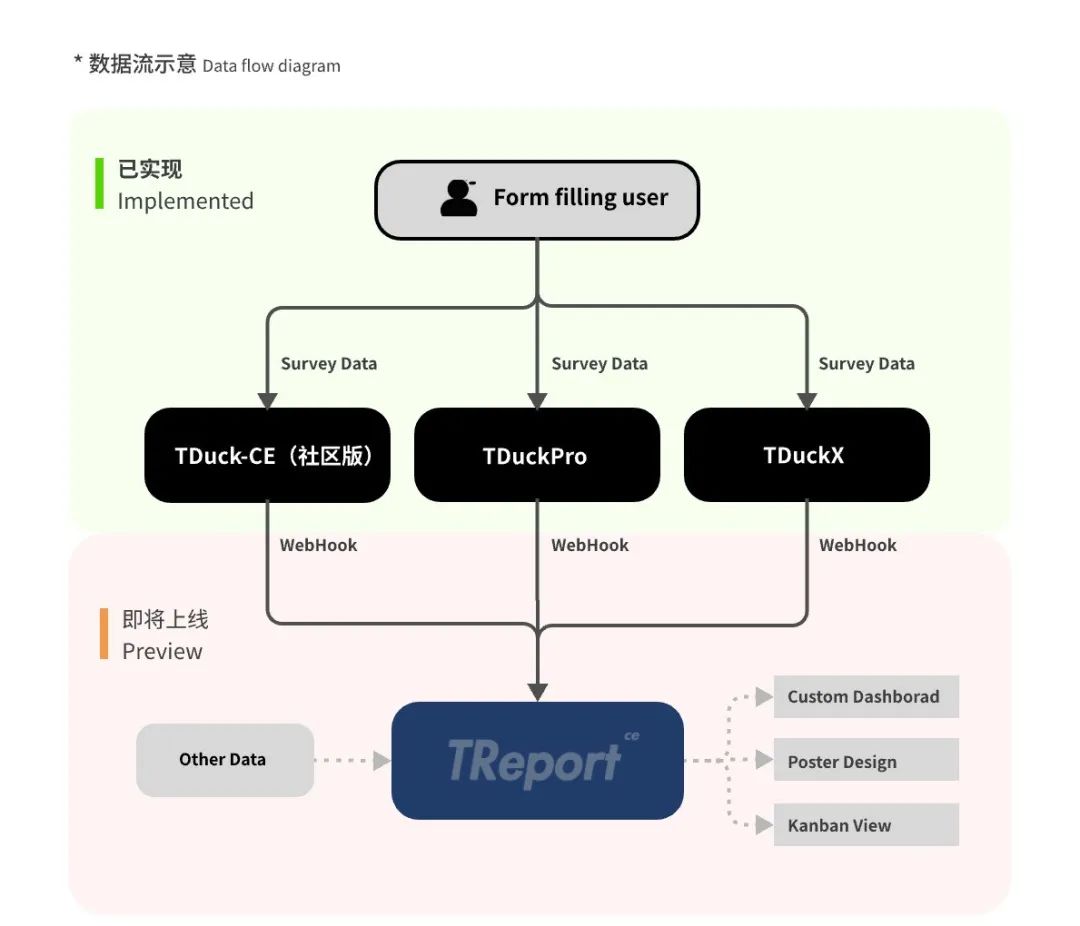
【重磅更新】开源表单系统填鸭表单v5版发布!
亲爱的TDucker,你们好。 真诚感谢您对填鸭表单的关注与支持。今天我们将为您带来新版本的更新说明,以便您更好的使用我们的产品。 社区版版V5更新概览: ✅ 增加WebHook数据推送功能,集成TReport实现数据大屏展示。 ✅ 增加主题…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...

三分算法与DeepSeek辅助证明是单峰函数
前置 单峰函数有唯一的最大值,最大值左侧的数值严格单调递增,最大值右侧的数值严格单调递减。 单谷函数有唯一的最小值,最小值左侧的数值严格单调递减,最小值右侧的数值严格单调递增。 三分的本质 三分和二分一样都是通过不断缩…...

Ubuntu Cursor升级成v1.0
0. 当前版本低 使用当前 Cursor v0.50时 GitHub Copilot Chat 打不开,快捷键也不好用,当看到 Cursor 升级后,还是蛮高兴的 1. 下载 Cursor 下载地址:https://www.cursor.com/cn/downloads 点击下载 Linux (x64) ,…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...
 Module Federation:Webpack.config.js文件中每个属性的含义解释)
MFE(微前端) Module Federation:Webpack.config.js文件中每个属性的含义解释
以Module Federation 插件详为例,Webpack.config.js它可能的配置和含义如下: 前言 Module Federation 的Webpack.config.js核心配置包括: name filename(定义应用标识) remotes(引用远程模块࿰…...