python标准库常用方法集合
前段时间准备第十五届蓝桥杯python a组,因为赛中不允许导包,因此对py中的标准库进行了笔记和总结,即不导包即可使用的常用方法。包含了内置函数、math、random、datetime、os、sys、re、queue、collections、itertools库的常用方法,以当工具博客方便查阅。
目录
- 内置函数
- 数学函数
- 数据转换函数
- 对象创建函数
- 迭代器操作函数
- 字符串操作函数
- 对字符串进行大小写改写操作
- 删除字符串空白:
- math库
- 数学常数
- 常用数学函数
- 数值运算函数
- 特殊函数
- random库
- datatime库
- os库
- sys库
- re库
- queue库
- collections库
- deque双端队列
- Counter计数字典
- namedtuple具有字段名的元组
- itertools库
内置函数
数学函数
abs() 函数:取绝对值
print(abs(-1))
# 1
divmod() 函数 :同时取商和余数
print(divmod(7,2))
# (3, 1)
sum() 函数 :求和计算
print(sum([1,2,3]))
# 6
round() 函数: 四舍五入
print(round(5.4))# 5
print(round(5.5))# 6
pow() 函数 :计算任意N次方值
print(pow(2,3))# 2^3 = 8
# 也可以使用‘**’
print(2**3)
min()、max() 函数 :获取最小、最大值
print(min(9,5,2,7))# 2
print(max(9,5,2,7))# 9
数据转换函数
hex() 函数: 十转十六进制
print(hex(100)) # 0x64
oct() 函数: 十转八进制
print(oct(100)) # 0o144
bin() 函数 :十进制转换成二进制
print(bin(100)) # 0b1100100
bool() 函数 :将指定的参数转换成布尔类型
float() 函数 :转换成浮点数
ord() 函数 :获取单个字符的ASCII数值
print(ord('A')) # 65
chr() 函数: 转换一个整数并返回所对应的字符
print(chr(65)) # A
list() 函数: 将可迭代对象转换为列表
print(list(range(1,10)))
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
对象创建函数
range()函数:创建一个可迭代对象,内容是指定范围内的连续整数
for i in range(5):print(i)
'''
0
1
2
3
4
'''
set()函数:创建一个无序不重复元素集合,可用作去重
set([1,2,1,1,3,4,4,6,5])
# {1, 2, 3, 4, 5, 6}
迭代器操作函数
all() 函数: 判断指定序列中的所有元素是否都为 True,则返回 True,如果有一个为 False,则返回 False。
a = [1,2,0]
print(all(a))
# False
any()函数: 判断指定序列中的所有元素是否都为 False,则返回 False,如果有一个为 True,则返回 True。
a = [1,0,0]
print(any(a))
# True
sorted() 函数: 对可迭代对象进行临时排序
a = [3,1,4,2]
print(sorted(a))
# [1, 2, 3, 4]
len()函数: 返回一个对象的元素或项目个数
print(len([1,2,3,4]))
# 4
map()函数: 通过自定义函数实现对序列的元素映射操作并返回操作后的结果
list(map(int,['1','2','3']))
# [1, 2, 3]
字符串操作函数
format( )函数: 格式化数据
"{} {}".format("hello", "world")
# 'hello world'
print("{:.2f}".format(3.1415926));
# 3.14
a = "good"
b = "luck"
t = "{} {}".format(a,b)
# good luck
t = f"{a.title()} {b}"
# 可以引入.title()来改写字符串格式,这里需要注意的是,f字符串是有py3.6引入的
# Good luck
count( ), 返回子串str2 在 str1 里面出现的次数
str1 = 'dsaddddd'
str2 = 'd'
print(str1.count(str2, 0, len(str1))) # 6
print(str1.count(str2, 0, 3)) # 1
endswith() 用于检查字符串是否以指定的后缀结束,如果字符串以指定的后缀结束,则返回 True,否则返回 False。
my_str = "Hello, world!"
print(my_str.endswith("world!")) # True
print(my_str.endswith("Python")) # False
find( ), 检测 子字符串是否包含在指定字符串中,find到返回开始的索引值,否则返回-1
str1 = 'dsaddddd'
str2 = 'd'
print(str1.find(str2, 0, len(str1))) # 0
print(str1.find(str2, 1, 3)) # -1
join(), 以 接收可选的参数 sep作为分隔符,将接受的一个可迭代对象(如列表、元组等)将参数中所有的元素(的字符串表示)合并为一个新的字符串
my_list = ["Hello", "world", "!"]
str1 = ' '
result = str1.join(my_list)
print(result) # 输出:"Hello|world|!"
str2 = '@'
result = str2.join(my_list)
print(result) # 输出:"Hello@world@!"
对字符串进行大小写改写操作
t = "good Luck"
t.title( )
#对每个单词首字母改为大写,Good Luck
t.upper( )
#字母全大写,GOOD LUCK
t.lower( )
#字母全小写,good luck
t.swapcase()
# 翻转大小写,GOOD lUCK
删除字符串空白:
t = " python "
print(t.lstrip())
# 对开头空白进行删除
print(t.rstrip())
# 对末尾空白进行删除
print(t.strip())
# 对两端空白进行删除
需要注意的是,上述的三个方法只是暂时的,并没有改变原来的内容
math库
提供数学相关的函数,如三角函数、指数函数、对数函数等
数学常数
math.e:自然常数 e 的值,约等于 2.71828。
math.pi:圆周率 π 的值,约等于 3.14159。
import math
print(math.e) # 2.718281828459045
print(math.pi) # 3.141592653589793
常用数学函数
math.sqrt(x):返回 x 的平方根。
math.pow(x, y):返回 x 的 y 次方。
math.exp(x):返回 e 的 x 次方。
math.log(x, base=math.e):返回 x 的对数。base 参数为对数的底数,默认为自然对数 e。
math.sin(x)、math.cos(x)、math.tan(x):返回 x 的正弦、余弦和正切值。
math.asin(x)、math.acos(x)、math.atan(x):返回 x 的反正弦、反余弦和反正切值。
import mathprint(math.sqrt(9)) # 3.0 类型为float
print(math.pow(2, 3)) # 8.0 类型为float
print(math.exp(1)) # 2.71828182845904523536963
print(math.log(2, 10)) # log10^2print(math.sin(math.pi / 2))
print(math.cos(math.pi / 3))
print(math.tan(math.pi / 4))
# 1.0
# 0.5000000000000001
# 0.9999999999999999print(math.asin(1))
print(math.acos(1))
print(math.atan(1))
# 1.5707963267948966
# 0.0
# 0.5707963267948966
数值运算函数
math.ceil(x):返回不小于 x 的最小整数。
import math
print(math.ceil(3.14)) # 输出:4
print(math.ceil(-3.14)) # 输出:-3
math.floor(x):返回不大于 x 的最大整数。
import math
print(math.floor(3.14)) # 输出:3
print(math.floor(-3.14)) # 输出:-4
math.trunc(x):返回 x 的整数部分。
math.modf(x):返回 x 的小数部分和整数部分,以元组形式返回。
import mathprint(math.trunc(3.14)) # 输出:3
print(math.modf(3.14)) # 输出:(0.14000000000000012, 3.0)
math.fabs(x):返回 x 的绝对值。
math.factorial(x):返回 x 的阶乘。
math.gcd(a, b):返回 a 和 b 的最大公约数。
import math
print(math.fabs(-3.14)) # 输出:3.14
print(math.factorial(5)) # 输出:1*2*3*4*5=120print(math.gcd(12, 15)) # 输出:3
特殊函数
math.erf(x)
误差函数返回了给定值 x 的误差,即标准正态分布中,比 x 大的概率。
import math# 计算 2 的误差函数
print(math.erf(2)) # 输出:0.9953222650189345
math.erfc(x)
余误差函数返回了给定值 x 的余误差,即标准正态分布中,比 x 小的概率。
import math# 计算 2 的余误差函数
print(math.erfc(2)) # 输出:0.00467773498106536
math.gamma(x)
伽马函数是阶乘函数的拓展版本,可以用于计算组合数。
import math# 计算 5 的伽马函数
print(math.gamma(5)) # 输出:24
math.lgamma(x)
伽马函数的自然对数。
import math# 计算 5 的伽马函数的自然对数
print(math.lgamma(5)) # 输出:2.302585092994046
random库
提供随机数相关的函数,如生成随机整数、随机浮点数、随机序列等
random.randint(a, b):返回一个范围为 [a, b] 的随机整数。
import random
print(random.randint(1, 10)) # 输出:一个介于 1 和 10 之间的随机整数,包括 1 和 10
random.uniform(a, b):返回一个范围为 [a, b] 的随机浮点数。
import random
print(random.uniform(1, 10)) # 输出:一个介于 1 和 10 之间的随机浮点数,包括 1 和 10
random.choice(sequence):从给定的序列(如列表、元组等)中随机选择一个元素。
import randommy_list = [1, 2, 3, 4, 5]
print(random.choice(my_list)) # 输出:my_list 中的一个随机元素
random.shuffle(x[, random]):将给定的列表或元组进行随机排序。
import randommy_list = [1, 2, 3, 4, 5]
random.shuffle(my_list)
print(my_list) # 输出:一个随机排序后的列表
datatime库
提供日期和时间相关的函数,如获取当前日期、时间差计算、日期格式化等
datetime.datetime.now():返回当前的日期和时间
from datetime import datetime
print(datetime.now())
timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0):创建一个时间间隔
from datetime import datetime, timedelta# 创建一个表示 7 天的时间间隔
seven_days = timedelta(days=7)
# 获取当前时间
now = datetime.now()# 计算 7 天后的时间
future = now + seven_days
print(future)
datetime.strftime('%Y-%m-%d %H:%M:%S'):将日期和时间格式化为字符串
from datetime import datetime# 获取当前时间
now = datetime.now()# 将当前时间格式化为字符串
formatted_now = now.strftime('%Y-%m-%d %H:%M:%S')
print(formatted_now)
os库
提供操作系统相关的函数,如文件和目录操作、进程管理等
os.getcwd():获取当前工作目录
os.listdir():列出当前目录下的所有文件和子目录
import oscurrent_dir = os.getcwd()
print("当前工作目录:", current_dir)files_and_dirs = os.listdir(current_dir)
print("当前目录下的文件和子目录:", files_and_dirs)
os.path.join():将多个路径组件连接在一起
import ospath1 = "/home"
path2 = "user"
path3 = "documents"full_path = os.path.join(path1, path2, path3)
print("完整路径:", full_path)
os.path.exists():检查一个路径是否存在
import ospath = "/home/user/documents"
if os.path.exists(path):print("路径存在")
else:print("路径不存在")
os.system():运行一个系统命令
import oscommand = "ls -l"
result = os.system(command)
print("命令结果:", result)
sys库
提供与 Python 解释器相关的函数和变量,如获取命令行参数、获取系统版本等
sys.argv[]:获取命令行参数
import sys
print("命令行参数:", sys.argv)
sys.version_info.major:获取Python版本的主要部分
import sys
version_major = sys.version_info.major
print("Python版本主要部分:", version_major)
sys.exit():退出程序,将导致程序立即退出,不再执行后续代码,可以当强化版break
import sysprint('live')
sys.exit()
print('kill')
re库
提供正则表达式相关的函数,用于字符串匹配和替换等操作
^:匹配字符串开头
" * " 匹配前面的子表达式零次或多次
" + " 匹配前面的子表达式一次或多次
" ? " 匹配前面的子表达式零次或一次
" [abc]" :方括号表示字符集合,例子表示一个字符串有一个 “a” 或 “b” 或 “c” 等价于 [a|b|c]
" [a-z]“: 表示一个字符串中存在一个 a 和 z 之间的所有字母
" [^a-z]” :表示一个字符串中不应该出现 a 到 z 之间的任意一个字母
" [0-9]“: 表示一个字符串中存在一个 0 和 9 之间的所有数字
" \d " 匹配一个数字字符,等价[0-9]
" \D " 匹配一个非数字字符,等价[^0-9]
" \w” 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”
" \W" 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”
group()是正则表达式匹配对象的方法,用于获取匹配到的字符串。
re.match(pattern, string[, flags]):从字符串的开头开始匹配,如果开头部分匹配成功,返回一个匹配对象,否则返回None。
其中,pattern是正则表达式,string是需要匹配的字符串,flags是可选的匹配标志。
import repattern = r'[a-z]+'
text = 'abc567aa'match = re.match(pattern, text)
if match:print("匹配成功:", match.group())
else:print("匹配失败")
# 匹配成功: abc
re.search(pattern, string[, flags]):在整个字符串中搜索匹配的子串,如果找到,返回一个匹配对象,否则返回None。
import repattern = r'\d+'
text = 'abc123def'search = re.search(pattern, text)
if search:print("匹配成功:", search.group())
else:print("匹配失败")# 匹配成功: 123
re.findall(pattern, string[, flags]):返回字符串中所有匹配的子串,返回一个列表。
import repattern = r'\d+'
text = 'abc123def456'findall = re.findall(pattern, text)
print("匹配成功:", findall)
# 匹配成功: ['123', '456']
re.sub(pattern, repl, string[, count, flags]):替换字符串中所有匹配的子串。函数的第一个参数是正则表达式模式,第二个参数是要替换的字符串。
其中,pattern是正则表达式,repl是替换字符串,string是需要匹配的字符串,count是可选的替换次数,默认是0
import repattern = r'\d+'
text = 'abc123def456'
replace = re.sub(pattern, 'X', text[6:])
print("替换成功:", replace)
# 替换成功: defX
queue库
使用更高级的队列和栈数据结构
queue模块提供了多种队列实现方式,包括先进先出队列(FIFO)、后进先出队列(LIFO)和优先级队列。队列实现是线程安全的,因此适用于多线程编程。
queue.Queue():这是一个标准的队列实现,遵循先进先出(FIFO)的规则
import queueq = queue.Queue()
q.put('a')
q.put('b')
q.put('c')while not q.empty():print(q.get())
'''
a
b
c
'''
queue.LifoQueue():后进先出(LIFO)队列
import queueq = queue.LifoQueue()
q.put('a')
q.put('b')
q.put('c')while not q.empty():print(q.get())
'''
c
b
a
'''
queue.PriorityQueue():优先级队列。元素被赋予优先级,优先级高的元素会被优先处理。
import queueq = queue.PriorityQueue()
q.put((1, 'a'))
q.put((3, 'b'))
q.put((2, 'c'))while not q.empty():print(q.get())
'''
(1, 'a')
(2, 'c')
(3, 'b')
'''
collections库
deque双端队列
允许从两端添加或删除元素,在某些方面类似于列表,但它更适用于需要频繁从两端添加或删除元素的场合。deque的实现使用了append()和pop()方法来添加和删除元素,这些操作的时间复杂度为O(1)。因此,deque在处理大量数据时比列表更高效。
以下是deque的一些常用用法:
创建一个双端队列:
from collections import deque
d = deque([1, 2, 3])
添加元素到队列的两端:
d.append(4) # 在队列末尾添加元素
d.appendleft(0) # 在队列开头添加元素
print(d) # deque([0, 1, 2, 3, 4])
从队列的两端删除元素:
d.pop() # 删除并返回队列末尾的元素
d.popleft() # 删除并返回队列开头的元素
print(d) # deque([1, 2, 3])
切片操作:
d[0] # 获取队列开头的元素
d[-1] # 获取队列末尾的元素
d[1:3] # 获取队列中索引为1到2的元素,即元素2和3
索引操作:
d.index(2) # 返回队列中元素2的索引
计数操作:
d.count(2) # 返回队列中元素2的个数
这些操作与列表的操作类似,但deque在处理大量数据时更高效。
Counter计数字典
跟踪可迭代对象中元素的出现次数。
例如,我们可以使用Counter来统计一个列表中每个元素出现的次数:
from collections import Counterlst = [1, 2, 3, 1, 2, 3, 1, 2, 3]
counter = Counter(lst)print(counter) # 输出:Counter({1: 3, 2: 3, 3: 3})
Counter对象可以进行许多操作,例如:
- 元素个数:
len(counter) - 某个元素出现的次数:
counter[element] - 添加新元素:
counter[element] += 1 - 删除元素:
del counter[element] - 元素迭代:
for element in counter - 元素计数:
sum(counter.values())
namedtuple具有字段名的元组
例如,我们可以使用namedtuple来创建一个表示点的坐标:
from collections import namedtuplePoint = namedtuple('Point', ['x', 'y'])
p = Point(3, 4)print(p) # 输出:Point(x=3, y=4)namedtuple创建的类型具有与元组相同的内存结构,但可以更方便地访问其字段。例如,我们可以直接使用p.x和p.y来访问点的坐标,而不需要使用索引。
此外,namedtuple还支持一些其他操作,例如:
- 字段名索引:
p[0]、p[1] - 切片:
p[:2]、p[1:] - 迭代:
for field in p - 元素计数:
len(p) - 元素测试:
3 in p
itertools库
itertools是Python的一个标准库,它提供了一系列用于高效循环迭代的工具。
itertools中的函数和类主要用于生成迭代器,这些迭代器可以用于循环、迭代以及其他需要重复执行操作的场景。
以下是一些常用的itertools库中的函数和类:
chain(*iterables):创建一个迭代器,将多个可迭代对象连接起来。
from itertools import chaina = [1, 2, 3]
b = [4, 5, 6]for x in chain(a, b):print(x) # 输出:1 2 3 4 5 6
combinations(iterable, r):创建一个迭代器,返回可迭代对象中元素的所有r长度组合。
from itertools import combinationsfor x in combinations([1, 2, 3], 2):print(x) # 输出:(1, 2) (1, 3) (2, 3)
permutations(iterable, r=None):创建一个迭代器,返回可迭代对象中元素的所有r长度排列。
from itertools import permutationsfor x in permutations([1, 2, 3], 2):print(x) # 输出:(1, 2) (1, 3) (2, 1) (2, 3) (3, 1) (3, 2)
product(iterable, repeat=1):创建一个迭代器,返回可迭代对象中元素的所有组合。
from itertools import productfor x in product([1, 2], ['a', 'b'], repeat=2):print(x)
# 输出:(1, 'a', 1, 'a') (1, 'a', 1, 'b') (1, 'a', 2, 'a') (1, 'a', 2, 'b') (1, 'b', 1, 'a') (1, 'b', 1, 'b') (1, 'b', 2, 'a') (1, 'b', 2, 'b') (2, 'a', 1, 'a') (2, 'a', 1, 'b') (2, 'a', 2, 'a') (2, 'a', 2, 'b') (2, 'b', 1, 'a') (2, 'b', 1, 'b') (2, 'b', 2, 'a') (2, 'b', 2, 'b')
cycle(iterable):创建一个迭代器,返回可迭代对象中元素无限循环的迭代器。
from itertools import cyclefor x in cycle([1, 2, 3]):print(x) # 输出:1 2 3 1 2 3 1 2 3 ...
groupby(iterable, key=None):创建一个迭代器,将可迭代对象中具有相同键值的元素分组。
from itertools import groupbyfor x in groupby([1, 2, 2, 3, 3, 3], key=lambda x: x):print(x) # 输出:((1,), (2, 2), (3, 3, 3))
islice(iterable, start, stop=None, step=1):创建一个迭代器,返回可迭代对象中指定范围内的元素。
from itertools import islicefor x in islice([1, 2, 3, 4, 5], 2, 5):print(x) # 输出:2 3 4
相关文章:

python标准库常用方法集合
前段时间准备第十五届蓝桥杯python a组,因为赛中不允许导包,因此对py中的标准库进行了笔记和总结,即不导包即可使用的常用方法。包含了内置函数、math、random、datetime、os、sys、re、queue、collections、itertools库的常用方法࿰…...
智谱AI通用大模型:官方开放API开发基础
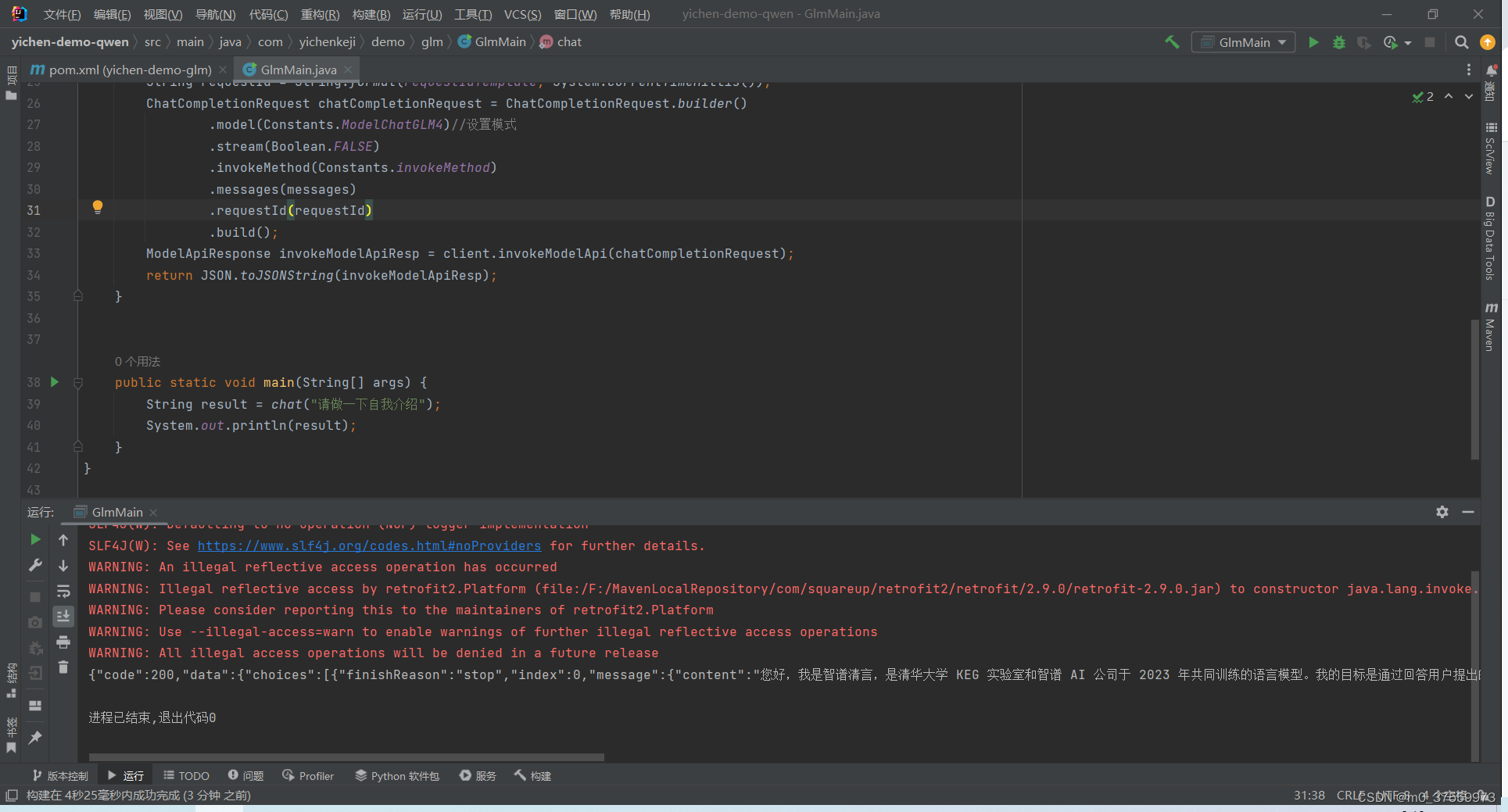
目录 一、模型介绍 1.1主要模型 1.2 计费单价 二、前置条件 2.1 申请API Key 三、基于SDK开发 3.1 Maven引入SDK 3.2 代码实现 3.3 运行代码 一、模型介绍 GLM-4是智谱AI发布的新一代基座大模型,整体性能相比GLM3提升60%,支持128K上下文&#x…...

单片机家电产品--OC门电路
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 单片机家电产品–OC门电路 前言 记录学习单片机家电产品内容 已转载记录为主 一、知识点 1OC门电路和OD门电路的区别 OC门电路和OD门电路的区别 OC门:三极管…...

gcc常用命令指南(更新中...)
笔记为gcc常用命令指南(自用),用到啥方法就具体研究一下,更新进去... 编译过程的分布执行 64位系统生成32位汇编代码 gcc -m32 test.c -o test -m32用于生成32位汇编语言...
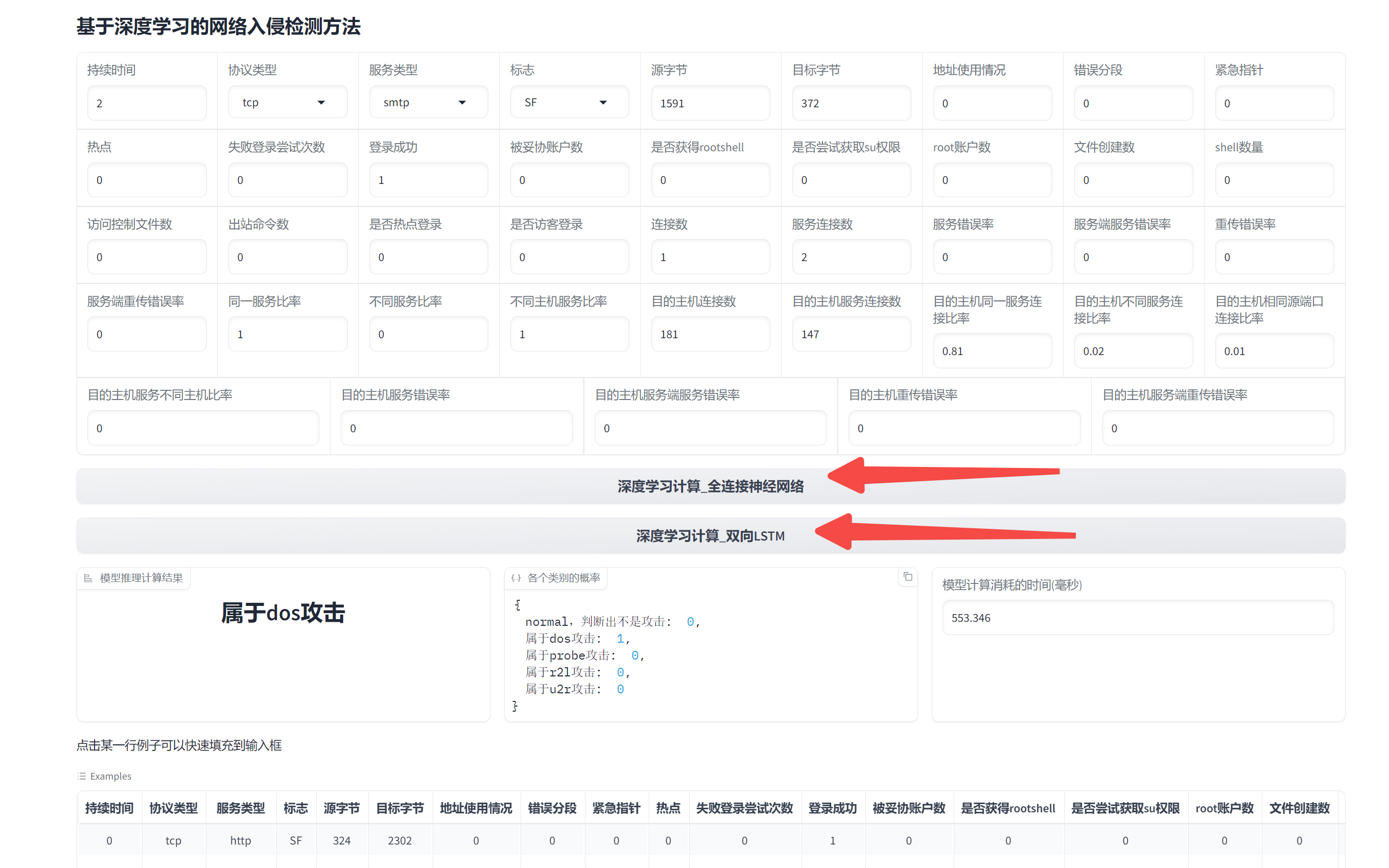
【深度学习】【机器学习】用神经网络进行入侵检测,NSL-KDD数据集,基于机器学习(深度学习)判断网络入侵,网络攻击,流量异常【3】
之前用NSL-KDD数据集做入侵检测的项目是: 【1】https://qq742971636.blog.csdn.net/article/details/137082925 【2】https://qq742971636.blog.csdn.net/article/details/137170933 有人问我是不是可以改代码,我说可以。 训练 我将NSL_KDD_Final_1.i…...
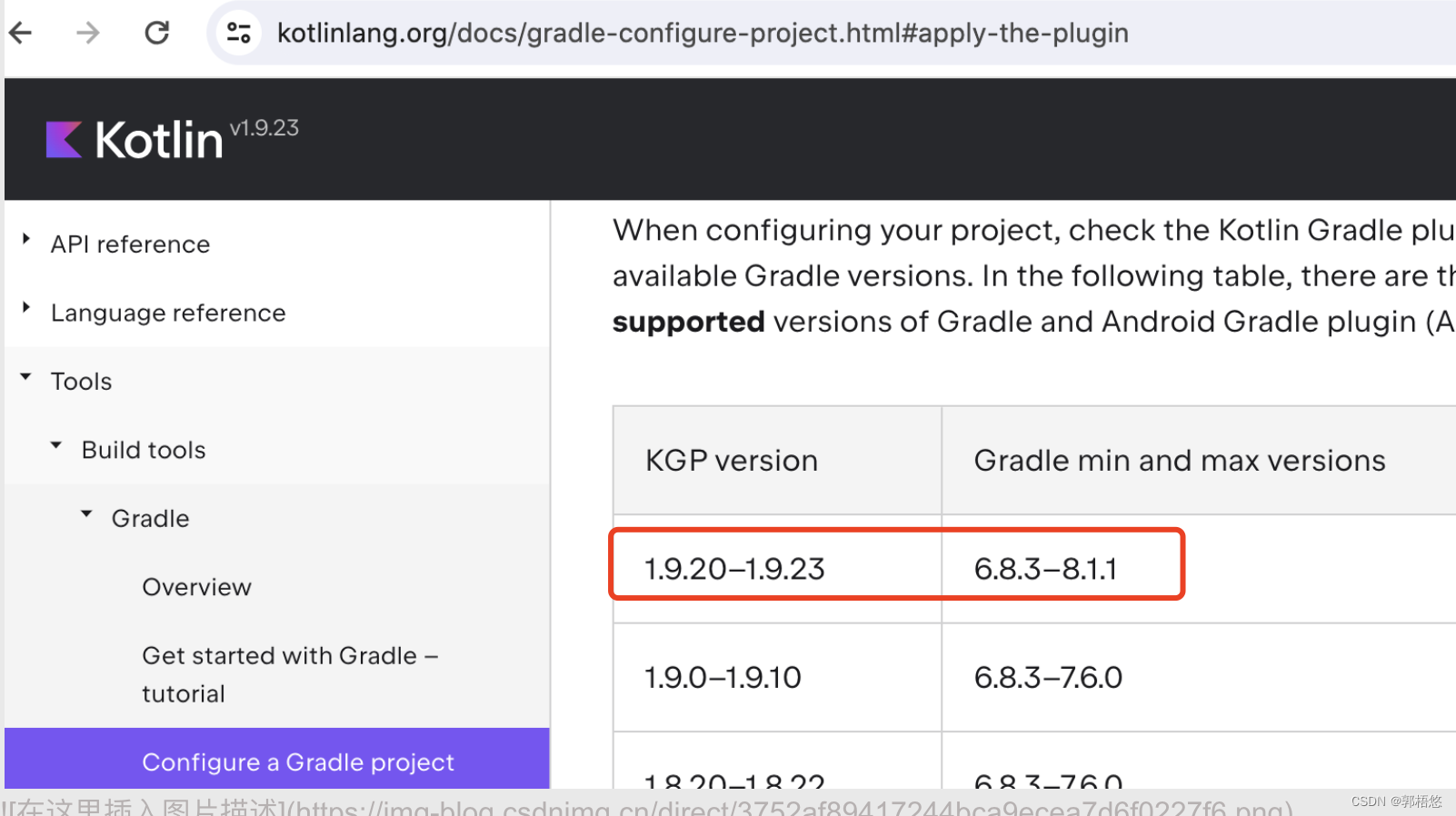
两步解决 Flutter Your project requires a newer version of the Kotlin Gradle plugin
在开发Flutter项目的时候,遇到这个问题Flutter Your project requires a newer version of the Kotlin Gradle plugin 解决方案分两步: 1、在android/build.gradle里配置最新版本的kotlin 根据提示的kotlin官方网站搜到了Kotlin的最新版本是1.9.23,如下图所示: 同时在Ko…...
ArcGIS加载的各类地图怎么去除服务署名水印
昨天介绍的: 一套图源搞定!清新规划底图、影像图、境界、海洋、地形阴影图、导航图-CSDN博客文章浏览阅读373次,点赞7次,收藏11次。一体化集成在一起的各类型图源,比如包括影像、清新的出图底图、地形、地图阴影、道路…...

AttributeError: module ‘cv2.face’ has no attribute ‘LBPHFaceRecognizer_create’
问题描述: 报错如下: recognizer cv2.face.LBPHFaceRecognizer_create() AttributeError: module ‘cv2.face’ has no attribute ‘LBPHFaceRecognizer_create’ 解决方案: 把opencv-python卸载了,然后安装ope…...
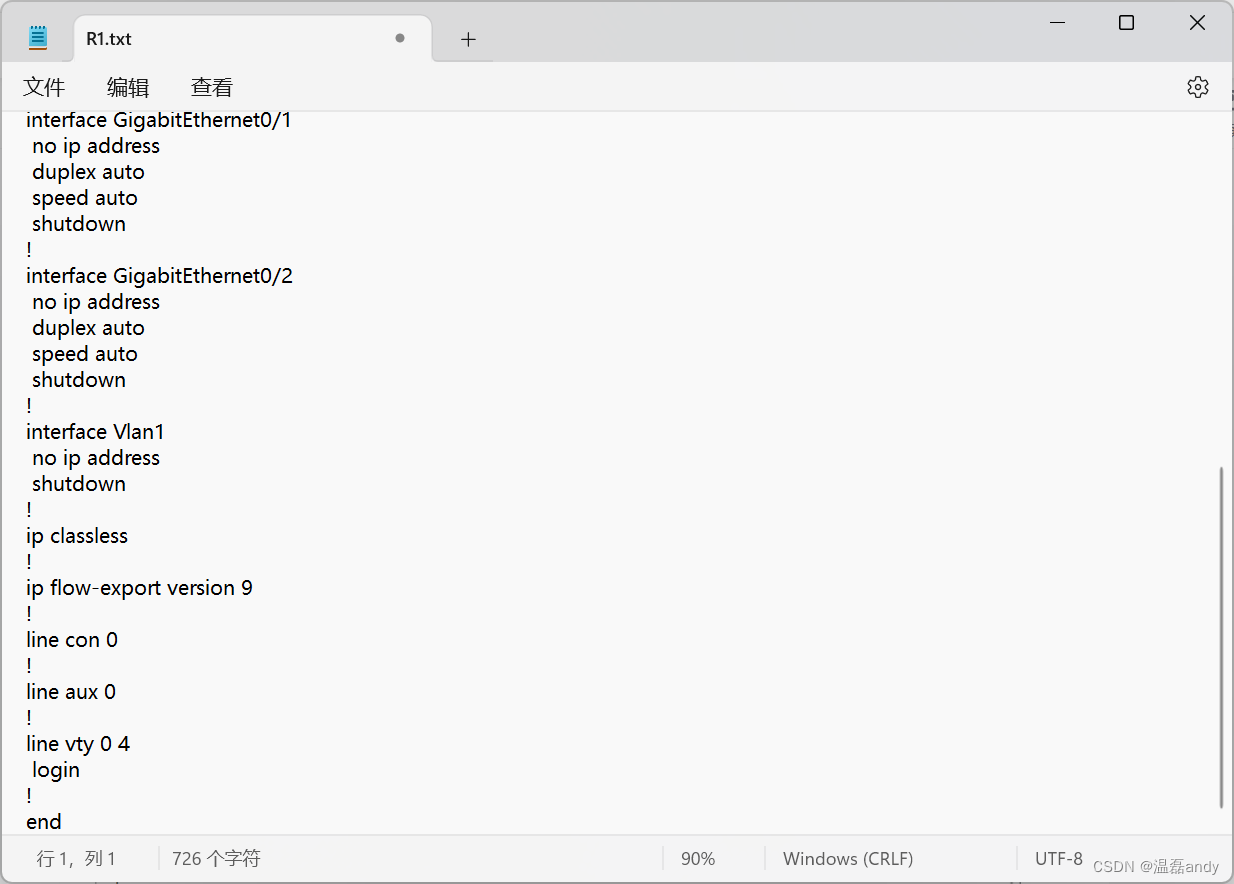
配置路由器实现互通
1.实验环境 实验用具包括两台路由器(或交换机),一根双绞线缆,一台PC,一条Console 线缆。 2.需求描述 如图6.14 所示,将两台路由器的F0/0 接口相连,通过一台PC 连接设备的 Console 端口并配置P地址(192.1…...

Google Guava第五讲:本地缓存实战及踩坑
本地缓存实战及踩坑 本文是Google Guava第五讲,先介绍为什么使用本地缓存;然后结合实际业务,讲解如何使用本地缓存、清理本地缓存,以及使用过程中踩过的坑。 文章目录 本地缓存实战及踩坑1、缓存系统概述2、缓存架构演变2.1、无缓存架构2.2、引入分布式缓存问题1:为什么选…...
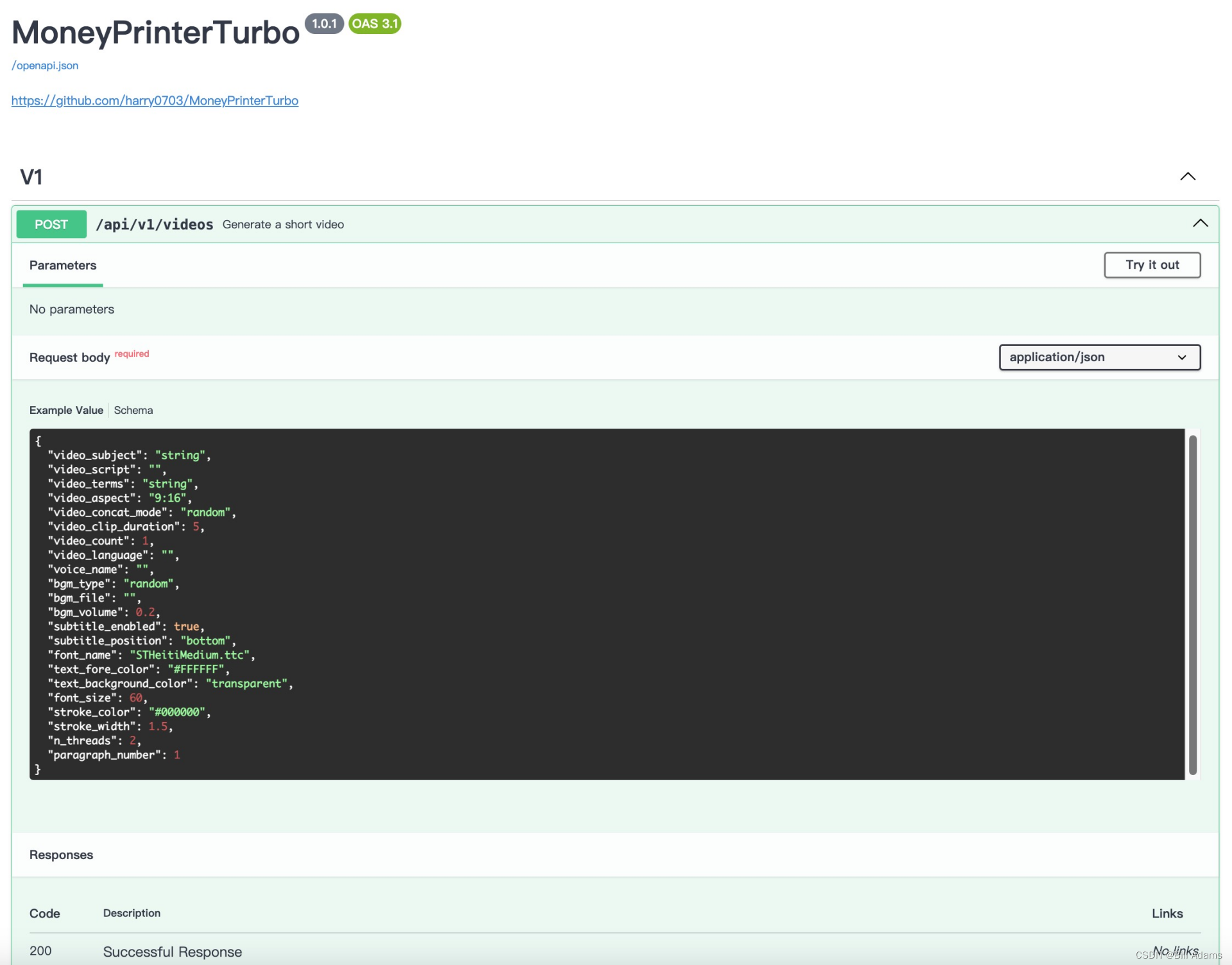
一个文生视频MoneyPrinterTurbo项目解析
最近抖音剪映发布了图文生成视频功能,同时百家号也有这个功能,这个可以看做是一个开源的实现,一起看看它的原理吧~ 一句话提示词 大模型生成文案 百家号生成视频效果 MoneyPrinterTurbo生成视频效果 天空为什么是蓝色的? 天空之所以呈现蓝色,是因为大气中的分子和小粒子会…...
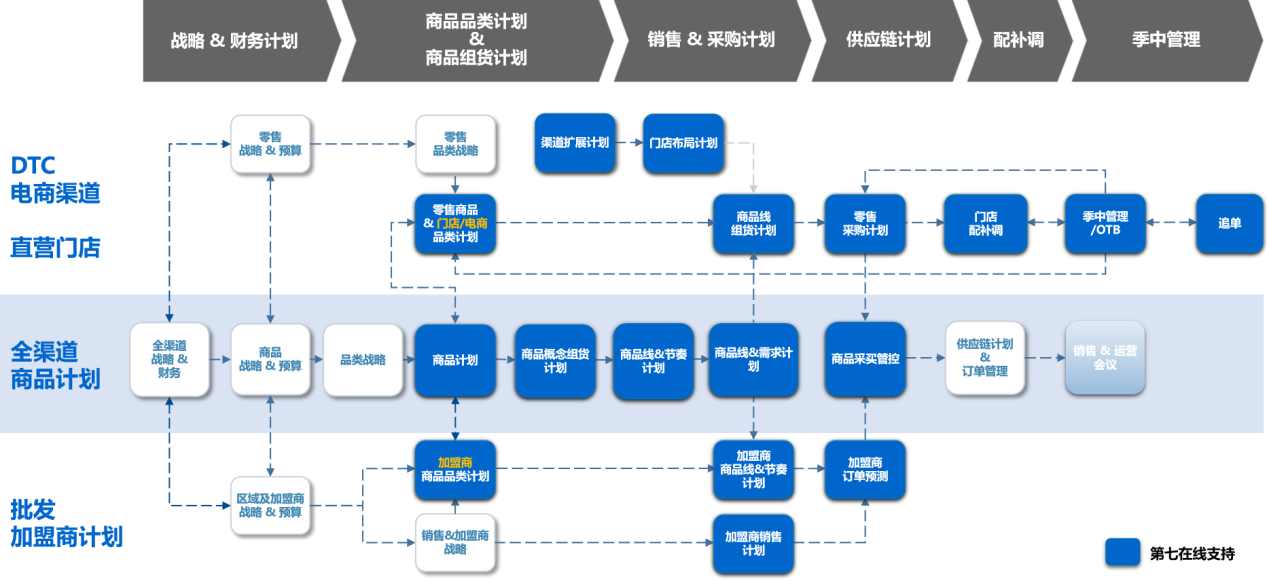
智能商品计划系统如何提升鞋服零售品牌的竞争力
国内鞋服零售企业经过多年的发展,已经形成了众多知名品牌,然而近年来一些企业频频受到库存问题的困扰,这一问题不仅影响了品牌商自身,也给长期合作的经销商带来了困扰。订货会制度在初期曾经有效地解决了盲目生产的问题࿰…...

OpenHarmony开发案例:【分布式遥控器】
1.概述 目前家庭电视机主要通过其自带的遥控器进行操控,实现的功能较为单一。例如,当我们要在TV端搜索节目时,电视机在遥控器的操控下往往只能完成一些字母或数字的输入,而无法输入其他复杂的内容。分布式遥控器将手机的输入能力…...

如何将Oracle 中的部分不兼容对象迁移到 OceanBase
本文总结分析了 Oracle 迁移至 OceanBase 时,在出现三种不兼容对象的情况时的处理策略以及迁移前的预检方式,通过提前发现并处理这些问题,可以有效规避迁移过程中的报错风险。 作者:余振兴,爱可生 DBA 团队成员&#x…...
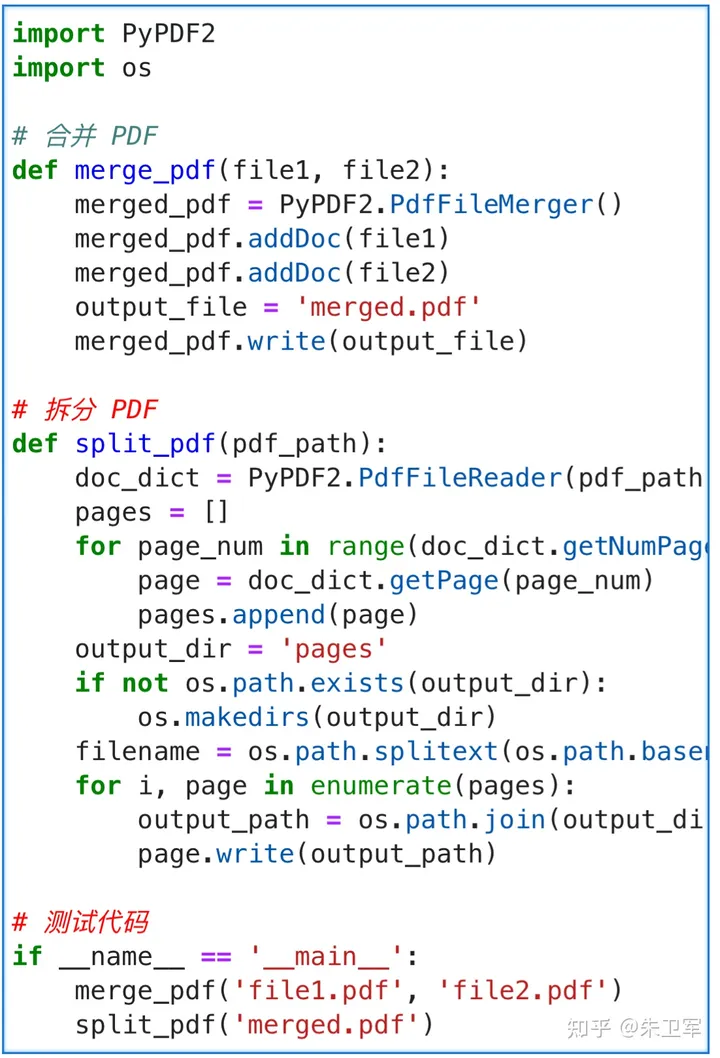
Python也可以合并和拆分PDF,批量高效!
PDF是最方便的文档格式,可以在任何设备原样且无损的打开,但因为PDF不可编辑,所以很难去拆分合并。 知乎上也有人问,如何对PDF进行合并和拆分? 看很多回答推荐了各种PDF编辑器或者网站,确实方法比较多。 …...
迭代器和生成器)
python笔记(14)迭代器和生成器
迭代器的优势 延迟计算:迭代器按需提供数据,无需一次性加载整个数据集到内存中,特别适合处理大规模或无限数据流。资源效率:减少内存占用,尤其在处理大量数据时,避免一次性构建完整数据结构带来的开销。统…...

简单3步,OpenHarmony上跑起ArkUI分布式小游戏
标准系统新增支持了方舟开发框架(ArkUI)、分布式组网和 FA 跨设备迁移能力等新特性,因此我们结合了这三种特性使用 ets 开发了一款如下动图所示传炸弹应用。 打开应用在通过邀请用户进行设备认证后,用户须根据提示完成相应操作&am…...

GPT-3和自然语言处理的前沿:思考AI大模型的发展
引言 自然语言处理(NLP)是人工智能(AI)领域中最富有挑战性和活跃的研究领域之一。近年来,随着深度学习技术的发展和计算能力的提高,大型语言模型,尤其是OpenAI的GPT-3,已成为推动该…...

傅里叶变换例题
目录 傅里叶转化例题: 时移 频移 尺度 时域卷积性质:卷积==乘机...
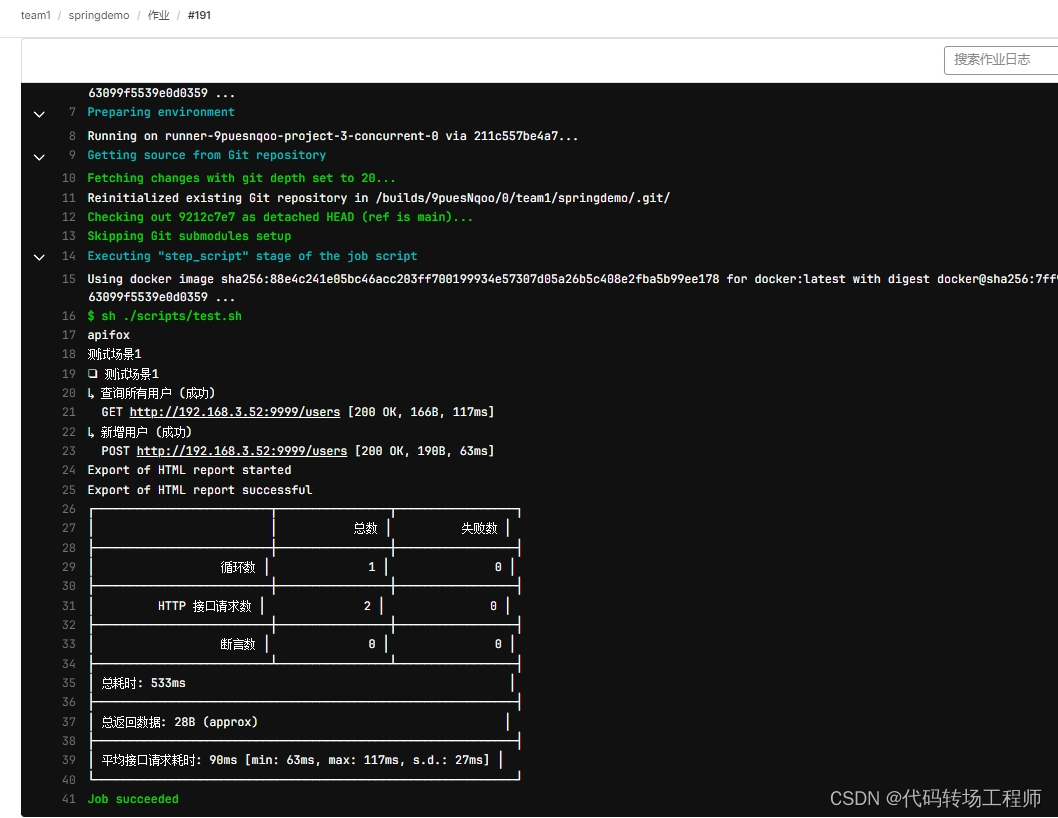
基于Docker构建CI/CD工具链(六)使用Apifox进行自动化测试
添加测试接口 在Spring Boot Demo项目里实现一个简单的用户管理系统的后端功能。具体需求如下: 实现了一个RESTful API,提供了以下两个接口 : POST请求 /users:用于创建新的用户。GET请求 /users:用于获取所有用户的列…...

避坑!这些毕设太好抄了,3000+毕设案例推荐第1023期
231、基于Java的废品回收公司智慧管理系统的设计与实现(论文+代码+PPT)废品回收公司智慧管理系统主要功能包括:会员管理、经手人管理、客户管理、供应商管理、废品管理、收购管理、废品入库、销售出库、期间入库、经手人入库查询、期间出库、…...

SEO整站优化服务需要哪些专业技能_SEO整站优化服务如何提高网站的技术优化
SEO整站优化服务需要哪些专业技能_SEO整站优化服务如何提高网站的技术优化 在当今数字化时代,网站的成功与否在很大程度上取决于其在搜索引擎上的排名。SEO整站优化服务作为提高网站可见度和流量的关键手段,需要一系列专业技能的支持。本文将详细探讨SE…...

XPT2046触摸驱动设计与车载嵌入式集成实践
1. XPT2046 触摸控制器驱动技术解析与嵌入式集成实践XPT2046 是一款广泛应用于嵌入式人机交互系统的 12 位逐次逼近型(SAR)模数转换器(ADC),专为四线/五线电阻式触摸屏设计。其核心功能并非独立显示驱动,而…...

基于MAKLINK图理论的混合蚁群算法与Dijkstra算法在二维空间路径规划中的优化实现
【蚁群算法】/改进蚁群算法/Dijkstra算法/遗传算法/人工势场法实现二维/三维空间路径规划 本程序为蚁群算法Dijkstra算法MAKLINK图理论实现的二维空间路径规划 算法实现: 1)基于MAKLINK图理论生成地图,并对可行点进行划分; 2&…...

[安卓逆向]问题解决:Xposed-Disable-FLAG_SECURE的截图限制解除与实战部署
[安卓逆向]问题解决:Xposed-Disable-FLAG_SECURE的截图限制解除与实战部署 【免费下载链接】Xposed-Disable-FLAG_SECURE Xposed Module to Disable FLAG_SECURE, enabling screenshots, screen sharing and recording in apps that normally wouldnt allow it. 项…...

2025届最火的降AI率神器推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 近期,知网发布了有关人工智能生成内容,也就是AIGC的检测服务以及使用…...

COMSOL 6.1版本皮秒多脉冲激光烧蚀模型:双温模型、变形几何与烧蚀模拟
COMSOL 6.1版本 皮秒多脉冲激光烧蚀模型 模型内容:涉及双温模型,变形几何,烧蚀,皮秒脉冲热源,电子、晶格温度 优势:模型注释清晰明了,各个情况都有涉及可参考性极强,可以修改&#x…...

如何用 GitHub Actions 自部署 GitHub Readme Stats,并统计私有仓库数据
目录背景介绍通过 GitHub Actions 自部署 GitHub Readme Stats如何使用 GitHub Actions 配置统计私有仓库数据1. 生成 Personal Access Token (PAT) 以统计私有仓库**如何生成 Personal Access Token (PAT)**:2. 使用 GitHub Secrets 存储 PAT3. 为什么默认配置无法…...

突破系统壁垒:APK Installer实现Windows运行安卓应用的技术方案
突破系统壁垒:APK Installer实现Windows运行安卓应用的技术方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 随着跨平台应用需求的增长,Wind…...

Odoo 19 AI功能实战:不用写代码,用自然语言就能自动化你的业务流程
Odoo 19 AI功能实战:不用写代码,用自然语言就能自动化你的业务流程 想象一下,早晨打开电脑,你只需要对系统说"把昨天所有未处理的客户咨询按优先级排序,并生成回复草稿",30秒后就能收到整理好的列…...