深浅拷贝——利用模拟实现basic_string深入理解
深浅拷贝——利用模拟实现basic_string深入理解

一、深浅拷贝的基本概念
深拷贝和浅拷贝都是指在对象复制时,复制对象的内存空间的方式。

1.1 深浅拷贝的不同之处
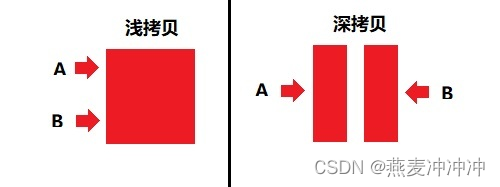
浅拷贝是指将一个对象的所有成员变量都直接拷贝给另一个对象,包括指针成员变量,两个对象共享同一块内存空间。
深拷贝是指在对象复制时,分配一块新的内存空间,将原对象的成员变量复制到新的内存空间中。
1.2 适用场景及优缺点
浅拷贝通常用于类的复制操作,可以在一定程度上提高性能,但是如果一个对象的成员变量指向的是堆内存空间,那么当其中一个对象释放了这块内存空间后,另一个对象仍然指向这块内存空间,容易出现问题。
浅拷贝适用于对象的成员变量是基本数据类型,或指向栈空间的指针的情况。因为这些数据类型的内存是在栈上分配的,所以可以直接拷贝,共享同一块内存空间也不会带来问题。
深拷贝可以避免两个对象共享同一块内存空间带来的问题,但是也会增加内存空间的消耗,以及复制成员变量的时间消耗。
深拷贝适用于对象的成员变量是指向堆内存空间的指针,或者成员变量是对象的情况。因为这些情况下,如果采用浅拷贝的方式,两个对象共享同一块内存空间,可能会导致一个对象释放了内存空间,另一个对象还在使用这块内存空间,造成不可预料的错误。
二、basic_string的模拟实现

2.1 中规中矩的传统写法
#include<iostream>;
#include<string.h>;using namespace std;//深浅拷贝——利用模拟实现basic_string深入理解
namespace yfy
{class string{public:string(const char* str):_str(new char[strlen(str) + 1]) //若此处不在堆上开空间,而是将str作为参数赋值给_str,就是浅拷贝,其后果是无法修改常量字符串{strcpy(_str, str);}string(const string& s):_str(new char[strlen(s._str) + 1]) //自定义拷贝构造函数,深拷贝————开辟同样大小空间,并将数据拷贝{strcpy(_str, s._str);}~string(){delete[] _str;_str = nullptr;}char& operator[](size_t pos){return _str[pos];}string& operator=(const string& s) //不管左值右值谁长,直接将左值释放,开辟和右值同样大小空间,再拷贝右值{if (this != &s) //防止自己给自己赋值{char* tmp = new char[strlen(s._str) + 1]; //如果先释放_str,new失败了会导致赔了夫人又折兵,new如果失败会抛异常,所以先不要释放_str,new成功后再释放delete[] _str; _str = tmp;strcpy(_str, s._str);}return *this;}private:char* _str;};void test_string1(){string s1("hello");s1[0] = 'x';string s2(s1);//若是编译器默认实现的拷贝构造,则为浅拷贝————导致:1、同一块空间析构两次 2、一个对象修改值,另一个随之改变string s3("hello world");s1 = s3;}
}int main()
{yfy::test_string1();return 0;
}
2.2 富有"资本主义"的现代写法
//拷贝构造string(const string& s):_str(nullptr) //若不置空,tmp作为临时变量,在生命结束时调用析构,此时tmp为一个随机值,会出问题{string tmp(s._str); //调用构造函数为tmp开空间swap(_str, tmp._str);}//赋值string& operator=(string s){swap(_str, s._str);return *this;}
3.3 basic_string模拟汇总
#include<iostream>
#include<string.h>
#include<assert.h>using namespace std;//深浅拷贝——利用模拟实现basic_string深入理解
namespace yfy
{class string{public:typedef char* iterator; //string 中的迭代器就是原生指针typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}const_iterator begin() const{return _str;}const_iterator end() const{return _str + _size;}/*string() //默认构造函数:_str(new char[1]), _size(0), _capacity(0){*_str = '\0';//初始化}*/string(const char* str = "") //给一个空串作为缺省值即可替代上面的默认构造函数:_size(strlen(str)),_capacity(_size){_str = new char[_capacity + 1];strcpy(_str, str);}void swap(string& s){::swap(_str, s._str); //swap前加作用域限定符代表调用全局域中的swap函数,若不加,编译器无法区分::swap(_size, s._size);::swap(_capacity, s._capacity);}string(const string& s):_str(nullptr) //若不置空,tmp作为临时变量,在生命结束时调用析构,此时tmp为一个随机值,会出问题{string tmp(s._str); //调用构造函数为tmp开空间this->swap(tmp);}~string(){delete[] _str;_str = nullptr;}//可读可写char& operator[](size_t pos){assert(pos < _size);return _str[pos];}//只读const char& operator[](size_t pos) const{assert(pos < _size);return _str[pos];}string& operator=(string s){this->swap(s);return *this;}void reserve(size_t n) //重新开辟空间{if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void resize(size_t n, char ch = '\0'){if (n <= _size){_size = n;_str[_size] = '\0';}else{if (n > _capacity){reserve(n);}for (size_t i = _size; i < n; i++){_str[i] = ch;}_size = n;_str[_size] = '\0';}}void push_back(char ch){//if (_size >= _capacity)//{// size_t newcapactiy = _capacity == 0 ? 4 : _capacity * 2;// reserve(newcapactiy);//}//_str[_size] = ch;//++_size;//_str[_size] = '\0';insert(_size, ch);}void append(const char* str){//size_t len = strlen(str);//if (_size + len > _capacity)//{// reserve(_size + len);//}//strcpy(_str + _size, str);//_size += len;insert(_size, str);}string& operator+=(char ch){push_back(ch);return *this;}string& operator+=(const char* str){append(str);return *this;}string& operator+=(const string& s){*this += s._str;return *this;}size_t size() const{return _size;}size_t capacity() const{return _capacity;}string& insert(size_t pos, char ch){assert(pos <= _size);if (_size == _capacity){size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}int end = _size; //进行头插时,此处的end会变为负数,在与pos比较时会整型提升到无符号数,从而导致死循环while (end >= (int)pos) //解决方案:将比较时的pos强转为int或控制end不能为负数{_str[end + 1] = _str[end];end--;}_str[pos] = ch;_size++;return *this;}string& insert(size_t pos, const char* str){assert(pos <= _size);size_t len = strlen(str);if (len == 0) //插入空串{return *this;}if (_size + len > _capacity){reserve(_size + len);}size_t end = _size + len;while (end >= pos + len) //字符移位{_str[end] = _str[end - len];end--;} for (int i = 0; i < len; i++) //字符填充{_str[pos + i] = str[i];}_size += len;return* this;}string& erase(size_t pos, size_t len = npos){assert(pos < _size);if (len == npos || pos + len >= _size) //删除的长度大于剩余的长度{_str[pos] = '\0';_size = pos;}else //删除的长度小于剩余长度,需要把遗留字符移花接木 {strcpy(_str + pos, _str + pos + len);_size -= len;}return *this;}const char* c_str(){return _str;}void clear(){_str[0] = '\0';_size = 0;}size_t find(char ch, size_t pos = 0){for (size_t i = pos; i < _size; i++){if (_str[i] == ch){return i;}}return npos;}size_t find(const char* sub, size_t pos = 0){const char* p = strstr(_str + pos, sub);if (p == nullptr){return npos;}else{return p - _str;}}private:char* _str;size_t _size;size_t _capacity;static const size_t npos;};const size_t string::npos = -1;ostream& operator<<(ostream& out, const string& s){for (size_t i = 0; i < s.size(); i++){out << s[i];}return out;}istream& operator>>(istream& in, string& s){s.clear();char ch;//in >> ch; //如此写会自动忽略换行和空格,导致死循环ch = in.get();while (ch != ' ' && ch != '\n'){s += ch;ch = in.get();}return in;}istream& getline(istream& in, string& s){s.clear();char ch;ch = in.get();while (ch != '\n') //区别在于读到空格不结束{s += ch;ch = in.get();}return in;}void print(const string& s1) //输入时用于清空字符串{for (int i = 0; i < s1.size(); i++){cout << s1[i] << " "; //s1不可修改,所以[]需要有两个版本}cout << endl;string::const_iterator it = s1.begin(); //s1不可修改,所以定义const迭代器和重载begin和endwhile (it != s1.end()){cout << *it << " ";it++;}cout << endl;}bool operator>(const string& s1, const string& s2){size_t i1 = 0, i2 = 0;while (i1 < s1.size() && i2 < s2.size()){if (s1[i1] > s2[i2]){return true;}else if (s1[i1] < s2[i2]){return false;}else{i1++;i2++;}}//abc abc false//abcd abc true//abc abcd falseif (i1 == s1.size()){return false;}else{return true;}}bool operator==(const string& s1, const string& s2){size_t i1 = 0, i2 = 0;while (i1 != s1.size() && i2 != s2.size()){if (s1[i1] != s2[i2]){return false;}else{i1++;i2++;}}if (i1 == s1.size() && i2 == s2.size()){return true;}else{return false;}}bool operator!=(const string& s1, const string& s2){return !(s1 == s2);}bool operator>=(const string& s1, const string& s2){return (s1 > s2 || s1 == s2);}bool operator<(const string& s1, const string& s2){return !(s1 >= s2);}bool operator<=(const string& s1, const string& s2){return !(s1 > s2);}string operator+(const string& s1, const char* str){string ret = s1; //存在深拷贝对象,尽量少用ret += str;return ret;}void test_string1(){string s1("hello");s1[0] = 'x';string s2(s1);//若是编译器默认实现的拷贝构造,则为浅拷贝————导致:1、同一块空间析构两次 2、一个对象修改值,另一个随之改变string s3("hello world");s1 = s3;s1.push_back(' ');s1.append("by");s1 += ' ';s1 += "cplusplus";}void test_string2(){string s1;string s2(s1);//s1 += 'x';s1 += "hello";s1.resize(2);s1.resize(8, 'x');}void test_string3(){string s1("hello world");//遍历字符串————三种方式:普通for循环、迭代器、范围forfor (int i = 0; i < s1.size(); i++){cout << s1[i] << " ";}cout << endl;string::iterator it = s1.begin(); //指定iterator在string类域中,而不在全局中while (it != s1.end()){cout << *it << " ";it++;}cout << endl;for (auto e : s1) //语法上支持迭代器、迭代器命名规范即可使用范围for--本质上是替换为迭代器{cout << e << " ";}cout << endl;print(s1);}void test_string4(){string s1("hello world");s1.insert(5, 'x');s1.push_back('!');s1.insert(0, ' ');s1.insert(0, "hehe");s1.erase(0, 5);cout << s1.c_str() << endl;}void test_string5(){string s1("hello world");s1.resize(20);s1[18] = 'x';cout << s1 << endl; //区别在于输出了_size个字符cout << s1.c_str() << endl; //遇到\0就终止string s2("hehe");cin >> s2;cout << s2 << endl;}void test_string6(){string s1;//cin >> s1; //输入带空格的字符//cout << s1 << endl;getline(cin, s1);cout << s1 << endl;}
}int main()
{//yfy::test_string1();//yfy::test_string2();//yfy::test_string3();//yfy::test_string4();//yfy::test_string5();yfy::test_string6();return 0;
}
三、关于string对象的大小
在 Visual Studio 2019 中,当 basic_string 的长度小于等于 15 个字符时,标准库会将字符串的字符数组存储在 basic_string 对象内部的一个名为 buf 的字符数组中,而不是动态分配内存。这个 buf 数组的大小是 16 个字节,其中包括 15 个字符和一个用于存储字符串结尾的 null 字符的位置。
因此,如果你在 VS2019 的 32 位环境下创建一个 basic_string 对象,它的大小可能是 28 个字节。其中,16 个字节用于存储 buf 数组,4 个字节用于存储指向 buf 数组的指针,4 个字节用于存储 size_,4 个字节用于存储 capacity_。但需要注意的是,这个大小可能因为编译器版本、编译器选项等因素而有所不同。
四、 浅拷贝缺陷的解决方案
下面我们再来回顾一下浅拷贝:
C++中浅拷贝是指当对象被复制时,只复制指向数据的指针,而不是数据本身。这意味着当一个对象的内容发生更改时,所有指向该对象的指针都会受到影响,从而导致潜在的内存泄漏和程序错误,例如对象的生命周期结束时,多次调用析构函数。
4.0 浅拷贝改深拷贝
浅拷贝的缺陷示例:
class MyClass {
public:MyClass(int size) {m_data = new int[size];m_size = size;}~MyClass() {delete[] m_data;}
private:int* m_data;int m_size;
};MyClass obj1(10);
MyClass obj2 = obj1;
在这个例子中,当obj2被复制为obj1时,m_data指针也被复制,这意味着两个对象都指向相同的内存地址。如果一个对象更改了其内部数据,另一个对象也会受到影响。
要解决这个问题,可以使用深拷贝来复制对象。深拷贝不仅复制指针,而且复制指针所指向的数据本身,因此每个对象都有其自己的内存空间。
以下是深拷贝的示例实现:
class MyClass {
public:MyClass(int size) {m_data = new int[size];m_size = size;}~MyClass() {delete[] m_data;}// 拷贝构造函数MyClass(const MyClass& other) {m_size = other.m_size;m_data = new int[m_size];memcpy(m_data, other.m_data, m_size * sizeof(int));}// 赋值操作符MyClass& operator=(const MyClass& other) {if (this != &other) {delete[] m_data;m_size = other.m_size;m_data = new int[m_size];memcpy(m_data, other.m_data, m_size * sizeof(int));}return *this;}
private:int* m_data;int m_size;
};MyClass obj1(10);
MyClass obj2 = obj1; // 使用拷贝构造函数进行深拷贝
MyClass obj3(5);
obj3 = obj1; // 使用赋值操作符进行深拷贝
4.1 引用计数
引用计数是一种内存管理技术,它通过跟踪对象被引用的次数来决定何时释放内存。当对象被创建时,引用计数被初始化为1。每当对象被复制时,引用计数也会增加1。当对象不再被使用时,引用计数会减少1。当引用计数为0时,内存被释放。
class MyClass {
public:MyClass(int size) {m_data = new int[size];m_size = size;m_refCount = new int(1);}~MyClass() {if (--(*m_refCount) == 0) {delete[] m_data;delete m_refCount;}}// 拷贝构造函数MyClass(const MyClass& other) {m_data = other.m_data;m_size = other.m_size;m_refCount = other.m_refCount;++(*m_refCount);}// 赋值操作符MyClass& operator=(const MyClass& other) {if (this != &other) {if (--(*m_refCount) == 0) {delete[] m_data;delete m_refCount;}m_data = other.m_data;m_size = other.m_size;m_refCount = other.m_refCount;++(*m_refCount);}return *this;}
private:int* m_data;int m_size;int* m_refCount;
};MyClass obj1(10);
MyClass obj2 = obj1;
MyClass obj3(5);
obj3 = obj1;
在这个例子中,引用计数被实现为一个指向整数的指针,它被存储在对象中。每当对象被复制时,引用计数都会增加1。当对象不再被使用时,引用计数会减少1。当引用计数为0时,内存被释放。这种方法可以避免浅拷贝的问题,并且在对象被复制时不需要进行大量的数据复制。但是,引用计数需要额外的内存空间来存储计数器,而且在多线程环境下,需要进行额外的同步和保护。
引用计数指针不能直接写成int类型,因为这样会导致内存管理出现问题。
如果我们将引用计数实现为一个普通的int类型,那么当对象被复制时,每个副本都将拥有一个独立的引用计数。这意味着,如果其中一个副本被销毁,它的引用计数会减少,但是其它副本的引用计数并不会减少,这会导致内存泄漏。
使用一个指向int的指针可以解决这个问题。每个副本都可以共享同一个引用计数,这样当其中一个副本被销毁时,它的引用计数会减少,而其它副本的引用计数也会随之减少,从而避免了内存泄漏的问题。
4.2 写时拷贝
写时拷贝(Copy on Write,简称COW)是一种内存管理技术,它允许多个对象共享同一块内存,在对象被修改时才进行复制,从而减少内存的消耗。
在COW中,当一个对象被拷贝时,只有指向原始对象的引用被复制,而不是整个对象。在拷贝对象被修改时,COW会将原始对象复制到一个新的内存地址,并且将引用指向新的内存地址。这个过程是透明的,使用者无需关心内部实现。
COW实现:
#include <iostream>
#include <string.h>class MyString {
public:MyString(const char* str) {m_data = new char[strlen(str) + 1];strcpy(m_data, str);m_refCount = new int(1);}~MyString() {if (--(*m_refCount) == 0) {delete[] m_data;delete m_refCount;}}// 拷贝构造函数MyString(const MyString& other) {m_data = other.m_data;m_refCount = other.m_refCount;++(*m_refCount);}// 赋值操作符MyString& operator=(const MyString& other) {if (this != &other) {if (--(*m_refCount) == 0) {delete[] m_data;delete m_refCount;}m_data = other.m_data;m_refCount = other.m_refCount;++(*m_refCount);}return *this;}// 修改字符串时进行复制void ModifyString() {if (*m_refCount > 1) {char* newData = new char[strlen(m_data) + 1];strcpy(newData, m_data);--(*m_refCount);m_data = newData;m_refCount = new int(1);}}
private:char* m_data;int* m_refCount;
};int main() {MyString str1("hello");MyString str2 = str1;std::cout << "str1: " << str1 << std::endl;std::cout << "str2: " << str2 << std::endl;str2.ModifyString();std::cout << "str1: " << str1 << std::endl;std::cout << "str2: " << str2 << std::endl;return 0;
}
在这个例子中,MyString类中的m_data指向一个包含字符串的内存块,m_refCount存储引用计数。在拷贝对象时,只有指向m_data的指针被复制,m_refCount也被增加。当对象被修改时,如果引用计数大于1,则表示有多个对象共享同一块内存,此时MyString类会将原始数据复制到一个新的内存地址,并将指针指向新的内存地址。这个过程是透明的,使用者无需关心内部实现。
在上述示例代码中,ModifyString()函数模拟了对字符串进行修改的操作,如果对象被多个引用共享,则会将数据复制到一个新的内存地址,并将引用指向新的内存地址。这样,其他对象的数据不会被修改,也就避免了浅拷贝带来的问题。
COW技术的缺点是它会增加额外的开销,因为每次修改对象时,都需要检查引用计数并复制数据。因此,COW适用于多读少写的场景,在写操作比较频繁的场景中可能会带来性能问题。
相关文章:
深浅拷贝——利用模拟实现basic_string深入理解
深浅拷贝——利用模拟实现basic_string深入理解 一、深浅拷贝的基本概念 深拷贝和浅拷贝都是指在对象复制时,复制对象的内存空间的方式。 1.1 深浅拷贝的不同之处 浅拷贝是指将一个对象的所有成员变量都直接拷贝给另一个对象,包括指针成员变量&#…...
大模型分布式系统
背景:模型越来越大,训练复杂度越来越高,需要训练的时间也是越来越长。那么我们该如何在现有的硬件基础上对模型做训练呢。模型规模的扩大,对硬件(算力、内存)的发展提出要求。然而,因为 内存墙 …...

【时序】时序预测任务模型选择如何选择?
时间序列是什么时间序列是一种特殊类型的数据集,其中一个或多个变量随着时间的推移被测量。 在时间序列中,观测值是随着时间的推移而测量的。你的数据集中的每个数据点都对应着一个时间点。这意味着你的数据集的不同数据点之间存在着一种关系。这对可以应用于时间序列数据集的…...
重温数据结构与算法之深度优先搜索
文章目录前言一、实现1.1 递归实现1.2 栈实现1.3 两者区别二、LeetCode 实战2.1 二叉树的前序遍历2.2 岛屿数量2.3 统计封闭岛屿的数目2.4 从先序遍历还原二叉树参考前言 深度优先搜索(Depth First Search,DFS)是一种遍历或搜索树或图数据结…...

STM32F103驱动LD3320语音识别模块
STM32F103驱动LD3320语音识别模块LD3320语音识别模块简介模块引脚定义STM32F103ZET6开发板与模块接线测试代码实验结果LD3320语音识别模块简介 基于 LD3320,可以在任何的电子产品中,甚至包括最简单的 51 作为主控芯片的系统中,轻松实现语音识…...

2023 最新可用Google镜像地址 长期更新
Google镜像说明 由于种种原因,国家还未开放Google搜索的使用。虽然可以通过某些技术手段实现访问,但是还是有一些同学需要借助Google搜索镜像才可以达到访问的目的;笔者特意搜集了一些2022年最新的Google搜索镜像供有需求的童鞋使用…...
及其算法变种(附matlab和python代码实现))
MATLAB算法实战应用案例精讲-【优化算法】蝗虫优化算法(GOA)及其算法变种(附matlab和python代码实现)
目录 前言 算法原理 算法思想 GOA 算法的数学模型 迭代模型 算法流程...

数据结构与算法 顺序表、链表总结
文章目录顺序表1、顺序表的基本概念链表1 简介链表概念链表特点链表与数组的对比2 链表的类型分类链表循环单向链表1 简介概念2 数据存储和实现数据存储数据实现3 操作基本操作实现线性表(List):零个或多个数据元素的有限序列。在较复杂的线性…...

Nginx集群搭建-三台
1.使用root用户登录Linux服务器 2.创建用户 输入 adduser test 后回车 #test 为创建的用户 3.为创建的用户设置密码 输入 passwd test 后回车 输入两次密码 4.出现 passwd:所有的身份验证令牌已经成功更新。证明Linux新用户和密码创建成功 5.使用新用户test登录Linu…...

【算法】图的存储和遍历
作者:指针不指南吗 专栏:算法篇 🐾或许会很慢,但是不可以停下🐾 文章目录1. 图的存储1.1 邻接矩阵1.2 邻接表2. 图的遍历2.1 dfs 遍历2.2 bfs 遍历1. 图的存储 引入 一般来说,树和图有两种存储方式&#…...
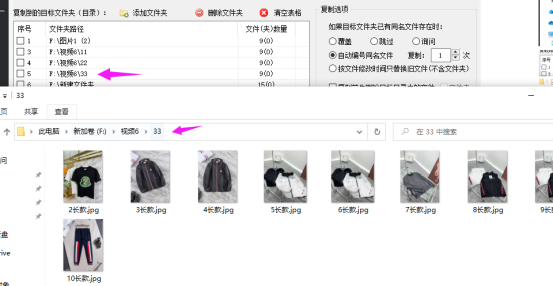
文件如何批量复制保存在多个文件夹中
在日常工作中经常需要整理文件,比如像文件或文件夹重命名或文件批量归类,文件批量复制到指定某个或多个文件来中保存备份起来。一般都家最常用方便是手动一个一个去重命名或复制到粘贴到某个文件夹中保存,有没有简单好用的办法呢,…...

16N60-ASEMI高压MOS管16N60
编辑-Z 16N60在TO-220封装里的静态漏极源导通电阻(RDS(ON))为0.2Ω,是一款N沟道高压MOS管。16N60的最大脉冲正向电流ISM为48A,零栅极电压漏极电流(IDSS)为10uA,其工作时耐温度范围为-55~150摄氏度。16N60功耗…...
)
Open3D 多个点云配准(C++版本)
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 多路配准(多个点云配准)是指在全局空间中对齐多个几何块的过程。输入的数据可以是点云或深度图像 P i P_i P...

java实现Hbase 增删改查
目录 一、新建一个maven工程 二、代码实现 2.1、配置hbase信息,连接hbase数据库 2.2、创建命名空间 2.3、创建表 2.4、删除表,删除之前要设置为禁用状态 2.5、添加数据 2.6、获取命令表空间 / tables列表 2.7、get方法查看表的内容 2.8、scan方法…...

1109. 航班预订统计 差分数组
1109. 航班预订统计 差分数组技巧适⽤于频繁对数组区间进⾏增减的场景 1.由数组a生成差分数组b{b[0]0,i0(或者b[0]a[0],i0)b[i]a[i]−a[i−1],i>01.由数组a生成差分数组b\left\{\begin{array}{l}b[0]0,i0(或者b[0]a[0],i0)\\ b[i]a[i]-a[i-1],i>0\end{array}\right. 1.由…...

图床搭建,使用typora上传
1. 准备gitee作为图床的仓库 新建仓库 准备仓库的私人令牌,后面配合使用 点击个人设置——》私人令牌 注意私人令牌,复制保存好,后面不能再看了 2. 准备PicGO,并进行相关配置 PicGo官方下载链接 下载安装好node.js,下载网址 安…...
低代码开发的优势是什么?
低代码开发的优势是什么?低代码开发这个概念这两年来经常出现在人们的视野中,市场对于低代码的需求也越来越庞大。 Gartner预测,到2025年,75%的大型企业将使用至少四种低代码/无代码开发工具,用于IT应用开发和公民开发计划。 可…...

Ip2Resion线上部署报数据越界及错误处理
上篇在本地测试调用Ip2Resigon解析行政区划 Ip2Region的Java本地实现运行正常,但部署到测试环境,抛出数组越界(java.lang.ArrayIndexOutOfBoundsException)异常。 环境信息 ip2Resion是2.7版本,对应文件后缀为 xdb。 …...

致敬我的C++启蒙老师,跟着他学计算机编程就对了 (文末赠书5本)
致敬我的C启蒙老师,跟着他学计算机编程就对了 摘要 讲述了一个故事,介绍了一位良师,一段因C而续写的回忆,希望对各位看官有所帮助和启发。 文章目录1 写在前面2 我的C启蒙老师3 谈谈老师给我的启发4 友情推荐5 文末福利1 写在前面…...

CSS中的伪元素和伪类
一直被伪类和伪元素所迷惑,以为是同一个属性名称,根据CSS动画,索性开始研究a:hover:after,a.hover:after的用法。 伪元素 是HTML中并不存在的元素,用于将特殊的效果添加到某些选择器。 对伪元素的描述 伪元素有两…...

FastGithub终极指南:3步解决GitHub访问卡顿,让开发效率提升5倍
FastGithub终极指南:3步解决GitHub访问卡顿,让开发效率提升5倍 【免费下载链接】FastGithub github定制版的dns服务,解析访问github最快的ip 项目地址: https://gitcode.com/gh_mirrors/fa/FastGithub 你是否曾经因为GitHub访问缓慢而…...

水壶装箱检测怎么做?一个独立开发者的实战经验
水壶装箱检测怎么做?一个独立开发者的实战经验 作者:馒头 | 离散型智能制造项目经理 MES开发2年 项目经理3年,主导过电子、机械行业的百万级MES项目。 独立开发过一套装箱检测系统,从需求分析到上线落地全程主导。 踩过的坑、走过…...
)
别再瞎试了!用Matlab手把手教你做拉丁超立方抽样(附10个点二维案例代码)
别再瞎试了!用Matlab手把手教你做拉丁超立方抽样(附10个点二维案例代码) 当面对昂贵的仿真或物理实验时,如何用最少的样本点获取最全面的数据特征?传统随机抽样可能导致样本点扎堆或分布不均,而拉丁超立方抽…...

Claude Code 用户如何通过 Taotoken 解决访问不稳定与 Token 不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何通过 Taotoken 解决访问不稳定与 Token 不足问题 对于依赖 Claude Code 进行开发的用户而言,服务…...

python flash加一个字段
USE product_db; ALTER TABLE products ADD COLUMN remark TEXT COMMENT 商品备注信息,支持长文本 AFTER cost_price;2. 修改数据访问层(product_dao.py)需要在以下函数中添加 remark 字段的处理:修改 get_all_products 函数&…...

zotero-addons:Zotero生态扩展框架的模块化设计与架构解析
zotero-addons:Zotero生态扩展框架的模块化设计与架构解析 【免费下载链接】zotero-addons Zotero Add-on Market | Zotero插件市场 | Browsing and installing plugins within Zotero 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-addons 在学术研究…...

别再只看benchmark!Claude的“类人延迟响应”背后藏着7种语境锚定策略
更多请点击: https://intelliparadigm.com 第一章:类人延迟响应的本质:为什么“慢”才是更高级的智能 人类在面对复杂问题时,并非即时作答,而是经历感知、检索、权衡、修正等多阶段认知循环——这种可观察的“延迟”&…...

装配骨架:每一帧重新构建简笔人物,文本围绕当前姿势环绕显示
【导语:资讯介绍了装配骨架的相关情况,包括每一帧重新构建简笔人物,文本围绕当前姿势环绕显示,还有波浪动画等视觉效果及闲置状态。】简笔人物的帧构建在装配骨架的过程中,每一帧都会依据基本的排除部分重新构建一个简…...

从零开始掌握ShiroAttack2:5步搞定Shiro反序列化漏洞利用
从零开始掌握ShiroAttack2:5步搞定Shiro反序列化漏洞利用 【免费下载链接】ShiroAttack2 shiro反序列化漏洞综合利用,包含(回显执行命令/注入内存马)修复原版中NoCC的问题 https://github.com/j1anFen/shiro_attack 项目地址: https://gitc…...

中国工业物理AI落地优势显著,江行智能全栈模型架构助力工业变革
中国工业物理AI的优势与落地情况中国工业物理AI的真正优势不在于模型参数,而在于全球12倍的工业机器人部署密度、两倍的发电量和密集的5G边缘节点。场景密度、基建底座和开源模型的合力,正推动物理AI从实验室走向规模化落地。江行智能提出的工业物理AI三…...