竞赛 基于GRU的 电影评论情感分析 - python 深度学习 情感分类
文章目录
- 1 前言
- 1.1 项目介绍
- 2 情感分类介绍
- 3 数据集
- 4 实现
- 4.1 数据预处理
- 4.2 构建网络
- 4.3 训练模型
- 4.4 模型评估
- 4.5 模型预测
- 5 最后
1 前言
🔥 优质竞赛项目系列,今天要分享的是
基于GRU的 电影评论情感分析
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1.1 项目介绍
其实,很明显这个项目和微博谣言检测是一样的,也是个二分类的问题,因此,我们可以用到学长之前提到的各种方法,即:
朴素贝叶斯或者逻辑回归以及支持向量机都可以解决这个问题。
另外在深度学习中,我们可以用CNN-Text或者RNN以及LSTM等模型最好。
当然在构建网络中也相对简单,相对而言,LSTM就比较复杂了,为了让不同层次的同学们可以接受,学长就用了相对简单的GRU模型。
如果大家想了解LSTM。以后,学长会给大家详细介绍。
2 情感分类介绍
其实情感分析在自然语言处理中,情感分析一般指判断一段文本所表达的情绪状态,属于文本分类问题。一般而言:情绪类别:正面/负面。当然,这就是为什么本人在前面提到情感分析实际上也是二分类问题的原因。
3 数据集
学长本次使用的是非常典型的IMDB数据集。
该数据集包含来自互联网的50000条严重两极分化的评论,该数据被分为用于训练的25000条评论和用于测试的25000条评论,训练集和测试集都包含50%的正面评价和50%的负面评价。该数据集已经经过预处理:评论(单词序列)已经被转换为整数序列,其中每个整数代表字典中的某个单词。
查看其数据集的文件夹:这是train和test文件夹。
接下来就是以train文件夹介绍里面的内容
然后就是以neg文件夹介绍里面的内容,里面会有若干的text文件:
4 实现
4.1 数据预处理
#导入必要的包import zipfileimport osimport ioimport randomimport jsonimport matplotlib.pyplot as pltimport numpy as npimport paddleimport paddle.fluid as fluidfrom paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear, Embeddingfrom paddle.fluid.dygraph.base import to_variablefrom paddle.fluid.dygraph import GRUUnitimport paddle.dataset.imdb as imdb#加载字典def load_vocab():vocab = imdb.word_dict()return vocab#定义数据生成器class SentaProcessor(object):def __init__(self):self.vocab = load_vocab()def data_generator(self, batch_size, phase='train'):if phase == "train":return paddle.batch(paddle.reader.shuffle(imdb.train(self.vocab),25000), batch_size, drop_last=True)elif phase == "eval":return paddle.batch(imdb.test(self.vocab), batch_size,drop_last=True)else:raise ValueError("Unknown phase, which should be in ['train', 'eval']")步骤
-
首先导入必要的第三方库
-
接下来就是数据预处理,需要注意的是:数据是以数据标签的方式表示一个句子,因此,每个句子都是以一串整数来表示的,每个数字都是对应一个单词。当然,数据集就会有一个数据集字典,这个字典是训练数据中出现单词对应的数字标签。
4.2 构建网络
这次的GRU模型分为以下的几个步骤
- 定义网络
- 定义损失函数
- 定义优化算法
具体实现如下
#定义动态GRU
class DynamicGRU(fluid.dygraph.Layer):
def init(self,
size,
param_attr=None,
bias_attr=None,
is_reverse=False,
gate_activation=‘sigmoid’,
candidate_activation=‘relu’,
h_0=None,
origin_mode=False,
):
super(DynamicGRU, self).init()
self.gru_unit = GRUUnit(
size * 3,
param_attr=param_attr,
bias_attr=bias_attr,
activation=candidate_activation,
gate_activation=gate_activation,
origin_mode=origin_mode)
self.size = size
self.h_0 = h_0
self.is_reverse = is_reverse
def forward(self, inputs):
hidden = self.h_0
res = []
for i in range(inputs.shape[1]):
if self.is_reverse:
i = inputs.shape[1] - 1 - i
input_ = inputs[ :, i:i+1, :]
input_ = fluid.layers.reshape(input_, [-1, input_.shape[2]], inplace=False)
hidden, reset, gate = self.gru_unit(input_, hidden)
hidden_ = fluid.layers.reshape(hidden, [-1, 1, hidden.shape[1]], inplace=False)
res.append(hidden_)
if self.is_reverse:
res = res[::-1]
res = fluid.layers.concat(res, axis=1)
return res
class GRU(fluid.dygraph.Layer):def __init__(self):super(GRU, self).__init__()self.dict_dim = train_parameters["vocab_size"]self.emb_dim = 128self.hid_dim = 128self.fc_hid_dim = 96self.class_dim = 2self.batch_size = train_parameters["batch_size"]self.seq_len = train_parameters["padding_size"]self.embedding = Embedding(size=[self.dict_dim + 1, self.emb_dim],dtype='float32',param_attr=fluid.ParamAttr(learning_rate=30),is_sparse=False)h_0 = np.zeros((self.batch_size, self.hid_dim), dtype="float32")h_0 = to_variable(h_0)self._fc1 = Linear(input_dim=self.hid_dim, output_dim=self.hid_dim*3)self._fc2 = Linear(input_dim=self.hid_dim, output_dim=self.fc_hid_dim, act="relu")self._fc_prediction = Linear(input_dim=self.fc_hid_dim,output_dim=self.class_dim,act="softmax")self._gru = DynamicGRU(size=self.hid_dim, h_0=h_0)def forward(self, inputs, label=None):emb = self.embedding(inputs)o_np_mask =to_variable(inputs.numpy().reshape(-1,1) != self.dict_dim).astype('float32')mask_emb = fluid.layers.expand(to_variable(o_np_mask), [1, self.hid_dim])emb = emb * mask_embemb = fluid.layers.reshape(emb, shape=[self.batch_size, -1, self.hid_dim])fc_1 = self._fc1(emb)gru_hidden = self._gru(fc_1)gru_hidden = fluid.layers.reduce_max(gru_hidden, dim=1)tanh_1 = fluid.layers.tanh(gru_hidden)fc_2 = self._fc2(tanh_1)prediction = self._fc_prediction(fc_2)if label is not None:acc = fluid.layers.accuracy(prediction, label=label)return prediction, accelse:return prediction
4.3 训练模型
def train():
with fluid.dygraph.guard(place = fluid.CUDAPlace(0)): # # 因为要进行很大规模的训练,因此我们用的是GPU,如果没有安装GPU的可以使用下面一句,把这句代码注释掉即可
# with fluid.dygraph.guard(place = fluid.CPUPlace()):
processor = SentaProcessor()train_data_generator = processor.data_generator(batch_size=train_parameters["batch_size"], phase='train')model = GRU()sgd_optimizer = fluid.optimizer.Adagrad(learning_rate=train_parameters["lr"],parameter_list=model.parameters())steps = 0Iters, total_loss, total_acc = [], [], []for eop in range(train_parameters["epoch"]):for batch_id, data in enumerate(train_data_generator()):steps += 1doc = to_variable(np.array([np.pad(x[0][0:train_parameters["padding_size"]], (0, train_parameters["padding_size"] - len(x[0][0:train_parameters["padding_size"]])),'constant',constant_values=(train_parameters["vocab_size"]))for x in data]).astype('int64').reshape(-1))label = to_variable(np.array([x[1] for x in data]).astype('int64').reshape(train_parameters["batch_size"], 1))model.train()prediction, acc = model(doc, label)loss = fluid.layers.cross_entropy(prediction, label)avg_loss = fluid.layers.mean(loss)avg_loss.backward()sgd_optimizer.minimize(avg_loss)model.clear_gradients()if steps % train_parameters["skip_steps"] == 0:Iters.append(steps)total_loss.append(avg_loss.numpy()[0])total_acc.append(acc.numpy()[0])print("step: %d, ave loss: %f, ave acc: %f" %(steps,avg_loss.numpy(),acc.numpy()))if steps % train_parameters["save_steps"] == 0:save_path = train_parameters["checkpoints"]+"/"+"save_dir_" + str(steps)print('save model to: ' + save_path)fluid.dygraph.save_dygraph(model.state_dict(),save_path)draw_train_process(Iters, total_loss, total_acc)

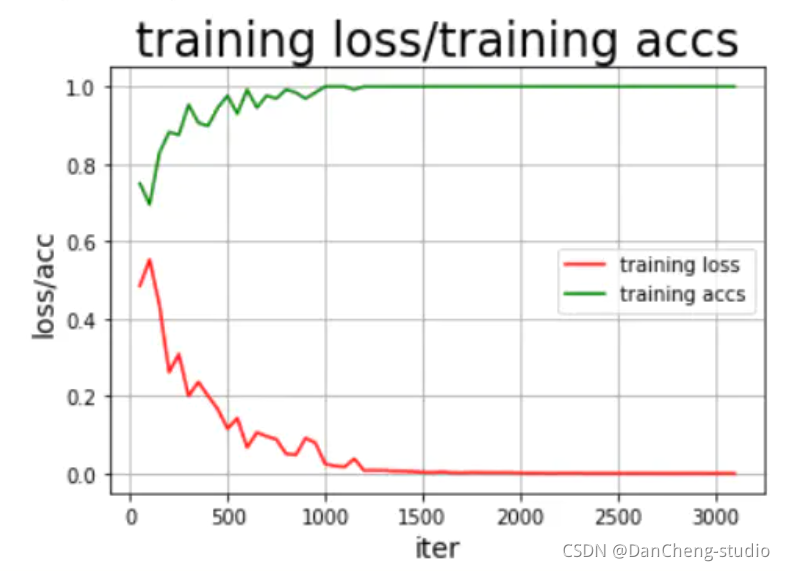
4.4 模型评估

结果还可以,这里说明的是,刚开始的模型训练评估不可能这么好,很明显是过拟合的问题,这就需要我们调整我们的epoch、batchsize、激活函数的选择以及优化器、学习率等各种参数,通过不断的调试、训练最好可以得到不错的结果,但是,如果还要更好的模型效果,其实可以将GRU模型换为更为合适的RNN中的LSTM以及bi-
LSTM模型会好很多。
4.5 模型预测
train_parameters[“batch_size”] = 1
with fluid.dygraph.guard(place = fluid.CUDAPlace(0)):sentences = 'this is a great movie'data = load_data(sentences)print(sentences)print(data)data_np = np.array(data)data_np = np.array(np.pad(data_np,(0,150-len(data_np)),"constant",constant_values =train_parameters["vocab_size"])).astype('int64').reshape(-1)infer_np_doc = to_variable(data_np)model_infer = GRU()model, _ = fluid.load_dygraph("data/save_dir_750.pdparams")model_infer.load_dict(model)model_infer.eval()result = model_infer(infer_np_doc)print('预测结果为:正面概率为:%0.5f,负面概率为:%0.5f' % (result.numpy()[0][0],result.numpy()[0][1]))

训练的结果还是挺满意的,到此为止,我们的本次项目实验到此结束。
5 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛 基于GRU的 电影评论情感分析 - python 深度学习 情感分类
文章目录 1 前言1.1 项目介绍 2 情感分类介绍3 数据集4 实现4.1 数据预处理4.2 构建网络4.3 训练模型4.4 模型评估4.5 模型预测 5 最后 1 前言 🔥 优质竞赛项目系列,今天要分享的是 基于GRU的 电影评论情感分析 该项目较为新颖,适合作为竞…...

软件杯 深度学习图像修复算法 - opencv python 机器视觉
文章目录 0 前言2 什么是图像内容填充修复3 原理分析3.1 第一步:将图像理解为一个概率分布的样本3.2 补全图像 3.3 快速生成假图像3.4 生成对抗网络(Generative Adversarial Net, GAN) 的架构3.5 使用G(z)生成伪图像 4 在Tensorflow上构建DCGANs最后 0 前言 &#…...

java日志log4j使用
1、导入jar包 log4j-1.2.17.jar log4j-api-2.0-rc1.jar log4j-core-2.0-rc1.jar https://download.csdn.net/download/weixin_44201223/89148839 所需jar包下载地址 2、创建 log4j.properties src 下创建 log4j.properties (路径和名称都不允许改变),放置 src 下…...

探索Python爬虫利器:Scrapy框架解析与实战
探索Python爬虫利器:Scrapy框架解析与实战 在当今信息时代,数据的价值不言而喻。而Python爬虫技术,作为获取网络数据的重要手段,已经成为了许多数据分析师、开发者和研究者必备的技能。本文将为您详细介绍Python爬虫技术中的利器—…...
Rust腐蚀服务器修改背景和logo图片操作方法
Rust腐蚀服务器修改背景和logo图片操作方法 大家好我是艾西一个做服务器租用的网络架构师。在我们自己搭建的rust服务器游戏设定以及玩法都是完全按照自己的想法设定的,如果你是一个社区服那么对于进游戏的主页以及Logo肯定会有自己的想法。这个东西可以理解为做一…...

【架构-15】NoSQL数据库
NoSQL(Not Only SQL)数据库是一类非关系型数据库,与传统的关系型数据库(如MySQL、Oracle)相对而言。NoSQL数据库的设计目标是针对大规模数据和高并发访问的需求,具有高可扩展性、高性能和灵活的数据模型。 …...

中国人工智能产业年会智能交通与自动驾驶专题全景扫描
中国人工智能产业年会(CAIIAC)是中国人工智能技术发展和应用的重要展示平台,不仅关注创新,还涵盖了市场和监管方面的内容,对于促进人工智能领域的发展起到了重要作用。年会汇集了来自学术界、工业界和政府的专家&#…...
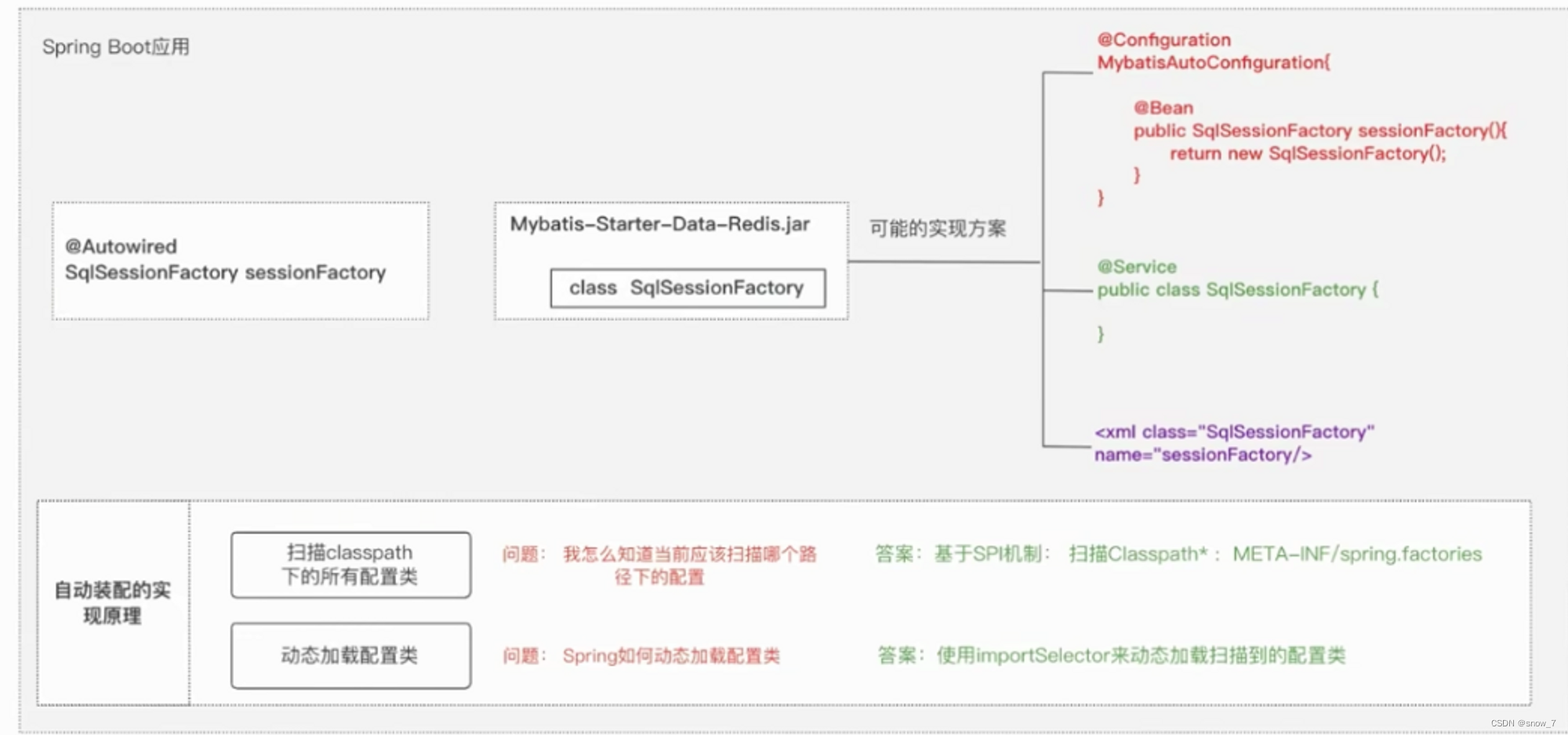
SpringBoot相关知识点总结
1 SpringBoot的目的 简化开发,开箱即用。 2 Spring Boot Starter Spring Boot Starter 是 Spring Boot 中的一个重要概念,它是一种提供依赖项的方式,可以帮助开发人员快速集成各种第三方库和框架。Spring Boot Starter 的目的是简化 Sprin…...
 clicked() clicked(bool)}达成巧用)
【QT】关于qcheckbox常用的三个信号,{sstateChanged(int) clicked() clicked(bool)}达成巧用
在 Qt 中,QCheckBox 是一个提供复选框功能的小部件,允许用户选择和取消选择一个或多个选项。QCheckBox 提供了几种信号来响应用户的交互,其中 stateChanged(int), clicked(), 和 clicked(bool) 是常用的。下面解释这些信号的意义及其用法。 …...
在线音乐网站的设计与实现
在线音乐网站的设计与实现 摘 要 在社会和互联网的快速发展中,音乐在人们生活中也产生着很大的作用。音乐可以使我们紧张的神经得到放松,有助于开启我们的智慧,可以辅助治疗,达到药物无法达到的效果,所以利用现代科学…...

【电路笔记】-数字缓冲器
数字缓冲器 文章目录 数字缓冲器1、概述2、单输入数字缓冲器3、三态缓冲器3.1 有效“高”三态缓冲器3.2 有效“高”反相三态缓冲器3.3 有效“低”三态缓冲器3.4 有效“低”反相三态缓冲器4、三态缓冲器控制数字缓冲器和三态缓冲器可以在数字电路中提供电流放大以驱动输出负载。…...

Opencv | 基于ndarray的基本操作
这里写目录标题 一. Opencv 基于ndarray的基本操作1. 浅拷贝2. np.copy ( ) 深拷贝3. 堆叠3.1 np.vstack ( ) 垂直方向堆叠3.2 np.hstack ( ) 水平方向堆叠 4. numpy创建图像5 np.transpose ( ) 更改维度顺序6. cv.resize ( ) 放大缩小7. np.clip ( ) 一. Opencv 基于ndarray的…...
【大语言模型】应用:10分钟实现搜索引擎
本文利用20Newsgroup这个数据集作为Corpus(语料库),用户可以通过搜索关键字来进行查询关联度最高的News,实现对文本的搜索引擎: 1. 导入数据集 from sklearn.datasets import fetch_20newsgroupsnewsgroups fetch_20newsgroups()print(fNu…...

UT单元测试
Tips:在使用时一定要注意版本适配性问题 一、Mockito 1.1 Mock的使用 Mock 的中文译为仿制的,模拟的,虚假的。对于测试框架来说,即构造出一个模拟/虚假的对象,使我们的测试能顺利进行下去。 Mock 测试就是在测试过程…...
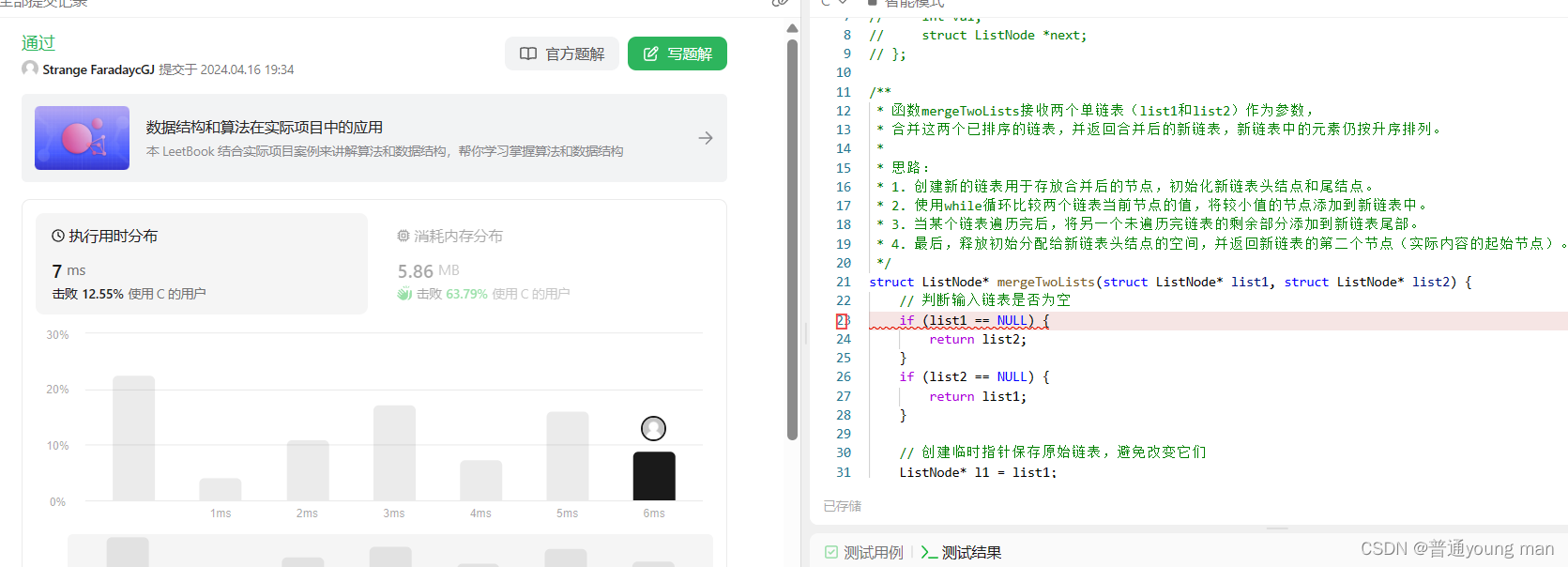
leetcode-合并两个有序链表
目录 题目 图解 方法一 方法二 代码(解析在注释中) 方法一 编辑方法二 题目 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 示例 1: 输入:l1 [1,2,4], l2 [1,3,4] 输出:[1,1…...
006Node.js cnpm的安装
百度搜索 cnpm,进入npmmirror 镜像站https://npmmirror.com/ cmd窗口输入 npm install -g cnpm --registryhttps://registry.npmmirror.com...

web server apache tomcat11-01-官方文档入门介绍
前言 整理这个官方翻译的系列,原因是网上大部分的 tomcat 版本比较旧,此版本为 v11 最新的版本。 开源项目 同时也为从零手写实现 tomcat 提供一些基础和特性的思路。 minicat 别称【嗅虎】心有猛虎,轻嗅蔷薇。 系列文章 web server apac…...

java的总结
由于最近已经开始做项目了,所以对java的基础知识的学习都是一个离散化的状态没有一个很系统的学习,都是哪里不会就去学哪里。 先来讲一下前后端的区别吧 在我的理解前端就是:客户端在前端进行点击输入数据,前端将这些数据整合起来…...
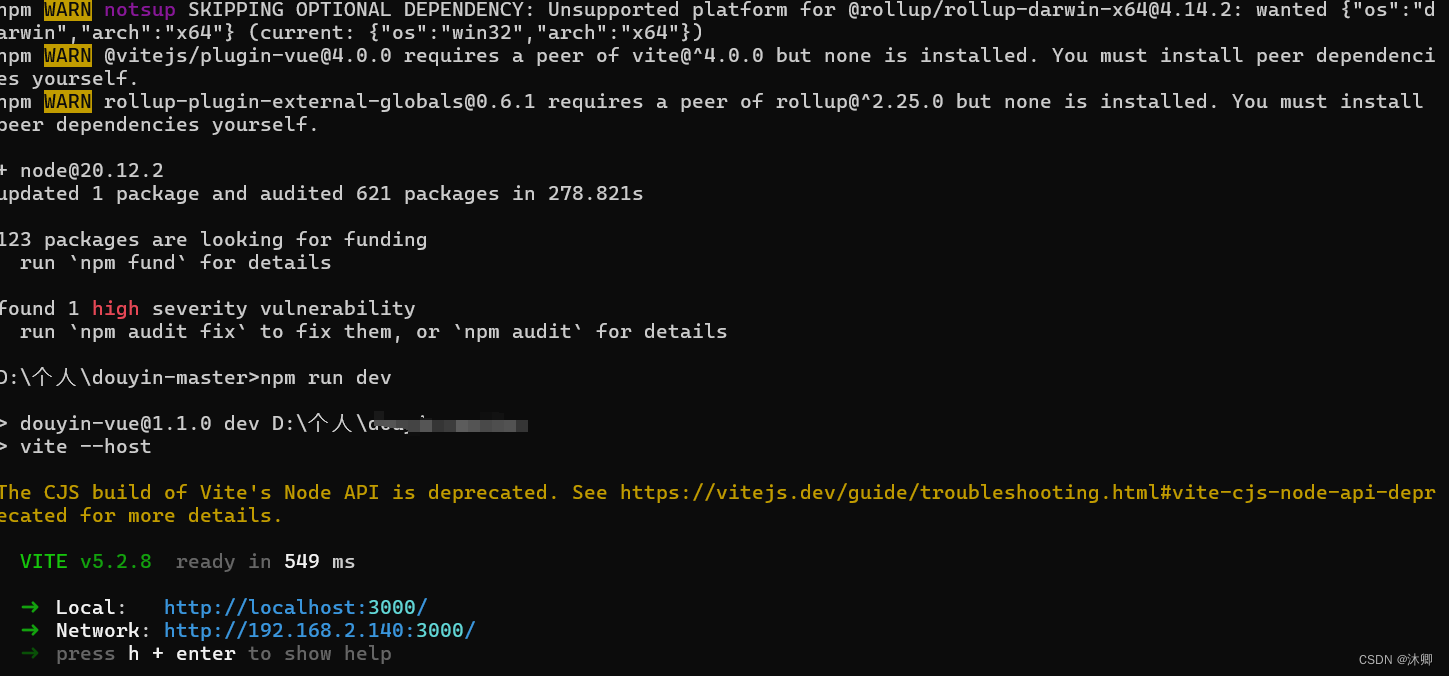
解决npm run dev跑项目,发现node版本不匹配,怎么跑起来?【已解决】
首先问题点就是我们npm run dev 运行项目的时候发现出错,跑不起来,类型下面这种 这里的出错的原因在于我们的node版本跟项目的版本不匹配 解决办法 我这里的问题是我的版本是node14的,然后项目需要node20的,执行下面的就可以正…...
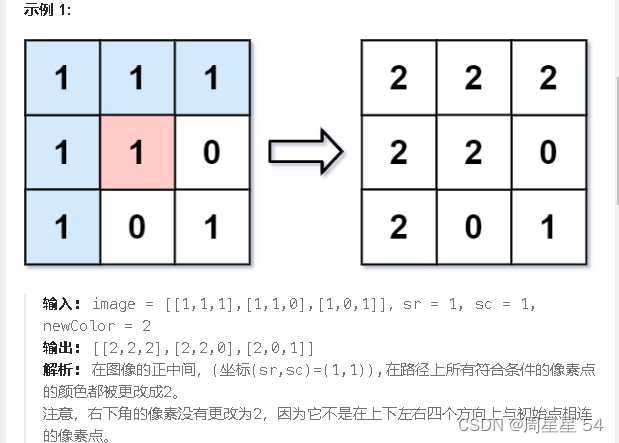
flood_fill 算法|图形渲染
flood fill 算法常常用来找极大连通子图,这是必须掌握的基本算法之一! 图形渲染 算法原理 我们可以利用DFS遍历数组把首个数组的值记为color,然后上下左右四个方向遍历二维数组数组如果其他方块的值不等于color 或者越界就剪枝 return 代码…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...
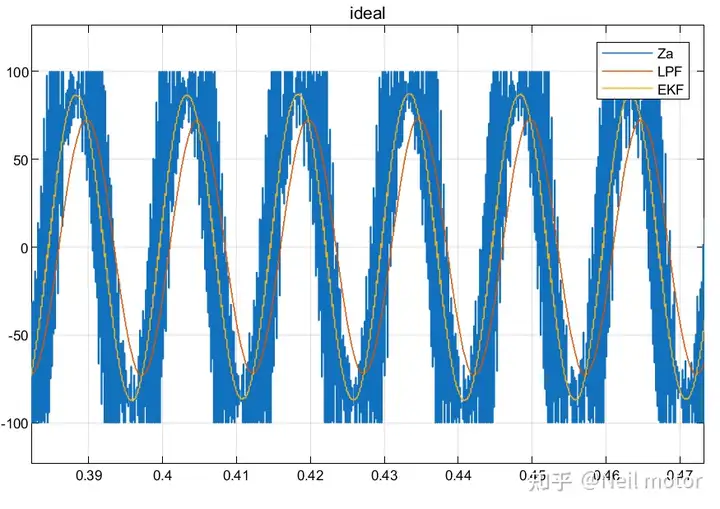
永磁同步电机无速度算法--基于卡尔曼滤波器的滑模观测器
一、原理介绍 传统滑模观测器采用如下结构: 传统SMO中LPF会带来相位延迟和幅值衰减,并且需要额外的相位补偿。 采用扩展卡尔曼滤波器代替常用低通滤波器(LPF),可以去除高次谐波,并且不用相位补偿就可以获得一个误差较小的转子位…...

前端调试HTTP状态码
1xx(信息类状态码) 这类状态码表示临时响应,需要客户端继续处理请求。 100 Continue 服务器已收到请求的初始部分,客户端应继续发送剩余部分。 2xx(成功类状态码) 表示请求已成功被服务器接收、理解并处…...