【R: mlr3:超参数调优】
本次分享官网教程地址
https://mlr3book.mlr-org.com/chapters/chapter4/hyperparameter_optimization.html
型调优 当你对你的模型表现不满意时,你可能希望调高你的模型表现,可通过超参数调整或者尝试一个更加适合你的模型,本篇将介绍这些操作。本章主要包括3个部分的内容:超参数调整机器学习模型都有默认的超参数,但是这些超参数不能根据数据自动调整,往往不能得到更好的性能表现。但是手动调整往往也不能获得最佳的表现,mlr3包含自动调参的策略,在此包中实现自动调参,需要指定:搜索空间(search_space),优化算法(调参方法),评估方法(重抽样策略),评价指标。特征选择主要是通过mlr3filter和mlr3select包进行。嵌套重抽样调整超参数 很多人戏称调参的过程就像是"炼丹"!确实差不多,而且很多时候你调整后的结果可能还不如默认的结果好!这就好比打游戏,“一顿操作猛如虎,一看战绩0比5”!模型调优一定要基于对算法和数据的理解进行,不是随便调的。我们使用著名的糖尿病数据集进行演示,首先创建任务library(mlr3verse) ## 载入需要的程辑包:mlr3 task <- tsk("pima") print(task) ## <TaskClassif:pima> (768 x 9) ## * Target: diabetes ## * Properties: twoclass ## * Features (8): ## - dbl (8): age, glucose, insulin, mass, pedigree, pregnant, pressure, ## triceps选择算法,查看算法支持的超参数learner <- lrn("classif.rpart") learner$param_set ## <ParamSet> ## id class lower upper nlevels default value ## 1: cp ParamDbl 0 1 Inf 0.01 ## 2: keep_model ParamLgl NA NA 2 FALSE ## 3: maxcompete ParamInt 0 Inf Inf 4 ## 4: maxdepth ParamInt 1 30 30 30 ## 5: maxsurrogate ParamInt 0 Inf Inf 5 ## 6: minbucket ParamInt 1 Inf Inf <NoDefault[3]> ## 7: minsplit ParamInt 1 Inf Inf 20 ## 8: surrogatestyle ParamInt 0 1 2 0 ## 9: usesurrogate ParamInt 0 2 3 2 ## 10: xval ParamInt 0 Inf Inf 10 0 1 在这里我们选择调整复杂度参数cp和最小分支参数minsplit,并设定超参数的调整范围:search_space <- ps(cp = p_dbl(lower = 0.001, upper = 0.1),minsplit = p_int(lower = 1, upper = 10) ) search_space ## <ParamSet> ## id class lower upper nlevels default value ## 1: cp ParamDbl 0.001 0.1 Inf <NoDefault[3]> ## 2: minsplit ParamInt 1.000 10.0 10 <NoDefault[3]>然后选择重抽样方法和性能指标hout <- rsmp("holdout", ratio = 0.7) measure <- msr("classif.ce") 1 2 接下来进行调参有两种方法。方法一:通过tuninginstancesinglecrite和tuner训练模型 library(mlr3tuning) ## 载入需要的程辑包:paradoxevals20 <- trm("evals", n_evals = 20) # 设定何时停止训练# 统一放入instance中 instance <- TuningInstanceSingleCrit$new(task = task,learner = learner,resampling = hout,measure = measure,terminator = evals20,search_space = search_space ) instance ## <TuningInstanceSingleCrit> ## * State: Not optimized ## * Objective: <ObjectiveTuning:classif.rpart_on_pima> ## * Search Space: ## <ParamSet> ## id class lower upper nlevels default value ## 1: cp ParamDbl 0.001 0.1 Inf <NoDefault[3]> ## 2: minsplit ParamInt 1.000 10.0 10 <NoDefault[3]> ## * Terminator: <TerminatorEvals> ## * Terminated: FALSE ## * Archive: ## <ArchiveTuning> ## Null data.table (0 rows and 0 cols)关于何时停止训练,mlr3给出了5种方法:Terminate after a given time:一定时间后停止 Terninate after a given number of iterations:特定迭代次数后停止 Terminate after a specific performance has been reached:达到特定性能指标后停止 Terminate when tuning dose find a better configuration for a given number of iterations:在给定迭代次数中确实找到表现很好的参数组合后停止 A combination of above in ALL or ANY fashon:上面几种方法组合 然后还需要设置超参数搜索的方法:mlr3tuning目前支持以下超参数搜索的方法:Grid search:网格搜索 Random search:随机搜索 Generalized simulated annealing Non-Linear optimization # 这里选择网格搜索 tuner <- tnr("grid_search", resolution = 5) # 网格搜索 1 2 接下来就是进行训练模型,上面我们设置了网格搜索的分辨率是5,我们有2个超参数需要调整,所以理论上一共有5 * 5 = 25个组合,但是在前面的停止搜索的方法中我们选择了n_evals = 20,所有实际上在评价完20个组合后就会停止了!#lgr::get_logger("mlr3")$set_threshold("warn") #lgr::get_logger("bbotk")$set_threshold("warn") # 减少屏幕打印内容tuner$optimize(instance) ## INFO [20:51:28.312] [bbotk] Starting to optimize 2 parameter(s) with '<TunerGridSearch>' and '<TerminatorEvals> [n_evals=20, k=0]' ## INFO [20:51:28.331] [bbotk] Evaluating 1 configuration(s) ## 省略输出 ## INFO [20:51:29.306] [bbotk] uhash ## INFO [20:51:29.306] [bbotk] 58eb421d-f0ed-4246-8430-3c1832ae615c ## INFO [20:51:29.309] [bbotk] Finished optimizing after 20 evaluation(s) ## INFO [20:51:29.310] [bbotk] Result: ## INFO [20:51:29.310] [bbotk] cp minsplit learner_param_vals x_domain classif.ce ## INFO [20:51:29.310] [bbotk] 0.02575 3 <list[3]> <list[2]> 0.2130435 ## cp minsplit learner_param_vals x_domain classif.ce ## 1: 0.02575 3 <list[3]> <list[2]> 0.2130435查看调整好的超参数:instance$result_learner_param_vals ## $xval ## [1] 0 ## ## $cp ## [1] 0.02575 ## ## $minsplit ## [1] 3查看模型性能: instance$result_y ## classif.ce ## 0.2130435 1查看每一次迭代的结果,只有20个:instance$archive ## <ArchiveTuning> ## cp minsplit classif.ce runtime_learners timestamp batch_nr ## 1: 0.026 3 0.21 0.02 2022-02-27 20:51:28 1 ## 2: 0.075 8 0.21 0.00 2022-02-27 20:51:28 2 ## 3: 0.050 5 0.21 0.00 2022-02-27 20:51:28 3 ## 4: 0.001 1 0.30 0.00 2022-02-27 20:51:28 4 ## 5: 0.100 3 0.21 0.02 2022-02-27 20:51:28 5 ## 6: 0.026 5 0.21 0.02 2022-02-27 20:51:28 6 ## 7: 0.100 8 0.21 0.01 2022-02-27 20:51:28 7 ## 8: 0.001 8 0.27 0.00 2022-02-27 20:51:28 8 ## 9: 0.001 5 0.28 0.00 2022-02-27 20:51:28 9 ## 10: 0.100 5 0.21 0.02 2022-02-27 20:51:28 10 ## 11: 0.075 10 0.21 0.00 2022-02-27 20:51:28 11 ## 12: 0.050 10 0.21 0.01 2022-02-27 20:51:28 12 ## 13: 0.075 5 0.21 0.00 2022-02-27 20:51:28 13 ## 14: 0.050 8 0.21 0.01 2022-02-27 20:51:29 14 ## 15: 0.001 10 0.26 0.00 2022-02-27 20:51:29 15 ## 16: 0.050 3 0.21 0.00 2022-02-27 20:51:29 16 ## 17: 0.050 1 0.21 0.02 2022-02-27 20:51:29 17 ## 18: 0.100 10 0.21 0.00 2022-02-27 20:51:29 18 ## 19: 0.075 1 0.21 0.01 2022-02-27 20:51:29 19 ## 20: 0.026 1 0.21 0.00 2022-02-27 20:51:29 20 ## warnings errors resample_result ## 1: 0 0 <ResampleResult[22]> ## 2: 0 0 <ResampleResult[22]> ## 3: 0 0 <ResampleResult[22]> ## 4: 0 0 <ResampleResult[22]> ## 5: 0 0 <ResampleResult[22]> ## 6: 0 0 <ResampleResult[22]> ## 7: 0 0 <ResampleResult[22]> ## 8: 0 0 <ResampleResult[22]> ## 9: 0 0 <ResampleResult[22]> ## 10: 0 0 <ResampleResult[22]> ## 11: 0 0 <ResampleResult[22]> ## 12: 0 0 <ResampleResult[22]> ## 13: 0 0 <ResampleResult[22]> ## 14: 0 0 <ResampleResult[22]> ## 15: 0 0 <ResampleResult[22]> ## 16: 0 0 <ResampleResult[22]> ## 17: 0 0 <ResampleResult[22]> ## 18: 0 0 <ResampleResult[22]> ## 19: 0 0 <ResampleResult[22]> ## 20: 0 0 <ResampleResult[22]>接下来就可以把训练好的超参数应用于模型,重新应用于数据:learner$param_set$values <- instance$result_learner_param_vals learner$train(task) 1 2 这个训练好的模型就可以用于预测了,使用learner$predict()即可!以上步骤写起来有些复杂,与tidymodels相比不够简洁好理解,我刚开始学习的时候经常记不住,后来版本更新后终于有了简便写法:instance <- tune(task = task,learner = learner,resampling = hout,measure = measure,search_space = search_space,method = "grid_search",resolution = 5,term_evals = 25 ) ## INFO [20:51:29.402] [bbotk] Starting to optimize 2 parameter(s) with '<TunerGridSearch>' and '<TerminatorEvals> [n_evals=25, k=0]' ## INFO [20:51:29.403] [bbotk] Evaluating 1 configuration(s) ## INFO [20:51:29.411] [mlr3] Running benchmark with 1 resampling iterations ## 省略。。。 ## INFO [20:51:30.535] [bbotk] 0.02575 10 <list[3]> <list[2]> 0.2347826instance$result_learner_param_vals ## $xval ## [1] 0 ## ## $cp ## [1] 0.02575 ## ## $minsplit ## [1] 10 instance$result_y ## classif.ce ## 0.2347826 learner$param_set$values <- instance$result_learner_param_vals learner$train(task)mlr3也支持同时设定多个性能指标:measures <- msrs(c("classif.ce","time_train")) # 设定多个评价指标evals20 <- trm("evals", n_evals = 20)instance <- TuningInstanceMultiCrit$new(task = task,learner = learner,resampling = hout,measures = measures,search_space = search_space,terminator = evals20 )tuner$optimize(instance) ## INFO [20:51:30.595] [bbotk] Starting to optimize 2 parameter(s) with '<TunerGridSearch>' and '<TerminatorEvals> [n_evals=20, k=0]' ## INFO [20:51:30.597] [bbotk] Evaluating 1 configuration(s) ## 省略输出。。。查看结果:instance$result_learner_param_vals ## [[1]] ## [[1]]$xval ## [1] 0 ## ## [[1]]$cp ## [1] 0.0505 ## ## [[1]]$minsplit ## [1] 1 ## ## ## [[2]] ## [[2]]$xval ## [1] 0 ## ## [[2]]$cp ## [1] 0.07525 ## ## [[2]]$minsplit ## [1] 1 ## ## ## [[3]] ## [[3]]$xval ## [1] 0 ## ## [[3]]$cp ## [1] 0.07525 ## ## [[3]]$minsplit ## [1] 10 ## ## ## [[4]] ## [[4]]$xval ## [1] 0 ## ## [[4]]$cp ## [1] 0.1 ## ## [[4]]$minsplit ## [1] 8 ## ## ## [[5]] ## [[5]]$xval ## [1] 0 ## ## [[5]]$cp ## [1] 0.02575 ## ## [[5]]$minsplit ## [1] 3 ## ## ## [[6]] ## [[6]]$xval ## [1] 0 ## ## [[6]]$cp ## [1] 0.07525 ## ## [[6]]$minsplit ## [1] 8 ## ## ## [[7]] ## [[7]]$xval ## [1] 0 ## ## [[7]]$cp ## [1] 0.1 ## ## [[7]]$minsplit ## [1] 3 ## ## ## [[8]] ## [[8]]$xval ## [1] 0 ## ## [[8]]$cp ## [1] 0.1 ## ## [[8]]$minsplit ## [1] 5 ## ## ## [[9]] ## [[9]]$xval ## [1] 0 ## ## [[9]]$cp ## [1] 0.02575 ## ## [[9]]$minsplit ## [1] 5 ## ## ## [[10]] ## [[10]]$xval ## [1] 0 ## ## [[10]]$cp ## [1] 0.07525 ## ## [[10]]$minsplit ## [1] 5 ## ## ## [[11]] ## [[11]]$xval ## [1] 0 ## ## [[11]]$cp ## [1] 0.0505 ## ## [[11]]$minsplit ## [1] 8 ## ## ## [[12]] ## [[12]]$xval ## [1] 0 ## ## [[12]]$cp ## [1] 0.0505 ## ## [[12]]$minsplit ## [1] 3 ## ## ## [[13]] ## [[13]]$xval ## [1] 0 ## ## [[13]]$cp ## [1] 0.07525 ## ## [[13]]$minsplit ## [1] 3 ## ## ## [[14]] ## [[14]]$xval ## [1] 0 ## ## [[14]]$cp ## [1] 0.0505 ## ## [[14]]$minsplit ## [1] 5 ## ## ## [[15]] ## [[15]]$xval ## [1] 0 ## ## [[15]]$cp ## [1] 0.02575 ## ## [[15]]$minsplit ## [1] 1 instance$rusult_y ## NULL以上就是第一种方法,接下来介绍第二种方法。方法二:通过autotuner训练模型 这种方式方法把调整参数、将调整好的参数应用于模型放到一起了,但是也需要提前设定好各种需要的参数。task <- tsk("pima") # 创建任务leanrer <- lrn("classif.rpart") # 选择学习器search_space <- ps(cp = p_dbl(0.001, 0.1),minsplit = p_int(1,10) ) # 设定搜索范围terminator <- trm("evals", n_evals = 10) # 设定停止标志tuner <- tnr("random_search") # 选择搜索方法resampling <- rsmp("holdout") # 选择重抽样方法measure <- msr("classif.acc") # 选择评价指标# 训练 at <- AutoTuner$new(learner = learner,resampling = resampling,search_space = search_space,measure = measure,tuner = tuner,terminator = terminator )自动选择最优参数并作用于数据:at$train(task) ## INFO [20:51:31.873] [bbotk] Starting to optimize 2 parameter(s) with '<OptimizerRandomSearch>' and '<TerminatorEvals> [n_evals=10, k=0]' ## INFO [20:51:31.882] [bbotk] Evaluating 1 configuration(s) ##省略巨多输出 ## INFO [20:51:32.332] [bbotk] 0.02278977 3 <list[3]> <list[2]> 0.7695312 at$predict(task) ## <PredictionClassif> for 768 observations: ## row_ids truth response ## 1 pos pos ## 2 neg neg ## 3 pos neg ## --- ## 766 neg neg ## 767 pos neg ## 768 neg neg这个方法也有个简便写法:auto_learner <- auto_tuner(learner = learner,resampling = resampling,measure = measure,search_space = search_space,method = "random_search",term_evals = 10 )auto_learner$train(task) ## INFO [20:51:32.407] [bbotk] Starting to optimize 2 parameter(s) with '<OptimizerRandomSearch>' and '<TerminatorEvals> [n_evals=10, k=0]' ## INFO [20:51:32.414] [bbotk] Evaluating 1 configuration(s) ## INFO [20:51:32.421] [mlr3] Running benchmark with 1 resampling iterations ## INFO [20:51:32.425] [mlr3] Applying learner 'classif.rpart' on task 'pima' (iter 1/1) ##省略巨多输出 auto_learner$predict(task) ## <PredictionClassif> for 768 observations: ## row_ids truth response ## 1 pos pos ## 2 neg neg ## 3 pos neg ## --- ## 766 neg neg ## 767 pos neg ## 768 neg neg超参数设定的方法 每次单独设置超参数的范围等可能会显得比较笨重无聊,mlr3也提供另外一种可以在选择学习器时进行设定超参数的方法。# 在选择学习器时设置超参数范围 learner <- lrn("classif.svm") learner$param_set$values$kernel <- "polynomial" learner$param_set$values$degree <- to_tune(lower = 1, upper = 3)print(learner$param_set$search_space()) ## <ParamSet> ## id class lower upper nlevels default value ## 1: degree ParamInt 1 3 3 <NoDefault[3]>但其实这样也有问题,这个方法要求你对算法很熟悉,能够记住所有超参数记忆它们在mlr3中的拼写!但很显然这有点困难,所有我还是推荐第一种,每次单独设置,记不住还可以查看一下具体的超参数。参数依赖 某些超参数只有在某些条件下才有效,比如支持向量机(SVM),它的degree参数只有在kernel是polynomial时才有效,这种情况也可以在mlr3中设置好。library(data.table) search_space = ps(cost = p_dbl(-1, 1, trafo = function(x) 10^x), # 可进行数据变换kernel = p_fct(c("polynomial", "radial")),degree = p_int(1, 3, depends = kernel == "polynomial") # 设置参数依赖 ) rbindlist(generate_design_grid(search_space, 3)$transpose(), fill = TRUE) ## cost kernel degree ## 1: 0.1 polynomial 1 ## 2: 0.1 polynomial 2 ## 3: 0.1 polynomial 3 ## 4: 0.1 radial NA ## 5: 1.0 polynomial 1 ## 6: 1.0 polynomial 2 ## 7: 1.0 polynomial 3 ## 8: 1.0 radial NA ## 9: 10.0 polynomial 1 ## 10: 10.0 polynomial 2 ## 11: 10.0 polynomial 3 ## 12: 10.0 radial NA
超参数设置
超参数设置是通过paradox包完成的。
reference-based objects
paradox是ParamHelpers的重写版,完全基于R6对象。
library("paradox")ps = ParamSet$new() ps2 = ps ps3 = ps$clone(deep = TRUE) print(ps) # ps2和ps3是一样的 ## <ParamSet> ## Empty.
ps$add(ParamLgl$new("a")) print(ps) ## <ParamSet> ## id class lower upper nlevels default value ## 1: a ParamLgl NA NA 2 <NoDefault[3]>
设定参数范围(parameter space)
paradox包里面的超参数主要有以下类型:
ParamInt: 整数
ParamDbl: 浮点数(小数)
ParamFct: 因子
ParamLgl: 逻辑值,TRUE / FALSE
ParamUty: 能取代任意值的参数
设定超参数范围的完整写法(前面几篇用到的是简写):
library("paradox")
parA = ParamLgl$new(id = "A")
parB = ParamInt$new(id = "B", lower = 0, upper = 10, tags = c("tag1", "tag2"))
parC = ParamDbl$new(id = "C", lower = 0, upper = 4, special_vals = list(NULL))
parD = ParamFct$new(id = "D", levels = c("x", "y", "z"), default = "y")
parE = ParamUty$new(id = "E", custom_check = function(x) checkmate::checkFunction(x))
相关文章:

【R: mlr3:超参数调优】
本次分享官网教程地址 https://mlr3book.mlr-org.com/chapters/chapter4/hyperparameter_optimization.html 型调优 当你对你的模型表现不满意时,你可能希望调高你的模型表现,可通过超参数调整或者尝试一个更加适合你的模型,本篇将介绍这些操…...
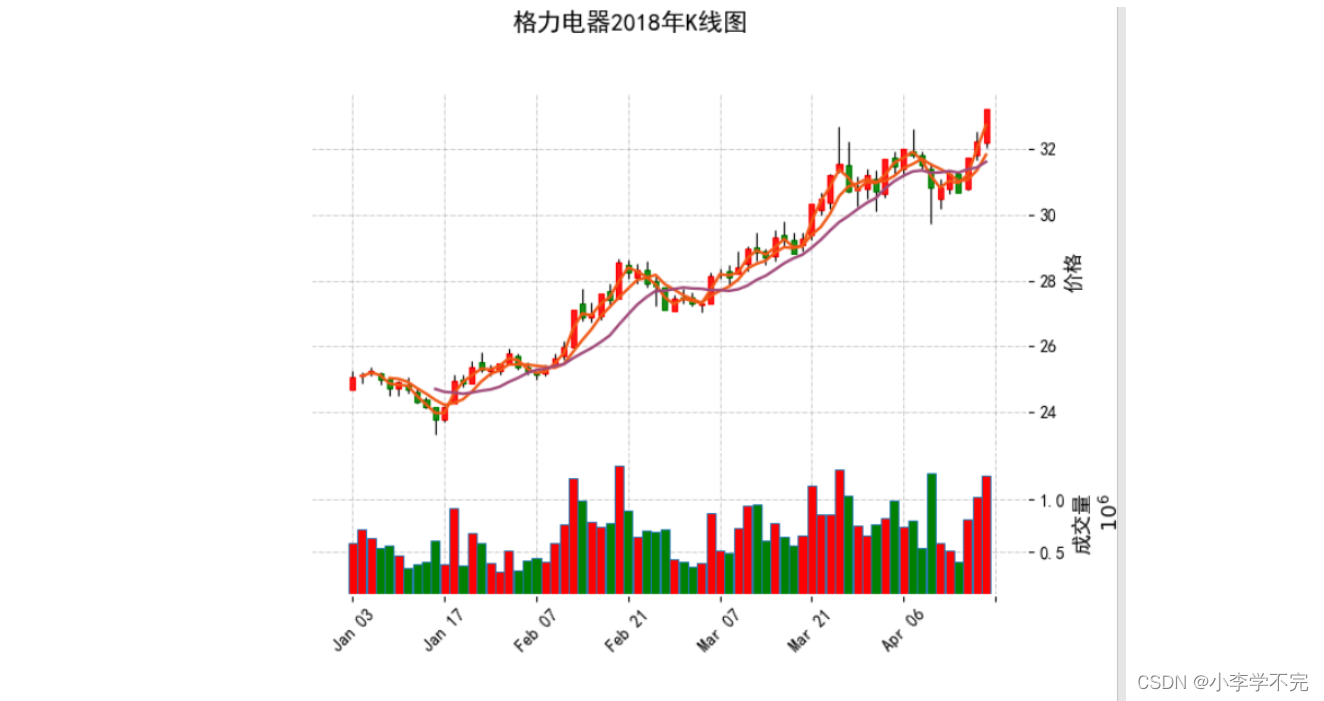
使用Pandas实现股票交易数据可视化
一、折线图:展现股价走势 1.1、简单版-股价走势图 # 简洁版import pandas as pdimport matplotlib.pyplot as plt# 读取CSV文件df pd.read_csv(../数据集/格力电器.csv)data df[[high, close]].plot()plt.show() 首先通过df[[high,close]]从df中获取最高价和收盘…...

蓝桥杯刷题-乌龟棋
312. 乌龟棋 - AcWing题库 /* 状态表示:f[b1,b2,b3,b4]表示所有第 i种卡片使用了 bi张的走法的最大分值。状态计算:将 f[b1,b2,b3,b4]表示的所有走法按最后一步选择哪张卡片分成四类:第 i类为最后一步选择第 i种卡片。比如 i2,则…...

美国纽扣电池认证标准要求16 CFR 第 1700和ANSI C18.3M标准
法规背景 为了纪念瑞茜哈姆史密斯(Reese Hamsmith)美国德州一名于2020年12月因误食遥控器里的纽扣电池而不幸死亡的18个月大的女婴。 美国国会于2022年8月16日颁布了H.R.5313法案(第117-171号公众法)也称为瑞茜法案(Reese’s Law)…...

华硕ROG幻16笔记本电脑模式切换管理工具完美替代华硕奥创中心管理工具
文章目录 华硕ROG幻16笔记本电脑模式切换管理工具完美替代华硕奥创中心管理工具1. 介绍2. 下载3. 静音模式、平衡模式、增强模式配置4. 配置电源方案与模式切换绑定5. 启动Ghelper控制面板6. 目前支持的设备型号 华硕ROG幻16笔记本电脑模式切换管理工具完美替代华硕奥创中心管理…...
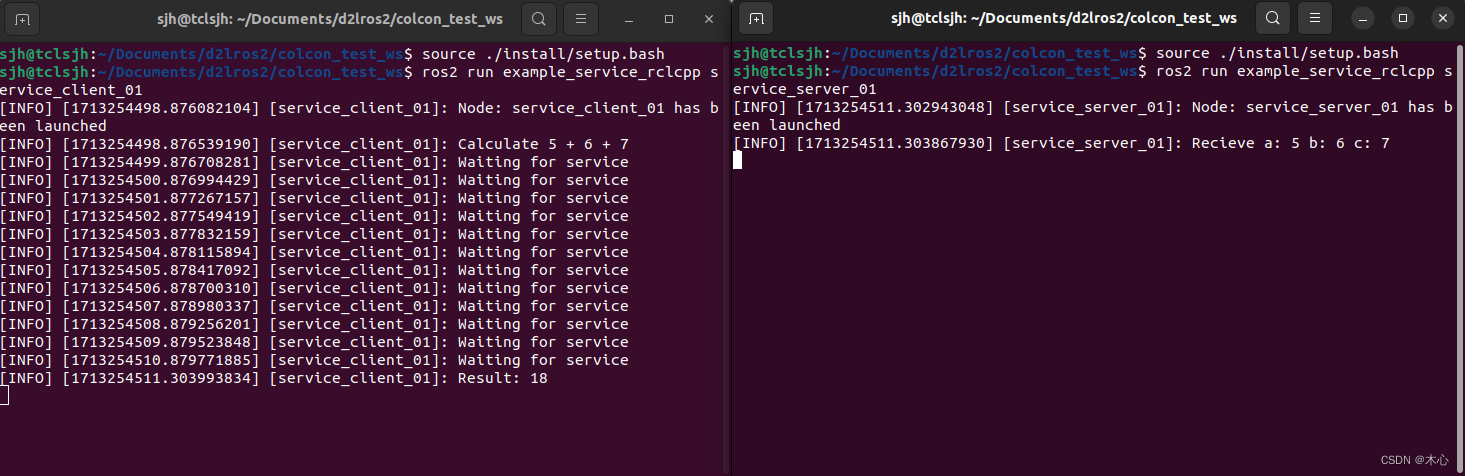
【ROS2笔记六】ROS2中自定义接口
6.ROS2中自定义接口 文章目录 6.ROS2中自定义接口6.1接口常用的CLI6.2标准的接口形式6.3接口的数据类型6.4自定义接口Reference 在ROS2中接口interface是一种定义消息、服务或动作的规范,用于描述数据结构、字段和数据类型。ROS2中的接口可以分为以下的几种消息类型…...

设计模式-代理模式(Proxy)
1. 概念 代理模式(Proxy Pattern)是程序设计中的一种结构型设计模式。它为一个对象提供一个代理对象,并由代理对象控制对该对象的访问。 2. 原理结构图 抽象角色(Subject):这是一个接口或抽象类࿰…...

中伟视界:智慧矿山智能化预警平台功能详解
矿山智能预警平台是一种高度集成化的安全监控系统,它能够提供实时的监控和报警功能,帮助企业和机构有效预防和响应潜在的安全威胁。以下是矿山智能预警平台的一些关键特性介绍: 报警短视频生成: 平台能够在检测到报警时自动生成短…...

如何在PPT中获得网页般的互动效果
如何在PPT中获得网页般的互动效果 效果可以看视频 PPT中插入网页有互动效果 当然了,获得网页般的互动效果,最简单的方法就是在 PPT 中插入网页呀。 那么如何插入呢? 接下来为你讲解如何获得(此方法在 PowerPoint中行得通&#…...
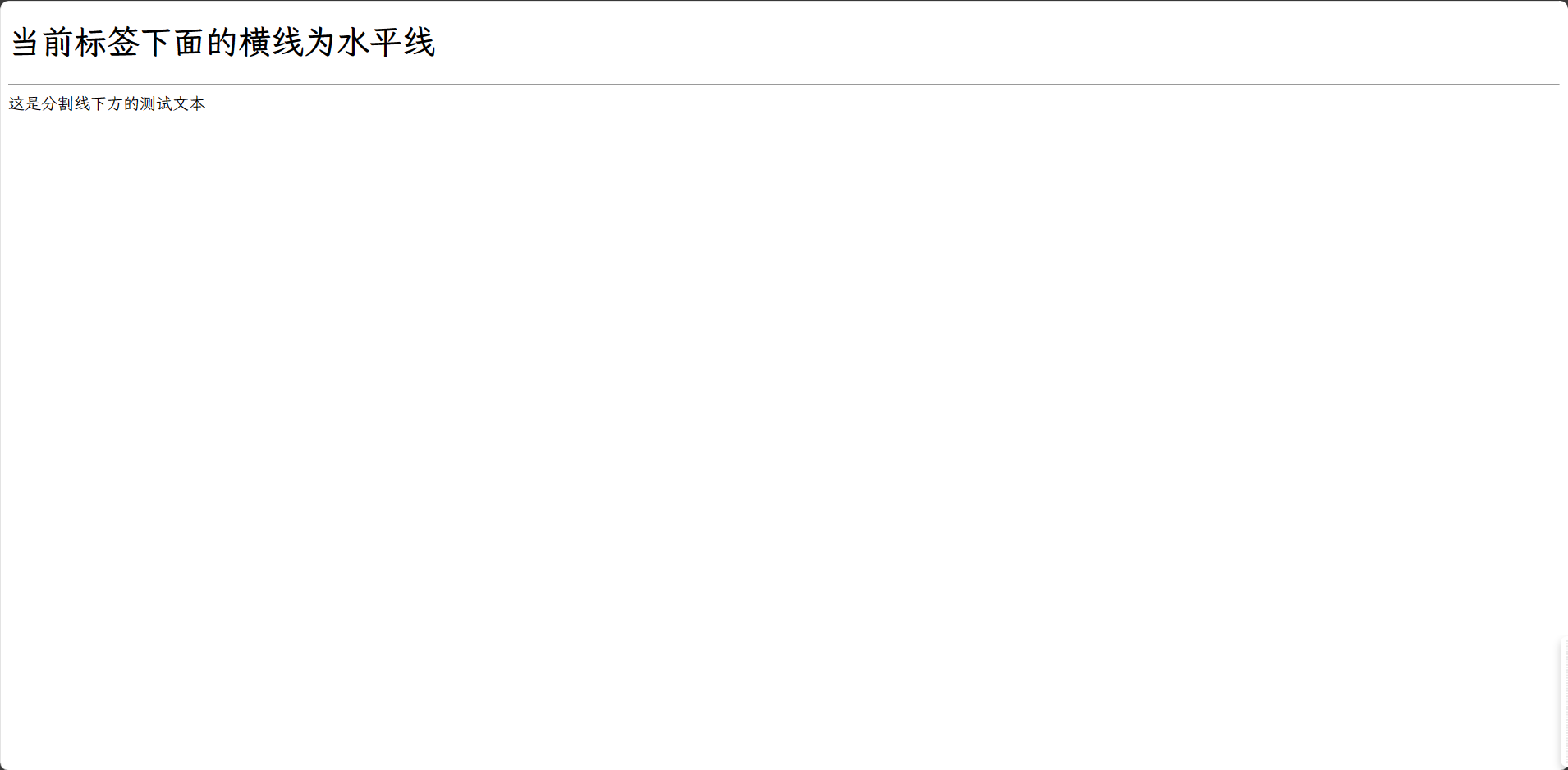
HTML段落标签、换行标签、文本格式化标签与水平线标签
目录 HTML段落标签 HTML换行标签 HTML格式化标签 加粗标签 倾斜标签 删除线标签 下划线标签 HTML水平线标签 HTML段落标签 在网页中,要把文字有条理地显示出来,就需要将这些文字分段显示。在 HTML 标签中,<p>标签用于定义段落…...

NVIC简介
NVIC(Nested Vectored Interrupt Controller)是ARM处理器中用于中断管理的一个重要硬件模块。它负责处理来自多个中断源的中断请求,并根据中断的优先级来安排处理器执行相应的中断服务例程(ISR)。NVIC是ARM Cortex-M系…...
LeetCode-924. 尽量减少恶意软件的传播【深度优先搜索 广度优先搜索 并查集 图 哈希表】
LeetCode-924. 尽量减少恶意软件的传播【深度优先搜索 广度优先搜索 并查集 图 哈希表】 题目描述:解题思路一:解题思路二:0解题思路三:0 题目描述: 给出了一个由 n 个节点组成的网络,用 n n 个邻接矩阵图…...
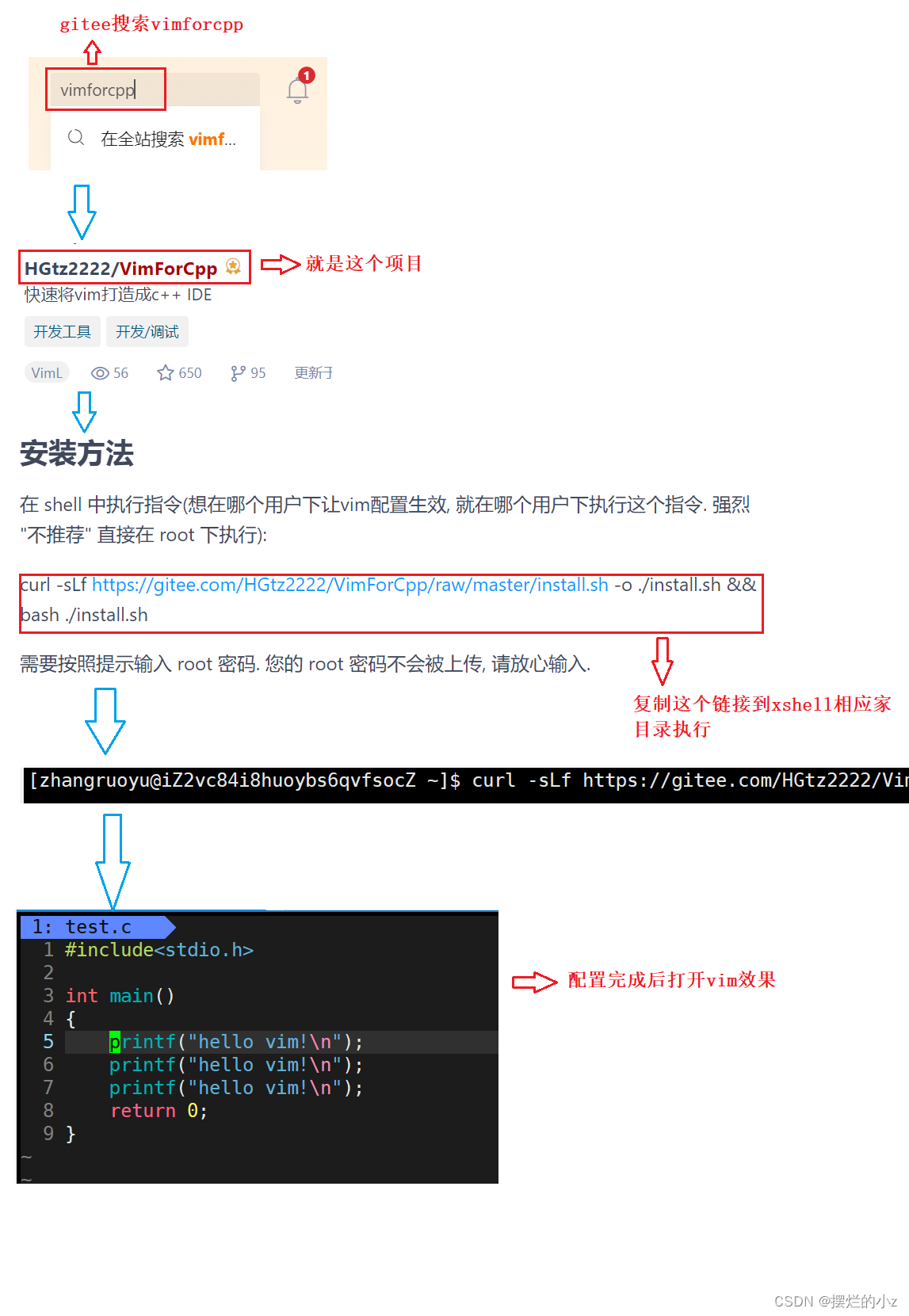
【linux】yum 和 vim
yum 和 vim 1. Linux 软件包管理器 yum1.1 什么是软件包1.2 查看软件包1.3 如何安装软件1.4 如何卸载软件1.5 关于 rzsz 2. Linux编辑器-vim使用2.1 vim的基本概念2.2 vim的基本操作2.3 vim命令模式命令集2.4 vim底行模式命令集2.5 vim操作总结补充:vim下批量化注释…...

excel试题转word格式
序号试题选项答案 格式如上。输出后在做些适当调整就可以。 import pandas as pd from docx import Document from docx.shared import Inches# 读取Excel文件 df pd.read_excel(r"你的excel.xlsx")# 创建一个新的Word文档 doc Document()# 添加标题 doc.add_headi…...
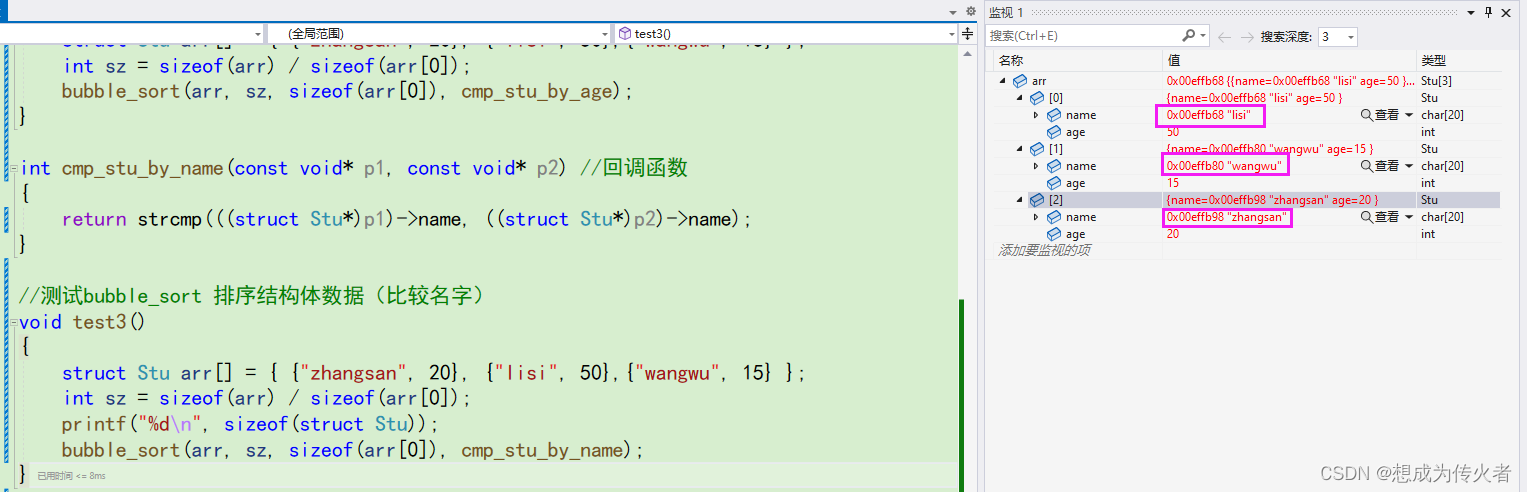
C语言学习笔记之指针(二)
指针基础知识:C语言学习笔记之指针(一)-CSDN博客 目录 字符指针 代码分析 指针数组 数组指针 函数指针 代码分析(出自《C陷阱和缺陷》) 函数指针数组 指向函数指针数组的指针 回调函数 qsort() 字符指针 一…...

在Debian 12系统上安装Docker
Docker 在 Debian 12 上的安装 安装验证测试更多信息 引言 在现代的开发环境中,容器技术发挥着至关重要的作用。Docker 提供了快速、可靠和易于使用的容器化解决方案,使开发人员和 DevOps 专业人士能够以轻松的方式将应用程序从一个环境部署到另一个环…...

策略者模式(代码实践C++/Java/Python)————设计模式学习笔记
文章目录 1 设计目标2 Java2.1 涉及知识点2.2 实现2.2.1 实现两个接口飞行为和叫行为2.2.2 实现Duck抽象基类(把行为接口作为类成员)2.2.3 实现接口飞行为和叫行为的具体行为2.2.4 具体实现鸭子2.2.5 模型调用 3 C(用到了大量C2.0的知识&…...
)
vue2/Vue3项目中,通过请求接口来刷新列表中的某个字段(如:Axios)
vue2/Vue3项目中,通过请求接口来刷新列表中的某个字段。可以使用 Vue 的异步请求库(如 Axios)来发送请求,并在请求成功后更新相应的字段。 示例如下(Vue2): 简单的示例如下,假设列…...

Java多线程锁定
前言 利用多线程编程虽然能极大地提升运行效率,但是多线程本身的不稳定也会带来一系列的问题,其中最经典莫过于售票问题;这时就需要人为地加以限制和干涉已解决问题,譬如今日之主题——锁定。 锁定是我们在多线程中用来解决售票…...
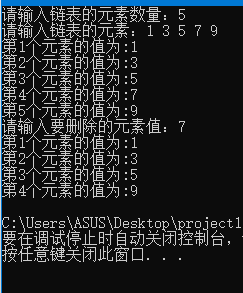
【C 数据结构】单链表
文章目录 【 1. 基本原理 】1.1 链表的节点1.2 头指针、头节点、首元节点 【 2. 链表的创建 】2.0 创建1个空链表(仅有头节点)2.1 创建单链表(头插入法)*2.2 创建单链表(尾插入法) 【 3. 链表插入元素 】【…...

ARM指令集优化:MVN、ORR与PLD指令深度解析
1. ARM指令集基础与优化技术概览在嵌入式系统和低功耗计算领域,ARM架构凭借其精简高效的指令集设计占据了主导地位。作为ARMv7/v8架构的核心组成部分,逻辑运算指令和内存预取指令对程序性能有着决定性影响。MVN(位取反)、ORR&…...

100GbE技术演进:背板PAM4与光模块25G的路线之争
1. 高速以太网技术演进中的十字路口:100GbE的“戏剧性”挑战在通信与网络设备、半导体设计与制造这个圈子里待久了,你会发现技术标准的制定过程,其精彩程度丝毫不亚于一部精心编排的戏剧。尤其是当我们谈论到以太网,这个支撑起全球…...

告别Windows!手把手教你用Proxmox虚拟机零成本体验深度Deepin 20.6
在Proxmox虚拟环境中优雅体验Deepin:技术爱好者的零成本尝鲜指南 对于技术爱好者而言,尝试新操作系统总伴随着两难:既想深度体验系统特性,又担心影响现有工作环境。Proxmox VE作为开源的虚拟化平台,配合Deepin这一国产…...

植物大战僵尸95版下载2026最新版及与原本区别介绍
一、游戏版本简介 植物大战僵尸95版是基于官方原版修改优化的经典改版,也是国内玩家知名度最高、流传最广的怀旧改版之一。该版本保留原版全部关卡、场景、背景音乐以及基础玩法,没有大幅度颠覆原作设定,仅对植物属性、僵尸数值、判定机制进…...

降AI率软件双降能力测评:嘎嘎降一次到位vs两套工具反复打架!
降AI率软件双降能力测评:嘎嘎降一次到位vs两套工具反复打架! 「先降 AI 再降重」两步流程的真实代价 我硕士论文用 DeepSeek 写过几个章节,送维普测出来——AI 率 55%,重复率 28%。两个都超学校 20% 严标准。 朋友推荐我「先买…...
)
企业级Angular微前端架构中,Claude如何安全介入模块拆分与契约校验(含TS类型推导审计日志)
更多请点击: https://intelliparadigm.com 第一章:企业级Angular微前端架构中Claude介入的边界与安全基线 在企业级 Angular 微前端系统中,将 Claude 类大语言模型(LLM)作为辅助开发工具引入时,必须严格界…...

无人机协议
1. MAVLink协议 概述:MAVLink是一种轻量级、低带宽的无人机通信协议,它支持点对点、广播和多播通信,并且可以在不同的平台上使用。应用:MAVLink协议广泛应用于PX4、ArduPilot等开源飞控系统中,用于地面站和无人机之间…...

别再被格式拖后腿了!Paperxie 用这招让本科论文排版一步到 “校标”
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能格式排版/文献综述/AI PPThttps://www.paperxie.cn/format/typesettinghttps://www.paperxie.cn/format/typesetting 你有没有过这种经历:导师只改了一句 “格式不对,重排”,你对着 Wor…...

086、Python数据压缩与归档:zipfile与tarfile实战笔记
086、Python数据压缩与归档:zipfile与tarfile实战笔记 一、从线上故障说起 上周排查一个生产环境问题:某服务每天生成的日志文件把磁盘撑满了。 查看代码发现,开发同事用 open().write() 直接写文本,一年下来积累了上千个文件。 其实这类场景最适合用压缩归档——既节省空…...

在自动化脚本中集成Taotoken实现按需调用不同大模型的能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化脚本中集成Taotoken实现按需调用不同大模型的能力 对于需要处理多种任务的自动化脚本,单一模型往往难以满足所…...