关联规则Apriori算法
1.前置知识
经典应用场景:购物车商品的关联规则。
符号表示:
I代表项集,项是可能出现的值,例如购物车中能有尿布、啤酒、奶粉等,I={尿布、啤酒、奶粉},尿布是项
K代表I中包含的项的数目,上面的k=3
事务T,是项的子集,一个父亲进入超市买了啤酒和尿布,这里的事务是{尿布,啤酒}
D代表事务库,相当于超市的系统账单
支持度(存在数量):support(尿布奶粉) = 包含尿布奶粉的事务条数/总的事务条数,换句话说,尿布奶粉同时购买的购物记录条数/超市总的购物记录条数 ,绝对支持是出现次数,相对支持是频率。一般都是说的P,频率。
可信度/置信度:confidence(A->B) = support(AB)/support(A),也就是单从包含A的购物记录中找出B存在的记录,得到一个存在比值。
频繁项集:也就是项集出现的频率>minsup(最小支持度)。
强关联规则 R :关联项集频率>minsup and 关联项集置信度>minconf
提升度LIFT:顾名思义:LIFT(A=>B)代表商品 A 的出现,对商品 B 的出现概率提升的”程度 。所以提升度公式是 AB置信度/B支持度 = P(A->B)/P(B) = P(AB)/(P(A)*P(B))。这个公式背后的意思就是 B在含A事务集中的占比/B在所有事务中的占比。
提升度>1代表关联关系强,=1代表没有关系,<1代表 负 关联关系。
性质**:频繁项集的子集仍为频繁项集,非频繁项集的超集仍为非频繁项集。
很好理解,频繁项集出现多少次,子集就出现多少次,当然频繁。非频繁项集出现频率低,包含它的超集出现次数只能是最多等于它。
2.Apriori-找关联规则的算法
关联规则的寻找分为两步:1.寻找频繁项集 2.从频繁项集中寻找>=最小置信度的规则
频繁项集用Lk表示,可能包括频繁项集的集合用Ck表示(C全名可能是Collection?)。k代表集合中项的个数。
Apriori是从频繁1项集L1生成频繁2项集L2,再用频繁2项集L2生成频繁3项集L3的算法.又名Level-wise.
具体过程:首先项集itemsets里的每一条项集itemset里的项item必须按照排序,如果是名字,按拼音排序,排序后是为了方便比对,从Lk-1生成Lk,需要用 Lk-1和 Lk-1进行组合生成组合,组合的规则是循环拿出itemset1(记作l1) in Lk-1,itemset2(记作l2) in Lk-1,l1、l2前 k-2个数 必须相同,l1、l2最后一个数坐标是k-1必须不同。例如 l1 {橘子,苹果,牛奶}和l2{橘子,苹果,汽水},我要生成4项集,就要比对橘子=橘子,苹果=苹果,最后一个数牛奶!=汽水,然后组合在一起是{橘子,苹果,牛奶,汽水}。但是这种两两比对的方式会生成很多组合集,再拿去在总的事务库中扫描每一条事务记录,看是不是频繁项集,这样的搜索次数非常高。由此,Apriori算法引入先验属性。
先验属性剪枝就是,生成一个剪枝过的Ck,再到数据库里去搜索,剪枝过的Ck子集都是频繁子集,但是不能保证它本身就是频繁项集,生成Ck之前看到每一条itemset如果有k-1子项集不在Lk里的,删去,循环操作,生成Lk.因为上面所说的性质,也叫先验知识丢弃会剪枝,减少工作量的意思)。先从事务库D生成频繁项集L1,再从L1生成C2。这里就是因为不频繁项集的超集一定是不频繁项集,那我们就只能从L1中选取项集生成C2.
// 伪代码input:D(事务集),min_sup
output:L(频繁项集itemsets)L1 = find_fre_1_itemset(D); //这里先生成C1,还是L1都是一样的
for(k=2;Lk-1不为空;k++){Ck = apriori_generation(L k-1) //先验属性生成Ckfor each t 属于 D{ //循环扫描事务库集Ct = find_subsets(Ck,t) //找到事务库事务中也存在的 候选频繁项集(Ck中的)for each c 属于 Ct{c.count++ //循环将频繁项集的数量属性加1}}Lk = {c属于Ck|c.count>=min_sup}
}
return L(所有频繁项集)// 找到候选K项集
apriori_generation(Lk-1)for each itemset l1 in L k-1{for each itemset l2 in L k-1{// 集合要排序对齐,后面还要剪枝if (l1[0]==l2[0]) and (l1[1]==l2[1]) and ... and(l1[k-1]<l2[k-1]){c = l1Xl2}if has_infrequent_subsets(c,Lk-1){delete c}else{add c into Ck}}}return Ck//先验属性剪枝
has_infrequent_subsets(c,Lk-1)for each k-1 subset s in c{if s 不属于 Lk-1{return True}}return False实际举例
0.输入
D:
| 事务 | |
| 1 | I1,I2,I3,I4,I7 |
| 2 | I2,I3,I4,I5,I7 |
| 3 | I1,I3,I4I7 |
| 4 | I3,I4,I7 |
| 5 | I2,I3,I4,I5,I6,I7 |
min_sup = 2
1.生成L1
| 候选1项集 | sup_count |
| I1 | 2 |
| I2 | 3 |
| I3 | 5 |
| I4 | 5 |
| I5 | 2 |
| I6 | 1 |
| I7 | 5 |
min_sup筛选一下(写候选1的这个步骤也可以省去)
L1
| I1 | 2 |
| I2 | 3 |
| I3 | 5 |
| I4 | 5 |
| I5 | 2 |
| I7 | 5 |
2.生成候选2项集C2
L1XL1:
{I1,I2},{I1,I3},{I1,I4},{I1,I5},{I1,I7},
{I2,I3},{I2,I4},{I2,I5},{I2,I7}
{I3,I4},{I3,I5},{I3,I7}
{I4,I5},{I4,I7}
{I5,I7}
剪枝
注意候选2项集比较特殊,不用剪枝,因为k-1子集是频繁1项集,全部符合min_sup.后面的C3..Ck要剪枝。
3.生成L2
用c2循环事务库D,过滤不频繁项集
得
{I1,I3},{I1,I4},{I1,I7},
{I2,I3},{I2,I4},{I2,I5},
{I3,I4},{I3,I5},{I3,I7}
{I4,I5},{I4,I7}
{15,17}
4.生成C3
L2XL2:
{I1,I3,I4}(这举个例子,是I1,I3和I1,I4组合,那主要看I3,I4是不是频繁项集来剪枝),{I1,I3,I7},{I1,I4,I7}
{I2,I3,I4},{I2,I3,I5},{I2,I4,I5}
{I3,I4,I5},{I3,I4,I7},{I3,I5,I7},
{I4,I5,I7}
剪枝,循环每一个2项集看在不在L2里,都在。
5.生成L3
用c3循环事务库D,过滤不频繁项集
得
{I1,I3,I4},{I1,I3,I7},{I1,I4,I7}
{I2,I3,I4},{I2,I3,I5},{I2,I4,I5}
{I3,I4,I5},{I3,I4,I7},{I3,I5,I7},
{I4,I5,I7}
6.生成C4
L3XL3
{I1,I3,I4,I7}(记得顺序,{I1,I3,I4}和{I1,I4,I7}合不上,因为I1=I1,I3!=I4第二步不等于就结束了,为什么要前面全等于,最后一个不等于,如果能合得上有{I1,I3,I4,I7},那一定存在{I1,I3,I4}和{I1,I3,I7}是频繁项集,这个例子在上一步集合比较就已经出来这个结果了)
{I2,I3,I4,I5}
{I3,I4,I5,I7}
子集都在频繁项集,不剪枝。
7.生成L4
用C4循环事务库D,过滤不频繁项集
得
{I1,I3,I4,I7}
{I2,I3,I4,I5}
{I3,I4,I5,I7}
8.C5集合为空(第一个数没有相同得,l1!=I2,I1!=I3,I2!=I3)
9.L5集合为空,返回全部频繁项集
reference:
[1]Han Jiawei ,Kamber Micheline , Pei,Jian ."data mining "3rd ed 253 page
相关文章:

关联规则Apriori算法
1.前置知识 经典应用场景:购物车商品的关联规则。 符号表示: I代表项集,项是可能出现的值,例如购物车中能有尿布、啤酒、奶粉等,I{尿布、啤酒、奶粉},尿布是项 K代表I中包含的项的数目,上面的k3 事…...
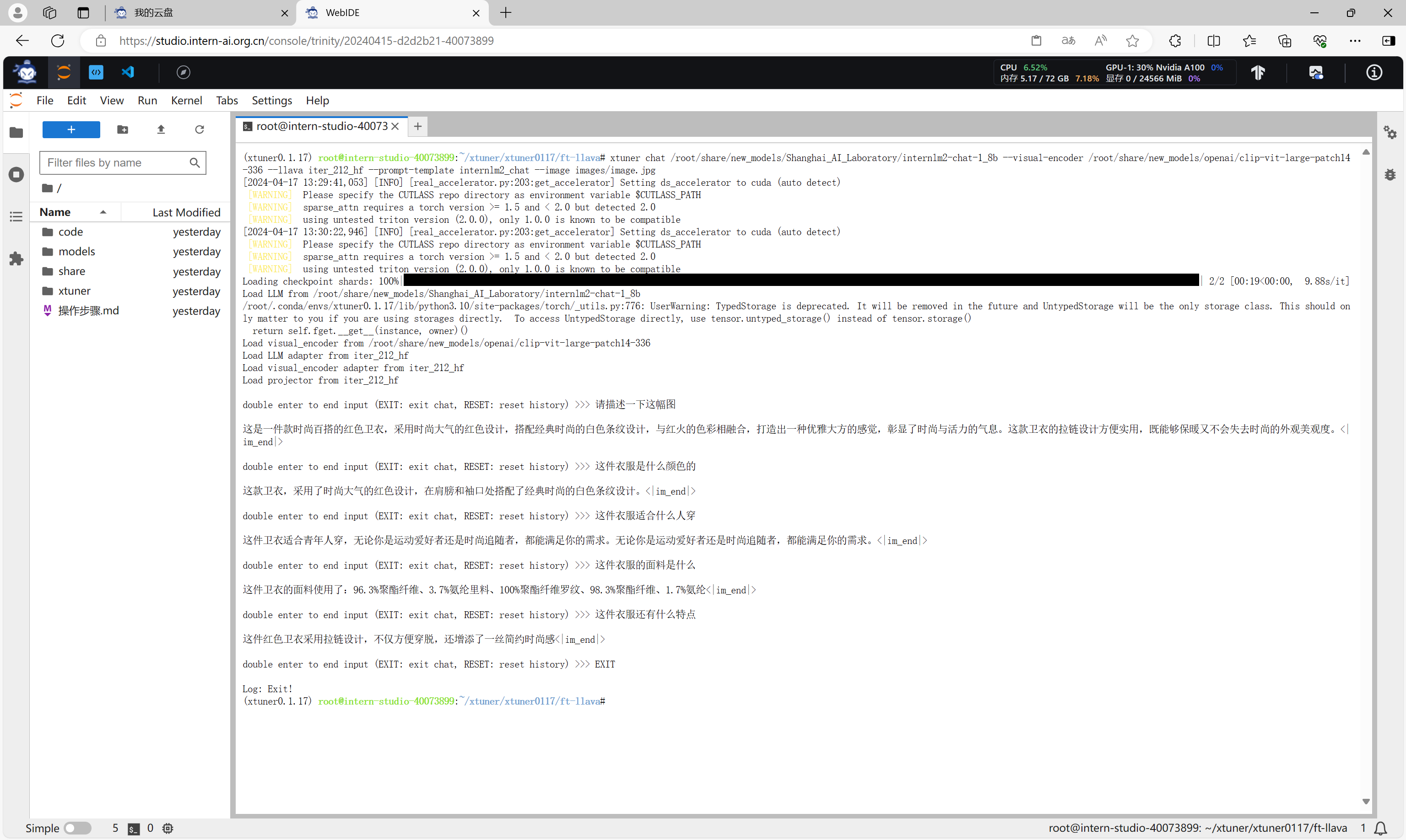
书生·浦语大模型全链路开源体系-第4课
书生浦语大模型全链路开源体系-第4课 书生浦语大模型全链路开源体系-第4课相关资源XTuner 微调 LLMXTuner 微调小助手认知环境安装前期准备启动微调模型格式转换模型合并微调结果验证 将认知助手上传至OpenXLab将认知助手应用部署到OpenXLab使用XTuner微调多模态LLM前期准备启动…...

HTML优化SEO
在网站开发中,除了关注设计和用户体验,SEO(搜索引擎优化)也是提升网站流量和可见度的关键。合理的HTML结构和元素运用能够帮助搜索引擎更好地理解页面内容,从而提高搜索排名。以下是一些基于HTML的SEO优化技巧…...
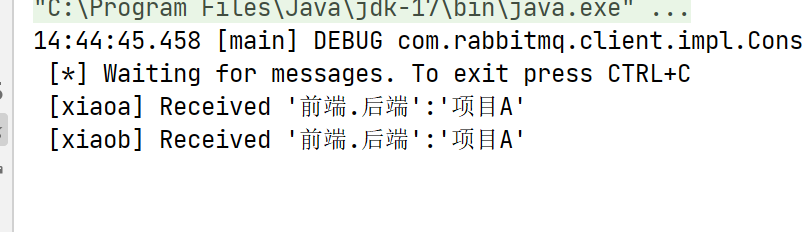
RabbitMQ-交换机
文章目录 交换机fanoutDirecttopicHeadersRPC 交换机 **交换机 **是消息队列中的一个组件,其作用类似于网络路由器。它负责将我们发送的消息转发到相应的目标,就像快递站将快递发送到对应的站点,或者网络路由器将网络请求转发到相应的服务器…...
)
mapreduce中的MapTask工作机制(Hadoop)
MapTask工作机制 MapReduce中的Map任务是整个计算过程的第一阶段,其主要工作是将输入数据分片并进行处理,生成中间键值对,为后续的Shuffle和Sort阶段做准备。 1. 输入数据的划分: 输入数据通常存储在分布式文件系统(…...

景区文旅剧本杀小程序亲子公园寻宝闯关系统开发搭建
要开发景区文旅剧本杀小程序亲子公园寻宝闯关系统,您需要考虑以下步骤: 1. 设计游戏场景和规则:根据亲子公园的主题和特点,设计适合亲子游玩的游戏场景和规则。您需要考虑游戏的安全性、趣味性和互动性,确保孩子们能够…...

性能优化---webpack优化
1、如何提高webpack打包速度 a、优化Loader--影响Loader打包速度的首要元素是Babel,Babel 会将代码转为字符串生成 AST,然后对 AST 继续进行转变最后再生成新的代码,项目越大,转换代码越多,效率就越低。先优化 Loader …...

YOLOv9改进策略 | 损失函数篇 | EIoU、SIoU、WIoU、DIoU、FocusIoU等二十余种损失函数
一、本文介绍 这篇文章介绍了YOLOv9的重大改进,特别是在损失函数方面的创新。它不仅包括了多种IoU损失函数的改进和变体,如SIoU、WIoU、GIoU、DIoU、EIOU、CIoU,还融合了“Focus”思想,创造了一系列新的损失函数。这些组合形式的…...

贪心算法-跳跃游戏
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。 示例 1: 输…...

sql知识总结二
一.报错注入 1.什么是报错注入? 这是一种页面响应形式,响应过程如下: 用户在前台页面输入检索内容----->后台将前台输入的检索内容无加区别的拼接成sql语句,送给数据库执行------>数据库将执行的结果返回给后台ÿ…...

VSCode和CMake实现C/C++开发
VSCode和CMake实现Ubuntu下C/C++开发总结 目录 0.简介1.Linux系统介绍2.开发环境搭建2.1 编译器,调试器安装2.2 CMake安装3.GCC编译器3.1 编译过程3.2 g++重要编译参数4.g++编译实战4.0 编译前4.1 直接编译4.2 生成库文件并编译4.3 编译后4.3.1 编译完成后的目录结构4.3.2 运行…...
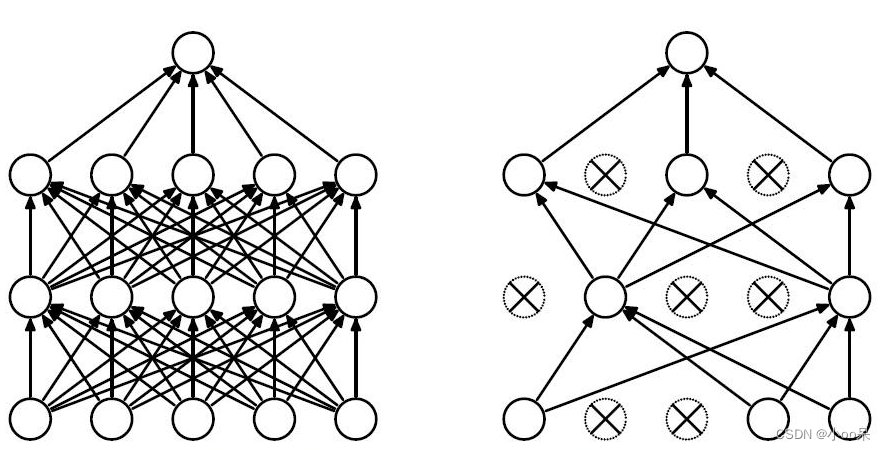
【机器学习300问】74、如何理解深度学习中L2正则化技术?
深度学习过程中,若模型出现了过拟合问题体现为高方差。有两种解决方法: 增加训练样本的数量采用正则化技术 增加训练样本的数量是一种非常可靠的方法,但有时候你没办法获得足够多的训练数据或者获取数据的成本很高,这时候正则化技…...
)
C语言程序设计每日一练(4)
完全平方数 首先,我们需要明确什么是完全平方数。完全平方数是指一个整数,它可以表示为另一个整数的平方。例如,1、4、9、16等都是完全平方数,因为它们分别是1、2、3、4的平方。 现在,让我们回到这个问题。我们知道这…...

m4p转换mp3格式怎么转?3个Mac端应用~
M4P文件格式的诞生伴随着苹果公司引入FairPlay版权管理系统,该系统旨在保护音频的内容。M4P因此而生,成为受到FairPlay系统保护的音频格式,常见于苹果设备的iTunes等平台。 MP3文件格式的多个优点 MP3格式的优点显而易见。首先,其…...
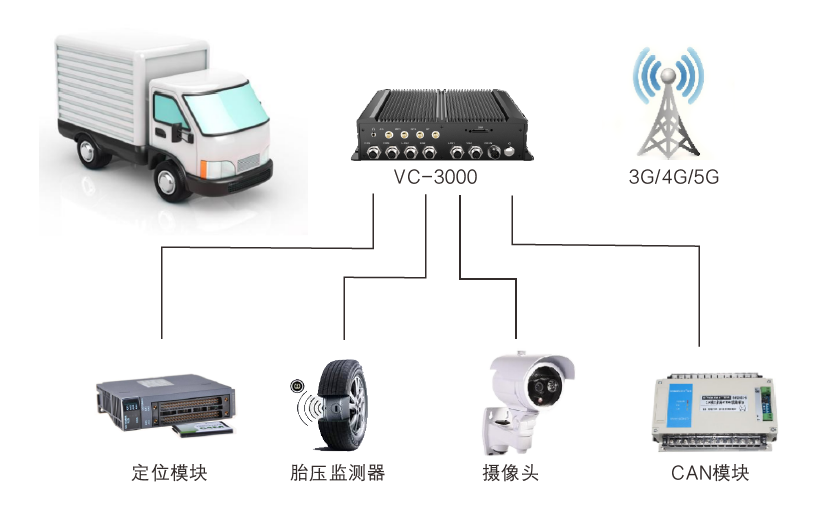
全国产化无风扇嵌入式车载电脑在车队管理嵌入式车载行业应用
车队管理嵌入式车载行业应用 车队管理方案能有效解决车辆繁多管理困难问题,配合调度系统让命令更加精确有效执行。实时监控车辆状况、行驶路线和位置,指导驾驶员安全有序行驶,有效降低保险成本、事故概率以及轮胎和零部件的磨损与损坏。 方…...

爬虫入门——Request请求
目录 前言 一、Requests是什么? 二、使用步骤 1.引入库 2.请求 3.响应 三.总结 前言 上一篇爬虫我们已经提及到了urllib库的使用,为了方便大家的使用过程,这里为大家介绍新的库来实现请求获取响应的库。 一、Requests是什么࿱…...
创建一个javascript公共方法的npm包,js-tool-big-box,发布到npm上,一劳永逸
前端javascript的公共方法太多了,时间日期的,数值的,字符串的,搞复制的,搞网络请求的,搞数据转换的,几乎就是每个新项目,有的拷一拷,没有的继续写,放个utils目…...
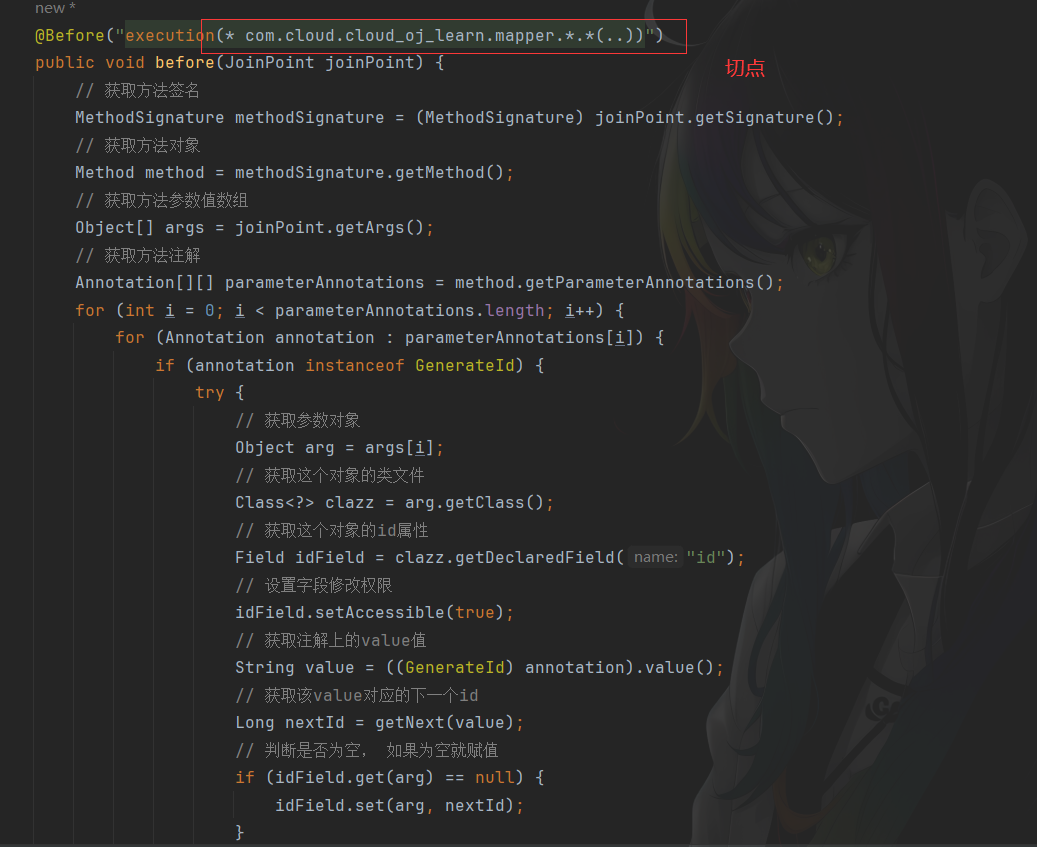
【在线OJ系统】自定义注解实现分布式ID无感自增
实现思路 首先自定义参数注解,然后根据AOP思想,找到该注解作用的切点,也就是mapper层对于mapper层的接口在执行前都会执行该aop操作:获取到对于的方法对象,根据方法对象获取参数列表,根据参数列表判断某个…...
35. UE5 RPG制作火球术技能
接下来,我们将制作技能了,总算迈进了一大步。首先回顾一下之前是如何实现技能触发的,然后再进入正题。 如果想实现我之前的触发方式的,请看此栏目的31-33篇文章,讲解了实现逻辑,这里总结一下: …...
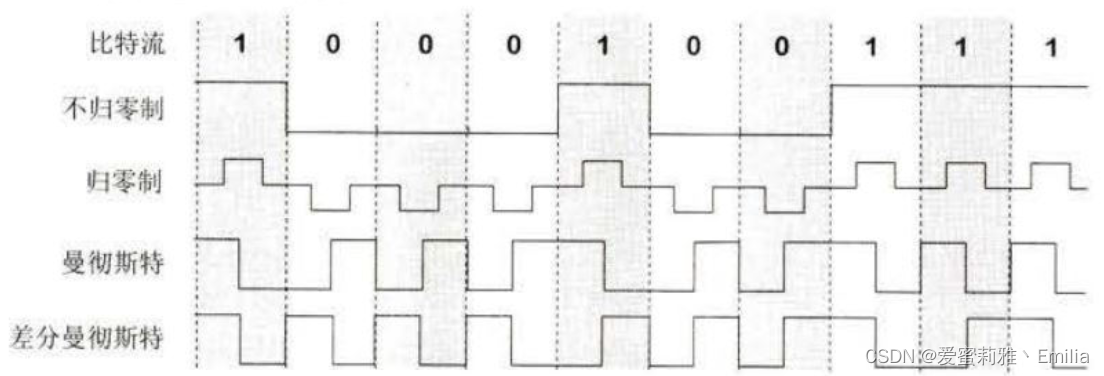
计算机网络 TCP/IP体系 物理层
一. TCP/IP体系 物理层 1.1 物理层的基本概念 物理层作为TCP/IP网络模型的最低层,负责直接与传输介质交互,实现比特流的传输。 要完成物理层的主要任务,需要确定以下特性: 机械特性:物理层的机械特性主要涉及网络…...

如何用wxhelper实现高效PC微信自动化开发:从原理到实战指南
如何用wxhelper实现高效PC微信自动化开发:从原理到实战指南 【免费下载链接】wxhelper Hook WeChat / 微信逆向 项目地址: https://gitcode.com/gh_mirrors/wx/wxhelper 在数字化办公与社交自动化需求日益增长的今天,PC微信作为重要的沟通工具&am…...

《Python 架构师的自动化哲学:从基础语法到企业级作业调度系统与 Airflow 止损实战》
《Python 架构师的自动化哲学:从基础语法到企业级作业调度系统与 Airflow 止损实战》 引言:凌晨三点的警报声与调度的艺术 你好,我是你的 Python 技术向导。在多年的软件架构与数据工程生涯中,我见过无数技术团队的变迁。如果说…...

PySimpleGUI实战:从零构建Python桌面应用界面
1. 为什么选择PySimpleGUI开发桌面应用 第一次接触Python GUI开发时,我被各种框架的选择难住了。Tkinter太原始,PyQt学习曲线陡峭,wxPython文档晦涩难懂。直到发现PySimpleGUI,这个号称"让GUI开发像写Python脚本一样简单&quo…...

直连链接获取:告别城通网盘下载烦恼的高效解决方案
直连链接获取:告别城通网盘下载烦恼的高效解决方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 在数字化办公与学习中,城通网盘作为常用的文件存储与分享平台,其下…...

4个突破性步骤:Cellpose-SAM细胞图像分析完全指南
4个突破性步骤:Cellpose-SAM细胞图像分析完全指南 【免费下载链接】cellpose a generalist algorithm for cellular segmentation with human-in-the-loop capabilities 项目地址: https://gitcode.com/gh_mirrors/ce/cellpose 在生物医学研究中,…...

如何快速掌握OpenEMS:开源能源管理系统的完整指南
如何快速掌握OpenEMS:开源能源管理系统的完整指南 【免费下载链接】openems OpenEMS - Open Source Energy Management System 项目地址: https://gitcode.com/gh_mirrors/op/openems 想要打造智能能源管理系统却不知从何入手?OpenEMS开源能源管理…...

ollama部署embeddinggemma-300m:轻量模型在政务知识图谱中的应用
ollama部署embeddinggemma-300m:轻量模型在政务知识图谱中的应用 1. 引言:为什么选择轻量级嵌入模型 在日常政务工作中,工作人员经常需要快速查找相关政策文件、法规条文和办事指南。传统的关键词搜索往往不够精准,比如搜索&quo…...

Curvature as Safety: A Geometric Framework for Detecting Cognitive Singularities in Agentic AI
Curvature as Safety: A Geometric Framework for Detecting Cognitive Singularities in Agentic AI (曲率即安全:面向Agentic AI认知奇点的几何检测框架)作者:方见华 单位:世毫九实验室第一部分:问题定义(The Hook&a…...

什么是OPC
### 先说一个残酷的事实 你在公司干了十年,名片上印着"总监""教授""专家"。 但那些头衔,离职那天就跟你没关系了。 你带过的团队、做过的项目、写过的PPT,公司服务器一关,痕迹全无。 你真正能带走的…...

爬虫自动化:数据采集与智能运维实战,人形机器人的发展历程、技术演进与未来图景。
爬虫与自动化技术概述 爬虫与自动化技术是现代数据采集与智能运维的核心工具。爬虫通过模拟浏览器行为或直接请求接口获取目标数据,自动化技术则用于数据处理、任务调度和系统监控。两者结合可构建高效的数据管道,覆盖从数据采集到智能运维的全流程。核心…...