Python爬取猫眼电影票房 + 数据可视化
目录
- 主角查看与分析 爬取
- 可视化分析
- 猫眼电影上座率前10分析
- 猫眼电影票房场均人次前10分析
- 猫眼电影票票房占比分析
主角查看与分析 爬取
对猫眼电影票房进行爬取,首先我们打开猫眼

接着我们想要进行数据抓包,就要看网站的具体内容,通过按F12,我们可以看到详细信息。

通过两个对比,我们不难发现User-Agent和 signKey数据是变化的(平台使用了数据加密)

所以我们需要对User-Agent与signKey分别进行解密。
通过造一个content字符串,包含请求方法、时间戳、User-Agent、index等信息,并对其进行MD5加密得到sign。最后将这些参数放入params字典中,准备发送请求。
def getData():url = 'https://piaofang.maoyan.com/dashboard-ajax/movie'useragents = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.183'headers = {'User-Agent':useragents,'Referer':'https://piaofang.maoyan.com/dashboard/movie'}useragents = str(base64.b64encode(useragents.encode('utf-8')),'utf-8')index = str(round(random.random() * 1000))times = str(math.ceil(time.time() * 1000))content = "method=GET&timeStamp={}&User-Agent={}&index={}&channelId=40009&sVersion=2&key=A013F70DB97834C0A5492378BD76C53A".format(times,useragents,index)md5 = hashlib.md5()md5.update(content.encode('utf-8'))sign = md5.hexdigest()params = {'orderType': '0','uuid': '17d79b87a00c8-015087c7514df4-5919145b-144000-17d79b87a00c8',# 时间戳'timeStamp': times,# base64加密'User-Agent': useragents,# 随机数 * 1000取整'index': index,'channelId': '40009','sVersion': '2',# md5加密'signKey': sign}
接着我们就可以对于猫眼电影票房数据进行爬取了,比如上座率、场均人次、票房占比、电影名称、上映时间、综合票房、排片场次和排片占比等。
resps = requests.get(url = url , headers = headers, params = params).json()# print(resps)# 上座率数据缺省值这么使用数据data_avgSeatView = jsonpath.jsonpath(resps, '$..avgSeatView')# print(data_avgSeatView)# 场均人次data_avgShowView=jsonpath.jsonpath(resps,'$..avgShowView')# 票房占比data_boxRate=jsonpath.jsonpath(resps,'$..boxRate')# 电影名称data_name=jsonpath.jsonpath(resps,'$..movieName')# 上映时间data_time=jsonpath.jsonpath(resps,'$..releaseInfo')# 综合票房data_sumBoxDesc=jsonpath.jsonpath(resps,'$..sumBoxDesc')# 排片场次data_showCount=jsonpath.jsonpath(resps,'$..showCount')# 排片占比data_showCountRate=jsonpath.jsonpath(resps,'$..showCountRate')data={'电影名称':data_name,'上映时间':data_time,'上座率':data_avgSeatView,'场均人次':data_avgShowView,'票房占比':data_boxRate,'综合票房':data_sumBoxDesc,'排片场次':data_showCount,'排片占比':data_showCountRate}df = pd.DataFrame(pd.DataFrame.from_dict(data, orient='index').values.T, columns=list(data.keys()))print(df)df.to_csv("猫眼电影1.csv",index=False,encoding='utf-8')
通过DataFrame输出到控制台我们可以看到爬取成功。

可视化分析
import pandas as pd
data=pd.read_csv("猫眼电影1.csv")

数据缺省值处理
# 去除空值
data.dropna(inplace=True)
data

猫眼电影上座率前10分析
data_sorted = data.sort_values(by='上座率', ascending=False)
data_top10=data_sorted.head(10)
data_top10

data_top10['电影名称'].tolist()

percentage=data_top10['上座率'].tolist()
data_shangan=[percentage.replace("%", "") for percentage in percentage]
data_shangan

from pyecharts.charts import Bar,Line,Map,Page,Pie
from pyecharts import options as opts
from pyecharts.globals import SymbolType
from pyecharts.charts import Bar
# from pyecharts.charts import opts
#条形图
#bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1 = Bar()
bar1.add_xaxis(data_top10['电影名称'].tolist())
bar1.add_yaxis('', data_shangan)
bar1.set_global_opts(title_opts=opts.TitleOpts(title='猫眼电影上座率前10分析'),xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),visualmap_opts=opts.VisualMapOpts(max_=28669)) bar1.render_notebook()

猫眼电影票房场均人次前10分析
data_sum = data.groupby('电影名称')['场均人次'].sum().sort_values(ascending=False)
data_sum[:10]

bar3 = Bar()
bar3.add_xaxis(data_sum[:10].index.tolist())
bar3.add_yaxis('', data_sum[:10].values.tolist())
bar3.set_global_opts(title_opts=opts.TitleOpts(title='猫眼电影票房场均人次前10分析'),visualmap_opts=opts.VisualMapOpts(max_=900))
bar3.render_notebook()

猫眼电影票票房占比分析
data_pf= data.groupby('电影名称')['票房占比'].sum().sort_values(ascending=False)
data_pfzb=data_pf.tail(24)
data_pfzb.head(10)

data_pftop10 = [list(z) for z in zip(data_pf.index.tolist(), data_pf.values.tolist())]# 绘制饼图
pie1 = Pie()
pie1.add('', data_pftop10, radius=['35%', '60%'])
pie1.set_global_opts(title_opts=opts.TitleOpts(title='猫眼电影票票房占比分析'), legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_left='2%'))
pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
pie1.set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34', '#D8BFD8', '#00BFFF', '#7FFFAA'])
pie1.render_notebook()

相关文章:
Python爬取猫眼电影票房 + 数据可视化
目录 主角查看与分析 爬取可视化分析猫眼电影上座率前10分析猫眼电影票房场均人次前10分析猫眼电影票票房占比分析 主角查看与分析 爬取 对猫眼电影票房进行爬取,首先我们打开猫眼 接着我们想要进行数据抓包,就要看网站的具体内容,通过按F12…...

Spring Boot深度解析:是什么、为何使用及其优势所在
在Java企业级应用开发的漫长历史中,Spring框架以其卓越的依赖注入和面向切面编程的能力,赢得了广大开发者的青睐。然而,随着技术的不断进步和项目的日益复杂,传统的Spring应用开发流程逐渐显得繁琐和低效。为了解决这一问题&#…...

面向对象——类与对象
文章目录 类与对象构造函数、析构函数get/set方法函数:类内声明、类外定义static 类与对象 #include<iostream> #include<string> using namespace std; /* 类与对象 */ class Person{public:string name;// 固有属性,成员变量 int age;pu…...

Golang的[]interface{}为什么不能接收[]int?
在 Go 中,[]interface{} 和 []int 是两种不同的类型,虽然它们的底层数据结构都是切片,但是它们的元素类型不同。[]interface{} 是一个空接口切片,可以容纳任意类型的元素,而 []int 是一个整数切片,只能容纳…...
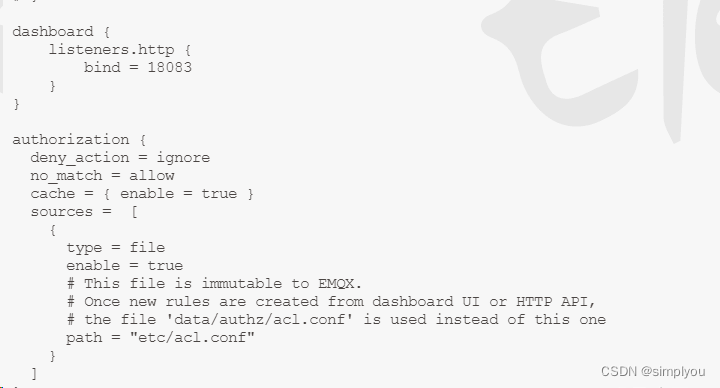
重启服务器或重启docker,导致emqx的Dashboard的密码重置为public
最近在项目中突然发现重启服务器,或者重启docker 修改好的emqx的Dashboard的密码重置为public 技术博客 http://idea.coderyj.com/ 1.解决办法就是固定 emqx的节点 # 拉取镜像 docker pull emqx/emqx# 创建目录,进行目录挂载 mkdir -p /docker/emqx/{etc,lib,data,…...

就业班 第三阶段(ansible) 2401--4.16 day2 ansible2 剧本+角色
六、Ansible playbook 简介 playbook 是 ansible 用于配置,部署,和管理被控节点的剧本。 通过 playbook 的详细描述,执行其中的一系列 tasks ,可以让远端主机达到预期的状态。playbook 就像 Ansible 控制器给被控节点列出的的…...

常用的过滤网站扫描网站攻击的路径是那些,比如:/etc/passwd等
网站攻击中经常被尝试的路径主要包括利用漏洞获取敏感文件、执行系统命令或者注入恶意代码的尝试。以下是一些常见的被攻击者尝试访问的路径和文件,这些通常在网络入侵检测系统(IDS)和网络防火墙的过滤规则中被特别关注: 系统文件…...
考研数学|《1800》《660》《880》如何选择和搭配?(附资料分享)
直接说结论:基础不好先做1800、强化之前660,强化可选880/1000题。 首先,传统习题册存在的一个问题是题量较大,但难度波动较大。《汤家凤1800》和《张宇1000》题量庞大,但有些题目难度不够平衡,有些过于简单…...

论文笔记:Are Human-generated Demonstrations Necessary for In-context Learning?
iclr 2024 reviewer 评分 6668 1 intro 大型语言模型(LLMs)已显示出在上下文中学习的能力 给定几个带注释的示例作为演示,LLMs 能够为新的测试输入生成输出然而,现行的上下文学习(ICL)范式仍存在以下明显…...

C语言 | Leetcode C语言题解之第28题找出字符串中第一个匹配项的下标
题目: 题解: int strStr(char* haystack, char* needle) {int n strlen(haystack), m strlen(needle);if (m 0) {return 0;}int pi[m];pi[0] 0;for (int i 1, j 0; i < m; i) {while (j > 0 && needle[i] ! needle[j]) {j pi[j - …...

「Python大数据」数据采集-某东产品数据评论获取
前言 本文主要介绍通过python实现数据采集、脚本开发、办公自动化。数据内容范围:星级评分是1-3分、获取数据页面是前50页。 友情提示 法律分析:下列三种情况,爬虫有可能违法,严重的甚至构成犯罪: 爬虫程序规避网站经营者设置的反爬虫措施或者破解服务器防抓取措施,非法…...

ORACLE错误提示概述
OceanBase分布式数据库-海量数据 笔笔算数 保存起来方便自己查看错误代码。 ORA-00001: 违反唯一约束条件 (.) ORA-00017: 请求会话以设置跟踪事件 ORA-00018: 超出最大会话数 ORA-00019: 超出最大会话许可数 ORA-00020: 超出最大进程数 () ORA-00021: 会话附属于其它某些进程…...

2024年4月13日美团春招实习试题【第一题:好子矩阵】-题目+题解+在线评测【模拟】
2024年4月13日美团春招实习试题【第一题:好子矩阵】-题目题解在线评测【模拟】 题目描述:输入描述输出描述样例 解题思路一:模拟解题思路二:思路二解题思路三:直接判断 题目描述: 塔子哥定义一个矩阵是”好矩阵”&…...
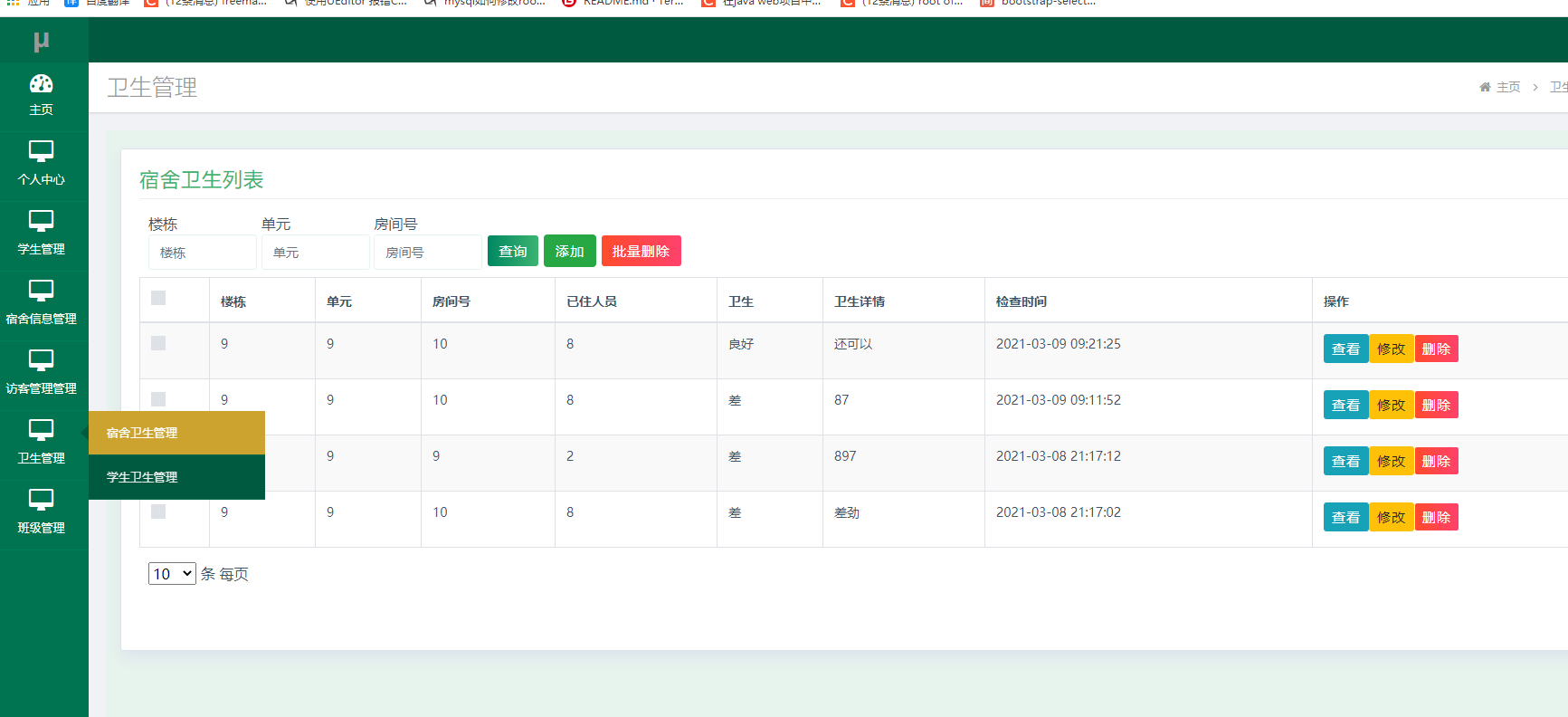
ssm057学生公寓管理中心系统的设计与实现+jsp
学生公寓管理中心系统设计与实现 摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本学生公寓管理中心系统就是在这样的大环境下诞生,其可以帮助管…...

循环神经网络(RNN):概念、挑战与应用
循环神经网络(RNN):概念、挑战与应用 1 引言 1.1 简要回顾 RNN 在深度学习中的位置与重要性 在深度学习的壮丽图景中,循环神经网络(Recurrent Neural Networks,RNN)占据着不可或缺的地位。自从…...
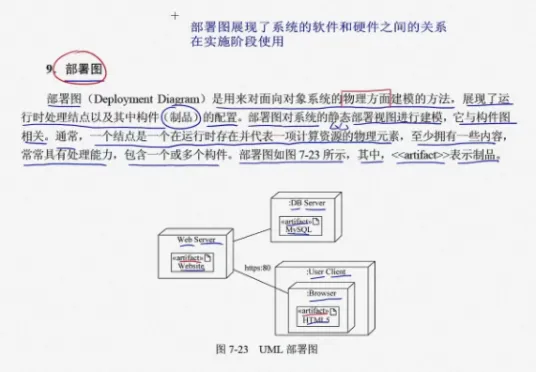
UML 介绍
前言 UML 简介。 文章目录 前言一、简介1、事务2、关系1)依赖2)关联聚合组合 3)泛化4)实现 二、类图三、对象图四、用例图五、交互图1、序列图(顺序图)2、通信图 六、状态图七、活动图八、构件图࿰…...

Pytorch——训练时,冻结网络部分参数的方法
一、原理: 要固定训练网络的哪几层,只需要找到这几层参数(parameter),然后将其 .requires_grad 属性设置为 False 即可。 二、代码: # 根据参数层的 name 来进行冻结 unfreeze_layers ["text_id"] # 用列表 # 设置冻…...
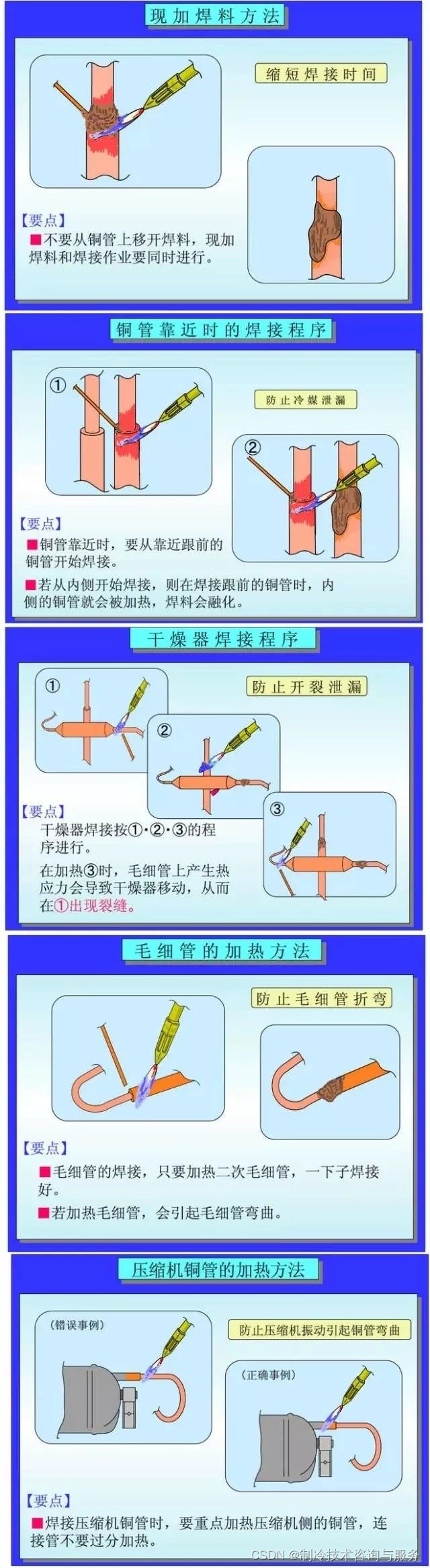
制冷铜管焊接介绍
铜管是制冷装置的重要原材料,它主要有两种用途:①制作换热器。②制作连接管道和管件。常用的焊料类型有铜磷焊料、银铜焊料、铜锌焊料等。在焊接时要根据管道材料的特点,正确的选择焊料及熟练的操作,以确保焊接的质量。 1.1对同类…...
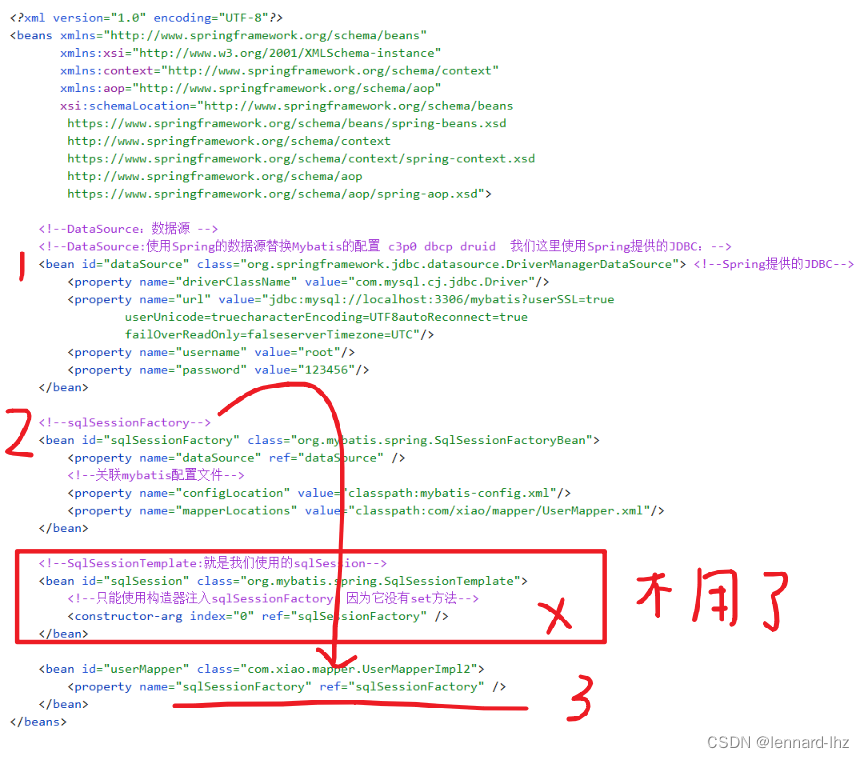
spring06:mybatis-spring(Spring整合MyBatis)
spring06:mybatis-spring(Spring整合MyBatis) 文章目录 spring06:mybatis-spring(Spring整合MyBatis)前言:什么是 MyBatis-Spring?MyBatis-Spring 会帮助你将 MyBatis 代码无缝地整合…...
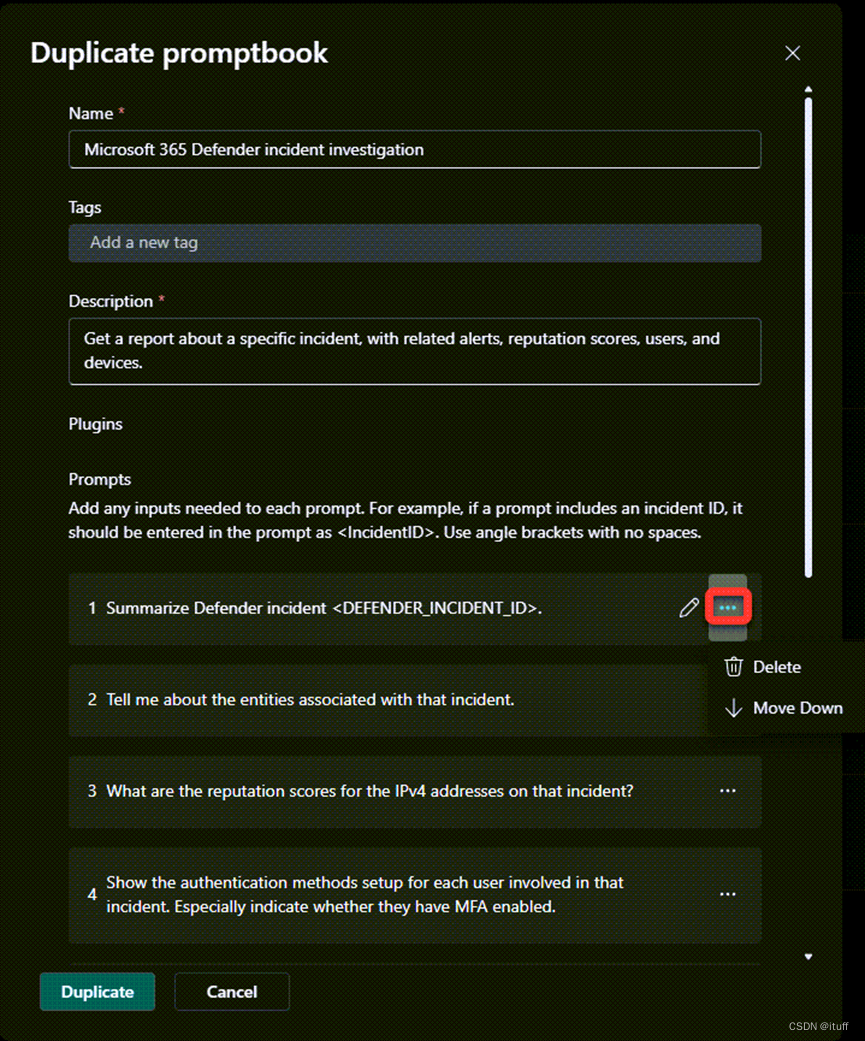
如何使用自定义Promptbooks优化您的安全工作流程
在当今的数字化时代,安全工作流程的优化变得前所未有的重要。安全团队需要快速、有效地响应安全事件,以保护组织的数据和资产。Microsoft Copilot for Security提供了一种强大的工具——自定义Promptbooks,它可以帮助安全专家通过自动化和定制…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...

LCTF液晶可调谐滤波器在多光谱相机捕捉无人机目标检测中的作用
中达瑞和自2005年成立以来,一直在光谱成像领域深度钻研和发展,始终致力于研发高性能、高可靠性的光谱成像相机,为科研院校提供更优的产品和服务。在《低空背景下无人机目标的光谱特征研究及目标检测应用》这篇论文中提到中达瑞和 LCTF 作为多…...
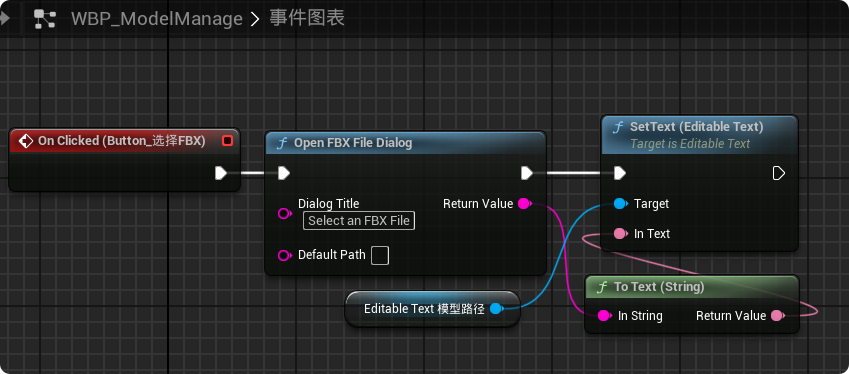
【UE5 C++】通过文件对话框获取选择文件的路径
目录 效果 步骤 源码 效果 步骤 1. 在“xxx.Build.cs”中添加需要使用的模块 ,这里主要使用“DesktopPlatform”模块 2. 添加后闭UE编辑器,右键点击 .uproject 文件,选择 "Generate Visual Studio project files",重…...
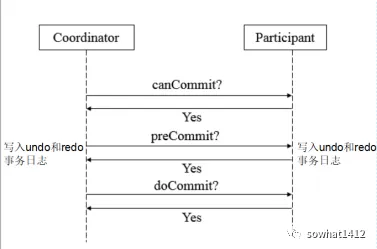
解析两阶段提交与三阶段提交的核心差异及MySQL实现方案
引言 在分布式系统的事务处理中,如何保障跨节点数据操作的一致性始终是核心挑战。经典的两阶段提交协议(2PC)通过准备阶段与提交阶段的协调机制,以同步决策模式确保事务原子性。其改进版本三阶段提交协议(3PC…...
32单片机——基本定时器
STM32F103有众多的定时器,其中包括2个基本定时器(TIM6和TIM7)、4个通用定时器(TIM2~TIM5)、2个高级控制定时器(TIM1和TIM8),这些定时器彼此完全独立,不共享任何资源 1、定…...
 ----- Python的类与对象)
Python学习(8) ----- Python的类与对象
Python 中的类(Class)与对象(Object)是面向对象编程(OOP)的核心。我们可以通过“类是模板,对象是实例”来理解它们的关系。 🧱 一句话理解: 类就像“图纸”,对…...