并行执行的概念—— 《OceanBase 并行执行》系列 一
From 产品经理:
这是一份姗姗来迟的关于OceanBase并行执行的系统化产品文档。
自2019年起,并行执行功能已被许多客户应用于多种场景之中,其重要性日益凸显。然而,遗憾的是,我们始终未能提供一份详尽的用户使用文档,这无疑给业务团队在运用并行执行功能时带来了诸多困扰。今日,我们决心弥补这一缺憾。
关于并行执行的内容,我们将通过七篇博客系列进行详尽的解析,而本文正是这一系列的第一篇。
并行执行是指单个SQL语句能够同时利用多个 CPU 和 I/O 资源的能力。本文将深入探讨并行执行的工作机制,同时阐明如何在OceanBase数据库中对其进行控制、管理与监控。
1 并行执行概念
并行执行是指将一个 SQL 查询任务分成多个子任务,并允许这些子任务在多个处理器上同时运行,以提高整个查询任务的执行效率。在现代计算机系统中,多核处理器、多线程和高速网络连接广泛应用,这使得并行执行成为了一种可行的高效率查询技术。
并行执行能够极大降低计算密集型大查询的响应时间,被广泛应用在离线数据仓库、实时报表、在线大数据分析等业务场景,同时还应用在批量导数,快速构建索引表等领域。
以下场景会从并行执行中获益:
- 大表扫描,大表连接,大数据量排序,聚合
- 大表 DDL 操作,如修改主键、改变列类型,建索引等
- 从已有大数据建表(Create Table As Select)
- 批量插入、删除、更新
本节包含如下内容:
- 什么场景适用并行执行
- 什么场景不适用并行执行
- 硬件要求
- 并行执行工作原理
- 并行执行工作线程
- 通过均衡负载来优化性能
1.1 什么场景适用并行执行
并行执行通过充分利用多个 CPU 和 IO 资源,以达到降低 SQL 执行时间的目的。
当满足下列条件时,使用并行执行会优于串行执行:
- 访问的数据量大
- SQL 并发低
- 要求低延迟
- 有充足的硬件资源
并行执行用多个处理器协同并发处理同一任务,在这样的系统中会有收益:
- 多处理器系统(SMPs)、集群
- IO 带宽足够
- 内存富余(可用于处理内存密集型操作,如排序、建 hash 表等)
- 系统负载不高,或有峰谷特征(如系统负载一般在 30% 以下)
如果你的系统不满足上述特征,那么并行执行可能不会带来显著收益。在一些高负载,小内存,或 IO 能力弱的系统里,并行执行甚至会带来负面效果。
并行执行不仅适用于离线数据仓库、实时报表、在线大数据分析等分析型系统,而且在 OLTP 领域也能发挥作用,可用于加速 DDL 操作、以及数据跑批工作等。但是,对于 OLTP 系统中的普通 SELECT 和 DML 语句,并行执行并不适用。
1.2 什么场景不适用并行执行
串行执行使用单个线程来执行数据库操作,在下面这些场景下使用串行执行优于并行执行:
- Query 访问的数据量很小
- 高并发
- Query 执行时间小于 100 毫秒
并行执行一般不适用于如下场景:
- 系统中的典型 SQL 执行时间都在毫秒级。并行查询本身有毫秒级的调度开销,对于短查询来说,并行执行带来的收益完全会被调度开销所抵消。
- 系统负载本就很高。并行执行的设计目标就是去充分利用系统的空余资源,如果系统本身已经没有空余资源,那么并行执行并不能带来额外收益,相反还会影响系统整体性能。
1.3 硬件要求
并行执行对硬件没有特殊要求。需要注意的是,CPU 核数、内存大小、存储 I/O 性能、网络带宽都会影响并行执行性能,其中任意一项成为瓶颈都会拖累并行执行性能。
1.4 并行执行工作原理
并行执行将一个 SQL 查询任务分解成多个子任务,并调度这些子任务到多个处理器上运行。
本节包含如下内容:
- SQL 语句的并行执行
- 生产者消费者流水线模型
- 并行的粒度
- 生产者和消费者之间的数据分发方式
- 生产者和消费者之间的数据传输机制
1.4.1 SQL 语句的并行执行
当一个 SQL 被解析为并行执行计划后,会按照下面的步骤执行:
- SQL 主线程(接收、解析SQL的线程)根据计划形态预约并行执行需要的线程资源。这些线程资源可能来自集群中的多台机器。
- SQL 主线程打开并行调度算子(PX COORDINATOR)。
- 并行调度算子解析计划,将它们切分成多个操作步骤,按照自底向上的顺序调度执行这些操作。每个操作都会尽可能并行执行。
- 当所有操作并行执行完成后,并行调度算子会接收计算结果,并将结果吐给它的上层算子(如 Aggregate 算子),串行完成剩余不可并行的计算(如最终的 SUM 计算)。
1.4.2 生产者-消费者流水线模型
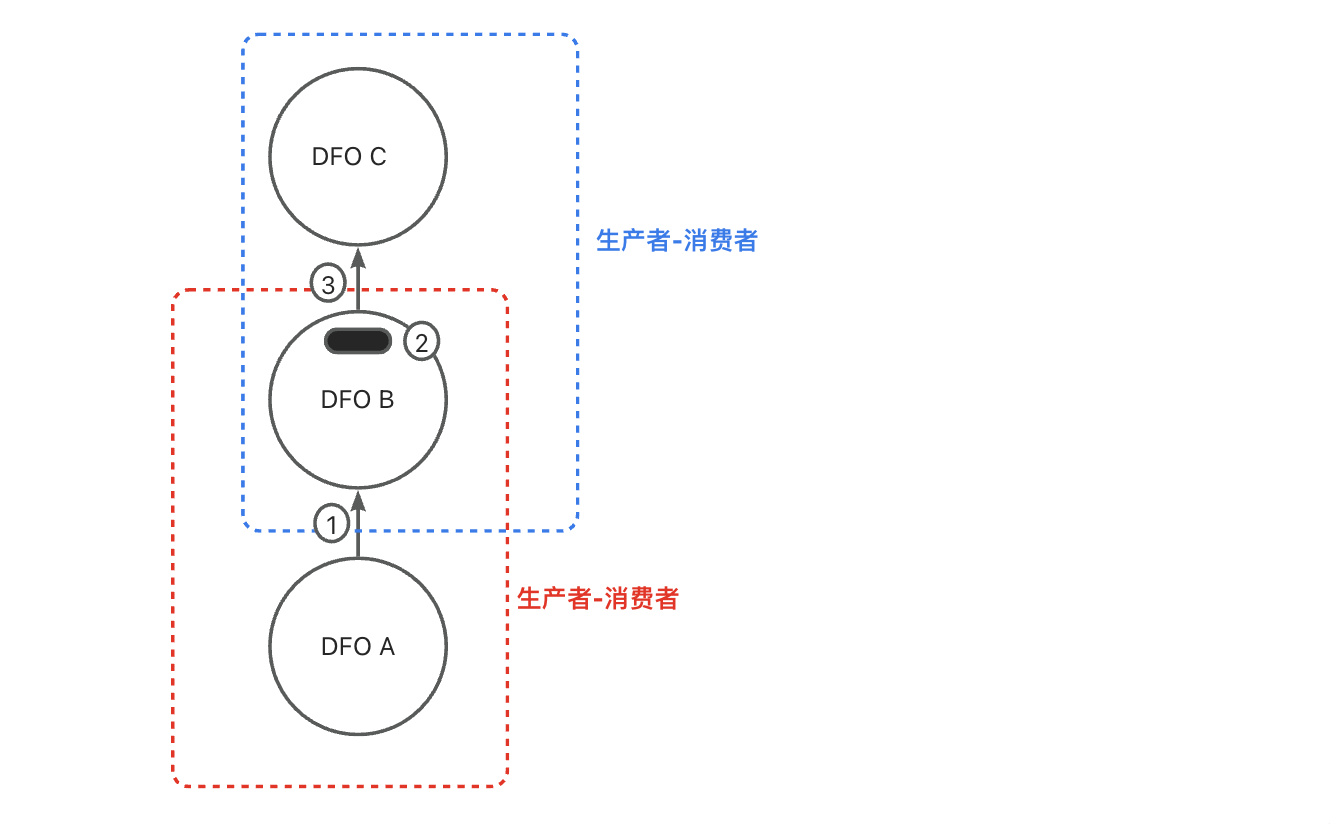
并行执行使用生产者-消费者模型来进行流水执行。并行调度算子解析计划,将它们切分成多个操作步骤,每个操作步骤称之为一个 DFO(Data Flow Operation)。
一般情况下,并行调度算子在同一时刻会启动两个 DFO,DFO 之间会以生产者-消费者的模式连接起来,这称为 DFO 间的并行执行。每个 DFO 会使用一组线程来执行,这称为 DFO 内的并行执行,这个 DFO 使用的线程数称为 DOP(Degree Of Parallisim)。
上一阶段的消费者 DFO 会成为下一阶段的生产者 DFO。在并行调度算子的协调下,会同时启动消费者 DFO 和生产者 DFO。
下图中:
(1)DFO A 生成的数据会立即传输给DFO B 进行计算;
(2)DFO B 完成计算后,会将数据暂存在当前线程中,等待它的上层 DFO C 启动;
(3)当 DFO B 收到 DFO C 启动完成通知后,会将自己的角色转变成生产者,开始向 DFO C 传输数据,DFO C 收到数据后开始计算。
考虑下面的查询:
create table game (round int primary key, team varchar(10), score int)partition by hash(round) partitions 3;insert into game values (1, "CN", 4), (2, "CN", 5), (3, "JP", 3);
insert into game values (4, "CN", 4), (5, "US", 4), (6, "JP", 4);select /*+ parallel(3) */ team, sum(score) total from game group by team;查询语句对应的执行计划:
OceanBase(admin@test)>explain select /*+ parallel(3) */ team, sum(score) total from game group by team;
+---------------------------------------------------------------------------------------------------------+
| Query Plan |
+---------------------------------------------------------------------------------------------------------+
| ================================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------------------------- |
| |0 |PX COORDINATOR | |1 |4 | |
| |1 | EXCHANGE OUT DISTR |:EX10001|1 |4 | |
| |2 | HASH GROUP BY | |1 |4 | |
| |3 | EXCHANGE IN DISTR | |3 |3 | |
| |4 | EXCHANGE OUT DISTR (HASH)|:EX10000|3 |3 | |
| |5 | HASH GROUP BY | |3 |2 | |
| |6 | PX BLOCK ITERATOR | |1 |2 | |
| |7 | TABLE SCAN |game |1 |2 | |
| ================================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([INTERNAL_FUNCTION(game.team, T_FUN_SUM(T_FUN_SUM(game.score)))]), filter(nil), rowset=256 |
| 1 - output([INTERNAL_FUNCTION(game.team, T_FUN_SUM(T_FUN_SUM(game.score)))]), filter(nil), rowset=256 |
| dop=3 |
| 2 - output([game.team], [T_FUN_SUM(T_FUN_SUM(game.score))]), filter(nil), rowset=256 |
| group([game.team]), agg_func([T_FUN_SUM(T_FUN_SUM(game.score))]) |
| 3 - output([game.team], [T_FUN_SUM(game.score)]), filter(nil), rowset=256 |
| 4 - output([game.team], [T_FUN_SUM(game.score)]), filter(nil), rowset=256 |
| (#keys=1, [game.team]), dop=3 |
| 5 - output([game.team], [T_FUN_SUM(game.score)]), filter(nil), rowset=256 |
| group([game.team]), agg_func([T_FUN_SUM(game.score)]) |
| 6 - output([game.team], [game.score]), filter(nil), rowset=256 |
| 7 - output([game.team], [game.score]), filter(nil), rowset=256 |
| access([game.team], [game.score]), partitions(p[0-2]) |
| is_index_back=false, is_global_index=false, |
| range_key([game.round]), range(MIN ; MAX)always true |
+---------------------------------------------------------------------------------------------------------+
29 rows in set (0.003 sec)select语句的执行计划会首先对 game 表做全表扫描,按照 team 做分组求和,然后算出每个 team 的总分数。这个查询的执行示意图如下:
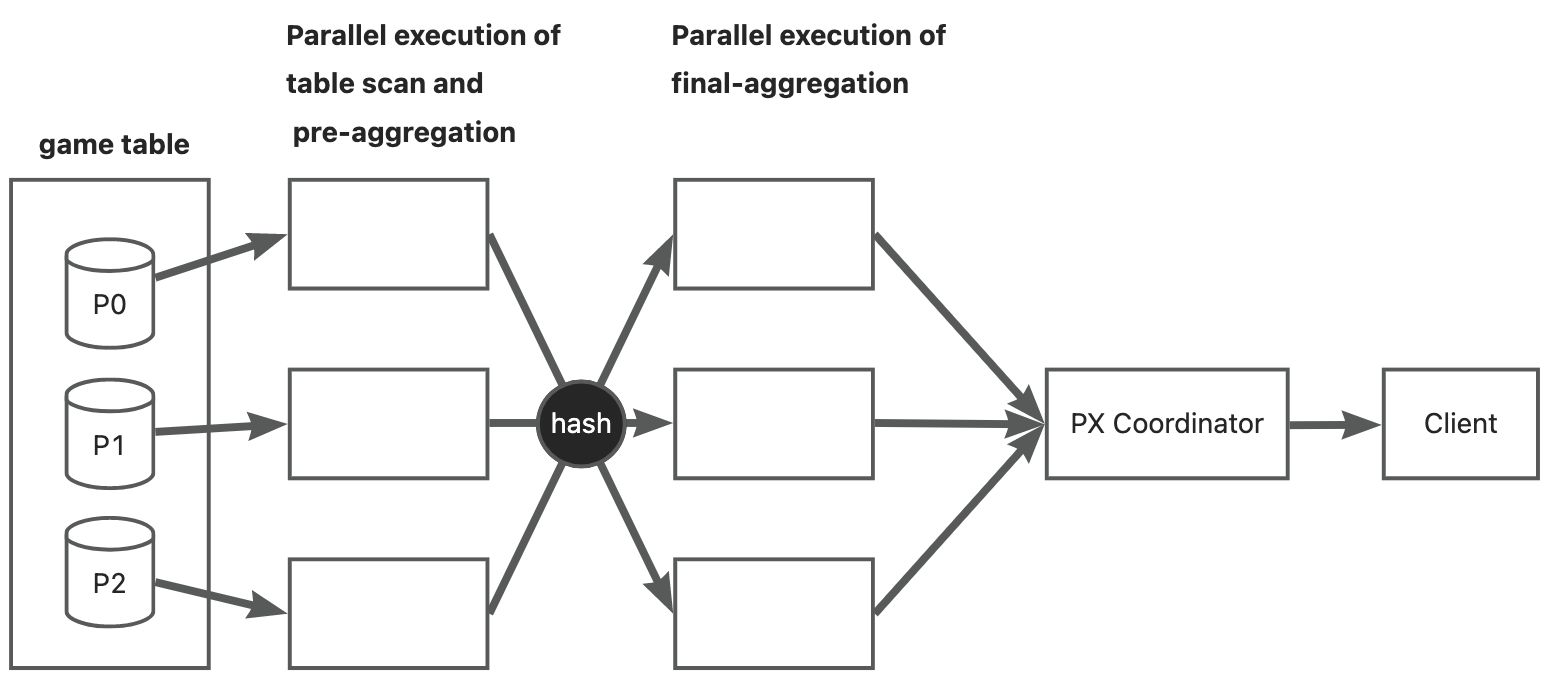
从图中可以看到,这个查询实际使用了 6 个线程。
- 第一步:前三个线程负责 game 表扫描,并且在每个线程内对 game.team 数据做预聚合;
- 第二步:后三个线程负责对预聚合的数据做最终聚合;
- 第三步:最终聚合结果发给并行调度器,由它返回给客户端。
第一步的数据发给第二步时,需要用 game.team 字段做 hash,决定将预聚合数据发给哪个线程。
1.4.3 并行的粒度
并行数据扫描的基本工作单元称为 granule。OceanBase 将表扫描工作划分成多个 granule,每个 granule 描述了一段扫描任务的范围。因为 granule 不会跨表分区 ,所以每段扫描任务一定是位于一个分区内。
根据 granule 的粒度特征,可以划分为两类:
- Partition Granule
Partition granule 描述的范围是一整个分区,扫描任务涉及到多少个分区,就会划分出多少个 partition granule。这里的分区既可以是主表分区,也可以是索引分区。
Partition Granule 最常用的应用场景是 partition wise join,两张表里对应的分区通过 partition granule 可以确保被同一个工作线程处理。
- Block Granule
Block granule 描述的范围是一个分区中的一段连续数据。数据扫描场景里,一般都是使用 block granule 划分数据。每个分区都会被划分为若干个 block,这些 block 再以一定的规则串联起来形成一个任务队列,供并行工作线程消费。
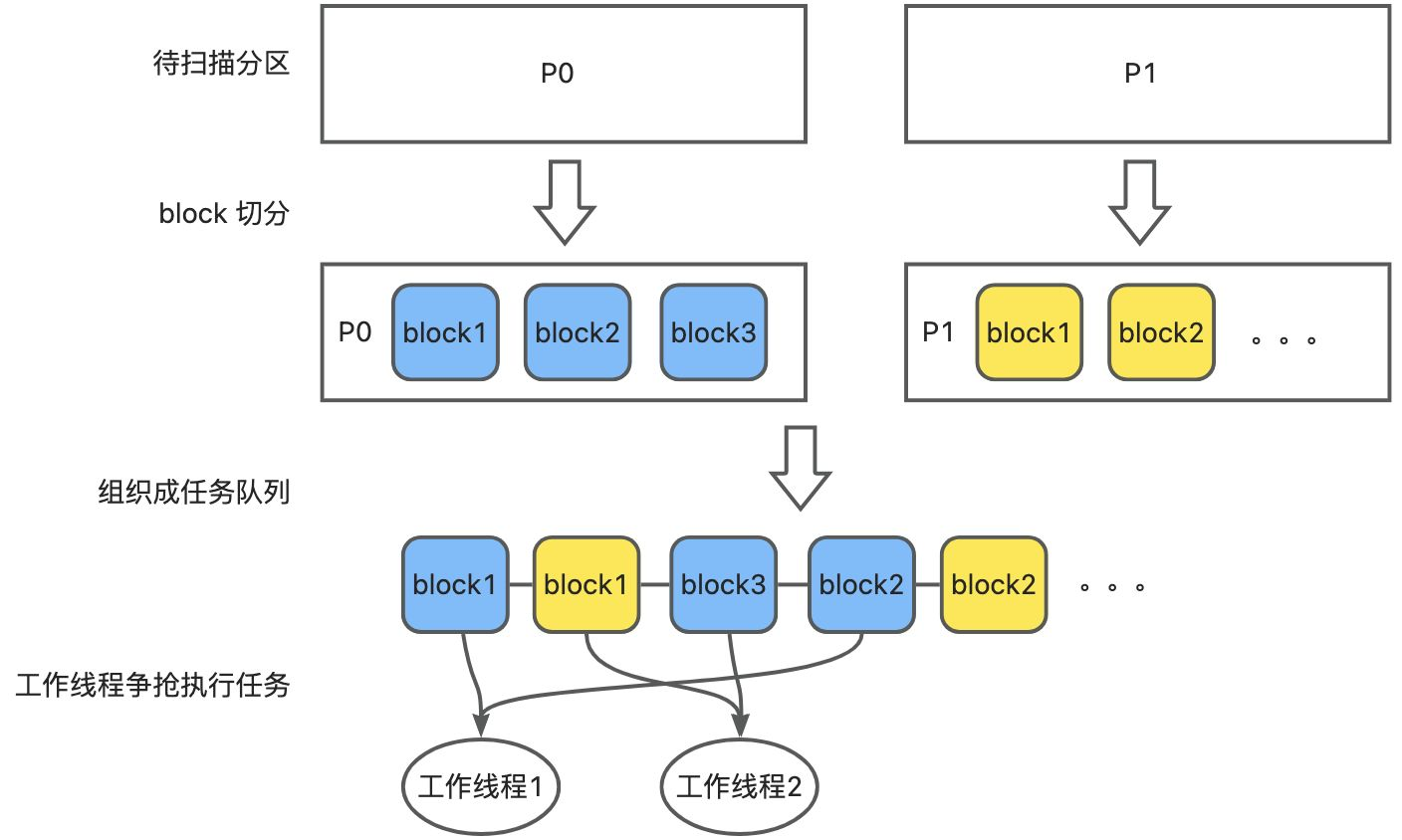
在给定并行度的情况下,为了确保扫描任务的均衡,优化器会自动选择将数据划分成分区粒度(Partition Granule)或块粒度(Block Granule)。如果选择了 Block Granule,并行执行框架会在运行时决策 block 的划分,总体原则是确保一个 block 既不会太大,也不会太小。太大,可能导致数据倾斜,让部分线程少干活;太小,会导致频繁的扫描切换开销。
划分好分区粒度后,每个粒度对应一个扫描任务。Table Scan 扫描算子会一个接一个地处理这些扫描任务,处理完一个之后,接着处理下一个,直到所有任务处理完毕。
1.4.4 生产者和消费者之间的数据分发方式
数据分发方式指的是,数据从一组并行执行工作线程(生产者)发送给另一组(消费者)时使用的方法。优化器会使用一系列的优化策略,决策使用哪种数据重分布方式,以达到最优的性能。
并行执行中的常见数据分发方式包括:
- Hash Distribution
使用 Hash distribution 发送数据时,生产者根据 distribution key 对数据行计算 hash 值并取模,算出发给哪个消费者工作线程。大部分情况下,使用 hash distribution 能将数据较为均匀的分发给多个消费者线程。
- Pkey Distribution
使用 Pkey Distribution 时,生产者计算出数据行对应的目标表所在分区,然后将行数据发给处理这个分区的消费者线程。
Pkey Distribution 常用于 partitial partitions wise join 场景。在 partitial partitions wise join 场景下,消费者侧的数据不需要做重分布,就可以和生产者侧的数据做 Partition Wise Join。这种方式可以减少网络通信量,提升性能。
- Pkey Hash Distribution
使用 Pkey Hash Distribution 时,生产者首先需要计算出数据行对应的目标表所在的分区。然后,根据 distribution key 对数据行进行 hash 计算,以便决定将其发给哪一个消费者线程来处理。
Pkey Hash Distribution 常常应用于 Parallel DML 场景中。在这种场景下,一个分区可以被多个线程并发更新,因此需要使用 Pkey Hash Distribution 来确保相同值的数据行被同一个线程处理,不同值的数据行尽可能均分到多个线程处理。
- Broadcast Distribution
使用 broadcast distribution 时,生产者将每一个数据行发送消费者端的每一个线程,使得消费者端每一个线程都拥有全量的生产者端数据。
Broadcast distribution 常用于将小表数据复制到所有执行 join 的节点,然后做本地 join 操作。这种方式可以减少网络通信量。
- Broadcast to Host Distribution(简称 BC2HOST)
使用 broadcast to host distribution 时,生产者将每一个数据行发送消费者端的每一个节点上,使得消费者端每一个节点都拥有全量的生产者端数据。然后,节点里的消费者线程协同处理这份数据。
Broadcast to host distribution 常用于 NESTED LOOP JOIN、SHARED HASH JOIN 场景。NESTED LOOP JOIN 场景里,消费端的每个线程会从共享数据里取一部分数据行作为驱动数据,去目标表里做 join 操作;SHARED HASH JOIN 场景里,消费端的每个线程会基于共享数据协同构建 hash 表,避免每个线程独立构建相同 hash 表导致的不必要开销。
- Range Distribution
使用 Range distribution 时,生产者将数据按照 range 范围做划分,让不同消费者线程处理不同范围的数据。
Range distribution 常用于排序场景,各个消费者线程只需排序好发给自己的数据,数据就能在全局范围内有序。
- Random Distribution
使用 Random distribution 时,生产者将数据随机打散,发给消费者线程,使得每个消费者线程处理的数据数量几乎一致,从而达到均衡负载的目的。
Random distribution 常用于多线程并行 UNION ALL 场景,该场景只要求数据打散,负载均衡,数据之间无其它关联约束。
- Hybrid Hash Distribution
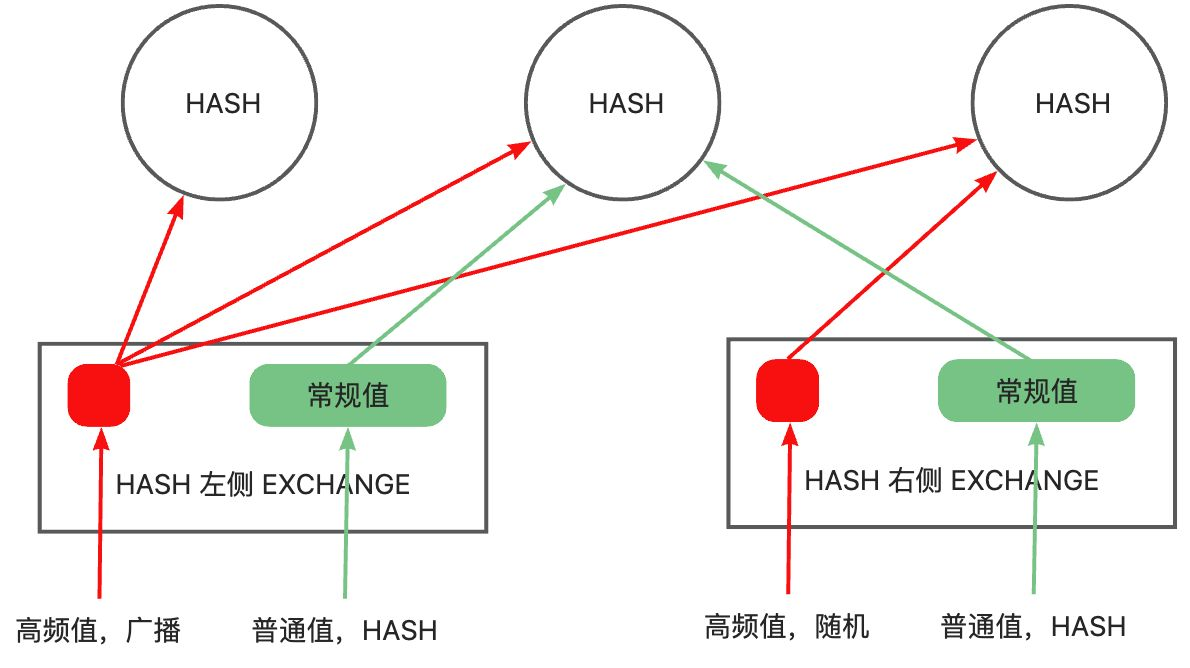
Hybrid hash distribtuion 用于自适应的 join 算法。结合收集的统计信息,OceanBase 提供了一组配置项来定义常规值和高频值。Hybrid hash distribtuion 方法将 join 两侧的常规值做 hash 分布,左侧的高频值使用 broadcast 分布,右侧的高频值使用 random 分布。
1.4.5 生产者和消费者之间的数据传输机制
并行调度算子在同一时刻会启动两个 DFO,DFO 之间会以生产者-消费者的模式连接起来并行执行。为了方便在生产者和消费者之间传输数据,需要创建一个传输网络。
例如,生产者 DFO 以 DOP = 2 来做数据扫描,消费者 DFO 以 DOP = 3 来做数据聚合计算,每个生产者线程都会创建 3 个虚拟链接去连接消费者线程,总计会创建 6 个虚拟链接。如下图:
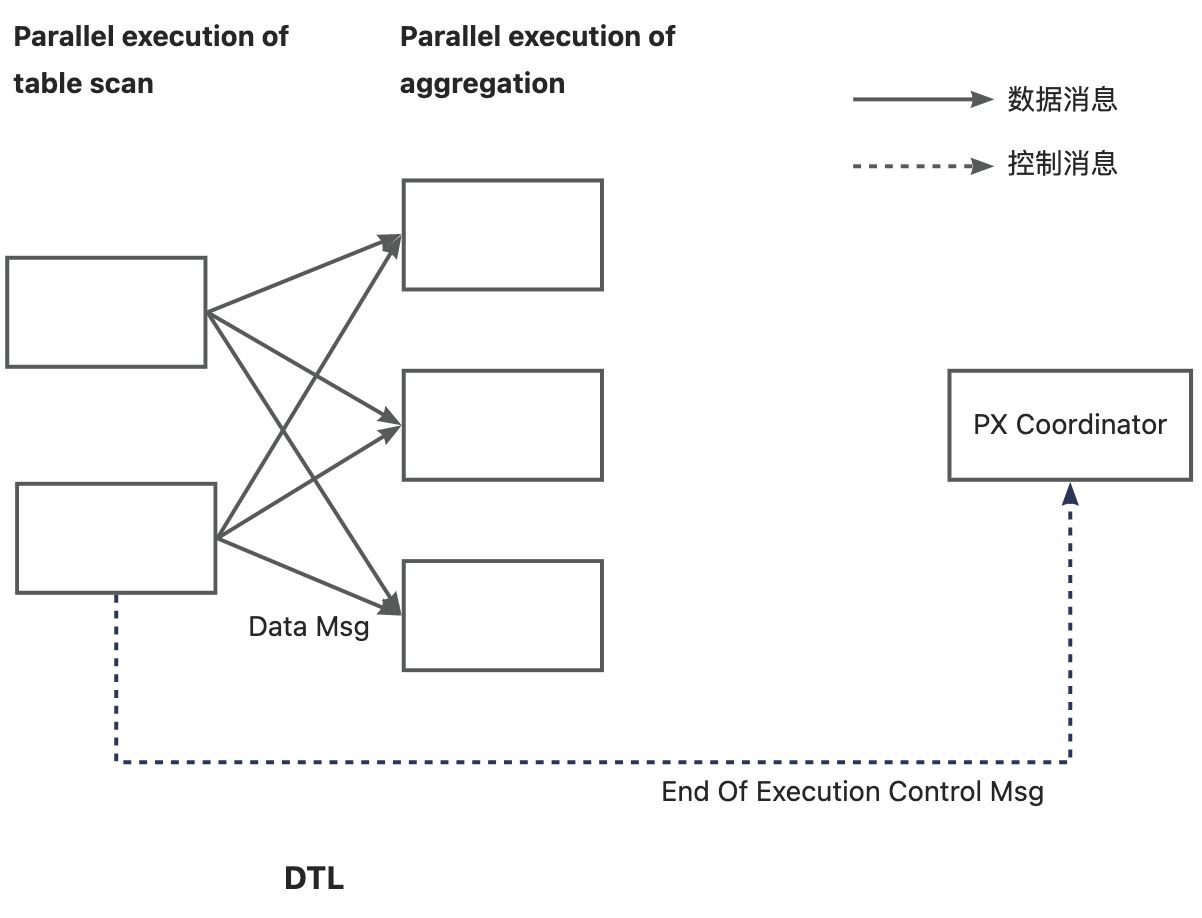
生产者和消费者之间创建的虚拟传输网络被称为数据传输层(Data Transfer Layer,简称 DTL)。OceanBase 并行执行框架中,所有的控制消息和行数据都通过 DTL 进行收发。每个工作线程可以对外建立数千个虚拟链接,具有高度的可扩展性。除此之外,DTL 还具有数据缓冲、批量数据发送和自动流量控制等能力。
当 DTL 链接的两端位于同一个节点时,DTL 会通过内存拷贝的方式来传递消息;当 DTL 链接的两端位于不同节点时,DTL 会通过网络通信的方式来传递消息。
1.5 并行执行工作线程
一个并行查询会使用两类线程:1个主线程,若干个并行工作线程。其中主线程和普通的 TP 查询使用的线程没有任何区别,来自普通工作线程池,并行工作线程来自专用线程池。
OceanBase 使用专用线程池模型来分配并行工作线程。每个租户在其所属的各个节点里都有一个租户专属的并行执行线程池,并行查询工作线程都通过这个线程池来分配。
并行调度算子在调度每个 DFO 之前,会去线程池中申请线程资源。当 DFO 执行完成时,会立即源释放线程资源。
线程池的初始大小为 0,按需增长,没有上限。为了避免空闲线程数过多,线程池引入自动回收机制。对于任意线程:
- 如果空闲时间超过 10 分钟,并且线程池中剩余线程数大于 8 个,则被回收销毁;
- 如果空闲时间超过 60 分钟,则无条件销毁
虽然线程池的大小没有上限,但是通过下面两个机制,能在绝大多数场景里形成事实上限:
- 并行执行开始执行前,需要通过 Admission 模块预约线程资源,预约成功后才能投入执行。通过这个机制,能限制并发查询数量。Admission 模块的详细内容参考本文中 《3 并发控制与排队》一节。
- 查询每次从线程池申请线程时,单次申请的线程数量不会超过 N, N 等于租户 UNIT 的 MIN_CPU 乘以 px_workers_per_cpu_quota,如果超过,则最多只分配 N 个线程。px_workers_per_cpu_quota 是租户级配置项,默认值为 10。例如,一个 DFO 的 DOP = 100,它需要从 A 节点申请 30 个线程,从 B 节点申请 70 个线程,UNIT 的 MIN_CPU = 4,px_workers_per_cpu_quota = 10,那么 N = 4 * 10 = 40。最终这个 DFO 在 A 节点上实际申请到 30 个线程,B 节点上实际申请到 40 个线程,它的实际 DOP 为 70。
1.6 通过均衡负载来优化性能
为了达到最优性能,所有工作线程分到的工作任务应该尽量相等。
SQL 使用 Block Granule 划分任务的时候,工作任务会动态地分配到工作线程之间。这样可以最小化工作负载不均衡问题,即一些工作线程的工作量不会明显超过其它工作线程。SQL 使用 Partition Granule 划分任务时,可以通过让任务数是工作线程数的整数倍来优化性能。这适用于 Partition Wise Join 和并行 DML 场景。
举个例子,假设一个表有 16 个分区,每个分区的数据量差不多。你可以使用 16 工作线程(DOP 等于 16)以大约十六分之一的时间完成工作,你也可以使用五个工作线程以五分之一的时间完成工作,或使用两个线程以一半的时间完成工作。
但是,如果你使用 15 个线程来处理 16 个分区,则第一个线程完成一个分区的工作后,就开始处理第 16 个分区。而其他线程完成工作后,它们变为空闲状态。当每个分区的数据量差不多时,这种配置会导致性能不优;当每个分区的数据量有所差异时,实际性能则会因情况而异。
类似地,假设你使用 6 个线程来处理 16 个分区,每个分区的数据量差不多。在这种情况下,每个线程在完成其第一个分区后,会处理第二个分区,但只有四个线程会处理第三个分区,而其他两个线程会保持空闲。
一般来说,不能假设在给定数量的分区(N)和给定数量的工作线程(P)上执行并行操作所花费的时间等于 N 除以 P。这个公式没有考虑到一些线程可能需要等待其他线程完成最后的分区。但是,通过选择适当的 DOP,可以最小化工作负载不均衡问题并优化性能。
相关文章:
并行执行的概念—— 《OceanBase 并行执行》系列 一
From 产品经理: 这是一份姗姗来迟的关于OceanBase并行执行的系统化产品文档。 自2019年起,并行执行功能已被许多客户应用于多种场景之中,其重要性日益凸显。然而,遗憾的是,我们始终未能提供一份详尽的用户使用文档&…...

使用 ipdb 调试回调函数
一、问题概述 回调函数是指一个函数执行完后,调用另外一个函数的过程。 一般步骤是,回调函数作为参数传递给原始函数,原始函数执行完自己的逻辑后,自动调用回调函数并将自己的执行结果作为参数传递给回调函数。 根据不同的用法&a…...
)
介绍一下mybatis的基本配置(mybatis-config.xml)
src/main/resources/mybatis-config.xml 这句代码,是XML的声明,它指定了,XML的版本 和 编码方式 <?xml version"1.0" encoding"UTF-8" ?>这句代码,声明了XML文档类型,它告诉解析器&#x…...
【MySQL】第一次作业
【MySQL】第一次作业 1、在官网下载安装包2、解压安装包,创建一个dev_soft文件夹,解压到里面。3、创建一个数据库db_classes4、创建一行表db_hero5、将四大名著中的常见人物插入这个英雄表 写一篇博客,在window系统安装MySQL将本机的MySQL一定…...

10个免费视频素材网站,剪辑师们赶紧收藏!
剪辑师们不知道去哪里找免费视频素材,就上这10个网站,免费下载部分还可商用,赶紧收藏起来! 1、菜鸟图库 https://www.sucai999.com/video.html?vNTYwNDUx 菜鸟图库虽然是个设计素材网站,但除了设计类素材之外还有很多…...
【毕业设计】基于SSM的运动用品商城的设计与实现
1.项目介绍 在这个日益数字化和信息化的时代,随着人们购物习惯的转变,传统的实体商店已经无法满足人们日益增长的在线购物需求。因此,基于SSM(Spring Spring MVC MyBatis)框架的运动用品商城项目应运而生࿰…...
【Web】CTFSHOW 中期测评刷题记录(1)
目录 web486 web487 web488 web489 web490 web491 web492 web493 web494 web495 web496 web497 web498 web499 web500 web501 web502 web503 web505 web506 web507 web508 web509 web510 web486 扫目录 初始界面尝试文件包含index.php&am…...
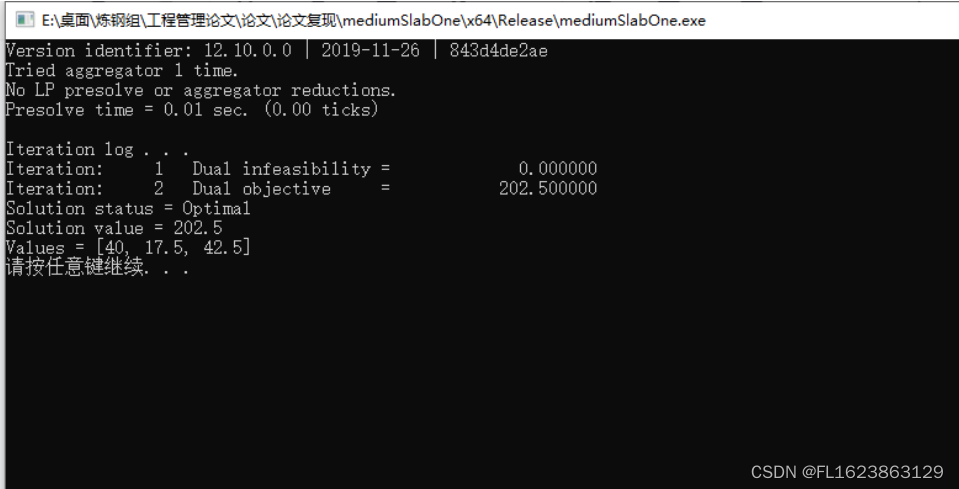
vs配置cplex12.10
1.创建c空项目 2.修改运行环境 为release以及x64 3.创建cpp文件 4.鼠标右键点击项目中的属性 5.点击c/c,点击第一项常规,配置附加库目录 5.添加文件索引,主要用于把路径导进来 6.这一步要添加的目录与你安装的cplex的目录有关系 F:\program…...
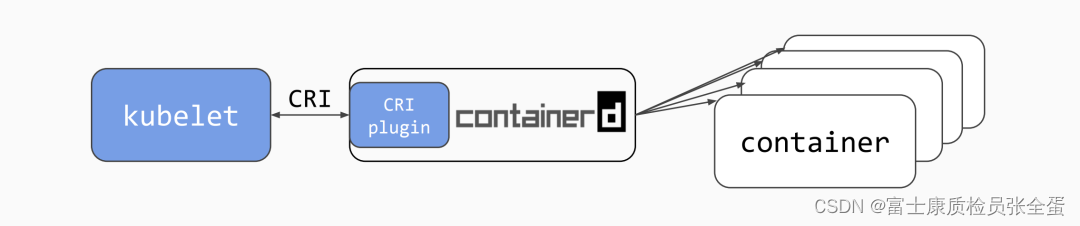
Kubernetes 弃用Docker后 Kubelet切换到Containerd
containerd 是一个高级容器运行时,又名 容器管理器。简单来说,它是一个守护进程,在单个主机上管理完整的容器生命周期:创建、启动、停止容器、拉取和存储镜像、配置挂载、网络等。 containerd 旨在轻松嵌入到更大的系统中。Docke…...

函数模板含有多个模板参数
如果一个模板接受多个参数,用逗号分隔参数。 使用时必要情况下需要主动传入模板参数。 #include <iostream> #include <vector>/* Compute the greatest common divisor of two integers, using Euclids algorithm. */ template<class T, class U&g…...

Sprd Android 13 增加系统属性判断当前有无 OTG U盘插入,App 读取系统属性
添加系统属性,通过监听插拔广播判断当前有无OTG U盘插入 --- a/frameworks/base/services/core/java/com/android/server/policy/PhoneWindowManager.java +++ b/frameworks/base/services/core/java/com/android/server/policy/PhoneWindowManager.java @@ -246,6 +246,7 @@ …...
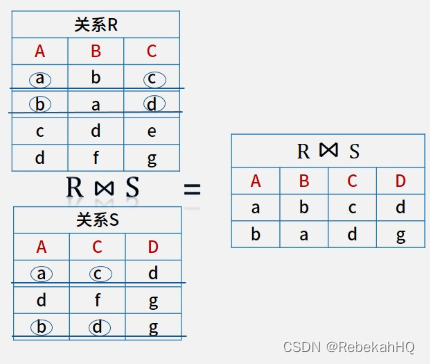
第11章 数据库技术(第一部分)
一、数据库技术术语 (一)术语 1、数据 数据描述事物的符号描述一个对象所用的标识,可以文字、图形、图像、语言等等 2、信息 现实世界对事物状态变化的反馈。可感知、可存储、可加工、可再生。数据是信息的表现形式和载体,信…...
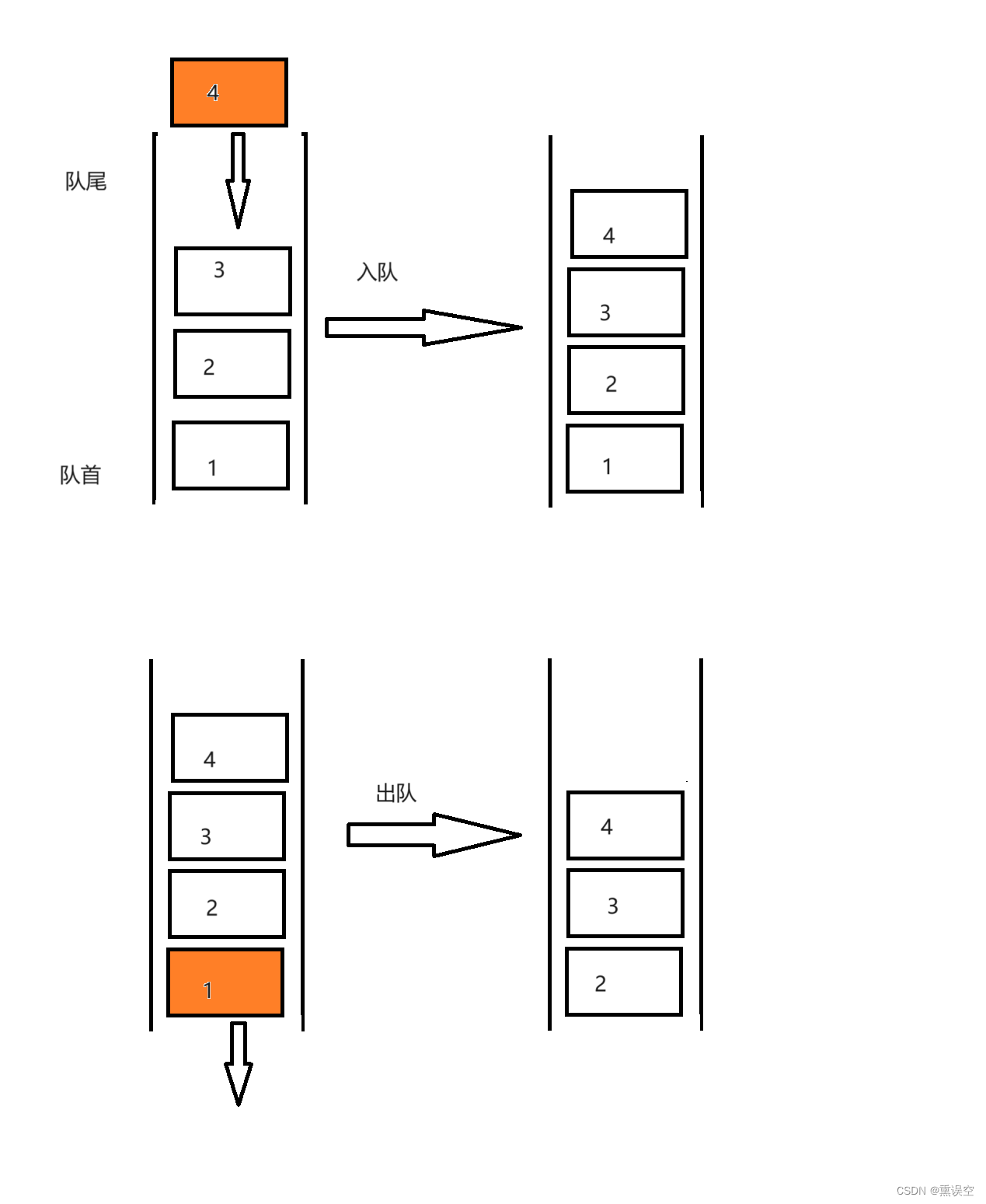
数据结构––队列
1.队列的定义 2.队列的分类 2.1循环队 2.2链式队 3.队列的实现 3.1循环队 3.1.1声明 typedef int QDataType; #define MAXSIZE 50 //定义元素的最大个数 /*循环队列的顺序存储结构*/ typedef struct {QDataType *data;int front; //头指针int rear; //尾指针 }Queue;…...

010_redhat安装zookeeper
目录 1.环境准备2.下载上传zookeeper安装包1)[官网下载zookeeper-3.6.4安装包](https://archive.apache.org/dist/zookeeper/zookeeper-3.6.4/apache-zookeeper-3.6.4-bin.tar.gz)2)创建soft文件夹 3.解压4.配置启动1、配置zoo.cfg2、启动zookeeper 小结 1.环境准备 准备一台l…...

【网络】gateway 可以提供的一些功能之一 “ 提供web静态资源服务 ”
gateway 可以提供的一些功能之一 “ 提供web静态资源服务 ” 一、提供web静态资源服务1.1、web静态资源服务是什么1.2、web静态资源服务有什么作用1.3、web静态资源服务怎么实现 二、提供Restful服务器路由转发三、支持Eureka服务发现四、服务检查五、灰度发布 一、提供web静态…...

MySQL第一次作业
解压完安装包 以管理员进入命令行 初始化并记住初始随机密码 创建服务名称 启动mysql 使用随机密码登录 修改密码 退出并重登服务器 MySQL创建数据库和表 创建数据库 创建表 1.进入数据库 创建表 向表中插入数据...
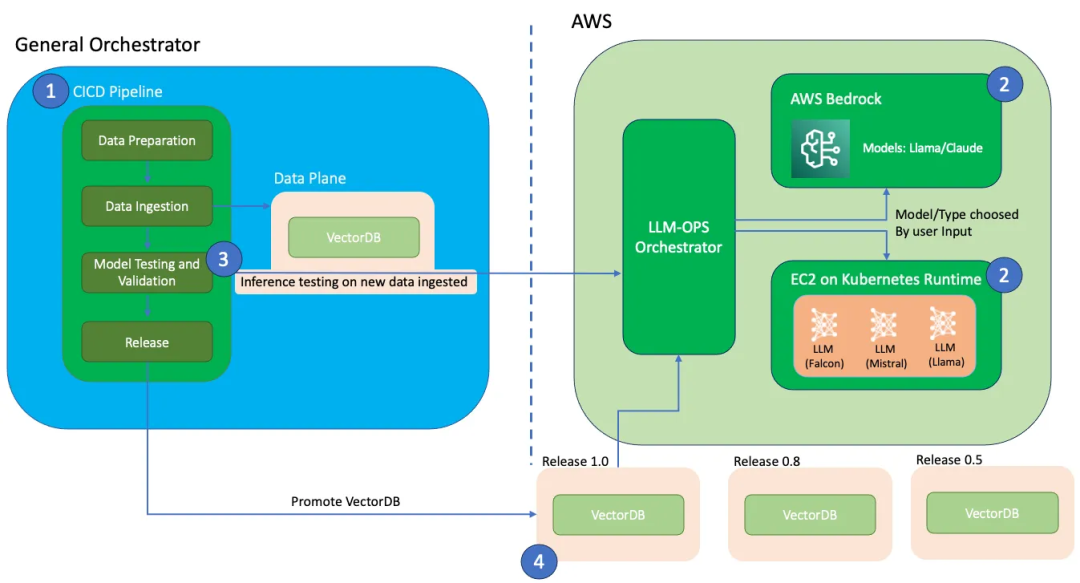
详解LLMOps,将DevOps用于大语言模型开发
大家好,在机器学习领域,随着技术的不断发展,将大型语言模型(LLMs)集成到商业产品中已成为一种趋势,同时也带来了许多挑战。为了有效应对这些挑战,数据科学家们转向了一种新型的DevOps实践LLM-OP…...

牛客NC275 和为S的两个数字【简单 map C++/Java/Go/PHP】
题目 题目链接: https://www.nowcoder.com/practice/390da4f7a00f44bea7c2f3d19491311b 思路 map参考答案C #include <vector> class Solution {public:vector<int> FindNumbersWithSum(vector<int> array, int sum) {vector<int> ans;m…...

ax200/ax201/ax210/ax211/ax411等intel网卡无法开启5G热点问题解决方案汇总
目录 故障原因解决方案windowslinuxkernel < 5.5kernel > 5.5方案1 修改linux内核模块代码(iwlwifi内核模块),重新编译内核模块并重新导入方案2 修改hostapd代码 最后更新于2024.04.28 故障原因 根本原因是因为英特尔在内核中开启了LA…...
JVM的垃圾回收机制(GC机制)
在Java代码运行的过程中,JVM发现 某些资源不需要再使用的时候,就会自动把资源所占的内存给回收掉,就不需要程序员自行操作了。“自动回收资源”就是JVM的“垃圾回收机制”,“垃圾回收机制”也称"GC机制"。 对于Java代码…...

PyCharm配置PySide6工具链避坑指南:解决虚拟环境路径、命令报错那些事儿
PyCharm配置PySide6工具链避坑指南:解决虚拟环境路径、命令报错那些事儿 刚接触PySide6开发的朋友,十有八九会在PyCharm配置Designer、UIC和RCC工具时踩坑。明明照着教程一步步操作,却总是遇到"程序不存在"、"命令执行错误&qu…...
)
HTML 开发 - HTML 描述列表标签(<dl>、<dt>、<dd>)
HTML 描述列表标签 1、基本介绍在 HTML 中,<dl>、<dt>、<dd> 标签用于创建描述列表(Description List)描述列表是一种专门用于展示 术语 - 描述 或 名称 - 值 对结构的语义化标签标签说明<dl>Description List&#…...

OpenClaw多账户管理:Kimi-VL-A3B-Thinking不同项目的环境隔离方案
OpenClaw多账户管理:Kimi-VL-A3B-Thinking不同项目的环境隔离方案 1. 为什么需要多账户环境隔离 上周我同时处理三个项目时遇到了一个尴尬场景:个人博客自动发布脚本误读了工作项目的敏感数据,导致草稿内容错乱。这次事故让我意识到——当O…...

Vue3 + xterm.js 4.x + WebSocket 打造现代化Web终端实战指南
1. 为什么选择Vue3 xterm.js 4.x WebSocket组合? 在构建现代化Web终端时,技术选型直接影响开发效率和最终用户体验。Vue3提供了响应式编程范式和组件化开发优势,xterm.js 4.x是最新版本的浏览器终端模拟器,而WebSocket则实现了…...

百度智能云千帆AppBuilder API调用全攻略:从密钥获取到实战代码示例
百度智能云千帆AppBuilder API深度集成指南:从密钥管理到高效调用实践 在人工智能应用开发领域,快速集成可靠的AI能力已成为开发者提升效率的关键。百度智能云千帆AppBuilder作为一站式AI原生应用开发平台,其API接口的灵活调用能力让开发者能…...

探索汽车LAR LQG半主动/主动悬架:基于Simulink的奇妙之旅
汽车lar lqg 半主动/主动悬架 simulink在汽车工程领域,悬架系统犹如车辆的“脚”,直接影响着行驶的平顺性和安全性。今天咱们就来唠唠汽车的LAR LQG半主动/主动悬架,顺便用Simulink来比划比划。 LAR LQG悬架原理简述 LAR(Linear …...

5分钟学会在Windows上直接安装Android应用:APK-Installer终极指南
5分钟学会在Windows上直接安装Android应用:APK-Installer终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上运行某个只有…...

实战应用:基于快马平台开发一个具备节点测速功能的网络工具面板
最近在折腾服务器节点管理时,发现手动测试各个节点的延迟特别麻烦。正好看到InsCode(快马)平台这个在线开发环境,就尝试用它快速搭建了一个带测速功能的网络工具面板。整个过程比想象中简单很多,分享下具体实现思路。 项目构思 这个工具的核…...

Koodo Reader:您的跨平台电子书阅读解决方案,让阅读无处不在
Koodo Reader:您的跨平台电子书阅读解决方案,让阅读无处不在 【免费下载链接】koodo-reader A modern ebook manager and reader with sync and backup capacities for Windows, macOS, Linux, Android, iOS and Web 项目地址: https://gitcode.com/Gi…...

MediaPipe模型离线部署与本地Demo实战指南
1. MediaPipe模型离线部署全攻略 遇到MediaPipe模型下载失败的问题,相信不少开发者都踩过这个坑。特别是在内网环境或者网络不稳定的情况下,官方自动下载功能经常无法正常工作。我去年在给某制造企业部署智能质检系统时就遇到过类似情况,他们…...